1. Introduction
Optimization between risk and cost is an important topic in the field of industrial and systems engineering. In past decades, researchers have paid attention to risk assessment and optimization methods for complex systems based on probability theory, such as Faddoul et al. [
1], Hong et al. [
2], Liu et al. [
3], Ma et al. [
4] and Yousefi et al. [
5]. However, to take probability theory as a mathematical basis for risk evaluation and optimization, three basic premises need to be met at the same time: events need to be clearly defined; there are a large number of samples; there is probability repeatability between samples. and In the field of engineering, it is difficult to obtain sufficient data. Therefore, experts are invited to evaluate the technical condition of systems, which are often described with ambiguous language. In 1965, Zadeh [
6] proposed the concept of fuzzy set to deal with imprecise and subjective information. After that, researchers began to deal with various optimization problems in fuzzy environments, such as Mortazavi [
7], Sayyaadi and Baghsheikhi [
8], Yang et al. [
9], Zhou et al. [
10], and so on. Unfortunately, Liu [
11] showed that fuzzy theory is unsuitable for modeling belief degree via a counter example of the strength of a bridge. A similar situation exists in the field of system risk evaluation. For example, system risk is evaluated by experts as approximately 0.0. If the system risk is regarded as a triangular fuzzy variable (0.005, 0.01, 0.015), it can be concluded that the possibility of the system risk is exactly 0.01 is 1 and the possibility of the system risk is not 0.01 is 1 based on the possibility measure. It is usually thought that the possibility of the system risk is exactly 0.01 is 0. In addition, the system risk is exactly 0.01 and the system risk is not 0.01 have the same possibility measure. This contradictory conclusion also shows that the belief degree of experts is unsuitable for modeling by the possibility measure because it does not have a duality property.
In order to measure belief degree, uncertainty theory was founded by Liu [
12] and refined by Liu [
13] based on normality, duality, subadditivity, and product measure axioms. In recent years, uncertainty theory has been widely used in various fields, such as reliability analysis [
14], inference controller [
15], risk assessment [
16], and statistics [
17]. In terms of optimization problems, uncertainty theory is still an effective mathematical modeling tool. For instance, Ke and Yao [
18] regarded the units as uncertain variables and proposed a block replacement strategy in uncertain environments. Liu et al. [
19] gave the upper and lower bounds of insurance premiums with uncertain random losses and established a mathematical model of an optimal insurance problem. Zhang and Peng [
20] solved the uncertain optimal assignment problem by giving the uncertainty distribution of the optimal assignment profit. Li et al. [
21] regarded the return rate of risky assets as an uncertain variable and established an uncertain model for portfolio optimization. Li et al. [
22] provided a new reliability metric that encompassed two types of task time uncertainties and developed a multiple objective to maximize the reliability and efficiency of assembly lines. Wen et al. [
23] presented the minimal expected backorder model and the minimal backorder rate model with the constraints of costs and supply availability based on an uncertain measure. Li et al. [
24] derived some useful theorems related to the optimal solutions by modeling the uncertain task time. Guo et al. [
25] established a multiechelon multi-indenture optimization LORA model that took the best cost-effectiveness ratio as the criterion.
GA and NSGA-II, as well-known evolutionary algorithms for solving optimization problems, have been successfully applied to different real-world applications, including reliability optimization.
Andrews and Bartlett [
26] used GA for the single objective optimization of a firewater deluge system on an offshore platform, in which the system was presented with the structure of a fault tree. Pattison and Andrews [
27] described a design optimization scheme for systems that require a high likelihood of functioning on demand by using GA. Cui et al. [
28] proposed a novel reliability design and optimization method of planetary gears using the GA, based on the Kriging model. Ardakan and Rezvan [
29] considered the multiobjective optimization of the reliability–redundancy allocation problem with a cold-standby strategy using NSGA-II. Bhattacharyya and Cheliyan [
30] solved a subsea production system optimization problem by using GA and NSGA-II, in which the risk was evaluated with fault tree analysis. Due to the advantages of GA and NSGA-II, we continued to use the above two algorithms to solve optimization models.
