
Adaptive Spatial-Temporal Regularization for Correlation Filters Based Visual Object Tracking


Abstract
:1. Introduction
2. Related Work
3. Revisiting Traditional Correlation Filter Tracking
3.1. Revisting Standard Correlation Filter
3.2. Revisiting STRCF
3.3. Revisiting ASRCF
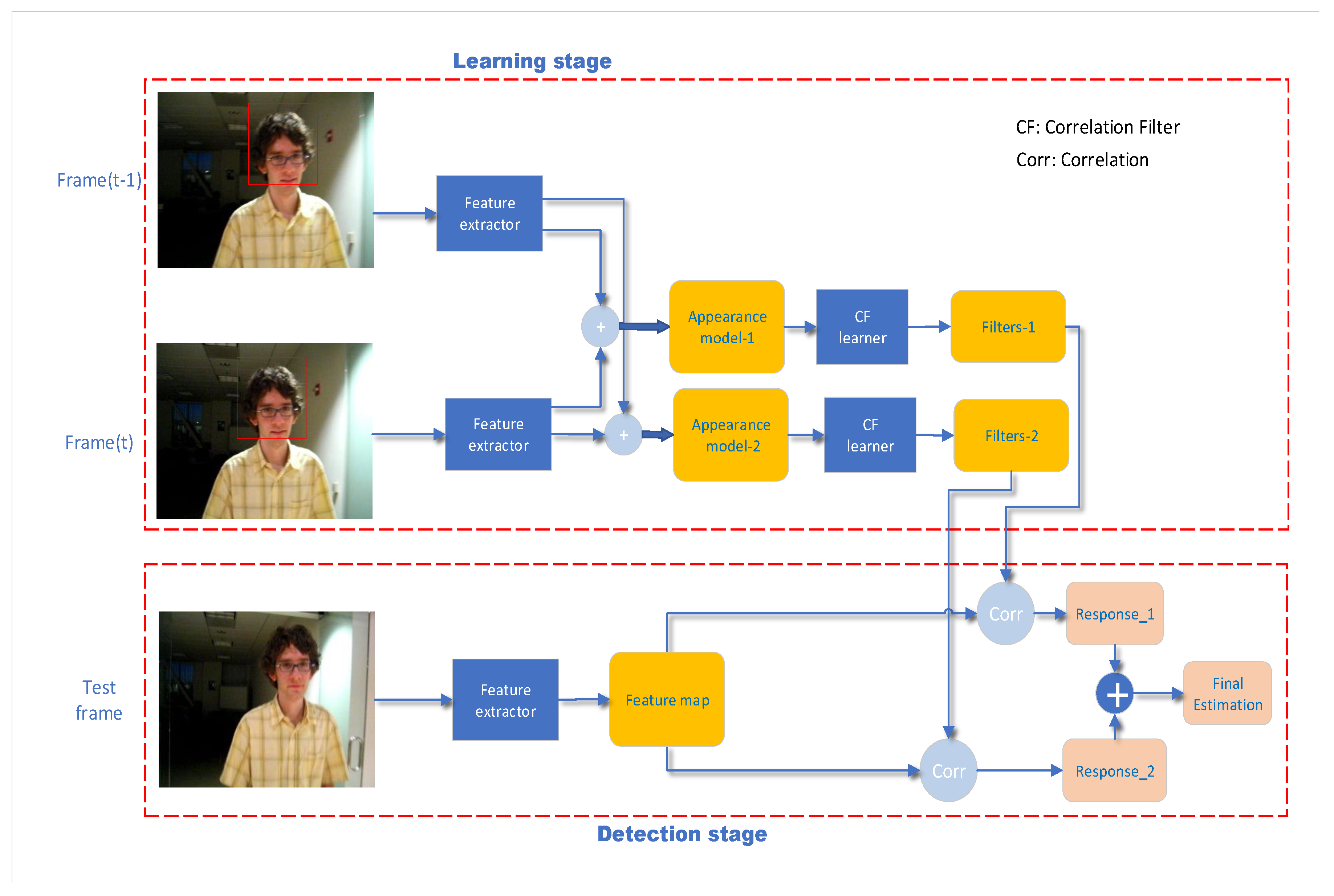
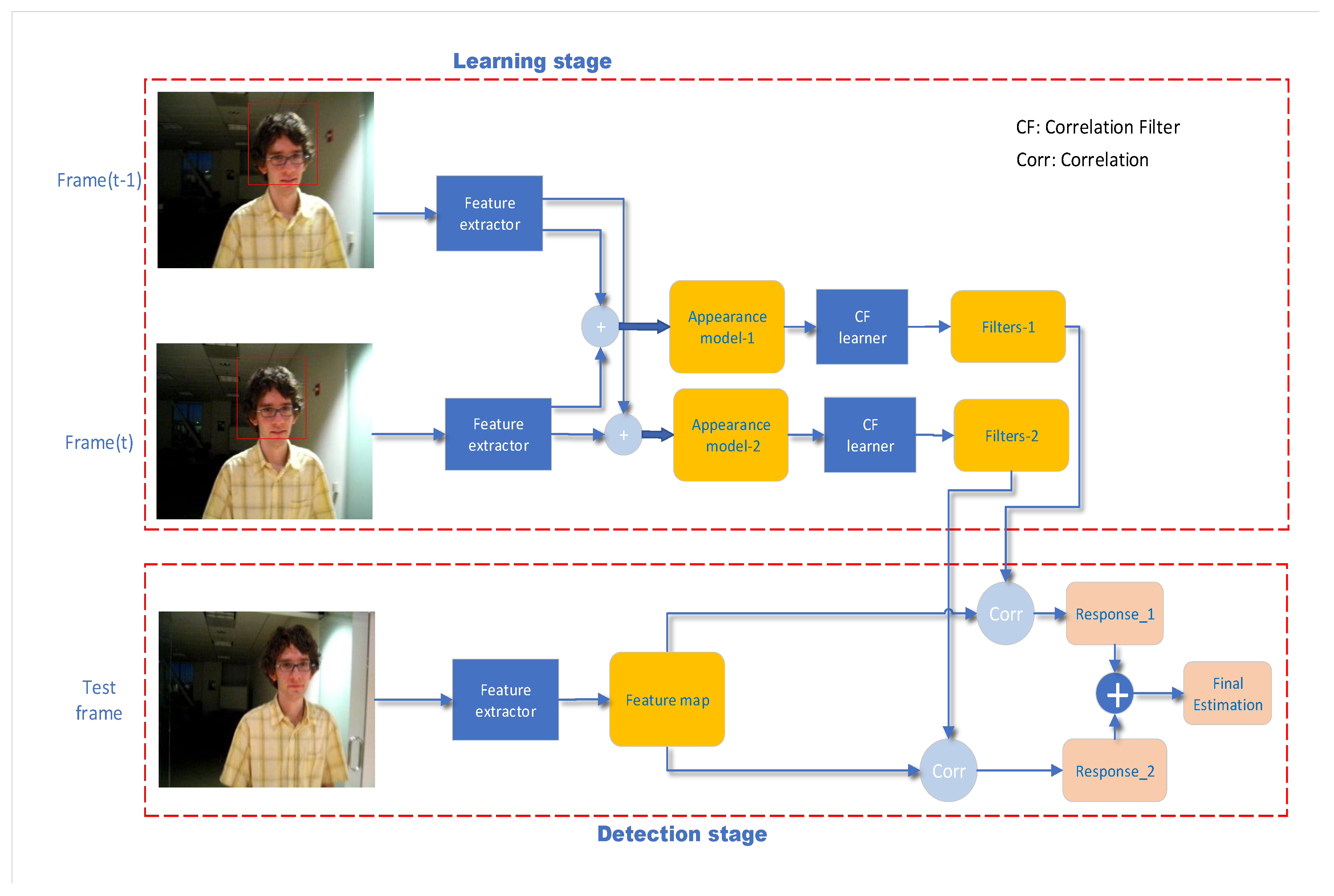
4. Our Approach
4.1. Adaptive Spatial-Temporal Regularization
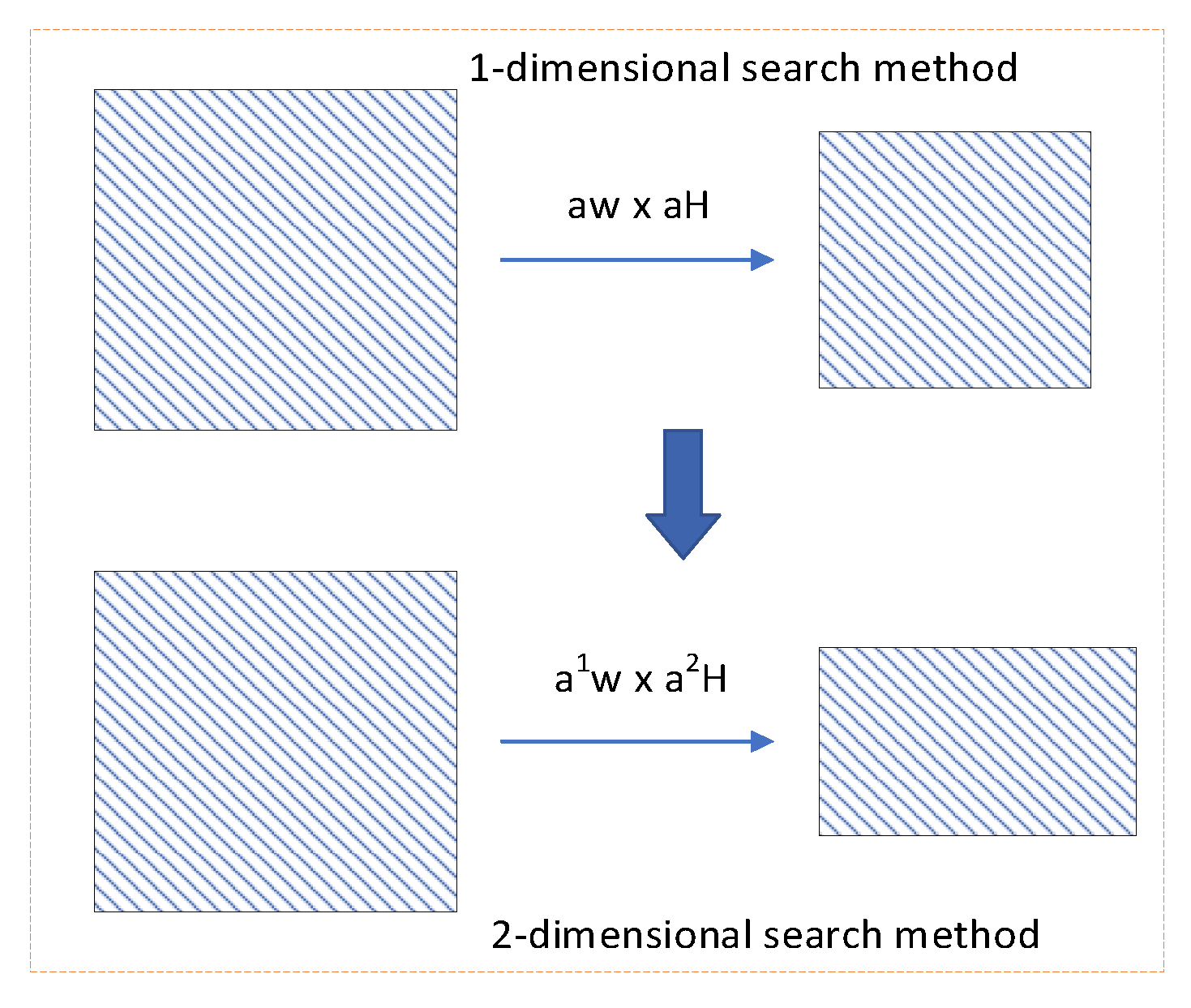
4.2. 2-Dimensional Scale Space Search Method
4.3. The Impact of Learning Rate
5. Experiments
5.1. Experimental Implementations
| Algorithm 1 The proposed tracking algorithm: iteration at time step t |
|
5.2. Evaluation Methodology
5.3. Ablation Study
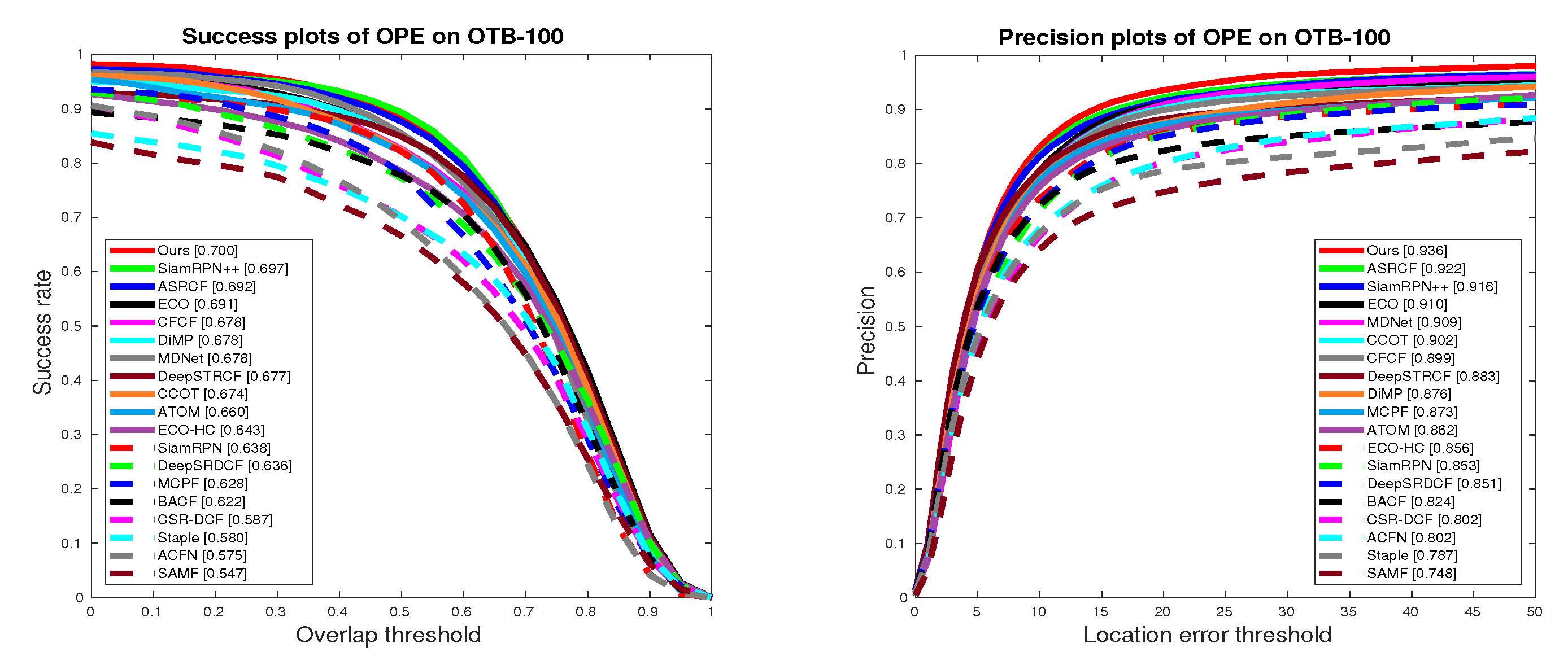
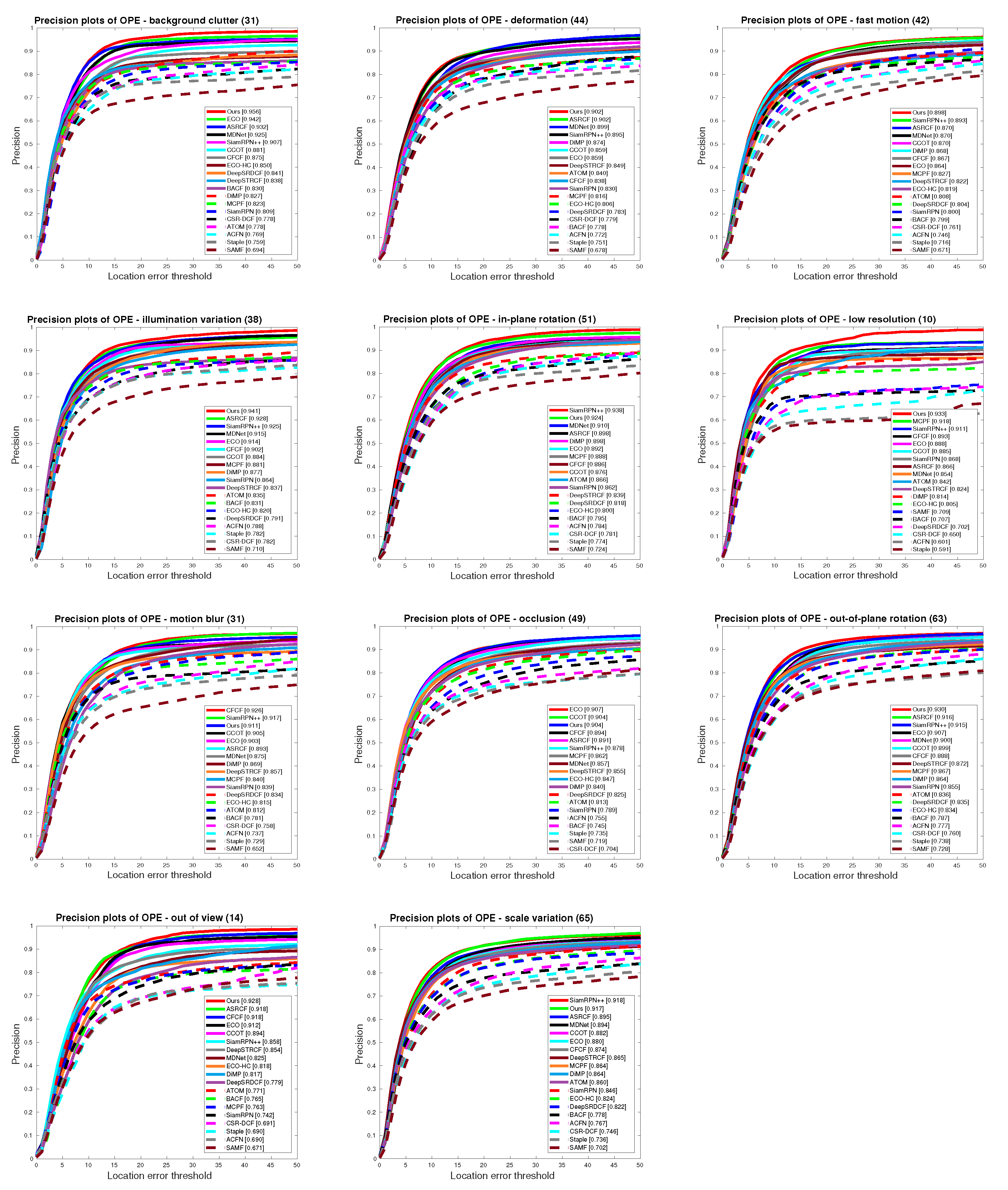
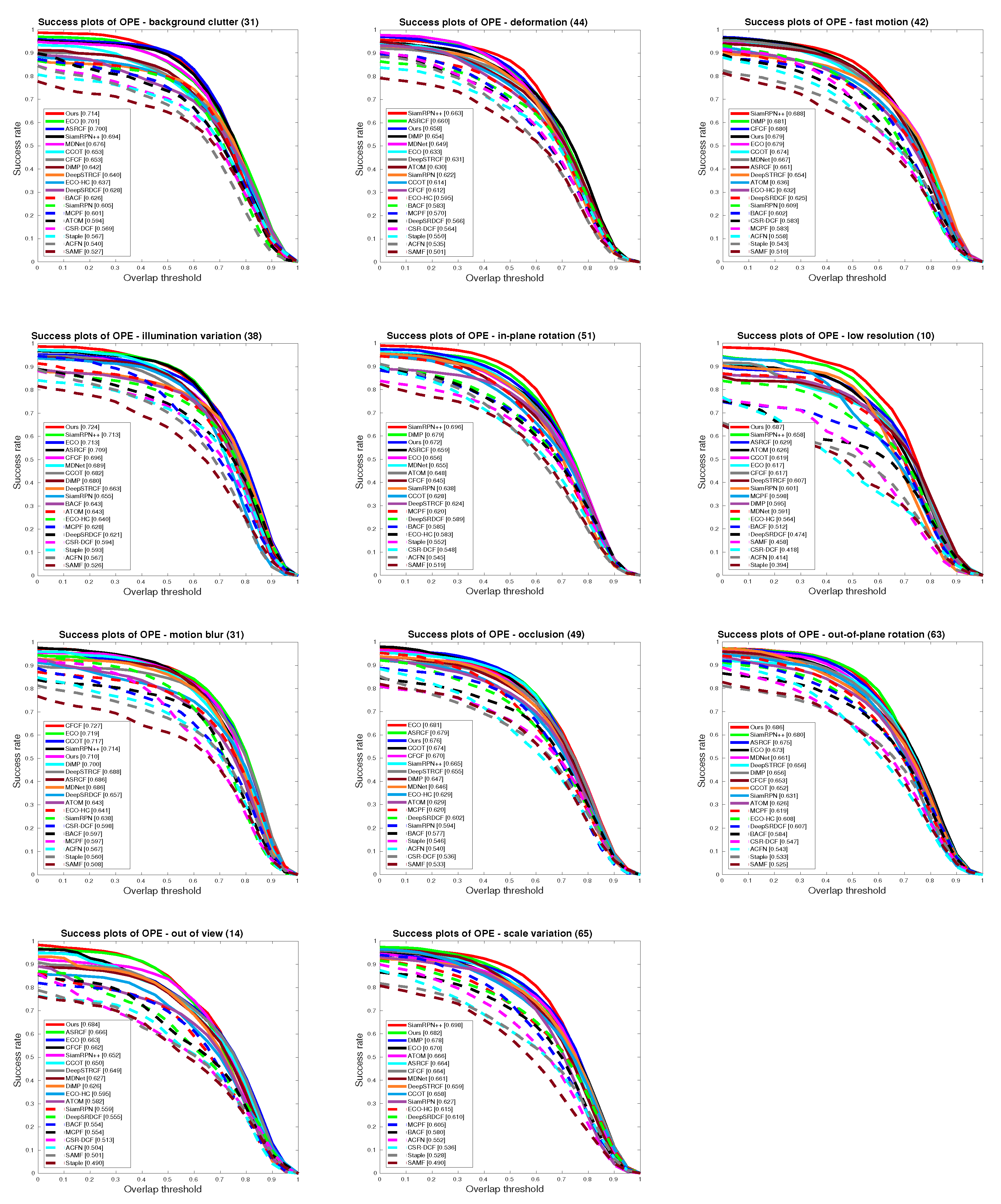
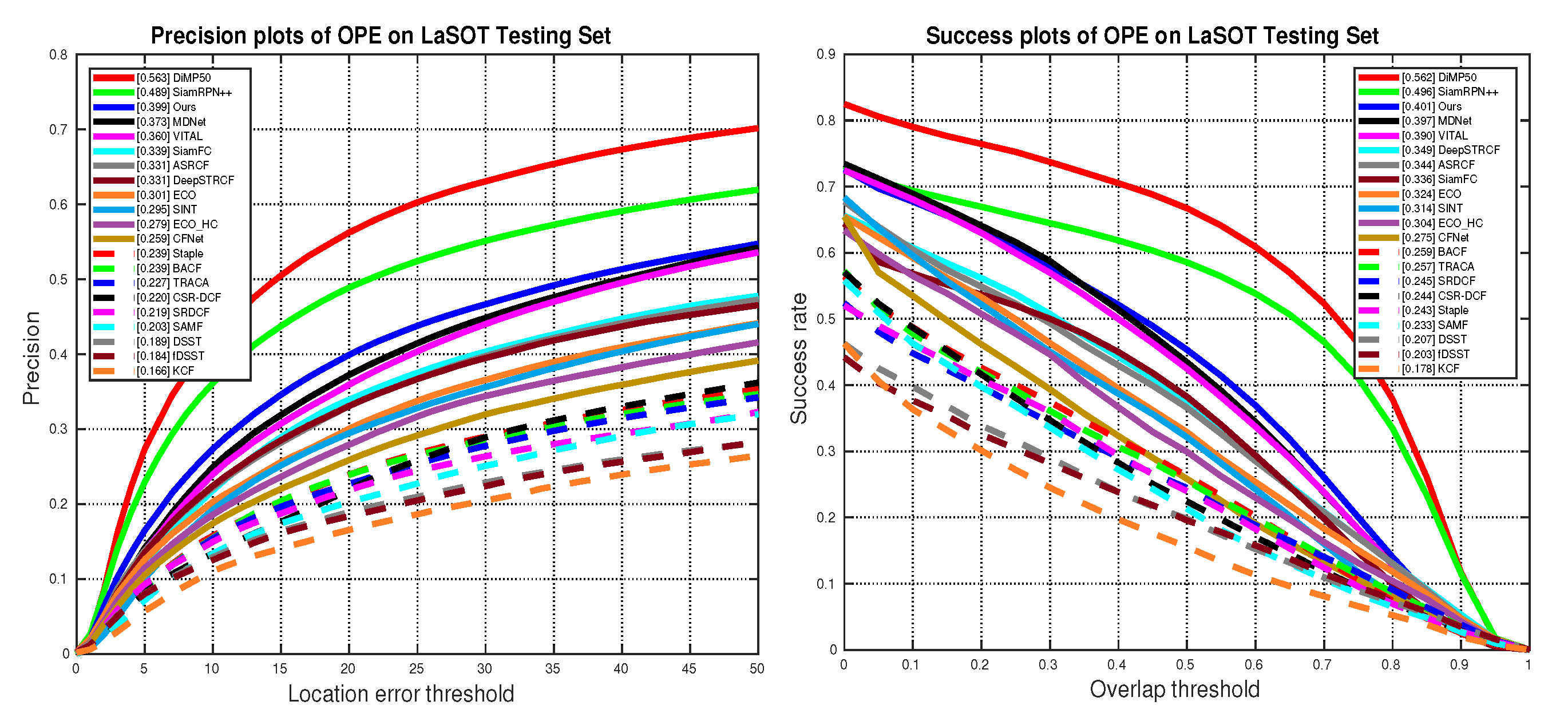
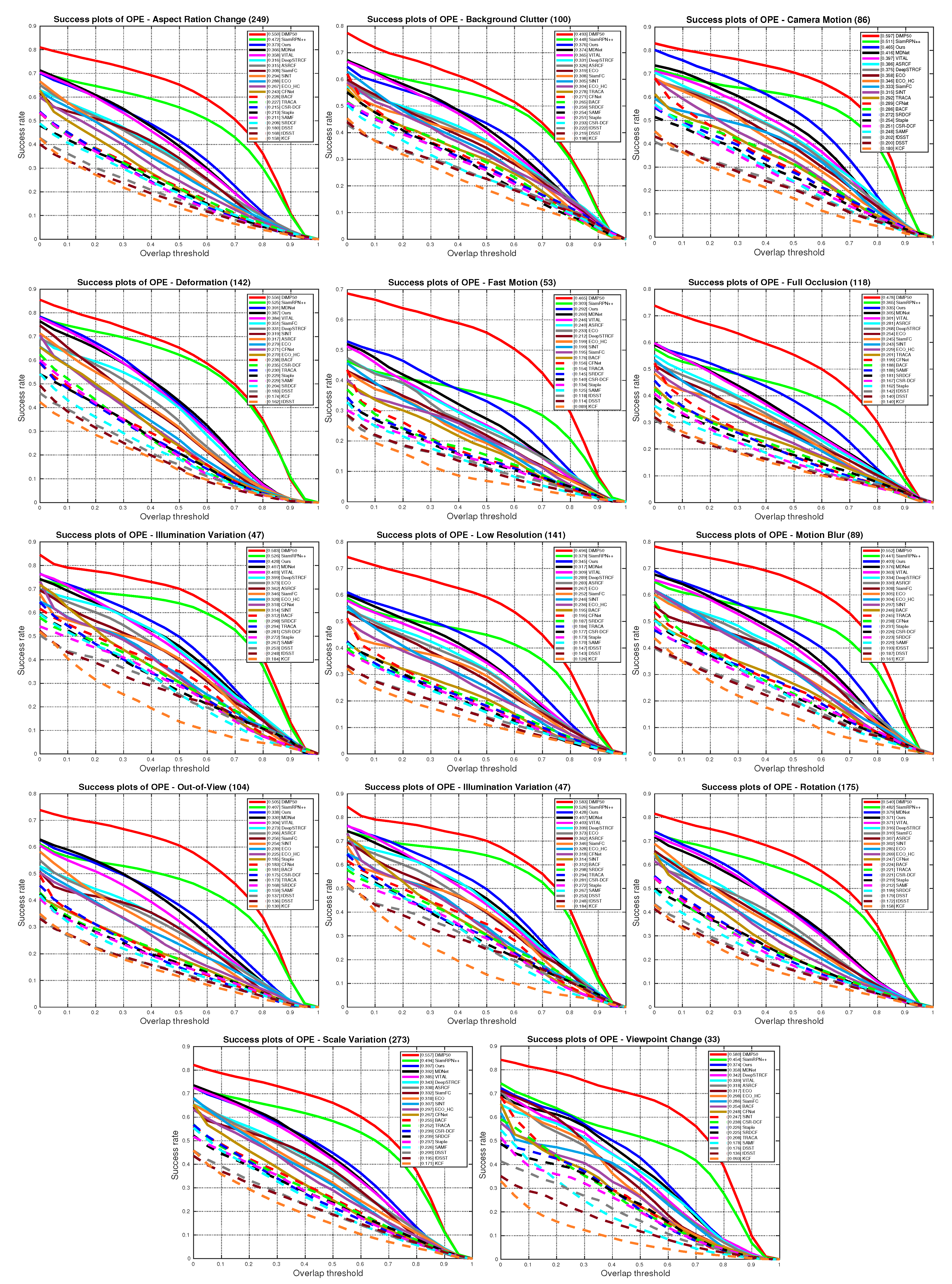
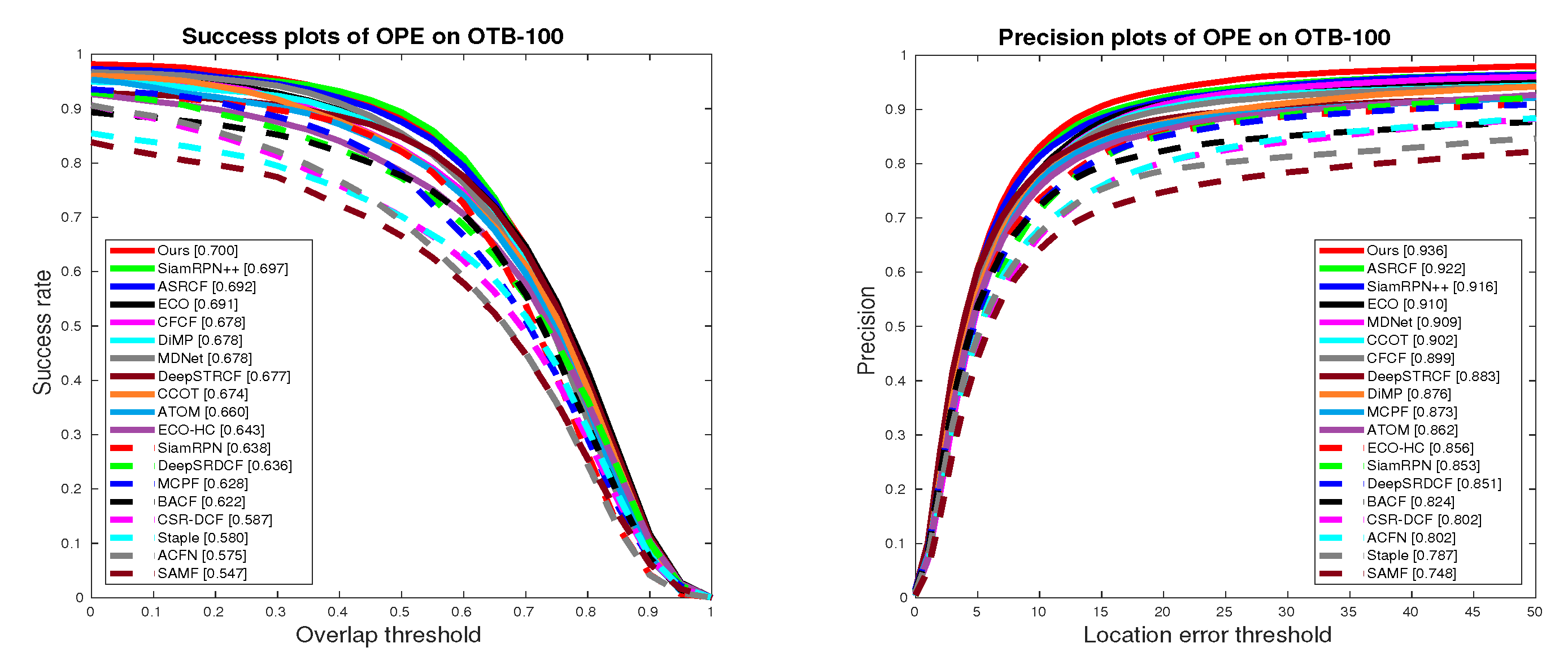
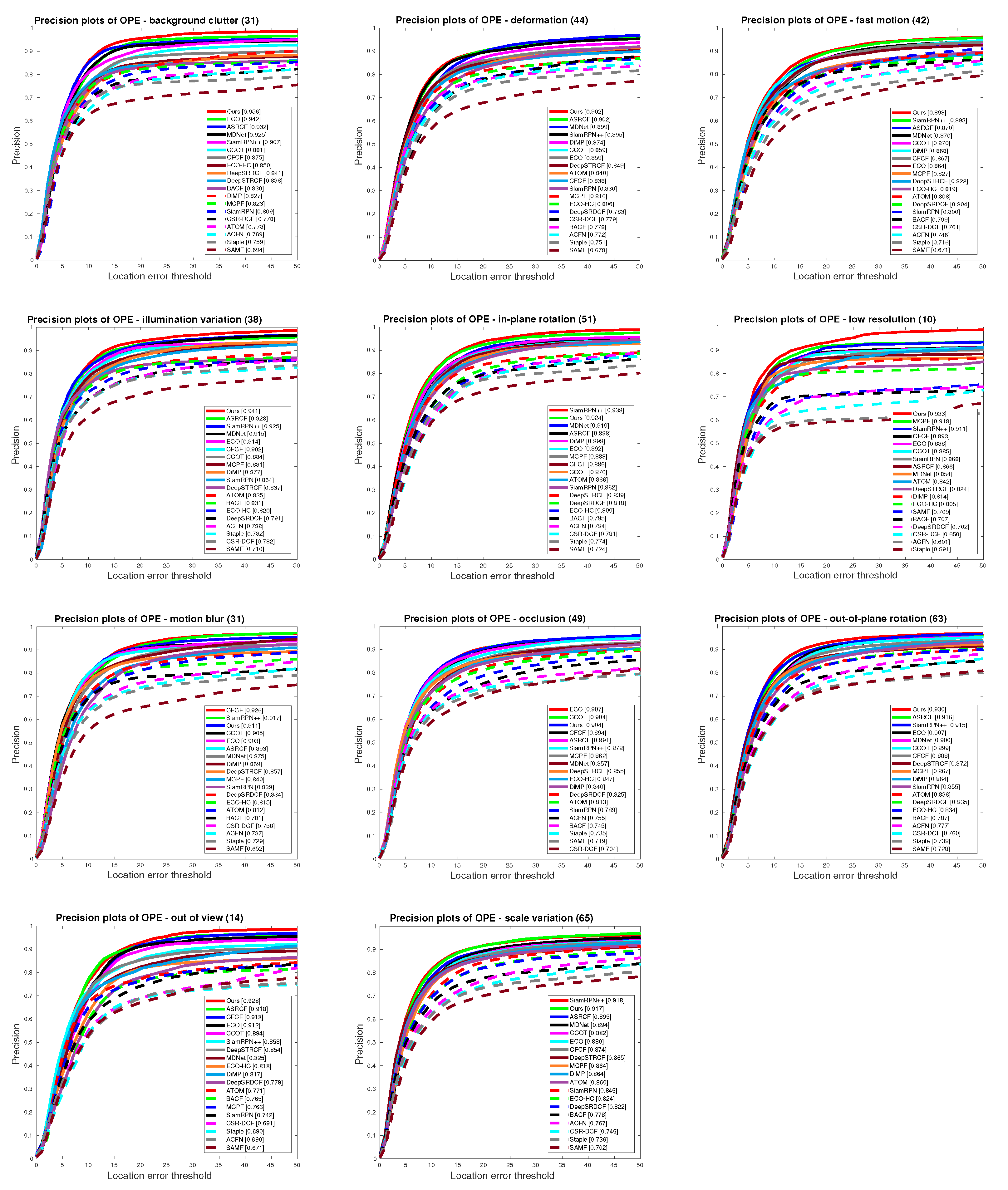
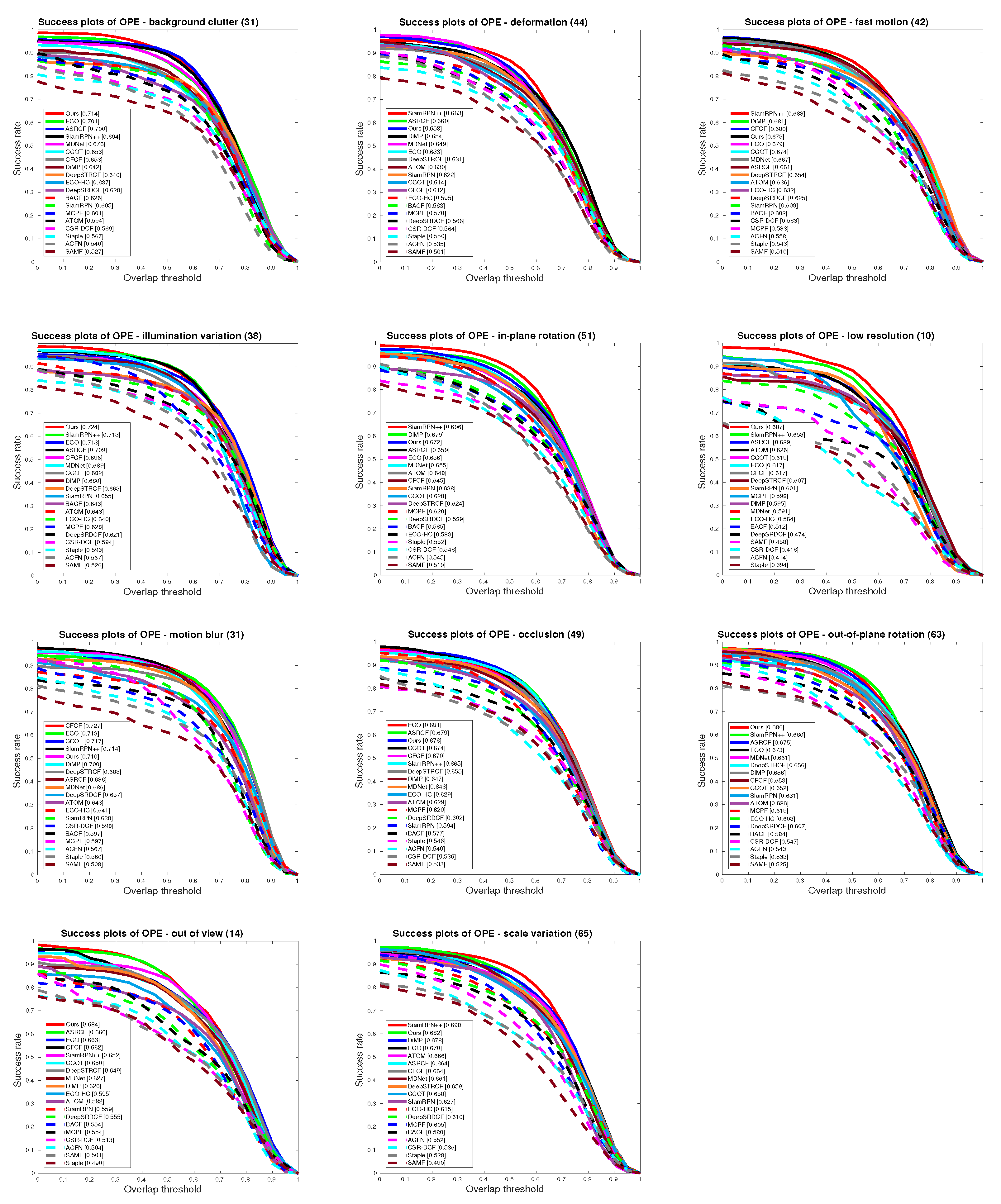
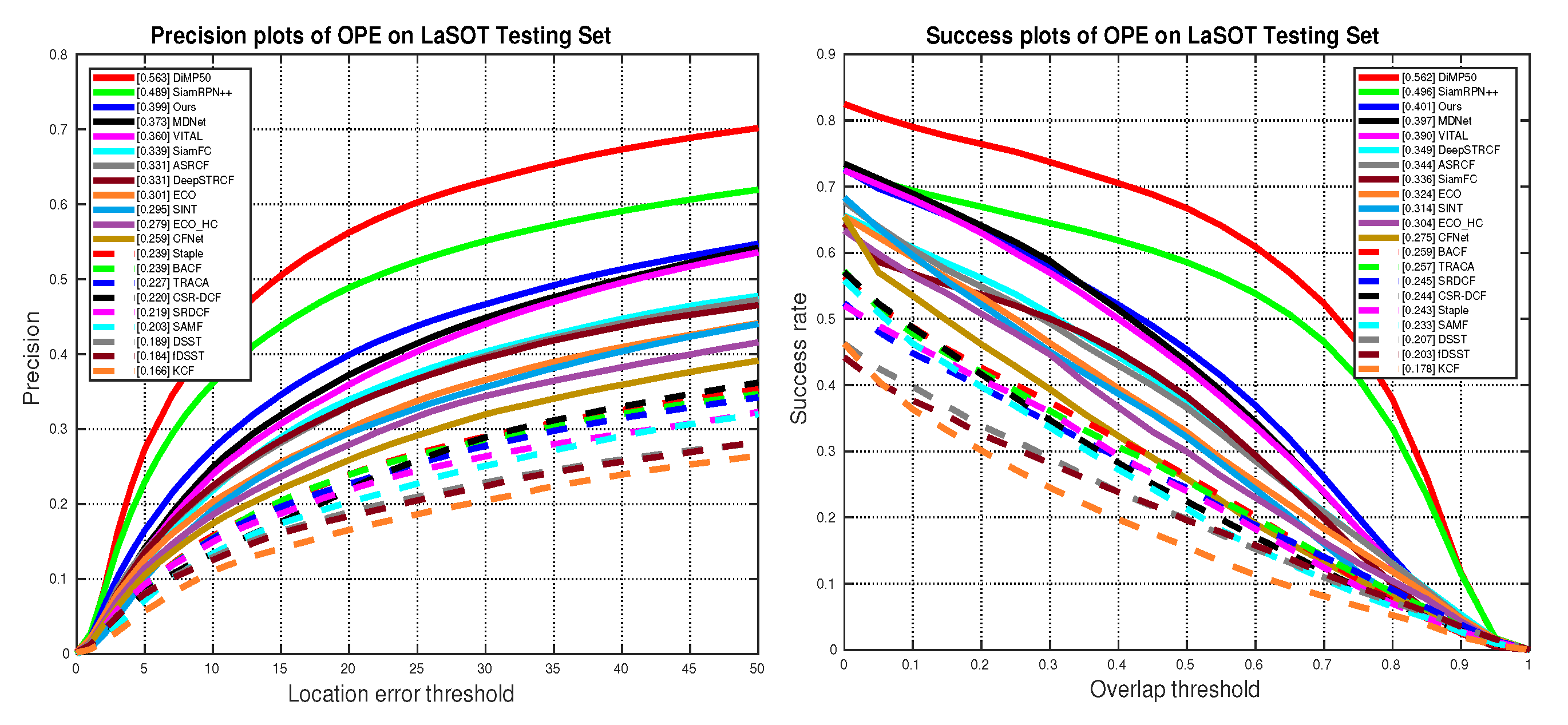
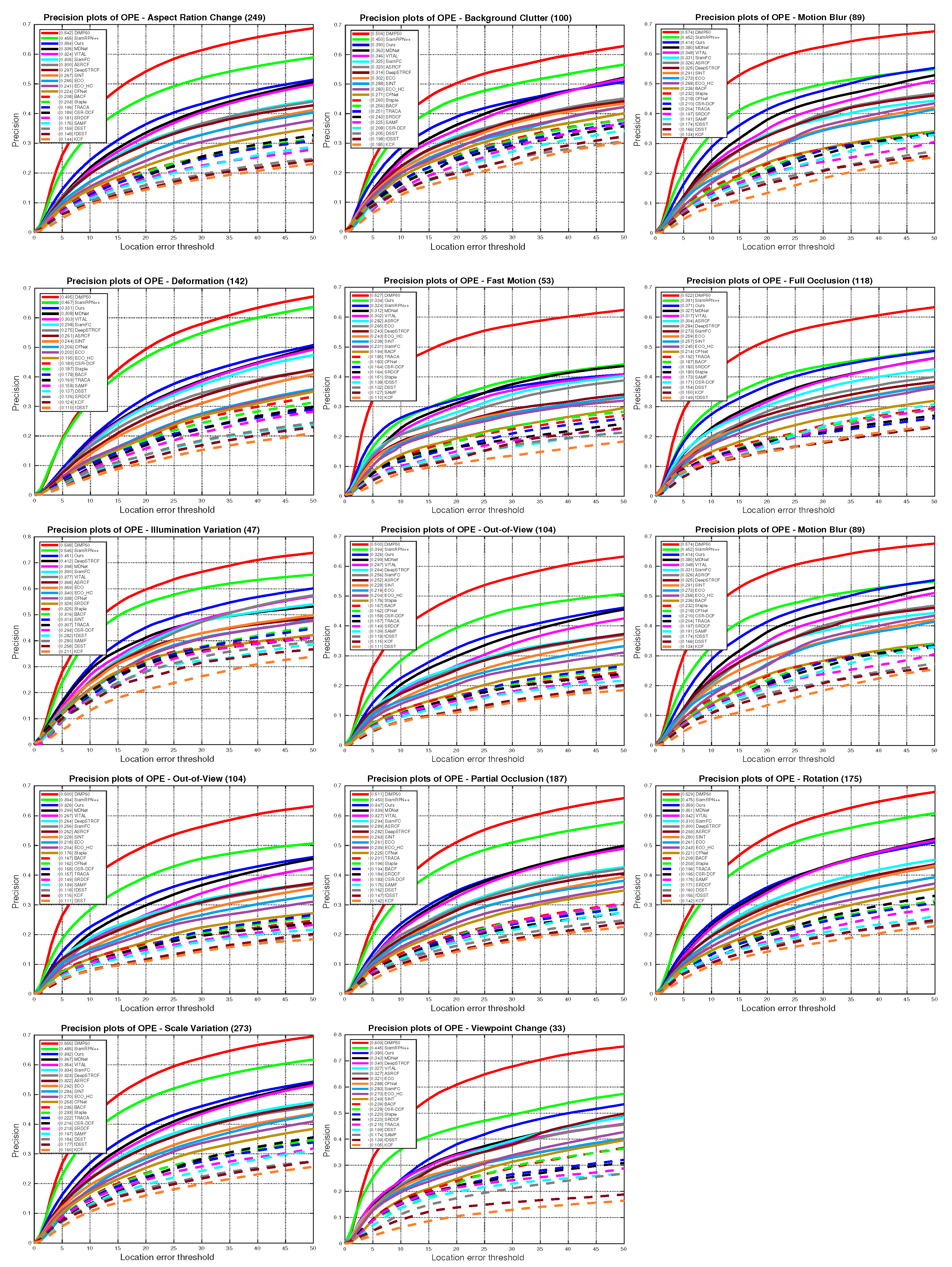
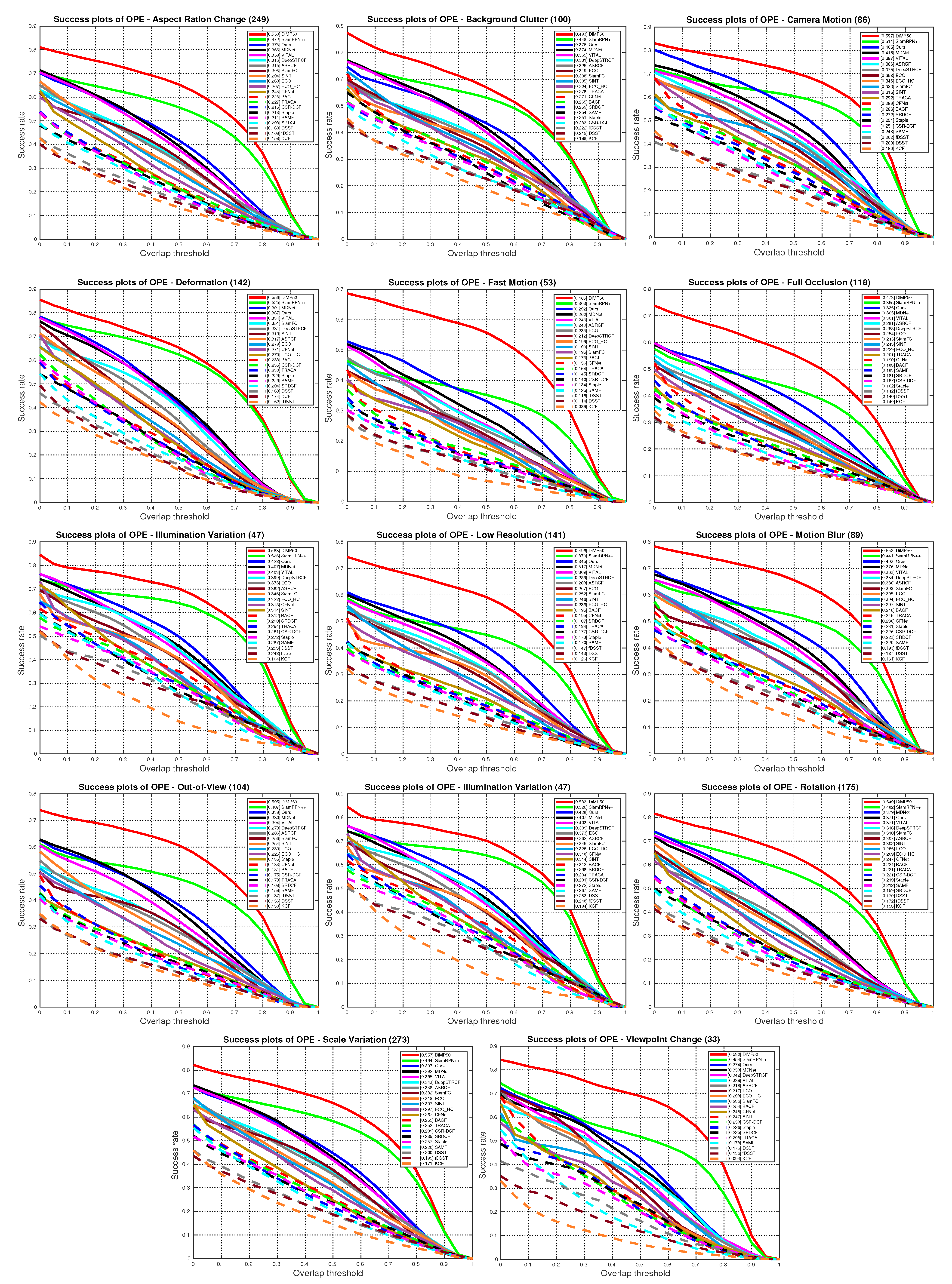
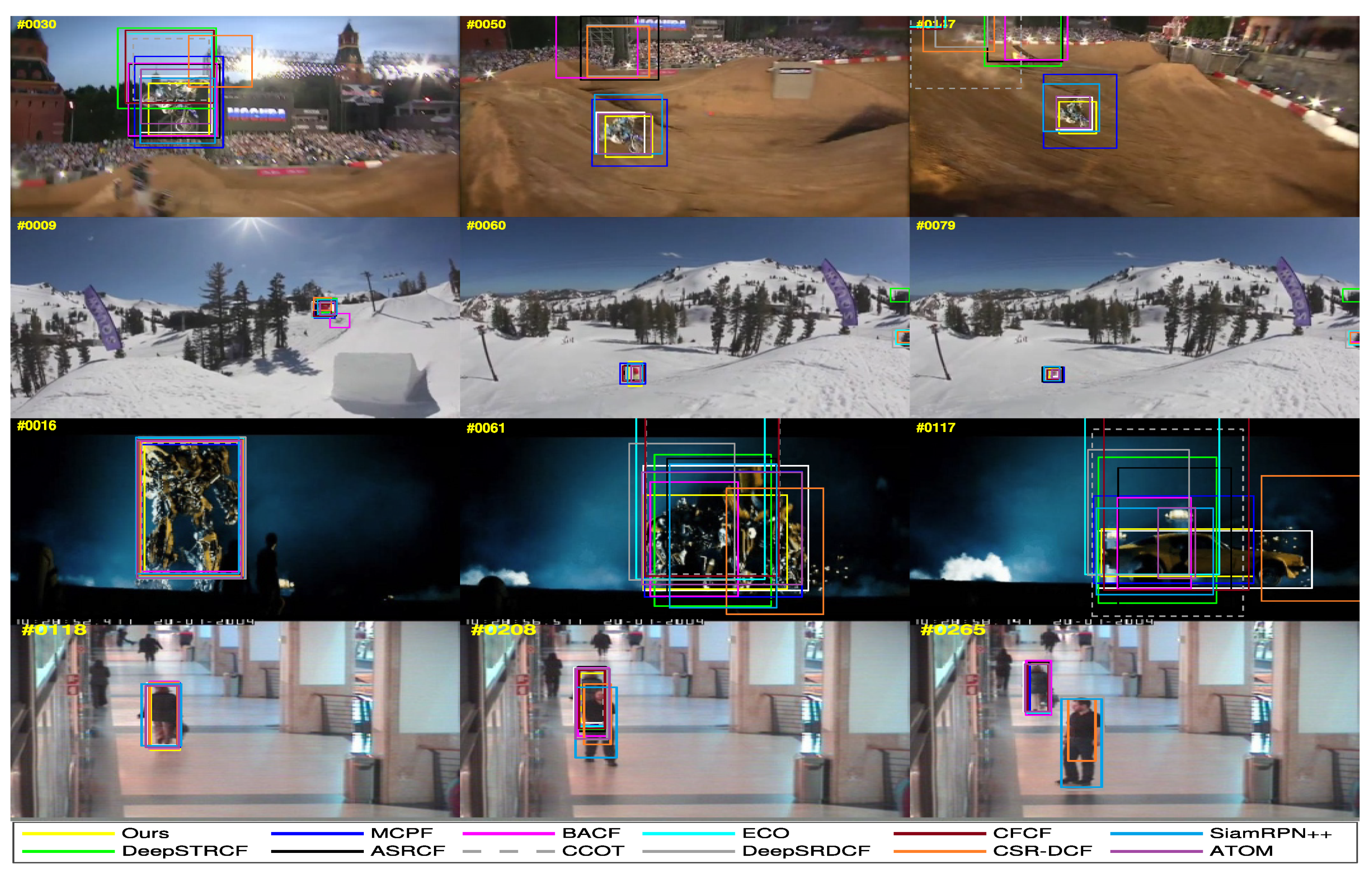
5.4. State-of-the-Art Comparison
5.4.1. Quantitative Evaluation
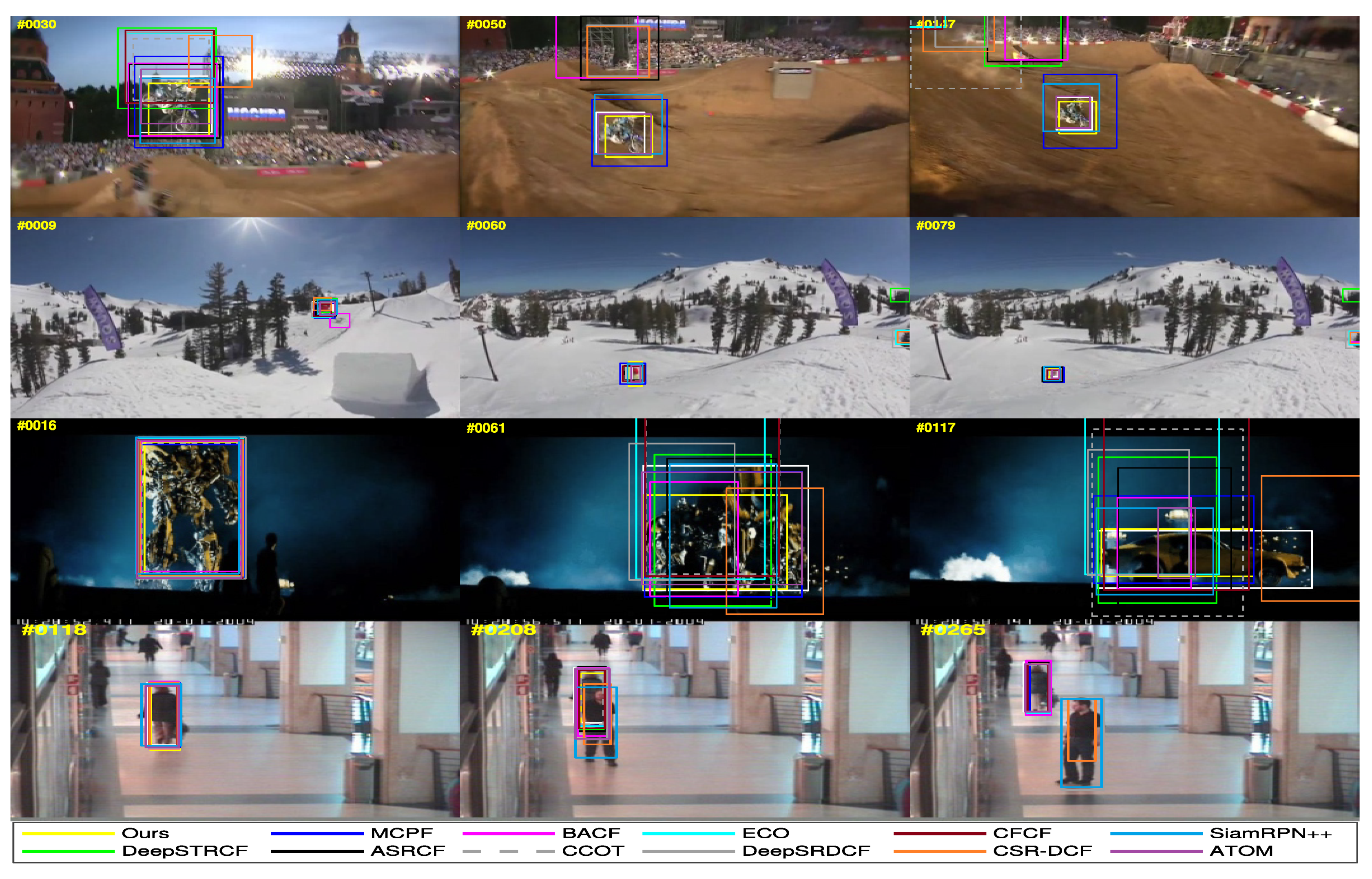
5.4.2. Qualitative Results
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Pau, G.; Arena, F.; Gebremariam, Y.E.; You, I. Bluetooth 5.1: An Analysis of Direction Finding Capability for High-Precision Location Services. Sensors 2021, 21, 3589. [Google Scholar] [CrossRef] [PubMed]
- Bolme, D.S.; Beveridge, J.R.; Draper, B.A.; Lui, Y.M. Visual Object Tracking using Adaptive Correlation Filters. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 13–18 June 2010; pp. 2544–2550. [Google Scholar]
