Abstract
This study concentrates on the investigation, development, and evaluation of Text-to-Speech Synthesis systems based on Deep Learning models for the Azerbaijani Language. We have selected and compared state-of-the-art models-Tacotron and Deep Convolutional Text-to-Speech (DC TTS) systems to achieve the most optimal model. Both systems were trained on the 24 h speech dataset of the Azerbaijani language collected and processed from the news website. To analyze the quality and intelligibility of the speech signals produced by two systems, 34 listeners participated in an online survey containing subjective evaluation tests. The results of the study indicated that according to the Mean Opinion Score, Tacotron demonstrated better results for the In-Vocabulary words; however, DC TTS indicated a higher performance of the Out-Of-Vocabulary words synthesis.
1. Introduction
Speech is one of the simplest sources of communication, yet it is a challenging phenomenon. Spoken communication includes two distinct aspects, which are the verbal component and the prosodic component. The former component combines two systems in which the first forms words from phonemes and the second constructs sentences from words. The prosodic component of the speech aims to transmit the intonational facet of language rather than symbolic. In other words, it helps to express emotions, to stress a particular word or the end of a sentence [1]. Both components share the same speech signal; however, they play peculiar roles in formulating natural language.
With the advances in technology and the increase in the number of portable devices, modern means of communication are becoming more attractive. The main goal of a speech synthesizer or text-to-speech (TTS) is the artificial reproduction of the human voice from the given text. The system primarily focuses on achieving a clear understandable synthesis of the speech, which does not sound robotic. TTS has a wide range of applications such as call-center automation, weather announcements or schedule reports, reading text out loud for visually impaired people, and for those who lost their voice.
In this paper, we describe previous approaches of TTS development, then, we introduce the architecture of two models for a better understanding of the synthesis process. Next, we provide information about the database collected from scratch specifically for the Azerbaijani language, which is used in the training process for both TTS models. Lastly, the experiments are carried out and both speech synthesizers are evaluated to ensure the accuracy of the models.
2. Related Work
Different approaches of speech synthesis have been investigated and analyzed throughout the years. Previous research in this area has made significant progress, thus, accelerating the training process of the model and improving the quality of speech synthesis, allowing creating speech similar to humans. One of the well-known architectures represents formant synthesis, which involves the generation of artificial spectrograms to simulate formant characteristics produced by the vocal tract. This technique does not utilize instances of human speech, however, focuses on the extraction of formant parameters and transition between phonemes based on the rules derived by linguists from spectrograms. The formant synthesized speech is intelligible and is suitable for systems with limited memory since it does not store samples of human speech, however, it has not reached a high level of naturalness [2]. Articulatory synthesis produces speech by creating synthetic human articulatory systems and includes parameters such as positions of jaws, lips, and tongue [3]. The data for this model is gathered from MRI or X-ray images. Thus, one of the challenges to build an articulatory model is data acquisition considering expenses and availability of appropriate equipment [4]. Concatenative synthesis mainly represents two types of approaches, which are diphone synthesis and unit selection synthesis. Diphone synthesis is achieved by recording natural speech that involves each possible phoneme of context, which are then segmented and labeled. After, these diphones should be modified by signal processing methods to adjust prosody of the speech [2]. Synthesis based on the unit selection, however, does not require any signal processing since it stores multiple samples of units with varying prosodies in the database [5]. One problem with the rule-based systems is the storage of various occurrences of each acoustic unit, which leads to the consumption of large memory resources. In contrast, Hidden Markov Model (HMM) retrieves averages of similar sounding speech segments rather than storing each instance of speech from the database and represents relatively smooth transitions [6]. Recently, Deep Neural Network (DNN) algorithms have been applied to achieve natural and high-quality speech synthesis. Experiments indicated that DNN speech synthesis can outperform HMM-based approach given the same number of speech parameters [7].
In [8], authors from Baidu keep traditional text-to-speech pipelines and adopt the same structure, while replacing all components with neural networks and using simpler features. They propose a novel way of performing phoneme boundary detection DNN using connectionist temporal classification (CTC) loss. For the audio synthesis model, they implement WaveNet that completes training faster than the original.
Deep reinforcement learning (DRL) algorithms are also being employed in audio signal processing to learn directly from speech, music, and other sound signals in order to create audio-based autonomous systems that have many promising applications in the real world. Despite DRL applied widely in the natural language processing (NLP) tasks, there is no broad investigation of DRL for speech synthesis [9].
The encoder-decoder architecture with self-attention or bi-directional long short-term (BLSTM) units can produce high-quality speech. However, these models’ synthesis speed is slower for longer inputs. Authors of [10] propose a multi-rate attention architecture that breaks the latency and RTF bottlenecks by computing a compact representation during encoding and recurrently generating the attention vector in a streaming manner during decoding.
The project GraphSpeech proposes a novel neural TTS model that is formulated under graph neural network framework [11]. GraphSpeech encodes explicitly the syntactic relation of input lexical tokens in a sentence, and incorporates such information to derive syntactically motivated character embeddings for the TTS attention mechanism. Experiments show that GraphSpeech consistently outperforms the Transformer TTS baseline in terms of spectrum and prosody rendering of utterances.
Similarly, studies have proposed different approaches for Azerbaijani Text-to-Speech synthesis. One of the studies [12] describes the process of conversion text to speech by suggesting the search of individual words in the dictionary. If the word is not in the proposed dictionary, then it searches according to the “Root and Affix” splitting method. In case of the absence of “root forms” or affixes, conversion of letters to sounds is performed to match the best pronunciation. Another study [13] proposes the combination of concatenative and formant synthesis to achieve naturality and intelligibility of the produced speech. However, researchers have not studied the application of DNN models for Azerbaijani TTS systems. Most of the existing research on speech technologies for the Azerbaijani language is related to speech recognition [14]. In this paper, we propose the development and evaluation of Azerbaijani DNN TTS systems.
3. Lexicon of the Azerbaijani Language
The Azerbaijani language contains quite a few aspects that affect the different pronunciations of words. In addition to the most important aspects—accent and dialect—there are also basic rules of pronunciation of vowels and consonants in this language. Contrary to English that contains 44 phonemes, the Azerbaijani language comprehends 34 phonemes, 9 vowels, and 25 consonants. However, if we differentiate nine short (i,ü,e,ö,ə,a,o,u,ı) and six long (i:,e:,ö:,ə:,a:,u:) vowels, then the total number of phonemes will be 40.
Pronunciation rules for vowels:
- Two identical vowels, one following the other in a word, are pronounced as one long vowel (e.g., “saat” [sa:t] (“clock”)).
