
Refined Inference on the Scale Parameter of the Generalized Logistic Distribution Based on Adjusted Profile Likelihood Functions

Abstract
1. Introduction
2. Profile Likelihood Function for the Generalized Logistic Distribution
3. Adjusted Profile Likelihood Functions
4. Sizes of Adjusted Profile Likelihood Ratio Tests
5. Real Data Example
- 3.264, 3.220, 3.145, 2.474, 2.350, 3.125, 2.132, 3.223, 3.871, 2.624, 2.659, 2.454, 1.901, 2.525, 4.225
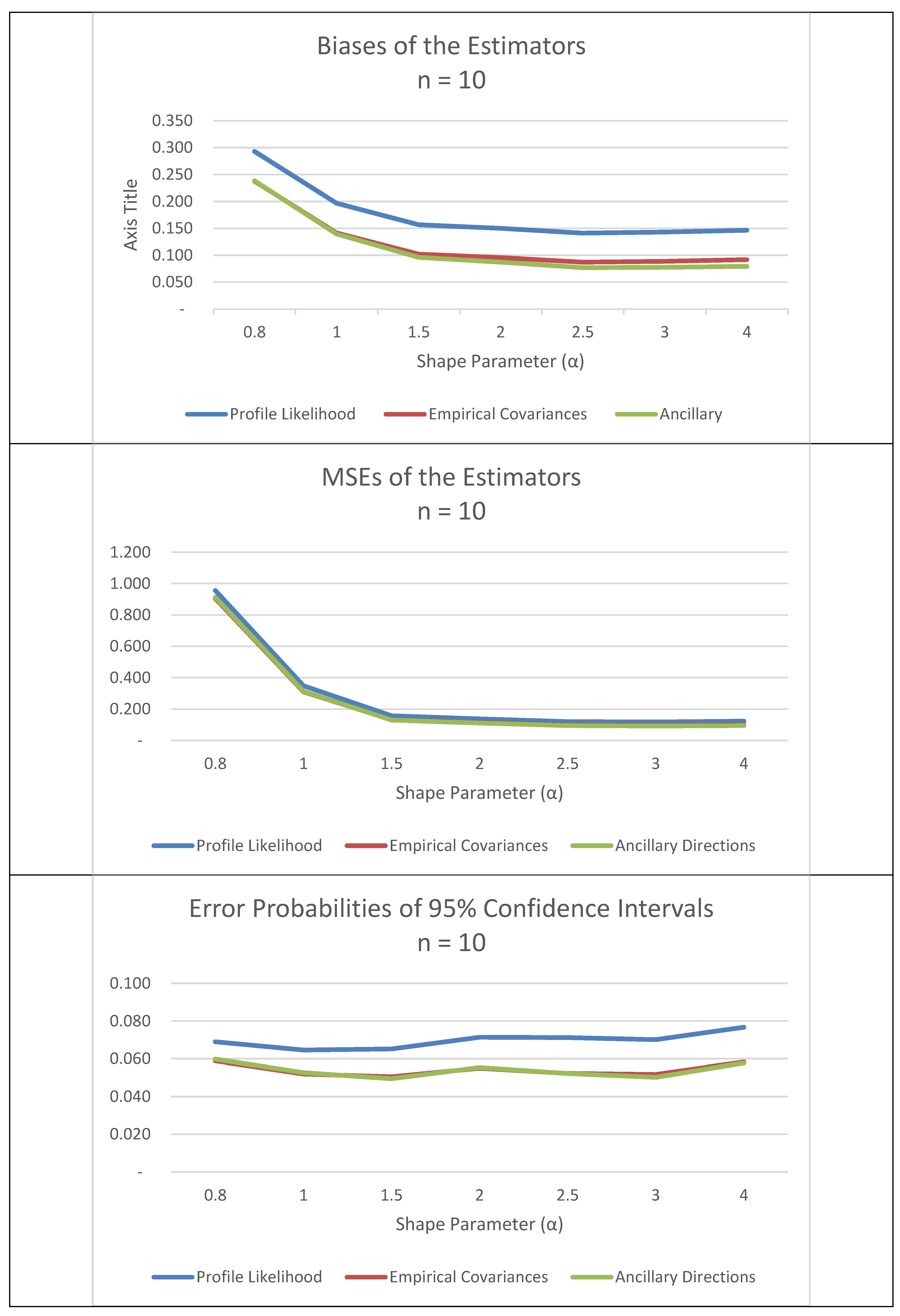
6. Simulation Study
7. Findings and Conclusions
Funding
Conflicts of Interest
References
- Balakrishnan, N.; Leung, M.Y. Order statistics from the type I generalized logistic distribution. Commun. Stat.—Simul. Comput. 1988, 17, 25–50. [Google Scholar] [CrossRef]
- Alkasasbeh, M.R.; Raqab, M.Z. Estimation of the generalized logistic distribution parameters: Comparative study. Stat. Methodol. 2009, 6, 262–279. [Google Scholar] [CrossRef]
- Verhulst, P. Recherches mathematiques sur la loi d’accresioement de la population. Acad. R. Sci. Et Metr. Bruxelee Ser. 2 1845, 18, 1–38. [Google Scholar]
- Ahuja, J.C.; Nash, S.W. The generalized Gompertz_Verhulst family of distributions. Sankhya Ser. A 1967, 29, 141–156. [Google Scholar]
- Asgharzadeh, A. Point and Interval Estimation for a Generalized Logistic Distribution Under Progressive Type II Censoring. Commun. Stat.—Theory Methods 2006, 35, 1685–1702. [Google Scholar] [CrossRef]
- Sreekumar, N.; Yageen Thomas, P. Estimation of the Parameters of Type-I Generalized Logistic Distribution Using Order Statistics. Commun. Stat.—Theory Methods 2008, 37, 1506–1524. [Google Scholar] [CrossRef]
- Ahsanullah, M. On Generalized Type 1 Logistic Distribution. Afr. Stat. 2013, 8, 491–497. [Google Scholar] [CrossRef][Green Version]
- Abdelfattah, A. Skew-Type I Generalized Logistic Distribution and its Properties. Pak. J. Stat. Oper. Res. 2015, XI, 267–282. [Google Scholar] [CrossRef][Green Version]
- Lagos-Álvarez, B.; Jerez-Lillo, N.; Navarrete, J.; Figueroa-Zúñiga, J.; Leiva, V. A Type I Generalized Logistic Distribution: Solving Its Estimation Problems with a Bayesian Approach and Numerical Applications Based on Simulated and Engineering Data. Symmetry 2022, 14, 655. [Google Scholar] [CrossRef]
