1. Introduction
With the advance of Internet technology, there are an increasing number of options available to users in terms of news, movies, music, and books, among other online content and services. The proliferation of information may be overwhelming for users, which is a well-known issue with Internet technology. Recommender systems (RS) intend to reduce the impact of information overload by searching and recommending a small range of content matched to users’ personalized preferences.
Collaborative filtering (CF) [
1] is a common and widely utilized approach among all recommendation models that bases recommendations on users’ potential preferences by considering users’ similar historical interactions or items’ similar attributes. Due to their reliance on previous interactions between users and items, CF-based methods suffer a significant sparsity of user-item interactions and cold start problems. Researchers have experimented with including side information in CF, such as social networks [
2], knowledge graphs [
3], images [
4], and contexts [
5], in an attempt to mitigate this.
Knowledge graphs (KGs), a sort of directed heterogeneous network in which nodes correspond to entities and edges to relations between entities, have been a popular choice among other types of supplementary information since KGs include significantly more valuable information and associations about items. Items and their features can be mapped to KGs to make the relationships between items clearer. Motivated by the effectiveness of utilizing KG in a range of tasks, such as question answering [
6], text classification [
7], KG completion [
8], and word embedding [
9], researchers have attempted to enhance recommender system performance by utilizing KG. The advantages of incorporating KG into recommendations are evident when compared to KG-free methods [
10]: (1) The fruitful semantic relatedness between items in KG can aid in exploring potential associations and enhancing the accuracies of results; (2) the numerous relations available in KG aid in extending the user’s interests and enhancing the variety of recommended items; and (3) KG supplies interpretable recommendations by connecting the user’s historical behavior to recommended items.
As a rule, existing KG-based recommender systems can be roughly classified into three categories [
3]: embedding-based methods [
4,
11,
12], path-based methods [
13,
14], and unified methods [
10,
15,
16,
17,
18,
19,
20]. The semantic information representation of users and items is not fully taken into consideration by the existing methods, which makes it impossible to reflect the connectivity between users and items accurately. Instead, the methods only use the semantic information of users or items in link propagation to the recommendation. As a result, certain unconnected entities may seriously impact the recommendation outcomes.
To address the limitation of existing KG-based recommendation methods, we propose a personalized relationships-based knowledge graph for recommender systems with dual-view items (PRKG-DI), a novel end-to-end symmetry framework for knowledge graph-aware recommendation. PRKG-DI is a click-through rate (CTR) prediction model that takes a user-item pair as input and calculates the probability of the user clicking an item with which the user has never interacted. In particular, PRKG-DI has two crucial components. (1) Heterogeneous link propagation compiles information on higher-order user-item interactions. (2) The knowledge-aware enhanced attention representation mechanism generates a weighted representation of entities. PRKG-DI splits the item semantic information into collaboration information representation from the user-oriented entity view and knowledge information representation from the item-oriented entity view, respectively, in order to enhance the item semantic information. PRKG-DI additionally presents a scoring mechanism as a filter for personalized relationships by aggregating and incorporating neighborhood information with bias, which can explore users’ personalized and potential interests.
Empirically, we apply PRKG-DI to three real-world scenarios of music, movies, and books. The experiment results show that PRKG-DI outperforms the best of baselines by 1.6%, 2.1%, and 0.8% on , and 1.8%, 2.3%, and 0.8% on in music, book, and movie datasets, respectively.
To sum up, the following is a summary of our contributions to this work:
We propose PRKG-DI, an end-to-end symmetry framework that effectively incorporates collaboration information representation and knowledge information representation for enriching item semantic information.
We apply a scoring mechanism as a filter for personalized relationships to learn each user’s personalized and potential interests.
To demonstrate the superiority of PRKG-DI, we conduct trials on three real-world recommendation scenarios with KGs of varying sizes.
2. Related Work
We discuss a number of theories and models that are pertinent to our work in this section, including knowledge graph embedding and pre-existing KG-based recommendation models.