- The sound [y] is included between two different consecutive vowels (e.g., “radio” [radiyo] (“radio”)).
- Once the so-called vowels “əa”, “üə”, “üa” converge, the first one falls and the second one stretches (e.g., “müavin” [ma:vin] (”deputy”)).
- In the case that o or ö are followed by the sound [v], the v drops and the vowels are stretched (e.g., “dovşan” [do:şan] (“rabbit”)).
- When certain suffixes with conjunctive y at the beginning are added to polysyllabic words ending in “a” or “ə”, these vowels become one of the closed vowel sounds ([ı], [i], [u], [ü]) during pronunciation (e.g “babaya” [babıya] (“to grandfather”)).
Pronunciation rules for consonants:
- If the consonants “qq”, “pp”, “tt”, “kk” merge in the middle of a word, one of them changes during pronunciation (e.g., “tappıltı” [tapbıltı] (“thud”)).
- If the sounds b, d, g, c, q, k, z come at the end of a word, they change during pronunciation to p, t, k, ç, x, x’, s, respectively (e.g., “almaz” [almas] (“diamond”)).
- If a consonant comes after the k sound in the middle of a word, its pronunciation is k = x ‘ (e.g., məktəbli [məx’təbli] (“student”)).
4. Methodology
Different methods have been used for the systems designed for speech synthesis. Each system has both advantages and drawbacks. For this reason, two of the most popular systems have been chosen to preserve most of the models’ privileges: Tacotron and Deep Convolutional Text-to-Speech (DC TTS).
Both Tacotron and DC TTS models have a different structure and design. Therefore, the initial study of these systems allows a better understanding of their performance and their impact on the result.
4.1. Tacotron
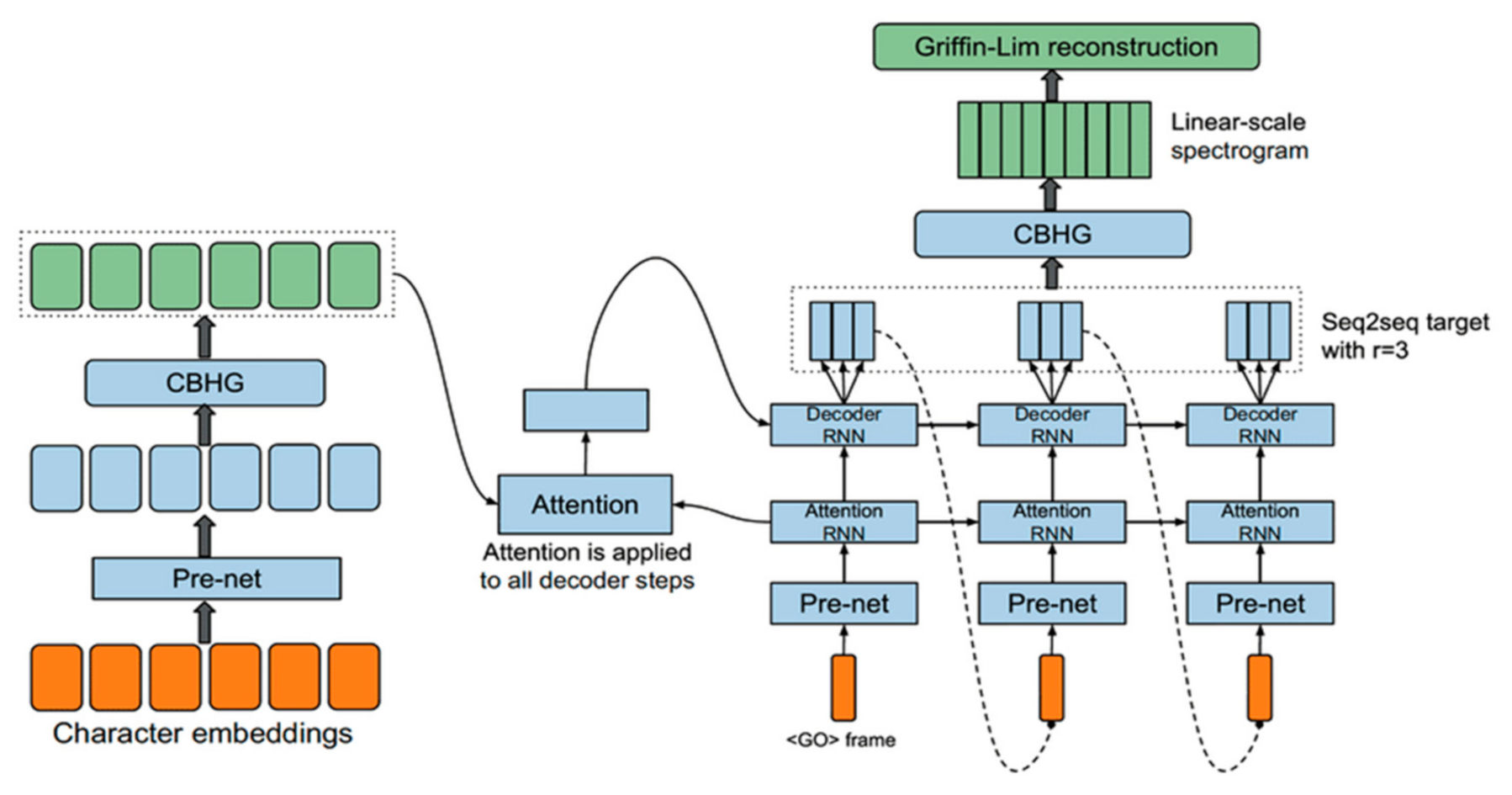
Tacotron is a system that uses the seq2seq [15] model to produce spectrogram frames, which are needed to create waveforms, from the input characters. According to [16], the architecture of the model consists of an encoder, an attention-based decoder, and a post-processing net (Figure 1).
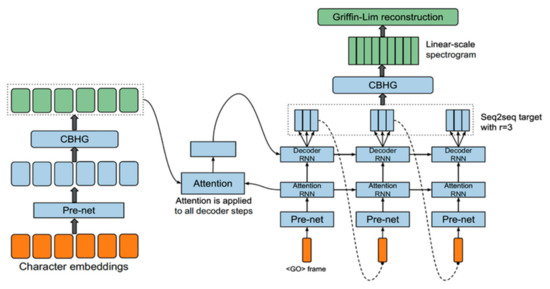
Figure 1.
Tacotron architecture [16].
