Abstract
Bilateral correlated data frequently arise in medical clinical studies such as otolaryngology and ophthalmology. Based on an equal correlation coefficient model, this paper mainly aimed to investigate the statistical inference for the odds ratio of two proportions in bilateral correlated data, including not only three test procedures but also four confidence interval (CI) constructions. Through iterative algorithms, all unknown parameters are estimated in order to construct the likelihood ratio, score and Wald-type tests. Furthermore, the profile likelihood CI, score CI, and Wald-type CI are obtained by the bisection root-finding algorithm. We provided another Wald-type CI based on an asymptotic normality property. The performance of the proposed tests were investigated with regard to empirical type I error rate and power, and CI methods were compared in terms of mean coverage probability and mean interval width. Numerical simulations show that the score test is more robust, and has higher power than other tests. The score CI also has a shorter interval width, and its coverage probability is closer to 0.95. A real example is used to illustrate the proposed methods.
Keywords:
correlation coefficient model; odds ratio; likelihood ratio test; score test; Wald-type test; confidence interval MSC:
62F03; 62F05; 62F12
1. Introduction
Binary data are often encountered when an investigator takes measurements from the paired organs of a patient. Observations may be related because they come from the same patient, such as both eyes, hands, arms, legs, or sides of the face [1,2,3,4]. For example, Mandel et al. [5] conducted a double-blind randomized clinical trial to compare cefaclor and amoxicillin for the treatment of otitis media with effusion in children with bilateral tympanocentesis. Sainani [6] reviewed some examples of correlated data and demonstrated that errors arise when correlations are ignored. Therefore, the misleading statistical inference may be obtained from ignoring the correlation between the responses of paired organs [7,8].
For the correlated binary outcomes, we briefly reviewed the developments of three main statistical models: Ronser’s model, Dallal’s model, and Donner’s model. An interclass correlation model was proposed by Ronser [9] based on the assumption that the probability of a response at one side given a response at the other side is proportional to the prevalence rate of the corresponding group. Ma et al. [10] analyzed the equality of the response rates for multiple groups under Ronser’s model. Tang et al. [11,12] proposed the test procedures and asymptotic confidence intervals (CIs) about risk differences based on Ronser’s model. Dallal [13] pointed out that Ronser’s model will give a poor fit if the characteristic is almost certain to occur bilaterally with widely varying group-specific prevalence and then considered that the probability of a response at one side given a response at the other side to be constant. Under Dallal’s model, Sun et al. [14] derived risk difference tests for stratified binary data. However, Dallal’s model had its own limitation. Furthermore, Donner [15] established an alternative model when the correlation coefficient between two paired organs is a fixed constant . Liu et al. [16] derived several statistics from testing the equality of correlation coefficients for paired binary data. Pei et al. [17] constructed CI methods for risk differences under Donner’s model. Under these models, the risk difference, relative risk ratio, and odds ratio are the three most used methods to compare disease risk among different groups. In the first two forms, various approaches were used to describe and quantify the statistical inference in a given population. For more details about this topic, we refer the reader to [18,19,20,21,22,23]. However, the research into the odds ratio is still in its infancy and has had fewer achievements for the bilateral correlated data.
It is noteworthy that the odds ratio is a preferred measure of association in prospective, retrospective, or cross-sectional sampling designs. However, most of the aforementioned results usually focus on the test or CI problems of risk difference and relative risk ratio. In this paper, we focused on the study of statistical inference for the odds ratio of two proportions in bilateral correlated data. Under Donner’s model, the novelty and contribution embody several aspects: (i) three statistics are proposed to test whether the odds ratio of response rates equals a specific value . The performance of these statistics is investigated in terms of type I error rate and power. (ii) We propose the use of CI methods for any specific value . These intervals have some advantages; they contain the true value with a given probability. In addition, these can answer the testing problem and give a range of values for . The remainder of the paper is organized as follows. In Section 2, we briefly review some notations, data structure, and Donner’s model. The unconstrained and constrained MLEs are obtained in Section 3. Three different test procedures are proposed in Section 4, and four asymptotic CI methods are provided in Section 5. In Section 6, the simulation studies were conducted to investigate the performance of three tests and four CIs. A real example is used to illustrate our proposed methods in Section 7, and we conclude in Section 8.
