1. Introduction
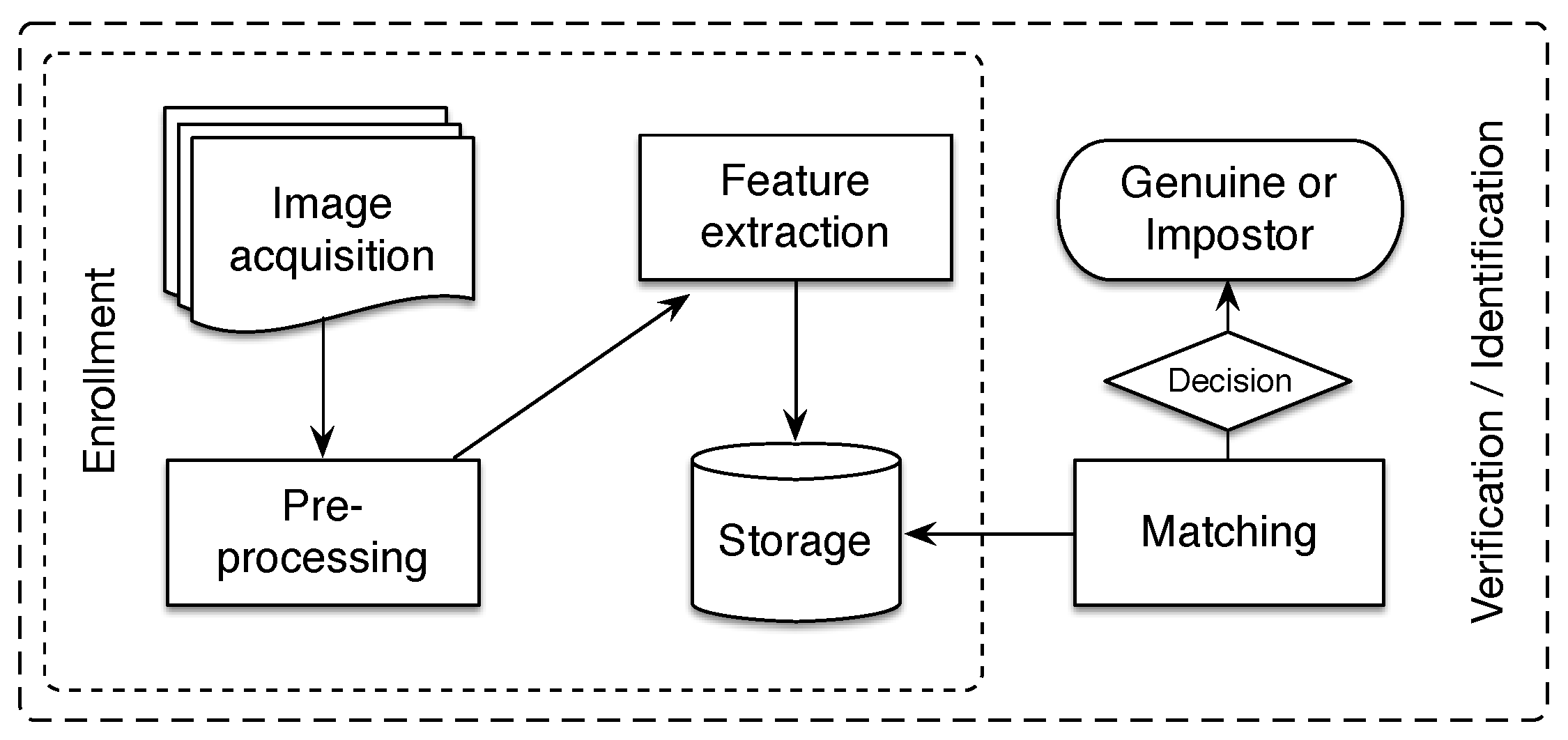
Currently, biometric systems are developed as a response to current increasing security demands. People identification and authentication through biometric procedures are basic tools in present-day society, as they can prevent frauds, impersonation, access control to human beings movement, and undesired access to office, without utilizing passwords, keys, ID, magnetic cards, or any other vulnerable means of identification [
1]. They are very useful in e-commerce since they help the consumer to carry out safe transactions in an undisturbed way. In the current state of affairs in the world, in which digital mobility and e-commerce are on the rise, these benefits are increasingly important [
2]. It should be mentioned that in the last six years 112 billion US dollars have been lost around the world due to identity supplantation, which is equivalent to a loss of 35,600 US dollars every minute [
3].
Unar et al. [
4] extensively review the biometric technology along their potentialities, market value, trends, and prospects. A biometric system aims to recognize the identity of a person based on its physiological characteristics or other behavioral traits [
5,
6]. Jain et al. [
5] established the criteria that should be satisfied by any biometric trait, essentially: universality, distinctiveness, collectability, performance, acceptability, and circumvention. Thus, several types of biometric traits have been proposed, such as fingerprint [
7,
8], face [
9,
10], iris [
11,
12], palmprint [
13,
14], voice [
15,
16], finger and palm vein [
17,
18], gait [
19,
20], signature [
21,
22], DNA [
23,
24], among others.
Particularly, finger and palm vein patterns, also known as vascular biometrics, have focused the attention of the scientific community in recent years [
25]. Finger and palm vein are internal structures in the human body, which present significant biometric attributes such as universality, distinctiveness, permanence, and acceptability. Besides, vascular biometrics have three distinct advantages [
26]: (1) must be caught in a living body, avoiding fraud techniques with parts of deceased individuals; (2) are very difficult to duplicate or adulterate; and (3) do not present harms because of external components, contrarily to fingerprint, iris, or face. These advantages guarantee the high security the technique, which has multiple applications such as in banks, legality support, as well as countless applications with high-security requirements.
Table 1 compares the main characteristics of the most used biometric techniques [
17].
The performance and quality of the results in the recognition of finger vein patterns have been improved by several approaches in recent years [
17,
27,
28]. During the image acquisition process, the captured images present deformation effects due to the contactless capturing procedure, as is shown in
Figure 1. Commonly, most of the methods try to prevent the influence of these deformations in recognition performance. On the contrary, the approach proposed by Meng et al. [
27] is highlighted because it proves that the displacement information between finger vein images can be used as discriminatory information, achieving a high recognition performance. The principles introduced in the work by the authors of [
27] prove that the geometric structure of finger vein images remains invariant, despite the affine transformations produced during the acquisition process. These considerations are closely related to the most modern interpretation of symmetry phenomena introduced by Darvas [
29]. Thus, the proposed approach applies the generalized symmetry concept [
29] in order to establish the correspondences between genuine and imposter samples. However, the main disadvantage of their methodology is related to the high computation time of the matching process due to the dense correspondence between images.
Among the real applications of finger vein recognition are those that verify the identity of people. The biometric system compares the test sample and the previously stored template for the individual, performing only a 1:1 matching. There are multiple examples and reports about authentication applications in the field of physical security at banks, financial applications, hospitals, and others [
30,
31,
32,
33,
34]. However, to the best of our knowledge, no real applications of individuals identification are known, where exhaustive comparisons are required within a database of millions of people. Thus, to identify individuals in a massive database, a finger vein recognition system requires performing a real-time-matching process. Hence, our work contributes to reduce the execution time of the matching process between finger vein images.
In the literature, some techniques that interpolate the optical flow from sparse correspondences [
35,
36,
37,
38], contrarily to dense correspondences proposed in Meng et al. [
27]. These methods are known as sparse matching algorithms and they show great success in efficiency and accuracy. In the present work, we address the limitations of dense correspondences by using an efficient sparse matching algorithm. The proposed methodology achieves state-of-the-art accuracy and highly outperforms the baseline method in time efficiency. Our proposal aims to develop a new method for real-time individuals identification, able to use a large database. Thus, our method combines the efficiency and accuracy of a sparse-matching technique with the speed-up of a multicore parallel, platform for improving finger vein recognition for massive identification. Therefore, our approach has three major contributions:
First, in contrast to other authors that use global normalization and histogram equalization to improve the image quality during the preprocessing step, we apply a block-local normalization and a sharpening filtering aiming to enhance the local details of vein images.
Section 3.1 explains the preprocessing procedure implemented in our approach.
Second, we propose to use the Coarse-to-fine PatchMatch (CPM) algorithm [
38] as a sparse-matching technique to reduce the number of comparisons of dense correspondences during the matching process. This method achieves equivalent recognition performance in comparison to the baseline approach proposed by Meng et al. [
27] and highly outperforms its results in terms of execution time, achieving a speed-up of 9×.
Section 3.2 and
Section 3.3 present the details of the feature extraction and matching processes.
Third, to increase the number of queries per second and reduce the computation time of the matching process, we implement a master-worker scheme in a round-robin fashion to compute the similarity tests between finger vein images. To the best of our knowledge, our approach is the first that incorporate parallel techniques for finger vein recognition.
Section 3.5 describes the implemented parallel scheme.
The structure of the paper is as follows. First, in
Section 2, we review the related works regarding finger vein recognition and image matching techniques based on optical flow.
Section 3 describes the proposed methodology. Finally, we discuss the experimental results in
Section 4, and conclusions are given in
Section 5.