In addition to the basic modules, this model also uses a building block CBHG for extracting representations from sequences. This module consists of three parts:
- 1-D convolutional filters bank, where the convolved inputs are used to generate local and contextual information. Afterward, the outputs are added together and combined over time to build increased local invariances. This sequence is then passed to the several fixed-width 1-D convolutions and added with the input sequence.
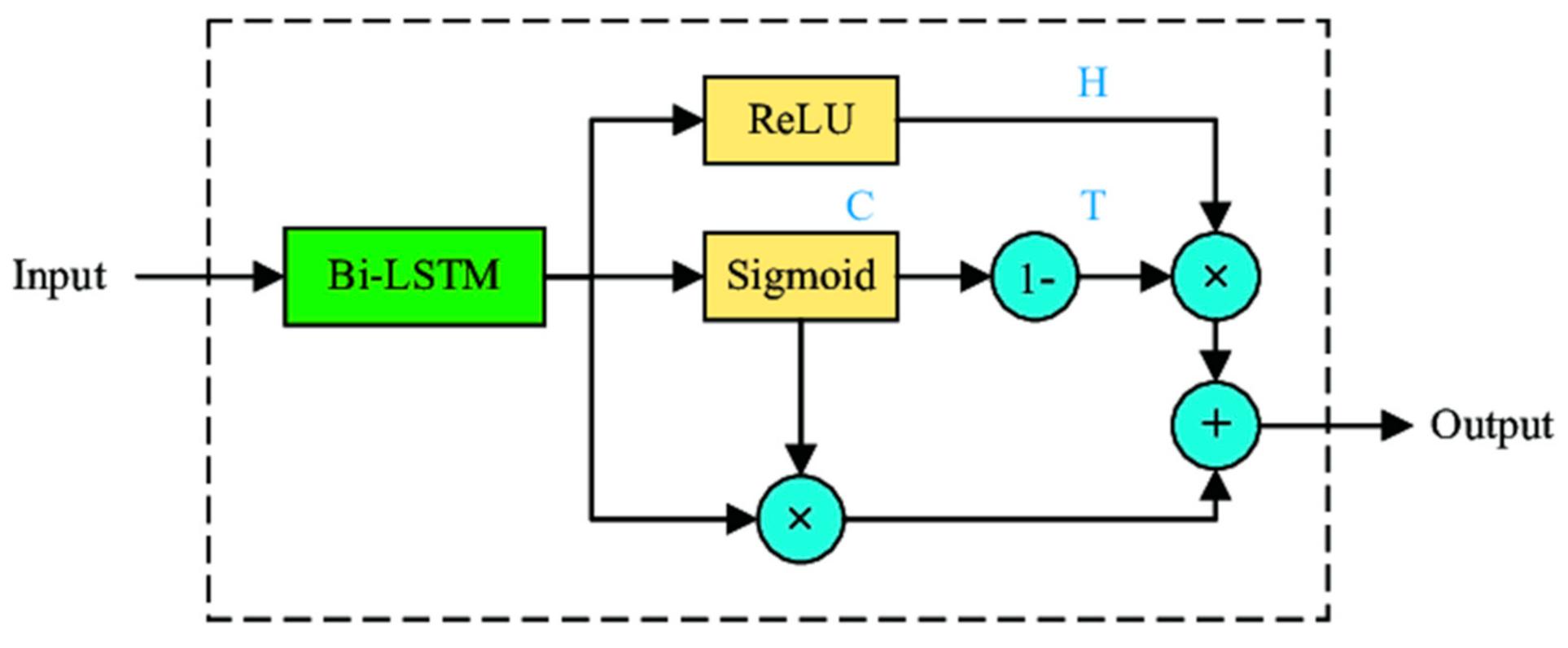
- Highway networks (Figure 2) [17] which are used to extract high-level features.
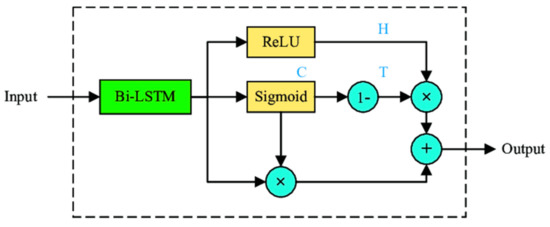 Figure 2. Highway network architecture [18].
Figure 2. Highway network architecture [18]. - Bidirectional gated recurrent unit (GRU) [19] recurrent neural network (RNN) [20] used to derive sequential features from the forward context and backward context.
- Encoder module is necessary for extracting solid, consistent text representations. The procedure starts with the embedding of the one-hot representation of each character into a continuous vector. Subsequently, the vector passes through the non-linear transformations of the bottleneck layer, also known as pre-net, which helps to improve generalization, and the transformations of the CBHG module to reduce overfitting and mispronunciations. This gives the final representation of the outputs of the encoder used as the attention module.
- Decoder is a content-based tanh attention decoder, where the input is a concatenated context vector with the attention RNN output. During each time step, it creates the attention query. In addition, the decoder is implemented with a GRU stack containing vertical residual connections as it helps to speed up convergence. Moreover, due to the highly redundant representation of the raw spectrogram, and as the seq2seq target can be highly compressed while it provides prosody information for an inversion process, the 80-band mel-scale spectrogram is used as the target of the seq2seq, that will be further converted to waveform in post-processing network.
- The decoder output layer represents a fully connected output layer. It serves to anticipate the decoder targets. As the prediction process uses prediction of r frames at once, it reduces training time together with inference time as well as increases the convergence rate.
- Post-processing net is necessary to convert the seq2seq target to target, which will be further converted into a waveform. This network learns to predict the spectral value displayed on a linear frequency scale. Information contained in the post-processing net that includes both forward and backward information is used to correct the prediction error. As a post-processing net, Tacotron uses the CBHG module.
This system uses as a synthesis from the predicted spectrogram the Griffin-Lim algorithm [21].
