
On the Relationship between Generalization and Robustness to Adversarial Examples




Abstract
1. Introduction
2. Material and Methods
2.1. Datasets
2.2. Methods
2.3. Metrics
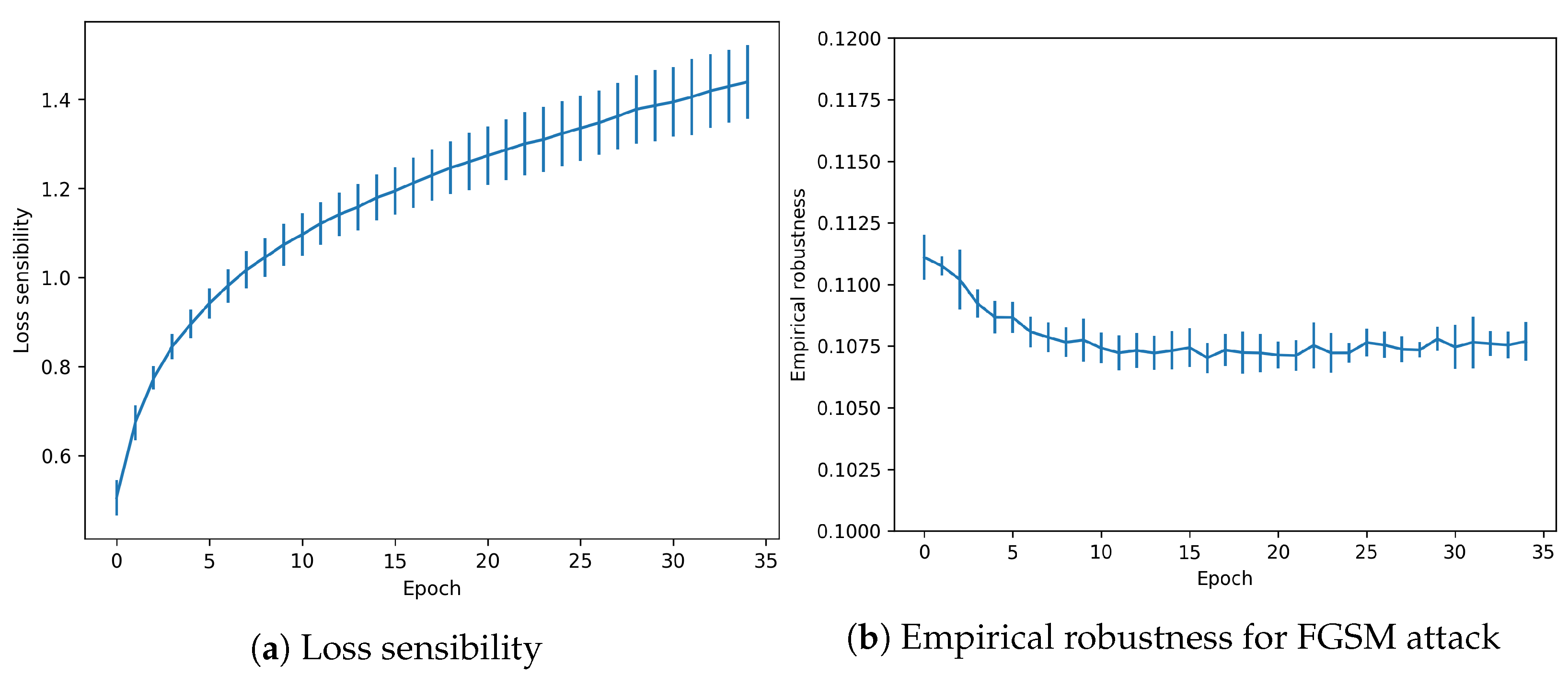
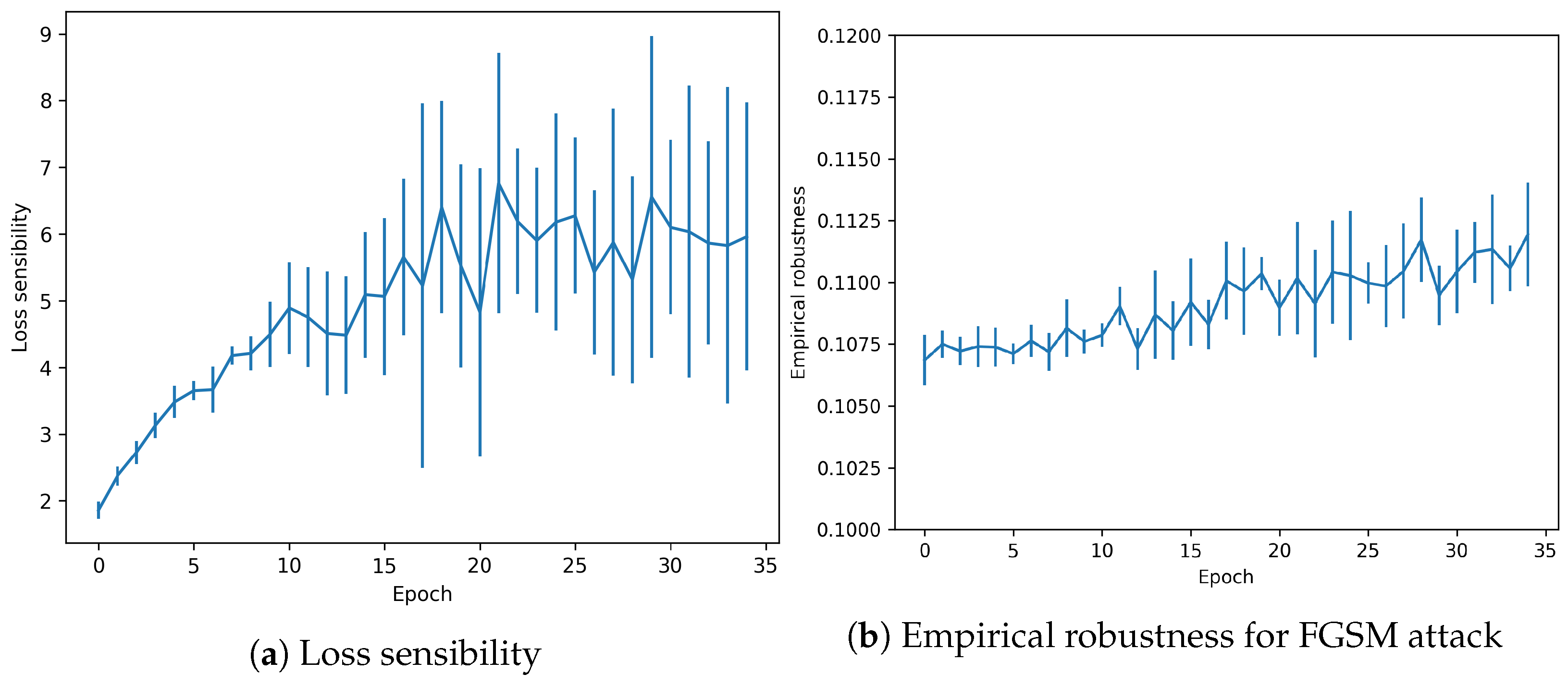
- Loss Sensitivity: proposed in [8] it computes the local loss sensitivity estimated through the gradients of the prediction. It measures the effect of the gradients for each example, which translates into a measure of how much an example is memorized. The larger the value, the greater the overfitting to this particular example.
- Empirical Robustness: as described by [23], it is equivalent to computing the minimal perturbation value that the attacker must introduce for a successful attack, as estimated with the FGSM method.
