
An Adaptive Search Algorithm for Multiplicity Dynamic Flexible Job Shop Scheduling with New Order Arrivals



Abstract
1. Introduction
- (1)
- We propose a fluid randomized adaptive search algorithm for addressing the MDFJSP, effectively bridging the existing research gap in this area.
- (2)
- A dynamic fluid model is developed for the first time to address the MDFJSP with new order arrivals.
- (3)
- The proposed FRAS algorithm surpasses existing algorithms due to two design features. Firstly, we developed a fluid construction heuristic that incorporates an online fluid dynamic tracking policy to optimize the initial solution. Secondly, we propose a tabu search procedure based on the public critical operation to enhance the efficiency of the solution space search.
2. Literature Review
2.1. Methodologies for the FJSP
2.2. Fluid Model
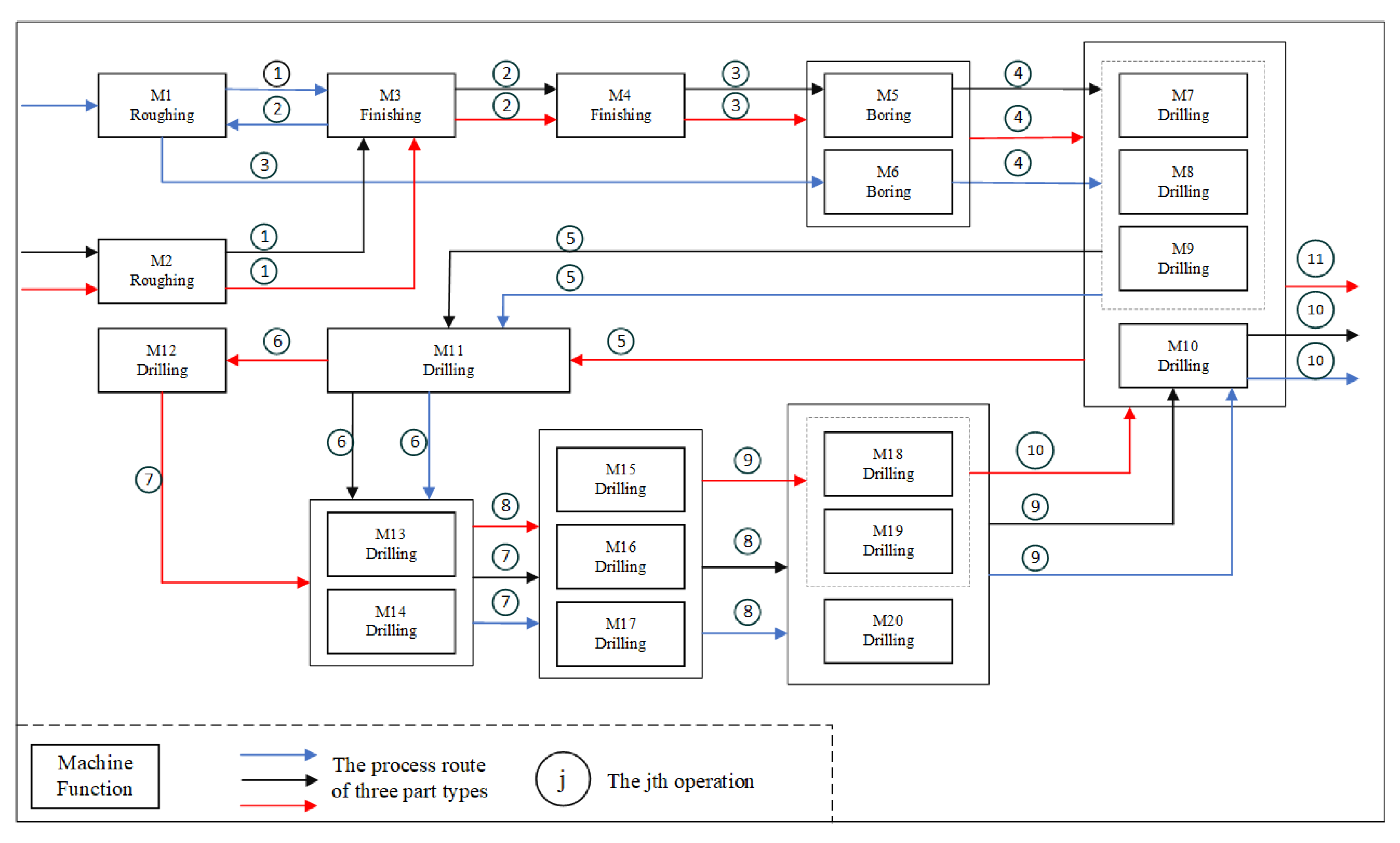
3. Problem Description
- (1)
- Machines are assumed to be ready for operation at the beginning of the time horizon.
- (2)
- The same type of jobs can be processed on a specified series of machines. However, it is not permitted for any given machine to perform more than one operation simultaneously.
- (3)
- Operations must be completed without interruption.
- (4)
- Operations must be conducted in a specified order, with no operation starting before the previous one has finished.
- (5)
- Setup times between operations are not considered.
| Notation | Description |
| Indexes: | |
| s | Orders, . |
| m | Machines, . |
| Job types, . | |
| Jobs belonging to job types r and , , . | |
| Operations of job types r and , , . | |
| Parameters: | |
| R | The number of job types. |
| M | The number of machines. |
| The operation quantity of job type r. | |
| Job of type r. | |
| Operation of the job pertaining to job type r. | |
| Operation of type r. | |
| The processing time for operation on machine m. | |
| Notation | Description |
| Sets: | |
| The complete set of machines, . | |
| The specific set of machines that are eligible to perform the operation . | |
| The set of all job types, . | |
| The set of all jobs belonging to type r, . | |
| The set of all operations belonging to job type r, . | |
| The complete set of operations belonging to all job types, . | |
| The set of operations that machine m can perform, . | |
| Variables: | |
| S | The quantity of new orders. |
| The arrival time of order s; order is the first order, and . | |
| The due date of order s. | |
| The due date of job ; if . | |
| The total job quantity of job type r in order s. | |
| The total job quantity in order s, . | |
| The total job quantity of job type r in all orders, . | |
| N | The number of jobs in all orders, . |
| The completion time of operation . | |
| Decision variables: | |
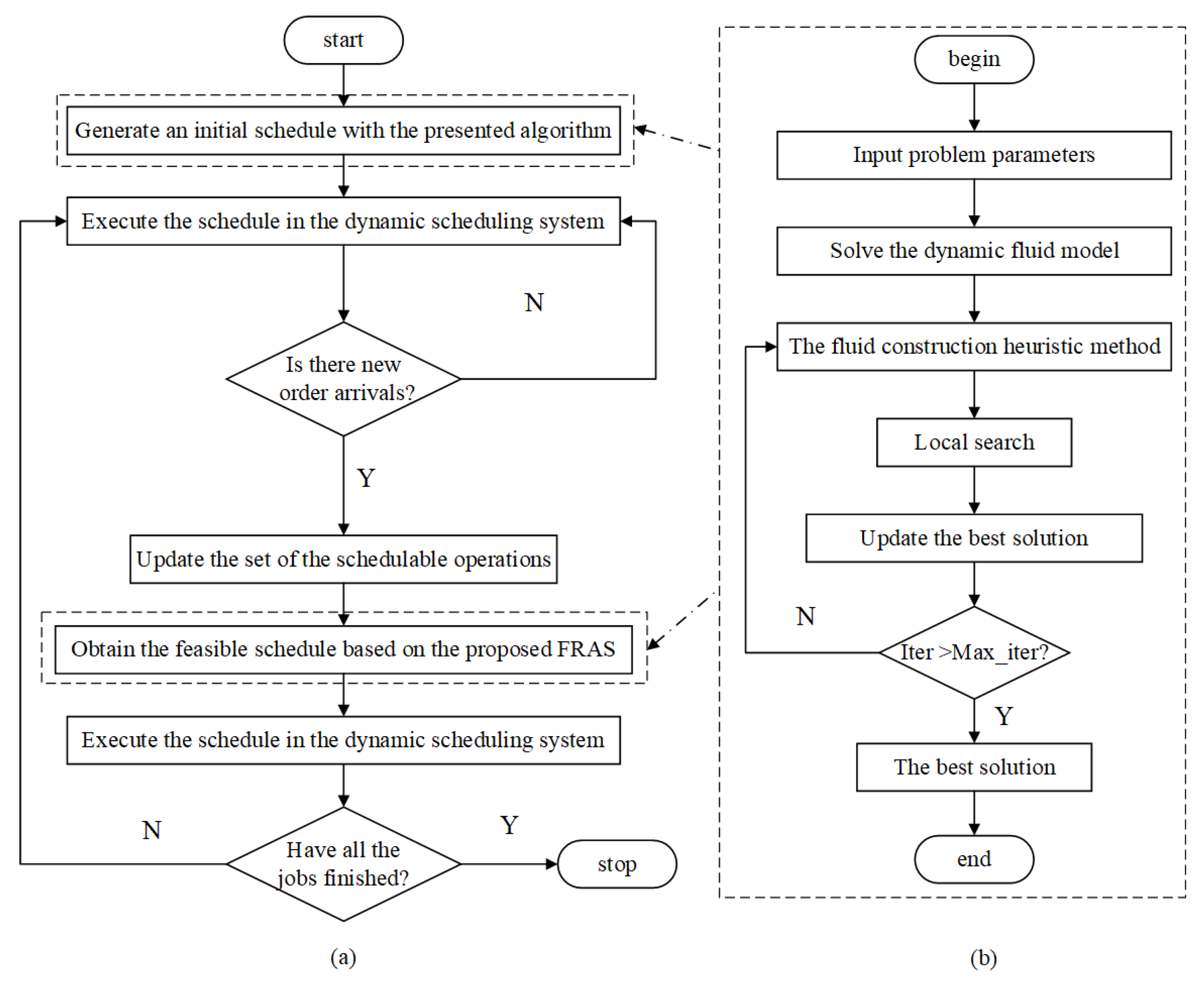
4. Fluid Randomized Adaptive Search Algorithm
4.1. Construction Phase
4.1.1. Dynamic Fluid Model and Control Problem
| Notations | Description |
| Indexes: | |
| The fluid which represents the operation in the dynamic fluid model. | |
| Parameters: | |
| The processing rate of fluid on machine m. | |
| The total processing rate of fluid , . | |
| Sets: | |
| F | The set of fluids, . |
| The subset of fluids that machine m can process, . | |
| The subset of machines that can process fluid , . | |
| Variables: | |
| The proportion of processing time that machine m devotes to fluid . | |
| The completion time of fluid . | |
| The amount of fluid at time t. | |
| The job quantity in operation stage at time t. | |
| The total amount of fluid not processed at time t. | |
| The total job quantity in operation not processed at time t. | |
| The total amount of fluid not processed by machine m at time t. | |
| The total job quantity in operation not processed by machine m at time t. |
4.1.2. Online Fluid Dynamic Tracking Policy
- Fluid-Gap: At time t, the gap between the total job quantity that operation has not been processed and the amount of fluid , which has not been processed, is calculated as follows:
- Fluid–Machine-Gap: At time t, the gap between the total job quantity with operation not processed by machine m and the number of fluid not processed by machine m is calculated as follows:
- Machine selection step: The machine is selected to process the selected operation at the operation selection step.
