1. Introduction
With the advance of information science, more data are being collected into databases, storing a large amount of information for science, governments, businesses, and society [
1]. Most scientific research focuses on constructing a general pattern map for most data. However, abnormal data are often more valuable than normal data because they often represent a small number of the most specific features. Outlier detection is a significant, emerging, and promising research direction [
2]. As a part of data mining, it is the highest priority in many domains; for example, intrusion detection, bank fraud [
3], credit analysis, and wireless sensor abnormality detection [
4]. It is also a method of preprocessing data in data mining, or can be used as a standalone tool for discovering certain, specific, and implicit pieces of information in a data sample. Its task is to find data whose characteristics are completely different from most of the data features, which are called “outliers”.
In recent decades, outliers were not valued by researchers, but were treated as “by-products” or “noise” of data mining methods. In 1980, Hawkins [
5] defined an outlier in his classic book “Identification of Outliers”: outliers behave relatively differently from most data objects in a dataset, so it is suspected that the object is caused by other mechanisms. In recent years, many scholars have been working on finding more efficient and reliable outlier-detection algorithms. In general, three major categories of outliers can be detected [
6]: supervised outlier detection, semi-supervised outlier detection and unsupervised outlier detection. In supervised and semi-supervised modes, the model is built from the training dataset and it takes both time and labor to label the dataset. Conversely, unsupervised modes do not need training datasets and can be divided into global and local detection algorithms [
7]. Therefore, this paper mainly studies unsupervised outlier detection methods.
In recent years, researchers have proposed various unsupervised outlier detection algorithms, including statistics-based, distance-based [
8,
9,
10], clustering-based [
11], and density-based algorithms [
3,
12]. However, the most common detection methods are based on distance or density.
The study of outliers began with statistical learning models, especially in the field of statistical learning methods. If a data object deviates too much from the standard distribution, it is considered an outlier [
13]. Outlier detection methods based on statistical learning are relatively simple to use, and the application of the model does not require much change; however, there are high requirements regarding the users’ knowledge of the dataset. Therefore, this method is not suitable for datasets with unknown conditions.
The distance-based method does not need to assume the distribution of any data. Most methods use existing distance measurement methods to calculate the distance between all data objects, and identify anomaly values according to the distance relationship. The
