
Image Caption Generation Using Multi-Level Semantic Context Information

Abstract
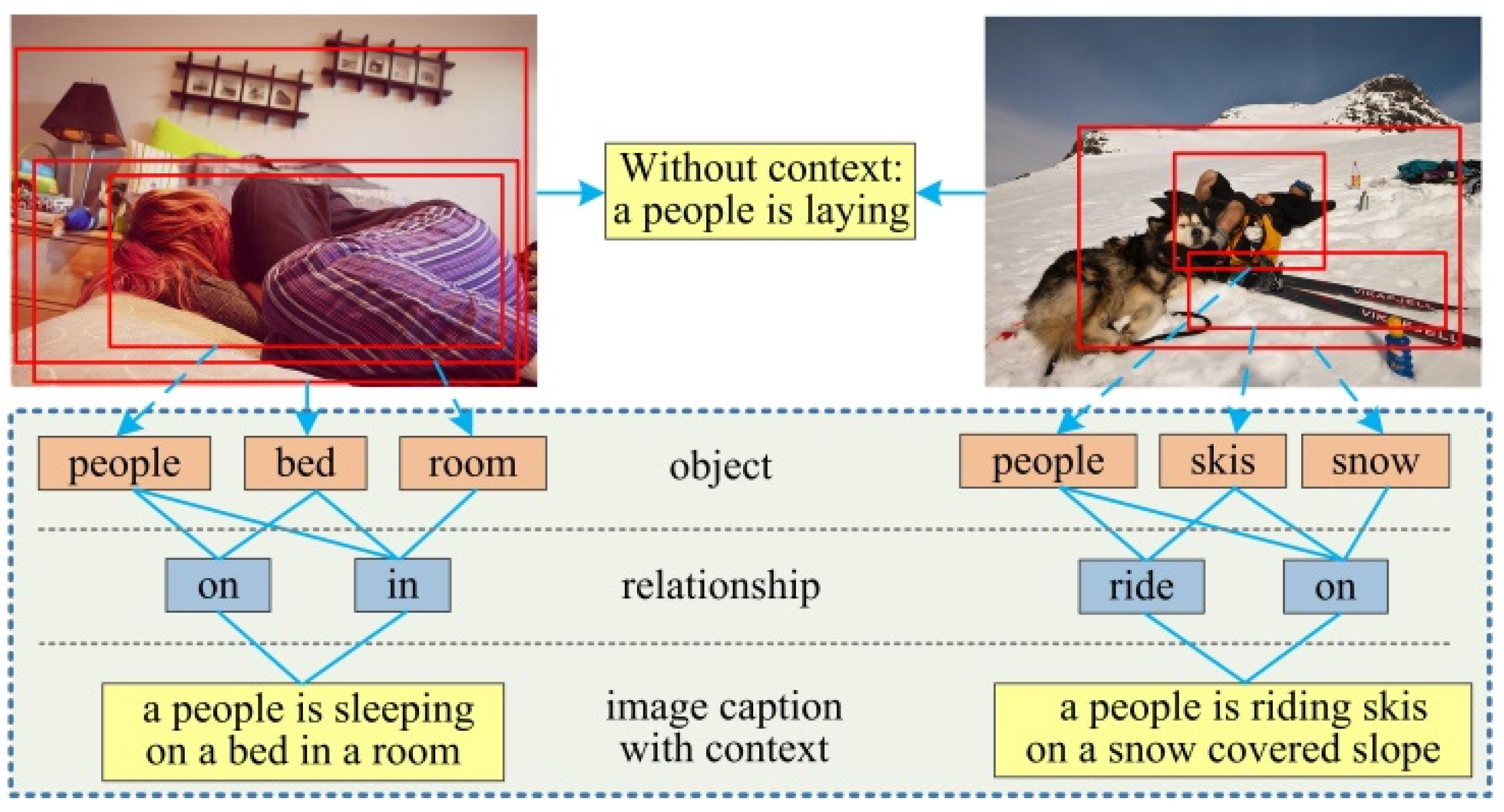
:1. Introduction
- We propose a multi-level semantic context information network model to simultaneously solve the object detection, visual relationship detection, and image-captioning tasks.