- Danelljan, M.; Häger, G.; Khan, F.; Felsberg, M. Accurate scale estimation for robust visual tracking. In Proceedings of the British Machine Vision Conference (BMVC), Nottingham, UK, 1–5 September 2014. [Google Scholar]
- Danelljan, M.; Hager, G.; Shahbaz Khan, F.; Felsberg, M. Learning Spatially Regularized Correlation Filters for Visual Tracking. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 11–18 December 2015; pp. 4310–4318. [Google Scholar]
- Danelljan, M.; Hager, G.; Khan, F.S.; Felsberg, M. Convolutional Features for Correlation Filter Based Visual Tracking. In Proceedings of the IEEE International Conference on Computer Vision Workshop, Santiago, Chile, 7–13 December 2015; pp. 621–629. [Google Scholar]
- Li, F.; Tian, C.; Zuo, W.; Zhang, L.; Yang, M.H. Learning spatial-temporal regularized correlation filters for visual tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 4904–4913. [Google Scholar]
- Danelljan, M.; Robinson, A.; Khan, F.S.; Felsberg, M. Beyond Correlation Filters: Learning Continuous Convolution Operators for Visual Tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016; pp. 472–488. [Google Scholar]
- Li, B.; Wu, W.; Wang, Q.; Zhang, F.; Xing, J.; Yan, J. Siamrpn++: Evolution of siamese visual tracking with very deep networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 4282–4291. [Google Scholar]
- Mueller, M.; Smith, N.; Ghanem, B. Context-aware Correlation Filter Tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1387–1395. [Google Scholar]
- Galoogahi, H.K.; Fagg, A.; Lucey, S. Learning Background-aware Correlation Filters for Visual Tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 21–26. [Google Scholar]
- Dai, K.; Wang, D.; Lu, H.; Sun, C.; Li, J. Visual Tracking via Adaptive Spatially-Regularized Correlation Filters. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 4670–4679. [Google Scholar]
