1. Introduction
The human face is a significant feature of human identity and plays an essential role in social interaction. Facial features, such as the eyes, eyebrows, nose, and mouth, exhibit significant symmetry in terms of shape, texture, and position when viewed with a neutral expression and frontal angle. With the development of AI technology, facial recognition has seen widespread use in areas such as security, finance, and social media, where the quality and accuracy of facial images are of utmost importance. However, in real-world environments, facial images are often partially obstructed by various factors such as wearing masks, glasses, or hats, or the presence of hair or other objects. These occlusions lead to the loss of facial features, which negatively affects facial recognition and analysis, making face restoration an important challenge for improving recognition accuracy and human–computer interaction. This is a crucial issue in real-world scenarios.
Research on face restoration has evolved rapidly from traditional image processing techniques to deep learning methods. Early image restoration techniques were mostly based on traditional image processing, with images repaired by using the structure and texture information of known regions. Criminisi et al. proposed a sample-based image restoration method that uses texture information from a known region to fill in the missing parts, which proved effective in removing large occlusions. However, when dealing with irregular or complex missing regions, issues such as discontinuous boundaries or inconsistent structures in the restoration may arise [
1]. Wu et al. applied the idea of diffusion to iteratively propagate low-level features in the occluded region, which is suitable for smaller, structure-rich regions [
2].
With the development of deep learning, particularly the application of convolutional neural networks (CNNs) and Generative Adversarial Networks (GANs), significant progress has been made in face restoration technology. CNNs, by simulating the way the biological visual neural system works, can effectively perform image restoration tasks. U-Net, a typical convolutional neural network structure, uses an encoder–decoder architecture to repair facial images, preserving the continuity and consistency of facial features. However, it often falls short in restoring complex textures and details, such as facial expressions, skin textures, and hair [
3]. GANs, by utilizing the concept of adversarial training, generate realistic images. Deepak et al. used an encoder–decoder structure combined with adversarial loss to restore damaged images and enhance the convenience of image repair [
4]. Yu et al. proposed a GAN model based on Gated Convolution for image restoration tasks. This method can handle irregular missing areas and recover the details of facial images. The gating mechanism allows the generator to generate more precise restoration areas, improving the restoration quality. However, when dealing with large missing regions, the restoration results may exhibit unnatural or distorted areas [
5]. In 2021, Dosovitskiy et al. introduced Vision Transformer (ViT) [
6]. In 2022, Zhu et al. proposed a reference-guided image inpainting method based on Vision Transformer, capable of generating high-quality inpainting results by utilizing reference images [
7]. Compared to a GAN, ViT has limited capability in detail restoration and higher computational complexity, making it more suitable for repairing large missing areas and capturing the global structure of images.
Determining how to restore complex textures and details in facial restoration, especially under large-area occlusions, remains a key research challenge. This study proposes an improved occluded-face restoration network based on facial landmarks and GANs, with the following main contributions:
- (1)
A lightweight network structure is constructed using MobileNet’s depthwise separable convolutions, forming a lightweight facial landmark prediction network.
- (2)
An enhanced GAN occluded-face restoration network is developed by improving upon the U-Net and Patch-GAN architectures.
The experimental results demonstrate that the proposed facial restoration network achieves high-quality restoration results under both free-form occlusion and 25% center occlusion scenarios.
2. GAN
GANs were proposed by Goodfellow et al. in 2014 [