- Prokhorov, A.V. Scale parameter. In Encyclopedia of Mathematics; Springer: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Koski, T. Scale Parameter; KTH Royal Institute of Technology: Stockholm, Sweden, 2019. [Google Scholar]
- Yang, Z.; Xie, M. Efficient estimation of the Weibull shape parameter based on a modified profile likelihood. J. Stat. Comput. Simul. 2003, 73, 115–123. [Google Scholar] [CrossRef]
- Cox, D.R.; Reid, N. Parameter orthogonality and approximate conditional inference. J. R. Stat. Soc. B 1987, 49, 1–39. [Google Scholar] [CrossRef]
- Ferrari, S.; Da Silva, M.; Cribari–neto, F. Adjusted profile likelihoods for the Weibull shape parameter. J. Stat. Comput. Simul. 2007, 77, 531–548. [Google Scholar] [CrossRef]
- Barndorff-Nielsen, O. On a formula for the distribution of the maximum likelihood estimator. Biometrika 1983, 70, 343–365. [Google Scholar] [CrossRef]
- Severini, T.A. An approximation to the modified profile likelihood function. Biometrika 1998, 85, 403–411. [Google Scholar] [CrossRef]
- Severini, T.A. An empirical adjustment to the likelihood ratio statistic. Biometrika 1999, 86, 235–247. [Google Scholar] [CrossRef]
- Sewailem, M.; Baklizi, A. Modified Profile Likelihood Estimation in the Lomax Distribution. Math. Stat. 2022, 10, 383–389. [Google Scholar] [CrossRef]
- Montoya, J.A.; Figueroa, G.; Puksic, N. Profile Likelihood Estimation of the Vulnerability P(X > v) and the Mixing Proportion p Parameters in the Gumbel Mixture Model. Rev. Colomb. De Estadística 2013, 36, 193–208. [Google Scholar]
- Bartolucci, F.; Bellio, R.; Salvan, A.; Sartori, N. Modified Profile Likelihood for Fixed-Effects Panel Data Models. Econom. Rev. 2016, 35, 1271–1289. [Google Scholar] [CrossRef]
- Jochmans, K. Modified-Likelihood Estimation of the β-Mode; Working Papers hal-03393203; Hal Open Science: Paris, France, 2016. [Google Scholar]
- Jochmans, K. Modified-Likelihood Estimation of Fixed-Effect Models for Dyadic Data; Cambridge Working Papers in Economics; Faculty of Economics, University of Cambridge: Cambridge, UK, 1958. [Google Scholar]
- Severini, T.A. Likelihood Methods in Statistics; Oxford University Press: Oxford, UK, 2000. [Google Scholar]
