1. Introduction
The crystal population in igneous rocks determines the textural characteristics and records the physical processes. The habit of the crystal population records melt compositions, conditions, or magma convections [
1,
2,
3,
4,
5] and can also be used for CSDCorrections [
3,
6,
7] to convert 2D crystal size to true 3D size or to distinguish crystal populations and analyze crystallization environments. The crystal habit can be measured individually by computed tomography [
8,
9,
10] or sectioning grinding [
11]. These direct measurements require specialized equipment and limited crystal size. Another method is the statistical estimation by stereological conversion from 2D cut-sections under a thin section, and one sample corresponds to one statistical distribution. This conversion is of low cost and has many applications, from outcropping photos to electron microscope images. Because of the cut-section and intersection-probability effects [
6,
12,
13], it is impossible to identify the 3D habit directly from 2D sections. Previous works used statistical parameters of the 2D sections to solve the conversion [
13,
14,
15], of which it is easy and convenient to identify the crystal habit. Another method is to compare the distributions of the unknown sample with the pre-set data and find the best-match result of the crystal habit. This method uses the overall distribution to represent a 3D habit. It is more accurate but complicated than the statistical parameters, such as CSDSlice [
16], widely used to estimate 3D habit in natural samples (e.g., Basu Sarbadhikari, et al. [
17], Jerram, et al. [
18], Martin, et al. [
19], Blundy and Cashman [
20], Ruprecht, et al. [
21], Vinet and Higgins [
22]). In igneous rocks, crystal habits are associated with crystallization conditions. For example, the plagioclase habit changes from tabular to prismatic then to skeletal and dendritic with increasing undercooling [
4,
23]. Crystal habit also indicates a high chemical potential gradient [
15], shearing and stirring of magma flow [
3], or cooling and decompression [
24]. Many crystallization experiments provide more similar information on condition and crystal habit [
25,
26,
27,
28,
29]. Changes in crystal habit show variant conditions; thus, we can discover more detailed information by crystal habit. Natural samples recording multiple crystallization or magma processes are complex in crystal habit. Multiple crystal populations with different habits may exist in one sample, if two batches of magma mix with each other or if one batch has undergone multiple crystallization stages. Cheng and Costa [
30] used representative 2D sections of zoning plagioclase to identify multiple populations, but crystal habit could be helpful if crystals show no zoning. For another example, flower-like glomerocrysts [
31] seem to have different crystal habits between the inner and outer parts, equivalent to populations with different habits mixed to form the flowers. Accurate estimations of glomerocrysts can be obtained when mixed crystal habits are considered. Thus, we can explore more details of crystallization conditions by habits of mixed populations.
However, these statistical methods mentioned above have drawbacks. The methods assume that there is only one crystal habit in the sample, and the estimated results may have some errors if crystal populations with different habits exist in a thin section. Thus, it is difficult to estimate crystal habit if one sample has populations of multiple habits. In this case, the estimated result is dominant or equivalent to the average. It may have some errors when populations have similar crystal numbers, and previous methods cannot accurately estimate the habits of the mixed populations. Based on previous methods and to obtain more accurate results, for a single crystal habit, we use a similar matching method with pre-set habits akin to CSDSlice to estimate the crystal habit. Besides the conventional histogram, we also adopt the kernel density estimation to represent the distribution, which is smooth, continuous, and better than the discrete histogram. We then use the weighted average of combinations of pre-set habits to match the unknown sample and to select the best-fit results for mixed populations. The method is time-consuming but can find end-members of mixed populations. A Python-based program containing the methods proposed in our study named “HabitEst3D” is developed for habit estimation with an easy-to-use graphic user interface. In this study, our model of 3D habit estimation and HabitEst3D is designed to (1) estimate the statistical crystal habit from 2D sections; (2) explore the habits of mixed crystal populations.