8]. The design of GANs is inspired by the game theory concept of adversarial play, with the generator and discriminator in deep neural networks simulating this idea.
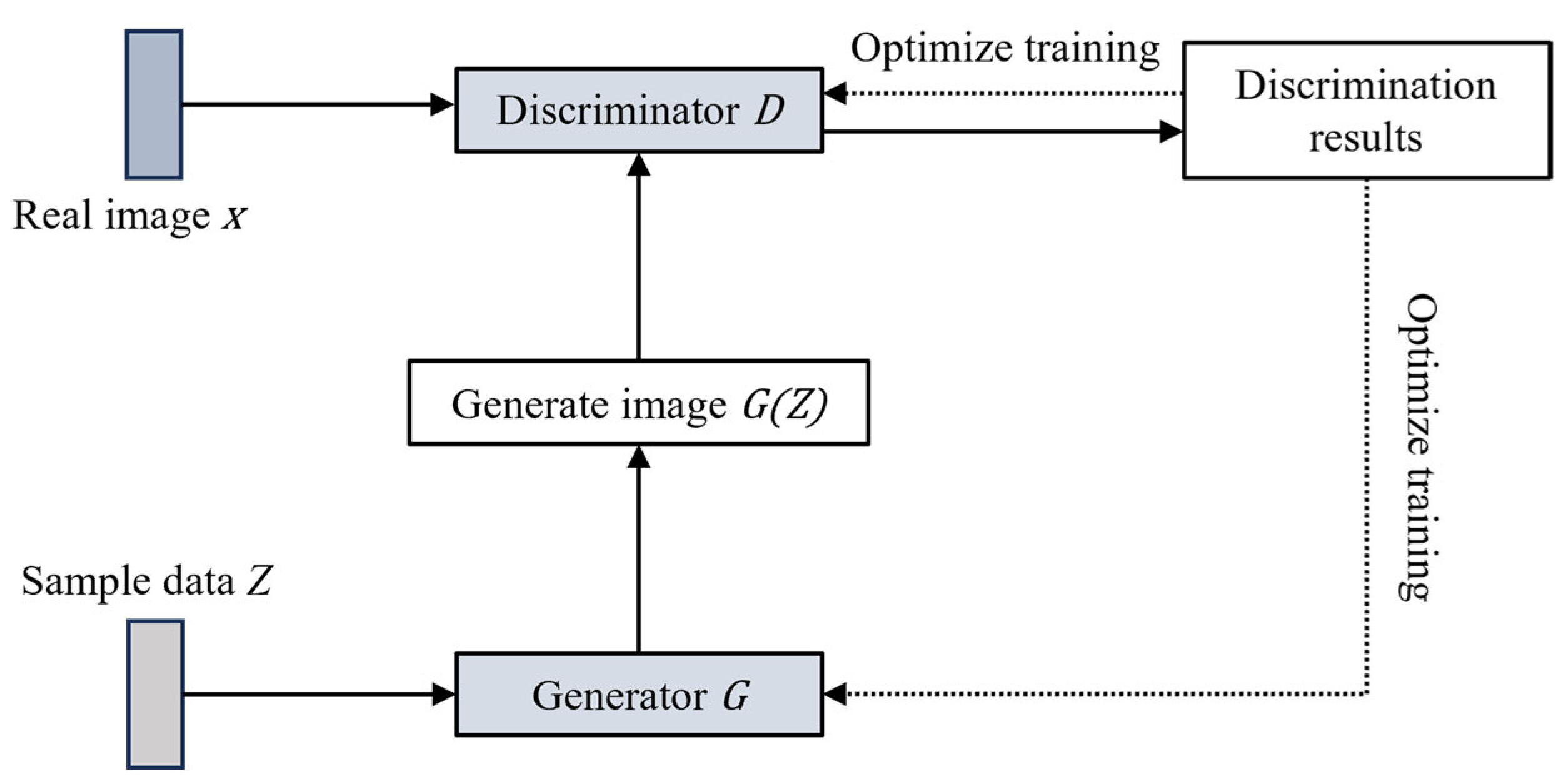
Figure 1 shows the GAN model, where the generator creates an image
by capturing the data distribution in sample data
, and the discriminator uses real images to determine whether the generated image is correct. The discriminator is essentially a binary classifier, marking real images with a “1” and generated images with a “0”. When the discriminator classifies an image as fake, it sends the result back to the generator, which continues learning and optimizing based on the discriminator’s feedback to create more realistic images to deceive the discriminator. This process repeats until the generated image is indistinguishable from the real one according to the discriminator.
The training loss of the GAN includes adversarial loss and generation loss. The objective function
is expressed as follows:
where
represents real data,
is the pixel distribution of the real images,
represents the sample data,
denotes the distribution of input random noise,
is the image generated by the generator,
represents the expected value of the distribution function, and
is the probability of classifying the generated sample as real.
represents the expected outcome of the discriminator’s judgment on real samples. To make the discriminator optimal, the discriminator’s result for real samples, , should be 1, i.e., should be 0. If the discriminator is not optimal, will be less than 0. In other words, to optimize the discriminator, should be as large as possible. Similarly, represents the expected outcome of the discriminator’s judgment on fake samples. To make the discriminator optimal, the discriminator’s result for fake samples, , should be 0, meaning that should be 0. If the discriminator is not optimal, will be less than 0. In other words, to optimize the discriminator, should be as large as possible. The value function is the sum of the two terms above and is essentially a cross-entropy loss function. The better the discriminator, the larger the value of .
At the same time, when the parameters of the generator
are fixed, the optimal discriminator can be represented as
where
is the distribution of the generated samples
when
, and
is the distribution of real samples.
To optimize both the generator and discriminator, the generator model and the discriminator model must be trained so that through continuous adversarial interactions, they reach their optimal states.
After training, the generator model and the discriminator model reach a balanced state, meaning the samples generated by the generator are very similar to the real samples. As a result, the discriminator finds it difficult to distinguish whether the samples generated by the generator are real or not, and thus assigns a score of 0.5 for any input, i.e., . In most cases, the discriminator loss and generator loss do not converge simultaneously. For example, when the discriminator has very high accuracy, its loss may quickly drop to zero, preventing it from providing useful information for training the generator. This results in unstable GAN training and defeats the purpose of adversarial learning.
3. Methodology
To further enhance the restoration quality of the face restoration network, this study improves it based on GANs. The generator in the network is built upon a modified U-Net architecture. During the downsampling process, convolutional layers are used instead of max-pooling layers, and normalization layers are introduced before the activation functions to stabilize the training. Seven residual blocks with dilated convolutions are added to reduce the loss of fine details during the feature extraction process. The upsampling process employs three decoders, with a dilation block introduced before each decoder to expand the receptive field. Additionally, skip connections are added between the corresponding encoder–decoder layers and residual modules, fully utilizing the feature information extracted during the downsampling process.
The discriminator is based on the Patch-GAN structure and incorporates a spectral normalization (SN) module. Furthermore, a Self-attention Module is added to adaptively process the features. By using real feature points to evaluate the generated image, the network can better assess the restoration quality of details, thus improving the preservation of local details.
