wUUNet: Advanced Fully Convolutional Neural Network for Multiclass Fire Segmentation



Abstract
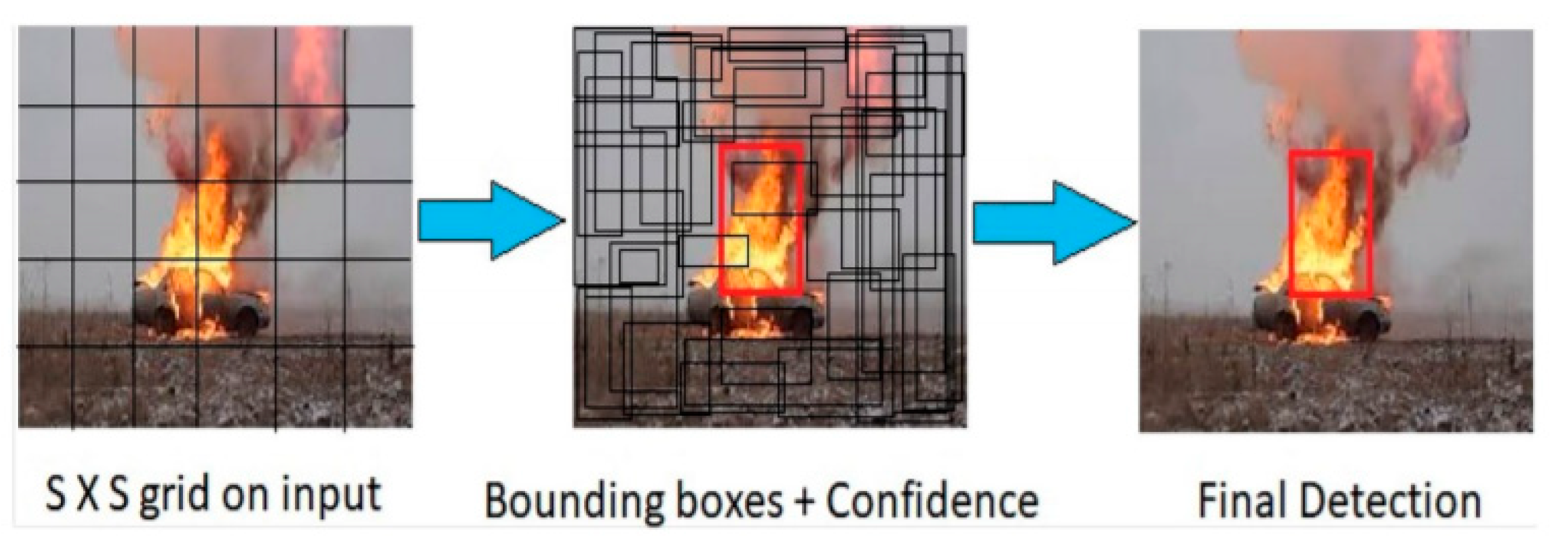
1. Introduction
2. Materials and Methods
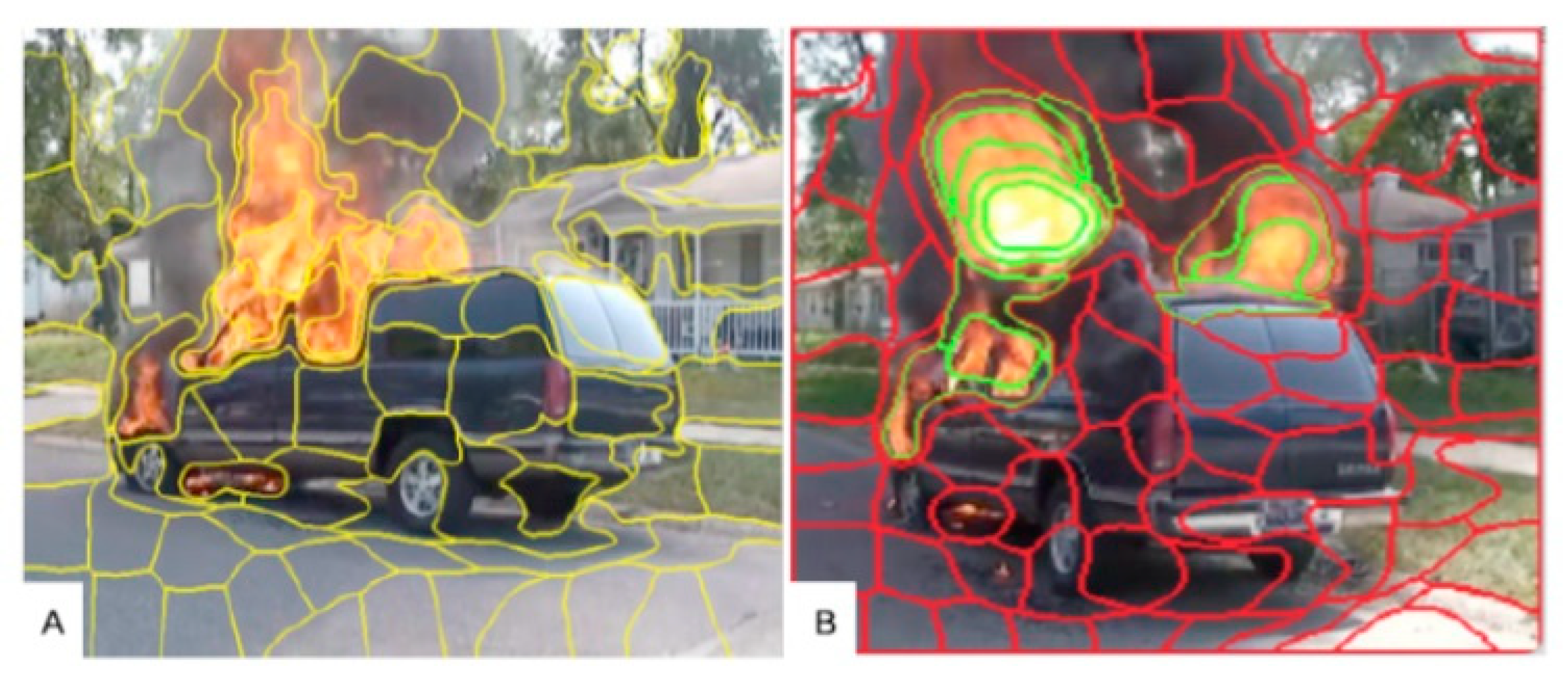
2.1. Dataset
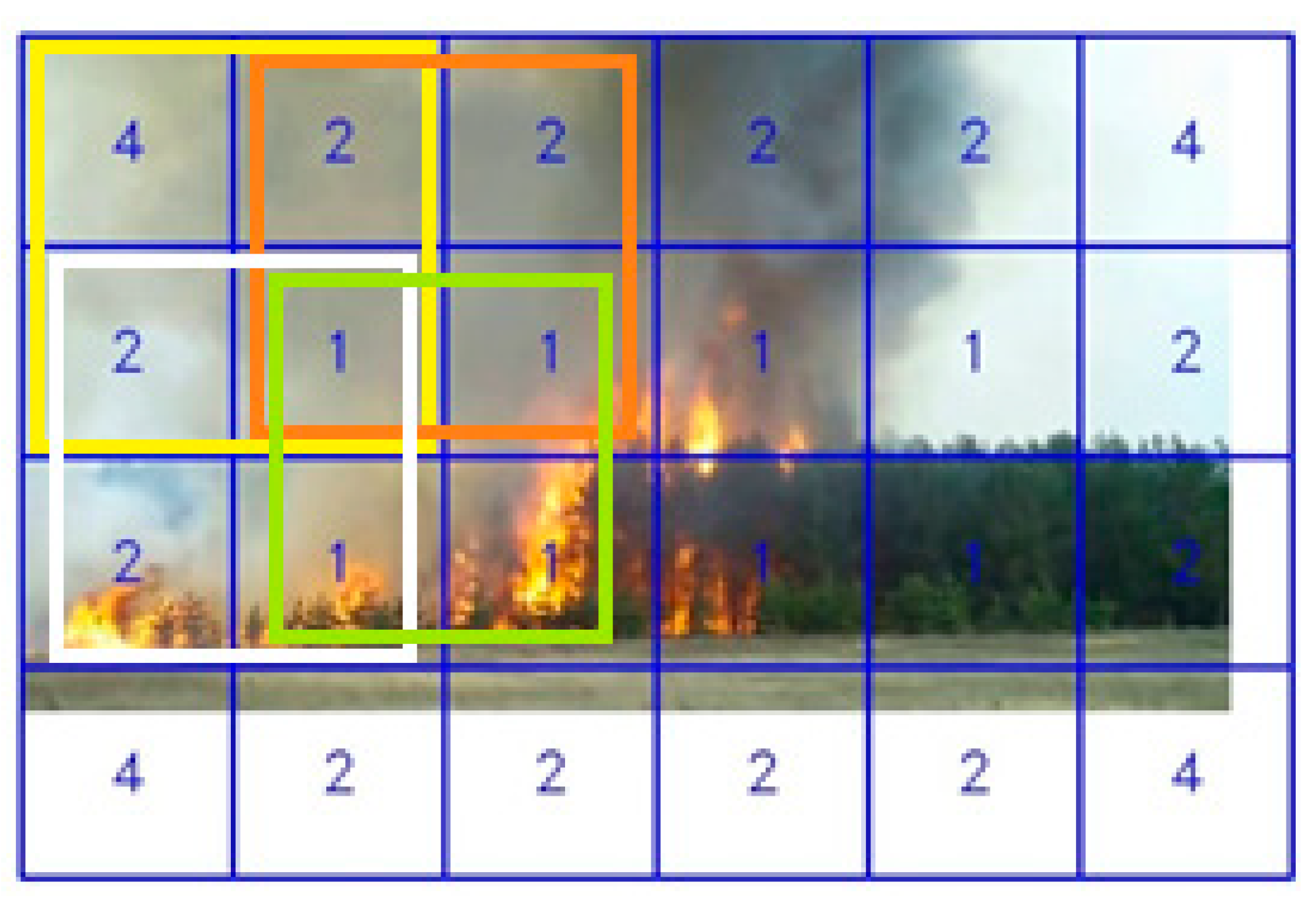
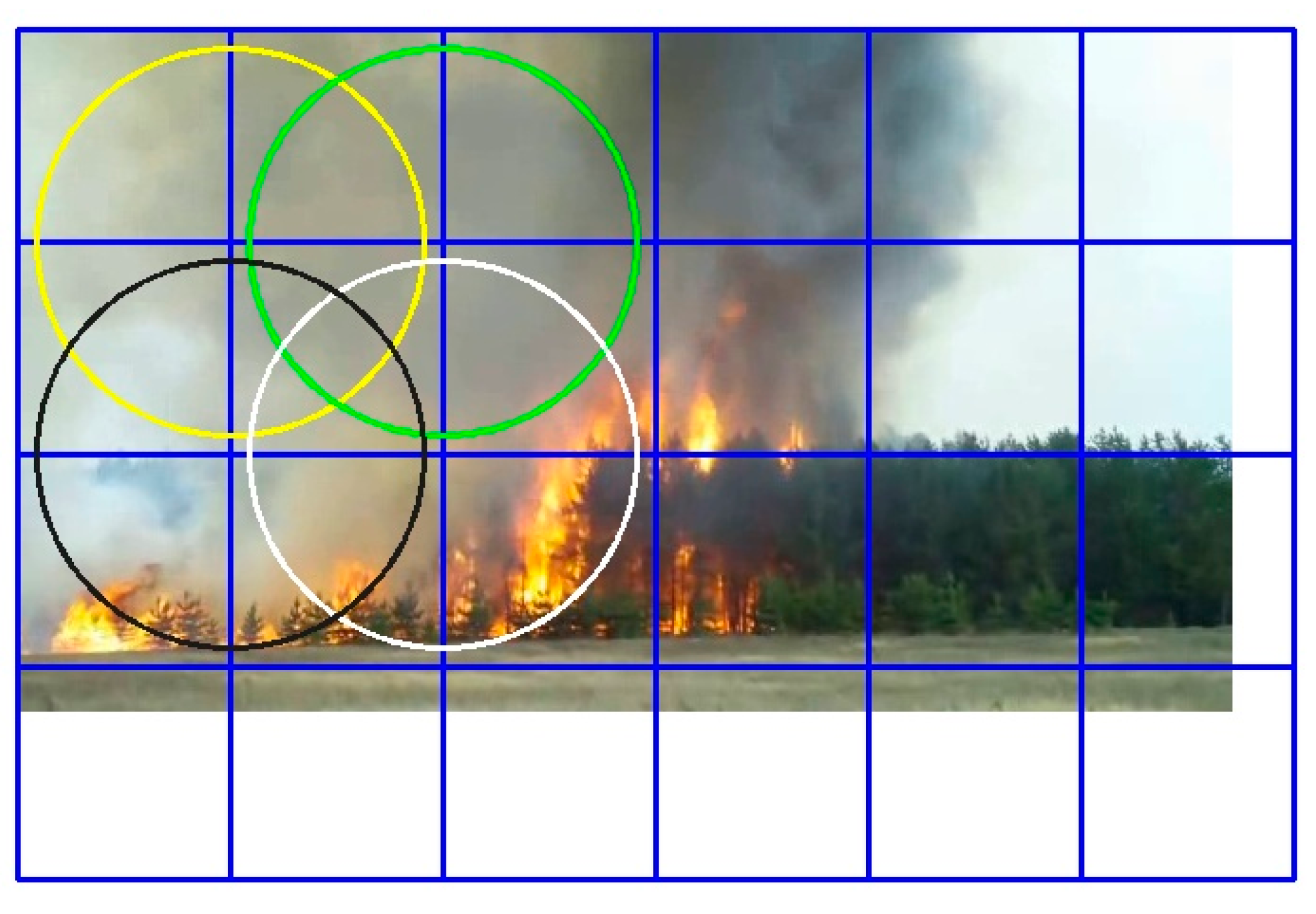
2.2. Proposed Segmentation Schemes
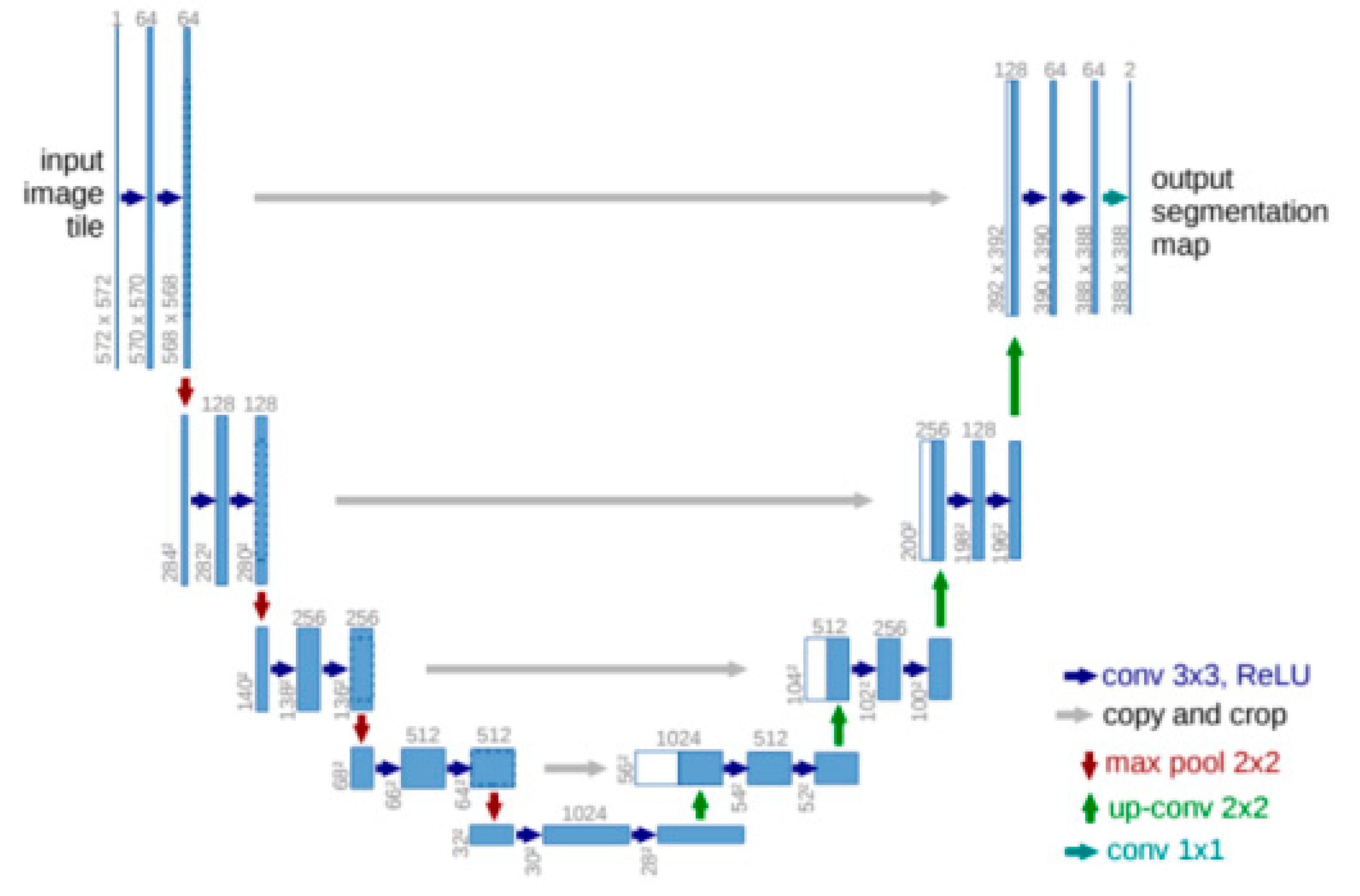
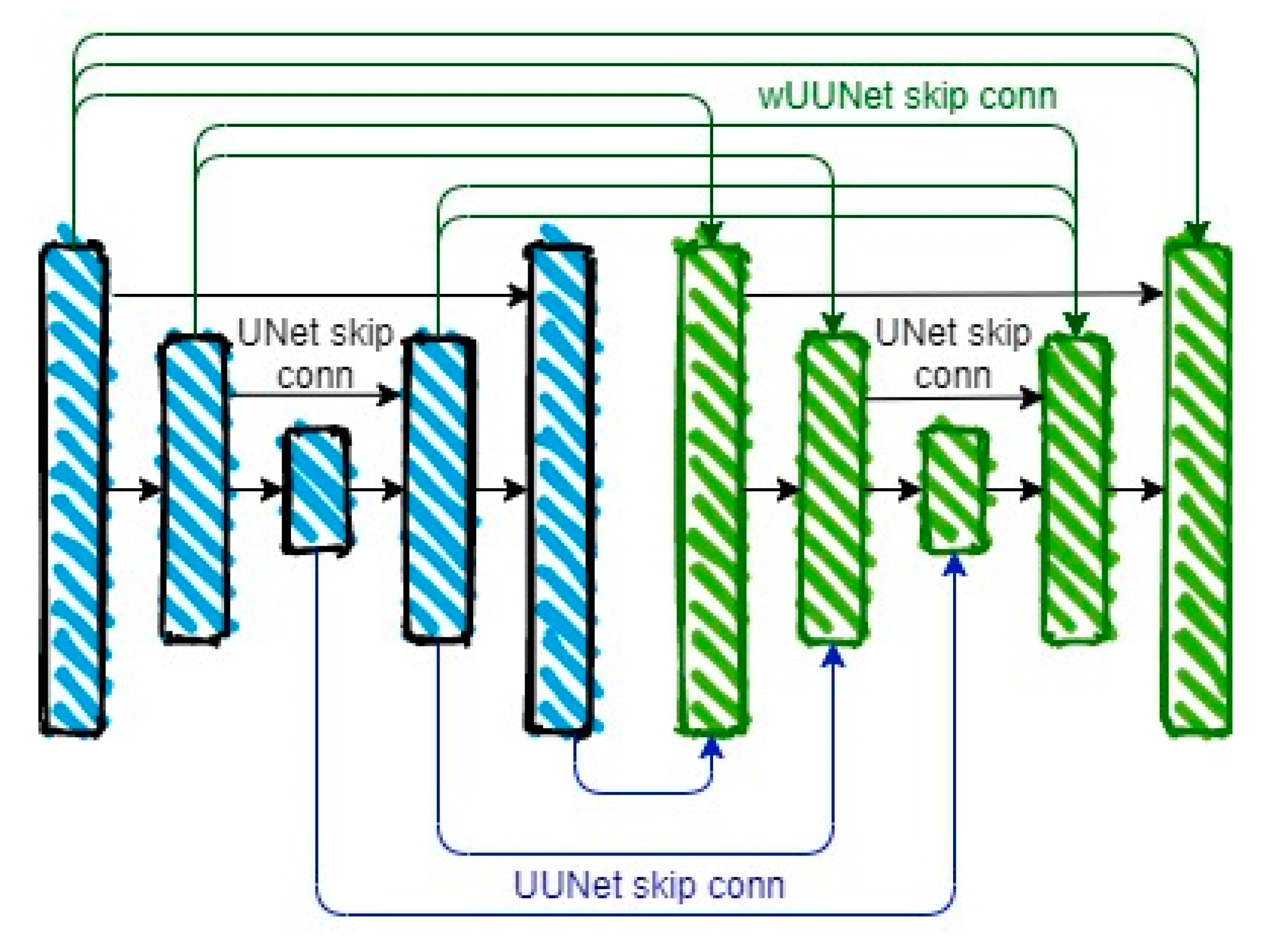
2.3. UUNet-Concantine and wUUNet
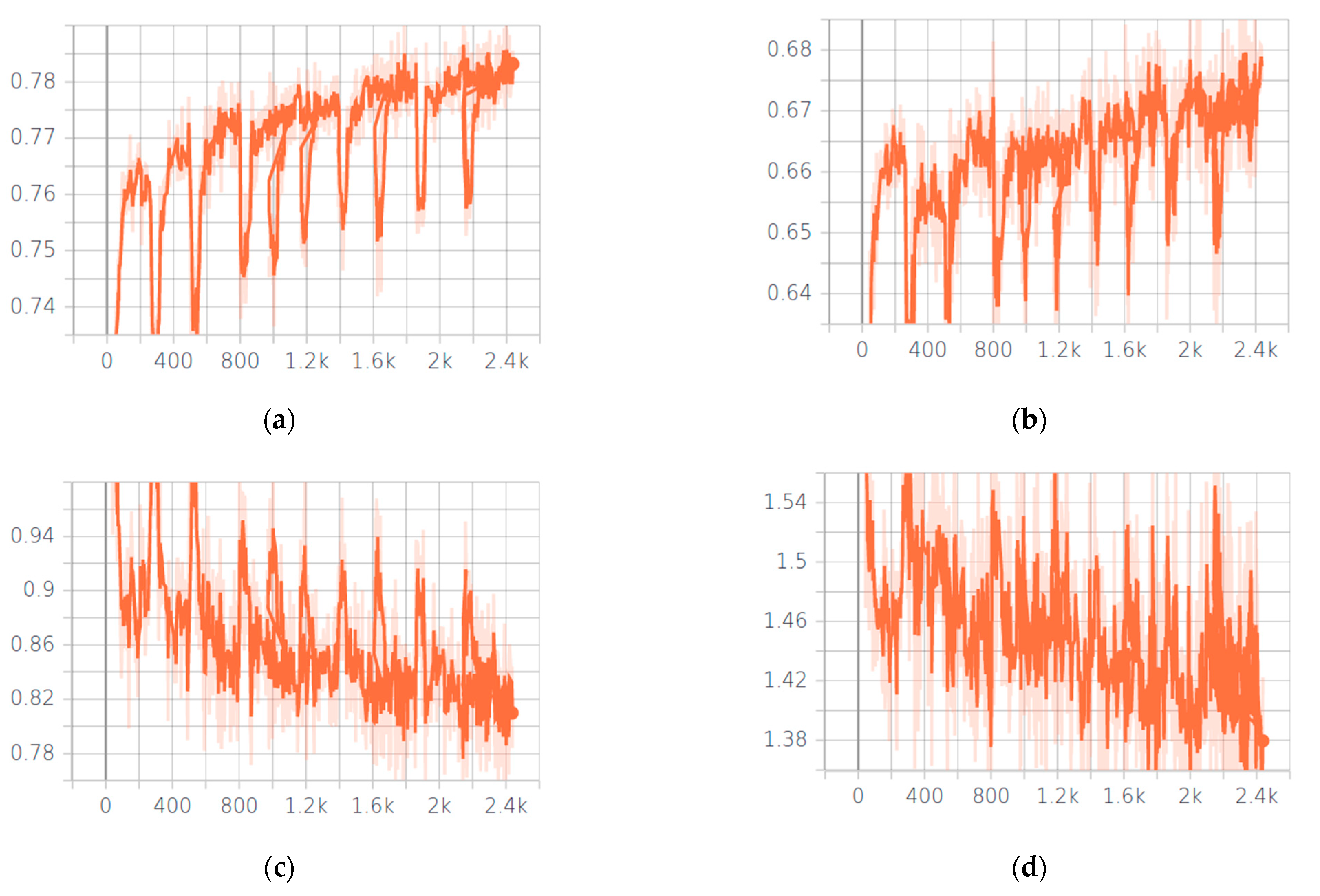
3. Results
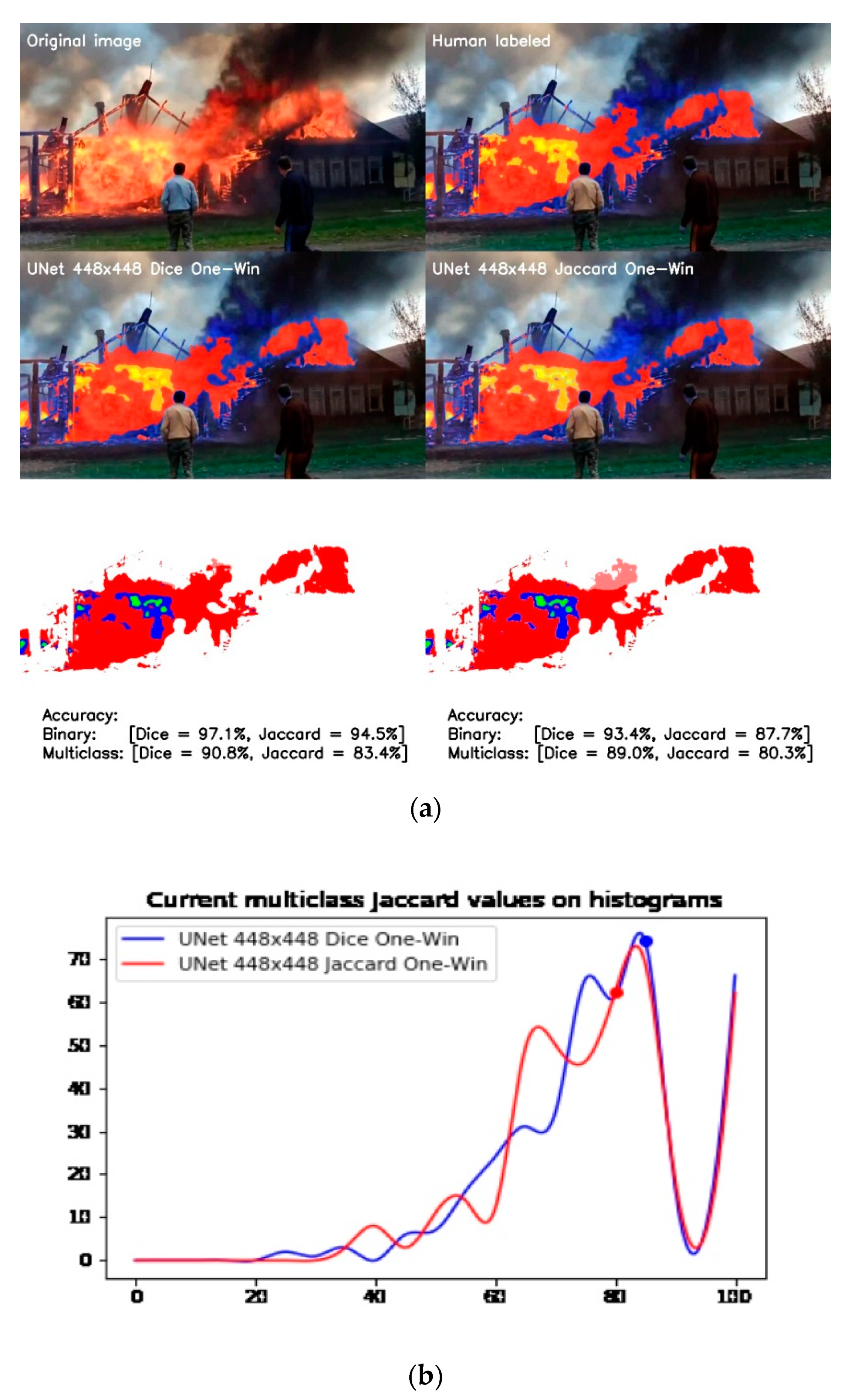
3.1. UNet One-Window vs. Full-Size
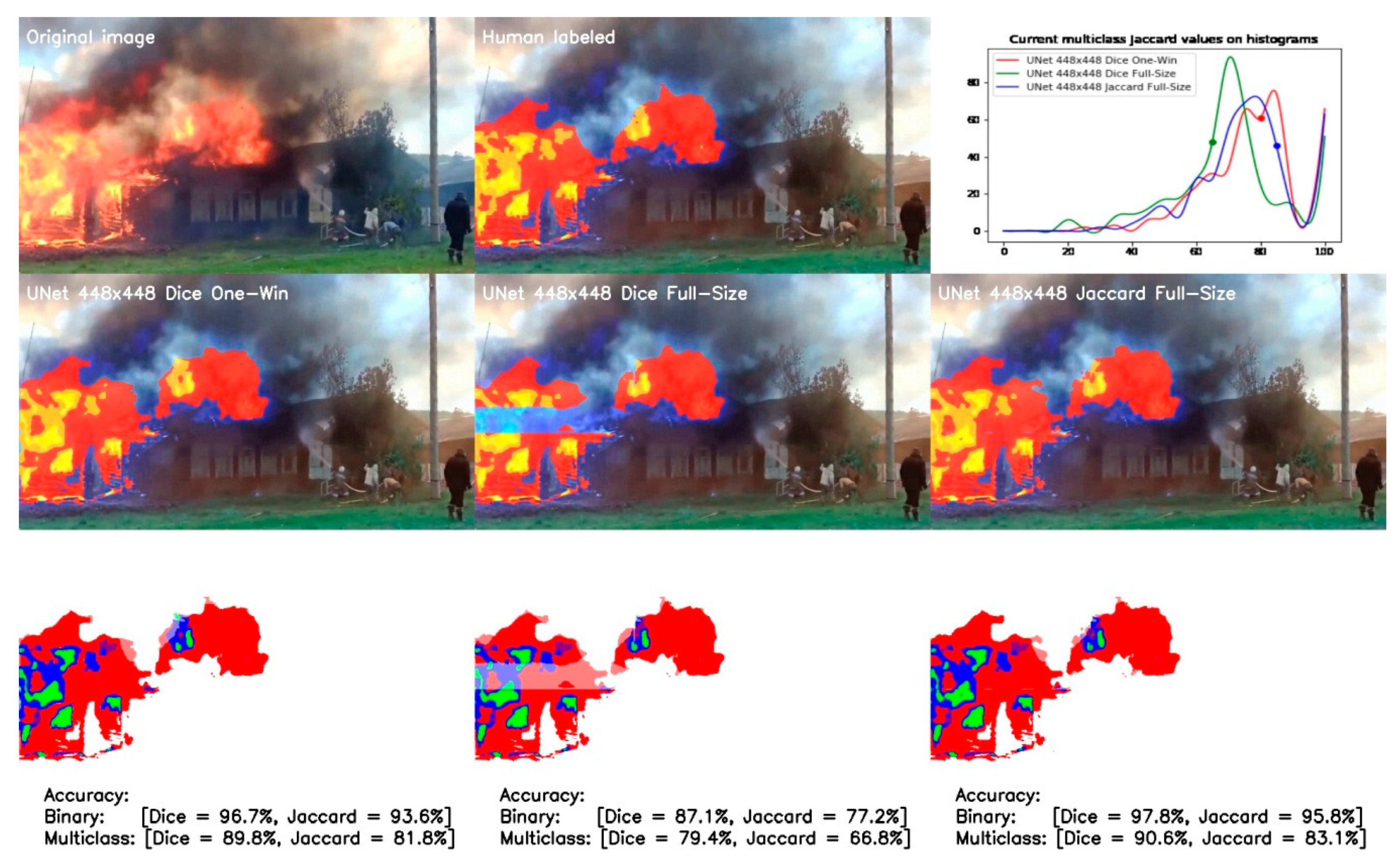
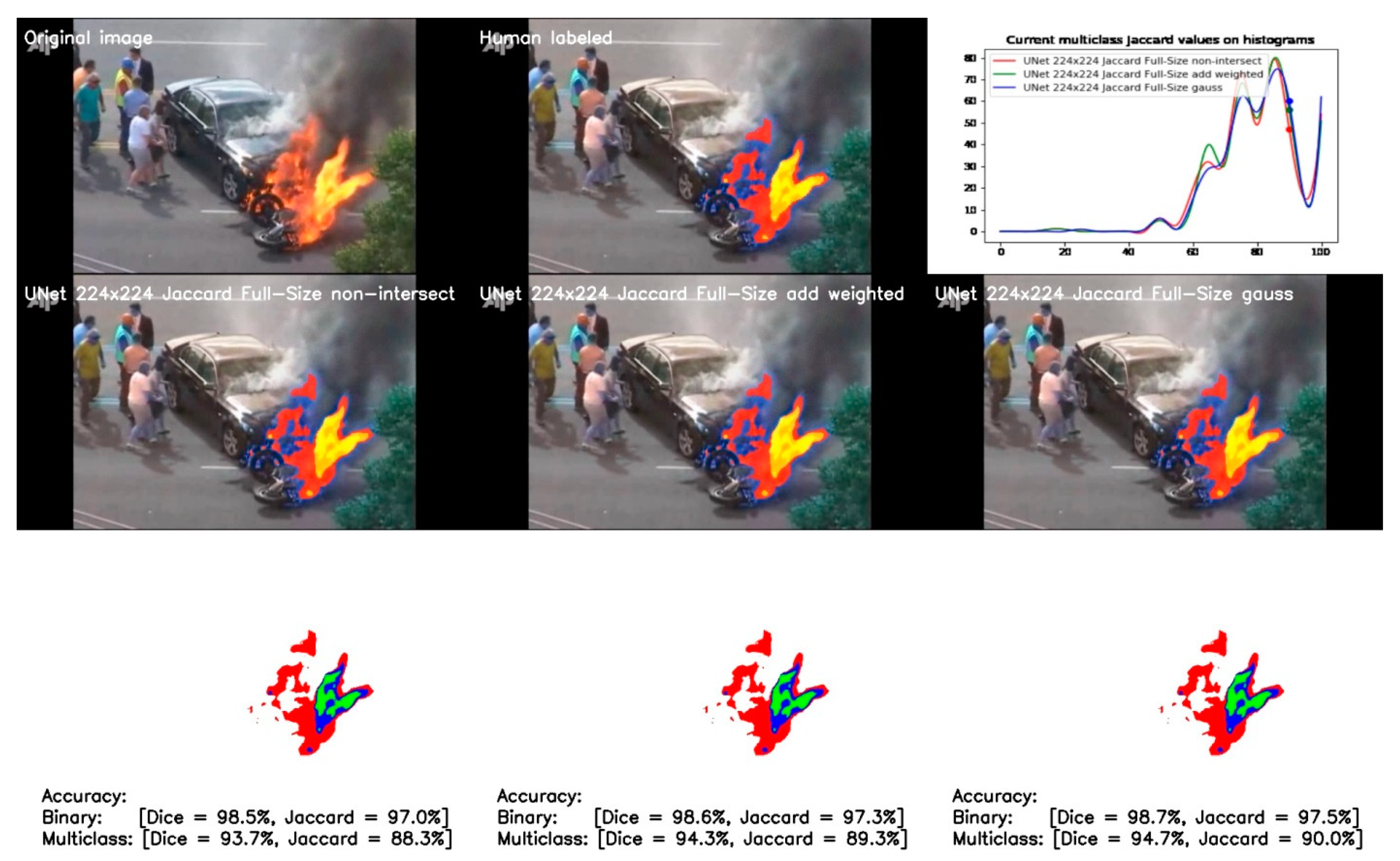
3.2. Non-Intersected vs. Averaged Half-Intersected Calculation Schemes
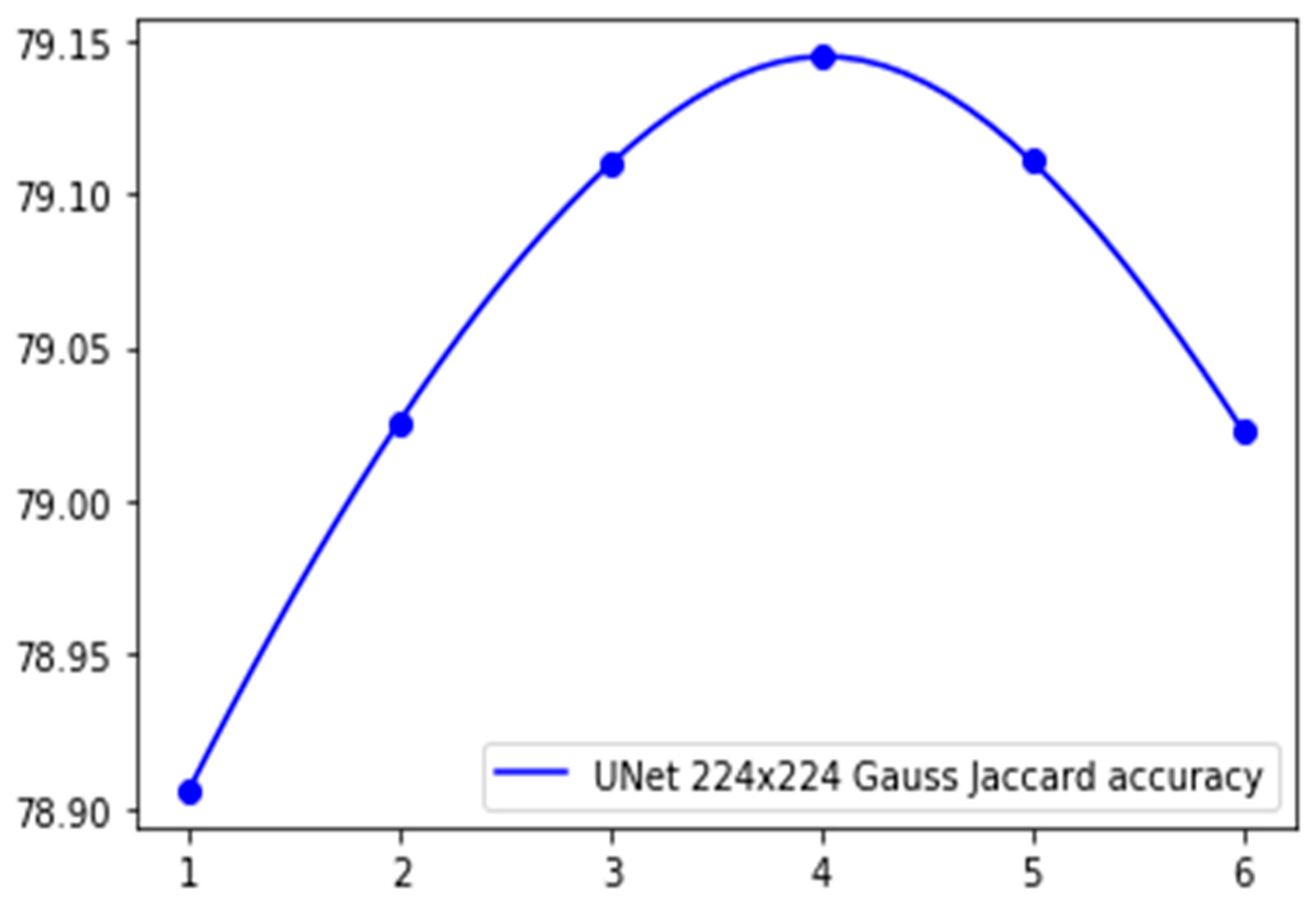
3.3. UUNet and wUUNet
4. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Saponara, S.; Elhanashi, A.; Gagliardi, A. Real-time video fire/smoke detection based on CNN in antifire surveillance systems. J. Real-Time Image Process. 2020, 1–13. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. arXiv 2016, arXiv:1612.08242. [Google Scholar]
- Dunnings, A.; Brecknon, T.P. Experimentally defined convolutional neural network architecture variants for non-temporal real-time fire detection. In Proceedings of the International Conference on Image Processing, Athens, Greece, 7–10 October 2018. [Google Scholar]
- Wang, Z.; Zhang, H.; Guo, X. A novel fire detection approach based on CNN-SVM using tensorflow. In Proceedings of the International Conference on Intelligent Computing, Liverpool, UK, 7–10 August 2017. [Google Scholar]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Hartwig, A. Encoder-decoder with altrous separable convolution for semantic image segmentation. arXiv 2018, arXiv:1802.02611. [Google Scholar]
- Harkat, H.; Nascimento, J.; Bernandino, A. Fire segmentation using a DeepLabv3+ architecture. Image Signal Process. Remote Sens. 2020, XXVI, 11533. [Google Scholar]
- Mlich, J.; Kolpik, K.; Hradis, M.; Zemcik, P. Fire segmentation in Still images. In Proceedings of the International Conference on Advanced Concepts for Intelligent Vision Systems, Auckland, New Zealand, 10–14 February 2020. [Google Scholar]
- Korobeinichev, O.P.; Paletskiy, A.A.; Gonchikzhapov, M.B.; Shundrina, I.K.; Chen, H.; Liu, N. Combustion chemistry and decomposition kinetics of forest fuels. Procedia Eng. 2013, 62, 182–193. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fisher, P.; Brox, T. U-Net: Convolutional networks for biomedical image segmentation. arXiv 2015, arXiv:1505.04597. [Google Scholar]
- Kataeva, L.Y.; Maslennikov, D.A.; Loshchilova, N.A. On the laws of combustion wave suppression by free water in a homogeneous porous layer of organic combustive materials. Fluid Dyn. 2016, 51, 389–399. [Google Scholar] [CrossRef]