2.1. Knowledge Graph Embedding
The purpose of KGE is to represent the knowledge graph using low-dimensional dense vectors or matrices in a continuous vector space while maintaining the original information contained in the knowledge graph. KGE algorithms are mainly divided into two categories [
21]: (1) Translational distance models, such as TransE [
22], TransH [
23], TransR [
8], and TransD [
24] assess the plausibility of a fact by measuring the distance between the two entities connected by the relationship. For example, TransE [
22] represents both entities and relations as vectors in the same space when triple (
h,
r,
t) holds, so that
, where
h,
r, and
t are the corresponding representation vectors of
h,
r, and
t. (2)Semantic matching models such as ComplEx [
25], and DisMult [
26] compare the similarities between the underlying semantics of entities and the relations contained in the vector space representation to measure the plausibility of facts.
Although the KGE algorithm, in accordance with the learning goals, is more suited to in-KG applications, such as entity classification or link prediction, compared to the conventional word vector, KGE reflects more similarly the degree of similarity between entities and relationships and can break through the boundary of the in-KG application, expand to a wider range of areas effectively solve the data sparse problem, and make knowledge acquisition, integration, and reasoning performance improved significantly. PRKG-DI acquires semantic information representation using the translational distance model TransR [
8], which can well solve the relationship between 1-to-N, N-to-1, and N-to-N in entities.
2.2. KG-Based Recommendation Models
The usage of knowledge graphs to handle sparsity and cold start concerns is gaining traction in the context of recommender systems.
The embedding-based methods adopt the KGE algorithm to pre-process the KG and map entities and relations to low-dimensional dense semantic vectors. For example, CKE [
4] combines a CF framework with structural information, textual information, and image information, which generates item semantic embeddings via TransR [
8]. KTUP [
12] utilizes TransH [
23] to jointly build a recommendation and knowledge graph completion model that captures the relationships between users and items by exploiting implicit preference representations. However, the information linking patterns of the KGE algorithms applied in these models are neglected, failing to provide causally recommended results [
27].
The path-based methods explore various connection patterns between items in the KG for recommendations by utilizing meta-paths and associated user-item pairs. For example, In PER [
13], KG is treated as a heterogeneous information network, with possible characteristics based on meta-routes extracted to reflect the connections between users and items via various kinds of relational paths. KPRN [
14] constructs the extracted path sequence using relation and entity embeddings and then employs a selection algorithm to extract qualified paths. The path-based approaches improve the interpretability of the recommendation process, but the key issue is that domain expertise is typically required to specify the types and amounts of meta pathways, and designing meta paths artificially is time-consuming and laborious.
The unified methods make superior recommendations by leveraging the semantic representations of entities and relationships with connectivity information from the KG [
28]. For example, RippleNet [
10] is a memory network model similar to water ripples that propagate the user’s potential interests from historical interests along the path in the KG. KGAT [
17] is a hybrid model combining knowledge graph and user–item graph, which recursively obtains the embeddings of entity neighbors to supplement the semantic information of entities. KGCN [
15] and KGNN-LS [
16] apply graph convolutional networks (GCNs) or graph neural networks (GNNS) to KG, then utilize a personalized relation score function to transform the KG into a user-specific weighted graph. CKAN [
18] explicitly encodes collaborative signals through cooperation propagation and provides an attention mechanism to distinguish the contributions of various neighbors.
PRKG-DI is a unified method, which integrates the advantages of embedding-based and path-based methods to provide interpretable recommendations using semantic representation and connectivity patterns of entities.
3. Methodology
3.1. Problem Formulation
In a conventional recommender model, a set of
M users and a set of
N items are denoted as
and
, respectively, in a typical recommender system. According to users’ implicit feedback, the user–item interaction matrix is denoted as
, where
It is worth noting that shows that there is an implicit interaction between user u and item v, such as clicking. Although such interactions do not ensure that the user might prefer the items, they tend to offer information about what the user could desire. Otherwise, does not imply that the user is uninterested in the item, and it is possible that the user enjoys the item but accidentally skips it. In this article, observable interactions are seen as positive instances representing users’ potential preferences, while unobserved interactions are regarded as negative. In addition, there is a knowledge graph composed of a large number of entity-relation-entity triples . The head entity, relation, and tail entity of the knowledge triple are indicated by h, r, and t, respectively. The sets of entities and relations in the knowledge graph are symbolized by and . Moreover, an aligned set is defined in this research to denote that the associated entity set of the item can be established in the knowledge graph .
