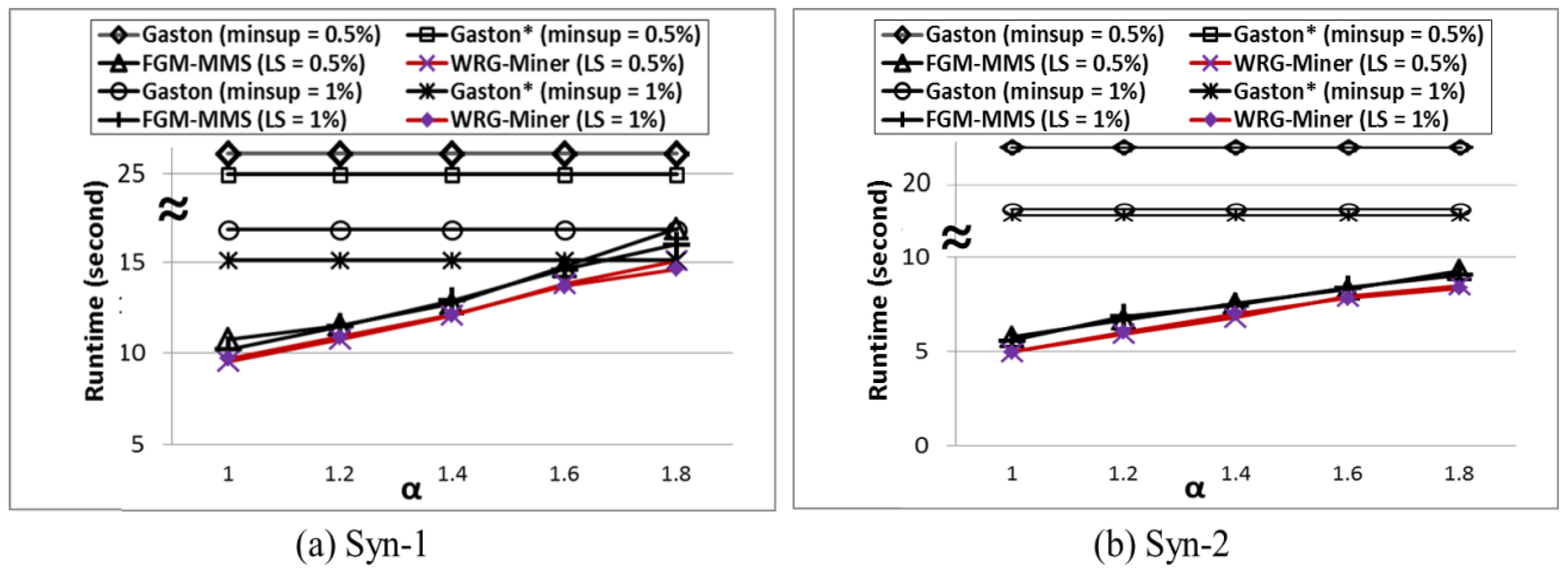
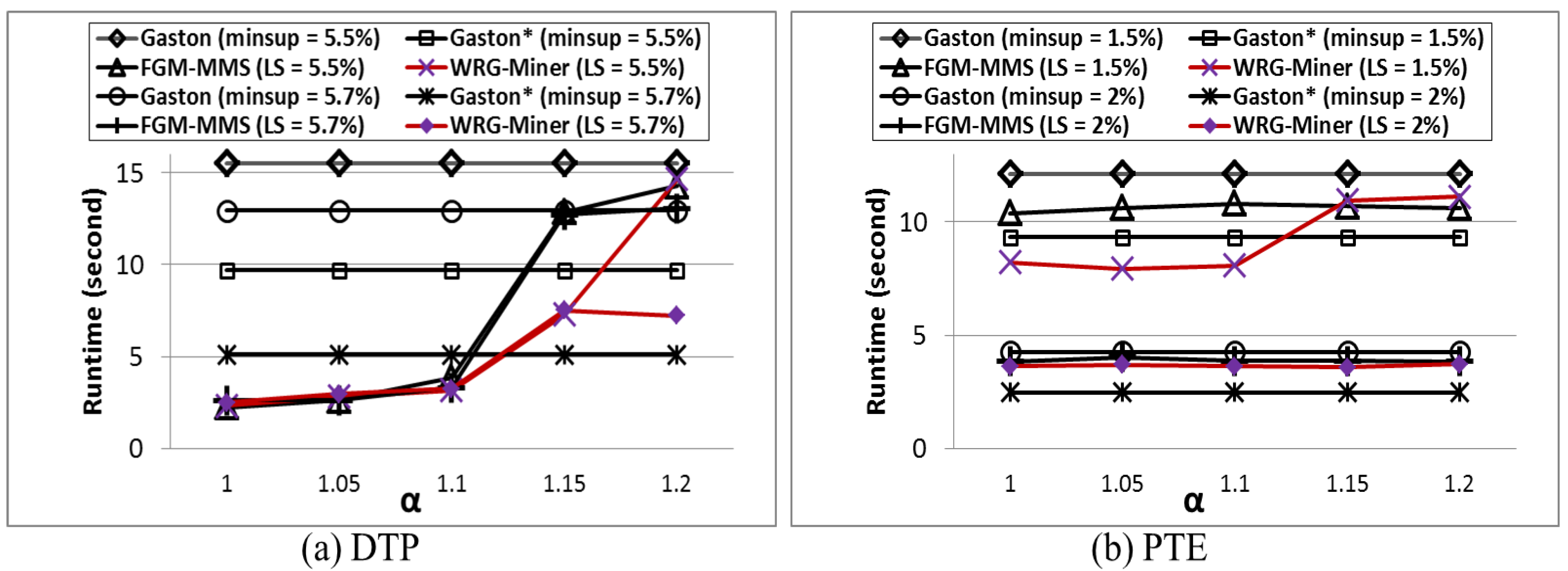
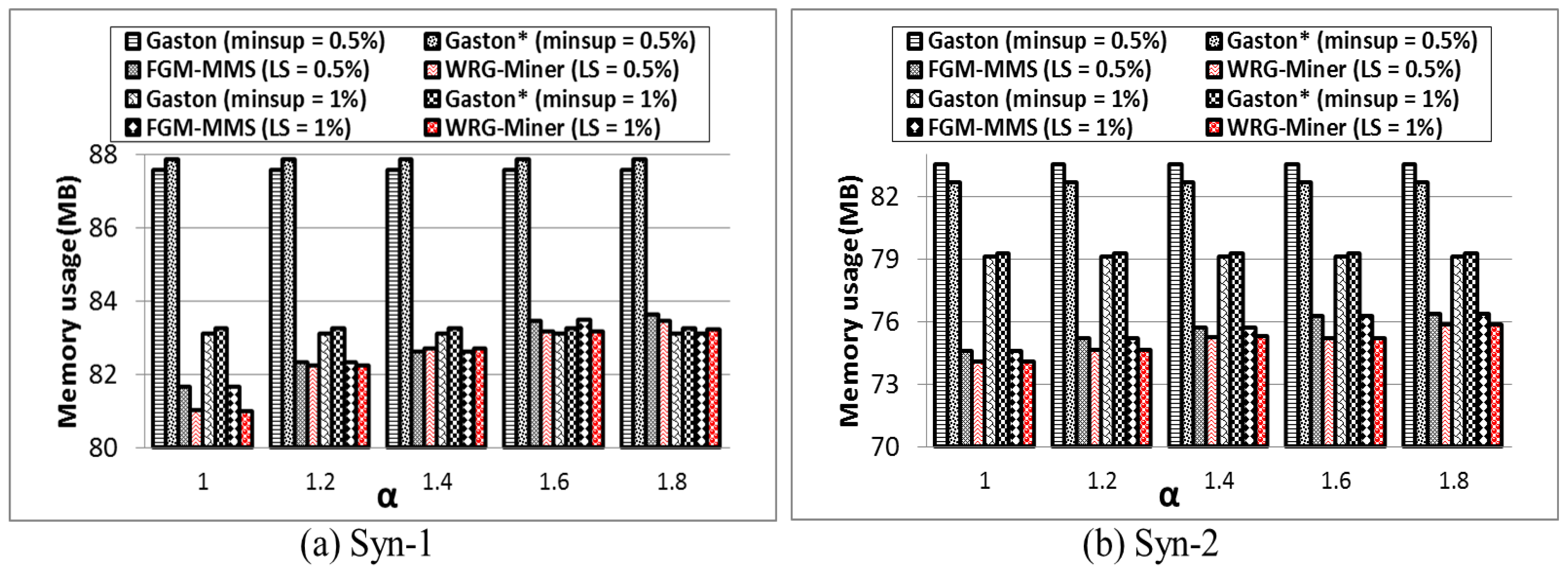
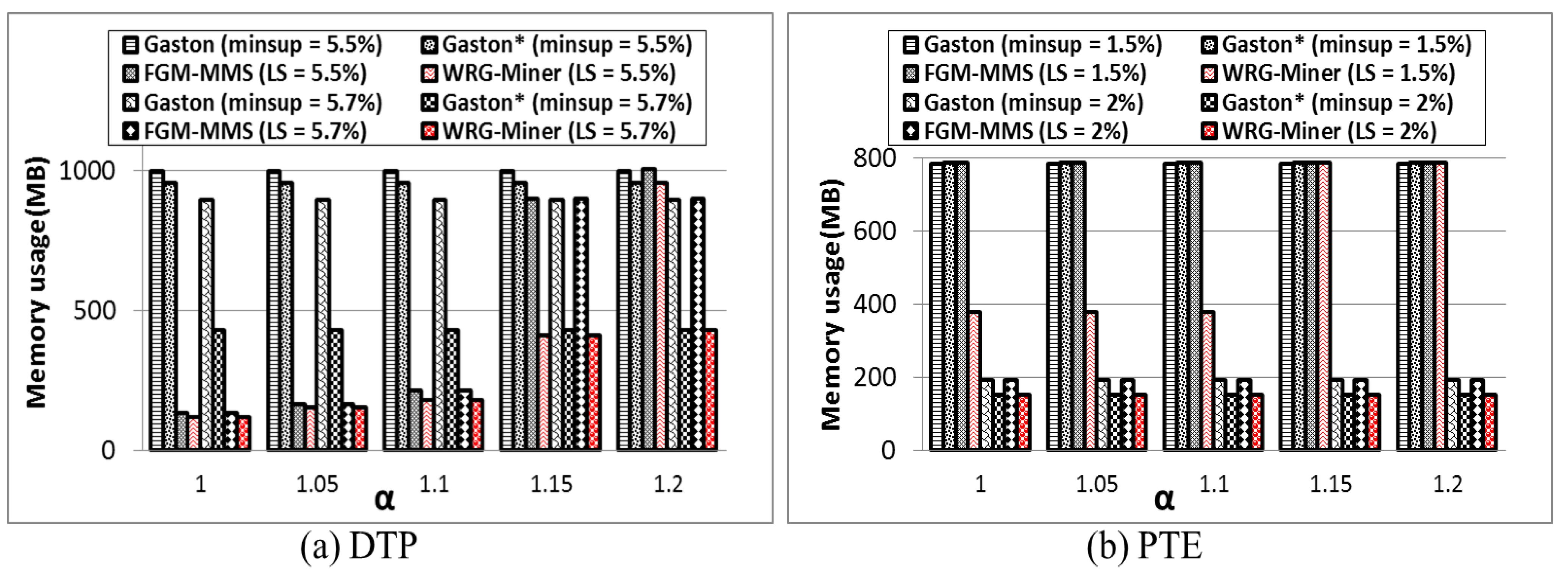
1. Introduction
Data mining has been actively researched because of its useful applications such as classifying malicious information on web pages [
1], mining consumer attitude and behavior [
2], detecting or diagnosing important information [
3,
4], and other various mining applications [
5,
6,
7,
8,
9]. As one of the interesting areas in data mining, frequent pattern mining [
10,
11,
12] has been proposed, and numerous approaches related to this have been suggested [
13,
14]. However, traditional frequent pattern mining methods only focusing on databases composed of simple items have limitations that do not deal with complex types of data with graph forms such as network data [
15,
16,
17]. It is essential to mine such complex data because recent data obtained from real world applications has become increasingly massive and complicated. To overcome these limitations, frequent graph pattern mining has been proposed and a variety of related methods have been studied [
18,
19,
20,
21] by developing novel techniques for performance improvement or effectively integrating graph mining with other mining fields.
