1. Introduction
Approximation by the sparse linear combination of elements from a fixed redundant system continues to develop actively, which is driven not only by theoretical interest but also by frequent applications from areas such as signal processing and machine learning, cf. [
1,
2,
3,
4,
5,
6,
7]. This type of approximation is called highly nonlinear approximation. Greedy-type algorithms have been used as a tool for generating such approximations. Among others, the orthogonal greedy algorithm (OGA) has been widely used in practice. In fact, the OGA is regarded as the most powerful algorithm to solve the problem of approximation with respect to redundant systems, cf. [
8,
9,
10].
We recall some notations and definitions from the theory of greedy algorithms. Let
be a Hilbert space with an inner product
and the norm
We say that a set
of elements from
is a dictionary if
We consider redundant dictionaries, which have been utilized frequently in the field of signal processing. Here, a redundant dictionary means that the elements of the dictionary may be linearly dependent.
We now recall the definition of the OGA from [
1].
ORTHOGONAL GREEDY ALGORITHM (OGA)
Set
For each
, we inductively find
such that
and define
where
is the operator of the orthogonal projection onto
.
In [
11], Liu and Temlyakov proposed the orthogonal super greedy algorithm (OSGA). The OSGA selects more than one element from a dictionary in each iteration step and hence reduces the computational burden of the conventional OGA. Therefore, the OSGA is more efficient than the OGA from the viewpoint of the computational complexity.
ORTHOGONAL SUPER GREEDY ALGORITHM (OSGA(s))
Set For a natural number and each , we inductively define:
- (1)
are elements of the dictionary
satisfying the following inequality. Denote
and assume that
- (2)
Let
and
denote the operator of the orthogonal projection onto
Define
- (3)
Define the residual after the
m-th iteration of the algorithm
Note that, in the case OSGA(s) coincides with OGA.
In this paper, we study the approximation capability of the OSGA with respect to
-coherent dictionaries in Hilbert spaces. We denote by
the coherence of a dictionary. The coherence
is a blunt instrument to measure the redundancy of dictionaries. It is clear that if
is an orthonormal basis, then
. The smaller the
the more the
resembles an orthonormal basis. We study dictionaries with small values of coherence
and call them
-coherent dictionaries.
In [
11], the authors found that such computational burden reduction of OSGA does not degrade the approximation capability if
f belongs to the closure of the convex hull of the symmetrized dictionary
, which is denoted by
.
Theorem 1. Let be a dictionary with coherence parameter Then, for the algorithm OSGA(s) provides an approximation of with the following error bound: It seems that a dimensional independent convergence rate was deduced, but the condition that the target element belongs to becomes more and more stringent as the number of the elements in grows, cf. [2]. Fang, Lin, and Xu [12] studied the behavior of OSGA for They defined and for , and obtained the following theorem. Theorem 2. Let be a dictionary with coherence Then, for all and arbitrary the OSGA(s) provides an approximation of f with the error bound: The -coherence of a dictionary is used in OSGA, which implies that computational burden reduction does not degenerate the approximation capability. Moreover, if then OSGA coincides with OGA.
Let
denote the collection of elements in
, which can be expressed as a linear combination of, at most,
m elements of the dictionary
, namely
For an element
, we define its best
m-term approximation error by
The inequality connecting the error of greedy approximation and the error of best
m-term approximation is called the Lebesgue-type inequality, cf. [
13,
14,
15]. In this paper, we will establish the Lebesgue-type inequalities for OSGA with respect to
-coherent dictionaries.
We first recall some results on the efficiency of OGA with respect to
-coherent dictionaries. These results relate the error of OGA’s
-th approximation to the error of the best
m-term approximation with an extra multiplier:
where
Gillbert, Muthukrishnan, and Strauss [
16] gave the first Lebesgue-type inequality for OGA. They proved
The constant in the above inequality was improved by Tropp in [
17]:
Donoho, Elad, and Temlyakov [
18] dramatically improved the factor in front of
and obtained that
where the constant 24 is not the best. Many researchers have sought to improve the factor
Temlyakov and Zheltov improved the above inequality in [
4]. They obtained
Livshitz [
19] took the parameters
in (1) and obtained the following profound result.
Theorem 3. For every μ-coherent dictionary and any the OGA applied to f provides By using the same method as in [
19], Ye and Wei [
20] improved slightly the constant 2.7.
Based on the above works, we give the error bound of the form (1) for OSGA with respect to dictionaries with small but non-vanishing coherence.
