Author Contributions
Conceptualization, W.A. and M.H.; Data curation, W.A. and L.A.; Formal analysis, W.A. and L.A.; Funding acquisition M.H.; Methodology, W.A. and M.H.; Project administration, M.H. and H.A.A.; Resources, M.H. and H.A.A.; Software, W.A.; Supervision, M.H. and H.A.A.; Validation, W.A.; Visualization, W.A.; Writing—original draft, W.A.; Writing—review and editing, M.H. and L.A. All authors have read and agreed to the published version of the manuscript.
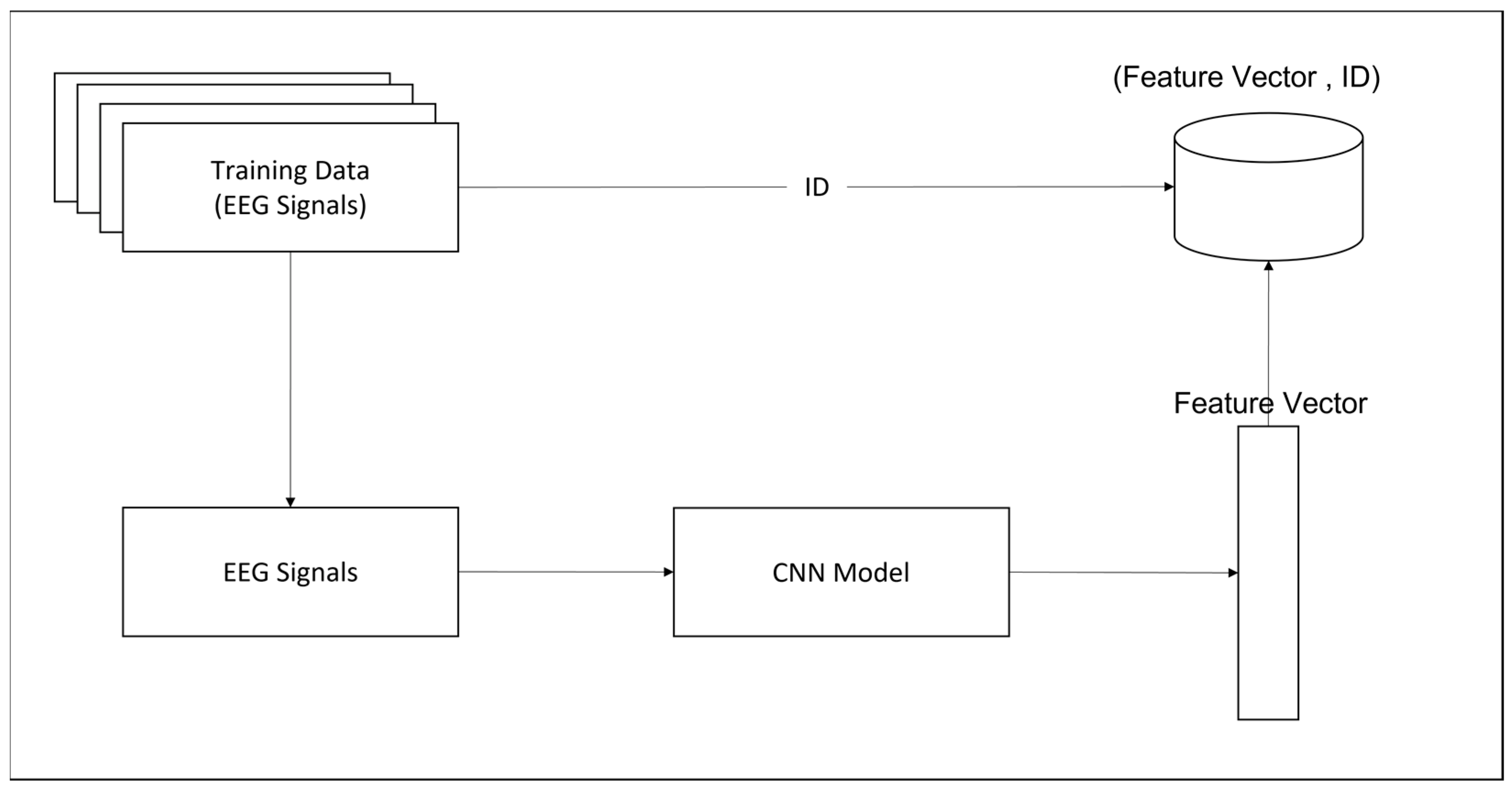
Figure 1.
Enrollment Phase.
Figure 1.
Enrollment Phase.
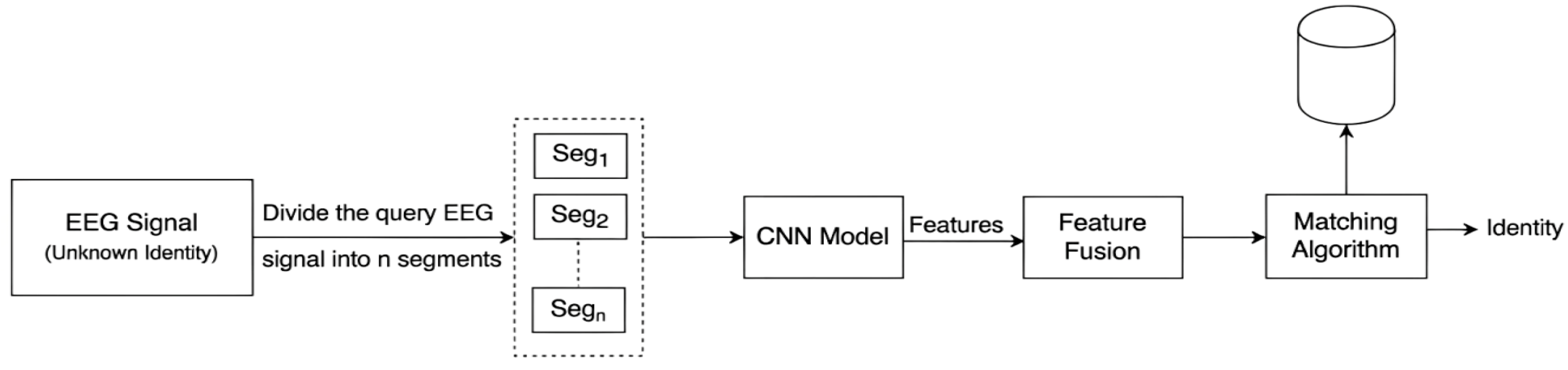
Figure 2.
Identification System.
Figure 2.
Identification System.