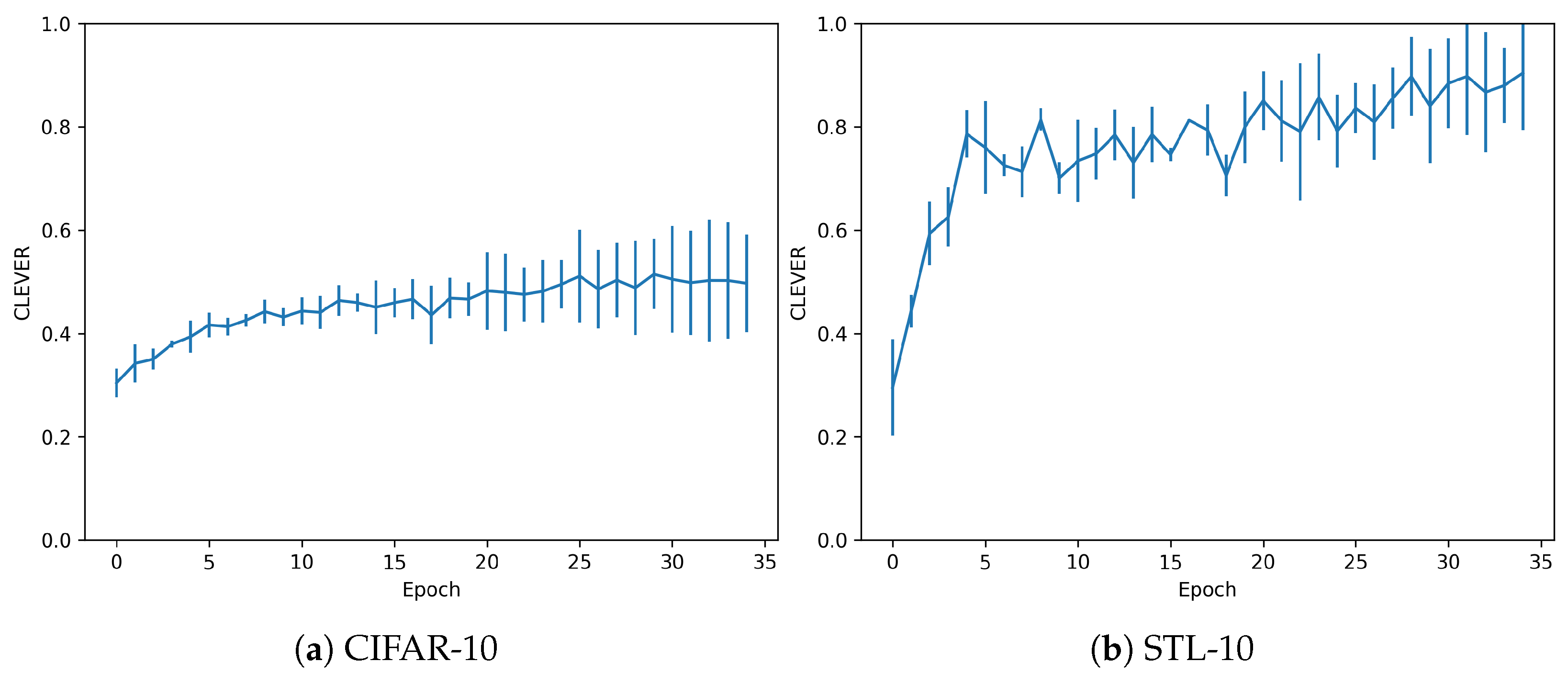
- CLEVER: elaborated in [24], this metric computes a lower bound on the distortion metric that is used to compute the adversarial. It is an attack-agnostic metric in which, the greater the value, the more robust a model is supposed to be.
3. Experimental Results and Discussion
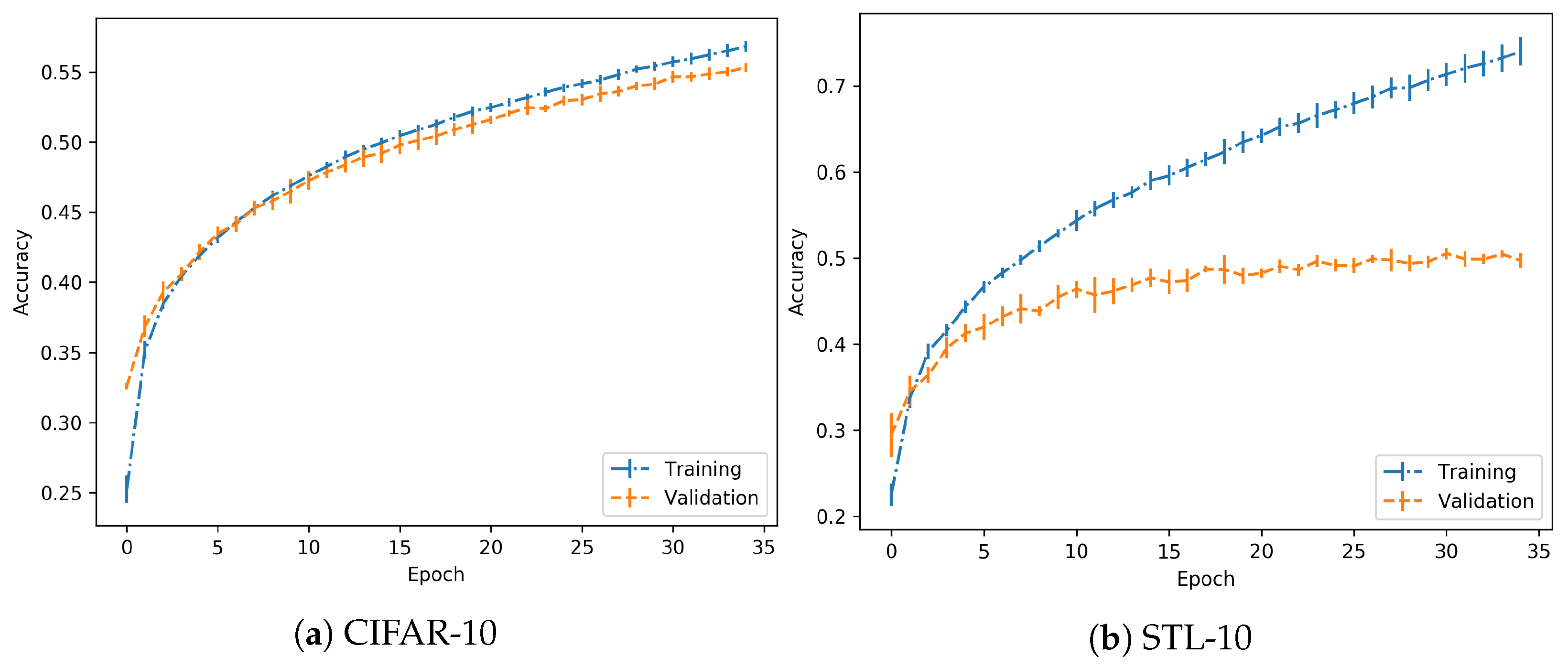
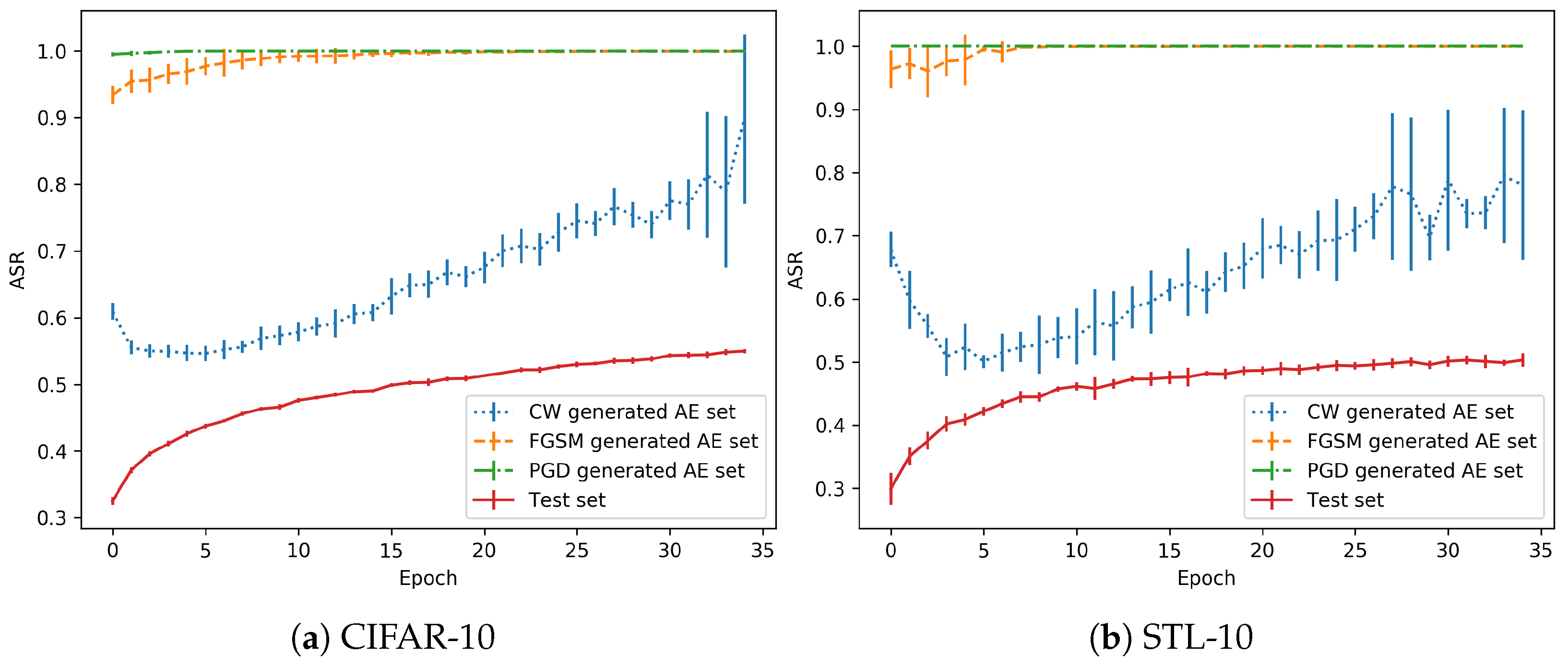
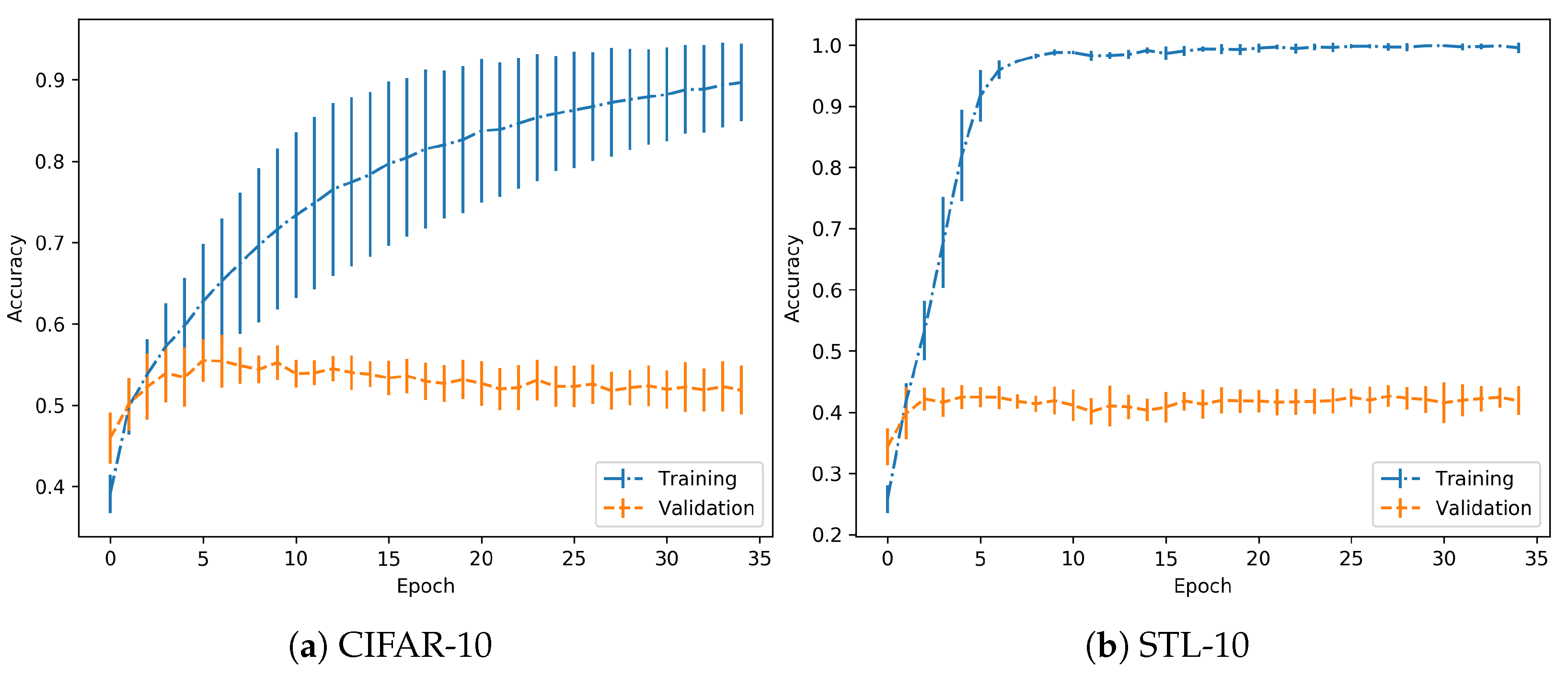
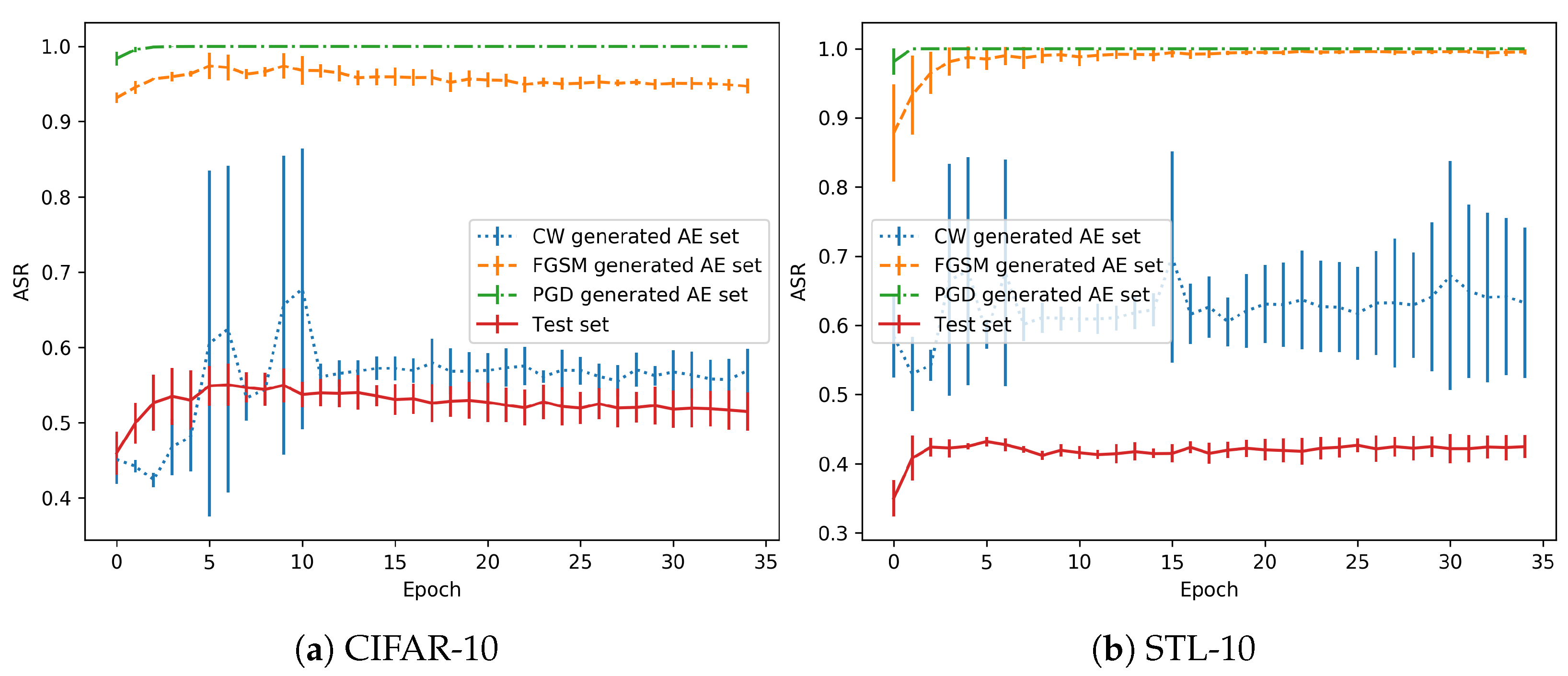
3.1. No Overfitting
3.2. Overfitting
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| AE | Adversarial Example |
| ASR | Adversarial Successful Rate |
| CIFAR | Canadian Institute For Advanced Research |
| CLEVER | Cross-Lipschitz Extreme Value for nEtwork Robustness |
| CW | Carlini & Wagner |
| FGSM | Fast Gradient Sign Method |
| MNIST | Modified National Institute of Standards and Technology |
| PGD | Projected Gradient Descent |
| STL | Self-Taught Learning |
References
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.; Fergus, R. Intriguing properties of neural networks. arXiv 2013, arXiv:1312.6199. [Google Scholar]
- Carlini, N.; Wagner, D. Towards evaluating the robustness of neural networks. In Proceedings of the 2017 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–24 May 2017; pp. 39–57. [Google Scholar]
