
Murine Motion Behavior Recognition Based on DeepLabCut and Convolutional Long Short-Term Memory Network


Abstract
1. Introduction
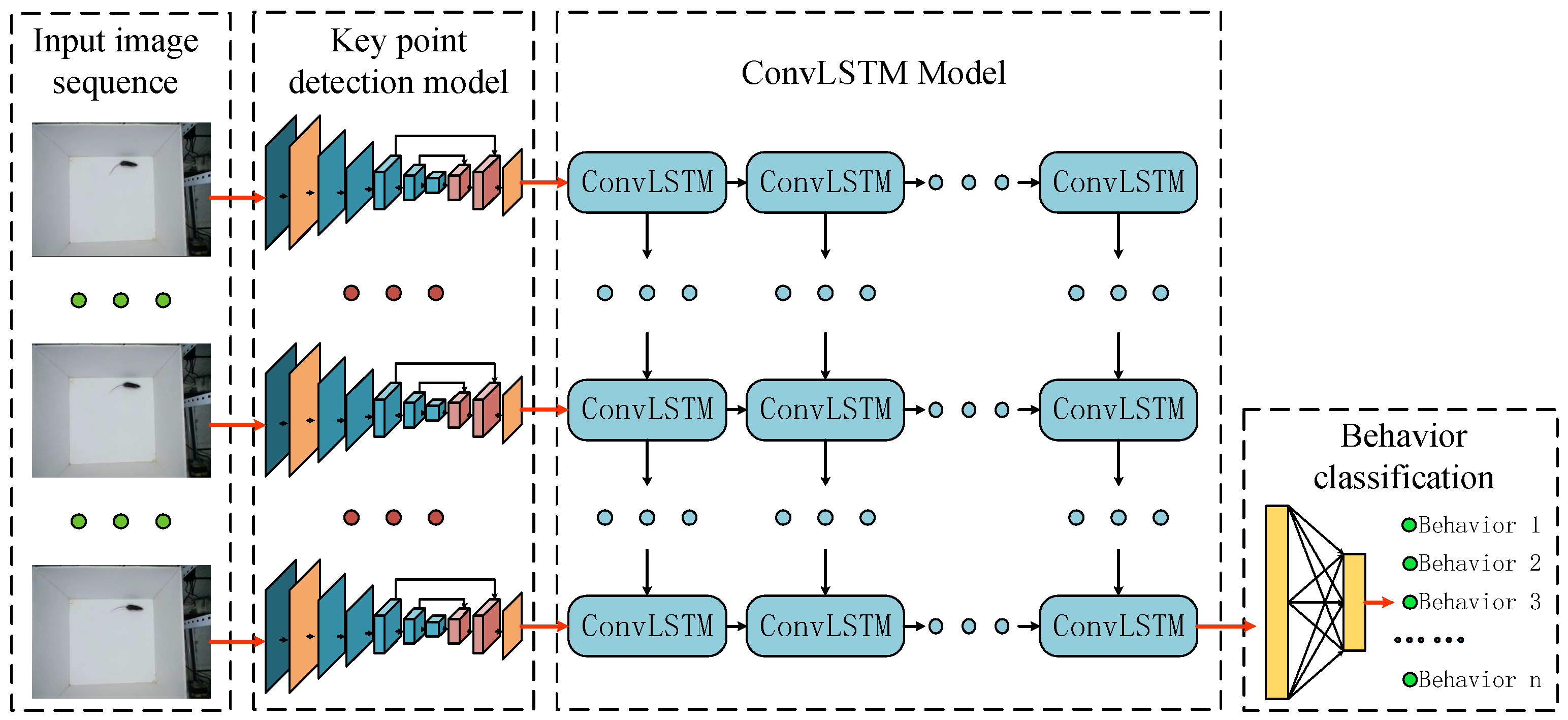
2. Motion Behavior Recognition Model
2.1. Structure of Algorithm
2.2. Improved DeepLabCut Network
2.3. Convolutional Long Short-Term Memory Network
3. Experiments and Results
3.1. Dataset
3.2. Evaluation Metrics
3.3. Experimental Details
3.4. Results
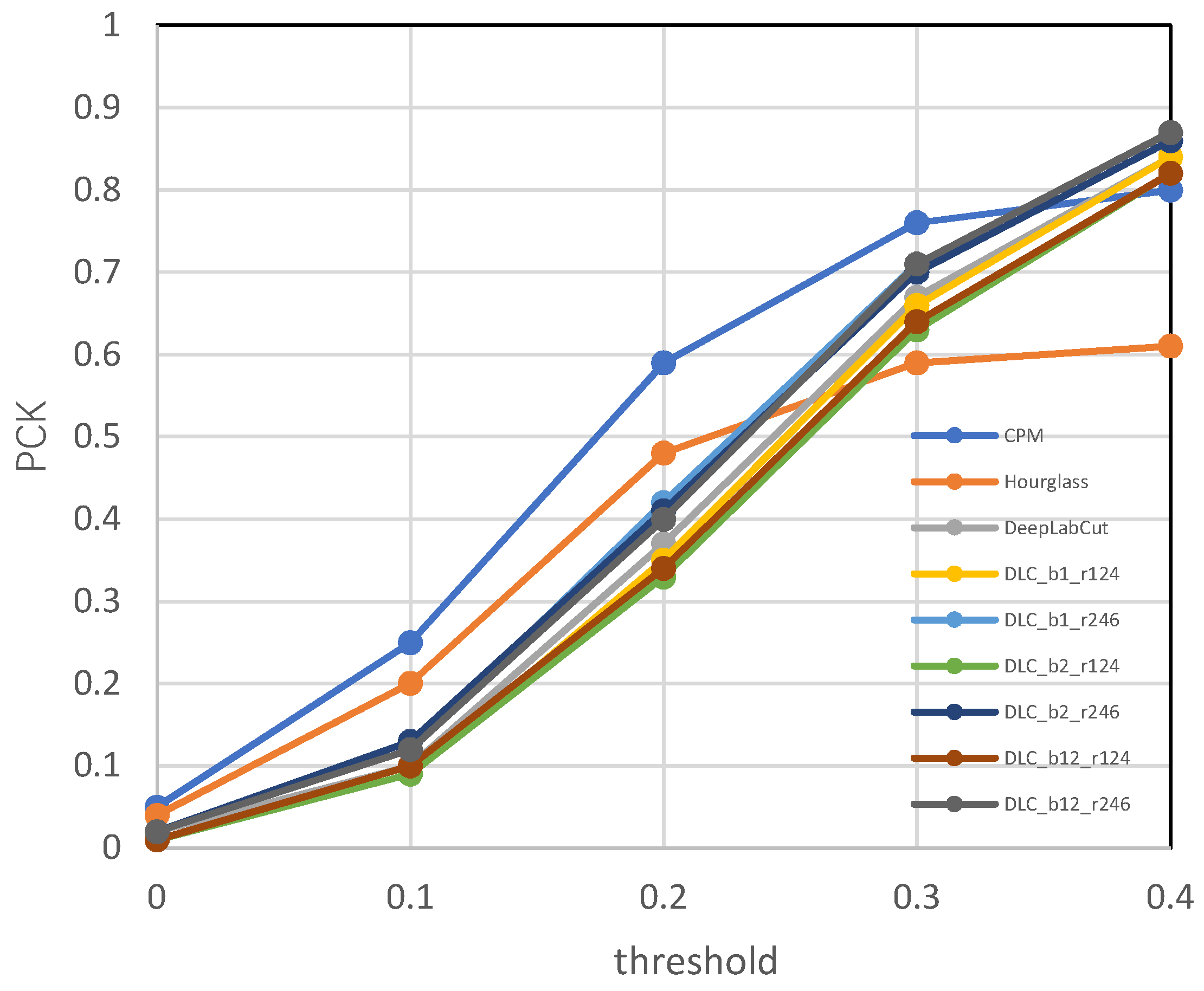
3.4.1. Results of Keypoint Detection
3.4.2. Results of Behavior Recognition
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Jin, W.L. Application of ethology to modern life science research. Lab. Anim. Comp. Med. 2008, 28, 1–3. [Google Scholar] [CrossRef]
- Xu, K. Outline of Neurobiology; Science Press: Beijing, China, 2001; pp. 1–15. ISBN 7030073975. [Google Scholar]
- Fernandez-Gonzalez, R.; Moreira, P.; Bilbao, A.; Jimenez, A.; Perez-Crespo, M. Long-term effect of in vitro culture of mouse embryos with serum on mRNA expression of imprinting genes, development, and behavior. Proc. Natl. Acad. Sci. USA 2004, 101, 5880–5885. [Google Scholar] [CrossRef] [PubMed]
- Zhang, S.; Yuan, S.; Huang, L.; Zheng, X.; Wu, Z.; Xu, K.; Pan, G. Human Mind Control of Rat Cyborg’s Continuous Locomotion with Wireless Brain-to-Brain Interface. Sci. Rep. 2019, 9, 1321. [Google Scholar] [CrossRef] [PubMed]
- May, C.H.; Sing, H.C.; Cephus, R.; Vogel, S.; Shaya, E.K.; Wagner, H.N. A new method of monitoring motor activity in baboons. Behav. Res. Methods Instrum. Comput. 1996, 28, 23–26. [Google Scholar] [CrossRef]
- Weerd, H.; Bulthuis, R.; Bergman, A.; Schlingmann, F.; Zutphen, L. Validation of a new system for the automatic registration of behaviour in mice and rats. Behav. Process. 2001, 53, 11–20. [Google Scholar] [CrossRef]
- Osechas, O.; Thiele, J.; Bitsch, J.; Wehrle, K. Ratpack: Wearable sensor networks for animal observation. In Proceedings of the International Conference of the IEEE Engineering in Medicine & Biology Society, Vancouver, BC, Canada, 20–25 August 2008. [Google Scholar] [CrossRef]
