1. Introduction
In traditional machine learning, learning models are generally considered trained on a previously prepared dataset, and then provide prediction for future unseen instances. However, in some real-world applications, such a paradigm is not applicable any more. Actually, in these specifical applications, data can be received in the form of successive stream in which the data distribution may be altered with time. In such a scenario, the traditional static learning models would be invalid, as they always require both training and testing data satisfying an independent identically distributed hypothesis. In other words, for a nonstationary data stream, the learning models are required to update themselves constantly to adapt to the new data distribution. We call this learning paradigm
online learning [
1,
2] and the phenomenon of the shifting data distribution
concept drift [
3,
4,
5]. Specifically, online learning has been frequently used in many real-world applications, including activity recognition [
6], face recognition [
7], recommendation systems [
8], intrusion detection [
9], fault diagnosis [
10], and marketing analysis [
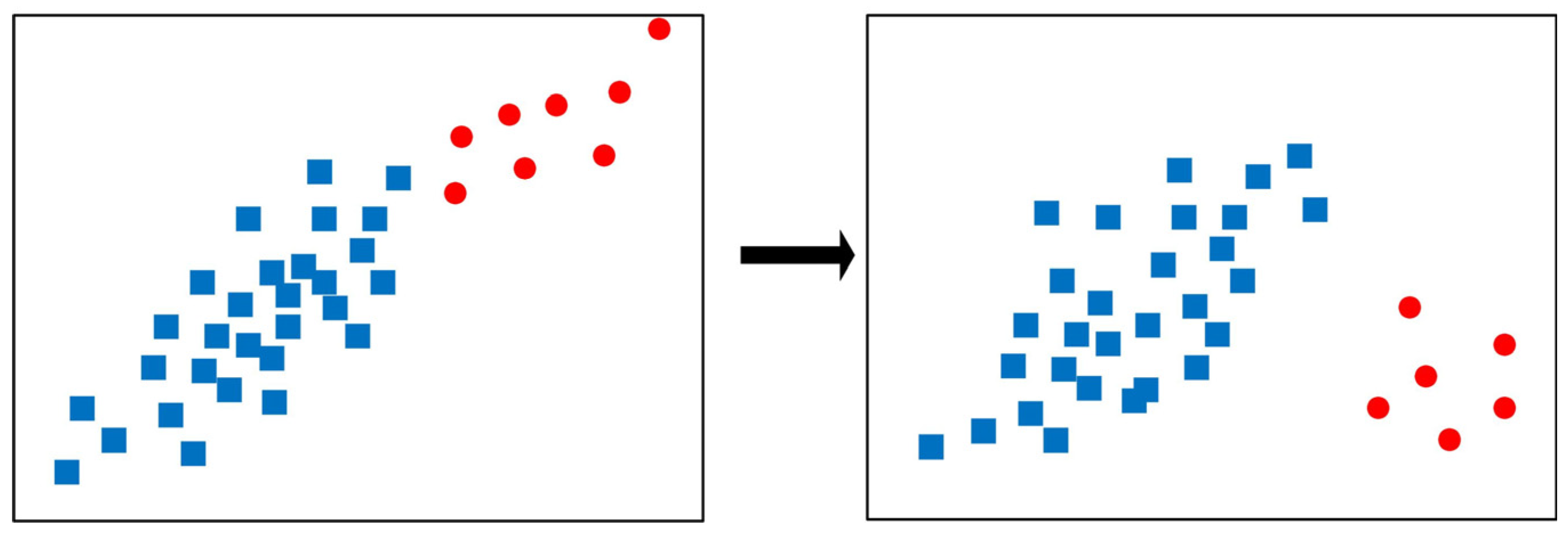
11]. As an example of concept drift, an intrusion detection system requires persistent upgrading of itself to cope with the potentially emerging new strategies of invasion developed by hackers. In this example, once the ways of intrusion vary, that means that the feature distribution or feature–class associations are simultaneously altered, causing the originally developed intrusion detection model be out of work (see
Figure 1).
As we know, learning from a data stream is significantly more difficult than learning from static data, as it needs to satisfy two basic requirements. The first one is
one pass, i.e., when new data are received, we need to immediately decide to use them or abandon them, but cannot reserve and revisit them. The
one pass requirement is proposed based on the hypothesis of that a real-world data stream is generally endless, and reserving all data will cause memory overflow.
One pass means that once useful data have been removed, they cannot be revisited to update the current model. However, there is always a lag for estimating the usefulness of data, and thus the
one pass requirement remains a critical challenge for an online learning model. The second one is that the model should adapt
concept drift emerging in a data stream, which requires detecting whether a
concept drift exists in time, and if it is yes, then the learning model is modified to make it coincide with the new data distribution. For the first requirement, it generally can be satisfied by one of two following solutions: the first one is to modify the conventional static learning algorithm to make it can rapidly tune the model parameters to adapt newly arrived data without considering whether they are useful [
12,
13], and the second one is to use ensemble learning to constantly train new learning models on newly received data and to adopt weighted voting to alleviate the effect of those models trained on useless data [
14,
15,
16]. As for the second requirement, it can be satisfied by either simultaneously adding concept drift detectors and a forgetting mechanism in single learning model adaption [
17], or adopting concept drift detectors to decide which base learners in the ensemble are useful and should be reserved, and how much weights should be assigned for them to vote, furthermore making the ensemble learning model track and adapt concept drift [
18,
19,
20]. Obviously, it would be more flexible and robust to adopt ensemble learning than a single learner in such a scenario.
There have been lots of algorithms that can be deployed in a streaming environment. However, most of them only focus on a single-label classification problem. In context of a multi-label problem, it may require considering more factors for online learning since
concept drift would become more complex [
21]. In multi-label learning, the model is required to simultaneously predict multiple class labels for an instance. For example, an image may contain several class labels, such as
cloud,
tree,
mountain,
grassland, and
animal (see
Figure 2). While the concept drift that happens in multi-label learning tasks may be associated with the alteration of the label distribution or label associations, e.g., during the World Cup, most news simultaneously covers several topics (class labels) about
sports,
the economy, and
tourism, but with the outbreak of a war, the news would be attracted to focus on the combination of several other topics of
war,
politics,
humanitarianism,
economy, and
munitions. In such a scenario, no matter the label correlation (which class labels tend to simultaneously emerge) shift or label distribution (which class labels tend to more emerge) shift, it can be regarded as the emergence of
concept drift. Therefore, when online learning meets multi-label data, the challenge would be significantly intensified.