2. Data Structure and Donner’s Model
We randomly allocate a total of N patients into control and treatment groups. In the comparative experiments, the control group members receive a standard treatment, a placebo, or no treatment at all. The recorded outcome would be none cured (no response), unilateral cured (one response), or bilateral cured (two responses). Let be the number of patients with response(s) in the ith group, where and . Denote the number of patients who have exactly l responses for by . Obviously, . Table 1 list the data structure.

Table 1.
Data structure for bilateral binary data.
Let be a random variable and represent the number of patients who have response(s) in the ith group, and be the probability that a patient in the ith group has exactly l responses . Denote and . Thus, follows a trinomial distribution with unknown parameter vector and its probability function satisfies
where and for .
In clinical research, bilateral correlated data often arise when investigators collect information from paired organs (or body parts). Donner’s model can be used to capture the intraclass correlation between observations. Let if there exists a response for the kth organ of the jth patient in the ith group ; otherwise, . Suppose that
for and , where represents the probability that the kth organ of the jth patient in the ith group has a response, and denotes the common correlation coefficient between the two random variables and for . From (1), we have
The probability function of satisfies
where . It follows that the expectation vector , where for and . Under the condition that the control and treatment groups are independent of each other, the joint probability function of the random vector can be given by
where are defined in (2).
Following Edwards [24], the odds is the probability of an event occurring, divided by the probability of that event not occurring. An odds ratio (OR) is the ratio of two odds. Define the odds ratio as If , the condition or event under study is equally likely to occur in both groups. That is to say, . If , it reflects that the condition or event is more likely to occur in the second group. Otherwise, the condition or event is less likely to happen in the second group. In this work, we are interested in testing whether the odds ratio of the two groups is equal to a specific value, that is
and constructing its confidence intervals.
3. Unconstrained and Constrained MLEs
For each observed data , the likelihood function is defined by
where are defined in (2) and does not depend on the unknown parameters and . Thus, the log-likelihood
For convenience, denote and the unknown parameter space
Regularity conditions are required to ensure the almost definite existence of a strongly consistent root of the log-likelihood equation. These conditions were first proposed by Chanda [25]. Hereafter, we assume
(A1) For all , the derivatives , , exist for . It is to ensure the existence of a Taylor expansion.
(A2) For almost all and every , we have
where and are finitely integrable functions and for all . It aims to justify the interchangeability of integration and differentiation for .
(A3) For all , Fisher’s information numbers are finite and non-zero. This condition guarantees that the random variables have finite, positive variances.
Under these regularity assumptions (A1)–(A3), there exists a strongly consistent root of the log-likelihood . In some situations, we cannot obtain the explicit expression of MLEs through the log-likelihood equations. Ma, Shan, and Liu [10] provided a two-step method formed by a third-order polynomial and Newton–Raphson algorithm to solve the problem. Mou and Li [26] compared three iterative algorithms, including the Fisher scoring algorithm, the two-step method, and the generalized expectation-maximization (GEM) algorithm. The result shows that the GEM algorithm takes more iterations to converge than the Fisher scoring algorithm and two-step method. Thus, we will use the Fisher scoring algorithm and two-step method to obtain the corresponding MLEs in this article.
3.1. Unconstrained MLEs
We first considered the unconstrained MLEs under the alternative hypothesis . Let and be the maximum likelihood estimations (MLEs) of unknown parameters and , respectively. Differentiating l to yields the score function , where
Although the MLE of is the solution of the following equations
there is no closed-form solution for the above equations. A global iterative algorithm is usually criticized for being time-consuming and unsatisfactory in terms of its convergence for searching MLEs with high-dimensional parameters. Thus, we adopt the two-step method proposed by Ma, Shan, and Liu [10] as follows:
Step 1. For the Equation (5), we transform them into the forms of a third-order polynomial
Step 2. The iteration procedures are formed in three stages as follows:
(i) The initial value of can be taken as , which is the same as the estimate under [27]. Based on the initial value , it can reduce iteration and enhance the algorithm’s stability.
(ii) For a given , we can obtain the solutions of (7), denoted by and .