Meanwhile, previous approaches of frequent graph pattern mining still have limitations because they cannot consider the following important issues in the real world: (1) the
rare item problem [
22] showing that items or patterns with low support values as well as ones with high supports may have meaningful information; and (2) the
different importance problem [
9] signifying that graph elements derived from real world applications have different importance or weight values depending on their characteristics. For this reason, to solve the limitations of the previous approaches and process these important issues in the graph pattern mining, we propose a new method that can mine
Weighted Rare Graph patterns (
WRGs) considering both different importance and multiple minimum support thresholds according to the features of elements, called
WRG-Miner. Moreover, by conducting various performance evaluation tests, we also demonstrate that the proposed algorithm has better mining performance than previous state-of-the-art algorithms in terms of graph pattern generation, execution time, and memory usage.
The remainder of this paper is organized as follows. In
Section 2, we introduce related work with several important previous studies. In
Section 3, details of the proposed algorithm and its techniques are described. In
Section 4, performance evaluation results among our method and previous state-of-the-art approaches are provided. Finally in
Section 5, we conclude this paper.
2. Related Work
Since the concept of frequent pattern mining was proposed [
10], a variety of methods have been actively researched.
Apriori [
10] is the first algorithm for mining frequent patterns from databases with simple items, where its mining process is based on a level-wise manner. Thereafter, to solve the inefficiency of the
Apriori algorithm, a tree-based pattern growth algorithm,
FP-growth [
11], was devised. Using its own special tree structure, called
FP-tree, the algorithm achieved better performance than that of
Apriori. Satisfying the
anti-monotone property during the mining process is one of the most important conditions in frequent pattern mining because this property can contribute to enhancing algorithm performance by suppressing any useless pattern generation in advance. The
anti-monotone property signifies that if a certain pattern is infrequent, all of its possible super patterns are also infrequent. Therefore, we can prune such invalid patterns in advance by employing this property.
In frequent pattern mining, multiple minimum support threshold-based various research [
18,
19,
22,
23] has been conducted to solve the
rare item problem.
MSApriori [
22] is an initial solution based on a level-wise manner. After that, a tree search-based algorithm,
CFP-growth [
18], and its advanced version,
CFP-growth++ [
23], were proposed. Although they make it possible to mine rare patterns applying multiple minimum support thresholds, they cannot consider different importance characteristics and their coverages are limited to simple itemset-based databases. Algorithms in the literature [
24,
25,
26,
27] are tree-based frequent pattern mining approaches considering importance of items’ own, but they cannot solve the rare item problem and process complex data such as graph databases.
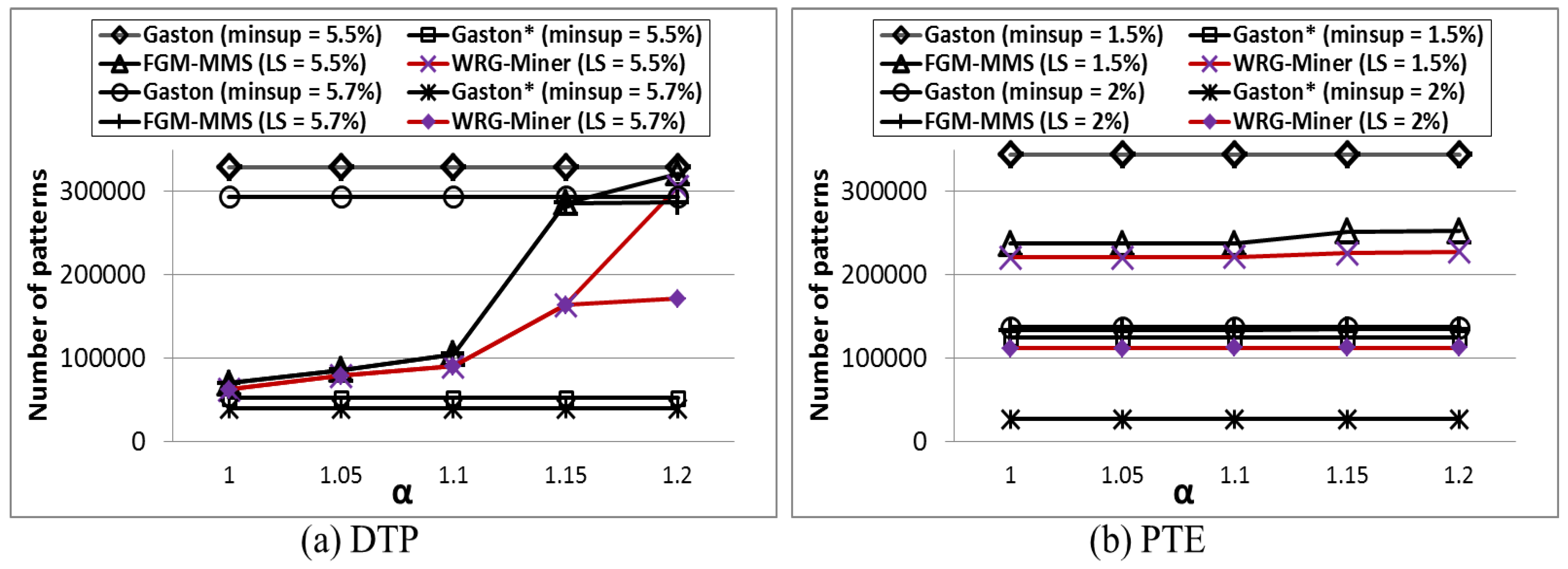
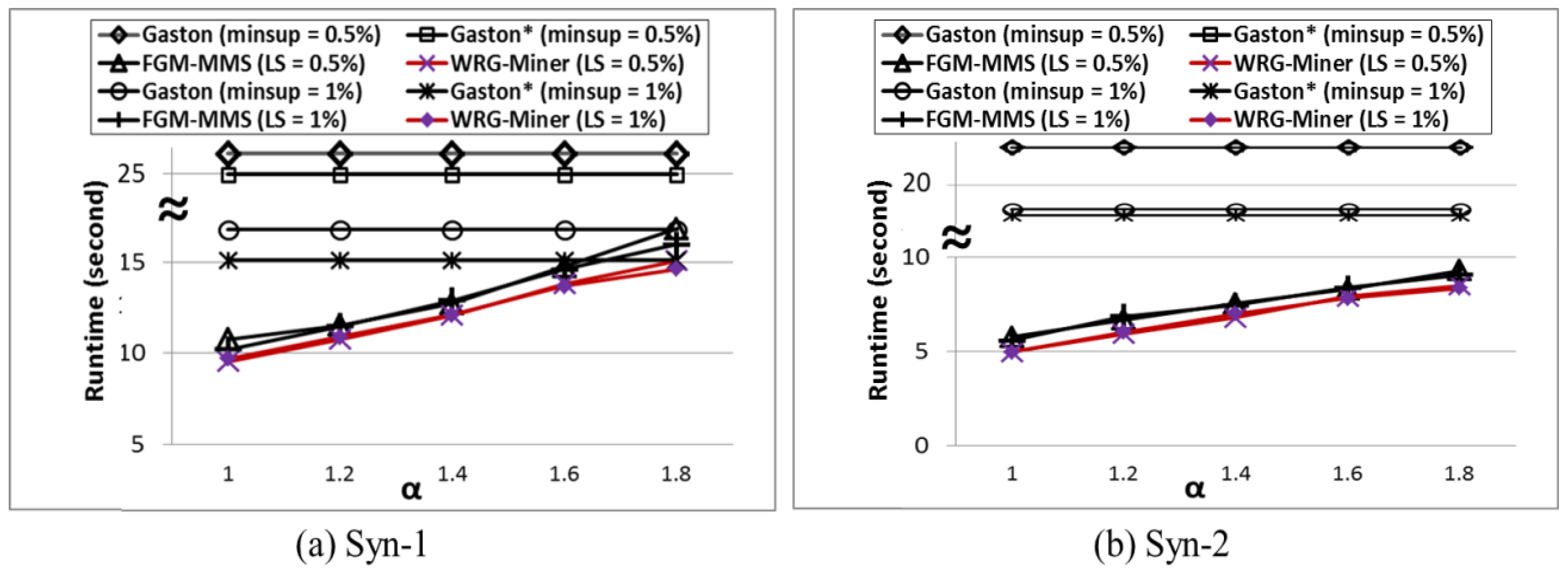
As one of the fundamental graph mining algorithms,
Gaston [
20] is known as the most efficient method in terms of runtime speed. The algorithm, which is an effective integration of multiple enumeration methods for path, free-tree, and cyclic graph forms, improves its mining performance by utilizing its own special techniques and list-based data structure.
FGM-MMS [
19] mines frequent and rare graph patterns by applying multiple minimum support constraints in a graph mining environment, but it still has a problem that cannot consider different importance or weights for each element within graphs.
3. Mining Weighted Rare Graph Patterns from Graph Databases with Multiple Minimum Support Thresholds
In this section, we describe techniques for applying multiple minimum support thresholds and importance characteristics of graph elements into a frequent graph mining environment and explain strategies for preventing fatal problems such as pattern losses that can be caused in the mining process. In addition, we also show how the proposed algorithm is performed through its overall operational procedure.