- We use the Gated Graph Neural Network (GGNN) [16] to pass and refine the features of different semantic layers, and then build a context information extraction network to respectively obtain the relationship context between objects and the scene context between object and image scene, the model can leverage the context information between the different semantic layers to simultaneously improve the accuracy of the visual tasks generation.
- We use the extracted context information as the input of the attention mechanism, and integrate its output into the decoder with the caption region features. In this way, the model can obtain more image features and while focus on the context information between objects, relationships, and image scene to improve the accuracy and comprehensiveness of the generated caption.
2. Related Work
2.1. Object Detection
2.2. Visual Relationship Detection
2.3. Image Captioning
2.4. Context Information
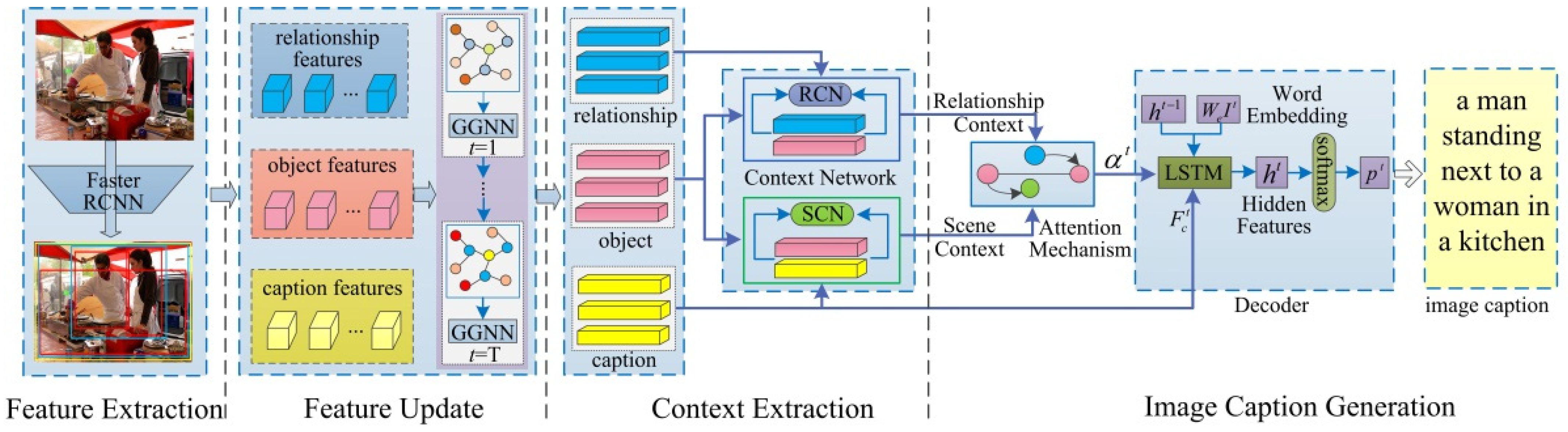
3. Method
3.1. Model Overview
3.2. Region Proposal and Feature Extraction
3.3. Feature Updating
3.4. Context Information Extraction
3.4.1. Relationship Context
3.4.2. Scene Context
3.5. Image Captioning
4. Experiments
4.1. Datasets and Evaluation Metrics
4.1.1. Datasets
4.1.2. Evaluation Metrics
4.2. Implementation Details
4.3. Performance Comparison and Analysis
4.3.1. Compared Methods
4.3.2. Performance Analysis
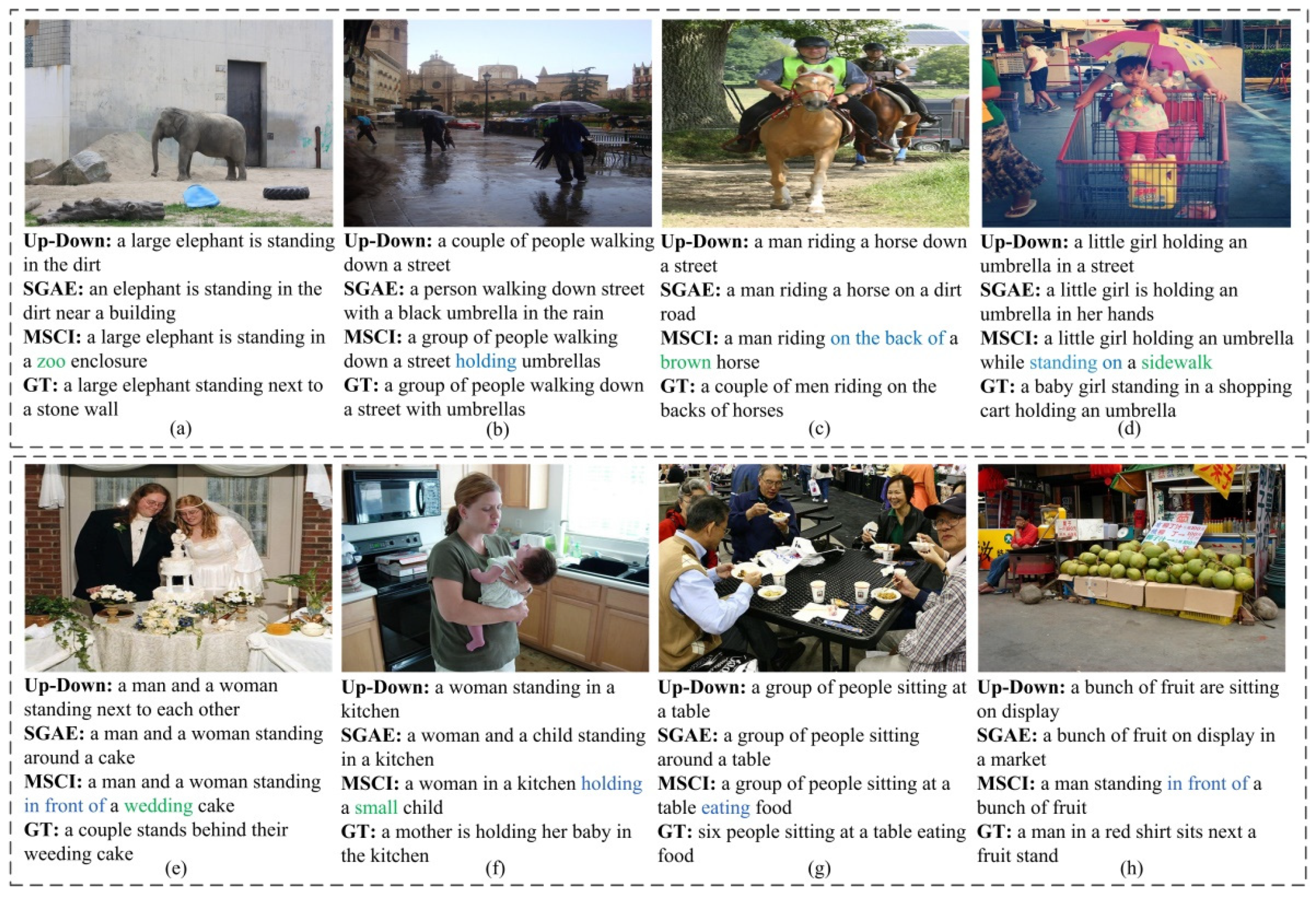
4.3.3. Qualitative Examples
4.4. Evaluation Analysis
4.4.1. Object Detection
4.4.2. Relationship Detection
4.5. Ablation Study
4.5.1. Performance Analysis
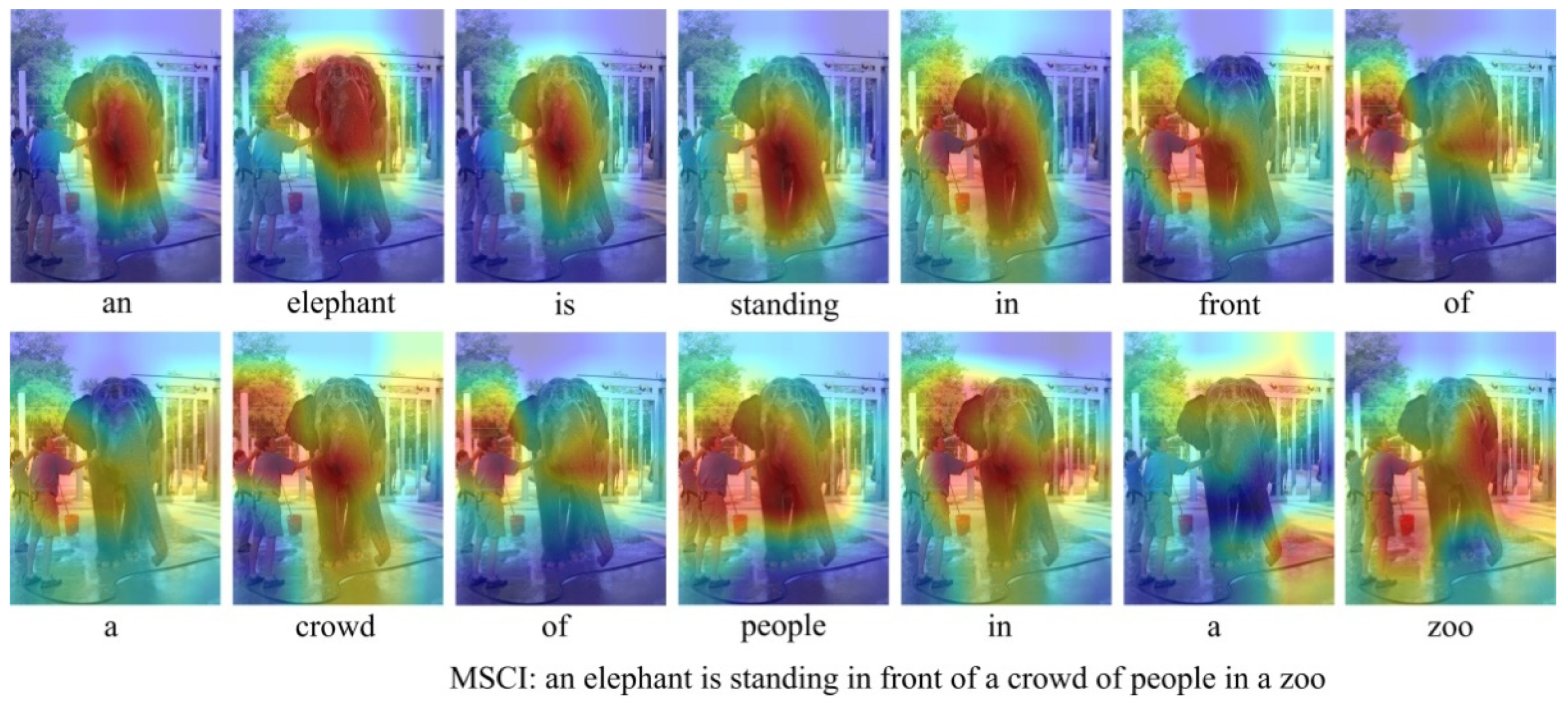
4.5.2. Qualitative Examples
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- He, K.; Zhang, X.; Ren, S. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Karpathy, A.; Li, F.-F. Deep Visual-Semantic Alignments for Generating Image Descriptions. In Proceedings of the IEEE Transactions on Pattern Analysis and Machine Intelligence, Boston, MA, USA, 7–12 June 2016; pp. 664–676. [Google Scholar]
- Yan, M.; Guo, Y. Deep learning for visual understanding: A review. Neurocomputing 2016, 187, 27–48. [Google Scholar]
- Wang, W.; Hu, H. Multimodal object description network for dense captioning. IEEE Electron. Lett. 2017, 53, 1041–1042. [Google Scholar] [CrossRef]