3.1. Overall Structure of the Restoration Network
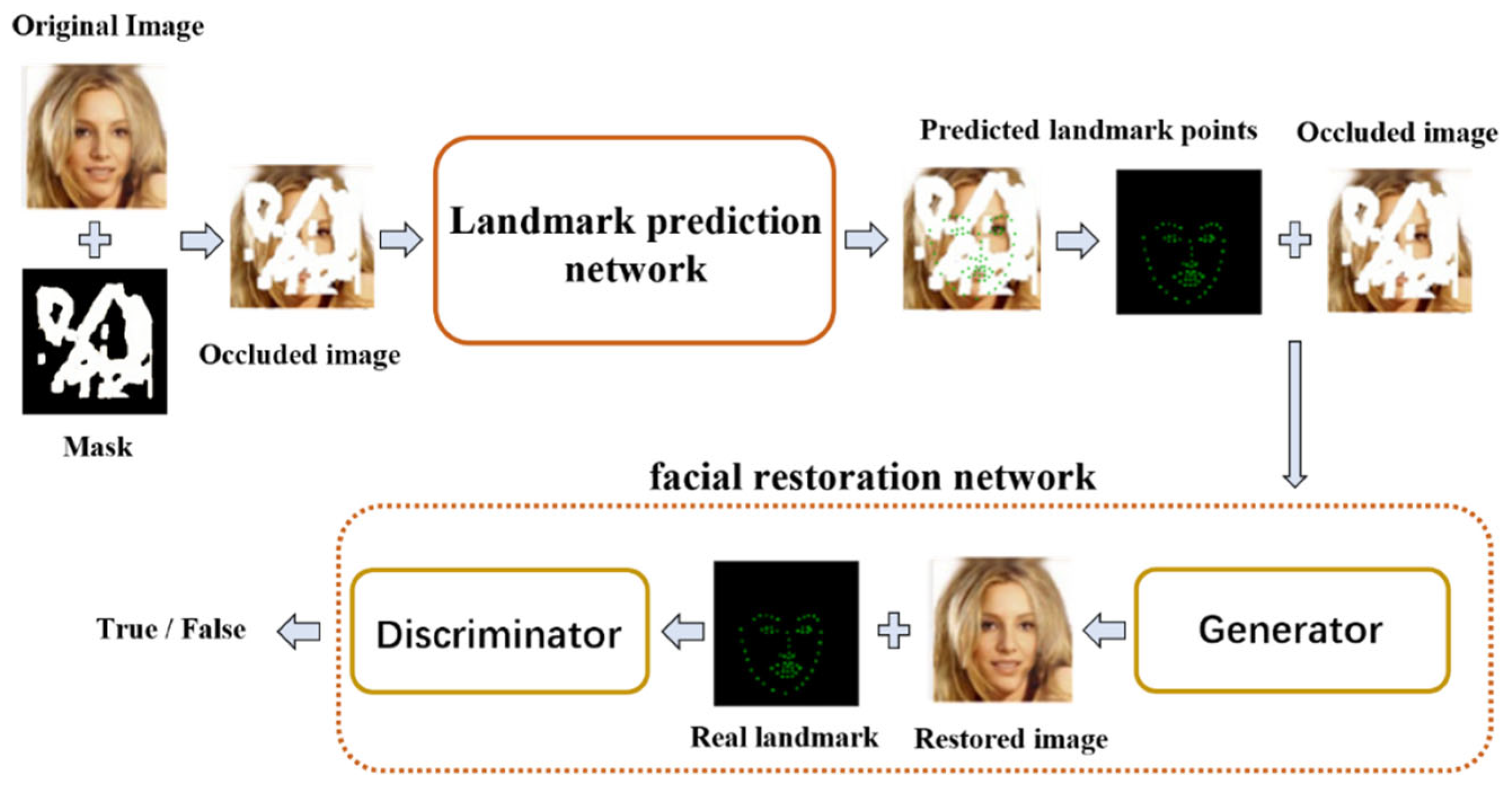
An ideal facial image restoration network should generate restored images that maintain the logical structure between facial features and attributes, making the restored image appear more natural and closer to the real result. This study establishes a facial image restoration network based on facial feature points to achieve high-precision occluded-face restoration. The network structure is shown in
Figure 2.
The face restoration network consists of two parts. The first part is the feature point prediction network, which is an improved facial feature point prediction network based on MobileNetV3-small. The image input to the network is the occluded image obtained by the Hadamard product of the real image and the masked image, and the output is the predicted facial feature points of the occluded image. The predicted feature points reflect facial expressions and the topological structure between facial features, which guide the restoration process of the occluded-face image. The second part is the occluded-face image restoration network, which consists of a generator and a discriminator. The generator is an improved version based on the U-Net structure. Its input is the image generated by combining the occluded image and the predicted facial feature points, and the output is the generated facial image. The discriminator is an improved version based on the Patch-GAN structure, and its input is the generated facial image and the real facial feature points.