3.1. Preliminaries
The following definitions and contents are fundamental preliminaries for more easily understanding frequent graph pattern mining.
Definition 1. (Graph pattern) Let G be a graph pattern composed of multiple elements, where there are two element types, vertex and edge. That is, G has a set of vertices, VG = {v1, v2, …, vm}, and a set of edges, EG = {e1, e2, …, en}. Note that we consider a simple, labeled, undirected graph form in this paper to help understand the contents of our approach more easily, but it is trivial to apply other graph forms in this approach through several additional considerations.
Definition 2. (
Support of a graph pattern) Let
GDB = {
Gtr1,
Gtr2, …,
Gtrk} be a given graph database composed of multiple graph transactions,
Gtrs, and
G be a graph pattern. Then, a support of
G,
Sup(
G) is calculated as follows:
Equation (1) is a function for determining whether G is included into each graph transaction, Gtrk, as a sub graph pattern. That is, Sup(G) obtained from Equation (2) presents how many times G appears in GDB. Hence, in traditional frequent graph pattern mining, if Sup(G) is higher than or equal to a given minimum support threshold, G is considered as a frequent graph pattern. Consequently, the main goal of frequent graph pattern mining is to find all of the possible graph patterns such that each of their supports is not lower than the threshold.
Definition 3. (
Degree of a graph pattern) Every graph has one of the three graph forms, path, free-tree, and cyclic graph, where their coverage is path ⊆ free-tree ⊆ cyclic graph. That is, a cyclic graph includes path and free-tree forms; a free-tree contains a path form. In the case of a path, all of its vertices except for both of its ends have degree 2, while both ends have degree 1. In other words, assuming that a given graph pattern,
G is a path with
n vertices, the following conditions are satisfied:
Deg means a degree of a corresponding vertex, and
v1 and
vn are the first and last vertices, respectively. |
VG| and |
EG| signify the number of vertices and edges in
G, respectively, where |
VG| is also equal to
n. In the case of free-tree, one or more vertices must have degree 3 or more and all of its edges have no cyclic relation. That is, if
G is a free-tree, it satisfies the following conditions:
Once a cyclic relation occurs in a path or free-tree, the corresponding graph pattern becomes a cyclic graph. In other words, if
G has one or more cyclic relations,
i.e., cyclic edges, the following condition holds:
3.2. Applying Symmetry Feature-Based Performance Improving Technique into the Graph Pattern Growth Process
Recall that all of the possible graph forms generated from graph miners must be one of the three graph types: path, free-tree, and cyclic graph. The mining procedure of the proposed algorithm employs a pattern growth framework based on a depth-first search (DFS) manner. In other words, an initial step of the graph pattern growth starts from a certain vertex and it is continually expanded by adding both an edge and a vertex or a cyclic edge. Therefore, the initial state of every graph pattern is always a path form. According to the shape and characteristics of graphs with a path form, we can consider their symmetry features in order to improve our mining performance in the graph pattern growth for paths. If a path is expanded as a longer path again, we can consider its expansion operation as two orientations: expansion at the first or last node in the path. Hence, if there is no limitation in the path expansion, a large number of duplicated graph patterns can be generated. To prevent such a problem, we employ a technique based on the symmetry features of graph patters with a path form. We consider the symmetry model of a path as three types:
the whole symmetry,
the start symmetry, and
the end symmetry. Using these symmetry models, we can effectively control the growth process for the path form without any duplication of path expansion. Given a path,
P = {
v1-
e1-
v2-
e2-…-
en-1-
vn}, each symmetry type can be denoted as follows:
Each of the symmetry types can have one of the three states:
Neutrality,
True, and
False.
Neutrality is set when the string corresponding to each type is symmetric; otherwise, it is set to
True or
False.
