1. Introduction
The development of autonomous vehicles is aimed at effecting fundamental changes in vehicle use, so that, through use of autonomous vehicles, it is hoped that benefits such as prevention of traffic accidents, additional free-time, and pollution reduction can be achieved. For successful autonomous driving, estimating optimal driving information is necessary, using various sensors such as infrared, radar, vision, thermal image, and Global Positioning System (GPS), among others. Globally, automobile manufacturers have recently been investing in automotive information technology and the development of technology for autonomous vehicle deployment [
1,
2,
3,
4,
5]. The key technologies that are applied in autonomous vehicles include recognition of the driving environment on behalf of the driver, detection of the vehicle position during driving, detection and recognition of objects on the road (such as other vehicles or pedestrians), and implementation of devices and components required for vehicle steering. Currently, advanced driver-assistance system (ADAS) technologies are the subject of continuous study, and have been developed to recognize information relating to various surroundings and objects on the road [
6,
7,
8,
9]. ADAS technology is one of the key technologies in autonomous vehicles for lane, road, vehicle, pedestrian, traffic light, and obstacle recognition. In particular, in analyzing the driving situation of vehicles, assisting the driver, determining distances to other moving vehicles, determining the motion direction of vehicles, and determining vehicle position in a lane are important. To obtain such information, vehicle location and motion-direction information is used, and expensive additional devices such as an infrared ray system, an ultrasonic wave system, radar, and a stereo camera need to be used for its acquisition. These devices are installed at the lower part of the front portion of the vehicle, making it possible that they would be incapacitated, or would need to be replaced, in cases of a minor contact accident which can result in increased damage. In recent years, the use of vehicle image-recording devices has grown rapidly, however, these devices are only used for determining responsibility after an accident. Information can be provided to a driver in advance through an image-processing algorithm [
10,
11,
12], however, interpreting three-dimensional (3D) structural information on the surroundings in which a vehicle is located by simply acquiring a two-dimensional (2D) image from the vehicle image-recording systems, such as a vehicle black box, can be challenging. Consequently, a method is needed that can develop 3D vehicle position information from a 2D image. Vanishing point (VP) detection technology has been applied to 2D and 3D images in several studies [
13,
14,
15,
16,
17,
18,
19,
20], to estimate objects, distances, camera parameters, 3D positions, depths, and the areas of objects of interest. The VP is used to reconstruct 3D objects, and the method that detects the VP of an image involves connecting adjacent feature information such as edges to draw a straight line, and to project the extension line in the image by selecting an intersection point. In other words, VP estimates using the symmetrical features of the surrounding structure in the image. There is a feature detection method to detect the vanishing point. In the feature detection method, the intersection of line segments is detected by analyzing the linear connection components between the features included in the image. Hough transform is used to detect the linear component of feature information in the image [
21,
22,
23].
In general, images are required so that extraction of meaningful feature information using irregular feature information caused by noise, uneven illumination, and color changes due to brightness discontinuity can proceed. Finding straight-line components connected to one another in the extracted meaningful feature information is possible by applying the Hough transform process. However, in an urban road environment with complicated background features, numerous straight-line segments can be detected, so that, to detect the actual VP, additional processing elements such as the number of lines, angles, and brightness threshold values are required.
Barnard [
24] used a Gaussian sphere to detect VPs, and accumulated the extensions of all the straight lines in a plane image in a Gaussian sphere. The accumulated values included the local maxima of the horizontal and vertical axes of the branch chosen as the VP, however, the difficulty with this method was that calculating the possibility of a straight line with respect to all pixels, and a plurality of local maximum values existed, which necessitated an additional processing step to select the VP.
Kong et al. [
25] used directional information from an image texture to detect the VP. Eight disjointed components with similar directions were detected in the image, including the point where most straight-line intersections occurred. A Gabor wavelet filter was applied to extract text directional information (five scales, 36 orientations), and converted each pixel of the input image into directional information. The local adaptive soft-voting method was then used iteratively, to calculate the information change rate between the directional information pixel and all other pixels. A VP was then selected, based on the connected candidate feature information showing a small rate of change. The real-time processing requirements necessary for application in autonomous vehicles was the disadvantage with this method, calculating the texture change rate for all pixels, in the 36 texture direction images in the five-step reduced image, could be too time consuming.
Suttorp and Bucher [
26] repeatedly selected a candidate VP by applying a line segmentation-based filtering method, and chose a pixel with the maximum accumulated selection value as the VP. Although this method presented the advantage of being applicable to different environments, it suffered limitations in the context of real-time applications for autonomous driving, due to the use of iterative algorithms. Based on these issues, most VP detection studies first select the candidate VPs in the image. To select an optimal candidate point among all other points, the VP is estimated by repeatedly applying low-level feature information from the image. To detect the optimal candidate VP, the methods considered so far suffer from limitations in real-time applications such as in autonomous vehicles due to long execution time they need to apply iterative algorithms, such as the expectation and maximization algorithm.
