
Stochastic Subgradient for Large-Scale Support Vector Machine Using the Generalized Pinball Loss Function


Abstract
:1. Introduction
2. Related Work and Background
Support Vector Machine
3. Proposed Stochastic Subgradient Generalized Pinball Support Vector Machine
3.1. Linear Case
| Algorithm 1 SG-GPSVM. |
| Input: Training samples are represented by , positive parameters , , and tolerance . 1: Set to zero; 2: while do 3: Choose , where , uniformly at random. 4: Compute stochastic subgradient using Equation (15). 5: Update by . 6: 7: end Output: Optimal hyperplane parameters . |
3.2. Nonlinear Case
| Algorithm 2 Nonlinear SG-GPSVM. |
| Input: Training samples are represented by , positive parameters , , and tolerance . 1: Set to zero; 2: while do 3: Choose , where , uniformly at random. 4: Compute stochastic subgradient using Equation (20). 5: Update by . 6: 7: end Output: Optimal hyperplane parameters . |
4. Convergence Analysis
5. Numerical Experiments
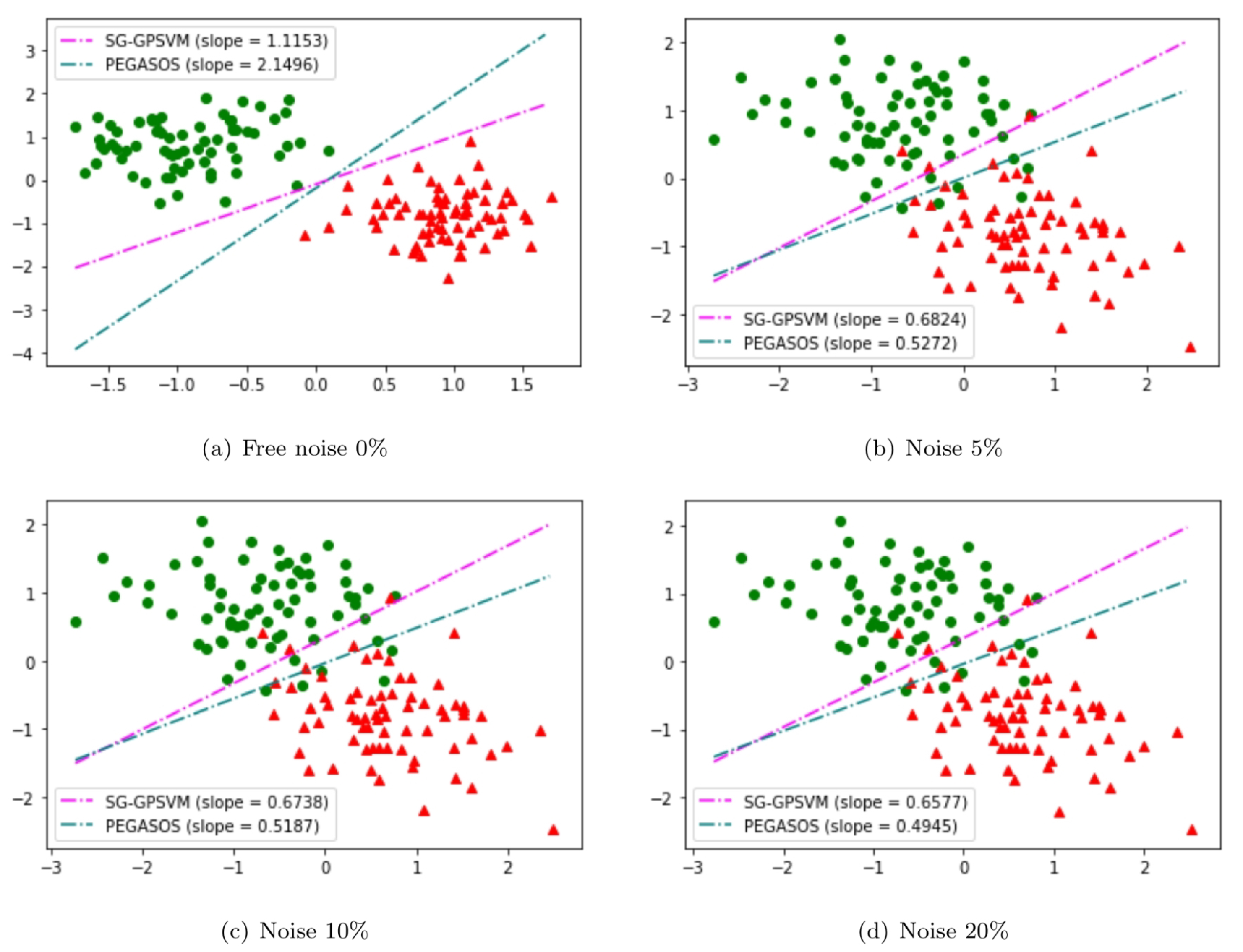
5.1. Artificial Datasets
5.2. UCI Datasets
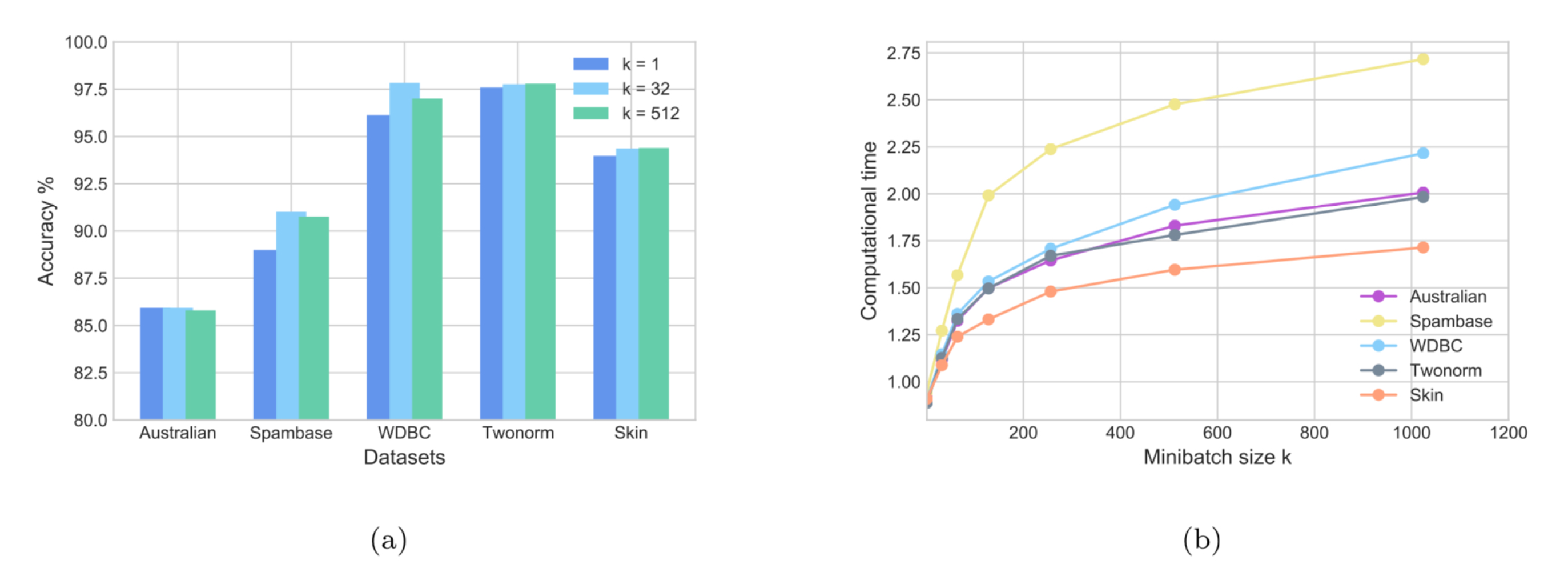
5.3. Large-Scale Dataset
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Vapnik, V.N. The Nature of Statistical Learning Theory; Springer: New York, NY, USA, 1995. [Google Scholar]
- Vapnik, V.N. Statistical Learning Theory; Wiley: New York, NY, USA, 1998. [Google Scholar]
- Vapnik, V.N. An overview of statistical learning theory. IEEE Trans. Neural Netw. 1999, 10, 988–999. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Colmenarez, A.J.; Huang, T.S. Face Detection With Information-Based Maximum Discrimination. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Juan, PR, USA, 17–19 June 1997; pp. 782–787. [Google Scholar]
- Osuna, E.; Freund, R.; Girosi, F. Training support vector machines: An application to face detection. In Proceedings of the IEEE Computer Vision and Pattern Recognition, San Juan, PR, USA, 17–19 June 1997. [Google Scholar]
- Joachims, T.; Ndellec, C.; Rouveriol, C. Text categorization with support vector machines: Learning with many relevant features. In Proceedings of the European Conference on Machine Learning, Chemnitz, Germany, 21–23 April 1998; pp. 137–142. [Google Scholar]
