Robust CFAR Detection for Multiple Targets in K-Distributed Sea Clutter Based on Machine Learning


Abstract
1. Introduction
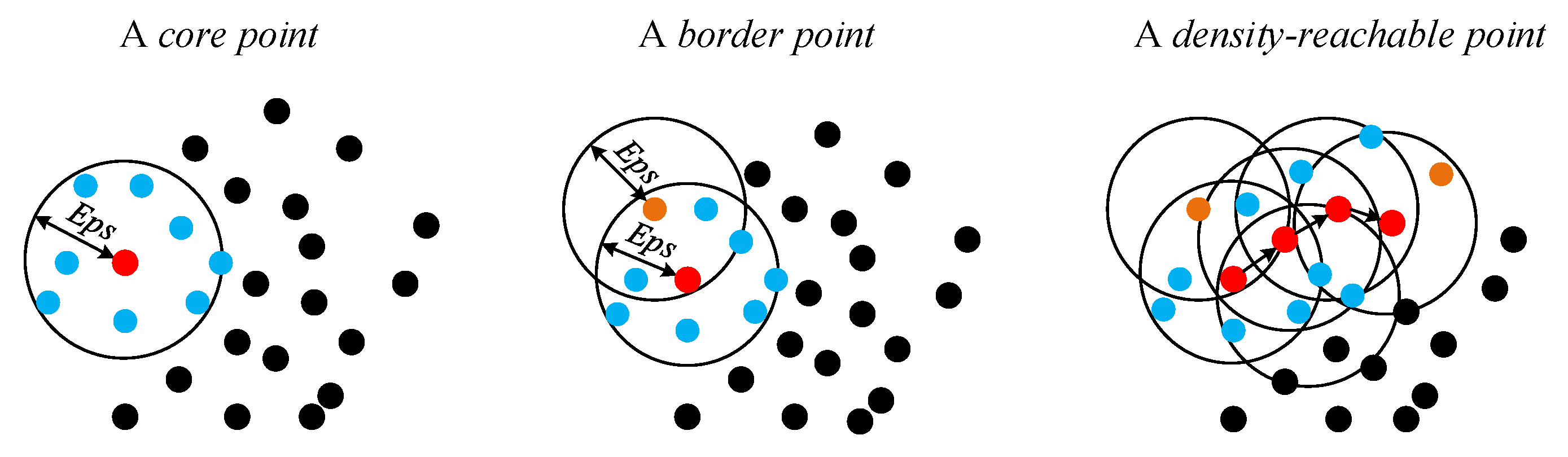
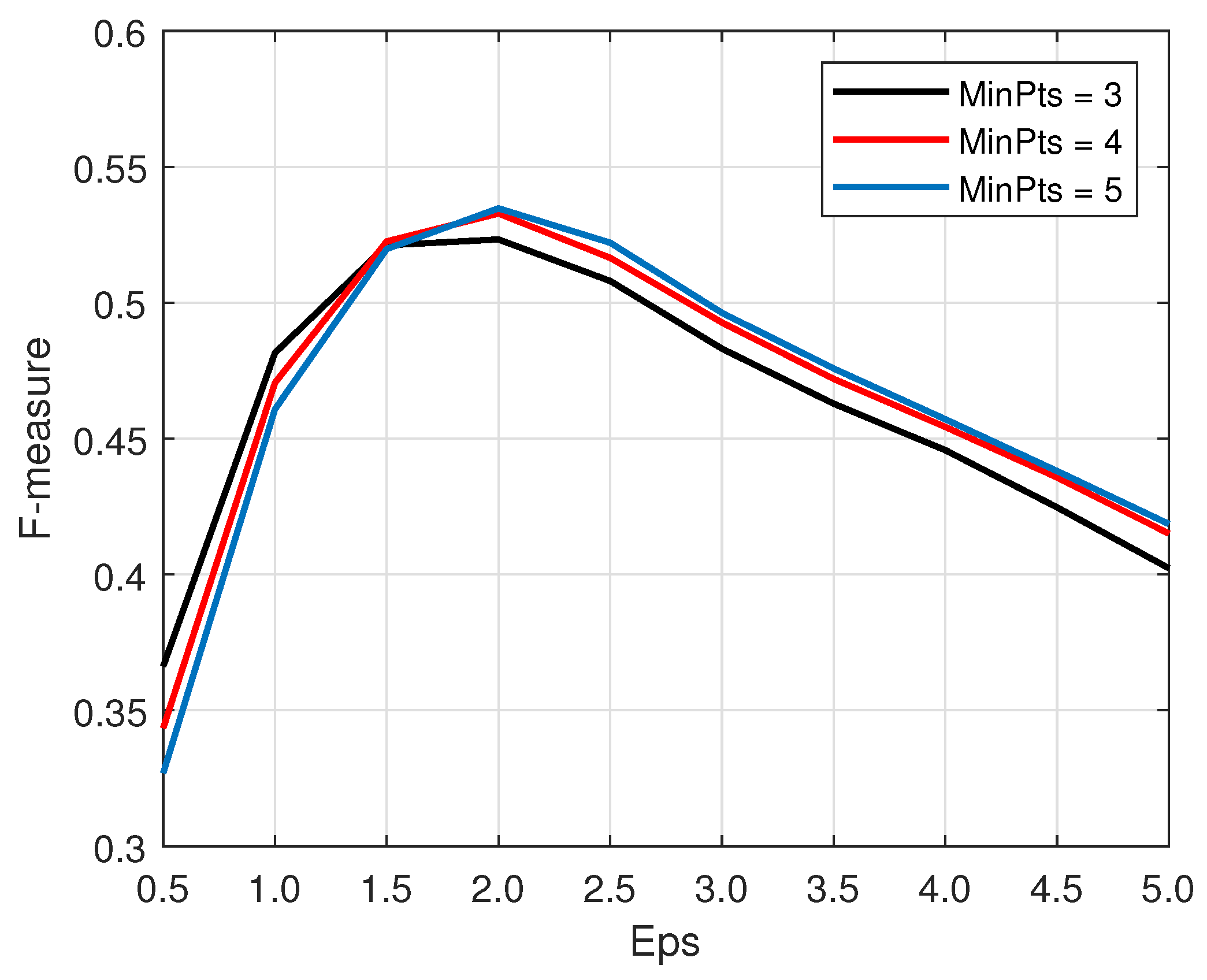
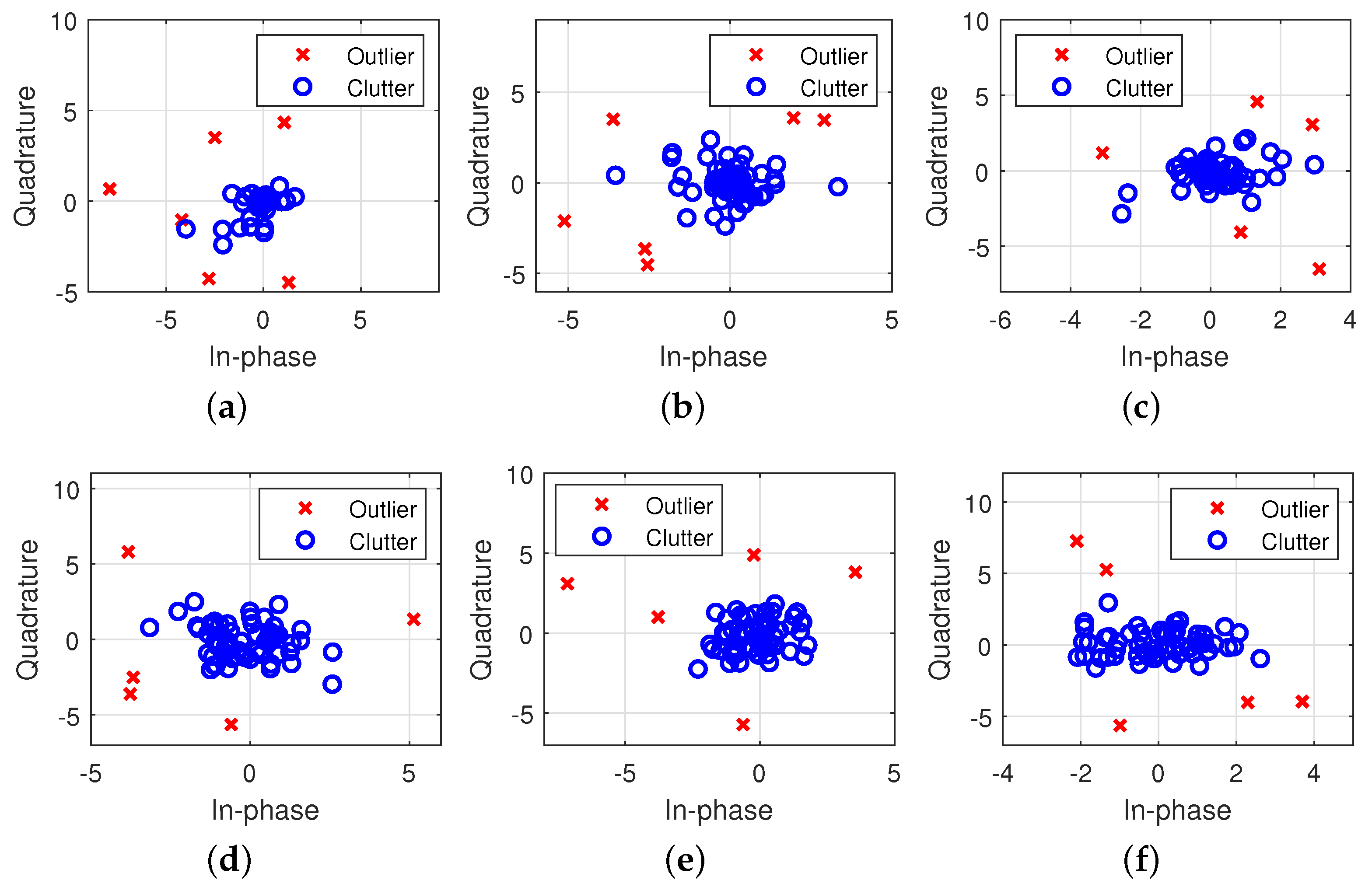
- We propose a novel CFAR processor based on the DBSCAN clustering algorithm, termed DBSCAN-CFAR, to eliminate outliers in the leading and lagging windows that are symmetrical about the CUT. Without a priori knowledge on the number and distribution of interference targets, the DBSCAN-CFAR can achieve an accurate estimation of the clutter background level for multiple-target scenarios. The configuration parameters of DBSCAN are predetermined according to the characteristics of the clutter data to ensure real-time performance of the detector.