-outliers approach proposed by Knorr and Ng [
14] is a classical distance-based method, and K-nearest neighbor (KNN) distance is used to calculate outlier scores [
15]. These methods have relatively intuitive concepts and are easier to understand, but cannot detect outliers in areas of different densities. Meanwhile, it is difficult to determine the threshold of the distance, which is critical for detection performance. Clustering-based methods will find some outliers that do not pertain to any cluster in the process of clustering, and these points called outliers [
16,
17].
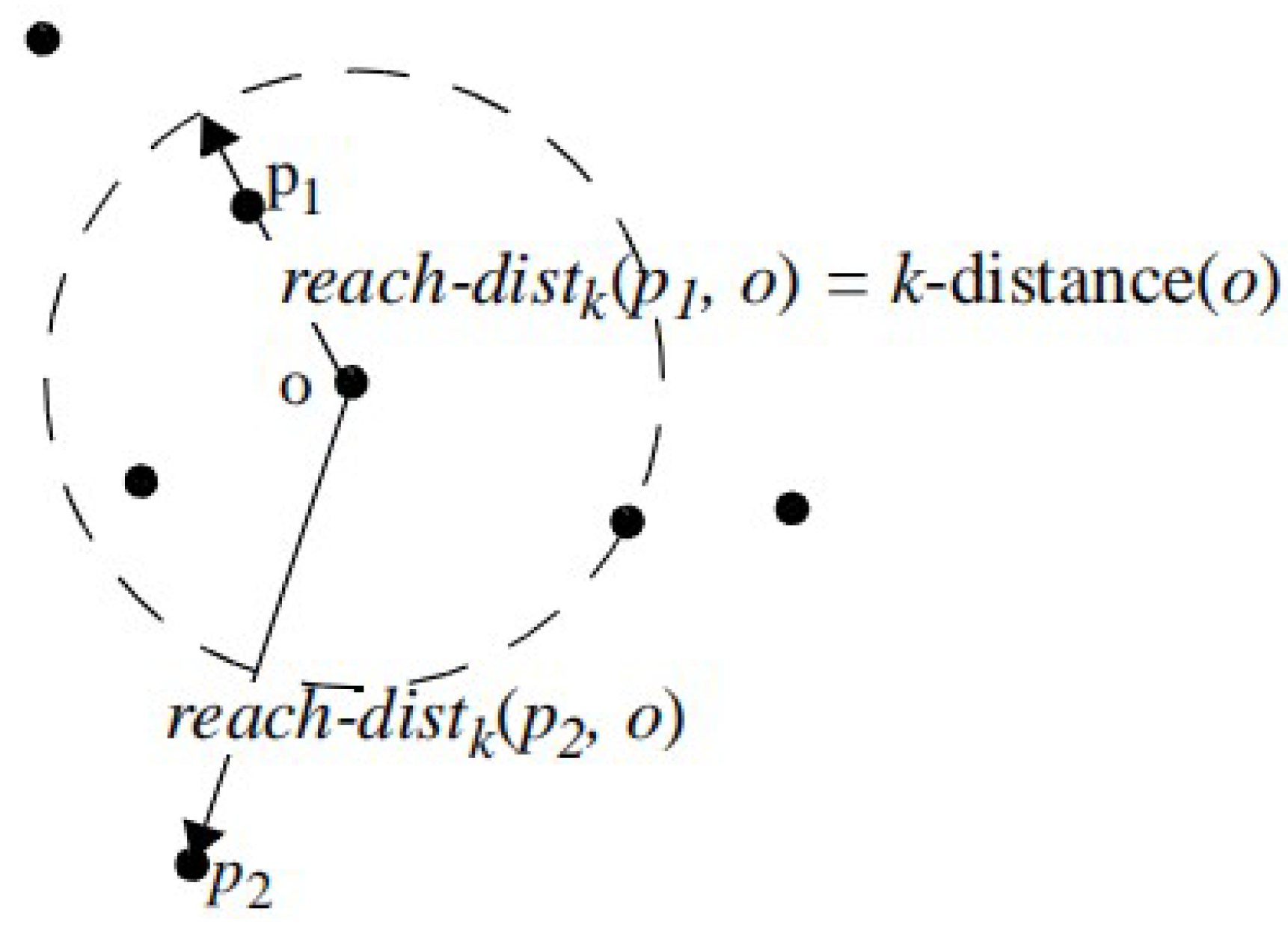
In the density-based method, if the density of the calculated target point is lower than its nearest neighbor’s density, it is called an outlier. The earliest algorithm is the local outlier factor (LOF) [
18]. The following research [
19] shows that LOF judges outliers according to the score of each point. Next, several extensions of the LOF model appeared, such as the connection-based outlier (COF) [
19]. This approach is very similar to LOF; the only difference is the way the density estimate is calculated. The weakness of this approach is that the data distribution is indirectly assumed, which will lead to poor density estimation. The local density factor (LDF) [
20] has a certain robustness, which is a further improvement to the LOF algorithm. With regard to kernel density estimation, several new methods have also been introduced recently. An outlier score based on relative density (RDOS) [
21] is proposed to measure the local outliers of the target point. Meanwhile, the extended nearest neighbors of the object are considered, and these neighbors are used to further use the local kernel density estimation. The adaptive-kernel density [
22] approach is assigned an outlier score to show local differences, and uses an adaptive kernel to improve the recognition ability. In 2018, a relative kernel density [
23] not only calculated the local density of the data points, but also calculated the density fluctuations between the fixed point and the adjacent points to further improve the accuracy. Next, Wahid et al. [
24] adopted the weighted kernel density estimation (WKDE) method. This not only uses self-adaptation, but also adds weight to the density, and uses extended nearest neighbor to calculate the score of outliers. Local-gravitation outlier detection (LGOD) [
25] introduces the concept of inter-sample gravity, which determines the extent of the anomalies by calculating the change in the gravity of a sample’s nearest neighbours. The average divergence difference (ADD) [
26] algorithm introduces the concept of average divergence difference to improve the accuracy of local outlier detection. Although the density of clusters in the datasets used varies greatly, the proposed methods have certain effects. However, if there are low-density patterns in the provided data, these methods will not accurately determine the outliers, and the effect will be degraded [
19]. Density-based methods tend to be insensitive to global outliers.