- Richhariya, B.; Tanveer, M. EEG signal classification using universum support vector machine. Expert Syst. Appl. 2018, 106, 169–182. [Google Scholar] [CrossRef]
- Mukherjee, S.; Osuna, E.; Girosi, F. Nonliner prediction of chaotic time series using a support vector machine. In Proceedings of the 1997 IEEE Workshop on Neural Networks for Signal Processing, Amelia Island, FL, USA, 24–26 September 1997. [Google Scholar]
- Ince, H.; Trafalis, T.B. Support vector machine for regression and applications to financial forecasting. In Proceedings of the International Joint Conference on Neural Networks (IEEE-INNSENNS), Como, Italy, 27 July 2000. [Google Scholar]
- Huang, Z.; Chen, H.; Hsua, C.-J.; Chen, W.-H.; Wu, S. Credit rating analysis with support vector machines and neural networks: A market comparative study. Decis. Support Syst. 2004, 37, 543–558. [Google Scholar] [CrossRef]
- Khemchandani, R.; Jayadeva; Chandra, S. Regularized least squares fuzzy support vector regression for nancial time series forecasting. Expert Syst. Appl. 2009, 36, 132–138. [Google Scholar] [CrossRef]
- Tao, D.; Tang, X.; Li, X.; Wu, X. Asymmetric bagging and random subspace for support vector machines-based relevance feedback in image retrieval. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 28, 1088–1099. [Google Scholar]
- Pal, M.; Mather, P. Support vector machines for classification in remote sensing. Int. J. Remote Sens. 2005, 26, 1007–1011. [Google Scholar] [CrossRef]
- Li, Y.Q.; Guan, C.T. Joint feature re-extraction and classification using an iterative semi-supervised support vector machine algorithm. Mach. Learn. 2008, 71, 33–53. [Google Scholar] [CrossRef]
- Bi, J.; Zhang, T. Support vector classification with input data uncertainty. In Proceedings of the Neural Information Processing Systems, Vancouver, BC, Canada, 13–18 December 2004. [Google Scholar]
- Huang, X.; Shi, L.; Suykens, J.A.K. Support vector machine classifier with pinball loss. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 984–997. [Google Scholar] [CrossRef]
- Rastogi, R.; Pal, A.; Chandra, S. Generalized pinball loss SVMs. Neurocomputing 2018, 322, 151–165. [Google Scholar] [CrossRef]