True is set when the corresponding string is the lowest and
False is assigned when the reverse string is the lowest, where the comparison is based on a lexicographical order. Through the above settings, we can easily decide what orientation leads to correct results of the graph pattern growth. If
the whole symmetry is
Neutrality, we do not need to select which one is correct because the corresponding path is symmetric and we just choose either the start or end node to expand the path. Otherwise, the expansion occurs at the last node corresponding to the
True condition or the first one corresponding to the
False condition. In addition,
the start and end symmetry information can be effectively used as follows. After a path expanding operation is performed,
the whole symmetry of the previous path becomes
the start or
end symmetry of the current one;
the whole symmetry of the current path can be easily obtained from
the start or
end symmetry of the previous one.
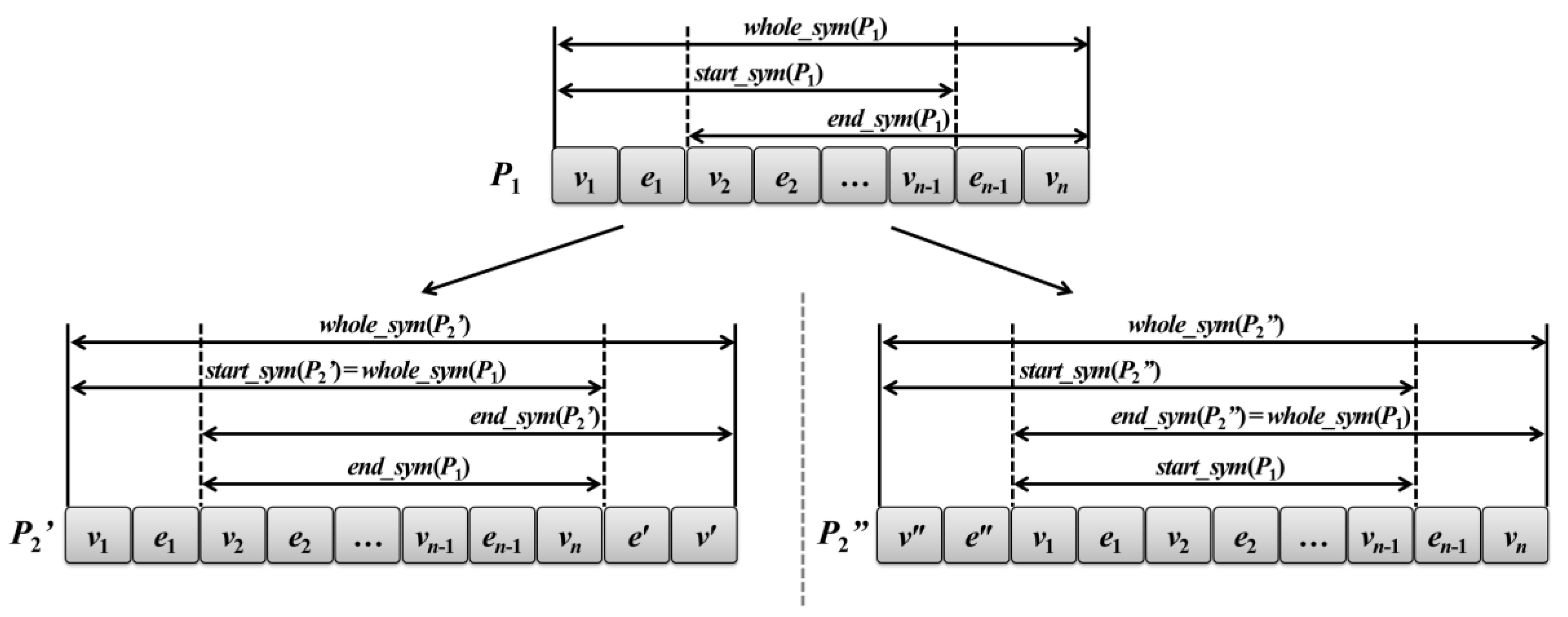
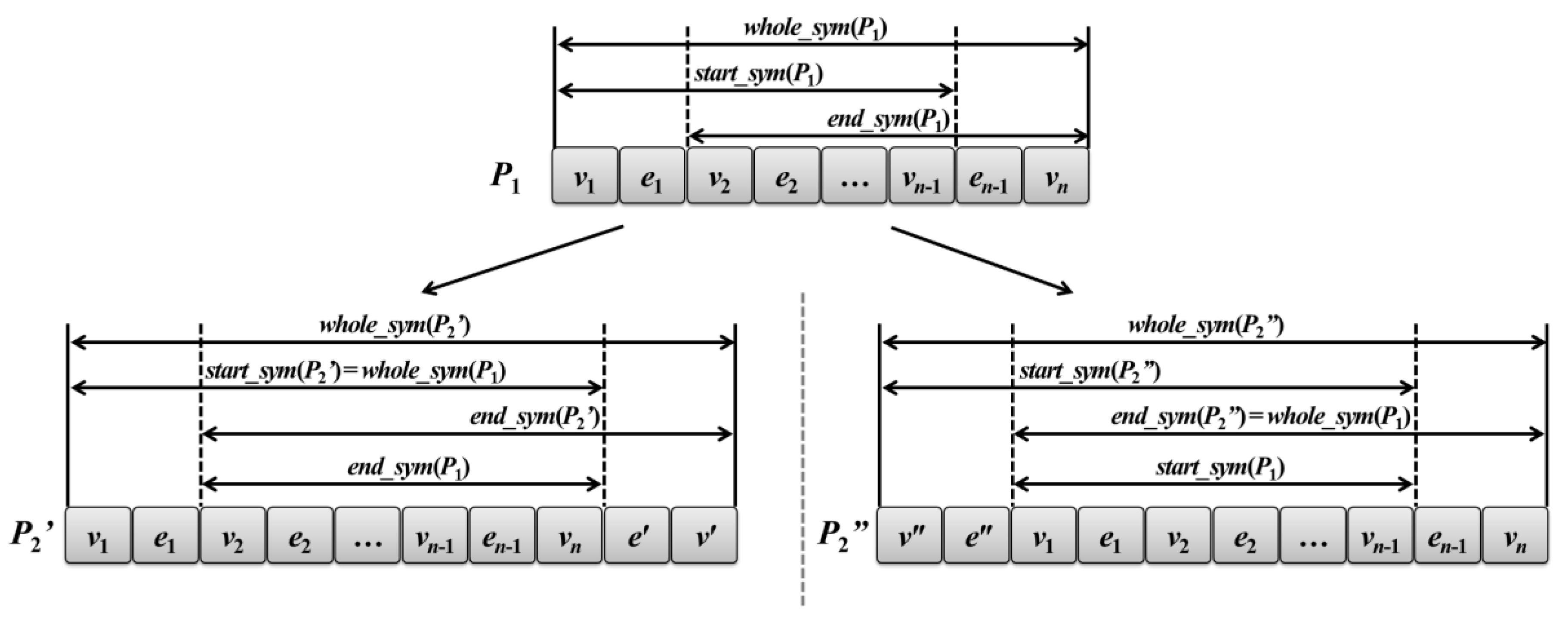
Figure 1 is the relations of these symmetry models for helping clearer understanding of the above contents. In the figure,
whole_sym,
start_sym, and
end_sym mean
the whole,
start, and
end symmetry models, respectively. Let
P1 be a given path and
P2′ and
P2″ be paths expanded from
P1. The symmetry models of
P1 are shown in the top of the figure. In the case of
P2′, a new edge and vertex,
e′ and
v′, have been inserted at the end of
P1. In this case,
start_sym(
P2′) is equal to
whole_sym(
P1).
