
Recovery-Enhanced Image Steganography Framework with Auxiliary Model Based on Invertible Neural Networks
Abstract
1. Introduction
- We present a novel multi-image steganography network based on an invertible neural network for high-quality recovery.
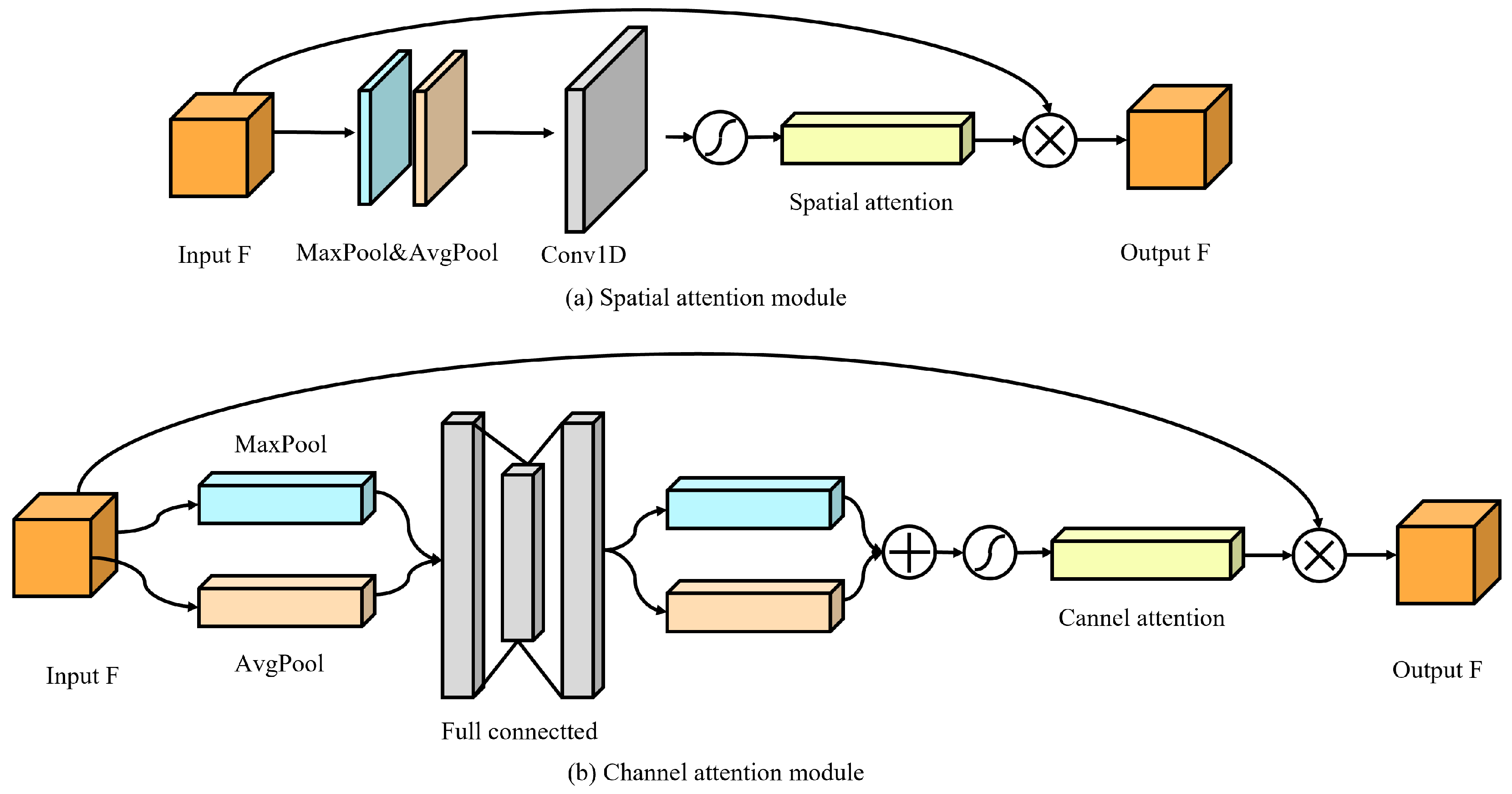
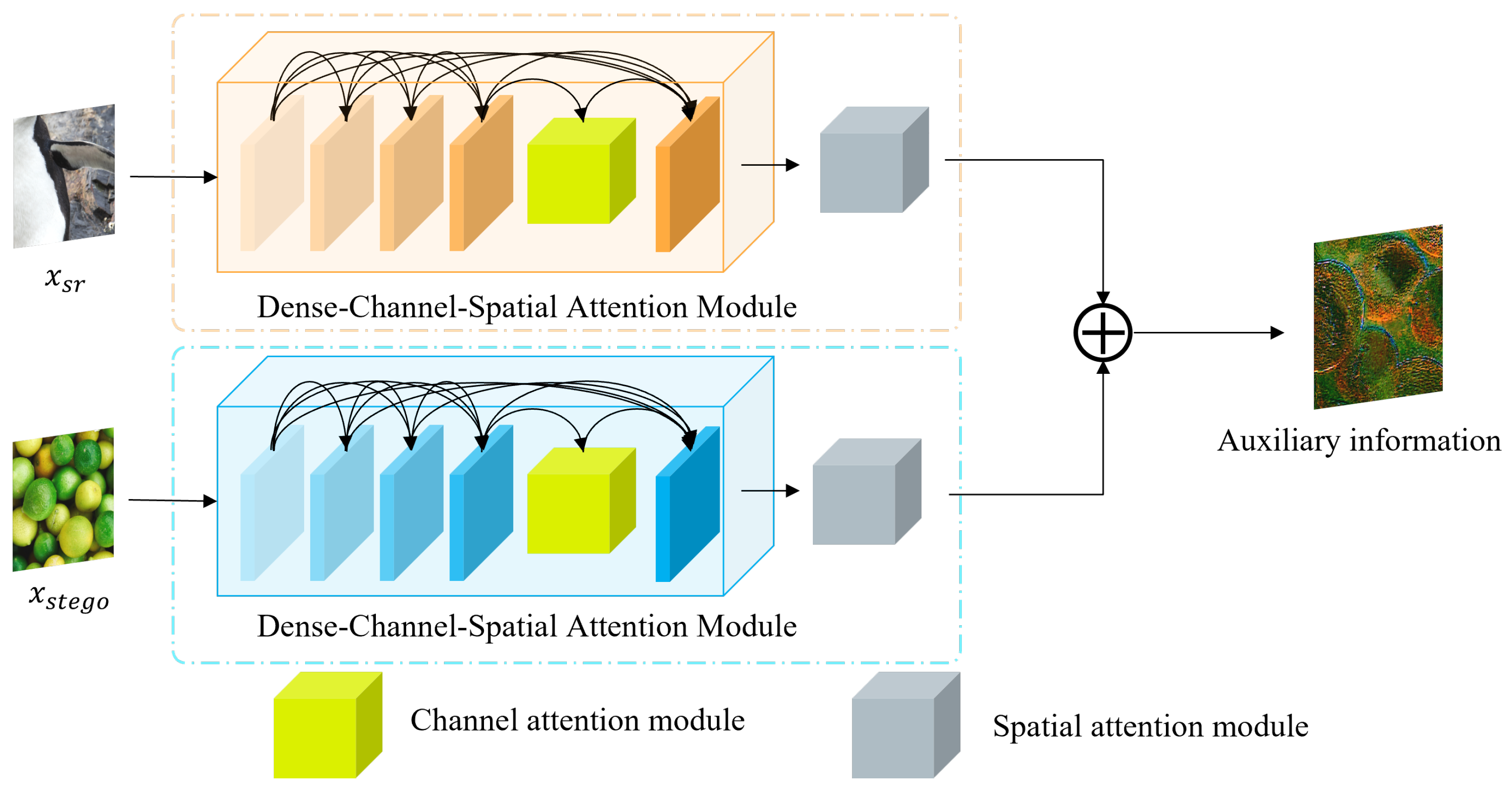
- We propose a Dense–Channel–Spatial Attention Module (DCSAM)-driven auxiliary model, employing cross-level feature fusion and dynamic weight allocation, to recover information lost during the hiding process and to provide auxiliary information for the second revealing process.
- We propose a multi-stage progressive training strategy to enhance model stability and reduce interference between the invertible neural network and the auxiliary model. This strategy prioritizes training with original secret images for rapid initial convergence, then gradually transitions to recovered images for dynamic adaptation, culminating in alternate fine-tuning for efficient fusion of the two models.
- We introduce a multi-scale wavelet loss function to restrict the multi-dimensional feature consistency of the cover image and stego image in the low-frequency approximation component and high-frequency detail component, thereby enhancing the security of the hiding process.
2. Related Works
2.1. Image Steganography
2.2. Invertible Neural Network
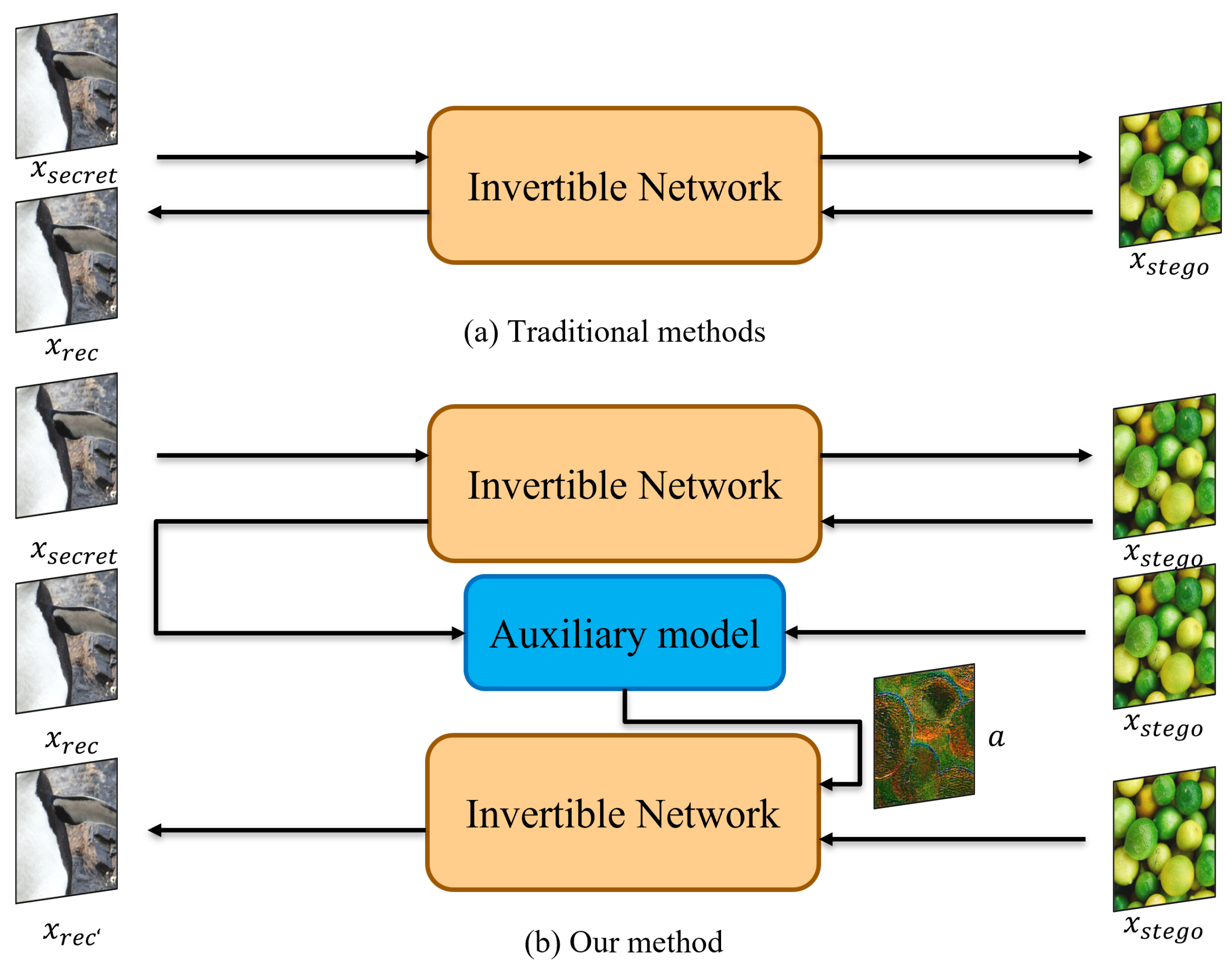
3. Proposed Method
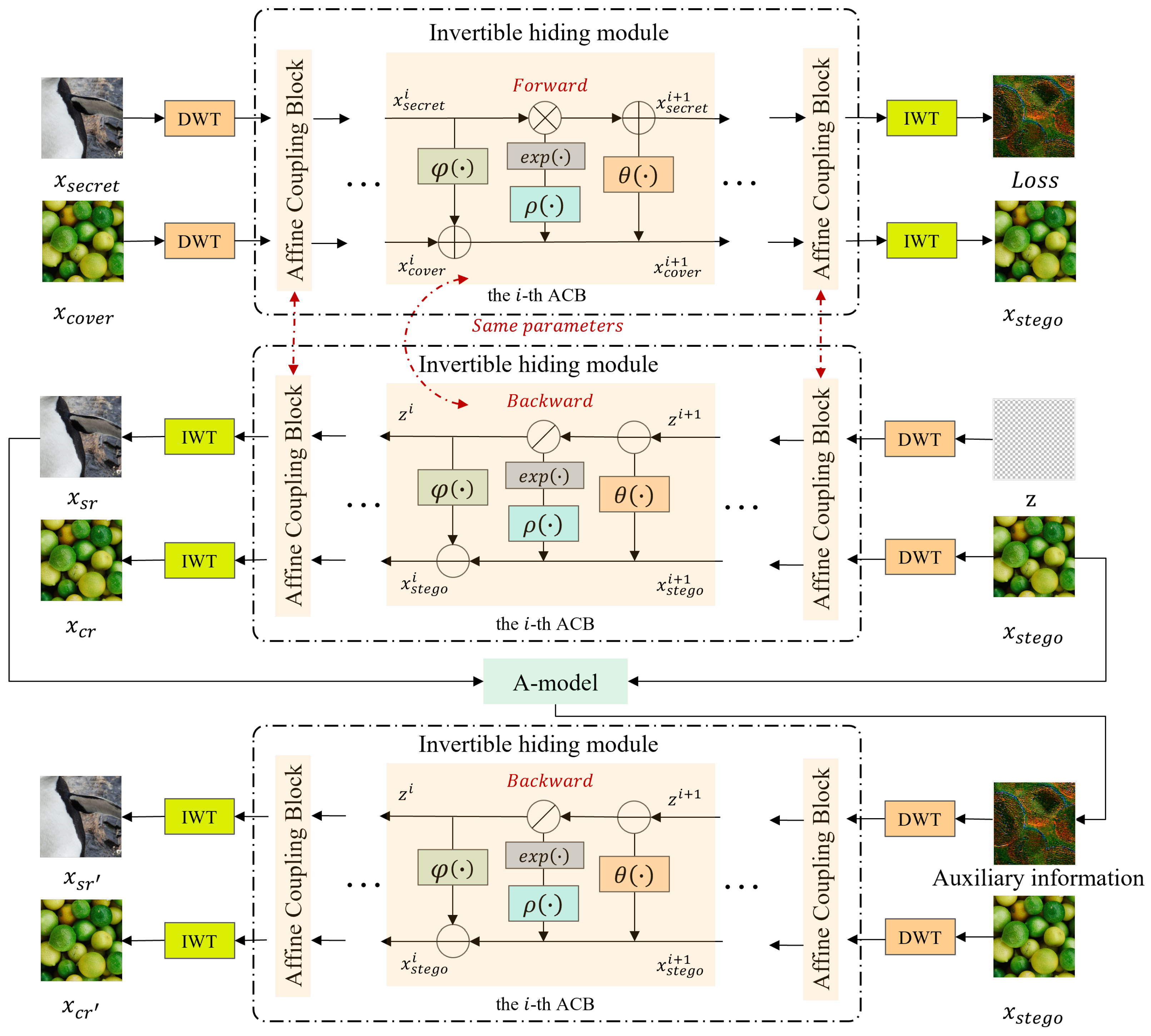
3.1. Framework
3.2. Invertible Concealing and Revealing Process
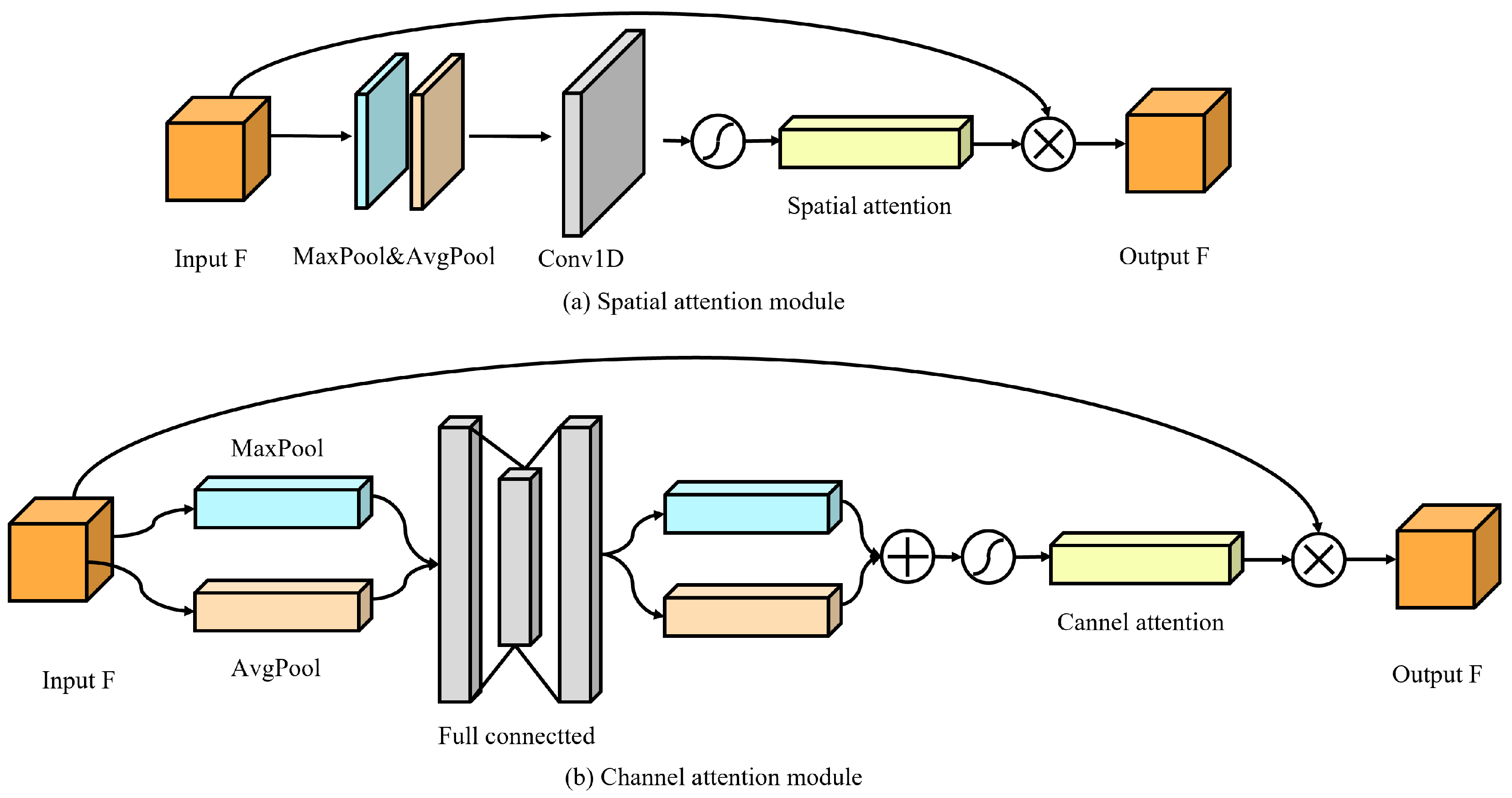
3.3. A-Model (The Auxiliary Model)
3.4. Training Strategy
3.5. Loss Function