4.2. Deep Convolutional Text-to-Speech
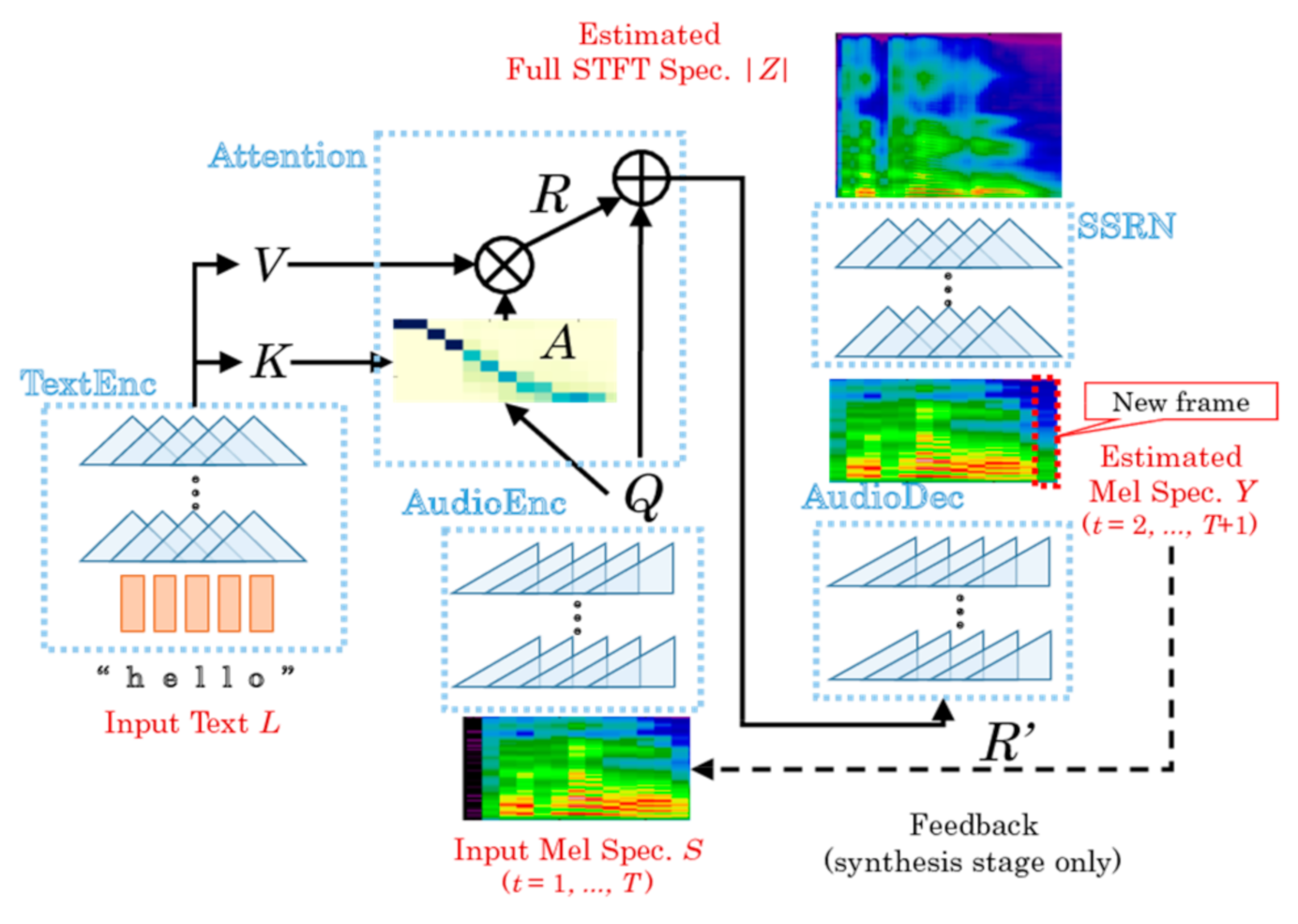
DC TTS is another speech synthesis technology based on convolutional seq2seq [22]. As described in [23], this model consists of two networks (Figure 3):
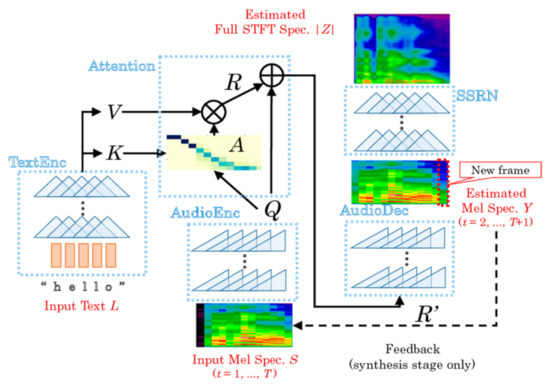
Figure 3.
DC TTS model [23].
- Text to mel spectrogram network, which forms a mel spectrogram from an input text and is composed of four submodules:
- The text encoder encodes an input sentence L of N characters into the matrices of keys and values K, V of dimension 256 × N.(K, V) = TextEnc(L)
- The audio encoder encodes the coarse mel spectrogram S1:F,1:T, considering that S is a normalized mel spectrogram with applied mel filter bank, where F is the number of frequency bins and T is the length of the previously spoken speech, into a matrix Q with dimension 256 × T.Q = AudioEnc (S1: F,1: T)
- Attention matrix A evaluates how closely the n-th character in the sentence is related with t-th time frame of the mel spectrogram.where softmax function determines whether it is the searched character or not. In case if Ant 1 with n-th character, it starts to look at ln + 1 or characters near it or near ln at the subsequent time t + 1. Assuming that these characters are encoded column V, then a seed R ∈ R256xT that is decoded to subsequent frames S1: F,2: T + 1R = Attention (Q, K, V): = V A
- Audio Decoder decodes the concatenated matrix R’ = [R, Q] to synthesize a coarse mel spectrogram.Y1: F,2: T + 1 = AudioDec (R’)Afterward, this result is compared with temporally shifted ground truth S1: F, 2: T + 1 by a loss function, which is the sum of L1 loss [24] function and binary convergence, that is calculated by:where Ýft = logit (Ýft). The error is back propagated to the network parameters.Dbin(Y|S) := Eft[−SftÝft + log(1 + expÝf)] + const
- Spectrogram Super-resolution network. The network synthesizes a full spectrogram from the obtained coarse mel spectrogram.
5. Data Collection and Processing
Each system based on neural networks depends on the data used during the training process. Despite the fact that large public domain speech datasets are available online, there is no Azerbaijani data for this specific purpose. Thus, the data collection process represents one of the significant stages of this project.
The data collected for the model training were obtained from the publicly available news portal consisting of around 24 h in total spoken by a single male speaker. Each acoustic data has its transcription which allows the training of models based on 16,780 <audio, text> pairs in total without phoneme-level alignment. The process of speech and text mapping was performed by applying the forced alignment technique, which, in turn, uses the Viterbi algorithm together with the linguistic model and an acoustic model [25]. Considering that longer duration of audio recordings in the data for training can lead to incorrectly trained models and also significantly slow down the training process, each audio clip varies in length from 1 to 15 s.
6. Evaluation Methods
Currently, the evaluation of text-to-speech systems occurs in different ways. However, not all methods are effective, some in turn are only suitable for certain cases such as one-word synthesis evaluation. The choice of a suitable method is, therefore, challenging.