Motivated by the issue mentioned above, we designed and developed an adaptive and just-in-time online multi-label learning algorithm named MLDME (multi-label learning with distribution matching ensemble). Specifically, it partially inherits our previously proposed DME (distribution matching ensemble) algorithm [
22]. DME first uses a Gaussian mixture model (GMM) [
23] to accurately measure the data distribution of each received data chunk. Then, it adopts the Kullback–Leibler divergence [
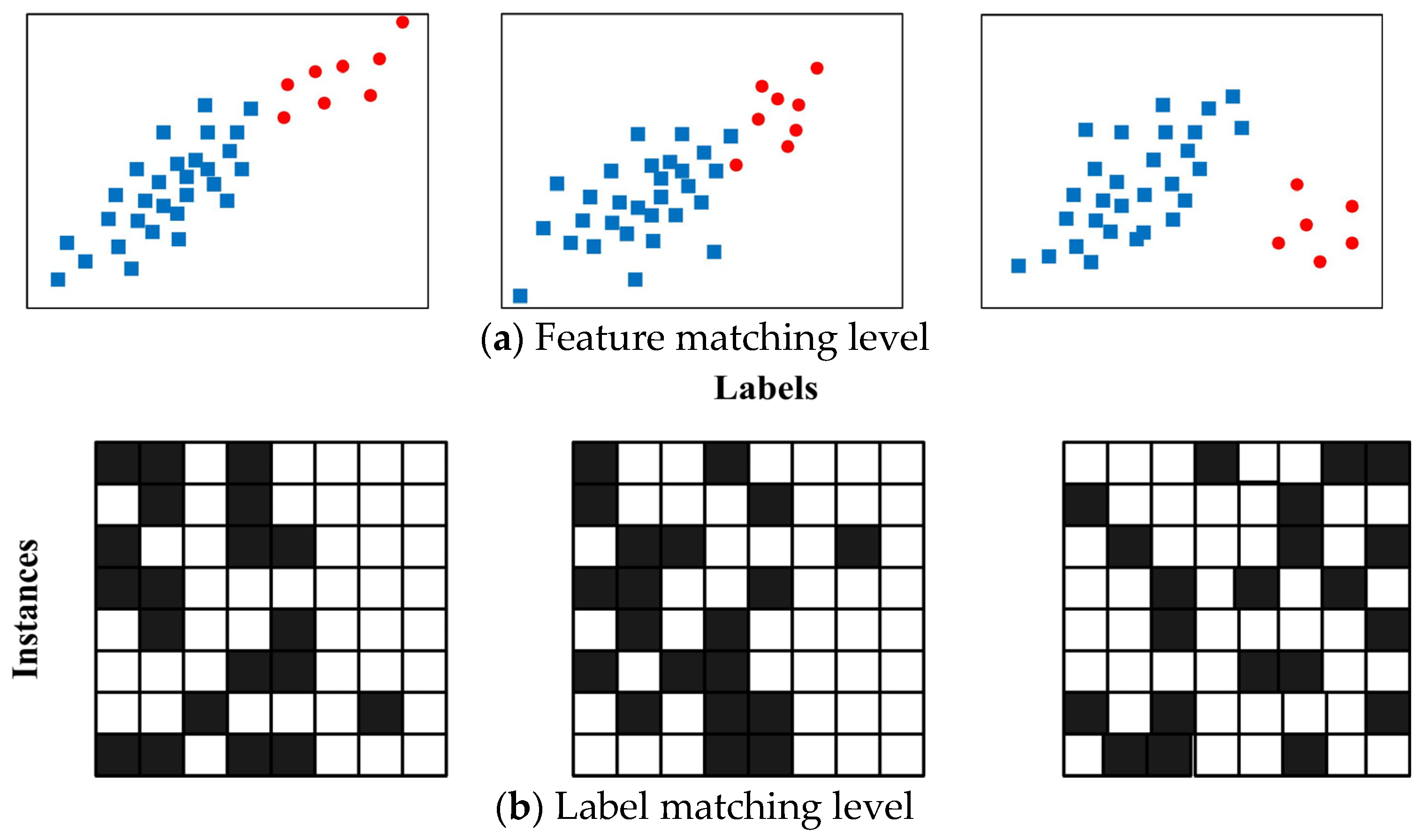
24] to detect the feature matching level (feature distribution similarity between two data chunks, see
Figure 3a) between each old data chunk and the newest received data chunk. Furthermore, it takes advantage of the feedback feature matching level to adaptively assign decision weights for each corresponding learner in the ensemble. Specifically, DME can provide a just-in-time decision, as it adequately takes advantage of the feature distribution of the newly arrived data chunk and its similarity with that of each reserved old data chunk. In this study, we extended DME to a multi-label data stream. In particular, in addition to the feature matching level, we also consider the degree of the label distribution alteration, i.e., label matching level (label distribution similarity between two data chunks, see
Figure 3b), using a label distribution drift detector (LD3) [
21]. That is to say, in our algorithm, the weight is adaptively allocated for each base learner in the ensemble by simultaneously considering the feature matching level and label matching level between each reserved data chunk and newly received data chunk. This amendment satisfies the requirement of a just-in-time classification of a nonstationary multi-label data stream. Additionally, in comparison with DME, the proposed MLDME adds a weight allocation threshold to avoid that of those base learners, which are trained on data chunks having a very low distribution similarity with the new data chunk, to participate in decision making. Furthermore, to avoid the infinite extension of ensemble classifiers, we still used a fixed-size buffer to store them and designed three different dynamic classifier updating rules. We conducted experiments on nine artificial and three real-world multi-label nonstationary data streams, and compared them with several popular and state-of-the-art online learning paradigms and algorithms, including two specifically designed ones for classifying a nonstationary multi-label data stream. The results indicate the effectiveness and superiority of the proposed algorithm.
The three main contributions of this study are concluded as follows:
- (1)
To adapt a multi-label online learning requirement, this study designs a concept drift detector (integrating both DME [
22] and LD3 [
21]) while simultaneously considering that drifts happen at the feature level and label level;
- (2)
To adapt the just-in-time decision requirement, this study considers collecting both data distribution information and pseudo-label information on a newly received unlabeled data chunk, and then adaptively assigns a decision weight for each base learner according the similarity between each old data chunk and the newly received one;
- (3)
Three different ensemble update rules are designed for the proposed algorithm to satisfy various drifting types in practical applications.
The rest of the paper is organized as follows:
Section 2 summarizes some related work. In
Section 3, the proposed method is described in detail.
Section 4 provides the experimental details and results, and further gives the analysis. Finally,
Section 5 concludes with the findings and contributions of this paper.
2. Related Work
In this section, we review several benchmark and state-of-the-art online learning algorithms related to our proposed work in this study.
Hoeffding Tree (HT) [
25] has been used as an incremental classifier for massive data streams. Different from those traditional decision tree algorithms that adopt a given split evaluation function to select best attribute, the HT uses the Hoeffding bound to calculate the number of samples necessary to select the right split node with a user-specified probability. It implements increment learning without the need for storing instances after they have been used. The drawback of the HT lies in that it cannot adapt concept drift, as old and new knowledge are both totally reserved.
In the context of online weighted ensemble learning, dynamic weighted majority (DWM) [
26] is a benchmark algorithm. It maintains a buffer of base classifiers to make a decision, and for each base learner, its weight can be continuously decayed when it provides a wrong prediction for a newly received instance. If the weight of a base classifier is lower than a given threshold, then it would be removed from the ensemble buffer. DWM adapts concept drift by both dynamically removing bad classifiers and adding new classifiers trained on new data.