Ebarhimpour et al. [
21] proposed a method for detecting straight lines using the Hough transform and the
K-means clustering algorithm on visual-information from an input image, to reduce the execution time in detecting the VP. The proposed method was effective in checking straight-line components with a 45° angle, which represent formal structures such as an indoor corridor. However, there was again the disadvantage that computation time, in this case for the
K-means clustering algorithm, was large.
Choi and Kim [
27] proposed a dynamic programming method using a block-based histogram of oriented gradient to reduce complex computation time and proposed an efficient VP detection method. Its disadvantages included poor accuracy of the input image, as the method was applied to pixel-based region segmentation, such as road-boundary selection, in the detection of a disappearing block, based on a 32 × 32 block unit. Consequently, real-time processing and accurate detection were required so that the VP acquisition in the image obtained from the video-recording device installed in the running vehicle could be applied to the vehicle.
In the VP detection of the previous research [
28], three directional text information (0, 45, 135) was used, and the processing time averaged 1.475 s except for the image analysis step. In addition, the accuracy of VP detection in [
28] is about 82%. In addition, the experiment was conducted only in the highway environment, and there is a problem of low VP detection rate in the actual road environment.
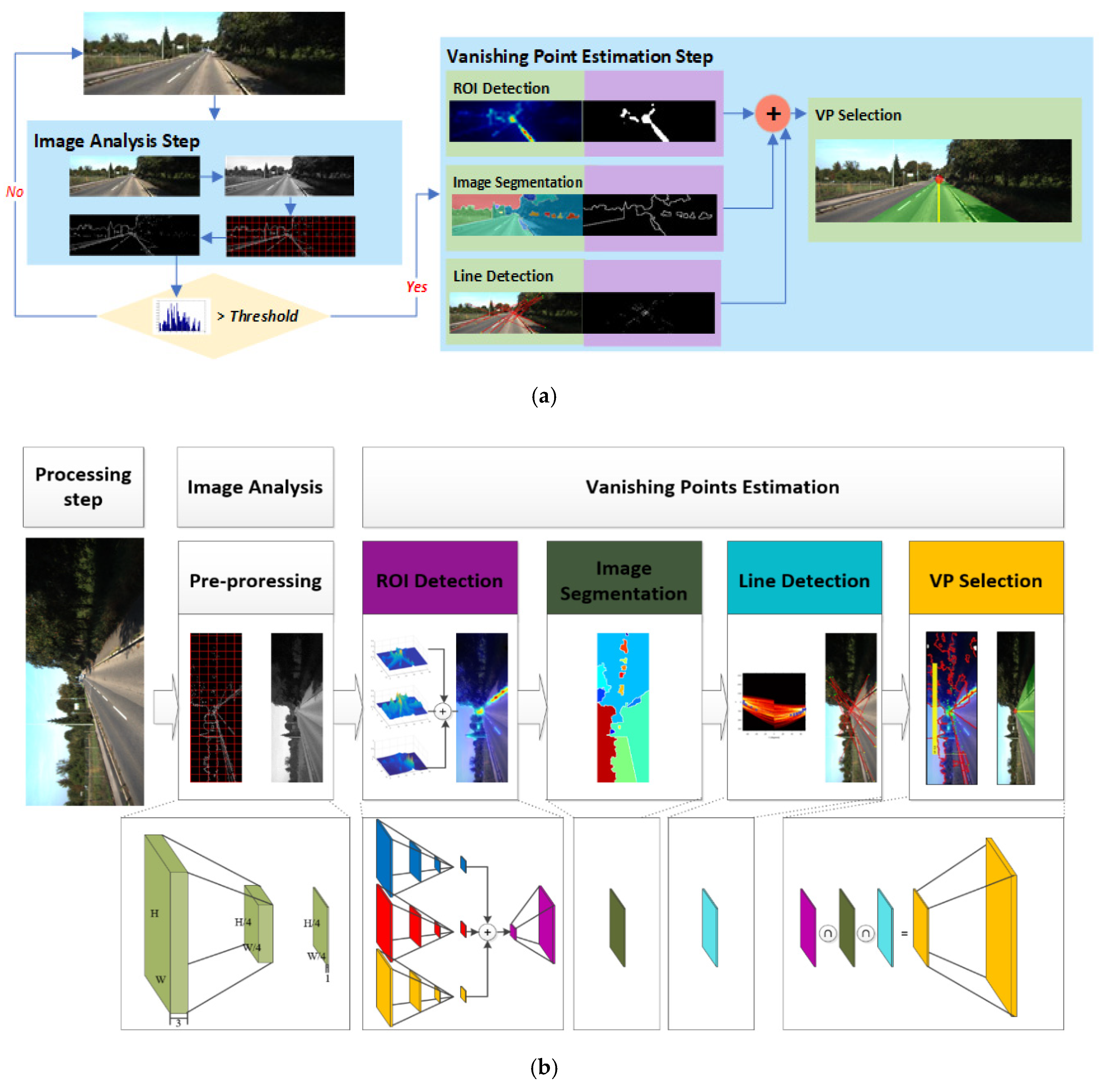
Considering all the issues mentioned above, we have proposed here a method that uses visual-attention area detection and Hough transformation of the edges, based on directional feature information, to detect the VP of a road image in real time. As mentioned earlier, to detect the VP, straight line and other directional information must be extracted from the feature information of the image, however, feature information and linear component extraction from all input image pixels suffers from the imposition if excessive real-time processing, due to increased calculation times. In addition, whereas existing feature voting methods can detect accurate VPs, they cannot be applied to real-time information such as road-driving situations. In our proposed method, the VP is determined by selecting candidate VP regions, and the Hough peak point is then selected using the Hough transform, to derive the fast-linear components, so that the position where at least two straight-line components intersect is then determined as the candidate VP. The point with the maximum value is then identified as the VP, by comparing the edges of the visual-attention regions (VRs), including the candidate VPs with texture directional feature information.
Definition of VP Location and Problems
A VP is a point that concentrated in one place on the 2D image plane while projecting lines parallel of each other in 3D space. In general, a VP is a point on the horizon, a place that is structurally concentrated in a 3D environment [
29]. For example, a VP can be chosen as the point where a road meets the sky, or where a vertically parallel road lane and a road boundary structure meet. However, because of complicated road environments, road imaging needs complete 3D structure analysis, which requires considerable processing.
