
Contiguous Loss for Motion-Based, Non-Aligned Image Deblurring



Abstract
1. Introduction
- Firstly, we developed a new structure to train a single generative model to recover sharp video frames from one motion-blurred image.
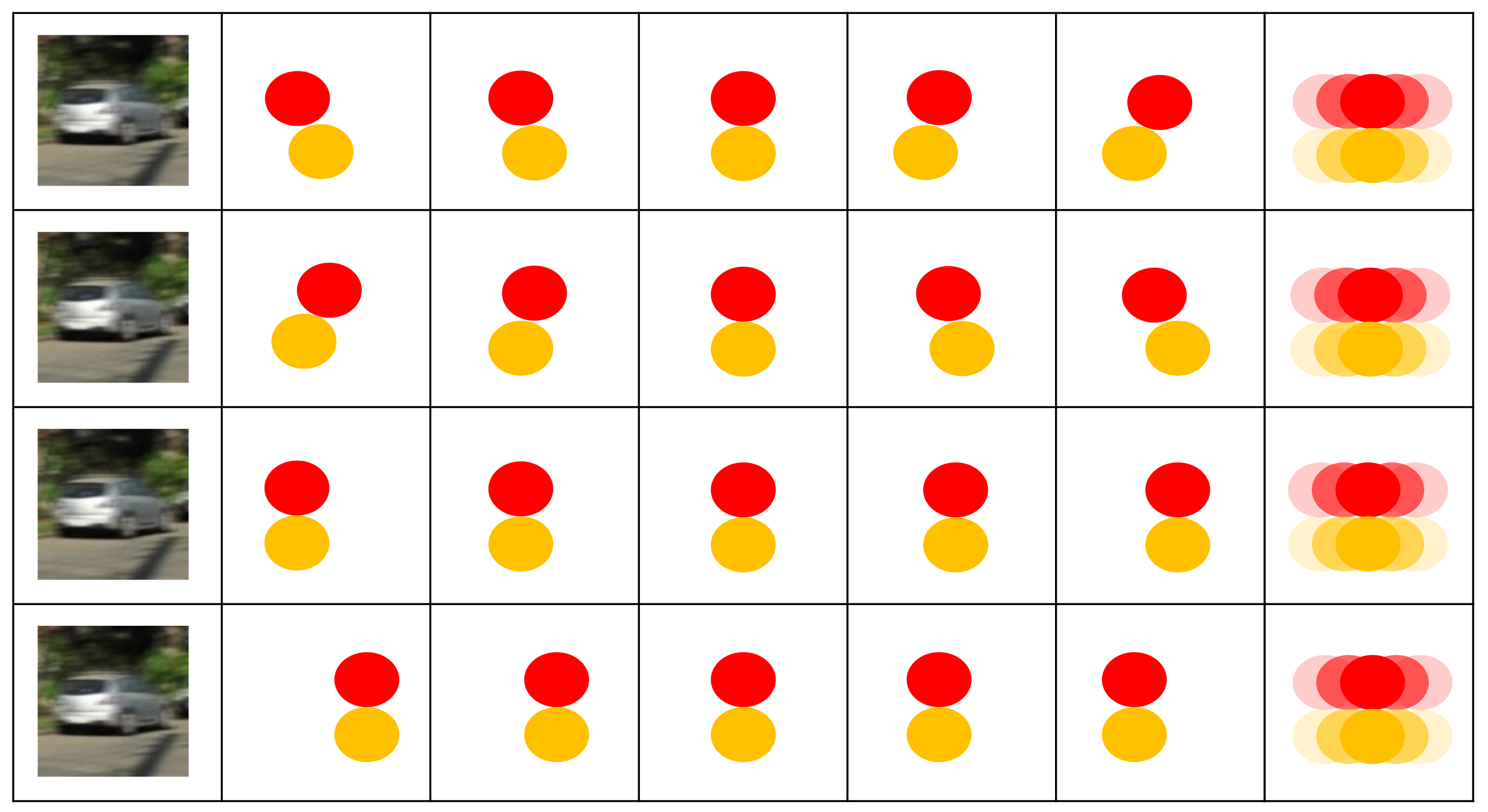
- Secondly, we introduced a contiguous blurry loss to constrain the estimation process, addressing the nonalignment problem between blurry images and sharp video sequences.