(iii) Given and , the th approximate of can be derived by the Newton–Raphson algorithm
where is given in (6), and
Repeat steps (ii) and (iii) until convergence and yield global MLEs and .
3.2. Constrained MLEs
In this subsection, we consider the constrained MLEs under the null hypothesis . Let and be the constrained MLEs of and , respectively. Since , we have . From (4), the log-likelihood l can be written by
There is no explicit solution for the two equations below
Next, we use the Fisher scoring algorithm for solving the constrained MLEs. To reduce its iteration and enhance its stability, we take the initial values and , where and are unconstrained MLEs of and . The Fisher scoring algorithm can obtain the constrained MLEs of and as follows
where is the inverse matrix of the Fisher information matrix I for and , defined by
We provide the detailed process in Appendix A.1.
4. Test Methods
4.1. Likelihood Ratio Test
Let and be the unconstrained and constrained MLEs of and , respectively. The likelihood ratio test is expressed by
where . Under the null hypothesis , asymptotically follows a chi-square distribution with one degree of freedom. For a given nominal level , the null hypotheses will be rejected if , where is the th quantile of the chi-square distribution with one degree of freedom.
4.2. Wald-Type Log-Linear Test
The log-transformed form of the odds ratio has an additive structure more rapidly converging towards normality. It is proper to infer an odds ratio on the log scale. Thus, the null hypothesis is equivalent to . That is to say,
which reveals the difference between the log-transformed odds. For simplicity, denote by . Thus, . The asymptotic distribution of is given by under the regularity conditions (A1)–(A3), where is the inverse matrix of Fisher information with respect to , and
We provide the elements of in Appendix A.2.
Denote and , where for . By the Delta method,
where
Denote and . The MLE of satisfies Moreover,
where and are the (1,1)th, (1,2)th and (2,2)th elements of inverse matrix . Therefore, a Wald log-linear statistic under has the following form
where let be the constrained MLEs of and . Similar to the test statistic , the asymptotic distribution of is a chi-square distribution with one degree of freedom. Reject the null hypothesis if , where is the th quantile of the chi-square distribution with one degree of freedom.
4.3. Score Test
Note that . Under , is the parameter of interest, and are nuisance parameters. The score function can be written as . Denote . Therefore, the score test is formed by
where is the th element of the inverse matrix of the Fisher information , and
Appendix A.3 provides the elements of . Under , asymptotically follows a chi-square distribution with one degree of freedom. The null hypothesis will be rejected if , where is the th quantile of the chi-square distribution with one degree of freedom.
5. CI Methods
5.1. Profile Likelihood CI
In this subsection, we consider the confidence interval procedure of the odds ratio by inverting the likelihood ratio test under the hypotheses vs. . Based on the regularity conditions (A1)–(A3), the likelihood ratio test as , where and be the unconstrained and constrained MLEs of and , respectively. Under , we know that and is an unknown constant. Thus, another form of the statistic is
where . Therefore, the likelihood CI of odds ratio satisfies or
where is the th quantile of the chi-square distribution with one degree of freedom. However, we cannot obtain the explicit upper and lower limits of through the set .
Then, we apply the bisection root-finding algorithm to search for the likelihood CI upper (LU) or lower (LL) limits of satisfying the above inequality. At a confidence level , the procedure of the CI upper limit is described by the following steps:
(i) Let the initial values , and , where and are unconstrained MLEs. Take an initial sign = 1 and step length = 0.1.
(ii) Update . Thus, for a given , we can obtain the constrained MLEs and under .
(iii) If , return to step (ii). Otherwise, set and , and then return to step (ii).
(iv) If the step length becomes small enough and the convergence is satisfactory, the iteration is stopped. The output is the likelihood CI upper limit of odds ratio .
The iteration of the CI lower limit is similar to that of the upper limit besides two points: (a) set the initial in step (i); (b) for step (iii), if , return to step (ii).