- We design and train an ameliorative ANN model with a symmetrical architecture to evaluate the shape parameter of K-distributed sea clutter with high precision. Through deriving the numerical relationship between the threshold factor and the shape parameter under different false alarm probabilities, the optimal parameter estimation value offered by the ANN method is instrumental in maintaining the CFAR property for DBSCAN-CFAR.
- We demonstrate the effectiveness and superiority of the proposed ANN-based DBSCAN-CFAR processor over several relevant competitors with respect to the variation of interference target numbers, shape parameters, and false alarm probabilities through extensive simulations. This performance improvement is at the expense of time that elapses.
2. Preliminary Theories
2.1. K-Distributed Sea Clutter Model
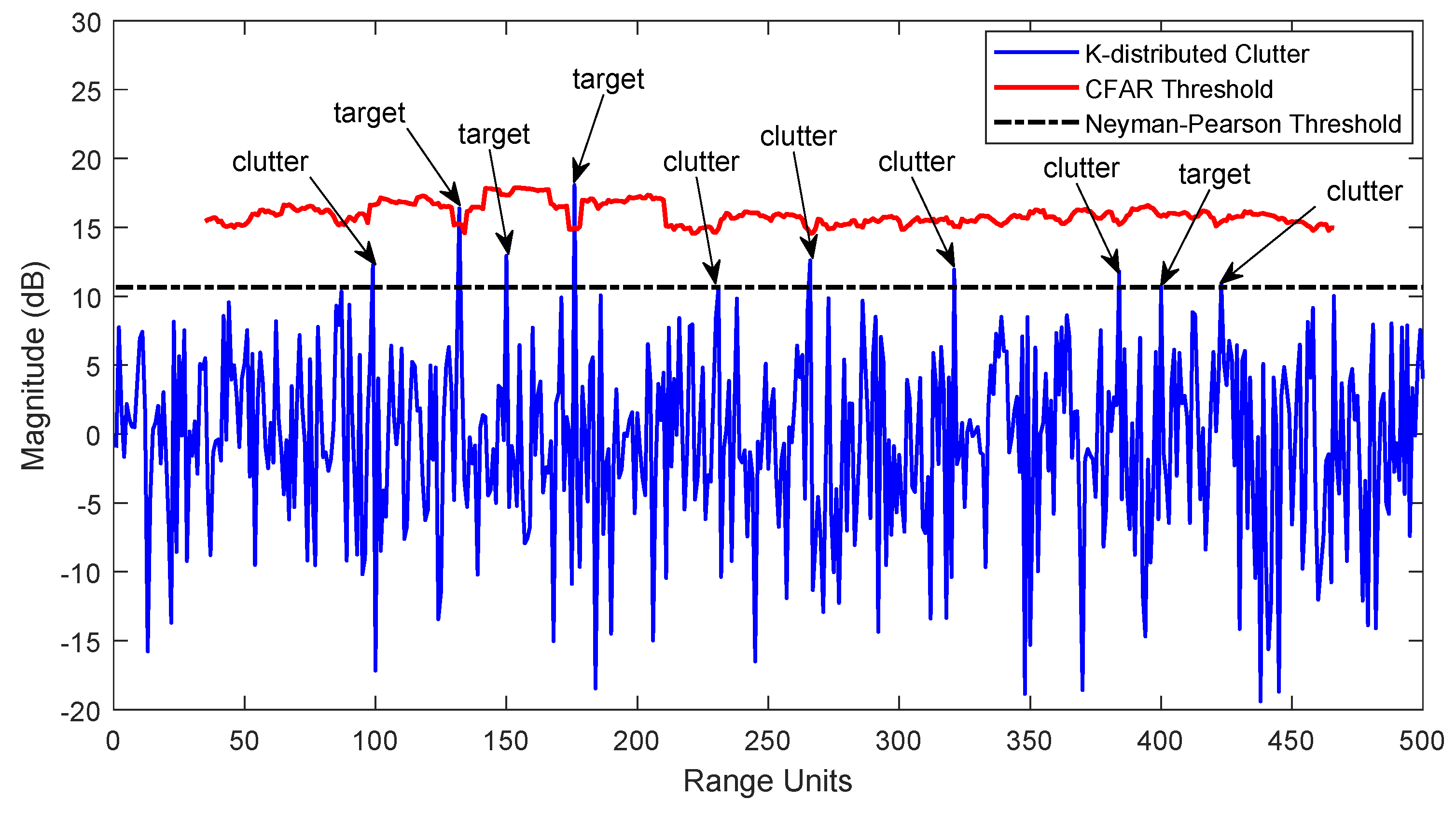