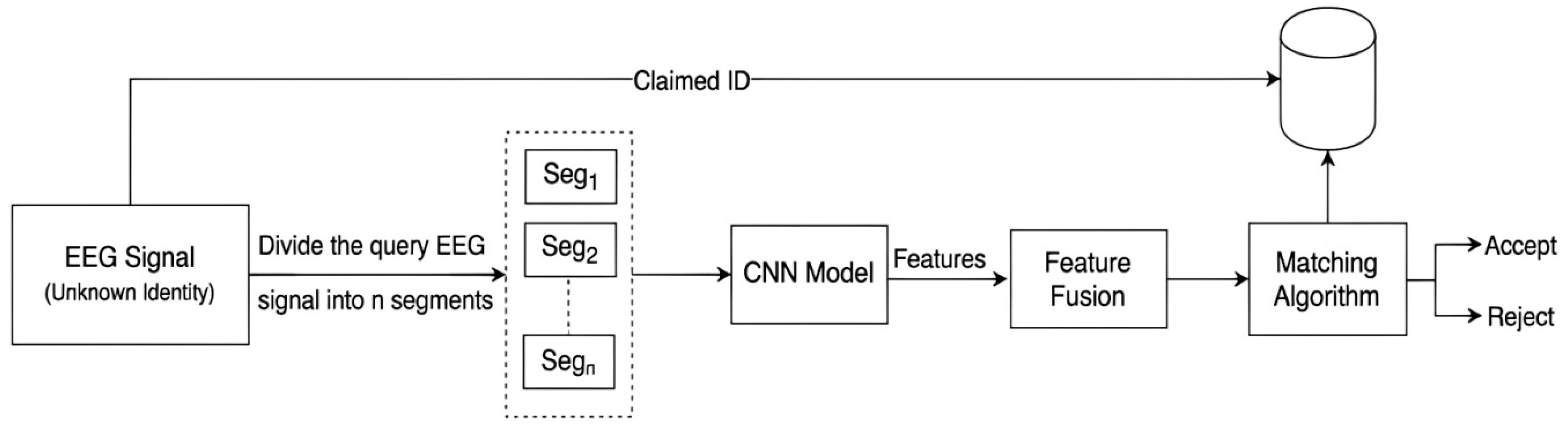
Figure 3.
Authentication System.
Figure 3.
Authentication System.
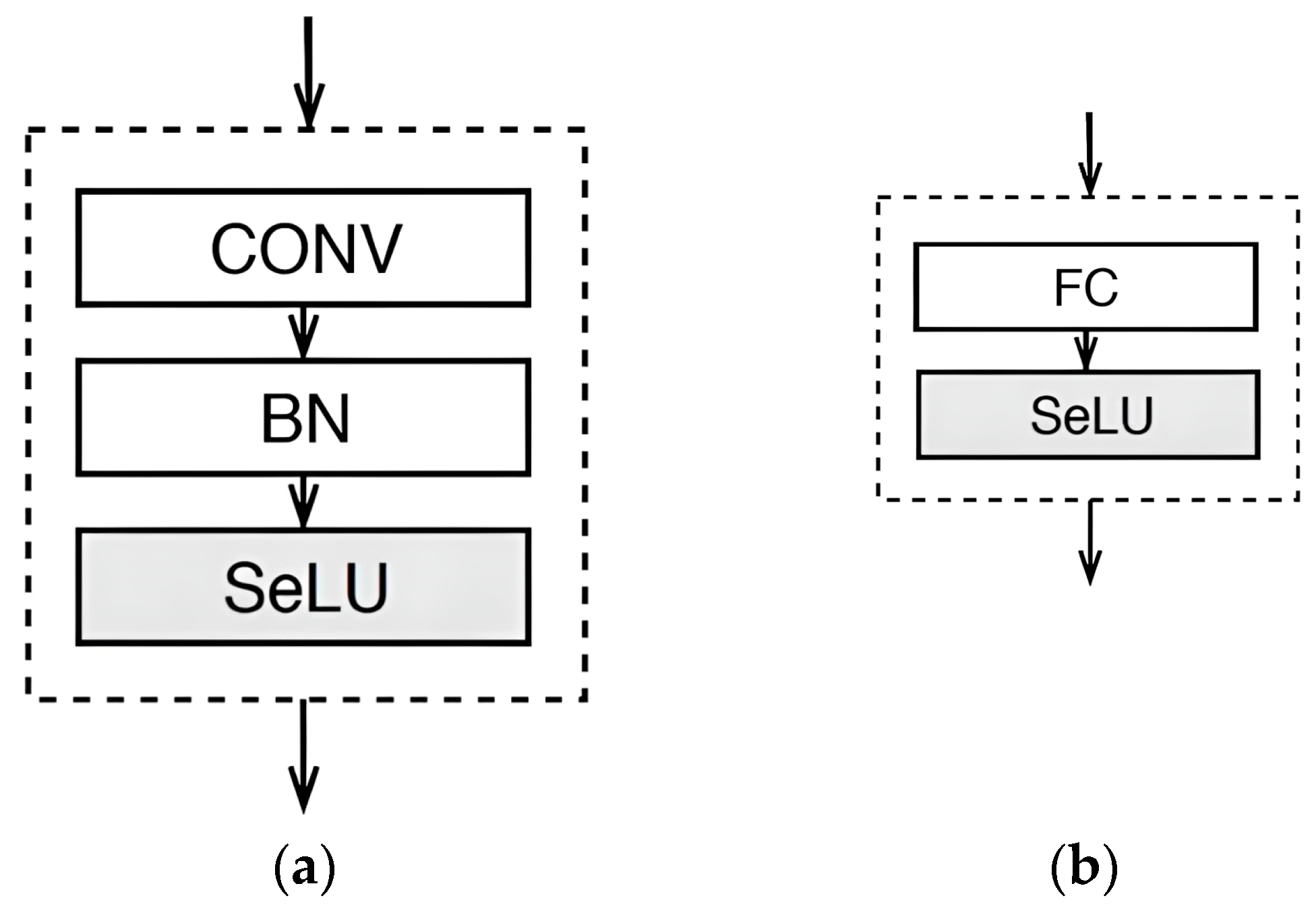
Figure 4.
Building Blocks of the CNN Model. (a) CONV Block, (b) FC Block.
Figure 4.
Building Blocks of the CNN Model. (a) CONV Block, (b) FC Block.
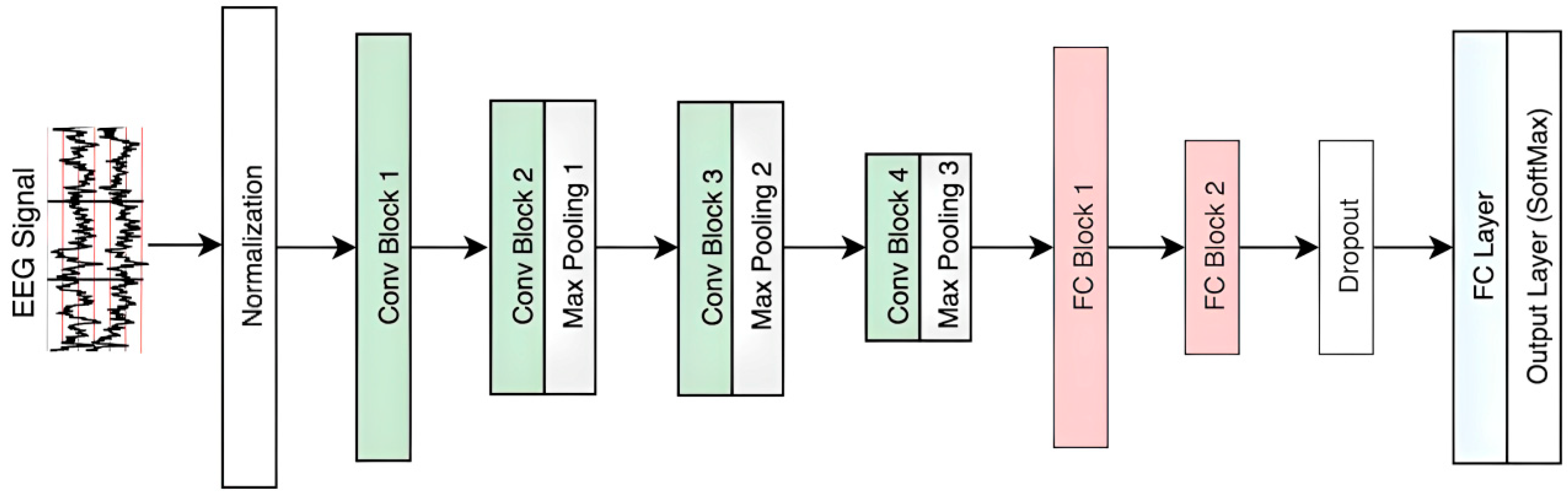
Figure 5.