Theorem 4. Let be a dictionary with coherence Then, for any and any the OSGA(s) applied to f providesfor all and an absolute constant Remark 1. - 1.
We remark that the values of μ and A for which (2) holds are coupled. For example, it is possible to obtain a smaller value of μ at the price of a larger value of A. Moreover, for sufficiently large A, μ can be arbitrarily close to zero.
- 2.
Our results improve Theorem 3 only in the asymptotic constant and not in the rate. Under the condition of Theorem 4, for taking as we can obtain Comparing it with Theorem 3, the constant that we obtain is better.
- 3.
The specific constant 2.24 in (2) is not the best. By adjusting parameters A and we can obtain a more general estimation:for where and are interdependent. Thus, Theorem 4 shows that OSGA(s) can achieve an almost optimal approximation on the first steps for dictionaries with small but non-vanishing coherence.
The paper is organized as follows. In
Section 2, we establish several preliminary lemmas. In
Section 3, for some closed subspace
L of
as defined below, we first give the estimations of
in different situations based on the lemmas in
Section 2. Then, we estimate the
Finally, combining the above two estimations, we provide the detailed proof of Theorem 4. In
Section 4, we test the performance of the OSGA in the case of finite dimensional Euclidean space. In
Section 5, we make some concluding remarks on our work.
3. Proof of Theorem 4
Based on the above preliminary lemmas, we will prove Theorem 4 step by step. We first introduce some notations. Define
Let
satisfy the following equations
Thus, for
,
we have
To obtain the upper bound of it suffices to estimate and By the definitions of sets and in OSGA, we first give the estimate of according to whether the intersection of and is an empty set.
Theorem 5. Let n satisfy and Then, Proof. By Lemma 3, for
Then, we have
so, we can obtain that
Since
we obtain
We define
By the definitions of
and the expression of (14), we have
. Then, we obtain
To obtain the final result, it suffices to estimate the upper bounds of and
For
, by (12) and (14), we have
where we have used the fact
On the one hand, for any
and
n satisfying
we obtain
Thus, by Lemma 1 and inequality (17), we obtain
On the other hand, by Lemma 2, we have, for
Thus, substituting (18) and (19) into (16), and then combining it with (13), we get the estimate
Finally, we estimate
Combining (15) and (20) with (21), we give
□
Theorem 5 gives the estimation of in the situation The following theorem deals with the situation .
Theorem 6. Let n satisfy and Then, Proof. Since
we set
and write
as
According to the following inequality,
we need to estimate
and
We first estimate
by
Next, we continue to estimate
It is not difficult to see that
By (18), for any
we have
Combining Lemma 2 with inequality (26), we obtain
for
and
For the last summand of the right-hand side of the inequality in (24), we have
Thus, combining (27) with (28), for
we have
We next estimate
Since
we need to give the upper bounds of
A and
By (18) and (19), we have
As for
since for
by Lemma 1, we know that
and
Combining (32) with (33), we have
Using Lemma 1 again, we obtain from (34) that
Thus, we get the upper bound of
by (30), (31) and (35), i.e.,
Combining (22), (23) and (29) with (36), we have
□
It remains to estimate
. We first recall a lemma proven by Fang, Lin and Xu in [
12].
Lemma 4. Assume that a dictionary has coherence Then, we have, for any distinct the inequalities Theorem 7. For any we have Proof. From Lemma 4, we know that
From Lemmas 1 and 2, we have, for any
Combining (37) with (38), we have
□
Next, using Theorems 5 and 6, we give the estimation of
Theorem 8. For and any positive integer the following inequalities hold. Proof. By using Theorems 5 and 6, we derive
which is equivalent to
Furthermore, we also have
□
Now, we can give the proof of our main result.
Proof of Theorem 4. From Theorem 7 and Theorem 8, we obtain that
Thus, we complete the proof of Theorem 4. □
4. Simulation Results
It is known from Theorem 4 that if , then , and hence . In this spirit, the OSGA can be used to recover sparse signals in compressed sensing, which is a new field of signal processing. We remark that in the field of signal processing, the orthogonal super greedy algorithm (OSGA) is also known as orthogonal multi-matching pursuit (OMMP). For the reader’s convenience, we will use the term OMMP instead of OSGA in what follows.