In general, image segmentation is a method for determining a location where a road area and a sky area meet each other. The vanishing point is a point where feature information is concentrated in an image, and in order to detect it effectively, it is necessary to select a place where feature information is collected the most. Therefore, a process of using a visual saliency model to detect where feature information is concentrated in a road image and detecting intersections of straight lines through a Hough transformation is required.
The proposed method proposes a method to detect vanishing points that combine image segmentation results, visual attention area detection results, and intersection point results of straight lines to detect vanishing points in road images. In this paper, we have proposed an effective method for VP detection on road images. First, a video-recording device was installed in a vehicle, at driver eye-level and horizontally relative to the road, in such a position that left–right and up–down slopes could be assumed to be zero.
In our method, the location of the VP in the image obtained from the black-box camera installed in the vehicle is defined in
Table 1. First, the VP has different characteristics from its neighboring pixels, and is located at the intersection point of feature information that can be connected in a straight line. In addition, the VP is located where as many straight lines pass as possible, and is on the boundary line of the segmented regions. Second, in the input image, the VP is located in the second to fourth divisions, when the image is divided vertically into five parts vertically, and in the second to third divisions, when the image is divided into five parts horizontally. Finally, the VP is located where two straight lines can make a triangle in the left and right positions at the bottom of the input image, and where the inner angle of the two straight lines is less than 170°.
Table 2 lists the problems of real-time detection and accurate VP detection.
In
Section 2, we have presented the method that we developed to address these
Table 1 issues, with associated experimental results given in
Section 3, and conclusions provided in
Section 4.
3. Experiments
To perform experiments to test the proposed method, images of city roads and highways obtained at various times of the day, and a road image provided by the Karlsruhe vision benchmark [
35] were used. To acquire road images, a video-recording device (1920 × 1080, 24-bit MPEG, 15 Hz) attached to the vehicle windscreen was used, as shown in
Figure 5. MATLAB was used in a Windows 2010 environment (Dual Hexa Core CPU: 3.3 GHz, RAM: 48 GB), with a Nvidia CUDA GPU (Dual 1080ti) for each parallel-processing stage, using IBM-compatible PCs. For the experiment, the input imaging rate was set to five frames per second, and a 1242 × 375 pixel, 24-bit color RGB image was used as the input image, for VP detection. Processing times for each step in the proposed method have been listed in
Table 4.
Image-analysis was performed in accordance with the edge information rate of change, instead of using every frame, which shortened average processing times. The ROI-detection process included repeated calculation operations for all pixels, explaining the longer execution time required (see
Table 4).
Table 4 shows that the average processing time needed for VP detection in the experimental image was approximately 1.43 s implying, that it could be applied in real time. This process was not performed for all input frames although it could be applied in real time using the VP result detected in the previous frame.
