1. Introduction
Let
be a real Hilbert space with an inner product
and the associated norm
. Let
C be a nonempty closed convex subset of
, and let
be a monotone operator defined by
for all
, and a
L-Lipschitz continuous operator defined by
for all
. The (Stampacchia) variational inequality problem is to find a point
such that
We will denote the solution set of the considered variational inequality by
and assume that it is nonempty. Since
has been utilized for modeling many mathematical and practical situations (see [
1] for insight discussions), many iterative methods have been proposed for solving it. The classical method is due to Goldstein [
2] which can be read in the form: for a given
, calculate
where
is a step-size parameter and
is the metric projection onto
C. By assuming that
F is
-strongly monotone and
L-Lipschitz continuous and
, it has been proved that the sequence generated by (
2) converges strongly to the unique solution of
.
As the convergence of the iterative scheme in (
2) needs to use the strong monotonicity of
F which is quite restricted, in 1976, Korpelevich [
3] proposed the so-called extragradient method (in short, EM), which is defined by the following form: for a given
, calculate
In the setting of a finite dimensional space, it has been proved that the sequence generated by EM (
3) converges to a solution of
governed by Lipschitz continuity and monotonicity of
F. From such starting point, several variants of Korpelevich’s EM have been investigated, for instance [
4,
5,
6,
7,
8,
9] and references there cited in. Especially, we only underline here the work of Censor, Gibali and Reich [
10]. As one can see from the above scheme, EM requires the performing of two metric projections in each iteration. For this reason, EM will be suitable for the case when the constrained set
C is simple enough so that the metric projection
onto
C has a closed-form expression, otherwise one needs to solve a hidden minimization sub-problem. To avoid this situation, Censor, Gibali and Reich proposed the so-called subgradient–extragradient method (SEM), which requires only one metric projection onto
C for updating
, meanwhile, another one is replaced by the metric projection onto a half-space containing
C for updating the next iterate
. The method essentially has the form:
where
It is worth noting that the closed-form expression of
is explicitly given in the literature (see the Formula (
7) for further details). The weak convergence result is also given in the paper [
10]. Several variants of SEM have been investigated, see for instance [
11,
12,
13,
14,
15,
16]. Note that, even if SEM has the advantage of reducing the performance of the metric projection onto
C when performing
, there still is the metric projection when evaluating
, in this situation the inner-loop iteration remains when the constrained set
C is not simple enough, for example, the intersection of a finite number of nonempty closed convex simple sets.
On the other hand, let us move to another aspect of the nonlinear problem. Let
be a nonlinear operator, the celebrate fixed-point problem is to find
. In order to solve this problem, we recall the classical Picard’s iteration which updates the next iterate
by using the information of the current iterate
, that is
This kind of method is known as the memoryless scheme, and it is well-known in the literature that the sequence generated by Picard’s iterative method may fail to converge to a point in
. In 1953, Mann [
17] proposed a modified version of Picard’s iteration as
where
denotes a convex combination of the iterates
, or in another word,
is a point in the convex hull of all previous iterates. This method is known as Mann’s mean value iteration. The advantage of Mann’s mean value iteration is underlined for avoiding some numerical desirable situations, for instance, the generated sequence may have zig–zag or spiral behavior around the solution set, see [
18] for more insight discussion. Some works based on the idea of Mann’s mean value iteration have been investigated, for instance [
18,
19].
In this work, we present an iterative method by utilizing the ideas of the celebrated SEM together with Mann’s mean value iteration for solving governed by monotone and Lipschitz continuous operator. We show that the sequence generated by the proposed method converges weakly to a solution of . To demonstrate the numerical behavior of the proposed method, we consider the constrained minimization problem in which the constrained set is given by the intersection of a finite family nonempty closed convex simple sets. We present numerical experiments which show that, under some suitable parameters, the proposed method outperforms the existing one.
2. Preliminaries
For convenience, we present here some notations which are used throughout the paper. For more details, the reader may consult the reference books [
20,
21].