- Concealing loss. The forward concealing process aims to hide into to generate a stego image . The stego image is required to be indistinguishable from the cover image . Toward this goal, we use mean square error (MSE) to measure the difference between the cover and stego image. The concealing loss is defined as follows:where is equal to , with indicating the invertible neural network.
- Multi-scale wavelet loss. To improve the security of steganography, we introduce a multi-scale wavelet loss function. In wavelet decomposition, low-frequency subbands (LL) usually contain the main structural information of the image, while high-frequency subbands (LH, HL, HH) contain the details of the image. Although the low-frequency subband loss calculation is effective in measuring the major structural differences between two images, it is significantly inadequate in capturing the detailed changes in the images. To achieve this, we introduce the Wasserstein distance in the high-frequency subband, which is a measure of the difference between two probability distributions and can effectively capture changes in image details. Therefore, the multi-scale wavelet loss function combines the mean square error (MSE) of the low-frequency subband with the Wasserstein distance of the high-frequency subband. Specific definitions are as follows:where L represents the number of wavelet decomposition layers and the parameters and are weights that balance the contributions of the low-frequency and high-frequency losses, respectively. Suppose that indicates the operation of extracting low-frequency subbands after wavelet decomposition; and are calculated as follows:where represents the set of all possible joint distributions of the distributions i and j combined, and , .
