
Multi-Task Conformer with Multi-Feature Combination for Speech Emotion Recognition


Abstract
:1. Introduction
2. Related Works
2.1. Deep Learning-Based Speech Emotion Recognition
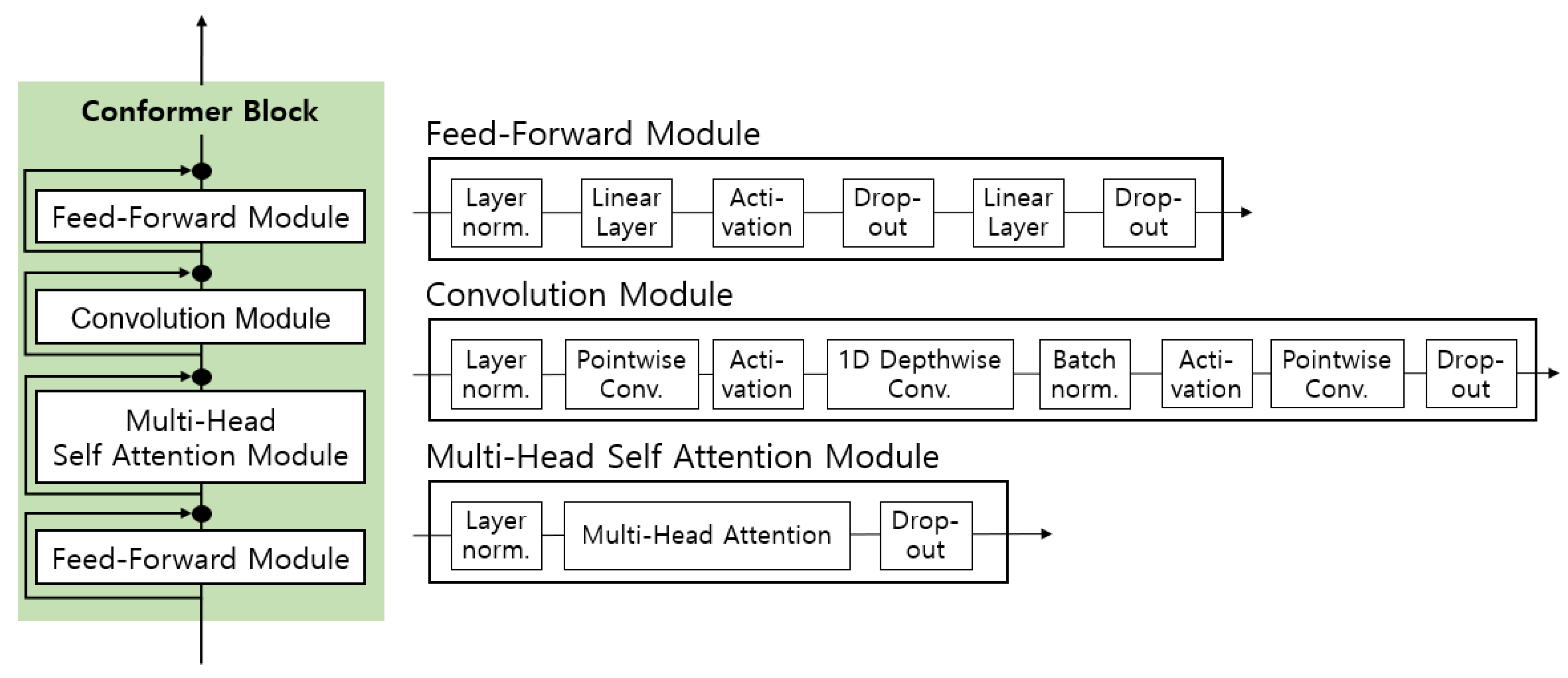
2.2. Conformer
2.3. Multi-Task Learning
2.4. Speech Features
3. Proposed Method
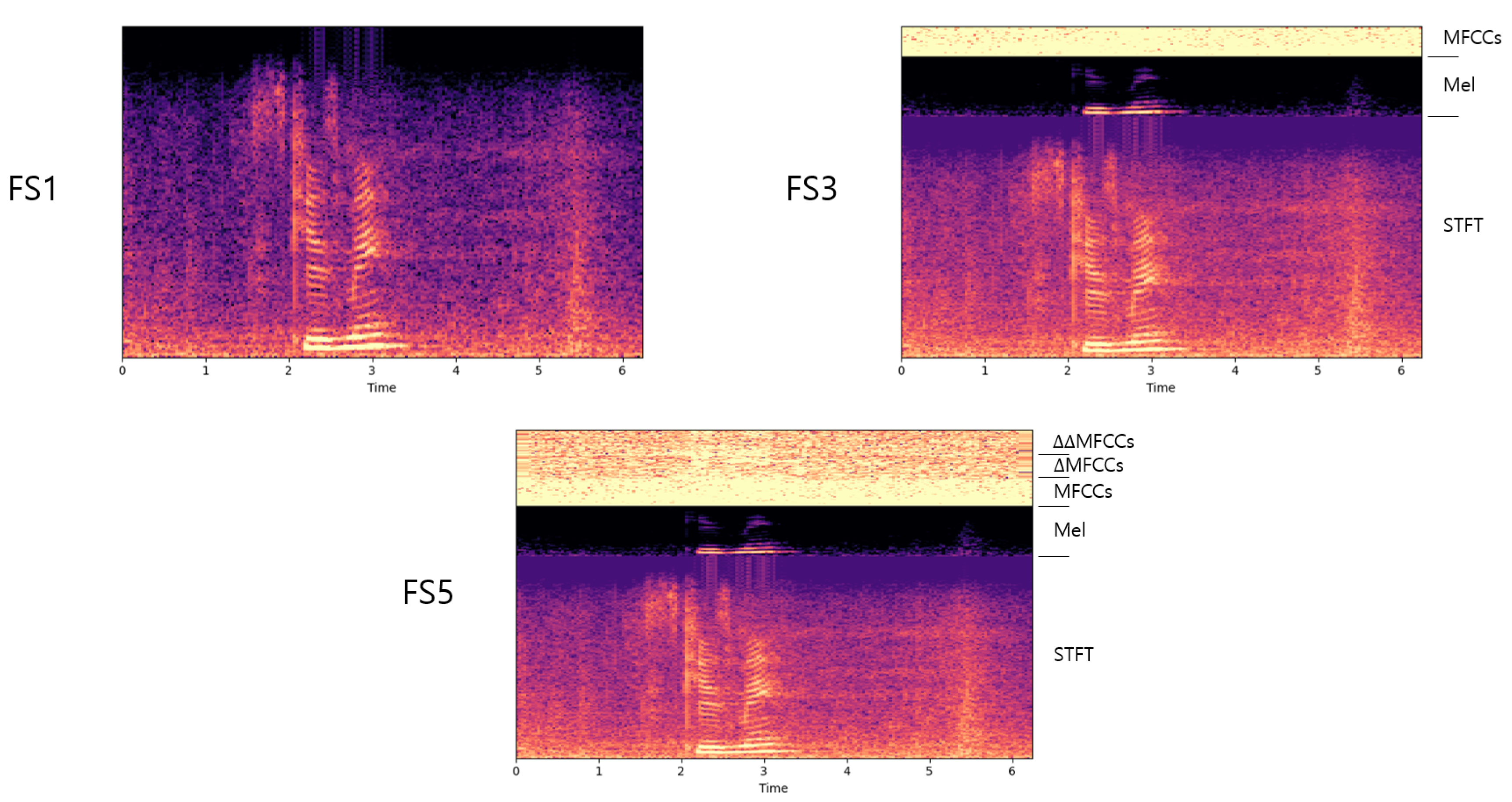
3.1. Multi-Feature Combination
3.2. Conformer-Based Model
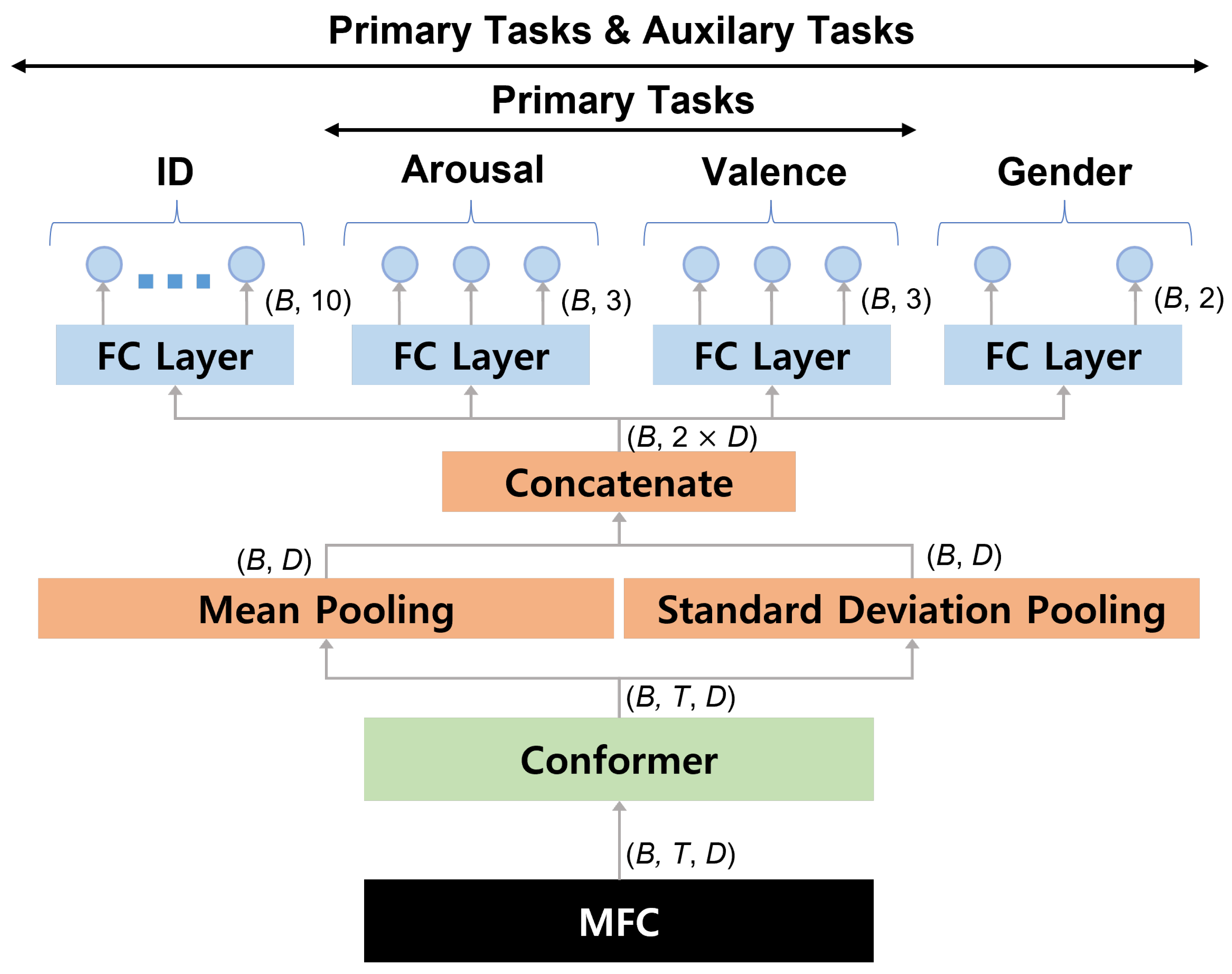
3.3. Multi-Task Learning
4. Experimental Setup
4.1. Model
4.2. Dataset
4.3. Feature Extraction and MFC
4.4. Training and Evaluation
5. Results
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Gulati, A.; Qin, J.; Chiu, C.C.; Parmar, N.; Zhang, Y.; Yu, J.; Han, W.; Wang, S.; Zhang, Z.; Wu, Y.; et al. Conformer: Convolution-augmented transformer for speech recognition. In Proceedings of the INTERSPEECH, ISCA, Shanghai, China, 25–29 October 2020; Volume 2020, pp. 5036–5040. [Google Scholar]
- Xu, Q.; Baevski, A.; Likhomanenko, T.; Tomasello, P.; Conneau, A.; Collobert, R.; Synnaeve, G.; Auli, M. Self-training and pre-training are complementary for speech recognition. In Proceedings of the ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), IEEE, Toronto, ON, Canada, 6–11 June 2021; pp. 3030–3034. [Google Scholar]
- Burkhardt, F.; Ajmera, J.; Englert, R.; Stegmann, J.; Burleson, W. Detecting anger in automated voice portal dialogs. In Proceedings of the INTERSPEECH, ISCA, Pittsburgh, PA, USA, 17–21 September 2006; Volume 2006, pp. 1053–1056. [Google Scholar]
- Huang, Z.; Epps, J.; Joachim, D. Speech landmark bigrams for depression detection from naturalistic smartphone speech. In Proceedings of the ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), IEEE, Brighton, UK, 12–17 May 2019; pp. 5856–5860. [Google Scholar]
- Busso, C.; Bulut, M.; Lee, C.C.; Kazemzadeh, A.; Mower, E.; Kim, S.; Chang, J.N.; Lee, S.; Narayanan, S.S. IEMOCAP: Interactive emotional dyadic motion capture database. Lang. Resour. Eval. 2008, 42, 335–359. [Google Scholar] [CrossRef]