Proposed CNN Model for EGG-based Recognition.
Figure 5.
Proposed CNN Model for EGG-based Recognition.
Figure 6.
Data Augmentation Schema 1.
Figure 6.
Data Augmentation Schema 1.
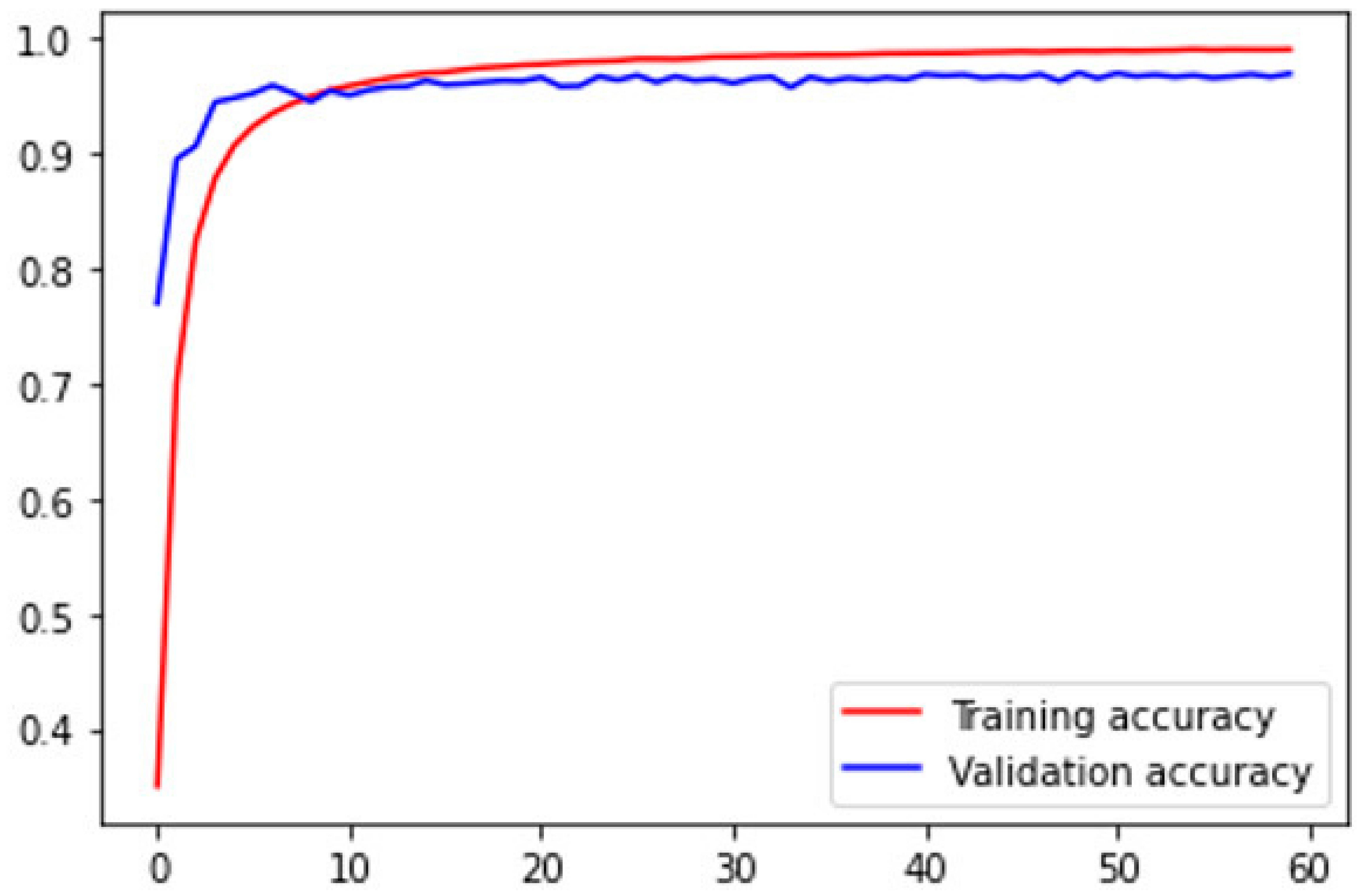
Figure 7.
Model Training.
Figure 7.
Model Training.
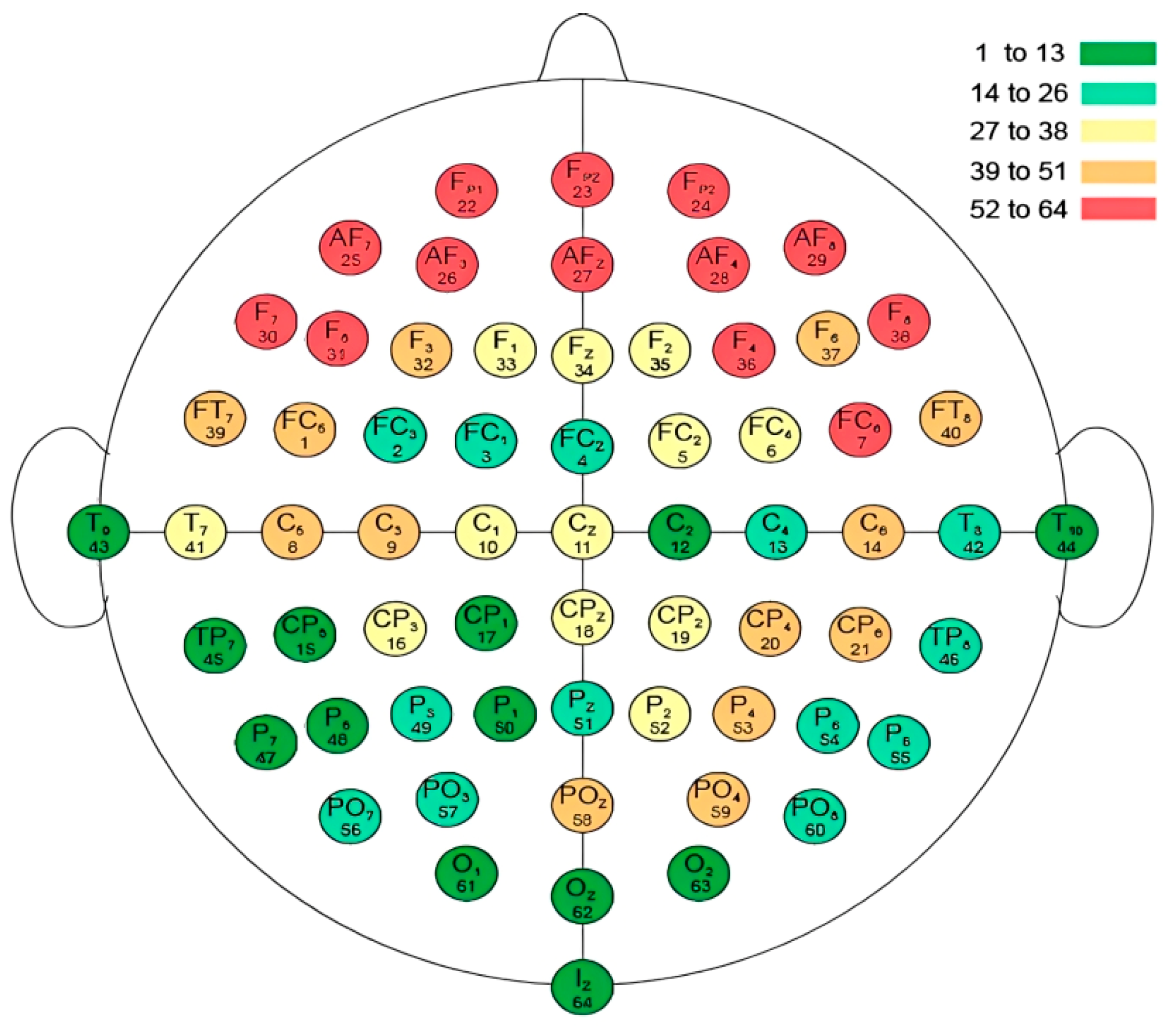
Figure 8.