- Thirdly, the experiment results show that our framework can generate sharp image sequences and achieve state-of-the-art performance.
2. Related Work
2.1. Image Deblurring
2.2. Video Deblurring
3. Approach
3.1. The Generation of Blurry Images
3.2. Loss Functions
3.3. The Model Architecture
3.3.1. ResNet-Based Model
3.3.2. GAN-Based Model
4. Results
4.1. Datasets
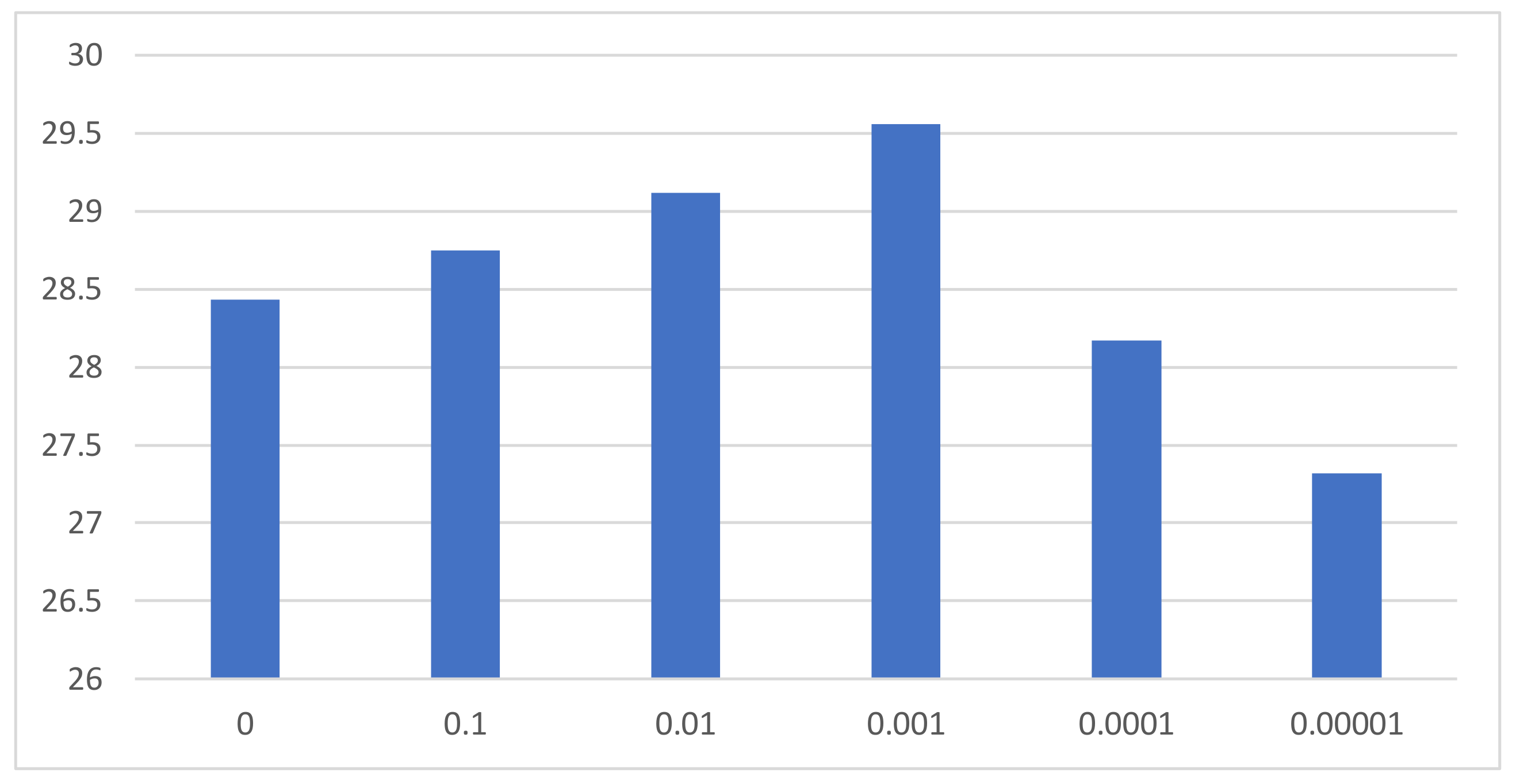
4.2. Implementation Details and Parameter Settings
4.3. The Effectiveness of the GAN-Based Model
4.4. The Effectiveness of Contiguous Blurry Loss
4.5. A Comparison with Other Approaches
4.6. Different Frames
4.6.1. Optimum Parameters
4.6.2. Motion Interpolation
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhang, K.; Luo, W.; Zhong, Y.; Ma, L.; Liu, W.; Li, H. Adversarial spatio-temporal learning for video deblurring. IEEE Trans. Image Process. 2018, 28, 291–301. [Google Scholar] [CrossRef]
- Xu, L.; Lu, C.; Xu, Y.; Jia, J. Image smoothing via L 0 gradient minimization. In Proceedings of the 2011 SIGGRAPH Asia Conference, Hong Kong, China, 13–15 December 2011. [Google Scholar]
- Xu, L.; Zheng, S.; Jia, J. Unnatural l0 sparse representation for natural image deblurring. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2013. [Google Scholar]
- Zhang, K.; Luo, W.; Stenger, B.; Ren, W.; Ma, L.; Li, H. Every moment matters: Detail-aware networks to bring a blurry image alive. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle WA USA, 12–16 October 2020; pp. 384–392. [Google Scholar]
- Whyte, O.; Sivic, J.; Zisserman, A.; Ponce, J. Non-uniform deblurring for shaken images. Int. J. Comput. Vis. (IJCV) 2012, 98, 168–186. [Google Scholar] [CrossRef]
- Gupta, A.; Joshi, N.; Zitnick, C.L.; Cohen, M.; Curless, B. Single image deblurring using motion density functions. In Proceedings of the European Conference on Computer Vision (ECCV), Crete, Greece, 5–11 September 2010. [Google Scholar]
- Hyun Kim, T.; Mu Lee, K. Segmentation-free dynamic scene deblurring. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Nah, S.; Kim, T.H.; Lee, K.M. Deep multi-scale convolutional neural network for dynamic scene deblurring. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Chakrabarti, A. A neural approach to blind motion deblurring. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Schuler, C.; Hirsch, M.; Harmeling, S.; Schölkopf, B. Learning to deblur. IEEE Trans. Pattern Anal. Mach. Intell. (TPAMI) 2015, 38, 1439–1451. [Google Scholar] [CrossRef] [PubMed]