- Chen, P.Y.; Sharma, Y.; Zhang, H.; Yi, J.; Hsieh, C.J. EAD: Elastic-net attacks to deep neural networks via adversarial examples. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Madry, A.; Makelov, A.; Schmidt, L.; Tsipras, D.; Vladu, A. Towards deep learning models resistant to adversarial attacks. arXiv 2017, arXiv:1706.06083. [Google Scholar]
- Tramèr, F.; Kurakin, A.; Papernot, N.; Goodfellow, I.; Boneh, D.; McDaniel, P. Ensemble adversarial training: Attacks and defenses. arXiv 2017, arXiv:1705.07204. [Google Scholar]
- Song, Y.; Kim, T.; Nowozin, S.; Ermon, S.; Kushman, N. Pixeldefend: Leveraging generative models to understand and defend against adversarial examples. arXiv 2017, arXiv:1710.10766. [Google Scholar]
- Papernot, N.; McDaniel, P.; Wu, X.; Jha, S.; Swami, A. Distillation as a defense to adversarial perturbations against deep neural networks. In Proceedings of the 2016 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 23–25 May 2016; pp. 582–597. [Google Scholar]
- Arpit, D.; Jastrzebski, S.; Ballas, N.; Krueger, D.; Bengio, E.; Kanwal, M.S.; Maharaj, T.; Fischer, A.; Courville, A.; Bengio, Y.; et al. A closer look at memorization in deep networks. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; Volume 70, pp. 233–242. [Google Scholar]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and harnessing adversarial examples. arXiv 2014, arXiv:1412.6572. [Google Scholar]