In general, the process of model evaluation can be performed on two types of tests:
- Subjective tests. These are the listening tests where each listener judges speech quality and naturalness.
- Objective tests. Tests where measurement of voice performance estimated by applying appropriate speech signal processing algorithms.
According to [5], the evaluation of the TTS system is based on two main metrics:
- Intelligibility-index of the correctness in the interpretation of the words. This metric can be evaluated using the following tests:
- Diagnostic Rhyme Test (DRT)-subjective test, based on pairs of words with confusable rhyming and differs only in a single phonetic feature. In this test, listeners have to identify the index of the given word [26]. The percentage of the right answers is used as an intelligibility metric.
- Modified Rhyme Test (MRT)-subjective test, similar to the previous test, except the fact that it is based on different sets of six words [27].
- Semantically Unpredictable Sentence (SUS)-subjective test, based on sentences of randomly selected words [28]. Using this method, the intelligibility can be evaluated using the formula below:where C is the number of the correct predicted sentences, S is the total number of the tested sentences and L is the number of listeners.
- Quality-index of the naturalness, fluency, clarity. This metric can be evaluated using the following methods:
- AB test-subjective test, where listeners measure the quality of different audio files with synthesized speech produced by system A and B by comparing the results of these systems with each other (Table 1) [29]. The final result shows which of the systems is better.
 Table 1. AB test rating scale.
Table 1. AB test rating scale. - ABX test-subjective test, where listeners make comparison between the synthesized sentence by system A and synthesized sentence by system B in terms of the closeness to the originally voiced sentence X [29].
- Mean Opinion Score (MOS)-subjective test, where listeners evaluate each sentence synthesized by the system on a 1–5 scale from bad to excellent (Table 2) [29].
Table 2. MOS rating scale.
Afterward, the sum of these scores is collected and divided by the total number of the evaluated sentences and the number of listeners.
- Mel Cepstral Distortion (MCD)-objective test, that measures the difference between synthesized and natural mel cepstral sequences consisting of extracted mel-frequency cepstral coefficients [30]. This difference shows how the reproduced speech is closer to the natural one. MCD can be calculated by the formula:where , are mel frequency cepstral coefficients of the t-th frame from the reference and predicted audio, d is dimension index from 0 to 24, t is time (frame index) and T’ is the number of non-silence frames.
- Segmental Signal-to-noise ratio (SNRseg) objective test, which measures noise ratio between two signals [29]. This ratio can be calculated using the formula below:where is the original signal, is the synthesized signal, N is the frame length, M is the number of frames in the speech signal.
- Perceptual evaluation of speech quality (PESQ)-objective test, which allows to predict the results of MOS evaluation [29]. This helps to automate the MOS evaluation and make this process faster. PESQ is calculated by the following formula:where a0 = 4.5, + a1 = −0.1, a2 = −0.0309, dsym is the average disturbance and dasym is the average asymmetrical disturbance value.PESQ = a0 + a1·dsym + a2·dasym
However, the evaluation tests mentioned above cannot guarantee an accurate result. All subjective tests require a large number of listeners for more accurate evaluation. Nevertheless, the cognitive factor, such as attention, dependency on the mood of the subject, an environment of listening tests, etc., often plays a role and affects the results. On the other hand, objective tests cannot give a full assessment of the model either, since the acoustic properties of natural and synthesized speech are different as well as prosody. These differences can contribute to the naturalness and an intelligibility loss for synthesized speech.
Despite all the inaccuracies, many systems use the most popular metric MOS for evaluating synthesized speech, taking into account only the quality of the speech, since the intelligibility metrics are not important in commerce.
7. Experiments
To evaluate two main attributes, which are the quality and the intelligibility of the speech signal, subjective assessments were carried out. Online survey was conducted among 34 participants, distinguishing 32 native and two nonnative speakers. It was recommended to participants to be in a quiet room and use headphones while evaluating sounds.
Test data was classified based on the presence of Out of Vocabulary (OOV) words and source type with a total of 53 sentences (Table 3). Specifically, 5 sentences without any OOV words were selected to evaluate the AB test, 14 sentences for each system were chosen for MOS assessment, where 3 of them include 1 OOV word, 6–2 OOV words, 4–3 OOV words, and 1 sentence contained 4 OOV words. Moreover, 10 sentences for each system were organized to assess the SUS test accordingly: 3 sentences with no OOV words, 4 sentences with 1 OOV word, and 3 sentences included 2 OOV words. In addition, it is noteworthy to mention that 25 sentences were taken from news resources, 8 sentences were selected from various storybooks and the rest of the 20 sentences were formed with random words specifically for the SUS test.
Table 3.
Classification of test sentences depending on the number of OOV words.
To assess the naturalness and clarity of synthesized speech produced by two systems, we used the AB metric that examines participants’ relative preference for either system A (Tacotron) or system B (DC TTS). In this test, listeners are asked to rate synthesized audios on a 3-point scale, where 0 indicated no significant difference between system A and system B, whereas the selection of 3 following by the system type (A or B) demonstrated a strong preference, and the selection of 1 illustrated a slight preference of participants for that particular system over another (Table 1). After, all scores are summed and divided to the total number of AB test sentences and to the number of participants.
In contrast to the AB test, which was used to compare generated audios of both systems at the same time, in the MOS test we presented synthesized audios of each system separately to let listeners assess speech quality and level of distortions (Table 2). Despite the fact that different sets of sentences were picked for each system, the number of OOV words in sentences was distributed equally to avoid possible future bias. Finally, the quality of the test signal produced by the system was obtained by averaging the ratings obtained from all listeners then, summing these averages and dividing the obtained sum by the number of total test sentences.
As the name suggests, for the SUS test we have selected random words that form grammatically correct sentences, however, they are unpredictable and do not have any semantic meaning. The SUS test measures the intelligibility of test sentences since it challenges listeners to type what they hear instead of predicting words based on the meaning of a whole sentence. At the beginning of the survey, participants were asked to listen to each synthesized recording up to two times and to write down the words that they heard in a sequence. Lastly, the SUS score was calculated for each system A and B by (Formula (7)).
