1. Introduction
The task of object detection is to find all the objects of interest in the image and infer their categories and positions, which is one of the crucial problems in the field of computer vision. However, object detection has always been a challenging problem due to the various objects’ different appearances, shapes, and postures of objects in the image. In 2014, the emergence of RCNN [
1] meant that the object detection algorithm based on deep learning began to become the mainstream research direction, and various high-quality two-stage detection models, SPPNet [
2], Fast RCNN [
3], Faster RCNN [
4] and the one-stage detection models YOLO [
5], SSD [
6], Retina Net [
7], etc., show the vigorous development of the object detection. Generally, the two-stage detector has a higher accuracy and slower speed, and the one-stage detector has faster speed and lower accuracy. Optimizing the detection accuracy while ensuring the detection speed has always been an urgent problem to be solved. We found that four significant factors affect accuracy and speed by studying some state-of-the-art models [
2,
6,
7,
8,
9,
10]. First, after passing through the deep feature extraction network, the information of small objects and medium objects will be lost, which means that the number of feature extraction network layers needs to be controlled within a reasonable range so as not to affect the subsequent process. Since the traditional feature extraction networks [
11,
12] extract features by repeatedly performing convolution, max-pooling, and down-sampling operations, regions in different parts of the whole image can be correlated after accumulating many convolutional layers. However, this method will significantly increase the calculation cost of the model. Vaswani et al. [
13] found that self-attention can capture long-distance dependence between objects. Convolution has local sensitivity but lacks a global perception of the image, and the calculation of self-attention is complex and more suitable for low-resolution input, so we combined traditional CNN and self-attention mechanisms in our work. Secondly, the size of the receptive field in the convolution process also affects the acquisition of information. A traditional method to increase the receptive field is to stack convolutional layers, but this will affect the efficiency of the network, so this work uses a module with dilated convolution to increase the receptive field with a low calculation cost. Thirdly, the inability to fully utilize the multi-level information of images is also an essential factor affecting detection accuracy. An efficient detection network must be able to fuse semantic information of different resolutions and levels, so this work designs a spatial feature fusion pyramid network. Finally, using a large number of hyperparameters to predefine the anchor boxes reduces the speed of the anchor-based detection model. Moreover, using a detection head to complete the classification and positioning tasks simultaneously will also reduce the detection accuracy. Therefore, this work adopts an anchor-free sibling detection head which is efficient in improving the detection speed and accuracy of the model.
Overall, our work proposes an adaptive multi-scale context information fusion model combined with a self-attention mechanism to solve the above-mentioned problems. First, to extract global contextual features of input images, we design a modified ResNet50 [
11] structure that incorporates a self-attention module as a feature extraction backbone of the model. Second, this work connects a feature pooling module after the backbone for fusing information from multiple receptive fields. Finally, to reduce the model complexity and make the classification and detection tasks unaffected by each other, this work uses a sibling anchor-free head at the end of the network. To evaluate the performance of the proposed model, we use the COCO2017 dataset to train our model and provide a comparison with the state-of-the-art method on the COCO2017 test dataset.
To summarize, the principal contributions of this paper are as follows:
We integrate the self-attention mechanism into the feature extraction network, which makes the model fully obtain the image’s global and local context information in the feature extraction phase;
We propose a receptive field feature enhancement module, which plays an important role in fusing global and local context information and enlarging the receptive fields of the network;
We adopt a spatial feature fusion pyramid network to fuse multi-level feature maps, which can make full use of multi-scale contextual information and enhance the transmission efficiency of shallow features;
We propose an anchor-free sibling detection head, which further improves the speed and accuracy of the detection network.
The rest of the paper is organized as follows.
Section 2 introduces similar contributions related to the content of this paper.
Section 3 presents the overall architecture of the model and the algorithms of each part in detail.
Section 4 demonstrates the specification of the dataset and discusses the experimental results. We conclude the paper in
Section 5.
2. Related Work
Reviewing the development of object detection algorithms, the methods to improve the accuracy and speed of object detection are mainly to adopt a better attention module, utilize more context information, multi-scale feature fusion, and an efficient detection head.