4.1.3. The Fluid Construction Heuristic Method
4.2. Local Search
| Algorithm 1 The fluid construction heuristic method. |
|
| Algorithm 2 The improved tabu search algorithm. |
|
4.3. Implementation
| Algorithm 3 The FRAS algorithm. |
|
5. Experiments and Results
5.1. Parameter Settings
5.2. Validation of Proposed Methods
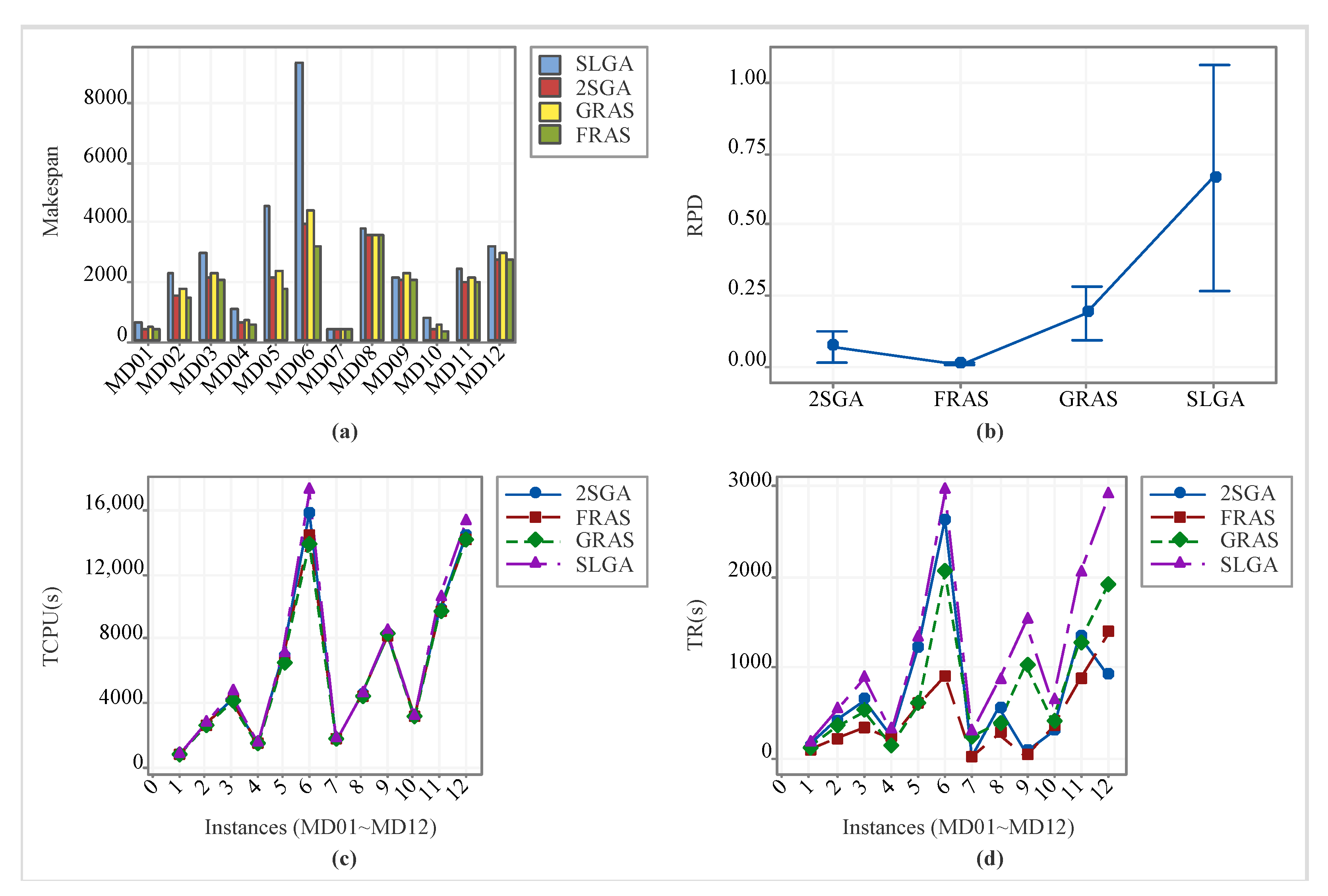
5.3. Comparison with Existing Algorithms
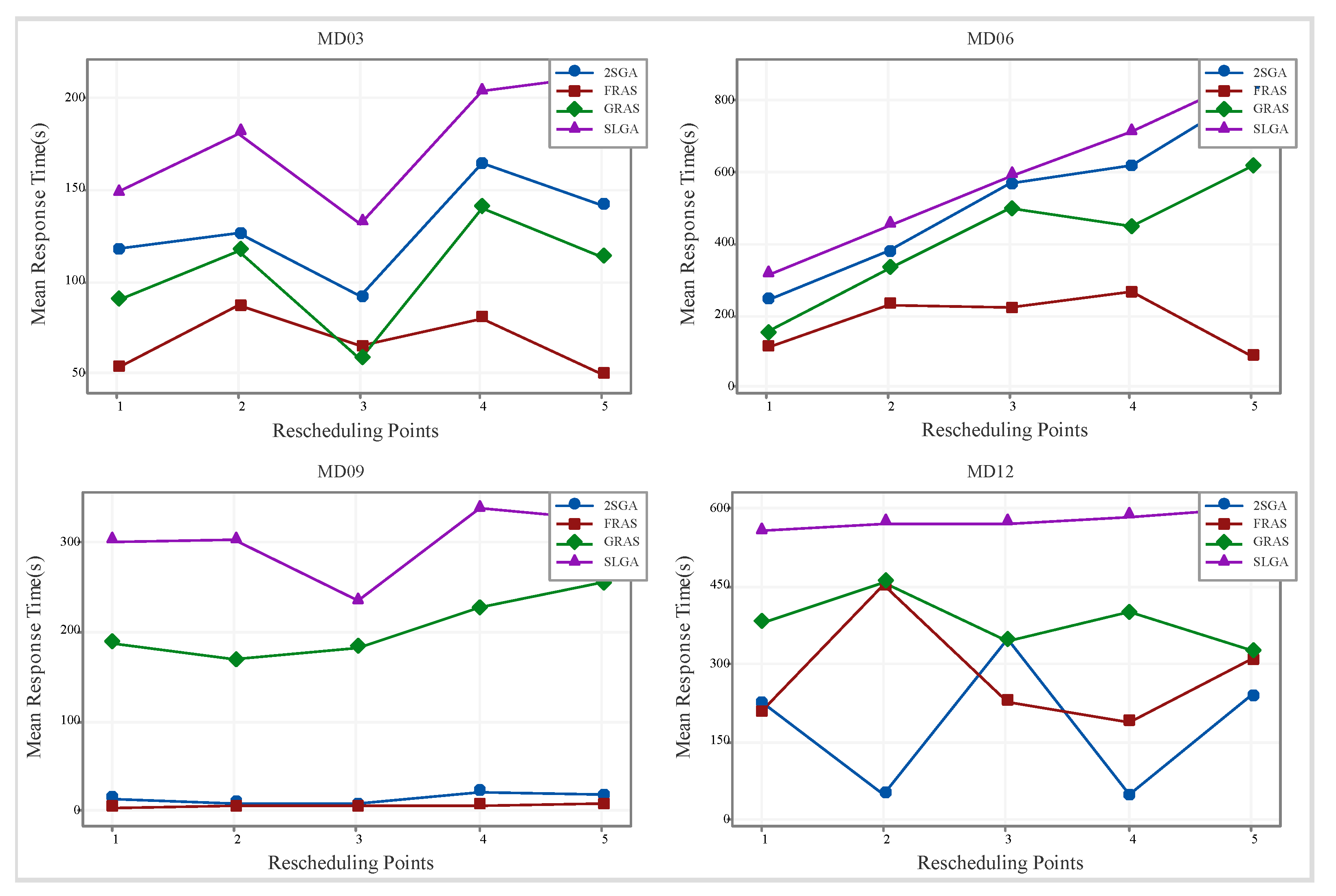
5.4. Industrial Application
6. Conclusions and Perspective
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
List of Abbreviations
| Abbreviation | Definition |
| JSP | Job shop scheduling problem |
| FJSP | Flexible job shop scheduling problem |
| DFJSP | Dynamic flexible job shop scheduling problem |
| MDFJSP | Multiplicity dynamic flexible job shop scheduling problem |
| FRAS | Fluid randomized adaptive search |
| FCH | Fluid construction heuristic |
| ITS | Improved tabu search |
| Average relative percentage deviation | |
| 2SGA | Two-stage genetic algorithm |
| GRAS | Greedy randomized adaptive search |
| SLGA | Self-learning genetic algorithm |
| TCPU | Total computation time |
| TR | Total response time |
| TS | Tabu search |
Appendix A. Comparison with Optimal Value

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Instance | N × M | KNITRO 9.0.1 | FRAS | |||
|---|---|---|---|---|---|---|
| Optimality Gap (%) | ||||||
| data01 | 3 × 3 | 303 | 0.34 | 0 | 303 (303) | 0.70 |
| data02 | 6 × 3 | 551 | 0.48 | 0 | 551 (553) | 1.05 |
| data03 | 6 × 5 | 370 | 0.59 | 0 | 370 (371) | 0.85 |
| data04 | 9 × 5 | 555 | 0.72 | 0 | 555 (557) | 1.19 |
| data05 | 9 × 10 | 272 | 46.76 | 0 | 272 (272.8) | 20.06 |
| data06 | 15 × 10 | 583 | 7200 | 19.68 | 394 (396.2) | 12.26 |
| data07 | 20 × 10 | 1574 | 7200 | 99.23 | 770 (772.5) | 22.88 |
| data08 | 40 × 10 | 1457 (1462.7) | 40.10 | |||
Appendix B. Experiments on Static Datasets
| Instance | R | TS | GA | 2SGA | GRAS | FRAS | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| LSM-Mk01 | 10 | 20 | 200 × 6 | 1212 (1241) | 69.54 | 1024 (1025) | 40.03 | 782 (784) | 7.10 | 941 (942) | 28.69 | 732 (732) | 0.00 |
| LSM-Mk02 | 10 | 20 | 200 × 6 | 973 (999) | 95.12 | 840 (851) | 66.21 | 567 (570) | 11.33 | 836 (847) | 65.43 | 512 (512) | 0.00 |
| LSM-Mk03 | 15 | 10 | 150 × 8 | 2780 (2984) | 46.27 | 2555 (2595) | 27.21 | 2040 (2040) | 0.00 | 2545 (2625) | 28.68 | 2040 (2047) | 0.34 |
| LSM-Mk04 | 15 | 10 | 150 × 8 | 889 (929) | 52.80 | 780 (781) | 28.45 | 608 (608) | 0.00 | 687 (692) | 13.82 | 617 (622) | 2.30 |
| LSM-Mk05 | 15 | 20 | 300 × 4 | 4687 (4782) | 39.21 | 4371 (4395) | 27.95 | 3602 (3607) | 5.01 | 3628 (3655) | 6.40 | 3435 (3435) | 0.00 |
| LSM-Mk06 | 10 | 10 | 100 × 15 | 1221 (1262) | 139.02 | 1139 (1140) | 115.91 | 584 (585) | 10.80 | 617 (623) | 17.99 | 528 (529) | 0.19 |
| LSM-Mk07 | 20 | 10 | 200 × 5 | 2483 (2578) | 85.33 | 2170 (2192) | 57.58 | 1559 (1565) | 12.51 | 1898 (1911) | 37.38 | 1391 (1391) | 0.00 |
| LSM-Mk08 | 20 | 10 | 200 × 10 | 6226 (6263) | 19.75 | 6056 (6075) | 16.16 | 5430 (5442) | 4.05 | 5489 (5505) | 5.26 | 5230 (5230) | 0.00 |
| LSM-Mk09 | 20 | 10 | 200 × 10 | 5274 (5294) | 74.66 | 4723 (4755) | 56.88 | 3337 (3344) | 10.33 | 3495 (3545) | 16.96 | 3031 (3036) | 0.16 |
| LSM-Mk10 | 20 | 10 | 200 × 15 | 4102 (4364) | 127.53 | 3649 (3671) | 91.40 | 2212 (2217) | 15.59 | 3217 (3228) | 68.30 | 1918 (1921) | 0.16 |
| #better | 10 | 10 | 8 | 10 | |||||||||
| #even | 0 | 0 | 1 | 0 | |||||||||
| #worse | 0 | 0 | 1 | 0 | |||||||||
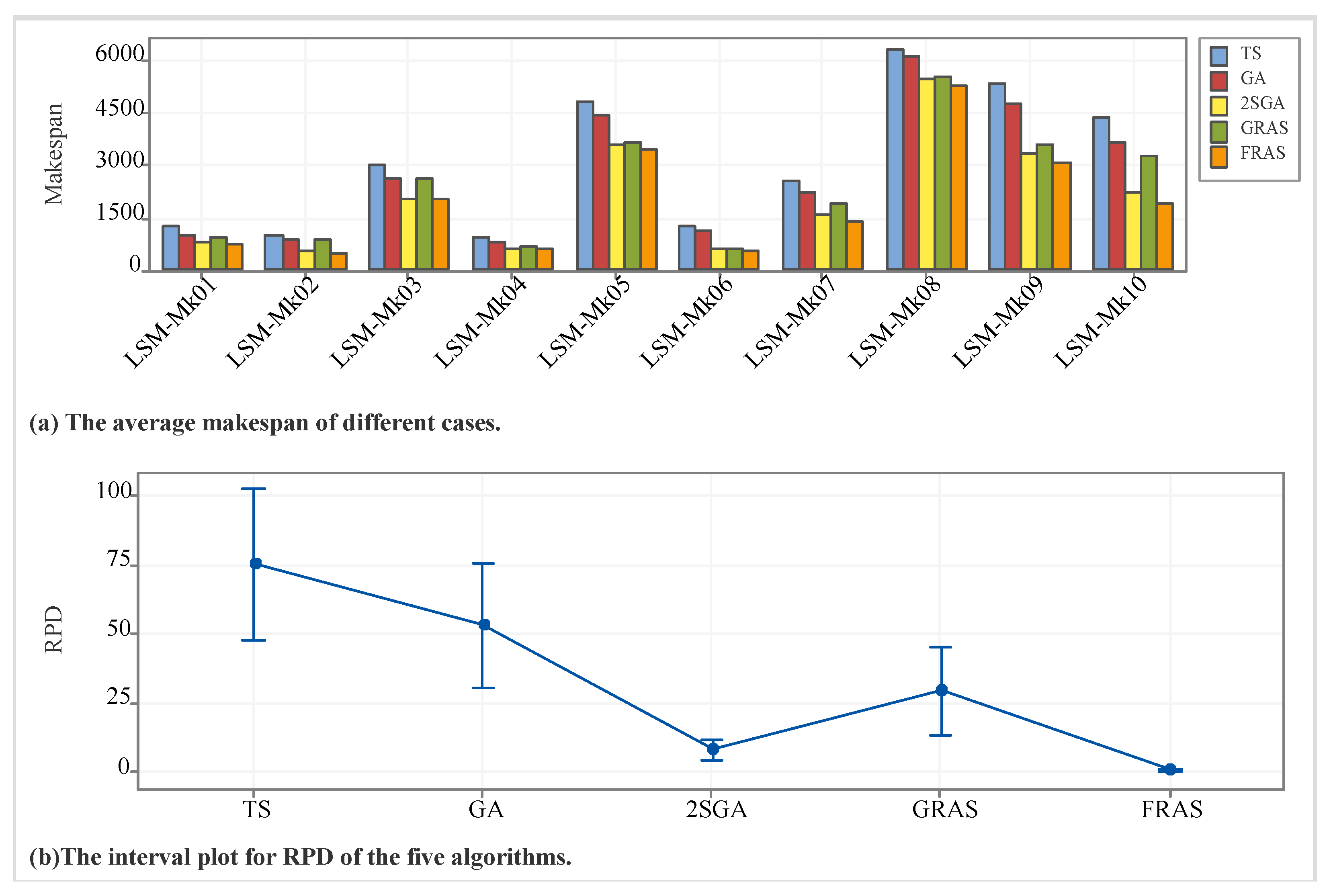
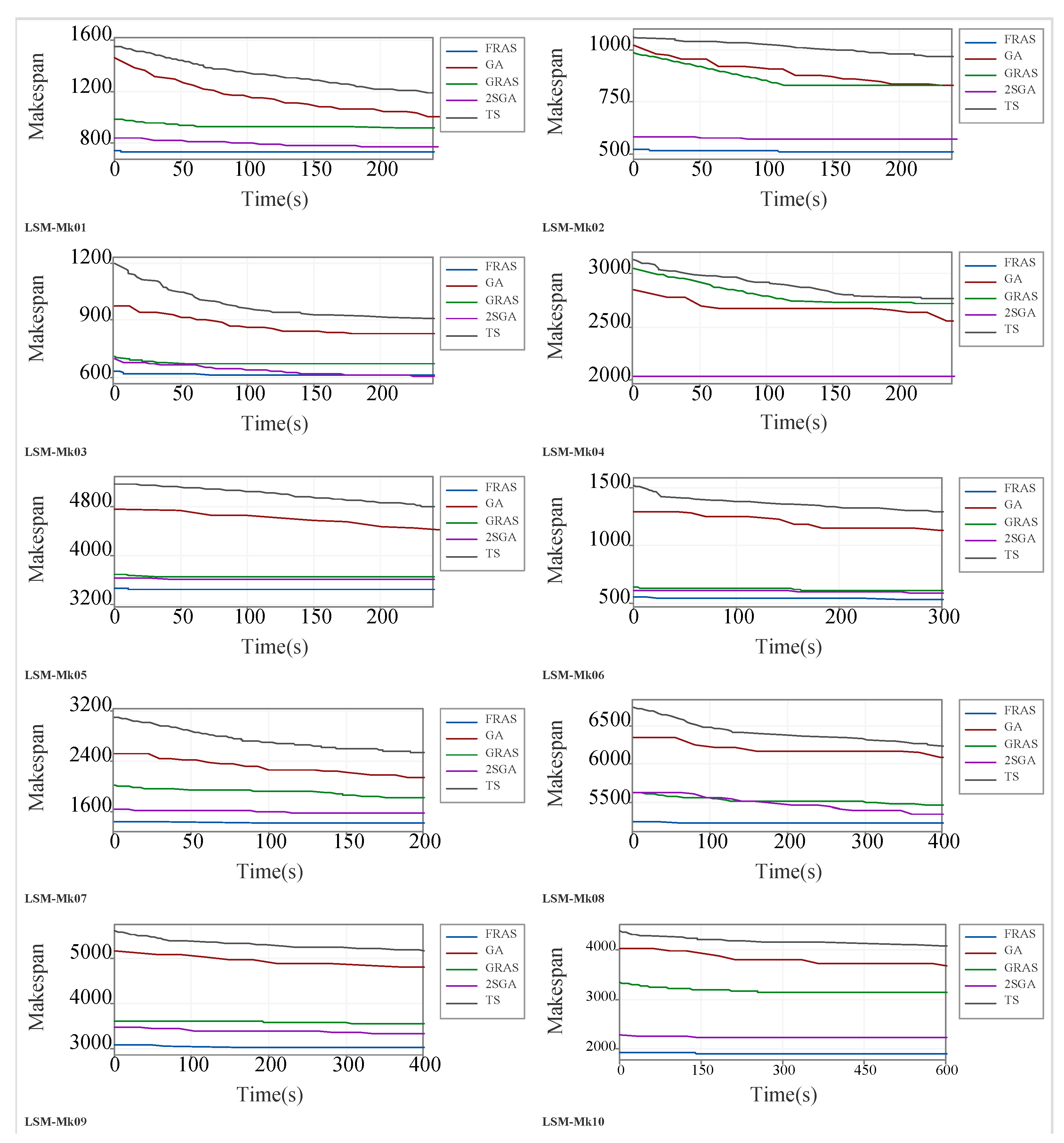
Appendix C. Statistical Analysis
| FRAS vs. | p-Value | ||
|---|---|---|---|
| SLGA | 36 | 0 | 0.00390625 |
| 2SGA | 36 | 0 | 0.00390625 |
| GRAS | 36 | 0 | 0.00390625 |