The Relationship between Brain Regions and Person Identification.
Figure 8.
The Relationship between Brain Regions and Person Identification.
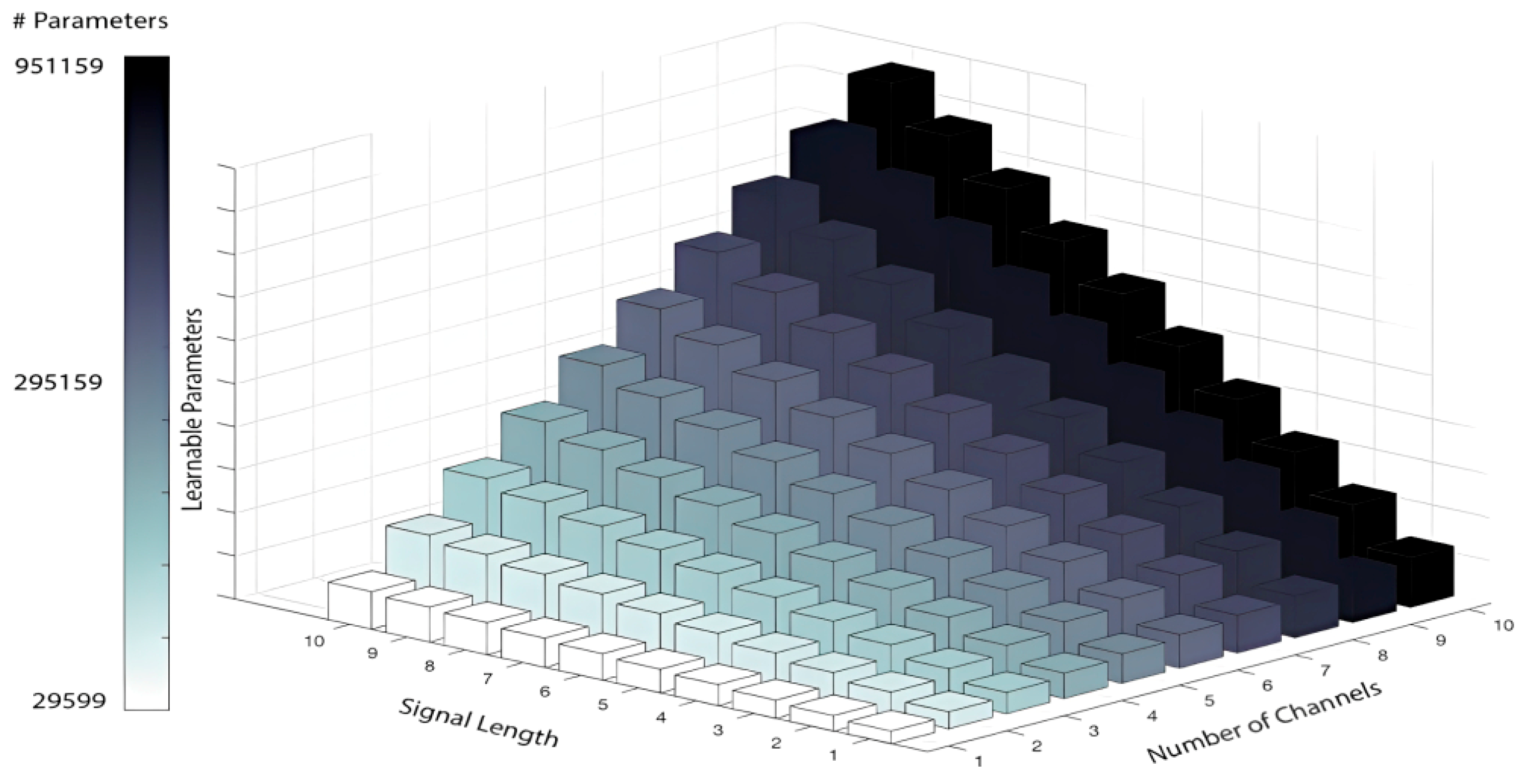
Figure 9.
Number of Learnable Parameters in Terms of Signal Length and Number of Channels.
Figure 9.
Number of Learnable Parameters in Terms of Signal Length and Number of Channels.
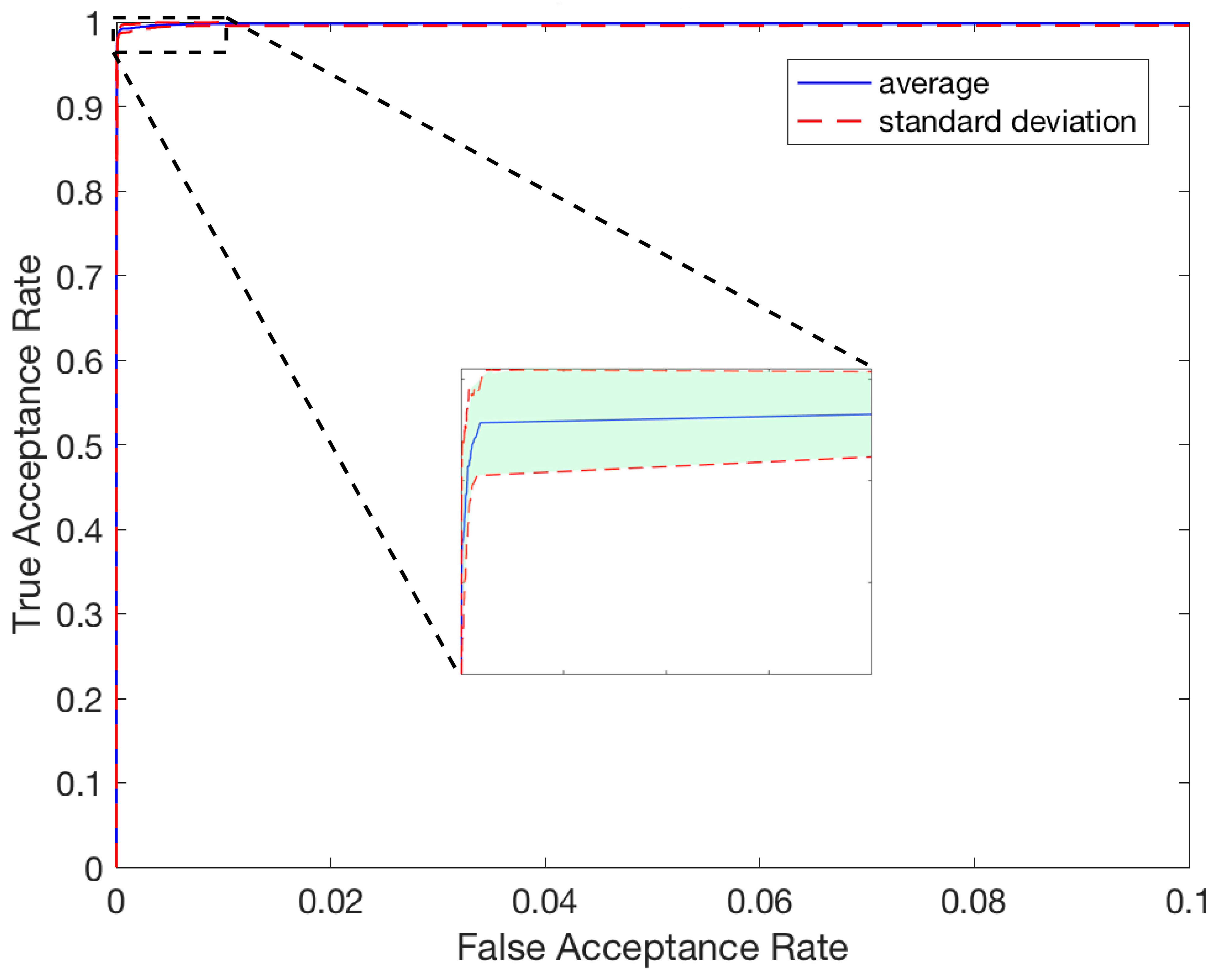
Figure 10.