In this study, we propose a new method to further calculate local density and relative distance based on natural neighborhood, where natural neighborhoods are neighbors to each other, and there is no need to manually determine neighborhood parameters. Combinatorial optimization is mainly to find optimal object from a limited set of objects. To find outliers through the combination of density and distance, through the fusion of these two measures, this method can be applied to low-density modes without setting the number of neighbors. First, an adaptive kernel density estimation method is proposed to compute the density of the target point. After the density of each target point is determined, the relative distance is introduced. The relative distance is mainly used to judge the proximity between the target object and the object in its own natural neighborhood set, which is mainly composed of the average distance from the target point to its natural neighbors and the distance between natural neighbors. Combining density and distance, a comprehensive outlier factor is obtained to more accurately detect outliers in the dataset. Compared with the current single-parameter outlier detection algorithm, this paper introduces the outlier factor of a two-parameter combination to judge the outlier. The main innovations of the article are summarized as below:
- (1)
The natural neighborhood is introduced into outlier detection, and iteration is used to determine the number of neighbors.
- (2)
A calculation method of adaptively setting kernel width is proposed to improve the discrimination ability of outlier detection.
- (3)
The density and distance are combined to form a new outlier factor.
- (4)
We set a suitable threshold as the boundary value to determine whether the object is abnormal, so that the final result does not consider the top-n problem.
The remainder of this article is outlined below.
Section 2 presents the preparatory work used to develop the improved method.
Section 3 presents the improvement method put forward in this paper.
Section 4 contains the comparison and analysis of the experimental results of some outlier detection methods and the improved methods. Finally,
Section 5 contains the conclusion and future work directions.
3. Proposed Method
The density-distance outlier detection algorithm based on natural neighborhood does not need to manually define the number of neighbors. If only density is used as the measurement condition, the boundary points will often be mistaken for outliers, and will increase with the increase in parameters. Therefore, we introduce the relative distance to eliminate the interference of boundary points and increase the difference between boundary points and outliers. Through the fusion of density and distance, a comprehensive outlier factor is obtained for evaluation.
3.1. Natural Neighbor
Natural neighbor is an extended concept of a neighbor, which has a stable structure. The understanding of objective reality gave birth to this concept. The number of real friends a person has should be the number of people who mutually regard him or her as their friend. For a data instance, if
x thinks that
y is a neighbor, and
y also acknowledges that
x is a neighbor, then object
y is one of the natural neighbors of object
x. The whole calculation process of natural neighbors can be completed automatically without any parameters. Therefore, the natural neighborhood stability structure formula of the data object is as follows:
where
is the
k nearest neighbors of object
.
The
k-nearest neighbor of object
refers to the collection of all points in the dataset whose distance from
is not greater than that between
and its
k-th neighbor. The formation process of the stable structure of natural neighbors is as follows: the search of neighbor range is expanding, from 1 to
(
as natural neighbor eigenvalue (NaNE)). The NaNE refers to the minimum
k value when the algorithm termination condition is satisfied. In each search, the number of reverse neighbors of each instance in the dataset is calculated and the following conditions are judged: (1) all instances have reverse neighbors; (2) the number of instances without reverse neighbors remains unchanged. The reverse neighbor of a target object refers to an object that treats the target object as one of its
k-nearest neighbors. When any of the above conditions is satisfied, the stable structure of natural neighbors has been formed. Then our NaNE value is equal to the
k value used in the search.
is obtained by the following formula.
where
is the number of reverse nearest neighbors of
in iteration
k.
is defined as follows:
Definition 4 (natural neighbors).
The natural neighbor of is the neighbor when k iterates to the natural neighbor eigenvalue, which is defined as follows: Algorithm 1 shows the search algorithm process of natural neighbors.
| Algorithm 1: Natural Neighbor Search Algorithm |
 |
3.2. Local Density Estimation
Generally speaking, density is a measure of how close a data object is to its neighborhood objects, and which method to use to estimate the density is also crucial. We adopted adaptive Gaussian kernel density estimation, which greatly reduces the dependence of kernel function on required parameters.
For a present dataset
, where
for
the distribution density can be computed as:
where
indicates the kernel function and
is the width that controls the smoothness of the kernel density function.
and
standardize the density estimation and make it integral to 1 in the range of
x. Kernel functions satisfy the following expression [
27]. The distribution estimate in Formula (8) provides a lot of good features, such as being nonparametric, continuous, and differentiable [
28].