3. Software Description
3.1. Overview
HabitEst3D is cross-platform written in Python3 containing four major parts, an entrance with a graphical user interface (GUI), a data processing module, a calculation module, and the database. The program requires Numpy [
42] and Scipy [
43,
44] for calculation, Pandas [
45] for spreadsheet processing, Matplotlib [
46] for data visualization, and Numba [
47] for acceleration. All the files are in the format of Python source without any packaging or compilation, so the user can freely modify the parameters as needed. The panel interface is split into the left and right parts. The left part is a textbox that displays the log, such as input data, set parameters, or estimation results. On the top of the right side is a switch panel where the user can toggle the estimation mode between the single or multiple habits, and the “About” button on the upper right corner shows the author’s information. All the variables are reset empty when the user switches the mode. The bottom half of the right part is the operation panel, where the user can set parameters, press the “run” button to start the calculation, and press the “View results” button to view the calculated results. The “Restart” button is to reset the program, equal to switching the modes or restarting the program so that variables and data in memory are cleaned up (
Figure 3). The user can run the program by double-clicking on the “bat” file or using the python command to directly execute the “main.py” file. A terminal window appears after the program starts, and the main window pops up. The terminal window can print some error information, and the program will be closed when the terminal is stopped. However, in estimating the mixed crystal populations, the program generates a temporary python file and executes the file to do the calculation in a new independent process outside the GUI. The terminal window must be closed if the user wants to stop the calculation or the program crashes.
3.2. Load Data
The “Load data file” button in the operation panel is in the upper left corner (
Figure 3). The user can open the data file and load the sectional data. A file dialog appears when pressing the button, and only one data file is accepted to load into the memory. The data file should be in the extension of “.xls”, “.xlsx” or “.csv”. The spreadsheet created by ImageJ [
48] is actually in a “.csv” format but has the “.xls” extension. The program first opens the data file in “.xls” or “.xlsx”. If an error occurs, the file is opened in ".csv" format. The program is designed without viewing the loaded data, so the data file should be specified. The spreadsheet should contain the columns with the headers named “Major” and “Minor”, or a single column named “AR” is also acceptable. If the sectional data are successfully loaded, the file name and the data size are printed in the textbox. The data are input as aspect ratio and logarithmically transformed for habit estimation.
3.3. Set Parameters
When the data are successfully loaded, those grayed buttons, checkboxes, or combo-boxes are available to set parameters. After setting the parameters, the user needs to press the “Get parameters” button so that the program reads the parameter variables, prints the information on the textbox, and passes them to the calculation module. There is a radio button for the user to choose the calculation method. The histogram has fixed 30 bins, and the KDE has 150 data points on the curve for comparison. The user can change the number of best-match results to select the required estimation results. If the number is set to 10, then the top 10 best-match results by RMSE are selected, with others abandoned. In the multiple habits mode, there are another two parameters to set, the number of habits and multiprocessing. The number of habits for multiple habits estimation should be two or more. Logically, the habit number can be any integer larger than one. However, as the number of habits increases, the combinations increases nearly exponentially, then the calculation may take much memory and time, which is intolerable. Moreover, too many habits are difficult to estimate the true habits. For example, many Gaussian distributions with different weights can match an unknown curve in the Gaussian Mixture Model. Similarly, too many end-members may affect each other and result in inaccurate estimations, which may not be consistent with the petrography. Thus, combining petrographic observations to determine possible crystal populations is essential. Multiprocessing is used only for parallel computing to accelerate calculation, and the value of multiprocessing should be no larger than CPU cores. The data are split into chunks to save memory usage. When the loop times reach the chunk size, the program stops the old processes and generates new ones to continue the calculation, releasing the memory occupied by the old.
3.4. Calculation
After the user presses the “Get parameters” button, the variables of parameters and logarithmical sectional data are sent to the calculation module included in the file “shape_fit.py”. Then, the user can press the “Run” button to start the calculation procedure. The module calculates the PDF, loads the database, and substitutes the unknown PDF and the pre-set data into Equation (1). The module contains two functions to calculate the single and multiple habits. In addition, the user can take out the module separately to perform the calculation in python code if there are many samples to analyze.
