
Image Semantic Segmentation Use Multiple-Threshold Probabilistic R-CNN with Feature Fusion



Abstract
1. Introduction
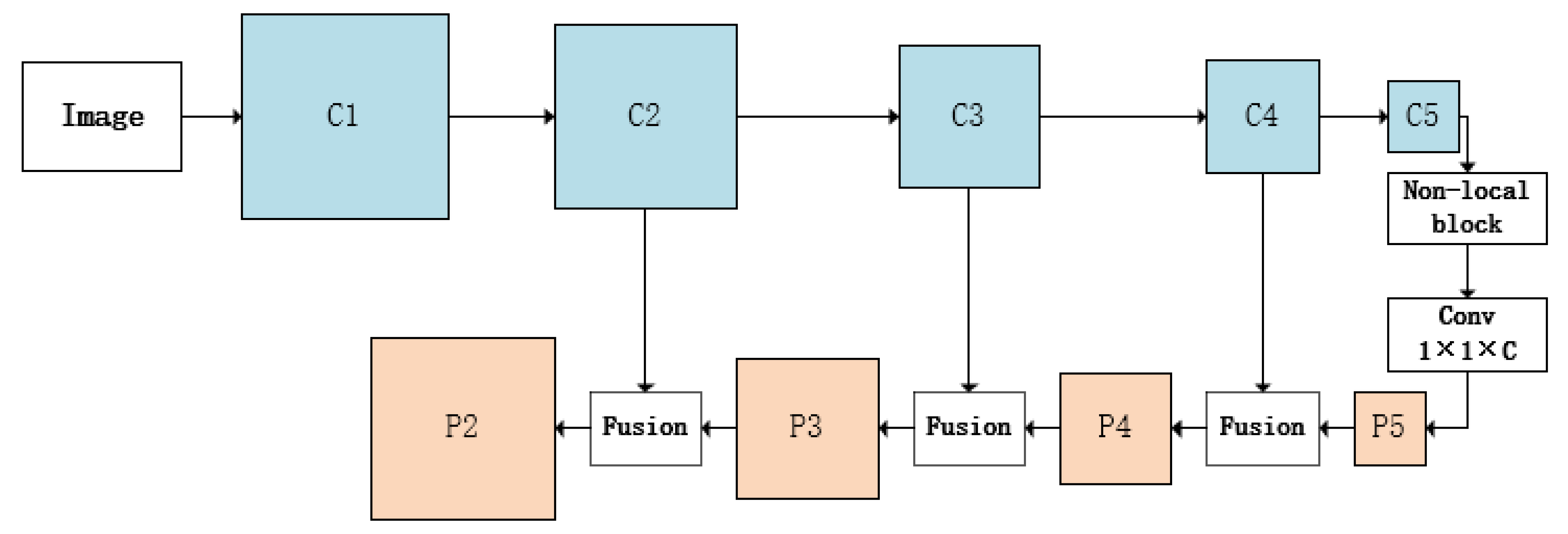
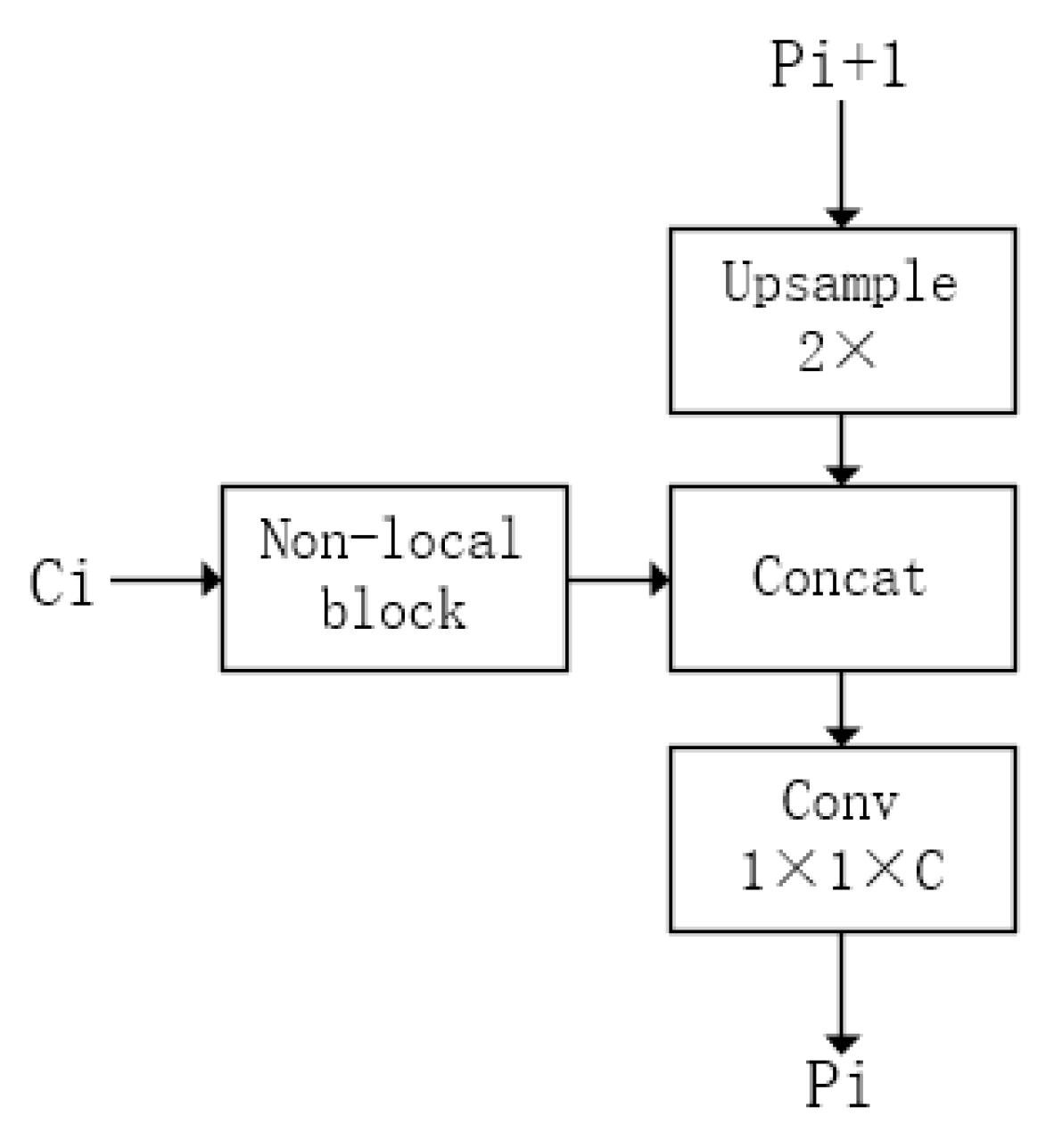
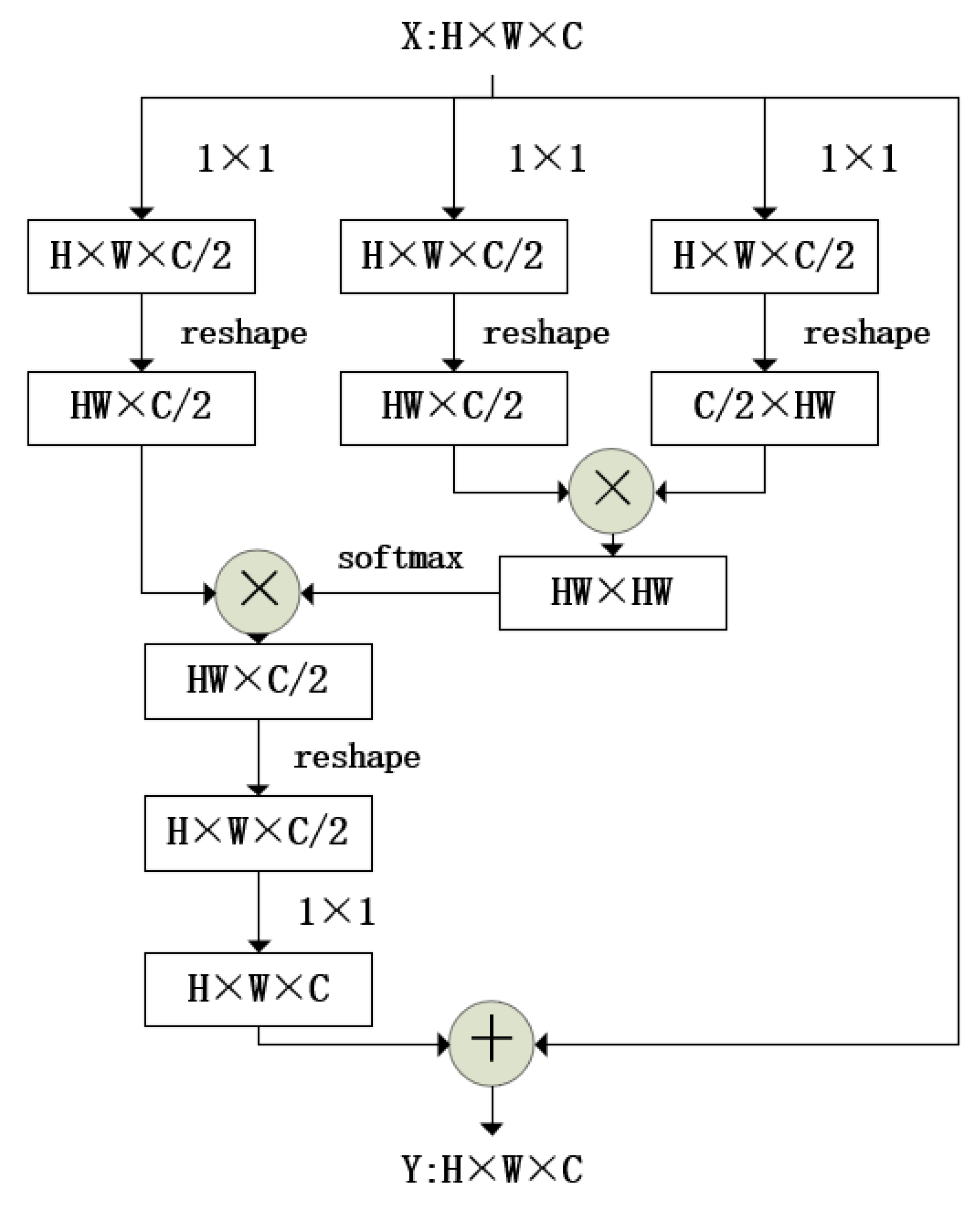
- We optimize the feature extraction of the network. Based on the feature pyramid, we propose a feature fusion method, combining two feature maps of different sizes to obtain a new feature map.
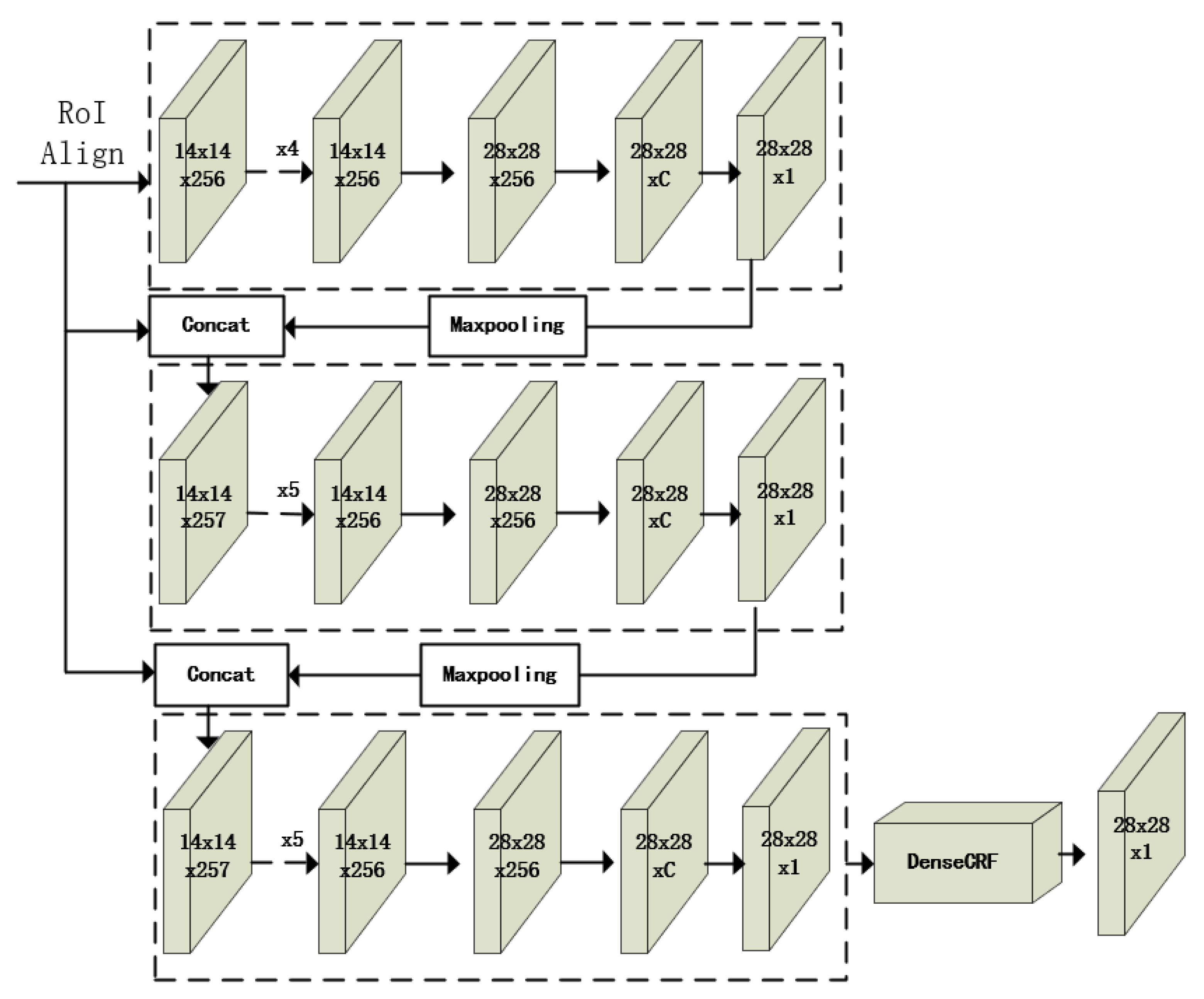
- We propose a multiple threshold segmentation architecture as the segmentation branch of the network. A multiple threshold architecture can better filter redundant information. The integration of a Dense Conditional Random Field (DenseCRF) improves the network performance further.
2. Related Work
2.1. Mask Scoring R-CNN
2.2. Cascade R-CNN
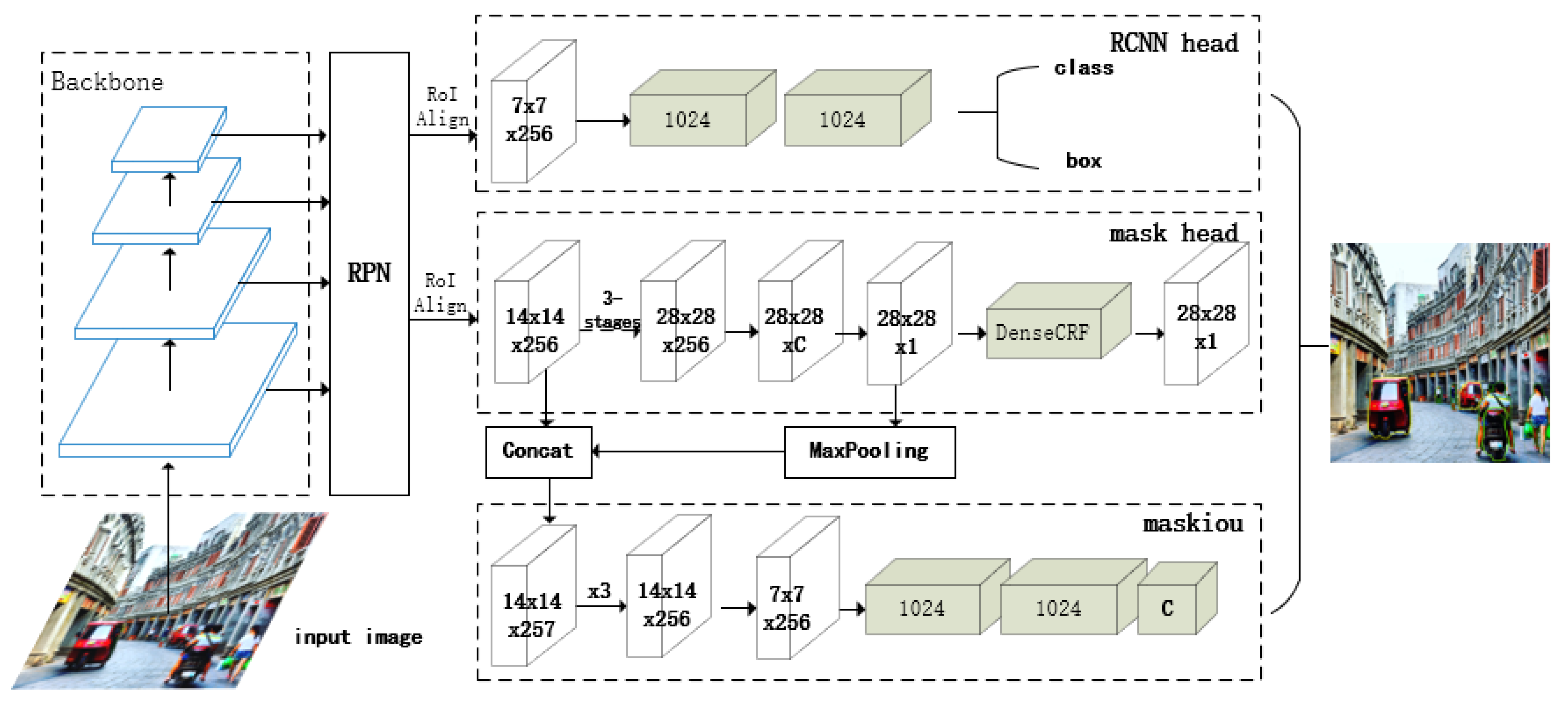
3. Methods
3.1. Backbone