Another popular online weighted ensemble learning algorithm is the accuracy update ensemble (AUE2) [
27]. Unlike DWM, which is constructed in the scenario of one-by-one instance receiving, it assumes that we received new data in form of a data chunk. After a new data chunk has been labeled, AUE2 lets each reserved classifier provide a prediction on that data chunk and acquires the corresponding error rates. Then, it updates the weight of each classifiers by the feedback of error rates. Specifically, in each round, the classifier with the least accuracy would be replaced by the one trained on the new data chunk, while the new added classifier would be given the largest weight, as it is generally regarded as ‘perfect’ classifier based on the underlying hypothesis that each data block always has the most approximate distribution with that close to it. In addition, AUE2 differs from DWM, as it makes each base classifier incrementally learn from the newly received data chunk, which can be well-suited to concept drift.
We note that most emerging online weighted ensemble learning algorithms are based on the basic underlying hypothesis that each data block always has the most approximate distribution with that emerging after it. It is obviously wrong when concept drift happens between two adjacent data chunks. That means when concept drift happens, most ensemble learning algorithms could only provide a delayed decision. Assuming that a ‘perfect’ classifier exists in the ensemble buffer, it could not be assigned a higher weight to provide a prediction for the newly received unlabeled data block. To solve this issue, in our recent work, an algorithm called distribution matching ensemble (DME) [
22] was proposed to provide an adaptive and just-in-time prediction for the data stream. Specifically, DME assumes that if two data blocks have an approximate distribution in feature space, then they would hold similar experience on concept prediction. Therefore, we make DME use a Gaussian mixture model (GMM) [
23] to accurately measure the data distribution of each received data chunk and the Kullback–Leibler (KL) divergence [
24] to detect the feature matching level between each old data chunk and the newest received data chunk. Furthermore, we take advantage of the feedback feature matching level to adaptively assign a decision weight for each corresponding classifier in the ensemble. It not only abides by the
one pass rule, as only the GMM parameters of each data chunk in the ensemble are reserved, but also satisfies the requirement of a just-in-time adaptive prediction, since the experience of the newly received data block is used.
As for learning from a multi-label data stream, it will be more complex than learning from a single-label data stream, as
concept drift has been re-defined. As we know, multi-label data frequently exist in real-world applications, and in such scenarios, the label correlation should be focused [
28,
29,
30,
31]. That means that even if two data blocks have very approximate feature distributions,
concept drift would still happen if they have vastly different label correlation distributions [
21]. Roseberry and Cano [
32] proposed a punitive k nearest neighbors algorithm with a self-adjusting memory (MLSAMP) to classify drifting multi-label data streams. It maintains a sliding window to reserve recent instances and uses the traditional majority-voting KNN classifier in the window to provide a prediction for the newly received instance. Specifically, it also develops a variable window size technique to adapt to various concept drifts, i.e., maintaining a large window when incremental or gradual drifts exist, and a small window if a sudden drift has been detected. In addition, a punitive removal mechanism is designed to immediately remove those instances that have contributed to errors in the window. The MLSAMP algorithm has low time complexity and good adaption for various potential concept drifts. In [
33], the authors focused on the negative impact of using a fixed
k value for MLSAMP, and hence proposed an improved algorithm called multi-label self-adjusting
k nearest neighbors algorithm (MLSA). It adds a label-specific adaptive
k module to MLSAMP to adaptively assign an optimal
k value for each label in decision making.
It is clear that although several online multi-label learning algorithms for classifying drifting data streams have been developed, they always focused on the scenario of one-by-one instance receiving but ignored the scenario with chunk-by-chunk. In addition, they customarily used a single model with an adaptive forgetting mechanism, but neglected the more flexible and accurate ensemble learning model. Therefore, in this study, we present a more effective and efficient algorithm for adapting chunk-by-chunk multi-label drifting streams.
3. Methods
In this section, we first briefly give the preliminary knowledge related to this study, including the types of concept drift and the basic paradigm of online weighted ensemble learning. Then, we describe how to measure the similarity matching level between two multi-label data blocks in feature space and label space. Finally, we describe the flow path of MLDME algorithm and discuss its time complexity.
3.1. Preliminary Knowledge
3.1.1. Types of Concept Drift
According to the opinions of Webb et al. [
3], concept drift is very complex because it not only associates with the variations of feature space, label distribution, and their dependencies but also relates to the variation frequency with time. Suppose
denotes the joint distribution of the received data block
, where
, in which
represents the dimension of the feature space and
N represents the number of instances in
, and
, in which
C represents the number of classes. If after a time increment
, we observe
, then it means that concept drift has happened. The drift may be incurred by
,
, or
. Based on the time increment
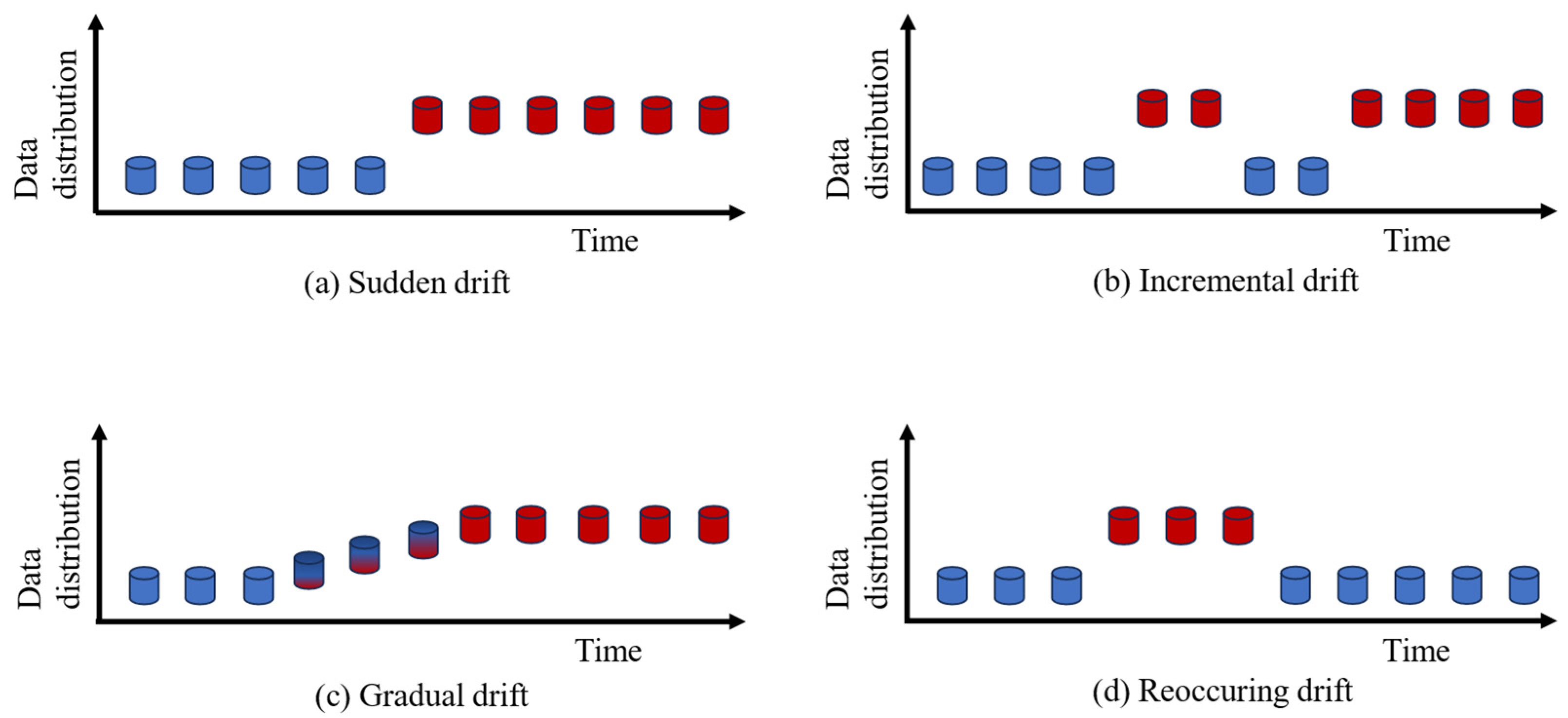
and the difference level between two distributions, concept drift can be divided into four types (see
Figure 4) as follows:
Sudden drift generally corresponds to a large difference between two continuously received data blocks, i.e., , and then the distribution tends to be stable for the next received data block;
Incremental drift generally denotes that the data frequently vibrate between the old distribution and new distribution in a long period, and then it tends to be stable in the form of the new data distribution;
Gradual drift conducts a slight distribution variation of the old data distribution and is gradually changed to be a new data distribution, and then it becomes stable in the form of the new data distribution;
Reoccurring drift suddenly becomes the new data distribution from the old distribution, and then after several or some data blocks, it will become the old distribution again, which means that the drift happens repeatedly.