5.2. Wald-Type CI
We provide two methods to construct the CIs of odds ratio based on the Wald-type statistic. The first method is through the bisection root-finding algorithm. Under , the Wald-type statistic asymptotically follows a chi-square distribution. Similarly to the procedure of CI construction in Section 4.1, the Wald-type CI of satisfies or
A bisection root-finding algorithm obtains the Wald-type CI upper (WU) and lower (WL) limits of , satisfying the above inequality. Given a confidence level of , the procedure of the CI upper limit includes steps (i), (ii), (iii)’ and (iv), where:
(iii)’ If , return to step (ii). Otherwise, set and , and then return to step (ii).
The CI lower limit can be obtained according to the above steps by replacing in step (i) and in step (iii)’.
Another method is based on the asymptotic normality distribution of . Obviously, we have since as . Thus, the Wald-type CIs of is given by
where is the th quantile of the standard normal distribution. The explicit Wald-type CI upper (WU) and lower (WL) limits of are expressed by
The Wald-type CI of is denoted by .
5.3. Score CI
Since the statistic , the score CI satisfies ; that is,
For a given confidence level , the score CI upper (SU) and lower (SL) limits of can be obtained by the bisection root-finding algorithm, including steps (i), (ii), (iii)” and (iv), where:
(iii)” If , return to step (ii). Otherwise, set and , and then return to step (ii).
The CI lower limit of can be obtained by replacing in step (i) and in step (iii)”.
6. Simulation Studies
6.1. Odds Ratio Test
In this subsection, we investigate the performance of various test statistics for the odds ratio in terms of the behaviors of empirical type I error rates (TIEs) and empirical powers. 10,000 replicates are randomly generated from the null hypothesis or alternative for each configuration. The empirical TIEs of test at a nominal level are computed by dividing the number of times that the null hypothesis is rejected by 10,000 replicates that come from the null hypothesis . Following Cochran [28] and Tang et al. [11], a test at a nominal level 0.05 is said to be liberal if the empirical TIE is greater than 0.06; conservative if the TIE is less than 0.04; and robust if the TIE is between 0.04 and 0.06.
Under the parameter settings: , and , and Table 2 provides the empirical TIEs of various tests for at a nominal level , respectively. In the table, if the value of the corresponding TIE is less than 0.04, or greater than 0.06, it is highlighted in bold. We observe that the empirical TIEs of the likelihood ratio and score tests are closer to 0.05. Thus, these two tests are more robust than the Wald-type test for the specific parameter settings. To further compare the three test statistics, we randomly choose 1000 parameter settings: , , and . In Figure 1, a set of boxplots shows the distribution for the empirical TIEs for tests , respectively. Among these tests, the score test is the most robust because its TIEs are closer to the pre-specified nominal level of 0.05, followed by the likelihood ratio test. However, the Wald-type test is liberal or conservative under certain conditions. Thus, the score test is recommended based on empirical TIEs.
Table 2.
Empirical TIEs of tests under .
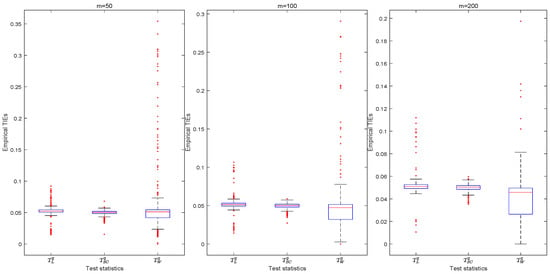
Figure 1.
Boxplots of empirical TIEs for 1000 parameter settings.
We evaluate the empirical powers of the three proposed test statistics by the percentage of rejecting with 10,000 replicates that come from the alternative hypothesis . Under at , we still use the parameter settings , and . Table 3 displays the empirical powers of and under the given settings. The power values of the three tests increase when the sample size m or increases. Given and m, if the power is the largest in the table, it is highlighted in bold. Compared with these tests, the largest powers are mostly found in the score test, the Wald-type test, and the likelihood ratio test. On the other hand, we chose some new settings of parameters to illustrate the powers of the above tests: and for under and . Figure 2 shows the trajectories of empirical powers for our proposed tests and . As expected, the empirical powers of all tests are larger as the sample size m increases. Moreover, we observed that the powers of the likelihood ratio and the score tests are close, but the Wald-type test has lower power under specific conditions.
Table 3.
Empirical powers of tests under vs. .
