1. Introduction
Today’s industry demands more optimization in its processes. Weichert et al. [
1] assure that advances in the manufacturing industry and the resulting available data have brought important progress and large interest in optimization-related methods to improve production processes. In several different disciplines, engineers have to take many technological and managerial decisions at different stages for optimization purposes. The literature shows different examples of this, such as the case of [
2,
3,
4], with research that successfully involves optimization for different purposes. The ultimate goal is either to minimize the effort required or to maximize the desired benefit. For instance, Balafkandeh et al. [
5] and Juangphanich et al. [
6] focus their efforts on optimizing operations to minimize outputs, while, Oleksy-Sobczak and Klewicka [
7] and Delavar and Naderifar [
8] pursue optimization of inputs to maximize results.
However, companies are not only concerned with creating more products with less resources; they also have the intention of performing right operations the first time. Several organizations around the world use statistical approaches as the core of process problem solving. According to Bryant [
9], problem solving constitutes the ambition to transcend the limits of ordinary capability, sometimes against rational ideas and the limitation of human capabilities, because people still have the need to reduce potential complexity and manage cognitive load. Inside an industrial environment, problem solving is widely related to productivity and it is an everyday issue to solve. In this scenario, each company is responsible for its own development. As noted by Apsemidis et al. [
10], the complexity of the industrial environment may be large enough to avoid classical process monitoring techniques and substitute new statistical learning methodologies. This is why mathematical and statistical approaches are being designed for organizations to obtain higher performance in their processes.
There are several quantitative methods such as Design Of Experiments (DOE), intended to analyze and improve processes. As explained by Montgomery [
11], experiments are useful to understand the performance of a process or any system that combines operations, machines, methods, people and other resources to transform some inputs (commonly a material) into an output with one or more observable response variables. Likewise, experimental designs have found several methods of learning through a series of activities, with the aim of making conjectures about a process to drive innovation in the product realization process, resulting in improvement of process yield, reduction of variability, closer conformance to nominal, reduction of development time and, finally, reducing costs by the optimization of processes.
For instance, Sheoran and Kumar [
12] studied a set of processing parameters that needed to be carefully selected for a specific output requirement. It was noted that some of these parameters were more significant for the response variable than the rest; this significance needed to be identified and optimized. Therefore, researchers explored different experimental or statistical approaches such as DOE for optimization and property improvement purposes.
The task of optimizing systems is always complex because of the quantity of factors involved. Beyond DOE, there is a method called Response Surface Methodology (RSM) used for this purpose. As stated by Myers et al. [
13], a RSM is a collection of statistical techniques useful for developing, improving and optimizing a process. In the case of industrial processes, it is very useful to apply this method particularly in situations where different input variables influence the performance or quality characteristics of the product (the response variable). This method is useful in the solution of several problems such as mapping a response surface over a particular region of interest, selection of operating conditions to achieve specifications, customer requirements and, of course, optimization of a response.
For example, Karimifard and Moghaddam [
14] presents RSM as a powerful tool for designing experiments and analyzing processes related to different environmental wastewater treatment operations with successfully optimized outputs.
Beyond these strategic tools, an auxiliary method to analyze the behavior of a response is called the Steepest Ascent or Descent Method (SADM). It is useful to obtain a region where optimization is feasible. Myers et al. [
13] remarks that this method searches for such regions through experimental design, model-building procedure and sequential experimentation. The type of designs that are most frequently used are the two-level factorial and fractional factorial designs. It is fundamental to remember that the strategy involves sequential movement in the factors from one region to another, resulting in more than one experiment. As mentioned by De Oliveira et al. [
15], optimization of processes commonly involves statistical techniques such as the RSM as one of the most effective ways to pursue optimization by modeling techniques.
A great exemplification of this is application of SADM by Chavan and Talange [
16], who applied a full factorial statistical design to obtain a model to find which input factors affect the response variables significantly in a process of fuel cells. The steepest ascent method was applied to find the maximum power delivered by these fuel cells within the defined ranges of input factors.
Since the SADM entails consecutive individual experimentation, it becomes necessary to have a procedure that gives mathematical support to recognize when the response has been improved and no more experimentation needs to be carried out. They are called Stopping Rules (SRs).
Myers and Khuri [
17] presented a procedure that consists in performing a sequence of sets of trials with the information provided by the first-order fitting. This Myers and Khuri Stopping Rule (MKSR) is used to determine a path to observe an increasing or decreasing response. This procedure considers the random error variation in the response and avoids the need to take many observations when the true mean response is decreasing. Furthermore, it prevents premature stopping decisions when the true mean response is decreasing. The stopping procedure is applied once a steepest path is developed and has been used in experimental strategy in optimum seeking methodology. There have been different informal procedures to stop, such as one that orders a stop at the first drop. Another informal tendency has been stopping after three consecutive drops. Nevertheless, due to the presence of random error variation in the observed response, the dropping of the response may not be true all along the function. Therefore, the need to design formal rules such as the MKSR has been important. The most important characteristic of the MKSR is that it assumes that
is normally distributed with mean
and variance
from a sequence of independent normal variables.
Similarly, Miró-Quesada and Del Castillo [
18] reported that a first-order experimental design is commonly followed by a steepest ascent search where there is a need for a stopping rule to determine the optimal point in the search direction. This procedure, known as Del Castillo’s Recursive Parabolic Rule (RPR), has been studied for quadratic responses. It is assumed that it is of interest to maximize the response, so the steepest ascent case is considered. In real experimentation, stopping a search before the maximum response over a path means that the optimum value will not be selected and the procedure will not be able to be efficient because of the wasting of resources in experimentation. One of the most important considerations when applying the RPR is that this procedure tries to fit a quadratic behavior to the observed data. It also recursively updates the estimate of the second-order coefficient and tests if the first derivative is negative. However, the necessity of developing a more robust procedure to also consider non-quadratic behavior is starting to be an important issue to solve.
Finally, Del Castillo [
19] explains a procedure to also consider non-quadratic behavior, called the Recursive Parabolic Rule Enhanced (RPRE). It has the advantage of being more robust because it becomes more sensitive when the standard deviation of the error is small. It mainly consists of three modifications to the traditional recursive rule. The intercept and the first order term, in addition to the second term, are recursively fitted. Furthermore, only a local parabolic model along the search direction is fitted, defined by a new concept called window. Finally, a coding scheme on the numbers of steps is used to reduce variance.
In this paper, a comprehensive study is carried out. It considers two simulated processes that offer response variables after a set of inputs (different levels and factors) configured according to a factorial design. The application and comparison of the mentioned three SRs will be illustrated, with the objective of recognizing the best performance. This analysis is important and relevant considering that current literature lacks recent studies of this nature, where three of the most important formal stopping rules are applied over a path of improvement that considers the coefficients of a linear model. This study is characterized by its lack of comparability with previous studies, because the response variables obtained by the simulators applied were specially obtained for this particular experiment. This means that comparison with previous studies is not feasible, since it can only be applied to the special conditions where responses were exclusively obtained for this case.