- Ñanculef, R.; Frandi, E.; Sartori, C.; Allende, H. A Novel Frank-Wolfe Algorithm. Analysis and Applications to Large-Scale SVM Training. Inf. Sci. 2014, 285, 66–99. [Google Scholar] [CrossRef] [Green Version]
- Xu, J.; Xu, C.; Zou, B.; Tang, Y.Y.; Peng, J.; You, X. New incremental learning algorithm with support vector machines. IEEE Trans. Syst. Man Cybern. Syst. 2018, 49, 2230–2241. [Google Scholar] [CrossRef]
- Platt, J. Fast training of support vector machines using sequential minimal optimization. In Advances in Kernel Methods—Support Vector Learning; MIT Press: Cambridge, MA, USA, 1999; pp. 185–208. [Google Scholar]
- Mangasarian, O.; Musicant, D. Successive overrelaxation for support vector machines. IEEE Trans. Neural Netw. 1999, 10, 1032–1037. [Google Scholar] [CrossRef] [Green Version]
- Fan, R.; Chang, K.; Hsieh, C.; Wang, X.; Lin, C. LIBLINEAR: A library for large linear classification. J. Mach. Learn. Res. 2008, 9, 1871–1874. [Google Scholar]
- Zhang, T. Solving large-scale linear prediction problems using stochastic gradient descent algorithms. In Proceedings of the International Conference on Machine Learning, Banff, AB, Canada, 4–8 July 2004. [Google Scholar]
- Xu, W. Towards optimal one pass large-scale learning with averaged stochastic gradient descent. arXiv 2011, arXiv:1107.2490. [Google Scholar]
- Shai, S.; Singer, Y.; Srebro, N.; Cotter, A. Pegasos: Primal estimated subgradient solver for SVM. Math. Program. 2011, 127, 3–30. [Google Scholar]
- Alencar, M.; Oliveira, D.J. Online learning early skip decision method for the hevc inter process using the SVM-based Pegasos algorithm. Electron. Lett. 2016, 52, 1227–1229. [Google Scholar]
- Reyes-Ortiz, J.; Oneto, L.; Anguita, D. Big data analytics in the cloud: Spark on Hadoop vs MPI/OpenMP on Beowulf. Procedia Comput. Sci. 2015, 53, 121–130. [Google Scholar] [CrossRef] [Green Version]
- Sopyla, K.; Drozda, P. Stochastic gradient descent with barzilaicborwein update step for SVM. Inf. Sci. 2015, 316, 218–233. [Google Scholar] [CrossRef]
- Dua, D.; Taniskidou, E.K. UCI Machine Learning Repository; School of Information and Computer Science, University of California: Irvine, CA, USA, 2019; Available online: http://archive.ics.uci.edu/ml (accessed on 24 September 2018).