- Fraser, D.A.S.; Reid, N. Ancillaries and third order significance. Util. Math. 1995, 7, 33–53. [Google Scholar]
- Fraser, D.A.S.; Reid, N.; Wu, J. A simple general formula for tail probabilities for frequentist and Bayesian inference. Biometrika 1999, 86, 249–264. [Google Scholar] [CrossRef]
- Bader, M.G.; Priest, A.M. Statistical aspects of Fisher and bundle strength in hybrid composites. In Progress in Science and Engineering Composites, ICCM-IV; Hayashi, T., Kawata, K., Omekawa, S., Eds.; ICCM-IV: Tokyo, Japan, 1982; pp. 1129–1136. [Google Scholar]
- Casella, G.; Berger, R.L. Statistical Inference, 2nd ed.; Duxbury Press: Pacific Grove, CA, USA, 2002. [Google Scholar]
- Srikanth Reddy, K.; Panwar, K.; Panigrahi, B.; Kumar, R. Computational Intelligence for Demand Response Exchange Considering Temporal Characteristics of Load Profile via Adaptive Fuzzy Inference System. IEEE Trans. Emerg. Top. Comput. Intell. 2018, 2, 235–245. [Google Scholar] [CrossRef]
- Tang, Y.; Zhang, L.; Bao, G.; Ren, F.; Pedrycz, W. Symmetric implicational algorithm derived from intuitionistic fuzzy entropy. Iran. J. Fuzzy Syst. 2022, 19, 19–27. [Google Scholar] [CrossRef]
- Xu, A.; Zhou, S.; Tang, Y. A Unified Model for System Reliability Evaluation Under Dynamic Operating Conditions. IEEE Trans. Reliab. 2021, 70, 65–72. [Google Scholar] [CrossRef]
- Luo, C.; Shen, L.; Xu, A. Modelling and estimation of system reliability under dynamic operating environments and lifetime ordering constraints. Reliab. Eng. Syst. Saf. 2022, 218 Pt A, 108136. [Google Scholar] [CrossRef]
- Zhang, L.; Xu, A.; An, L.; Li, M. Bayesian Inference of System Reliability for Multicomponent Stress-Strength Model Under Marshall-Olkin Weibull Distribution. Systems 2022, 10, 196. [Google Scholar] [CrossRef]


{kind=link}
| Method | Point Estimation | 95% Confidence Interval | Test Statistic (p-Value) |
|---|---|---|---|
| Profile Likelihood | 1.9588 | (1.2804, 2.8019) | 5.6315 (0.0176) |
| Empirical Covariances Adjustment | 1.8859 | (1.2512, 2.7245) | 6.4126(0.0113) |
| Ancillary Directions Adjustment | 1.8789 | (1.2114, 2.7135) | 6.5397(0.0105) |
| 0.2 | 5 | 4.537 | 4.481 | 4.501 | 39.572 | 39.454 | 39.517 |
| 0.2 | 10 | 2.540 | 2.511 | 2.518 | 21.509 | 21.454 | 21.479 |