- Danelljan, M.; Bhat, G.; Khan, F.S.; Felsberg, M. ECO: Efficient Convolution Operators for Tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6931–6939. [Google Scholar]
- Henriques, J.F.; Caseiro, R.; Martins, P.; Batista, J. High-speed Tracking with Kernelized Correlation Filters. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 583–596. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tang, M.; Feng, J. Multi-kernel Correlation Filter for Visual Tracking. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 11–18 December 2015; pp. 3038–3046. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Diego, CA, USA, 20–25 June 2005. [Google Scholar]
- Danelljan, M.; Khan, F.S.; Felsberg, M.; Van De Weijer, J. Adaptive Color Attributes for Real-Time Visual Tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 1090–1097. [Google Scholar]
- Chatfield, K.; Simonyan, K.; Vedaldi, A.; Zisserman, A. Return of the Devil in the Details: Delving Deep into Convolutional Nets. In Proceedings of the British Machine Vision Conference (BMVC), Nottingham, UK, 1–5 September 2014. [Google Scholar]
- Wu, Y.; Lim, J.; Yang, M.H. Object Tracking Benchmark. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1834–1848. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kristan, M.; Leonardis, A. The Visual Object Tracking VOT2016 Challenge Results; Springer: Amsterdam, The Netherlands, 2016; Volume 8926, pp. 191–217. [Google Scholar]
- Kristan, M.; Leonardis, A.; Matas, J. The sixth visual object tracking vot2018 challenge results. In Proceedings of the European conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Fan, H.; Ling, H.; Lin, L.; Yang, F.; Chu, P.; Deng, G.; Yu, S.; Bai, H.; Xu, Y.; Liao, C. LaSOT: A High-Quality Benchmark for Large-Scale Single Object Tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 5374–5383. [Google Scholar]
