1. Introduction
Deep recurrent neural networks (RNNs) are powerful deep learning models with the ability to learn from the large sets of sequential data that characterise many tasks such as natural language processing [
1], time series prediction [
2], machine translation [
3] and image captioning [
4]. Deep RNNs have self-looped connected deep layers, which can retain information from the past and make it possible to learn arbitrarily long time sequences. However, despite their theoretical power, they have well-known computational issues such as training difficulties due to vanishing and exploding gradients [
5], the need for implementation in hardware and memory limitations [
6]. Besides, designing a deep learning model to perform a particular task could be very time-consuming as it involves many optimisation steps such as selecting a proper network architecture, finding the optimum hyperparameters of the selected architecture, and choosing the correct training algorithm for the model. Training a deep RNN is making it learn higher-level nonlinear features from large amounts of sequential data, which is typically a nonconvex optimisation problem [
6]. This problem can be formulated as the minimisation of nonlinear loss functions with multiple local optima and saddle points. From the perspective of optimisation, even convex optimisation problems have many challenges. Additional difficulties therefore arise in training deep neural networks because of the nonconvex nature of the problem. For example, Stochastic Gradient Descent (SGD), which is a commonly used training algorithm, could easily get trapped at local minima or saddle points, and it cannot guarantee convergence to the global optimum because of the nonlinear transformations in each hidden layer. Moreover, the gradient of nonlinear activation functions cannot be computed backward through the network layers without vanishing or exploding over many training time steps, which causes the loss of direction in parameter updating to reach a feasible solution [
7].
To date, researchers have mainly focused on two alternative pathways to deal with long-term dependencies. The first pathway is to devise new network architectures such as Long Short-Term Memory (LSTM) models [
8], Gated Recurrent Units (GRU) [
9] and Temporal Restricted Boltzmann Machines (TRBM) [
10]. Although these architectures have proved successful in many applications, they are more complex to implement and require long implementation and computation times, in addition to specialised software and powerful hardware. The second pathway is to develop search methods and optimisation algorithms specifically to handle the vanishing and exploding gradient problem. Recently, two popular methods, gradient clipping and gradient scaling, were proposed to avoid the gradient explosion issue. Gradient clipping [
5] which employs a shrinking strategy when the gradient becomes too large, is used to avoid remembering only recent training steps. Shrinking has also been employed by second-order optimisation algorithms, but these have been replaced by simple SGD as a fair and practical technique because of the computational cost of Hessian matrices in second-order optimisation [
11].
The learning performance of deep learning models does not depend only on improving the training algorithm. The initial design parameters also play a key role in the ability to find global optima without becoming trapped at local stationary points. For example, the initial weights of a deep network can significantly affect training performance and good solutions often cannot be reached with gradient-based training algorithms because of the nonlinearity and “butterfly-effects” of the iterative updating procedure [
5]. Generally, design parameters are adjusted manually, and the designer has to evaluate the model performance repeatedly to determine the best objective functions, learning rates, or training algorithm for their task. Besides, even when the optimal model could be designed, additional regularisation strategies such as dropout [
12] are required to handle the overfitting problem of a deep model. It is well-known that these procedures are very time-consuming, and new strategies are needed to develop practical solutions.
Numerical methods and exact algorithms cannot handle the nonconvexity of the objective functions of deep RNNs, which are unable to capture curvature information, causing the optimisation process to be trapped at local solutions. Nature-inspired metaheuristic algorithms have been developed to handle nonlinear, multi-constraint and multi-modal optimisation problems. They have proved to be robust and efficient optimisation tools that can avoid the issue of local optima. They can adapt to problem conditions like the nature of the search space (i.e., continuous or discrete), decision parameters, varying constraints and other challenges encountered in the training and designing of RNN models. Previous research into the optimisation of deep learning models has focused on three main areas, namely, hyperparameter optimisation, neural architecture or topology optimisation, and weight optimisation. These studies have been conducted for specified tasks with the numbers of hidden and recurrent neurons limited to a maximum of five, and new practical approaches are needed to be useful for deeper RNN models [
13].
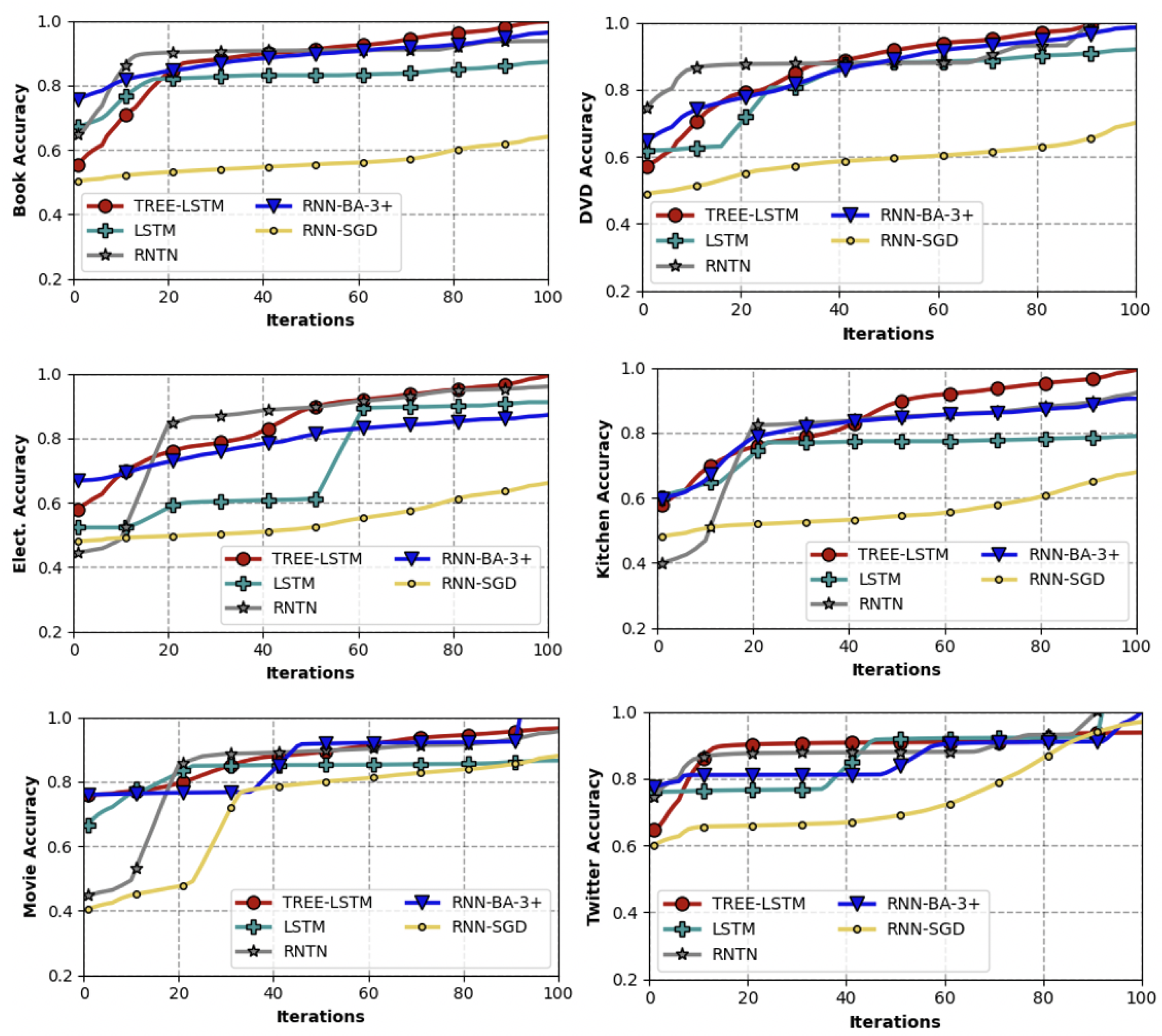
This paper proposes using an enhanced Ternary Bees Algorithm (BA-3+) to obtain the optimum weights of a deep RNN model for sentiment classification. Existing population-based optimisation algorithms need to operate with large populations and, as a result, are generally slow. The Bees Algorithm [
14] is a population-based algorithm that has been successfully employed to solve many complex real-world optimisation problems including continuous [
15] and combinatorial [
16] optimisation problems. It is able to find both local and global optima without needing to calculate the gradient of the objective function. The Ternary Bees Algorithm (BA-3) first described in [
17] is an improvement on other population-based algorithms that employs a population of just three individual solutions. The BA-3+ algorithm presented in this paper is an enhanced version of BA-3, that also uses only three individual solutions, the global-best solution, the worst solution and an in-between solution. BA-3+ combines the exploration power of the basic Bees Algorithm to escape from local optima and the greedy exploitation drive of new local search operators to improve solutions. The new local search operators comprise one for neighbourhood search using Stochastic Gradient Descent (SGD) and one for search control employing Singular-Value Decomposition (SVD). SGD is a greedy operator for reaching a local optimum quickly. SVD is adopted to stabilise the trainable parameters of the model and overcome the problem of vanishing and exploding gradients of the selected weights when SGD is applied to derive the in-between solution. The aim is to use the strengths of gradient-based backpropagation training as the most commonly used RNN training method, but without its limitations like local optimum traps and vanishing and exploding gradients through long time dependencies. As the proposed algorithm uses only three individual bees, it is very fast, being able to find the global optimum within polynomially-bounded computation times [
17]. Experiments with the sentiment classification of English and Turkish movie reviews and Twitter tweets show that the Ternary BA performs well, providing faster and more accurate results compared to previous studies.