3. Methodology
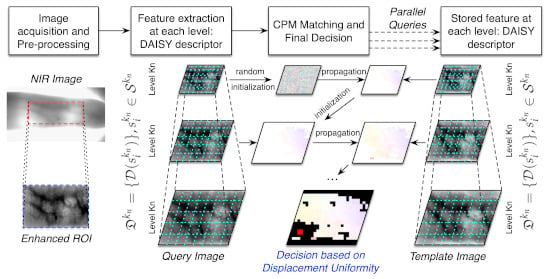
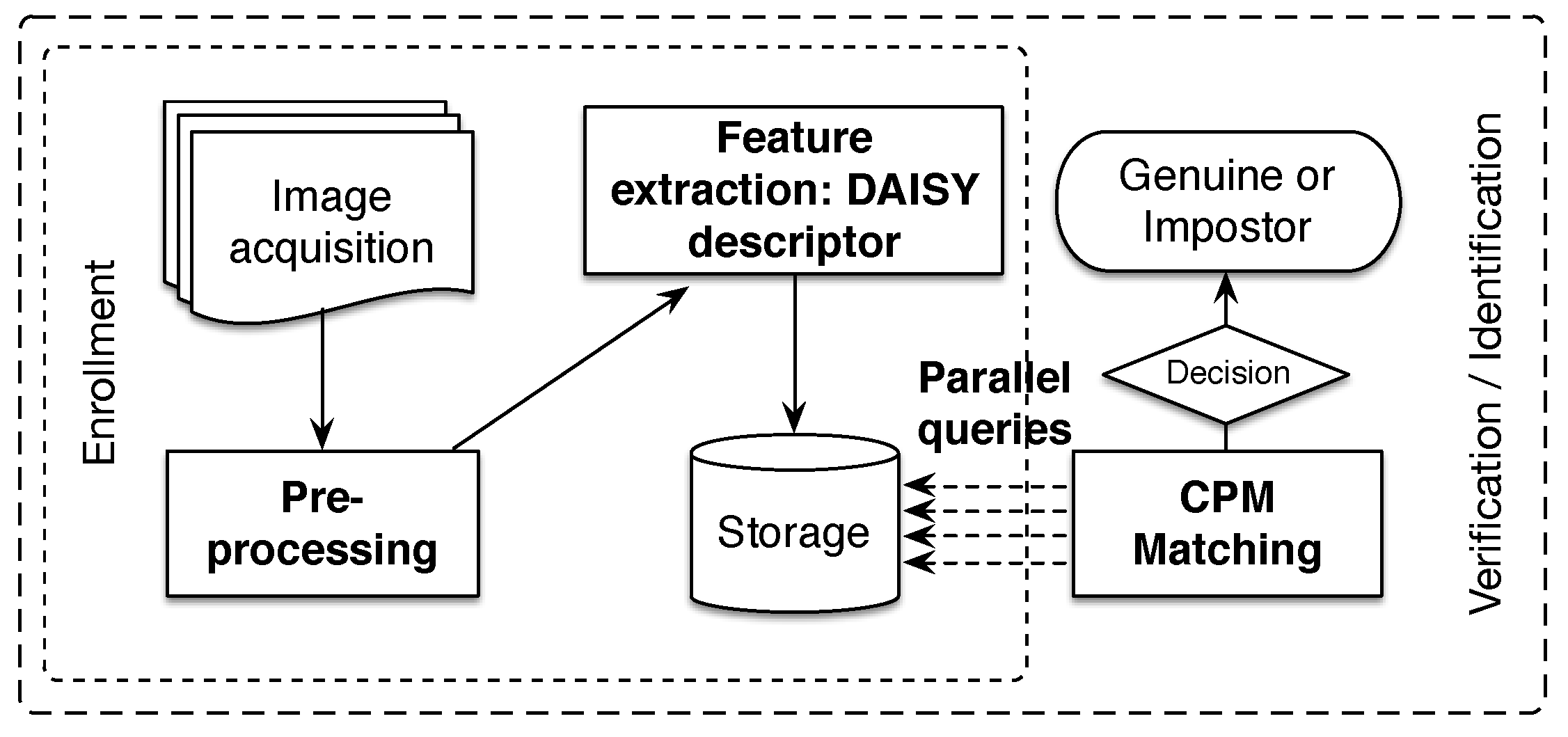
In this section, we present the different processes of the proposed finger vein recognition method, which is depicted in
Figure 4. In the following, we pay special attention to our main contributions highlighted in bold text in the above figure. As a typical finger vein system, the presented methodology is composed of four processes for enrollment and verification/identification stages. The flowchart starts by capturing finger vein image samples. For this purpose, a scanner device with NIR illumination (700–1000 nm) is often used. Later, a preprocessing step is required for segmentation of the ROI and to improve the quality of the image. From the final enhanced image, we compute the DAISY descriptor [
71] for every pixel on all hierarchical levels, which represents stored finger vein samples in the database. During the verification/identification stage, the matching process is performed by CPM algorithm [
38], resulting in the displacement matrices. Finally, the similarity score between finger vein samples is calculated on the basis of the uniformity degree of the displacements matrices, which is represented by the feature of the uniformity texture [
66].
3.1. Preprocessing of Finger Vein Images
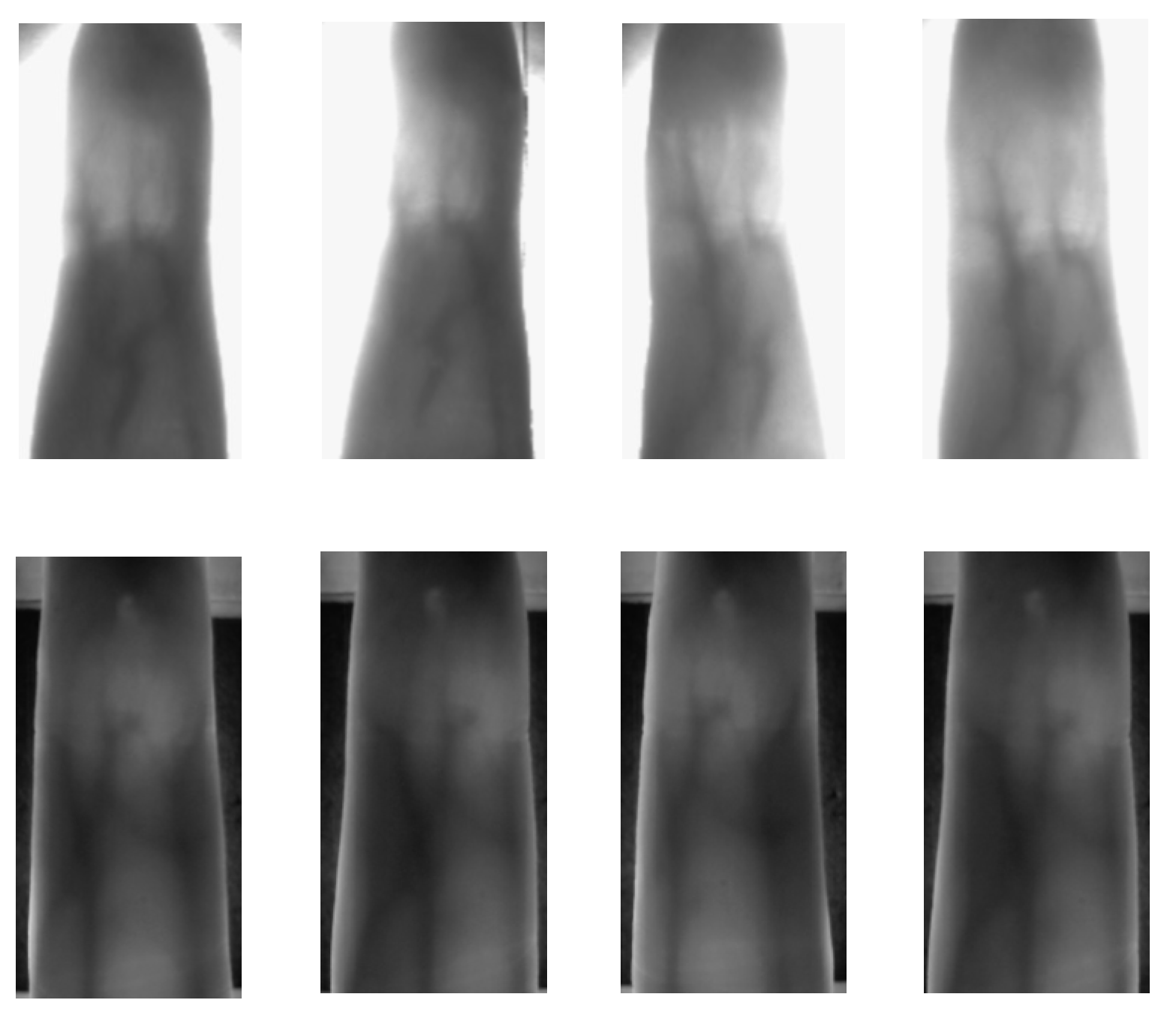
Generally, the NIR illumination used during the image acquisition process causes low contrast and noise in the finger vein images. Therefore, the preprocessing step is very important to enhance the quality of the images. Thus, our first contribution aims to improve the image quality during the preprocessing step. After the ROI segmentation, we apply a block-local normalization and sharpening filtering, in contrast to other authors that use global normalization and histogram equalization. These procedures lead to enhance the local details of vein patterns while improving the accuracy results.
Figure 5 shows examples of images obtained during the preprocessing procedures.
ROI segmentation should find the same region of a finger vein image with sufficient finger vein patterns for feature extraction. Besides, a good accuracy of ROI extraction greatly improves the recognition performance of the system while reduces the computation complexity of subsequent processes. Further, we applied the ROI extraction algorithm proposed in the work by the authors of [
72]. The method proposed by Yang et al. [
72] is robust to finger displacement and rotation. First, we determine the boundaries of the finger by applying the Sobel edge detection algorithm [
73]. We obtain the ROI candidate region by subtracting the binary finger edge image with the binarized image. Besides, the resulting finger edges are used to determine whether the finger is skewed or not, and the middle line between finger edges is used for skew correction of the image. Then, the interphalangeal area of the finger is detected by using a sliding window and it is employed to determine the height of ROI. Next, the left and right boundaries of the ROI are delimited by the internal tangents of finger edges. Finally, we standardize the size of the ROI segmented image in order to reduce the processing time during feature extraction and matching processes. For this purpose, we rescale the image to 64 × 96 pixels with bicubic interpolation.
Later, the intensity of the ROI segmented image is normalized because of another problem related to the illumination of the image acquisition procedure. The finger vein images present different intensity ranges as the thin fingers are more illuminated than the thick fingers; tissues and bones absorb a small amount of light, causing different intensity distributions. Most approaches use a global normalization technique to reduce the difference of intensities in the finger vein images [
72,
74,
75]. Contrarily, we apply the block-local normalization proposed by Kočevar et al. [
76]. This approach considers small local patches and not the entire image in order to average the intensities of pixels, which is more appropriate because of the varying of gray values in different areas of finger vein images.