CMC Curve for the Top 10 Rank.
Figure 10.
CMC Curve for the Top 10 Rank.
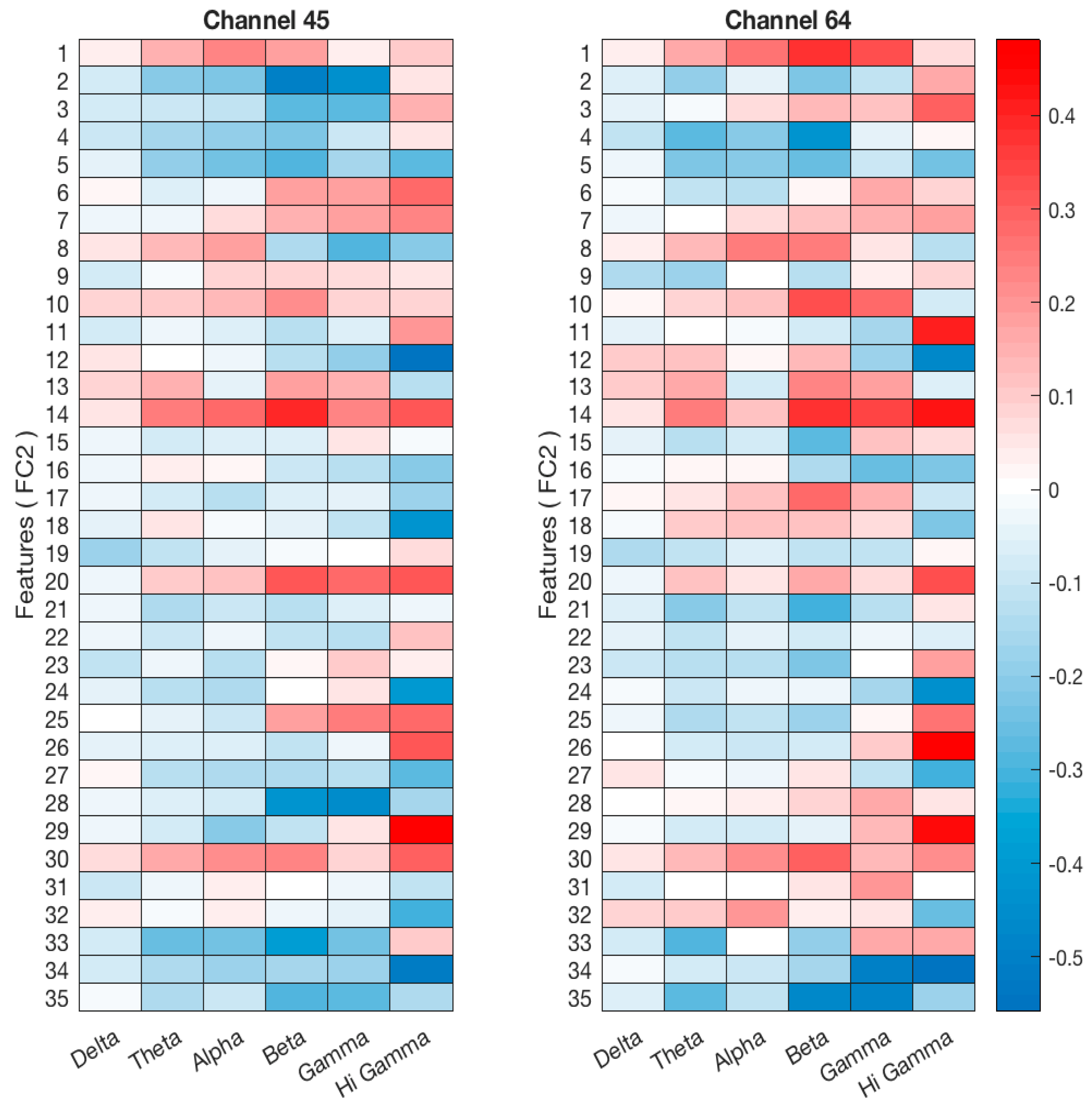
Figure 13.
Correlation Coefficients between the EEG Sub-bands and CNN Features. The x-axis represents the frequency bands (Delta, Theta, Alpha, Beta, and Gamma), and the y-axis represents the features extracted from the fully connected layer (FC2).
Figure 13.
Correlation Coefficients between the EEG Sub-bands and CNN Features. The x-axis represents the frequency bands (Delta, Theta, Alpha, Beta, and Gamma), and the y-axis represents the features extracted from the fully connected layer (FC2).
Table 1.
EEG-based Identification Methods. Notations: CL—Classifier, S—Subjects, C—EEG channels, PL—Pattern/Instance length, L1—Cityblock distance, PSD—Power spectral density, COH—Spectral coherence connectivity, AR—Autoregressive, PCA—Principal component analysis, MPCA—Multilinear PCA, KNN—K-nearest neighbors, FLDA—Fischer linear discriminant classifier, PLV—Phase Locking Index, RHO—Synchronization index measures deviation of relative phase, GVAE—Graph Variational Auto Encoder.
Table 1.