In the classical density problem, estimated previously using the Parzen window, all points use a fixed width parameter h. However, the estimation results of the kernel function are different for the width. Against the background of anomaly detection, the favorable setting of kernel width is the exact opposite of density evaluation. In areas with a high density, we tend not to care about these interesting structures, because they do not provide any value for the determination of outliers. Larger widths may lead to over-smoothing and structure cleaning, but in the low-density region, smaller widths may lead to noise estimation. Therefore, the best choice of width may depend on its specific location in the data space.
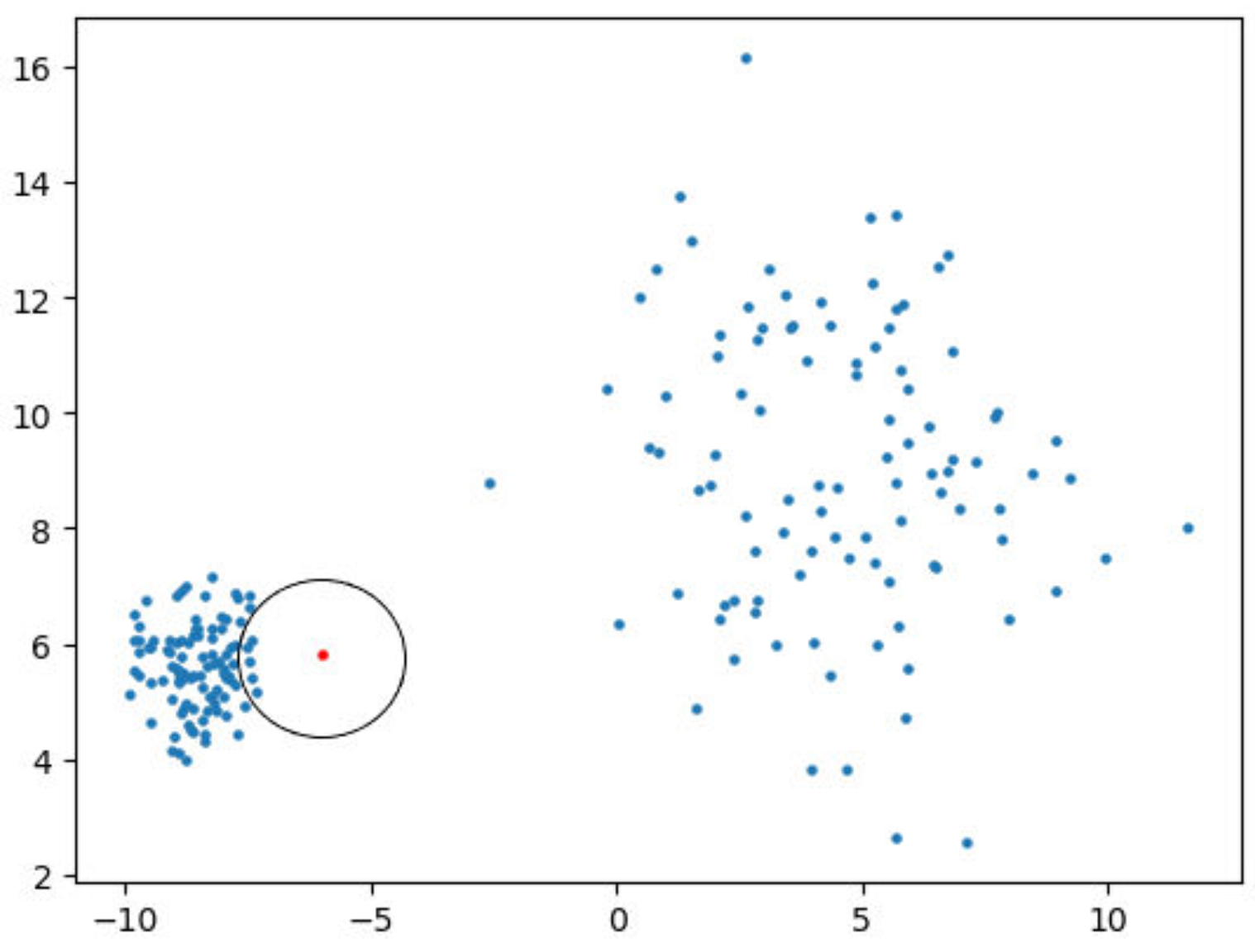
Below is a concrete example: consider a 1D dataset . The last one is suspected to an exception. Suppose we can correctly apply the above ideas; then, the dataset can be converted to . Finally, we can more clearly see that the last one is an anomaly.