3.2. Region Proposal Network and Region of Interest Align Layer
3.3. Class Head, Bbox Head, and Mask Head
3.4. Loss Function
4. Experiment
4.1. Implementation Details
4.2. Multiple-Threshold Probabilistic R-CNN with Different Backbones
4.3. Ablation Experiments
4.4. Comparison with the State-of-the-Art
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Pinheiro, P.O.; Collobert, R.; Dollár, P. Learning to segment object candidates. arXiv 2015, arXiv:1506.06204. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Huang, Z.; Huang, L.; Gong, Y.; Huang, C.; Wang, X. Mask scoring r-cnn. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 6409–6418. [Google Scholar]
- Tian, Y.; Yang, G.; Wang, Z.; Li, E.; Liang, Z. Instance segmentation of apple flowers using the improved mask R–CNN model. Biosyst. Eng. 2020, 193, 264–278. [Google Scholar] [CrossRef]
- Zhang, B.; Zhang, J. A Traffic Surveillance System for Obtaining Comprehensive Information of the Passing Vehicles Based on Instance Segmentation. IEEE Trans. Intell. Transp. Syst. 2020. [Google Scholar] [CrossRef]
- Liu, D.; Zhang, D.; Song, Y.; Huang, H.; Cai, W. Cell r-cnn v3: A novel panoptic paradigm for instance segmentation in biomedical images. arXiv 2020, arXiv:2002.06345. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: High quality object detection and instance segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2019. [Google Scholar] [CrossRef] [PubMed]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7794–7803. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. arXiv 2015, arXiv:1506.01497. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Krähenbühl, P.; Koltun, V. Efficient Inference in Fully Connected Crfs with Gaussian Edge Potentials. arXiv 2011, arXiv:1210.5644. [Google Scholar]