- Singh, P.; Saha, G.; Sahidullah, M. Deep scattering network for speech emotion recognition. arXiv 2021, arXiv:2105.04806. [Google Scholar]
- Provost, E.M.; Shangguan, Y.; Busso, C. UMEME: University of Michigan emotional McGurk effect data set. IEEE Trans. Affect. Comput. 2015, 6, 395–409. [Google Scholar] [CrossRef]
- Parthasarathy, S.; Busso, C. Jointly Predicting Arousal, Valence and Dominance with Multi-Task Learning. In Interspeech; ISCA: Stockholm, Sweden, 2017; Volume 2017, pp. 1103–1107. [Google Scholar]
- Chen, J.M.; Chang, P.C.; Liang, K.W. Speech Emotion Recognition Based on Joint Self-Assessment Manikins and Emotion Labels. In Proceedings of the 2019 IEEE International Symposium on Multimedia (ISM), IEEE, San Diego, CA, USA, 9–11 December 2019; pp. 327–3273. [Google Scholar]
- Atmaja, B.T.; Akagi, M. Improving Valence Prediction in Dimensional Speech Emotion Recognition Using Linguistic Information. In Proceedings of the 2020 23rd Conference of the Oriental COCOSDA International Committee for the Co-Ordination and Standardisation of Speech Databases and Assessment Techniques (O-COCOSDA), IEEE, Yangon, Myanmar, 5–7 November 2020; pp. 166–171. [Google Scholar]
- Metallinou, A.; Wollmer, M.; Katsamanis, A.; Eyben, F.; Schuller, B.; Narayanan, S. Context-sensitive learning for enhanced audiovisual emotion classification. IEEE Trans. Affect. Comput. 2012, 3, 184–198. [Google Scholar] [CrossRef]
- Zhang, Z.; Wu, B.; Schuller, B. Attention-augmented end-to-end multi-task learning for emotion prediction from speech. In Proceedings of the ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), IEEE, Brighton, UK, 12–17 May 2019; pp. 6705–6709. [Google Scholar]
- Latif, S.; Rana, R.; Khalifa, S.; Jurdak, R.; Epps, J.; Schuller, B.W. Multi-task semi-supervised adversarial autoencoding for speech emotion recognition. IEEE Trans. Affect. Comput. 2020, 11, 992–1004. [Google Scholar] [CrossRef] [Green Version]