Finally, the proposed preprocessing procedure focuses on highlighting or enhancing fine details of veins patterns due to the blurring effect is introduced in the image by the NIR acquisition process. In this regard, different approaches aim to enhance finger vein images by using complex techniques to avoid the influence of the noise that affects the above traditional methods [
63,
77,
78]. However, typically most approaches use histogram equalization [
74,
79,
80] or contrast limited adaptive histogram equalization (CLAHE) [
75,
81,
82]. HE-based methods increase the contrast of the finger vein region and highlight the vein texture details. Contrarily to other authors, we propose to apply a sharpening filter to increase the sharpness of finger vein images. Sharpening filtering increases the contrast between bright and dark regions to bring out features. Moreover, the image sharpening process is an edge-preserving filter that can remove noise completely and preserve the edge effectively.
In this paper, we use a kernel-based sharpening method,
where
is the filtered image,
I is the original image, and
k is the kernel as a
convolution matrix:
The sharpen kernel emphasizes differences in adjacent pixel values, thus blood vessel edges become more prominent. Besides, sharpening filtering is very suitable for corner feature extraction, and is also effective for block feature extraction. Furthermore, its major advantage is that can obtain similar results comparing to state-of-the-art techniques with lower computational complexity. This characteristic is very important in our proposal because we aim to develop an efficient finger vein technique.
In
Section 4.4, we evaluate the impact of the preprocessing procedures introduced in our proposal, particularly block-local normalization and sharpening filtering.
3.2. Image Representation with DAISY Descriptor
In the work by the authors of [
27], a SIFT descriptor is used to obtain dense correspondences based on the DenseSIFT algorithm [
65], which is very time-consuming. Regarding this, Tola et al. [
71] found that DAISY descriptor retains the robustness of SIFT while being more suitable for practical usage because it can be computed efficiently at the pixel level. Therefore, our proposed feature extraction process obtains an image representation with the DAISY descriptor.
The DAISY extraction process starts computing orientation maps, which each is convolved several times with Gaussian kernels of different sizes. As a result, each pixel location is represented by a vector of values from the convolved orientation maps for different sized regions. Formally, the DAISY descriptor as defined by the authors of [
71], for each pixel location
on a given image
I, as the concatenation of
vectors:
where
is the normalized vector of the values at location
in the convolved orientation maps by a Gaussian kernel of standard deviation ∑;
is the location with distance
R from
in the direction given by
j when the directions are quantized into
T values; and
Q represents the number of different circular layers.
It should be noted that the efficiency of DAISY is improved because convolutions operations are separable and can be implemented by using separate Gaussian filters. Thus, the descriptor avoids the computation of convolutions with a large Gaussian kernel by using several consecutive convolutions with smaller kernels. Furthermore, according to the authors of [
71], the algorithm can be parallelized easily in both multicore and GPU parallel platforms.
Moreover, Tola et al. [
71] studied the influence of the DAISY parameters on the performance and the computation time. Their analysis suggests the descriptor is relatively insensitive to parameters choice. Thus, the authors proposed the standard set of parameters in order to reduce the computation time while improving accuracy. In our approach, we use the DAISY implementation in OpenCV library [
83] with the standard parameter settings fixed as Radius (R) = 15, Radius Quantization (Q) = 3, Angular Quantization (T) = 8, and Histogram Quantization (H) = 8.
3.3. Matching Process Based on a Sparse Technique
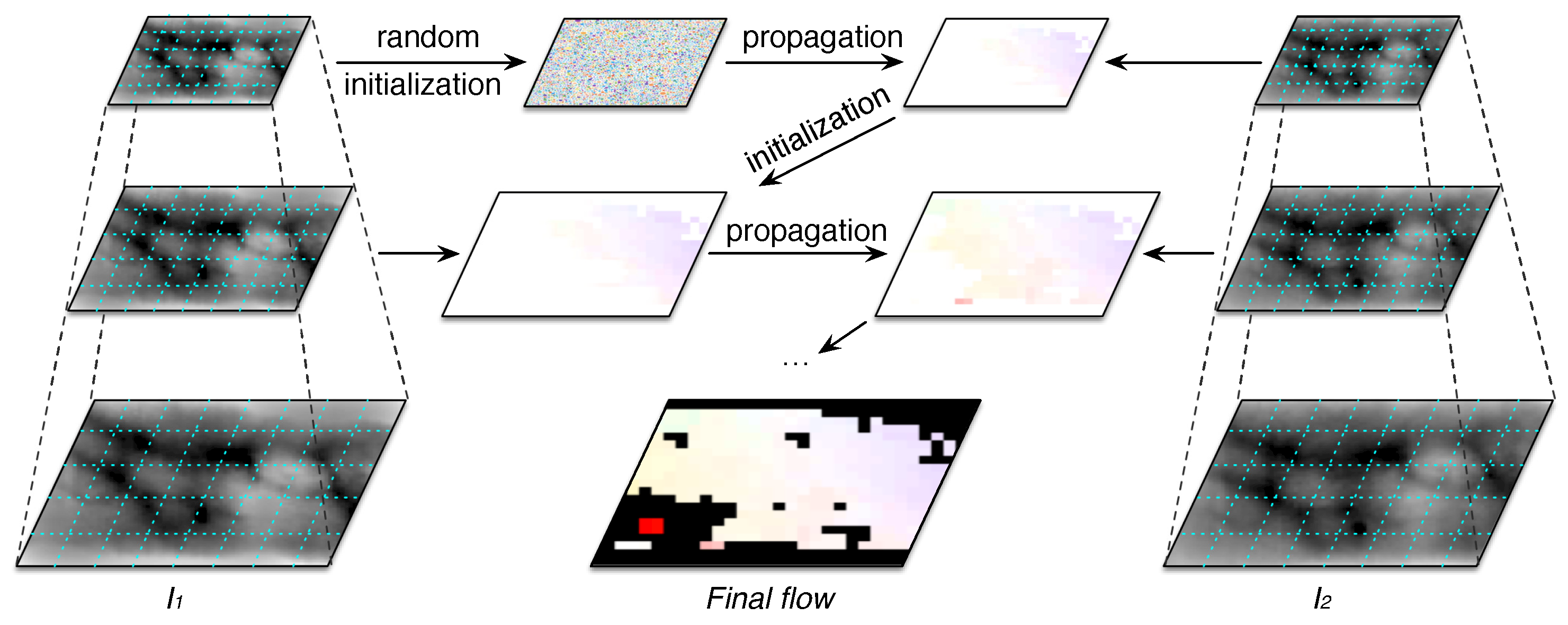
The matching process of the proposed methodology is based on a sparse technique to obtain the displacement matrices between finger vein samples. We use the CPM algorithm [
38] to compute sparse correspondences between patches of finger vein images to be compared. Contrary to the baseline method [
27], which finds dense correspondences for each pixel of the image, the CPM algorithm [
38] combines a random search strategy with a coarse-to-fine scheme for matching correspondences with larger patch size. Thus, the matching process implements a fast approximate structure in order to avoid finding correspondences of every pixel, which reaches a significant reduction of the computation time. An overview of the CPM matching is given in
Figure 6.
Given two images,
and
, and a collection of seeds,
, at position
, the CPM matching process to compute the flow of each seed is defined as in the work by the authors of [
38]:
where
is the matching position for the seed
of
in
.
The images are divided in
nonoverlapping blocks and the seeds are the cross points of this regular grid, obtaining only one seed for each patch. Iteratively, the matching algorithm propagates the results from the neighborhood to the current seed in an interleaved manner. The propagation is performed in scan order on odd iterations and reversely on even iterations, only if the neighbor seeds have already been examined in the current iteration, as in the following equation,
where
denotes the match cost between patch centered at
in
and the corresponding patch in
with a displacement of
, and
is the set of neighbor seeds of
. Next, a random search is performed by exponentially decreasing a maximum search radius
. Thus, for the current seed
, the algorithm tests candidate flows around the best flow
.
CPM performs
n iterations of the above matching process. Besides, in order to handle the ambiguity of small patches, the algorithm constructs a
k-levels pyramid with a downsampling factor
, for both
and
. This coarse-to-fine scheme is depicted in
Figure 6, where the number of seeds is the same on each level and they preserve the same neighboring relation on each level. Thus, the algorithm finds the correspondences for each seed and it propagates the flow from top to bottom. The matching process randomly initializes the flow of the the top-level
, and for each level,
, the computed flow serves as initialization of the next level
.
According to the evaluation by the authors of [
36,
38], the parameter set
achieves the best accuracy performance while reduces the computation complexity. However, to find the optimized parameter settings of CPM for finger vein recognition, in
Section 4.7, we analyze the impact of each parameter on the performance of the system.
3.4. Decision Based on Displacement Uniformity
The final step of the proposed methodology is deciding whether the sample is genuine or impostor. Based on the key ideas proposed in the work by the authors of [
27], this decision is determined by analyzing the uniformity of displacement matrices. Thereby, the flow previously obtained by the CPM matching process is represented as an image and the uniformity feature of the texture [
66] is computed from the intensity histogram of the flow image.
Let
h be the normalized histogram of the flow image, where
indicates the number of pixels with a displacement
i, the uniformity of the displacements is calculated as
This measure is maximum when all intensity levels are equal (maximally uniform) and decreases from there. Consequently, the final similarity degree between two finger vein samples to be compared lies between 0 and 1.
