
Node Selection Algorithm for Network Coding in the Mobile Wireless Network

Abstract
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
1. Introduction
2. Materials and Methods
2.1. The Construction of Network Model
2.2. The Selection Analysis of Encoding Nodes
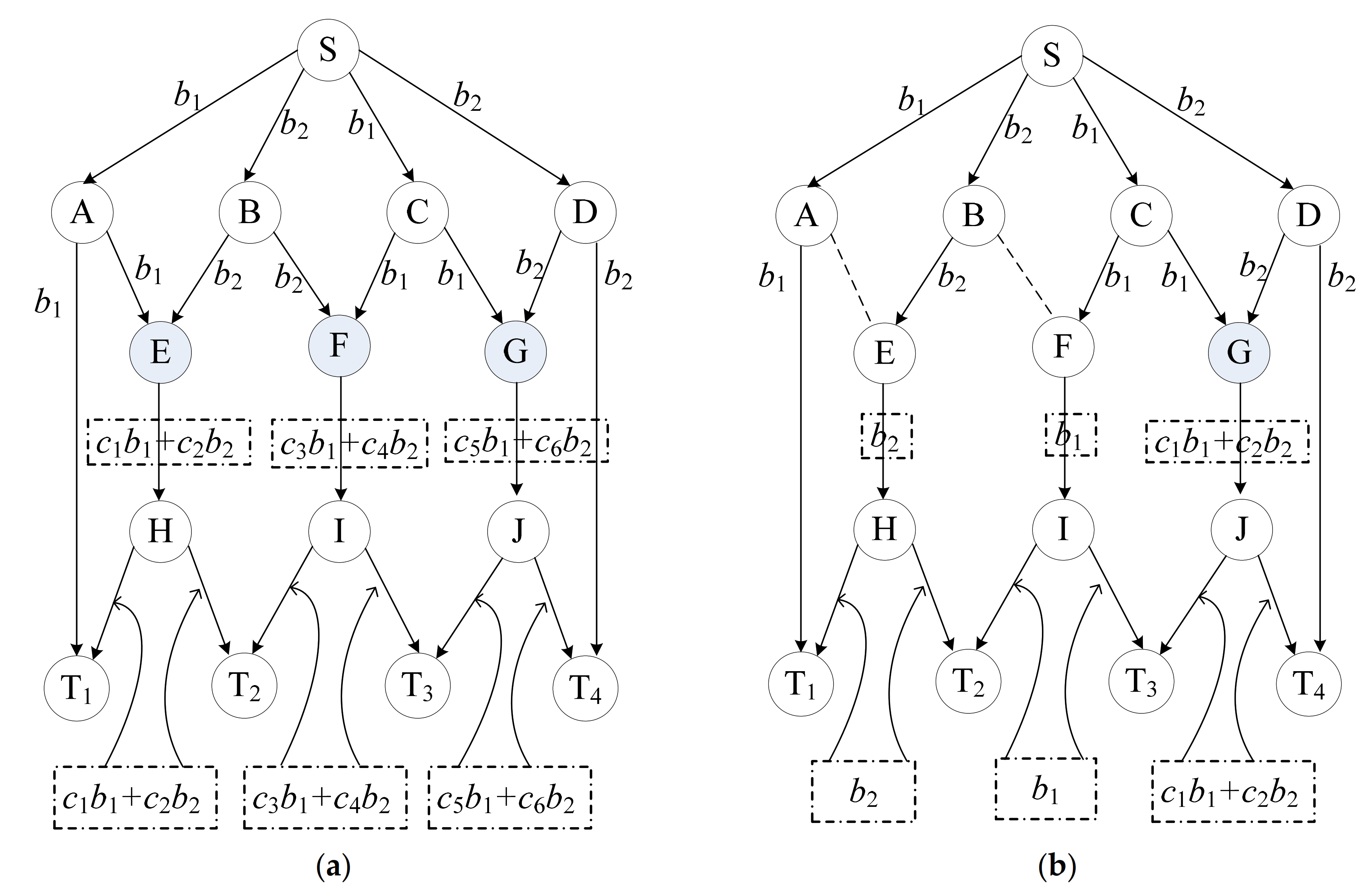
2.2.1. The Intermediate Node
2.2.2. The Encoding Nodes
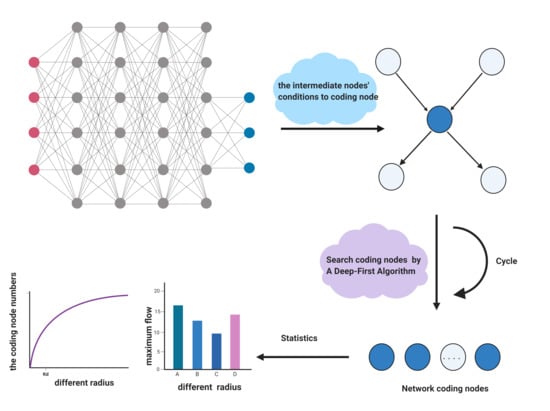
2.3. The Algorithm of Encoding Nodes
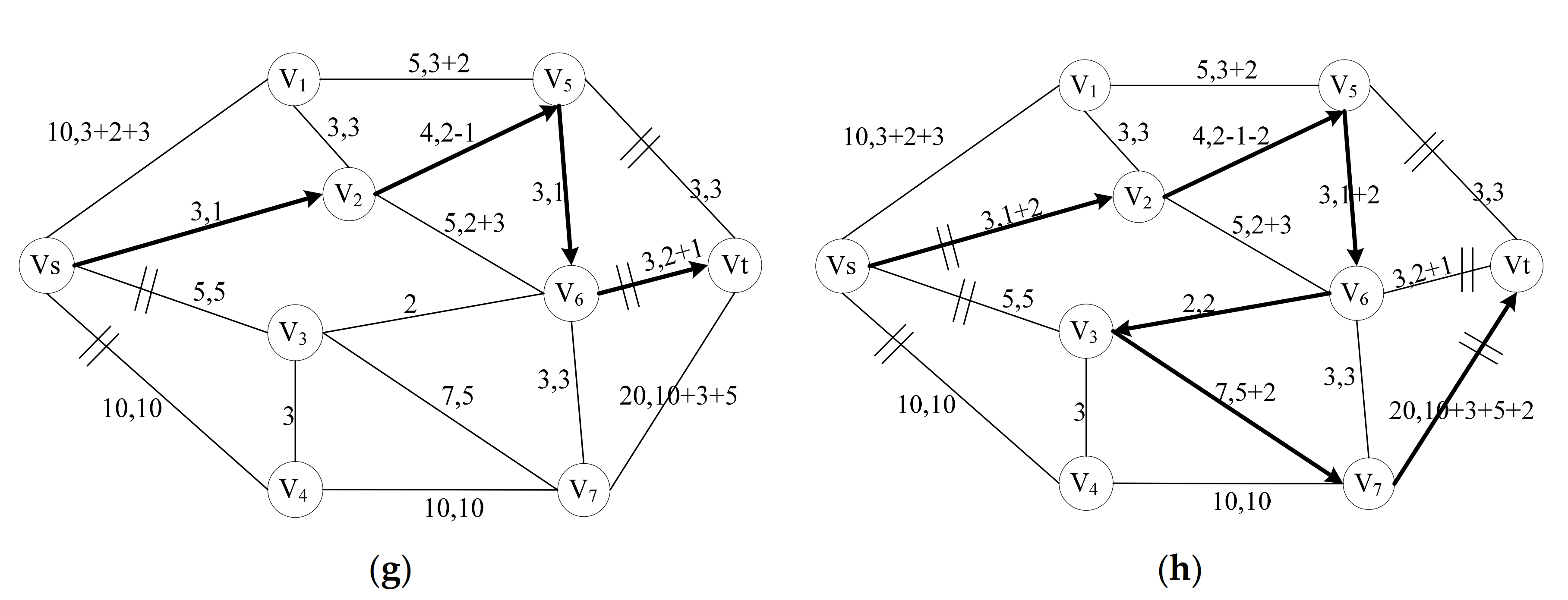
2.3.1. The Maximum Flow Algorithm Base on Depth-First Search Method
2.3.2. The Process of Computing Network-Codes Nodes
3. Results
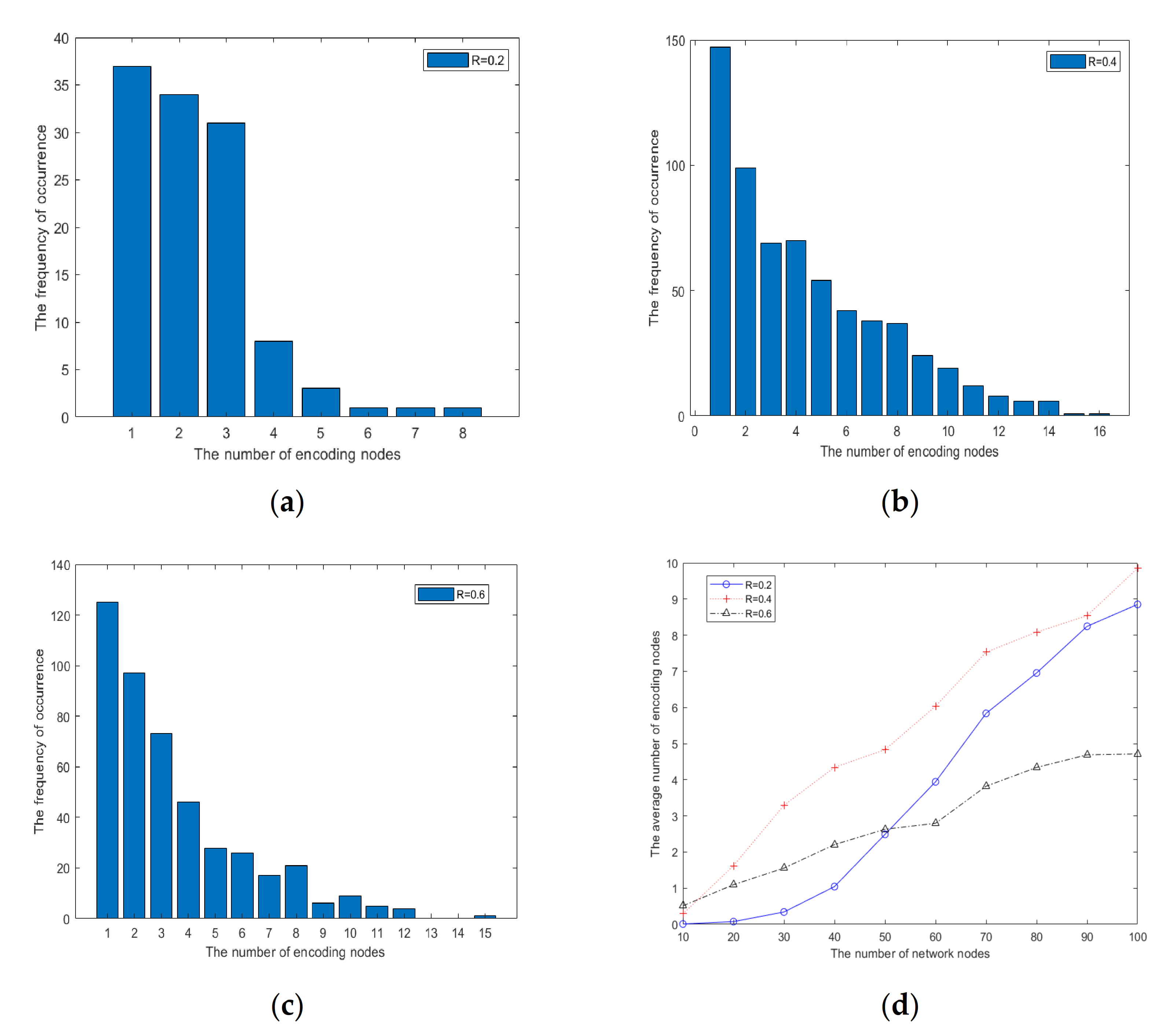
3.1. The Simulation Result of Different Destinations
3.2. The Simulation Result of Different Radiuses
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Ahlswede, R.; Cai, N.; Li, S.-Y.R.; Yeung, R.W. Network information flow. IEEE Trans. Inf. Theory 2000, 46, 1204–1216. [Google Scholar] [CrossRef]
- Bhadra, S.; Shakkottai, S.; Gupta, P. Min-Cost Selfish Multicast with Network Coding. IEEE Trans. Inf. Theory 2006, 52, 5077–5087. [Google Scholar] [CrossRef]
- Zhang, J.; Fan, P. On network coding in wireless ad-hoc networks. Int. J. Ad Hoc Ubiquitous Comput. 2007, 2, 140. [Google Scholar] [CrossRef]
- Huang, J.; Xing, C.; Chang, Z. Multi-hop D2D Communications with Network Coding: From a Performance Perspective. IEEE Trans. Veh. Technol. 2019, 68, 2270–2282. [Google Scholar] [CrossRef]