- Lian, Z.; Liu, B.; Tao, J. CTNet: Conversational transformer network for emotion recognition. IEEE/ACM Trans. Audio, Speech, Lang. Process. 2021, 29, 985–1000. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Long Beach, CA, USA, 2017; pp. 5998–6008. [Google Scholar]
- Zhang, Y.; Qin, J.; Park, D.S.; Han, W.; Chiu, C.C.; Pang, R.; Le, Q.V.; Wu, Y. Pushing the limits of semi-supervised learning for automatic speech recognition. arXiv 2020, arXiv:2010.10504. [Google Scholar]
- Chan, W.; Park, D.; Lee, C.; Zhang, Y.; Le, Q.; Norouzi, M. SpeechStew: Simply mix all available speech recognition data to train one large neural network. arXiv 2021, arXiv:2104.02133. [Google Scholar]
- Shor, J.; Jansen, A.; Han, W.; Park, D.; Zhang, Y. Universal Paralinguistic Speech Representations Using Self-Supervised Conformers. arXiv 2021, arXiv:2110.04621. [Google Scholar]
- Xia, R.; Liu, Y. A multi-task learning framework for emotion recognition using 2D continuous space. IEEE Trans. Affect. Comput. 2017, 8, 3–14. [Google Scholar] [CrossRef]
- Kim, J.G.; Lee, B. Appliance classification by power signal analysis based on multi-feature combination multi-layer LSTM. Energies 2019, 12, 2804. [Google Scholar] [CrossRef] [Green Version]
- Wang, X.; Wang, M.; Qi, W.; Su, W.; Wang, X.; Zhou, H. A Novel end-to-end Speech Emotion Recognition Network with Stacked Transformer Layers. In Proceedings of the ICASSP 2021 - 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), IEEE, Toronto, ON, Canada, 6–11 June 2021; pp. 6289–6293. [Google Scholar]
- Li, Y.; Zhao, T.; Kawahara, T. Improved End-to-End Speech Emotion Recognition Using Self Attention Mechanism and Multitask Learning. In Interspeech; ISCA: Graz, Austria, 2019; pp. 2803–2807. [Google Scholar]
- Makhzani, A.; Shlens, J.; Jaitly, N.; Goodfellow, I.; Frey, B. Adversarial autoencoders. arXiv 2015, arXiv:1511.05644. [Google Scholar]
- Rana, R.; Latif, S.; Khalifa, S.; Jurdak, R.; Epps, J. Multi-task semisupervised adversarial autoencoding for speech emotion. arXiv 2019, arXiv:1907.06078. [Google Scholar]