The input to the facial image restoration network
is the occluded image
and the predicted feature points
. Let
be the network parameters, and the restored image can be defined as
3.2. Lightweight Facial Feature Point Prediction Network
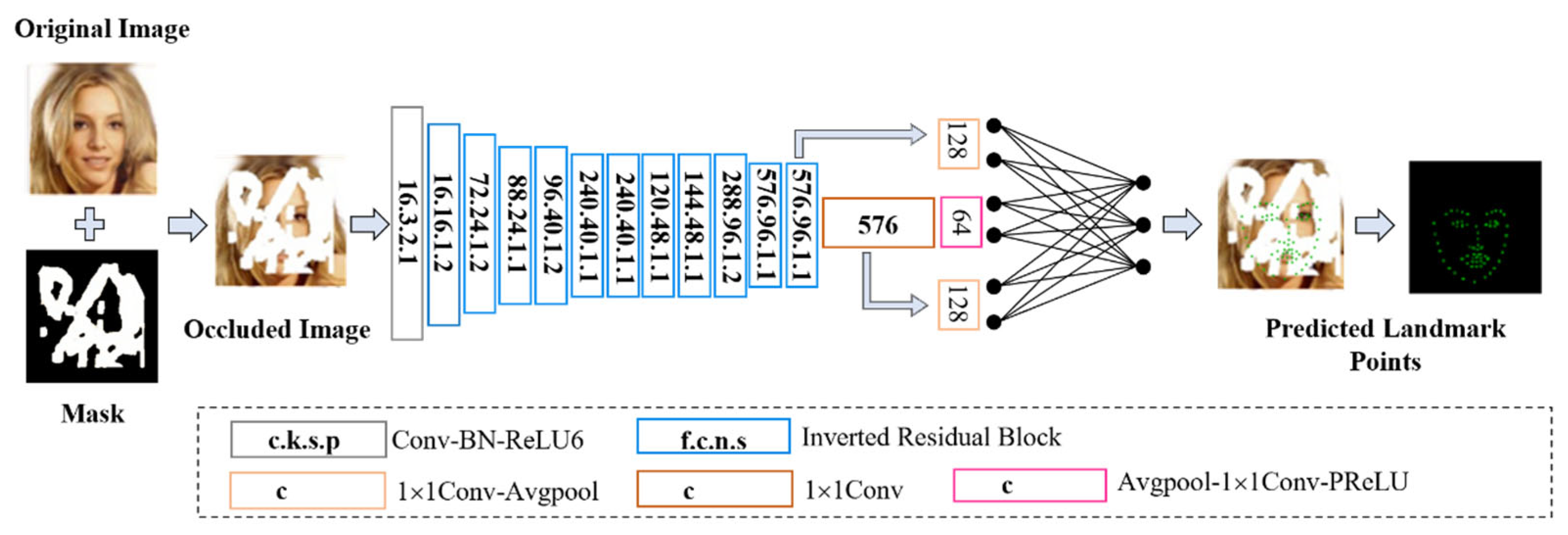
Facial feature points can be seen as discrete points sampled from key areas of the face. These discrete points form a structure that preserves facial expression features and maintains the topological structure between facial features. The lightweight facial feature point prediction network is an improvement based on the MobileNetV3-small network [
9]. It adopts a lightweight network structure formed of MobileNet’s depthwise separable convolutions and introduces SENet. To solve the issue of slow convergence when training key points with SENet, improvements such as batch normalization, reverse residual structures, linear bottleneck structures, and average pooling are applied. Feature point prediction loss
is used to train the feature point prediction module. A lightweight facial feature point prediction network for 256 × 256 facial images is constructed, and the network structure is shown in
Figure 3.
In the figure, c represents the number of output channels, k is the kernel size, s is the convolution or deconvolution stride, p is the padding, f is the dilation factor, and n is the number of repetitions.
3.3. Generator Network Based on Dilated Convolutions
The generator is an improved version based on the U-Net structure [
3]. This network consists of two parts: the first part is the downsampling encoder section, and the second part is the upsampling decoder section. The downsampling process is mainly used for feature extraction and feature compression, while the upsampling process is mainly used for feature concatenation and sampling. The structure of the generator is shown in
Figure 4.
In the figure, c represents the number of channels, k is the kernel size, s is the stride of the convolution or deconvolution layer, and p is the padding. The image input to the generator is the occluded-face image, combined with the facial key points predicted by the key point prediction network.
First, three progressively downsampling encoder blocks are used, each consisting of a convolution layer, an Instance Normalization (IN) layer, and a nonlinear activation function (ReLU) connected sequentially [
10,
11]. Following this, there are seven residual blocks with dilated convolutions and one long short-term attention block.
The second half of the network is the upsampling process, with three decoder modules. Before the decoders, a stacked dilation block is introduced. The decoder modules have the same structure as the encoder. The dilation block is composed of a deconvolution layer, an IN layer, and a nonlinear activation function (ReLU) connected sequentially. The final decoder module removes the normalization layer and sets the activation function to tanh.