At this point, the originality of the contribution of this paper not only relies on the verification and comparison of performance of SRs, but also on the interaction of SRs with the behavior of the outputs. SR performance is similar when the response obeys a parametric function and differs when the output follows a stochastic behavior. It is important that further analysis over stochastic behaviors continue to pursue an even better procedure to stop over the path of improvement.
After this first section of introduction,
Section 2 is intended to show the method used for the paper and explain the application of rules.
Section 3 presents the results obtained with both of the cases after the application of the three SRs. Finally, discussion and conclusion are presented in
Section 4 and
Section 5, respectively.
2. Method
This procedure is intended to follow the main objective, which consists in running a first-order designed experiment and subsequently performing a steepest ascent/descent. The core of this analysis is to run the SRs previously addressed to discover the best performance between the MKSR, the RPR and the RPRE under the conditions of the specific experimentation schemes and cases considered.
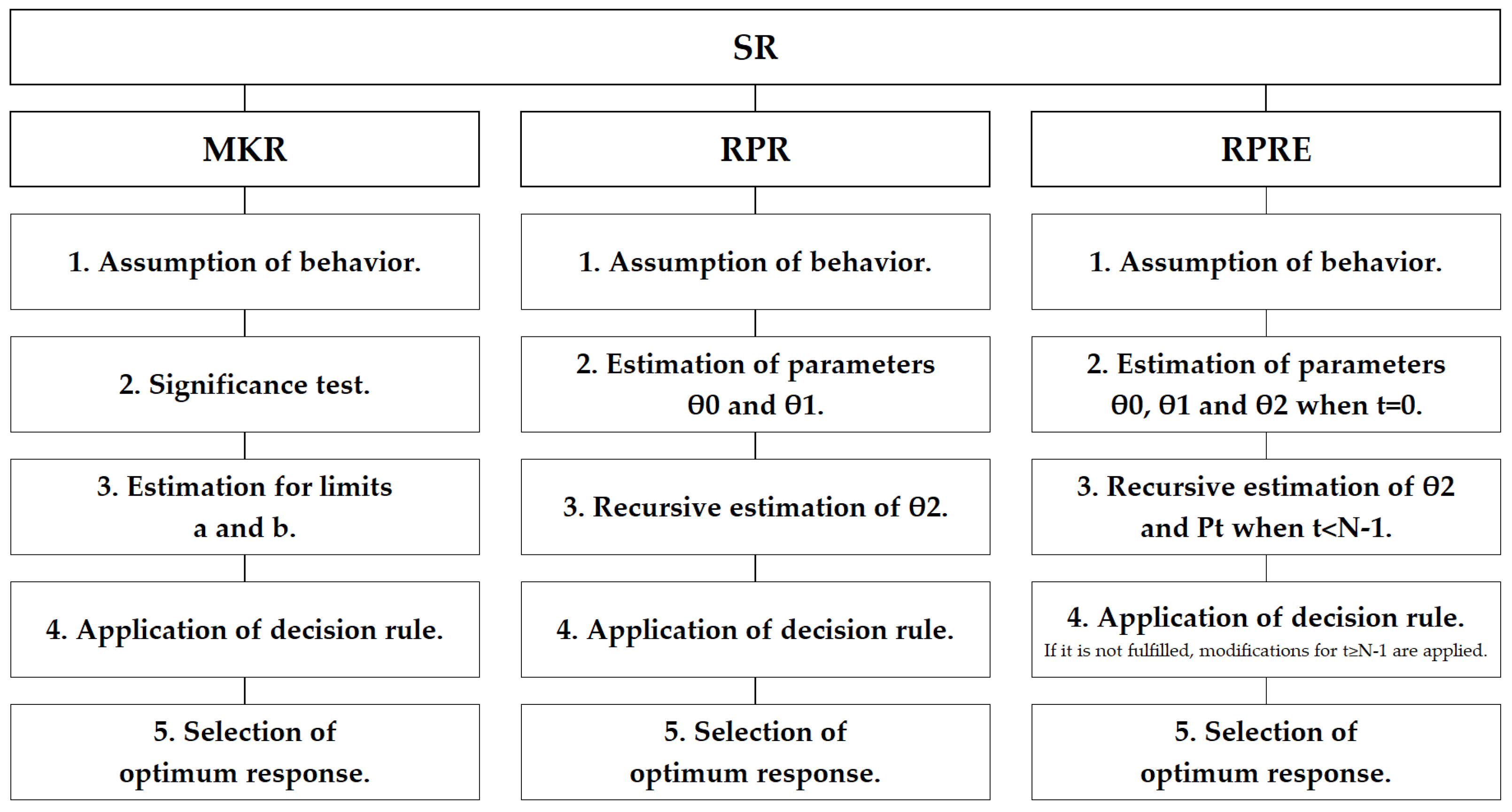
The method is explained in
Figure 1 as a flow chart to easily visualize the progress.
The first stage of the method consists in the considerations of the three cases that will be presented. Second, the first-order model is fitted; a linear regression equation is used. Then, the steepest path with the first-order model is determined so that the application of the MKSR, RPR and RPRE is possible. Finally, the selection of the rule with the best performance is denoted for each of the analyzed cases.
a. Considerations of the case study
The analysis considers two different simulated cases, both of which will consider the implementation of a factorial experimentation design. This factorial analysis includes seven factors, two levels, six center points and two replicates. It gives a total of 262 experimental runs. For ANOVA, the main assumptions of normality, equality of variances and independence of residuals must be assured for a well-performed analysis [
20].
b. Fit the first order model
The execution of the designed experiment starts with the consideration of the levels for each of the seven factors given by the simulators. The factorial design with the replicates and center points is given by a statistical software. Once the design is done, specific values of the factors are set in the simulators so that a response variable can be obtained from each of the two simulators. Once the responses are obtained, a factorial analysis is performed. The analysis offers a Coded Coefficients (CC) table which is used to build the Coded Unit Regression Equation (CURE). This first order model is obtained as the base for the development of the path for the SADM.
c. Determine the steepest path with the first order model
Once the coded unit regression equation is obtained. the steepest path can now be built. According to [
13], it is necessary to give a general algorithm to determine the coordinates of a point on the path. Considering that the point
is the origin point, it is necessary to:
* Select a step size for the path. The variable with the largest absolute regression coefficient is the one selected;
* Calculate the step size in the other variables with (
1) as follows:
where
represent the regression coefficient of the factor whose step size is to be estimated and
represents the regression coefficient of the factor with the largest absolute coefficient, while
and
work as the step size of the process variables;
* Convert from the coded variables to the natural variables.
d. Application of MKSR, RPR and RPRE
The intention is to utilize a formal procedure in order to stop at a required value. For this paper, the MKSR, RPR and RPRE will be applied for comparison.
