
A Few-Shot Dental Object Detection Method Based on a Priori Knowledge Transfer


Abstract
:1. Introduction
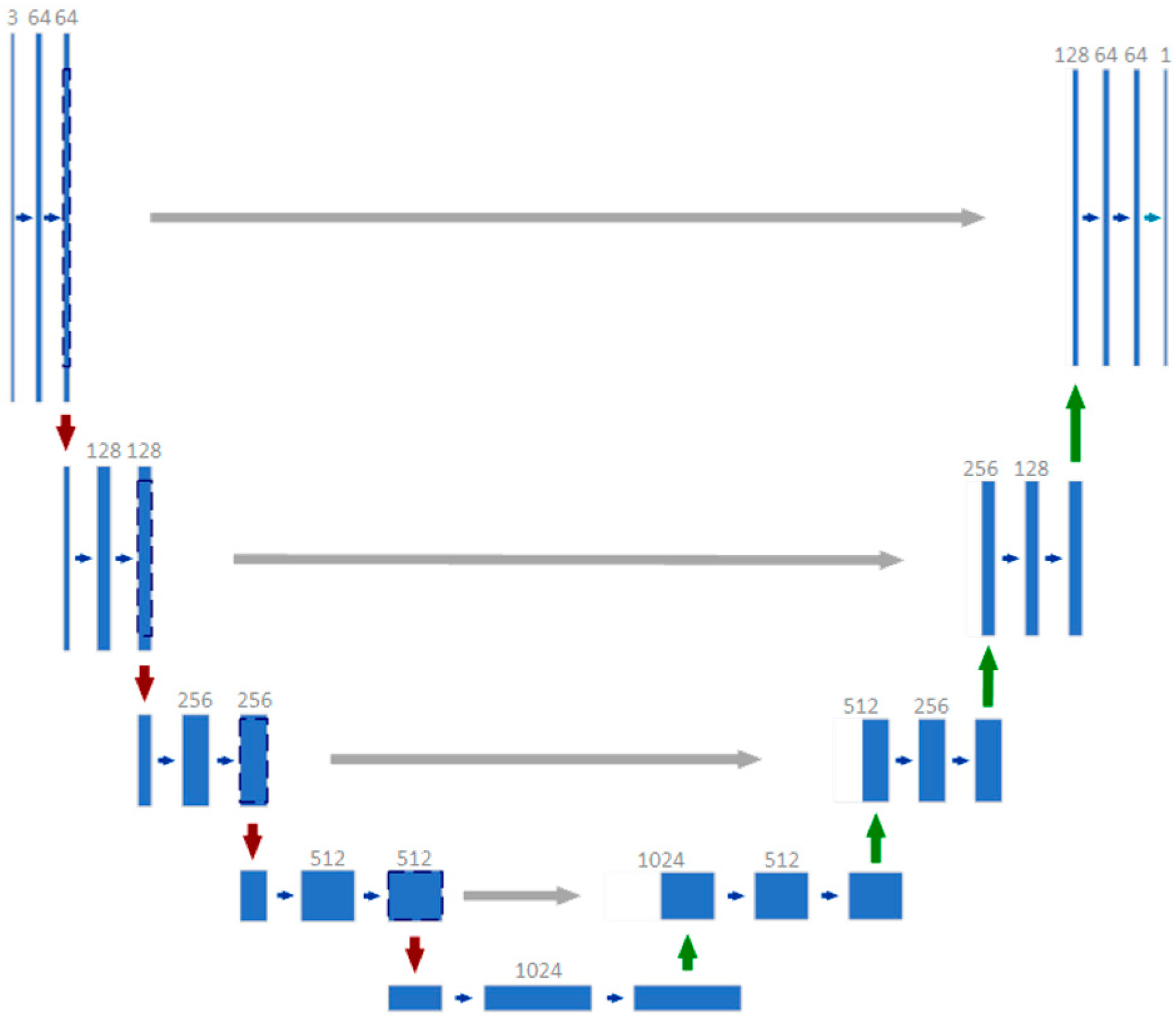
- Image segmentation technology is widely used in the field of medical image recognition, this study proposes an object detection method using dental image data, which uses a priori knowledge of dental semantics to generate a key point of the object instance. From the perspective of symmetry, in the process of generating the a priori knowledge feature map, the same structure of the network is used in the generation process of the edge and semantic feature map, and there is no master–slave relationship (as shown in Figure 1). Then, it generates a single object instance using the a priori knowledge of the object key point and the dental semantic. Compared with the direct use of a semantic segmentation model, the accuracy and recall of SPSC-NET are higher. In addition, the object detection in SPSC-NET is based on image segmentation. This technology is widely used and is a cornerstone method in the medical imaging field. Therefore, the proposed method is more suitable for dental medical images when compared to Faster-RCNN.
- 2.
- Since the characteristic differences between each kind of tooth are relatively small, improving the classification performance of teeth in the model can significantly improve the final object detection performance. This study proposes a tooth object classification method based on structural information images. In the specific case of teeth classification, the extracted dental semantic feature information is transferred to the target domain as a priori knowledge; the feature map of the a priori knowledge is called a tooth structure information feature. With only 10 training set images, the proposed method is superior to a neural network classification method based on grayscale teeth images. In addition, this study uses information entropy compression methods to enhance the classification performance, which was proven through experiments.