The rest of the paper is structured as follows.
Section 2 briefly reviews methods to handle vanishing and exploding gradients (VEG) problem of the deep RNNs.
Section 3 presents detailed information about deep RNNs and the difficulties with training them.
Section 4 details the proposed algorithm and its local search operators, and describes its configuration for training deep RNNs for sentiment classification.
Section 5 provides information about the datasets used, the hyperparameters of the model, and the experimental results obtained.
Section 6 concludes the paper.
2. Related Work
This section reviews the approaches that have been used to handle the vanishing and exploding gradient (VEG) problem in deep RNN training.
The first way to handle the VEG problem is to use newer types of RNN architectures such as Long-Short-Term Memory (LSTM) [
8], Gated-Recurrent Units (GRUs) [
9] and Echo-State-Networks (ESNs) [
18]. These architectures can model sequences and they produced good results for many applications [
19]. However, they have issues such as limited non-linearity learning abilities [
20], training times that can sometimes be many days or even months, and are still not completely free from the same gradient problem. Some metaheuristic approaches have been implemented to handle these issues of the advanced deep recurrent networks. Yang et al. proposed an improved whale optimization algorithm (IWOA) to predict the carbon prices, hybrid model, incorporating modified ensemble empirical mode decomposition (MEEMD) and LSTM [
21]. Peng et al. proposed a fruit fly optimization algorithm (FOA) to find optimal hyper-parameter of the LSTM network to solve time series problems [
22]. ElSaid et al. have also proposed employing the ACO algorithm to evolve the LSTM network structure [
23]. Rashid et al. proposed to use Harmony Search (HS), Gray Wolf Optimizer (GWO), Sine Cosine (SCA), and Ant Lion Optimization algorithms (ALOA) algorithms to train LSTMs for classification and analysis of real and medical time series data sets [
24]. Besides these, hyperparameter optimisation and initial parameter tuning are also needed to improve their performances [
25]. For example, an improved version of the sine cosine optimization algorithm (SCOA) was used to identify the optimal hyperparameters of LSTM [
26]. Similarly, Bouktif et al. proposed to use GA and PSO algorithms to find optimum hyperparameters of the LSTM-RNN model for electric load forecasting [
27]. In a similar way to the using of new architectures, some researchers have proposed to use new activation functions. [
28] had been proposed to use Rectified linear unit (ReLU) function instead of hyperbolic tangent or sigmoid functions. Similarly, Glorot et al. has proposed Deep Sparse Rectifier Neural Networks (SRNNs), that helps optimizing weights during training with rectifier units [
29]. However, these approaches have limitations as well. For example, since the ReLU function is positive definite, it causes a bias shift effect and behaves like a bias term for the next layer of the model [
30]. Hence, it decreases the learning capacity of the model [
31].
The second way to handle the VEG problem is the stabilisation of the updated recurrent weights [
32]. Gradient clipping [
5] is a well-known heuristic approach to rescale gradients. It controls parameter updating by using a given threshold and prevents unexpected falls to zero or rises to infinity before operating the gradient-descent learning rule.
and
regularisation has also been applied to the recurrent weights to prevent overfitting. They are used as a penalty term during training mainly to bring weights closer to zero [
6]. Initialisation methods have also been employed to limit the values of the updated parameters by using the identity or orthogonal shared matrix. Le et al. showed that combining the proper initialisation with rectified linear units can handle the VEG problems of RNNs [
33]. Xu et al. proposed a hybrid deep learning model by combining RNNs and CNNs, which is used Rectified Linear Units(ReLUs) and initialised with the identity matrix [
34]. Vorontsov et al. used Singular Value Decomposition (SVD) to find the orthogonal matrices of the weight matrix, They proposed to update the parameters at each iteration by using geodesic GD and Cayley methods [
35]. Similarly, [
36] proposed to use the SVD operator to stabilise gradients of deep neural network, which has been proposed as a Spectral-RNN. However, these methods require the computation of inverse matrices and the unitary initial matrices cannot be held after many training iterations, and the same issues arise again.
In addition to the aforementioned approaches, Hessian-free (HF) optimisation methods and novel training algorithms have also been proposed to model the curvature of the nonlinear functions of deep RNN models using random initialisation. Martens et al. has proposed to train RNNs by using hessian-free optimisation [
20]. They have been inspired by the second-order derivative method and Newton optimisation method, which is also called a truncated Newton or the pseudo-Newton method [
37]. Nevertheless, besides their sophisticated nature, they do not have enough generalisation ability to learn and need additional damping among hidden layers when they have been applied to large-scale architectures [
11]. To date, Kag et al. proposed a novel forward propagation algorithm, (FPTT) to handle the VEG problem, which has been outperformed by the BPTT for many tasks including language modeling [
38]. Some gradient independent methods have been developed to address the training difficulties of the Depp RNNs. One of the first best-known heuristic approaches is the simulated annealing method that performs a random neighborhood search to find the optimal weights of the system [
7]. In addition to their advantages, the simulated annealing training period may be very long, hence Bengio et al. have recommended improving alternative practical training algorithms [
7].
To date, metaheuristic algorithms have been successfully applied to solve many nonlinear optimisation problems with their good initialisation strategies and local search abilities that bring crucial advantages to handle local optima issues such as getting trapped at local optima [
39]. Although the number of studies for optimisation of deep architectures is less than that for conventional architectures [
40], some studies have been carried out to improve the optimisation performances for the specified and generalized tasks using the intelligent nature of population-based algorithms [
41]. The studies are mainly focused on hybridisation approaches, which are used to evolve deep architectures and to optimise the hyperparameters of the deep learning models. They can focuses on various application field such as time-series forecasting [
42], classification problem [
43], prediction problem [
44] and design problem [
45].
Studies for evolving network topology with metaheuristics aim to design optimum network architecture. For example, Dessel et al. have proposed to evolve a deep RNN network by using ACO [
46]. They present a strategy to design an optimal RNN model with five hidden and five recurrent layers to predict aviation flights. Similarly, Juang et al. proposed a hybrid training algorithm combining GA and PSO for evolving RNN architecture. They called the algorithm HGAPSO and applied the algorithm for RNN design to a temporal sequence production problem [
47]. The NeuroEvolution of Augmenting Topologies (NEAT) approach has been developed based on the GA for the optimisation of neural model architectures [
48]. Desell et al. have used Ant Colony Optimisation (ACO) to design a deep RNN architecture with five hidden and five recurrent units for predicting flight data [
46]. Similarly, Ororbia et al. have implemented Evolutionary eXploration of Augmenting Memory Models (EXAMM) and different versions of it such as GRU, LSTM, MGU and, UGRNN to evolve RNNs [
49]. Wang et al. proposed an evolutionary recurrent neural network algorithm for the proxy of image captioning task [
50]. A Random Error Sampling-based Neuroevolution (RESN) has been proposed as an evolutionary algorithm to evolve RNN architecture for prediction task [
51]. Mo et al. proposed an EA for topology optimisation of the hybrid LSTM-CNN network for remaining useful life prediction [
52].
Studies to find the optimum weights and to handle VEG problem of the RNN network focused on hybrid training algorithms. Kang et al. proposed a hybrid training algorithm to get rid of the local optima and saddle points by using the PSO and backpropagation algorithm. They got an improvement on convergence and accuracy results of four different datasets [
53]. Ge et al. have presented the modified particle Swarm Optimisation (MPSO) [
54] algorithm for training dynamic Recurrent Elman Networks [
55]. The proposed method aims to find the initial network structure and initial parameters to learn the optimal value of the network weights for controlling Ultrasonic Motors. Xiao et al. have proposed a hybrid training algorithm with PSO and backpropagation (BP) for Impedance Identification [
56]. The RNN architecture has been trained based on finding the minimum MSE and the largest gradient. Zhang et al. have also proposed hybrid PSO and Evolutionary Algorithm (EA) to train RNN for solar radiation prediction [
57]. Likewise, Cai et al. have used hybrid PSO-EA for time series prediction with RNN [
58]. A real-coded (continuous) Genetic Algorithm (GA) has been employed for training RNN by updating weight parameters using random real-valued chromosomes [
59]. Nawi et al. proposed a Cuckoo Search (CS) algorithm for training Elman Recurrent Networks combined with backpropagation for data classification compared to the Artificial Bee Colony and conventional backpropagation algorithm [
60]. A recurrent NARX neural network has been trained by a Genetic Algorithm (GA) to improve the state of charge (SOC) of lithium batteries [
61].