- Galloway, A.; Taylor, G.W.; Moussa, M. Predicting adversarial examples with high confidence. arXiv 2018, arXiv:1802.04457. [Google Scholar]
- Kubo, Y.; Trappenberg, T. Mitigating Overfitting Using Regularization to Defend Networks Against Adversarial Examples. In Proceedings of the Canadian Conference on Artificial Intelligence, Kingston, ON, Canada, 28–31 May 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 400–405. [Google Scholar]
- Ilyas, A.; Santurkar, S.; Tsipras, D.; Engstrom, L.; Tran, B.; Madry, A. Adversarial examples are not bugs, they are features. arXiv 2019, arXiv:1905.02175. [Google Scholar]
- Deniz, O.; Vallez, N.; Bueno, G. Adversarial Examples are a Manifestation of the Fitting-Generalization Trade-off. In Proceedings of the International Work-Conference on Artificial Neural Networks, Gran Canaria, Spain, 12–14 June 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 569–580. [Google Scholar]
- Su, D.; Zhang, H.; Chen, H.; Yi, J.; Chen, P.Y.; Gao, Y. Is Robustness the Cost of Accuracy?—A Comprehensive Study on the Robustness of 18 Deep Image Classification Models. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 631–648. [Google Scholar]
- Bottou, L.; Cortes, C.; Denker, J.S.; Drucker, H.; Guyon, I.; Jackel, L.D.; Le Cun, Y.; Muller, U.A.; Säckinger, E.; Simard, P.; et al. Comparison of classifier methods: A case study in handwritten digit recognition. In Proceedings of the 12th IAPR International Conference on Pattern Recognition, Conference B: Computer Vision & Image Processing, Jerusalem, Israel, 9–13 October 1994; Volume 2, pp. 77–82. [Google Scholar]
- Yadav, C.; Bottou, L. Cold Case: The Lost MNIST Digits. In Advances in Neural Information Processing Systems (NIPS) 32; Curran Associates, Inc.: Red Hook, NY, USA, 2019. [Google Scholar]
- Xiao, H.; Rasul, K.; Vollgraf, R. Fashion-mnist: A novel image dataset for benchmarking machine learning algorithms. arXiv 2017, arXiv:1708.07747. [Google Scholar]
- Coates, A.; Ng, A.; Lee, H. An analysis of single-layer networks in unsupervised feature learning. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, Ft. Lauderdale, FL, USA, 11–13 April 2011; pp. 215–223. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Li, F.-F. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami Beach, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Krizhevsky, A. Learning Multiple Layers of Features from Tiny Images; Technical Report; University of Toronto: Toronto, ON, Canada, 2009. [Google Scholar]
- Pedraza, A.; Deniz, O.; Bueno, G. Approaching Adversarial Example Classification with Chaos Theory. Entropy 2020, 22, 1201. [Google Scholar] [CrossRef] [PubMed]