- Sorensen, T. A method of establishing groups of equal amplitude in plant sociology based on similarity of species and its application to analyses of the vegetation on Danish commons. Kongelie Dan. Vidensk. Selsk. 1948, 5, 1–34. [Google Scholar]
- Dice, L.R. Measures of the amount of ecologic association between species. Ecology 1945, 26, 297–302. [Google Scholar] [CrossRef]
- Jaccard, P. Etude comparative de la distribution florale dans une portion des Alpes et des Jura. Bull. Soc. Vaudoise Sci. Nat. 1901, 37, 547–579. [Google Scholar]
- Kingma, D.; Ba, J. Adam. A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers. Suprassing human-level performance on ImageNet classification. arXiv 2015, arXiv:1502.01852. [Google Scholar]
- Loshchilov, I.; Hutter, F. SGDR: Stochastic gradient descent with warm restarts. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
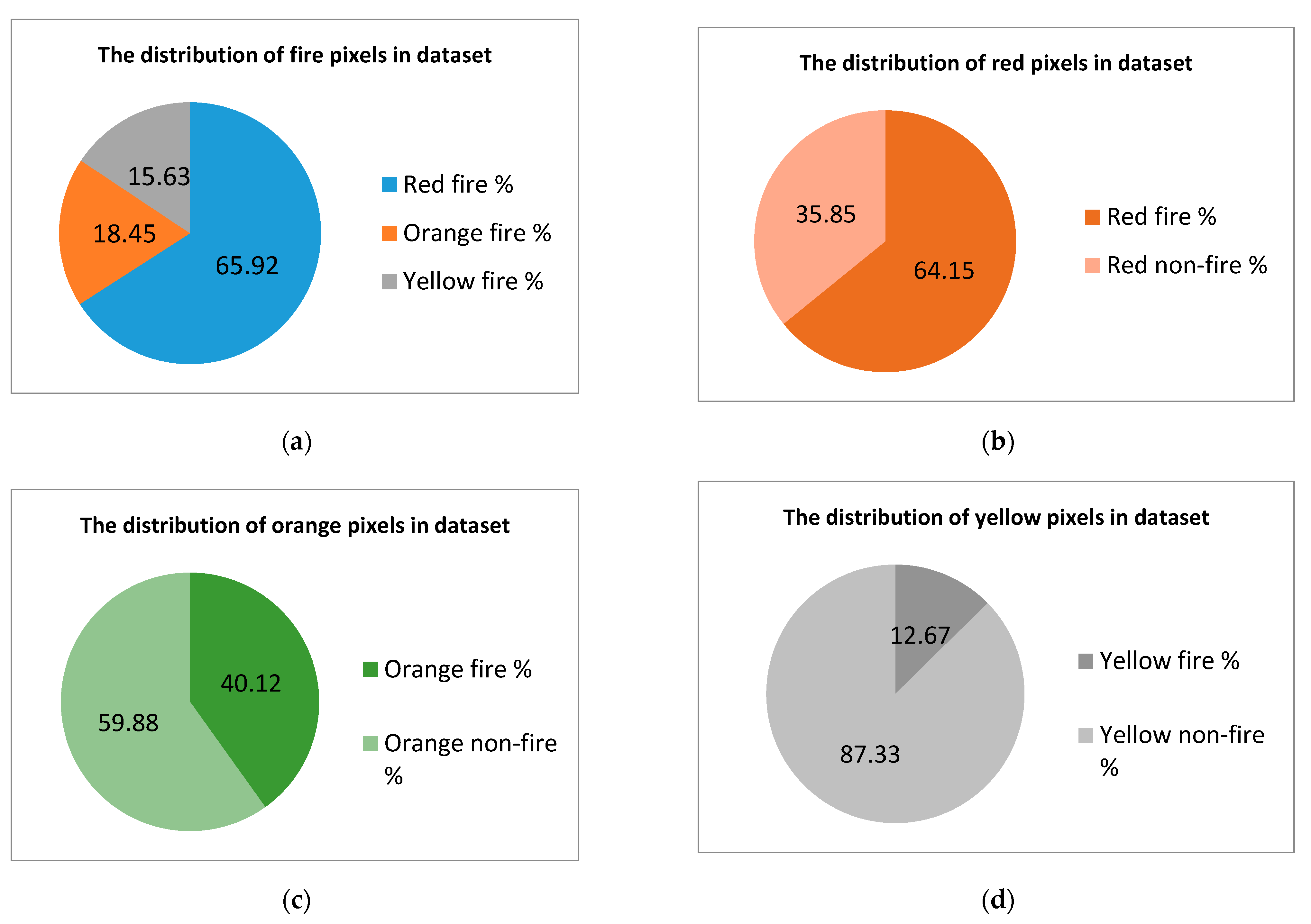{kind=link}
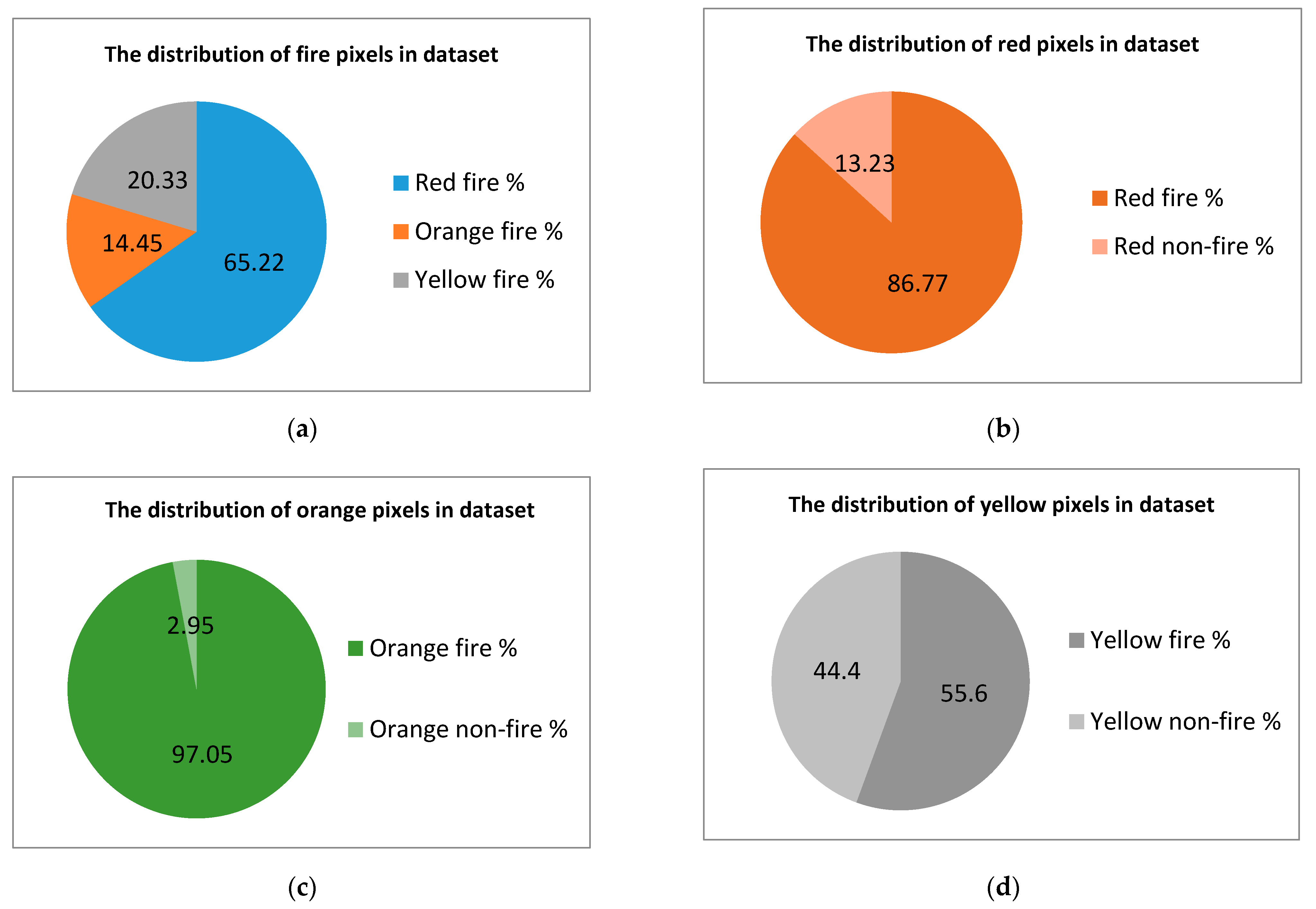{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type of Dataset | Number of Video Fragments | Number of Images 640 × 360 | Number of Images 640 × 480 | Number of Images with a Fire | Number of Images without a Fire |
|---|---|---|---|---|---|
| Training | 21 | 234 | 8 | 186 | 56 |
| Validation | 15 | 172 | 0 | 162 | 10 |
| Type of Dataset | Total Pixel Number | Number of Pixels Marked as Fire (%) | Number of Pixels Not Marked as Fire (%) |
|---|---|---|---|
| Training | 56,371,200 | 2.7 | 97.3 |
| Test | 39,628,800 | 8.33 | 91.67 |
| Model | Binary Dice | Binary Jaccard | Multiclass Dice | Multiclass Jaccard | ||||
|---|---|---|---|---|---|---|---|---|
| OW Jacc | 88.78 | 19.57 | 83.44 | 19.96 | 83.37 | 10.69 | 74.51 | 12.25 |