Although the proposed hybrid approaches can train or optimize the topology of the RNNs, those networks do not have so many hidden layers that they can be considered as deep architectures, since the number of hidden layers of most studies is not as high as deep learning architectures. For example, Bas et al. proposed RNN models that have two to five hidden layers for forecasting using the PSO algorithm. The performance of the proposed algorithm was compared to the LSTM and Pi-Sigma NN architectures, which are trained by using gradient-based algorithms that performed similar [
62]. There have only been limited studies into optimizing the architecture of a deep RNN [
46] or deep LSTM [
23] models. The authors of [
46] have used ACO to convert fully connected RNNs into less complex Elman ANNs.
In addition to these studies, some examples of metaheuristic approach focusing on network training in recent years. A neural network training algorithm was proposed by Kaya et al. namely ABCES (Artificial Bee Colony Algorithm Based on Effective Scout Bee Stage) [
63]. They proposed to use ABCES to train a feedforward neural network model to detect the nonlinearity of given static systems, including 13 different numerical optimisation problems. Shettigar et al. proposed an ANN model for surface quality detection, which is trained by using traditional backpropagation algorithm, GA, ABC algorithms compared to the RNN architecture. RNN and BP-NN algorithms performed comparable, and ABC-NN and RNN models gave better results compared to the others [
64]. A BeeM-NN algorithm has been proposed as a bee mutation optimizer for training the RNN model for cloud computing application [
65]. A Parallel Memetic Algorithm (PMA) has been proposed to train RNNs for the energy efficiency problem by Ruiz et al. [
66]. Hu et al. implement a hybrid grey wolf optimizer (GWO) and PSO to determine the endometrial carcinoma disease with Elman RNN. on the [
67]. Tian et al. have also proposed a metaheuristics recommendation system for training deep RNNs to optimise real-world optimization problems, such as the aerodynamic design of turbine engines and automated trading [
68]. Roy et al. have proposed an Ant-Lion optimizer for training RNN to find energy scheduling in micro grid-connected system [
69]. A data-driven deep learning model has been proposed by Aziz et al. by using 10 different classification datasets [
70]. Elman RNN and NN models have been trained by PSO that improved the classification accuracy. Similarly, Hassib et al. proposed a data-driven classification framework using Whale Optimization Algorithm (WOA) for feature selection and training the Bidirectional Recurrent Neural Network [
71]. A Global Guided Artificial Bee Colony (GGABC) algorithm proposed for Recurrent Neural Network training by for breast cancer prediction dataset [
72]. Kumar et al. proposed hybrid flower pollination and PSO algorithm for training LSTM-RNN model to predict Intra-day stock market [
73].
According to the review study, recently over two hundred studies have been made focusing on evolutionary swarm intelligence and deep learning models for topology optimization, hyper-parameter optimization, and training parameter optimisation [
74].
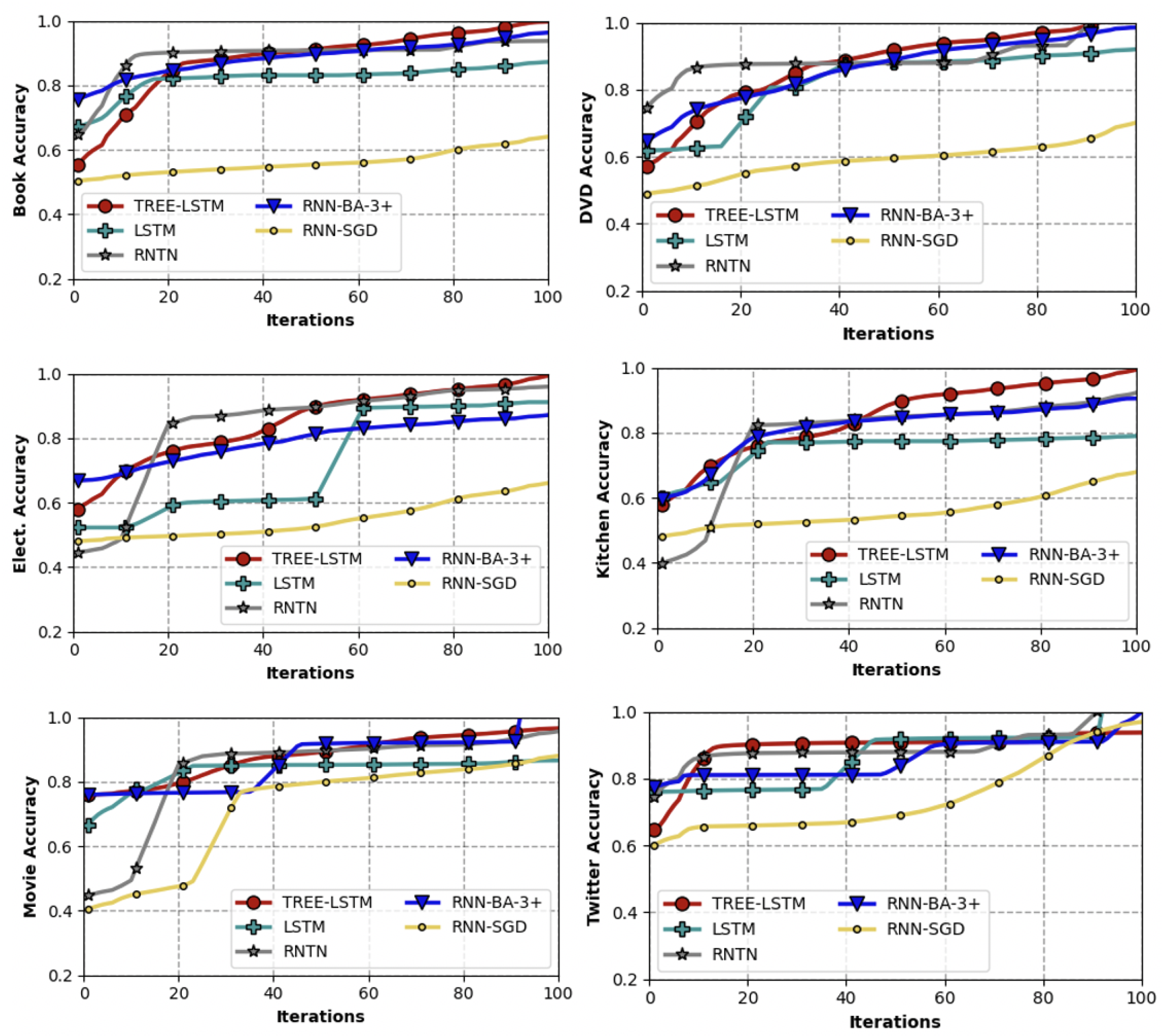
Table 1 reports some of the selected works related to deep RNNs. Even though there are many studies focusing on training artificial neural networks, most of the proposed metaheuristics for training recurrent deep learning models do not comprise many deep hidden layers that could cause the VEG problem. The existing proposed methods have worked over big population numbers, and they are not trying to optimize the deep RNN architectures. The proposed BA-3+ algorithm has only three bees as a population number, and as we proved in
Section 5, the total training time is much lower than the Differential Evolution (DE) and Particle Swarm Optimization (PSO). In addition, the choice of the BA-3+ algorithm is motivated by the No Free Lunch theorem [
75], as it released there is no universally efficient algorithm for all kinds of problems. Hence we can say if algorithm A could perform better than algorithm B in some class of problems and datasets, algorithm B could perform better than algorithm A in some other class of problems and datasets. Hence in this study, we focus on exploring the advantages of the BA-3+ approach for improving the deep recurrent learning abilities as a solution for the VEG problem, which has been discussed in detail in the next section.