- Heeren, D.J.; Cools, A.R. Classifying postures of freely moving rodents with the help of fourier descriptors and a neural network. Behav. Res. Methods Instrum. Comput. 2000, 32, 56–62. [Google Scholar] [CrossRef][Green Version]
- Zhang, M. Study and Application of Animal Behavior Automatic Analysis Based on Posture Recognition; Zhejiang University: Hangzhou, China, 2005. [Google Scholar]
- Alexander, M.; Pranav, M.; Cury, K.M.; Taiga, A.; Murthy, V.N.; Weygandt, M.M.; Matthias, B. DeepLabCut: Markerless pose estimation of user-defined body parts with deep learning. Nat. Neurosci. 2018, 21, 1281–1290. [Google Scholar] [CrossRef]
- Nguyen, N.G.; Phan, D.; Lumbanraja, F.R.; Faisal, M.R.; Satou, K. Applying Deep Learning Models to Mouse Behavior Recognition. J. Biomed. Sci. Eng. 2019, 12, 183–196. [Google Scholar] [CrossRef]
- Carreira, J.; Zisserman, A. Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Du, T.; Wang, H.; Torresani, L.; Ray, J.; Lecun, Y. A Closer Look at Spatiotemporal Convolutions for Action Recognition. In Proceedings of the 31st IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar] [CrossRef]
- Liu, D.; Li, W.; Ma, C.; Zheng, W.; Yao, Y.; Tso, C.F.; Zhong, P.; Chen, X.; Song, J.H.; Choi, W.; et al. A common hub for sleep and motor control in the substantia nigra. Science 2020, 367, 440–448. [Google Scholar] [CrossRef]
- Milletari, F.; Navab, N.; Ahmadi, S.A. V-Net: Fully Convolutional Neural Networks for Volumetric Medical Image Segmentation. In Proceedings of the 4th IEEE International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 386–397. [Google Scholar] [CrossRef]
- Wang, H.; Kläser, A.; Schmid, C.; Liu, C.-L. Dense trajectories and motion boundary descriptors for action recognition. Int. J. Comput. Vis. 2013, 103, 60–79. [Google Scholar] [CrossRef]
- Fu, Z.R.; Wu, S.X.; Wu, X.Y. Human Action Recognition Using BI-LSTM Network Based on Spatial Features. J. East China Univ. Sci. Technol. 2021, 47, 225–232. [Google Scholar] [CrossRef]