- Revealing loss. The revealing loss is used to encourage the recovered secret image to resemble the original secret image in the backward revealing process. We also use the MSE to denote the mean square error between the recovered secret image and the corresponding original secret image . So, we define the revealing loss as follows:
- Auxiliary-model loss. The auxiliary-model loss is used to encourage the auxiliary information a to resemble the lost information r, so as to help the neural network model to better recover the secret image. Similarly, we use the MSE and Wasserstein distance to denote the mean square error between the loss information r and the auxiliary information a. So, we define the revealing loss as follows:
- Total loss function. Since our method requires three-step training, there are three total loss functions.The first total loss function is a weighted sum of concealing loss , revealing loss , and multi-scale wavelet loss as follows:Here, , , and are weights for balancing different loss terms. In this training process, we set .Then, the second total loss function is a weighted sum of the first revealing loss , auxiliary-model loss , and second revealing loss , as follows:Here, , , and are weights for balancing different loss terms. In this training process, we set .Then, the third total loss function is a weighted sum of concealing loss , the first revealing loss , multi-scale wavelet loss , auxiliary-model loss , and the second revealing loss , as follows:Here, , , , , , and are weights for balancing different loss terms. In this training process, is set to 2, while others are set to 1. The overall training process of our proposed method is detailed in Algorithm 1.
| Algorithm 1 The Training Process of Our proposed method for Single Image Hiding |
|
4. Experiments
4.1. Datasets
4.2. Implementation Details
4.3. Evaluation Metrics
5. Results and Discussion