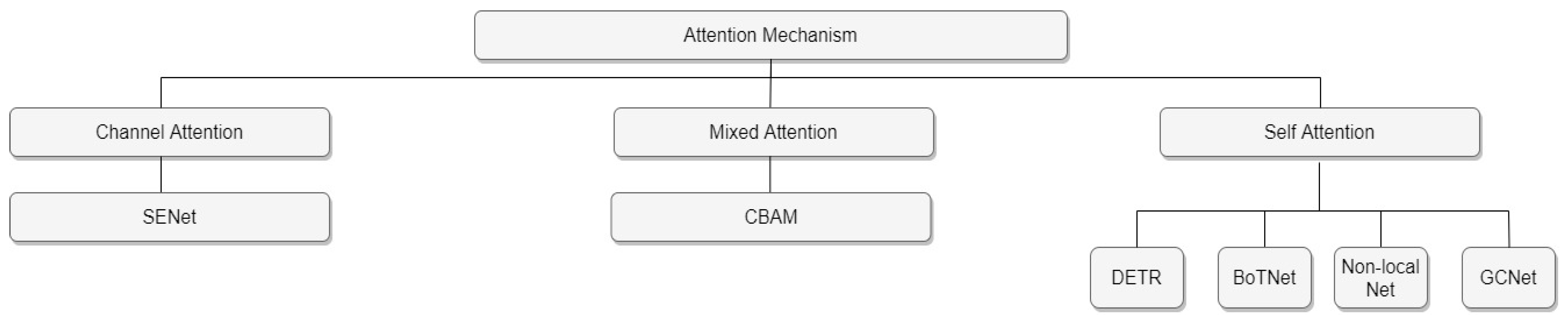
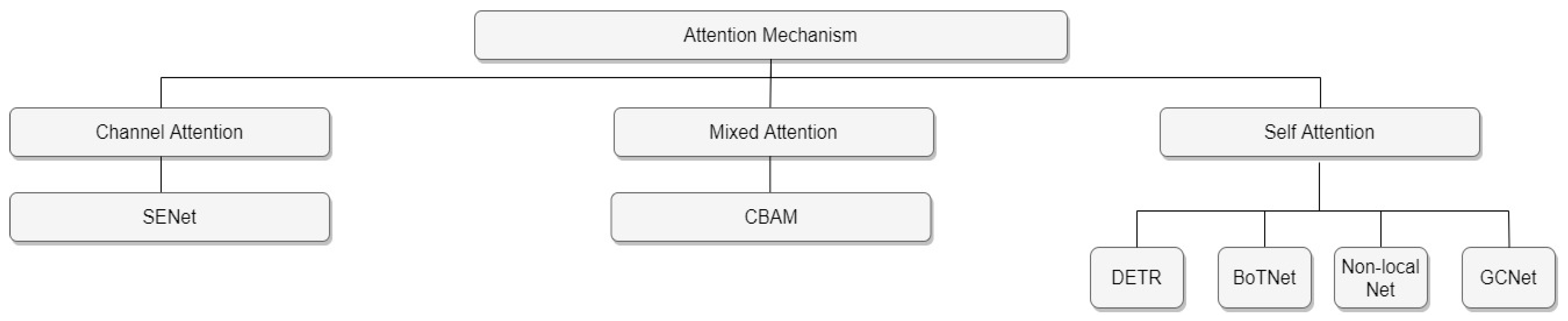
Attention mechanism: When humans observe the scene in front of them, the brain will automatically pay attention to the areas they want to focus on while ignoring irrelevant areas, which is an attention mechanism of the brain. The attention mechanism in object detection gives more weight to relevant areas and less weight to irrelevant areas to quickly get to what you want to know. Therefore, the attention mechanism can be regarded as a dynamic weight adjustment process based on features of the input image [
14]. As shown in
Figure 1, attention mechanisms can be divided into three categories: channel attention, mixed attention, and self-attention. The representative model of channel attention is SENet [
14]. SENet proposes to generate a weight for each feature channel to represent the importance of the feature channel and complete the re-calibration of the original features in the channel dimension. Nevertheless, it only considers channel information and ignores the importance of positional information. The mixed attention mechanism refers to the combination of the channel attention module (CAM) and the spatial attention module (SAM), and the classical model is CBAM [
15]. CBAM tries to introduce location information by global pooling on the channel, but this method can only capture local information and cannot obtain long-range dependent information. In recent years, the convolution-based architecture widely used in object detection needs to stack multiple convolution layers, capture the calculation results of local information, and then perform a global integration. With the deepening of the convolution network, it is possible to focus on global information gradually. The self-attention mechanism is used to directly focus on the global information, so the network combined with the self-attention is not deep and can achieve similar performance. Self-attention is more effective than convolution stacking. The more popular models that use self-attention mechanism are DETR [
8], BoTNet [
16], Non-local Net [
17], GCNet [
18]. Hachaj et al. [
19] proposed in their study that the encoder–decoder structure can be applied to visual attention prediction, and DETR [
8] also uses this structure for detection. The self-attention module has a stronger ability to capture long-term dependencies and can obtain more contextual information for the object detection model.