The dilated convolution-based generator network improves upon the U-Net network. The downsampling part has three key improvements. First, instead of using the max pooling layers found in the original U-Net network after each sampling step, three encoder blocks use convolution layers with strides of 1, 2, and 2 for image feature downsampling. The benefit of this approach, compared to the original U-Net, is that the network can learn through training to optimize feature downsampling. Second, an IN layer is added after each convolution layer and before the activation function, stabilizing training and accelerating model convergence. Third, dilated convolutions are used along with the introduction of residual blocks and long short-term attention layers. Dilated convolutions help preserve more details in the final feature map by preventing it from becoming too small. The residual blocks help reduce computational complexity, and the long-short term attention layer connects temporal feature maps [
12].
In the upsampling part, dilation blocks are introduced to enlarge the receptive field, enabling consideration of a broader range of features. The final decoder module sets the activation function to tanh, which helps alleviate the gradient vanishing problem [
13] and improves robustness. By combining low-level features, the final feature map is processed to restore the image to the same size as the input.
Additionally, to better extract semantic information from the missing parts of the image and fully utilize the extracted shallow image features, skip connections are added between the corresponding encoder–decoder layers and residual blocks. This allows for the reuse of low-level features, enhancing the network’s ability to leverage these features spatially and temporally. Skip connections efficiently pass features from the encoding modules, helping the network capture more useful information from the input image, which improves the detail restoration of the generated face image. Moreover, skip connections between residual blocks provide gradient flow information from shallow to deep layers, improving training speed and further enhancing training performance. Before each decoding layer, a 1 × 1 convolution operation is performed through channel attention to adjust the weights of the features from the skip connection and the last layer.
Table 1 shows the network architecture parameters for the generator. In the table, c represents the number of channels, k is the kernel size, s is the stride of the convolution or deconvolution layer, and p is the padding. The input image is a 256 × 256 four-channel image generated from the original image and the occlusion mask.
3.4. Discriminator Network Improved Based on Patch-GAN
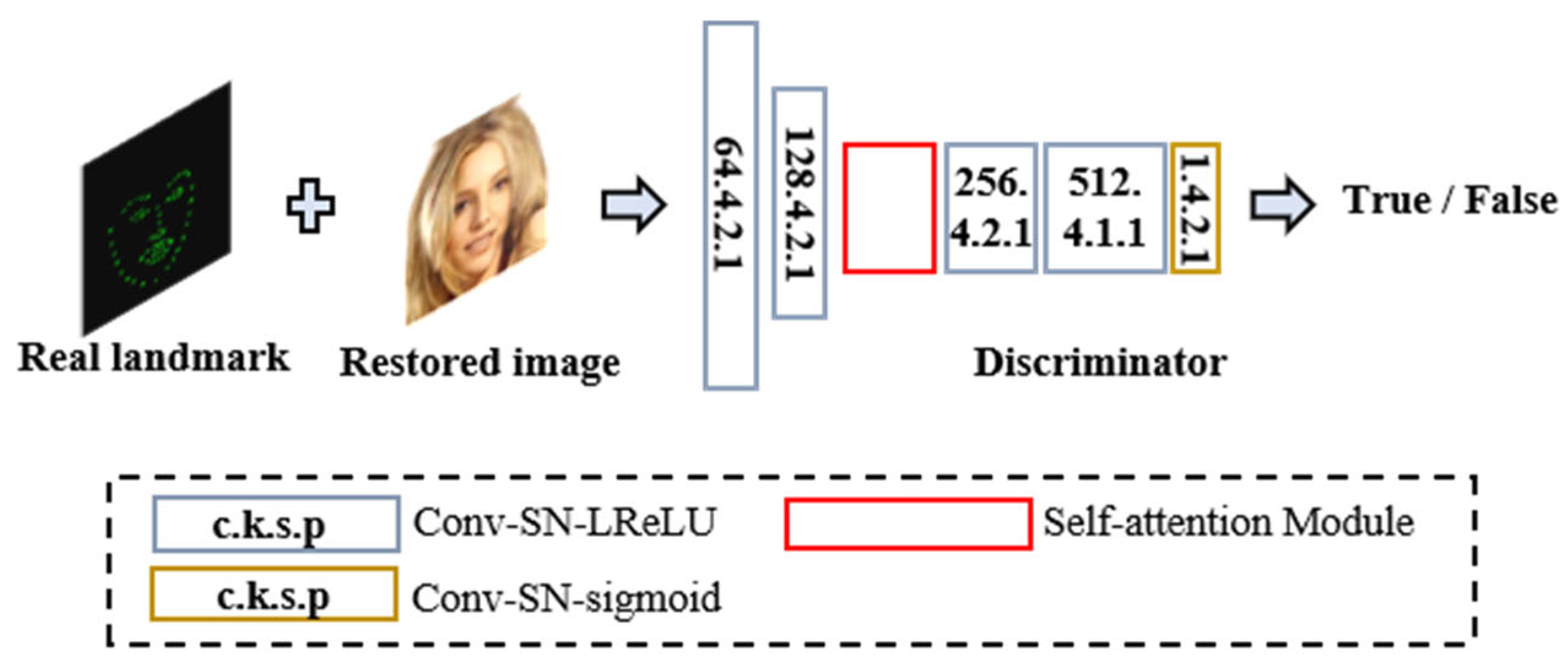
The discriminator is responsible for distinguishing whether the input data are real and providing feedback to the generator based on the discrimination result. The ideal state at the end of training is that the data generated by the generator are very similar to the real data, and the discriminator’s output is unable to distinguish the authenticity of the generator’s output because the generated data are so realistic, resulting in a straight line with a value close to 0.5 (between real and fake).