- Mei, X.; Ling, H. Robust Visual Tracking and Vehicle Classification via Sparse Representation. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 2259–2272. [Google Scholar] [PubMed] [Green Version]
- Zhang, T.; Ghanem, B.; Liu, S.; Ahuja, N. Robust Visual Tracking via Multi-task Sparse Learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 2042–2049. [Google Scholar]
- Zhang, T.; Xu, C.; Yang, M.H. Multi-task Correlation Particle Filter for Robust Object Tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4819–4827. [Google Scholar]
- Babenko, B.; Yang, M.H.; Belongie, S. Robust Object Tracking with Online Multiple Instance Learning. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 1619–1632. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hare, S.; Golodetz, S.; Saffari, A.; Vineet, V.; Cheng, M.M.; Hicks, S.L.; Torr, P.H. Struck: Structured Output Tracking with Kernels. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 2096–2109. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Henriques, J.o.F.; Caseiro, R.; Martins, P.; Batista, J. Exploiting the Circulant Structure of Tracking-by-detection with Kernels. In Proceedings of the European Conference on Computer Vision (ECCV), Firenze, Italy, 7–13 October 2012; pp. 702–715. [Google Scholar]
- Wen, L.; Ma, Q.; Yu, S.; Chui, K.T.; Xiong, N. Variational Regularized Tree-Structured Wavelet Sparsity for CS-SENSE Parallel Imaging. IEEE Access 2018, 6, 61050–61064. [Google Scholar]
- Lukežič, A.; Vojíř, T.; Zajc, L.Č.; Matas, J.; Kristan, M. Discriminative Correlation Filter with Channel and Spatial Reliability. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4847–4856. [Google Scholar]
- Ma, C.; Huang, J.; Yang, X.; Yang, M. Hierarchical Convolutional Features for Visual Tracking. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 11–18 December 2015; pp. 3074–3082. [Google Scholar]