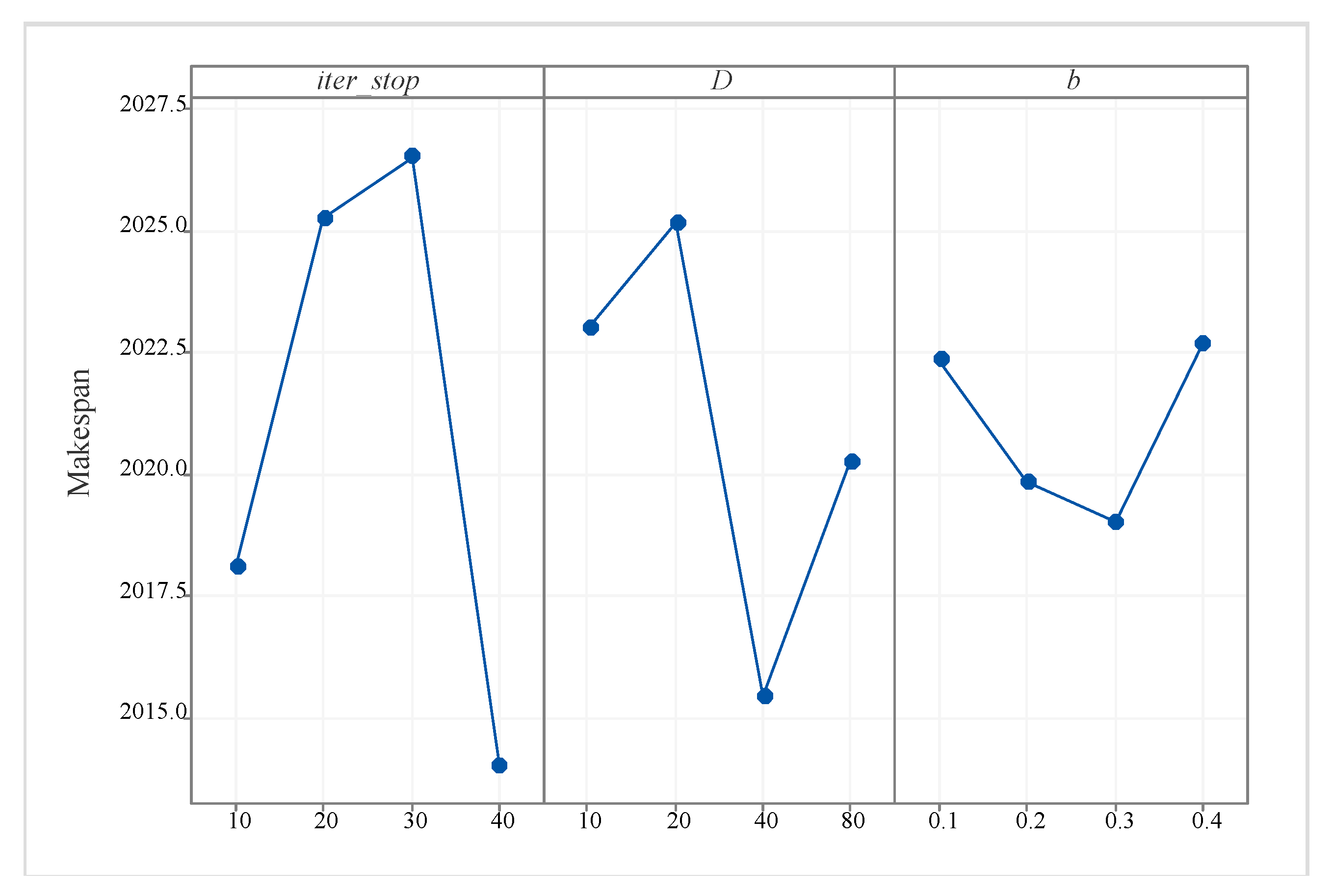
Appendix D. Sensitivity Analysis
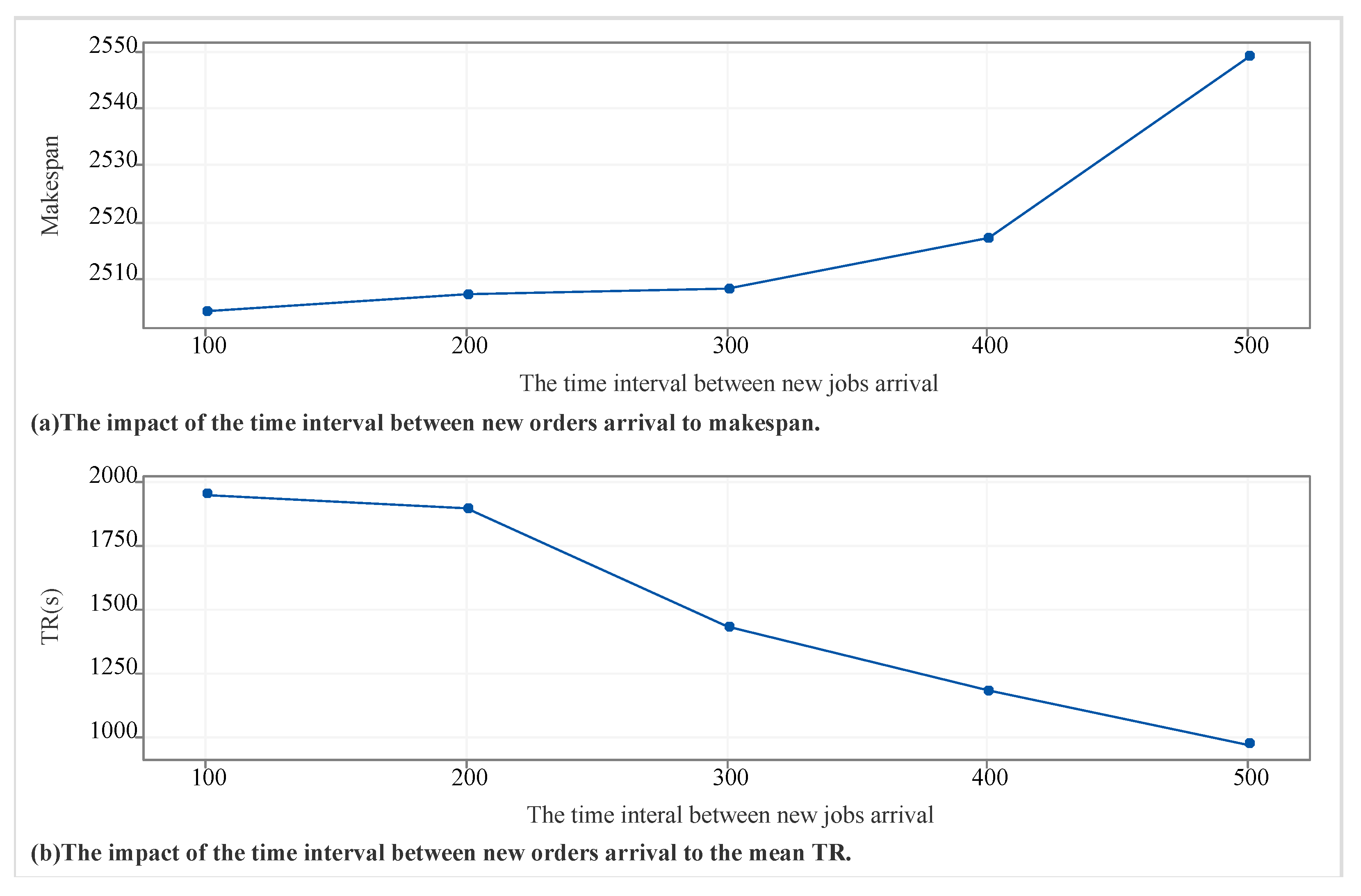
Appendix E. Process Information Furthermore, Production Data
| Part Types | Operation | Processing Time |
|---|---|---|
| r | j | |
| 1 | 1 | (1, 1, 1, 18) |
| 2 | (1, 2, 3, 10) | |
| 3 | (1, 3, 1, 21) | |
| 4 | (1, 4, 6, 19) | |
| 5 | (1, 5, 7, 28) (1, 5, 8, 28) (1, 5, 9, 28) | |
| 6 | (1, 6, 11, 10) | |
| 7 | (1, 7, 13, 20) (1, 7, 14, 20) | |
| 8 | (1, 8, 15, 32) (1, 8, 16, 32) (1, 8, 17, 32) | |
| 9 | (1, 9, 18, 19) (1, 9, 19, 19) (1, 9, 20, 19) | |
| 10 | (1, 10, 10, 8) | |
| 2 | 1 | (2, 1, 2, 18) |
| 2 | (2, 2, 3, 10) | |
| 3 | (2, 3, 4, 21) | |
| 4 | (2, 4, 5, 19) | |
| 5 | (2, 5, 7, 28) (2, 5, 8, 28) (2, 5, 9, 28) | |
| 6 | (2, 6, 11, 10) | |
| 7 | (2, 7, 13, 20) (2, 7, 14, 20) | |
| 8 | (2, 8, 15, 32) (2, 8, 16, 32) (2, 8, 17, 32) | |
| 9 | (2, 9, 18, 19) (2, 9, 19, 19) (2, 9, 20, 19) | |
| 10 | (2, 10, 10, 8) | |
| 3 | 1 | (3, 1, 2, 23) |
| 2 | (3, 2, 3, 14) | |
| 3 | (3, 3, 4, 25) | |
| 4 | (3, 4, 5, 26) (3, 4, 6, 26) | |
| 5 | (3, 5, 7, 42) (3, 5, 8, 42) (3, 5, 9, 42) (3, 5, 10, 42) | |
| 6 | (3, 6, 11, 15) | |
| 7 | (3, 7, 12, 25) | |
| 8 | (3, 8, 13, 31) (3, 8, 14, 31) | |
| 9 | (3, 9, 15, 48) (3, 9, 16, 48) (3, 9, 17, 48) | |
| 10 | (3, 10, 18, 28) (3, 10, 19, 28) | |
| 11 | (3, 11, 7, 10) (3, 11, 8, 10) (3, 11, 9, 10) (3, 11, 10, 10) |
| Cases | Orders (s) | Arrival Time () | Number of Parts for Different Types | ||
|---|---|---|---|---|---|
| Data01 | 1-1 | 0 | 22 | 13 | 16 |
| 1-2 | 537 | 19 | 17 | 29 | |
| Data02 | 2-1 | 0 | 11 | 14 | 15 |
| 2-2 | 641 | 22 | 20 | 29 | |
| 2-3 | 2537 | 12 | 16 | 11 | |
| Data03 | 3-1 | 0 | 11 | 15 | 26 |
| 3-2 | 1075 | 19 | 18 | 15 | |
| 3-3 | 1652 | 15 | 21 | 18 | |
| 3-4 | 4247 | 24 | 12 | 25 | |
| Data04 | 4-1 | 0 | 18 | 16 | 28 |
| 4-2 | 2253 | 29 | 16 | 15 | |
| 4-3 | 2885 | 19 | 19 | 28 | |
| 4-4 | 4726 | 25 | 24 | 20 | |
| 4-5 | 4937 | 11 | 12 | 11 | |
| Data05 | 5-1 | 0 | 24 | 13 | 12 |
| 5-2 | 1161 | 29 | 24 | 11 | |
| 5-3 | 3214 | 22 | 13 | 24 | |
| 5-4 | 3327 | 20 | 26 | 23 | |
| 5-5 | 3437 | 29 | 20 | 28 | |
References
- Gu, X.; Koren, Y. Mass-Individualisation–the twenty first century manufacturing paradigm. Int. J. Prod. Res. 2022, 60, 7572–7587. [Google Scholar] [CrossRef]
- Leng, J.; Zhu, X.; Huang, Z.; Li, X.; Zheng, P.; Zhou, X.; Mourtzis, D.; Wang, B.; Qi, Q.; Shao, H.; et al. Unlocking the power of industrial artificial intelligence towards Industry 5.0: Insights, pathways, and challenges. J. Manuf. Syst. 2024, 73, 349–363. [Google Scholar] [CrossRef]
- Basantes Montero, D.T.; Rea Minango, S.N.; Barzallo Núñez, D.I.; Eibar Bejarano, C.G.; Proaño López, P.D. Flexible Manufacturing System Oriented to Industry 4.0. In Proceedings of the Innovation and Research: A Driving Force for Socio-Econo-Technological Development 1st, Sangolquí, Ecuador, 1–3 September 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 234–245. [Google Scholar]
- Margherita, E.G.; Braccini, A.M. Industry 4.0 technologies in flexible manufacturing for sustainable organizational value: Reflections from a multiple case study of Italian manufacturers. Inf. Syst. Front. 2023, 25, 995–1016. [Google Scholar] [CrossRef]
- Leng, J.; Chen, Z.; Sha, W.; Lin, Z.; Lin, J.; Liu, Q. Digital twins-based flexible operating of open architecture production line for individualized manufacturing. Adv. Eng. Inform. 2022, 53, 101676. [Google Scholar] [CrossRef]
- Zhang, W.; Xiao, J.; Liu, W.; Sui, Y.; Li, Y.; Zhang, S. Individualized requirement-driven multi-task scheduling in cloud manufacturing using an extended multifactorial evolutionary algorithm. Comput. Ind. Eng. 2023, 179, 109178. [Google Scholar] [CrossRef]