3.1.2. The Basic Framework of Online Weighted Ensemble Learning
As indicated in
Section 1, for nonstationary data streams, online weighted ensemble learning is a more flexible and robust paradigm than an incremental single learning model with a forgetting mechanism. Therefore, in this study, we consider the use of online weighted ensemble learning for dealing with drifting multi-label data streams.
Suppose is an endless multi-label data stream, where denotes the data block received at time . Each data block generally contains an equal number of instances, i.e., , where denotes the feature vector of the ith instance in , , , denotes the number of labels, and represents the number of instances in a data block. For an online data stream, it is generally supposed that when a data block is just received, its label set is unknown; when and only when the next data block is received, the real label set for can be obtained.
In the online weighted ensemble learning framework, a fixed-size ensemble buffer is generally maintained to restore some base classifiers
, where
represents the classifier trained on a data block and
denotes the size of the ensemble buffer. When a new data block
is received, it can be predicted by
, where
and
, respectively, denote the feature vector and predicted labels of
, and {
} represents the decision weight corresponding to each classifier in
. In general, the weights are adaptively assigned based on the illustration of each classifier for the data chunk
, such as DWM [
26] and AUE2 [
27], or their illustrations on the data chunk
, e.g., DME [
22]. Then, when the new data chunk
arrives, the new classifier trained on
will be added to
, and an old classifier in
will be removed based on a preset rule. Next, a new iteration begins.
3.2. Feature Matching Level
As indicated above, data drift may happen in a variety of forms, i.e.,
may be incurred by
,
, or
. To provide just-in-time adaptive weighting, it is necessary to first detect the feature matching level between any old data chunk and the newly received data chunk. Here, we inherit from the idea of DME [
22] to use GMM [
23] to extract the distribution information from each data chunk and KL divergence [
24] to detect the feature matching level between two data chunks.
GMM [
23] has been widely used as to estimate the probability density function (
pdf) for any kind of data distribution. In order to approximate any distribution, GMM generally assumes that a unknown probability density function constitutes of
known Gaussian
pdfs, and it can be calculated as the weighted sum of these
pdfs, i.e.,
where
represents the weight of each Gaussian
pdf, and meanwhile,
.
corresponds to a Gaussian
pdf in
with the mean vector
and covariance matrix
. Specifically, the EM algorithm is generally used to iteratively estimate those parameters existing in GMM. At the E stage, we generally assign
examples to each cluster
, and then calculate the probability of a sample
emerging in that cluster by Equation (2). Next, we assign the example to the cluster which has provided the highest probability.
At the M stage, the following equations are used to model a mixture
pdf:
Specifically, when we designate a suitable , GMM can accurately approximate any distribution in theory.
As for KL divergence, it is always used to estimate the similarity and/or dissimilarity between two
pdfs. Considering there are two different
pdfs and
defined on
, where
denotes the dimension of the observed vectors, their KL divergence is defined as follows:
If both
and
are Gaussian
pdfs, then the KL divergence has a closed-form expression described as follows:
However, for GMM
pdfs, there is no a closed-form expression. In such a case, the KL divergence can be approximated to be other functions that may be calculated efficiently. In this study, we adopted the variational approximation strategy proposed by Hershey and Olsen [
34] to address this problem.
Let
, where
. The KL divergence can be replaced by a decomposition as follows:
Then the lower bounds for
and
can be obtained using Jensen’s inequality:
These lower bounds can be used as approximations for the corresponding quantities, further acquiring the approximation of KL divergence:
However, the KL divergence is asymmetric, which means that
. To address this issue, it can be transformed to be a Jensen–Shannon (JS) divergence [
35], which can be calculated as follows:
where
denotes the medium distribution between
f and
g. It is clear that
, and a larger
corresponds to a smaller similarity between two data distributions. In other words, JS divergence is a symmetric similarity metric that can provide a stable measure for similarity between two different distributions.
3.3. Label Matching Level
As we know, the feature matching level only detects the similarity between
and
, which cannot perfectly estimate whether concept drift has occurred. Specifically, in multi-label data streams, the variation in label dependency can be also seen as concept drift. In this study, we use the LD3 (label dependency drift detector) [
21] to calculate the label matching level between two data chunks existing in a multi-label data stream. The result of LD3 can partially reflect the similarity between
and
.
In LD3, each data block generates a co-occurrence matrix that is obtained by counting the number of times each class label occurs as “1” alongside other labels. The generated matrix is then ranked within each row, which is called local ranking, by creating a ranking for each label based on their co-occurrence frequencies. After acquiring the local ranking, the ranks can be further aggregated as global ranking as follows:
where
denotes the ranking score of the label
, and
represents the ranking of the label
in the
jth row of the local ranking matrix. Next, we obtain the global ranking position sequence
R by ranking all
in ascending rankings. Suppose
and
, respectively, denote the global ranking sequences of two different data blocks
and
; then, the label matching correlation between these two data blocks can be calculated as follows:
where
denotes the weight of the label
, which ensures that higher ranking labels have more influence. The numerator
is the ranking distance of
within the two rankings and the denominator scales the distance. It is clear that the higher the
Corr is, the more similar the label dependency order between two multi-label data blocks is.