- Shwartz, S.; Ben-David, S. Understanding Machine Learning Theory Algorithms; Cambridge University Press: Cambridge, MA, USA, 2014; 207p. [Google Scholar]
- Xu, Y.; Yang, Z.; Pan, X. A novel twin support-vector machine with pinball loss. IEEE Trans. Neural Netw. Learn. Syst. 2017, 28, 359–370. [Google Scholar] [CrossRef]
- Shao, Y.; Zhang, C.; Wang, X.; Deng, N. Improvements on twin support vector machines. IEEE Trans. Neural Netw. 2011, 22, 962–968. [Google Scholar] [CrossRef] [PubMed]
- Khemchandani, R.; Jayadeva; Chandra, S. Optimal kernel selection in twin support vector machines. Optim. Lett. 2009, 3, 77–88. [Google Scholar] [CrossRef]
- Rudin, W. Principles of Mathematical Analysis, 3rd ed.; McGraw-Hill: New York, NY, USA, 1964. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Cristianini, N.; Shawe-Taylor, J. An Introduction to Support Vector Machines and Other Kernel-Based Learning Methods; Cambridge University Press: Cambridge, UK, 2000. [Google Scholar]
- Shawe-Taylor, J.; Cristianini, N. Kernel Methods for Pattern Analysis; Cambridge University Press: Cambridge, UK, 2004. [Google Scholar]
- Lee, Y.; Mangasarian, O. RSVM: Reduced support vector machines. In Proceedings of the First SIAM International Conference on Data Mining, Chicago, IL, USA, 5–7 April 2001. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
| Datasets | # of Samples | # of Features | # in Negative Class | # in Positive Class |
|---|---|---|---|---|
| Appendicitis | 106 | 7 | 85 | 21 |
| Ionosphere | 351 | 33 | 126 | 225 |
| Monk-2 | 432 | 6 | 204 | 228 |
| Monk-3 | 432 | 6 | 204 | 228 |
| Saheart | 462 | 9 | 302 | 160 |
| WDBC | 569 | 30 | 357 | 212 |
| Australian | 690 | 14 | 383 | 307 |
| Spambase | 4597 | 57 | 2785 | 1812 |
| Phoneme | 5404 | 5 | 3818 | 1586 |
| Twonorm | 7400 | 21 | 3703 | 3697 |
| Coil2000 | 9822 | 86 | 9236 | 586 |
| Datasets | r | SVM | Pegasos | SG-GPSVM | SG-GPSVM |
|---|---|---|---|---|---|
| Time (s) | Time (s) | Time (s) | Time (s) | ||
| Appendicitis | 0 | 85.82 ± 14.33 | 83.82 ± 13.72 | 84.82 ± 13.02 | 87.91 ± 10.45 |
| 0.0008 | 0.3198 | 0.4800 | 0.0899 | ||
| 0.05 | 83.00 ± 14.17 | 81.82 ± 15.16 | 84.73 ± 11.34 | 88.91 ± 10.74 | |
| 0.0020 | 0.3099 | 0.4321 | 0.0883 | ||
| 0.10 | 84.00 ± 8.61 | 85.55 ± 14.96 | 85.64 ± 13.33 | 86.91 ± 9.69 | |
| 0.0020 | 0.3169 | 0.4393 | 0.0887 | ||