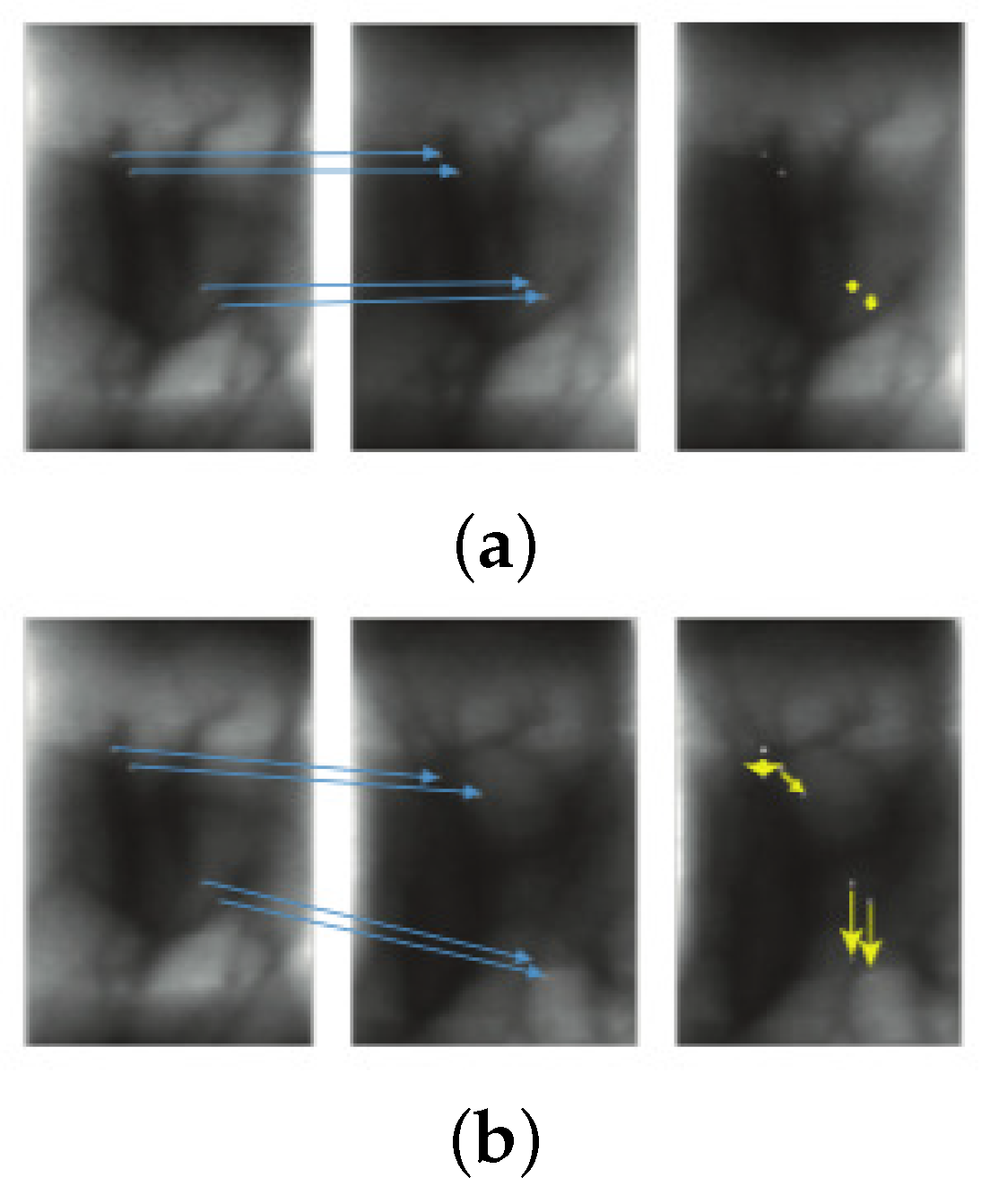
Figure 7 shows two examples of genuine and impostor finger vein samples. Note that the number of matches is relatively large and uniform for genuine samples and, in contrast with the impostor samples, present a large number of no matches and a poorly uniformity. Thus, the function
f is used as a similarity score to discriminate between genuine or impostor finger vein samples, which tends to be relatively high for genuine and has a tendency to zero for impostor matching.
3.5. Matching Process under Multicore Platform
Our proposed methodology introduces some improvements concerning the baseline method [
27], achieving a significant speed-up for the matching process, which is demonstrated in
Section 4.5. Moreover, our proposal aims to accelerate the matching process of finger vein images in order to lead a real-time recognition. On this regard, we propose the implementation of a multithread parallel algorithm by using OpenMP [
84] to compute the matching process under a multicore platform. Thus, in the proposed system, multiple similarity queries are executed by CPM under a multithread scheme, which is represented with multiple arrows between storage and the matching process in
Figure 4.
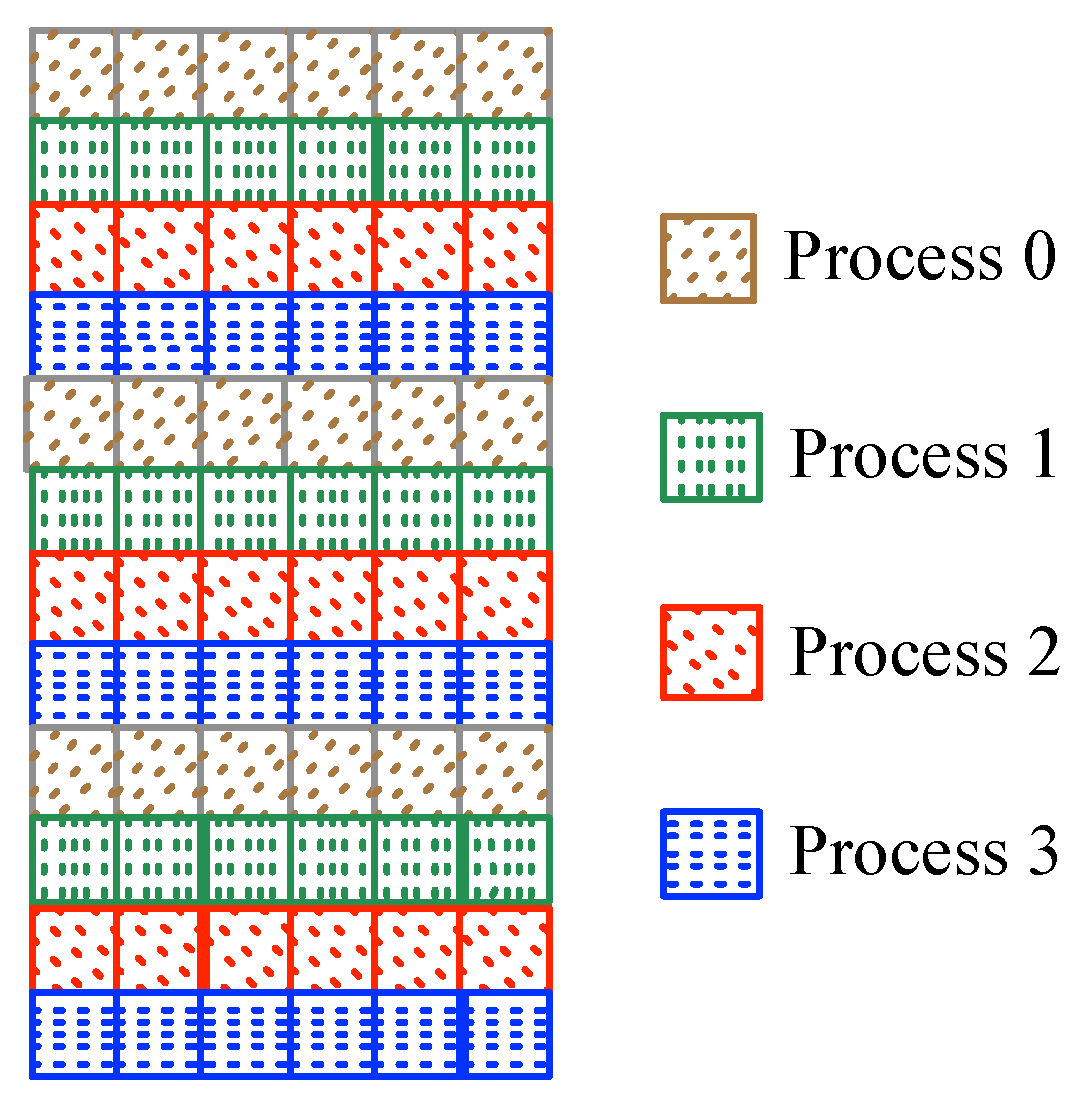
In our approach, we use a master-worker scheme aiming to avoid synchronization problems between threads. As it is depicted in
Figure 8, the proposed solution implements a task distribution scheme in a round-robin fashion for the allocation of similarity tests among the worker processes. Therefore, each worker process computes the similarity score between a tested sample and a subset of the stored templates. On the other hand, the master process manages the results given by workers and return the final result.
4. Performance Evaluation and Discussion
In this section, we evaluate the performance of the proposed methodology. For this purpose, we analyze the performance of our approach on two publicly available datasets, which are used in several works of the state-of-the-art. The details of both databases are described in the following.
The PolyU database [
85] consists of finger vein images of 156 volunteers, both male and female. Approximately 93% of the subjects are under 30 years old. The images were captured over a period of eleven months in two sessions separated by an interval between one and six months. In each session, the volunteers gave 6 samples of images of the index finger and middle finger of the left hand. As in the baseline method [
27], we only use finger vein images captured in the first session, consisting of 1872 images.
The SDUMLA-HMT database [
86] contains a subset of finger vein images, which is used as the second database and we reference as SDU-MLA dataset. The dataset was captured from both hands of 106 subjects. Each individual contributes 6 samples from the index, middle, and ring finger, with 36 finger vein images per individual, for a total of 3816 images. This database is more challenging because it was obtained in an uncontrolled way, and the reported recognition performances are lower than those in the PolyU database.
In our experiments, we analyze the recognition performance of the proposed approach in verification and identification modes. Aiming to make an equivalent comparison, we use the same experimentation settings for interclass and intraclass matching reported in [
27]. Besides, we use the decimal format to report all the experimentation results, both in charts and tables, except in
Section 4.1, where equal error rates (EER) values are reported in percent in order to obtain a clear representation of the charts. Furthermore, we compare different sparse matching methods in order to analyze their performance for finger vein recognition.