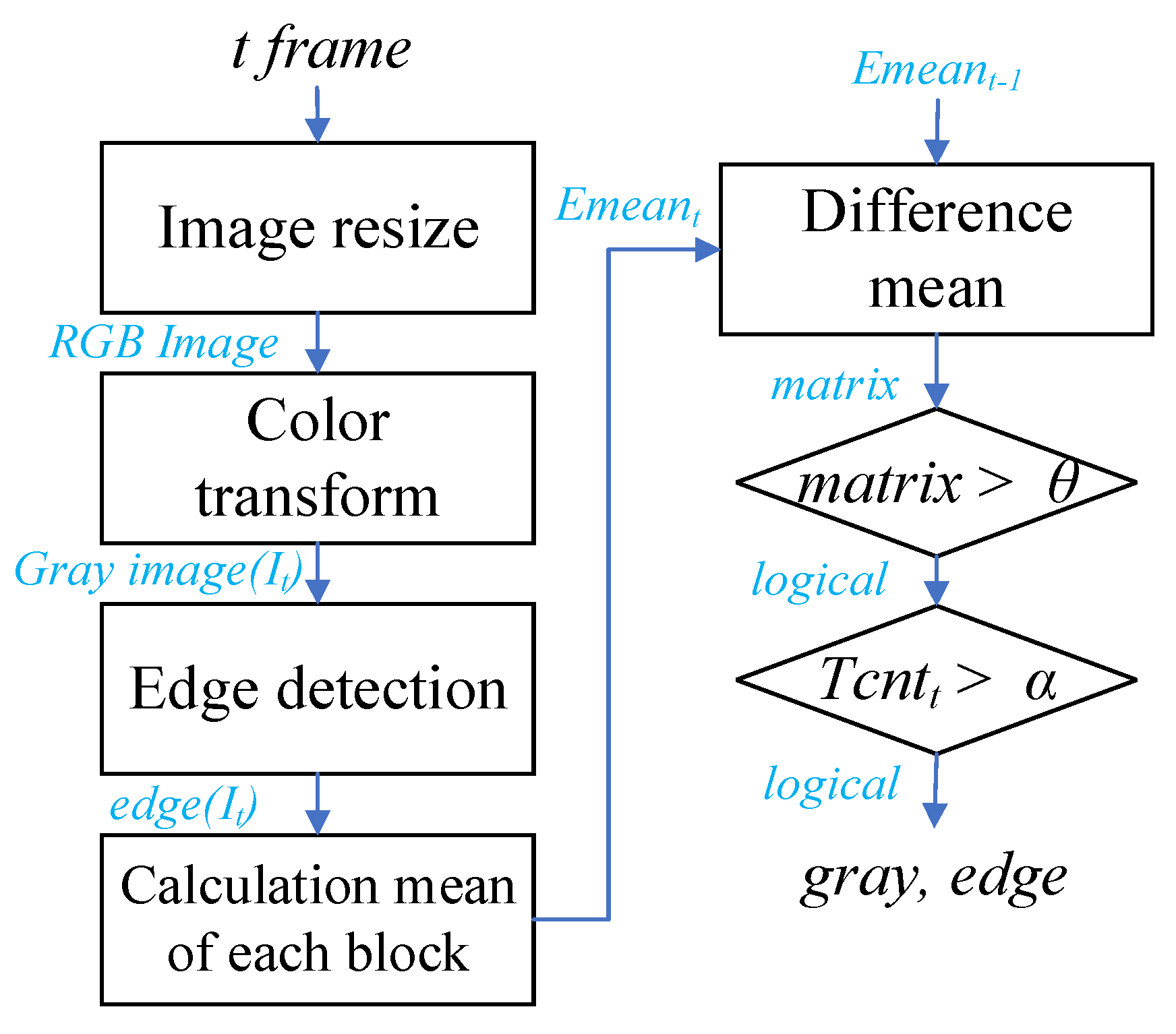
3.1. The Effect of Image Analysis
To perform pre-processing for the image-analysis step, a color image with a pixel size of 1242 × 375 was reduced to half its size, a gray image was transformed, and a 3 × 3 pixel 2D median filter was applied to remove noise. The resultant image (pixel size 621 × 188) was then divided into 70 blocks, each with a pixel size of 32 × 32 pixels, and the Sobel edge pixels were calculated for each block.
After, the number of edge pixels was calculated for each block, the number of blocks in which the number of edge pixels was larger than the threshold value,
θ, was then calculated. If this number of blocks was larger than
α, the VP detection step was performed for the frame. If the degree of change in the block with the edge pixel number was less than the threshold value
α, the position of the VP calculated in the previous frame was also applied to the current frame. The key objective for this step was to avoid the process of calculating VPs for every frame. Therefore, the accuracy of this step had the potential to affect the performance of the entire system, and thus, it was necessary to secure the reliability of these analysis results.