5.1. Single-Image Hiding
- Quantitative results: Table 2 compares the numerical results of our model with HiDDeN [19], Baluja [20], and HiNet [21]. Table 2 presents a comprehensive comparison of our proposed model against existing state-of-the-art methods, evaluating performance across all relevant metrics for both the cover/stego image pairs and the secret/recovery image pairs. The results clearly demonstrate the superior performance of our approach.Specifically, our model achieves substantial improvements in PSNR for the crucial secret/recovery image pairs. We observe significant gains of 4.13 dB, 3.30 dB, and 3.23 dB on the challenging DIV2K, COCO, and ImageNet datasets, respectively. These improvements highlight the effectiveness of our model in accurately extracting the hidden secret image from the stego image.Furthermore, our model also yields notable PSNR improvements for the cover/stego image pairs, with gains of 1.25 dB, 1.62 dB, and 0.8 dB observed across the aforementioned datasets. These results indicate that our model is capable of hiding the secret image while maintaining high visual quality in the stego image.Consistent with the PSNR trends, we observe similar performance enhancements in SSIM across all datasets and image pairs. This further validates the effectiveness of our proposed approach in preserving structural information during the hiding and revealing processes. These results underscore the efficacy of our proposed multi-scale wavelet loss function, the incorporation of auxiliary models, and the design of a tailored training strategy. By jointly optimizing these components, our model effectively enhances both the hiding and revealing performance, leading to significant improvements in image quality and secret image recovery accuracy.