All the experiments were executed on a dedicated server with the hardware characteristics reported in
Table 2. We use the original source codes provided by authors for DenseSIFT [
65], CPM [
38], DeepMatching [
37], and SparseFlow [
35]. We implements sequential and multicore versions of the system by using C++ with OpenCV [
87] and OpenMP [
84] libraries.
4.1. Analysis of Parameter Settings of CPM
In the works by the authors of [
36,
38], the authors of CPM analyzed the parameter sensitivity of the algorithm. They found the parameter settings
achieved the best accuracy results while also reducing computation complexity. However, to get better performance and to decrease the execution time of CPM for finger vein recognition, we optimize the parameter set for this task. For this purpose, we empirically vary the parameter setting each by one and maintaining the rest as proposed by the authors of [
36,
38].
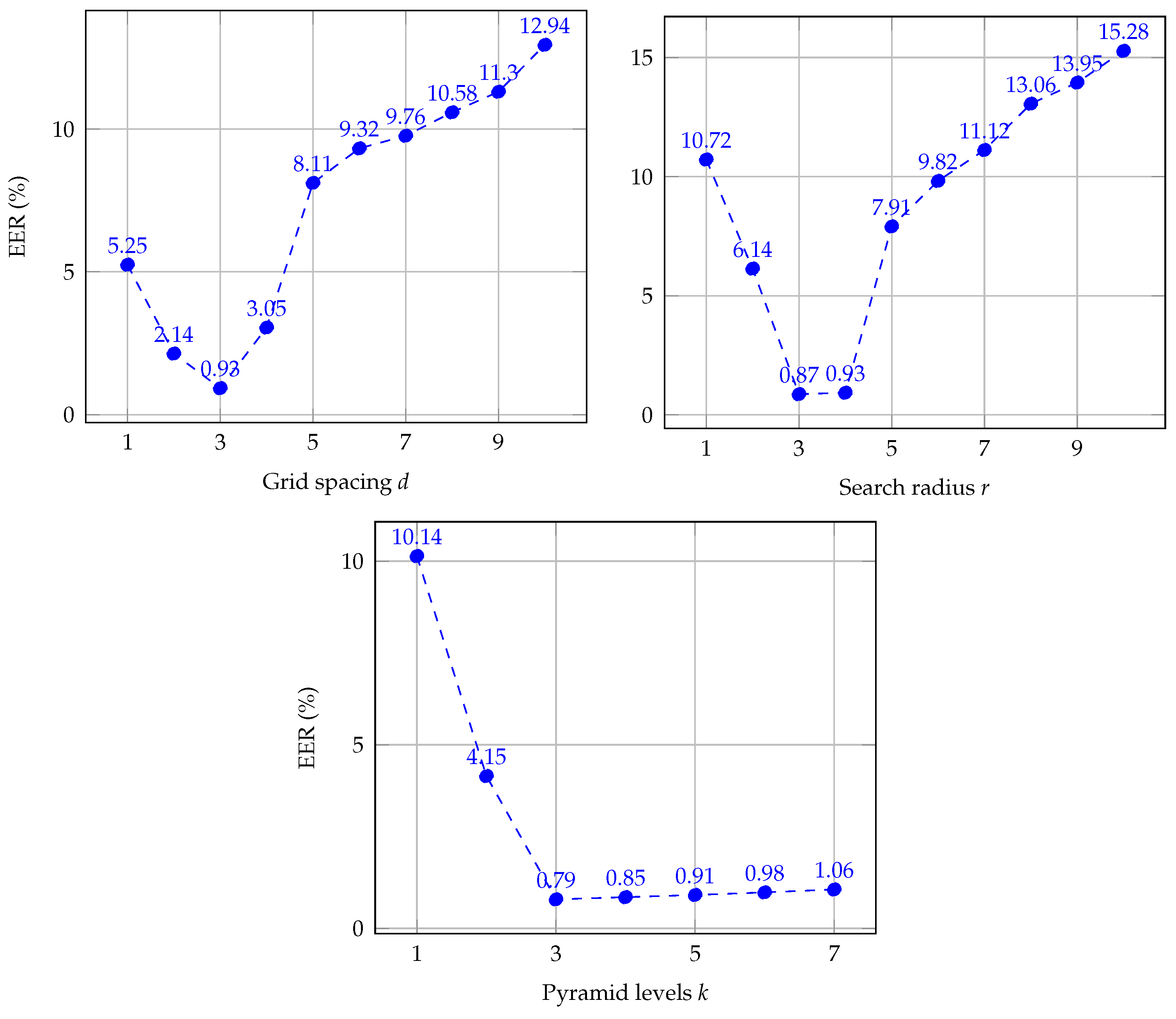
Figure 9 summarizes the results for each parameter, we report the EER on a training set of finger vein images from both databases. The training set was randomly selected using 20% of each database. We did not use each dataset separately because both do not have a large number of subjects. Thus, the obtained parameter settings have been optimized for finger vein recognition tasks in general. Different from the rest of the experiments, EER (equal error rate) values are reported in percent (%), in order to obtain a clear representation of the charts.
As it is depicted in
Figure 9, the results are equivalent to the evaluation made by the authors of [
36,
38]. The use of a small grid spacing improves the performance, resulting in
the best. It should be noted that as
r increases, the values of EER become progressively worse, whereas for small values of
r, the results also lie to deteriorate. Thus, we find the best results for
, which is smaller than proposed by authors of CPM due to finger vein images are also smaller. On the other hand, the effect of varying the number of hierarchical levels,
k, increases the quality because the propagation is more discriminative on higher levels. In this sense, a value of
obtains the smallest results of EER. Regarding the number of iterations
n, a larger
n leads to more accurate matching but a higher computation time. Hence, we set
, which is equal to default parameter settings, because it is optimal for converging of the matching process. Concerning the influence in computation time, parameters
d and
n affect the complexity of the matching methods, for small and large values, respectively. However, the optimal values obtained in this experiment for both parameter present a balance between accuracy and time-consuming. As a result of the evaluation in this section, we found the optimal parameter set,
, for both vascular databases, which is the parameter setting that we use in the following experiments.
4.2. Experimentation in Verification Mode
The accuracy results of our method are contrasted with the baseline algorithm [
27] in verification mode. To evaluate the biometric performance of our system a considerable high number of genuine and impostor test were performed with the proposed method and all similarity scores were saved. Then, by varying a score threshold for the similarity scores, we calculated FAR (false acceptance rate) and FRR (false rejection rate) as the proportion of times the system grants access to an unauthorized person, and the proportion of times it denied access to an authorized person, respectively. Besides, EER is used to determine the threshold for its FAR and FRR are equal. These three metrics are widely used in the literature and they are very important when comparing two systems because the more accurate one would show lower FRR at the same level of FAR.