3.4. The Proposed MLDME Algorithm
By integrating the feature matching level and label matching level, it is easy to estimate the similarity between two multi-label data blocks. However, for a newly received unlabeled data chunk, to achieve a just-in-time prediction by taking advantage of prior information, it can directly acquire feature information, while real labels are unknown. In this study, we use the pseudo-labels predicted by each classifier in to calculate its label dependency order. Although the predicted results may be not accurate, they can still reflect the difference between two data blocks enough.
Suppose
denotes the
pdf of the data block corresponding to the classifier
in the current ensemble buffer
, and
denotes the
pdf of the newly received data block; then, the feature matching level between these two data blocks can be calculated as follows:
In addition, suppose
denotes the label global ranking sequence of the data block corresponding to the classifier
, and
denotes that based on the predicted labels by
for the newly received data block; then, the label matching level between these two data blocks can be calculated as follows:
Next, the similarity level between two data blocks can be further integrated as follows:
where
denotes a regulatory factor to tune the relative significance between the feature level and label level. In this study,
has been empirically designated as 0.5, i.e., the feature level has an equal significance to label level.
Moreover, the voting weight of each classifier
can be calculated by its similarity level. Specifically, to avoid the classifiers constructed on the data blocks having significant differences with the newly received data block to participate, a threshold
is predesignated. If
, then the classifier
is removed from the prediction. That means that for each newly received data chunk, only
classifiers are assigned weights for conducting the ensemble prediction, where
. In this study,
is empirically set to be 0.2. The weight of each classifier participating in the ensemble decision can be calculated as follows:
It is clear that a reserved data chunk has more similar feature and label distributions with the newly received data chunk, and it contributes more to the prediction. In addition, to avoid a decision deficiency when the similarity level of each reserved data chunk with the newly received one is lower than , e.g., a sudden drift happens in the new data chunk, we designate the classifier corresponding to the highest similarity to provide a prediction in such a scenario.
The procedure of the proposed MLDME is described as follows (Algorithm 1):
| Algorithm 1 MLDME |
| Input: a multi-label chunk-based data stream in which each data chunk has n instances and |L| labels, the number of GMM is , the regulatory factor is , the decision threshold is , and the size of the ensemble buffer is M |
| Output: with the label distribution information and label global ranking sequence of each corresponding data block |
| Procedure: |
- 1.
;
|
- 2.
While new data chunk is received
|
- 3.
If
|
- 4.
Wait real labels of the data chunk ;
|
- 5.
Extract GMM distribution information ;
|
- 6.
Calculate label global ranking sequence ;
|
- 7.
Train a classifier on ;
|
- 8.
Put , and into ;
|
- 9.
else
|
- 10.
For j = 1 to ||
|
- 11.
Extract GMM distribution information ;
|
- 12.
Calculate by Equation (12);
|
- 13.
Calculate by Equation (15);
|
- 14.
Predict pseudo-labels for by ;
|
- 15.
Calculate label global ranking sequence by pseudo-labels;
|
- 16.
Calculate by Equation (16);
|
- 17.
Calculate by Equation (17);
|
- 18.
If <
|
- 19.
;
|
- 20.
End If
|
- 21.
End For
|
- 22.
Calculate decision weight for each classifier in by Equation (18);
|
- 23.
Provide prediction for by weighted ensemble voting;
|
- 24.
If ||=M
|
- 25.
Remove a classifier in by a pre-setting ensemble update rule;
|
- 26.
End IF
|
- 27.
Wait real labels of the data chunk ;
|
- 28.
Train a classifier on ;
|
- 29.
Put , and into ;
|
- 30.
End If
|
- 31.
End While
|
In the algorithm description, we note that when the first data chunk is received, it lacks prior knowledge to a provide prediction for it, and hence the first data chunk cannot be predicted, but needs to wait for its real label set. In addition, when and only when the ensemble buffer is full, the classifier update rule is used to replace the most useless classifier by the newly trained one. Here, we designed three different ensemble update rules.
First follows the FIFO principle to replace the earliest constructed classifier in
with the new one.
AVE maintains a score for each classifier, which uses the decision threshold
to calculate the ratio between the participating ensemble decision and undergoing data chunks of that classifier. Certainly, the score is also compulsively decayed with time. This rule reflects the significance of each classifier in the ensemble, and always selects to remove the most useless one.
Rec modifies the
AVE rule, and it only finds the lowest
AVE classifier from the most half oldest ones in the ensemble to guarantee that those newly added classifiers can be reserved longer. It can be seen as a trade-off between two first rules. In this study, we used
Rec as the default updating rule. Regarding the performance difference among these three rules, we will discuss it in
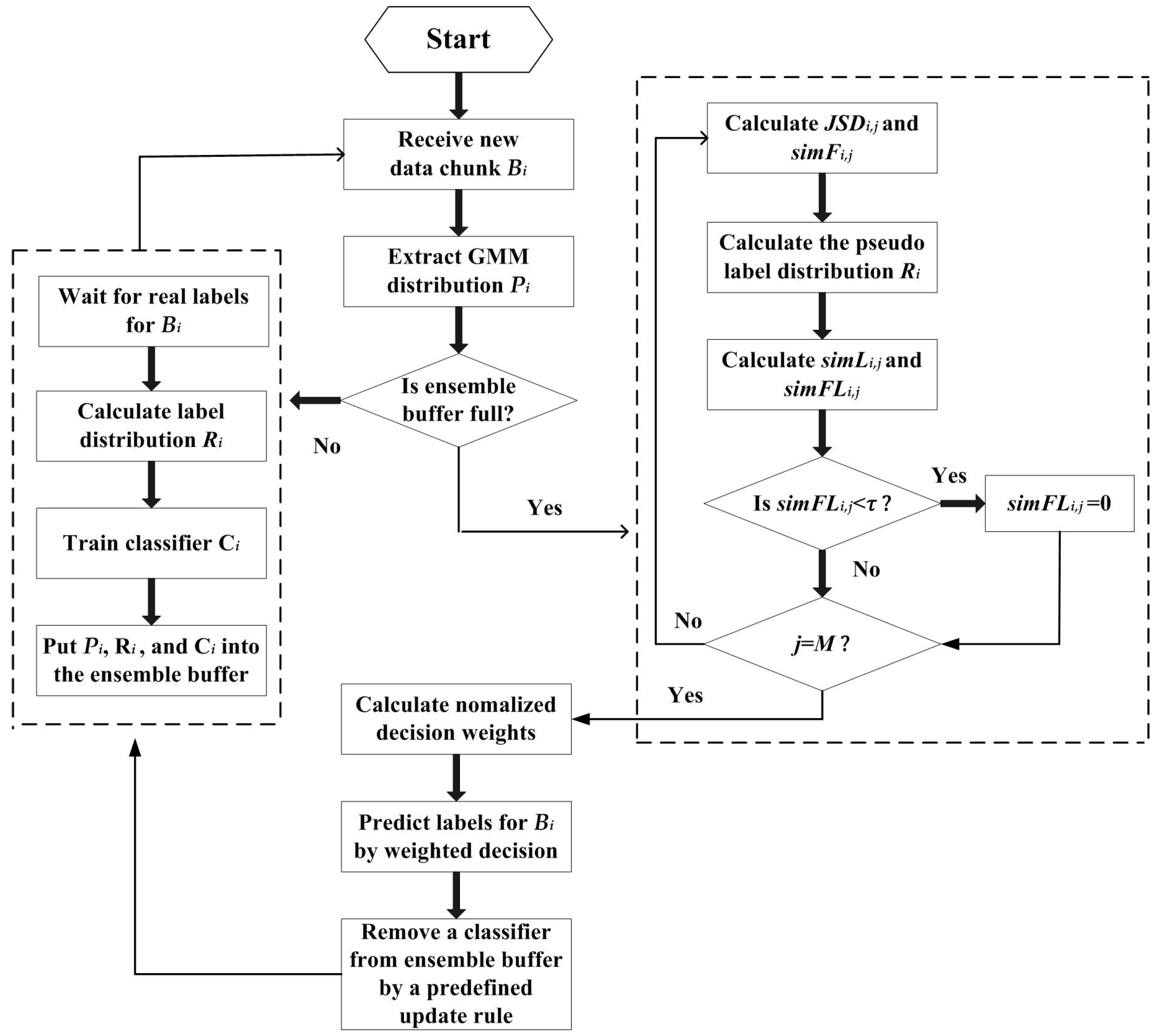
Section 4. To further clarify the algorithm procedure, a flow chart of the MLDME algorithm is presented in
Figure 5.