The purpose of PRKG-DI is to forecast if a user u is potentially interested in an item v with which he has not previously engaged, by employing a user-item interaction matrix and a knowledge graph , and the ultimate goal is to generate a prediction function , where is the predicted probability of whether user u will have a latent preference for item v, and stands for the model parameters of the function .
3.2. Framework
The framework of the proposed PRKG-DI model is discussed in this section, and then the essential components are thoroughly described. The architecture of PRKG-DI is illustrated in
Figure 1, which takes a user-item pair
as input, and outputs the probability of user
u interaction with the item
v. To enhance the item’s semantic information, we obtain the semantic information representation of item
v from the user-oriented entity view and the item-oriented entity view, respectively. Instead of adopting a traditional independent latent vector representation for the input user
u, we obtain a semantic information representation of user
u using heterogeneous link propagation. Finally, we forecast the interaction probability
by combining the semantic information representation of user
u and item
v.
3.2.1. Heterogeneous Link Propagation
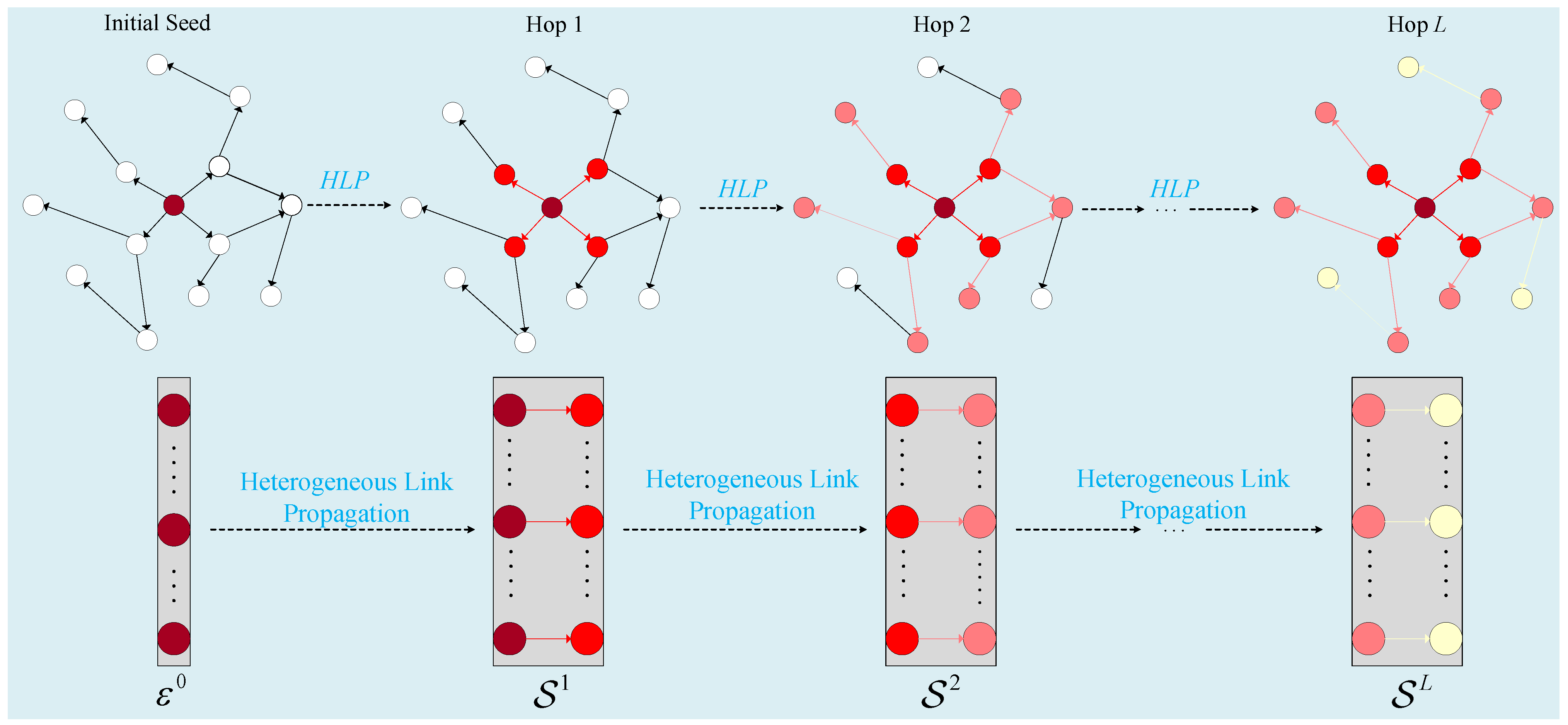
The knowledge graph has a wide range of entities and intricate relationships that offer a novel way to assess users’ potential interests and the potential characteristics of items. Each item
v can be associated with one or more entities in
, as shown in
Figure 2. The
initial seed entity, which each item corresponds to in the knowledge graph, recursively expands outward along the related links in KG to the first hop, second hop, and so on, until the specified hop stops, allowing it to gather the higher-order information between the user and the item, thereby improving the model’s capacity to represent the user and the item. Since an item is associated with more initial seed entities, we define these as
initial entity sets , propagating along connections in KG, we can acquire
expended entity sets and
triple sets for each hop based on the initial entity sets. The formula of expanded entity sets and extended triple sets is given recursively as:
We define the process of obtaining the higher-order interaction information of users and items as heterogeneous link propagation.
In general, the items with which a user has previously interacted can provide some information about the user’s behavior preferences. Instead of using the user’s embedding vector directly, we represent the user
u by using the set of items
he interacted with. The aligned set
through link propagation can convert the associated item into the initial seed entities. The initial entity set definition for user
u is as follows:
Propagating along connections in KG, we can obtain the l- expended entity set and expended triple set of user u to extend the potential representation of user u.
