1. Introduction
In reliability theory, a component’s life is defined using stress–strength (SS) models, which include a random strength (
) exposed to a random stress (
Y). When the stress level applied to a component exceeds its strength level, the component fails immediately. The basic SS model
was first considered in [
1]. Another important SS model is the type of
, which illustrates the situation where a strength
should not only be larger than a stress
but also smaller than a stress
As a concrete example, it is common that electronic devices are unable to function at excessively low and high temperatures, and the SS model becomes of interest to model this phenomenon. Recently, a lot of effort has been put into estimating SS models for different stress and strength distributions. The maximum likelihood estimator (MLE) and uniform minimum unbiased estimator for
were developed in [
2]. Ref. [
3] constructed estimators of
, where
,
and
were all random variables that follow the normal distribution. Ref. [
4] investigated an estimator of
, where the stresses and strength were exponentially distributed. Ref. [
5] offered an estimate of
for the Weibull distribution in the presence of outliers. The estimation of
when the strength and stress random variables follow the Dagum distribution was explored in [
6,
7]. Ref. [
8] studied the reliability estimator of
from the inverse Rayleigh distribution using data outliers. Ref. [
9] looked into some classical estimation methods, assuming an inverse Rayleigh distribution for both stresses and strength random variables. Ref. [
10] dealt with the SS parameter, when
X,
and
had three independent Kumaraswamy distributions.
On the other hand, an efficient and successful alternative for simple random sampling (SRS) is ranked set sampling (RSS). When the sampling units are expensive and challenging to measure, this is frequently used to obtain samples that are more representative of the underlying population, simple and inexpensive to order in accordance with the variable of interest. Numerous studies have been conducted on alterations of the RSS procedure. The reader can find further information on the RSS system in, for example, [
11,
12,
13,
14]. Several authors have performed studies concerning the reliability estimation of SS models under the RSS, including [
15,
16,
17,
18,
19].
To the best of our knowledge, there have been no papers published that employed RSS design to assess the reliability parameter of type in the literature. Thus, our motivation here was to assess the reliability estimator of using the maximum likelihood procedure, given that stresses and strength are three independent random variables that follow the generalized inverse exponential distribution (GIED) with distinct shape parameters and a similar scale parameter. The reliability estimator of is discussed in the following cases:
- (i)
The first and second reliability estimators of were derived when X, and Z are independent random variables with the same sampling design (RSS or SRS).
- (ii)
The third estimator of was constructed when the observed stress random variables and came from the RSS and the data for strength random variable came from the SRS.
- (iii)
Finally, we obtained the fourth estimator, assuming that the observed samples of and came from the SRS design, and the data of X came from the RSS scheme.
Furthermore, a simulation study employing iterative methods, such as the Newton–Raphson algorithm, was used to compare the performance of various estimators, based on certain accuracy measures. Finally, real datasets were analyzed for illustrative purposes.
The rest of this article is organized as follows: A description of the RSS scheme is given in
Section 2.
Section 3 contains the exact formulation of
based on the GIED. The MLE of
is derived using the SRS and RSS in
Section 4 and
Section 5, respectively.
Section 6 gives the reliability estimator of
, assuming the observed samples of
and
come from the RSS, and the selected samples of
come from the SRS.
Section 7 provides the reliability estimator of
, assuming the collected samples of
and
are selected from the RSS, and the selected samples of
are taken from the SRS.
Section 8 contains a simulation study and its results. Three real data sets are provided in
Section 9, to examine the behavior of the proposed estimators. Finally, in
Section 10, we bring the paper to a close.
2. Structure of Ranked Set Sampling
In contrast to the same number of observations collected from SRS, the goal of RSS design is to collect observations from a population that are more likely to cover the entire range of values in the population. RSS has numerous applications in science, particularly in environmental and ecological studies, where the main focus is on cost-effective and efficient sampling techniques. Ref. [
20] pioneered the theory of RSS in cases where the quantification of sample items is too expensive or impossible, but the variable to be monitored may be ranked more readily and cheaply than measured. The authors claimed that using RSS to estimate a population’s mean is far more useful and preferable to using SRS. Ref. [
21] demonstrated mathematically that the RSS mean estimator outperformed SRS.
2.1. RSS Description
The steps listed below provide an explanation of RSS
Randomly select
n2 units from the targeted population and arrange them into
n sets, each of size
n. We denote the result by
- 2
The
n units within each set are sorted according to the variable of interest using visual examination or any other inexpensive approach. The number of units,
n, in each row is called the set size. The result is presented as
- 3
After ranking all sets, the smallest ranked unit is quantified from the first set. Similarly, the second smallest ranked unit is quantified from the second set, and the procedure continues until the largest ranked unit is quantified from the last set. As a result, the RSS associated with this cycle will be . The measured observations constitute a balanced RSS of size n, where the descriptor “balanced” refers to the fact that we have collected one judgment order statistic (OS) for each of the ranks 1, 2, …,n.
- 4
Repeat steps (1)–(3) d times (cycles) until obtaining a sample of size where n is the set size. The RSS of sample size , will be It should be noted that we use the notations , rather than for the sake of brevity, then the RSS can be written as
If the judgment ranking is perfect, the probability density function (PDF) of
ith OS
is given by
2.2. Choices of Set Size and Cycle Number
Any RSS procedure’s performance is highly dependent on the set size. Each measured RSS observation uses additional information derived from its ranking compared to
n − 1 other units in the population for a given set size
n. Perfect rankings is preferable to use a set size
n that is as large as is economically feasible, given the resources at our disposal. In order to achieve ideal rankings, we would like to increase the set size
n to the maximum level that is economically feasible given the resources at our disposal. It is also evident that the likelihood of ranking errors increases with the set size, i.e., the larger
n is, the more probable ranking errors are to occur. As a result, in order to best choose the set size
n, one must be able to estimate the probability of imperfect rankings and evaluate how they will affect the RSS statistical methods [
22]. Ref. [
20] suggested that set sizes larger than five would probably not improve the efficiency of the RSS very much because set sizes this large would likely result in too many ranking errors.