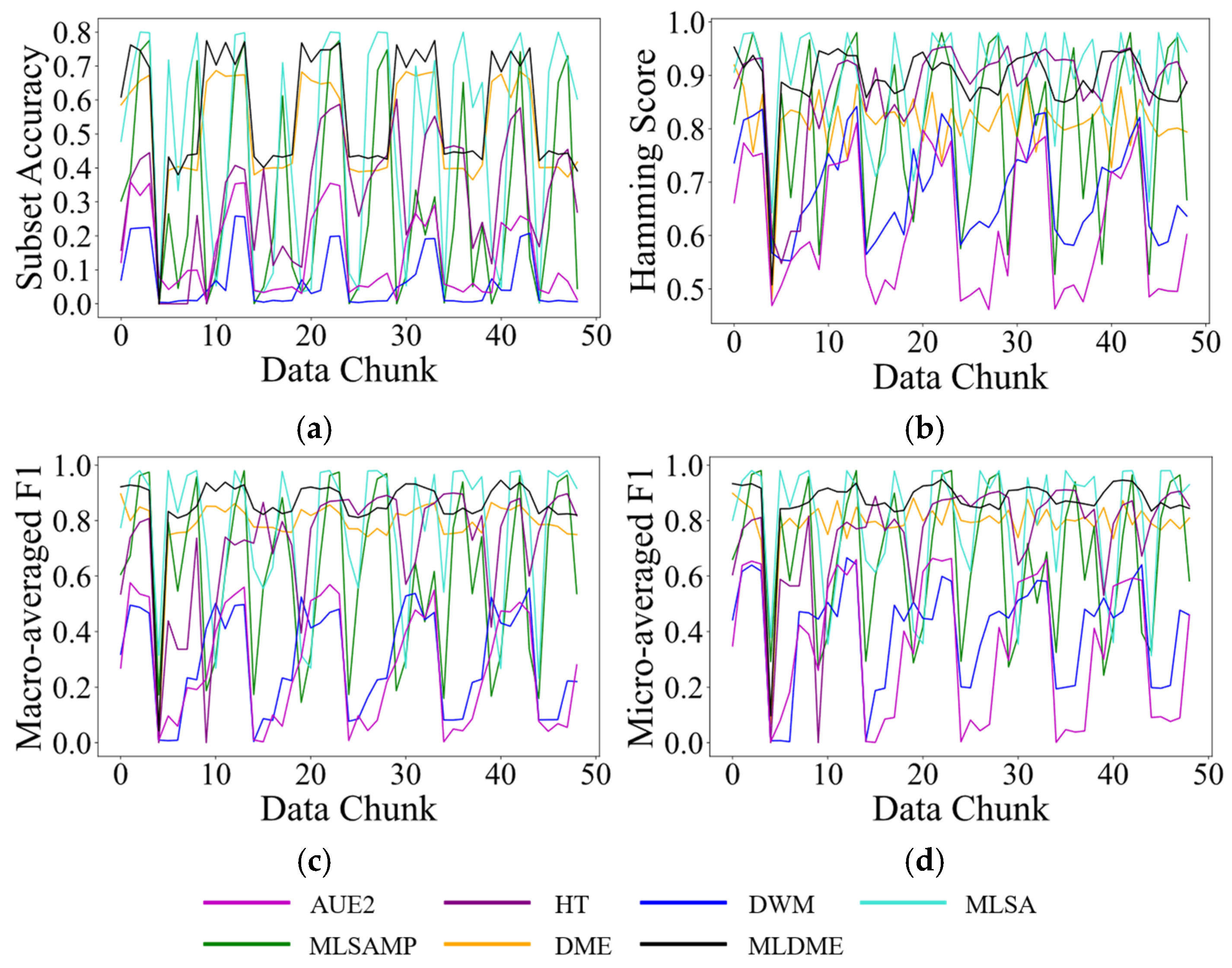
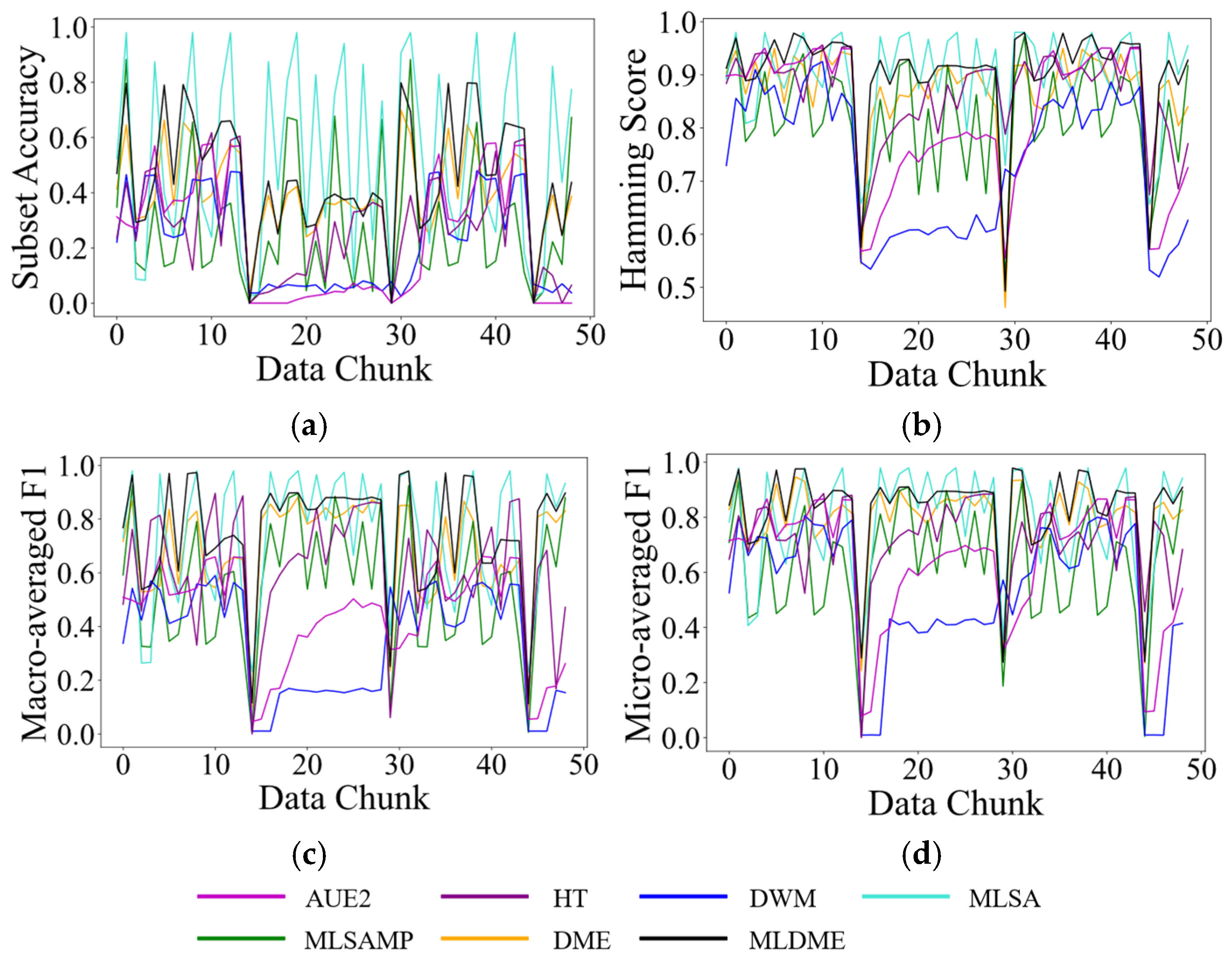
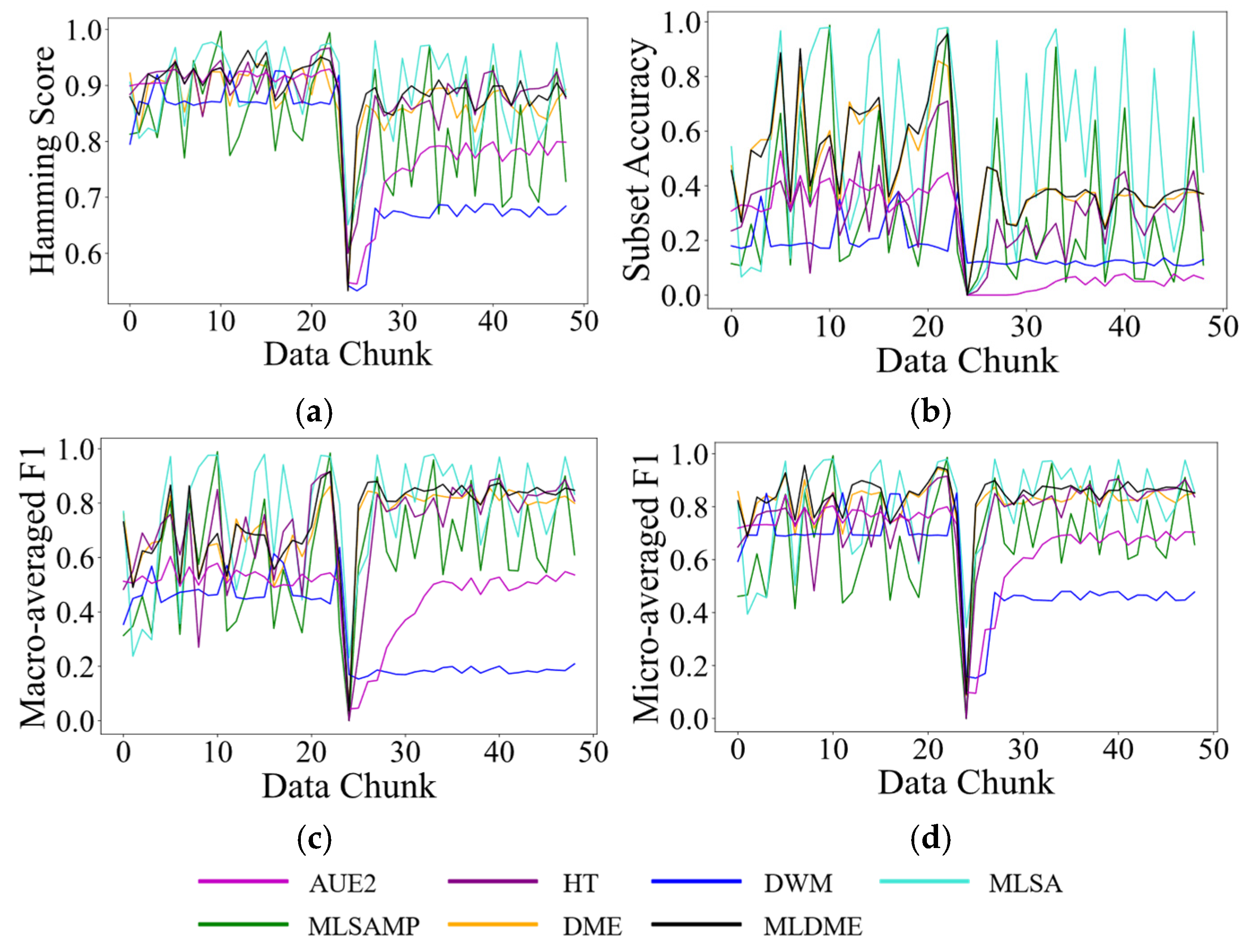
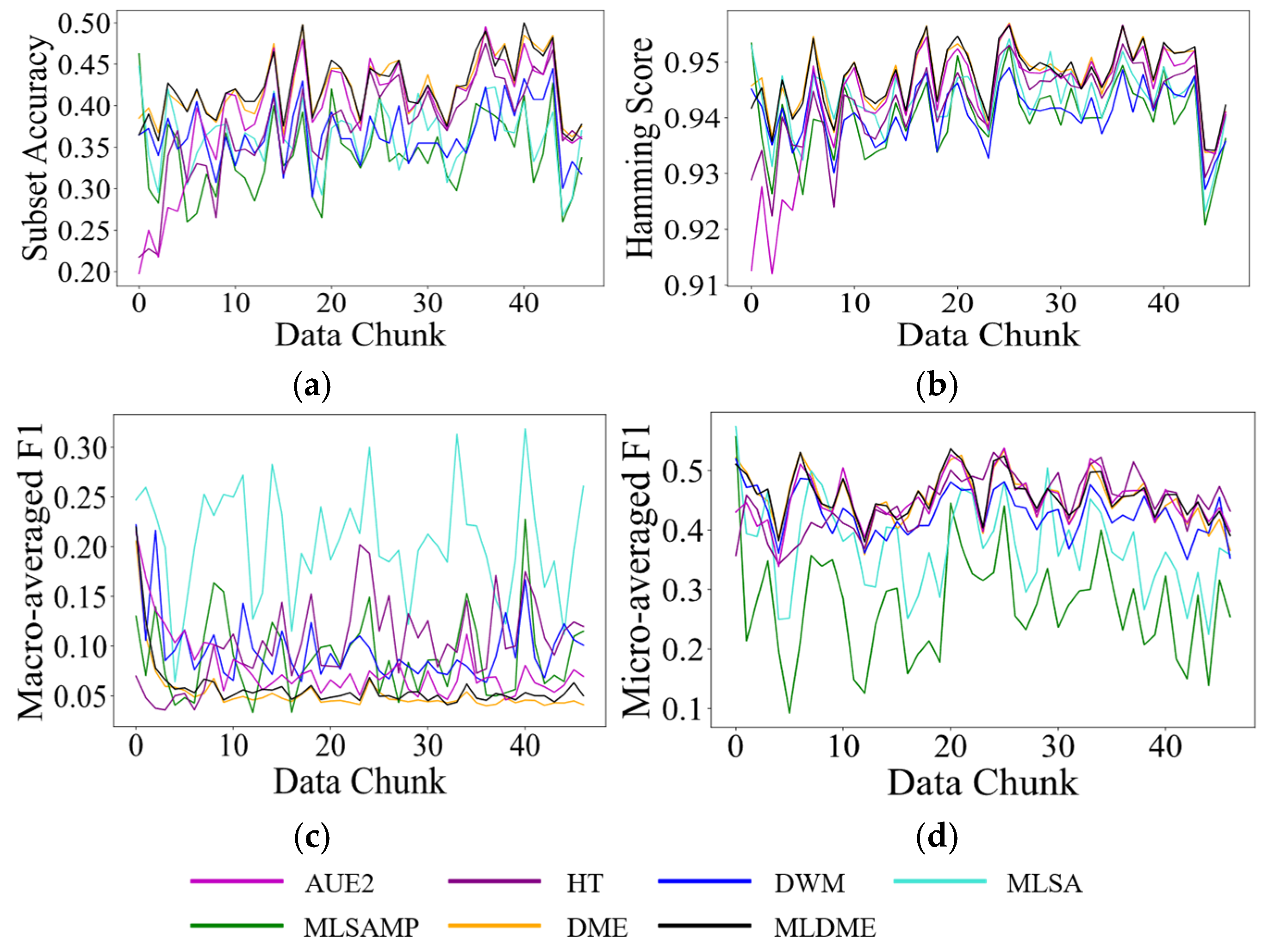
Since MLDME only reserves M GMM distribution information, label global ranking sequences, and classifiers, it satisfies the