Persistence Analysis and Prediction of Low-Visibility Events at Valladolid Airport, Spain

 , ,
, , 
Abstract
1. Introduction
2. Data and Methods
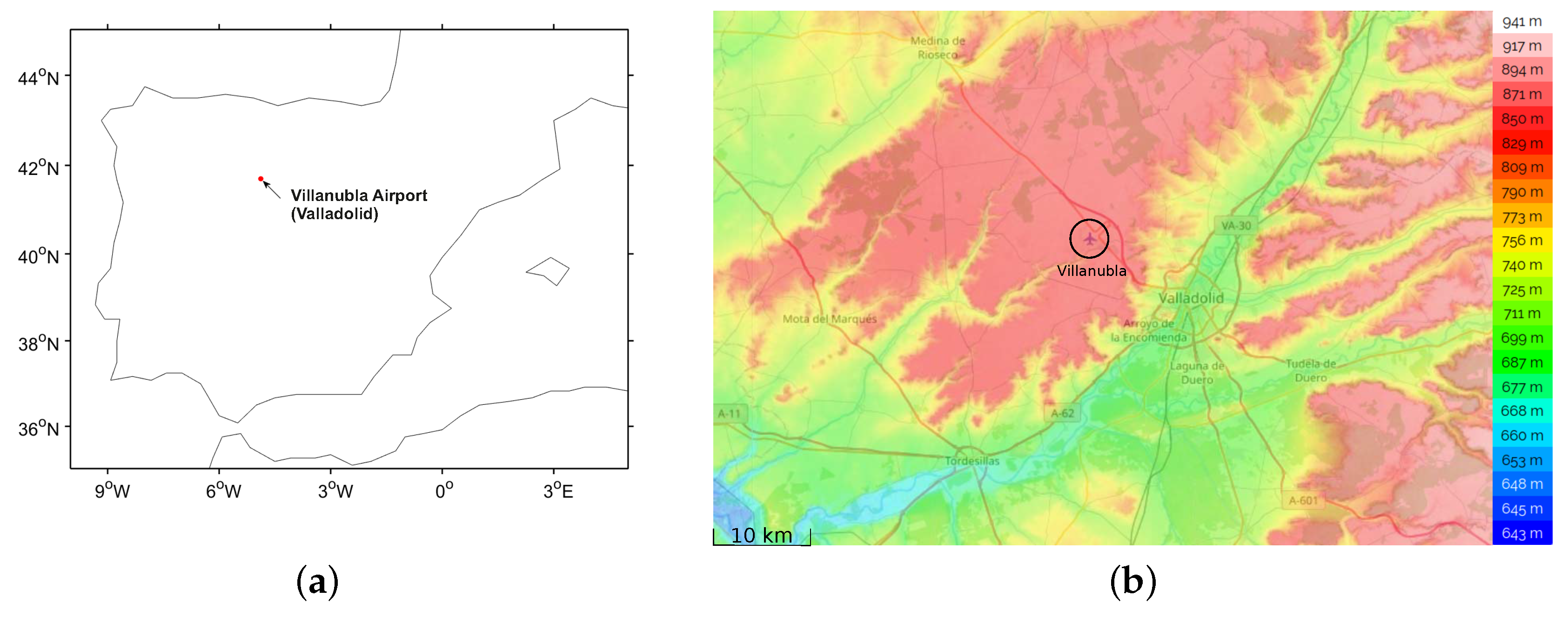
2.1. Data Description
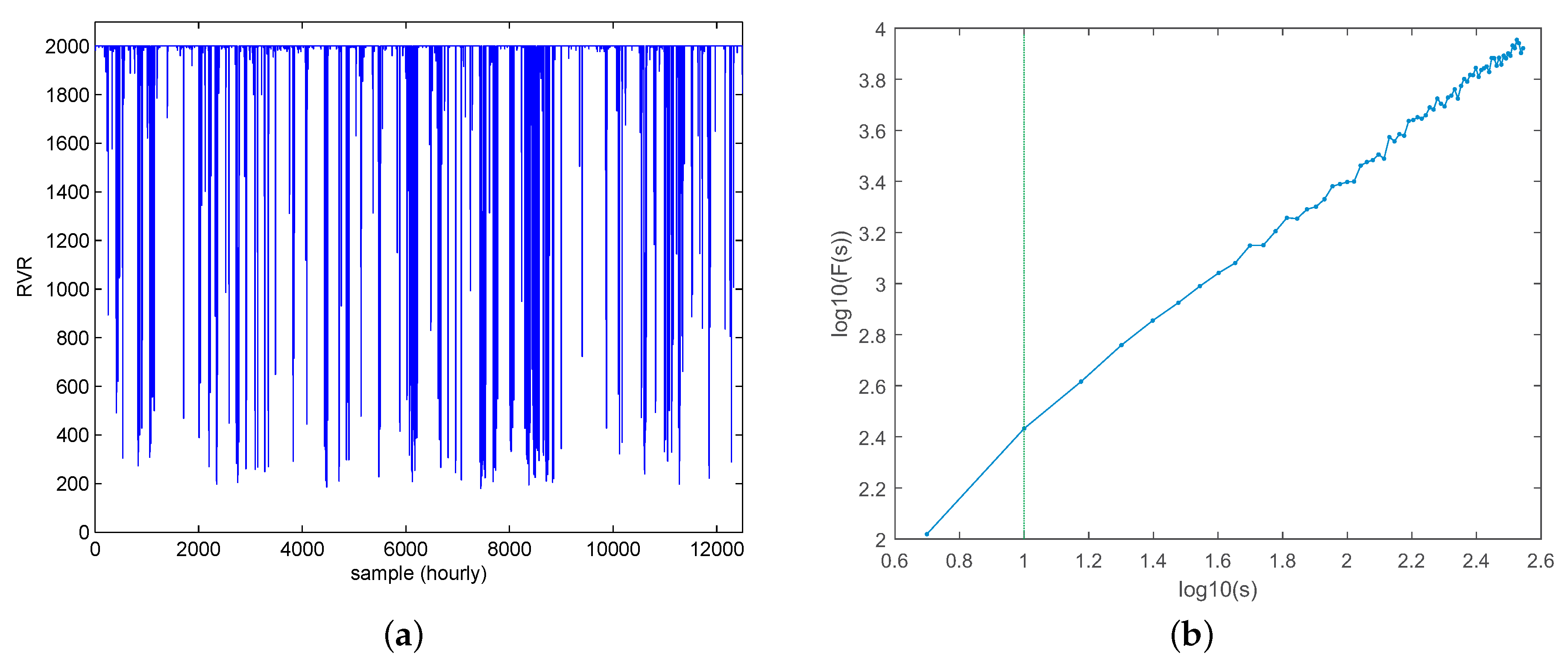
2.2. Methods for Long-Term Persistence: Detrended Fluctuation Analysis.
- (1)
- We first remove the periodic annual cycle of the time series, by the procedure explained in detail in [22]. Adapted to our problem, the process consists of standardizing the input time series of length N as follows:where stands for the original hourly RVR time series, represents the mean value of the hourly RVR time series and is its standard deviation.
- (2)
- Then, the time series profile is computed as follows:The profile is divided into non-overlapping segments of equal length s.For each segment , we calculate the local least squares straight-line