EEG-based Identification Methods. Notations: CL—Classifier, S—Subjects, C—EEG channels, PL—Pattern/Instance length, L1—Cityblock distance, PSD—Power spectral density, COH—Spectral coherence connectivity, AR—Autoregressive, PCA—Principal component analysis, MPCA—Multilinear PCA, KNN—K-nearest neighbors, FLDA—Fischer linear discriminant classifier, PLV—Phase Locking Index, RHO—Synchronization index measures deviation of relative phase, GVAE—Graph Variational Auto Encoder.
| Paper | Feature | CL | Database | S, C | PL | Acc (%) | Learnable Parameters |
|---|
| Rocca et al., 2014 [14] | PSD, COH | L1 | PhysioNet | 108, 56 | 10 s | 100.00 | N/A |
| Maiorana et al., 2015 [15] | AR, PSD, COH | L1 | Private | 50, 7 | 5 s | 90.00 | N/A |
| Maiorana et al., 2016 [6] | AR | L1 | Private | 50, 19 | 5 s | 88.00 | N/A |
| Maiorana et al., 2016 [7] | PCA, MPCA | KNN | PhysioNet | 30, 19 | 5 s | 71.00 | N/A |
| Suppiah and Vinod 2018 [13] | PSD | FLDA | PhysioNet | 109, 1 | 12 s | 97.00 | |
| Wang et al., 2020 [16] | RHO | Mahalanobis distance | PhysioNet | 109, 64 | 1 s | 98.83 | N/A |
| Mao et al., 2017 [10] | Raw EEG | CNN | BCIT | 100, 64 | 1 s | 97.00 | N/A |
| Sun et al., 2019 [11] | Raw EEG | CNN, LSTM | PhysioNet | 109, 16 | 1 s | 99.58 | 505,281,566 |
| Sun et al., 2019 [11] | Raw EEG | CNN, LSTM | PhysioNet | 109, 4 | 1 s | 94.28 | 505,281,566 |
| Wang et al., 2019 [12] | PLV | GCNN | PhysioNet | 109, 64 | 5.5 s | 99.98 | 81,901 |
| Wang et al., 2019 [12] | PLV | GCNN | Private | 59, 46 | 5.5 s | 98.96 | N/A |
| Behrouzi and Hatzinakos 2022 [17] | GVAE | SVM | PhysioNet | 109, 64 | 1 s | 99.78 | 258 |
| Bidgoly et al., 2022 [18] | Raw EEG | CNN | PhysioNet | 109, 3 | 1 s | 98.04 | N/A |
Table 2.
EEG-based Authentication. Notations: CL—Classifier, S—Subjects, C—EEG channels, PL—Pattern/instance length, L2—Euclidean distance, EER—Equal Error Rate.
Table 2.
EEG-based Authentication. Notations: CL—Classifier, S—Subjects, C—EEG channels, PL—Pattern/instance length, L2—Euclidean distance, EER—Equal Error Rate.
| Paper | Features | CL | Protocol | S, C | PL | EER (%) |
|---|
| Das et al., 2016 [20] | EEG Sub-bands | Cosine | Private | 50, 17 | 600 ms | 8.00 |
| Jijomon and Vinod 2018 [22] | EEG Sub-band, PSD | Cross Correlation | PhysioNet | 109, 10 | 7.5 s | 0.016 |
| Schons et al., 2018 [21] | EEG Sub-bands, CNN | L2 | PhysioNet | 109, 64 | 12 s | 0.19 |
| Sun et al., 2019 [11] | Raw EEG | CNN, LSTM | PhysioNet | 109, 16 | 1 s | 0.41 |
| Sun et al., 2019 [11] | Raw EEG | CNN, LSTM | PhysioNet | 109, 4 | 1 s | 0.56 |
Table 3.
CNN Model Network Architecture.
Table 3.
CNN Model Network Architecture.
| Layer Name | #Filters #Neurons | Filter Size/Stride/Pad | Input Shape | Learnable Parameters |
|---|
| Input Layer | - | - | 2 × 480 | - |
| CONV Block 1 | 64 | 1 × 5/1/0 | 2 × 480 | 384 |
| CONV Block 2 | 32 | 1 × 5/1/0 | 2 × 476 × 64 | 10,272 |
| Max Pooling 1 | - | 1 × 3/1/0 | 2 × 472 × 32 | - |
| CONV Block 3 | 32 | 1 × 3/1/0 | 2 × 157 × 32 | 3104 |
| Max Pooling 2 | - | 1 × 3/1/0 | 2 × 155 × 32 | - |
| CONV Block 4 | 16 | 1 × 3/1/0 | 2 × 51 × 32 | 1552 |
| Max Pooling 3 | | 1 × 3/1/0 | 2 × 49 × 32 | - |
| FC Block 1 | 100 | - | 512 | 51,300 |
| FC Block 2 | 35 | - | 100 | 3535 |
| Dropout (0.3) | - | - | - | - |
| FC | 109 | - | 35 | 3924 |
| SoftMax | - | - | - | - |
| Total Parameters | | | | 74,071 |
Table 4.
Distance Fusion Segments.
Table 4.
Distance Fusion Segments.
| # of Seg | Seg-1 | Seg-2 | Seg-3 | Seg-4 | Seg-5 |
|---|
| 3 | 0 s–3 s | 1 s–4 s | 2 s–5 s | | |
| 4 | 0 s–3 s | 0.75 s–3.75 s | 1.25 s–4.25 s | 2 s–5 s | |
| 5 | 0 s–3 s | 0.5 s–3.5 s | 1 s–4 s | 1.5 s–4.5 s | 2 s = 5 s |
Table 5.
Top 10 Channel Ranking for (a) eyes opened (EO), (b) eyes closed (EC), (c) eyes opened and closed (EO+EC).
Table 5.
Top 10 Channel Ranking for (a) eyes opened (EO), (b) eyes closed (EC), (c) eyes opened and closed (EO+EC).
| | (a) EO | (b) EC | (c) EO+EC |
|---|
| Rank | Channel # | Acc (%) | Channel # | Acc (%) | Channel # | Acc (%) |
|---|
| 1 | 64 | 88.87 | 64 | 87.27 | 64 | 92.48 |
| 2 | 62 | 82.68 | 45 | 81.08 | 45 | 86.29 |
| 3 | 47 | 82.45 | 42 | 81.08 | 61 | 86.25 |
| 4 | 56 | 82.22 | 47 | 79.82 | 62 | 84.91 |
| 5 | 61 | 82.22 | 61 | 79.59 | 47 | 84.51 |
| 6 | 42 | 81.99 | 43 | 79.36 | 43 | 84.23 |
| 7 | 10 | 81.53 | 62 | 78.78 | 63 | 83.25 |
| 8 | 43 | 81.3 | 56 | 76.61 | 44 | 83.19 |
| 9 | 45 | 81.19 | 44 | 76.38 | 12 | 83.02 |
| 10 | 52 | 81.07 | 63 | 75.69 | 48 | 82.97 |
Table 6.
Model Selection.
Table 6.
Model Selection.
| (a) Activation Function | (b) Loss Function | (c) Optimizer |
|---|
| Function | Acc (%) | Function | Acc (%) | Optimizer | Acc (%) |
|---|
| SeLU [32] | 97.88 | Cross-entropy | 97.88 | Adadelta [30] | 98.25 |
| Prelu [33] | 97.52 | Hinge | 97.53 | RMSProp [34] | 97.88 |
| LeakyReLU (0.1) [35] | 96.88 | Kullback Leibler Divergence | 97.53 | Adam [36] | 97.61 |
| ReLU [37] | 96.83 | | | Nadam [38] | 97.56 |
| ELU [39] | 96.51 | | | Adamax [40] | 97.29 |
Thresholded
ReLU (0.1) [41] | 95.96 | | | SGD [42] | 96.97 |
| | | | | Adagrad [43] | 96.83 |
Table 7.