- Li, J.; Hong, Z.; Zhao, B. Robust Visual Tracking by Exploiting the Historical Tracker Snapshots. In Proceedings of the IEEE International Conference on Computer Vision Workshop (ICCVW), Santiago, Chile, 7–13 December 2015; pp. 604–612. [Google Scholar]
- Li, J.; Deng, C.; Xu, R.Y.D.; Tao, D.; Zhao, B. Robust Object Tracking With Discrete Graph-Based Multiple Experts. IEEE Trans. Image Process. 2017, 26, 2736–2750. [Google Scholar] [CrossRef] [PubMed]
- Wang, N.; Zhou, W.; Tian, Q.; Hong, R.; Wang, M.; Li, H. Multi-cue Correlation Filters for Robust Visual Tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 4844–4853. [Google Scholar]
- Bhat, G.; Johnander, J.; Danelljan, M.; Shahbaz Khan, F.; Felsberg, M. Unveiling the power of deep tracking. In Proceedings of the European conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 483–498. [Google Scholar]
- Wang, H.; Wang, L.; Zhou, Z.; Tao, X.; Pau, G.; Arena, F. Blockchain-Based Resource Allocation Model in Fog Computing. Appl. Sci. 2019, 9, 5538. [Google Scholar] [CrossRef] [Green Version]
- Bertinetto, L.; Valmadre, J.; Henriques, J.F.; Vedaldi, A.; Torr, P.H. Fully-convolutional Siamese Networks for Object Tracking. In Proceedings of the European conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016; pp. 850–865. [Google Scholar]
- Valmadre, J.; Bertinetto, L.; Henriques, J.; Vedaldi, A.; Torr, P.H. End-to-end Representation Learning for Correlation Filter Based Tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5000–5008. [Google Scholar]
- Li, B.; Yan, J.; Wu, W.; Zhu, Z.; Hu, X. High Performance Visual Tracking With Siamese Region Proposal Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 8971–8980. [Google Scholar]
- Danelljan, M.; Bhat, G.; Khan, F.S.; Felsberg, M. ATOM: Accurate Tracking by Overlap Maximization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 4660–4669. [Google Scholar]