We learn item semantic information representation from the user-oriented entity view and the item-oriented entity view, respectively, to explore more potential item semantic information. For the user-oriented entity view, we observe that users who have interacted with the same item
v, which is defined as
collaboration user set, can add to the feature representation of item
v through shared behavioral interests. We define these items that have been interacted with by the collaboration user as the
collaboration item set of item
v and formulate as
. The initial collaboration entity set definition for item
v is as follows:
For the item-oriented entity view, the mapping entity of the item
v itself in the KG can also contribute to its semantic representation, and the initial entity set definition for item
v is as follows:
Similarly, propagating along a connection in KG, the l- collaboration entity set , expended entity set , collaboration triple set , and expended triple set of item v can be obtained.
3.2.2. Knowledge-Aware Enhanced Attention Representation Mechanism
We gained the triple sets for each hop as previously described for heterogeneous link propagation. The capacity of the model to represent the user and the item with a potential vector is significantly enhanced by the high-order interaction contained within these sets regarding the user’s preferences and the item’s potential features. As a consequence, we provide a knowledge-aware enhanced attention representation mechanism to incorporate triple sets of each hop into the semantic information representation of user u and item v.
Consider the
i-th triple
in the
l-th hop triple set, the following is the generation and formulation of a pertinent attention weight
of the tail entity:
where
is the head entity embedding and
is the relation embedding. ReLU is the nonlinear activation function and
is the Sigmoid activation function. ‖ is the concatenation operation.
W and
b are trainable parameters. Hereafter, we normalize the relevance attention weight across all triples of each hop by using the softmax function:
Finally, the semantic information representation of the
h-th hop triple set for use
u and item
v can be obtained:
where
is the tail entity embedding and
is the number of the triples in triple set
.
We add the representation of the 0-th hop initial entity set for both user and item since it is evident that the initial entity set has a strong connection to the original user and item:
After that, we formulate the semantic information representation set for user
u and item
v as follows:
so we incorporate the above multiple representations by using three types of aggregators (i.e., sum, pooling, and concatenation aggregators) similar to CKAN [
18] into the final semantic vector for user
u and item
v. The three types of aggregators are defined as follows:
where
W and
b are the trainable weight and bias,
is the sigmoid activation function, and ‖ is the concatenation operation.