- Liu, Q.; Feng, G.; Guo, Y. A Framework of Joint Scheduling and Network Coding for Real-Time Traffic with Diverse Delay Constraints. Wirel. Pers. Commun. 2017, 97, 4855–4876. [Google Scholar] [CrossRef]
- Fan, Y.; Jiang, Y.; Zhu, H.; Chen, J.; Shen, X.S. Network Coding Based Privacy Preservation against Traffic Analysis in Multi-Hop Wireless Networks. IEEE Trans. Wirel. Commun. 2011, 10, 834–843. [Google Scholar] [CrossRef]
- Jaggi, S.; Sanders, P.; Chou, P.A.; Effros, M.; Tolhuizen, L.M. Polynomial time algorithms for multicast network code construction. IEEE Trans. Inf. Theory, 2005, 51, 1973–1982. [Google Scholar] [CrossRef]
- Fragouli, C.; Soljanin, E. Information flow decomposition for network coding. IEEE Trans. Inf. Theory 2006, 52, 829–848. [Google Scholar] [CrossRef]
- Langberg, M.; Sprintson, A.; Bruck, J. The encoding complexity of network coding. IEEE Int. Trans. Inf. Theory 2006, 52, 2386–2397. [Google Scholar] [CrossRef]
- Wu, Y.; Chou, P.; Kung, S.-Y. Minimum-Energy Multicast in Mobile Ad Hoc Networks Using Network Coding. IEEE Trans. Commun. 2005, 53, 1906–1918. [Google Scholar] [CrossRef]
- Li, Y.; Wang, J.; Zhang, S.; Bao, Z.; Wang, J. Efficient Coastal Communications with Sparse Network Coding. IEEE Netw. 2018, 32, 122–128. [Google Scholar] [CrossRef]