We denote the strong convergence and weak convergence of a sequence to by and , respectively. We denote the identity operator on by .
Let
C be a nonempty, closed, and convex subset of
. For each point
there exists a unique nearest point in
C, denoted by
, that is,
The mapping
is called the metric projection of
onto
C. Note that
is a nonexpansive mapping of
onto
C, i.e.,
Moreover, the metric projection
satisfies the variational property:
Let
and
, we define the hyperplane in
by
and the half-space in
by
It is clear that both hyperplane and half-space are closed and convex sets. Moreover, it is important to note that the metric projection onto the half-space
can be done explicitly as the following formula:
For a point
and a nonempty closed convex
, we say that a point
separates
C from
x if,
We say that an operator
is a separator of
C if the point
separates
C from a point
x for all
. It is clear from the relation (
6) that the projection
is a separator of
C. It is worth noting that for any
, the hyperplane
cuts the space
into two half-spaces. One space contains the element
x while the other one contains the subset
C. We also know that
and the hyperplane
is a supporting hyperplane to
C at the point
.
Let
be a set-valued operator. We denote its graph by
We denote the set of all zeros of
A by
The operator
A is said to be monotone if
for all
and it is called maximally monotone if its graph is not properly contained in the graph of any other monotone operator. Note that if
A is maximally monotone, then
is a convex and closed set.
Let
be a nonempty closed convex set. We denote by
the normal cone to
C at
, i.e.,
Let
be a monotone continuous operator and
C be a nonempty closed convex subset of
. Define the operator
by
Then, we have
A is a maximally monotone operator, and the following important property holds:
3. Mann’s Type Mean Extragradient Algorithm
In this section, we present a mean extragradient algorithm for solving the considered variational inequality problem.
We start with recalling the so-called averaging matrix as follows. An infinite lower triangular row matrix is said to be averaging if the following conditions are satisfied:
- (A1)
for all , ;
- (A2)
for all , if , then ;
- (A3)
for all , ;
- (A4)
for all , .
For a sequence
and an averaging matrix
, we denote the mean iterate by
for all
.
Now, we are in position to state the Mann mean extragradient method (Mann-MEM) as follows Algorithm 1.
| Algorithm 1: Mann’s type mean extragradient method (Mann-MEM). |
Initialization: Select a point , a parameter and an averaging matrix .
Step 1: Given a current iterate , compute the mean iterate
Compute
Step 2: If , then and STOP.
If not, construct the half-space defined by
and calculate the next iterate
Update and go to Step 1.
|
Remark 1. In the case that the averaging matrix is the identity matrix, then Mean-MEM is reduced to the classical subgradient extragradient method proposed by Censor et al. [10] Algorithm 4.1. The following proposition confirms us a stopping criterion of Mann-MEM on Step 2.
Proposition 1. Let and be sequences generated by . If there is such that , then .
Proof. Let
be such that
. Then, by the definition of
, we have
, which yields that
. For every
, we have from the inequality (
6) that
and then
which holds by the fact that
. Hence, we conclude that
as required. □
According to Proposition 1, for the rest of our convergence analysis, we may assume throughout this section that Mann-MEM does not terminate after a finite number of iterations, that is, we assume that for all .
The following technical lemma is a key tool in order to prove the convergence result of a sequence generated by .
Lemma 1. Let be a sequence generated by . For every and , it holds that Proof. Let
and
be fixed. Since
F is monotone, we note that
which implies that
where the second inequality holds true by the fact that
and
. Thus, we also have
Now, invoking the definition of
, we note that
and, it follows that
Denoting
, we note that
Note that, it follows from the variational property of
that
and which yields that
By substituting (
11) in (
10), we obtain
Thus, from above inequality and by using (
8), (
9), we have
By using the
L-Lipschitz continuity of
F and the fact that
for all
, we have
Finally, by using the assumption that
is an averaging matrix, and the convexity of
, we have
and the proof is completed. □
Next, we recall the following concept which plays a crucial role in the convergence analysis of our work. The following proposition is very useful in our convergence proof, and it is due to [
22] (Section 3.5, Theorem 4).