- Qualitative Results: Figure 6 presents a visual comparison of stego and recovered images generated by our proposed model and the HiNet method. Due to space constraints and the conceptual similarities between HiNet variants, we focus our visualization comparison on the superior performing HiNet model evaluated on the DIV2K dataset. Our method demonstrates near-perfect secret image concealment, exhibiting negligible visual discrepancies between cover and stego images. Furthermore, the accuracy of the recovery process is evident in the near-black residual map, indicating minimal information loss. In contrast, HiNet exhibits noticeable texture-copying artifacts, particularly prominent in smooth image regions. These artifacts manifest as distortions and color inconsistencies in both the stego and recovered images. Our model demonstrably outperforms HiNet in both recovery accuracy and color fidelity, effectively mitigating such artifacts and preserving image integrity throughout the hiding and extraction processes.Figure 7 shows the comparison between our model and the enlarged and recovered loaded images generated by the HiNet method. By zooming in, you can clearly see the difference in the processing of image details between the two methods. Here, we chose a more complex pair of carrier/secret images for comparison. It is clear that although there is some distortion in the residual image of both, our model performs better in detail retention. Specifically, our model is better able to retain the texture and edge information of the image, whereas the HiNet method is blurred on these key details. This shows that our model has stronger robustness and higher fidelity when processing complex images. For example, our model employs multi-scale wavelet loss, which allows the model to learn representations of different frequencies, thus preserving fine detail. In addition, our auxiliary model also introduces the attention mechanism, which can help the model to better focus on the important areas in the image, so as to better retain the details of these areas in the generation of auxiliary information, so as to obtain higher recovered image quality.
- Computational efficiency analysis: On the NVIDIA GeForce RTX4060 GPU (8 GB memory), the end-to-end processing speed of a single image (including steganography generation and secret recovery) was tested and compared with HiNet. The results show that the average processing time for the HiNet method is ms, corresponding to a real-time frame rate of FPS = 2.8. In contrast, the processing time of the proposed method is ms, corresponding to an FPS of 1.58. Although the introduction of an auxiliary module and a secondary recovery mechanism resulted in an increase in inference time of and a decrease in FPS of , the proposed approach achieved a better balance between performance and complexity.Specifically, the total number of parameters for the proposed method is 4.30 M (4.05 M for the main INN module and 0.25 M for the auxiliary model), with the auxiliary model accounting for only of the total parameters (). Therefore, the total number of parameters is comparable to HiNet (4.05 M). In addition, the peak memory usage for a single inference is 3.1 GB, which is an increase of compared to HiNet’s 2.8 GB. However, on the same test set, the proposed method improves the PSNR of the key secret/recovered image pairs by 4.13 dB, significantly enhancing the quality of image recovery.In summary, although the proposed method is slightly lower in inference efficiency compared to HiNet, it successfully enhances the model’s performance by introducing auxiliary modules and a secondary recovery mechanism, while maintaining a low computational complexity.
5.2. Multi-Image Hiding
- Quantitative results: Table 3 compares the numerical results of our model with ISN [22], DeepMIH [24], and iSCMIS [25]. Due to the presence of a second reveal phase, which increases complexity during model training, more GPU memory is required, which our experimental device (GeForce RTX4060; 8GB) cannot support. To accomplish the task of hiding multiple images on our device, we reduced the size of the input image. Thus, some of our results are naturally slightly less favorable than DeepMIH and iSCMIS.As shown in Table 3, our model significantly outperforms the previous two methods across all four metrics for the secret/recovery-1, cover/stego-2, and secret/recovery-2 image pairs, with a slight exception in the cover/stego-2 comparison with iSCMIS. Specifically, mirroring the single-image hiding results, our method achieves substantial PSNR gains for the secret/recovery-1 image pair, improving upon the second-best performing method by 0.92 dB, 0.56 dB, and 0.55 dB on the DIV2K, COCO, and ImageNet datasets, respectively. Similarly, for the secret/recovery-2 image pair, we observe consistent PSNR improvements of approximately 1 dB across all three datasets. However, for the cover/stego-2 image pairs, our model’s PSNR is slightly lower than iSCMIS by 0.63 dB, 0.57 dB, and 0.50 dB on the DIV2K, COCO, and ImageNet datasets, respectively. This slight decrease in stego image quality for the multiple-image hiding scenario warrants further investigation. In addition, the SSIM indicator showed a similar improvement trend in secret image recovery, while the performance of hidden image quality decreased slightly in the case of multiple hiding. This comprehensive analysis of PSNR and SSIM metrics demonstrates the effectiveness of our approach in recovering hidden images, while also highlighting areas of potential improvement for maintaining steganographic image fidelity when embedding multiple secrets.
- Qualitative results: Figure 8 compares the stego and recovery images of our model and DeepMIH. Similarly, due to space constraints and model similarities, here we only compare the visualization with the better DeepMIH [24] on DIV2K (iSCMIS is not compared because its code is not publicly available). As shown in the figure, the visual difference between the cover and stego images produced by our method is nearly imperceptible, demonstrating successful concealment of the secret image. Furthermore, our method recovers the secret image more accurately compared to DeepMIH. On the DIV2K dataset, even at 20× magnification, the visual discrepancies between cover/stego and secret/recovered image pairs are negligible, validating the effectiveness of our approach. However, as observed in the quantitative analysis, the visual errors become more pronounced on the COCO and ImageNet datasets, which is consistent with the trend observed in the PSNR and SSIM results. This suggests that while our method performs exceptionally well on high-quality datasets like DIV2K, its performance may be more sensitive to the increased complexity and variability present in datasets like COCO and ImageNet.