Subsea production systems are mainly composed of Xmas trees, manifolds, jumper tubes, umbilical cables, pipelines, etc. [
31]. With the increase in service time of subsea production systems, more and more safety problems have emerged, especially leakage. The leakage of subsea production systems results in serious environment pollution and significant economic losses. Therefore, it is essential to ensure the safety of subsea production systems. Additionally, the total maintenance cost is expected as low as possible. Bhattacharyya and Cheliyan [
30] paid attention to such problems and optimized the cost and reliability of a subsea production system on the basis of a traditional fault tree. Unfortunately, it is difficult to obtain sufficient data to evaluate the risk of subsea production systems. In this situation, experts must evaluate the key performance indicators of a subsea production system. Then, Cheliyan and Bhattacharyya [
32] assessed the leakage risk of a subsea production system based on a fuzzy fault tree, in which the epistemic uncertainty was modeled with fuzzy set theory. Because the possibility measure has no duality property, a self-dual measure is absolutely needed in both theory and practice.
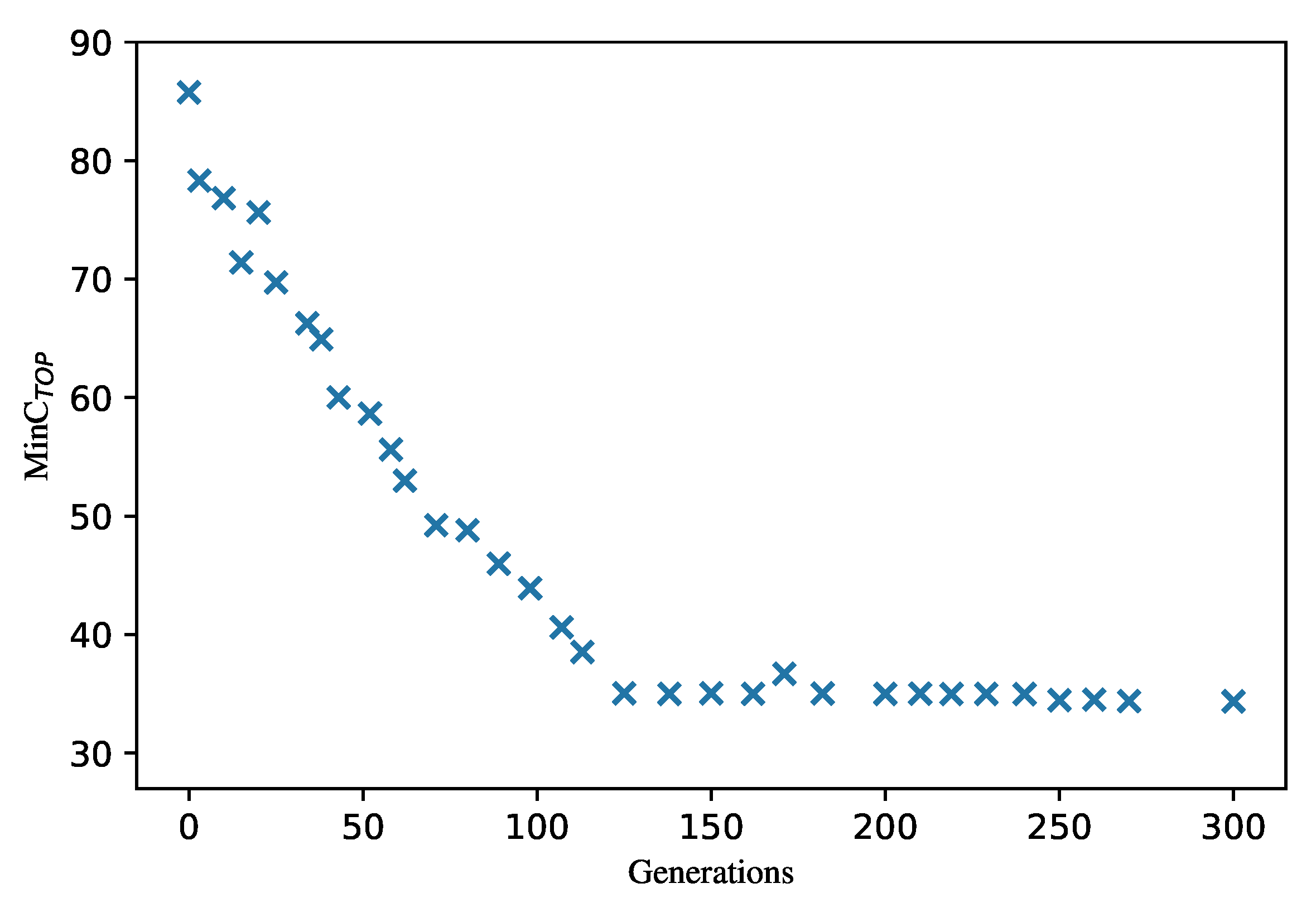
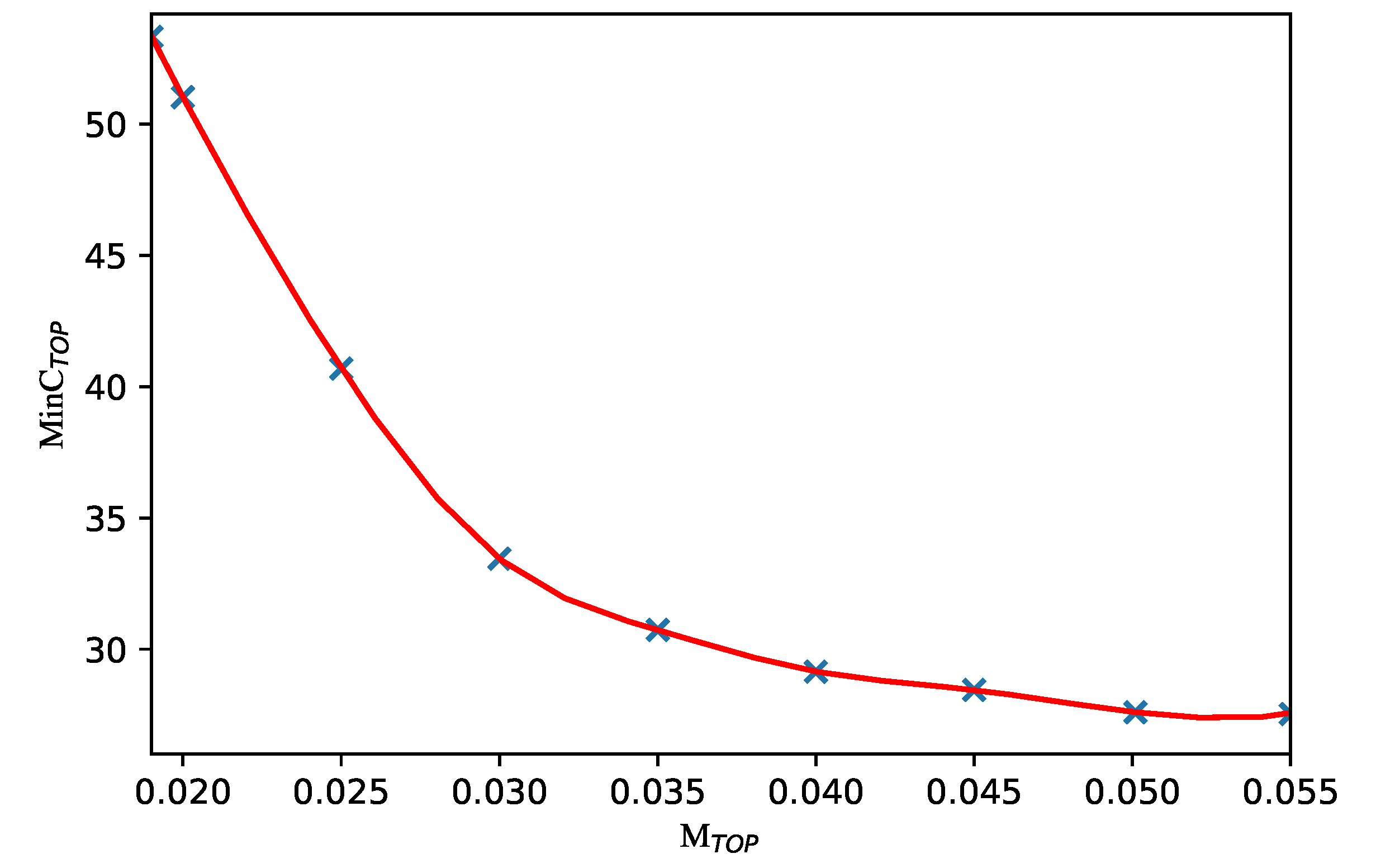
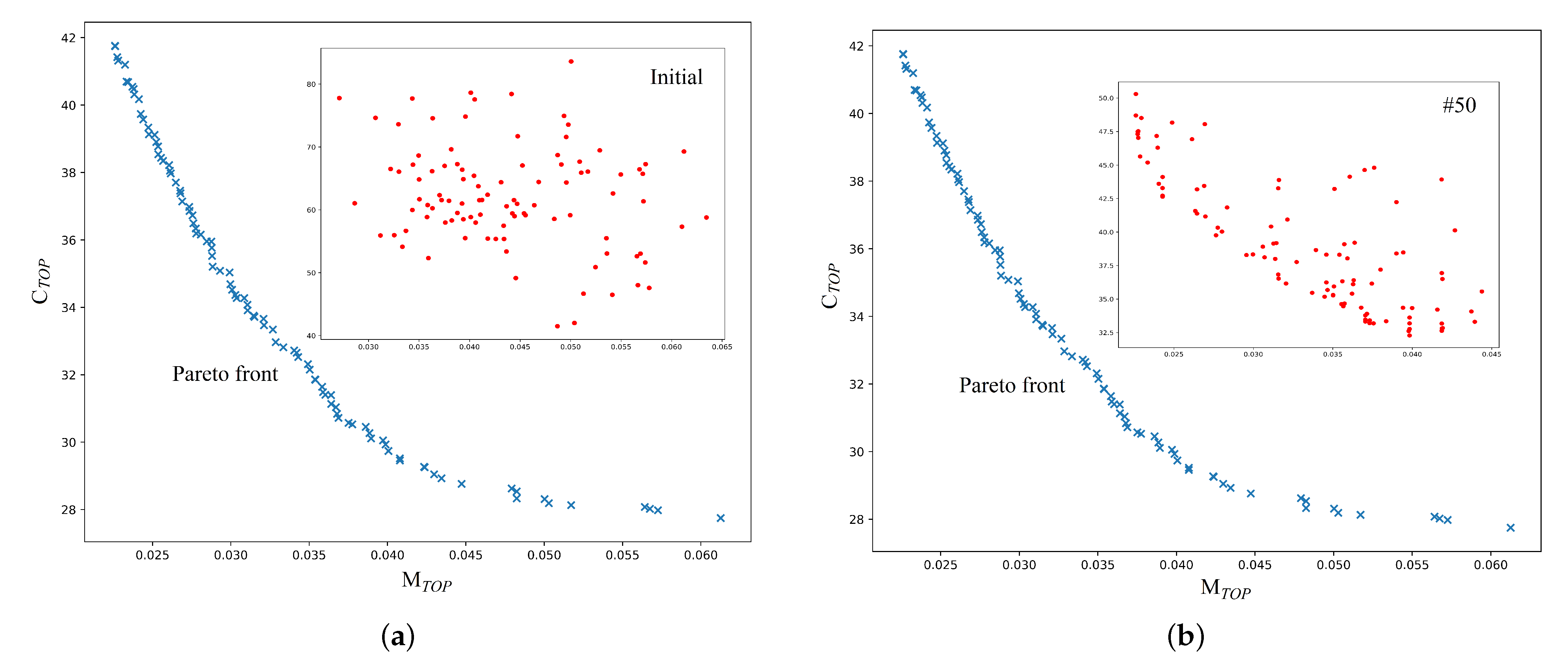
The major contributions of this study are as follows: A risk assessment method for complex systems with insufficient data is proposed based on uncertain fault tree analysis; two general optimization models are established for complex systems with insufficient data, and the GA and NSGA-II are applied to solve the two optimization models, separately. Leakage risk is evaluated; two optimization models of the leakage risk and maintenance cost are established for a subsea production system. Then, the optimization results are discussed.
The remainder of this paper is organized as follows
Section 2 proposes a risk assessment method for systems with insufficient data.
Section 3 establishes two general optimization models based on uncertain fault tree and describes the algorithms for solving the two optimization models.