3. Description of the Model
In this section, we provide an expression for system reliability assuming that the random variables , and follow the GIED with different shape parameters. For this, we need a short review of the GIED.
Inverted distributions were created to address certain laws in several widely used distributions in a variety of fields, including the biological sciences, survival research, and engineering sciences. Different aspects of the behavior of the related probability functions may be seen in these distributions. Ref. [
23] proposed a useful two-parameter extension of the inverted exponential distribution, known as the GIED. They mentioned that the GIED offers a superior fit than the gamma, Weibull, generalized exponential, and inverted exponential distributions in a number of situations. The probability density function (PDF) of the GIED with the shape parameter
and the scale parameter
is given by
The cumulative distribution function (CDF) of the GIED is given by
The hazard rate function (HRF) of the GIED is given by
Ref. [
24] mentioned that the GIED is a special case of the exponentiated Fréchet distribution. Due to the CDF closed shape, the GIED is frequently used in studies, including accelerated life testing, horse racing, grocery store lines, sea currents, wind speeds, and a variety of other topics (see [
25]).
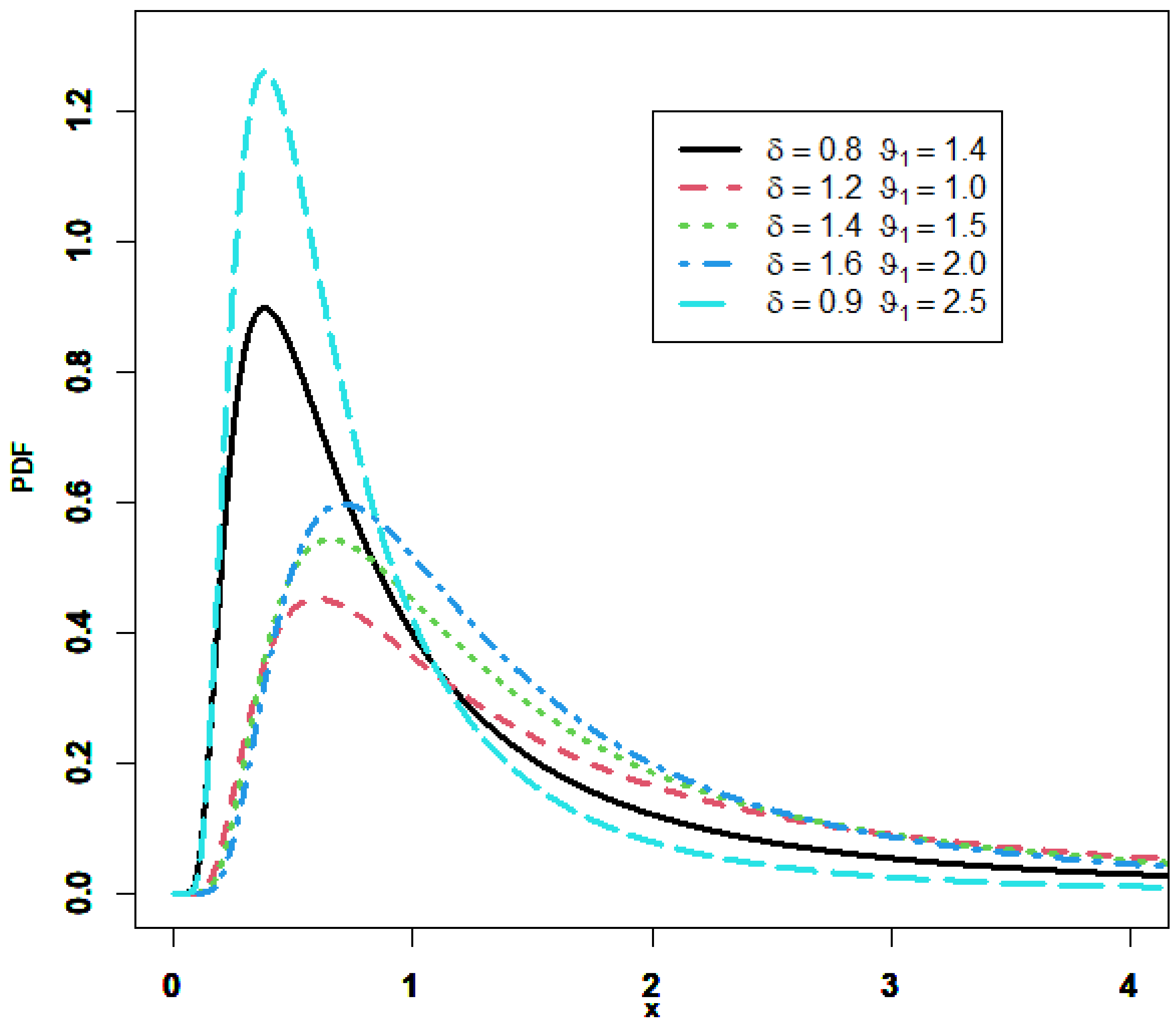
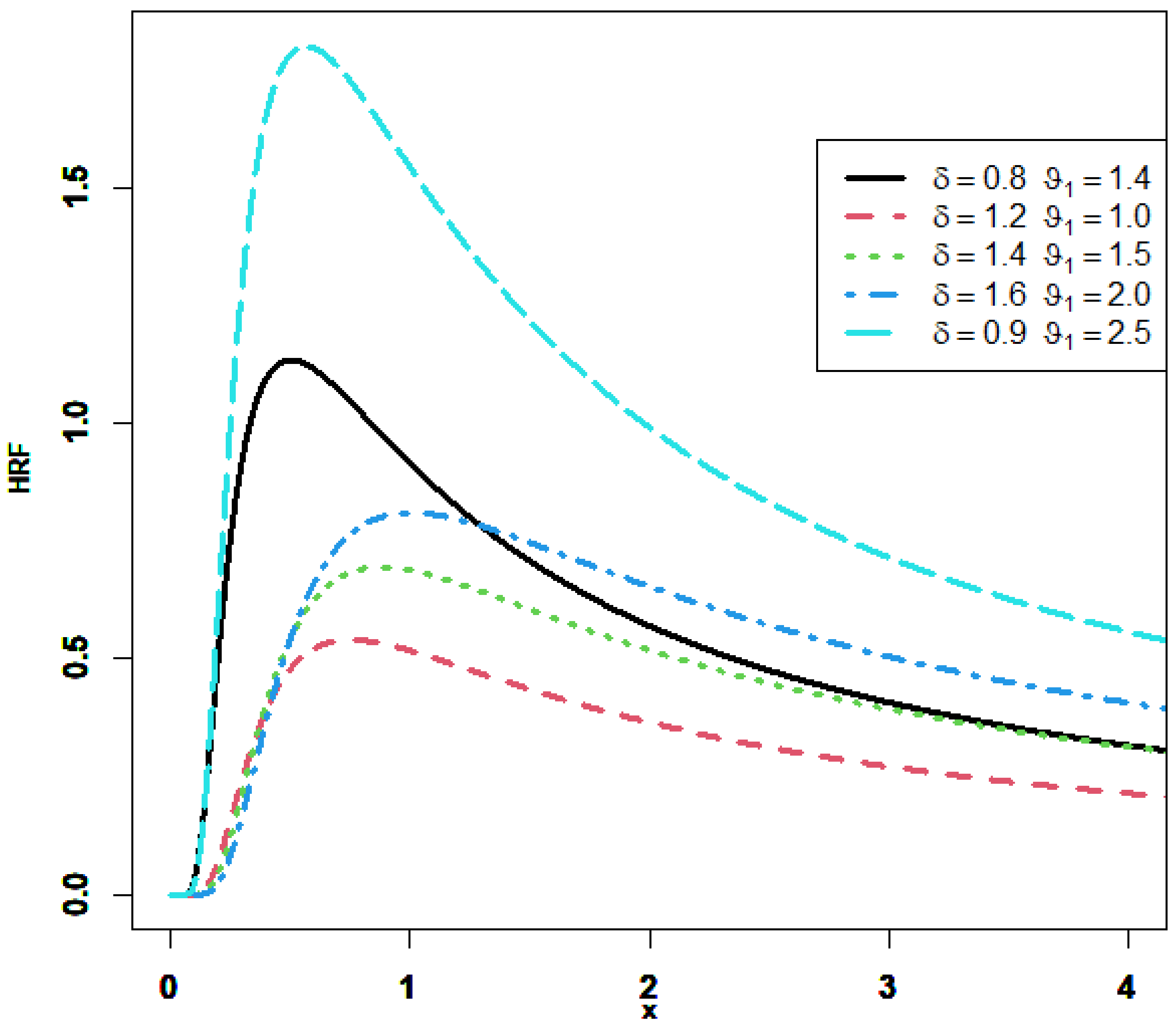
Figure 1 displays the different forms achieved with the PDF. We can observe that it is right-skewed and unimodal. Depending on the distribution’s shape parameter, the HRF of the GIED increases then decreases, in an upside-down shape, but it is not constant, as illustrated in
Figure 2.
Researchers have made various contributions and applications in various fields using different types of data relevant to the GIED. For example, in reliability studies, Ref. [
26] explored reliability estimates for the GIED in progressively censored samples. A parameter estimation for the GIED using different methods and schemes was provided in [
27,
28]. In statistical quality control, Ref. [
29] discussed a two-stage acceptance sampling plan for the GIED. Under hybrid random censoring, Ref. [