which measures its local trend. As a result, we obtain a linear piece-wise function compounding each linear fitting:where the superscript s refers to the time window length used to the linear fitting of each piece.
- (3)
- We then obtain the so-called fluctuation as the root-mean-square error from this linear piece-wise function and the profile , varying the time window length s:At the time scale range where the scaling holds, increases with the time window s following a power law . Thus, the fluctuation versus the time scale s would be depicted as a straight line in a log-log plot. The slope of the fitted linear regression line is the scaling exponent , also called correlation exponent. The scaling exponent in the DFA method is a generalization of the Hurst exponent (H) [35], and in this context they have the same meaning. The Hurst coefficient is frequently used as a measure of long-term persistence of time series, i.e., H (or in our case) provides a measure of possible simple power law scaling of the power spectrum with frequency f (sometimes referred to as “self-similar” behavior [36]):where the scaling exponent is given by .Note that when the coefficient , the time series is uncorrelated, which means that there is no long-term persistence in the time series. For larger values of (), the time series is positively long-term correlated, which also means the long-term persistence exists across the corresponding scale range. When the process is anti-persistent. For , the persistence becomes so extreme that the time series exhibits non-stationary behavior.
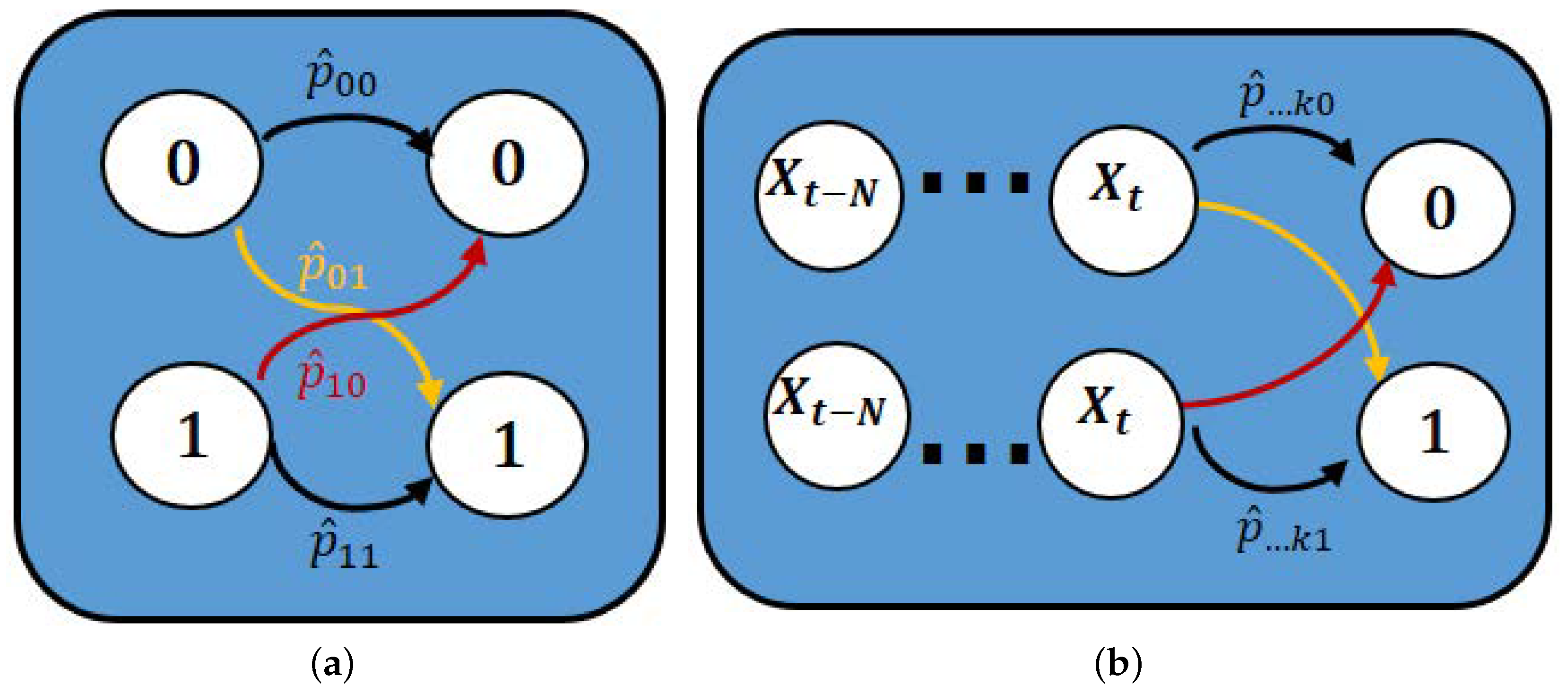
2.3. Methods for Short-Term Persistence: Markov Chain Models
2.4. Machine Learning Techniques for Classification and Prediction
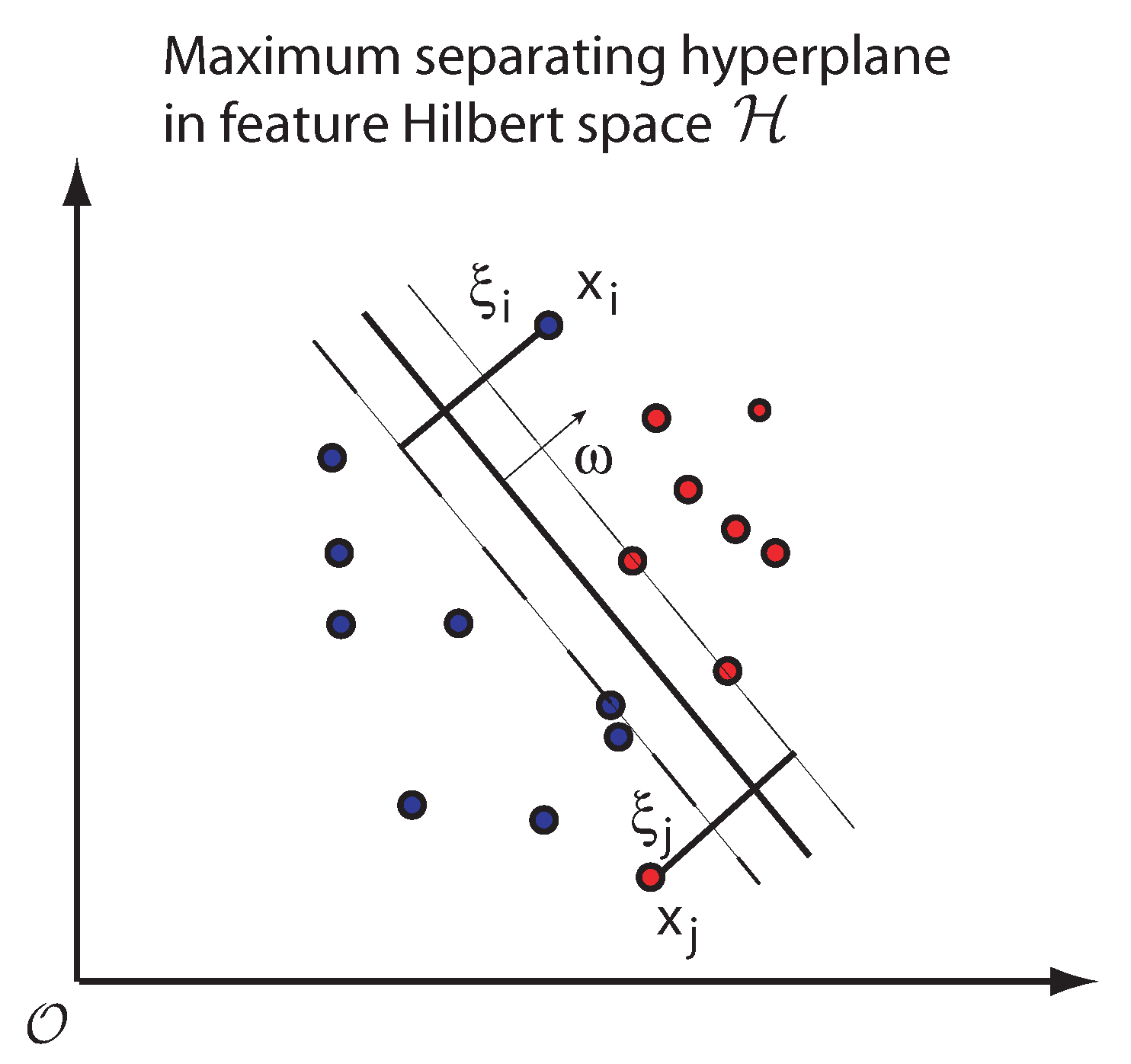