Proposition 2. Let be a real sequence, , and be an averaging matrix. If , then .
An averaging matrix
is said to be
M-concentrating [
18] if for every nonnegative real sequences
, and
such that
and it holds that
where
, for all
, we have the limit
exists.
Note that in view of Lemma 1, if we add an additional prior criterion on so that the term of the right-hand side is nonpositive, together with the assumtion that the averaging matrix is M-concentrating, it will yield the convergence of the sequence . Now, we are in a position to formally state the convergence analysis of Mann-MEM.
Theorem 1. Assume that the averaging matrix is M-concentrating and . Then any sequence generated by converges weakly to a solution in .
Proof. Let
and
be fixed. Now, we note from Lemma 1 that
Since
, we have
and then the inequality (
14) can be written as
In view of
and
for every
in (
13), and by using the assumption that the averaging matrix
is M-concentrating, we obtain that
exists, say
. Invoking Lemma 2, we have
exists with the same limit
, and subsequently, it follows from these together with (
14) and
that
Moreover, we note that from Lemma 1 again that
we also have
.
Since the sequence
is bounded, there are a weak cluster point
and a subset
such that
. Thus, it follows from (
16) that
.
Now, let us define the operator
by
Then, we know that
A is a maximally monotone operator and
. Further, for
, that is
, we have
which means that
Thus, by the variational property of
, we have
that is,
for all
. Hence, by using (
17) and (
18) and replacing
y by
and
by
, respectively, we have
Taking the limit as
, we obtain
Now, since A is a maximally monotone operator, we obtain that
Next, we show that the whole sequence converges weakly to
. Assume that there is a subsequence
of
such that it converges weakly to some
. By following all above statements, we also obtain that
and
. Invoking the Opial’s condition, we note that
which is a contradiction. Therefore,
, and hence we conclude that
converges weakly to
□
Next, we will discuss an important example of the M-concentrating averaging matrix, for simplicity, we will make use of the following notions. For a given averaging matrix
, we denote
for all
.
An averaging matrix
is said to satisfy the
generalized segmenting condition [
18] if
If for all , then is said to satisfy the segmenting condition.
The following proposition indicates the sufficient and necessary condition for an averaging matrix satisfying the generalized segmenting condition to be M-concentrating.
Proposition 3. Let be an averaging matrix satisfying the generalized segmenting condition. Then, is M-concentrating if and only if .
Proof. The sufficient to be M-concentrating can be found in [
18] (Example 2.5). The necessary case is proved in [
23] (Proposition 3.4) □
Example 1. An averaging matrix satisfies the generalized segmenting condition and is the infinite matrix which is defined by where the parameter .
4. Numerical Result
In this section, we present the effectiveness of the proposed algorithm by minimizing the distance of a given point over the intersection of a finite number of linear half-spaces.
Let
and
and
be given data, for all
. In this experiment, we want to solve the constrained minimization problem of the form:
Note that the function
is convex Fréchet differentiable with
is 1-Lipschitz continuous gradient, and the constrained set
is a nonempty closed convex set. Thus, the problem (
19) fits into the setting of the variational inequality problem (
1), where
and
. One can easily see that
F is 1-Lipschitz continuous. In this situation, the obtained theoretical results hold and we can apply Mann-MEM for solving the problem (
19).
All the experiments were performed under MATLAB 9.6 (R2019a) running on a MacBook Pro 13-inch, 2019 with a 2.4 GHz Intel Core i5 processor and 8 GB 2133 MHz LPDDR3 memory. All computational times are given in seconds (sec.). In all tables of computational results, SEM means the classical subgradient extragradient method [
10], while Mann-MEM means the Mann type mean extragradient method with the generalized segmenting averaging matrix
is given by
where the parameter
. Note that the set
in Mann-MEM is a supporting hyperplane to
C at the point
. In this situation, the metric projection
can be computed explicitly by the Formula (
7) provided that the estimate
. Nevertheless, if the estimate
, we have that the half-space
turns out to be the whole space
so that the iterate
is nothing else but the estimate
.