2. Related Works
3. Few-Shot Teeth Detection Method-SPSC-NET
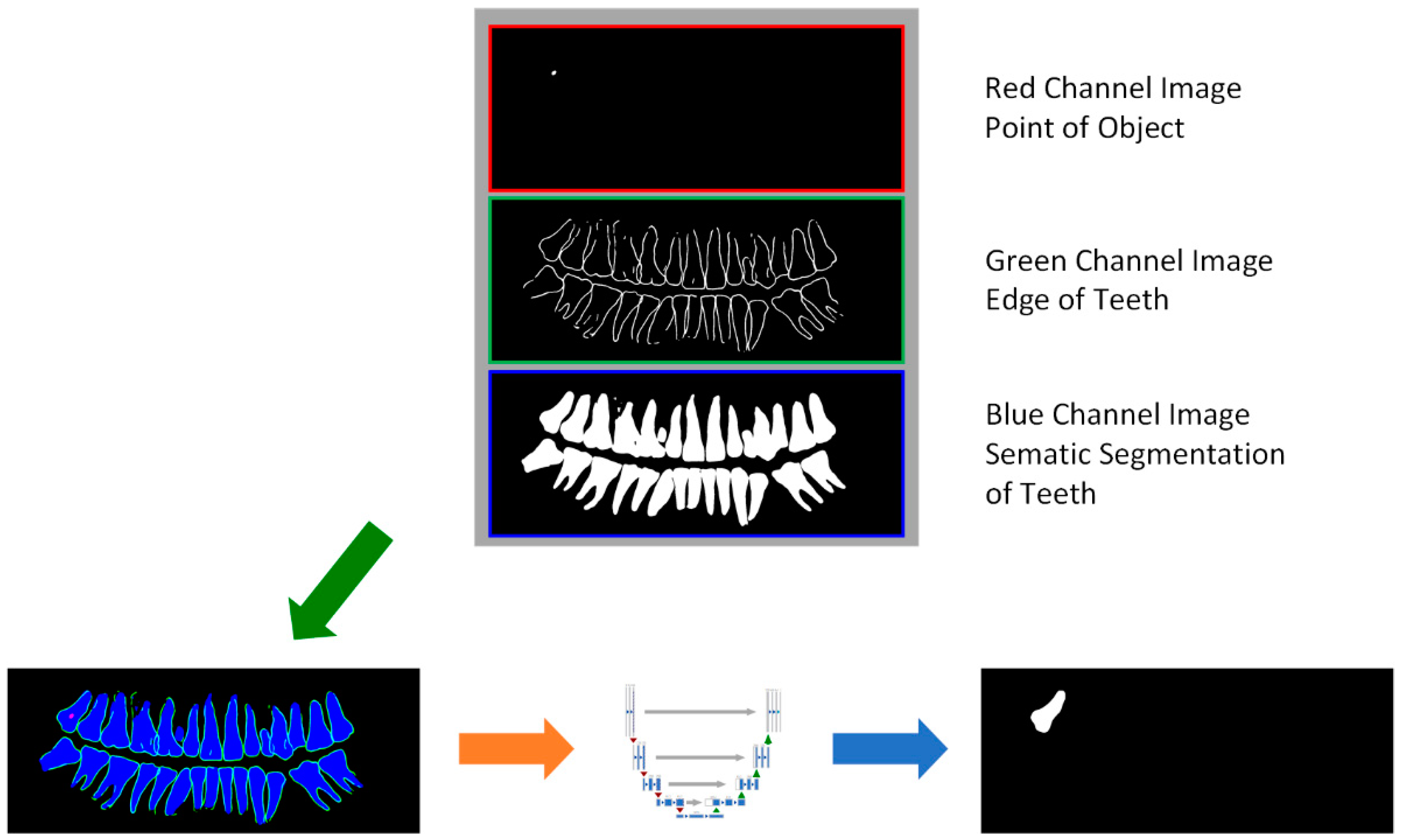
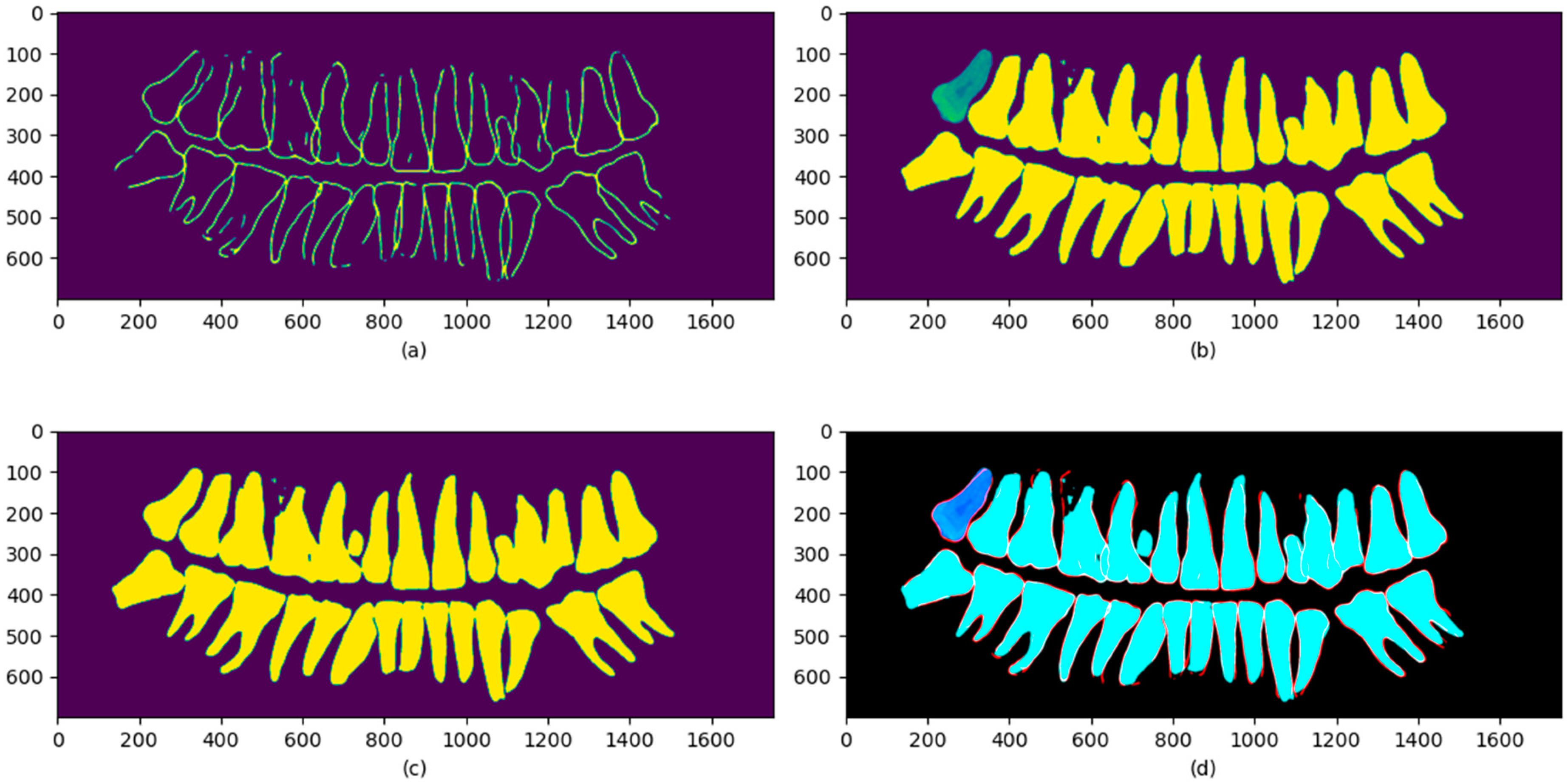
3.1. Extraction of Key Regions of Teeth Based on Semantic Information
| Algorithm 1 |
| INPUT: Semantic segmentation image S OUTPUT: Coordinate of Upper left and Lower right X1, Y1, X2, Y2 Parameters: Width of Sub image w Height of Sub image h W is the width of Semantic segmentation image H is the height of Semantic segmentation image |
3.2. Training Set Augmentation Method Based on Teeth Semantic Information