- Xu, L.; Ren, J.S.; Liu, C.; Jia, J. Deep convolutional neural network for image deconvolution. Adv. Neural Inf. Process. Syst. (NIPS) 2014, 27, 1790–1798. [Google Scholar]
- Sun, J.; Cao, W.; Xu, Z.; Ponce, J. Learning a convolutional neural network for non-uniform motion blur removal. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Jin, M.; Meishvili, G.; Favaro, P. Learning to Extract a Video Sequence from a Single Motion-Blurred Image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Hyun Kim, T.; Ahn, B.; Mu Lee, K. Dynamic scene deblurring. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2013. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. (TPAMI) 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Zhang, K.; Huang, Y.; Du, Y.; Wang, L. Facial expression recognition based on deep evolutional spatial-temporal networks. IEEE Trans. Image Process. (TIP) 2017, 26, 4193–4203. [Google Scholar] [CrossRef] [PubMed]
- Burger, H.C.; Schuler, C.J.; Harmeling, S. Image denoising: Can plain neural networks compete with BM3D? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012. [Google Scholar]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Learning a deep convolutional network for image super-resolution. In Proceedings of the European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014. [Google Scholar]
- Ren, W.; Liu, S.; Zhang, H.; Pan, J.; Cao, X.; Yang, M.H. Single image dehazing via multi-scale convolutional neural networks. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar]
- Gong, D.; Yang, J.; Liu, L.; Zhang, Y.; Reid, I.; Shen, C.; Van Den Hengel, A.; Shi, Q. From motion blur to motion flow: A deep learning solution for removing heterogeneous motion blur. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Hradiš, M.; Kotera, J.; Zemcık, P.; Šroubek, F. Convolutional neural networks for direct text deblurring. In Proceedings of the British Machine Vision Conference (BMVC), Swansea, UK, 7–10 September 2015. [Google Scholar]
- Zhang, K.; Luo, W.; Zhong, Y.; Ma, L.; Stenger, B.; Liu, W.; Li, H. Deblurring by realistic blurring. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–18 June 2020; pp. 2737–2746. [Google Scholar]