- Johnson, J.; Karpathy, A.; Li, F.-F. DenseCap: Fully Convolutional Localization Networks for Dense Captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 4565–4574. [Google Scholar]
- Xu, K.; Ba, J.; Kiros, R. Show, attend and tell: Neural image caption generation with visual attention. In Proceedings of the 32nd International Conference on International Conference on Machine Learning (ICML), Lille, France, 6–7 July 2015; pp. 2048–2057. [Google Scholar]
- Gu, J.; Wang, G.; Cai, J. An Empirical Study of Language CNN for Image Captioning. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 1222–1231. [Google Scholar]
- Zhang, Y.; Shi, X.; Mi, S. Image Captioning with Transformer and Knowledge Graph. Pattern Recognit. Lett. 2021, 143, 43–49. [Google Scholar] [CrossRef]
- Zhang, Z.; Wu, Q.; Wang, Y. Exploring Region Relationships Implicitly: Image Captioning with Visual Relationship Attention. Image Vis. Comput. 2021, 109, 104146. [Google Scholar] [CrossRef]
- Zhou, Y.; Sun, Y.; Honavar, V. Improving Image Captioning by Leveraging Knowledge Graphs. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa Village, HI, USA, 8–10 January 2019; pp. 283–293. [Google Scholar]
- You, Q.; Jin, H.; Wang, Z. Image captioning with semantic attention. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 4651–4659. [Google Scholar]
- Lu, J.; Xiong, C.; Parikh, D. Knowing when to look: Adaptive attention via a visual sentinel for image captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 375–383. [Google Scholar]
- Gao, L.; Fan, K.; Song, J. Deliberate Attention Networks for Image Captioning. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), Honolulu, HI, USA, 27–31 January 2019; pp. 33, 8320–8327. [Google Scholar]
- Yang, X.; Tang, K.; Zhang, H. Auto-Encoding Scene Graphs for Image Captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–21 June 2019; pp. 10685–10694. [Google Scholar]
- Zhong, Y.; Wang, L.; Chen, J. Comprehensive Image Captioning via Scene Graph Decomposition. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; pp. 211–229. [Google Scholar]