- Ghaleb, M.; Zolfagharinia, H.; Taghipour, S. Real-time production scheduling in the Industry-4.0 context: Addressing uncertainties in job arrivals and machine breakdowns. Comput. Oper. Res. 2020, 123, 105031. [Google Scholar] [CrossRef]
- Luo, D.; Thevenin, S.; Dolgui, A. A state-of-the-art on production planning in Industry 4.0. Int. J. Prod. Res. 2023, 61, 6602–6632. [Google Scholar] [CrossRef]
- Sangaiah, A.K.; Suraki, M.Y.; Sadeghilalimi, M.; Bozorgi, S.M.; Hosseinabadi, A.A.R.; Wang, J. A new meta-heuristic algorithm for solving the flexible dynamic job-shop problem with parallel machines. Symmetry 2019, 11, 165. [Google Scholar] [CrossRef]
- Zhou, J.; Zheng, L.; Fan, W. Multirobot collaborative task dynamic scheduling based on multiagent reinforcement learning with heuristic graph convolution considering robot service performance. J. Manuf. Syst. 2024, 72, 122–141. [Google Scholar] [CrossRef]
- Han, X.; Cheng, W.; Meng, L.; Zhang, B.; Gao, K.; Zhang, C.; Duan, P. A dual population collaborative genetic algorithm for solving flexible job shop scheduling problem with AGV. Swarm. Evol. Comput. 2024, 86, 101538. [Google Scholar] [CrossRef]
- Pezzella, F.; Morganti, G.; Ciaschetti, G. A genetic algorithm for the Flexible Job-shop Scheduling Problem. Comput. Oper. Res. 2008, 35, 3202–3212. [Google Scholar] [CrossRef]
- Gui, Y.; Tang, D.; Zhu, H.; Zhang, Y.; Zhang, Z. Dynamic scheduling for flexible job shop using a deep reinforcement learning approach. Comput. Ind. Eng. 2023, 180, 109255. [Google Scholar] [CrossRef]
- Tang, D.B.; Dai, M.; Salido, M.A.; Giret, A. Energy-efficient dynamic scheduling for a flexible flow shop using an improved particle swarm optimization. Comput. Ind. 2016, 81, 82–95. [Google Scholar] [CrossRef]
- Monch, L.; Fowler, J.W.; Dauzere-Peres, S.; Mason, S.J.; Rose, O. A survey of problems, solution techniques, and future challenges in scheduling semiconductor manufacturing operations. J. Sched. 2011, 14, 583–599. [Google Scholar] [CrossRef]
- Purba, H.H.; Aisyah, S.; Dewarani, R. Production capacity planning in motorcycle assembly line using CRP method at PT XYZ. In Proceedings of the IOP Conference Series: Materials Science and Engineering, Chennai, India, 16–17 September 2020; IOP Publishing: Bristol, UK, 2020; Volume 885, p. 012029. [Google Scholar]
- Han, J.H.; Lee, J.Y. Scheduling for a flow shop with waiting time constraints and missing operations in semiconductor manufacturing. Eng. Optim. 2023, 55, 1742–1759. [Google Scholar] [CrossRef]
- Zhang, F.; Mei, Y.; Nguyen, S.; Zhang, M. Evolving scheduling heuristics via genetic programming with feature selection in dynamic flexible job-shop scheduling. IEEE Trans. Cybern. 2020, 51, 1797–1811. [Google Scholar] [CrossRef] [PubMed]
- Tang, H.; Xiao, Y.; Zhang, W.; Lei, D.; Wang, J.; Xu, T. A DQL-NSGA-III algorithm for solving the flexible job shop dynamic scheduling problem. Expert Syst. Appl. 2024, 237, 121723. [Google Scholar] [CrossRef]
- Jing, X.; Yao, X.; Liu, M.; Zhou, J. Multi-agent reinforcement learning based on graph convolutional network for flexible job shop scheduling. J. Intell. Manuf. 2024, 35, 75–93. [Google Scholar] [CrossRef]
- Ding, L.; Guan, Z.; Zhang, Z.; Fang, W.; Chen, Z.; Yue, L. A hybrid fluid master–apprentice evolutionary algorithm for large-scale multiplicity flexible job-shop scheduling with sequence-dependent set-up time. Eng. Optim. 2024, 56, 54–75. [Google Scholar] [CrossRef]
- Ding, L.; Guan, Z.; Rauf, M.; Yue, L. Multi-policy deep reinforcement learning for multi-objective multiplicity flexible job shop scheduling. Swarm. Evol. Comput. 2024, 87, 101550. [Google Scholar] [CrossRef]
- Guo, C.T.; Jiang, Z.B.; Zhang, H.; Li, N. Decomposition-based classified ant colony optimization algorithm for scheduling semiconductor wafer fabrication system. Comput. Ind. Eng. 2012, 62, 141–151. [Google Scholar] [CrossRef]