The discriminator is improved based on a 70 × 70 Patch-GAN structure [
14]. The first, second, fourth, and fifth convolutional modules are composed of a convolutional layer, a spectral normalization (SN) layer, and a nonlinear activation function LReLU layer [
15]. The introduction of spectral normalization ensures the global structure of facial features and maintains attribute consistency. The sixth convolutional module uses the sigmoid activation function with a range of (0, 1) for judgment. The third module inserts an attention layer to adaptively process features. The discriminator discriminates the generated image based on real feature points, allowing it to better evaluate the quality of detail restoration in the repaired image. By focusing on the feature points of the image, the discriminator can better preserve local details. The structure of the discriminator is shown in
Figure 5.
Table 2 shows the network structure of the discriminator. The structure of each module in the discriminator is the same, but the number of channels in the network varies due to the different resolutions of the input image patches.
3.5. Loss Function
The landmark prediction loss
is used to train the landmark prediction module
, which measures the fit between the generated landmark
and the real landmark
. The training loss is as follows:
This loss is used to generate landmarks for facial image contours, ensuring recognition of the topological structure between facial features.
In the training of the image inpainting network generation model, the generator’s loss function is expressed using pixel-wise loss
, total variation loss
, perceptual loss
, style loss
, and adversarial loss
. The loss function is formulated as follows:
where the pixel-wise loss
is defined as
Here, denotes the norm, and is the mask size used to adjust the discriminator’s judgment requirements. This loss measures the difference between the image generated by the generator and the real image, helping to generate high-resolution images.
To add more texture structures to the inpainting results, adversarial loss
is introduced. The adversarial loss
is defined as
where D is the discriminator’s output,
is the real feature points,
is the face image inpainting network, and
is the occluded image, with
predicting the feature points.
The total variation loss
is introduced to improve the visual consistency between the repaired region pixels and the known region pixels. The total variation loss is defined as
where
is the gradient magnitude of the image, and
is the number of pixels in the real image.
The perceptual loss
measures the difference between the feature maps extracted from a pre-trained network, defined as
In the formula,
and
represent the size and dimension of the feature map from the
-th layer of the pre-trained network, and
denotes the
-dimensional feature map of size
from the
-th layer of the pre-trained network.
where
, and
corresponds to the Gram matrix.
The discriminator loss for the inpainting network is defined as
In the deep learning-based inpainting network established in this paper, the parameters are set as , , , and for the experiment. Through the training of the inpainting network, the losses of the generator and discriminator are alternately minimized, and eventually, the generator is able to produce more natural images that closely resemble real images, thereby achieving the inpainting functionality.
4. Experiments and Results
4.1. Experimental Environment and Parameter Settings
The training and testing in this paper were conducted on a server running Windows 10 Professional. The main specifications of the server were as follows: the hardware configuration included a CPU (Intel Xeon, Hillsboro, OR, USA), 4 GPUs (NVIDIA TITAN Xp, Santa Clara, CA, USA), a Supermicro X10DRG-Q motherboard (San Jose, CA, USA), 256 GB of Micron RAM (Manassas, VA, USA), and a 2 TB hard drive. The software configuration included CUDA 10.0, Anaconda3, PyCharm 2019, Python 3.7, and others. All experiments in this paper were based on the PyTorch1.10.0 deep learning framework.
The experiment used 30,000 images from the CelebA-HQ dataset with a resolution of 256 × 256 for the network. The CelebA-HQ dataset is one of the most widely used datasets. Its facial image data are an extension of the CelebA dataset, resulting in a high-definition dataset that contains a total of 202,599 facial images. The downloaded CelebA-HQ dataset was divided into three parts: 29,500 images for the training set, 200 images for the validation set, and 300 images for the test set. During the training process, an Adam optimizer with exponential decay rates of
and
was used [
16]. The learning rate for the feature point prediction network was set to 0.0001, and the batch size for the images was set to 16. The learning rate for the facial inpainting network was set to 0.00001, with a batch size of 4.
4.2. Evaluation Parameters for Experimental Results
To evaluate the quality of the face inpainting network, three objective metrics were used for quantitative assessment: the Peak Signal-to-Noise Ratio (PSNR), Structural Similarity Index (SSIM), and Fréchet Inception Distance (FID) [
17,
18]. The PSNR is used to assess the error between corresponding pixel points of two images, where a higher value indicates less distortion. The SSIM evaluates the overall similarity of two images in terms of brightness, contrast, and structure; a value closer to 1 indicates higher similarity. The FID is used to assess the quality of two images, with lower values indicating better image quality.
The PSNR (Peak Signal-to-Noise Ratio) refers to the ratio of the maximum signal to the noise, and it is typically used to quantify the difference between the maximum signal and the background noise. In most cases, compressed images differ from the original images, so the PSNR is commonly used as a standard for evaluating image quality.