4. An Enhanced Ternary Bees Algorithm (BA-3+) to Handle VEG Problem of Training Deep RNN
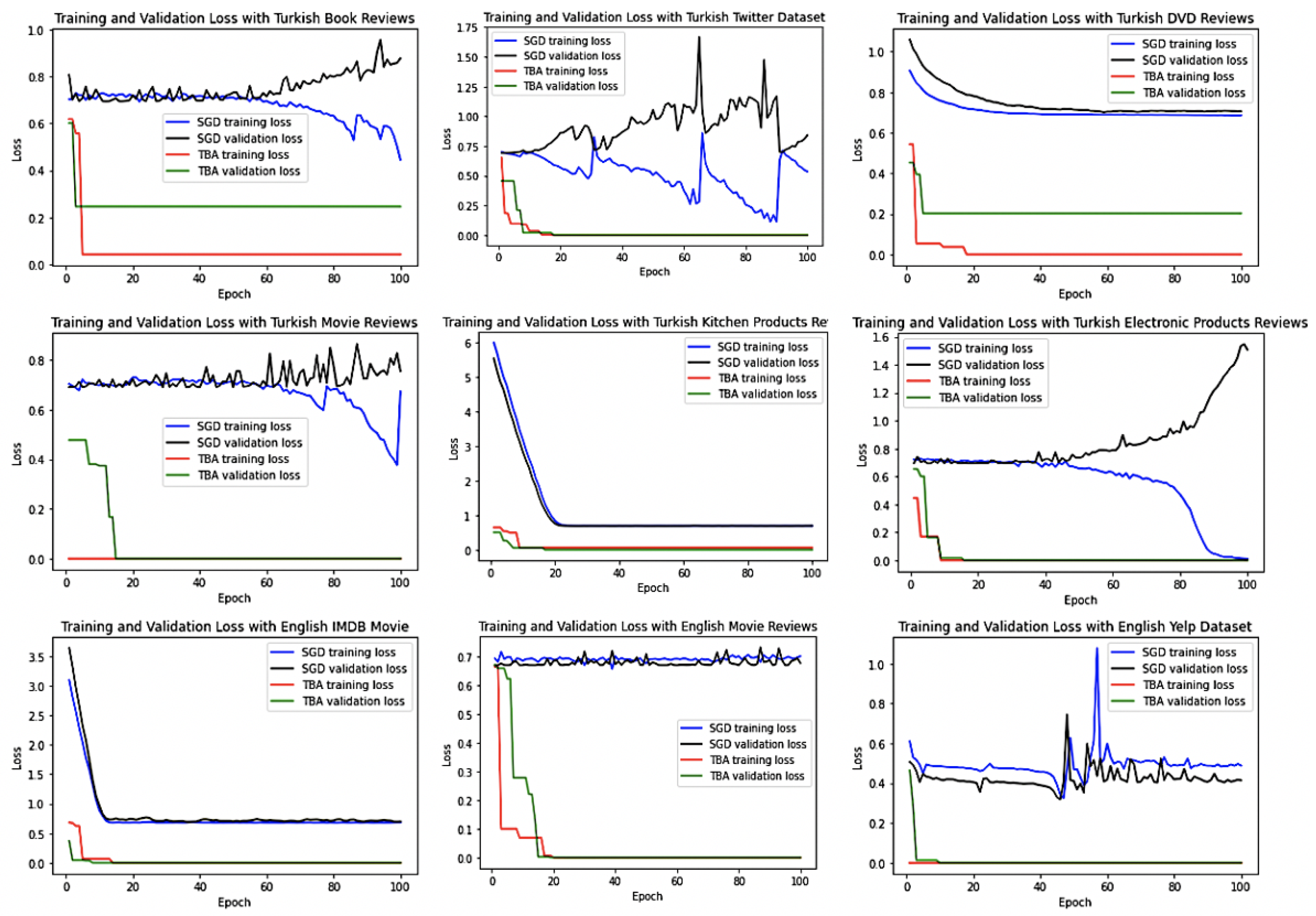
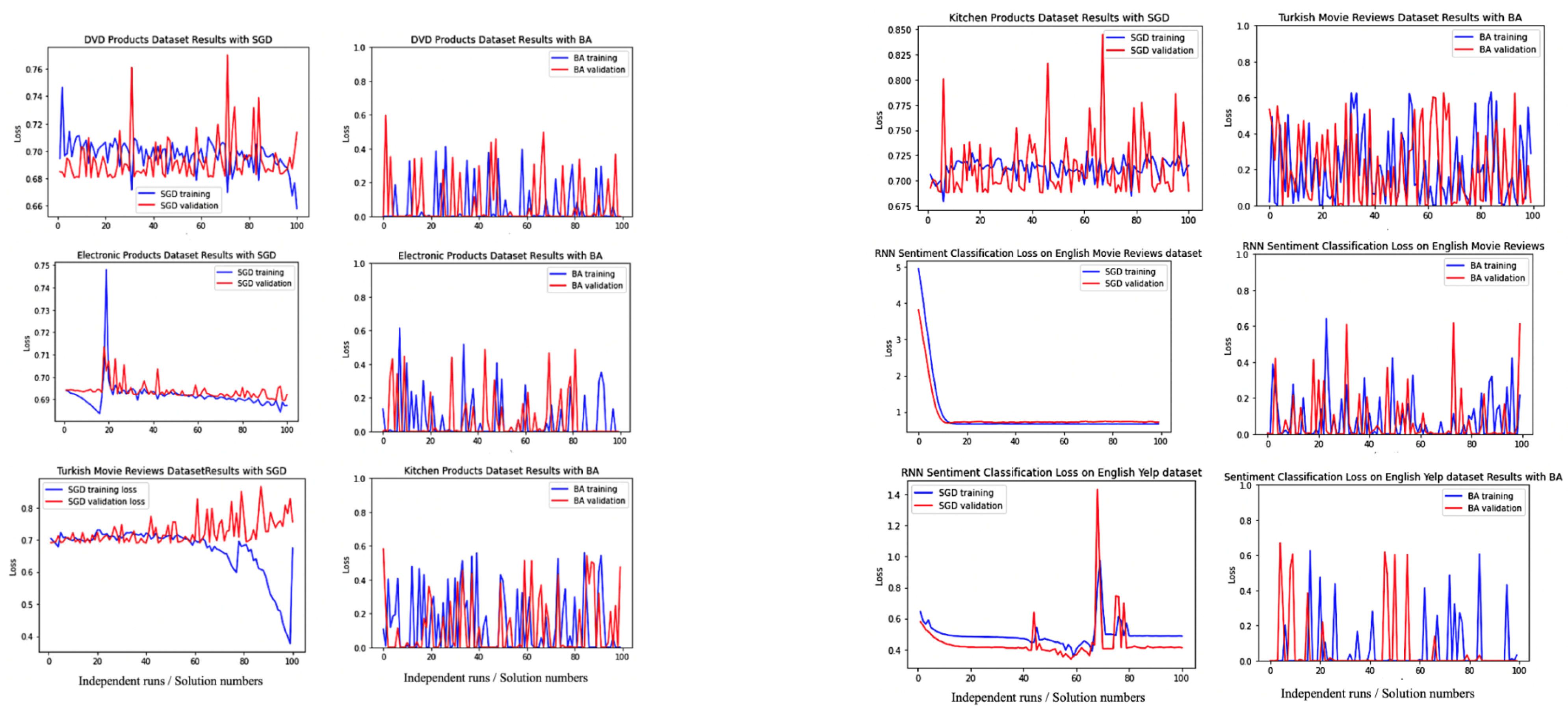
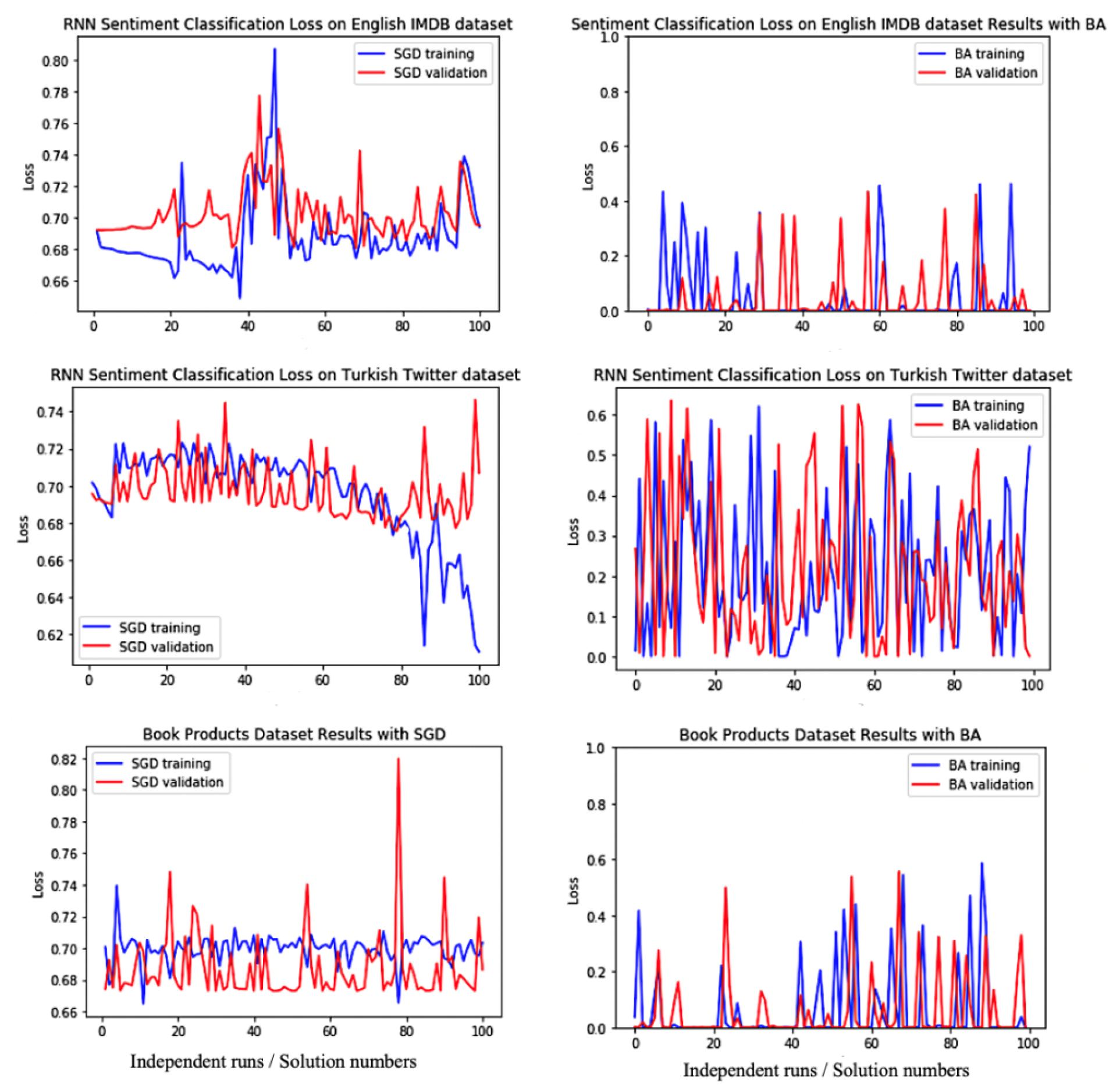
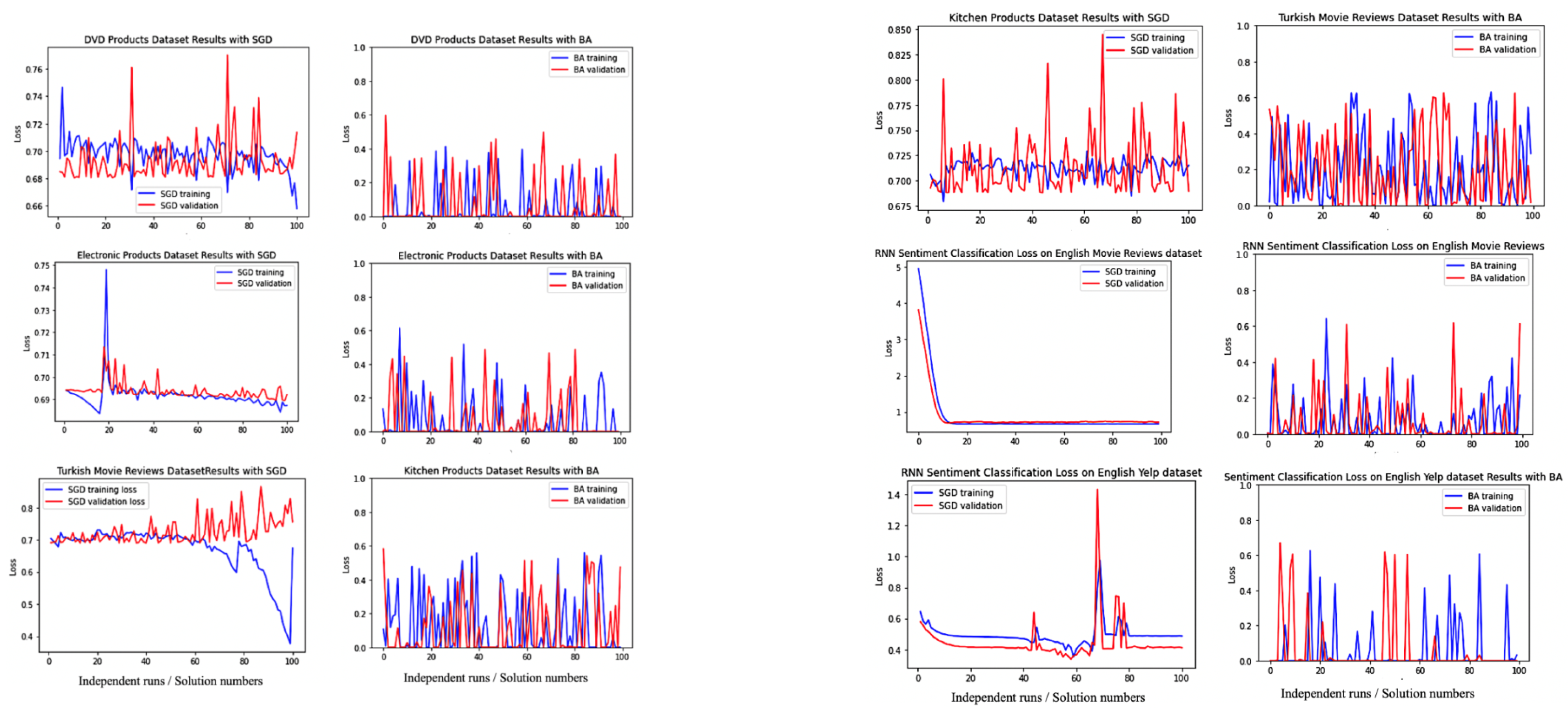
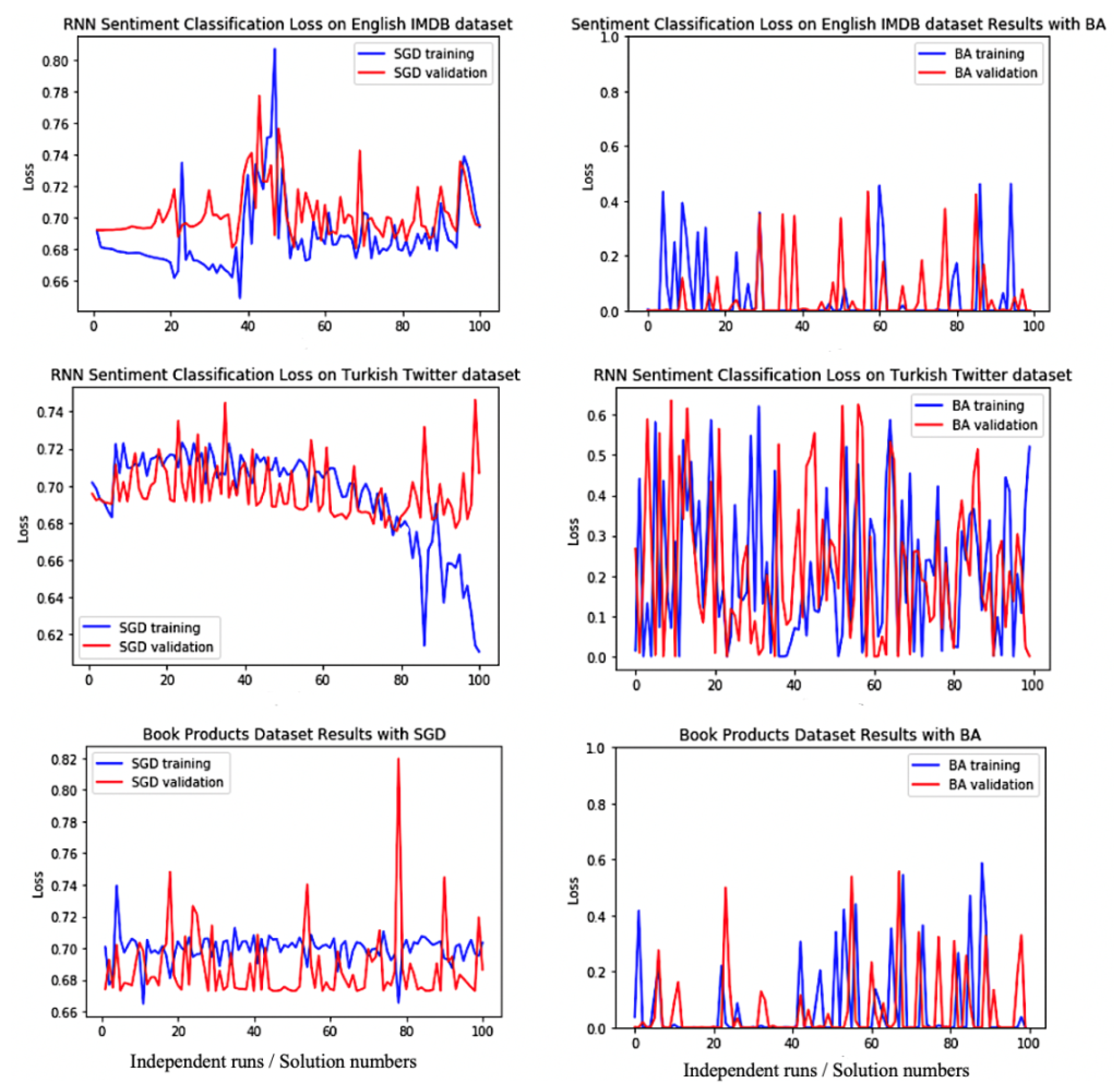
In this section, a population-based search algorithm for training deep RNNs is presented. The learnable parameters are the same as in SGD, which is defined as a candidate solution in BA-3+, and try to minimise the binary cross-entropy loss function for each pair of the sequential input , the desired-targeted output t, and the predicted value y.