Observe that the extragradient type methods require the computation of the metric projection onto the constrained set
C which is the intersection of a finite number of linear half-spaces. Of course, the metric projection
of this constrained set is not computed explicitly, and we need to solve the sub-optimization problem (
5) in order to obtain the metric projection onto the constrained set. To deal with this situation, we make use of the classical Halpern iteration by performing the inner loop: pick arbitrary initial point
and a sequence
, we compute
It is well-known that if the sequence
satisfies
,
, and
, then the sequence
converges to the unique point
(see [
20] Theorem 30.1), which is nothing else than the point
in Mann-MEM. In order to approximate the point
, in all experiment, we use the stopping criterion
for the inner loop. Notice that this strategy is also used when performing SEM.
In the first experiment, we considered behavior of SEM and Mann-MEM in a very simple situation. We choose
,
,
,
,
,
, and
. It can be noted that the unique solution in the problem is nothing else than the point
. We start with the influence of the stepsize
for various choices of parameter
when performing SEM and Mann-MEM. We choose the starting point
, the stepsize
, and the parameter
in (
20) to be
. We terminate the methods by, for SEM, the stopping criterions
or after 100 iterations, whichever came first, and for Mann-MEM, the stopping criterions
or after 100 iterations, whichever came first. We present in
Table 1 the influences of the parameters
on the computational time (Time), the number of iterations (
k) (#(Iters)), and the total number of inner iterations (