For this experiment, we compute a set of matching scores in order to establish the threshold for intraclass and interclass matching. For PolyU database, there are 4680 () intraclass and 3,493,152 () interclass matching pairs. For SDU-MLA dataset, there are 9540 () intraclass and 14,538,960 () interclass matching pairs.
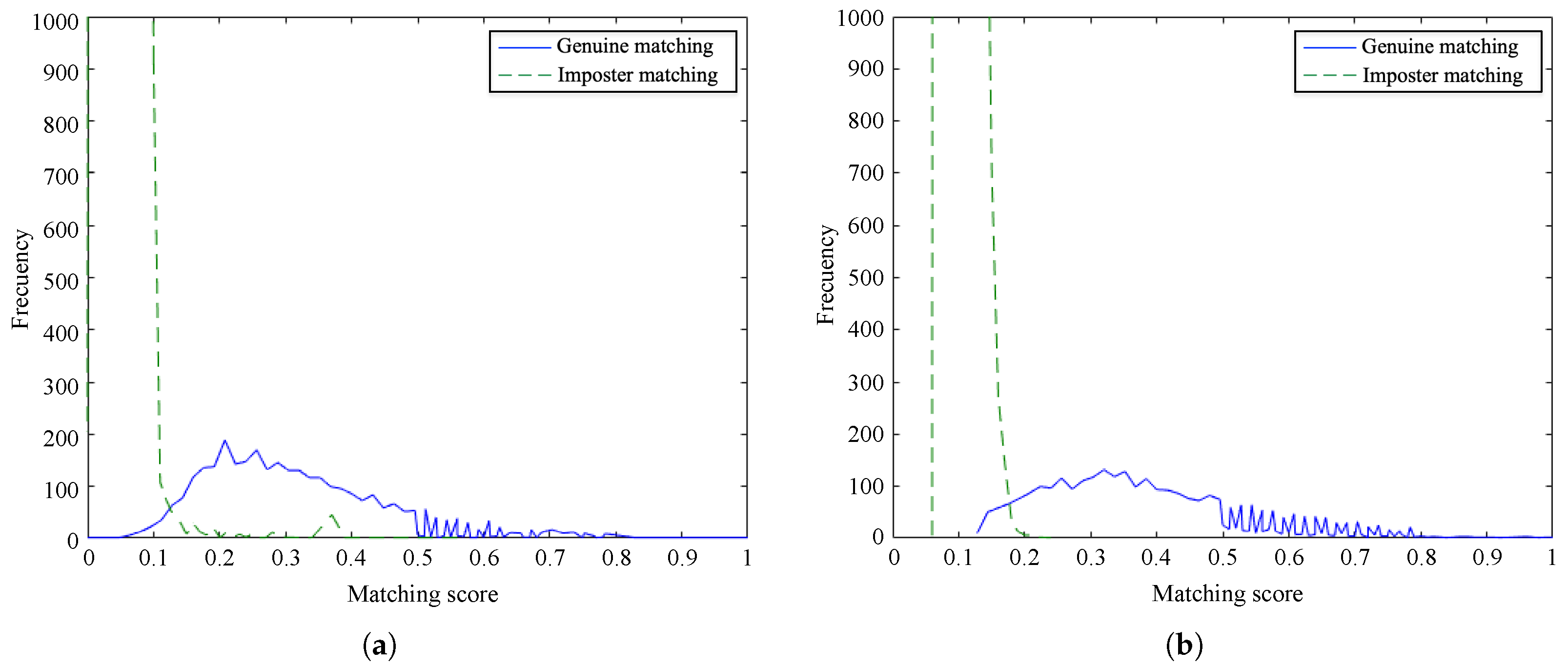
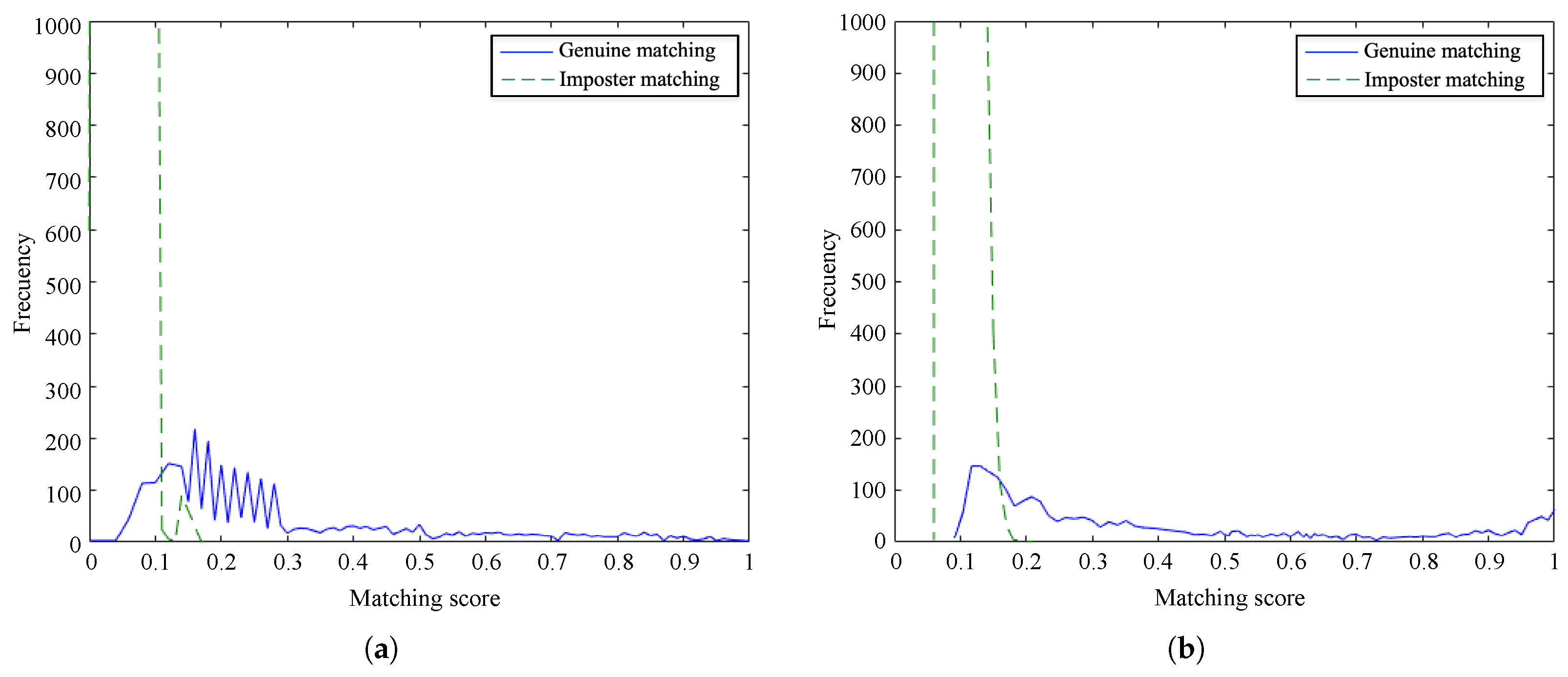
Figure 10 and
Figure 11 show the frequency of the obtained matching scores for genuine and imposter matching by the proposed method and the baseline algorithm for PolyU database and SDU-MLA dataset, respectively. It is noticeable that the overlap between genuine and imposter matching scores is larger for our method than the baseline on both databases. However, the matching scores of the proposed method are more dense, obtaining scores closer to 0 for imposter matching and being smaller than scores of the baseline. In spite of this, it is appreciable that there are not important differences between the distributions of scores of the methods. These results suggest that our approach accurately recognizes genuine finger vein samples while distinguishing impostor samples.
The accuracy results of our method are contrasted with the baseline algorithm [
27].
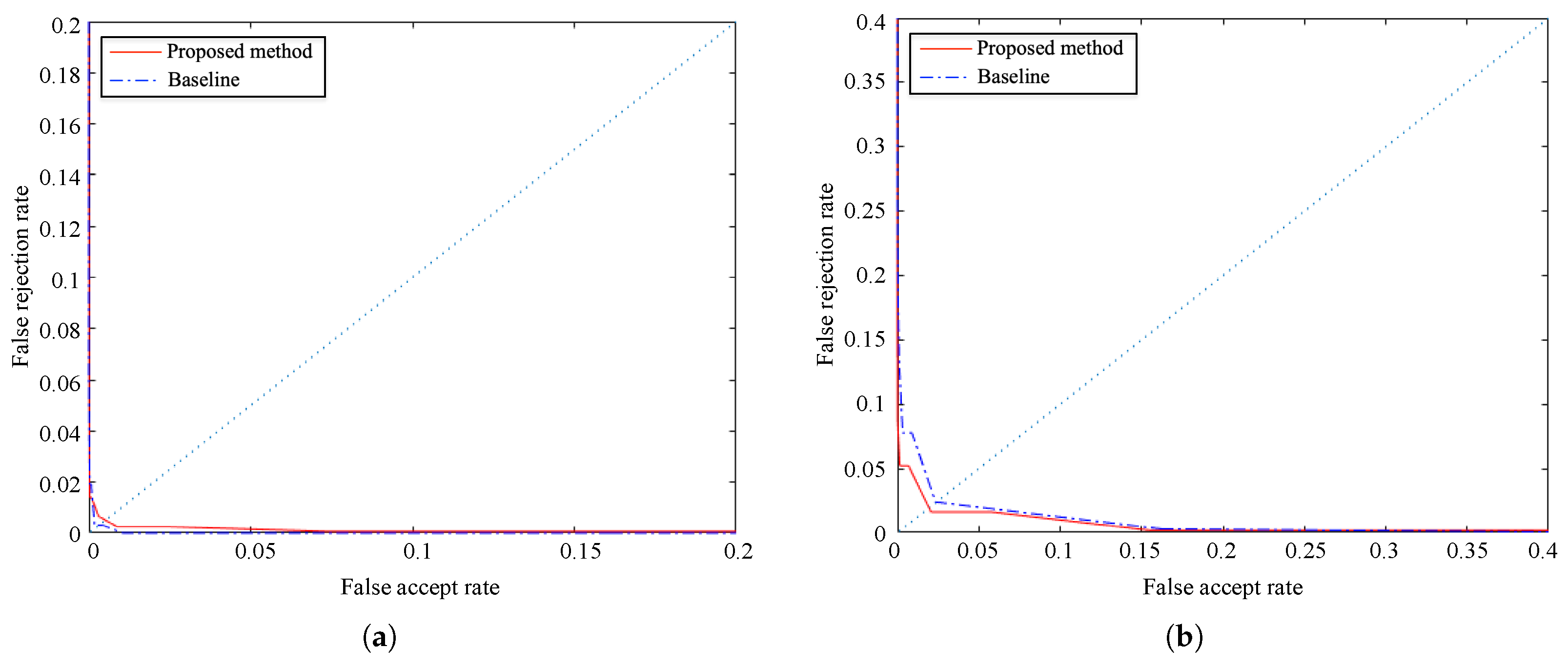
Figure 12 depicts ROC curves obtained for FAR (false acceptance rate) and FRR (false rejection rate) results on both databases. Besides,
Table 3 compares the results of EER (equal error rate), FRR at-zero-FAR, and FAR at-zero-FRR.
The results of FAR and FRR show the high accuracy of the proposed method. The EERs of the proposed method are 0.0049 and 0.0185 on the PolyU database and SDU-MLA dataset, respectively. Although the previous values are not better than those of the baseline, they demonstrate the effectiveness of our proposal that even obtains a slightly lower EER on SDU-MLA dataset. Besides, the results of FRR at-zero-FAR and FAR at-zero-FRR of the proposed method are both slightly higher on both databases, with the FAR at-zero-FRR being very close to 1.
Even though the experimental results show that CPM achieves high accuracy for finger vein recognition, the discriminability of the baseline algorithm is not improved, but similar results are obtained. Thus, these results in verification mode task indicate that CPM is a good alternative to the time-consuming dense matching proposed by Meng et al. [
27], which is our main motivation and contribution.
4.3. Experimentation in Identification Mode
In this section, the recognition performance of our approach is evaluated in the identification mode. In the identification mode, a biometric system computes a similarity score for each pair of a testing sample and every known template in the database. For this purpose, we implement the same experimentation settings proposed in the work by the authors of [
27]. The first three finger vein images of each person are used as testing samples and randomly selected one finger vein image from the remaining three images of each person as a template of the database. Therefore, there are 312 (
) templates and 292,032 (
) tests of similarity on the PolyU database, while on SDU-MLA dataset, there are 636 (
) templates and 1,213,488 (
) tests of similarity.