- Bhat, G.; Danelljan, M.; Van Gool, L.; Timofte, R. Learning Discriminative Model Prediction for Tracking. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Long Beach, CA, USA, 27 October–2 November 2019; pp. 6182–6191. [Google Scholar]
- Zhang, Z.; Peng, H. Deeper and wider siamese networks for real-time visual tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 4591–4600. [Google Scholar]
- Boyd, S.; Parikh, N.; Chu, E.; Peleato, B.; Eckstein, J. Distributed Optimization and Statistical Learning via the Alternating Direction Method of Multipliers. Found. Trends Mach. Learn. 2011, 3, 1–122. [Google Scholar] [CrossRef]
- Sherman, J.; Morrison, W.J. Adjustment of an Inverse Matrix Corresponding to a Change in One Element of a Given Matrix. Ann. Math. Stat. 1950, 21, 124–127. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Nam, H.; Han, B. Learning Multi-domain Convolutional Neural Networks for Visual Tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 4293–4302. [Google Scholar]
- Choi, J.; Chang, H.J.; Yun, S.; Fischer, T.; Demiris, Y.; Choi, J.Y. Attentional Correlation Filter Network for Adaptive Visual Tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4828–4837. [Google Scholar]
- Bertinetto, L.; Valmadre, J.; Golodetz, S.; Miksik, O.; Torr, P.H. Staple: Complementary Learners for Real-time Tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1401–1409. [Google Scholar]
- Li, Y.; Zhu, J. A Scale Adaptive Kernel Correlation Filter Tracker with Teature Integration. In Proceedings of the European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014; pp. 254–265. [Google Scholar]
- Zhang, J.; Ma, S.; Sclaroff, S. MEEM: Robust Tracking via Multiple Experts using Entropy Minimization. In Proceedings of the European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014; pp. 188–203. [Google Scholar]
- Sun, C.; Wang, D.; Lu, H.; Yang, M.H. Learning Spatial-aware Regressions for Visual Tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 8962–8970. [Google Scholar]