5.3. Security Analysis
5.4. Ablation Study
- A-modelAs shown in Table 4, the A-model plays an important role in improving the performance of our method. Specifically, as we can see from the first and second rows in Table 4, the PSNR value with the A-model increases by 1.83 dB and 1.29 dB for cover/stego and secret image/recovery pairs, respectively. The possible reason is that the A-model can successfully help the model to better recover the secret image, and the process of reducing the loss can also make it more effective for information hiding.
- Training strategyWe can see from the second and third rows of Table 4 that for single-image hiding, using the training strategy improves PSRN by about 2 dB on the cover/stego and secret/recovered image pair. We have a similar effect on the hiding of multi-images. It fully demonstrates the effectiveness of the training strategy. The possible reason is that the multi-stage training strategy can successfully help the invertible neural network model and the A-model to do their respective jobs and finally perform better information concealing and revealing together.
- Multi-scale wavelet loss functionWe can see from the third and last rows of Table 4 that the application of the multi-scale wavelet loss function in single-image hiding tasks results in a significant improvement in PSNR by approximately 2 dB for the cover/stego image pair. This enhancement is also observed in the secret/recovered image pair, where the PSNR is similarly elevated by around 1 dB. The likely reason for this enhancement is that the multi-scale wavelet loss function effectively constrains the differences between the cover and stego images, ensuring that the stego image remains similar to the original cover image.
6. Conclusions
- Enhancing Hiding Capacity via Adversarial Training: To overcome the current limitations in hiding capacity imposed by the auxiliary model’s training objective, we propose integrating adversarial training techniques. This approach aims to fortify the concealing process by training the model to generate steganographic data that are increasingly indistinguishable from cover data, thus improving its resilience against steganalysis.
- Enhancing robustness through noise injection technology: Noise injection can simulate the noise environment in actual channels during the training phase, allowing the model to learn under diverse noise conditions, thereby enhancing its adaptability to noise. Introducing this method is expected to significantly improve the model’s performance and reliability in complex real-world environments, providing a more promising solution for the development of image steganography technology.
- Extending to high-value domains: The inherent flexibility of our framework lends itself to adaptation within other sensitive domains. A particularly compelling direction is medical image steganography, where the imperative to safeguard patient data within medical images (e.g., MRI scans) while preserving their diagnostic integrity is paramount.
- Extending this framework to video steganography: This extension takes advantage of the properties of video data to hide information. Unlike methods that directly embed data in the pixel domain, video steganography converts video frames into other forms (for example, via a DCT or a wavelet transform) and then changes or emphasizes secret information in the converted data.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Johnson, N.F.; Jajodia, S. Exploring steganography: Seeing the unseen. Computer 1998, 31, 26–34. [Google Scholar] [CrossRef]
- Marvel, L.; Boncelet, C.; Retter, C. Spread spectrum image steganography. IEEE Trans. Image Process. 1999, 8, 1075–1083. [Google Scholar] [CrossRef]
- Pevný, T.; Filler, T.; Bas, P. Using High-Dimensional Image Models to Perform Highly Undetectable Steganography. Lect. Notes Comput. Sci. 2010, 6387, 161–177. [Google Scholar]
- Holub, V.; Fridrich, J. Designing Steganographic Distortion Using Directional Filters. In Proceedings of the IEEE Workshop on Information Forensic and Security, Costa Adeje, Spain, 2–5 December 2012. [Google Scholar]
- Holub, V.; Fridrich, J.; Denemark, T. Universal distortion function for steganography in an arbitrary domain. Eurasip J. Inf. Secur. 2014, 2014, 1. [Google Scholar] [CrossRef]
- Chan, C.K.; Cheng, L.M. Hiding data in images by simple LSB substitution. Pattern Recognit. 2004, 37, 469–474. [Google Scholar] [CrossRef]
- Tsai, P.; Hu, Y.C.; Yeh, H.L. Reversible image hiding scheme using predictive coding and histogram shifting. Signal Process. 2009, 89, 1129–1143. [Google Scholar] [CrossRef]
- Wu, D.C.; Tsai, W.H. A steganographic method for images by pixel-value differencing. Pattern Recognit. Lett. 2003, 24, 1613–1626. [Google Scholar] [CrossRef]
- Pan, F.; Li, J.; Yang, X. Image steganography method based on PVD and modulus function. In Proceedings of the 2011 International Conference on Electronics, Communications and Control (ICECC), Ningbo, China, 9–11 September 2011. [Google Scholar]