3.2.3. Personalized Relationship
The movie recommender system based on the knowledge graph is shown in
Figure 3. The user watches three movies, and the recommender system recommends “Avatar” and “Blood Diamond”, based on the user’s behavior preferences to the user. We assume that in a certain situation, the user has more potential interest in his favorite star Leonardo, regardless of the genre of the movie, so the system should provide the user with more accurate recommendations such as “Blood Diamond”. So, we present a scoring function as a filter for personalized relationships by aggregating and incorporating neighborhood information with bias, which is able to explore users’ personalized and potential behavior preferences. The following
Figure 4 illustrates the personalized relationship realization process.
The scoring function is implemented as follows:
where
u is the semantic information representation of user
u, and
r is the embedding representation of relation
r. Propagating along links in KG, it can be extended to higher-order neighborhood information with a bias to form potential vector representations with personalized relationships.
3.2.4. Learning Algorithm
The predicted clicking probability is calculated utilizing the final semantic vector for user
u and item
v that we obtained in
Section 4.2:
PRKG-DI is improved using the same negative sampling as CKAN [
18] and the following loss function:
where
is the cross-entropy loss and
is a positive
pair while
is the opposite, and the last term is the
-regularizer. The learning algorithm of PRKG-DI is presented in Algorithms 1 and 2.
| Algorithm 1 PRKG-DI Prediction Model Algorithm |
| Input: Interaction Matrix ; Knowledge Graph ; Relationship function g;
|
| Output: Prediction function ;
|
- 1:
Initialize all parameters; - 2:
Calculate the initial entity sets for each u and v; - 3:
while PRKG-DI Prediction Model has not converged do - 4:
for in do - 5:
for do - 6:
Calculate entity sets and triple sets ; - 7:
; - 8:
end for - 9:
; - 10:
; - 11:
for do - 12:
for do - 13:
; - 14:
end for - 15:
; - 16:
, ; - 17:
end for - 18:
, ; - 19:
; - 20:
Calculate predicted probability ; - 21:
Update parameters by gradient descent; - 22:
end for - 23:
end while - 24:
return .
|
| Algorithm 2 Knowledge-aware Enhanced Attention Representation Algorithm |
- 1:
: - 2:
for
do - 3:
; - 4:
; - 5:
; - 6:
end for - 7:
; - 8:
; - 9:
return .
|
3.2.5. Time Complexity Analysis
The time cost of the PRKG-DI model mainly comes from four parts: knowledge graph construction, semantic information representation generation, heterogeneous link propagation, and attention representation mechanism. The computational complexity of building a knowledge graph is , depending on the number of entities and relationships in the dataset. The semantic information representation generation has a computational complexity of . For the heterogeneous link propagation part and the attention representation mechanism part, the time cost of the two parts is , and and are the sizes of the triple set for the current hop and the previous hop. Finally, the overall computational complexity of the PRKG-DI model is .
4. Experiments
The effectiveness of PRKG-DI is assessed in this section using three well-liked real-world scenarios: music, book, and movie recommendations. We initially describe the datasets, underlying models, and experimental setup before presenting and analyzing the outcomes.
4.1. Datasets
To verify the effectiveness of PRKG-DI in different application scenarios, the following three datasets are used in the music, book, and movie recommendation experiments:
Last.FM contains the listening information of about 2000 users from the Last.FM online music system.
Book-Crossing provides 1,149,780 explicit ratings of various books from various readers collected from the Book-Crossing community on a scale of 0 to 10.
MovieLens-20M is a popular benchmark dataset for movie recommendations, collecting around 20 million ratings on a scale of 0 to 5 from the MovieLens website.
Since Last.FM, Book-Crossing, and MovieLens-20M are explicit feedback, the ratings need to be converted to implicit feedback, where 1 means that the user rated the item (positive sample) and 0 means that the user did not rate or interact with the item (negative sample). MovieLens-20M has a rating threshold of 4; the ratings greater than or equal to 4 are set as positive samples, and the ratings of less than 4 are set as negative samples. However, Last.FM and Book-Crossing do not set thresholds due to their sparsity. Additionally, knowledge graphs need to be constructed for each dataset, and
Table 1 summarizes the fundamental statistics for the three datasets.