More contextual information: Context information can help localize the region proposals and improve the detection and classification accuracy. The most common method to acquire more contextual information is to increase the depth and width of the model, but it will increase the parameters of the network, resulting in overfitting and gradient dispersion. The inception structure [
20,
21,
22,
23] stacks convolution and pooling operations of different scales together. This structure can extract more semantic-level features and enrich feature information. The 1 × 1 convolution kernels are used for reducing the number of feature map channels, thereby decreasing the number of parameters and reducing the complexity of the network. However, the inception structure relies too much on manual design, which is not conducive to the model’s modularity. Using dilated convolutions can generate larger receptive fields, keep the feature map at a higher resolution, and capture more contextual information from a larger area. The receptive field feature enhancement module is designed with this kind of structure. It acquires receptive fields of different sizes in multiple branches and adds more contextual information to the shallow layer.
Multi-scale feature fusion: FPN [
24] first proposed constructing a multi-scale feature fusion model. PANet [
20] proposed a bidirectional feature pyramid structure with an adaptive feature pooling operation. AC-FPN [
25] exploits discriminative information from various large receptive fields by integrating an attention-guided multi-path function. FPT [
26] (Feature Pyramid Transformer) proposes a fully activated feature fusion across space and scale, which well preserves low-level information. FPN and its variants combine low-resolution feature maps with high-resolution feature maps through a top-down horizontal connection structure to construct full-scale high-level semantic feature maps, essential for object detection.
Efficient detection head: An efficient detection head can improve the speed and accuracy of the detection model. Anchor-free detection and sibling detection heads are two important improvement directions for the study of detection heads.
Anchor-free detection: The anchor-based object detection model needs to predefine many anchor boxes for each pixel on the feature map, resulting in a considerable number of anchor boxes, which leads to the imbalance of positive and negative samples. Moreover, using hyper-parameters, such as aspect ratio, makes network tuning more difficult and increases the complexity and computation of the network. In 2015, Huang et al. proposed to apply FCN [
27] to object detection. Every pixel in the output map is converted to a bounding box with a score. In 2019, Tian et al. [
28] used a low-quality prediction bounding box far from the target center, adding a center-ness branch parallel to the classification branch.
Sibling Head: When the same feature is used for classification and regression, the model’s performance cannot be well balanced. Therefore, a decoupling operation can be used to deal with classification and regression tasks separately. An original proposal can generate two proposals, one for classification and the other for regression, to generate the required features respectively and improve the algorithm’s performance through asymptotic constraints. The sibling head [
29] proposed by Song et al. verifies this idea well, and experiments show that object detectors with sibling heads perform better than those without. Wu et al. [
30] proved that using convolution and full connection together can improve object detection accuracy.
3. Method
This section introduces the framework of our proposed model CSA-Net (
Figure 2) and then introduces four main parts, including the improved ResNet-SA, the receptive field feature enhancement module RFFE, the spatial feature fusion pyramid network, and the anchor-free sibling detection head.