2.2. CFAR Detection
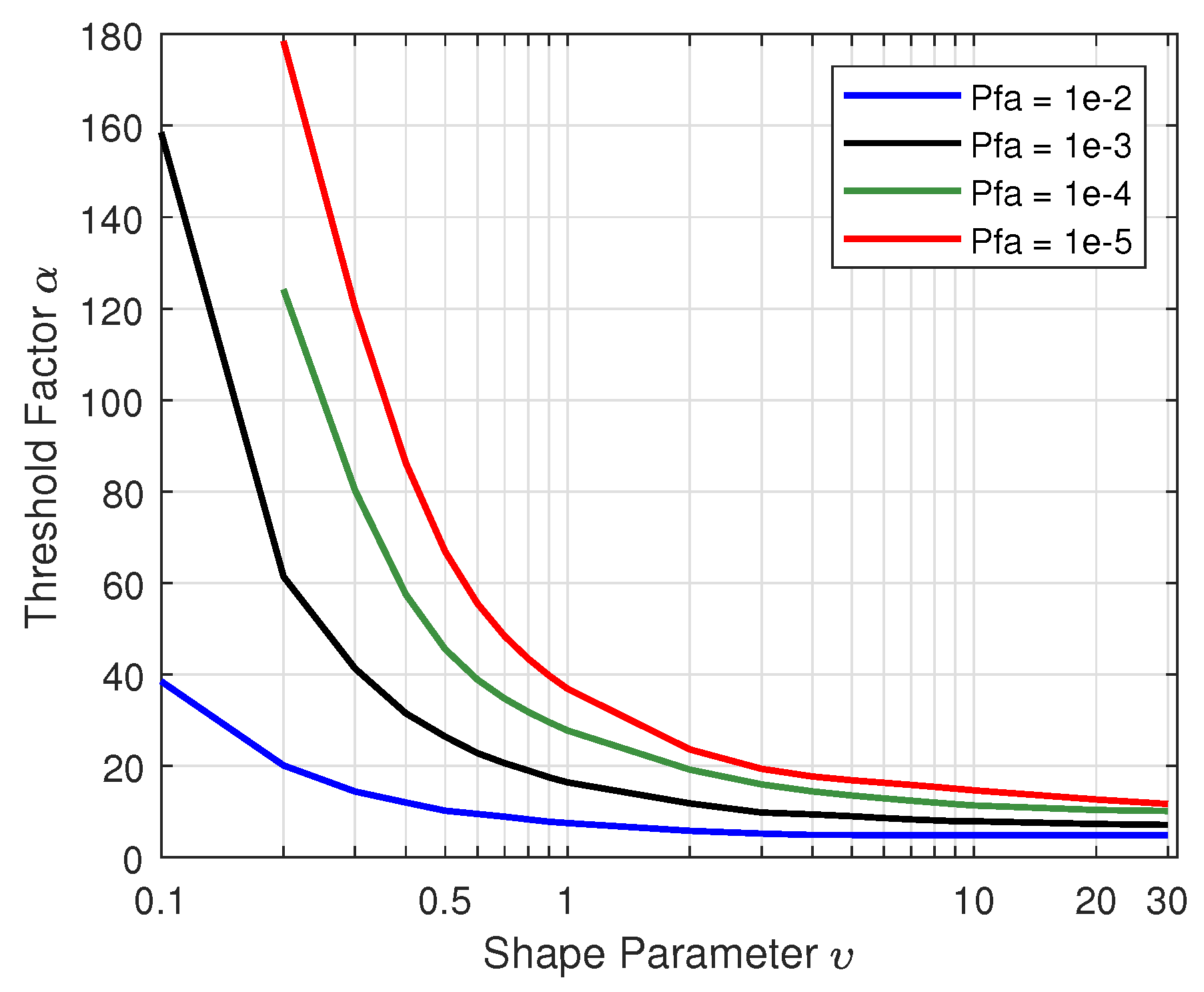
2.3. Shape Parameter Estimation
3. Proposed Methods
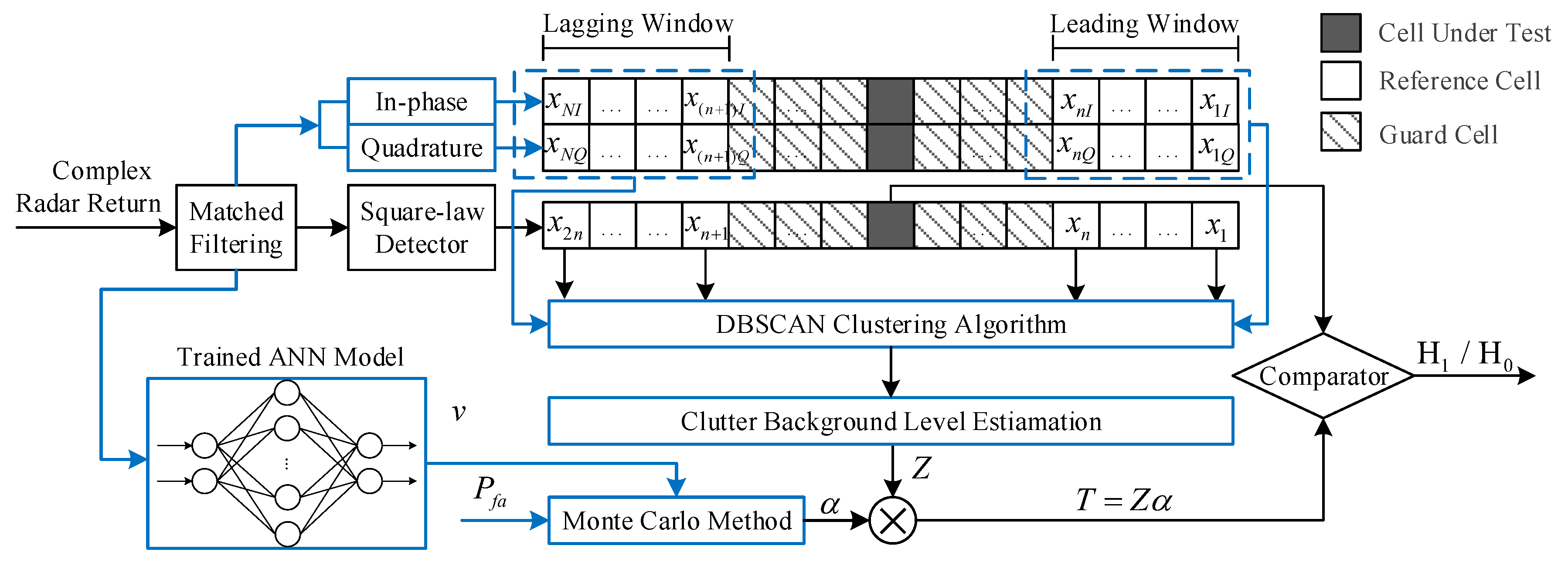
3.1. DBSCAN-CFAR Processor
| Algorithm 1 Proposed DBSCAN-CFAR Processor |
| Input: Number of reference cells N, number of guard cells M, complex samples of radar return in reference window , and clustering parameters of and . Output: Target detection result ( or ).