Figure 6 shows the changes in the average edge-pixel number differences for the 70 blocks corresponding to each frame of the experimental image.
Figure 6 shows that when many changes occurred in the number of edges between two frames, a large difference in the value existed. In other cases, a value between 0.0 and 0.02 occurred, which meant that no significant change occurred as a feature of the images between adjacent frames. Therefore, threshold value
θ, which determined the average number edge-pixel changes in each block corresponding to two adjacent frames, was set to at least 0.02, as shown in
Figure 6. Threshold
α, which indicates how many of the 70 blocks must be processed when the change occurs, was set to 13, which was the block number where the occurrence probability was greater than 90%, as shown in
Figure 6c. Therefore, if the number of blocks with a mean difference value of more than 0.02 blocks between two frames was 13 or more, the VP detection step was performed.
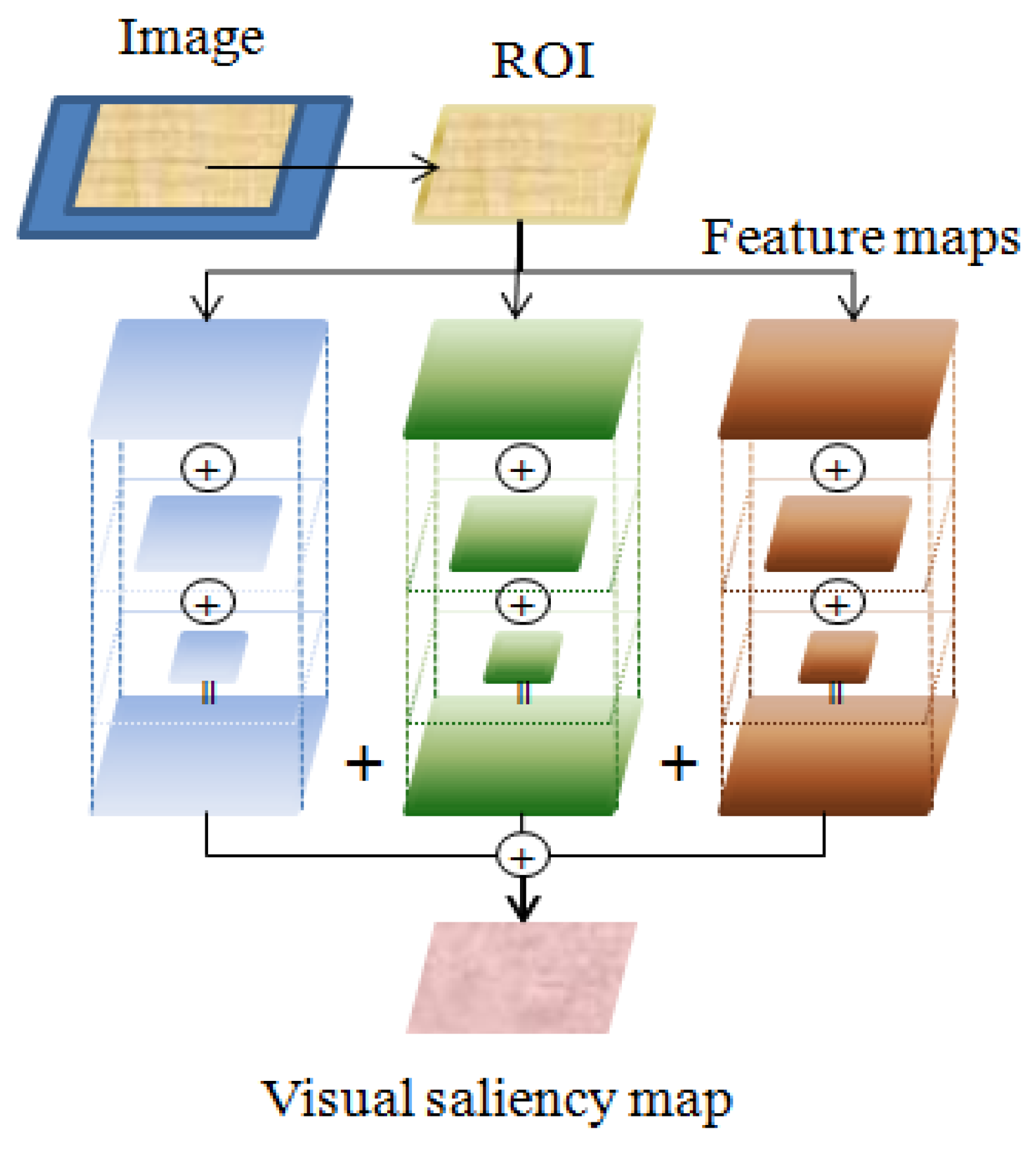
3.2. The Effect of ROI Detection
The ROI detection step for a gray image detects the VR using the visual-saliency model. In the VR, visual-saliency values were selected by binarizing just the top 20% of the values, and the ROI was detected and then among the detected VR, the top 20% visual-saliency regions were selected and binarized, to detect the final ROI. A visual-saliency map was created by generating feature maps from the input image, and importance maps were then generated from these feature maps. The feature maps were generated using edge and Gabor filter-based 2D texture orientation (45°, 135°) information from the input image. Therefore, the feature map was represented by three layers using a Gaussian pyramid, and one edge and two components of the directional information were used to form three feature maps. To generate the importance maps, a center-difference operation among the Gaussian parametric levels was then performed, and through this process, the contrast difference between a pixel and its neighbors was calculated, and the visual-saliency pixels were represented by a 2D map. The importance map removed unnecessary regions by increasing the value of the high-value regions in the feature maps and decreasing values for other parts. A visual-saliency map was generated using the sum of the weights (ω1 = 0.1, ω2 = 0.2) in Equation (2) for the two importance maps.