30] presented the Bayesian inference on the GIED parameters. In life testing experiments, Ref. [
31] investigated the estimation and prediction for the GIED based on progressively censored first-failure data. Ref. [
32] looked into Bayesian estimators and SS reliability (SSR) estimators related to the GIED, based on progressively censored first-failure data. Ref. [
33] investigated parameter estimation in the context of the GIED using an adaptive progressive hybrid censoring scheme. Ref. [
34] investigated the reliability of Bayesian analysis in multicomponent SS for the GIED using upper record data. Ref. [
35] investigated a competing risks model where the lifetimes were independent random variables that followed the GIED.
To obtain SSR,
let the strength
~GIED
the stress
~GIED
, and stress
~GIED
, where
,
and
are independent random variables (the tilde notation meaning “follows the distribution”). According to Ref. [
3], the reliability formula of the SS model of
takes the following form:
where
is the CDF of
,
is the CDF of
at
x, and
is the survival function of
at
x. Hence,
is derived as follows:
Let
then
obtains the following ratio-parametric formula:
It is worth noting that the SS parameter in (7) is dependent on the parameters and
4. Estimator of
In this section, the MLE of
, say
is discussed, where
and
are independent random variables of the GIED with parameters
, and
respectively, under the SRS. To calculate the MLE of
, we first obtain the MLE of
, and
The joint log likelihood function of the random samples
, and
is
where
The equations below are determined using differentiation (Equation (8)) linked to the population parameters.
where
and
Put (9)–(11) with zero to yield the MLEs of
and
as a function of
They are explicated as:
Set (13) in (12) and equate with zero, which leads to the following equation:
Using the Newton–Raphson iterative method, the MLE of , say is produced from (14). Hence, the MLEs of and say and are yielded by inserting in (13). The SS estimator is also provided by putting and in (7).
5. Estimator of
In this section, the MLE of , say , is obtained where strength , and stresses and , are independent random variables that follow the GIED with parameters , and respectively, using the RSS method.