- Li, Y.; Tarlow, D.; Brockschmidt, M. Gated Graph Sequence Neural Networks. In Proceedings of the IEEE International Conference on Learning Representations (ICLR), San Juan, PR, USA, 2–4 May 2016; pp. 1–20. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Ren, S.; He, K.; Girshick, R. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934v1. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D. SSD: Single Shot MultiBox Detector. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Li, Y.; Ouyang, W.; Zhou, B. Factorizable net: An efficient subgraph-based framework for scene graph generation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 335–351. [Google Scholar]
- Lv, J.; Xiao, Q.; Zhong, J. AVR: Attention based Salient Visual Relationship Detection. arXiv 2020, arXiv:2003.07012. [Google Scholar]
- Liang, X.; Lee, L.; Xing, E.P. Deep Variation-structured Reinforcement Learning for Visual Relationship and Attribute Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 848–857. [Google Scholar]
- Lu, C.; Krishna, R.; Bernstein, M. Visual Relationship Detection with Language Priors. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; pp. 852–869. [Google Scholar]
- Dai, B.; Zhang, Y.; Lin, D. Detecting visual relationships with deep relational networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3076–3086. [Google Scholar]
- Chen, T.; Yu, W.; Chen, R. Knowledge-Embedded Routing Network for Scene Graph Generation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 6156–6164. [Google Scholar]
- Kulkarni, G.; Premraj, V.; Ordonez, V. Babytalk: Understanding and generating simple image descriptions. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 2891–2903. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Elliott, D.; Keller, F. Image description using visual dependency representations. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing (EMNLP), Seattle, WA, USA, 18–21 October 2013; pp. 1292–1302. [Google Scholar]
- Verma, Y.; Gupta, A.; Mannem, P. Generating image descriptions using semantic similarities in the output space. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2013; pp. 288–293. [Google Scholar]
- Devlin, J.; Cheng, H.; Fang, H. Language models for image captioning: The quirks and what works. In Proceedings of the Annual Meeting of the Association for Computational Linguistics (ACL), Beijing, China, 26–31 July 2015; pp. 100–105. [Google Scholar]
- Zhu, Z.; Wang, T.; Qu, H. Macroscopic Control of Text Generation for Image Captioning. arXiv 2021, arXiv:2101.08000. [Google Scholar]