- Hameed, M.A.; Abdel-Aleem, O.A.; Hassaballah, M. A secure data hiding approach based on least-significant-bit and nature-inspired optimization techniques. J. Ambient. Intell. Humaniz. Comput. 2023, 14, 4639–4657. [Google Scholar] [CrossRef]
- Fridrich, J. Statistically undetectable jpeg steganography: Dead ends challenges, and opportunities. In Proceedings of the 9th Workshop on Multimedia & Security, Dallas, TX, USA, 20–21 September 2007. [Google Scholar]
- Sallee, P. Model-Based Steganography; Springer: Berlin/Heidelberg, Germany, 2003. [Google Scholar]
- Provos, N.; Honeyman, P. Hide and seek: An introduction to steganography. IEEE Secur. Priv. 2003, 1, 32–44. [Google Scholar] [CrossRef]
- Hetzl, S.; Mutzel, P. A Graph–Theoretic Approach to Steganography. In Proceedings of the Communications & Multimedia Security, Ifip Tc-6 Tc-11 International Conference, CMS, Salzburg, Austria, 19–21 September 2005. [Google Scholar]
- Chang, C.C.; Lin, C.C.; Tseng, C.S.; Tai, W.L. Reversible hiding in DCT-based compressed images. Inf. Sci. 2007, 177, 2768–2786. [Google Scholar] [CrossRef]
- Husien, S.; Badi, H. Artificial neural network for steganography. Neural Comput. Appl. 2015, 26, 111–116. [Google Scholar] [CrossRef]
- Kandi, H.; Mishra, D.; Gorthi, S.R.S. Exploring the learning capabilities of convolutional neural networks for robust image watermarking. Comput. Secur. 2017, 65, 247–268. [Google Scholar] [CrossRef]
- Mun, S.M.; Nam, S.H.; Jang, H.U.; Kim, D.; Lee, H.K. A Robust Blind Watermarking Using Convolutional Neural Network. arXiv 2017, arXiv:abs/1704.03248. [Google Scholar]
- Zhu, J.; Kaplan, R.; Johnson, J.; Fei-Fei, L. HiDDeN: Hiding Data With Deep Networks. In Proceedings of the Computer Vision—ECCV 2018: 15th European Conference, Munich, Germany, 8–14 September 2018; pp. 682–697. [Google Scholar] [CrossRef]
- Baluja, S. Hiding Images in Plain Sight: Deep Steganography. In Proceedings of the Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Jing, J.; Deng, X.; Xu, M.; Wang, J.; Guan, Z. HiNet: Deep Image Hiding by Invertible Network. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 4713–4722. [Google Scholar] [CrossRef]
- Lu, S.P.; Wang, R.; Zhong, T.; Rosin, P.L. Large-capacity Image Steganography Based on Invertible Neural Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 19–25 June 2021. [Google Scholar]
- Fang, H.; Qiu, Y.; Chen, K.; Zhang, J.; Zhang, W.; Chang, E.C. Flow-Based Robust Watermarking with Invertible Noise Layer for Black-Box Distortions. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; Volume 37, pp. 5054–5061. [Google Scholar] [CrossRef]
- Guan, Z.; Jing, J.; Deng, X.; Xu, M.; Jiang, L.; Zhang, Z.; Li, Y. DeepMIH: Deep invertible network for multiple image hiding. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 372–390. [Google Scholar] [CrossRef]
- Li, F.; Sheng, Y.; Zhang, X.; Qin, C. iSCMIS: Spatial-Channel Attention Based Deep Invertible Network for Multi-Image Steganography. IEEE Trans. Multimed. 2023, 26, 3137–3152. [Google Scholar] [CrossRef]
- Wang, T.; Cheng, H.; Liu, X.; Xu, Y.; Chen, F.; Wang, M.; Chen, J. Lossless image steganography: Regard steganography as super-resolution. Inf. Process. Manag. 2024, 61, 103719. [Google Scholar] [CrossRef]
- ur Rehman, A.; Rahim, R.; Nadeem, S.; ul Hussain, S. End-to-End Trained CNN Encoder-Decoder Networks for Image Steganography. In Proceedings of the Computer Vision—ECCV 2018 Workshops, Munich, Germany, 8–14 September 2018; pp. 723–729. [Google Scholar] [CrossRef]
- Weng, X.; Li, Y.; Chi, L.; Mu, Y. High-Capacity Convolutional Video Steganography with Temporal Residual Modeling. In Proceedings of the 2019 on International Conference on Multimedia Retrieval, Ottawa, ON, Canada, 10–13 June 2019. [Google Scholar]
- Baluja, S. Hiding Images Within Images. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 1685–1697. [Google Scholar] [CrossRef]
- Zheng, Z.; Hu, Y.; Bin, Y.; Xu, X.; Yang, Y.; Shen, H.T. Composition-Aware Image Steganography Through Adversarial Self-Generated Supervision. IEEE Trans. Neural Netw. Learn. Syst. 2023, 34, 9451–9465. [Google Scholar] [CrossRef]
- Yao, Y.; Wang, J.; Chang, Q.; Ren, Y.; Meng, W. High invisibility image steganography with wavelet transform and generative adversarial network. Expert Syst. Appl. 2024, 249, 123540. [Google Scholar] [CrossRef]
- Hu, X.; Fu, Z.; Zhang, X.; Chen, Y. Invisible and Steganalysis-Resistant Deep Image Hiding Based on One-Way Adversarial Invertible Networks. IEEE Trans. Circuits Syst. Video Technol. 2024, 34, 6128–6143. [Google Scholar] [CrossRef]
- Dinh, L.; Krueger, D.; Bengio, Y. NICE: Non-linear Independent Components Estimation. arXiv 2014, arXiv:1410.8516. [Google Scholar]
- Dinh, L.; Sohl-Dickstein, J.; Bengio, S. Density estimation using Real NVP. arXiv 2016, arXiv:1605.08803. [Google Scholar]
- Kingma, D.P.; Dhariwal, P. Glow: Generative Flow with Invertible 1x1 Convolutions. arXiv 2018, arXiv:1807.03039. [Google Scholar]