The procedure of Myers and Khuri [
17] is as follows:
1. The MKSR assumes the behavior in the observed response to be normally distributed; thus ;
2. A significance test is run using confidence intervals as follows:
; where individual experimentation continues;
; where individual experimentation continues;
; where individual experimentation stops;
3. A solution is established for the limits of the procedures
a and
in (
2) as follows:
where
a and
b work as the limits of the interval for the significance test,
is the normal cumulative distribution function,
is a guess of the number of individual experimentation runs to arrive to the improvement and
is the square root of the adjusted mean square of ANOVA from the factorial analysis;
4. Once the values for
a and
b are computed, the decision to stop is determined with (
3) as follows:
where
is a present value from the response variables in the path of improvement from SADM,
is a past value from the path and
a is a limit of the interval of the significance test of the procedure;
5. The moment where individual experimentation stopped is the time where the response is considered to be the best. Nevertheless, if a better response is identified in a previous time, that value is the new best response.
On the other hand, ref. [
18] presents the RPR procedure:
1. It assumes the behavior of the observed response to be quadratic and proposes to obtain the first derivative of to obtain ; thus ;
2. The parameters or , and are estimated as follows:
a. is obtained by computing the arithmetic mean of center points of the experiment;
b.
is estimated by calculating (
4):
where
is one of the parameter estimations that assists computation in the procedure and
represent the regression coefficients of the linear model;
c. must be recursively estimated. Therefore, there will be one for each iteration or individual experimentation t. This means the estimation of ;
3. should be estimated as follows:
a. For
, (
5) is considered:
where
works as an estimation for the procedure when
, and
works as an initial guess about the number of iterations or individual experiments that are considered to be necessary to reach the optimum value;
b. For
starting from
, the updating is calculated using (
6) as follows:
where
represents the response variable in
t time in the path of improvement.
c. To calculate
in
, Miró-Quesada and Del Castillo [
18] propose that it is necessary to establish an initial value, similar to the initial guess of
;
d. For
starting from
, the updating is calculated using (
7), as shown next:
where
is considered the scaled variance of
after
t iterations of individual experimentation, noted as:
;
e. An estimation for the variance of the error
is obtained with (
8) as follows:
This result will be used next for comparison purposes;
4. A decision rule is applied to state if (
9) is fulfilled. If so, individual experimentation stops. The in-equation is as follows:
The intention is to compare both sides of (
9) to assure the stopping iteration;
5. The iteration where t stopped is the value in y where the response is considered to be the best answer. Nevertheless, if a better response is identified in a previous time, that value is the new best response (the same as in the MKSR).
Finally, Del Castillo [
19] explains the RPRE, which recursively fits the intercept and the first-order term in addition to the second-order term in (
10), as shown here:
where
denotes the operation
.
The procedure can be summarized with the following five main steps:
1. The recursive fitting increases the robustness for non-quadratic behavior by specifying a maximum number of experiments in the recursive least squares algorithm, applying a concept called “window” to fit only a local parabolic model along the search direction to make it less sensitive to large scale deviations from quadratic behavior. The “window” size
is determined using an indicator called “Signal-to-Noise Ratio” (SNR) estimated with (
11) as follows:
where
is the standard deviation from the center points of the experiment.
The variable
is estimated using (
12) as follows:
Finally, it is necessary to identify N in a table of values of window sizes. In the enhanced stopping rule, it is proposed to visualize the vector and the scalar ;
2. As in the procedure for the RPR,
continues to be an initial guess about the number of individual experiments that are suggested to be necessary to reach the optimum value. Now, for the estimation of parameters when
, computations (
13)–(
15) are suggested, as illustrated next:
where
represents the average of the response variables obtained from the center points of the experiment. Furthermore:
where
represents the square root of the sum of the squares of the regression coefficients of the linear model of the experiment. Next:
where the constant 2 proposed by the author of the rule has the intention of making the value of
more robust;
3. The algorithm makes use of the matrix definitions (
16)–(
19) for updating the three parameters
,
and
:
The large value of 10 given to makes the rule robust against possibly large discrepancies between and , giving “adaptation” ability to varying curvature.
Now, (
20) is used to update
:
Furthermore, (
21) is used to update
:
4. If (
22) is fulfilled, the search stops and returns to
, such that the maximum response is determined by
. The rule is shown next:
where −1.645 represents a standardized value of the normal distribution for a significance level of 0.05.
Otherwise, the procedure continues computing
following the next steps according to Del Castillo [
19]:
a. Perform an experiment at step ;
b. Update vector with the observed value by discarding its first element, shifting the remaining elements one position up in the vector and including as the last element in ;
c. Read
and
using the table of values of window size
N in the enhanced stopping rule proposed by [
19], where it is possible to visualize the
vector
and the scalar
. After this, continue individual experimentation until (
23) is fulfilled:
5. If the inequality holds, then stop the search and return such that .
Next,
Figure 2 shows the steps to follow in each of the SRs previously mentioned.
e. Selection of the rule with best performance for each case.
In this last stage of the method, the response value with the best performance is observed for each of the simulators. This means that through the analysis, either the MKSR, RPR or RPRE will have better performance according to the application of each SR and their adjustment with the behavior of the data. For each simulator, the best value and SR is mentioned.
3. Results
The analysis considers two cases. The selection of these two simulated cases is based on the importance of a well-performed approach to processes with several inputs and only one output. The combination of levels and factors is vital to understanding the interactions in the system; nonetheless, identifying relevant factors even among several of them is indispensable in terms of optimization of the response. Furthermore, as multiple experiments are required for the comparison of the considered stopping rules, the simulated processes may represent an important option, as they offer practical scenarios that can be reproducible for optimization purposes. These two cases follow factorial designs, which contain seven factors, two levels, six center points and two replicates. This gives a total of 262 experimental runs per case. The first case has factors
and
V. The low levels for each of these factors are 11, 68, 67, 275, 0.4, 70 and 16, respectively. The high levels for the factors are 13.5, 84, 92, 300, 0.5, 80 and 20, respectively. After the factorial analysis was performed using Minitab
®, only factors
and
U were significant for the response. The second case has factors
and
G. The low levels for each of these factors are 325, 650, −2, 1.4, 1, 28.5 and 9, respectively. The high levels for these factors are 350, 700, 0, 1.5, 3.0, 31 and 13, respectively. Only factors
and
G were significant. This information was used in both cases to build the steepest path using the procedure in [
13] to determine the step size of the path for each of the significant factors. The sufficiency of diversity in the nature of these experiments to generalize findings and make more general recommendations will follow the conditions and properties of the experiment itself. This means that all conclusions will be highly valuable for oncoming situations with similar natures and characteristics to the ones here presented.
Next, the application of the three mentioned SRs in Case 1.
3.1. Results for Case 1
The coded unit regression equation for Case 1 is:
.
The path for the steepest ascent is built considering:
The selection of a step size for this path. The variable with the largest absolute regression coefficient is the one selected. In this case, factor Q is selected;
The proposed natural step size for the factor Q is . Through conversion from coded to natural units, the coded step size for Q is ;
The calculation of the coded step sizes for the rest of the variables is performed with (
1).