- Kurakin, A.; Goodfellow, I.; Bengio, S. Adversarial examples in the physical world. arXiv 2016, arXiv:1607.02533. [Google Scholar]
- Moosavi-Dezfooli, S.M.; Fawzi, A.; Frossard, P. Deepfool: A simple and accurate method to fool deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2574–2582. [Google Scholar]
- Weng, T.W.; Zhang, H.; Chen, P.Y.; Yi, J.; Su, D.; Gao, Y.; Hsieh, C.J.; Daniel, L. Evaluating the robustness of neural networks: An extreme value theory approach. arXiv 2018, arXiv:1801.10578. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Papernot, N.; McDaniel, P.; Goodfellow, I. Transferability in machine learning: From phenomena to black-box attacks using adversarial samples. arXiv 2016, arXiv:1605.07277. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Norm | Calculation | Explanation |
|---|---|---|
| non-zero elements | number of perturbed pixels | |
| Euclidean distance | distance in the image space | |
| largest value | highest perturbation at any pixel |
| Method | |||
|---|---|---|---|
| CW | 1024.00 ± 0.00 | 0.43 ± 0.48 | 0.07 ± 0.06 |
| FGSM | 1017.92 ± 25.30 | 8.93 ± 0.48 | 0.30 ± 0.00 |
| PGD | 1018.99 ± 20.87 | 8.10 ± 0.57 | 0.30 ± 0.00 |
| Method | |||
|---|---|---|---|
| CW | 9216.00 ± 0.00 | 0.97 ± 1.42 | 0.06 ± 0.06 |