|
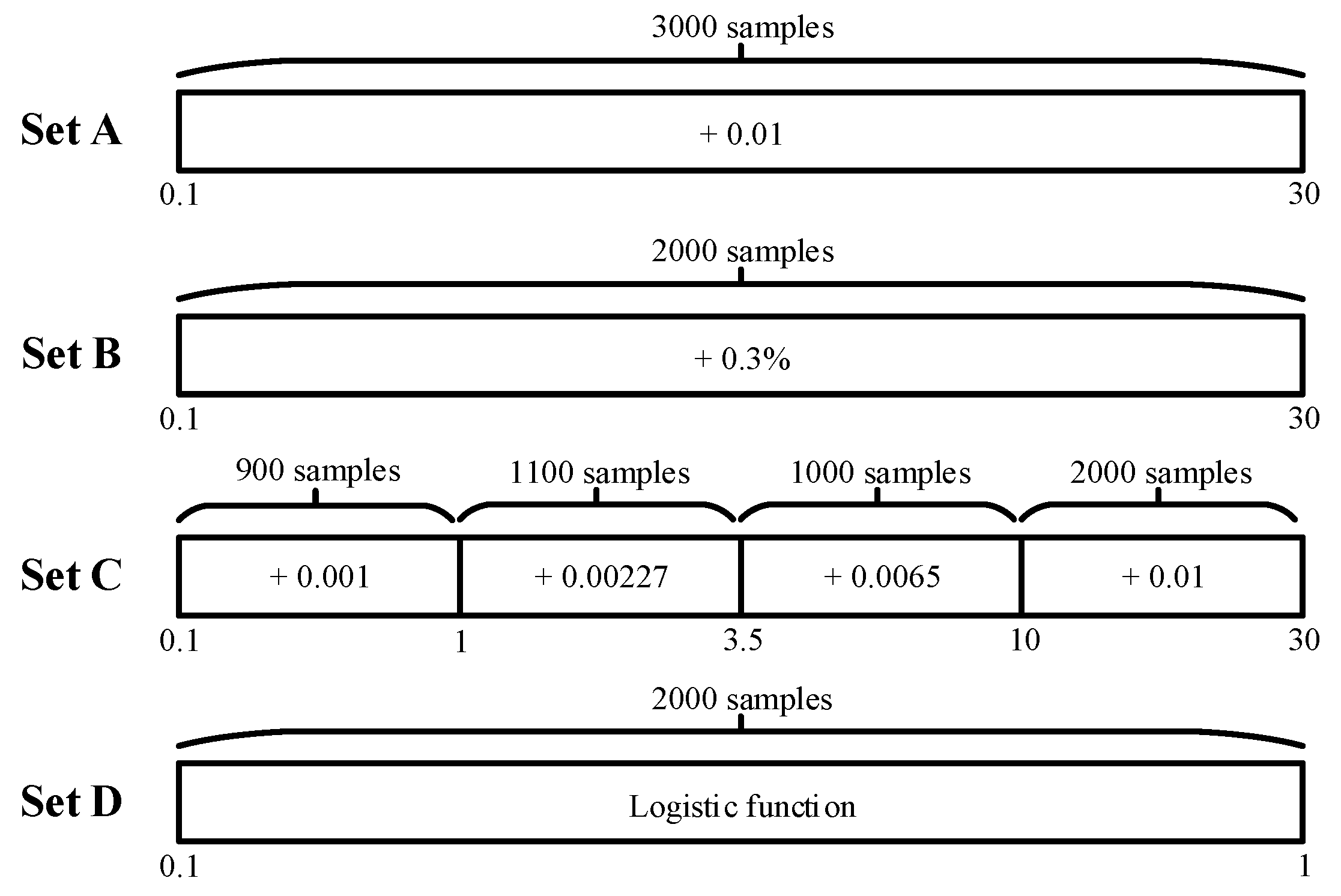
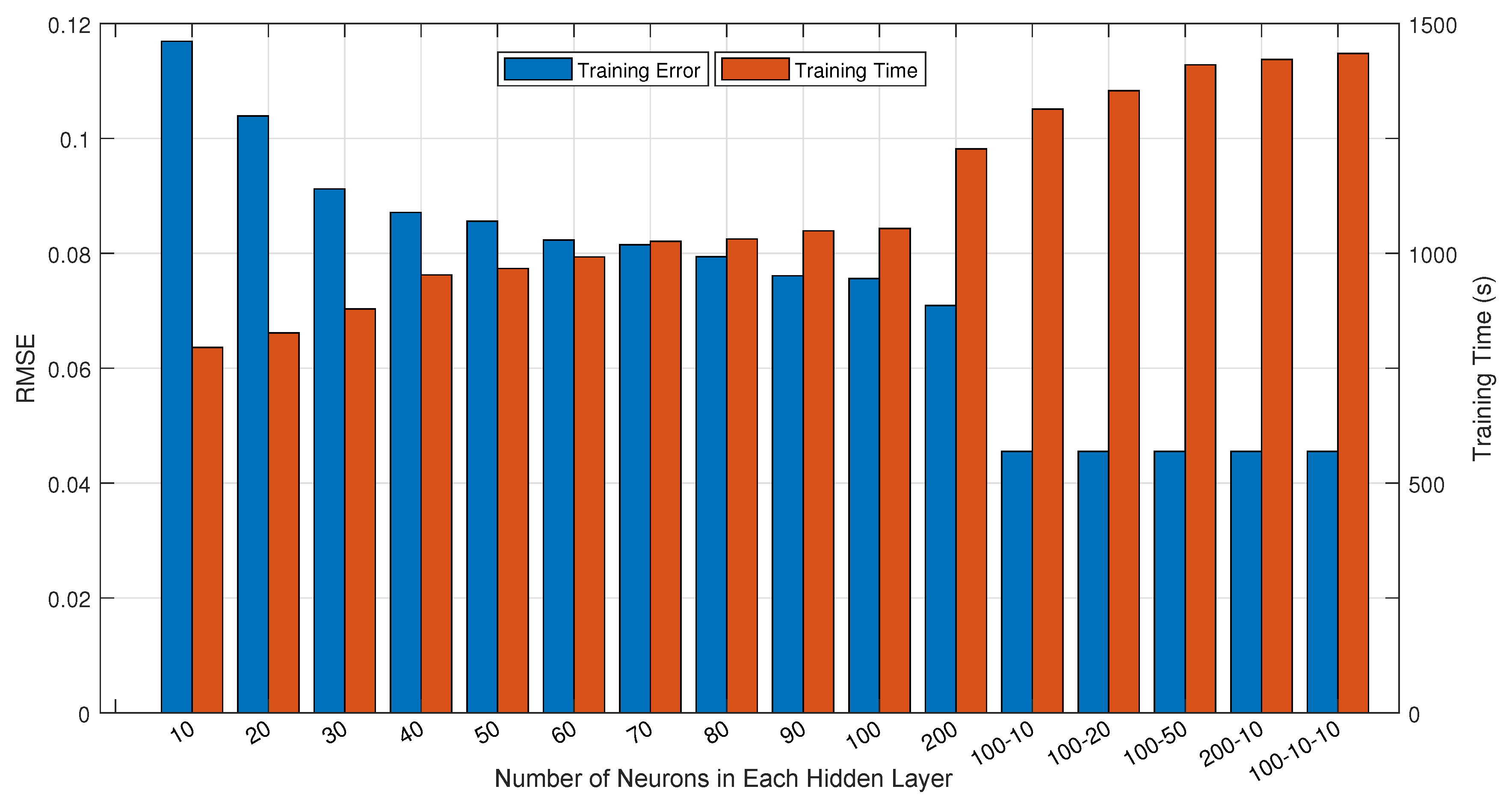