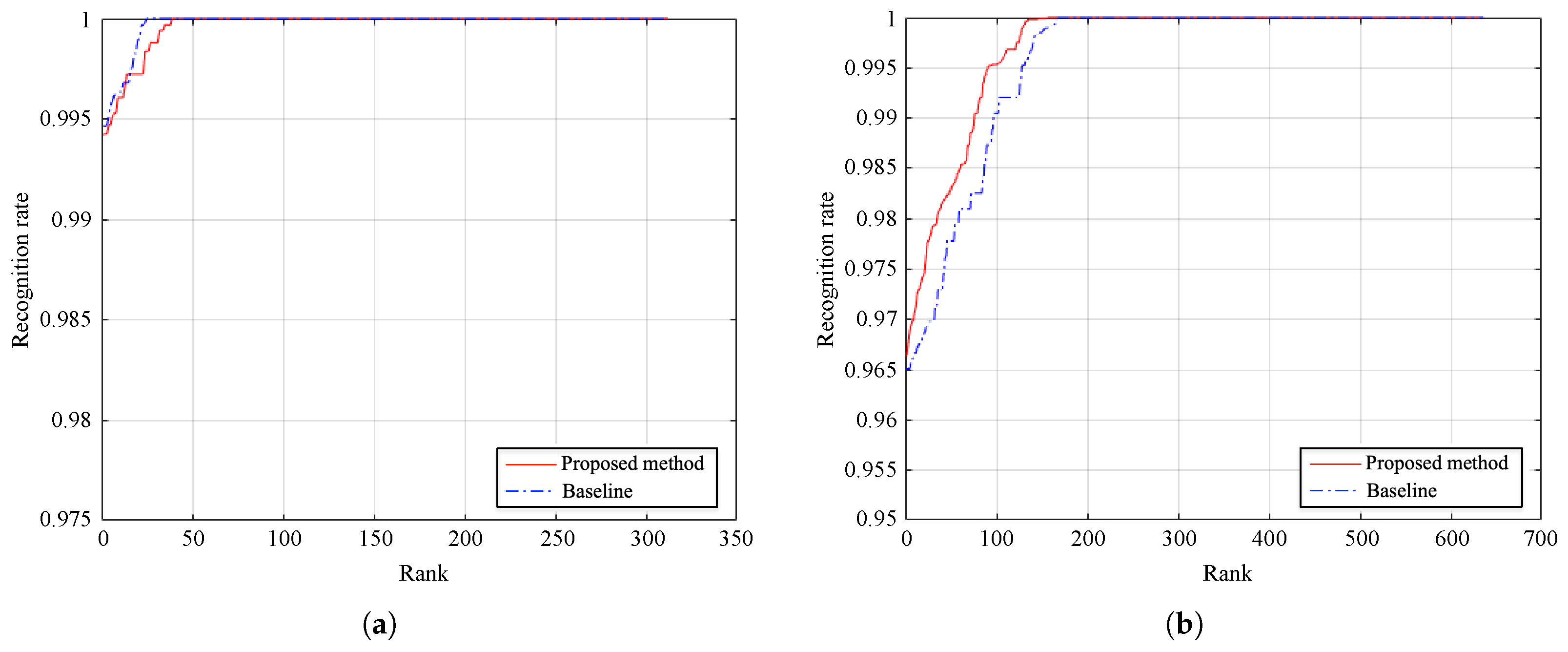
Figure 13 depicts the cumulative match curves of the method and the baseline. We compute the ranking of each testing sample by descending sorting of the similarity scores. Besides, we compare the identification accuracy of both methods in
Table 4. As it can be seen, the proposed approach improves baseline results, achieving average recognition rates of 99.43% and 96.64% on PolyU database and SDU-MLA dataset, respectively. Besides, the performance comparison shows that modifying the baseline method, by using CPM instead of DenseSIFT, we can obtain similar values of accuracy for the recognition task. Moreover, taking into account the results reported in
Section 4.5, we consider that the small differences of accuracy are almost negligible compared to the improvement in time efficiency. All reported results were obtained by averaging 10 repetitions of the experiments in order to obtain an unbiased result.
As our main motivation is to develop a finger vein recognition method for real-time individual identification, it should be discussed the difficulties and limitations faced in the identification mode. In our humble opinion, there are different factors that limit more extensive use of this technology for massive individual identification, from simple to more technical reasons. These factors also preclude researchers to collect databases with high quality containing a high number of individuals in order to be used for identification tasks. Currently, the publicly available databases are only in the order of hundreds of subjects. Besides, there are not a robust synthetic generator of vein images contrarily to other traits such as fingerprint. Moreover, it should be mentioned that its major disadvantage regarding being widely used for individuals identification is because vein images must be caught in a living body. Although it avoids some fraud techniques, this issue does not allow identify a dead person for example in case of a disaster differently to fingerprint. All the aforementioned reasons make the wider use of vein-based biometrics for massive identification of people difficult.
In the identification mode, a biometric system requires to calculate a matching or similarity score for each 1:N pair (unknown sample:every stored sample) by performing an exhaustive search in the database. Then, the identity of the most similar template is used as the identity of the unknown sample. Therefore, the security and convenience of the system are important requiring high accuracy and fast response times. Regarding that, we compute a considerable number of similarity tests satisfying both requirements with a recognition rate above to 99% and an average processing time of 70.89 ms.
In our experimentation scheme, we used three finger vein images per person as testing samples and only one finger vein image per person as a template sample. In general, this is, practically, a rather challenging experimental environment, which simulates practical application configurations because, in many real applications, there are usually not many samples available per subject. However, the main difficulty in the evaluation was the number of subjects of the databases to evaluate the scalability of the system. Theoretically, on the basis of the algorithm implemented in our methodology, our approach should be suitable for GPU parallel programming. Then, we have proposed as future work in the conclusions, performing further studies in order to evaluate the scalability of our method for massive identification of people. Nevertheless, on the basis of obtained results, our work contributes to obtaining a fast and effective finger vein recognition technique for real-time individuals identification, able to use a large database.
4.4. Impact of Preprocessing Procedures on the Accuracy
The proposed preprocessing procedure in our methodology includes techniques as ROI segmentation, a block-local intensity normalization, and a sharpening filtering process. These techniques aim to enhance the quality of finger vein samples in order to improve the accuracy of the matching process. In this experiment, we evaluate the impact of the preprocessing procedures introduced in our proposal, particularly block-local normalization and sharpening filtering.
Table 5 compares the accuracy results of the proposed method with and without each preprocessing procedures, but keeping the others. Also, we evaluate our method by varying normalization and enhancement processes by using global normalization and CLAHE equalization for each process, respectively, instead of the proposed techniques and leaving the others as default. The accuracy results are presented as EER on both databases with the same evaluation protocol of our verification experiment.
The obtained results clearly show that preprocessing procedures are very important for improving recognition accuracy. Regarding the normalization step, it is noticeable that global normalization is worse than local normalization. It proves that considering the entire image with global normalization is less appropriate than taking a local variation of intensities values as in local normalization. Besides, although there are not large differences between sharpening filtering and CLAHE equalization, the sharpening procedure obtains better results preserving the fine details of finger vein patterns.
4.5. Evaluation of the Impact of the CPM Algorithm on the Time Efficiency
Our method uses CPM as a sparse matching algorithm, contrarily to the baseline [
27] that uses DenseSIFT as a dense matching technique. In this section, we evaluate the impact of CPM on the time efficiency of the system pipeline. We examine how much faster is our approach than the baseline method in
Table 6, comparing the execution time of each process. Besides, in
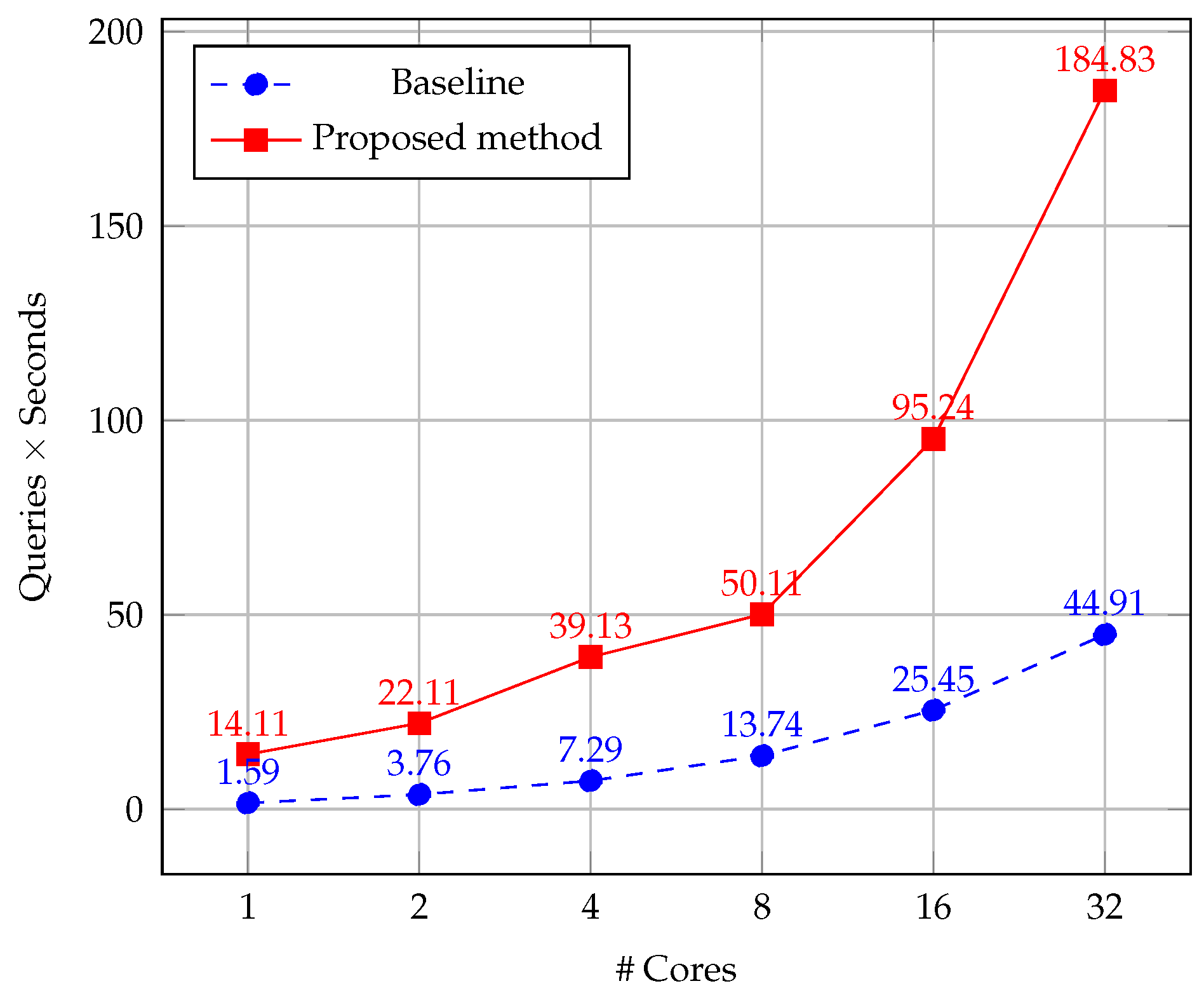
Figure 14 we represent the effect of our multicore implementation on the computed queries per second by varying the number of processing cores. For this purpose, we average the results of 10 repetitions of the test on a set of 1296 images from PolyU database and SDU-MLA dataset.