Section 4 outlines a leakage risk evaluation for a subsea production system, establishes the optimization models of maintenance cost and leakage risk for the subsea production system, and we discuss the optimization results. In addition, the steps of GA and NSGA-II are provided in
Appendix A.
2. Risk Assessment Method Based on Uncertain Fault Tree
A fault tree is called an uncertain fault tree if the occurrences of the input events are evaluated by the uncertain measure proposed by Liu [
12]. The system risk is the belief degree of the occurrence of the top event; for the operation rules, refer to Liu [
33].
Theorem 1. If are independent input events, the belief degree of the occurrence of output event Λ is Proof. If independent input events
are connected by an “AND” gate, the belief degree of the occurrence of the output event
can be derived by
If independent input events
are connected by an “OR” gate, the belief degree of the occurrence of the output event
can be derived by
The proof is completed. □
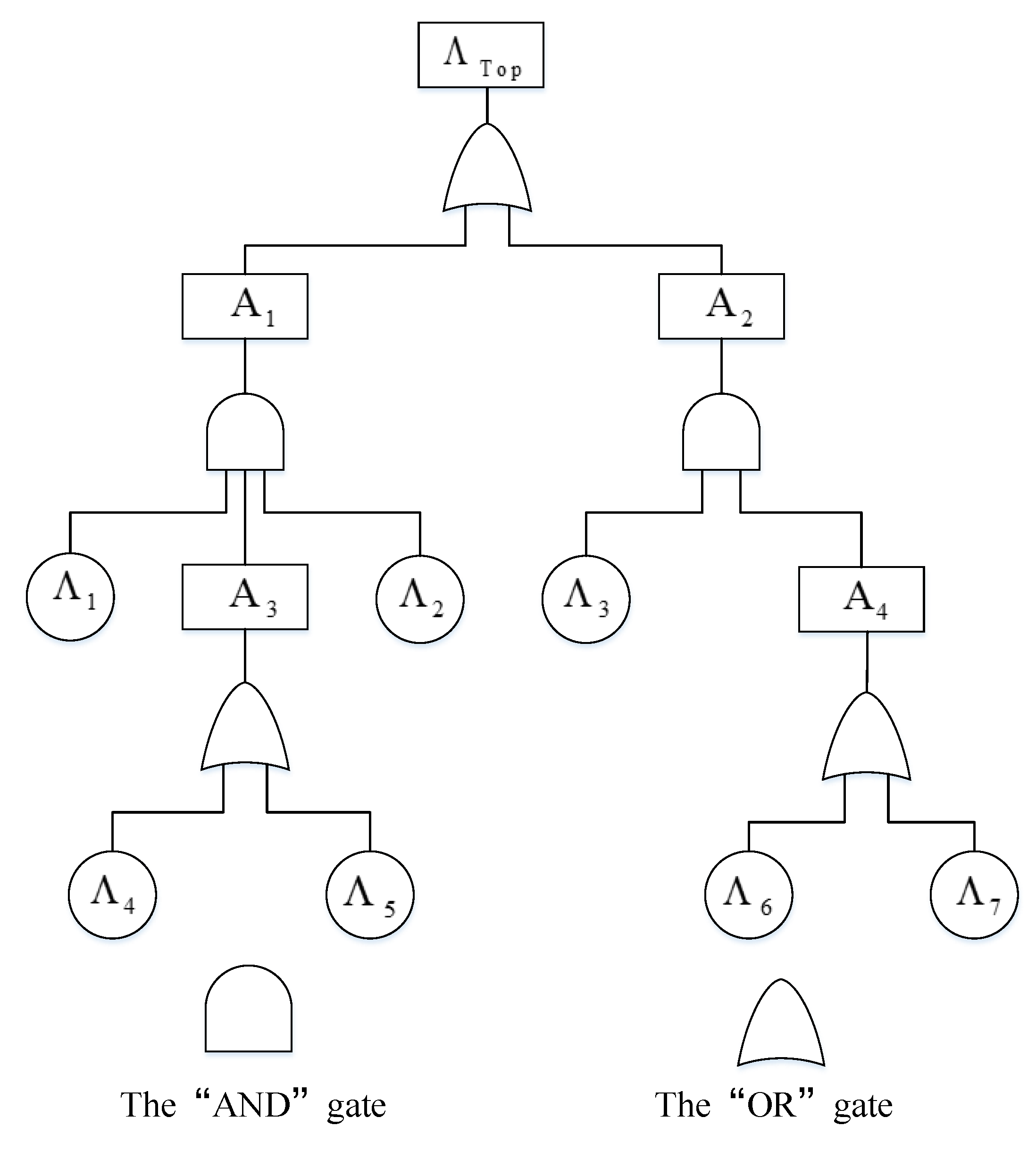
Example 1. The fault tree shown in Figure 1 describes the system risk. , denote independent basic events, , denote the intermediate events, and denotes the top event in the fault tree. Table 1 lists the belief degrees of the occurrence of the basic events. As shown in Figure 1, the top event can be expressed as Then, the belief degree of occurrence of the top event can be determined, i.e., the risk of the top event , namely, If the belief degree is replaced by probability in Example 1, then the risk of the top event
can be calculated with the probability method, namely,
It can be seen that and are different, which implies when the data are sufficient, traditional fault tree analysis is applied to evaluate the probability of the occurrence of the top event; when the data are insufficient, uncertain fault tree analysis is used to evaluate the belief degree of the occurrence of the top event.
