1. Introduction
The concept, techniques and applications of artificial intelligence (AI) and machine learning (ML) in solving real-life problems have become increasingly practical over the past years. The general aim of machine learning lies in attempting to ‘learn’ data and make some predictions from a variety of techniques. In the financial industry, they offer a more flexible and robust predictive capacity compared to the classical mathematical and econometric models. They equally provide significant advantages to the financial decision makers and market participants regarding the recent trends in financial modeling and data forecasting. The core applications of AI in finance are risk management, algorithmic trading, and process automation [
1]. Hedge funds and broker dealers utilize AI and ML to optimize their execution. Financial institutions use the technologies to estimate their credit quality and evaluate their market insurance contracts. Both private and public sectors use these technologies to detect fraud, assess data quality, and perform surveillance. ML techniques are generally classified into supervised and non-supervised systems. A branch of ML (supervised) techniques that have been fully recognized is deep learning, as it provides and equips machines with practical algorithms needed to comprehend the fundamental principles, and pattern detection in a significant portion of data. The neural networks, the cornerstones of these deep learning techniques, evolved and developed in the 1960s. In the fields of quantitative finance, the neural networks are applied in the optimization of portfolios, financial model calibrations [
2], high-dimensional futures [
3], market prediction [
4], and exotic options pricing with local stochastic volatility [
5].
For the methodology employed in this paper, artificial neural networks (ANNs) are systems of learning techniques which focus on a cluster of artificial neurons forming a fully connected network. One aspect of the ANN is the ability to generally ‘learn’ to perform a specific task when fed with a given dataset. They attempt to replicate or mimic a mechanism which is observable in nature, and they gain their inspiration from the structure, techniques and functions of the brain. For instance, the brain is similar to a huge network with fully interconnected nodes (neurons, for example, the cells) through links, also referred to as synapses, biologically. The non-linearity feature is introduced to the network within these neurons as the non-linear activation functions are applied. The non-linearity aspect of the neural network tends to approximate any integrated function reasonably well. One significant benefit of the ANN method is that they are referred to as ‘universal approximators’. This feature implies that they can fit any continuous function, together with functions having non-linearity features, even without the assumption of any mathematical relationship which connects the input and the output variables. Essentially, the ANNs are also fully capable of approximating the solutions to partial differential equations (PDE) [
6], and they easily permit parallel processing, which facilitates evaluation processes on graphics processing units (GPUs) [
7]. The presence of this universal approximator function is often a result of their typical architecture, training and prediction process.
Meanwhile, due to the practical significance of the use of financial derivatives, these instruments have sharply risen in more recent years. This has led to the development of sophisticated economic models, which tend to capture the dynamics of the markets, and there has also been an increase in proposing faster, more accurate and more robust models for the valuation process. The pricing of these financial contracts has significantly helped manage and hedge risk exposure in finance and businesses, improve market efficiencies and provide arbitrage opportunities for sophisticated market participants. The conventional pricing techniques of option valuation are theoretical, resulting in the formulation of analytical closed forms for some of these option types. In contrast, others rely heavily on numerical approximation techniques, such as Monte Carlo simulations, finite difference methods, finite volume methods, binomial tree methods, etc. These theoretical formulas are mainly based on assumptions about the behavior of the underlying prices of securities, constant risk-free interest rates, constant volatility, etc., and they have been duly criticized over the years. However, modifications have been made to the Black–Scholes model, thereby giving rise to such models as the mixed diffusion/pure jump models, displaced diffusion models, stochastic volatility models, constant elasticity of variance diffusion models, etc. On the other hand, neural networks (NNs) have proved to be emerging computing techniques that offer a modern avenue to explore the dynamics of financial applications, such as derivative pricing [
8].
Recent years have seen a huge application of AI and ML, as they have been utilized greatly in diverse financial fields. They have contributed significantly to financial institutions, the financial market, and financial supervision. Li in [
9] summarized the AI and ML development and analyzed their impact on financial stability and the micro-macro economy. In finance, AI has been utilized greatly in predicting future stock prices, and the concept lies in building AI models which utilize ML techniques, such as reinforcement learning or neural networks [
10]. A similar stock price prediction was conducted by Yu and Yan [
11]; they used the phase-space reconstruction method for time series analysis in combination with a deep NN long- and short-term memory networks model. Regarding applying neural networks to option pricing, one of the earliest research can be found in Malliaris and Salchenberger [
12]. They compared the performance of the ANN in pricing the American-style OEX options (that is, options defined on Standard and Poor’s (S&P) 100) and the results from the Black–Scholes model [
13] with the actual option prices listed in the
Wall Street Journal. Their results showed that in-the-money call options were valued significantly better when the Black–Scholes model was used, whereas the ANN techniques favored the out-of-the-money call option prices.
In pricing and hedging financial derivatives, researchers have incorporated the classical Black–Scholes model [
13] into ML to ensure robust and more accurate pricing techniques. Klibanov et al. [
14] used the method of quasi-reversibility and ML to predict option prices in corporations with the Black–Scholes model. Fang and George [
15] proposed valuation techniques for improving the accuracy rate of Asian options by using the NN in connection with Levy approximation. Hutchinson et al. in [
16] further priced the American call options defined on S&P 500 futures by comparing three ANN techniques with the Black–Scholes pricing model. Their results proved the supremacy of all three ANNs to the classical Black–Scholes model. Other comparative research studies on the ANN versus the Black–Scholes model are also applicable in pricing the following: European-style call options (with dividends) on the Financial Times Stock Exchange (FTSE) 100 index [
17], American-style call options on Nikkei 225 futures [
8], Apple’s European call options [
18], S&P 500 index call options with an addition of neuro-fuzzy networks [
19], and in the pricing call options written on the Deutscher Aktienindex (DAX) German stock index [
20]. Similar works on pricing and hedging options using the ML techniques can be found in [
21,
22,
23,
24,
25].
Other numerical techniques, such as the PDE-based and the DeepBSDE-based (BSDE—-backward stochastic differential equations) methods, have also been employed in valuing the barrier options. For instance, Le et al. in [
26] solved the corresponding option pricing PDE using the continuous Fourier sine transform and extended the concept of pricing the rebate barrier options. Umeorah and Mashele [
27] employed the Crank–Nicolson finite difference method in solving the extended Black–Scholes PDE, describing the rebate barrier options and pricing the contracts. The DeepBSDE concept initially proposed by Han et al. in [
28] converted high-dimensional PDE into BSDE, intending to reduce the dimensionality constraint, and they redesigned the solution of the PDE problem as a deep-learning problem. Further implementation of the BSDE-based using the numerical method with deep-learning techniques in the valuation of the barrier options is found in [
29,
30].