3.3. Single-Object Segmentation Image Generation Method Based on Information Entropy Compression Using Few-Shot Datasets
| Algorithm 2 |
| INPUT: Edge segmentation image S OUTPUT: Output Image So Parameters: Fill Color Cf, Boundary Color Cb Function Seedfilling (x, y, S, Cf, Cb): If c not equals tIf c not equals to Cf and c not equals to Cb: Seedfilling (x + 1, y, Cf, Cb) Seedfilling (x − 1, y, Cf, Cb) Seedfilling (x, y + 1, Cf, Cb) Seedfilling (x, y − 1, Cf, Cb) |
3.4. Teeth Classification Method Based on Fusion of Semantic Images
| Algorithm 3 |
| INPUT: Edge segmentation image S1 Semantic segmentation image S2 Single tooth segmentation image S3 OUTPUT: Output Image S0 S0 is a new RGB image length and width is same as S1 For i in (0, length of S1): For j in (0, width of S1): If S3i,j equals to 0: S0i,j,G = S2i,j Else: S0i,j,G = S3i,j Endif S0R = S1 S0B = S2 |
4. Experiments and Discussion
4.1. Experimental Setup and Datasets
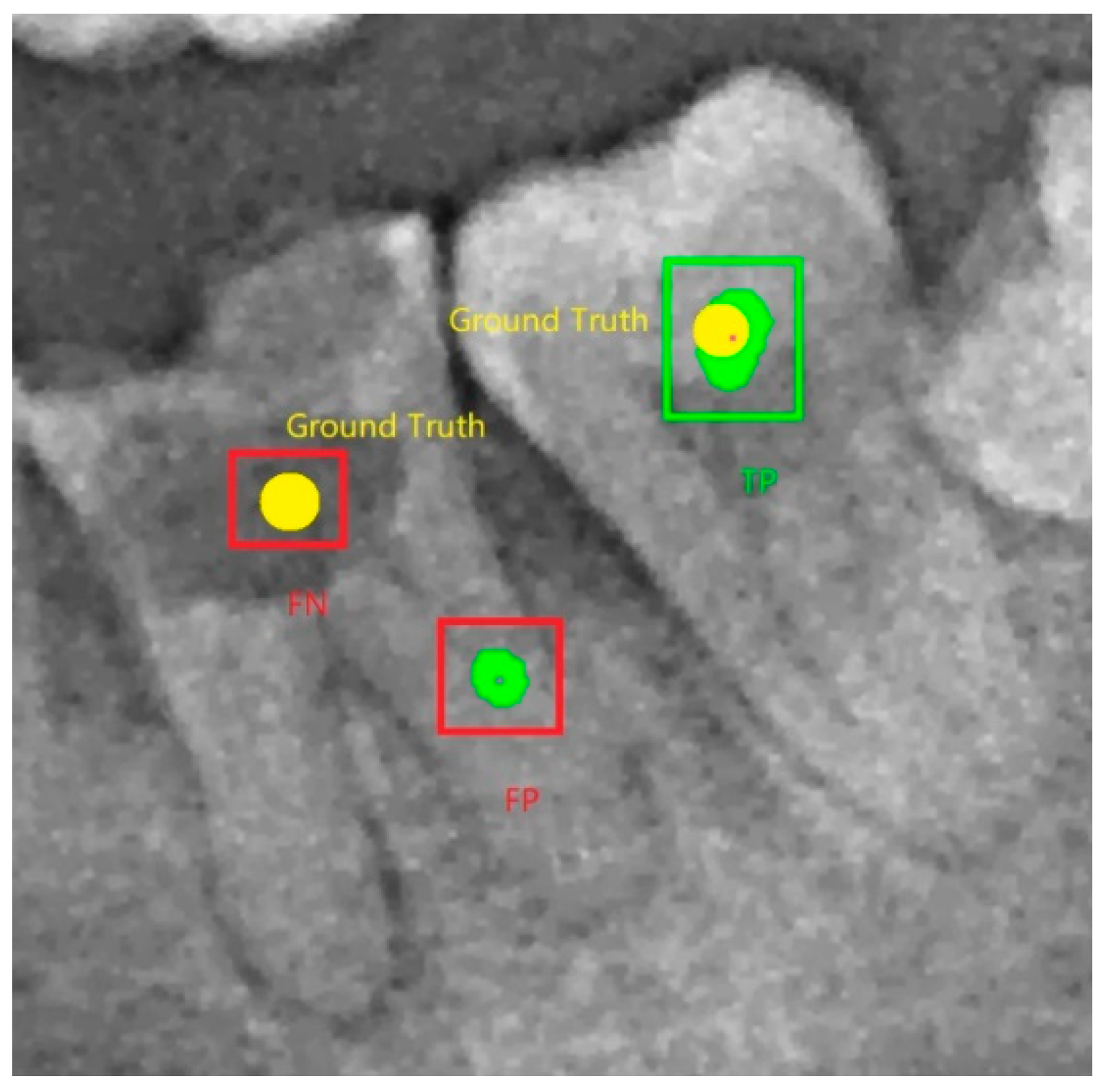
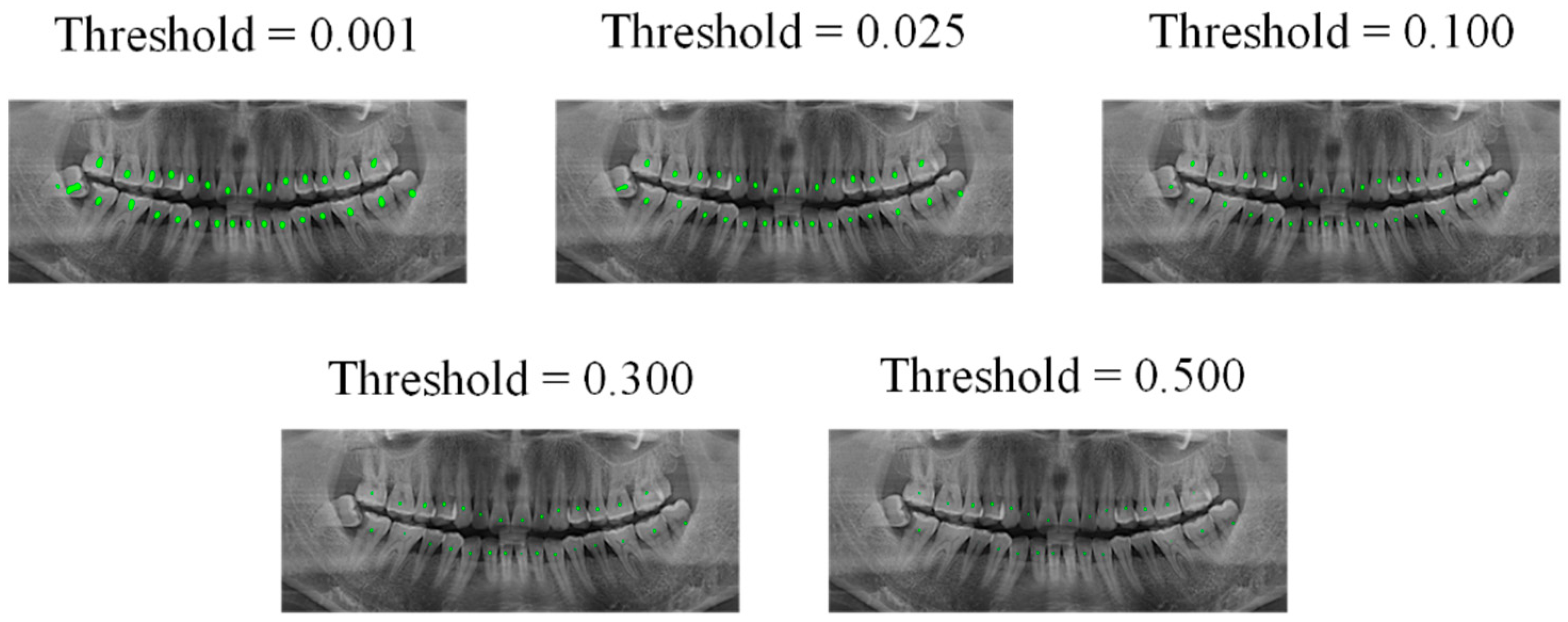
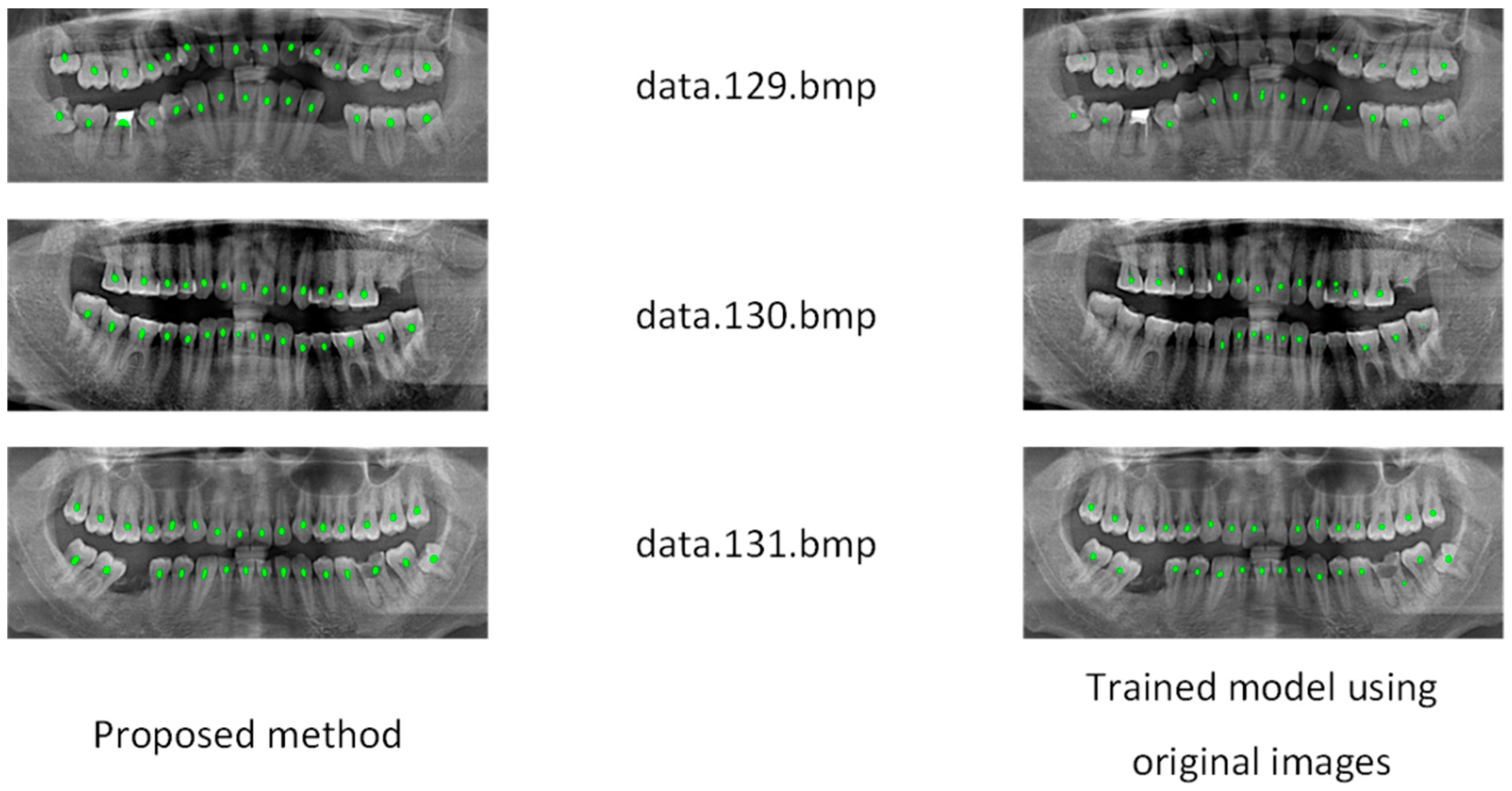
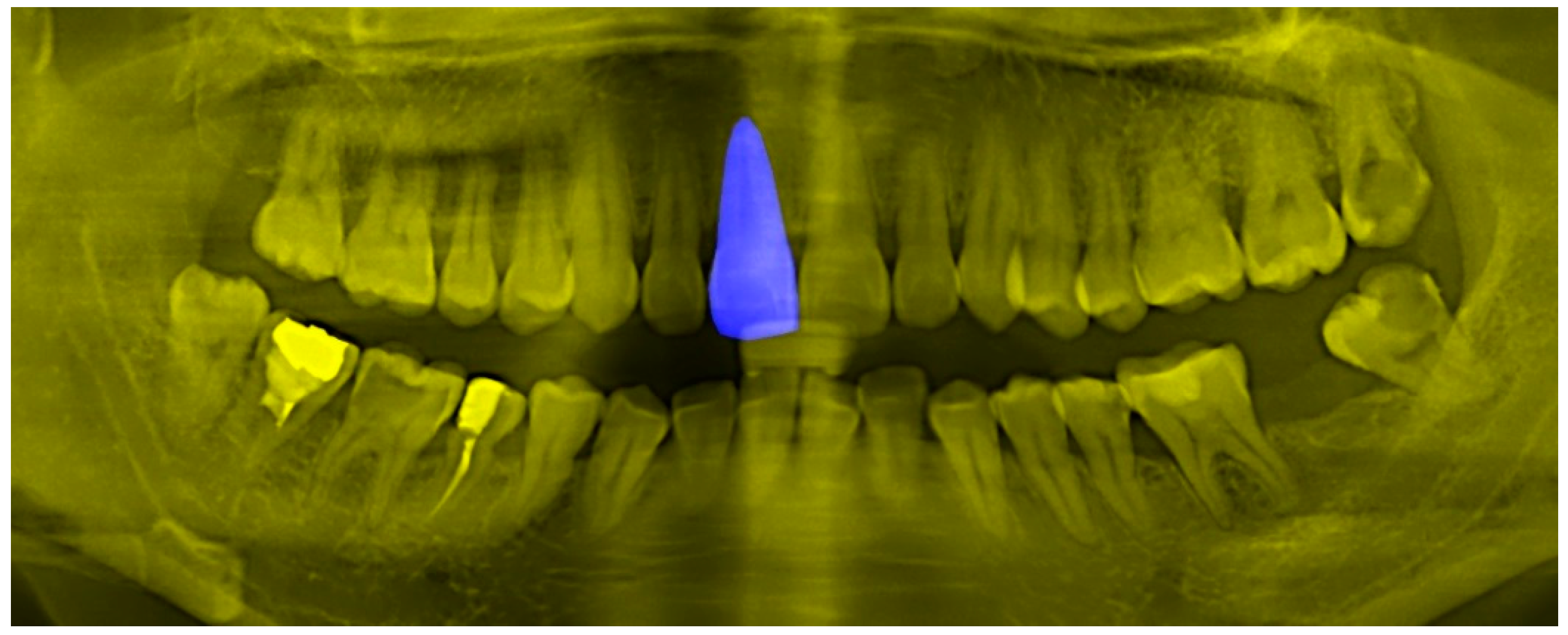
4.2. Teeth Central Point Detection Capability Test