- Law, N.M.; Mackay, C.D.; Baldwin, J.E. Lucky imaging: High angular resolution imaging in the visible from the ground. Astron. Astrophys. 2006, 446, 739–745. [Google Scholar] [CrossRef]
- Joshi, N.; Cohen, M. Seeing Mt. Rainier: Lucky imaging for multi-image denoising, sharpening, and haze removal. In Proceedings of the IEEE International Conference on Computational Photography (ICCP), Cambridge, MA, USA, 29–30 March 2010. [Google Scholar]
- Cho, S.; Wang, J.; Lee, S. Video deblurring for hand-held cameras using patch-based synthesis. ACM Trans. Graph. (TOG) 2012, 31, 1–9. [Google Scholar] [CrossRef]
- Klose, F.; Wang, O.; Bazin, J.C.; Magnor, M.; Sorkine-Hornung, A. Sampling based scene-space video processing. ACM Trans. Graph. (TOG) 2016, 35, 1–11. [Google Scholar] [CrossRef]
- Delbracio, M.; Sapiro, G. Burst deblurring: Removing camera shake through fourier burst accumulation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Delbracio, M.; Sapiro, G. Hand-held video deblurring via efficient fourier aggregation. IEEE Trans. Comput. Imaging 2015, 1, 270–283. [Google Scholar] [CrossRef]
- Li, D.; Xu, C.; Zhang, K.; Yu, X.; Zhong, Y.; Ren, W.; Suominen, H.; Li, H. ARVo: Learning All-Range Volumetric Correspondence for Video Deblurring. arXiv 2021, arXiv:2103.04260. [Google Scholar]
- Mechrez, R.; Talmi, I.; Zelnik-Manor, L. The contextual loss for image transformation with non-aligned data. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Adv. Neural Inf. Process. Syst. (NIPS) 2014, 3, 2672–2680. [Google Scholar] [CrossRef]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Su, S.; Delbracio, M.; Wang, J.; Sapiro, G.; Heidrich, W.; Wang, O. Deep video deblurring for hand-held cameras. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 June 2017. [Google Scholar]
- Niu, B.; Wen, W.; Ren, W.; Zhang, X.; Yang, L.; Wang, S.; Zhang, K.; Cao, X.; Shen, H. Single image super-resolution via a holistic attention network. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 191–207. [Google Scholar]
- Zhang, K.; Luo, W.; Ren, W.; Wang, J.; Zhao, F.; Ma, L.; Li, H. Beyond monocular deraining: Stereo image deraining via demantic understanding. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layers | Kernel Size | Output Channels | Operations | Skip Connection |
|---|---|---|---|---|
| L1 | 16 | ReLU | - | |
| L2 | 64 | ReLU | L4, L28 | |
| L3 | 64 | ReLU | - | |