3.1. Framework Overview
As shown in
Figure 2, the framework consists of four components: (1) In order to reduce the interference of the background region to the object region and extract global context information, we proposed a feature extraction network called ResNet-SA; (2) A receptive field feature enhancement module (RFFE) was designed to integrate local features and global features and enlarge receptive fields. (3) A spatial feature fusion pyramid network is adopted to fuse multi-scale features, which is a symmetrical structure. (4) The last part of the model is an anchor-free sibling detection head used to output detection results. The whole model CSA-Net operates as follows. In the first step, the image to be detected is fed into the feature extraction network ResNet-SA to generate corresponding features. In the second step, the feature maps obtained through the feature extraction network are passed through the RFFE module to enhance the feature information and obtain the feature map
P3 (As shown in
Figure 2). The third step is to select the feature map
P1 (which is the output feature map of the stage 3 of ResNet-SA), the feature map
P2 (Which is the output feature map of the stage 4 of ResNet-SA), and the output feature map
P3 of the RFFE module as the input {
P1,
P2,
P3} of the three-layer spatial feature fusion pyramid, and the pyramid structure transforms {
P1,
P2,
P3} into {
N1,
N2,
N3}. Then through the spatial feature fusion process, {
N1,
N2,
N3} are converted into {
SFF-1,
SFF-2,
SFF-3}. The last step is to use the three-level output {
SFF-1,
SFF-2,
SFF-3} of the spatial feature pyramid as the input of the three detection heads, respectively, and the classification and regression are performed to obtain the object detection results. In what follows, we will present these components in detail.
3.2. Improved Backbone Network ResNet-SA
Our feature extraction network ResNet-SA is modified from ResNet50 [
11], which is a backbone with few parameters and excellent feature extraction ability. Our work utilizes convolutional layers to extract local information and obtain low-resolution feature maps, and finally, we insert self-attention blocks into the model. Tay et al. [
31] found that the memory and computation for self-attention scales quadratically with spatial dimensions, which means processing large-resolution images requires substantial computational cost. Moreover, Wang et al. [
17] found through experiments that although adding more non-local blocks into the backbone can increase the detection accuracy, the performance improvement is much smaller than the increase in the amount of computation. ResNet-SA and ResNet50 differ only in the last bottleneck. The structure comparison of the two bottlenecks is shown in
Figure 3.
Figure 3a shows the last bottleneck structure of the original ResNet50, and
Figure 3b shows our improvement on the last bottleneck (stage 5 in
Table 1). The specific structure of ResNet-SA is demonstrated in
Table 1. ResNet-SA consists of five stages and is modified from the ResNet50 [
11], which replaces the 3 × 3 convolution in the last bottleneck block of ResNet50 with the MHSA blocks. Stage 2, stage 3, stage 4 and stage 5 consist of 3, 4, 6, and 3 residual blocks, respectively.
Multi-head self-attention (MHSA) is a self-attention module embedded in the feature extraction network ResNet-SA. The structure of MHSA is shown in
Figure 4. From the
Figure 4, we can obtain the following formula:
where z is the output of the self-attention block, and qp
T + qk
T represents the attention logits.
From Equation (1), we can know that the MHSA block can successfully obtain the global contextual information and context interaction information of the input feature map because the attention logit qpT + qkT fuses qpT (which contains content-position information) and qkT (which contains content-content information).
3.3. Receptive Field Feature Enhancement Module
The accuracy of object detection models tends to increase as the network deepens, but it will lead to higher computational costs. What is more, the receptive field of each layer of CNN is fixed, which will lose some information and the ability to distinguish different fields of vision, such as the center part. A module is needed that can reasonably utilize the receptive field mechanism to extract more semantic-level features (all pixels do not contribute equally to the output to emphasize the essential information) without increasing the network’s complexity. What is more, for complex multi-object detection, the size of the objects in the same image varies greatly. Therefore, performing a multi-scale pooling operation on the feature maps before feeding them into the neck of the model (spatial feature fusion pyramid network) will improve the network’s performance. We designed a receptive field feature enhancement module (RFFE) based on the above analyses. The structure of RFFE is shown in
Figure 5.