- Tits, N.; Haddad, K.E.; Dutoit, T. Asr-based features for emotion recognition: A transfer learning approach. arXiv 2018, arXiv:1805.09197. [Google Scholar]
- Wu, J.; Dang, T.; Sethu, V.; Ambikairajah, E. A Novel Markovian Framework for Integrating Absolute and Relative Ordinal Emotion Information. arXiv 2021, arXiv:2108.04605. [Google Scholar] [CrossRef]
- Ramachandran, P.; Zoph, B.; Le, Q.V. Searching for activation functions. arXiv 2017, arXiv:1710.05941. [Google Scholar]
- Kim, Y.; Lee, H.; Provost, E.M. Deep learning for robust feature generation in audiovisual emotion recognition. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, IEEE, Vancouver, BC, Canada, 26–31 May 2013; pp. 3687–3691. [Google Scholar]
- Han, K.; Yu, D.; Tashev, I. Speech emotion recognition using deep neural network and extreme learning machine. In Interspeech 2014; ISCA: Singapore, 2014; Volume 2014, pp. 223–227. [Google Scholar]
- Meng, H.; Yan, T.; Yuan, F.; Wei, H. Speech emotion recognition from 3D log-mel spectrograms with deep learning network. IEEE Access 2019, 7, 125868–125881. [Google Scholar] [CrossRef]
- Wang, J.; Xue, M.; Culhane, R.; Diao, E.; Ding, J.; Tarokh, V. Speech emotion recognition with dual-sequence LSTM architecture. In Proceedings of the ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), IEEE, Barcelona, Spain, 4–8 May 2020; pp. 6474–6478. [Google Scholar]
- Fahad, M.S.; Deepak, A.; Pradhan, G.; Yadav, J. DNN-HMM-based speaker-adaptive emotion recognition using MFCC and epoch-based features. Circuits Syst. Signal Process. 2021, 40, 466–489. [Google Scholar] [CrossRef]
- Allen, J.B.; Rabiner, L.B. A unified approach to short-time Fourier analysis and synthesis. Proc. IEEE 1977, 65, 1558–1564. [Google Scholar] [CrossRef]