- Bhattad, K.; Ratnakar, N.; Koetter, R.; Narayanan, K. Minimal network coding for multicast. In Proceedings of the International Symposium on Information Theory 2005, ISIT 2005, Adelaide, SA, Australia, 4–9 September 2005; pp. 1730–1734. [Google Scholar]
- Kim, M.; Medard, M. Algebraic Network Coding Approach to Deterministic Wireless Relay Networks. In Proceedings of the 2010 48th Annual Allerton Conference on Communication, Control, and Computing (Allerton), Institute of Electrical and Electronics Engineers, Monticello, IL, USA, 29 September–1 October 2010; pp. 1518–1525. [Google Scholar]
- Malathy, S.; Porkodi, V.; Sampathkumar, A.; Hindia, M.H.D.N.; Dimyati, K.; Tilwari, V.; Qamar, F.; Amiri, I.S. An optimal network coding based backpressure routing approach for massive IoT network. Wirel. Netw. 2020, 26, 3657–3674. [Google Scholar] [CrossRef]
- Kwon, M.; Hyunggon, P. Network coding based evolutionary network formation for dynamic wireless net-works. IEEE Trans. Mob. Comput. 2018, 18, 1316–1329. [Google Scholar] [CrossRef]
- Singh, A.; Nagaraju, A. Heuristic-based opportunistic network coding at potential relays in multi-hop wireless networks. Int. J. Comput. Appl. 2020, 1–12. [Google Scholar] [CrossRef]
- Zhao, J.; Yang, F.; Zhang, Q.; Zhang, Z.; Zhang, F. LION: Layered Overlay Multicast with Network Coding. IEEE Trans. Multimed. 2006, 8, 1021–1032. [Google Scholar] [CrossRef]
- Chen, P.; Xie, Z.; Fang, Y.; Chen, Z.; Mumtaz, S.; Rodrigues, J.J.P.C. Physical-Layer Network Coding: An Efficient Technique for Wireless Communications. IEEE Netw. 2020, 34, 270–276. [Google Scholar] [CrossRef]