Generally, the concept of ANN can be classified into three phases: the neurons, the layers and the whole architecture. The neuron, which is the fundamental core processing unit, consists of three basic operations: summation of the weighted inputs, the addition of a bias to the input sum, and the computation of the output value via an activation function. This activation function is used after the weighted linear combination and implemented at the end of each neuron to ensure the non-linearity effect. The layers consist of an input layer, a (some) hidden layer(s) and an output layer. Several neurons define each layer, and stacking up various layers constitutes the entire ANN architecture. As the data transmission signals pass from the input layer to the output layer through the middle layers, the ANN serves as a mapping function among the input–output pairs [
2]. After training the ANN in options pricing, computing the in-sample and out-of-sample options based on ANN becomes straightforward and fast [
31]. Itkin [
31] highlighted this example by pricing and calibrating the European call options using the Black–Scholes model.
This research is an intersection of machine learning, statistics and mathematical finance, as it employs recent financial technology in predicting option prices. To the best of our knowledge, this ML approach to pricing the rebate and zero-rebate barrier options has received less attention. Therefore, we aim to fill the niche by introducing this option pricing concept to exotic options. In the experimental section of this work, we simulate the barrier options dataset using the analytical form of the extended Black–Scholes pricing model. This is a major limitation of this research, and the choice was due to the non-availability of the real data. (A similar synthetic dataset was equally used by [
32], in which they constructed the barrier option data based on the LIFFE standard European option price data by the implementation of the Rubenstein and Reiner analytic model. These datasets were used in the pricing of the up-and-out barrier call options via the use of a neural net model.) We further show and explain how the fully connected feed-forward neural networks can be applied in the fast and robust pricing of derivatives. We tuned different hyperparameters and used the optimal in the modeling and training of the NN. The performance of the optimal NN results is compared by benchmarking the results against other ML models, such as the random forest regression model and the polynomial regression model. Finally, we show how the barrier options and their Greeks can be trained and valued accurately under the extended Black–Scholes model. The major contributions of this research are classified as follows:
We propose a non-parametric technique of barrier option valuation and hedging using the concept of a fully connected feed-forward NN.
Using different evaluation metrics, we measure the performance of the NN algorithm and propose the optimal NN architecture, which prices the barrier options effectively in connection to some specified data-splitting techniques.
We prove the accuracy and performance of the optimal NN model when compared to those produced by other ML models, such as the random forest and the polynomial regression, and extract the barrier option prices and their corresponding Greeks with high accuracy using the optimal hyperparameter.
The format of this paper is presented as follows: In
Section 1, we provide a brief introduction to the topic and outline some of the related studies on the applications of ANN in finance.