Given a reconstructed image
and an inpainted image
of size
, the Mean-Squared Error (MSE) is defined as
Furthermore, the definition of the PSNR is
where
is the maximum possible pixel value of the image, and
, where
is the bit depth of the pixels. If the pixel values are represented by 8-bit numbers, then
. The unit of the PSNR is decibels (dB), and the smaller the MSE, the larger the PSNR value, indicating better inpainting performance. Conversely, the larger the MSE, the smaller the PSNR value, indicating worse inpainting performance.
The Structural Similarity Index (SSIM) is a metric used to measure the similarity between two images. When one image is a distortion-free image and the other is a distorted version, their structural similarity can be used as a measure of the image quality of the distorted image. Compared to the Peak Signal-to-Noise Ratio (PSNR), the SSIM is a better metric for evaluating image quality in terms of human visual perception. The SSIM measures image similarity based on three aspects, brightness, contrast, and structure, as follows:
where
is the reconstructed image,
is the inpainted image,
is the luminance comparison,
is the contrast comparison,
is the structural comparison,
is the covariance between image
and image
,
and
are the standard deviations of image
and image
, respectively, and
and
are the mean pixel values of image
and image
.
,
, and
are small constant values. The constants
,
, and
are introduced to avoid division by zero in the formula. The SSIM is defined as
where
,
, and
are constants greater than zero. The value of the SSIM ranges from 0 to 1, and a higher value indicates better quality of the inpainted image.
The Fréchet Inception Distance (FID) is a metric used to evaluate the quality of generated images, often employed to measure the similarity between images generated by Generative Adversarial Networks (GANs) and real images. The FID is widely used in image generation tasks, particularly in image synthesis, style transfer, and image inpainting. It measures the similarity between generated and real images by computing the Fréchet distance between their feature distributions in the InceptionV3 network’s feature space. The formula is as follows:
where
and
are the feature means of the real and generated images,
and
are the covariance matrices of the real and generated images,
denotes the squared Euclidean distance, and
represents the trace of the matrix (the sum of its diagonal elements).
The smaller the FID value, the closer the distribution of the generated images is to that of the real images, indicating better generation quality. A larger value indicates a greater difference between the generated and real images, implying poorer image quality.
4.3. Experimental Results
The experiment used 300 images with a resolution of 256 × 256 from the CelebA-HQ dataset, which were not involved in training. The test images were generated by combining the original images with masked images. The masked images came from the test section of the mask dataset provided by Liu et al., along with 25% central masks. The masks were randomly distributed with coverage proportions of 10–20%, 20–30%, 30–40%, 40–50%, 50–60%, and 25% for the central mask. The experimental results were compared and analyzed against the CA, EC, and LaFIn face inpainting networks [
19,
20,
21].
CA (Contextual Attention) is an image inpainting method based on a Contextual Attention mechanism that repairs the missing parts of an image by capturing its contextual information. EC (Edge Connect) is a facial image inpainting technique based on edge information that helps the network more accurately restore the details and contours of an image by incorporating edge conditions during the inpainting process. LaFIn (Latent Face Inpainting) is a face image inpainting method based on latent space that maps face images into latent space and utilizes deep generative models to learn the latent features of face images, generating more natural and high-quality inpainted images.
Figure 6 shows the face restoration process used in this study. The original image (a) and the masked image (b) are multiplied using the Hadamard product to obtain the occluded image (c). The feature point prediction module first predicts the feature points of the occluded image, resulting in predicted feature points (d). Then, the restoration module performs the restoration of the image generated by combining the predicted feature points with the occluded image.
Figure 7 shows the inpainting results of the model on facial frontal images with four different mask coverage percentages. In the figure, the first row shows the mask covering 30–40% of the image, the second row 40–50%, and the third row 50–60%, and the fourth row is a central mask with 25% coverage.
From
Figure 7, it can be seen that all of the networks—CA, EC, LaFIn, and the improved face inpainting network—are able to complete face inpainting under partial occlusion. Among them, the CA algorithm only utilizes the unoccluded areas to inform the inpainting of the occluded areas, which leads to a lack of coherence in the semantic structure, resulting in obvious deformations in the inpainted image. For example, the mouth in the first and third rows; the left eye in the second row; and the eyes, nose, and mouth in the fourth row are either fully or mostly occluded, causing a large discrepancy between the inpainted face and the original image, with unnatural facial expressions. The EC algorithm introduces edge conditions to restore facial details and contours, providing stronger inpainting capability than the CA network, and is able to reconstruct the overall facial structure in various occlusion cases. However, the repaired expressions still show considerable differences from the original image. For example, the nose and mouth in the first row; the left eye in the second row; and the nose, mouth, and facial contours in the third and fourth rows show noticeable differences in the topological structure of the facial features compared to the original image. LaFIn and the improved face inpainting network outperform CA and EC in terms of inpainting results. Compared with LaFIn, the improved face inpainting network demonstrates better results in restoring facial feature shapes and expressions, and provides smoother transitions between inpainted areas. For example, the mouth and eye features in the first row are more realistic and clearer, and the eyes in the fourth row are closer to those in the original image, with smoother transitions around the mouth.
Figure 8 shows the inpainting results of the model on facial side-view images with four different mask coverage percentages. In the figure, the first row shows a mask covering 30–40% of the image, the second row 40–50%, and the third row 50–60%, and the fourth row is a central mask with 25% coverage.