2.4.1. Support Vector Machines
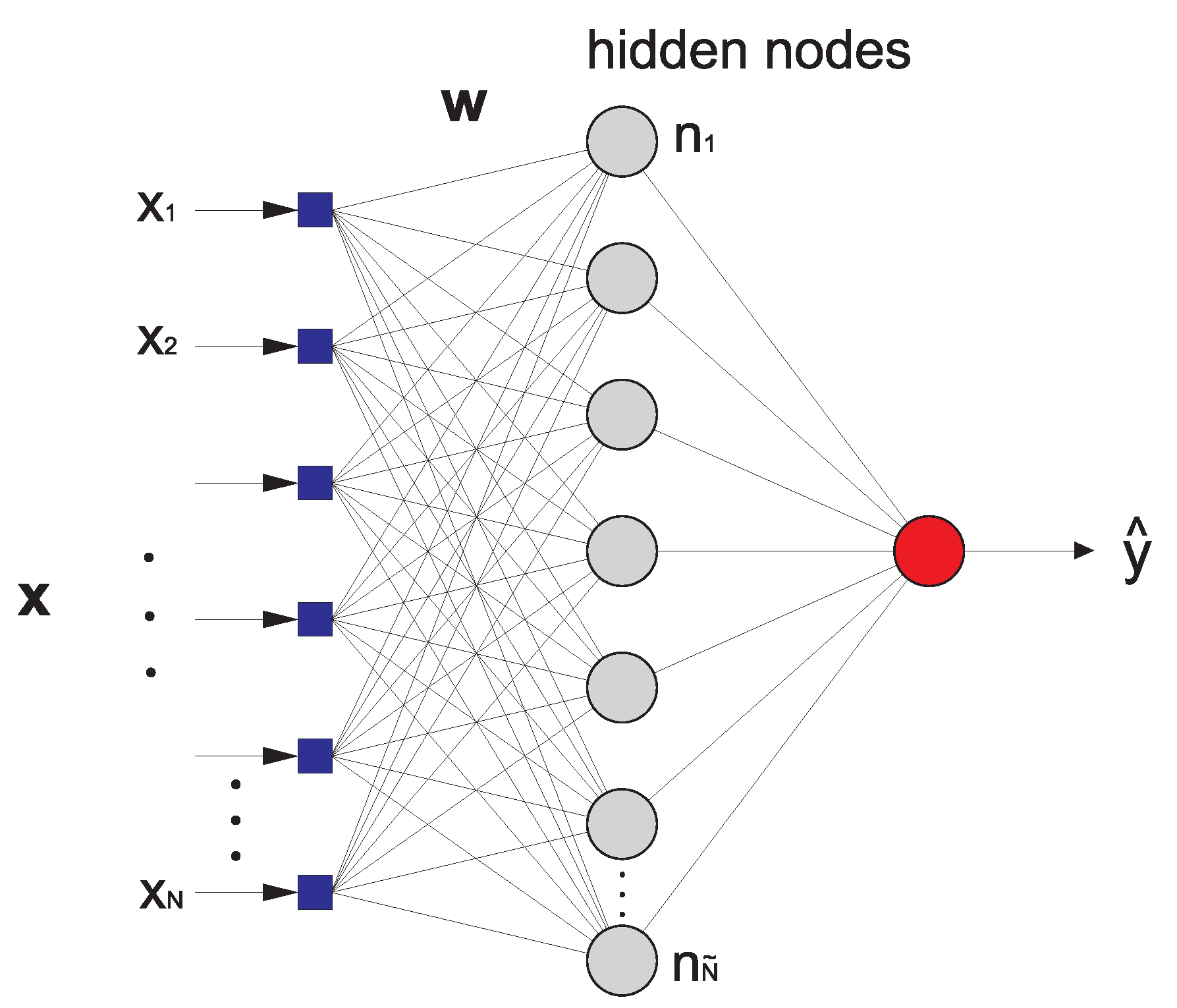
2.4.2. Extreme-Learning Machines
- Randomly assign ELM weights values and the bias , where , according to a uniform probability distribution in the interval .
- Calculate the hidden-layer output matrix , defined as follows:
- Finally, calculate the output weight vector as follows:where is the Moore-Penrose inverse of the matrix [42], and is the training output vector, .
2.4.3. Synthetic Minority Over-Sampling Technique
- Let be a vector of characteristics and N the number of features.
- Let X be a sample with N features for which its KNN are calculated.
- Let Y be one of its KNN with the same size.
- The synthetic sample, Z, would be:where is a uniform random variable equally distributed in the interval , which causes the selection of an aleatory point in the segment between two particular features.