3.5. Single Habit Mode
After the user presses the “Get parameters” button, the variables of parameters and logarithmical sectional data are sent to the calculation module included in a single file. Then, the user can press the “Run” button to start the calculation procedure. The module calculates the PDF, loads the database, and substitutes the unknown PDF and the pre-set data into Equation (1). The module contains two functions to estimate the habit. In addition, the user can take out the module separately to perform the calculation in python code if there are many samples to analyze. The workflow for the single habit estimation is shown in
Figure 4a.
3.6. Multiple Habits Mode
The user can perform the estimation of mixed habits as introduced above. The workflow shown in
Figure 4b is easy to operate, but the program is a bit more complex. When the user clicks on the “Run” button to start the calculation procedure, the program first calculates the PDF of the set method. It generates a temporary python file according to the parameters with a pickle file storing the PDF of the unknown sample. The temporary “.py” file is then executed to continue the calculation with acceleration. Here, the temporary python file plays the role of the main program that the sample PDF compares to all the possible combinations. After the calculation, the file stores the array of
RMSE values with the labels into a new pickle file. Meanwhile, the main program is suspended in the background and monitors the newly generated pickle file. Once the new file is found, the main program reads its content, deals with the results, and cleans up all the temporary files. The generated “.py” file executes the calculation separately from the main program, and the user should close the terminal window to stop the calculation thoroughly.
3.7. View Results
There is a button named “View results” for visualizing the selected best-fit results, whether in the single habit mode or multiple habits mode. The button is available only when the calculation finishes. The program stores the calculation results in an array containing labels and their
RMSE values. Thus, the program needs to display the figures of PDFs by visualization. When the user clicks on the button, a child window pops up, and the main program reads the results in the array and plots them one by one in the child window (
Figure 3c). A “Save” button is in the upper right corner to save the data or figures. The “Save” button connects to a save-file dialog that the user can choose a file format in the drop-down box to save, for example, “.html” of the web page, “.eps”, “.pdf”, “.svg” of the vector plot and “.png” of the bitmap, as well as raw data in “.xls”. Likewise, the program needs to convert the array to those file formats.
4. Robustness
Our model uses distributions of various pre-set habits to estimate the 3D habit in a sample. If the assumption of the model is met, the uncertainty mainly comes from whether the pre-set habits accord with the cut-sectional data in the thin section. Technically, the pre-set habits are in a wide range, and each set of sectional data in that range can find a corresponding habit. When the crystal number is small, the distribution curve may vary due to the limited sample size, which leads to inaccurate estimation. Except for errors from the smaller number of crystals in estimating multiple habits, another uncertainty is the proportions of multiple crystal populations. Even though pre-set habits can fit the end-members well (for example, all end-members have higher crystal numbers), the majority may cover the feature of the minority, of which the latter is hard to estimate accurately. When the proportions of the end-members are close to each other, a better estimation is obtained.