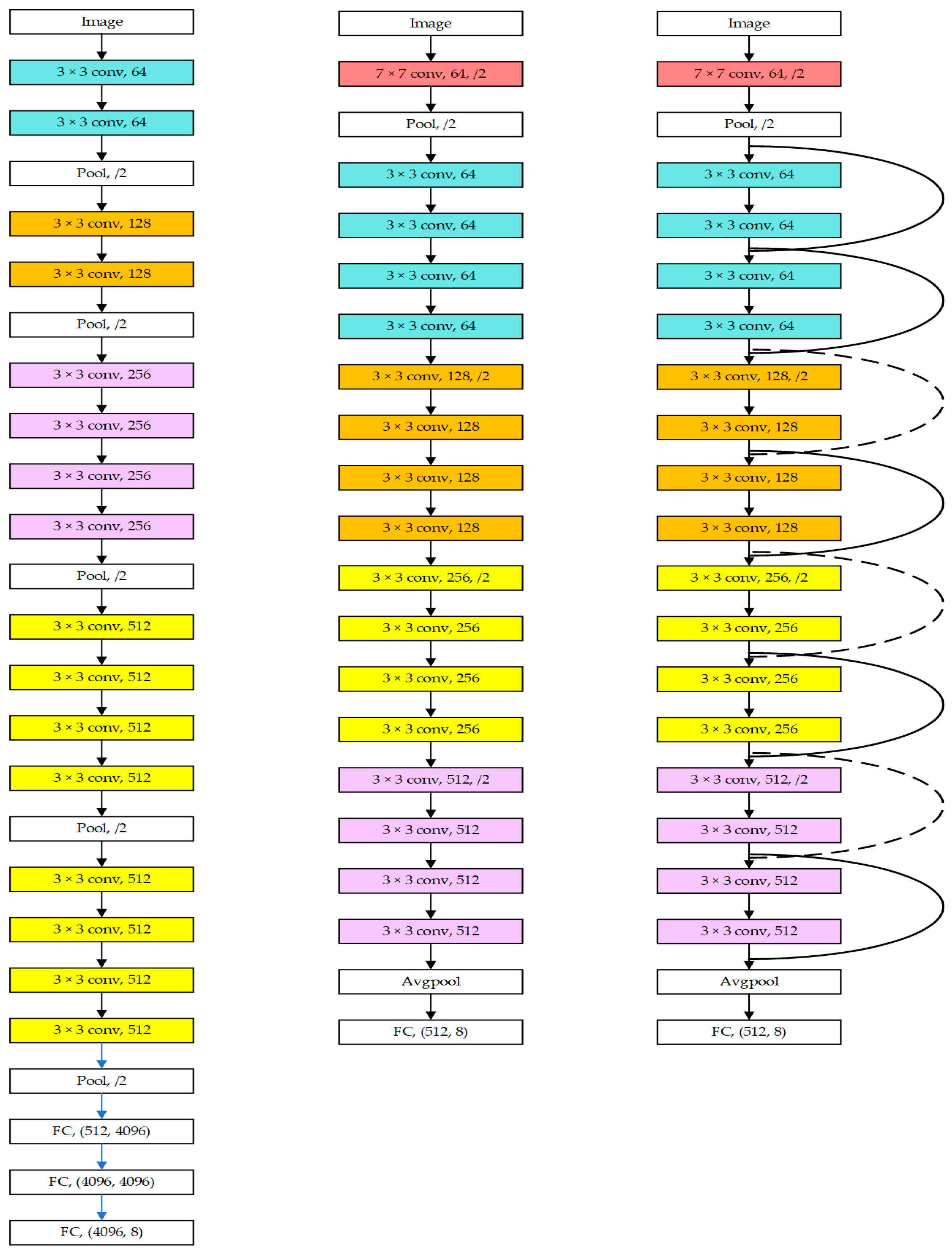
4.3. Teeth Classification Capability Test
4.3.1. Datasets
4.3.2. Models
4.4. Teeth Detection Capability Test
5. Conclusions
- The center point detection method based on the fusion of tooth structure semantics can generate center points of objects under a small-size dataset; and from the perspective of symmetry, the network for extracting the tooth structure semantics information is a symmetric structure, compared with the direct use of the semantic segmentation model, and the precision and recall rate of the SPSC-NET method reached 99.84 and 99.29.