3. Experiments and Results
3.1. Results: Long-Term Persistence Analysis
3.2. Results: Short-Term Persistence Analysis
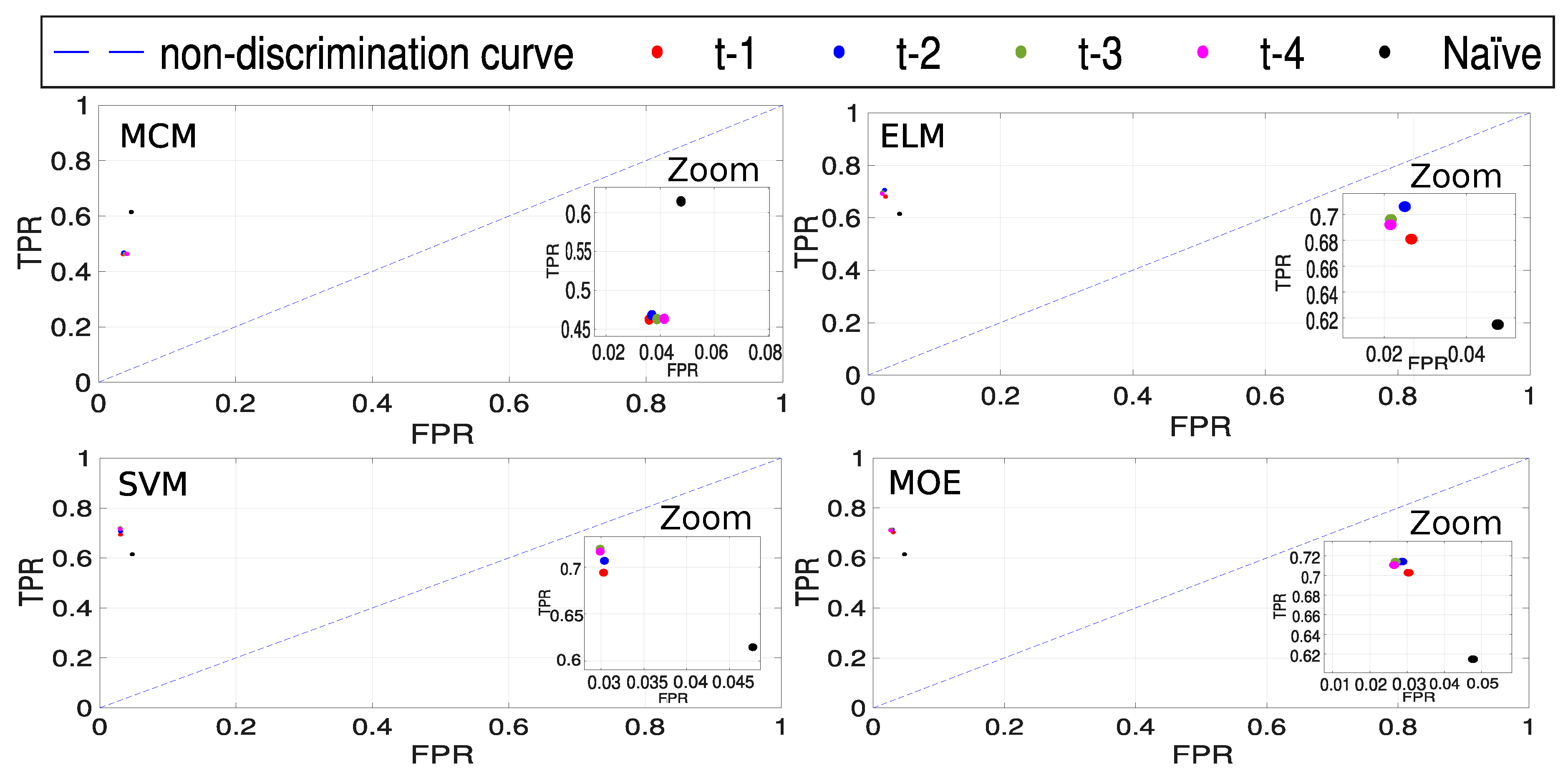
3.3. Results: Short-Term Prediction
3.4. Discussion of the Results
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| RVR | Runway Visual Range |
| DFA | Detrended Fluctuation Analysis |
| ML | Machine Learning |
| MCM | Markov Chain Model |
| MOE | Mixture of Experts |
| ELM | Extreme Learning Machine |
| SVM | Support Vector Machine |
| SV | Support Vector |
| SMOTE | Synthetic Minority Over-sampling Technique |
| KNN | k nearest neighbors |
| ACC | Accuracy |
| TPR | True Positive Rate |
| TNR | True Negative Rate |
| F1S | F1 score |
| TP | True Positive |
| TN | True Negative |
| FP | False Positive |
| FPR | False Positive Rate |
| FN | False Negative |
| P | Number of real positives |
| N | Number of real negatives |
References
- da Rocha, R.P.; Gonçalves, F.L.; Segalin, B. Fog events and local atmospheric features simulated by regional climate model for the metropolitan area of Sao Paulo, Brazil. Atmos. Res. 2015, 151, 176–188. [Google Scholar] [CrossRef]
- Huang, H.; Chen, C. Climatological aspects of dense fog at Urumqi Diwopu International Airport and its impacts on flight on-time performance. Nat. Hazards 2016, 81, 1091–1106. [Google Scholar] [CrossRef]
- Dey, S. On the theoretical aspects of improved fog detection and prediction in India. Atmos. Res. 2018, 202, 77–80. [Google Scholar] [CrossRef]
- Bergot, E.T.; Terradellas, J.; Cuxart, A.; Mira, O.; Liechti, M.; Mueller, N.; Nielsen, W. Intercomparison of single-column numerical models for the prediction of radiation fog. J. Appl. Meteor. Clim. 2007, 46, 504–521. [Google Scholar] [CrossRef]
- der Velde, I.V.; Steeneveld, G.; Wichers-Schreur, B.; Holtslag, A. Modeling and forecasting the onset and duration of severe radiation fog under frost conditions. Month. Weather Rev. 2010, 138, 4237–4253. [Google Scholar] [CrossRef]
- Zhou, B.; Du, J.; Gultepe, I.; Dimego, G. Forecast of low visibility and fog from NCEP: Current status and efforts. Pure App. Geoph. 2011, 169, 895–909. [Google Scholar] [CrossRef]
- Román-Cascón, C.; Yagüe, C.; Sastre, M.; Maqueda, G.; Salamanca, F.; Viana, S. Observations and WRF simulations of fog events at the Spanish northern plateau. Adv. Sci. Res. 2012, 8, 11–18. [Google Scholar] [CrossRef]
- Steeneveld, G.; Ronda, R.; Holtslag, A. The challenge of forecasting the onset and development of radiation fog using mesoscale atmospheric models. Bound. Layer Met. 2015, 154, 265–289. [Google Scholar] [CrossRef]
- Koziara, M.; Robert, J.; Thompson, W. Estimating marine fog probability using a model output statistics scheme. Month. Weather Rev. 1983, 111, 2333–2340. [Google Scholar] [CrossRef]
- Fabbian, D.; De-Dear, R.; Lellyett, S. Application of artificial neural network forecasts to predict fog at Canberra international airport. Weather Forecast. 2007, 22, 372–381. [Google Scholar] [CrossRef]
- Miao, Y.; Potts, R.; Huang, X.; Elliott, G.; Rivett, R. A fuzzy logic fog forecasting model for Perth Airport. Pure App. Geoph. 2012, 169, 1107–1119. [Google Scholar] [CrossRef]
- Colabone, R.O.; Ferrari, A.; da Silva-Vecchia, F.; Bruno-Tech, A. Application of artificial neural networks for fog forecast. J. Aerosp. Technol. Manag. 2015, 7, 240–246. [Google Scholar] [CrossRef]