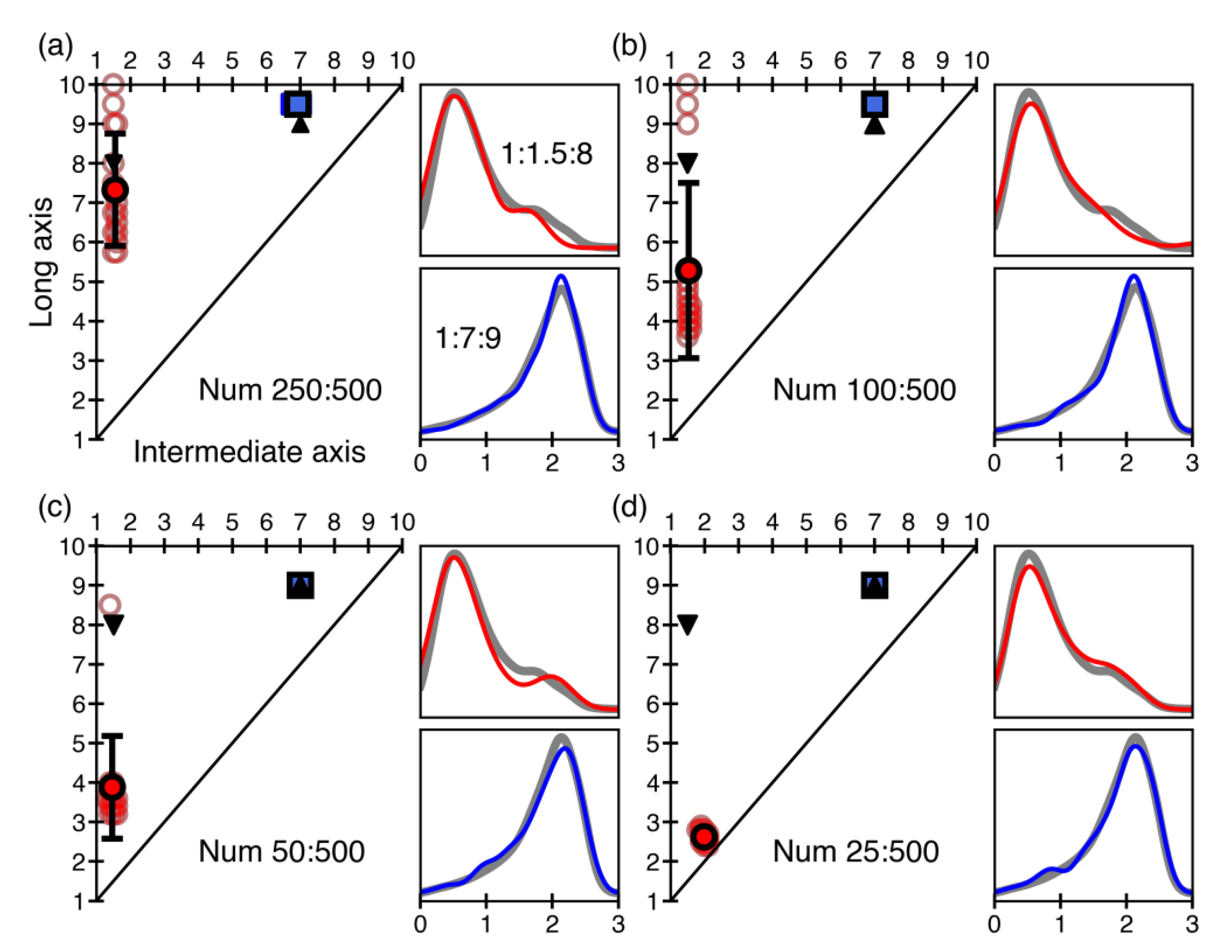
To test the robustness of our model, we take the mix of a prismatic habit (1:1.5:8) and a tabular habit of different crystal numbers as sample data and use the model to identify the end-members. Here, we analyze two cases, one of which is that the end-members are mixed in equal proportions, from 25:25 to 200:200 (
Figure 5), to verify the impact of the crystal number on the estimation. The other case is the end-members in different proportions. The dominant tabular habit has 500 crystals, and the crystal number of the prismatic habit ranges from 250 to 25 (
Figure 6) to explore whether the model can distinguish a minority. We randomly select the 2D cut-sections of the two habits and compose the simulated samples for estimation. The independent randomly picked sections are irrelevant to the averaged pre-set curve in the database; thus, they can be used as datasets to test the model.
In
Figure 5, the model can give accurate results if the end-members match the pre-set habits well. The long axis of the prismatic habit is hard to estimate accurately and is easy to obfuscate by the other habit, as the long axis can be cut in a low probability. More than 200 crystals of the prismatic can give us a better result. The tabular habit, however, needs fewer crystals for a stable distribution. In
Figure 5b,c, the red curve deviates from the gray one, but we can still obtain a precise intermediate axis, although the long axis is hard to estimate. The blue curve in
Figure 5a also goes off the pre-set data, and the estimated blue square still shows a similar tabular habit not far from the up-pointing triangle. Thus, our model is not sensitive to the deviations from pre-set habits. The results are acceptable when the end-members are roughly similar to the pre-set habits, regardless of the details. However, the crystal number of an end-member should be large enough if more accurate estimations are needed.