8. Discussion and Results
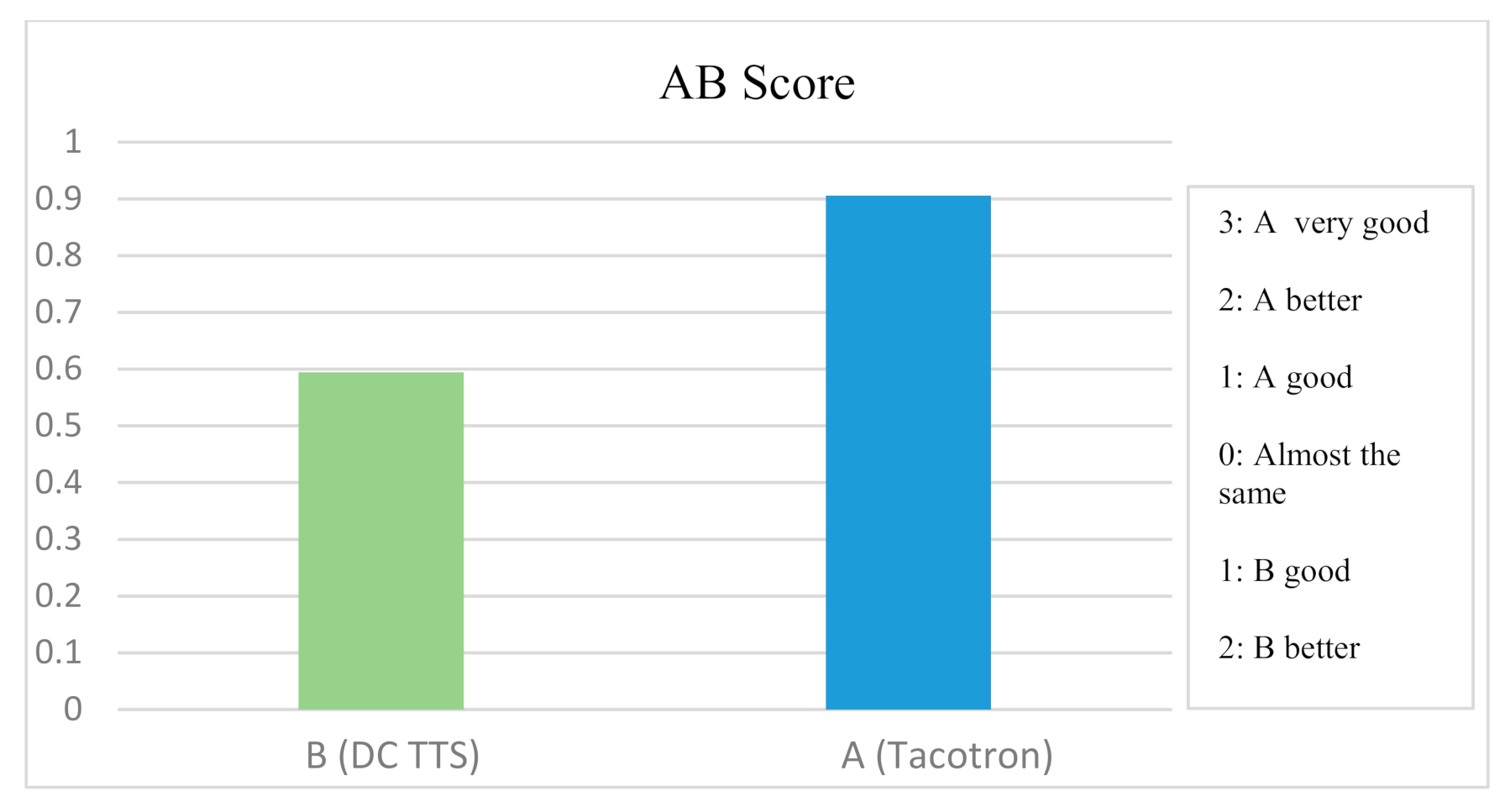
Findings suggest inconsiderable dominance of Tacotron in the comparison of average results of evaluation metrics and relatively higher individual evaluation scores of DC TTS for sentences that contain more OOV words. Firstly, while assessing the quality of the two systems by the AB score, we have observed the value of 0.90 for Tacotron and 0.59 for DC TTS. Figure 4 illustrates that Tacotron outperforms DC TTS in the AB test and the AB score is close to 1, which indicates that the quality of audios produced by Tacotron is “good” according to the 0–3 scale. Moreover, the score obtained by DC TTS indicates that the quality of synthesized sounds is between “almost the same with another system” and “good”.
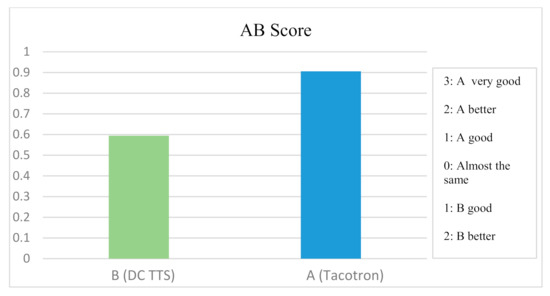
Figure 4.
AB Score for A (Tacotron) and B (DC TTS).