- Boneh, T.; Weymouth, G.; Newham, P.; Potts, R.; Bally, J.; Nicholson, A.; Korb, K. Fog forecasting for Melbourne airport using a Bayesian decision network. Weather Forecast. 2015, 30, 1218–1233. [Google Scholar] [CrossRef]
- Dutta, D.; Chaudhuri, S. Nowcasting visibility during wintertime fog over the airport of a metropolis of India: Decision tree algorithm and artificial neural network approach. Nat. Hazards 2015, 75, 1349–1368. [Google Scholar] [CrossRef]
- Cornejo-Bueno, L.; Casanova-Mateo, C.; Sanz-Justo, J.; Cerro-Prada, E.; Salcedo-Sanz, S. Efficient prediction of low-visibility events at airports using Machine-Learning regression. Bound. Layer Met. 2017, 165, 349–370. [Google Scholar] [CrossRef]
- Guijo-Rubio, D.; Gutiérrez, P.A.; Casanova-Mateo, C.; Sanz-Justo, J.; Salcedo-Sanz, S.; Hervás-Martínez, C. Prediction of low-visibility events due to fog using ordinal classification. Atmos. Res. 2018, 214, 64–73. [Google Scholar] [CrossRef]
- Fernández-González, S.; Bolgiani, P.; Fernández-Villares, J.; González, P.; Garcá-Gil, A.; Suarez, J.C.; Merino, A. Forecasting of poor visibility episodes in the vicinity of Tenerife Norte Airport. Atmos. Res. 2019, 223, 49–59. [Google Scholar] [CrossRef]
- Perez-Ortiz, M.; Gutierrez, P.A.; Tino, P.; Casanova-Mateo, C.; Salcedo-Sanz, S. A mixture of experts model for predicting persistent weather patterns. In Proceedings of the International Joint Conference on Neural Networks, Rio de Janeiro, Brazil, 8–13 July 2018. [Google Scholar]
- Bunde, A.; Havlin, S.; Koscielny-Bunde, E.; Schellnhuber, H.J. Longterm persistence in the atmosphere: Global laws and tests of climate models. Physica A 2001, 302, 255–267. [Google Scholar] [CrossRef]
- Bunde, A.; Havlin, S. Power-law persistence in the atmosphere and in the oceans. Physica A 2002, 314, 15–24. [Google Scholar] [CrossRef]
- Pelletier, J.D.; Turcotte, D.L. Long-range persistence in climatological and hydrological time series: Analysis, modeling and application to drought hazard assessment. J. Hydrol. 1997, 203, 198–208. [Google Scholar] [CrossRef]
- Yang, L.; Fu, Z. Process-dependent persistence in precipitation records. Physica A 2019, 527, 121459. [Google Scholar] [CrossRef]
- Koçak, K. Practical ways of evaluating wind speed persistence. Energy 2008, 33, 65–70. [Google Scholar] [CrossRef]
- Gadian, A.; Dewsbury, J.; Featherstone, F.; Levermore, J.; Morris, K.; Sanders, C. Directional persistence of low wind speed observations. J. Wind Eng. Ind. Aerodyn. 2004, 92, 1061–1074. [Google Scholar] [CrossRef]
- Jiang, L. Mean wind speed persistence over China. Physica A 2018, 502, 211–217. [Google Scholar] [CrossRef]
- Zhang, W.F.; Zhao, Q. Asymmetric long-term persistence analysis in sea surface temperature anomaly. Physica A 2015, 428, 314–318. [Google Scholar] [CrossRef]
- Voyant, C.; Notton, G. Solar irradiation nowcasting by stochastic persistence: A new parsimonious, simple and efficient forecasting tool. Renew. Sustain. Energy Rev. 2018, 92, 343–352. [Google Scholar] [CrossRef]
- Harrouni, S.; Guessoum, A. Using fractal dimension to quantify long-range persistence in global solar radiation. Chaos Sol. Fract. 2009, 41, 1520–1530. [Google Scholar] [CrossRef]
- Morales-Rodriguez, C.; Ortega-Villazan, M. Approximation to the study of fogs in middle Duero valley. Geogr. Res. 1994, 12, 23–44. [Google Scholar]