Figure 7 shows the results obtained by selecting the top 10% region in the visual-saliency map generated by the visual-saliency model.
Figure 7a,b and show the results of the generation of the edge and texture-orientation feature maps from a multiresolution image where the image size was reduced to 50% and 25% of the input image, respectively. The importance map was generated using the feature maps, as shown in
Figure 7c, and the visual-saliency map shown in
Figure 7d was then generated based on center-difference calculations from the two importance maps.
Figure 7e show the result of projecting a visual-saliency map onto the input image, and the visual-saliency map that corresponded to just the top 10% of the value of the visual-saliency map onto the input image, respectively.
3.3. The Effect of Image Segmentation
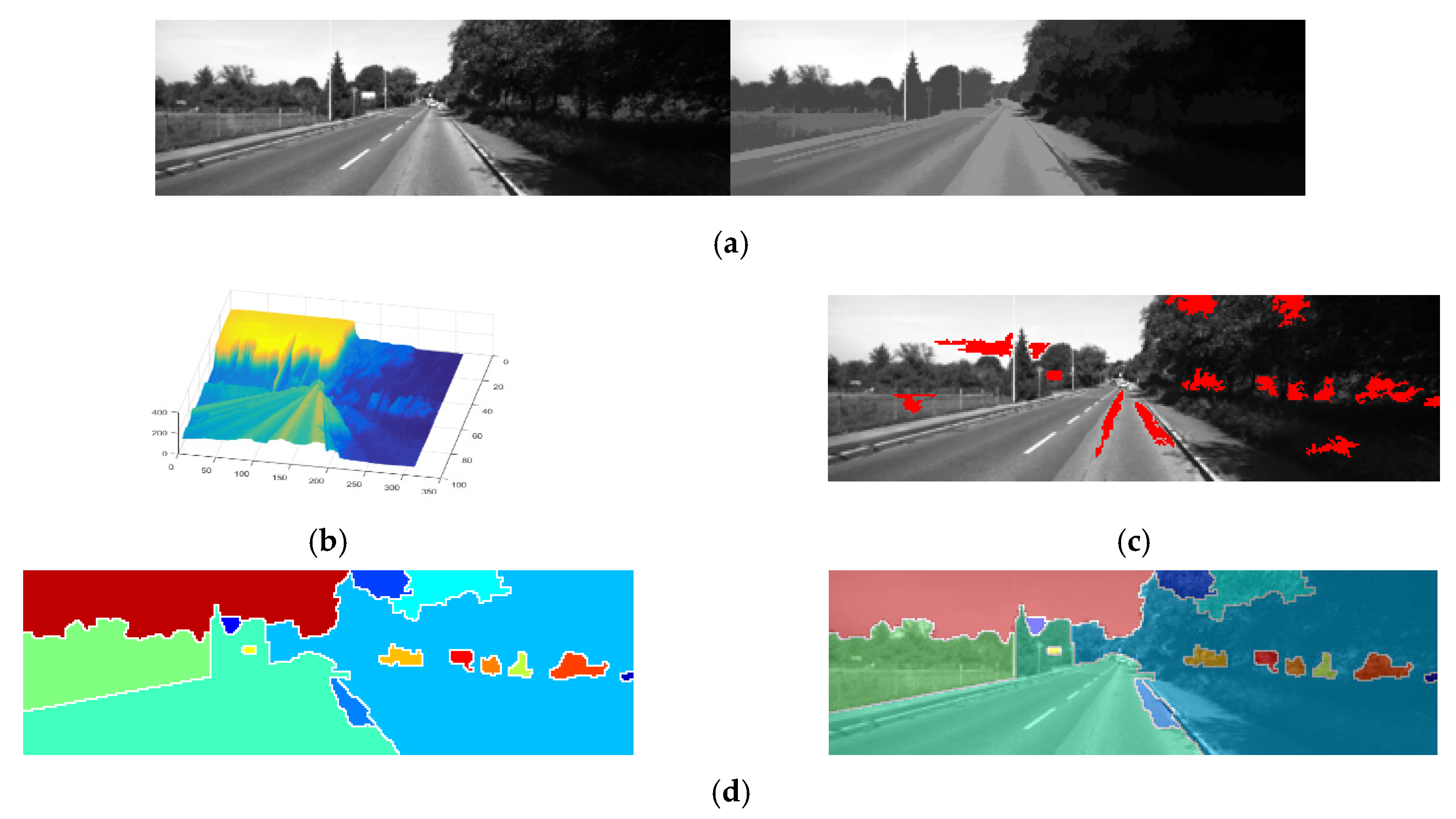
A watershed algorithm based on markers was applied to segment the gray image, although it was not possible to solve the problem in which the image was overdetermined, based only on positioning. To perform this, we needed to distinguish the boundaries of each area clearly, and to solve the problem in which the image was over-segmented in the watershed algorithm, the proposed method designated a marker, which was the initial starting point for image segmentation. Generally, a road image can be divided into a plurality of adjoining regions using connected pixels of similar color and texture, such as the sky and road region where the vehicle is located. In the proposed method, a morphology operation has been applied to the input image, to distinguish the road area from the background area.
To do this, we applied a filtering process using a square operator with a 10 × 10 pixel size. To reduce the execution time and determine the approximate position of the initial marker through the application of multiple morphology operations, computation was performed on image version that was one quarter the size of the input image. In the image segmentation process, the resized input image was combined with the results of the erode- and dilate-reconstruction morphology operations to obtain a smoothed image, as shown in
Figure 8a.