Section 2 introduces the concept of the Black–Scholes pricing model, together with the extended Black–Scholes pricing models for barrier options and their closed-form Greeks.
Section 3 focuses on the machine learning models, such as the ANN, as well as its applications in finance, random forest regression and the polynomial regression models. In
Section 4, we discuss the relevant results obtained in the course of the numerical experiments, and
Section 5 concludes our research study with some recommendations.
4. Results and Discussion
4.1. Data Structure and Description
For the ANN model input parameters, we generated 100,000 sample data points and then used Equation (
8) to obtain the exact price for the rebate barrier call options. These random observations will train, test and validate an ANN model to mimic the extended Black–Scholes equation. We consider the train–test split and the cross-validation split on the dataset and then measure these impacts on the loss function minimization and the option values. The generated samples consist of eight variables, that is
, which are sampled uniformly, except the option price
, and following the specifications and logical ranges of each of the input variables (See
Table 3). During the training process, we fed the ANN the training samples with the following inputs
, where
is the expected output. In this phase, the ANN ‘learns’ the extended Black–Scholes model from the generated dataset, and the testing phase follows suit, from which the required results are predicted. Meanwhile, under the Black–Scholes framework, we assume that the stock prices follow a geometric Brownian motion, and we used
GBM(
) for the random simulation.
Table 3 below shows the extended Black–Scholes parameters used to generate the data points, whereas
Table 4 gives the sample data generated. The range for the rebate, strike and barrier is from the uniform random distribution, and they are multiplied by the simulated stock price to obtain the final range.
Statistics and Exploratory Data Analysis
In this section, we aim to summarize the core characteristics of our option dataset by analyzing and visualizing them. The descriptive statistics which summarize the distribution shape, dispersion and central tendency of the dataset are presented in
Table 5. The following outputs were obtained: the number of observations or elements, mean, standard deviation, minimum, maximum and quartiles (25%, 50%, 75%) of the dataset. We observed that the distribution of the simulated stock is left skewed since the mean is lesser than the median, whereas the distributions of the option values, strike price and barrier levels are right skewed.
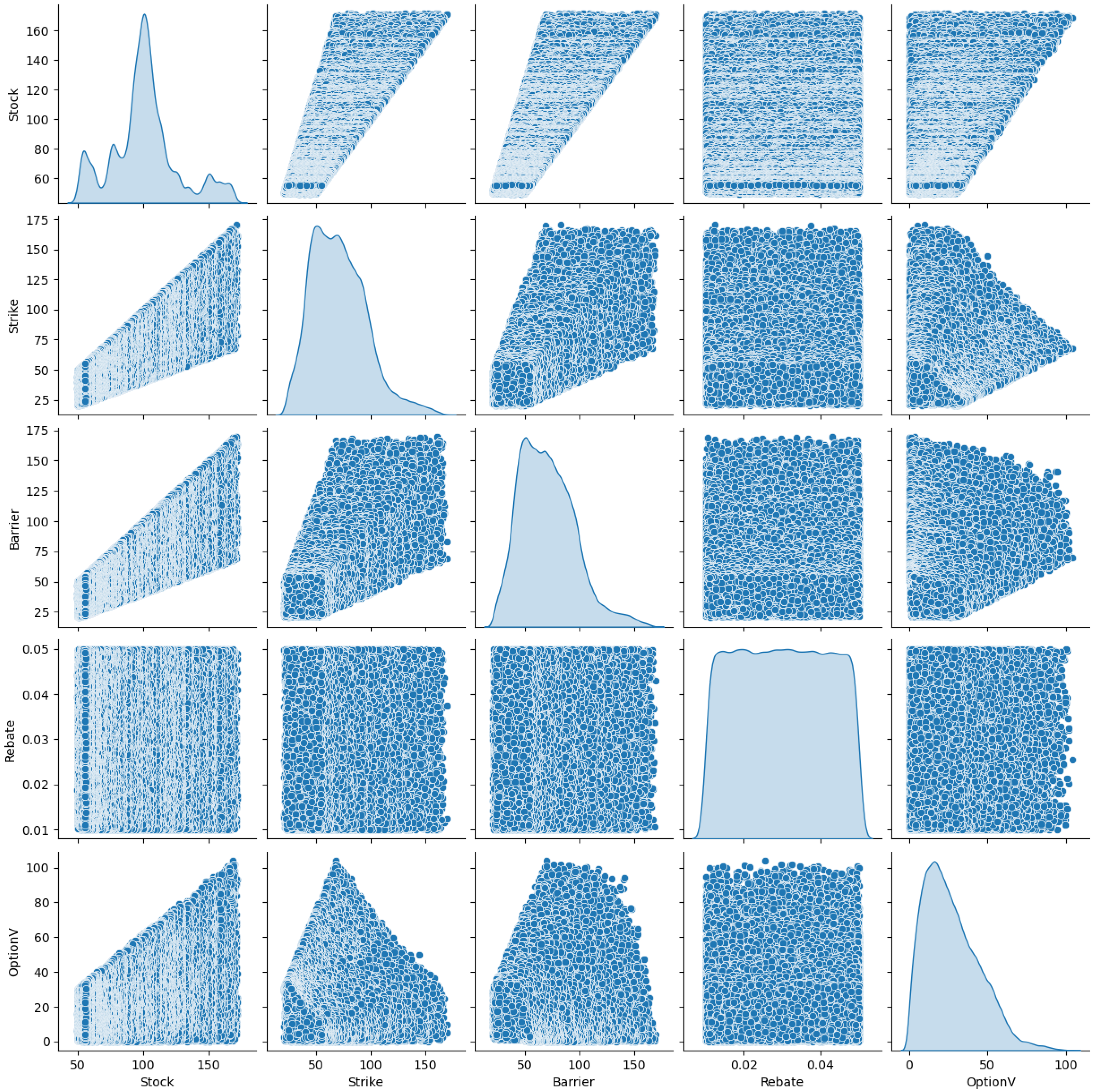
In
Figure 1, we consider the visualization using the
seaborn library in connection with the
pairplot function to plot a symmetric combination of two main figures, that is, the scatter plot and the kernel density estimate (KDE). The KDE plot is a non-parametric technique mainly used to visualize the nature of the probability density function of a continuous variable. In our case, we limit these KDE plots to the diagonals. We focus on the relationship between the stock, strike, rebate and the barrier with the extended Black–Scholes price (OptionV) for the rebate barrier options. From the data distribution for the feature columns, we notice that the sigma, time and rate columns could be ignored. This is because the density distribution shows that these features are basically uniform, and the absence of any variation makes it very unlikely to improve the model performance. Suppose we consider this problem as a classification problem; then, no split on these columns will increase the entropy of the model.