i) given by (
21) (#(Inner)) when the stopping criterions were met.
It can be seen from
Table 1 that, in each of these two algorithms tested, the larger values of parameter
give the better algorithm performances, that is the least computational time is achieved when the parameter
is as large as possible. This behavior may probably due to the larger stepsize
, which is defined by the parameter
, can make the inner loop (
21) terminate in fewer iterations so that the algorithmic runtime decreases. However, we can see that SEM with
and Mann-MEM with
need more than 100 iterations to reach the stopping criterion. We observe that the high performance of both SEM and Mann-MEM is obtained by the choice of
, moreover, Mann-MEM with
gives the best result of algorithm runtime 0.0607 seconds.
In
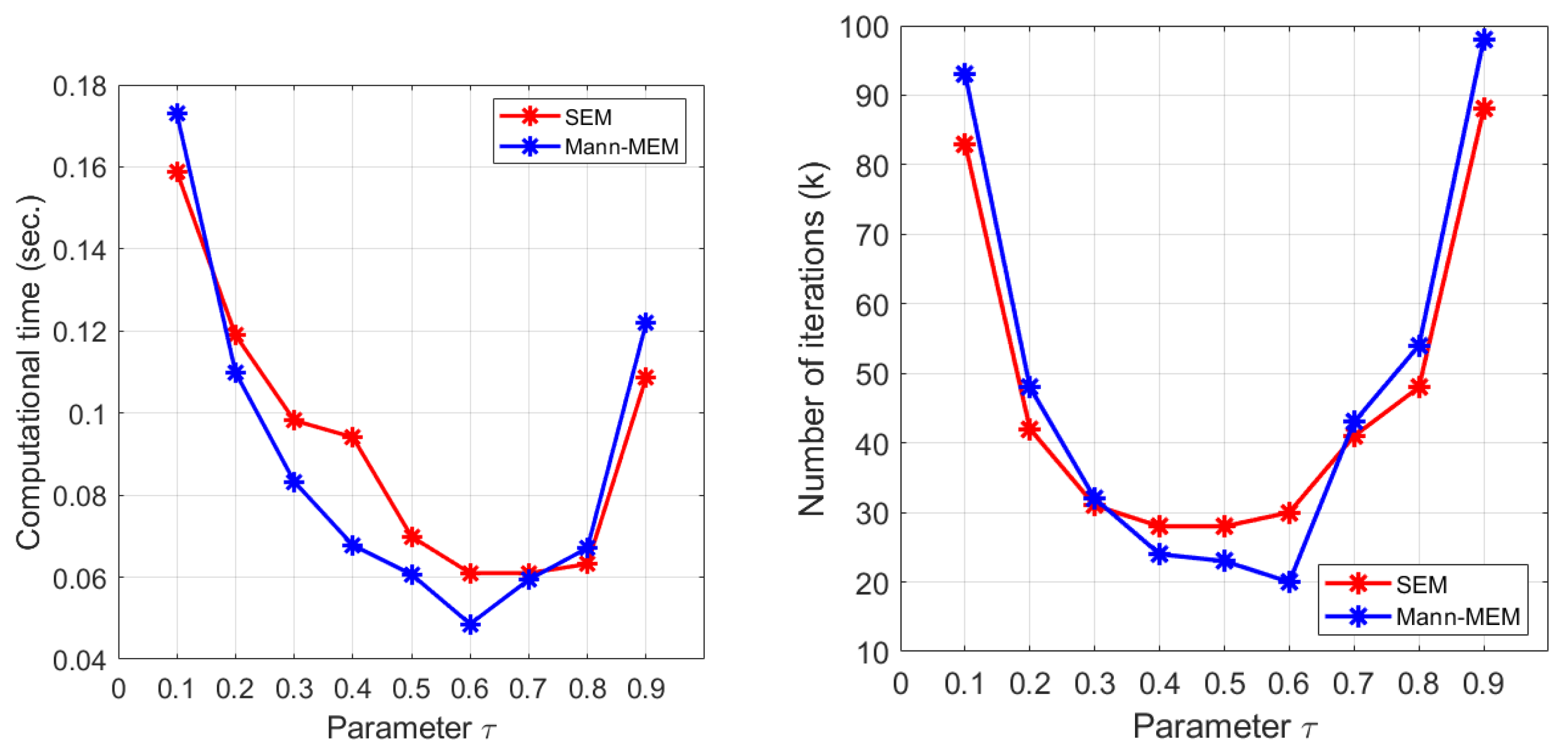
Figure 1, we perform the experiments with varying the the stepsize
in the two tested methods. With the same setting as above experiment and putting the inner-loop stepsize
for SEM and Mann-MEM. We observe that the best computational time for both SEM and Mann-MEM is obtained by the choice of
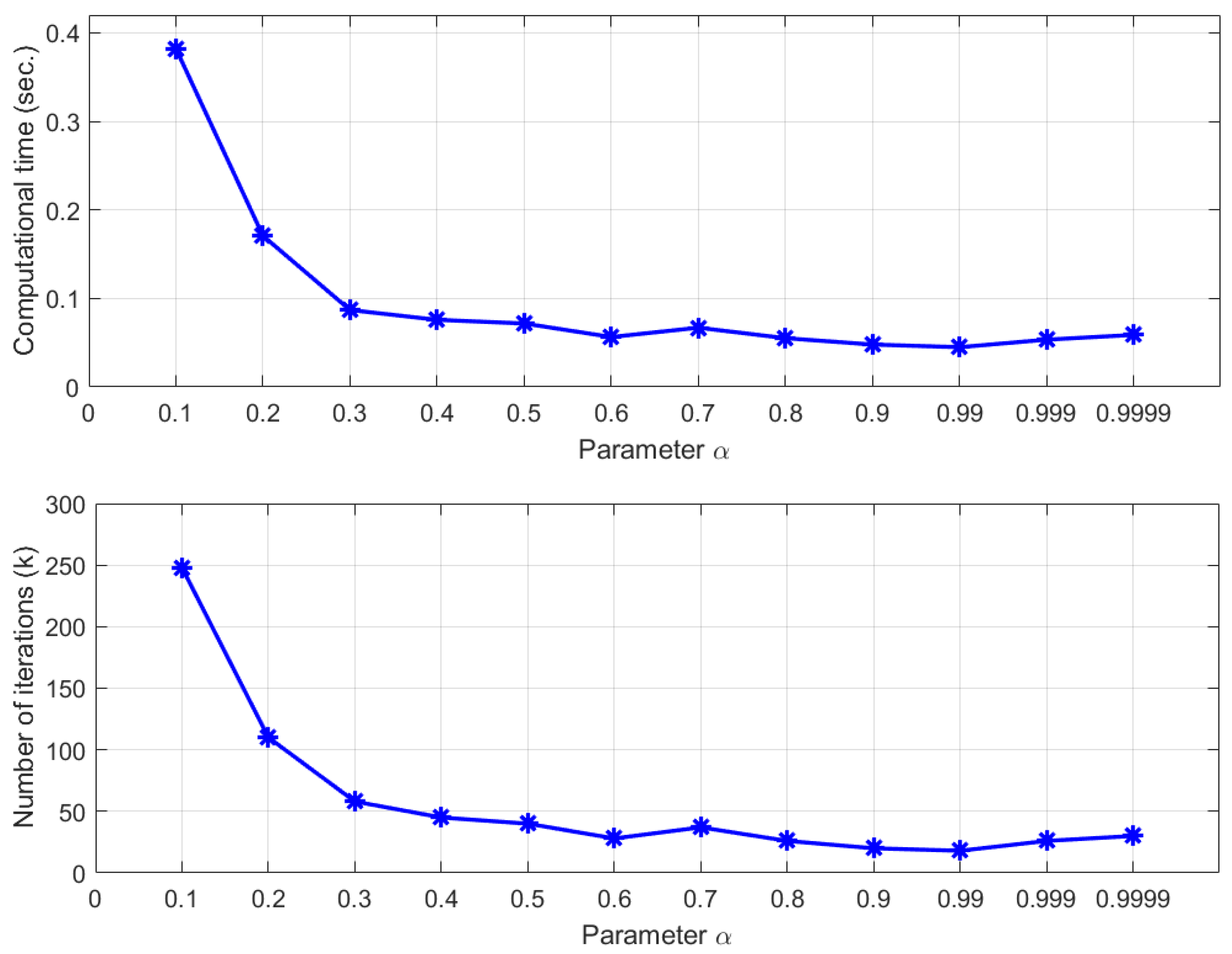
For more insight into the convergence behavior of Mann-MEM, we also consider the influence of the parameter
given in Mann-MEM. We put
, and
, and the results are presented in
Figure 2. It can be observed that the least computational time and the number of iterations are achieved when the parameter
is quite large, that is, the best algorithm’s performance is obtained by the choice of
.
In the next experiment, we also considered the solving of the problem (