Segment Length and Number of Channels.
Table 7.
Segment Length and Number of Channels.
| | Number of Channels |
|---|
| | | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|
| Segment Length | 1 s | 78.24 | 92.2 | 93.99 | 95.6 | 96.06 | 97.28 | 97.24 | 98.31 | 98.77 | 98.62 |
| 2 s | 89.99 | 96.49 | 97.53 | 98.24 | 98.08 | 98.79 | 98.54 | 99.41 | 99.2 | 99.58 |
| 3 s | 92.24 | 97.98 | 98.62 | 98.57 | 99.08 | 99.22 | 99.17 | 99.35 | 99.44 | 99.77 |
| 4 s | 93.78 | 98.75 | 98.72 | 99.33 | 99.33 | 99.54 | 99.49 | 99.49 | 99.59 | 99.38 |
| 5 s | 95.01 | 98.68 | 98.5 | 99.08 | 99.25 | 99.65 | 99.42 | 99.48 | 99.71 | 99.77 |
| 6 s | 95.28 | 98.88 | 99.08 | 99.34 | 99.08 | 99.73 | 99.73 | 99.08 | 99.54 | 99.54 |
| 7 s | 96.33 | 98.54 | 98.54 | 98.92 | 99.08 | 99.61 | 99.77 | 99.31 | 99.23 | 99.38 |
| 8 s | 95.5 | 98.25 | 98.8 | 98.62 | 98.99 | 99.44 | 99.35 | 99.62 | 99.44 | 99.44 |
| 9 s | 95.64 | 99.08 | 99.08 | 98.5 | 98.62 | 99.65 | 99.19 | 99.54 | 98.08 | 99.54 |
| 10 s | 95.87 | 98.16 | 98.13 | 98.74 | 98.01 | 99.38 | 99.69 | 99.08 | 99.23 | 99.08 |
Table 8.
Different Model Architectures, where: F: filters, #N: number of neurons, No: not in the model.
Table 8.
Different Model Architectures, where: F: filters, #N: number of neurons, No: not in the model.
| | | M1 (Proposed) | Reverse of M1 | M2 | M3 |
|---|
| Layer Name | F/Stride/Pad | #F #N | Parameters | #F #N | Parameters | #F #N | Parameters | #F #N | Parameters |
|---|
| Input Layer | - | - | - | - | - | - | - | - | - |
| CONV Block 1 | 1 × 5/1/0 | 64 | 384 | 16 | 96 | 64 | 384 | 64 | 384 |
| CONV Block 2 | 1 × 5/1/0 | 32 | 10,272 | 32 | 2592 | 32 | 10,272 | 32 | 10,272 |
| Max Pooling 1 | 1 × 3/1/0 | - | - | - | - | - | - | - | - |
| CONV Block 3 | 1 × 3/1/0 | 32 | 3104 | 32 | 3104 | 16 | 1552 | 32 | 3104 |
| Max Pooling 2 | 1 × 3/1/0 | - | - | - | - | - | - | - | - |
| CONV Block 4 | 1 × 3/1/0 | 16 | 1552 | 64 | 6208 | No | 16 | 1552 |
| Max Pooling 3 | 1 × 3/1/0 | - | - | - | - | No | - | - |
| CONV Block 5 | 1 × 3/1/0 | No | No | No | 16 | 784 |
| FC Block 1 | - | 100 | | | | | | | |
| FC Block 2 | - | 35 | | | | | | | |
| Dropout (0.3) | - | - | - | | - | | - | | - |
| FC | - | 109 | 3204 | 109 | 3924 | 109 | 11,009 | 109 | 3924 |
| SoftMax | - | - | - | - | - | - | - | - | - |
| Total Parameters | | | 74,071 | | 224,359 | | 186,517 | | 74,935 |
| Acc % | | | 97.77 ± 0.82 | | 97.64 ± 1.00 | | 96.5 ± 1.15 | | 97.24 ± 0.91 |
Table 9.
Identification System Results (Rank 1).
Table 9.
Identification System Results (Rank 1).
| Fold Number | 3 s (%) | 5 s–3 Seg (%) | 5 s–4 Seg (%) | 5 s–5 Seg (%) |
|---|
| Min | Avg | Max | Min | Avg | Max | Min | Avg | Max |
|---|
| Fold 1 | 97.02 | 98.17 | 98.85 | 98.39 | 98.62 | 98.39 | 98.85 | 98.17 | 98.39 | 98.17 |
| Fold 2 | 97.49 | 99.08 | 99.08 | 99.08 | 98.17 | 98.62 | 98.85 | 98.62 | 98.62 | 98.85 |
| Fold 3 | 97.49 | 99.08 | 98.39 | 98.62 | 99.31 | 99.31 | 98.31 | 99.08 | 98.85 | 98.62 |
| Fold 4 | 98.39 | 99.54 | 99.31 | 99.77 | 99.31 | 98.85 | 99.54 | 99.54 | 99.31 | 99.54 |
| Fold 5 | 98.62 | 99.54 | 99.31 | 99.54 | 99.77 | 99.77 | 99.77 | 99.77 | 99.54 | 99.77 |
| Fold 6 | 98.62 | 99.31 | 98.31 | 99.54 | 99.31 | 99.08 | 99.54 | 99.31 | 99.31 | 99.31 |
| Fold 7 | 97.82 | 99.54 | 98.62 | 99.54 | 99.77 | 98.85 | 99.54 | 99.08 | 98.62 | 99.54 |
| Fold 8 | 98.05 | 99.31 | 98.39 | 99.31 | 99.31 | 99.08 | 99.08 | 99.08 | 98.62 | 99.08 |
| Fold 9 | 97.94 | 99.31 | 98.85 | 99.08 | 99.08 | 99.08 | 99.31 | 99.54 | 99.31 | 99.54 |
| Fold 10 | 98.28 | 99.77 | 99.08 | 99.54 | 99.54 | 99.54 | 99.54 | 99.54 | 99.31 | 99.54 |
| Avg ± std | 98.06 ± 0.47 | 99.26 ± 0.44 | 98.91 ± 0.36 | 99.24 ± 0.44 | 99.21 ± 0.49 | 99.05 ± 0.41 | 99.33 ± 0.31 | 99.17 ± 0.48 | 98.99 ± 0.41 | 99.19 ± 0.5 |
Table 10.
Authentication System Results (EER).
Table 10.