- Ji, J.; Xu, C.; Zhang, X. Spatio-Temporal Memory Attention for Image Captioning. IEEE Trans. Image Process. 2020, 29, 7615–7628. [Google Scholar] [CrossRef]
- Anderson, P.; He, X.; Buehler, C. Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake, UT, USA, 18–23 June 2018; pp. 6077–6086. [Google Scholar]
- Wang, W.; Chen, Z.; Hu, H. Hierarchical Attention Network for Image Captioning. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), Honolulu, HI, USA, 27–31 January 2019; pp. 8957–8964. [Google Scholar]
- Mi, J.; Lyu, J.; Tang, S. Interactive Natural Language Grounding via Referring Expression Comprehension and Scene Graph Parsing. Front. Neurorobot. 2020, 14, 43. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Jiang, S. Know More Say Less: Image Captioning Based on Scene Graphs. IEEE Trans. Multimed. 2019, 21, 2117–2130. [Google Scholar] [CrossRef]
- Mottaghi, R.; Chen, X.; Liu, X. The Role of Context for Object Detection and Semantic Segmentation in the Wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 891–898. [Google Scholar]
- Zeng, X.; Ouyang, W.; Yang, B. Gated Bi-directional CNN for Object Detection. In Proceedings of the IEEE European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; pp. 354–369. [Google Scholar]
- Ma, Y.; Guo, Y.; Liu, H. Global Context Reasoning for Semantic Segmentation of 3D Point Clouds. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Snowmass Village, CO, USA, 2–5 March 2020; pp. 2931–2940. [Google Scholar]
- Lin, C.-Y.; Chiu, Y.-C.; Ng, H.-F. Global-and-Local Context Network for Semantic Segmentation of Street View Images. Sensors 2020, 20, 2907. [Google Scholar] [CrossRef] [PubMed]
- Dvornik, N.; Mairal, J.; Schmid, C. On the Importance of Visual Context for Data Augmentation in Scene Understanding. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 2014–2018. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhuang, B.; Liu, L.; Shen, C. Towards Context-Aware Interaction Recognition for Visual Relationship Detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 589–598. [Google Scholar]
- Zellers, R.; Yatskar, M.; Thomson, S. Neural motifs: Scene graph parsing with global context. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake, UT, USA, 18–23 June 2018; pp. 5831–5840. [Google Scholar]