For example, the coded step size of P is:
Thus, the coded step sizes for the significant factors are:
for P,
for Q,
for S and;
for U.
The natural step sizes for the same factors are:
for P,
for Q,
for S and;
for U.
The path for Case 1 is built next.
Application of MKSR to Case 1
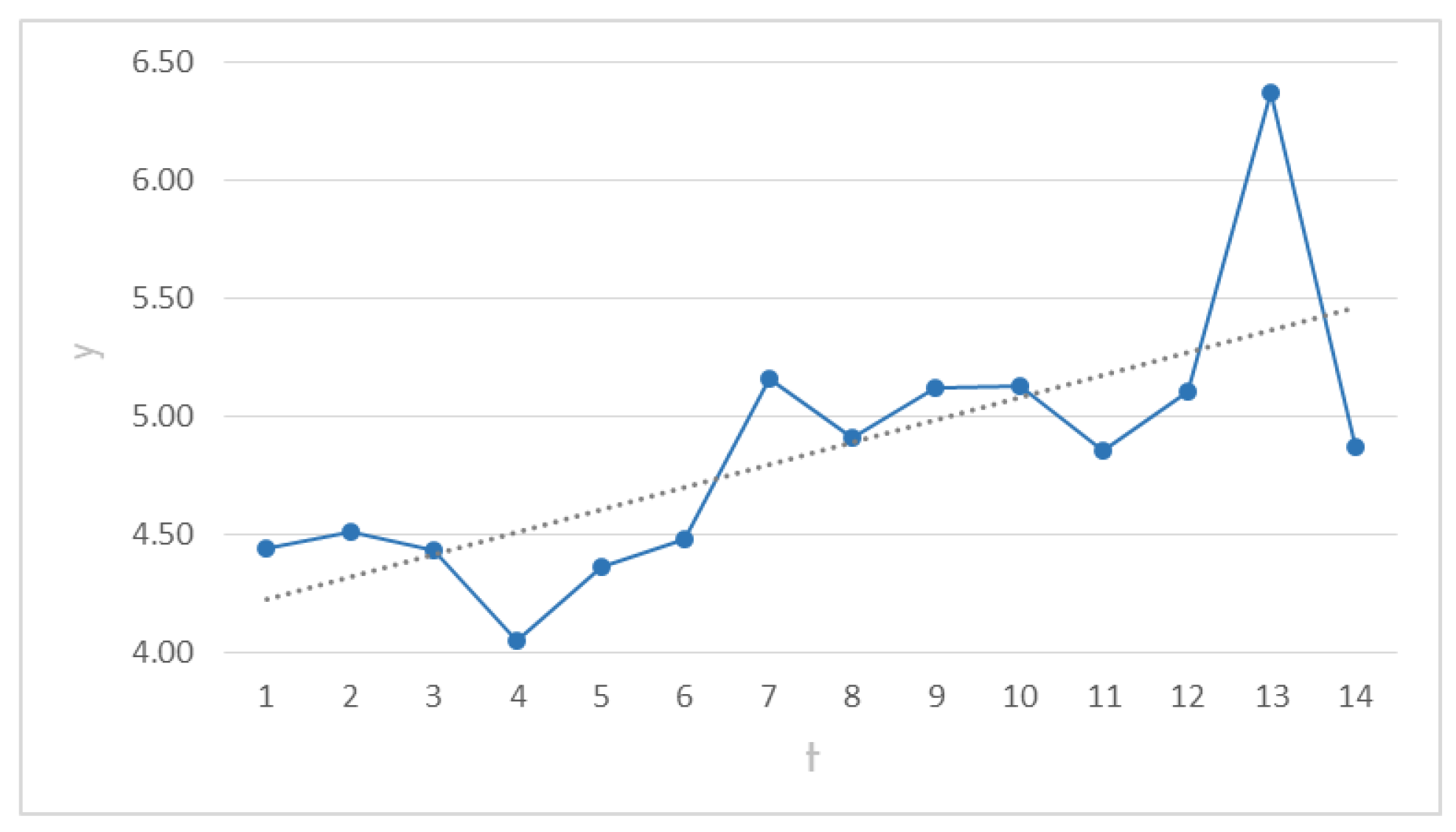
1. Assumption of behavior in Case 1. The steepest direction is shown in
Table 1, running 15 iterations. It starts with step 0, computing the center points of the experiment.
This procedure assumes a normally distributed behavior in response
.
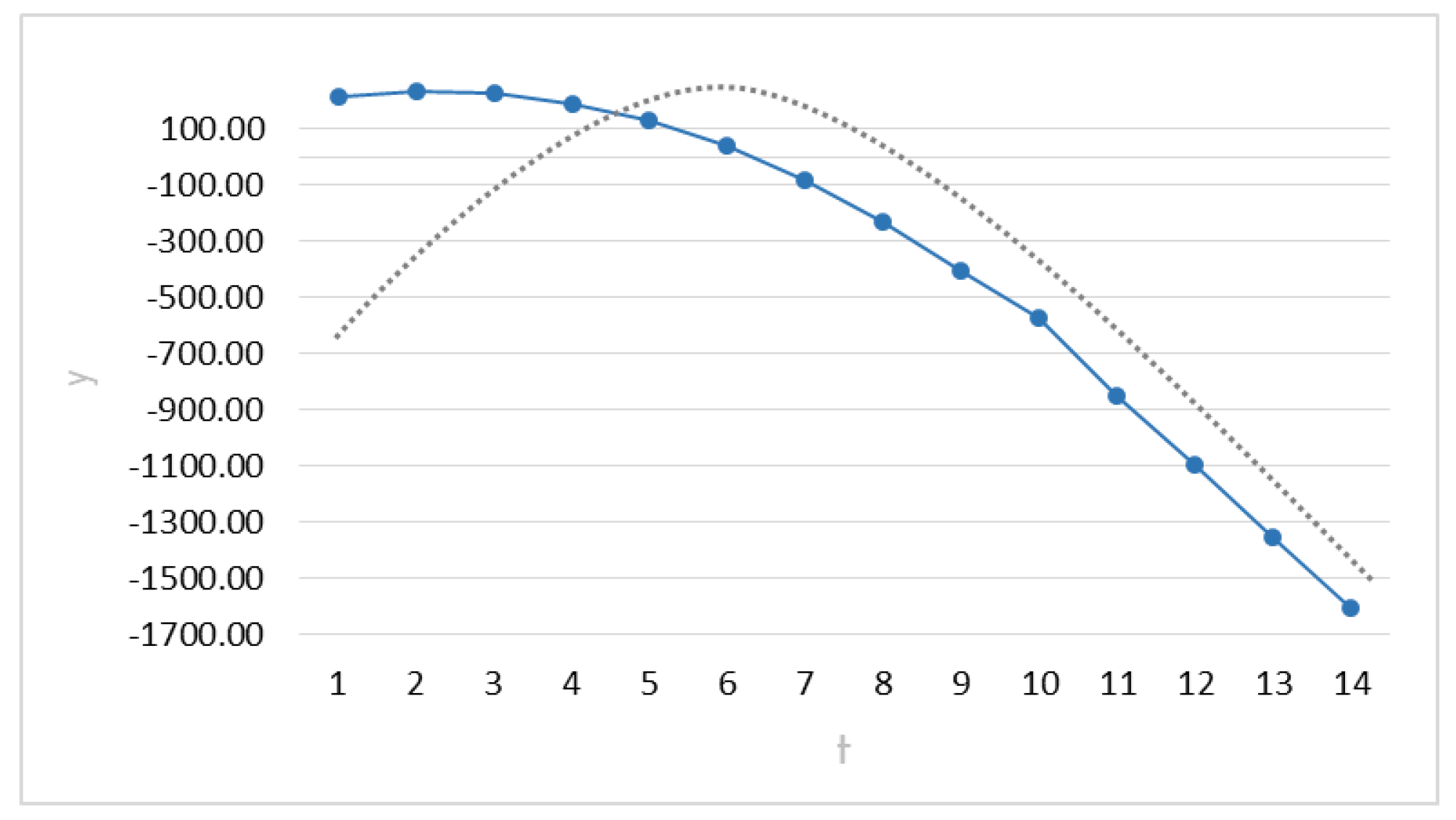
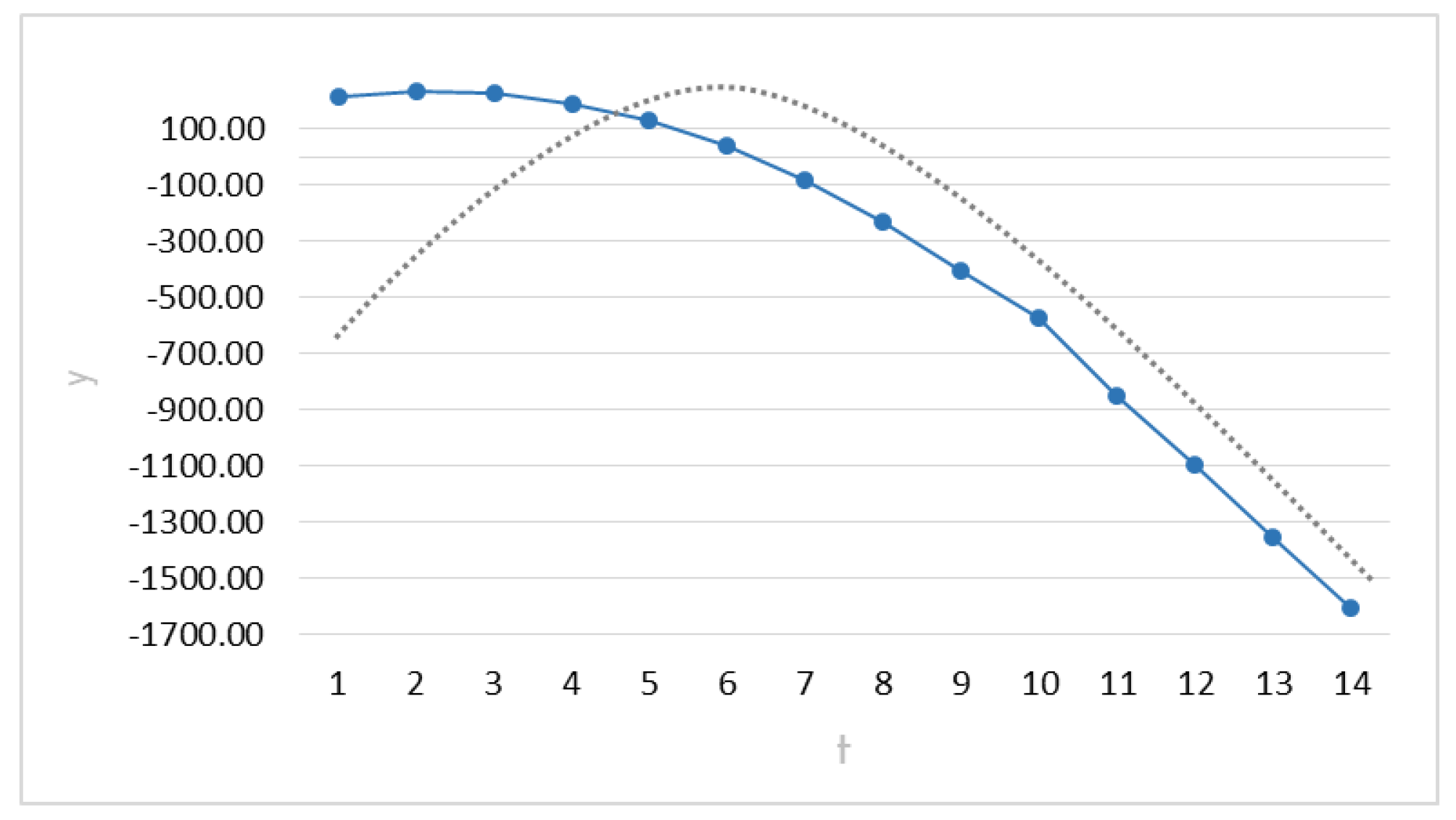
Figure 3 shows the behavior of the response in its steepest path from
to
. The straight line tries to illustrate the assumption of normality for the response.
2. Significance test in Case 1. Iterations or individual experimentation through the steepest path stop when .
3. Estimation for limits a and b in Case 1. Limits
and
are calculated using (
2) as shown in
Table 2. Those limits are used to identify the moment where (
3) is fulfilled. It is important to remember that the value of
is a guess of the number of individual experimentation runs to arrive at the improvement. In this case, the considered value of
.
4. Application of decision rule in Case 1. The decision to stop is determined by (
3). This means that the time
t should stop when
. The behavior of the data is shown in
Table 3.
5. Selection of optimum response in Case 1. If , the search stops and it returns to such that As noted, the best performance for the MKSR us found in iteration 13, with a response of 6.37 units.