3.3. Adaptive Kernel Width
At present, we further consider the adaptive setting of the width
in the Formula (10). Considering the effect of kernel width, we strictly limit this to numbers greater than 0. Considering the
ith point, the average distance to its natural neighbor is expressed by
; i.e.,
. Then, we let
and
show the maximum and minimum quantity in the set
, respectively. Similar to Silverman’s rule [
29], the rough estimation of point density can be expressed by
, and then the negative correlation among width
and
is constructed. Through the above demands, the adaptive width is defined by the following formula:
where scaling factor
c (
) controls smoothing result,
is a very small number used to ensure that the core width is not 0 (e.g.,
). This method of setting the core width has two advantages: (a) it improves the discriminative power of the outlier metric; (b) it smoothes the difference between normal samples’ difference. The term
was introduced for two reasons. Firstly, the calculated width must be positive. Secondly, even if there is no scale factor
c, the denominator width and numerator in the index of Formula (11) will be in the same proportion.
With the adaptive width, the local density of the target point can be expressed as
. We can see that the measure of local density in our proposed method is not necessarily probability density. Therefore, it is not necessary to normalize the formula. The most common Gaussian kernel is used as the kernel function; then, the local density of
ith point is as follows:
The right side of Formula (11) does not include the contribution of the target point itself (). The relative difference in density can be reflected (for example, the quantity is much smaller than the quantity ).
3.4. Relative Distance
In previous density outlier detection methods, outliers can be determined only by kernel density estimation. However, in order to detect outliers more accurately and overcome the problem that local density cannot be used to detect low-density patterns, this paper also considers the influence of the relative distance of the target points.
The relative distance mainly examines the closeness of the object to the object in its own natural neighborhood set, which is composed of natural neighborhood distance and internal neighborhood distance. First, the formula for the natural neighborhood distance is shown in Formula (12).
where
is the natural neighborhood distance of the object
,
is an object in the natural neighbor set of object
, and
is the Euclidean distance between object
and object
.
The natural neighborhood distance is actually an average distance, which is the average of the sum of the distances from each object in the candidate set to each object in its own natural neighbor set. Next, the internal neighborhood distance is determined, the formula is as follows:
where
is the internal neighborhood distance of the object
,
is the Euclidean distance between object
and object
.
The internal neighborhood distance is the average sum of the two distances of all natural neighbor objects using object
. After calculating the natural neighborhood distance and internal neighborhood distance of all points in the set, the relative distance of the objects can be obtained, as shown in Formula (14).
3.5. Density-Distance Outlier Detection Algorithm Based on Natural Neighborhood
It is difficult to raise the accuracy of the algorithm by using a single outlier factor as the key factor for judging outliers. Therefore, the combinatorial optimization problem of combining multiple factors to judge outlier gradually appears. Through the above-mentioned arguments, the algorithm steps are as follows:
- (1)
Compute the natural neighborhood of the target object;
- (2)
Compute the local density of the target object;
- (3)
Compute the relative distance of the target object;
- (4)
The calculation formula of the comprehensive outlier factor is obtained.
After evaluating the local density and relative distance of each point, the outlier factor of the object
can be determined, and a new algorithm, TPOD, is proposed, as defined below:
Density focuses on the degree of correlation between objects, while distance focuses on the degree of deviation between objects. Combining the characteristics of density and distance outlier detection methods, a new algorithm, TPOD, is proposed. The ratio of distance to density is used to determine the calculation of a new outlier factor. Using different outlier factors is important for outlier detection results. Algorithm 2 shows the pseudo-code of this method.