Firstly, the initial feature map
F0 of the RFFE module is generated by ResNet-SA. Then the initial feature map
F0 performs dimensionality reduction through a 1 × 1 convolution layer to generate
F1:
where
represents 1 × 1 convolution operation. Then
F1 is used to generate the intermediate feature set
Fk and
k represents the number of branches of the receptive field feature enhancement module:
where
represents the
kth packet of operation,
includes a 1 × 1 convolution, a dilated 3 × 3 convolution (dilation rate is 1), and a 5 × 5 max-pooling layer.
includes a 3 × 3 convolution, a dilated 3 × 3 convolution (dilation rate is 3), and a 5 × 5 max-pooling layer.
includes a 3 × 3 convolution, a dilated 3 × 3 convolution (dilation rate is 3) and a 5 × 5 max-pooling layer.
is a shortcut operation. Then four feature maps containing multi-scale contextual information are fused in concatenate mode to obtain the fused feature
Fconcat:
where
Concat represents the merging of information between channels.
Fconcat is the final output of the RFFE module.
Obviously, under the same branch, the size of the standard convolution kernel should match the size of the dilated convolution kernel. In the same way, the dilated convolution kernel’s size should match the pooling kernel’s size because a larger dilated convolution kernel can have a larger receptive field. The residual connection is used to preserve the original feature map information as much as possible. The convolution module allows the network to obtain receptive fields of different scales, providing richer global and local feature information. The pooling part realizes the fusion of local features and global features (the size of the largest pooling kernel is equal to the size of the feature map that needs to be pooled). In a word, the RFFE is helpful in enlarging the receptive field of the model, and it will not need too much computation, which increases the network width and the network’s adaptability to multi-scale objects.
3.4. Spatial Feature Fusion Pyramid Network
To fully utilize the semantic information of high-level features and the fine-grained features of low-level features, our model uses a symmetrical three-layer FPN structure to output multi-layer features to the detection head. Referring to the idea of Liu et al. [
9], our model adopts the spatial feature fusion method to adaptively fuse the three-layer output features to fully use different scales’ features. The spatial fusion feature pyramid is a symmetrical structure, and the detailed structure is shown in
Figure 6.
According to the definition of FPN (feature pyramid network), the feature layers of the same size are in the same network stage, and each feature level corresponds to a network stage. The three input feature maps
P1,
P2,
P3 are derived from stage 3 (128 × 128 pixels), stage 4 (64 × 64 pixels) of the ResNet-SA, and the RFFE module (32 × 32 pixels) of the ResNet-SA in
Table 1, respectively. The top-down path merges the more robust characteristics of high-level semantic information through horizontal connections from top to bottom. Each low-resolution feature image is upsampled, and the spatial resolution is expanded to match the size of the next layer of feature maps.
where
Pi represents the chosen output feature maps of ResNet-SA and the RFFE module. For each horizontal connection path, a 1 × 1 convolutional layer is used to change the dimensionality for the next fusion operation and obtain {
Ntemp1,
Ntemp2,
Ntemp3}:
where
Conv represents a 1 × 1 convolution operation. Then each horizontal connection merges feature maps of the same size into one stage. The top-down feature fusion process can be expressed as:
where
is the feature fusion operation, and
Resize is the up-sampling operation to match the resolution of the feature map to be fused in the lower layers.
After obtaining the three-layer preliminary fusion features of the traditional pyramid, a spatial feature fusion operation is performed to obtain the fusion results
SFFi,
SFF1,
SFF2,
SFF3 (which are shown in
Figure 6), which represent the fusion results of the three levels respectively. The spatial feature fusion process formulas are as follows:
where
represents the input vector whose 2-D coordinates are (
i,
j) from the
Ni feature map,
represents the output vector whose 2-D coordinates are (
i,
j),
l represents the
lth SFF feature map.
,
and
represent the importance weights for the feature maps at three different levels to level
. As is shown in Equation (4),
,
and
are designed by using the form of softmax function.
,
and
are the weight parameters for
,
and
respectively. The weight maps
,
,
can be computed by using 1 × 1 convolution layers from
,
,
respectively.
3.5. Anchor-Free Sibling Detection Head
3.5.1. Sibling Head
Classification tasks and regression tasks have different focuses. The classification task focuses on which of the extracted features is most similar to the existing category. The regression task pays more attention to the position coordinates of the ground-truth box to correct the bounding box parameters [
29]. Therefore, Different detection heads should be designed for different tasks. The structure of the sibling head is shown in
Figure 7. The input feature maps of the sibling head are the output feature maps of the spatial feature fusion pyramid.