On the contrary, however, if this was a generative model, then there would be no prior to updating given a uniform posterior distribution. Additionally, the model will learn a variate of these parameters since, by definition of the exact option price (referred to as OptionV) function, these are the parameters which can take on constant values. Another method to consider would be to take these parameters ‘sine’ functions as inputs to the model instead of the actual values. We observed from our analysis that this concept works, but there is not a significant improvement in model performance, which can be investigated in further research.
4.2. Neural Network Training
The first category (train dataset) is employed to fit the ANN model by estimating the weights and the corresponding biases. The model at this stage tends to observe and ‘learn’ from the dataset to optimize the parameters. In contrast, the other (test dataset) is not used for training but for evaluating the model. This dataset category explains how effective and efficient the overall ANN model is and the prediction probability of the model. Next and prior to the model training, we perform data standardization techniques to improve the performance of the proposed NN algorithm. The
StandardScalar function of the
Sklearn python library was used to standardize the distribution of values by ensuring that the distribution has a unit variance and a zero mean. During the compilation stage, we plot the loss (MSE) and the evaluation metrics (accuracy) values for both the train and validation datasets. We equally observe that the error difference between the training and the validation dataset is not large, and as such, there is no case of over- or under-fitting of the ANN models. Once the ‘learning’ phase of the model is finished, the prediction phase will set in. The performance of the ANN model is measured and analyzed in terms of the MSE and the MAE.
Table 6 gives the evaluation metrics for both the out-sample prediction (testing dataset) and the in-sample prediction (training dataset).
Table 6 shows the model evaluation comparison for the train/test loss and accuracy. It is observed that the test loss is greater than the training loss, and the test accuracy is greater than the training accuracy for all the models. The differences in error sizes are not significant, and thus the chances of having an overfitting model are limited.
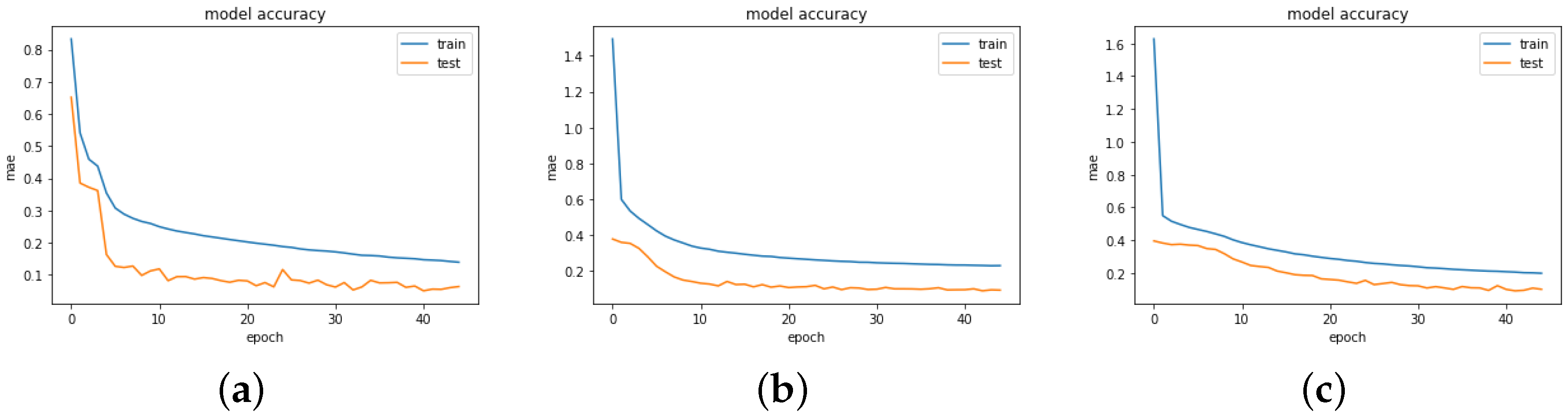
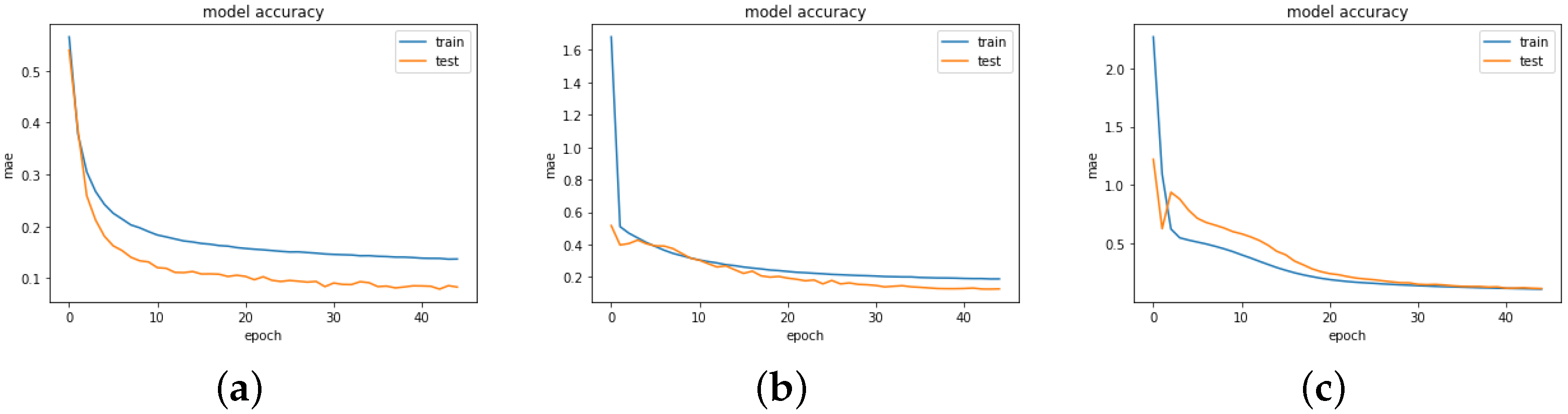
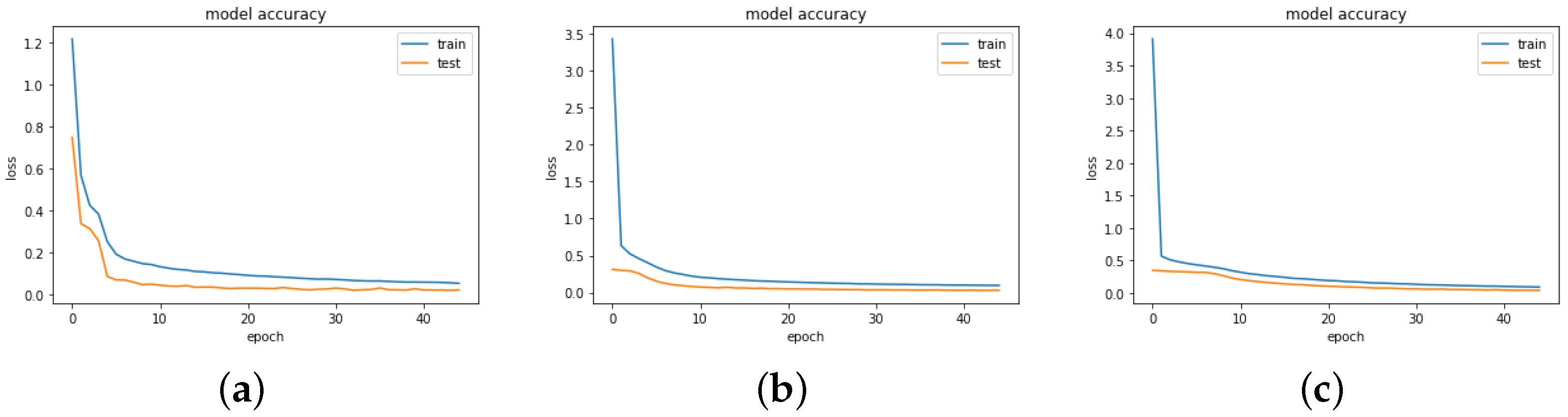
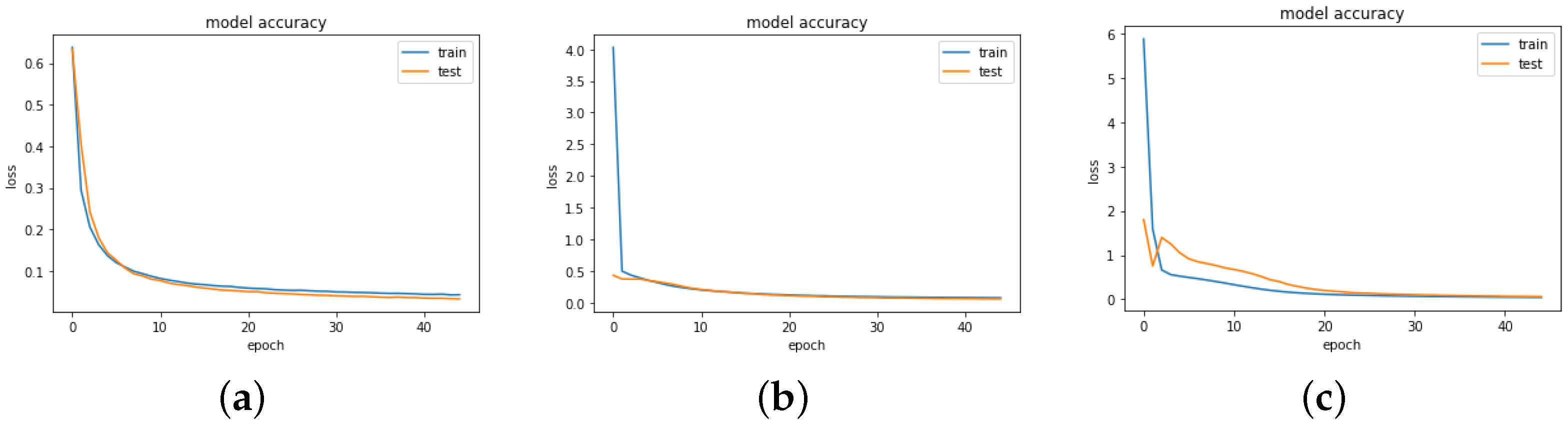
Figure 2,
Figure 3,
Figure 4 and
Figure 5 show the training and validation (test) of the loss and MAE values for all the models when the models are fitted and trained on epoch = 45, batch size = 256, and verbose = 1. We visualize these graphs to ascertain whether there was any case of overfitting, underfitting or a perfect fitting of the model. In underfitting, the NN model fails to model the training data and learn the problem perfectly and sufficiently, leading to slightly poor performance on the training dataset and the holdout sample. Overfitting occurs mainly in complex models with diverse parameters, which happens when the model aims to capture all data points present in a specified dataset. In all the cases, we observe that the models show a good fit, as the training and validation loss are decreased to a stability point with an infinitesimal gap between the final loss values. However, the loss values for Model B3 followed by Model B2 are highly optimal in providing the best fit for the algorithm.