| 0.2 | 15 | 1.469 | 1.449 | 1.452 | 11.540 | 11.511 | 11.521 |
| 0.2 | 20 | 0.881 | 0.866 | 0.868 | 6.138 | 6.121 | 6.125 |
| 0.2 | 25 | 0.570 | 0.558 | 0.559 | 3.314 | 3.303 | 3.305 |
| 0.2 | 30 | 0.363 | 0.353 | 0.354 | 1.656 | 1.649 | 1.650 |
| 0.2 | 50 | 0.152 | 0.146 | 0.147 | 0.296 | 0.294 | 0.294 |
| 0.2 | 70 | 0.092 | 0.088 | 0.088 | 0.110 | 0.109 | 0.109 |
| 0.2 | 100 | 0.056 | 0.053 | 0.053 | 0.051 | 0.050 | 0.050 |
| 0.5 | 5 | 1.984 | 1.875 | 1.894 | 15.702 | 15.437 | 15.542 |
| 0.5 | 10 | 0.623 | 0.573 | 0.578 | 3.620 | 3.556 | 3.572 |
| 0.5 | 15 | 0.279 | 0.247 | 0.249 | 0.950 | 0.926 | 0.930 |
| 0.5 | 20 | 0.158 | 0.134 | 0.135 | 0.299 | 0.288 | 0.289 |
| 0.5 | 25 | 0.113 | 0.095 | 0.096 | 0.186 | 0.180 | 0.181 |
| 0.5 | 30 | 0.094 | 0.079 | 0.080 | 0.096 | 0.092 | 0.092 |
| 0.5 | 50 | 0.050 | 0.041 | 0.041 | 0.041 | 0.040 | 0.040 |
| 0.5 | 70 | 0.034 | 0.028 | 0.028 | 0.027 | 0.026 | 0.026 |
| 0.5 | 100 | 0.023 | 0.018 | 0.019 | 0.016 | 0.016 | 0.016 |
| 0.8 | 5 | 1.057 | 0.932 | 0.935 | 6.670 | 6.393 | 6.457 |
| 0.8 | 10 | 0.293 | 0.238 | 0.238 | 0.956 | 0.905 | 0.912 |
| 0.8 | 15 | 0.142 | 0.108 | 0.108 | 0.211 | 0.196 | 0.197 |
| 0.8 | 20 | 0.096 | 0.070 | 0.070 | 0.097 | 0.090 | 0.090 |
| 0.8 | 25 | 0.072 | 0.052 | 0.052 | 0.065 | 0.060 | 0.060 |
| 0.8 | 30 | 0.061 | 0.045 | 0.045 | 0.048 | 0.045 | 0.045 |
| 0.8 | 50 | 0.033 | 0.024 | 0.024 | 0.024 | 0.023 | 0.023 |
| 0.8 | 70 | 0.023 | 0.016 | 0.016 | 0.016 | 0.016 | 0.016 |
| 0.8 | 100 | 0.017 | 0.012 | 0.012 | 0.011 | 0.010 | 0.010 |
| 1 | 5 | 0.724 | 0.598 | 0.591 | 3.730 | 3.484 | 3.516 |
| 1 | 10 | 0.197 | 0.141 | 0.140 | 0.349 | 0.311 | 0.314 |
| 1 | 15 | 0.118 | 0.083 | 0.082 | 0.121 | 0.108 | 0.108 |
| 1 | 20 | 0.080 | 0.055 | 0.054 | 0.067 | 0.061 | 0.061 |
| 1 | 25 | 0.063 | 0.043 | 0.042 | 0.050 | 0.047 | 0.047 |
| 1 | 30 | 0.053 | 0.036 | 0.036 | 0.040 | 0.037 | 0.037 |
| 1 | 50 | 0.031 | 0.021 | 0.021 | 0.021 | 0.020 | 0.020 |
| 1 | 70 | 0.022 | 0.015 | 0.015 | 0.014 | 0.014 | 0.014 |
| 1 | 100 | 0.014 | 0.009 | 0.009 | 0.009 | 0.009 | 0.009 |
| 1.5 | 5 | 0.472 | 0.348 | 0.321 | 1.426 | 1.226 | 1.204 |
| 1.5 | 10 | 0.157 | 0.102 | 0.096 | 0.157 | 0.131 | 0.130 |
| 1.5 | 15 | 0.098 | 0.062 | 0.060 | 0.080 | 0.070 | 0.070 |