Let represent the OS of the kth sample, k = 1, 2, …, n1, in the ath cycle, a = 1, 2, …, dx, from the GIED Hence, the RSS of the strength for (dx) cycle with sample size , where a = 1, 2, …, dx, and the set size, is represented as
Similarly, let , be the OS of sth sample, s = 1, 2, …,n2, in the bth cycle, b = 1, 2,…,dy, from the GIED Hence, the RSS of the stress for (dy) cycle with sample size , where, b = 1, 2,…,dy and the set size, is represented as
In addition, suppose that is the OS of tth sample, t = 1, 2, …,n3, in the cth cycle, c = 1, 2, …,dz, from the GIED Hence, the RSS of the stress for (dz) cycle with sample size , c = 1, 2, …,dz, and the set size is represented as
It is worth noting that the PDFs of
,
and
are equivalent to the PDFs of the
kth,
sth, and
tth OS, respectively. Based on PDF (1), the likelihood function of
,
and
using the RSS is given by
where
respectively,
The log-likelihood function, based on the RSS, is obtained as
The MLEs of
, and
are obtained by maximizing this function with respect to the parameters, and can be generated as follows:
Thus, the MLEs of , ,
, and are obtained by placing (15)–(18) to zero and solving numerically with an iterative technique, such as the Newton–Raphson algorithm; we obtain by putting these MLEs in (7).
6. Estimator of
In this section, the MLE, , is determined when the strength data of are taken from the SRS, while the stresses data of and Z are taken from the RSS design. We assume that ~GIED~GIED and ~GIED and that , and are independent.
Let
be a SRS observed from the GIED
Let
, be the OS of
sth sample,
s = 1, 2, …,
n2, in the
bth cycle,
b = 1, 2, …,
dy, with sample size
from the GIED
In addition, suppose that Z
tc is the OS of the
tth sample,
t = 1, 2, …,
n3, in the
cth cycle,
c = 1, 2, …,
dz, with sample size
from the GIED
The likelihood function
in this case is as follows:
The log-likelihood function, denoted by
is given by
The MLEs of
and
are derived by maximizing
with respect to them. The first partial derivatives of
, and
are produced in (9), (17), and (18). The first partial derivative of
is
Setting (9), (17), (18), and (19) to zero and solving numerically the yield MLEs of , and Then inserting these MLEs in (7) yield
7. Estimator of
In this section, the MLE, is obtained when the data of are collected from the RSS, while data of and Z are observed from the SRS design. We assume that ~GIED ~GIED, and ~GIED and that , and are independent.
Let
represent the OS of the
kth sample,
k = 1, 2, …,
n1, in the
ath cycle,
a = 1, 2, …,
dx, from the GIED
Let
be an SRS observed from the GIED
Let
be an SRS observed from the GIED
The likelihood function
in this case is as follows:
The log-likelihood function is given by
The MLEs of
, and
are obtained by maximizing this function with respect to the parameters. In order to obtain them via analytical equations, the first partial derivatives of
, and
are supplied in (16), (10), and (11). The partial derivative of
is yielded as
Thus, the MLEs of , and are obtained by setting (16), (10), (11), and (20) to zero and solving numerically. Consequently, is calculated after putting the MLEs of , and in (7).
8. Simulation Examination
In this section, we performed an extensive simulation study, to explore the behavior of various estimators under the suggested sampling procedures. The measures of precision, including the absolute bias (AB), standard error (SE), mean squared error (MSE), and relative efficiency (RE) were employed. The algorithm via MathCAD 14 is outlined in the following steps:
- ▪
The true parameters values of are selected as (1.8, 30, 0.6, 0.5), (2.35, 40, 0.49, 0.5), (5, 45, 0.5, 0.5), and (8, 185, 0.5, 0.5). The associated values of are as follows: 0.694, 0.773, 0.81, and 0.9. The number of cycles was selected as dx = dy = dz = d = 5 in all experiments.
- ▪
The observed SRS and , where the sample sizes are (10,10,10), (20,20,20), (30,30,30), (20,10,20), (30,10,30), (10,20,10), (10,30,10), (30,20,30), and (20,30,20).
- ▪
The RSS of , , and , are represented, respectively, by ; where a = 1, 2, …, dx, b = 1, 2 …, dy, c = 1, 2, …,dz, having set the following sizes: (n1, n2, n3) = (2,2,2), (4,4,4), (6,6,6), (4,2,4), (6,2,6), (2,4,2), (2,6,2), (6,4,6), and (4,6,4). Hence, the sample sizes are (10,10,10), (20,20,20), (30,30,30), (20,10,20), (30,10,30), (10,20,10), (10,30,10), (30,20,30), and (20,30,20), where the number of cycles is dx = dy = dz = d = 5.
- ▪
Generate 1000 SRS and RSS from ~GIED, ~GIED, and ~GIED using the inversion method.
- ▪
Under the selected sampling design, the estimates of the parameters as well as their reliability estimates and were calculated.