From results, it is highlighted that our method reaches an overall speed-up of up to 9×. On this regard, it should be noticed that the execution time of our sparse matching process is equal to 0.08 ms, whereas the dense matching of the baseline method is 7237 times higher. However, the computation time of our feature extraction is slightly higher than the baseline. It can be explained due to we use the OpenCV [
87] implementations for computing both descriptors, which are not the same used by Tola et al. [
71], whose results found the DAISY descriptor can be computed faster than SIFT. Nevertheless, this aspect is not a matter because the impact on the total time is small. Besides, it should be noted the DAISY algorithm is suitable to be parallelized, which we will study in the future.
As it can be seen in
Figure 14, the proposed parallel scheme linearly increases the computed queries per second computed with increasing of processing cores. On the contrary, the baseline algorithm presents a smaller improvement considering the increasing of processing cores. This behavior is explained by the fact that the algorithm enables very efficient memory access by combining CPM and DAISY descriptor. Besides, CPM implements a coarse-to-fine scheme with a random search on a sparse grid structure, instead of dense correspondences in the baseline method. The aforementioned advantages suggest that our proposal is also quite suitable for GPU parallel programming, which will be explored in future work to take advantage of the GPU computation for massive individuals identification.
4.6. Evaluation of Different Sparse Matching Methods
Following, we evaluate the performance results of our proposal by using CPM against two different sparse matching algorithms: DeepMatching [
37] and SparseFlow [
35]. For this purpose, we executed our proposed approach by modifying feature extraction and matching processes with these algorithms.
Table 7 compares the results of each variation against our proposal, given by EER, Rank-one recognition rate, and the computation time of the matching process, which are measured as in the previous experiment.
The comparison of results shows that CPM obtains the best performance on both databases. The main reason why CPM outperforms DeepMatching and SparseFlow is that it can produce more matches than them by default. Besides, it should be highlighted that computation times of sparse matching methods are lower than the dense matching used in the work by the authors of [
27]. Furthermore, recognition accuracy of DeepMatching [
37] and SparseFlow [
35] are higher than some state-of-the-art approaches, see
Table 7. The above results demonstrate that sparse matching methods are a good alternative for finger vein recognition based on displacement information, being the CPM algorithm the best of the studied methods.
4.7. Comparison with State-of-the-Art Approaches
In this section, we compare the recognition performance obtained by our approach against state-of-the-art approaches.
Table 8 summarizes the results of EER and Rank-one recognition rate achieved by methods based on different techniques and with experimentation on the same databases. Five types of approaches for finger vein recognition are compared, and they are identified as follows.
LBP-based approaches as local binary pattern (LBP) [
42] and local linear binary pattern (LLBP) [
43];
network-based methods such as mean curvature (MeanC) [
50], maximum curvature (MaxC) [
51], repeated lines tracking (RLT) [
26], and Even Gabor filtering with morphological processing (EGM) [
85];
minutiae-based techniques include scale-invariant feature transform (SIFT) [
53] and minutiae matching based on singular value decomposition (SVDMM) [
45];
CNN-based approaches such as fully connected network (FCN) [
57], CNN with Supervised Discrete Hashing (CNN+SDH) [
58], two-stream CNN (two-CNN) [
59], and the very deep CNN (deeper-CNN) proposed in the work by the authors of [
28]; and
deformation-based methods as the detection and correction method (DFVR) proposed by the authors of [
61] and the baseline method [
27].
From the results in
Table 7, it can be seen that the recognition performance of deformation-based methods is significantly more accurate than the rest on both databases. The results of the proposed approach are only outperformed by the baseline on PolyU database, which as it has seen previously, the results are slightly similar while our method improves the time efficiency of the baseline with a speed-up of 9×. Besides, the EER of the two-CNN approach proposed in the work by the authors of [
59] is better than our method on SDU-MLA dataset, but its average matching time is 171 ms. It should be noticed that deep learning approaches have been successfully applied and enhance finger vein recognition methods in recent years with remarkable results. Despite that, the performance of CNN-based finger vein recognition methods should be enhanced by employing large datasets. Also, these techniques require a time-consuming training process, which is not needed in the proposed methodology.
The proposed approach has two main advantages against state-of-the-art competitors, which improve their limitations regarding deformations and time efficiency. First, our proposal considers the displacement produced by deformations as discriminative information, and, contrary to other methods, their recognition performances are affected by deformations trying to reduce its influence. Secondly, our method uses an accurate and efficient matching process based on the CPM algorithm, which improves other image matching techniques in time efficiency with equivalent accuracy of the correspondences. CPM implements a fast approximate structure in order to avoid finding correspondences of every pixel, which reaches a significant reduction of the computation time. Besides, the foundation of CPM is closely related to the two key ideas that allow distinguishing between genuine and imposter samples based on the generalized symmetry concept [
29] and the ideas proposed by Meng et al. [
27]. Since the geometric structure of finger vein images remains invariant under the affine transformations produced during the acquisition process, particularly in the neighborhood of pixels, it is not required to find the correspondences of every pixel of the images. The aforementioned characteristics allow that the proposed approach outperforms other methods of the state-of-the-art.
Aiming to provide a statistical analysis of the results regarding the state-of-the-art, we followed the recommendations of Demšar [
88] and the extensions presented in the work by the authors of [
89] for the computations of adjusted
p-values. Note that some works show their experimental results on self-generated datasets, which do not allow to make an equivalent comparison. Thus, for this purpose, we only consider those works with reported results on both studied databases. Unfortunately, this issue made impossible for us to consider CNN-based approaches in our statistical analysis. In spite of that our results are slightly similar to CNN-based approaches. Thus, there should not have significant differences between our method and them, while our approach outperforms them in time efficiency.
First, we used the Friedman test to prove the null hypothesis that all the methods obtained the same results on average. When the Friedman test rejected the null hypothesis, we used the Bonferroni–Dunn test to know if our method considerably outperforms the next ranked method. Finally, we use Holm’s step-down procedure to complement the above multicomparison statistical analysis.
Table 9 shows the ranking of each approach based on EER results for both databases. In this scenario, we analyze the results to observe and detect considerable differences among compared methods. The Friedman test rejected the null hypothesis with
. After that, we applied the post hoc Bonferroni–Dunn test at
to recognize which approach performed equivalently to our method, which is the best ranked. Taking account the work by the authors of [
88], the performance of two approaches is considerable different if their corresponding ranks differ by at least the critical difference, calculated as
where
is the critical value based on the Studentized range statistic,
N is the number of studied datasets, and
k is the number of algorithms to compare. Based on the
criteria, the Bonferroni–Dunn test finds significant differences between our approach and SIFT method [
53], whereas others, such as LLBP [
43], LBP [
42], and EGM [
85], are near to the boundary of the critical difference. Aiming to contrast the above results, we report the results of the Holm’s step-down procedure in
Table 10. The Holm’s procedure at
rejects those hypotheses that have a
p-value
, finding significant differences with SIFT and LLBP. Also, it confirms that the proposed approach is slightly better than the other studied methods, but it is not statistically superior. It should be highlighted that the same tests based on recognition rate produced the same results.
From the previous results, we can conclude that our methodology achieves better results regarding the state-of-the-art methods on the evaluated databases, finding statistical differences respect to non-deformation-based approaches, which is significant in some cases. Thus, the results provide evidence that the sparse-matching approach introduced in this paper is suitable for finger vein recognition. Moreover, it also improves the time efficiency of the baseline algorithm with a considerable speed-up of greater than 9×.
5. Conclusions
In this paper, we introduce an optimized sparse matching algorithm as an effective and efficient alternative for finger vein recognition based on deformation information. Our methodology proposes preprocessing techniques that are used for robust ROI selection with a block-local intensity normalization and a sharpening filtering process, aiming to improve and preserve the local details in the vein patterns. For the feature extraction and matching processes, we combine the DAISY descriptor and the CPM algorithm (an optimized for a finger vein database) under a multicore platform, aiming to reduce the computation time and to increase the number of processed queries per second of the recognition pipeline. For this purpose, we implemented a master-worker parallel scheme based on a task distribution algorithm in a round-robin manner for the execution of similarity tests.
The main contribution of our proposal is reducing the execution time of the matching process on finger vein images keeping high efficiency. We present a fast finger vein recognition method for real-time individuals identification that can be used for individual massive identification using a large database. Experimental results on well-known databases show that our proposed approach achieves the state-of-the-art results of deformation-based techniques, finding statistical differences respect to non-deformation-based approaches. Moreover, the presented technique does not require a time-consuming training process with a large number of training images like CNN-based approaches. In terms of time efficiency, our method overcomes the limitations of the baseline method, achieving real-time recognition in only 70.89 ms with a significant speed-up of greater than 9×. Besides, the experiments show that our method is highly suitable for being executed under a multicore platform.
As future work, we propose to evaluate the scalability of our method under hybrid parallel platforms. Thus, we will explore different implementations of the DAISY descriptor and the CPM algorithm under a GPU parallel platform, in order to use multiples cores of a GPU on a real-world application for massive individuals identification.

 ,
, 















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}