| 1.5 | 20 | 0.070 | 0.044 | 0.043 | 0.051 | 0.046 | 0.045 |
| 1.5 | 25 | 0.054 | 0.033 | 0.032 | 0.038 | 0.035 | 0.034 |
| 1.5 | 30 | 0.044 | 0.027 | 0.026 | 0.030 | 0.027 | 0.027 |
| 1.5 | 50 | 0.026 | 0.016 | 0.015 | 0.016 | 0.015 | 0.015 |
| 1.5 | 70 | 0.017 | 0.010 | 0.010 | 0.011 | 0.010 | 0.010 |
| 1.5 | 100 | 0.014 | 0.009 | 0.009 | 0.007 | 0.007 | 0.007 |
| 2 | 5 | 0.414 | 0.292 | 0.254 | 0.878 | 0.706 | 0.661 |
| 2 | 10 | 0.150 | 0.095 | 0.087 | 0.138 | 0.114 | 0.111 |
| 2 | 15 | 0.088 | 0.052 | 0.049 | 0.063 | 0.055 | 0.054 |
| 2 | 20 | 0.065 | 0.039 | 0.037 | 0.045 | 0.040 | 0.039 |
| 2 | 25 | 0.050 | 0.029 | 0.028 | 0.031 | 0.029 | 0.029 |
| 2 | 30 | 0.043 | 0.026 | 0.025 | 0.025 | 0.023 | 0.023 |
| 2 | 50 | 0.025 | 0.015 | 0.014 | 0.014 | 0.013 | 0.013 |
| 2 | 70 | 0.018 | 0.010 | 0.010 | 0.010 | 0.009 | 0.009 |
| 2 | 100 | 0.012 | 0.007 | 0.007 | 0.006 | 0.006 | 0.006 |
| 3 | 5 | 0.378 | 0.258 | 0.211 | 0.616 | 0.464 | 0.407 |
| 3 | 10 | 0.143 | 0.089 | 0.078 | 0.118 | 0.096 | 0.092 |
| 3 | 15 | 0.088 | 0.052 | 0.047 | 0.060 | 0.052 | 0.050 |
| 3 | 20 | 0.064 | 0.038 | 0.035 | 0.040 | 0.036 | 0.035 |
| 3 | 25 | 0.052 | 0.031 | 0.029 | 0.029 | 0.026 | 0.026 |
| 3 | 30 | 0.040 | 0.023 | 0.021 | 0.024 | 0.022 | 0.022 |
| 3 | 50 | 0.024 | 0.013 | 0.013 | 0.013 | 0.012 | 0.012 |
| 3 | 70 | 0.017 | 0.009 | 0.009 | 0.008 | 0.008 | 0.008 |
| 3 | 100 | 0.012 | 0.007 | 0.007 | 0.006 | 0.006 | 0.006 |
| 4 | 5 | 0.391 | 0.269 | 0.217 | 0.675 | 0.511 | 0.443 |
| 4 | 10 | 0.146 | 0.092 | 0.079 | 0.123 | 0.100 | 0.095 |
| 4 | 15 | 0.089 | 0.053 | 0.048 | 0.058 | 0.050 | 0.048 |
| 4 | 20 | 0.066 | 0.039 | 0.036 | 0.039 | 0.034 | 0.034 |
| 4 | 25 | 0.052 | 0.031 | 0.028 | 0.029 | 0.026 | 0.026 |
| 4 | 30 | 0.042 | 0.024 | 0.022 | 0.023 | 0.021 | 0.021 |
| 4 | 50 | 0.024 | 0.013 | 0.013 | 0.012 | 0.012 | 0.012 |
| 4 | 70 | 0.016 | 0.008 | 0.008 | 0.008 | 0.008 | 0.008 |
| 4 | 100 | 0.011 | 0.006 | 0.005 | 0.005 | 0.005 | 0.005 |
| 0.2 | 5 | 0.003 | 0.003 | 0.003 | 0.017 | 0.016 | 0.016 | 0.054 | 0.046 | 0.046 |
| 0.2 | 10 | 0.003 | 0.003 | 0.003 | 0.038 | 0.035 | 0.035 | 0.115 | 0.108 | 0.109 |
| 0.2 | 15 | 0.007 | 0.007 | 0.007 | 0.067 | 0.064 | 0.065 | 0.146 | 0.144 | 0.143 |