- ▪
The AB, SE, and MSE were calculated using the following relations:
- ▪
The efficiencies of the different estimates under selective schemes with respect to the SRS were defined by
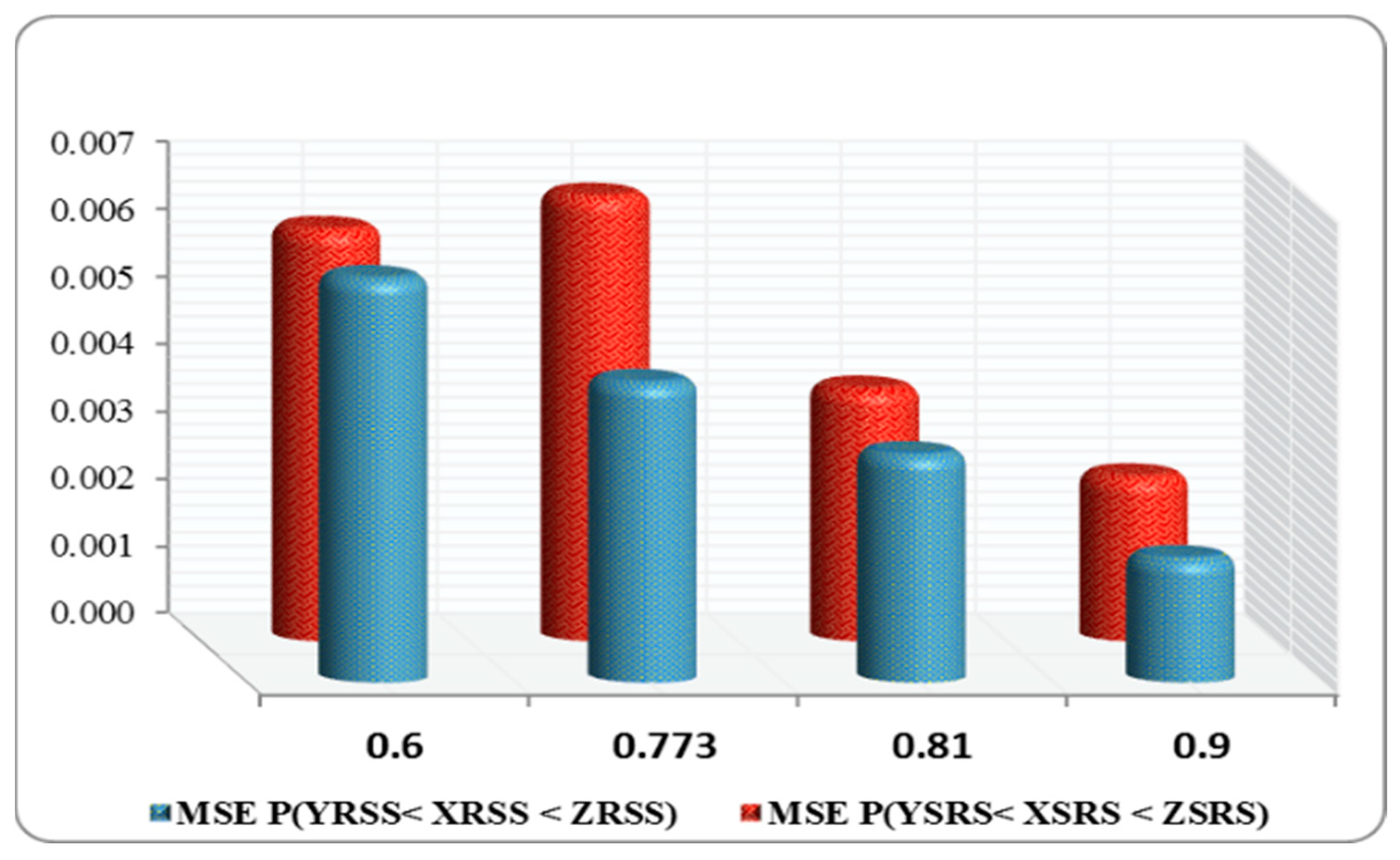
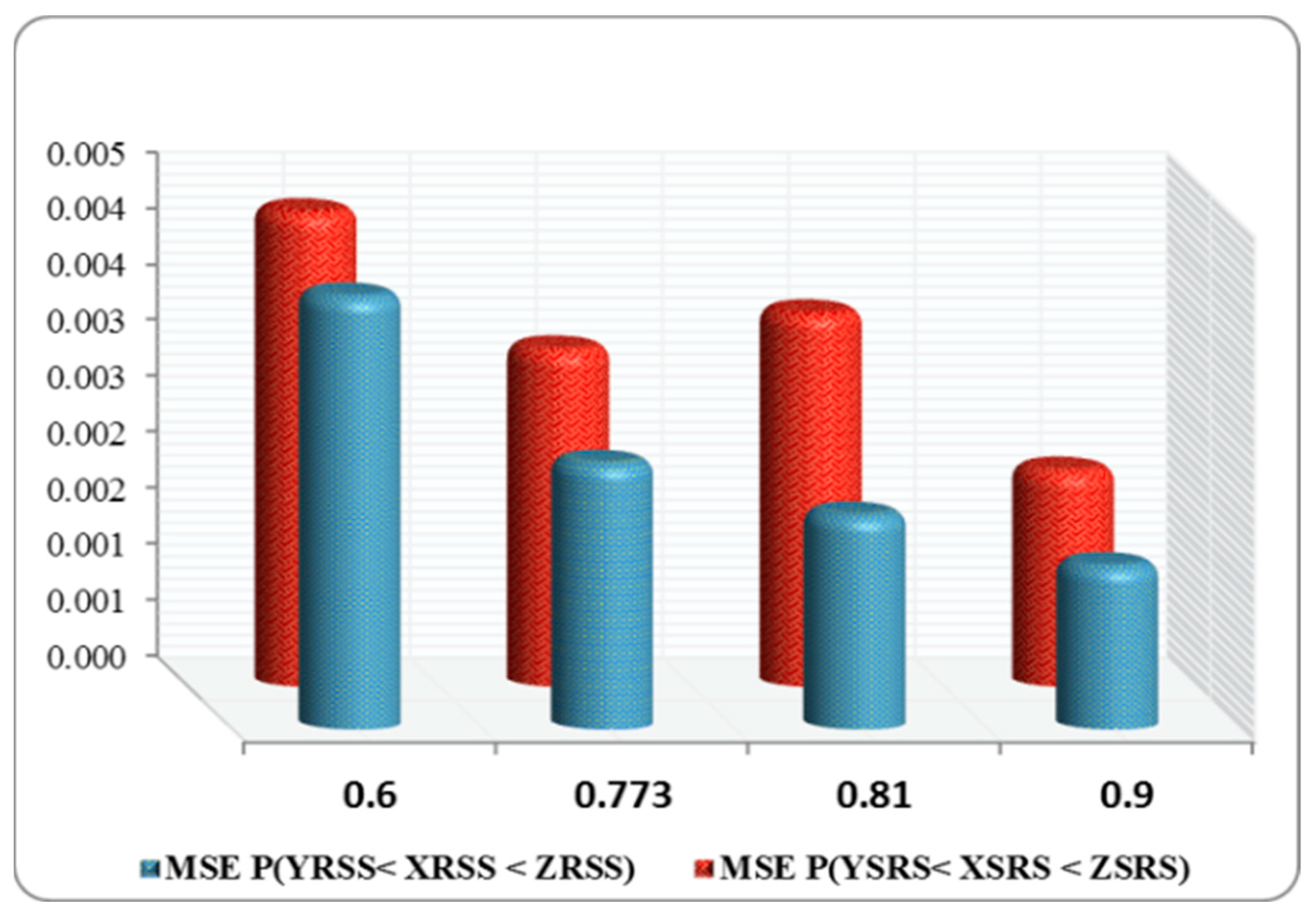
The values of the AB, SE, MSE, and RE are summarized in
Table 1,
Table 2,
Table 3,
Table 4,
Table 5,
Table 6,
Table 7 and
Table 8. From the numerical outcomes given in
Table 1,
Table 2,
Table 3,
Table 4,
Table 5,
Table 6,
Table 7 and
Table 8 and
Figure 3,
Figure 4,
Figure 5 and
Figure 6, we can conclude the following:
- ▪
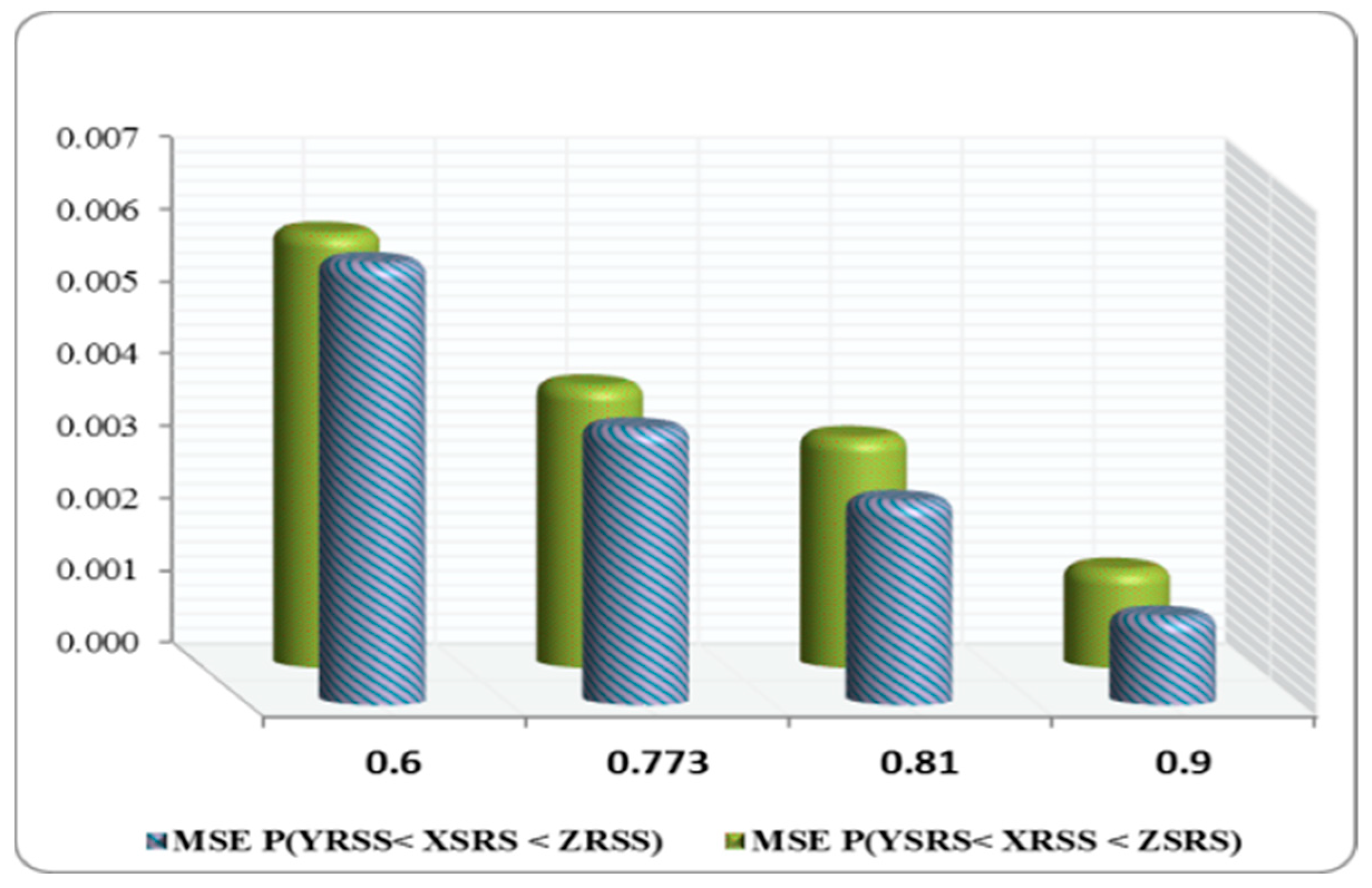
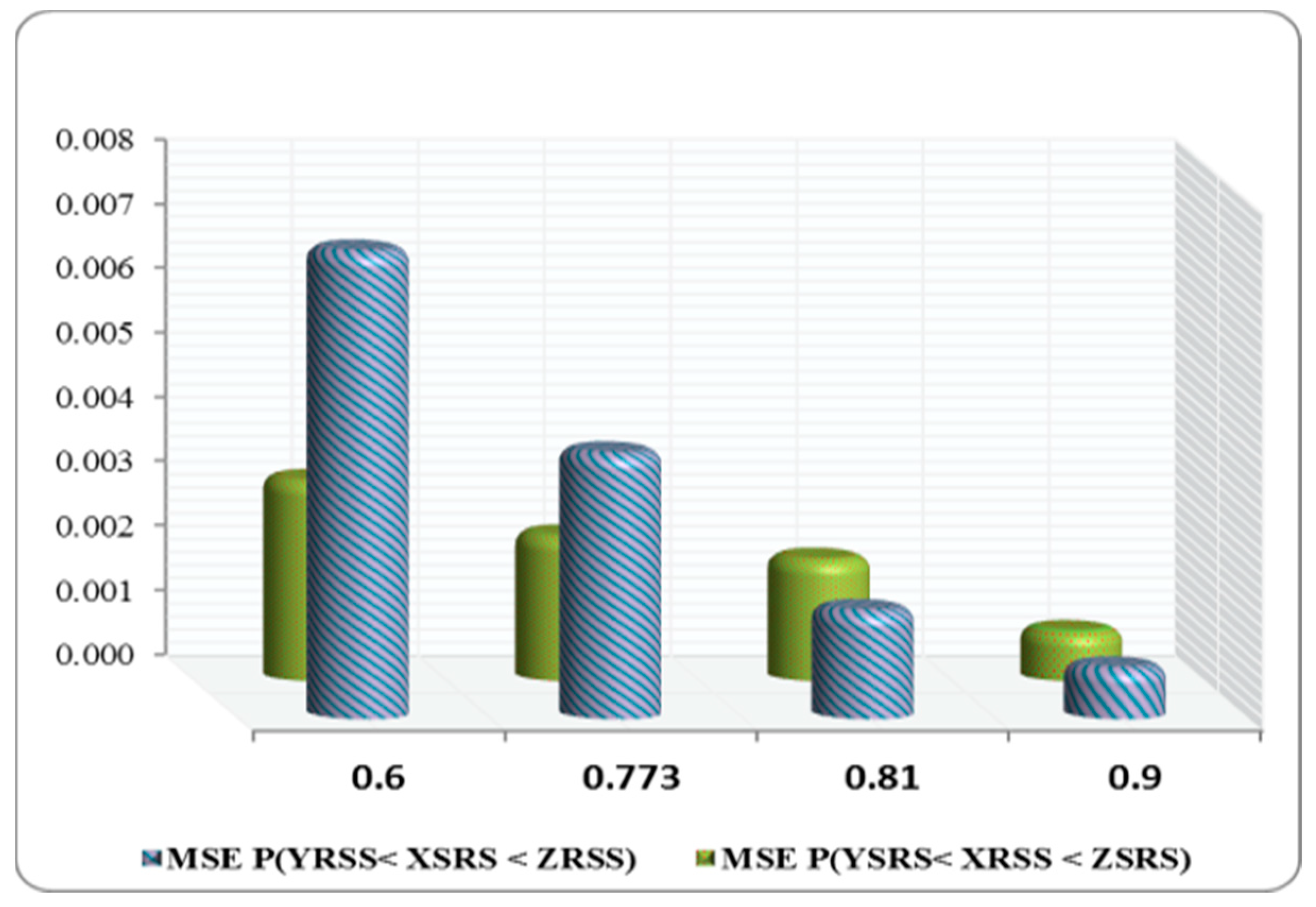
Table 3 and
Table 5 indicate that, in all cases, where
= 0.81 and 0.773, the reliability estimates obtained using the RSS approach were more efficient than those obtained using the SRS scheme.