Gradient-based learning algorithms are particularly sensitive to the initial value of the weights and noise variance of the dataset in non-convex optimisation. Hence, the difficulty of the training deep RNN model depends on not only keeping the information through long-term time but also initial values of the parameters. Most initialisation methods are generally based on the random initialisation [
84] or researchers choose to initiate the weights as an identity matrix or close to the identity conventionally [
85]. Therefore, finding optimum initial parameters for a specified model and exploring which parameters should be updated and learned are still remains an open difficult optimisation task, due to the lack of the exact knowledge about the which properties of these parameters are kept or learned, under which conditions [
6].
As mentioned above, this work uses an enhanced Ternary Bees Algorithm (BA-3+) for training deep RNNs. BA-3+ combines exploitative local search with explorative global search [
17]. Improvements to the training of deep RNN models with BA-3+ have been made in three key areas: finding promising candidate solutions and initialising the model with good initial weights and biases, improving local search strategies to enhance good solutions by neighbourhood search, particularly to overcome the vanishing and exploding gradients problem, and performing exploration to find new potential solutions with global search.
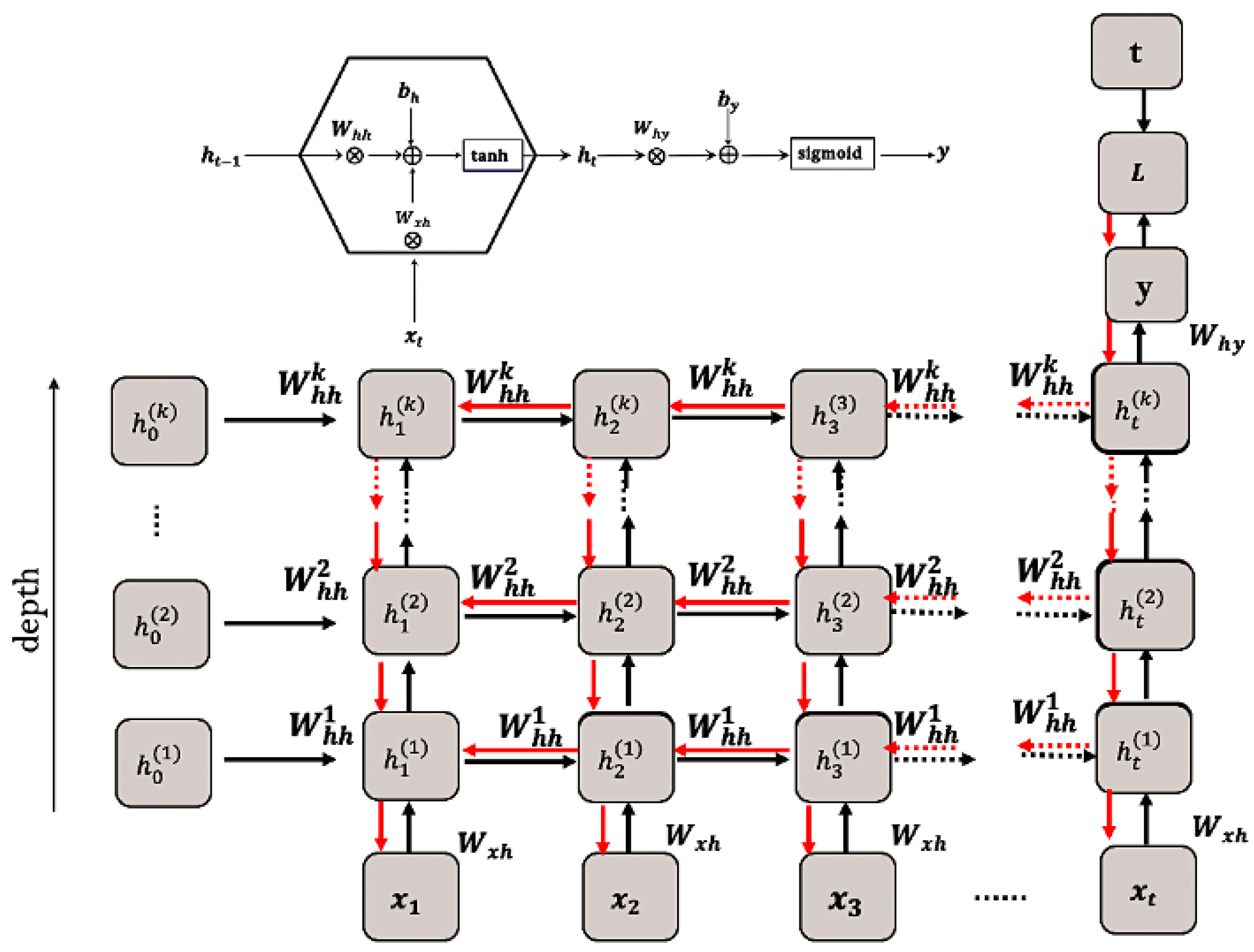
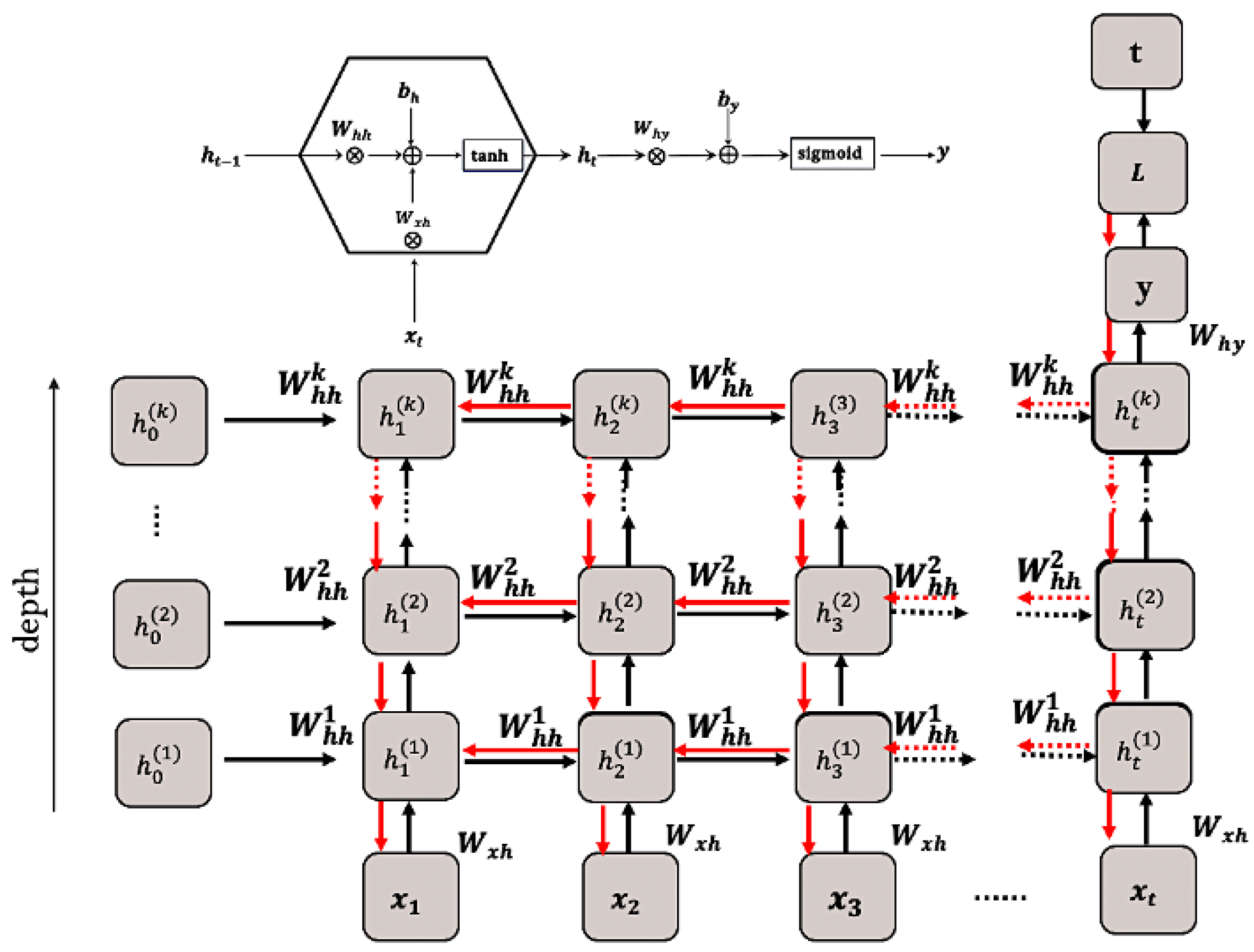
4.1. Representation of Bees for Deep RNN Model
The Bees Algorithm was developed by Pham et al. with inspiration from clever foraging behaviours of the honey bees in nature [
14]. In the proposed method the bee represents a sequential deep RNN model, which is modelled for the binary sentiment classification task. As can be seen in
Figure 1, every bee (Sequential model) instance has the input layer, hidden deep RNN layers, and the output layer. The proposed model has the learnable parameters
, and aims to classify the sequential input data
to its targeted class t.