- Kundakci, N.; Kulak, O. Hybrid genetic algorithms for minimizing makespan in dynamic job shop scheduling problem. Comput. Ind. Eng. 2016, 96, 31–51. [Google Scholar] [CrossRef]
- Lei, D.; Zhang, J.; Liu, H. An Adaptive Two-Class Teaching-Learning-Based Optimization for Energy-Efficient Hybrid Flow Shop Scheduling Problems with Additional Resources. Symmetry 2024, 16, 203. [Google Scholar] [CrossRef]
- Liu, J.; Sun, B.; Li, G.; Chen, Y. Multi-objective adaptive large neighbourhood search algorithm for dynamic flexible job shop schedule problem with transportation resource. Eng. Appl. Artif. Intell. 2024, 132, 107917. [Google Scholar] [CrossRef]
- Pei, Z.; Zhang, X.F.; Zheng, L.; Wan, M.Z. A column generation-based approach for proportionate flexible two-stage no-wait job shop scheduling. Int. J. Prod. Res. 2020, 58, 487–508. [Google Scholar] [CrossRef]
- Subramaniam, V.; Ramesh, T.; Lee, G.K.; Wong, Y.S.; Hong, G.S. Job shop scheduling with dynamic fuzzy selection of dispatching rules. Int. J. Adv. Manuf. Technol. 2000, 16, 759–764. [Google Scholar] [CrossRef]
- Zhang, H.; Roy, U. A semantics-based dispatching rule selection approach for job shop scheduling. J. Intell. Manuf. 2019, 30, 2759–2779. [Google Scholar] [CrossRef]
- Zhang, F.F.; Mei, Y.; Nguyen, S.; Zhang, M.J. Correlation Coefficient-Based Recombinative Guidance for Genetic Programming Hyperheuristics in Dynamic Flexible Job Shop Scheduling. IEEE Trans. Evol. Comput. 2021, 25, 552–566. [Google Scholar] [CrossRef]
- Đurasević, M.; Jakobović, D. Selection of dispatching rules evolved by genetic programming in dynamic unrelated machines scheduling based on problem characteristics. J. Comput. Sci. 2022, 61, 101649. [Google Scholar] [CrossRef]
- Holthaus, O.; Rajendran, C. Efficient jobshop dispatching rules: Further developments. Prod. Plan. Control 2010, 11, 171–178. [Google Scholar] [CrossRef]
- Ren, W.; Yan, Y.; Hu, Y.; Guan, Y. Joint optimisation for dynamic flexible job-shop scheduling problem with transportation time and resource constraints. Int. J. Prod. Res. 2021, 60, 5675–5696. [Google Scholar] [CrossRef]
- Fuladi, S.K.; Kim, C.S. Dynamic Events in the Flexible Job-Shop Scheduling Problem: Rescheduling with a Hybrid Metaheuristic Algorithm. Algorithms 2024, 17, 142. [Google Scholar] [CrossRef]
- Thi, L.M.; Mai Anh, T.T.; Van Hop, N. An improved hybrid metaheuristics and rule-based approach for flexible job-shop scheduling subject to machine breakdowns. Eng. Optim. 2023, 55, 1535–1555. [Google Scholar] [CrossRef]
- Guo, H.; Liu, J.; Wang, Y.; Zhuang, C. An improved genetic programming hyper-heuristic for the dynamic flexible job shop scheduling problem with reconfigurable manufacturing cells. J. Manuf. Syst. 2024, 74, 252–263. [Google Scholar] [CrossRef]
- Mohan, J.; Lanka, K.; Rao, A.N. A Review of Dynamic Job Shop Scheduling Techniques. Procedia Manuf. 2019, 30, 34–39. [Google Scholar] [CrossRef]
- Baykasoğlu, A.; Madenoğlu, F.S.; Hamzadayı, A. Greedy randomized adaptive search for dynamic flexible job-shop scheduling. J. Manuf. Syst. 2020, 56, 425–451. [Google Scholar] [CrossRef]
- Zhang, H.; Buchmeister, B.; Li, X.; Ojstersek, R. An Efficient Metaheuristic Algorithm for Job Shop Scheduling in a Dynamic Environment. Mathematics 2023, 11, 2336. [Google Scholar] [CrossRef]
- Xie, J.; Gao, L.; Peng, K.; Li, X.; Li, H. Review on flexible job shop scheduling. IET Collab. Intell. Manuf. 2019, 1, 67–77. [Google Scholar] [CrossRef]
- Chen, D.D.Y.H. Dynamic Scheduling of a Multiclass Fluid Network. Oper. Res. Lett. 1993, 41, 1104–1115. [Google Scholar] [CrossRef]
- Dai, J.G.; Weiss, G. A fluid heuristic for minimizing makespan in job shops. Oper. Res. 2002, 50, 692–707. [Google Scholar] [CrossRef]