- ▪
At the true value
= 0.81, the MSEs of
were more efficient than
in all cases (see
Table 4).
- ▪
Table 7 shows that
is more efficient than
in all situations.
- ▪
- ▪
For all true values of
where
(30,30,30), (30,20,30), (20,30,20), (10,30,10), and (10,20,10), the SEs of
based on the SRS, had larger values compared to
via the RSS (see
Table 1,
Table 3,
Table 5 and
Table 7).
- ▪
The SEs of
had the lowest values when compared to
for all true values of
and sample sizes (see
Table 2,
Table 4 and
Table 6).
- ▪
The MSEs of
gave the lowest values comparable with
for all sample sizes at
= 0.694 except for
) = (2,10,2) (see
Table 8).
- ▪
Table 6 clearly indicates that the MSEs of
are the lowest when compared with
for all sample sizes at
= 0.773 with the exception of
) = (2,10,2) and (2,20,2).
- ▪
For all sample sizes, at actual value
= 0.81, the MSEs of
and
had the minimum values compared with
and
respectively (see
Table 3 and
Table 4).
- ▪
Except for in a few cases, the MSEs of
obtained the minimum values when compared to
for all the sample size values (see
Table 1,
Table 3,
Table 5 and
Table 7).
9. Data Analysis
In this section, three data sets were considered and are described in detail, to illustrate the usefulness of the proposed models. The first two data sets were originally documented in [
36], and they show the strength measured in GPA for single carbon fibers of lengths of 10 mm (
: Data I,
n2 = 63) and 20 mm (
: Data II,
n1 = 69), which fit the GIED model (see [
17]). The Kolmogorov–Smirnov (K-S) distances were 0.086, and 0.041 for Data I and II, with 0.739 and 0.999
p-values, respectively. The fitted models based on these two data sets are provided in
Figure 7.