In this section, we test the performance of the orthogonal multi-matching pursuit with parameter
s (OMMP(
s)). We consider the following model. Suppose that
is an unknown
N-dimensional signal and we wish to recover it by the given data
where
is a known measurement matrix with
. Furthermore, since
, the column vectors of
are linearly dependent and the collection of these columns can be viewed as a redundant dictionary.
For arbitrary
, define
and
where
and
Obviously,
is a Hilbert space with the inner product
.
A signal
is said to be
K-sparse if
. We will recover the support of a
K-sparse signal via OMMP(s) under the model (40). It is well known that OMMP takes the following form; see, for instance, [
3].
ORTHOGONAL MULTI MATCHING PURSUIT (OMMP(s))
Input: Measurement matrix , vector y, and s, the stopping criterion.
Step 1: Set the residual , an initial approximation , the index set , and the iteration counter .
Step 2: Define
such that
Then,
and update the residual
End if the stopping condition is achieved. Otherwise, we set and turn to step 2.
Output: If the algorithm stops at the kth iteration, then output and .
In the experiment, we set the measurement matrix
to be a Gaussian matrix where each entry is selected from the
distribution and the density function of this distribution is
. We execute OMMP(s) with the data vector
and stop the algorithm when
. The mean square error(MSE) of
x is defined as follows:
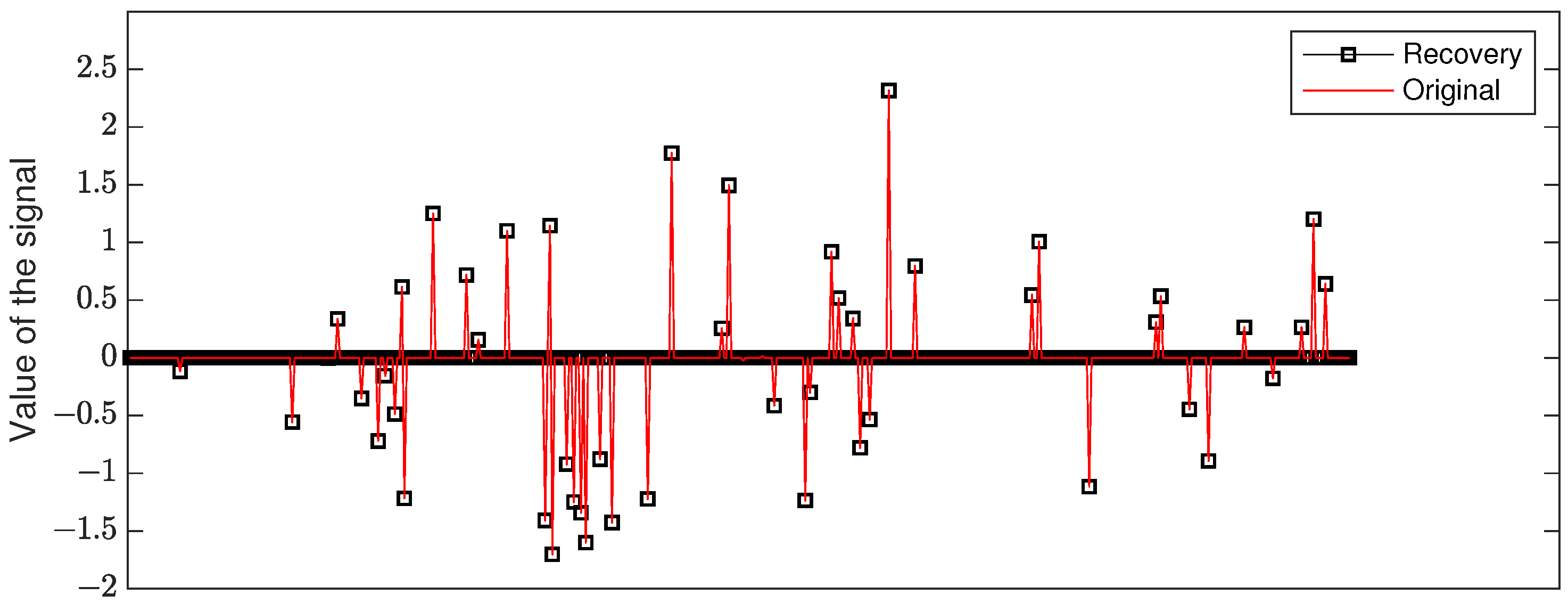
Figure 1 shows the performance of OMMP(s) with
for an input signal in dimension
with sparsity level
and number of measurements
, where the red line represents the original signal and the black squares represent the approximation. By repeating the test 1000 times, we calculate the mean square error: MSE =
.