- The performance of the proposed image generation mechanism for tooth semantic structure information in the classification of few-shot was much ahead of that based on the original image classification method (using DNN models directly), and its information entropy compression method can effectively improve the classification performance of the model.
- In terms of AP indicators and precision–recall curve, the object detection effect of SPSC-NET was better than that of Faster-RCNN, and it is more advantageous in the case of few-shot. The proposed tooth semantic structure information map can help the model greatly improve its final object detection performance. In the field of medical image research, image segmentation is a hot topic. The object detection method based on U-Net proposed in this paper can provide more ideas for subsequent medical image research. In addition, since SPSC-NET outputs single-object segmentation images and categories, in theory, this method can generate instance segmentation images.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Rampersad, H. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. Adv. Neural Inf. Process. Syst. 2020, 28, 159–183. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention 2015; Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Cham, Switzerland, 2015; Volume 9351, pp. 234–241. [Google Scholar] [CrossRef] [Green Version]
- Shelhamer, E.; Long, J.; Darrell, T. Fully convolutional networks for semantic segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar] [CrossRef]
- Li, C.; Tan, Y.; Chen, W.; Luo, X.; He, Y.; Gao, Y.; Li, F. ANU-Net: Attention-based nested U-Net to exploit full resolution features for medical image segmentation. Comput. Graph. 2020, 90, 11–20. [Google Scholar] [CrossRef]
- Sambyal, N.; Saini, P.; Syal, R.; Gupta, V. Modified U-Net architecture for semantic segmentation of diabetic retinopathy images. Biocybern. Biomed. Eng. 2020, 40, 1094–1109. [Google Scholar] [CrossRef]
- Diakogiannis, F.I.; Waldner, F.; Caccetta, P.; Wu, C. ResUNet-a: A deep learning framework for semantic segmentation of remotely sensed data. ISPRS J. Photogramm. Remote Sens. 2020, 162, 94–114. [Google Scholar] [CrossRef] [Green Version]
- Li, X.; Chen, H.; Qi, X.; Dou, Q.; Fu, C.-W.; Heng, P.-A. H-DenseUNet: Hybrid Densely Connected UNet for Liver and Tumor Segmentation From CT Volumes. IEEE Trans. Med. Imaging 2018, 37, 2663–2674. [Google Scholar] [CrossRef] [Green Version]
- Wang, C.-W.; Huang, C.-T.; Lee, J.-H.; Li, C.-H.; Chang, S.-W.; Siao, M.-J.; Lai, T.-M.; Ibragimov, B.; Vrtovec, T.; Ronneberger, O.; et al. A benchmark for comparison of dental radiography analysis algorithms. Med. Image Anal. 2016, 31, 63–76. [Google Scholar] [CrossRef]
- Duong, D.Q.; Nguyen, K.C.T.; Kaipatur, N.R.; Lou, E.H.; Noga, M.; Major, P.W.; Punithakumar, K.; Le, L.H. Fully Automated Segmentation of Alveolar Bone Using Deep Convolutional Neural Networks from Intraoral Ultrasound Images. In Proceedings of the Annual International Conference of the IEEE Engineering in Medicine and Biology Society, EMBS, Berlin, Germany, 23–27 July 2019; pp. 6632–6635. [Google Scholar] [CrossRef]
- Koch, T.L.; Perslev, M.; Igel, C.; Brandt, S.S. Accurate segmentation of dental panoramic radiographs with U-NETS. In Proceedings of the 2019 IEEE 16th International Symposium on Biomedical Imaging (ISBI 2019), Venice, Italy, 8–11 April 2019; pp. 15–19. [Google Scholar] [CrossRef]
- Gherardini, M.; Mazomenos, E.; Menciassi, A.; Stoyanov, D. Catheter segmentation in X-ray fluoroscopy using synthetic data and transfer learning with light U-nets. Comput. Methods Programs Biomed. 2020, 192, 105420. [Google Scholar] [CrossRef]
- Chen, Y.; Du, H.; Yun, Z.; Yang, S.; Dai, Z.; Zhong, L.; Feng, Q.; Yang, W. Automatic Segmentation of Individual Tooth in Dental CBCT Images From Tooth Surface Map by a Multi-Task FCN. IEEE Access 2020, 8, 97296–97309. [Google Scholar] [CrossRef]
- Xu, X.; Liu, C.; Zheng, Y. 3D Tooth Segmentation and Labeling Using Deep Convolutional Neural Networks. IEEE Trans. Vis. Comput. Graph. 2019, 25, 2336–2348. [Google Scholar] [CrossRef]
- Zhao, Y.; Li, P.; Gao, C.; Liu, Y.; Chen, Q.; Yang, F.; Meng, D. TSASNet: Tooth segmentation on dental panoramic X-ray images by Two-Stage Attention Segmentation Network. Knowl.-Based Syst. 2020, 206, 106338. [Google Scholar] [CrossRef]
- Al Kheraif, A.A.; Wahba, A.A.; Fouad, H. Detection of dental diseases from radiographic 2d dental image using hybrid graph-cut technique and convolutional neural network. Measurement 2019, 146, 333–342. [Google Scholar] [CrossRef]
- Laishram, A.; Thongam, K. Detection and classification of dental pathologies using faster-RCNN in orthopantomogram radiography image. In Proceedings of the 2020 7th International Conference on Signal Processing and Integrated Networks, SPIN 2020, Noida, India, 27–28 February 2020; pp. 423–428. [Google Scholar] [CrossRef]
- Tuzoff, D.V.; Tuzova, L.N.; Bornstein, M.M.; Krasnov, A.S.; Kharchenko, M.A.; Nikolenko, S.I.; Sveshnikov, M.M.; Bednenko, G.B. Tooth detection and numbering in panoramic radiographs using convolutional neural networks. Dentomaxillofac. Radiol. 2019, 48, 20180051. [Google Scholar] [CrossRef]
- Chen, H.; Zhang, K.; Lyu, P.; Li, H.; Zhang, L.; Wu, J.; Lee, C.-H. A deep learning approach to automatic teeth detection and numbering based on object detection in dental periapical films. Sci. Rep. 2019, 9, 3840. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 386–397. [Google Scholar] [CrossRef]
- Cui, Z.; Li, C.; Wang, W. ToothNet: Automatic tooth instance segmentation and identification from cone beam CT images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 6368–6377. [Google Scholar]
- Moutselos, K.; Berdouses, E.; Oulis, C.; Maglogiannis, I. Recognizing Occlusal Caries in Dental Intraoral Images Using Deep Learning. In Proceedings of the Annual International Conference of the IEEE Engineering in Medicine and Biology Society, EMBS, Berlin, Germany, 23–27 July 2019; pp. 1617–1620. [Google Scholar] [CrossRef]