| 0.20 | 80.18 ± 13.51 | 79.18 ± 12.74 | 84.82 ± 13.55 | 86.82 ± 12.38 | |
| 0.0015 | 0.2962 | 0.4972 | 0.0880 | ||
| Phoneme | 0 | 77.48 ± 1.41 | 75.98 ± 1.96 | 77.31 ± 1.40 | 77.15 ± 2.64 |
| 0.5502 | 0.3102 | 0.4015 | 0.0893 | ||
| 0.05 | 77.42 ± 1.44 | 77.15 ± 2.020 | 77.44 ± 1.56 | 76.87 ± 2.07 | |
| 0.5153 | 0.3490 | 0.4197 | 0.0891 | ||
| 0.10 | 77.18 ± 1.58 | 76.59 ± 1.71 | 76.48 ± 1.81 | 76.61 ± 2.15 | |
| 0.5020 | 0.3087 | 0.4083 | 0.0891 | ||
| 0.20 | 76.76 ± 1.69 | 75.61 ± 1.63 | 76.33 ± 1.57 | 76.44 ± 2.33 | |
| 0.5210 | 0.3016 | 0.3917 | 0.0893 | ||
| Monk-2 | 0 | 80.32 ± 8.96 | 79.85 ± 8.12 | 80.80 ± 7.66 | 81.48 ± 7.54 |
| 0.0134 | 0.2993 | 0.4268 | 0.0891 | ||
| 0.05 | 80.55 ± 8.96 | 79.38 ± 7.93 | 79.16 ± 6.33 | 79.86 ± 7.98 | |
| 0.0027 | 0.2835 | 0.4038 | 0.0894 | ||
| 0.10 | 79.39 ± 8.55 | 76.60 ± 6.33 | 80.54 ± 7.82 | 80.53 ± 6.56 | |
| 0.0023 | 0.2886 | 0.3876 | 0.0894 | ||
| 0.20 | 79.40 ± 7.07 | 77.09 ± 7.56 | 80.32 ± 8.14 | 80.11 ± 5.54 | |
| 0.0025 | 0.3099 | 0.3815 | 0.0900 | ||
| Monk-3 | 0 | 80.53 ± 4.61 | 77.75 ± 5.68 | 80.30 ± 4.50 | 84.47 ± 4.82 |
| 0.0047 | 0.2835 | 0.4899 | 0.0947 | ||
| 0.05 | 80.35 ± 4.75 | 78.01 ± 4.03 | 80.30 ± 4.38 | 84.23 ± 8.64 | |
| 0.0067 | 0.2932 | 0.4856 | 0.0970 | ||
| 0.10 | 78.69 ± 3.46 | 79.40 ± 4.59 | 80.07 ± 4.50 | 83.31 ± 8.07 | |
| 0.0031 | 0.2974 | 0.4675 | 0.0956 | ||
| 0.20 | 77.99 ± 4.86 | 77.32 ± 6.28 | 80.32 ± 3.36 | 81.93 ± 6.99 | |
| 0.0016 | 0.2875 | 0.4918 | 0.0994 | ||
| Saheart | 0 | 71.83 ± 7.22 | 70.52 ± 6.62 | 72.49 ± 7.45 | 72.32 ± 4.42 |
| 0.0047 | 0.3071 | 0.4038 | 1.4542 | ||
| 0.05 | 71.39 ± 7.66 | 71.84 ± 5.01 | 72.48 ± 6.70 | 71.87 ± 3.91 | |
| 0.0047 | 0.2989 | 0.3816 | 1.4453 | ||
| 0.10 | 72.27 ± 7.11 | 67.98 ± 4.19 | 71.38 ± 8.65 | 71.00 ± 5.38 | |
| 0.0052 | 0.3249 | 0.4107 | 1.4201 | ||
| 0.20 | 72.50 ± 7.65 | 72.47 ± 8.19 | 71.82 ± 10.10 | 70.80 ± 6.23 | |
| 0.0051 | 0.3160 | 0.3830 | 1.4503 | ||
| Ionosphere | 0 | 88.32 ± 6.94 | 84.02 ± 8.32 | 86.60 ± 6.15 | 91.46 ± 5.25 |
| 0.0080 | 0.3541 | 0.3913 | 0.0944 | ||
| 0.05 | 87.46 ± 5.75 | 86.03 ± 5.35 | 86.88 ± 6.30 | 91.45 ± 2.86 | |
| 0.0046 | 0.3176 | 0.4110 | 0.0937 | ||
| 0.10 | 83.74 ± 7.15 | 84.60 ± 6.31 | 86.03 ± 7.83 | 91.17 ± 3.25 | |
| 0.0076 | 0.3160 | 0.8683 | 0.0941 | ||
| 0.20 | 82.31 ± 7.78 | 85.46 ± 4.88 | 87.73 ± 5.74 | 90.03 ± 5.12 | |