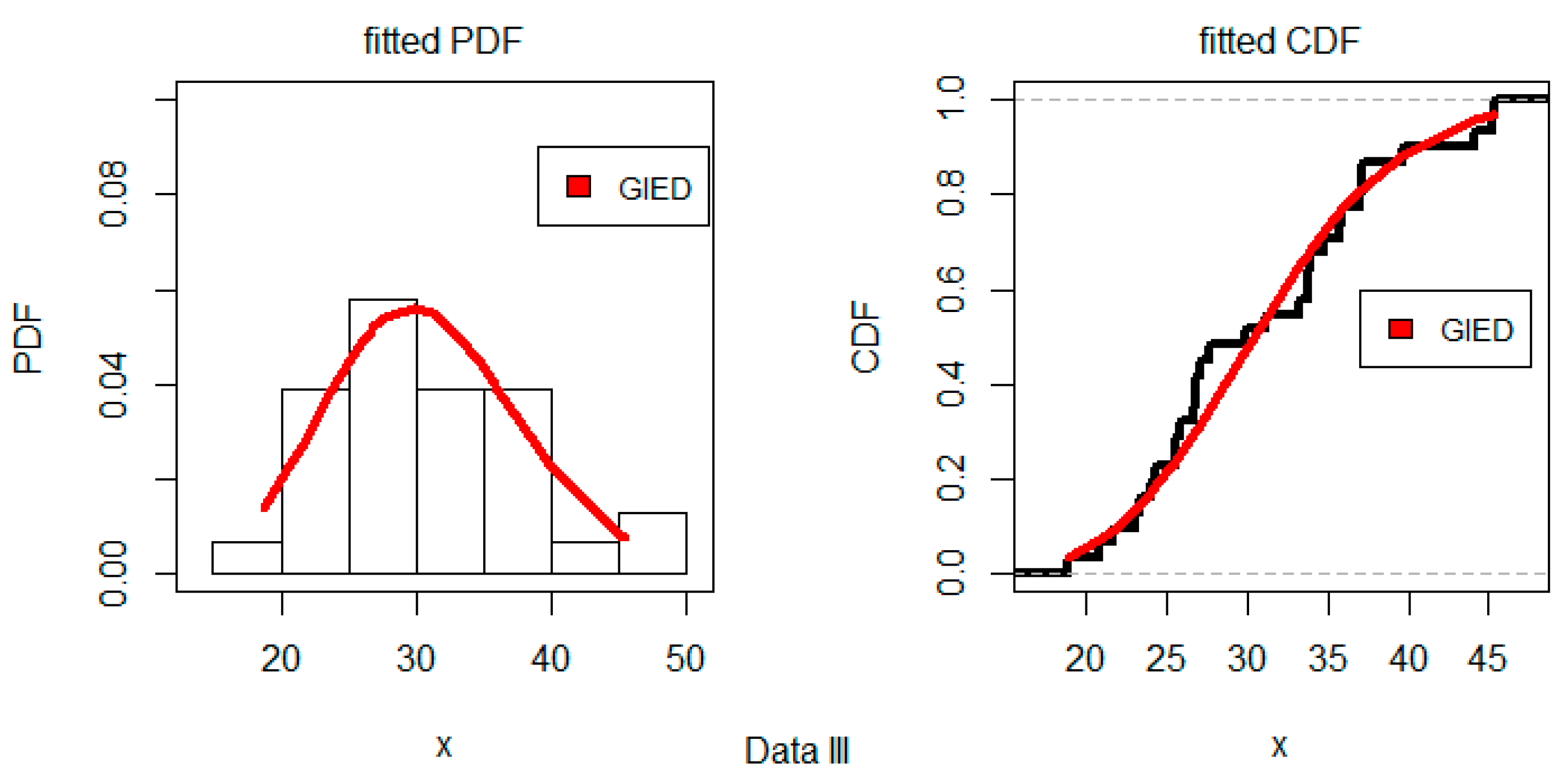
The set Data III (
) was provided by Ed Fuller of the NICT Ceramics Division in December 1993. It contains
n3 = 31 polished window strength data. Ref. [
37] described the use of this set to predict the lifetime of a glass airplane window. Here, we tested Data III against the fitted model using a KS test, where its distance was 0.138 and the corresponding
p-value was 0.595. This shows that the GIED fits this data set rather well.
Figure 8 shows the estimated PDF and CDF for the Data III. The GIED appeared to be an appropriate model for fitting these data based on this graph.
The RSS and SRS sampling procedures were used to examine real data sets based on the preceding theoretical conclusions. The RSS and SRS were produced using the R-package RSSampling and Data I, II, and III. The SSR estimates were calculated in the following cases:
- (i)
SS models with common scale parameters
Assuming that the strength
~GIED
the stress
~GIED
, and stress
~GIED
, where
,
and
are independent random variables. The SSR estimates were calculated from the GIED for different values of set size under five cycles, using four distinct scenarios, as seen in
Table 9.
- (ii)
The SS models with dissimilar scale parameters
Suppose that
~GIED
Y~GIED
, and
~GIED
the ML estimates of the model parameters and the SSR estimates were calculated under different RSS and SRS using the four proposed sample cases. In addition, the Fisher information matrices as well as their corresponding SEs are displayed between parentheses using Data I, II, and III.
Table 10 presents the parameter estimates, SSR estimates, and SEs for the different RSS and SRS.
- (iii)
Count Frequency of Data
Here, we calculate the empirical estimates of the probabilities P(Y < X < Z) from the equal samples X, Y, and Z, using different sampling designs from Data I, II, and III. These probabilities were obtained as count numbers by checking whether the samples from X, Y, and Z satisfied Y < X < Z. These calculations are provided in
Table 11.
10. Conclusions
We considered estimating an SSR, say when the strength X is accompanied by two stresses, Y and Z, that are independent but not identically distributed random variables from the GIED. The SSR estimators were considered based on four scenarios for the situation of SRS and RSS. The SSR estimators were constructed when the strength data were acquired from the RSS, while the stress data were taken from the SRS, and conversely. In addition, the SSR estimators were produced when the strength and stress data were accessible from the RSS/SRS. Finally, a simulation procedure was employed to compare the results of the various estimators. Three data sets were used to provide a real-world example that produced the following findings. In general, we concluded that the SSR estimators were more efficient when the strength random variable X was based on RSS, rather than on the SRS scheme, no matter what the stresses were. It is hoped that our research will be valuable to researchers working with the data used in the present study.


 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}