3.6. Threshold
The outlier score of data points in sparse areas is much higher than that in dense areas. In other words, we can set the threshold as the boundary to divide normal points and abnormal points. Therefore, we provide a new method for setting suitable thresholds, as shown below:
where
refers to the TPOD value of the data point
, and
is a coefficient, determined by experience. After experimental verification,
is usually 0.2 on synthetic datasets and 0.01 on real datasets. In general, if the TPOD value of the data point is smaller than the preset threshold
, then the data point is part of the normal range. Conversely, it will be deemed an abnormal value.
| Algorithm 2: A Density-Distance Approach for Outlier Detection |
 |
3.7. Time Complexity Analysis
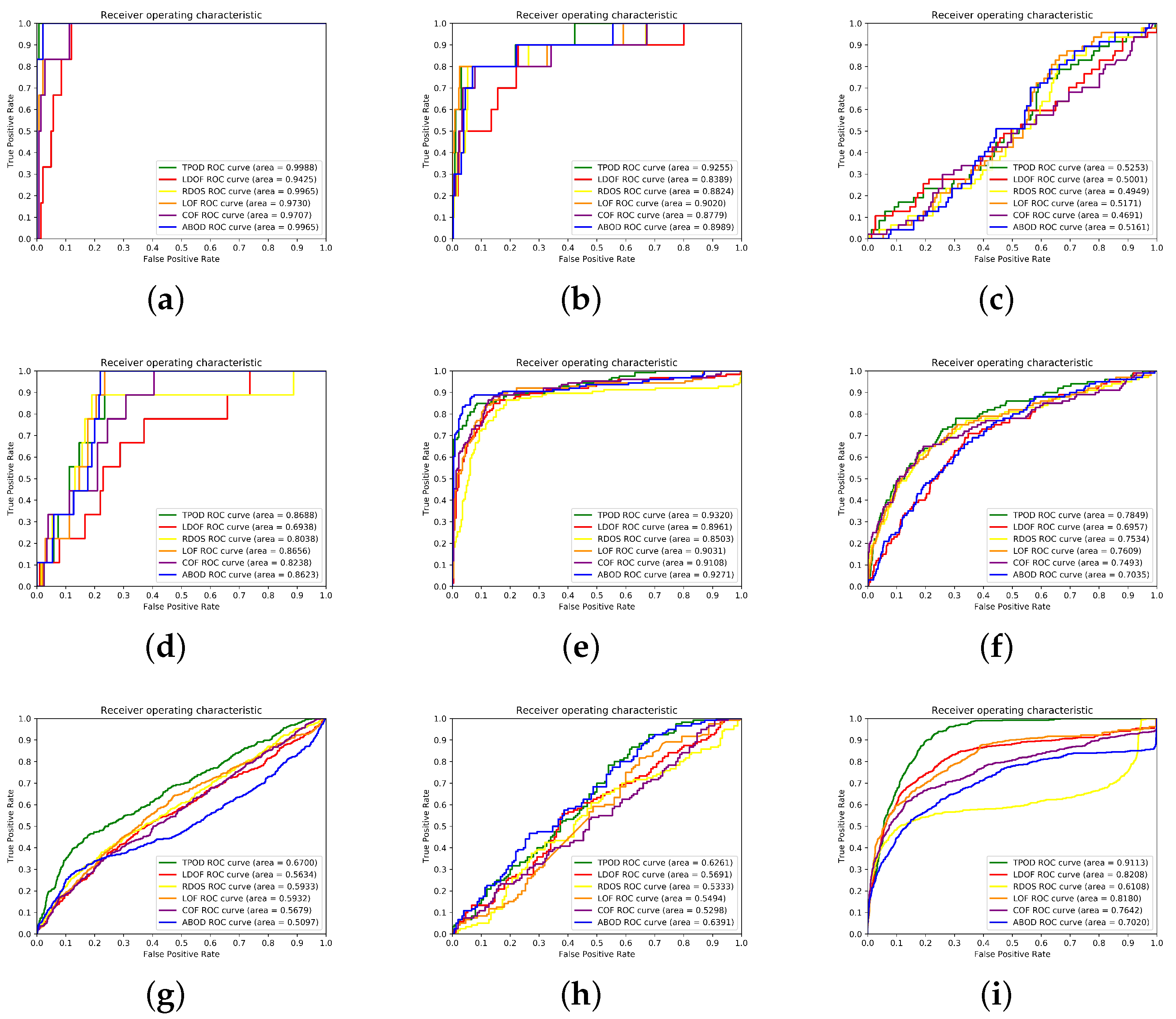
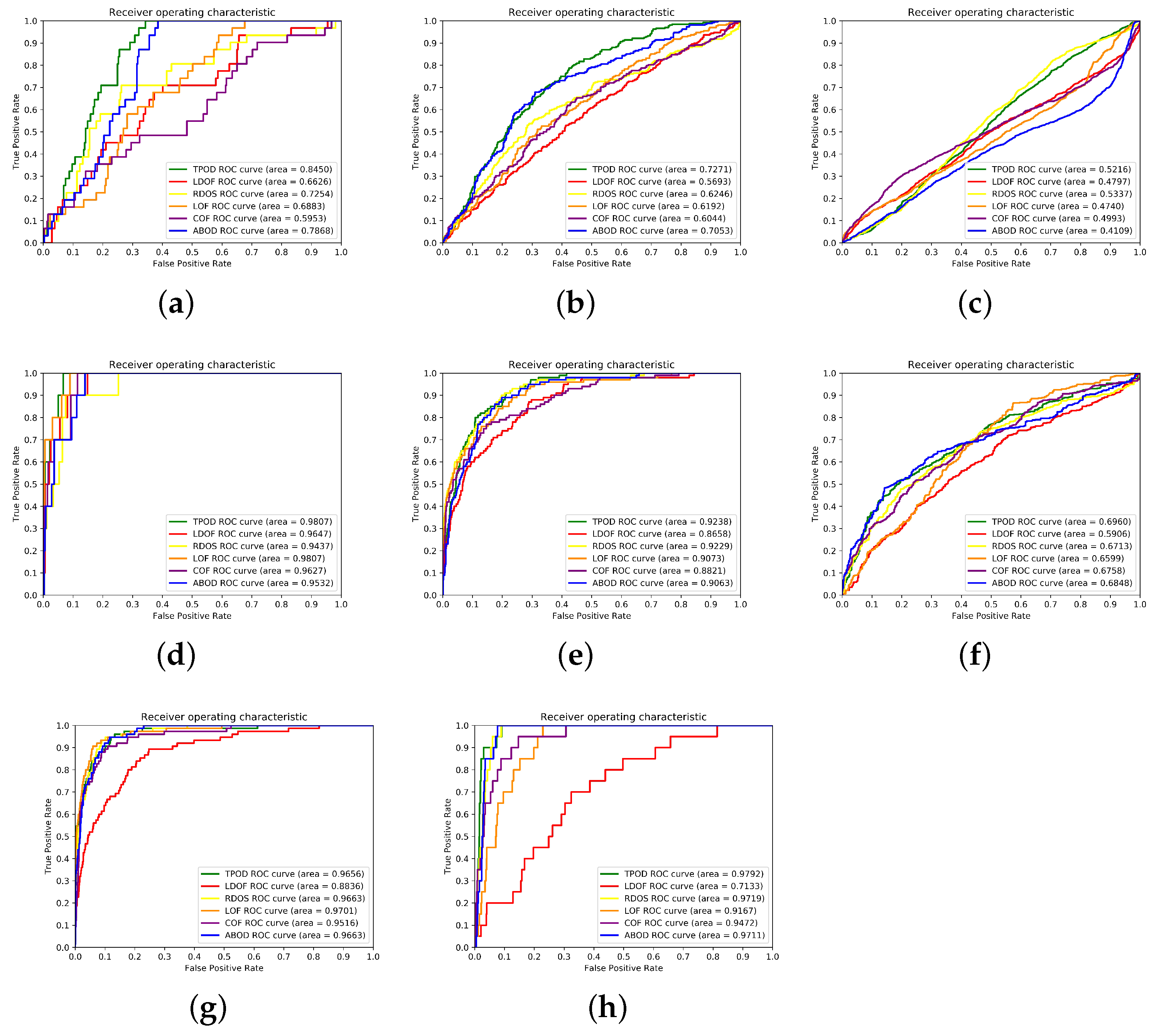
In this section, we analyzed the time complexity of the algorithm, as follows: In the first stage of the process of searching for natural neighbors, the KD tree was used to search for neighbor information, and its computational time complexity was , where n refers to the number of datasets. For the formation of a stable structure of natural neighbors, we conducted a -step iteration, and the time complexity of this search process was . The second step is to calculate the local density and relative distance of each point, using its natural neighbor information, so its time complexity is . Finally, we relied on these two values to obtain the final TPOD score, with a time complexity of . In summary, we finally obtained that the complexity of our proposed algorithm is .











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}