- Bertsimas, D.; Gamarnik, D.; Sethuraman, J. From fluid relaxations to practical algorithms for high-multiplicity job-shop scheduling: The holding cost objective. Oper. Res. 2003, 51, 798–813. [Google Scholar] [CrossRef]
- Masin, M.; Raviv, T. Linear programming-based algorithms for the minimum makespan high multiplicity jobshop problem. J. Sched. 2014, 17, 321–338. [Google Scholar] [CrossRef]
- Gu, J.W.; Gu, M.Z.; Lu, X.W.; Zhang, Y. Asymptotically optimal policy for stochastic job shop scheduling problem to minimize makespan. J. Comb. Optim. 2018, 36, 142–161. [Google Scholar] [CrossRef]
- Bertsimas, D.; Nasrabadi, E.; Paschalidis, I.C. Robust Fluid Processing Networks. IEEE Trans. Autom. Control 2015, 60, 715–728. [Google Scholar] [CrossRef]
- Bertsimas, D.; Gamarnik, D. Asymptotically optimal algorithms for job shop scheduling and packet routing. J. Algorithms 1999, 33, 296–318. [Google Scholar] [CrossRef]
- Bertsimas, D.; Sethuraman, J. From fluid relaxations to practical algorithms for job shop scheduling: The makespan objective. Math. Program. 2002, 92, 61–102. [Google Scholar] [CrossRef]
- Nazarathy, Y.; Weiss, G. A fluid approach to large volume job shop scheduling. J. Sched. 2010, 13, 509–529. [Google Scholar] [CrossRef]
- Boudoukh, T.; Penn, M.; Weiss, G. Scheduling jobshops with some identical or similar jobs. J. Sched. 2001, 4, 177–199. [Google Scholar] [CrossRef]
- Shen, X.N.; Yao, X. Mathematical modeling and multi-objective evolutionary algorithms applied to dynamic flexible job shop scheduling problems. Inf. Sci. 2015, 298, 198–224. [Google Scholar] [CrossRef]
- Vinod, V.; Sridharan, R. Dynamic job-shop scheduling with sequence-dependent setup times: Simulation modeling and analysis. Int. J. Adv. Manuf. Technol. 2008, 36, 355–372. [Google Scholar] [CrossRef]
- Glover, F. Tabu search-part II. ORSA J. Comput. 1990, 2, 4–32. [Google Scholar] [CrossRef]
- Li, J.Q.; Pan, Q.K.; Liang, Y.C. An effective hybrid tabu search algorithm for multi-objective flexible job-shop scheduling problems. Comput. Ind. Eng. 2010, 59, 647–662. [Google Scholar] [CrossRef]
- González, M.A.; Vela, C.R.; Varela, R. Scatter search with path relinking for the flexible job shop scheduling problem. Eur. J. Oper. Res. 2015, 245, 35–45. [Google Scholar] [CrossRef]
- Kemmoé-Tchomté, S.; Lamy, D.; Tchernev, N. An effective multi-start multi-level evolutionary local search for the flexible job-shop problem. Eng. Appl. Artif. Intell. 2017, 62, 80–95. [Google Scholar] [CrossRef]
- Mandavi, S.; Shiri, M.E.; Rahnamayan, S. Metaheuristics in large-scale global continues optimization: A survey. Inf. Sci. 2015, 295, 407–428. [Google Scholar] [CrossRef]
- Chen, R.H.; Yang, B.; Li, S.; Wang, S.L. A self-learning genetic algorithm based on reinforcement learning for flexible job-shop scheduling problem. Comput. Ind. Eng. 2020, 149. [Google Scholar] [CrossRef]
- Defersha, F.M.; Rooyani, D. An efficient two-stage genetic algorithm for a flexible job-shop scheduling problem with sequence dependent attached/detached setup, machine release date and lag-time. Comput. Ind. Eng. 2020, 147. [Google Scholar] [CrossRef]
- Resende, T.A.F.M.G.C. Greedy randomized adaptive search procedures. J. Glob. Optim. 1995, 6, 109–133. [Google Scholar]
- García, S.; Molina, D.; Lozano, M.; Herrera, F. A study on the use of non-parametric tests for analyzing the evolutionary algorithms’ behaviour: A case study on the CEC’2005 special session on real parameter optimization. J. Heuristics 2009, 15, 617–644. [Google Scholar] [CrossRef]
- Brandimarte, P. Routing and scheduling in a flexible job shop by tabu search. Ann. Oper. Res. 1993, 41, 157–183. [Google Scholar] [CrossRef]