| L4 | 64 | - | L6 | |
| L5 | 64 | ReLU | - | |
| L6 | 64 | - | L8 | |
| L7 | 64 | ReLU | - | |
| L8 | 64 | - | L10 | |
| L9 | 64 | ReLU | - | |
| L10 | 64 | - | L12 | |
| L11 | 64 | ReLU | - | |
| L12 | 64 | - | L14 | |
| L13 | 64 | ReLU | - | |
| L14 | 64 | - | L16 | |
| L15 | 64 | ReLU | - | |
| L16 | 64 | - | L18 | |
| L17 | 64 | ReLU | - | |
| L18 | 64 | L20 | ||
| L19 | 64 | ReLU | - | |
| L20 | 64 | - | L22 | |
| L21 | 64 | ReLU | - | |
| L22 | 64 | - | L24 | |
| L23 | 64 | ReLU | - | |
| L24 | 64 | - | L26 | |
| L25 | 64 | ReLU | - | |
| L26 | 64 | - | L28 | |
| L27 | 64 | ReLU | - | |
| L28 | 64 | - | - | |
| L29 | 256 | ReLU | - | |
| L20 | 256 | ReLU | - | |
| L31 | 21 | - | - |
| Layers | 1–2 | 3–6 | 7–11 | 12–16 | 17–18 | 19 |
|---|---|---|---|---|---|---|
| kernel | 3 × 3 | 3 × 3 | 3 × 3 | 3 × 3 | FC | FC |
| channels | 64 | 128 | 256 | 512 | 4096 | 2 |
| BN | BN | BN | BN | BN | - | - |
| ReLU | ReLU | ReLU | ReLU | ReLU | - | - |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |
|---|---|---|---|---|---|---|---|---|---|---|
| INPUT | 24.14 | 30.52 | 28.38 | 27.31 | 22.60 | 29.31 | 27.74 | 23.86 | 30.59 | 26.98 |
| Methods | ||||||||||
| PSDEBLUR | 24.42 | 28.77 | 25.15 | 27.77 | 22.02 | 25.74 | 26.11 | 19.71 | 26.48 | 24.62 |
| WFA [28] | 25.89 | 32.33 | 28.97 | 28.36 | 23.99 | 31.09 | 28.58 | 24.78 | 31.30 | 28.20 |
| DBN [36] | 25.75 | 31.15 | 29.30 | 28.38 | 23.63 | 30.70 | 29.23 | 25.62 | 31.92 | 28.06 |
| Our method | 27.73 | 32.56 | 31.38 | 30.54 | 24.59 | 31.11 | 30.39 | 26.16 | 33.32 | 29.89 |
| Our method (with CBL) | 28.29 | 33.46 | 32.68 | 31.32 | 25.37 | 32.33 | 31.39 | 27.23 | 34.56 | 30.74 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Niu, W.; Xia, K.; Pan, Y. Contiguous Loss for Motion-Based, Non-Aligned Image Deblurring. Symmetry 2021, 13, 630. https://doi.org/10.3390/sym13040630
Niu W, Xia K, Pan Y. Contiguous Loss for Motion-Based, Non-Aligned Image Deblurring. Symmetry. 2021; 13(4):630. https://doi.org/10.3390/sym13040630
Chicago/Turabian StyleNiu, Wenjia, Kewen Xia, and Yongke Pan. 2021. "Contiguous Loss for Motion-Based, Non-Aligned Image Deblurring" Symmetry 13, no. 4: 630. https://doi.org/10.3390/sym13040630
APA StyleNiu, W., Xia, K., & Pan, Y. (2021). Contiguous Loss for Motion-Based, Non-Aligned Image Deblurring. Symmetry, 13(4), 630. https://doi.org/10.3390/sym13040630