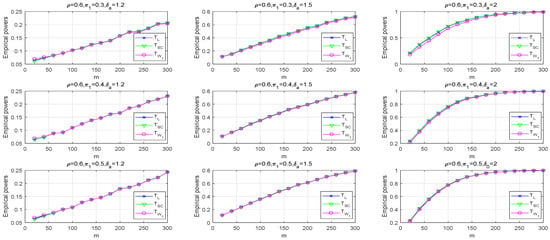
Figure 2.
Curves of empirical powers under .
Overall, the score test is more robust with a higher power than the likelihood ratio and the Wald-type tests. Therefore, the score statistic is recommended for testing whether the odds ratio of response rates is equal to a specific value .
6.2. CI Construction
In this subsection, we compared the four CI methods through the empirical mean coverage probability (MCP) and empirical mean interval width (MIW). Under , the MCP is defined as the proportions of samples that true odds ratio falls within the constructed CI, and the MIW is computed by dividing the sum of all widths by the total number of replicates. For the observed data , let and be the estimators of the CI lower limit and upper limit of , respectively. The formula of MCP and MIW is expressed by
where is the kth sample in the bilateral design, and is an indicator function. Here, the number of replicates = 10,000.
We consider the exact sample sizes and parameter setups for calculating the empirical TIE and power. Ten thousand replicates are generated from a trinomial distribution for each configuration, upon which MCP and MIW are computed. We list the performance of four CI methods in Table 4. In the table, if the value of MCPs is less than 0.94, or greater than 0.96, then it is bold. We observed that the MCPs of , , and are close to the confidence level of 0.95. Some MCPs of the method are slightly conservative, i.e., slightly above 0.95. On the other hand, the method has the shortest MIWs, followed by , then and . Although the method is slightly more conservative than , it has shorter MIWs than . The result reveals that the bisection root-finding algorithm is more effective than the asymptotic normality method in constructing the interval.
Table 4.
MCPs and MIWs of CI methods.
In conclusion, the method performs better with the satisfactory MCPs and the shortest MIWs among the proposed methods. Thus, the CI method based on the score statistic is recommended to construct the interval of odds ratio .
7. An Example
Mandel et al. (1982) conducted a double-blinded randomized clinical trial at two sites comparing cefaclor and amoxicillin for the treatment of acute otitis media with effusion (OME) in 214 children (293 ears). Each child underwent bilateral tympanocentesis and was randomly assigned to receive a 14-day course of either cefaclor or amoxicillin. Table 5 shows the OME status at 14 days in 75 children with bilateral OME. In this section, the real example was used to illustrate the performance of our proposed test statistics and CI methods (Table 5). According to Table 5, we have and . At a nominal level , we have and .
Table 5.
OME status after 14-day course of antibiotic treatment.
We first tested whether the two cured rates of cefaclor and amoxicillin are clinically equal; that is, vs. . Under the alternative hypothesis , the unconstrained MLEs of and are and . The constrained MLEs under null hypothesis are . The result reveals that there exists a correlation between the two ears of a patient. Under , the values of the three proposed test statistics are and , and the corresponding p-value . Since and , we failed to reject the null hypothesis at the significance level . Thus, there are no significant differences between cefaclor and amoxicillin.
Applying the proposed CI procedures, we then obtained four pairs of confidence limits:
The confidence limits contain 1. There are no significant differences between the two antibiotic treatments based on our proposed tests and CI methods. Through the example, we note that the same conclusions can explain with test statistics and CI methods. In addition, the CI methods contain more information than the hypothesis test.
8. Conclusions
In this paper, we proposed three test statistics for testing the odds ratio of two proportions and constructed four pairs of CIs for the ratio. Under an alternative hypothesis, we obtain the unconstrained MLEs by an iteration procedure through two steps. The constrained MLEs under the null hypothesis was given based on the Fisher scoring algorithm. Given the MLEs, the likelihood ratio test, the score test, and the Wald-type log-linear test were proposed, which asymptotically followed a chi-square distribution with one degree of freedom. Four CIs of the odds ratio of two proportions were based on inverting the three test statistics, including CI based on a likelihood ratio statistic, CI based on a score test, and two CI methods based on the Wald-type test. The bisection root-finding algorithm was used to search for the profile likelihood, Wald-type, score CI upper and lower limits of odds ratios. The asymptotic normality method obtained other CI upper and lower limits of the Wald-type case. We conducted simulation studies to compare the proposed tests about the empirical type I error, power, and CI methods in terms of the MCPs and MIEs. The results revealed that the score test performed better than other statistics, and the CI based on score statistic is recommended. A real example was provided to illustrate our results.