- He, A.; Luo, C.; Tian, X.; Zeng, W. A Twofold Siamese Network for Real-time Object Tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 4834–4843. [Google Scholar]
- Gundogdu, E.; Alatan, A.A. Good Features to Correlate for Visual Tracking. IEEE Trans. Image Process. 2018, 27, 2526–2540. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Danelljan, M.; Hager, G.; Khan, F.S.; Felsberg, M. Discriminative Scale Space Tracking. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1561–1575. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Tracker | Ironman | MotorRolling | Matrix | Skater2 | Singer2 | Soccer | KitSurf | Skiing | Skater | Trans | Models |
|---|---|---|---|---|---|---|---|---|---|---|---|
| STRCF | 0.117 | 0.094 | 0.010 | 0.639 | 0.039 | 0.189 | 0.716 | 0.088 | 0.601 | 0.570 | HC+VggM-14 |
| STRCF | 0.096 | 0.154 | 0.494 | 0.635 | 0.764 | 0.201 | 0.561 | 0.099 | 0.635 | 0.578 | HC+ResNet101-79+VggM-14 |
| ASRCF | 0.436 | 0.117 | 0.448 | 0.614 | 0.765 | 0.502 | 0.733 | 0.513 | 0.494 | 0.546 | HC+Vgg16-23+VggM-4 |
| ASRCF | 0.125 | 0.119 | 0.441 | 0.610 | 0.788 | 0.449 | 0.712 | 0.515 | 0.537 | 0.563 | HC+ResNet101-79+VggM-14 |
| Ours | 0.515 | 0.117 | 0.597 | 0.588 | 0.040 | 0.572 | 0.743 | 0.512 | 0.574 | 0.551 | HC+Vgg16-23+VggM-4 |
| Ours | 0.531 | 0.525 | 0.581 | 0.611 | 0.747 | 0.477 | 0.688 | 0.494 | 0.600 | 0.552 | HC+ResNet101-79+VggM-14 |
| Ours | 0.406 | 0.583 | 0.573 | 0.645 | 0.739 | 0.551 | 0.777 | 0.574 | 0.677 | 0.631 | 2D search method |
| Trackers | VOT2016 | VOT2018 | ||||
|---|---|---|---|---|---|---|
| Av | Rv | EAO | Av | Rv | EAO | |
| Ours | 0.528 | 0.177 | 0.402 | 0.507 | 0.225 | 0.339 |
| ASRCF [11] | 0.568 | 0.187 | 0.390 | 0.492 | 0.234 | 0.328 |
| DeepSTRCF [6] | 0.55 | 0.257 | 0.313 | 0.531 | 0.272 | 0.299 |
| ATOM [39] | 0.617 | 0.189 | 0.424 | 0.589 | 0.201 | 0.401 |