Based on the training procedure of the RNN model, each “bee model” has its own forward propagation action to calculate the initial solutions, local search procedure by gradient descent training with singular value decomposition (SVD), and global search actions to find the optimal parameters
via the binary cross-entropy loss function (fitness function)
as defined
Section 3.3.
BA-3+ does not require a large population, which is a drawback with other population-based methods. BA-3+ employs only three individual bees for each training time. Each iteration begins with these three initial solutions as a forward pass of the model and continues with specified search strategies including exploitative local search, stochastic gradient descent (SGD) stabilised by Singular Value Decomposition (SVD), and explorative global search.
As with the basic Bees Algorithm [
14], the initial candidate solutions are sorted. The maximum fitness value is selected as the best RNN bee for the local exploitative search. The worst fitness value (third bee) is selected for global search to avoid getting trapped at local optima, and the remaining RNN, i.e., the middle RNN bee is selected for stochastic gradient-descent learning with the stabilisation strategy of SVD operator to update weights and biases without vanishing and exploding gradients.
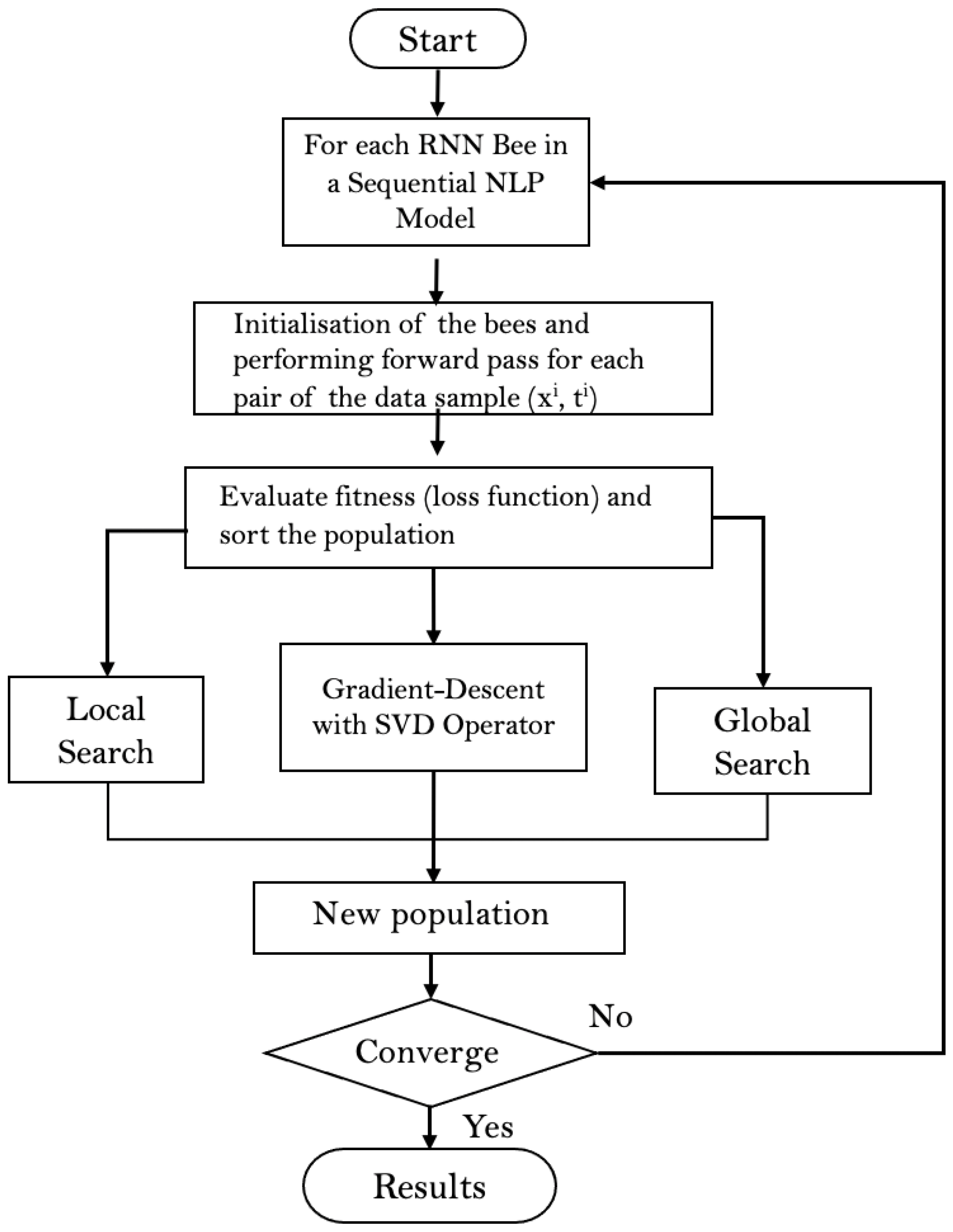
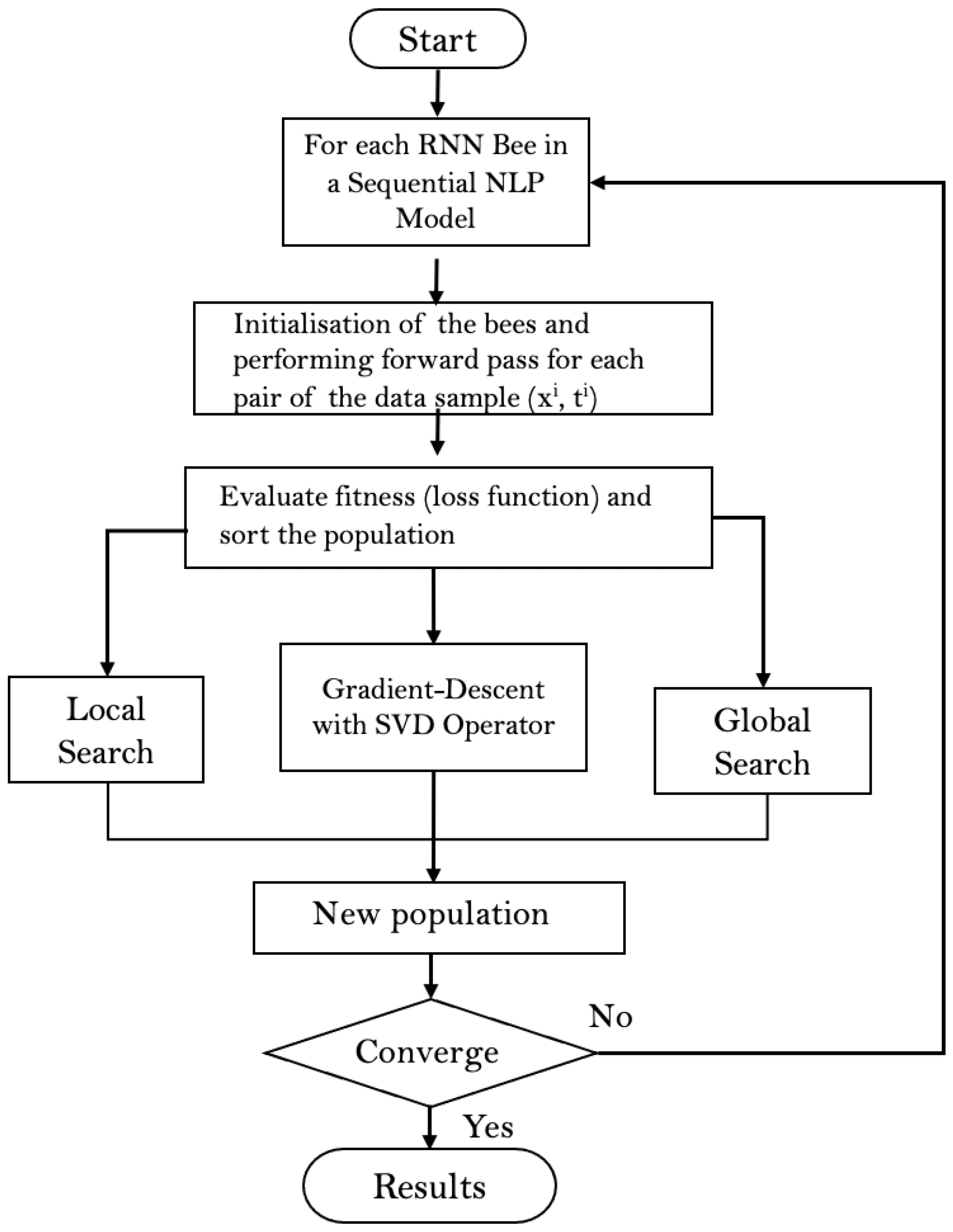
Figure 2 represents the flowchart of the proposed algorithm. (
) is the training sample from the dataset, that
is defined as an n-dimensional sequential input and
is its targeted sentiment class. Parameters of the deep RNN model trained by using BA-3+ are shown in
Table 3. Three initial solutions are calculated with the initial trainable parameters
(see
Table 4) and sorted according to the loss function. The elite (best) RNN bee performs the local search operator, the middle RNN bee performs stochastic gradient-descent with SGD operator, and the third RNN bee performs global search. The optimisation continues with a new population of bees until the stopping criteria met; in other words, until the loss value is converged to zero.