| 0.2 | 20 | 0.009 | 0.009 | 0.009 | 0.073 | 0.071 | 0.071 | 0.136 | 0.136 | 0.136 |
| 0.2 | 25 | 0.014 | 0.014 | 0.014 | 0.071 | 0.071 | 0.072 | 0.130 | 0.128 | 0.129 |
| 0.2 | 30 | 0.012 | 0.011 | 0.011 | 0.062 | 0.061 | 0.061 | 0.120 | 0.120 | 0.120 |
| 0.2 | 50 | 0.011 | 0.011 | 0.011 | 0.058 | 0.058 | 0.058 | 0.111 | 0.110 | 0.110 |
| 0.2 | 70 | 0.013 | 0.013 | 0.013 | 0.055 | 0.055 | 0.055 | 0.103 | 0.102 | 0.102 |
| 0.2 | 100 | 0.010 | 0.011 | 0.011 | 0.050 | 0.050 | 0.050 | 0.103 | 0.102 | 0.102 |
| 0.5 | 5 | 0.010 | 0.005 | 0.006 | 0.065 | 0.044 | 0.046 | 0.147 | 0.111 | 0.117 |
| 0.5 | 10 | 0.014 | 0.011 | 0.011 | 0.073 | 0.065 | 0.066 | 0.133 | 0.124 | 0.125 |
| 0.5 | 15 | 0.014 | 0.013 | 0.013 | 0.063 | 0.057 | 0.057 | 0.115 | 0.111 | 0.111 |
| 0.5 | 20 | 0.012 | 0.010 | 0.010 | 0.056 | 0.053 | 0.053 | 0.111 | 0.106 | 0.107 |
| 0.5 | 25 | 0.013 | 0.012 | 0.012 | 0.057 | 0.055 | 0.055 | 0.112 | 0.108 | 0.108 |
| 0.5 | 30 | 0.011 | 0.010 | 0.010 | 0.057 | 0.055 | 0.055 | 0.111 | 0.108 | 0.108 |
| 0.5 | 50 | 0.011 | 0.011 | 0.011 | 0.054 | 0.052 | 0.052 | 0.103 | 0.100 | 0.100 |
| 0.5 | 70 | 0.012 | 0.012 | 0.012 | 0.057 | 0.056 | 0.056 | 0.109 | 0.109 | 0.109 |
| 0.5 | 100 | 0.010 | 0.010 | 0.010 | 0.053 | 0.053 | 0.053 | 0.103 | 0.102 | 0.103 |
| 0.8 | 5 | 0.018 | 0.007 | 0.007 | 0.089 | 0.057 | 0.060 | 0.165 | 0.124 | 0.125 |
| 0.8 | 10 | 0.018 | 0.015 | 0.015 | 0.069 | 0.059 | 0.060 | 0.127 | 0.111 | 0.112 |
| 0.8 | 15 | 0.015 | 0.012 | 0.013 | 0.061 | 0.053 | 0.054 | 0.117 | 0.109 | 0.109 |
| 0.8 | 20 | 0.012 | 0.011 | 0.011 | 0.060 | 0.054 | 0.054 | 0.110 | 0.100 | 0.100 |
| 0.8 | 25 | 0.012 | 0.011 | 0.011 | 0.057 | 0.054 | 0.054 | 0.110 | 0.105 | 0.105 |
| 0.8 | 30 | 0.012 | 0.010 | 0.010 | 0.055 | 0.052 | 0.052 | 0.105 | 0.098 | 0.098 |
| 0.8 | 50 | 0.011 | 0.011 | 0.011 | 0.053 | 0.051 | 0.051 | 0.104 | 0.101 | 0.101 |
| 0.8 | 70 | 0.009 | 0.010 | 0.010 | 0.051 | 0.050 | 0.050 | 0.101 | 0.098 | 0.098 |
| 0.8 | 100 | 0.010 | 0.010 | 0.010 | 0.047 | 0.046 | 0.046 | 0.099 | 0.097 | 0.097 |
| 1 | 5 | 0.023 | 0.011 | 0.011 | 0.092 | 0.059 | 0.063 | 0.162 | 0.117 | 0.121 |
| 1 | 10 | 0.016 | 0.011 | 0.011 | 0.065 | 0.052 | 0.053 | 0.122 | 0.105 | 0.104 |