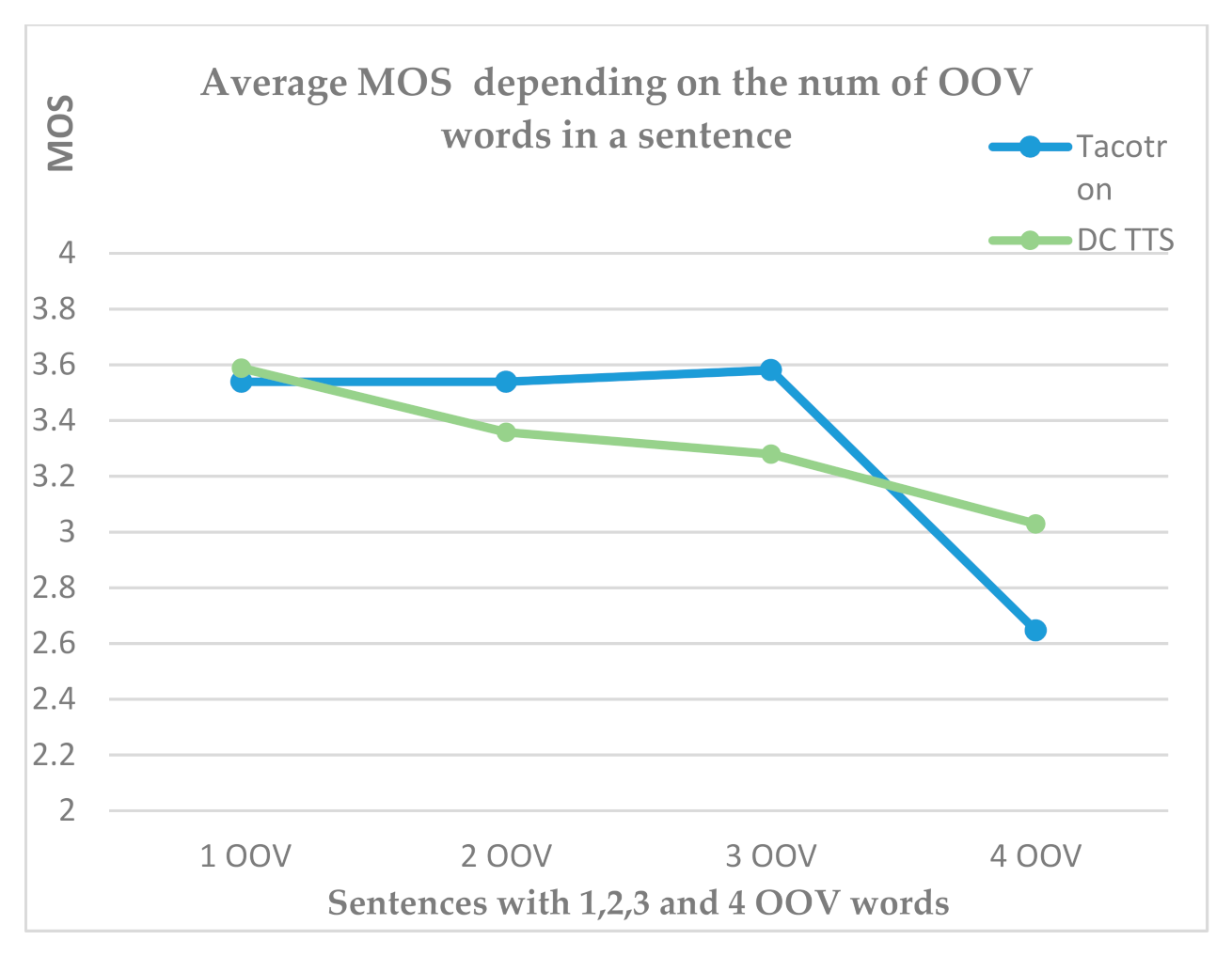
Table 4 demonstrates the comparison of MOS (95% Confidence Interval) for all sentences for both systems. The table shows that Tacotron achieves a MOS of 3.49 ± 0.193 and slightly outperforms DC TTS, which gets a MOS of 3.36 ± 0.187. In other words, both systems synthesize audios with “fair” sound quality and the level of distortion is perceptible, however, not considerably annoying. Furthermore, besides considering only the average MOS of all sentences without considering the number of OOV, we analyzed the average MOS of the sentences grouped by OOV words (Figure 5). Moreover, individual mean opinion scores were examined depending on the number of OOV words presented in separate test sentences. Surprisingly, although Tacotron demonstrated higher average MOS for the sentences containing few OOV words, it achieved lower values (<3.0) on the last two sentences containing three and four OOV words. On the other hand, DC TTS got higher scores (≤3.0) during the synthesis of sentences including three or four OOV words. These results may imply the future usage of a hybrid model for the Azerbaijani TTS system that combines Tacotron for the synthesis of sentences with words in the train data and DC TTS for sentences containing more OOV words.
Table 4.
Comparison of Mean Opinion Score (MOS) for Tacotron and DC TTS.
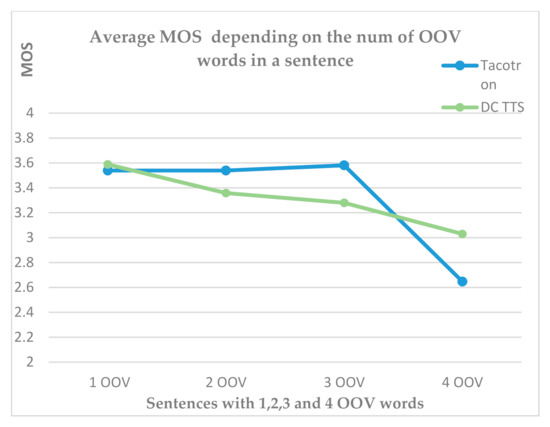
Figure 5.
Average MOS for Tacotron and DC TTS and sentences with OOV words.
Lastly, the percent of the SUS test for the systems is demonstrated in Table 5. The study shows that more sentences without semantic meaning were predicted correctly for audios produced by Tacotron and resulting in 49% of correct test sentences compared to DC TTS having 45%.
Table 5.
Comparison of SUS Score.
An apparent limitation of the study is the insufficient sample size of the included test sentences in surveys since 53 sentences took more than 40 min for listeners to evaluate synthesized audios. A possible solution could be dividing the survey questions according to the type of evaluation metrics.
9. Conclusions
The current research examines the architecture and evaluation of two speech synthesis systems based on DNN for the Azerbaijani language. DC TTS and Tacotron models were trained on the 24-h mono speaker data. Test sentences were classified and divided based on the number of OOV words to compare the results of the proposed models. We described and applied subjective evaluation metrics to measure the intelligence and the quality of the synthesized speech produced by systems. The AB, MOS, and SUS metrics indicated higher results for all test sentences synthesized by Tacotron. The study demonstrated that sentences prevailing words from train vocabulary achieved higher MOS metrics for Tacotron and sentences containing a higher number of OOV words obtained better MOS results for DC TTS. Thus, future research should consider the application of a hybrid model that optimizes benefits of both systems to achieve more natural and intelligible speech.
Author Contributions
Conceptualization, S.R.; methodology S.J., E.S., A.V. and S.R.; software S.J. and E.S.; validation A.V.; writing—original draft preparation E.S. and S.J.; writing—review and editing S.J., S.R. and A.V.; visualization S.J.; investigation A.V.; project administration S.R.; resources A.V. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by ATL Tech LLC.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Research data will remain confidential due to commercial reasons.
Acknowledgments
This work was carried out in the Center for Data Analytics Research at ADA University and in Artificial Intelligence Laboratory at ATL Tech.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Taylor, P. Communication and Language. In Text-to-Speech Synthesis; Cambridge University Press: Cambridge, UK, 2009; pp. 13–15. [Google Scholar]
- Tabet, Y.; Boughazi, M. Speech Synthesis Techniques. A Survey. In Proceedings of the International Workshop on Systems, Signal Processing and Their Applications (WOSSPA), Tipaza, Algeria, 9–11 May 2011. [Google Scholar]
- Kaur, G.; Singh, P. Formant Text to Speech Synthesis Using Artificial Neural Networks. In Proceedings of the 2019 Second International Conference on Advanced Computational and Communication Paradigms (ICACCP), Gangtok, India, 25–28 February 2019. [Google Scholar]
- Tsukanova, A.; Elie, B.; Laprie, Y. Articulatory Speech Synthesis from Static Context-Aware Articulatory Targets. In International Seminar on Speech Production; Springer: Berlin/Heidelberg, Germany, 2018; pp. 37–47. Available online: https://hal.archives-ouvertes.fr/hal-01937950/document (accessed on 30 September 2020).