whole_sym(
P2′) can be easily computed by
end_sym(
P1) because we have only to compare the edges and vertices next to both end of
end_sym(
P1),
v1 and
e2, and
e′ and
v′. In contrast,
end_sym(
P2″) is equal to
whole_sym(
P1), and
whole_sym(
P2″) is obtained from
start_sym(
P1). It is important to consider these three symmetry models in the growth step because we can easily determine whether or not a path is symmetric without computational overheads.
Through this symmetry method, the proposed algorithm can conduct its mining operations more efficiently.
Figure 1.
Graph pattern growth of the path form and corresponding relations of the symmetry models.
Figure 1.
Graph pattern growth of the path form and corresponding relations of the symmetry models.
3.3. Employing Element Importance and Multiple Minimum Support Thresholds in Frequent Graph Pattern Mining
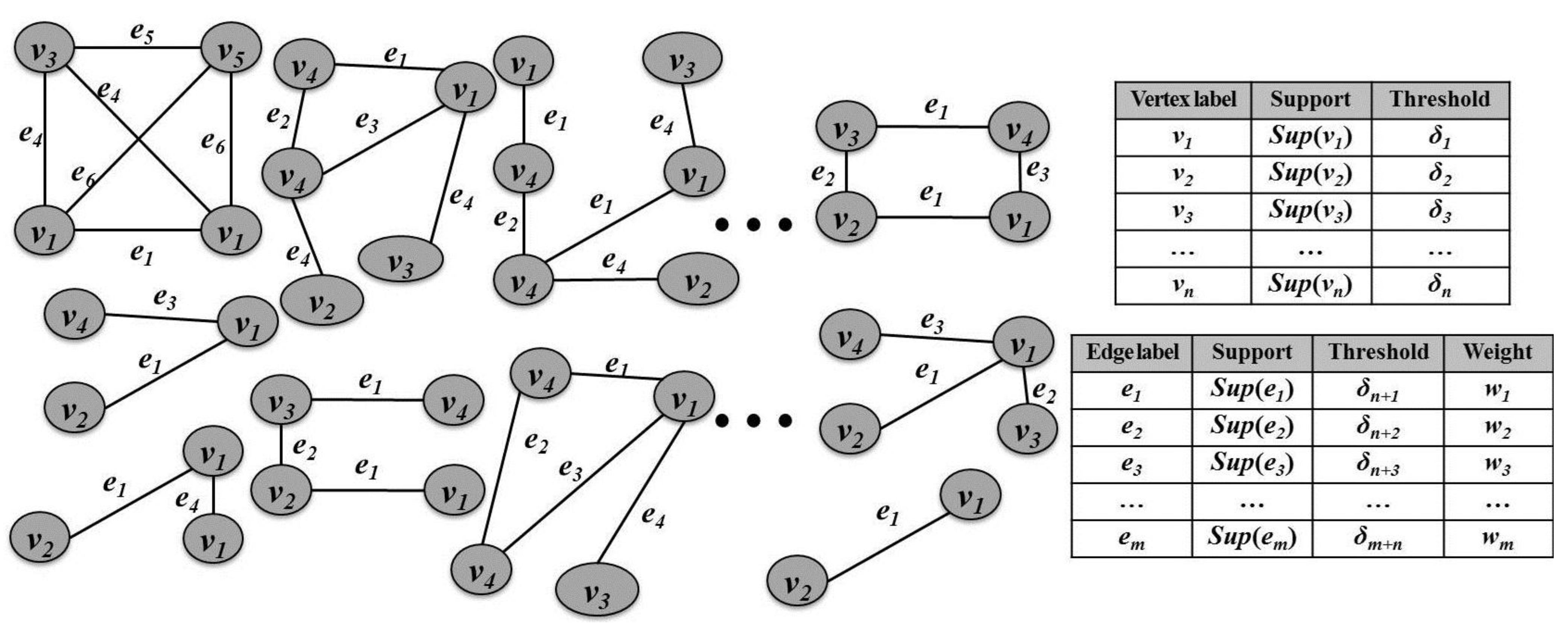
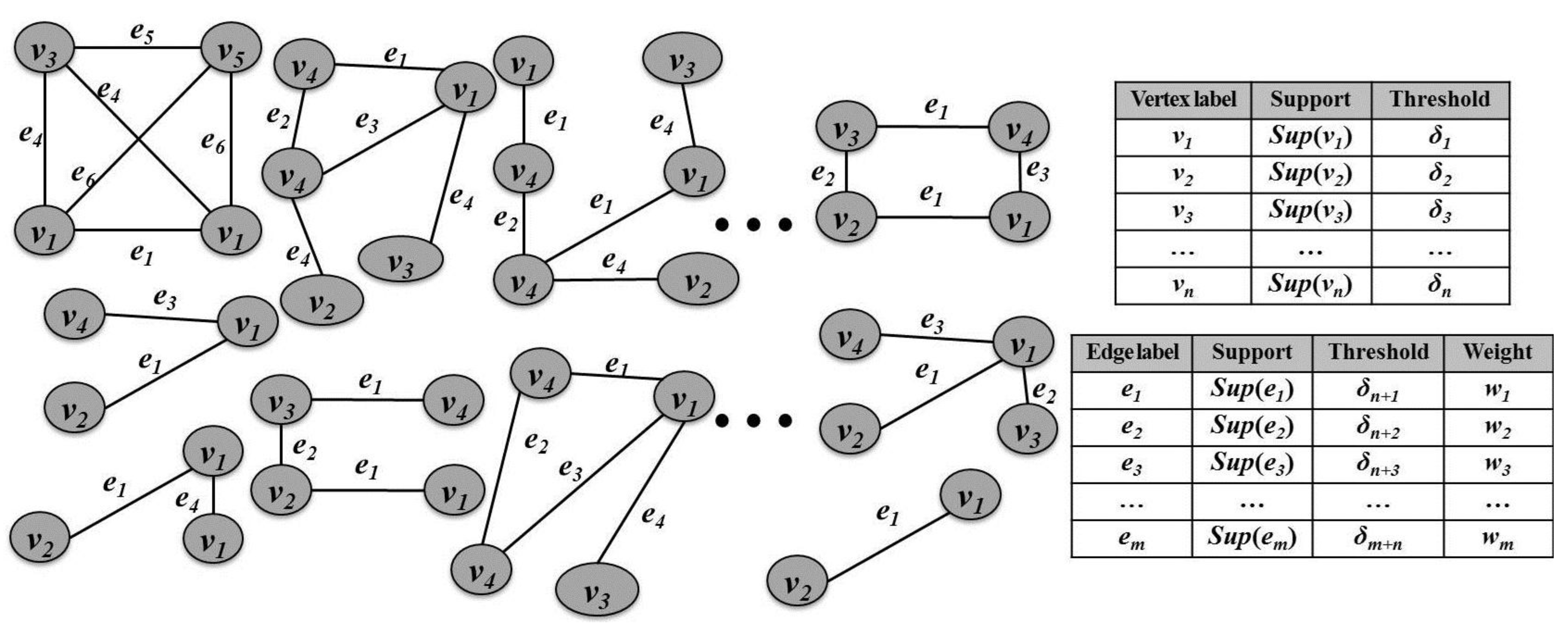
Figure 2 shows an example of a graph database including the information of multiple minimum support thresholds and edge weights. To apply different importance for each element composing graphs, we consider mining graph patterns from graph databases that assign a different weight value to each edge of the graphs. Since edges are important factors allowing us to determine correlations among vertices, edge weights are also valuable because they can be used to distinguish different importance of edges. As a result of the proposed algorithm, we can obtain a set of graph patterns considering both supports and weights of edges connected among nodes. The weighted support of a graph pattern is calculated as follows.
Figure 2.
Example of a graph database with weight and multiple minimum support information.
Figure 2.
Example of a graph database with weight and multiple minimum support information.
Definition 4. (
Weighted support of a graph pattern) Let
VG = {
v1,
v2, …,
vm},
EG = {
e1,
e2, …,
en}, and
WG = {
w1,
w2, …,
wn} be a set of vertices in a graph pattern,
G, a set of edges in
G, and a set of edge weights in
G. Then, the weighted support of
G,
Wsup(
G) is calculated as follows:
If Wsup(G) is not lower than a given minimum support threshold, G is regarded as a weighted frequent graph pattern.
In order to consider the rare item problem in the graph pattern mining area, we need multiple minimum support thresholds for each element (vertex and edge) composing a given graph database.