- AEMET. Aeronautical Climatology of Valladolid/Villanubla; Technical Report; Agencia Estatal de Meteorología: Madrid, Spain, 2015. [Google Scholar]
- CPeng, K.; Buldyrev, S.V.; Havlin, S.; Simons, M.; Stanley, H.E.; Goldberger, A.L. Mosaic organization of DNA nucleotides. Phys. Rev. E 1994, 49, 1685–1689. [Google Scholar]
- Peng, C.K.; Havlin, S.; Stanley, H.E.; Goldberger, A.L. Quantification of scaling exponents and crossover phenomena in nonstationary hear beat time series. Chaos 1995, 5, 82–87. [Google Scholar] [CrossRef]
- Li, J.M.; Wei, H.J.; Wei, L.D.; Zhou, D.P.; Qiu, Y. Extraction of frictional vibration features with multifractal Detrended Fluctuation Analysis and Friction State recognition. Symmetry 2020, 12, 272. [Google Scholar] [CrossRef]
- Hu, K.; Ivanov, P.C.; Chen, Z.; Carpena, P.; Stanley, H.E. Effect of Trends on Detrended Fluctuation Analysis. Phys. Rev. E 2001, 011114. [Google Scholar] [CrossRef] [PubMed]
- Graves, T.; Gramacy, R.; Watkins, N.; Franzke, C. A Brief History of Long Memory: Hurst, Mandelbrot and the Road to ARFIMA, 1951–1980. Entropy 2017, 19, 437. [Google Scholar] [CrossRef]
- Mann, M.E. On long range dependence in global surface temperature series. Clim. Chang. 2011, 107, 267–276. [Google Scholar] [CrossRef]
- Wilks, D.S. Statistical Methods in the Atmospheric Sciences; Academic Press: Cambridge, MA, USA, 2011; Volume 100. [Google Scholar]
- Cazacioc, L.; Cipu, E.C. Evaluation of the transition probabilities for daily precipitation time series using a Markov chain model. In Proceedings of the 3rd International Colloquium-Mathematics in Engineering and Numerical Physics, Bucharest, Romania, 7–9 October 2004; Volume 12, pp. 82–92. [Google Scholar]
- Katz, R.W. Precipitation as a Chain-Dependent Process. J. Appl. Met. 1977, 16, 671–676. [Google Scholar] [CrossRef]
- Cristianini, N.; Shawe-Taylor, J. An Introduction to Support Vector Machines and Other Kernel-Based Learning Methods; Cambridge University Press: New York, NY, USA, 2000. [Google Scholar]
- Salcedo-Sanz, S.; Rojo, J.L.; Martínez-Ramón, M.; Camps-Valls, G. Support vector machines in engineering: An overview. WIREs Data-Min. Know. Disc. 2014, 4, 234–267. [Google Scholar] [CrossRef]
- Huang, G.B.; Zhu, Q.Y. Extreme learning machine: Theory and applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- Huang, G.B.; Zhou, H.; Ding, X.; Zhang, R. Extreme Learning Machine for Regression and Multiclass Classification. IEEE Trans. Syst. Man Cybern. Part B 2012, 42, 513–529. [Google Scholar] [CrossRef] [PubMed]
- Pérez-Ortiz, M.; Jiménez-Fernández, S.; Gutiérrez, P.A.; Alexandre, E.; Hervás, C.; Salcedo-Sanz, S. A review of classification problems and algorithms in renewable energy applications. Energies 2016, 9, 607. [Google Scholar] [CrossRef]
- Schölkopf, B.; Smola, A. Learning with Kernels—Support Vector Machines, Regularization, Optimization and Beyond; MIT Press: Cambridge, MA, USA, 2002. [Google Scholar]
- Bhartendu, MATLAB Central File Exchange. Available online: https://www.mathworks.com/matlabcentral/fileexchange/63158-support-vector-machine (accessed on 18 December 2019).
- Huang, G.B. ELM Matlab Code. Available online: http://www.ntu.edu.sg/home/egbhuang/elm_codes.html (accessed on 22 June 2020).