- Lu, X.; Chia-Chih, C.; Aggarwal, J.K. View invariant human action recognition using histograms of 3D joints. In Proceedings of the 2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops (CVPR Workshops), Providence, RI, USA, 16–21 June 2012. [Google Scholar] [CrossRef]
- Yan, S.; Xiong, Y.; Lin, D. Spatial temporal graph convolutional networks for skeleton-based action recognition. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Shahroudy, A.; Liu, J.; Ng, T.-T.; Wang, G. NTU RGB plus D: A Large Scale Dataset for 3D Human Activity Analysis. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 27–30 June 2016; pp. 1010–1019. [Google Scholar] [CrossRef]
- Song, S.; Lan, C.; Xing, J. An end-to-end spatiotemporal attention model for human action recognition from skeleton data. arXiv 2016, arXiv:1611.06067. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, F.F. ImageNet: A Large-Scale Hierarchical Image Database. In Proceedings of the 2009 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2009), Miami, FL, USA, 20–25 June 2009. [Google Scholar] [CrossRef]
- Wei, S.E.; Ramakrishna, V.; Kanade, T.; Sheikh, Y. Convolutional Pose Machines. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 27–30 June 2016. [Google Scholar] [CrossRef]
- Newell, A.; Yang, K.U.; Deng, J. Stacked Hourglass Networks for Human Pose Estimation. In Proceedings of the 14th European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016; pp. 483–499. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Shi, X.; Chen, Z.; Wang, H.; Yeung, D.Y.; Wong, W.K.; Woo, W.C. Convolutional LSTM Network: A Machine Learning Approach for Precipitation Nowcasting. In Proceedings of the 29th Annual Conference on Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Hashimoto, T.; Izawa, Y.; Yokoyama, H.; Kato, T.; Moriizumi, T. A new video/computer method to measure the amount of overall movement in experimental animals (two-dimensional object-difference method). J. Neurosci. Methods 1999, 91, 115–122. [Google Scholar] [CrossRef]
- Andriluka, M.; Pishchulin, L.; Gehler, P.; Schiele, B. 2D Human Pose Estimation: New Benchmark and State of the Art Analysis. In Proceedings of the 27th IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014. [Google Scholar] [CrossRef]