Next, we display the plots obtained after compiling and fitting the models. The prediction is performed on the unseen data or the test data using the trained models.
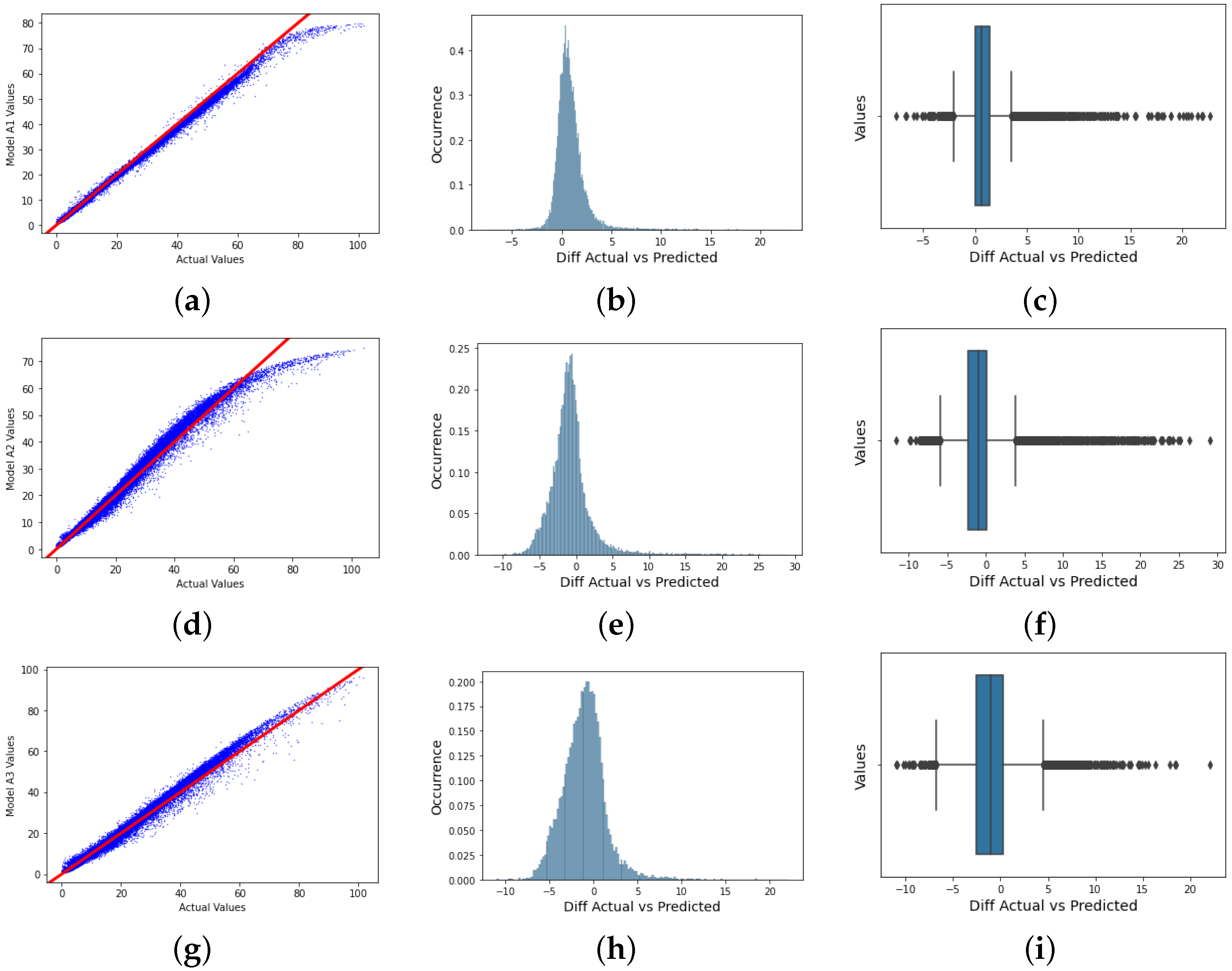
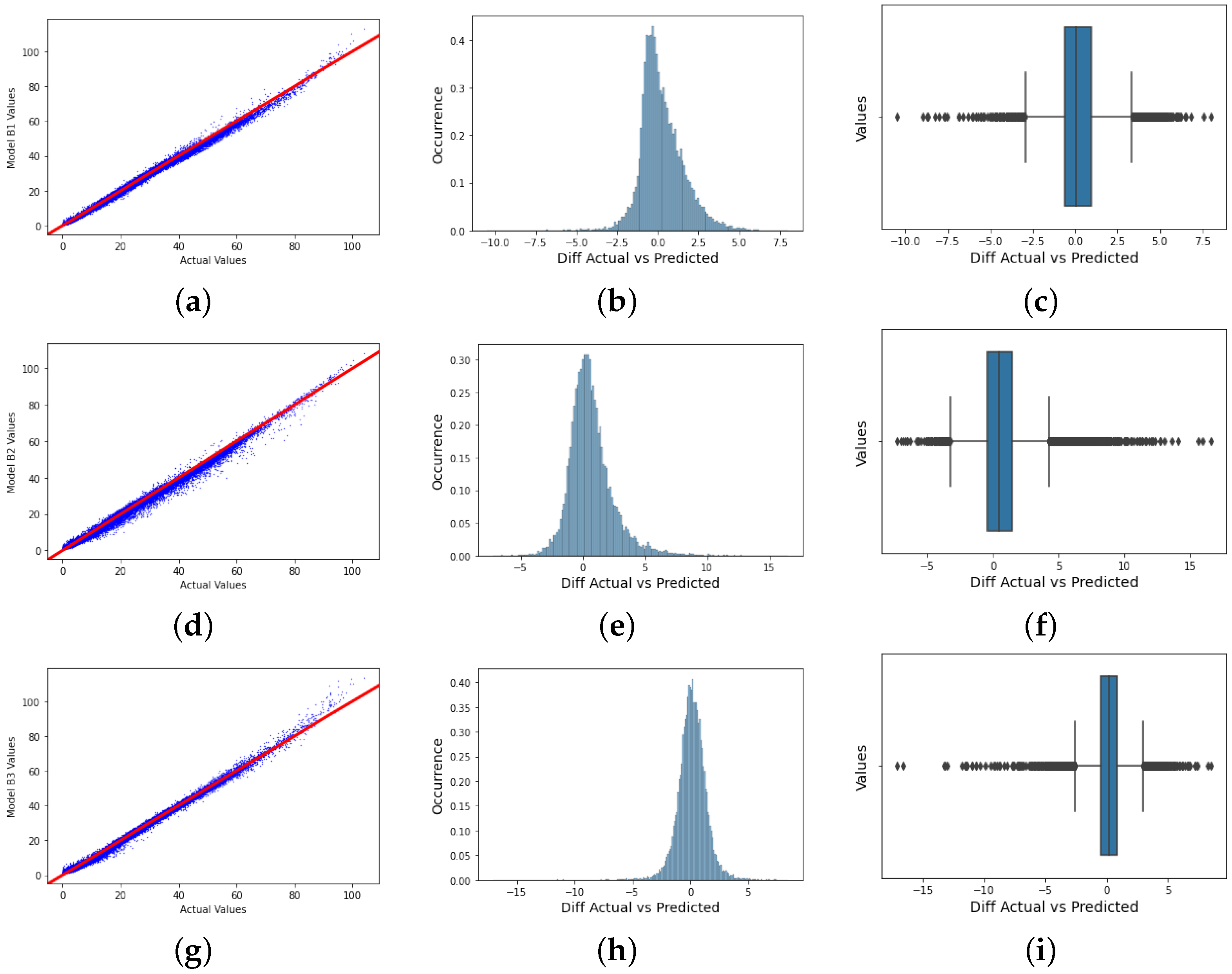
Figure 6 and
Figure 7 give the plot of the predicted values against the actual values, the density plot of the error values and the box plot of the error values for all six models.