Figure 6a–d, the proportions of the prismatic habit continuously decline, and the estimation results change to a cubic-like habit, with the long axis being negligible. The corner point on the right part of the distribution curve represents the long axis, and the main peak on the left represents the intermediate (the red point with the black edge in
Figure 6d). With the weight of the prismatic habit decreasing, the long axis is unlikely to estimate. For the ratios of 1:10 or 1:20 (
Figure 6c,d), the prismatic habit has a smaller weight that can be ignored, but our model can still identify the main peak of the distribution, showing that multiple populations exist.
The above cases are mixtures of two habits. What if three or four populations of different habits exist in one sample? For example, plagioclase crystals first grow in tabular at low undercooling following prismatic crystals in the same batch of magma due to higher undercooling. After that, the magma containing crystals of tabular and prismatic habit injects into a chamber in which early formed crystals are equant. Thus, the final mixed magma contains crystals of the equant, tabular and prismatic. It is hard to find a natural sample meeting these ideal situations; thus, we use raw cut-sectional data of specific habits as above to test whether our model can identify mixed habits of three or four end-members. Considering an extreme situation where there are three habits in one sample, we assume that the mixed habits are composed of 1:1.5:2, 1:3:8 and 1:6:8, with their numbers of crystals at 100, 150, and 200, respectively, as an example to test our model. Two-dimensional sections of each habit are randomly generated by the cutting simulation, forming independent datasets irrelevant to the processed database. As illustrated in
Figure 7a, the cubic habit of 1:1.5:2 is influenced largely by the flattened prismatic habit of 1:3:8, but the tabular habit is well estimated. This situation is unavoidable because the long axis of 3D crystal habit is hard to estimate. The habit 1:1.5:2 is similar to 1:3:8 in the intermediate axis, which is easy to confuse. Some crystals belonging to 1:3:8 are considered as a part of 1:1.5:2, yielding an incorrect estimation of 1:1.5:2. The intermediate axis of these three habits is well estimated. We then use the same three end-members whose crystal numbers are 600, 200, and 200, respectively, increasing the contents of 1:1.5:2 and 1:3:8 (
Figure 7b). As expected, 1:1.5:2 and 1:3:8 with similar intermediate axes are still difficult to distinguish, and long axes are easily confused. However, the estimation of
Figure 7b is far better than that of
Figure 7a, indicating better distinction due to higher crystal numbers.
Technically, while complex mixed habits can be estimated by our enumerative method, the reliability of the results needs evaluating, especially mixed habits with similar intermediate axes, for their long axes are easily confused. This problem can be fixed if the long axis is accurately estimated by new methods or higher crystal numbers. However, accurate estimation of the long axis still remains unsolved from previous studies to our model. In this example, the accurate estimation of end-members with similar intermediate axes is difficult to achieve, due to indistinguishable long axes. Thus, after the estimation, we should evaluate whether the results are consistent with the petrographic observations.
In conclusion, HabitEst3D is not sensitive to external distractions. It can give acceptable estimations to the unknown sample, and the enumeration used in our model can identify end-members even with small weights. We should pay attention to estimating a mixture of more than three habits, especially those with similar intermediate axes, whose long axes are hard to estimate and are easily influenced by each other.
5. Example
We calculate the habit of clinopyroxene in the gabbroic sample named Z-6 from Panzhihua, Emeishan large igneous province [
49]. The hand-traced outlines of clinopyroxene were processed by ImageJ [
48] to ellipse fitting, and the sectional data are taken as an example in this study to test the program. In the 2D thin section of Sample Z-6, some of the clinopyroxene crystals are granular, but others are similar to the rectangular or elliptic with a higher aspect ratio (
Figure 8a). Those sections with higher aspect ratios should belong to the short prismatic habit, which produces some granular sections due to the cut-section effect. According to the petrographic observation, we infer that there can be two populations, an isometric and a short prismatic habit. However, the values of these two habits are unknown and cannot be directly estimated from the 2D section.