one pass requirement of online learning. However, due to the participation of the complex calculation of the feature matching level and label matching level, MLDME has a relatively high time complexity. However, it is acceptable as in real-world applications, as there always exists a longer time interval between two continuous data chunks than that between two continuous instances. The specific running time of various compared algorithms will be given in next section.

 ,
, 

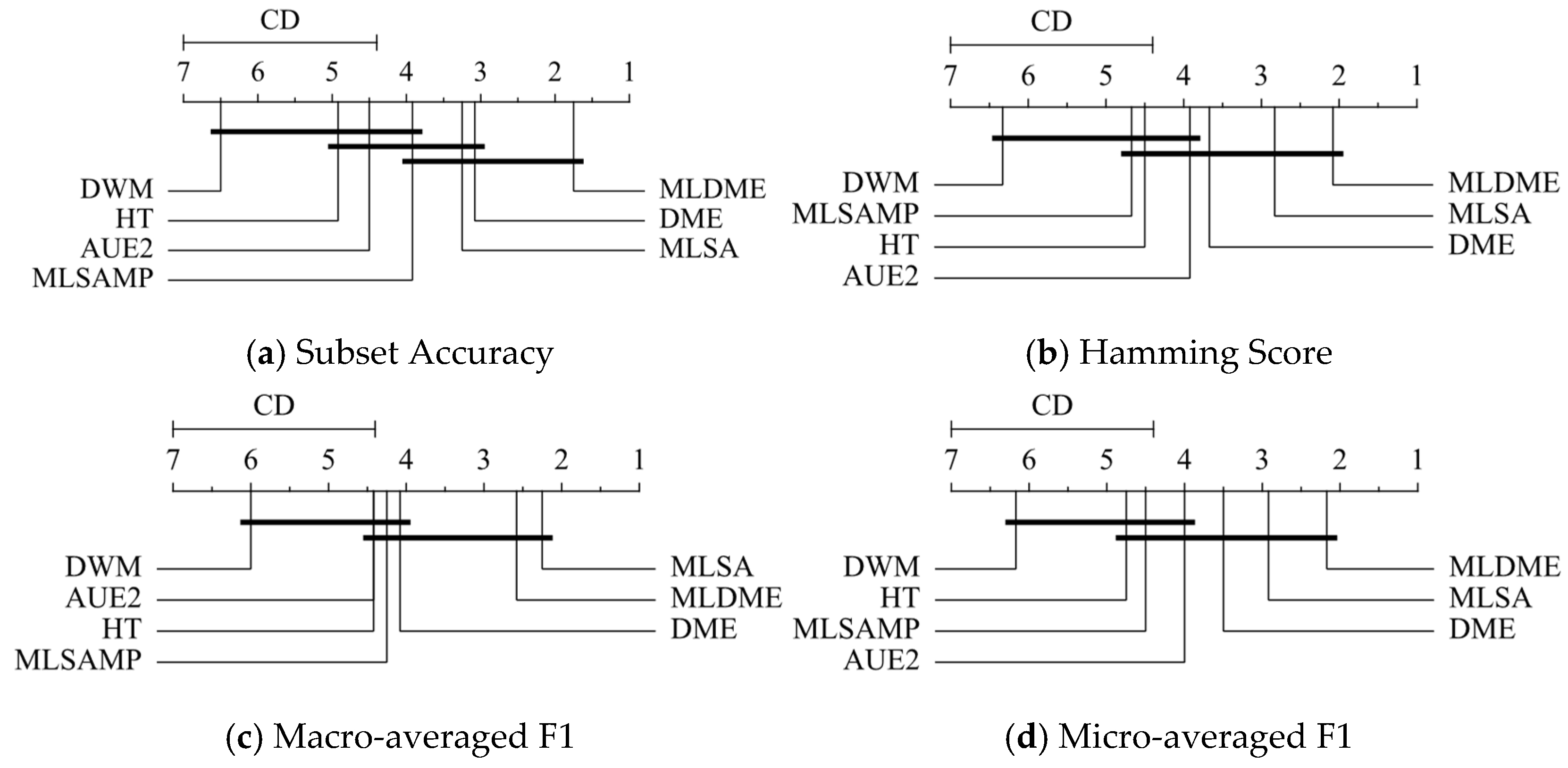

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}