The box plot enables visualization of the skewness and how dispersed the solution is. Model A2 behaved poorly, as this can be observed with the wide range of dispersion of the solution points, and the model did not fit properly. For a perfect fit, the data points are expected to concentrate along the red line, where the predicted values are equal to the actual values. This explanation is applicable to Models A2 and A3, as there was no perfect alignment in the regression plots. We could retrain the neural network to improve this performance since each training can have different initial weights and biases. Further improvements can be made by increasing the number of hidden units or layers or using a larger training dataset. For the purpose of this research, we already performed the hyperparameter tuning, which solves most of the above suggestions. To this end, we focus on Model B, another training algorithm.
Models B3 and B1 provide a good fit when their performance is compared to the other models, though there are still some deviations around the regression line. The deviation of these solution data points is also fewer than in the other models. It is quite interesting to note that the solution data points of Models B1 and B3 are skewed to the left, as can be seen in the box plots. This could be a reason for their high performance compared to other models, such as A1, A2, and A3, which are positively skewed. However, this behavior would be worth investigating in our future work.
Table 7 shows the error values in terms of the MSE, MAE, mean squared logarithmic error (MSLE), mean absolute percentage error (MAPE) and the
(coefficient of determination) regression score. It also shows the models’ comparison in terms of their computation speed, and it must be noted that the computation is measured in seconds. Mathematically, the MSLE and MAPE are given as
where
N is the number of observations,
is the exact option values and
is the predicted option values. For the MAPE, all the values lower than the threshold of 20% are considered ‘good’ in terms of their forecasting capacity [
45]. Thus, all the models have good forecasting scores, with Model A1 possessing a highly accurate forecast ability. Similarly, the values for the MSLE measure the percentile difference between the log-transformed predicted and actual values. The lower, the better, and we can observe that all the models gave relatively low MSLE values, with Models A1 and B1 giving the lowest MSLE values.Please check that intended meaning is retained.
From
Table 7, the
measures the capacity of the model to predict an outcome in the linear regression format. Models B1 and B3 gave the highest positive values compared to the other models, and these high
-values indicate that these models are a good fit for our options data. It is also noted that for well-performing models, the greater the
, the smaller the MSE values. Model B3 gave the smallest MSE, with the highest
, compared to the least performed model A2, which had the largest MSE and the smallest
score. The MAE measures the average distance between the predicted and the actual data, and the lower values of the MAE indicate higher accuracy.
Finally, we display the speed of the NN algorithm models in terms of their computation times, as shown in
Table 7. The computation time taken by the computer to execute the algorithm encompasses the data splitting stage, standardization of set variables, ANN model compilation and training, fitting, evaluation and the prediction of the results. As noted in Models A1 and A2, the use of Sigmoid and Tanh activation functions accounted for higher computation time, and this is due to the presence of exponential functions, which need to be computed. Model A1 was the least performed in terms of the computation time, and Model B3 was the best, accounting for a 66.56% decrease in time. We observe that the computation time is reduced when the
k-fold cross-validation split is implemented prior to the ANN model training, as compared to the traditional train–test split. This feature is evident as a further 41.62% decrease was observed when the average computation time for Model B was used against Model A.
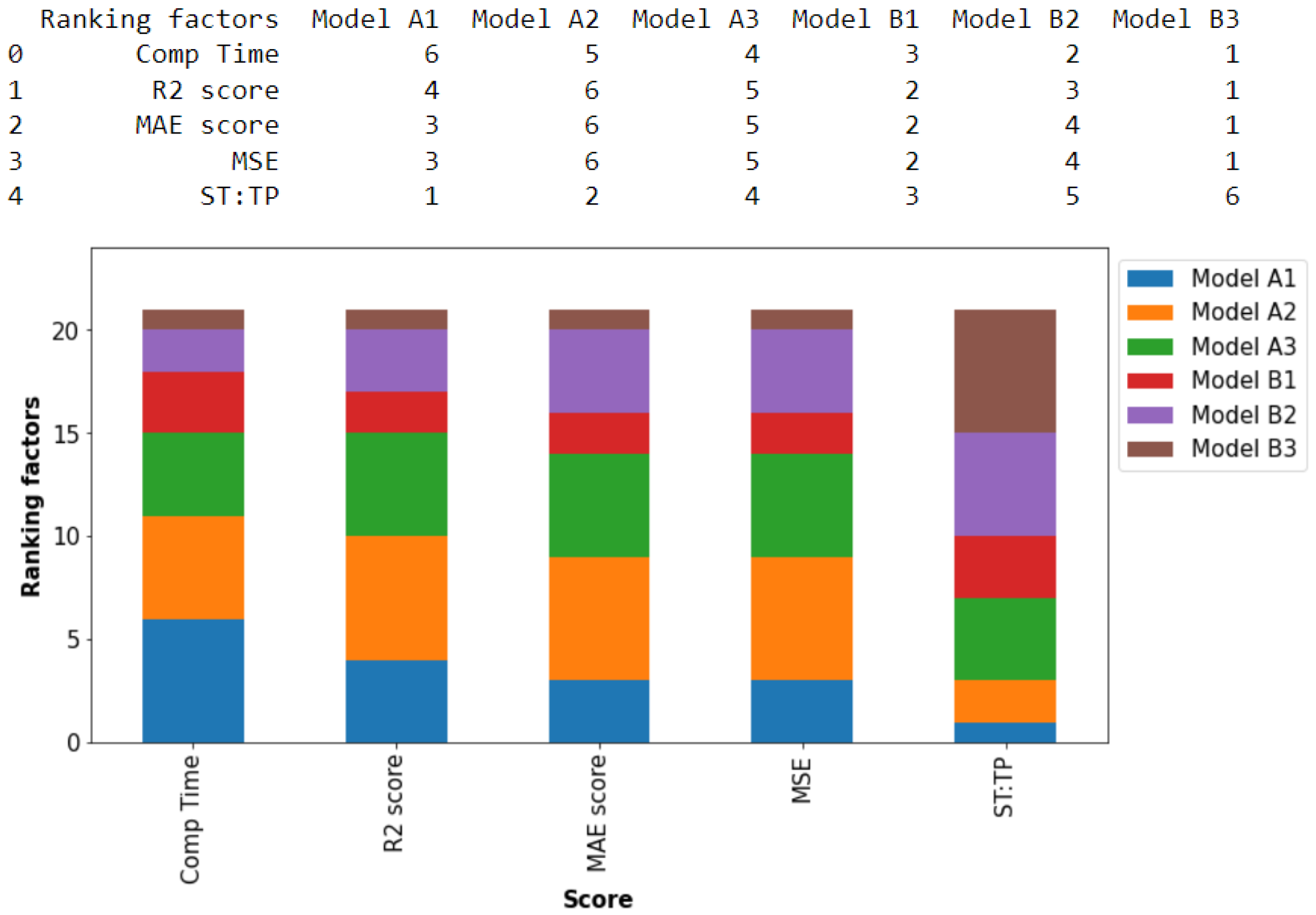
The overall comparison of the tuned models is presented in
Figure 8. Here, we rank the performance of each MLP model with regards to ST:TP, algorithm computation time, and finally, the errors spanning from the