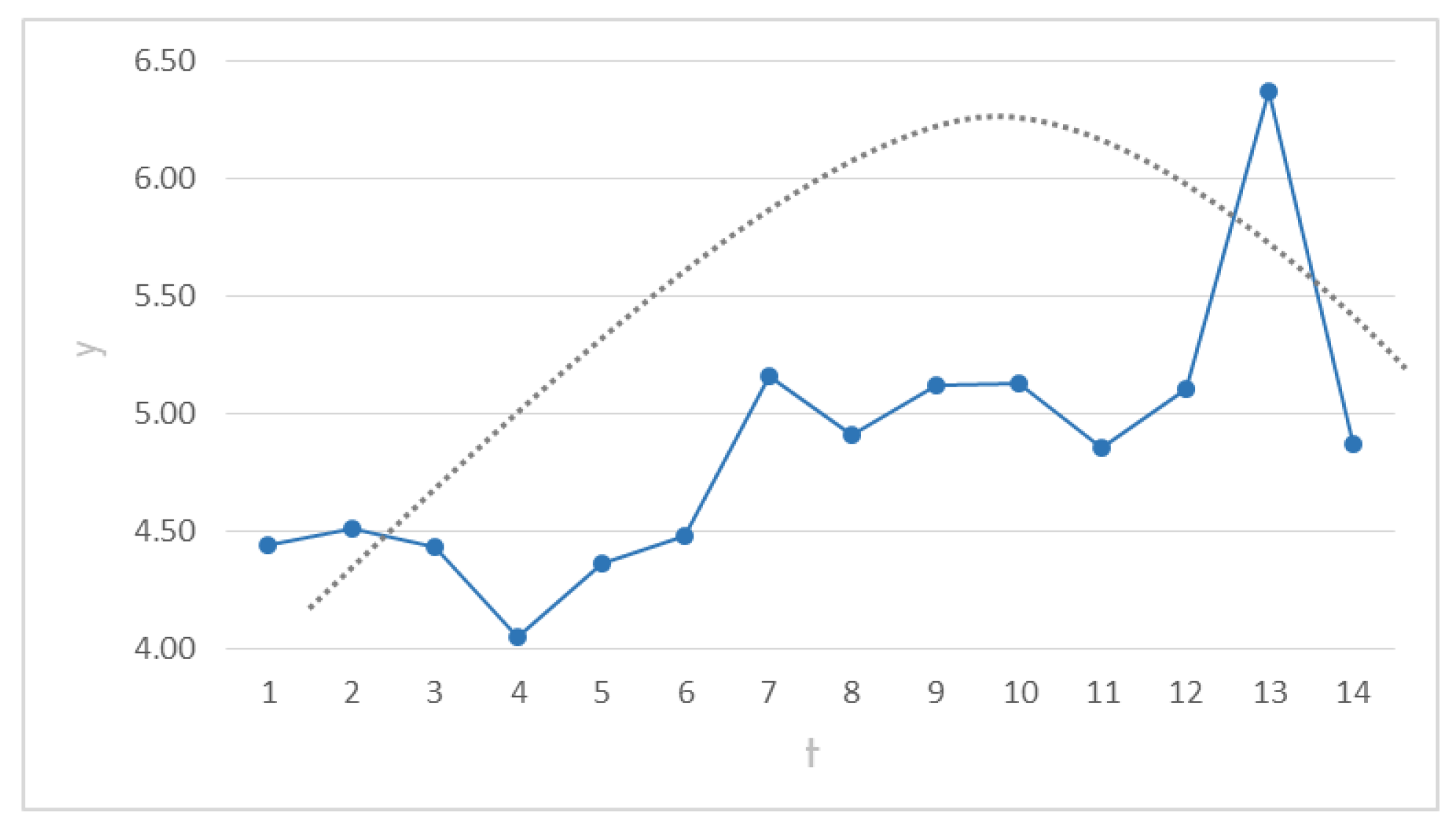
Application of RPR to Case 1
1. Assumption of behavior in Case 1. The steepest path applies the same way for this case. Now,
Figure 4 shows the behavior of the response in the steepest path from
to
. The curved line tries to illustrate the quadratic assumption of the response.
2. Estimation of parameters and in Case 1. The estimation starts with , which is obtained by calculating the arithmetic mean of center points. In this case:
; thus, .
Applying (4) through the coefficients of significant factors,
.
This is known as the slope of the response function at the origin in the steepest direction.
3. Recursive estimation of parameters in Case 1.Table 4 details the recursive estimation of parameters, which assists the stopping decision. For this case,
4. Application of decision rule in Case 1. The decision to stop is given when (
9) is fulfilled. The "Status" column of
Table 4 shows the moment that this occurs.
5. Selection of optimum response in Case 1. As seen in Table 8, the decision to stop occurred in iteration 5; nevertheless, the best response was at 4.62 units because it returns to such that
Application of RPRE to Case 1
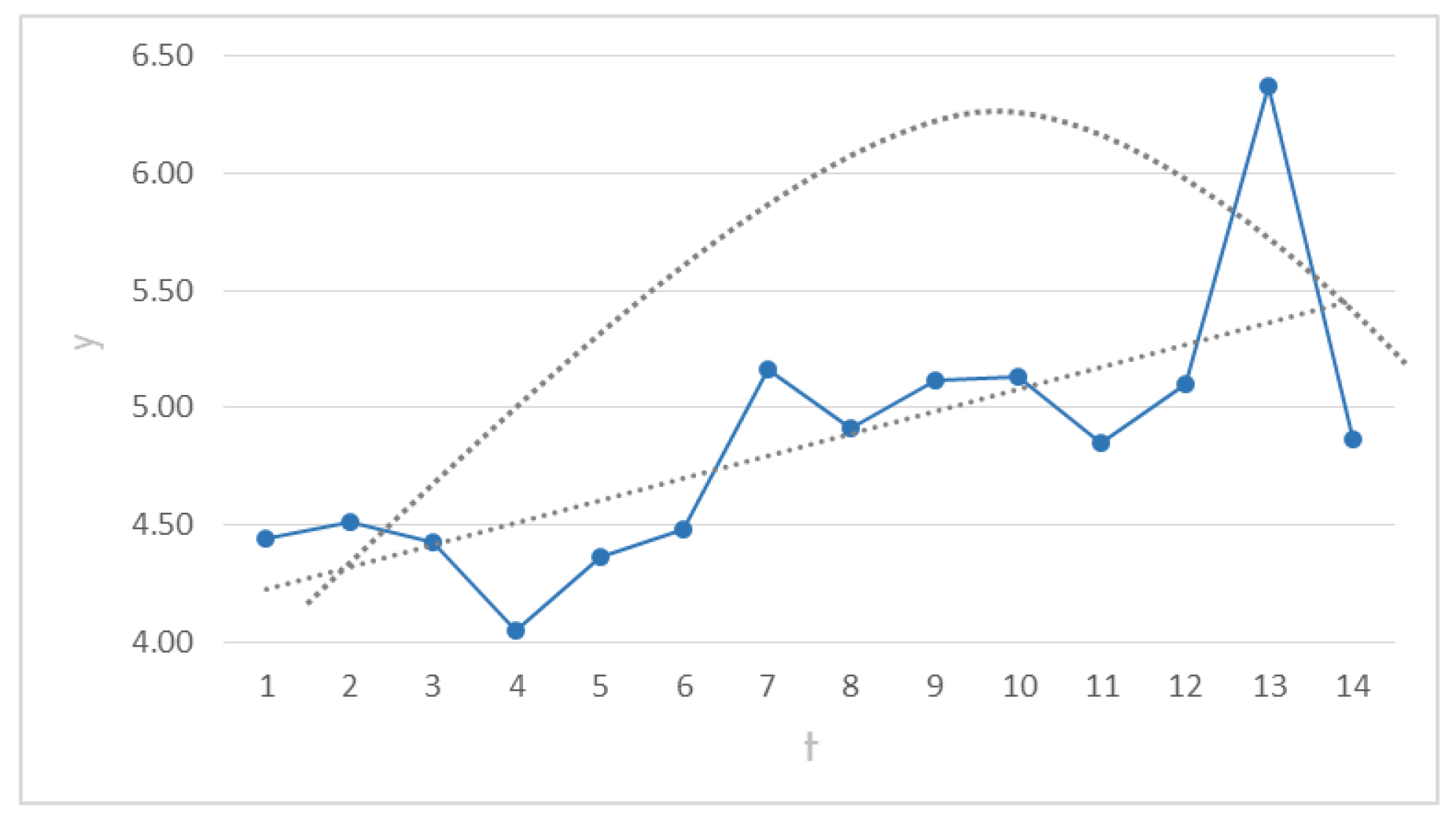
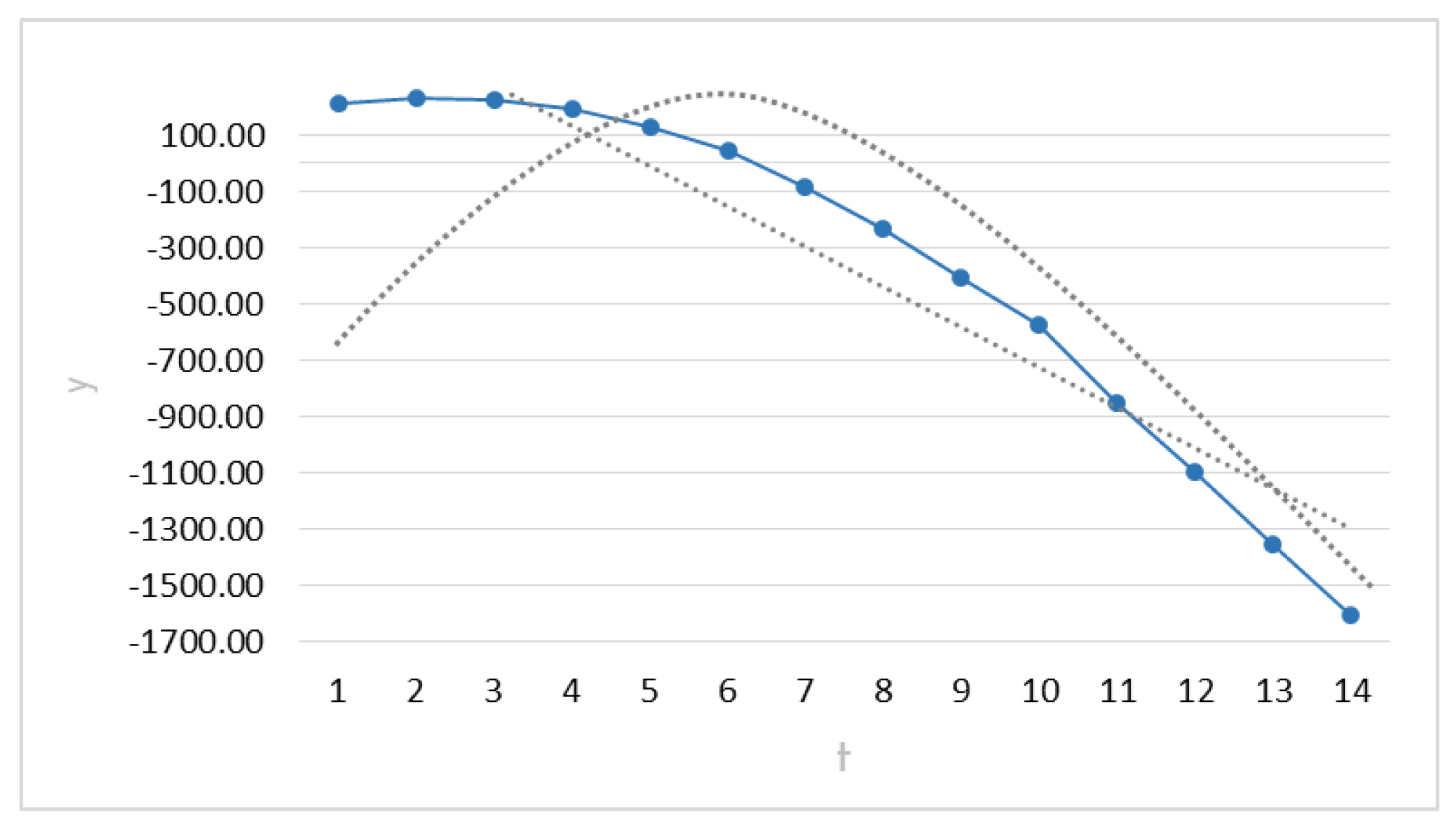
1. Assumption of behavior in Case 1.Figure 5 shows the response behavior in the steepest path and the assumption of both quadratic and non-quadratic behavior. The straight and curved lines illustrate the capability of this procedure to assume both types of behavior.
In order to estimate the indicator SNR and obtain the
N, it is necessary to use (
12) to compute:
.
This is the slope of the response function at the origin in the steepest direction.
Then, (
11) is applied to estimate the indicator
:
This indicator makes the value . It means that computations shall start for:
2. Estimation of parameters , and when in Case 1.
Results for parameters , and when are presented next:
; ; .
3. Recursive estimation of and when in Case 1.