Authentication System Results (EER).
| Fold Number | 3 s (%) | 5 s–3 Seg (%) | 5 s–4 Seg (%) | 5 s–5 Seg (%) |
|---|
| Min | Avg | Max | Min | Avg | Max | Min | Avg | Max |
|---|
| Fold 1 | 1.00 | 0.93 | 0.46 | 0.72 | 0.80 | 0.46 | 0.70 | 1.15 | 0.46 | 0.70 |
| Fold 2 | 0.56 | 0.70 | 0.23 | 0.44 | 0.81 | 0.23 | 0.69 | 0.92 | 0.23 | 0.82 |
| Fold 3 | 0.35 | 0.69 | 0.21 | 0.19 | 0.46 | 0.23 | 0.45 | 0.69 | 0.23 | 0.20 |
| Fold 4 | 0.24 | 0.46 | 0.23 | 0.46 | 0.46 | 0.23 | 0.45 | 0.23 | 0.23 | 0.46 |
| Fold 5 | 0.23 | 0.23 | 0.23 | 0.23 | 0.23 | 0.23 | 0.23 | 0.23 | 0.23 | 0.23 |
| Fold 6 | 0.44 | 0.46 | 0.23 | 0.23 | 0.46 | 0.23 | 0.45 | 0.46 | 0.23 | 0.23 |
| Fold 7 | 0.54 | 0.69 | 0.02 | 0.23 | 0.58 | 0.03 | 0.25 | 0.69 | 0.02 | 0.47 |
| Fold 8 | 0.32 | 0.46 | 0.03 | 0.03 | 0.92 | 0.23 | 0.04 | 0.70 | 0.23 | 0.03 |
| Fold 9 | 0.34 | 0.69 | 0.23 | 0.23 | 0.46 | 0.23 | 0.46 | 0.46 | 0.23 | 0.64 |
| Fold 10 | 0.24 | 0.12 | 0.00 | 0.02 | 0.46 | 0.01 | 0.23 | 0.23 | 0.01 | 0.23 |
| Avg ± std | 0.42 ± 0.23 | 0.54 ± 0.24 | 0.187 ± 0.16 | 0.27 ± 0.21 | 0.57 ± 0.22 | 0.21 ± 0.12 | 0.39 ± 0.20 | 0.57 ± 0.31 | 0.21 ± 0.12 | 0.40 ± 0.25 |
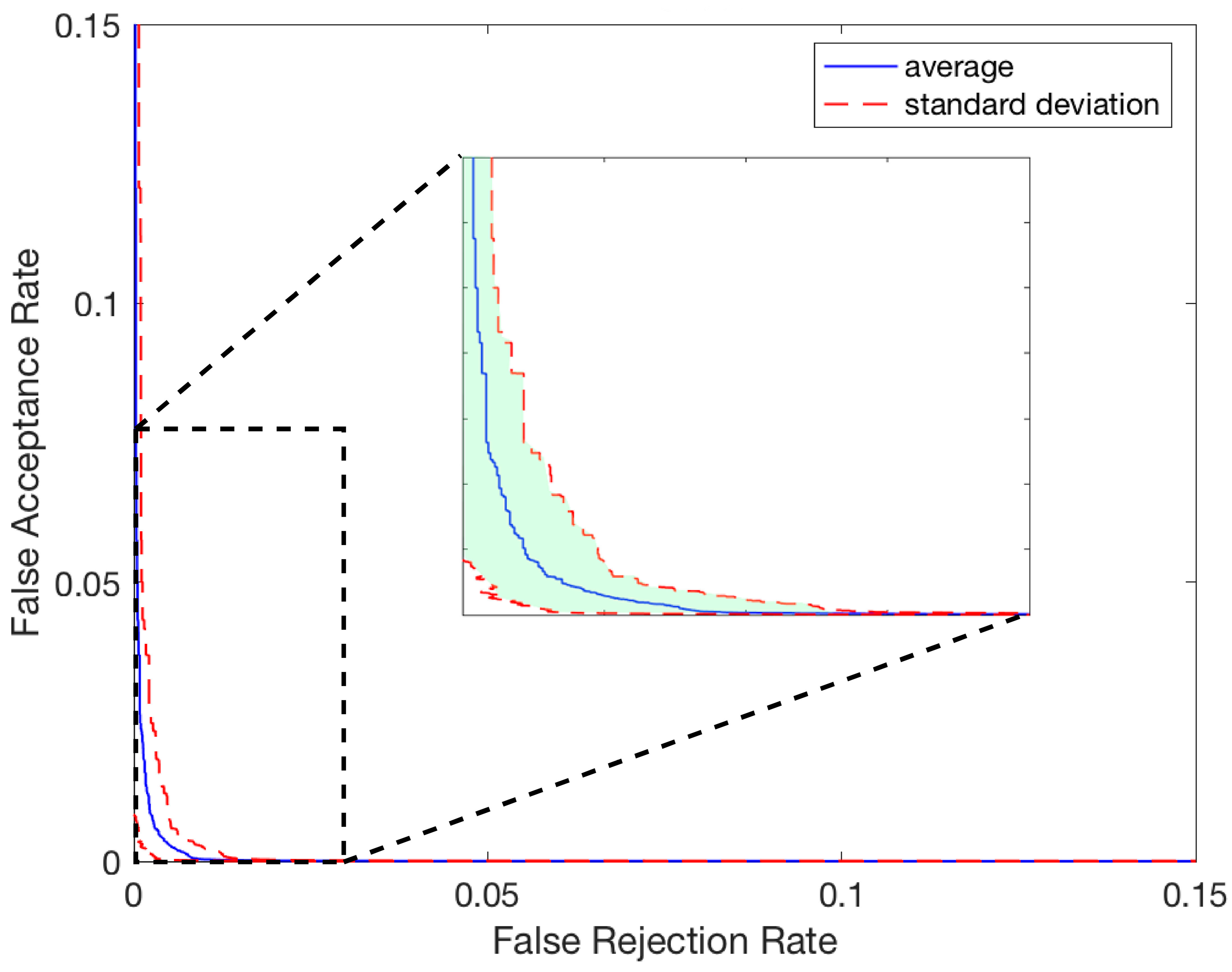
Table 11.
Authentication System 5 s–3 seg Results.
Table 11.
Authentication System 5 s–3 seg Results.
| Metrics | Avg ± Std |
|---|
| EER | 0.187% ± 0.16% |
| Minimum Half Total EER | 0.12% ± 0.1% |
| Authentication Rate at 1% FAR | 99.93% ± 0.15% |
| Authentication Rate at 0.1% FAR | 99.77% ± 0.22% |
| Authentication Rate at 0.01% | 99.11% ± 0.51% |
Table 12.
Learnable Parameters and Data Size.
Table 12.
Learnable Parameters and Data Size.
| | Learnable Parameters | Number of Training Instances |
|---|
| Schons et al., 2018 [21] | 78,857,325 | 42,696 |
| Sun et al., 2019 [11] | 505,281,566 | 177,040 |
| Wang et al., 2019 [12] | N/A | 33,795 |
| Current Work | 74,071 | 230,426 |
Table 13.
Comparison to Related Studies.
Table 13.
Comparison to Related Studies.
| | Method | Channels | Length | Acc (%) | EER (%) |
|---|
| Rocca et al., 2014 [14] | PSD, COH, L1 | 15 | 10 s | 100 | - |
| Schons et al., 2018 [21] | EEG [30:50], CNN | 64 | 12 s | - | 0.19 |
| Suppiah et al., 2018 [13] | PSD, FLDA | 1 | 12 s | 97 | - |
| Sun et al., 2019 [11] | Raw EEG, CNN, LSTM | 16 | 1 s | 99.58 | 0.41 |
| Sun et al., 2019 [11] | Raw EEG, CNN, LSTM | 4 | 1 s | 94.28 | 0.56 |
| Wang et al., 2019 [12] | PLV, GCNN | 64 | 5.5 s | 99.98 | - |
| Wang et al., 2020 [16] | RHO, Mahalanobis distance | 64 | 1 s | 98.83 | - |
| Behrouzi and Hatzinakos 2022 [17] | GVAE, SVM | 64 | 1 s | 99.78 | - |
| Bidgoly et al., 2022 [18] | Raw EEG, CNN, Cosine | 3 | 1 s | 98.04 | 1.96 |
| Current Study | Raw EEG, CNN, L1 | 2 | 5 s | 99.05 | 0.187 |

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}