We also needed to select an initial marker for watershed image segmentation in the smoothed image. The initial marker selected pixels adjacent to eight directions for each region in the smoothed image and 10 or more pixels connected with a maximum brightness value (
Figure 8b,c). Finally, the maximum value of the region was selected as the initial maker, and the image was segmented using the watershed algorithm (
Figure 8d). To evaluate image segmentation performance, we compared the image segmentation results obtained using the ground-truth method (
Segg) with the proposed method (
Sego) in 70 experimental images. The performance comparison was evaluated in terms of the degree of overlap [(
Sego∩
Segg)/
Segg] between the two segmentation results, and the experimental results demonstrated that the accuracy of the proposed method was greater than 94%.
3.4. The Effect of Line Detection
The Hough transformation was applied to the smoothed gray image in the image segmentation step, to detect straight lines. In the proposed method, we set the maximum Hough peak value to 20, and detected 10 lines that crossed the peak point. In our proposed method, we used line equations to detect the connecting line from the image boundary to the beginning and end, and classified the intersections of these lines as candidate VPs.
Figure 9 shows the result of applying the Hough transformation to the input image. The square position in the Hough transformation matrix refers to the peak maximum value.
The theta range was set to [−70:−70, 20:70] to exclude horizontal and vertical lines through the Hough transformation. Following detection of the line intersection points based on the Hough transformation (as shown in
Figure 9), only intersections that existed in the candidate region of the actual VP were selected. Intersection selection was performed at the intersection of the lines belonging to the area located from the second to the fourth areas when the image was vertically divided into five parts, and from the second to the third areas, when the image was horizontally divided into five parts, as shown in VP conditions 6 and 7, in
Table 1.
3.5. The Effect of VP Selection
In the proposed method, the VP was selected based on the VRs, the boundaries of the segmented regions (SB), and on line intersection points (CP). For VP selection, the position corresponding to Equation (4) was selected as the VP, while satisfying the VP criteria listed in
Table 1.