- Ji, S.; Xu, W.; Yang, M.; Yu, K. 3D Convolutional Neural Networks for Human Action Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 221–231. [Google Scholar] [CrossRef]
- Jiang, H.; Pan, Y.; Zhang, J.; Yang, H. Battlefield Target Aggregation Behavior Recognition Model Based on Multi-Scale Feature Fusion. Symmetry 2019, 11, 761. [Google Scholar] [CrossRef]
- Zhu, M.K.; Lu, X.L. Human Action Recognition Algorithm Based on Bi-LSTMAttention Model. Laser Optoelectron. Prog. 2019, 56, 9. [Google Scholar] [CrossRef]
- Park, S.; On, B.W.; Lee, R.; Park, M.W.; Lee, S.H. A Bi–LSTM and k-NN Based Method for Detecting Major Time Zones of Overloaded Vehicles. Symmetry 2019, 11, 1160. [Google Scholar] [CrossRef]
- Risse, B.; Mangan, M.; Webb, B.; Pero, L.D. Visual Tracking of Small Animals in Cluttered Natural Environments Using a Freely Moving Camera. In Proceedings of the 16th IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar] [CrossRef]
- Lorbach, M.; Kyriakou, E.I.; Poppe, R.; van Dam, E.A.; Noldus, L.P.J.J.; Veltkamp, R.C. Learning to recognize rat social behavior: Novel dataset and cross-dataset application. J. Neurosci. Methods 2018, 300, 166–172. [Google Scholar] [CrossRef] [PubMed]
- Haalck, L.; Mangan, M.; Webb, B.; Risse, B. Towards image-based animal tracking in natural environments using a freely moving camera. J. Neurosci. Methods 2020, 330, 108455. [Google Scholar] [CrossRef] [PubMed]
- Graving, J.M.; Chae, D.; Naik, H.; Li, L.; Koger, B.; Costelloe, B.R.; Couzin, I.D. DeepPoseKit, a software toolkit for fast and robust animal pose estimation using deep learning. Elife 2019, 8, 1–14. [Google Scholar] [CrossRef]
- Pereira, T.D.; Aldarondo, D.E.; Willmore, L.; Kislin, M.; Wang, S.S.H.; Murthy, M.; Shaevitz, J.W. Fast animal pose estimation using deep neural networks. Nat. Methods 2019, 16, 117–125. [Google Scholar] [CrossRef]
- Franco-Restrepo, J.E.; Forero, D.A.; Vargas, R.A. A Review of Freely Available, Open-Source Software for the Automated Analysis of the Behavior of Adult Zebrafish. Zebrafish 2019, 16, 223–232. [Google Scholar] [CrossRef]