- Mastrolilli, M.; Gambardella, L.M. Effective neighbourhood functions for the flexible job shop problem. J. Sched. 2000, 3, 3–20. [Google Scholar] [CrossRef]
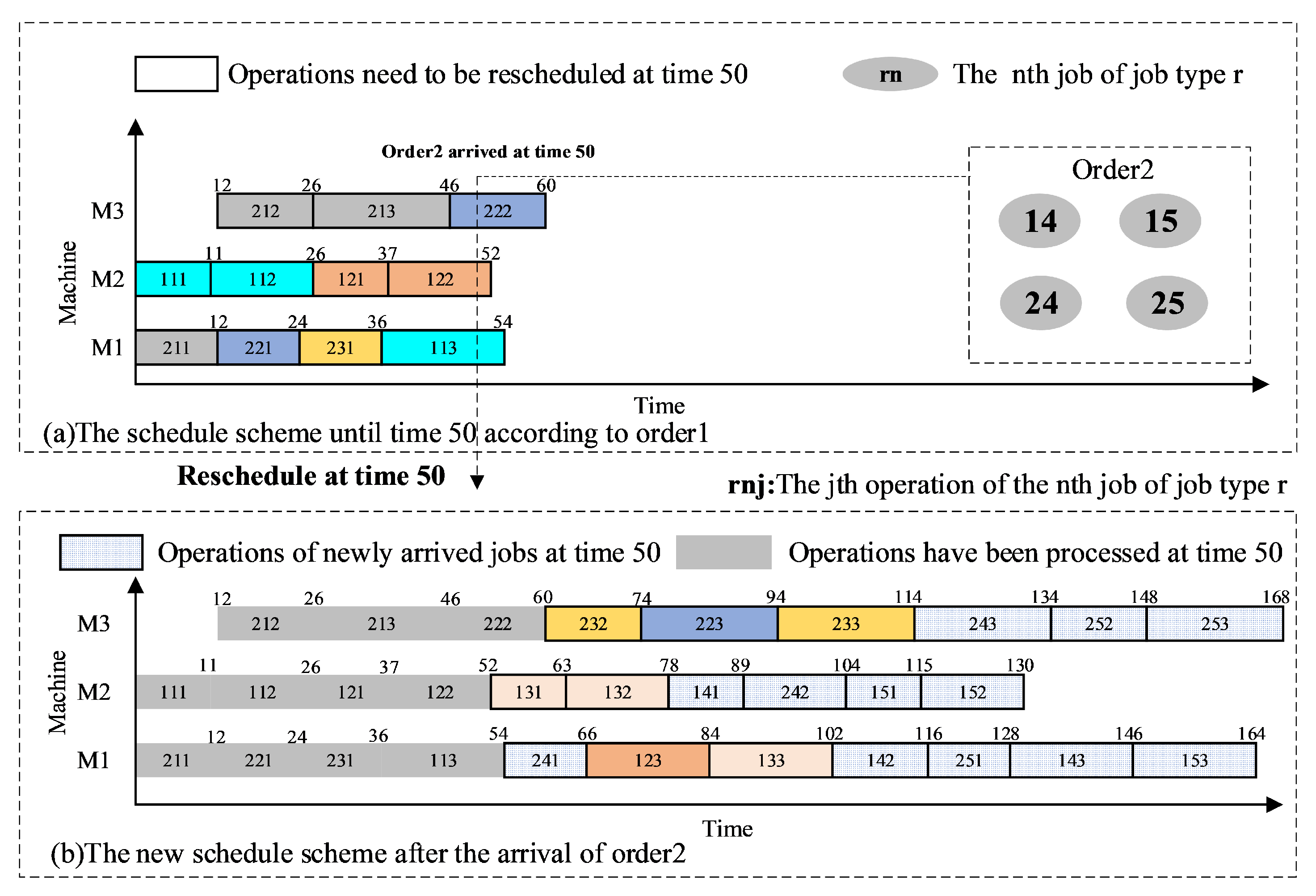

| Paper | Type of JSPs | Problem Scale | Objective | ||||
|---|---|---|---|---|---|---|---|
| Number of Multiplicity | Deterministic | Stochastic | Small | Large | Makespan | Holding Cost | |
| Bertsimas and Gamarnik (1999) [47] | Up to 2500 | ✔ | ✔ | ✔ | |||
| Boudoukh et al. (2001) [50] | Up to 1000 | ✔ | ✔ | ✔ | |||
| Dai and Weiss (2002) [42] | Up to 100,000 | ✔ | ✔ | ✔ | |||
| Bertsimas and Sethuraman (2002) [48] | Up to 1000 | ✔ | ✔ | ||||
| Bertsimas et al. (2003) [43] | Up to 10,000 | ✔ | ✔ | ✔ | |||
| Nazarathy and Weiss (2010) [49] | Up to | ✔ | ✔ | ✔ | |||
| Masin and Raviv (2014) [44] | Up to 10 | ✔ | ✔ | ✔ | |||
| Gu et al. (2018) [45] | Up to 100 | ✔ | ✔ | ✔ | |||
| r | j | |||||
|---|---|---|---|---|---|---|
| 1 | 29 | 11 | 28 | |||
| 3 | 2 | 1 | 2 | 14 | 15 | 24 |
| 3 | 18 | 25 | 25 | |||
| 1 | 12 | 16 | 25 | |||
| 3 | 2 | 2 | 2 | 22 | 15 | 14 |
| 3 | 26 | 26 | 20 |
| Parameter | Value |
|---|---|
| Total number of machines (M) | randi [10, 20] |
| Total number of job types (R) | randi [5, 10] |
| Total number of operations of job type r () | randi [5, 10] |
| Number of available machines per operation | randi [1, M] |
| Processing time of an operation () | randi [1, 20] |
| Total number of new orders (S) | randi [1, 5] |
| Total number of job type r in new order s () | randi [10, 20] |
| Mean interarrival time of new jobs () | randi [200, 800] |
| Combination | Parameters | |||
|---|---|---|---|---|
| 1 | 10 | 10 | 0.1 | 2010 |
| 2 | 10 | 20 | 0.2 | 2030.7 |
| 3 | 10 | 40 | 0.3 | 2017.7 |
| 4 | 10 | 80 | 0.4 | 2014 |
| 5 | 20 | 10 | 0.2 | 2025 |
| 6 | 20 | 20 | 0.1 | 2034 |
| 7 | 20 | 40 | 0.4 | 2016.7 |
| 8 | 20 | 80 | 0.3 | 2025.3 |
| 9 | 30 | 10 | 0.3 | 2032.3 |
| 10 | 30 | 20 | 0.4 | 2035.3 |
| 11 | 30 | 40 | 0.1 | 2021 |
| 12 | 30 | 80 | 0.2 | 2017.3 |
| 13 | 40 | 10 | 0.4 | 2024.7 |
| 14 | 40 | 20 | 0.3 | 2000.7 |
| 15 | 40 | 40 | 0.2 | 2006.3 |
| 16 | 40 | 80 | 0.1 | 2024.3 |
| Instance | M | R | S | FRAS_RANDOM | FRAS_TS | FRAS | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MD01 | 10 | 5 | 1 | 639 | 732.6 | 0.86 | 398 | 403.6 | 0.02 | 394 | 400.4 | 0.02 |
| MD02 | 10 | 5 | 3 | 2814 | 2951.6 | 1.05 | 1457 | 1468.4 | 0.02 | 1440 | 1457.2 | 0.01 |
| MD03 | 10 | 5 | 5 | 3489 | 3683.8 | 0.76 | 2101 | 2113.6 | 0.01 | 2089 | 2092.8 | 0.00 |
| MD04 | 10 | 10 | 1 | 1180 | 1277 | 1.30 | 570 | 575 | 0.04 | 555 | 556.4 | 0.00 |
| MD05 | 10 | 10 | 3 | 4721 | 5103 | 1.87 | 1789 | 1806 | 0.02 | 1778 | 1791.8 | 0.01 |
| MD06 | 10 | 10 | 5 | 9370 | 9569.6 | 2.07 | 3127 | 3137.2 | 0.00 | 3122 | 3148.2 | 0.01 |
| MD07 | 20 | 5 | 1 | 452 | 492.8 | 0.30 | 380 | 380 | 0.00 | 380 | 380 | 0.00 |
| MD08 | 20 | 5 | 3 | 3794 | 3841.2 | 0.09 | 3545 | 3548.4 | 0.00 | 3540 | 3541.6 | 0.00 |
| MD09 | 20 | 5 | 5 | 2347 | 2419.2 | 0.17 | 2078 | 2078 | 0.00 | 2075 | 2075 | 0.00 |
| MD10 | 20 | 10 | 1 | 775 | 929.4 | 1.53 | 395 | 401.4 | 0.09 | 367 | 373.6 | 0.02 |
| MD11 | 20 | 10 | 3 | 2577 | 2727.8 | 0.37 | 1992 | 1993.6 | 0.00 | 1986 | 1988.8 | 0.00 |
| MD12 | 20 | 10 | 5 | 3539 | 3667.6 | 0.34 | 2768 | 2773.2 | 0.01 | 2737 | 2737 | 0.00 |
| #better | 12 | 11 | ||||||||||
| #even | 0 | 1 | ||||||||||
| #worse | 0 | 0 | ||||||||||
| Instance | SLGA | 2SGA | GRAS | FRAS | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MD01 | 648 | 660.4 | 0.68 | 414 | 419.2 | 0.06 | 479 | 482.4 | 0.22 | 394 | 400.4 | 0.02 |
| MD02 | 2230 | 2282.8 | 0.59 | 1503 | 1511.4 | 0.05 | 1739 | 1754.2 | 0.22 | 1440 | 1457.2 | 0.01 |
| MD03 | 2928 | 2989.8 | 0.43 | 2131 | 2147.2 | 0.03 | 2255 | 2281 | 0.09 | 2089 | 2092.8 | 0.00 |
| MD04 | 1051 | 1086 | 0.96 | 619 | 625.4 | 0.13 | 674 | 684.6 | 0.23 | 555 | 556.4 | 0.00 |