- Shen, J.; Pang, R.; Weiss, R.J.; Schuster, M.; Jaitly, N.; Yang, z.; Chen, Z.; Zhang, Y.; Wang, Y.; Skerrv-Ryan, R.; et al. Natural TTS synthesis by conditioning wavenet on mel spectrogram predictions. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), IEEE, Calgary, AB, Canada, 15–20 April 2018; pp. 4779–4783. [Google Scholar]
- Logan, B. Mel frequency cepstral coefficients for music modeling. In Proceedings of the 1st International Symposium on Music Information Retrieval (ISMIR), Plymouth, MA, USA, 23–25 October 2000. [Google Scholar]
- Singh, Y.B.; Goel, S. A systematic literature review of speech emotion recognition approaches. Neurocomputing 2022, 492, 245–263. [Google Scholar] [CrossRef]
- Snyder, D.; Garcia-Romero, D.; Sell, G.; Povey, D.; Khudanpur, S. X-vectors: Robust dnn embeddings for speaker recognition. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), IEEE, Calgary, AB, Canada, 15–20 April 2018; pp. 5329–5333. [Google Scholar]
- Lozano-Diez, A.; Plchot, O.; Matejka, P.; Gonzalez-Rodriguez, J. DNN based embeddings for language recognition. In Proceedings of the In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), IEEE, Calgary, AB, Canada, 15–20 April 2018; pp. 5184–5188. [Google Scholar]
- Cooper, E.; Lai, C.I.; Yasuda, Y.; Fang, F.; Wang, X.; Chen, N.; Yamagishi, J. Zero-shot multi-speaker text-to-speech with state-of-the-art neural speaker embeddings. In Proceedings of the ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), IEEE, Barcelona, Spain, 4–8 May 2020; pp. 6184–6188. [Google Scholar]
- McFee, B.; Raffel, C.; Liang, D.; Ellis, D.P.; McVicar, M.; Battenberg, E.; Nieto, O. librosa: Audio and music signal analysis in python. In Proceedings of the 14th Python in Science Conference, Austin, TX, USA, 6–12 July 2015; Volume 8, pp. 18–25. [Google Scholar]
- Park, D.S.; Chan, W.; Zhang, Y.; Chiu, C.C.; Zoph, B.; Cubuk, E.D.; Le, Q.V. SpecAugment: A Simple Data Augmentation Method for Automatic Speech Recognition. Interspeech 2019, 2019, 2613–2617. [Google Scholar] [CrossRef] [Green Version]

{kind=link}
{kind=link}
{kind=link}
| Model | Conformer S | Conformer M | Conformer L |