4.2. Local Search Operator
The local search procedure in the basic Bees Algorithm includes improving a promising solution within the neighbourhood of the selected solution parameters. In Algorithms 1 and 2,
ngh represents the initial size of the neighbourhood for the local search. The neighbourhood begins as a large area and it is reduced by using a shrinking method [
86] at each iteration according to the formula
. Here,
is usually a number between 0 and 1. The neighbourhood matrix is generated with the same dimension of each weight matrix of the learnable parameters
, and then is aded to the original weight matrix to obtain the updated weights. The pseudo-code to generate neighbourhood weights is given in Algorithm 2. The updated local weights are used for the local search of BA-3+ that can be seen in Algorithm 4.
| Algorithm 1: Pseudo-code to generate neighbourhood weights. |
![Symmetry 13 01347 i001]() |
| Algorithm 2: Pseudo-code of the local search operator of BA-3+. |
![Symmetry 13 01347 i002]() |
4.3. Enhanced Local Search by SGD and Singular Value Decomposition (SVD) Operator
As analysed in
Section 3.2 and
Section 3.3 due to the sharing the same hidden matrix
across the deep hidden layers and multiplying it again and again at every time step of the BPTT algorithm, the eigenvalues of the Jacobian matrix exponentially grow or vanish after t time steps. To handle this issue, it has been proposed to use a singular value decomposition of the hidden layer matrix to stabilise the eigenvalues of the updated matrix in the enhanced local search of BA-3+. As an example, assume that the eigenvalues of the
are represented
The singular values of
can be founded by using the positive eigenvalues of the matrix
, for every
and
if
is positive semi-definite square matrix [
87]. Since the learnable parameters of the RNN can also be rectangular matrices, it is needed to find singular values of an arbitrary matrix A.
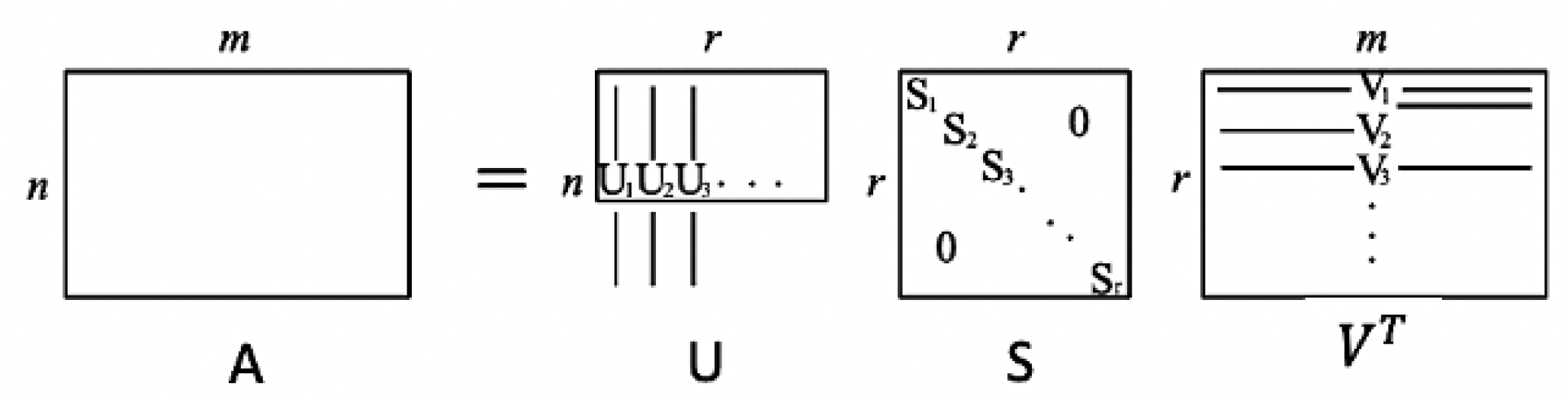
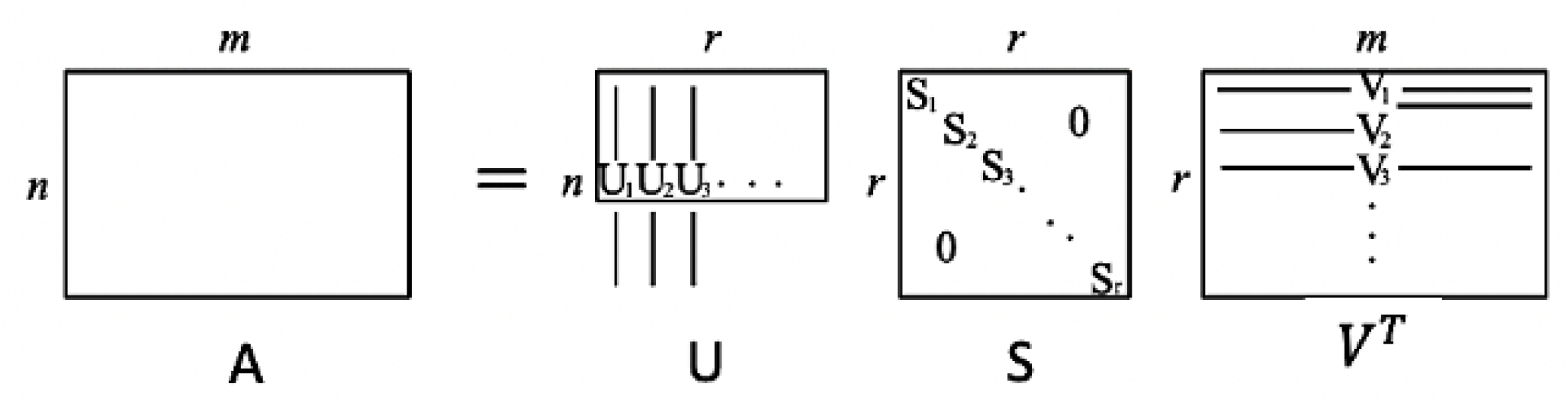
It is well-known that every arbitrary real matrix can be represented by the product of three matrices as
, which is called singular value decomposition (SVD) of matrix A, which is used to find the singular values [
88].
Figure 3 represents the SVD of an
dimensional matrix. Here, S is the
dimensional diagonal matrix
that each
represents the singular values of the matrix A, and U and V contain the corresponding singular vectors where U and V are orthogonal matrices with the
and
dimensions, respectively.
After updating each parameter of the
by SGD rule, the SVD operator has used to control the eigenvalues of each parameter. The method aims to keep the singular values of the updated matrix close to 1 for gradient stabilisation. To this end, the SVD decomposition of the updated matrix is performed to find the singular values, and then every singular vector is controlled to be close to the unit vector. As given in Algorithm 3, the singular values of the updated weight matrix are restricted to the interval
to avoid updating in the wrong direction. Here,
ngh is the initial neighbourhood size, which is chosen between
. As a result,
can be updated over time without vanishing or exploding gradients.
| Algorithm 3: Pseudo-code of SGD with the SVD operator. |
![Symmetry 13 01347 i003]() |
4.4. Global Search Operator
Besides the enhanced local search procedures, the proposed algorithm also includes a global search operator that combines random sampling chances which is also a good strategy for escaping local optimum points of the solution space. The third bee in a colony is used for the random exploration for potential new solutions of the search space. If the updated random weights gave a better solution for the loss function, then the third bee is updated with new global searched weights. This procedure gives the advantage to escape getting trapped at local optima, which results in converging to the global optimum faster during the training process. Algorithm 4 shows the pseudo-code of the proposed enhanced Ternary Bees Algorithm (BA-3+). The source code of the proposed algorithm is given at
Appendix A.
| Algorithm 4: Pseudo-code of the enhanced Ternary Bees Algorithm (BA-3+) for training deep RNN model. |
![Symmetry 13 01347 i004]() |
In this study, sentiment analysis is considered as a binary classification problem. The F1-score or F1 measure was used as a statistical measure for the analysis of the binary classification problem in addition to the accuracy measure. F1 measure is calculated as follows:
Precision is the total count of true positives divided by the total number of positive results. The recall is the total number of true positive results divided by the number of all samples that should have been classified as positive. F1 measure can also be defined as a harmonic mean of the precision and recall value. The next section reports the details of the proposed algorithm’s experimental setup and performance results and benchmarks.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}