| FGSM | 8969.59 ± 387.89 | 26.41 ± 1.39 | 0.30 ± 0.00 |
| PGD | 9049.55 ± 262.61 | 23.37 ± 1.17 | 0.30 ± 0.00 |
| Method | |||
|---|---|---|---|
| CW | 1024.00 ± 0.00 | 0.49 ± 1.15 | 0.06 ± 0.08 |
| FGSM | 1017.19 ± 27.86 | 8.64 ± 0.52 | 0.30 ± 0.00 |
| PGD | 1019.08 ± 20.05 | 7.62 ± 0.45 | 0.30 ± 0.00 |
| Method | |||
|---|---|---|---|
| CW | 9216.00 ± 0.00 | 0.82 ± 2.37 | 0.06 ± 0.07 |
| FGSM | 8951.35 ± 408.80 | 26.04 ± 1.47 | 0.30 ± 0.00 |
| PGD | 9021.16 ± 289.93 | 23.32 ± 1.29 | 0.30 ± 0.00 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pedraza, A.; Deniz, O.; Bueno, G. On the Relationship between Generalization and Robustness to Adversarial Examples. Symmetry 2021, 13, 817. https://doi.org/10.3390/sym13050817
Pedraza A, Deniz O, Bueno G. On the Relationship between Generalization and Robustness to Adversarial Examples. Symmetry. 2021; 13(5):817. https://doi.org/10.3390/sym13050817
Chicago/Turabian StylePedraza, Anibal, Oscar Deniz, and Gloria Bueno. 2021. "On the Relationship between Generalization and Robustness to Adversarial Examples" Symmetry 13, no. 5: 817. https://doi.org/10.3390/sym13050817
APA StylePedraza, A., Deniz, O., & Bueno, G. (2021). On the Relationship between Generalization and Robustness to Adversarial Examples. Symmetry, 13(5), 817. https://doi.org/10.3390/sym13050817