| MD05 | 4461 | 4517.2 | 1.54 | 2151 | 2163.8 | 0.22 | 2328 | 2344.2 | 0.32 | 1778 | 1791.8 | 0.01 |
| MD06 | 9189 | 9333.2 | 1.99 | 3916 | 3935.4 | 0.26 | 4360 | 4392.2 | 0.41 | 3122 | 3148.2 | 0.01 |
| MD07 | 420 | 436 | 0.15 | 380 | 380 | 0.00 | 393 | 396.2 | 0.04 | 380 | 380 | 0.00 |
| MD08 | 3795 | 3815 | 0.08 | 3543 | 3543.8 | 0.00 | 3560 | 3565.8 | 0.01 | 3540 | 3541.6 | 0.00 |
| MD09 | 2155 | 2168.2 | 0.04 | 2075 | 2075.6 | 0.00 | 2231 | 2255 | 0.09 | 2075 | 2075 | 0.00 |
| MD10 | 756 | 792.4 | 1.16 | 383 | 387 | 0.05 | 531 | 541.4 | 0.48 | 367 | 373.6 | 0.02 |
| MD11 | 2405 | 2419 | 0.22 | 2002 | 2011.2 | 0.01 | 2098 | 2106.4 | 0.06 | 1986 | 1988.8 | 0.00 |
| MD12 | 3135 | 3219.4 | 0.18 | 2754 | 2758 | 0.01 | 2929 | 2936.2 | 0.07 | 2737 | 2737 | 0.00 |
| #better | 12 | 10 | 12 | |||||||||
| #even | 0 | 2 | 0 | |||||||||
| #worse | 0 | 0 | 0 | |||||||||
| Instance | SLGA | 2SGA | GRAS | FRAS | ||||
|---|---|---|---|---|---|---|---|---|
| TCPU (s) | TR (s) | TCPU (s) | TR (s) | TCPU (s) | TR (s) | CPU (s) | TR (s) | |
| MD01 | 810.91 | 158.34 | 817.53 | 128.01 | 801.36 | 104.01 | 811.41 | 77.13 |
| MD02 | 2692.95 | 515.80 | 2627.61 | 405.75 | 2522.59 | 336.10 | 2593.53 | 204.81 |
| MD03 | 4617.25 | 873.66 | 4210.52 | 638.91 | 4048.66 | 516.81 | 4175.16 | 332.65 |
| MD04 | 1486.13 | 286.94 | 1479.06 | 246.47 | 1462.64 | 128.97 | 1472.91 | 218.72 |
| MD05 | 7037.06 | 1312.37 | 6870.16 | 1208.66 | 6454.06 | 589.96 | 6615.44 | 584.89 |
| MD06 | 17,062.52 | 2928.87 | 15,696.34 | 2623.23 | 13,776.69 | 2038.57 | 14,340.09 | 898.58 |
| MD07 | 1690.17 | 280.26 | 1688.42 | 10.19 | 1680.81 | 224.95 | 1685.28 | 3.22 |
| MD08 | 4471.08 | 843.80 | 4469.41 | 554.09 | 4425.31 | 374.18 | 4436.13 | 260.98 |
| MD09 | 8368.03 | 1497.52 | 8192.67 | 65.39 | 8194.89 | 1016.40 | 8128.34 | 21.76 |
| MD10 | 3156.47 | 614.29 | 3154.64 | 291.18 | 3121.53 | 400.18 | 3132.09 | 344.46 |
| MD11 | 10,460.31 | 2011.12 | 9734.64 | 1338.01 | 9601.25 | 1256.72 | 9600.47 | 852.91 |
| MD12 | 15,184.58 | 2880.93 | 14,310.42 | 905.46 | 14,043.11 | 1906.02 | 14,065.84 | 1379.80 |
| Example | SLGA | 2SGA | GRAS | FRAS | ||||
|---|---|---|---|---|---|---|---|---|
| TR (s) | TR (s) | TR (s) | TR (s) | |||||
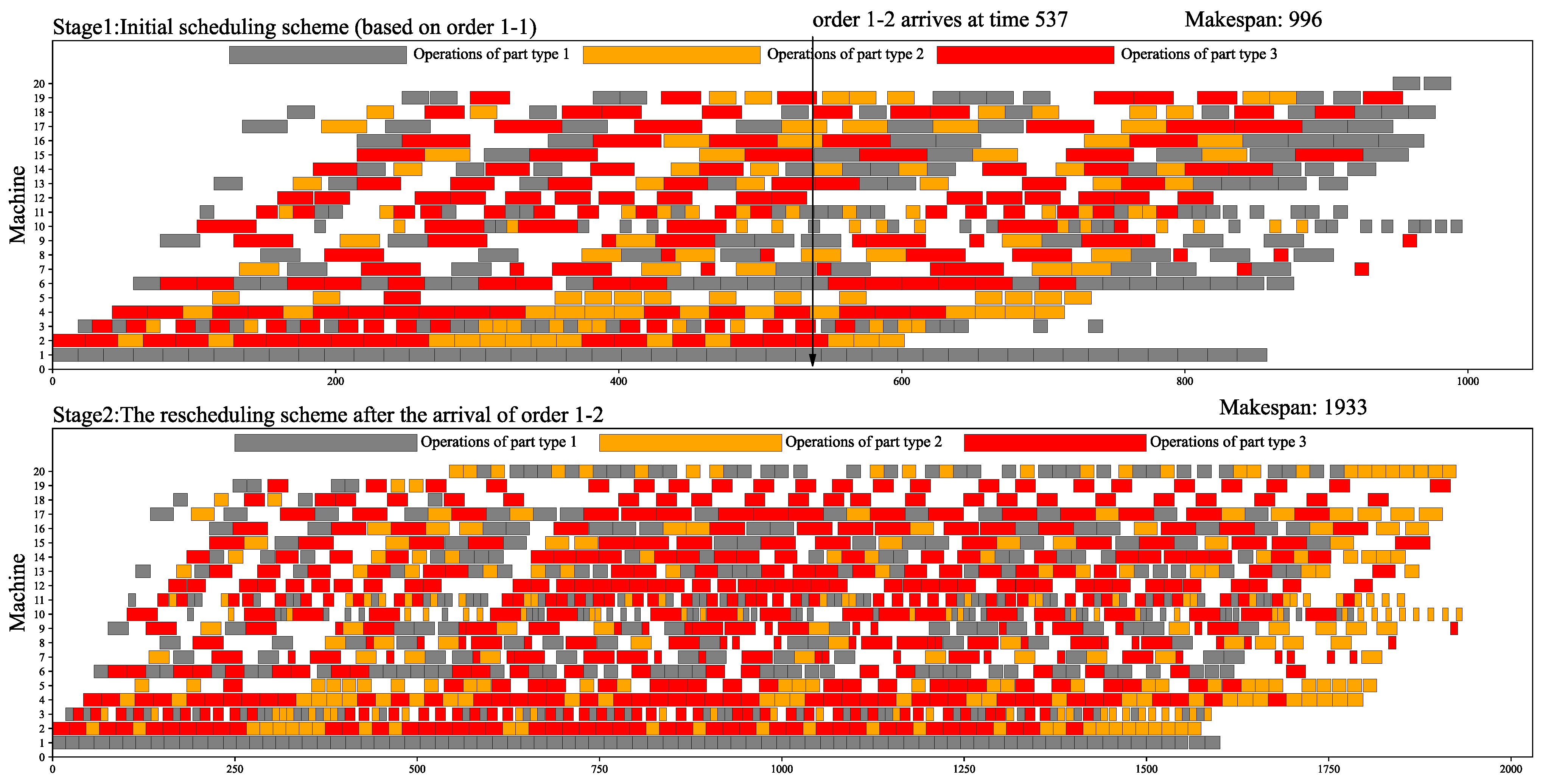
| Data01 | 3501 (3529) | 558.6 | 2851 (2960) | 548.5 | 2108 (2124) | 250.7 | 1933 (1959) | 39.5 |
| Data02 | 3828 (3856) | 718.6 | 3483 (3524) | 598.6 | 3416 (3422) | 412.2 | 3327 (3328) | 136.9 |
| Data03 | 6107 (6168) | 1072.8 | 5785 (5839) | 1002.5 | 5493 (5499) | 570.7 | 5376 (5378) | 199.4 |
| Data04 | 8358 (8443) | 1651.5 | 7566 (7572) | 1533.6 | 6632 (6641) | 736.5 | 6431 (6433) | 428.7 |
| Data05 | 10,698 (10,785) | 1803.5 | 9369 (9532) | 1748.2 | 6801 (6806) | 647.4 | 6502 (6504) | 273.2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ding, L.; Guan, Z.; Luo, D.; Rauf, M.; Fang, W. An Adaptive Search Algorithm for Multiplicity Dynamic Flexible Job Shop Scheduling with New Order Arrivals. Symmetry 2024, 16, 641. https://doi.org/10.3390/sym16060641
Ding L, Guan Z, Luo D, Rauf M, Fang W. An Adaptive Search Algorithm for Multiplicity Dynamic Flexible Job Shop Scheduling with New Order Arrivals. Symmetry. 2024; 16(6):641. https://doi.org/10.3390/sym16060641
Chicago/Turabian StyleDing, Linshan, Zailin Guan, Dan Luo, Mudassar Rauf, and Weikang Fang. 2024. "An Adaptive Search Algorithm for Multiplicity Dynamic Flexible Job Shop Scheduling with New Order Arrivals" Symmetry 16, no. 6: 641. https://doi.org/10.3390/sym16060641
APA StyleDing, L., Guan, Z., Luo, D., Rauf, M., & Fang, W. (2024). An Adaptive Search Algorithm for Multiplicity Dynamic Flexible Job Shop Scheduling with New Order Arrivals. Symmetry, 16(6), 641. https://doi.org/10.3390/sym16060641