We use the KDE method in HabitEst3D to estimate the crystal habit. In the single habit mode, the average of the top 15 results is 1:1.34 ± 0.1:1.91 ± 0.16, and the best-match result is 1:1.3:2 with
RMSE = 0.12 (
Figure 8b), which is an isometric–prismatic habit. The pre-set PDF does not fit the sample well, and
RMSE is relatively high. The crystals in the sample may belong to multiple populations, consistent with the petrographic observation. We then use the multiple habits mode to explore the possible combinations of multiple habits in the sample (
Figure 8c) with the number of habits set to two, and the top 15 results are selected. Those 15 results have
RMSE values ranging from 0.016 to 0.022, two end-members are 33%–64% 1:1–2.1:2.4–2.9 and 36%–67% 1:1–1.4:1.4–1.8. One habit is isometric, and the other is mainly short prismatic but includes four thick tabular data. The result is common that the short prismatic and the thick tabular habits all have numbers of elongated sections, which is hard to identify when the number of crystals is small. The top five results with the lowest
RMSE values have a narrow range of
RMSE from 0.016 to 0.019, indicating that the results are similar. The best-match habit is 51% 1:1.2:2.8 with 49% 1:1.3:1.8, and the average calculated by hand is 55% 1:1.28 ± 0.15:2.7 ± 0.07 with 45% 1:1.28 ± 0.13:1.68 ± 0.13. Thus, we can conclude that the habits in the sample are composed of the short prismatic and the isometric, although the thick tabular data in some combinations are hard to filter out, which may be offset due to higher
RMSE values. The results by the multiple habit mode are more reasonable because the simulated curve of mixed crystal habits fits the unknown PDF well, much better than the single habit estimation. In natural samples, the habits of crystals are commonly complex. If two or more habits exist in the sample, we can use the program to explore possible habit combinations close to the real one when one single habit deviates from the sample PDF.
Sample Z-6 consists of two similar habits. Here, we use another example containing two different types of oxide habits to test whether our model can distinguish between isometric and elongated 2D shapes. An example of a basaltic sample FS-16 [
50] is illustrated in
Figure 9 with a petrographic photo and hand-traced outlines of oxide. The total number of hand-traced oxide crystals is 1011, large enough to avoid uncertainties brought by smaller crystal numbers. We observe that oxide has elliptical and elongated 2D sections (
Figure 9a,b), probably two populations of different habits in the sample. In
Figure 9c, two tails of the sample and the estimated result do not fit well, indicating that the estimated long axis is inaccurate. In
Figure 9d, the estimation by multiple habits mode and the sample overlap well with
RMSE = 0.013, showing an accurate estimation. Our method can also give a good fit of a mixture of isometric and prismatic habits.
6. Discussion
Statistical methods for estimating true crystal habit in igneous rocks from 2D cut-sections have been developed for a long time. Higgins [
15] used mathematical expressions, and Garrido, Kelemen and Hirth [
14] used a diagram to estimate 3D habit. These statistical parameters generated by cutting simulations are fast and easy to explore regarding true crystal habits, but they may have larger errors when multiple crystal populations exist. The distributions of these cut-sections change regularly as the 3D habits vary, but these non-parametric complex distributions are hard to describe accurately only by some statistical parameters. Morgan and Jerram [
16] used pre-set distributions to match the unknown sample and found the best-fit habit. The raw distribution curve is a direct mapping of cut-sections. However, it ignores the rules of statistics, and comparing the pre-set PDFs with the sample is an accurate method if the database is strong enough.