| OW Dice | 91.74 | 15.04 | 86.89 | 15.79 | 85.12 | 9.95 | 76.56 | 11.99 |
| FS Dic 448 | 91.45 | 15.11 | 86.52 | 15.63 | 85.36 | 9.09 | 76.64 | 11.60 |
| FS Jacc 448 | 92.71 | 12.41 | 88.01 | 13.42 | 85.89 | 8.98 | 77.33 | 11.48 |
| FS Jacc 224 | 91.55 | 18.04 | 87.43 | 18.30 | 85.98 | 11.05 | 78.26 | 12.08 |
| Model | Binary Dice | Binary Jaccard | Multiclass Dice | Multiclass Jaccard | ||||
|---|---|---|---|---|---|---|---|---|
| UNet 448 | 92.71 | 12.41 | 88.01 | 13.42 | 85.89 | 8.98 | 77.33 | 11.48 |
| UNet non-int | 91.74 | 18.04 | 87.43 | 18.30 | 85.98 | 11.05 | 78.26 | 12.08 |
| UNet addw | 91.57 | 18.07 | 87.49 | 18.41 | 86.31 | 11.04 | 78.75 | 12.10 |
| UNet Gauss | 92.10 | 16.53 | 87.96 | 17.04 | 86.69 | 10.05 | 79.15 | 11.45 |
| Model | Binary Dice | Binary Jaccard | Multiclass Dice | Multiclass Jaccard | ||||
|---|---|---|---|---|---|---|---|---|
| UNet 448 | 92.71 | 12.41 | 88.01 | 13.42 | 85.89 | 8.98 | 77.33 | 11.48 |