- Li, Y.; Qi, H.; Dai, J.; Ji, X.; Wei, Y. Fully convolutional instance-aware semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2359–2367. [Google Scholar]
- Chen, L.C.; Hermans, A.; Papandreou, G.; Schroff, F.; Wang, P.; Adam, H. Masklab: Instance segmentation by refining object detection with semantic and direction features. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4013–4022. [Google Scholar]
- Wen, Y.; Hu, F.; Ren, J.; Shang, X.; Li, L.; Xi, X. Joint multi-task cascade for instance segmentation. J. Real-Time Image Process. 2020, 17, 1983–1989. [Google Scholar] [CrossRef]
- Cao, J.; Anwer, R.M.; Cholakkal, H.; Khan, F.S.; Pang, Y.; Shao, L. SipMask: Spatial Information Preservation for Fast Image and Video Instance Segmentation. arXiv 2020, arXiv:2007.14772. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Backbone | AP | AP@0.5 | AP@0.75 |
|---|---|---|---|---|
| MTP R-CNN | ResNet-18 | 34.3 | 53.9 | 33.2 |
| ResNet-50 | 36.9 | 57.2 | 39.8 | |
| ResNet-101 | 40.9 | 63.0 | 44.3 |
| Method | Feature Fusion | Multiple Threshold | AP | AP@0.5 | AP@0.75 |
|---|---|---|---|---|---|
| baseline | 38.3 | 58.8 | 41.5 | ||
| √ | 39.9 | 61.6 | 43.7 | ||
| √ | √ | 40.9 | 63.0 | 44.3 |
| Method | Backbone | AP | AP@0.5 | AP@0.75 | APS | APM | APL |
|---|---|---|---|---|---|---|---|
| FCIS+++ [17] | ResNet-101 | 33.6 | 54.5 | - | - | - | - |
| MaskLab [18] | 35.5 | 57.4 | 37.4 | 16.9 | 38.2 | 49.2 | |
| MaskLab+ [18] | 37.4 | 59.8 | 36.6 | 19.1 | 40.5 | 50.6 | |
| JMTC [19] | ResNet-101+FPN | 37.4 | 60.8 | 39.6 | 18.8 | 40.6 | 53.9 |
| SipMask [20] | 38.1 | 60.2 | 40.8 | 17.8 | 40.8 | 54.3 | |
| Mask R-CNN [5] | ResNet-101+FPN+DCN | 38.4 | 61.2 | 41.1 | 18.0 | 40.6 | 55.2 |
| MS R-CNN [6] | 39.6 | 60.7 | 43.1 | 18.8 | 41.5 | 56.2 | |