Based on previous studies, we use the pre-set habits and enumerate combinations to find the best-fit results, filling up the unknown curve with pre-set habits. In natural samples, multiple crystal populations with different habits may exist under changing environments or magma mixing. Previous methods cannot deal with multiple habits unless the mixed crystal populations can be separated manually. Our model finds possible end-members in a sample. The accuracy of the model depends on whether the sample meets the assumption. The database used in our study is built from random cut-sections of arbitrarily oriented cuboids. Thus, the estimation may have errors if the crystals or grains are rounded or foliated. Tabular and prismatic habits are easily influenced by magma flow. The distribution curve of oriented crystals is then changed, and a sharp peak may appear due to the fixed orientation of cut-sections. How the orientation affects the distribution curves remains unknown, including in previous studies related to 3D habit estimation. In this study, we performed simulations of randomly oriented cut-sections; thus, uncertain errors may occur if a sample is strongly affected by magma flow, which cannot be solved in our current model. The relationship between orientation and the distribution curve needs further careful quantitative evaluation. Therefore, we do not recommend using our current model in oriented samples. For further use applicable to oriented samples, a new database that fits the situation must be rebuilt to obtain more accurate estimations, and the whole procedure applied in the software can remain unchanged. In applications, our model can explore possible end-members of mixed crystal habits from 2D thin sections, indicating information on magma processes or crystallization dynamics [
11,
16,
24].
Since we have discussions on estimating multiple habits, we need to find a threshold to distinguish multiple habits in a sample. Although previous studies give thresholds [
16,
24] to determine whether the estimation is good or not, it is still hard to choose an
RMSE value to distinguish the existence of multiple habits as a threshold because
RMSE is influenced by crystal number or habit types. In general applications, with the KDE method,
RMSE equal to 0.015 indicates a good fit, and mixed crystal habits need to consider if
RMSE is higher than 0.025. Higher
RMSE occurs when the crystal number is smaller, for example, the threshold of 250 crystals mentioned previously [
11,
16]. In this case,
RMSE higher than 0.05 indicates a poor fit with multiple habits in one sample. For the histogram method,
RMSE higher than 0.15 indicates mixed crystal habits. There is another method to assess the goodness of fit qualitatively, whether or not the sample curve and the estimated result have similar trends or two curves that overlap well. The estimation by the KDE is more accurate than that by the histogram, so we recommend the KDE method for habit estimation.
Moreover, the average of these results is closer to the true habit, which is worth considering to reduce errors. As for multiple crystal populations, the model enumerates every possible combination to find the best-fit results. Logically, each pre-set habit has an equal chance of matching the unknown sample, but the key point is that the dominant habit covers some features of other habits with fewer crystals. The true habits can also appear in the results but may not within the top best-match ones. Cluster analyses such as k-means clustering [
51] can be applied to the results to introduce different main types, which play a role similar to the average. Cluster analysis is more convenient to reveal the main types, but we did not add this function to our software, for it is better to analyze the results supervised. Single habit estimation can use the average or cluster to obtain a stable result, but estimation for multiple habits is complex. The results of different end-members surround the true value but may gather together to form an accidental cluster if the end-members are close, influencing the final types when applying cluster analysis. Until now, we have not come up with a better solution to apply cluster analysis to the estimation results, avoiding improper clusters. Thus, we suggest that the users take the first few results for further analysis, in consideration of petrographic observations and specific 2D sections. Additionally, applying cluster or average to estimation abandons the weights of the results, for only specific results belonging to one estimation can be combined to restore the unknown sample, but the clusters do not meet the requirements.
The essence of our model is an unmixing problem that solves end-members with their weights. Many statistical or machine-learning-based methods have been applied to this series of questions. As for our study, we cannot find a suitable solution by machine-learning or statistical methods, because the end-members will not be determined easily. We generate a database covering a wide range of pre-set habits, and there are small differences between the habits, similar to each other. The machine-learning or statistical methods are unable to decompose the unknown sample data to valid end-members. In comparison to Gaussian mixture models, end-members are Gaussian distributions that can be obtained by the expectation–maximization algorithm. However, in our model, the end-members are non-parametric and are unrelated to the statistical parameters. Thus, the machine-learning or statistical methods are not suitable for our model to find the right end-members. Thus we use the enumerative method to find the best-fit result, not the machine-learning methods.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}