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intel. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Fawcett, T. An introduction to ROC analysis. Pattern Rec. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- Sasaki, Y. The truth of the F-measure. Teach Tutor Mater 2007, 1, 1–5. [Google Scholar]
- Kohavi, R. A study of cross-validation and bootstrap for accuracy estimation and model selection. Int. Jt. Conf. Artif. Intell. 1995, 14, 1137–1145. [Google Scholar]
- Matsoukas, C.; Islam, S.; Rodriguez-Iturbe, I. Detrended fluctuation analysis of rainfall and streamflow time series. J. Geophys. Res. 2000, 205, 165–172. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Height above the Ground (m) | Units | Instrument |
|---|---|---|---|
| Temperature | 97, 96.6, 35.5, 20.5, 10, 10.5, 2.3, 2 | C | Riso P2448A and P2642A |
| Relative Humidity | 97, 10, 2 | % | Vaissala HMP45A |
| Wind speed | 98.6, 74.6, 34.6, 9.6, 2.2 | m/s | Riso P2548A |
| Wind direction | 98.6, 74.6, 34.6, 9.6 | degrees true | Riso P2021A |
| Atmospheric pressure | 2 | hPa | Vaisala PA21 |
| RVR (target) | 2 | m | Vaisala FD12 |
85.47 % | 0 | 1 |
|---|---|---|
| 0 | 95.57 | 4.43 |
| 1 | 24.63 | 75.37 |
89.82 % | 0 | 1 |
|---|---|---|
| 00 | 95.90 | 4.10 |
| 01 | 50.22 | 49.78 |
| 10 | 88.60 | 11.40 |
| 11 | 16.26 | 83.74 |
91.36 % | 0 | 1 |
|---|---|---|
| 000 | 96.01 | 4.00 |
| 001 | 51.85 | 48.15 |
| 010 | 91.17 | 8.83 |
| 011 | 31.52 | 68.48 |
| 100 | 93.25 | 6.75 |
| 101 | 37.30 | 62.70 |
| 110 | 86.01 | 14.00 |
| 111 | 13.29 | 86.71 |
91.76% | 0 | 1 |
|---|---|---|
| 0000 | 96.13 | 3.87 |
| 0001 | 50.54 | 49.46 |
| 0010 | 91.19 | 8.81 |
| 0011 | 33.45 | 66.55 |
| 0100 | 94.41 | 5.59 |
| 0101 | 45.49 | 54.51 |
| 0110 | 90.04 | 9.96 |
| 0111 | 17.69 | 82.31 |
| 1000 | 93.22 | 6.78 |
| 1001 | 69.77 | 30.23 |
| 1010 | 90.43 | 9.56 |
| 1011 | 20.13 | 79.87 |
| 1100 | 92.02 | 7.98 |
| 1101 | 31.91 | 68.09 |
| 1110 | 84.19 | 15.81 |
| 1111 | 12.62 | 87.38 |
| Time Window | Model | ACC | TPR | TNR | F1S |
|---|---|---|---|---|---|
| t− 1 | MCM | 0.9053 | 0.4627 | 0.9641 | 0.5510 |
| ELM | 0.9299 | 0.6808 | 0.9734 | 0.7409 | |
| SVM | 0.9300 | 0.6941 | 0.9698 | 0.7427 | |
| MOE | 0.9306 | 0.7028 | 0.9696 | 0.7479 | |
| t− 2 | MCM | 0.9089 | 0.4682 | 0.9631 | 0.5533 |
| ELM | 0.9354 | 0.7059 | 0.9750 | 0.7625 | |
| SVM | 0.9311 | 0.7067 | 0.9696 | 0.7501 | |
| MOE | 0.9337 | 0.7141 | 0.9713 | 0.7594 | |
| t− 3 | MCM | 0.9084 | 0.4633 | 0.9612 | 0.5452 |
| ELM | 0.9370 | 0.6960 | 0.9784 | 0.7633 | |
| SVM | 0.9340 | 0.7196 | 0.9701 | 0.7619 | |
| MOE | 0.9356 | 0.7140 | 0.9731 | 0.7644 | |
| t− 4 | MCM | 0.9066 | 0.4635 | 0.9585 | 0.5383 |
| ELM | 0.9364 | 0.6919 | 0.9785 | 0.7613 | |
| SVM | 0.9333 | 0.7165 | 0.9701 | 0.7593 | |
| MOE | 0.9352 | 0.7105 | 0.9735 | 0.7632 | |
| t− 1 | Naïve | 0.9251 | 0.6148 | 0.9523 | 0.6421 |
| MCM | ELM | SVM | MOE | |
|---|---|---|---|---|
| t− 1 | 0.5385 | 0.3203 | 0.3074 | 0.29875 |
| t− 2 | 0.5331 | 0.2952 | 0.2949 | 0.28733 |
| t− 3 | 0.5381 | 0.3048 | 0.2820 | 0.28726 |
| t− 4 | 0.5381 | 0.3088 | 0.2851 | 0.29071 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cornejo-Bueno, S.; Casillas-Pérez, D.; Cornejo-Bueno, L.; Chidean, M.I.; Caamaño, A.J.; Sanz-Justo, J.; Casanova-Mateo, C.; Salcedo-Sanz, S. Persistence Analysis and Prediction of Low-Visibility Events at Valladolid Airport, Spain. Symmetry 2020, 12, 1045. https://doi.org/10.3390/sym12061045
Cornejo-Bueno S, Casillas-Pérez D, Cornejo-Bueno L, Chidean MI, Caamaño AJ, Sanz-Justo J, Casanova-Mateo C, Salcedo-Sanz S. Persistence Analysis and Prediction of Low-Visibility Events at Valladolid Airport, Spain. Symmetry. 2020; 12(6):1045. https://doi.org/10.3390/sym12061045
Chicago/Turabian StyleCornejo-Bueno, Sara, David Casillas-Pérez, Laura Cornejo-Bueno, Mihaela I. Chidean, Antonio J. Caamaño, Julia Sanz-Justo, Carlos Casanova-Mateo, and Sancho Salcedo-Sanz. 2020. "Persistence Analysis and Prediction of Low-Visibility Events at Valladolid Airport, Spain" Symmetry 12, no. 6: 1045. https://doi.org/10.3390/sym12061045
APA StyleCornejo-Bueno, S., Casillas-Pérez, D., Cornejo-Bueno, L., Chidean, M. I., Caamaño, A. J., Sanz-Justo, J., Casanova-Mateo, C., & Salcedo-Sanz, S. (2020). Persistence Analysis and Prediction of Low-Visibility Events at Valladolid Airport, Spain. Symmetry, 12(6), 1045. https://doi.org/10.3390/sym12061045