- Nazer, B.; Gastpar, M. Reliable Physical Layer Network Coding. Proc. IEEE 2011, 99, 438–460. [Google Scholar] [CrossRef]
- Ho, T.; Medard, M.; Koetter, R.; Karger, D.; Effros, M.; Shi, J.; Leong, B. A Random Linear Network Coding Approach to Multicast. IEEE Trans. Inf. Theory 2006, 52, 4413–4430. [Google Scholar] [CrossRef]
- Koetter, R.; Médard, M. An algebraic approach to network coding. IEEE/ACM Trans. Netw. 2003, 11, 782–795. [Google Scholar] [CrossRef]
- Ho, T.; Koetter, R.; Edard, M.M.; Karger, D.R.; Effros, M. The benefits of coding over routing in a randomized setting. In Proceedings of the IEEE International Symposium on Information Theory 2003, Yokohama, Japan, 29 June–4 July 2003; p. 442. [Google Scholar]
- Zhang, J.; Fan, P.; Letaief, B.K. Network Coding for Efficient Multicast Routing in Wireless Ad-hoc Networks. IEEE Trans. Commun. 2008, 56, 598–607. [Google Scholar] [CrossRef]
- Chen, S.; Zhao, C.; Wu, M.; Sun, Z.; Zhang, H.; Leung, V.C. Compressive network coding for wireless sensor networks: Spatio-temporal coding and optimization design. Comput. Netw. 2016, 108, 345–356. [Google Scholar] [CrossRef]
- Effros, M.; El Rouayheb, S.; Langberg, M. An equivalence between network coding and index coding. IEEE Int. Symp. Inf. Theory 2015, 61, 967–971. [Google Scholar] [CrossRef]