| UNet non-int | 91.74 | 18.04 | 87.43 | 18.30 | 85.98 | 11.05 | 78.26 | 12.08 |
| UNet addw | 91.57 | 18.07 | 87.49 | 18.41 | 86.31 | 11.04 | 78.75 | 12.10 |
| UNet Gauss | 92.10 | 16.53 | 87.96 | 17.04 | 86.69 | 10.05 | 79.15 | 11.45 |
| UUNet addw | 93.32 | 12.25 | 89.02 | 13.02 | 87.06 | 9.42 | 79.29 | 11.30 |
| UUNet Gauss | 93.77 | 12.33 | 89.92 | 13.00 | 87.47 | 9.37 | 79.91 | 11.12 |
| wUUNet non-int | 94.09 | 10.34 | 89.99 | 11.45 | 87.04 | 9.63 | 79.20 | 11.60 |
| wUUNet addw | 94.71 | 8.23 | 90.68 | 9.63 | 87.45 | 9.50 | 79.74 | 11.56 |
| wUUNet Gauss | 95.34 | 3.99 | 91.35 | 6.79 | 87.87 | 8.80 | 80.23 | 11.15 |
| Model | FPS | Number of Parallel Video Streams (RTX2070 8G) | Minimal Memory Consumption (RTX2070 8G, 1 Stream) in G |
|---|---|---|---|
| UNet 448 OW | 103 | 14 | 1.7 |
| UNet 448 FS | 102 | 7 | 2.1 |
| UNet 224 FS | 98 | 5 | 2.7 |
| UNet Gauss | 64 | 3 | 4.0 |
| UNet addw | 83 | 3 | 3.9 |
| UUNet Gauss | 63 | 2 | 4.1 |
| wUUNet Gauss | 63 | 2 | 5.5 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bochkov, V.S.; Kataeva, L.Y. wUUNet: Advanced Fully Convolutional Neural Network for Multiclass Fire Segmentation. Symmetry 2021, 13, 98. https://doi.org/10.3390/sym13010098
Bochkov VS, Kataeva LY. wUUNet: Advanced Fully Convolutional Neural Network for Multiclass Fire Segmentation. Symmetry. 2021; 13(1):98. https://doi.org/10.3390/sym13010098
Chicago/Turabian StyleBochkov, Vladimir Sergeevich, and Liliya Yurievna Kataeva. 2021. "wUUNet: Advanced Fully Convolutional Neural Network for Multiclass Fire Segmentation" Symmetry 13, no. 1: 98. https://doi.org/10.3390/sym13010098
APA StyleBochkov, V. S., & Kataeva, L. Y. (2021). wUUNet: Advanced Fully Convolutional Neural Network for Multiclass Fire Segmentation. Symmetry, 13(1), 98. https://doi.org/10.3390/sym13010098