Definition 5. (Minimum element support threshold)) Let GDB = {Gtr1, Gtr2, …, Gtrk} be a given graph database composed of multiple graph transactions, Gtrs, VGDB = {v1, v2, …, vx} be a set of separate vertices included in GDB, and EGDB = {e1, e2, …, ey} be a set of separate edges in GDB. Then, a minimum element support threshold for each element (v or e), δi (1 ≤ i ≤ x + y) is set as a value specified by a user.
If a weighted support of any element is lower than the corresponding δ value, it becomes a useless one. Consequently, the threshold of a graph pattern is determined as follows.
Definition 6. (Minimum graph support threshold) Given a graph pattern,
G, a set of vertices in
G,
VG = {
v1,
v2, …,
vn}, and a set of edges in
G,
EG = {
e1,
e2, …,
em}, a set of
δ values in
G including
VG and
EG,
TG, can be denoted as
TG = {δ
1, δ
2, …, δ
n+m}. Then, a minimum graph support threshold for
G,
MGST(
G), is computed as follows:
Therefore, if Wsup(G) is lower than MGST(G), it becomes an invalid graph pattern.
By calculating the threshold for a graph pattern in the above manner, we can consider the rarity of the graph’s each element. In other words, only weighted frequent graph patterns satisfying their own MGST conditions are finally regarded as valid results.
3.4. Maintaining the Correctness of the Proposed Algorithm
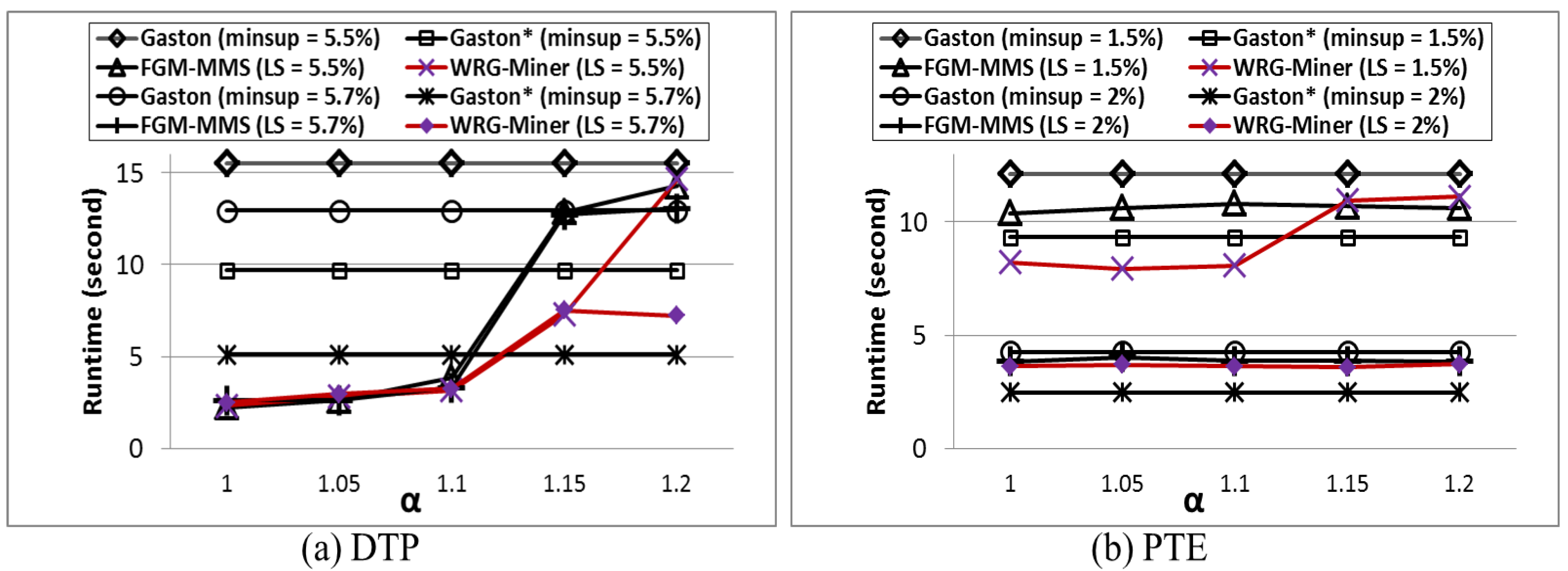
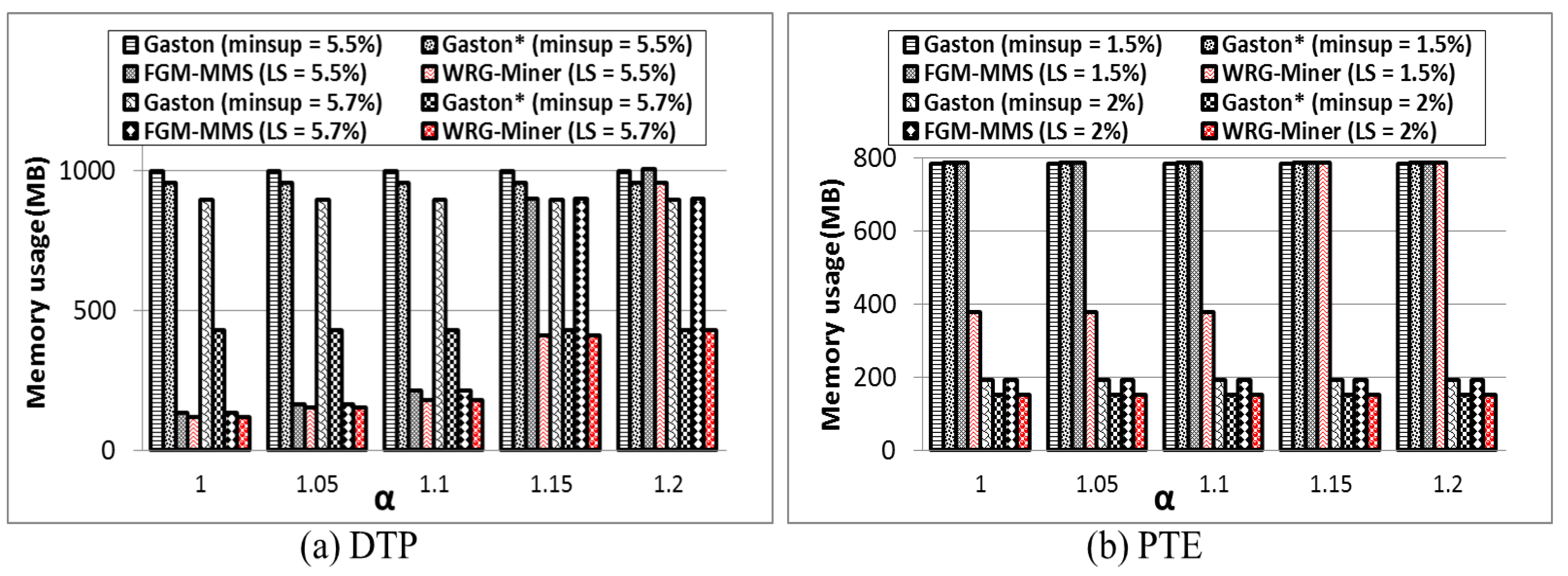
Through the aforementioned conditions, we can obtain a set of graph patterns that completely consider both the weight and rarity of elements. However, if we simply apply such conditions into the mining process without any additional considerations, fatal pattern losses can be caused since these conditions violate the anti-monotone property (or the downward closure property). Therefore, to guarantee not only the efficiency of the proposed algorithm but also its correctness, we employ (1) an overestimated weight method and (2) an underestimated minimum support method. In the first method, the maximum edge weight within a given graph database, called MaxW, is used instead of the real average weight factor used in Definition 4. That is, given a graph pattern, G, multiplying Sup(G) by MaxW, called Wsupover(G), is first applied in the mining process. Through