| 1 | 15 | 0.013 | 0.011 | 0.011 | 0.060 | 0.052 | 0.052 | 0.112 | 0.101 | 0.102 |
| 1 | 20 | 0.011 | 0.010 | 0.010 | 0.056 | 0.049 | 0.050 | 0.111 | 0.099 | 0.100 |
| 1 | 25 | 0.011 | 0.010 | 0.010 | 0.054 | 0.050 | 0.050 | 0.107 | 0.100 | 0.100 |
| 1 | 30 | 0.011 | 0.010 | 0.010 | 0.056 | 0.051 | 0.051 | 0.113 | 0.106 | 0.106 |
| 1 | 50 | 0.011 | 0.011 | 0.011 | 0.052 | 0.051 | 0.051 | 0.101 | 0.099 | 0.098 |
| 1 | 70 | 0.012 | 0.012 | 0.012 | 0.053 | 0.053 | 0.052 | 0.105 | 0.103 | 0.103 |
| 1 | 100 | 0.010 | 0.010 | 0.010 | 0.051 | 0.049 | 0.050 | 0.101 | 0.100 | 0.100 |
| 1.5 | 5 | 0.028 | 0.014 | 0.014 | 0.096 | 0.058 | 0.059 | 0.165 | 0.115 | 0.114 |
| 1.5 | 10 | 0.016 | 0.010 | 0.010 | 0.065 | 0.051 | 0.050 | 0.122 | 0.102 | 0.100 |
| 1.5 | 15 | 0.016 | 0.010 | 0.011 | 0.064 | 0.054 | 0.053 | 0.116 | 0.102 | 0.104 |
| 1.5 | 20 | 0.014 | 0.012 | 0.011 | 0.061 | 0.053 | 0.053 | 0.118 | 0.107 | 0.107 |
| 1.5 | 25 | 0.014 | 0.011 | 0.011 | 0.056 | 0.050 | 0.049 | 0.108 | 0.102 | 0.101 |
| 1.5 | 30 | 0.011 | 0.010 | 0.010 | 0.055 | 0.052 | 0.052 | 0.110 | 0.101 | 0.101 |
| 1.5 | 50 | 0.012 | 0.010 | 0.010 | 0.054 | 0.051 | 0.051 | 0.104 | 0.097 | 0.098 |
| 1.5 | 70 | 0.010 | 0.010 | 0.009 | 0.051 | 0.049 | 0.049 | 0.101 | 0.099 | 0.099 |
| 1.5 | 100 | 0.011 | 0.011 | 0.010 | 0.053 | 0.052 | 0.052 | 0.102 | 0.101 | 0.101 |
| 2 | 5 | 0.030 | 0.014 | 0.014 | 0.104 | 0.062 | 0.061 | 0.174 | 0.116 | 0.114 |
| 2 | 10 | 0.019 | 0.013 | 0.012 | 0.071 | 0.055 | 0.055 | 0.134 | 0.105 | 0.104 |
| 2 | 15 | 0.013 | 0.010 | 0.010 | 0.057 | 0.049 | 0.047 | 0.112 | 0.095 | 0.095 |
| 2 | 20 | 0.015 | 0.011 | 0.011 | 0.064 | 0.055 | 0.055 | 0.115 | 0.106 | 0.105 |
| 2 | 25 | 0.011 | 0.010 | 0.010 | 0.054 | 0.048 | 0.048 | 0.108 | 0.099 | 0.099 |
| 2 | 30 | 0.011 | 0.009 | 0.009 | 0.055 | 0.050 | 0.050 | 0.108 | 0.102 | 0.101 |
| 2 | 50 | 0.011 | 0.010 | 0.010 | 0.053 | 0.049 | 0.049 | 0.105 | 0.099 | 0.099 |
| 2 | 70 | 0.010 | 0.009 | 0.009 | 0.052 | 0.049 | 0.049 | 0.106 | 0.101 | 0.101 |
| 2 | 100 | 0.010 | 0.009 | 0.009 | 0.050 | 0.048 | 0.048 | 0.103 | 0.102 | 0.102 |
| 3 | 5 | 0.031 | 0.014 | 0.013 | 0.101 | 0.059 | 0.058 | 0.170 | 0.116 | 0.111 |
| 3 | 10 | 0.017 | 0.012 | 0.012 | 0.070 | 0.052 | 0.050 | 0.127 | 0.103 | 0.101 |