19) by the aforementioned tested methods. We compare the methods for various dimensions
n and the number of constraints
m. We put vectors
, whose coordinates are randomly chosen from the interval
, positive real numbers
, and the initial point
is a vector whose coordinates are randomly chosen from the interval
. We set the point
c to be a vector whose all coordinates are 1, and choose the best choices of parameters
, and stepsize
for SEM and
, and
for Mann-MEM. In the following numerical experiments, in order to terminate SEM, we applied the following stopping criterion
and in order to terminate Mann-MEM, we applied the following stopping criterion
We performed 10 independent tests for any collections of high dimensions
, 2000, and 3000 and the number of constraints
, and 200. The results are presented in
Table 2, where the average computational runtime and the average number of iterations for any collection of
n and
m are presented.
It is clear from
Table 2 that Mann-MEM is more efficient than SEM in the sense that Mann-MEM requires less computation than SEM in the average computational runtime. One notable behavior is that for the case when
m is quite large, Mann-MEM requires significantly below the average computational runtime. For each dimension, we observe that the larger problem sizes need more average computational runtime. This suggests that the use of the generalized segmenting averaging matrix is more efficient than SEM. In this situation, we can note that the essential superiority of Mann-MEM with respect to SEM is dependent on the optimal choice of the averaging matrix
which is, in our experiments, the generalized segmenting averaging matrix.






{kind=link}
{kind=link}