4.2. Baseline Models
The proposed PRKG-DI is compared with the following three recommendation methods: Embedding-based method (CKE), path-based method (PER), and unified method (RippleNet, KGCN, KGAT, KGNN-LS, and CKAN):
CKE [
4] combines a CF module with the structural content, textual content, and visual content of items for recommendation.
PER [
13] is a conventional path-based approach that employs the knowledge graph (KG) as a collection of heterogeneous information networks and extracts attributes based on meta-paths to reflect the connection between users and items.
RippleNet [
10] automatically explores users’ potential behavior preferences by recursively representing users’ preferences in the KG.
KGCN [
15] utilizes the graph convolutional networks (GCN) to aggregate neighborhood information with bias and extends to high-order to capture users’ potential preferences.
KGAT [
17] is a hybrid model combining knowledge graph and user–item graph, which recursively obtains the embeddings of entity neighbors to supplement the semantic information of entities.
KGNN-LS [
16] applies graph neural networks with label smoothness regularization to KG, then utilize a personalized relation score function to transform the KG into a user-specific weighted graph to compute personalized item embeddings.
CKAN [
18] explicitly encodes collaborative signals through cooperation propagation and provides an attention mechanism to distinguish the contributions of various neighbors.
4.3. Experiment Setup
For each dataset, the proportions of training, evaluation, and test set are 6: 2: 2, and we evaluate our model in two recommendation scenarios: the click-through rate (CTR) prediction and the top-K recommendation. In CTR prediction, we apply the trained model to predict the probability of each interaction in the test set and choose and to evaluate the performance of the model. In the top-K recommendation, we apply the trained model to select K items with the highest predicted probability for each user in the test set, and choose to evaluate the performance. Each evaluation experiment is repeated three times with 20 epochs each, and the average performance is reported. All of the models are optimized using adam, and the model parameters are set using Xavier initializer by default.
In PRKG-DI, the complete hyper-parameters are given in
Table 2 and are determined by optimizing
on a validation set, where
d is the dimension of embedding,
L is the maxed hop,
-
denotes the size of the triple set for user and item,
is the coefficient of
normalization, and
is the learning rate. In addition, the best hyper-parameters settings in the comparison methods are followed by the original papers.
4.4. Results
Table 3 and
Figure 5 are the results of all methods in the
prediction and the
-
K recommendation, respectively. We have the following observations:
PRKG-DI achieves the best performance on all three datasets compared with the state-of-the-art baselines. Specifically, PRKG-DI outperforms the best of baselines by 1.6%, 2.1%, and 0.8% on , and 1.8%, 2.3%, and 0.8% on in music, book, and movie recommendations, respectively. Notice that PRKG-DI improves the performance only slightly in the movie dataset since user interactions are so abundant in this dataset.
In all three datasets, PRKG-DI outperforms CKE by 12.6%, 11.9%, and 5.4% on , and by 13.1%, 9.2%, and 6% on compared with the embedded-based methods; PRKG-DI outperforms PER by 25%, 21.1%, and 14.5% on , and by 23%, 16.6%, and 14.8% on , compared with the path-based methods.
PRKG-DI also achieves outstanding performance in the -K recommendations where K becomes large in all datasets.
Judging from the experimental results, PER and CKE perform worst compared with others, and it is obvious that the embedding-based and the path-based methods are overwhelmed by the unified methods on three datasets across all the evaluation metrics. These experimental results demonstrate that PER and CKE cannot make full use of the KG, and combining embedding-based and path-based methods are of great help for the recommendation.
The fact that CKE performs better than PER is noteworthy, showing that it is challenging to identify ideal meta-paths in practice.
CKE performs comparably poorly in our experiments, which is probably because we only use the structural content available, without textual content and visual content.
The importance of heterogeneous link propagation and KG-based high-order connectivity has been confirmed by comparing the outcomes of all KG-based approaches. PRKG-D makes sense to explore user–item relatedness by mining the associated entities in the KG from the user-oriented entity view and item-oriented entity view to augment item semantic information.