- Jurafsky, D.; Martin, J.H. Speech and Language Processing, 2nd ed.; Prentice Hall: Hoboken, NJ, USA, 2008; pp. 249–284. [Google Scholar]
- Jeon, K.M.; Kim, H.K. HMM-Based Distributed Text-to-Speech Synthesis Incorporating Speaker-Adaptive Training. 2012. Available online: https://www.researchgate.net/publication/303917802_HMM-Based_Distributed_Text-to-Speech_Synthesis_Incorporating_Speaker-Adaptive_Training (accessed on 30 September 2020).
- Qian, Y.; Fan, Y.; Hu, W.; Soong, F.K. On the Training Aspects of Deep Neural Network (DNN) for Parametric TTS Synthesis. In Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; Available online: https://ieeexplore.ieee.org/document/6854318 (accessed on 30 September 2020).
- Arık, S.Ö.; Chrzanowski, M.; Coates, A.; Diamos, G.; Gibiansky, A.; Kang, Y.; Li, X.; Miller, J.; Raiman, J.; Sengupta, S.; et al. Deep Voice: Real-time Neural Text-to-Speech. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017. [Google Scholar]
- Latif, S.; Cuayahuitl, H.; Pervez, F.; Shamshad, F.; Ali, H.S.; Cambria, E. A survey on deep reinforcement learning for audio-based applications. arXiv 2021, arXiv:2101.00240. [Google Scholar]
- He, Q.; Xiu, Z.; Koehler, T.; Wu, J. Multi-rate attention architecture for fast streamable Text-to-speech spectrum modeling. arXiv 2021, arXiv:2104.00705. [Google Scholar]
- Liu, R.; Sisman, B.; Li, H. Graphspeech: Syntax-aware graph attention network for neural speech synthesis. arXiv 2020, arXiv:2104.00705. [Google Scholar]
- Rustamov, S.; Saadova, A. On an Approach to Computer Synthesis of Azerbaijan speech. In Proceedings of the Conference: Problems of Cybernetics and İnformatics, Baku, Azerbaijan, 12–14 September 2014. [Google Scholar]
- Aida–Zade, K.R.; Ardil, C.; Sharifova, A.M. The Main Principles of Text-to-Speech Synthesis System. Int. J. Signal Process. 2013, 6, 13–19. [Google Scholar]
- Valizada, A.; Akhundova, N.; Rustamov, S. Development of Speech Recognition Systems in Emergency Call Centers. Symmetry 2021, 13, 634. [Google Scholar] [CrossRef]
- Sutskever, I.; Vinyals, O.; Quoc, V.L. Sequence to Sequence Learning with Neural Networks. arXiv 2014, arXiv:1409.3215. [Google Scholar]
- Wang, Y.; Skerry-Ryan, R.; Stanton, D.; Wu, Y.; Weiss, J.R.; Jaitly, N.; Yang, Z.; Xiao, Y.; Chen, Z.; Bengio, S.; et al. Tacotron: Towards End-to-End Speech Synthesis. arXiv 2017, arXiv:1703.10135. [Google Scholar]
- Srivastava, R.K.; Greff, K.; Schmidhuber, J. Highway networks. arXiv 2015, arXiv:1505.00387. [Google Scholar]
- Jin, Y.; Xie, J.; Guo, W. LSTM-CRF Neural Network with Gated Self Attention for Chinese NER. IEEE Access 2019, 7, 136694–136703. [Google Scholar] [CrossRef]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Sherstinsky, A. Fundamentals of Recurrent Neural Network (RNN) and Long Short-Term Memory (LSTM) Network. arXiv 2018, arXiv:1409.3215. [Google Scholar]
- Griffin, D.; Lim, J. Signal estimation from modified short-time Fourier transform. IEEE Trans. Acoust. Speech Signal Process. 1984, 32, 236–243. [Google Scholar] [CrossRef]
- Gehring, J.; Auli, M.; Grangier, D.; Yarats, D.; Dauphin, Y.N. Convolutional sequence to sequence learning. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017. [Google Scholar]
- Tachibana, H.; Uenoyama, K.; Aihara, S. Efficiently Trainable Text-to-Speech System Based on Deep Convolutional Networks with Guided Attention. arXiv 2017, arXiv:1710.08969. [Google Scholar]
- Janocha, K.; Czarnecki, W.M. On Loss Functions for Deep Neural Networks in Classification. arXiv 2017, arXiv:1702.05659. [Google Scholar]
- ReadBeyond. Aeneas. 2020. Available online: https://github.com/readbeyond/aeneas (accessed on 13 May 2020).
- Voiers, W.; Sharpley, A.; Hehmsoth, C. Diagnostic Evaluation of Intelligibility in Present-Day Digital. In Research on Diagnostic Evaluation of Speech Intelligibility; National Technical Information Service: Springfield, VA, USA, 1975; pp. 87–92. Available online: https://apps.dtic.mil/dtic/tr/fulltext/u2/755918.pdf (accessed on 12 June 2020).
- House, A.; Williams, C.; Heker, M.; Kryter, K. Articulation testing methods: Consonantal differentiation with a closed response set. J. Acoust. Soc. Am. 1965, 37, 158–166. [Google Scholar] [CrossRef] [PubMed]
- Benoît, C.; Griceb, M.; Hazanc, V. The SUS test: A method for the assessment of text-to-speech synthesis intelligibility using Semantically Unpredictable Sentences. Speech Commun. 1988, 18, 381–392. [Google Scholar] [CrossRef]
- Loizou, P.C. Speech Quality Assessment. In Multimedia Analysis, Processing and Communications; Springer: Berlin/Heidelberg, Germany, 2011; pp. 623–654. Available online: https://ecs.utdallas.edu/loizou/cimplants/quality_assessment_chapter.pdf (accessed on 15 August 2020).
- Kominek, J.; Schultz, T.; Black, A.W. Synthesizer Voice Quality of New Languages Calibrated with Mean Mel Cepstral Distortion. In Proceedings of the SLTU-2008—First International Workshop on Spoken Languages Technologies for Under-Resourced Languages, Hanoi, Vietnam, 5–7 May 2008; Available online: https://www.cs.cmu.edu/~awb/papers/sltu2008/kominek_black.sltu_2008.pdf (accessed on 18 April 2021).
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).