Table 5 shows the recursive procedure of
and
when
. For this case,
obeys (
19) and
4. Application of decision rule in Case 1. If it is not fulfilled, modifications for are applied.
In this case, in-equation is fulfilled, so the search stops and returns to , such that .
5. Selection of optimum response in Case 1.Table 5 shows the decision to stop, which occurred in iteration 5. Nevertheless, the best response was at 4.62 units.
Now, the application of the three SRs in Case 2.
3.2. Results for Case 2
The coded unit regression equation for Case 2 is:
.
The path for the steepest ascent is built considering:
The selection of a step size for this path. The variable with the largest absolute regression coefficient is the one selected. In this case, factor E is the one selected to propose a natural step size;
The proposed natural step size for factor E is the unit; thus, the step size for E is . Through conversion from coded to natural units, the coded step size for E is . By coincidence, it is equal for both coded and natural units;
The calculation of coded step size in the other variables is performed with (1). For example, the coded step size of Z is:
Thus, the coded step sizes for the significant factors are:
for Y,
for Z,
for E and;
for G.
The natural step sizes for the same factors are:
for Y,
for Z,
for E and;
for G.
The path for Case 2 can now be built.
Application of MKSR to Case 2
1. Assumption of behavior in Case 2.
Table 6 shows the steepest path from iteration 0 to 14.
Next,
Figure 6 shows the behavior of the response in its steepest path from
to
.
2. Significance test in Case 2. As in Case 1, individual experimentation over the steepest path stops when .
3. Estimation for limits a and b in Case 2. Limits
and
are calculated using (
2) with
, as shown in
Table 7. Those limits are used to identify the moment where (
3) is fulfilled.
4. Application of decision rule in Case 2. The decision to stop occurs when
. The behavior is shown in
Table 8.