- Jader, G.; Fontineli, J.; Ruiz, M.; Abdalla, K.; Pithon, M.; Oliveira, L. Deep Instance Segmentation of Teeth in Panoramic X-Ray Images. In Proceedings of the 31st Conference on Graphics, Patterns and Images, SIBGRAPI 2018, Parana, Brazil, 17 January 2019; pp. 400–407. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Volume 9905, pp. 21–37. [Google Scholar] [CrossRef] [Green Version]
- Singh, N.K.; Raza, K. Progress in deep learning-based dental and maxillofacial image analysis: A systematic review. Expert Syst. Appl. 2022, 199, 116968. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Adv. Neural Inf. Process. Syst. 2012, 25. Available online: https://proceedings.neurips.cc/paper/2012/hash/c399862d3b9d6b76c8436e924a68c45b-Abstract.html (accessed on 9 April 2022). [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015-Conference Track Proceedings, San Diego, CA, USA, 7–9 May 2015; pp. 1–14. [Google Scholar] [CrossRef]
- Hiraiwa, T.; Ariji, Y.; Fukuda, M.; Kise, Y.; Nakata, K.; Katsumata, A.; Fujita, H.; Ariji, E. A deep-learning artificial intelligence system for assessment of root morphology of the mandibular first molar on panoramic radiography. Dentomaxillofac. Radiol. 2019, 48, 20180218. [Google Scholar] [CrossRef]
- Lee, J.-H.; Kim, D.-H.; Jeong, S.-N.; Choi, S.-H. Diagnosis and prediction of periodontally compromised teeth using a deep learning-based convolutional neural network algorithm. J. Periodontal Implant Sci. 2018, 48, 114–123. [Google Scholar] [CrossRef] [Green Version]
- Miki, Y.; Muramatsu, C.; Hayashi, T.; Zhou, X.; Hara, T.; Katsumata, A.; Fujita, H. Classification of teeth in cone-beam CT using deep convolutional neural network. Comput. Biol. Med. 2017, 80, 24–29. [Google Scholar] [CrossRef] [PubMed]
- Muramatsu, C.; Morishita, T.; Takahashi, R.; Hayashi, T.; Nishiyama, W.; Ariji, Y.; Zhou, X.; Hara, T.; Katsumata, A.; Ariji, E.; et al. Tooth detection and classification on panoramic radiographs for automatic dental chart filing: Improved classification by multi-sized input data. Oral Radiol. 2021, 37, 13–19. [Google Scholar] [CrossRef] [PubMed]
- Yang, J.; Xie, Y.; Liu, L.; Xia, B.; Cao, Z.; Guo, C. Automated Dental Image Analysis by Deep Learning on Small Dataset. In Proceedings of the 2018 IEEE 42nd Annual Computer Software and Applications Conference (COMPSAC), Tokyo, Japan, 23–27 June 2018; Volume 1, pp. 492–497. [Google Scholar] [CrossRef]
- Zhang, K.; Wu, J.; Chen, H.; Lyu, P. An effective teeth recognition method using label tree with cascade network structure. Comput. Med. Imaging Graph. 2018, 68, 61–70. [Google Scholar] [CrossRef] [PubMed]
- Oktay, A.B. Tooth detection with Convolutional Neural Networks. In Proceedings of the 2017 Medical Technologies National Congress (TIPTEKNO), Trabzon, Turkey, 12–14 October 2017; pp. 1–4. [Google Scholar] [CrossRef]
- Son, L.H.; Tuan, T.M.; Fujita, H.; Dey, N.; Ashour, A.; Ngoc, V.T.N.; Anh, L.Q.; Chu, D.-T. Dental diagnosis from X-Ray images: An expert system based on fuzzy computing. Biomed. Signal Process. Control 2018, 39, 64–73. [Google Scholar] [CrossRef]
- Avuçlu, E.; Başçiftçi, F. The determination of age and gender by implementing new image processing methods and measurements to dental X-ray images. Measurement 2020, 149, 106985. [Google Scholar] [CrossRef]
- Antonelli, S.; Avola, D.; Cinque, L.; Crisostomi, D.; Foresti, G.L.; Galasso, F.; Marini, M.R.; Mecca, A.; Pannone, D. Few-Shot Object Detection: A Survey. ACM Comput. Surv. 2021. [Google Scholar] [CrossRef]
- Kang, B.; Liu, Z.; Wang, X.; Yu, F.; Feng, J.; Darrell, T. Few-shot Object Detection via Feature Reweighting. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 8420–8429. [Google Scholar]
- Yan, X.; Chen, Z.; Xu, A.; Wang, X.; Liang, X.; Lin, L. Meta R-CNN: Towards General Solver for Instance-level Low-shot Learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 9577–9586. [Google Scholar]
- Pérez-Rúa, J.-M.; Zhu, X.; Hospedales, T.; Xiang, T. Incremental few-shot object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 13846–13855. Available online: http://openaccess.thecvf.com/content_CVPR_2020/html/Perez-Rua_Incremental_Few-Shot_Object_Detection_CVPR_2020_paper.html (accessed on 16 April 2022).
- Xiao, Y.; Marlet, R. Few-shot object detection and viewpoint estimation for objects in the wild. In Computer Vision—ECCV 2020; Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Cham, Switzerland, 2020; Volume 12362, pp. 192–210. [Google Scholar] [CrossRef]
- Wang, X.; Huang, T.E.; Darrell, T.; Gonzalez, J.E.; Yu, F. Frustratingly Simple Few-Shot Object Detection. arXiv 2020, arXiv:2003.06957. [Google Scholar] [CrossRef]
- Fan, Q.; Zhuo, W.; Tang, C.-K.; Tai, Y.-W. Few-Shot Object Detection with Attention-RPN and Multi-Relation Detector. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 4013–4022. [Google Scholar] [CrossRef]
- Chen, T.-I.; Liu, Y.-C.; Su, H.-T.; Chang, Y.-C.; Lin, Y.-H.; Yeh, J.-F.; Chen, W.-C.; Hsu, W. Dual-Awareness Attention for Few-Shot Object Detection. arXiv 2021, arXiv:2102.12152. [Google Scholar] [CrossRef]
- Akselrod-Ballin, A.; Karlinsky, L.; Hazan, A.; Bakalo, R.; Horesh, A.B.; Shoshan, Y.; Barkan, E. Deep learning for automatic detection of abnormal findings in breast mammography. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Springer: Cham, Switzerland, 2017; pp. 321–329. [Google Scholar] [CrossRef]
- Chung, M.; Lee, J.; Park, S.; Lee, M.; Lee, C.E.; Lee, J.; Shin, Y.-G. Individual tooth detection and identification from dental panoramic X-ray images via point-wise localization and distance regularization. Artif. Intell. Med. 2021, 111, 101996. [Google Scholar] [CrossRef]
- Vinayahalingam, S.; Xi, T.; Bergé, S.; Maal, T.; de Jong, G. Automated detection of third molars and mandibular nerve by deep learning. Sci. Rep. 2019, 9, 9007. [Google Scholar] [CrossRef]
- Chen, H.; Wang, Y.; Wang, G.; Qiao, Y. LSTD: A Low-Shot Transfer Detector for Object Detection. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; p. 32. Available online: https://ojs.aaai.org/index.php/AAAI/article/view/11716 (accessed on 9 April 2022).