score, MAE and the MSE. The ST:TP ratio denotes the search time per one trainable parameter. The ranking is ascending, with 1 being the maximum preference and 6 being the least preference. From the results and regardless of the number of search times per one trainable parameter, we observe that Model B3 is optimal, followed by Model B1, and the lowest performing is Model A2. Hence, we can conclude that models which consist of the
k-fold data split performed significantly well in the valuation of the rebate barrier options using the extended Black–Scholes framework.
4.3. Analysis of Result Performance
One avenue to show the accuracy of our proposed model is to test the architecture on a non-simulated dataset for the rebate barrier options. At present, we are not able to obtain such real market data due to non-accessibility, and this is one of the limitations of the research. However, we compare the NN results with other machine learning models, such as the polynomial regression and the random forest regression on the same dataset. Both techniques are capable of capturing non-linear relationships that exist amongst variables.
Polynomial regression provides flexibility when modeling the non-linearity. Improved accuracy can be obtained when the higher-order polynomial terms are incorporated, and this feature makes it easier to capture the non-complex patterns in the dataset. It is also very fast when compared to both our proposed NN methodology and the random forest regression (
Table 8). In this work, we only present the results obtained using the 2nd-, 3rd- and 4th-degree polynomial regressions. We observed that in terms of accuracy, polynomials of higher degrees gave rise to more accurate results and a significant reduction in their error components.
However, one of the issues facing the polynomial regression is model complexity; when the polynomial degree is high, the chances of model overfitting will be significantly high. Thus, we are faced with the trade-off between accuracy and over-fitting of the model. Regression random forest, on the other hand, combines multiple random decision trees, with each tree trained on a subset of data. We build random forest regression models using 10, 30, 50, and 70 decision trees, then we fit the model to the barrier options dataset, predict the target values, and then compute the error components. Finally, we compare these two models to the optimal model obtained with the NN results (Model B3), and we have the following table.
Increasing the number of decision trees leads to more accurate results, and Oshiro et al. (2012) explained that the range of trees should be between 64 and 128. This feature will make it feasible to obtain a good balance between the computer’s processing time, memory usage and the AUC (area under curve) [
46]; we observed this feature in our research. The model was tested on 80, 100, 120, 140, 160, 180, and 200 decision trees, and we obtained the following coefficient of determination
regression score (computation time): 0.9924 (34 secs), 0.9928 (52 secs), 0.9929 (62 secs), 0.9925 (75 secs), 0.9929 (83 secs), 0.9929 (89 secs) and 0.9926 (102 secs), respectively. We obtained the optimal decision tree to be between 110 and 120 with an
score of 0.9929, and any other value below 110 will give rise to a less accurate result. Any value above 120 will not lead to any significant performance gain but will only lead to more computational cost.
Table 8 compares the performance of our optimal NN model to the random forest and the polynomial regressions. The performance is measured based on the error values and the computational time. The NN model performed better than the random forest regression regardless of the number of decision trees used, and this was obvious from the results presented in
Table 8 above. On the other hand, polynomial regression of the 2nd and 3rd orders underperformed when compared to the NN model, but maximum accuracy was obtained when higher order (
) was used. This higher order posed a lot of complexity issues, which our optimal NN model does not face. Hence, more theoretical understanding is needed to further explain the phenomenon, and this current research does not account for it.
4.4. Option Prices and Corresponding Greeks
To compute the zero-rebate DO option prices and their corresponding Greeks, we simulate another set of data (1,000,000) in accordance with the extended Black–Scholes model, and the
Table 9 below gives a subset of the full dataset after cleansing.