By comparison of and in Example 1, it can be seen that is larger than . However, this does not mean that is always larger than . For example, if and change to , then and Therefore, we cannot simply compare the values of and without knowing the fault tree structure and the belief degrees and probabilities of the occurrence of all basic events.





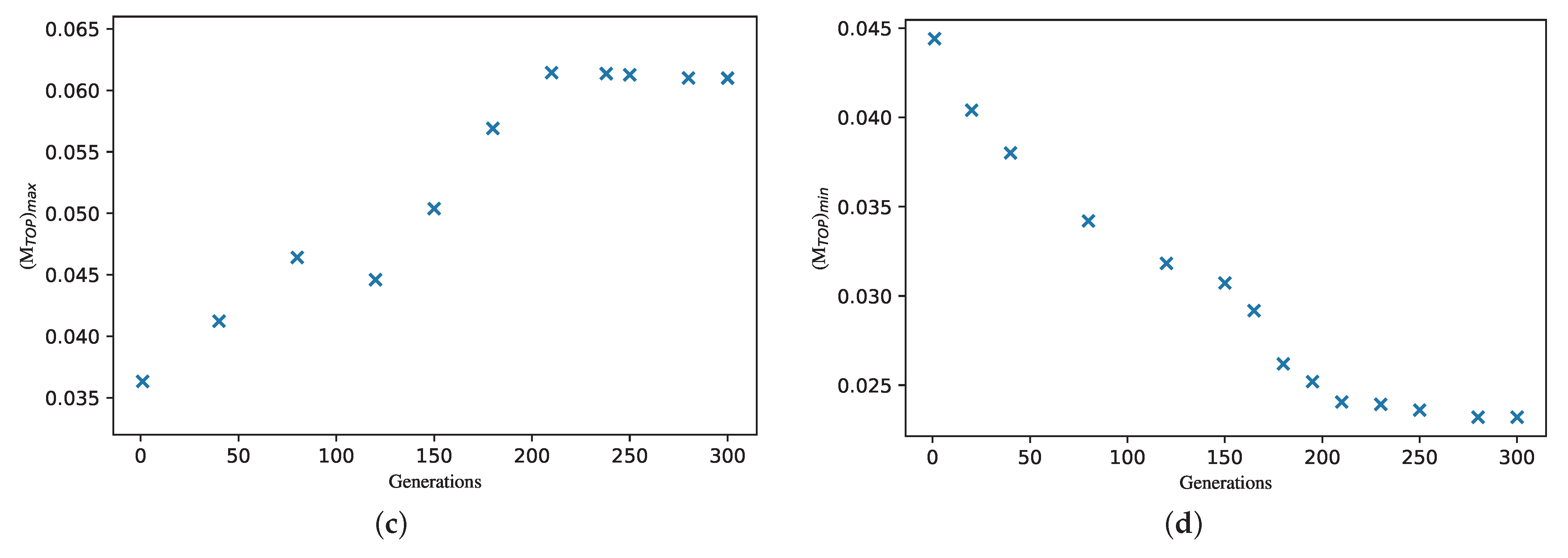

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}