| MTP R-CNN | ResNet-101+FPN | 40.9 | 63.0 | 44.3 | 19.2 | 42.0 | 56.5 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, J.; Geng, Y.; Zhao, J.; Zhang, K.; Li, W. Image Semantic Segmentation Use Multiple-Threshold Probabilistic R-CNN with Feature Fusion. Symmetry 2021, 13, 207. https://doi.org/10.3390/sym13020207
Liu J, Geng Y, Zhao J, Zhang K, Li W. Image Semantic Segmentation Use Multiple-Threshold Probabilistic R-CNN with Feature Fusion. Symmetry. 2021; 13(2):207. https://doi.org/10.3390/sym13020207
Chicago/Turabian StyleLiu, Jianxin, Yushui Geng, Jing Zhao, Kang Zhang, and Wenxiao Li. 2021. "Image Semantic Segmentation Use Multiple-Threshold Probabilistic R-CNN with Feature Fusion" Symmetry 13, no. 2: 207. https://doi.org/10.3390/sym13020207
APA StyleLiu, J., Geng, Y., Zhao, J., Zhang, K., & Li, W. (2021). Image Semantic Segmentation Use Multiple-Threshold Probabilistic R-CNN with Feature Fusion. Symmetry, 13(2), 207. https://doi.org/10.3390/sym13020207