| 3 | 15 | 0.015 | 0.011 | 0.010 | 0.064 | 0.050 | 0.051 | 0.119 | 0.106 | 0.105 |
| 3 | 20 | 0.014 | 0.012 | 0.011 | 0.061 | 0.051 | 0.050 | 0.116 | 0.107 | 0.106 |
| 3 | 25 | 0.012 | 0.010 | 0.009 | 0.057 | 0.052 | 0.052 | 0.109 | 0.099 | 0.098 |
| 3 | 30 | 0.013 | 0.011 | 0.011 | 0.058 | 0.054 | 0.053 | 0.113 | 0.101 | 0.101 |
| 3 | 50 | 0.011 | 0.010 | 0.010 | 0.054 | 0.050 | 0.050 | 0.107 | 0.101 | 0.100 |
| 3 | 70 | 0.011 | 0.010 | 0.010 | 0.050 | 0.048 | 0.048 | 0.099 | 0.095 | 0.094 |
| 3 | 100 | 0.010 | 0.009 | 0.009 | 0.053 | 0.051 | 0.050 | 0.104 | 0.101 | 0.101 |
| 4 | 5 | 0.031 | 0.014 | 0.013 | 0.102 | 0.059 | 0.058 | 0.171 | 0.115 | 0.111 |
| 4 | 10 | 0.019 | 0.013 | 0.013 | 0.077 | 0.058 | 0.058 | 0.140 | 0.111 | 0.110 |
| 4 | 15 | 0.016 | 0.012 | 0.011 | 0.061 | 0.050 | 0.051 | 0.118 | 0.100 | 0.099 |
| 4 | 20 | 0.014 | 0.011 | 0.011 | 0.058 | 0.052 | 0.052 | 0.113 | 0.099 | 0.099 |
| 4 | 25 | 0.014 | 0.011 | 0.010 | 0.059 | 0.049 | 0.049 | 0.113 | 0.103 | 0.103 |
| 4 | 30 | 0.012 | 0.009 | 0.009 | 0.060 | 0.053 | 0.052 | 0.114 | 0.106 | 0.105 |
| 4 | 50 | 0.013 | 0.011 | 0.012 | 0.057 | 0.054 | 0.054 | 0.108 | 0.104 | 0.103 |
| 4 | 70 | 0.011 | 0.010 | 0.010 | 0.055 | 0.052 | 0.051 | 0.109 | 0.105 | 0.104 |
| 4 | 100 | 0.009 | 0.008 | 0.008 | 0.048 | 0.046 | 0.045 | 0.093 | 0.092 | 0.091 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Baklizi, A. Refined Inference on the Scale Parameter of the Generalized Logistic Distribution Based on Adjusted Profile Likelihood Functions. Symmetry 2022, 14, 2369. https://doi.org/10.3390/sym14112369
Baklizi A. Refined Inference on the Scale Parameter of the Generalized Logistic Distribution Based on Adjusted Profile Likelihood Functions. Symmetry. 2022; 14(11):2369. https://doi.org/10.3390/sym14112369
Chicago/Turabian StyleBaklizi, Ayman. 2022. "Refined Inference on the Scale Parameter of the Generalized Logistic Distribution Based on Adjusted Profile Likelihood Functions" Symmetry 14, no. 11: 2369. https://doi.org/10.3390/sym14112369
APA StyleBaklizi, A. (2022). Refined Inference on the Scale Parameter of the Generalized Logistic Distribution Based on Adjusted Profile Likelihood Functions. Symmetry, 14(11), 2369. https://doi.org/10.3390/sym14112369