|---|---|---|---|
| Number of Parameters | 10.3 × 106 | 30.7 × 106 | 118.8 × 106 |
| Encoder Layers | 16 | 16 | 17 |
| Encoder Dimension | 144 | 256 | 512 |
| Decoder Dimension | 320 | 640 | 640 |
| W | F | T | p | ||
|---|---|---|---|---|---|
| 0 | 15 | 3 | 45 | 3 |
| Model | Arousal | Valence |
|---|---|---|
| Semi-supervised AAE (2020) [13] | 64.5 ± 1.5 | 62.2 ± 1.0 |
| Semi-supervised AAE (2019) [24] | 64.81 | 64.77 |
| MTC-SER | 70.0 ± 1.5 | 60.8 ± 1.3 |
| MTL Type | ||||
|---|---|---|---|---|
| Primary | Primary and Auxiliary | |||
| MFC Type | Arousal | Valence | Arousal | Valence |
| FS1 | 68.1 ± 2.5 | 60.0 ± 1.7 | 68.7 ± 2.2 | 60.0 ± 1.3 |
| FS3 | 68.2 ± 1.7 | 60.0 ± 1.8 | 69.0 ± 2.1 | 60.7 ± 2.0 |
| FS5 | 68.3 ± 2.3 | 58.8 ± 1.5 | 69.0 ± 2.8 | 59.7 ± 1.8 |
| Loss Weight Strategy | Major | Neutral | Minor | |
|---|---|---|---|---|
| MFC Type | FS1 | 68.7 ± 2.2 | 69.2 ± 3.1 | 68.7 ± 1.6 |
| FS3 | 69.0 ± 2.1 | 69.7 ± 1.7 | 69.1 ± 1.9 | |
| FS5 | 69.0 ± 2.8 | 69.9 ± 2.0 | 70.0 ± 1.5 | |
| Loss Weight Strategy | Major | Neutral | Minor | |
|---|---|---|---|---|
| MFC Type | FS1 | 60.0 ± 1.3 | 59.4 ± 2.1 | 52.9 ± 1.8 |
| FS3 | 60.7 ± 2.0 | 60.8 ± 1.3 | 53.1 ± 1.7 | |
| FS5 | 59.7 ± 1.8 | 59.0 ± 2.0 | 59.0 ± 2.0 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Seo, J.; Lee, B. Multi-Task Conformer with Multi-Feature Combination for Speech Emotion Recognition. Symmetry 2022, 14, 1428. https://doi.org/10.3390/sym14071428
Seo J, Lee B. Multi-Task Conformer with Multi-Feature Combination for Speech Emotion Recognition. Symmetry. 2022; 14(7):1428. https://doi.org/10.3390/sym14071428
Chicago/Turabian StyleSeo, Jiyoung, and Bowon Lee. 2022. "Multi-Task Conformer with Multi-Feature Combination for Speech Emotion Recognition" Symmetry 14, no. 7: 1428. https://doi.org/10.3390/sym14071428
APA StyleSeo, J., & Lee, B. (2022). Multi-Task Conformer with Multi-Feature Combination for Speech Emotion Recognition. Symmetry, 14(7), 1428. https://doi.org/10.3390/sym14071428