5. Selection of optimum response in Case 2. In this case, the best performance for the MKSR in Case 2 is the response of 232.75 units, because it stopped in such that
Application of RPR to Case 2
1. Assumption of behavior in Case 2.
Figure 7 shows behavior of the response in the steepest path.
2. Estimation of parameters and in Case 2. These estimations are shown next:
.
This next estimation is performed the same way as in the previous case (Case 1):
.
3. Recursive estimation of parameters in Case 2.Table 9 shows the recursive estimation needed with
4. Application of decision rule in Case 2. The “Status” column in
Table 9 shows the moment when (
9) is fulfilled.
5. Selection of optimum response in Case 2. Table 11 illustrates the decision to stop, which occurred in iteration 4. However, the selection falls in such that ; therefore, the best response was at 232.75 units.
Application of RPRE to Case 2
1. Assumption of behavior in Case 2.Figure 8 shows the behavior of the response in the steepest path and the assumption of both quadratic and linear behavior.
The variable .
The indicator .
This makes the value of .
This means that computations shall start for
2. Estimation of parameters , and when in Case 2.
Results for parameters , and when are presented next:
; ; .
3. Recursive estimation of and when in Case 2.
Table 10 shows the recursive procedure of
and
when
.
follows (19) and
4. Application of decision rule in Case 2. If it is not fulfilled, modifications for are applied.
In this case, in-equation
is not fulfilled, so the search continues for
, as seen in
Table 11.
5. Selection of optimum response in Case 2.Table 11 shows the decision to stop, which occurred in iteration 3. Nevertheless, the best response was at 232.75 units due to
in
4. Discussion
Now that the three SR procedures have been applied for both cases, the discussion and comparison of the best performance are presented next. In Case 1, the method from [
17] needed 14 iterations to stop, giving an optimum response of 6.37. The method from [
18] stopped at the fifth iteration, obtaining the optimum response of 4.62. The method from [
19] had the same results as the previous one. In Case 2, Ref. [
17] needed 3 iterations to stop, delivering a response of 232.75. Ref. [
18] stopped at the fourth iteration, with 232.75 as a response. Ref. [
19] obtained 232.75 after 3 iterations. The most important piece of information in this case is related to the maximized shown response. For these cases, the number of iterations is not as critical as the response obtained, due to the adaptation that it could suffer. This means that the higher the step size for the steepest path, the faster the maximum response will be reached. However, the intention is to carefully analyze the experiment and the obtained outcomes for comparison.
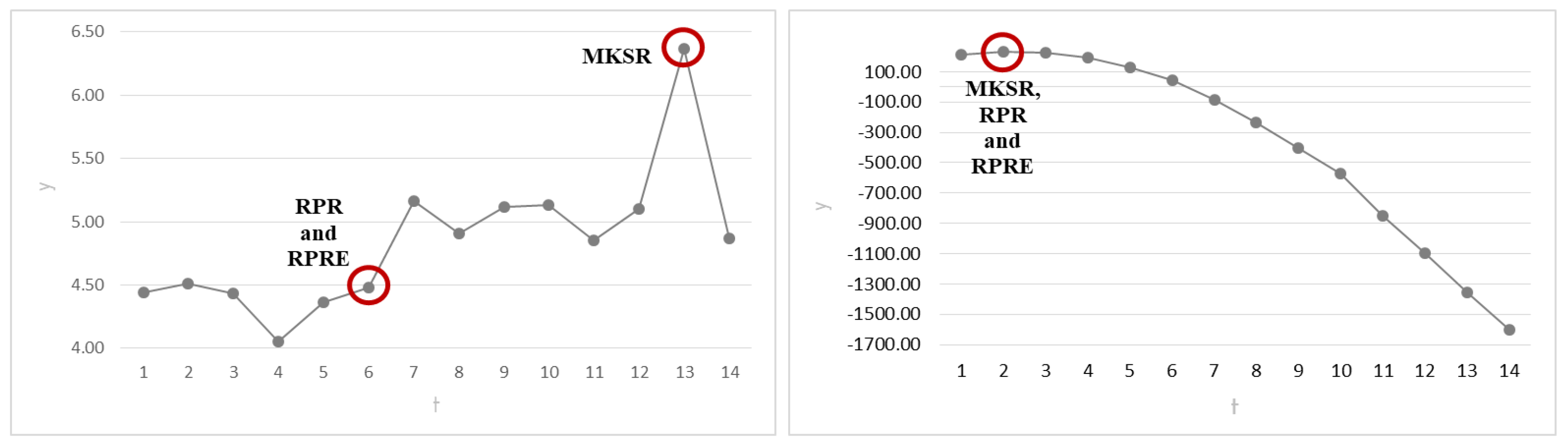
Table 12 illustrates information of the results. Furthermore,
Figure 9 shows the best results for each of the two analyzed cases.
The behavior of the responses of the individual experiments in both study cases is considerably different. In the graph on the right side of
Figure 9, the shape of the response tends to resemble a simple parametric function, which could be compared to a quadratic or even a logarithmic model. In these functions, it is relatively easy to find a maximum or a minimum point. This situation becomes evident when observing the way in which the three SRs determined the maximum point in the same place. However, the issue becomes complicated by a case such as the graph on the left side of
Figure 9, in which the response does not follow a fixed trend. On the contrary, it shows random variations up and down, so it cannot easily be assimilated into a specific behavior. When this occurs, it can be said that this is a case belonging to a stochastic model. An interesting phenomenon occurs in this type of behavior; the performances of the SRs are not the same; they does not coincide and are different from one another. In a few words, the evidence shown here suggests that the performances of the SRs are similar when the response obeys a parametric function. On the other hand, the performances of the SRs differ when the response exhibits stochastic behavior.
In the particular case of this analysis and under the conditions proposed, the MKSR seems to have better performance, while it is observed that the RPR and the RPRE show a lower output. This situation is not strange; it is explained due to the assumptions of each rule. The MKSR assumes normally distributed behavior, the RPR suggests a quadratic parametric function, and the RPRE obeys quadratic and non-quadratic behavior. None of the previous assumptions easily adjusted to the responses of these individual experiments; however, the MKSR adjusted to give a higher performance.
As previously mentioned, an important task here was to conduct experimentation to simulate behaviors for these three applied stopping procedures. This allowed the possibility of comparison and selection of the procedure with the best performance. The results, with responses and number of needed iterations, are visualized above.
At this point, the complexity of the behavior of the trajectory is particularly important, because it becomes necessary to not only infer using parametric known functions, but also to consider the analysis of these stochastic behaviors. Fortunately, there are several stochastic models that can be considered to characterize the behavior of a steepest ascent trajectory. The Wiener process may be a good option, as it has non-monotone increments with a drift and diffusion parameters that can characterize the randomness in a trajectory, which is the case of the steepest ascent. Stopping rules can be implemented in the stochastic process by considering specific parametric functions in the drift to define a recursive strategy to determine the stopping time.


 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}