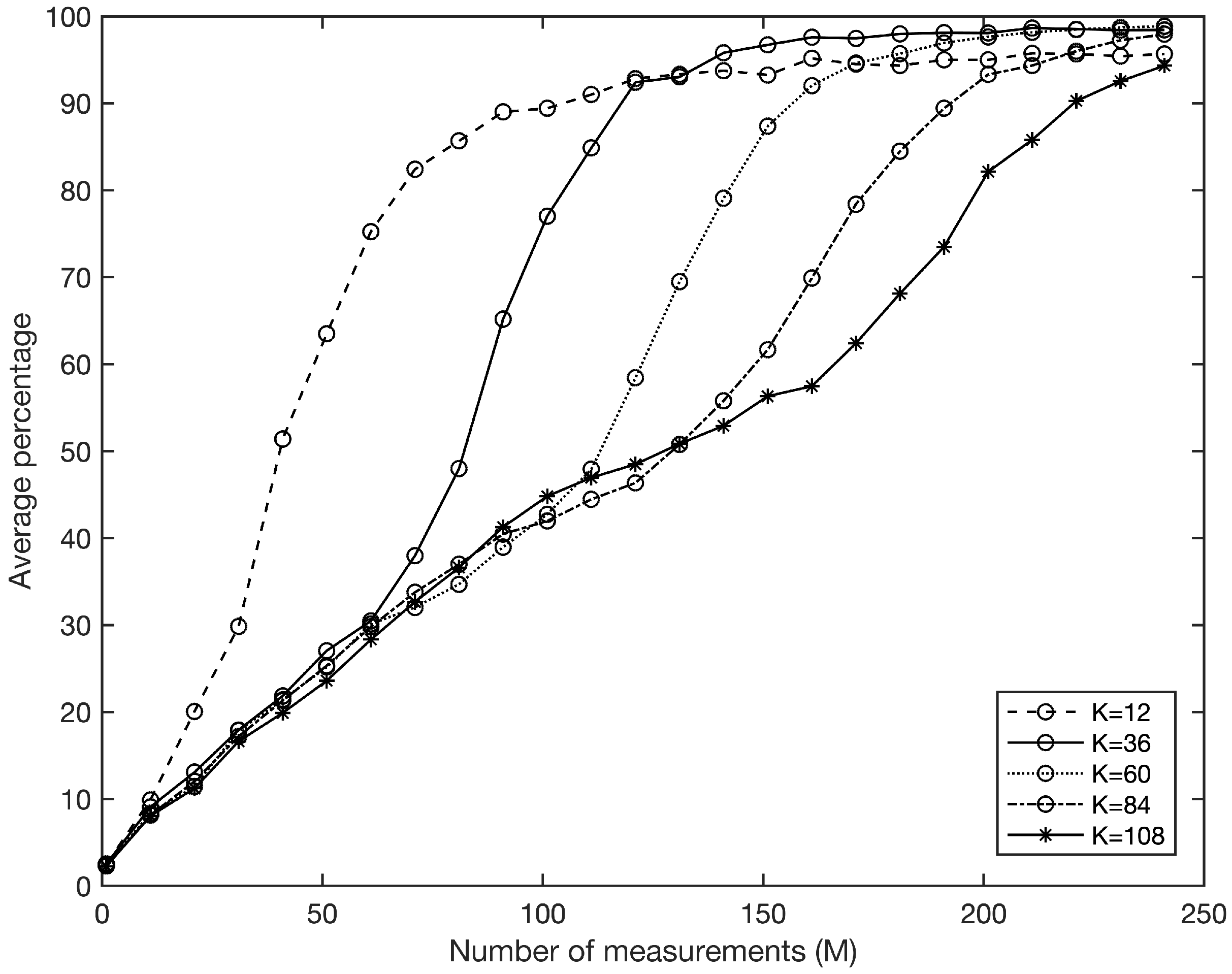
Figure 2 describes the case of the dimension
. It displays which percentage (the average of 100 input signals) of the elements in support can be found correctly as a function of
M with
. If the percentage equals
, it means that all the elements in support can be found, which implies that the input signal can be exactly recovered. As expected,
Figure 2 shows that when the sparsity level
K increases, more measurements are necessary to guarantee signal recovery.



{kind=link}
{kind=link}