4.4.1. Impact of the Dimension of Embedding
In order to further study the robustness of PRKG-DI, the effect of the size of the embedding d on the performance of PRKG-DI is changed. Entity and relationship embeddings use the same dimension size for ease of calculation.
Figure 6 and
Figure 7 demonstrate the results, which are pretty obvious: Increasing
d within a range can improve performance since a bigger
d can encode more information, whereas a too-large
d unfavorably results in a little overfitting.
4.4.2. Impact of the Size of the Triple Set in Each Hop
We examine the effect of the size of the triple set for user and item on the performance of PRKG-DI. To facilitate the experiment, we set the size of the item collaboration triplet set to be the same size as the extended triplet set. The results of AUC on the first two datasets (Last. FM and Book-Crossing) are presented in
Table 4 and
Table 5, respectively, from which we observe that as the set size increases, firstly, the performance of PRKG-DI improves, because larger sets can integrate more latent semantics from KG, but the performance drops when the size is too large. According to the experimental results, a size of 32 is sufficient for most datasets.
4.4.3. Impact of the Hop Number
We vary the maximal hop number
L of heterogeneous link propagation to investigate how the performance changes in PRKG-DI. The results are shown in
Table 6, from which we can observe that: the best performance is achieved when
L is 3, 2, and 1 in music, book, and movie, respectively. One possible reason for this phenomenon is long-distance propagation. Too small of an
L can hardly explore inter-entity relatednesses and dependencies in KG, while a too-large
L increases the amount of supplemental knowledge, but also significantly increases the amount of noise.
4.4.4. Impact of Aggregators
We experimented with PRKG-DI under different settings of the aggregator to explore the effect of aggregators. The results are shown in
Table 7, from which we can observe that:
is consistently superior to
and
, while the
performs worst compared with the others. This may be because the pooling aggregator loses useful information from the entity itself, while the concatenation aggregator retains more hidden information.
5. Discussion
The embedding-based methods adopt the KGE algorithm to pre-process the KG and map entities and relations to low-dimensional dense semantic vectors. The path-based methods explore various connection patterns between items in the KG for recommendations by utilizing meta-paths and associated user-item pairs. PRKG-DI combines the best of both approaches to provide better recommendations by leveraging the semantic representations of entities and relationships with connectivity information from the KG. Moreover, compared with the existing unified recommendation methods, PRKG-DI splits the item semantic information into collaboration information representation from the user-oriented entity view and knowledge information representation from the item-oriented entity view, respectively, in order to enhance the item semantic information, and the personalized relationships filter explore personalized and potential behavior preferences by aggregating and incorporating neighborhood information with a bias to provide better interpretable recommendations.
However, the PRKG-DI model has the following limitations:
First, PRKG-DI provides significant performance improvements in scenarios with sparse datasets such as Last.FM and Book-Crossing, while there is little room for improvement in scenarios with rich datasets such as Movie-Lens20M. Second, In the process of pre-training, the time to construct the knowledge graph increases with the amount of interactive information in the dataset. Finally, many recommendation scenarios are not limited to textual information recommendation, such as image information recommendation, and the PRKG-DI model cannot obtain image information for content recommendation.
6. Conclusions
In this paper, we propose PRKG-DI, a novel end-to-end symmetry framework for knowledge graph-aware recommendations that enrich item semantic information from the user-oriented entity view and the item-oriented entity view. PRKG-DI overcomes the limitations of existing embedding-based and path-based methods via heterogeneous link propagation to obtain high-order interaction information and utilize knowledge-aware enhanced attention representation mechanisms to incorporate them into semantic information representation of users and items. We conduct extensive experiments on three real-world public datasets. The empirical results demonstrate that our approach significantly outperforms several state-of-the-art baselines by 1.6%, 2.1%, and 0.8% on , and 1.8%, 2.3%, and 0.8% on when applied to three real-world scenarios for music, movie, and book recommendations, respectively.
As to future work, we plan to further evaluate the effectiveness of our model on more recommended scenarios. Moreover, we will introduce more side information to optimize our method. For example, by integrating image information with CKE, we can study how visual information influences recommendations. Integrating relational knowledge based on knowledge graphs with attribute knowledge based on structural information to offer effective storage is another intriguing research direction.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}