From
Figure 8, it can be seen that under partial occlusion of the face, CA, EC, and LaFIn and the improved face inpainting network can all successfully restore the facial image. Among them, the CA and EC algorithms show deficiencies in obtaining semantic information from the image, leading to blurry inpainted regions with significant structural differences from the original image. LaFIn and the improved face inpainting network achieve better results, with the latter producing more realistic and natural restorations, especially in terms of facial expressions and feature repair. For example, in the first and second rows with CA, and the third row with CA, EC, and LaFIn inpainting the occluded eyes, nose, and mouth, there is obvious blurriness, and the repair results are not smooth and natural. In the fourth row, CA and EC’s repair of the eyes and nose shows noticeable fuzziness and unnatural results. The inpainting results from the improved face inpainting network, while showing some differences from the original image, are clearer compared to those from CA, EC, and LaFIn, and the repair of facial features is more realistic and natural, being closest to the original image.
5. Discussion
Table 3 shows the quantitative comparison of the PSNR, SSIM, and FID for CA, EC, LaFIn, and the improved face inpainting network under different mask coverage percentages. The values in the table represent the average evaluation results of the generated images in the test set. From the data in
Table 3, it can be observed that the improved facial restoration network achieves higher PSNR and SSIM values under various mask occlusions compared to CA, EC, and LaFIn, indicating that the improved facial restoration network delivers higher-quality facial image restoration. Additionally, the FID values of the improved facial restoration network are lower than those of CA, EC, and LaFIn under various mask occlusions, demonstrating that the distribution of the restored facial images is closer to that of the real images, further confirming the superior restoration performance of the improved network.
Table 4 shows the quantitative comparison analysis of the PSNR, SSIM, and FID between the improved face inpainting network and CA, EC, and LaFIn under different mask coverage percentages.
From the data in the table, it can be seen that the EC network outperformed the CA network in terms of the PSNR, SSIM, and FID, while the LaFIn network had better objective metrics than both CA and EC. Among all of the algorithms, the improved face inpainting network achieved the highest PSNR and SSIM, along with the lowest FID value. Compared to the CA network, under various occlusions, the improved face inpainting network’s PSNR increased by up to 24.47%, its SSIM improved by 24.39%, and its FID decreased by 81.1%. Compared to the EC network, the PSNR increased by up to 7.89%, the SSIM improved by 10.34%, and the FID decreased by 27.2%. Compared to the LaFIn network, the PSNR improved by up to 3.4%, the SSIM increased by 3.31%, and the FID decreased by 9.19%. These experiments demonstrate that the improved face inpainting network achieves better restoration results.
The Shapiro–Wilk test indicated that at a significance level of α = 0.05, the SSIM values did not follow a normal distribution (p = 0.03). The Kruskal–Wallis test yielded p = 0.012 (p < 0.05), demonstrating statistically significant differences in the SSIM among CA, EC, LaFIn, and the improved network. A post hoc analysis using Dunn’s test with Bonferroni correction demonstrated statistically significant improvements in our proposed network over EC (p = 0.015), CA (p = 0.008), and LaFIn (p = 0.043).
Table 5 presents the ablation study of different structures. From the table, it can be observed that both the long short-term attention layer (LSTA) and facial landmark guidance (FLG) are beneficial for improving the performance of the facial restoration network.
From the above discussion, it can be seen that the improved facial restoration network achieves better restoration results under both free-form occlusion and 25% center occlusion compared to the CA, EC, and LaFIn networks. However, the restoration results under large-area occlusion still exhibit some differences in their details compared to the original images.
6. Conclusions
The face has significant symmetry, and symmetry, as has been previously demonstrated, has guiding significance in facial restoration. This study constructs an improved face inpainting network with occlusion, consisting of a lightweight facial landmark prediction network and a GAN-based face inpainting network. The facial landmark prediction network is improved based on the MobileNetV3-small architecture and trained to predict facial landmarks under different occlusion conditions. The improved occluded-face inpainting network is composed of a U-Net-based generator and a Patch-GAN-based discriminator. Repair tests were conducted on face images with free occlusion coverage, including 10–20%, 30–40%, 40–50%, and 50–60%, as well as a 25% center mask. The experiments demonstrate that the improved occluded-face inpainting network achieves the highest PSNR and SSIM, with the lowest FID value, and provides better restoration results under various occlusions, producing face images that are more natural and clear, and closer to the original image. The improved facial restoration network, incorporating facial landmark guidance and a U-Net-based generator architecture, contains more computational parameters compared to the CA and EC networks. While achieving enhanced performance, this design inevitably increases computational costs. Significant FID metric degradation occurs when processing large-area occlusions, primarily due to insufficient availability of facial information to guide repair.
The improved facial restoration network enhances the inpainting effect for occluded faces, thereby increasing the accuracy of facial recognition systems and improving the reliability of identity verification systems. In security surveillance systems, it can assist in restoring damaged or occluded-face images. In augmented reality applications, it can generate more realistic virtual avatars, enabling more natural human–computer interaction. In the future, facial restoration can develop towards dynamic scenes, multimodal fusion, and personalized restoration. With advancements in deep learning and multimodal technologies, facial restoration techniques will be widely applied in more fields, becoming one of the important research directions in the field of artificial intelligence.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}