| 0.0079 | 0.3233 | 0.4122 | 0.0936 |
| Datasets | SVM | Pegasos | SG-GPSVM | SG-GPSVM |
|---|---|---|---|---|
, | ||||
| Appendicitis | 1 | 10 | 100, 0.5, 0.75, 0.1, 1 | 10, 1, 1, 0.5, 0.5, 0.1 |
| Phoneme | 1 | 1 | 10, 0.5, 0.5, 0.1, 1 | 100, 1, 1, 0.25, 0.25, 1 |
| Monk-2 | 1 | 0.01 | 100, 1, 0.25, 0.1, 0.25 | 100, 0.25, 0.25, 0.1, 0.25, 0.1 |
| Monk-3 | 1 | 0.1 | 1, 1, 0.25, 0.5, 0.5 | 10, 1, 0.75, 0.25, 0.25, 0.1 |
| Saheart | 1 | 1 | 1, 0.5, 0.25, 0.25, 0.1 | 100, 1, 0.75, 0.25, 0.25, 0.1 |
| Ionosphere | 1 | 1 | 1, 0.75, 0.1, 0.25, 0.1 | 100, 1, 1, 1, 0.5, 0.1 |
| Datasets | # of Samples | # of Features | # in Negative Class | # in Positive Class |
|---|---|---|---|---|
| Credit card | 30,000 | 324 | 23,364 | 6636 |
| Skin | 245,057 | 3 | 194,198 | 50,859 |
| Kddcup | 4,898,431 | 41 | 972,781 | 3,925,650 |
| SUSY | 5,000,000 | 18 | 2,712,173 | 2,287,827 |
| Datasets | Mean Accuracy in % | |||
|---|---|---|---|---|
| Credit Card | Skin | Kddcup | Susy | |
| SVM | 80.82 ± 0.90 | 92.90 ± 0.16 | * | * |
| Time (s) | 0.4398 | 289.4454 | * | * |
| Pegasos | 79.74 ± 2.38 | 93.22 ± 0.78 | 95.31 ± 0.31 | 99.25 ± 1.37 |
| Time (s) | 0.2479 | 0.2676 | 1.9823 | 4.5164 |
| SG-GPSVM | 80.72 ± 0.95 | 93.98 ± 0.38 | 98.82 ± 0.60 | 99.97 ± 0.06 |
| Time (s) | 0.4417 | 0.3751 | 2.0474 | 5.3744 |
| SG-GPSVM | 77.88 ± 0.87 | 94.06 ± 1.13 | 96.92 ± 0.35 | 99.99 ± 0.02 |
| Time (s) | 1.0881 | 0.9738 | 2.8125 | 2.3218 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Panup, W.; Wangkeeree, R. Stochastic Subgradient for Large-Scale Support Vector Machine Using the Generalized Pinball Loss Function. Symmetry 2021, 13, 1652. https://doi.org/10.3390/sym13091652
Panup W, Wangkeeree R. Stochastic Subgradient for Large-Scale Support Vector Machine Using the Generalized Pinball Loss Function. Symmetry. 2021; 13(9):1652. https://doi.org/10.3390/sym13091652
Chicago/Turabian StylePanup, Wanida, and Rabian Wangkeeree. 2021. "Stochastic Subgradient for Large-Scale Support Vector Machine Using the Generalized Pinball Loss Function" Symmetry 13, no. 9: 1652. https://doi.org/10.3390/sym13091652
APA StylePanup, W., & Wangkeeree, R. (2021). Stochastic Subgradient for Large-Scale Support Vector Machine Using the Generalized Pinball Loss Function. Symmetry, 13(9), 1652. https://doi.org/10.3390/sym13091652