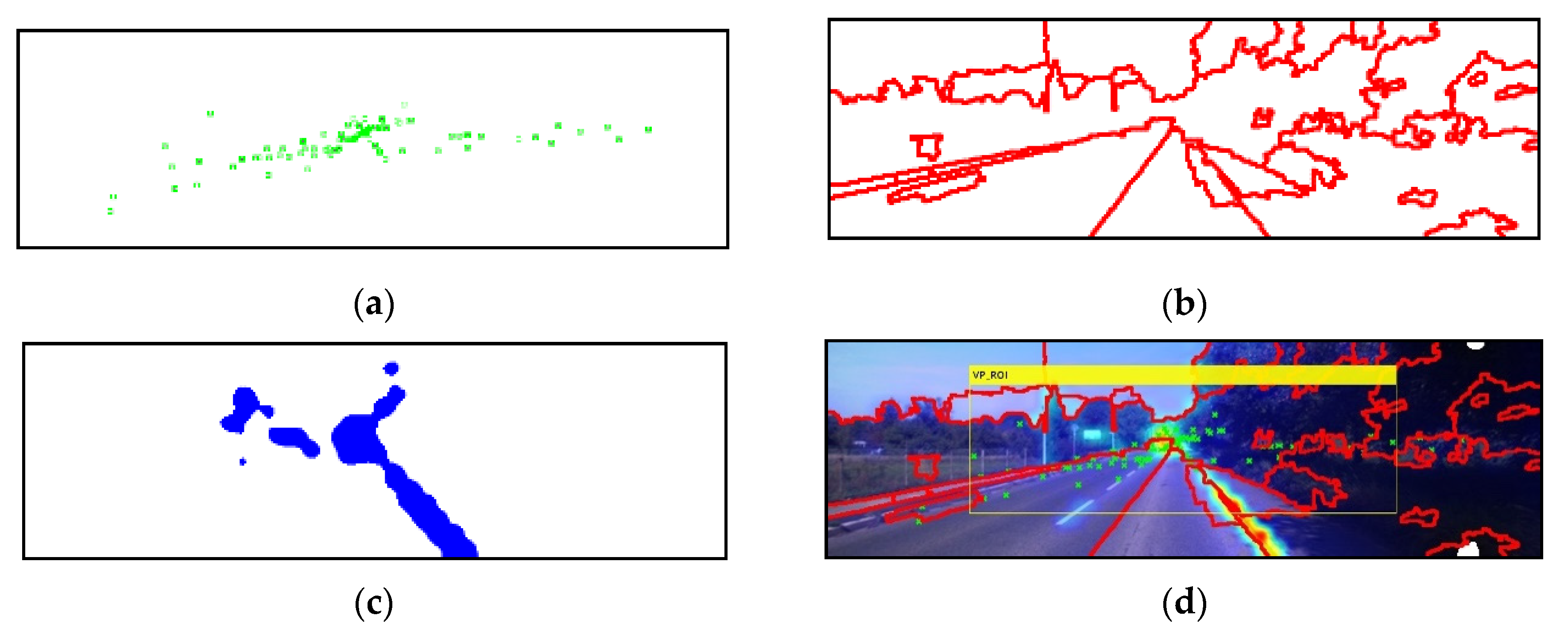
Figure 10 shows VP selection results from the input image initially shown in
Figure 3.
Figure 10a shows the intersection of the lines detected by the edge based on the Hough transform, and
Figure 10b shows the boundaries of the regions segmented by the watershed algorithm.
Figure 10c shows the results for the top 10% saliency region detected by the visual-attention model, while
Figure 10d shows an overlay of the results of
Figure 10a–c in the input image.
Figure 10e shows the results obtained by selecting candidate VPs in
Figure 10d, and
Figure 10f shows the result obtained by selecting the position with the largest value in the VR as the VP, displaying the results on the input image.
Figure 11 shows results attained for VP detection in various experimental environments. The experiments indicated that detecting the VP using edge information that was not noticeable in a natural image could be challenging, where the influence of roughness, such as a complicated background or a glow, is small. To verify the performance of the proposed method, we compared the ground-truth method, and Li [
36] and Kong [
37] methods, with the proposed method. The comparison was done using the precision and accuracy obtained using Equation (4), and execution time comparisons were also performed, using the distance differences between the ground-truth method and the VP position coordinates detected using each method.
In Equation (4), ax refers to the 11 × 11 region where the VP is the center point at x position, detected by the proposed method, and gx is a binary mask representing the 11 × 11 region detected by the ground-truth method. Here, P is precision, R is recall, and cnt( ) is a counting function.
Consequently, when the VPs were included in the 11 × 11 pixel region, we considered it as a correct detection, and the accuracy was calculated by the error with respect to the VP coordinate set using the ground-truth method.
Table 5 presents comparison results, in terms of precision, recall, and processing time for VP detection, in the experimental images.
Figure 11 shows VP location based on the ground-truth method, with
Figure 11a–d showing VP selection results obtained using the ground-truth method, our method, and Kong’s method [
36]. These results showed that, when comparing total execution time, Kong’s method needed an execution time three times longer than the proposed method based on VP detection using a voting system for all pixels.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}