- Qi, X.; Liao, R.; Jia, J. 3D Graph Neural Networks for RGBD Semantic Segmentation. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Kenneth, M.; Ruslan, S.; Abhinav, G. The More You Know: Using Knowledge Graphs for Image Classification. arXiv 2017, arXiv:1612.04844. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Lin, T.-Y.; Maire, M.; Belongie, S. Microsoft coco: Common objects in context. In Proceedings of the IEEE European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Plummer, B.-A.; Wang, L.; Cervantes, C.-M. Flickr30k entities: Collecting region-to-phrase correspondences for richer image-to-sentence models. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 13–16 December 2015; pp. 2641–2649. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T. BLEU: A method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting on Association for Computational Linguistics (ACL), Philadelphia, PA, USA, 6–12 July 2002; pp. 311–318. [Google Scholar]
- Banerjee, S.; Lavie, A. METEOR: An automatic metric for MT evaluation with improved correlation with human judgments. In Proceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization, Ann Arbor, MI, USA, 29 June 2005; pp. 65–72. [Google Scholar]
- Lin, C.-Y.; Hovy, E. Automatic evaluation of summaries using n-gram co-occurrence statistics. In Proceedings of the 2003 Human Language Technology Conference of the North American Chapter of the Association for Computational Linguistics (NAACL), Baltimore, MD, USA, 1–11 July 2003; pp. 71–78. [Google Scholar]
- Vedantam, R.; Zitnick, C.; Parikh, D. Cider: Consensus-based image description evaluation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 4566–4575. [Google Scholar]
- Anderson, P.; Fernando, B.; Johnson, M. Spice: Semantic propositional image caption evaluation. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; pp. 382–398. [Google Scholar]
- Kingma, D.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- He, X.; Shi, B.; Bai, X. Image caption generation with part of speech guidance. Pattern Recognit. Lett. 2019, 119, 229–237. [Google Scholar] [CrossRef]
- Nogueira, T.; Vinhal, C. Reference-based model using multimodal gated recurrent units for image captioning. Multimed. Tools Appl. 2020, 79, 30615–30635. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Cross-Entropy Loss | CIDEr Score Optimization | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Metric | B@1 | B@4 | M | R | C | S | B@1 | B@4 | M | R | C | S |