- Van der Ouderaa, T.F.A.; Worrall, D.E. Reversible GANs for Memory-efficient Image-to-Image Translation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Xiao, M.; Zheng, S.; Liu, C.; Wang, Y.; He, D.; Ke, G.; Bian, J.; Lin, Z.; Liu, T.Y. Invertible Image Rescaling. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; pp. 126–144. [Google Scholar] [CrossRef]
- Wang, Y.; Xiao, M.; Liu, C.; Zheng, S.; Liu, T.Y. Modeling Lost Information in Lossy Image Compression. arXiv 2020, arXiv:2006.11999. [Google Scholar]
- Xu, Y.; Mou, C.; Hu, Y.F.; Xie, J.; Zhang, J. Robust Invertible Image Steganography. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–20 June 2022; pp. 7865–7874. [Google Scholar]
- Wang, X.; Yu, K.; Wu, S.; Gu, J.; Liu, Y.; Dong, C.; Loy, C.C.; Qiao, Y.; Tang, X. ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks; Springer: Cham, Switzerland, 2018. [Google Scholar]
- Agustsson, E.; Timofte, R. NTIRE 2017 Challenge on Single Image Super-Resolution: Dataset and Study. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.J.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014. [Google Scholar]
- Kingma, D.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process 2004, 13, 600–612. [Google Scholar] [CrossRef]
- Boehm, B. StegExpose—A Tool for Detecting LSB Steganography. arXiv 2014, arXiv:1410.6656. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Meaning of Representation |
|---|---|
| Cover image: the image used to hide secret information | |
| Secret image: the image to be hidden | |
| Stego image: the image with secret information inside | |
| the recovered secret image from the stego image in the first revealing process | |
| the recovered secret image from the stego image in the second revealing process | |
| r | lost information: the information lost in the concealing process |
| z | auxiliary variable: the variable to help recover the image |
| a | auxiliary information: helps recover the image in the second revealing process |
| Methods | Cover/Stego Image Pair | |||||
| DIV2K | COCO | ImageNet | ||||
| PSNR (dB)↑ | SSIM↑ | PSNR (dB)↑ | SSIM↑ | PSNR (dB)↑ | SSIM↑ | |
| HiDDeN [19] | 35.21 | 0.9691 | 36.71 | 0.9876 | 34.79 | 0.9380 |
| Baluja [20] | 36.77 | 0.9645 | 36.38 | 0.9563 | 36.59 | 0.9520 |
| HiNet [21] | 46.53 | 0.9930 | 41.21 | 0.9852 | 41.60 | 0.9858 |
| Ours | 47.78 | 0.9952 | 42.83 | 0.9871 | 42.20 | 0.9884 |
| Methods | Secret/Recovery Image Pair | |||||
| DIV2K | COCO | ImageNet | ||||
| PSNR (dB)↑ | SSIM↑ | PSNR (dB)↑ | SSIM↑ | PSNR (dB)↑ | SSIM↑ | |
| HiDDeN [19] | 36.43 | 0.9696 | 37.68 | 0.9845 | 35.70 | 0.9601 |
| Baluja [20] | 35.88 | 0.9377 | 35.01 | 0.9341 | 34.13 | 0.9247 |
| HiNet [21] | 46.24 | 0.9924 | 40.10 | 0.9846 | 40.03 | 0.9807 |
| Ours | 50.37 | 0.9969 | 43.40 | 0.9881 | 43.26 | 0.9901 |
| Methods | Secret/Recovery-1 Image Pair | |||||
| DIV2K | COCO | ImageNet | ||||
| PSNR (dB)↑ | SSIM↑ | PSNR (dB)↑ | SSIM↑ | PSNR (dB)↑ | SSIM↑ | |
| ISN [22] | 37.21 | 0.9627 | 36.09 | 0.9513 | 36.01 | 0.9592 |
| DeepMIH [24] | 41.41 | 0.9801 | 36.55 | 0.9613 | 36.63 | 0.9604 |
| iSCMIS [25] | 41.75 | 0.9832 | 37.06 | 0.9646 | 37.29 | 0.9644 |
| Ours | 42.67 | 0.9880 | 37.62 | 0.9643 | 37.84 | 0.9665 |
| Methods | Cover/Stego-2 Image Pair | |||||
| DIV2K | COCO | ImageNet | ||||
| PSNR (dB)↑ | SSIM↑ | PSNR (dB)↑ | SSIM↑ | PSNR (dB)↑ | SSIM↑ | |
| ISN [22] | 40.19 | 0.9867 | 36.98 | 0.9598 | 37.20 | 0.9594 |
| DeepMIH [24] | 41.22 | 0.9838 | 37.21 | 0.9624 | 37.22 | 0.9612 |
| iSCMIS [25] | 43.01 | 0.9899 | 39.13 | 0.9773 | 39.21 | 0.9772 |
| Ours | 42.59 | 0.9865 | 38.44 | 0.9696 | 38.53 | 0.9723 |
| Methods | Secret/Recovery-2 Image Pair | |||||
| DIV2K | COCO | ImageNet | ||||
| PSNR (dB)↑ | SSIM↑ | PSNR (dB)↑ | SSIM↑ | PSNR (dB)↑ | SSIM↑ | |
| ISN [22] | 37.81 | 0.9625 | 36.86 | 0.9525 | 35.90 | 0.9620 |
| DeepMIH [24] | 42.53 | 0.9858 | 37.72 | 0.9696 | 37.83 | 0.9689 |
| iSCMIS [25] | 42.53 | 0.9836 | 37.48 | 0.9664 | 37.69 | 0.9661 |
| Ours | 43.90 | 0.9894 | 38.83 | 0.9762 | 38.98 | 0.9775 |
| A-Model | Training Strategy | Multi-Scale Wavelet Loss | Cover/Stego Image Pair | Secret/Recovery Image Pair | ||
|---|---|---|---|---|---|---|
| PSNR (dB) | SSIM | PSNR (dB) | SSIM | |||
| ✗ | ✗ | ✗ | 41.81 | 0.9775 | 46.52 | 0.9917 |
| ✔ | ✗ | ✗ | 43.64 | 0.9889 | 47.83 | 0.9936 |
| ✔ | ✔ | ✗ | 45.54 | 0.9901 | 49.65 | 0.9956 |
| ✔ | ✔ | ✔ | 47.78 | 0.9952 | 50.37 | 0.9969 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huo, L.; Wang, K.; Wei, J. Recovery-Enhanced Image Steganography Framework with Auxiliary Model Based on Invertible Neural Networks. Symmetry 2025, 17, 456. https://doi.org/10.3390/sym17030456
Huo L, Wang K, Wei J. Recovery-Enhanced Image Steganography Framework with Auxiliary Model Based on Invertible Neural Networks. Symmetry. 2025; 17(3):456. https://doi.org/10.3390/sym17030456
Chicago/Turabian StyleHuo, Lin, Kai Wang, and Jie Wei. 2025. "Recovery-Enhanced Image Steganography Framework with Auxiliary Model Based on Invertible Neural Networks" Symmetry 17, no. 3: 456. https://doi.org/10.3390/sym17030456
APA StyleHuo, L., Wang, K., & Wei, J. (2025). Recovery-Enhanced Image Steganography Framework with Auxiliary Model Based on Invertible Neural Networks. Symmetry, 17(3), 456. https://doi.org/10.3390/sym17030456