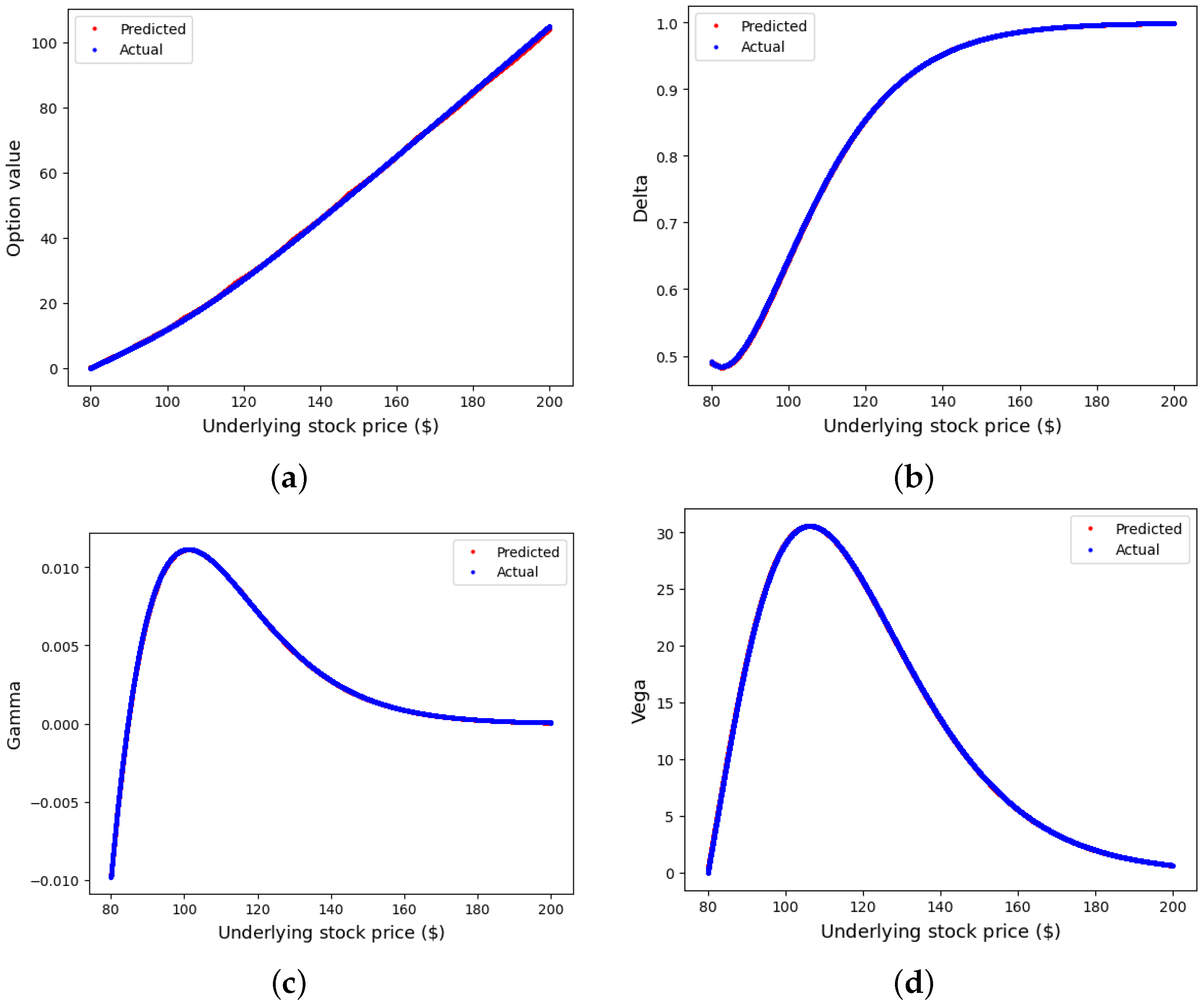
For the NN application, we used the hyperparameters of Model B3 to construct the NN architecture and train and predict the option values and their corresponding Greeks. The risks associated with the barrier options are complicated to manage and hedge due to their path-dependent exotic nature, which is more pronounced as the underlying approaches to the barrier level. For the Greeks considered here, we focus on predicting the delta, gamma and vega using the optimal NN model, and the following results were obtained.
Figure 9 shows the plot of the predicted and actual values of the DO option prices, together with the delta, gamma and vega values. For the option value, the DO call behaves like the European call when the option is far deep in-the-money, and this is because the impact of the barrier is not felt at that phase. The option value decreases and tends to zero as the underlying price approaches the barrier since the probability of the option being knocked out is very high. The in-the-money feature is equally reflected in the delta and gamma as they remain unchanged when the barrier is far away from the underlying. Here, the delta is one, and the gamma is zero.
Gammas for this option style are typically large when the underlying price is in the neighborhood of the strike price or even near the barrier, and it is the lowest for out-of-money options or knocked-out options. From
Figure 9c, gamma tends to switch from positive to negative without switching from long to short options. The values of gammas are usually bigger than the gamma for the standard call option. These extra features pose a great challenge to risk managers during the rebalancing of portfolios. Lastly, vega measures the sensitivity of the option value with respect to the underlying volatility. It measures the change in option value based on a 1% change in implied volatility. Vega declines as the options approach the knock-out phase; it falls when the option is out-of-money and deep in-the-money, and it is maximum when the underlying is around the strike price. Overall,
Figure 9a–d display how accurately Model B3 predicts the option values and their Greeks, as little or no discrepancies are observed in each dual plot.
5. Conclusions and Recommendations
This research suggested a more efficient and effective means of pricing the barrier call options, both with and without a rebate, by implementing the ANN techniques on the closed-form solution of these option styles. Barrier options belong to exotic financial options whose analytical solutions are based on the extended Black–Scholes pricing models. Analytical solutions are known to possess assumptions which are not often valid in the real world, and these limitations make them ideally imperfect in the effective valuation of financial derivatives. Hence, through the findings of this research, we were able to show that neural networks can be employed efficiently in the computation and the prediction of unbiased prices for both the rebate and non-rebate barrier options. This study showed that it is possible to utilize an efficient approximation method via the concept of ANN in estimating exotic option prices, which are more complex and often require expensive computational time. This research has provided an in-depth concept into the practicability of the deep learning technique in derivative pricing. This was made viable through some statistical and exploratory data analysis and analysis of the model training provided.
From the research, we conducted some benchmarking experiments on the NN hyperparameter tuning using the Keras interface and used different evaluation metrics to measure the performance of the NN algorithm. We finally estimated the optimal NN architecture, which prices the barrier options effectively in connection to some data-splitting techniques. We compared six models in terms of their data split and their hyperparameter search algorithm. The optimal NN model was constructed using the cross-validation data-split and the Bayesian optimization search algorithm, and this combination was more efficient than the other models proposed in this research. Next, we compared the results from the optimal NN model to those produced by other ML models, such as the random forest and the polynomial regression; the output highlights the accuracy and the efficiency of our proposed methodology in this option pricing problem.
Finally, hedging and risk management of barrier options are complicated due to their exotic nature, especially as the underlying is near the barrier. Our research extracted the barrier option prices and their corresponding Greeks with high accuracy using the optimal hyperparameter. The predicted and accurate results showed little or no difference, which explains our proposed model’s effectiveness. For future research direction, more theoretical underpinning seems to be lacking in connection to the evaluation/error analysis for all the proposed models used in this research. Another limitation of this work is the use of a fully simulated dataset; it will suffice to implement these techniques on a real dataset to estimate the effectiveness. The third limitation of this research lies in the convergence analysis of the proposed NN scheme, and future research will address this issue. In addition, more research can be conducted to value these exotic barrier options from the partial differential perspective, that is, solving the corresponding PDE from this model using the ANN techniques and extending the pricing methodology to other exotic options, such as the Asian or the Bermudian options.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}