| DA [13] | 0.758 | 0.357 | 0.274 | 0.562 | 1.119 | 0.205 | 0.799 | 0.375 | 0.285 | 0.582 | 1.256 | 0.223 |
| Trans-KG [8] | 0.764 | 0.344 | 0.277 | 0.565 | 1.128 | 0.209 | - | - | - | - | - | - |
| ORRA [36] | 0.767 | 0.338 | 0.262 | 0.549 | 1.103 | 0.198 | 0.792 | 0.363 | 0.276 | 0.568 | 1.202 | 0.214 |
| Sub-GC [15] | 0.768 | 0.362 | 0.277 | 0.566 | 1.153 | 0.207 | - | - | - | - | - | - |
| Up-Down [33] | 0.772 | 0.362 | 0.270 | 0.564 | 1.135 | 0.203 | 0.798 | 0.363 | 0.277 | 0.569 | 1.201 | 0.214 |
| HAN [34] | 0.772 | 0.362 | 0.275 | 0.566 | 1.148 | 0.206 | 0.809 | 0.376 | 0.278 | 0.581 | 1.217 | 0.215 |
| STMA [32] | 0.774 | 0.365 | 0.274 | 0.568 | 1.144 | 0.205 | 0.802 | 0.377 | 0.282 | 0.581 | 1.259 | 0.217 |
| SGAE [14] | 0.776 | 0.369 | 0.277 | 0.572 | 1.167 | 0.209 | 0.808 | 0.384 | 0.284 | 0.586 | 1.278 | 0.221 |
| MCTG [31] | 0.783 | 0.375 | 0.281 | 0.574 | 1.203 | 0.215 | 0.787 | 0.371 | 0.277 | 0.561 | 1.264 | 0.215 |
| VRAtt-Soft [9] | 0.792 | 0.369 | 0.283 | 0.609 | 1.143 | 0.208 | 0.804 | 0.375 | 0.285 | 0.616 | 1.221 | 0.221 |
| MSCI(Ours) | 0.793 | 0.378 | 0.292 | 0.586 | 1.186 | 0.216 | 0.812 | 0.393 | 0.295 | 0.593 | 1.275 | 0.225 |
| Model | B@1 | B@2 | B@3 | B@4 | M | R | C | S |
|---|---|---|---|---|---|---|---|---|
| PoS [55] | 0.638 | 0.446 | 0.307 | 0.211 | - | - | - | - |
| Trans-KG [8] | 0.676 | - | - | 0.260 | 0.219 | - | 0.575 | 0.163 |
| Adaptive-ATT [12] | 0.677 | 0.494 | 0.354 | 0.251 | 0.204 | - | 0.531 | - |
| r-GRU [56] | 0.694 | 0.458 | 0.336 | 0.231 | 0.298 | 0.442 | 0.479 | - |
| Sub-GC [15] | 0.707 | - | - | 0.285 | 0.223 | - | 0.619 | 0.164 |
| MSCI(Ours) | 0.705 | 0.503 | 0.374 | 0.294 | 0.238 | 0.457 | 0.613 | 0.167 |
| Model | B@1 | B@2 | B@4 | METER | ROUGE | CIDEr | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| c5 | c40 | c5 | c40 | c5 | c40 | c5 | c40 | c5 | c40 | c5 | c40 | |
| DA [13] | 0.794 | 0.944 | 0.635 | 0.880 | 0.368 | 0.674 | 0.282 | 0.370 | 0.577 | 0.722 | 1.205 | 1.220 |
| ORRA [36] | 0.792 | 0.944 | 0.626 | 0.872 | 0.354 | 0.658 | 0.273 | 0.361 | 0.562 | 0.712 | 1.151 | 1.173 |
| Up-Down [33] | 0.802 | 0.952 | 0.641 | 0.888 | 0.369 | 0.685 | 0.276 | 0.367 | 0.571 | 0.724 | 1.179 | 1.205 |