- Chen, X.; Jiang, M.; Zhao, Q. Leveraging Bottom-Up and Top-Down Attention for Few-Shot Object Detection. arXiv 2020. [Google Scholar] [CrossRef]
- Sun, B.; Li, B.; Cai, S.; Yuan, Y.; Zhang, C. Fsce: Few-shot object detection via contrastive proposal encoding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 7352–7362. [Google Scholar] [CrossRef]
- Li, Y.; Zhu, H.; Cheng, Y.; Wang, W.; Teo, C.S.; Xiang, C.; Vadakkepat, P.; Lee, T.H. Few-Shot Object Detection via Classification Refinement and Distractor Retreatment. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 15395–15403. [Google Scholar]
- Zhu, C.; Chen, F.; Ahmed, U.; Shen, Z.; Savvides, M. Semantic Relation Reasoning for Shot-Stable Few-Shot Object Detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 8778–8787. [Google Scholar] [CrossRef]
- Wu, A.; Han, Y.; Zhu, L.; Yang, Y. Universal-Prototype Enhancing for Few-Shot Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 9567–9576. [Google Scholar] [CrossRef]
- Xu, H.; Wang, X.; Shao, F.; Duan, B.; Zhang, P. Few-Shot Object Detection via Sample Processing. IEEE Access 2021, 9, 29207–29221. [Google Scholar] [CrossRef]
- Qiao, L.; Zhao, Y.; Li, Z.; Qiu, X.; Wu, J.; Zhang, C. DeFRCN: Decoupled Faster R-CNN for Few-Shot Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 8681–8690. [Google Scholar]
- Cartucho, J.; Ventura, R.; Veloso, M. Robust Object Recognition through Symbiotic Deep Learning in Mobile Robots. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 2336–2341. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Quantity |
|---|---|
| Central incisor | 403 |
| Lateral incisor | 399 |
| Canine | 397 |
| First premolar | 389 |
| Second premolar | 400 |
| First molar | 395 |
| Second molar | 395 |
| Third molar | 284 |
| Out Threshold | Precision | Recall | ||
|---|---|---|---|---|
| SPSC-NET | Native U-Net | SPSC-NET | Native U-Net | |
| 0.001 | 99.77 | 99.36 | 99.54 | 96.67 |
| 0.025 | 99.80 | 99.50 | 99.23 | 94.76 |
| 0.100 | 99.82 | 99.60 | 98.85 | 92.39 |
| 0.300 | 99.84 | 99.66 | 98.03 | 88.99 |
| 0.500 | 99.86 | 99.70 | 96.16 | 85.39 |
| Models | Accuracy | Precision | F1score | Loss |
|---|---|---|---|---|
| Resnet + structural information (ours) | 96.05 | 96.10 | 96.05 | 0.00644 |
| Resnet + structural information- 1 (ours) | 92.49 | 92.56 | 92.49 | 0.01286 |
| Efficientnetv2-m | 74.76 | 75.58 | 74.90 | 0.11094 |
| Resnet + ft | 59.90 | 60.20 | 59.70 | 0.15345 |
| Resnet | 74.20 | 74.98 | 74.31 | 0.04754 |
| Resnet + structural information (ours) (Without data augmentation) | 94.12 | 94.20 | 94.13 | 0.00902 |
| Efficientnetv2-m (Without data augmentation) | 63.72 | 64.06 | 63.55 | 0.10600 |
| Resnet + ft (Without data augmentation) | 51.53 | 51.22 | 51.06 | 0.31689 |
| Resnet (Without data augmentation) | 62.38 | 63.11 | 62.44 | 0.12297 |
| Model | AP | AP50 | AP75 | mIOU | Train Image |
|---|---|---|---|---|---|
| Retinanet + ft | 12.76% | 15.25% | 10.26% | 0.2602 | 10 |
| SSD + ft | 1.67% | 2.68% | 0.63% | 0.3077 | 10 |
| SSD Lite + ft | 11.98% | 15.57% | 8.38% | 0.1557 | 10 |
| Faster-RCNN [16] + ft (Laishram et al., Box score = 0.3) | 73.56% | 86.42% | 60.69% | 0.6063 | 10 |
| Faster-RCNN [16] + ft (Laishram et al., Box score = 0.5) | 72.26% | 84.61% | 59.91% | 0.6334 | 10 |
| Faster-RCNN [16] (Laishram et al.) | 91.03% | N/A | N/A | N/A | 96 |
| Chung et al. [46] (33 classes) | 81% | 91% | 90% | 0.84 | 818 |
| TFA w/fc [42] | 21.82% | 49.13% | 15.14% | N/A | 10 |
| TFA w/cos [42] | 32.06% | 48.43% | 15.69% | N/A | 10 |
| SPSC-NET | 88.28% | 92.94% | 83.62% | 0.8031 | 10 |
| SPSC-NET- | 19.41% | 20.39% | 18.43% | 0.5028 | 10 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, H.; Wu, Z. A Few-Shot Dental Object Detection Method Based on a Priori Knowledge Transfer. Symmetry 2022, 14, 1129. https://doi.org/10.3390/sym14061129
Wu H, Wu Z. A Few-Shot Dental Object Detection Method Based on a Priori Knowledge Transfer. Symmetry. 2022; 14(6):1129. https://doi.org/10.3390/sym14061129
Chicago/Turabian StyleWu, Han, and Zhendong Wu. 2022. "A Few-Shot Dental Object Detection Method Based on a Priori Knowledge Transfer" Symmetry 14, no. 6: 1129. https://doi.org/10.3390/sym14061129
APA StyleWu, H., & Wu, Z. (2022). A Few-Shot Dental Object Detection Method Based on a Priori Knowledge Transfer. Symmetry, 14(6), 1129. https://doi.org/10.3390/sym14061129