- Naeem, A.; Rehmani, M.H.; Saleem, Y.; Rashid, I.; Crespi, N. Network Coding in Cognitive Radio Networks: A Comprehensive Survey. IEEE Commun. Surv. Tutor. 2017, 19, 1945–1973. [Google Scholar] [CrossRef]
- Cai, N.; Chan, T. Theory of Secure Network Coding. Proc. IEEE 2011, 99, 421–437. [Google Scholar]
- Jiang, D.; Xu, Z.; Li, W.; Chen, Z. Network coding-based energy-efficient multicast routing algorithm for multi-hop wireless networks. J. Syst. Softw. 2015, 104, 152–165. [Google Scholar] [CrossRef]
- Xu, G.; Chen, X.-B.; Li, J.; Wang, C.; Yang, Y.-X.; Li, Z. Network coding for quantum cooperative multicast. Quantum Inf. Process. 2015, 14, 4297–4322. [Google Scholar] [CrossRef]










Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, D.; Li, L. Node Selection Algorithm for Network Coding in the Mobile Wireless Network. Symmetry 2021, 13, 842. https://doi.org/10.3390/sym13050842
Jiang D, Li L. Node Selection Algorithm for Network Coding in the Mobile Wireless Network. Symmetry. 2021; 13(5):842. https://doi.org/10.3390/sym13050842
Chicago/Turabian StyleJiang, Dexia, and Leilei Li. 2021. "Node Selection Algorithm for Network Coding in the Mobile Wireless Network" Symmetry 13, no. 5: 842. https://doi.org/10.3390/sym13050842
APA StyleJiang, D., & Li, L. (2021). Node Selection Algorithm for Network Coding in the Mobile Wireless Network. Symmetry, 13(5), 842. https://doi.org/10.3390/sym13050842