3.5.2. Anchor-Free
Anchor box-based detection requires clustering analysis to determine a set of anchor boxes to input into the subsequent network, increasing the detection head’s complexity. Anchor-free detection is a better choice because it can reduce hyperparameters and tricks design. To use the anchor-free mechanism, the number of the prediction of each position is assigned to 1, generating a prediction with each pixel as the center point. This prediction will directly predict four values: the predicted box’s width and height and the horizontal and vertical coordinates of the current pixel relative to the left-top corner of the grid width and height value. Referring to FCOS [
28], the center position of each object is considered the positive sample. To assign FPN levels for every object, we predefine a scale range. Anchor-free detection can reduce the number of model parameters and make the network achieve faster detection speed and better accuracy.
3.5.3. Loss Function
The loss function contains classification loss, regression loss and object loss. The formula for calculating the total loss of the network is shown in Equation (5).
where
Ltotal,
Lreg,
Lcls,
Lobj represent the total loss, regression loss, classification loss, and object loss, respectively.
is an IOU function.
Lcls and
Lobj are BCE functions.
reg is the weight coefficient of the regression loss, which is assigned a value of 5.0 in this paper. It means that the regression loss is the most important component of total loss.
5. Conclusions
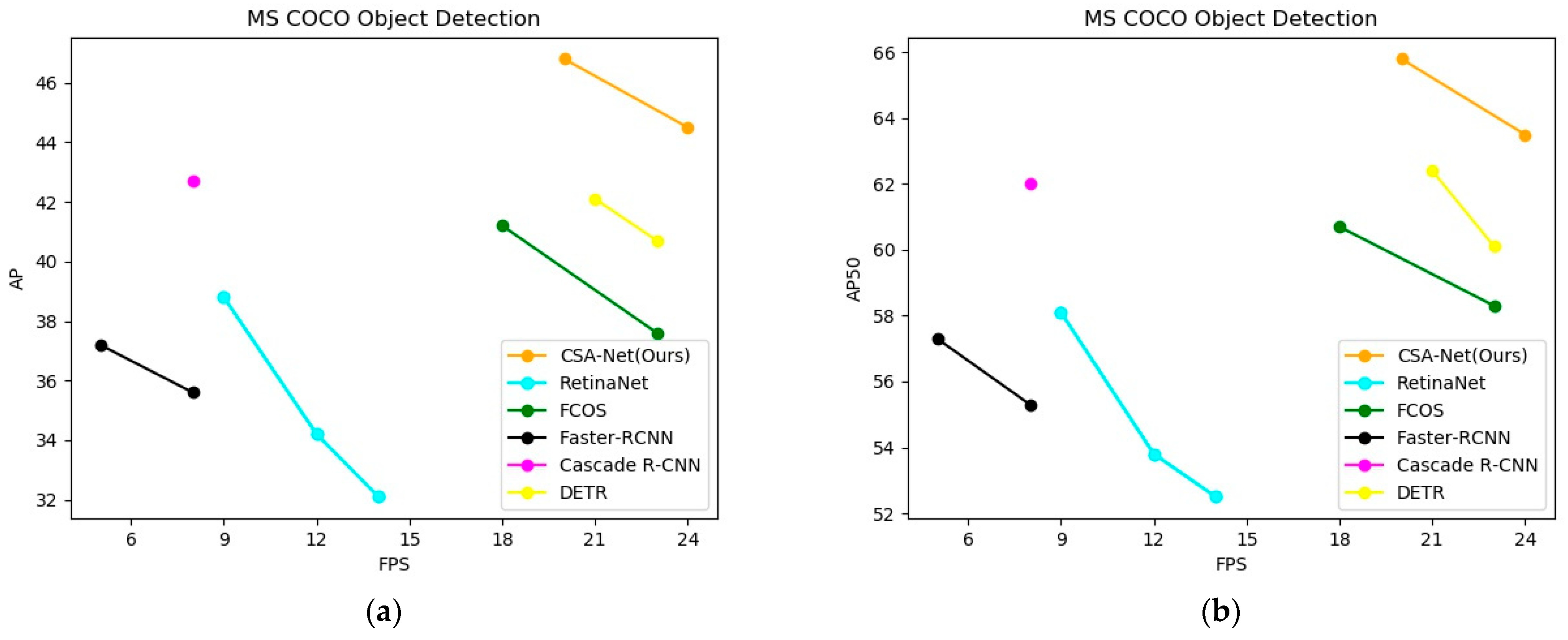
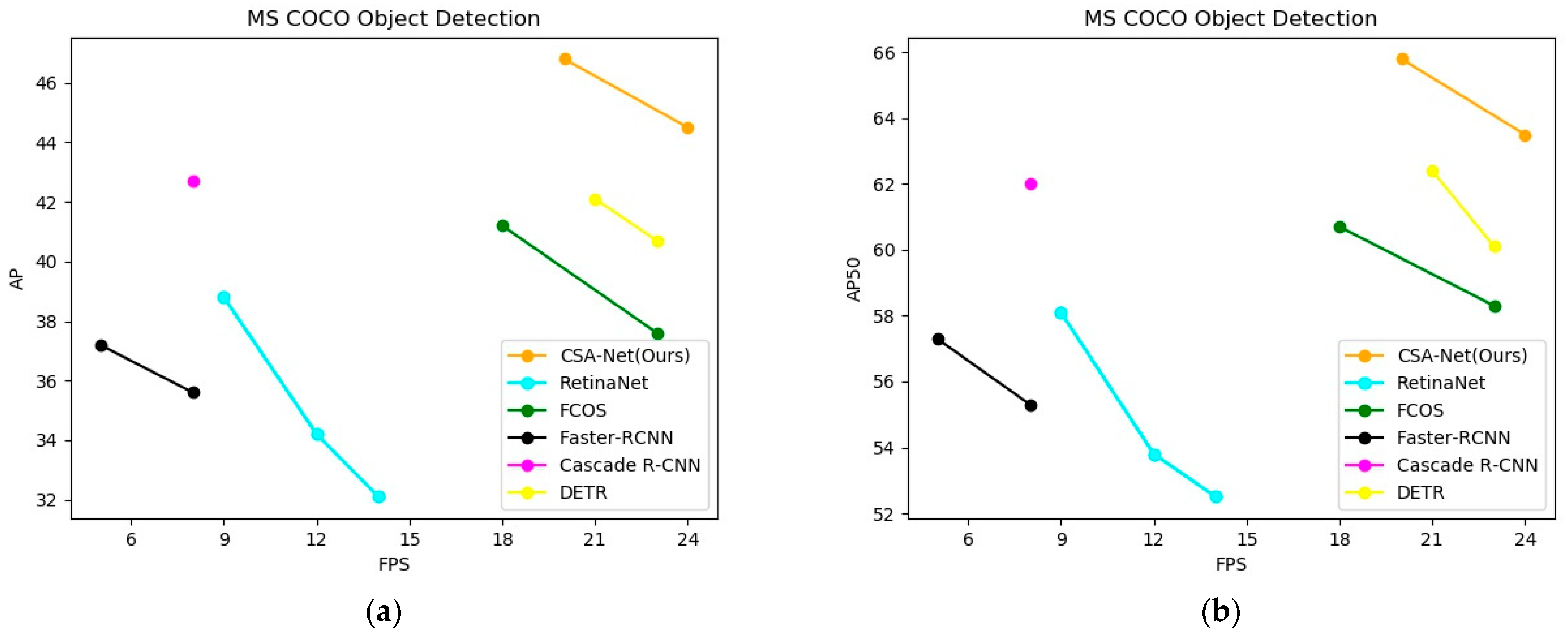
In this paper, to improve the accuracy and speed of object detection, we proposed a multi-scale context information fusion model combined with a self-attention block. First, to pay more attention to the target area, we add self-attention blocks to the model. Then, by enlarging receptive fields and fusing context information, the RFFE module works well so that the model can capture contextual information shown on different layers. The symmetric spatial feature fusion pyramid plays an important role in fusing semantic information of different resolutions and levels. Finally, the design of the anchor-free sibling detection head further improves the network performance. Our algorithm is tested on the MS COCO dataset. The experimental results show that our model has better detection accuracy and speed than some state-of-the-art methods, and the detection average accuracy reaches 46.8%. However, our model still has some optimization space in terms of accuracy and speed. We will consider improving a more efficient feature extraction network and combing our model with model pruning methods in future work.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}