- van den Boom, B.J.G.; Pavlidi, P.; Wolf, C.J.H.; Mooij, A.H.; Willuhn, I. Automated classification of self-grooming in mice using open-source software. J. Neurosci. Methods 2017, 289, 48–56. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Keypoints | Heights | Avg | FPS | |||||
|---|---|---|---|---|---|---|---|---|---|
| Nose | Left Ear | Right Ear | Tail Root | 60 cm | 70 cm | 80 cm | |||
| CPM | 15.1 | ||||||||
| Hourglass | 14.5 | ||||||||
| DeepLabCut | 18.4 | ||||||||
| DLC_b1_r1 | 17.5 | ||||||||
| DLC_b1_r2 | 16.7 | ||||||||
| DLC_b2_r1 | 16.9 | ||||||||
| DLC_b2_r2 | 17.2 | ||||||||
| DLC_b12_r1 | 15.4 | ||||||||
| DLC_b12_r2 | 14.6 | ||||||||
| Sequence Length | Sequence Interval | Resting | Grooming | Standing Upright | Walking Straight | Tuning | Avg |
|---|---|---|---|---|---|---|---|
| 6 | 0 | ||||||
| 1 | |||||||
| 2 | |||||||
| 7 | 0 | ||||||
| 1 | |||||||
| 2 | |||||||
| 8 | 0 | ||||||
| 1 | |||||||
| 2 |
| Method | Resting | Grooming | Standing Upright | Walking Straight | Turning | Avg |
|---|---|---|---|---|---|---|
| LSTM | ||||||
| Bi-LSTM | ||||||
| 3DCNN | ||||||
| ConvLSTM |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, R.; Zhu, J.; Rao, X. Murine Motion Behavior Recognition Based on DeepLabCut and Convolutional Long Short-Term Memory Network. Symmetry 2022, 14, 1340. https://doi.org/10.3390/sym14071340
Liu R, Zhu J, Rao X. Murine Motion Behavior Recognition Based on DeepLabCut and Convolutional Long Short-Term Memory Network. Symmetry. 2022; 14(7):1340. https://doi.org/10.3390/sym14071340
Chicago/Turabian StyleLiu, Ruiqing, Juncai Zhu, and Xiaoping Rao. 2022. "Murine Motion Behavior Recognition Based on DeepLabCut and Convolutional Long Short-Term Memory Network" Symmetry 14, no. 7: 1340. https://doi.org/10.3390/sym14071340
APA StyleLiu, R., Zhu, J., & Rao, X. (2022). Murine Motion Behavior Recognition Based on DeepLabCut and Convolutional Long Short-Term Memory Network. Symmetry, 14(7), 1340. https://doi.org/10.3390/sym14071340