such an overestimation method, we can maintain the anti-monotone property and prevent unintended pattern losses by the weight constraints. In the second method, among all the thresholds in Definition 5, we set the least value that does not violate the property and apply it into the mining process. Let L = {δ1, δ2, …, δx} be a list of all the elements’ δ values in GDB that are sorted in the descending order of their values. Then, starting from the last element in the list, we check whether or not the overestimated weighted support of the element is higher than its own δ value. If there is the first element satisfying this condition, its δ value becomes an underestimated minimum support threshold, called Least Minimum Support (LMS).
If any graph pattern does not satisfy the LMS condition, the pattern and all of its possible supersets become useless ones; hence, it can permanently be pruned in advance. Note that graph patterns obtained through the above conditions are candidate patterns, not final results. Among them, only partial ones satisfying the corresponding MGST conditions in Definition 6 finally become valid results.
3.5. WRG-Miner Algorithm
Figure 3 shows the overall procedure of the proposed algorithm. After finding sets of valid vertices and edges,
V and
E, from a given graph database,
GDB (lines 1–2), the algorithm performs graph pattern growth processes for mining a set of
WRGs,
S, with respect to each vertex of
V,
vi (lines 3–5). In this phase,
WRG-Miner continues to expand graphs for each edge,
ei, considering their current states (lines 6–9). For each expanded graph,
G’, if the overestimated weighted support of the graph is smaller than
LMS, it is permanently pruned (line 10). If the graph pattern’s real weighted support is not lower than its corresponding
MGST value, it is regarded as a valid result and the algorithm outputs it (line 11). Once the graph pattern has an overestimated weighted support higher than or equal to
LMS, growth operations for the pattern are recursively conducted regardless of whether it is really outputted or not (lines 12–13). After finishing all the recursive processes, we can obtain a complete set of
WRGs,
S.
Figure 3.
Procedure of Weighted Rare Graph (WRG)-miner.
Figure 3.
Procedure of Weighted Rare Graph (WRG)-miner.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}