One of the possible future works is to extend these test statistics and CI methods to general cases for bilateral correlated data.
Author Contributions
Methodology, Z.L.; software, Z.L., C.M.; writing—original draft preparation, Z.L., C.M.; writing—review and editing, Z.L., C.M.; supervision, C.M.; visualization, Z.L., C.M.; funding acquisition, Z.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by the National Natural Science Foundation of China (Grant No: 12061070) and the Natural Science Foundation of Xinjiang Uygur Autonomous Region (Grant No: 2021D01E13).
Data Availability Statement
Data available within the article.
Acknowledgments
We thank reviewers and editors for their constructive and useful advice for improving this article.
Conflicts of Interest
The authors declare no conflict to interest.
Appendix A. Derivation and Information Matrix
Appendix A.1. Differential Equations and Information Matrix I
The first-order differential equations of with respect to and yield
Several second-order differential equations are
The elements of Fisher information I are given by
where are defined in (2) for and .
Appendix A.2. Differential Equations and Information Matrix Iθ
The second-order differential equations are
Through the above equations, all th elements of can be obtained by
where is defined in (2) for and .
Appendix A.3. Information Matrix Iθ1
References
- Lewis, T.L.; Maurer, D.; Brent, H. Development of grating acuity in children treated for unilateral or bilateral congenital cataract. Investig. Ophthalmol. Vis. Sci. 1995, 36, 2080–2095. [Google Scholar]
- Pompeo, E.; Sergiacomi, G.; Nofroni, I.; Roscetti, W.; Simonetti, G.; Mineo, T.C. Morphologic grading of emphysema is useful in the selection of candidates for unilateral or bilateral reduction pneumoplasty. Eur. J.-Cardio-Thorac. Surg. 2000, 17, 680–686. [Google Scholar] [CrossRef]
- Brwon, M.M.; Brown, G.C.; Sharma, S.; Busbee, B.; Brown, H. Quality of life associated with unilateral and bilateral good vision. Ophthalmology 2001, 108, 643–648. [Google Scholar] [CrossRef]
- Newman, L.A.; Sahin, A.A.; Bondy, M.L.; Mirza, N.Q.; Vlastos, G.S.; Whitman, G.J.; Buchholz, T.A.; Lee, M.H.; Singletary, S.E. A case-control study of unilateral and bilateral breast carcinoma patients. Cancer 2001, 91, 1845–1853. [Google Scholar] [CrossRef]
- Mandel, E.M.; Bluestone, C.D.; Rockette, H.E.; Blatter, M.M.; Reisinger, K.S.; Wucher, F.P.; Harper, J. Duration of effusion after antibiotic treatment for acute otitis media: Comparison of cefaclor and amoxicillin. Pediatr. Infect. Dis. 1982, 1, 310–316. [Google Scholar] [CrossRef]
- Sainani, K. The importance of accounting for correlated observations. Am. Acad. Phys. Med. Rehabil. 2010, 2, 858–861. [Google Scholar] [CrossRef] [PubMed]
- Cessie, S.L.; Houwelingen, J.C. Logistic regression for correlated binary data. Appl. Stat. 1994, 43, 95–108. [Google Scholar] [CrossRef]
- Ying, G.; Maguire, M.G.; Glynn, R.; Rosner, B. Tutorial on biostatistics: Linear regression analysis of continuous correlated eye data. Ophthalmic Epidemiol. 2017, 24, 130–140. [Google Scholar] [CrossRef]
- Rosner, B. Statistical methods in ophthalmology: An adjustment for the intraclass correlation between eyes. Biometrics 1982, 38, 105–114. [Google Scholar] [CrossRef]