| SA-SIAM [52] | 0.543 | 0.337 | 0.291 | 0.5 | 0.459 | 0.236 |
| CSR-DCF [29] | 0.524 | 0.239 | 0.338 | 0.491 | 0.356 | 0.256 |
| CFCF [53] | 0.560 | 0.169 | 0.384 | 0.511 | 0.286 | 0.283 |
| CCOT [7] | 0.541 | 0.239 | 0.331 | 0.494 | 0.318 | 0.267 |
| SiamRPN [38] | 0.56 | 0.314 | 0.340 | 0.490 | 0.464 | 0.244 |
| SiamRPN++[8] | 0.637 | 0.178 | 0.478 | 0.6 | 0.234 | 0.414 |
| ECO [12] | 0.54 | 0.201 | 0.374 | 0.484 | 0.276 | 0.281 |
| ECO_HC [12] | 0.53 | 0.304 | 0.322 | 0.494 | 0.435 | 0.238 |
| DSST[54] | 0.535 | 0.707 | 0.181 | 0.395 | 1.452 | 0.079 |
| LSART [51] | 0.495 | 0.215 | 0.323 | 0.495 | 0.276 | 0.323 |
| MEEM [50] | 0.490 | 0.515 | 0.194 | 0.463 | 0.534 | 0.193 |
| Staple[48] | 0.547 | 0.379 | 0.295 | 0.530 | 0.688 | 0.169 |
| SRDCF [4] | 0.536 | 0.421 | 0.247 | 0.490 | 0.974 | 0.119 |
| DeepSRDCF [5] | 0.507 | 0.326 | 0.276 | 0.492 | 0.707 | 0.154 |
| SiamFC [36] | 0.532 | 0.461 | 0.88 | 0.503 | 0.585 | 0.188 |
| SAMF [49] | 0.507 | 0.590 | 0.186 | 0.484 | 1.302 | 0.093 |
| KCF [13] | 0.491 | 0.571 | 0.192 | 0.447 | 0.773 | 0.135 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, F.; Wang, X. Adaptive Spatial-Temporal Regularization for Correlation Filters Based Visual Object Tracking. Symmetry 2021, 13, 1665. https://doi.org/10.3390/sym13091665
Chen F, Wang X. Adaptive Spatial-Temporal Regularization for Correlation Filters Based Visual Object Tracking. Symmetry. 2021; 13(9):1665. https://doi.org/10.3390/sym13091665
Chicago/Turabian StyleChen, Fei, and Xiaodong Wang. 2021. "Adaptive Spatial-Temporal Regularization for Correlation Filters Based Visual Object Tracking" Symmetry 13, no. 9: 1665. https://doi.org/10.3390/sym13091665
APA StyleChen, F., & Wang, X. (2021). Adaptive Spatial-Temporal Regularization for Correlation Filters Based Visual Object Tracking. Symmetry, 13(9), 1665. https://doi.org/10.3390/sym13091665