| STMA [32] | 0.803 | 0.948 | 0.646 | 0.888 | 0.377 | 0.686 | 0.283 | 0.371 | 0.581 | 0.728 | 1.231 | 1.255 |
| HAN [34] | 0.804 | 0.945 | 0.638 | 0.877 | 0.365 | 0.668 | 0.274 | 0.361 | 0.573 | 0.719 | 1.152 | 1.182 |
| SGAE [14] | 0.806 | 0.950 | 0.650 | 0.889 | 0.378 | 0.687 | 0.281 | 0.370 | 0.582 | 0.731 | 1.227 | 1.255 |
| MSCI (Ours) | 0.806 | 0.949 | 0.652 | 0.897 | 0.389 | 0.706 | 0.293 | 0.382 | 0.589 | 0.742 | 1.221 | 1.248 |
| Object Det. | Faster R-CNN | Ours-CI | Ours |
|---|---|---|---|
| mAP(%) | 37.4 | 39.5 | 40.8 |
| Model | Relationship Detection | Phrase Detection | ||
|---|---|---|---|---|
| R@50 | R@100 | R@50 | R@100 | |
| LP [24] | 13.86 | 14.70 | 16.17 | 17.03 |
| DR-Net [25] | 16.94 | 20.20 | 19.02 | 22.85 |
| VRL [23] | 18.19 | 20.79 | 21.37 | 22.60 |
| F-Net [21] | 18.32 | 21.20 | 26.03 | 30.77 |
| AVR [22] | 22.83 | 25.41 | 29.33 | 33.27 |
| Baseline | 12.58 | 14.29 | 14.26 | 16.32 |
| Base+GGNN | 16.85 | 19.32 | 20.65 | 22.28 |
| Base+GGNN+RCI | 18.36 | 21.27 | 23.58 | 25.56 |
| ID | GGNN | RCI | SCI | AM | B@1 | B@2 | B@3 | B@4 | M | R | C | S |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | - | - | - | - | 0.725 | 0.549 | 0.408 | 0.313 | 0.241 | 0.526 | 0.957 | 0.186 |
| 2 | √ | - | - | - | 0.776 | 0.596 | 0.453 | 0.362 | 0.262 | 0.553 | 1.196 | 0.202 |
| 3 | √ | √ | - | - | 0.791 | 0.613 | 0.479 | 0.376 | 0.273 | 0.568 | 1.231 | 0.214 |
| 4 | √ | √ | √ | - | 0.805 | 0.632 | 0.495 | 0.384 | 0.286 | 0.582 | 1.259 | 0.221 |
| 5 | √ | √ | √ | √ | 0.812 | 0.655 | 0.502 | 0.393 | 0.295 | 0.593 | 1.275 | 0.225 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tian, P.; Mo, H.; Jiang, L. Image Caption Generation Using Multi-Level Semantic Context Information. Symmetry 2021, 13, 1184. https://doi.org/10.3390/sym13071184
Tian P, Mo H, Jiang L. Image Caption Generation Using Multi-Level Semantic Context Information. Symmetry. 2021; 13(7):1184. https://doi.org/10.3390/sym13071184
Chicago/Turabian StyleTian, Peng, Hongwei Mo, and Laihao Jiang. 2021. "Image Caption Generation Using Multi-Level Semantic Context Information" Symmetry 13, no. 7: 1184. https://doi.org/10.3390/sym13071184
APA StyleTian, P., Mo, H., & Jiang, L. (2021). Image Caption Generation Using Multi-Level Semantic Context Information. Symmetry, 13(7), 1184. https://doi.org/10.3390/sym13071184