- Ma, C.X.; Shan, G.; Liu, S. Homogeneity test for binary correlated data. PLoS ONE 2015, 10, e0124337. [Google Scholar] [CrossRef]
- Tang, M.L.; Tang, N.S.; Rosner, B. Statistical inference for correlated data in ophthalmologic studies. Stat. Med. 2006, 25, 2771–2783. [Google Scholar] [CrossRef] [PubMed]
- Tang, N.S.; Qiu, S.F.; Tang, M.L.; Pei, Y.B. Asymptotic confidence interval construction for proportion difference in medical studies with bilateral data. Stat. Meth. Med. Res. 2011, 20, 233–259. [Google Scholar] [CrossRef] [PubMed]
- Dallal, G.E. Paired Bernoulli trials. Biometrics 1988, 44, 253–257. [Google Scholar] [CrossRef]
- Sun, S.M.; Li, Z.M.; Ai, M.Y.; Jiang, H.J. Risk difference tests for stratified binary data under Dallal’s model. Stat. Meth. Med. Res. 2022, 31, 1135–1156. [Google Scholar] [CrossRef]
- Donner, A. Statistical methods in opthalmology: An adjusted chi-square approach. Biometrics 1989, 45, 605–611. [Google Scholar] [CrossRef] [PubMed]
- Liu, X.B.; Liu, S.; Ma, C.X. Testing equality of correlation coefficients for paired binary data from multiple groups. Stat. Compu. Simul. 2015, 86, 1686–1696. [Google Scholar] [CrossRef]
- Pei, Y.B.; Tang, M.L.; Wong, W.K.; Guo, J.H. Confidence intervals for correlated proportion differences from paired data in a two-arm randomised clinical trial. Stat. Meth. Med. Res. 2010, 21, 167–187. [Google Scholar] [CrossRef] [PubMed]
- Pei, Y.B.; Tian, G.L.; Tang, M.L. Testing homogeneity of proportion ratios for stratified correlated bilateral data in two-arm randomized clinical trials. Stat. Med. 2014, 33, 4370–4386. [Google Scholar] [CrossRef]
- Qiu, S.F.; Tang, N.S.; Tang, M.L.; Pei, Y.B. Sample Size for testing difference between two proportions for the bilateral-sample design. J. Biopharm. Stat. 2009, 19, 857–871. [Google Scholar] [CrossRef]
- Qiu, S.F.; Liu, Q.S.; Ge, Y. Confidence intervals of proportion differences for stratified combined unilateral and bilateral data. Commun. Stat. Simul. Comp. 2021. [Google Scholar] [CrossRef]
- Tang, N.S.; Tang, M.L.; Qiu, S.F. Testing the equality of proportions for correlated otolaryngologic data. Comput. Stat. Data Anal. 2008, 52, 3719–3729. [Google Scholar] [CrossRef]
- Tang, N.S.; Li, H.Q.; Tang, M.L.; Li, J. Confidence interval construction for the difference between two correlated proportions with missing observations. J. Biopharm. Stat. 2016, 26, 323–338. [Google Scholar] [CrossRef] [PubMed]
- Tang, M.L.; Pei, Y.B.; Wong, W.K.; Li, J.L. Goodness-of-fit tests for correlated paired binary data. Stat. Methods Med. Res. 2010, 21, 331–345. [Google Scholar] [CrossRef] [PubMed]
- Edwards, A.W.F. The measure of association in a 2 × 2 table. J. Roy. Stat. Soc. A Stat. 1963, 126, 109–114. [Google Scholar] [CrossRef]
- Chanda, K.C. A Note on the Consistency and Maxima of the Roots of Likelihood Equations. Biometrika 1954, 41, 56–61. [Google Scholar] [CrossRef]
- Mou, K.Y.; Li, Z.M. Homogeneity test of many-to-one risk differences for correlated binary data under optimal algorithms. Complexity 2021, 2021, 6685951. [Google Scholar] [CrossRef]
- Ma, C.X.; Liu, S. Testing equality of proportions for correlated binary data in ophthalmologic studies. J. Biopharm. Stat. 2017, 27, 611–619. [Google Scholar] [CrossRef]
- Cochran, W.G. The χ2 test of goodness of fit. Anal. Math. Stat. 1952, 23, 315–345. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).