3.2. ANN-Based Shape Parameter Estimation
4. Results and Analysis
4.1. Impact of Parameter Estimation Accuracy
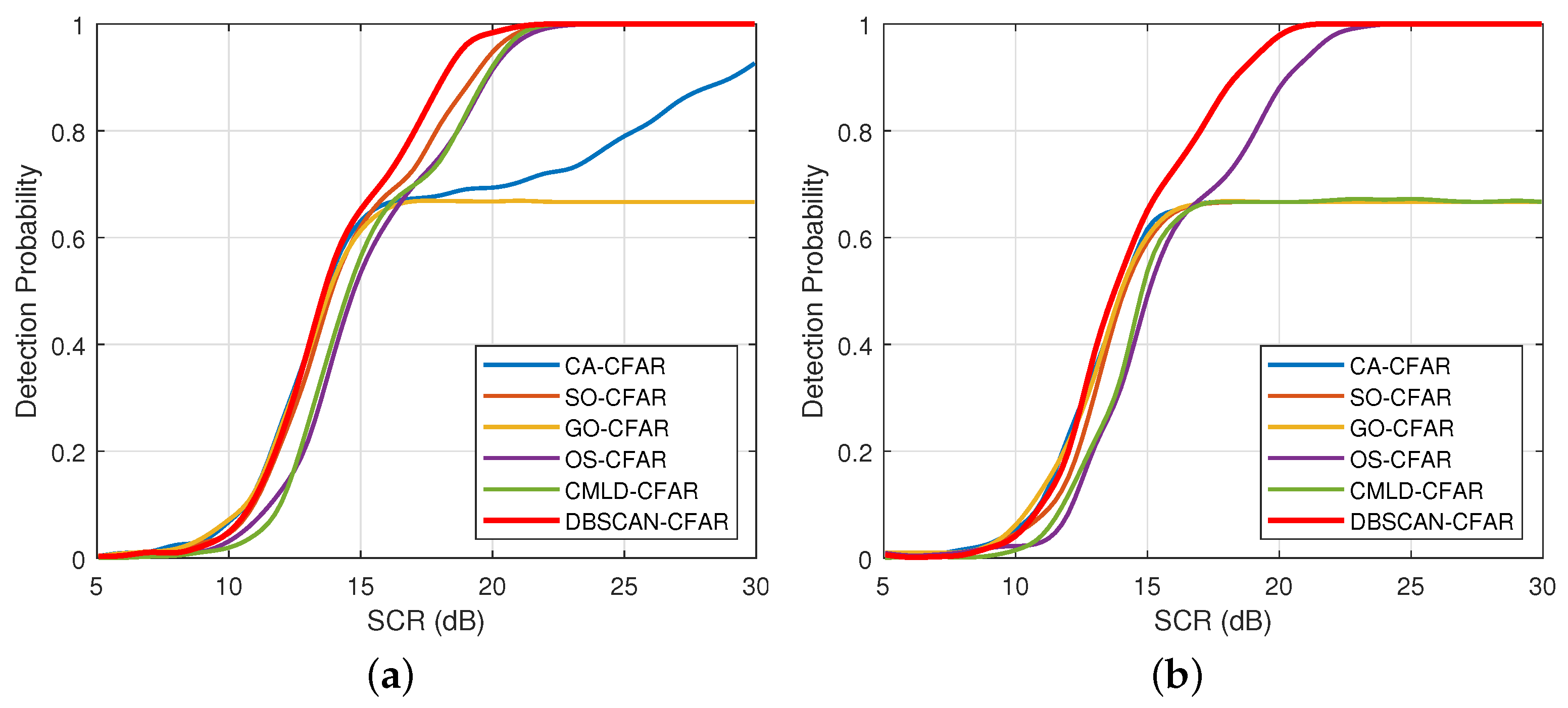
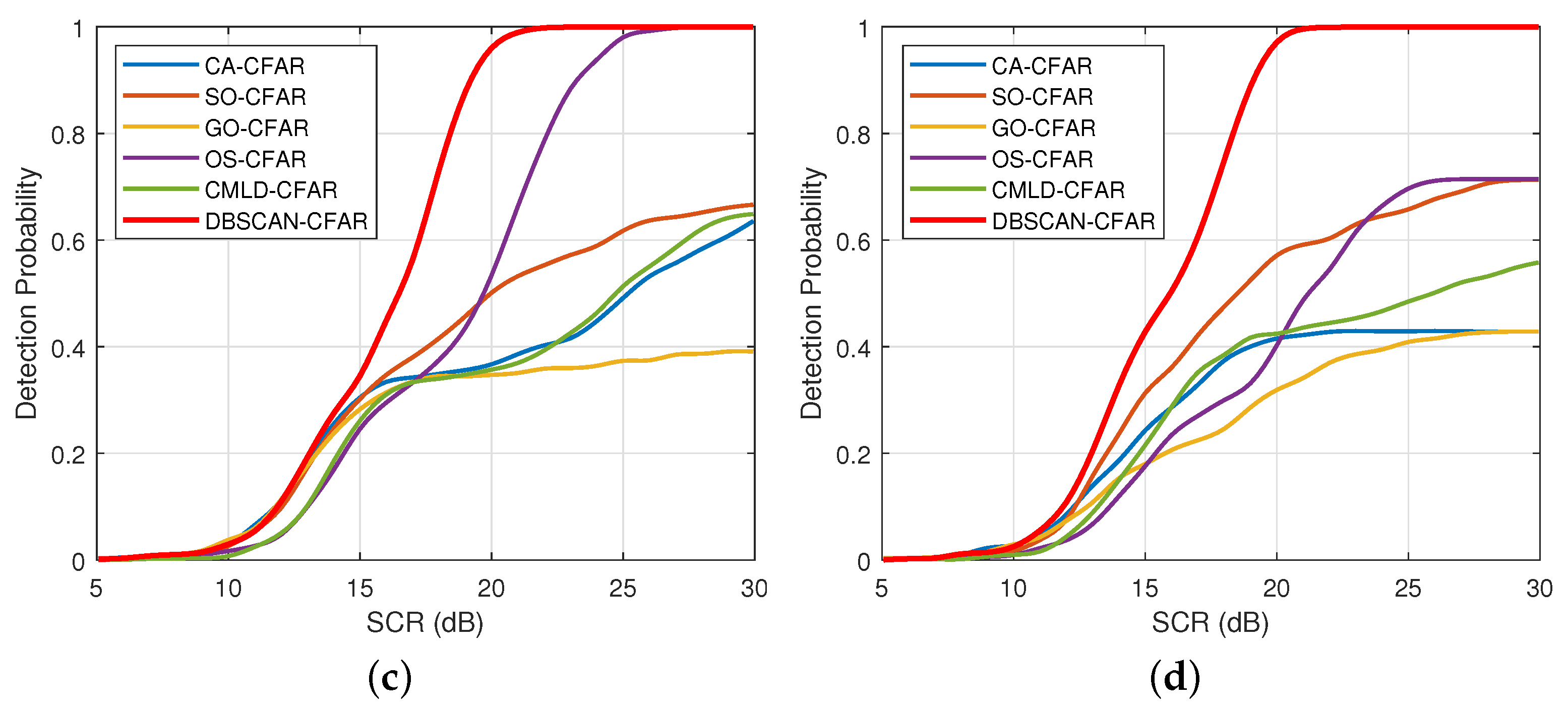
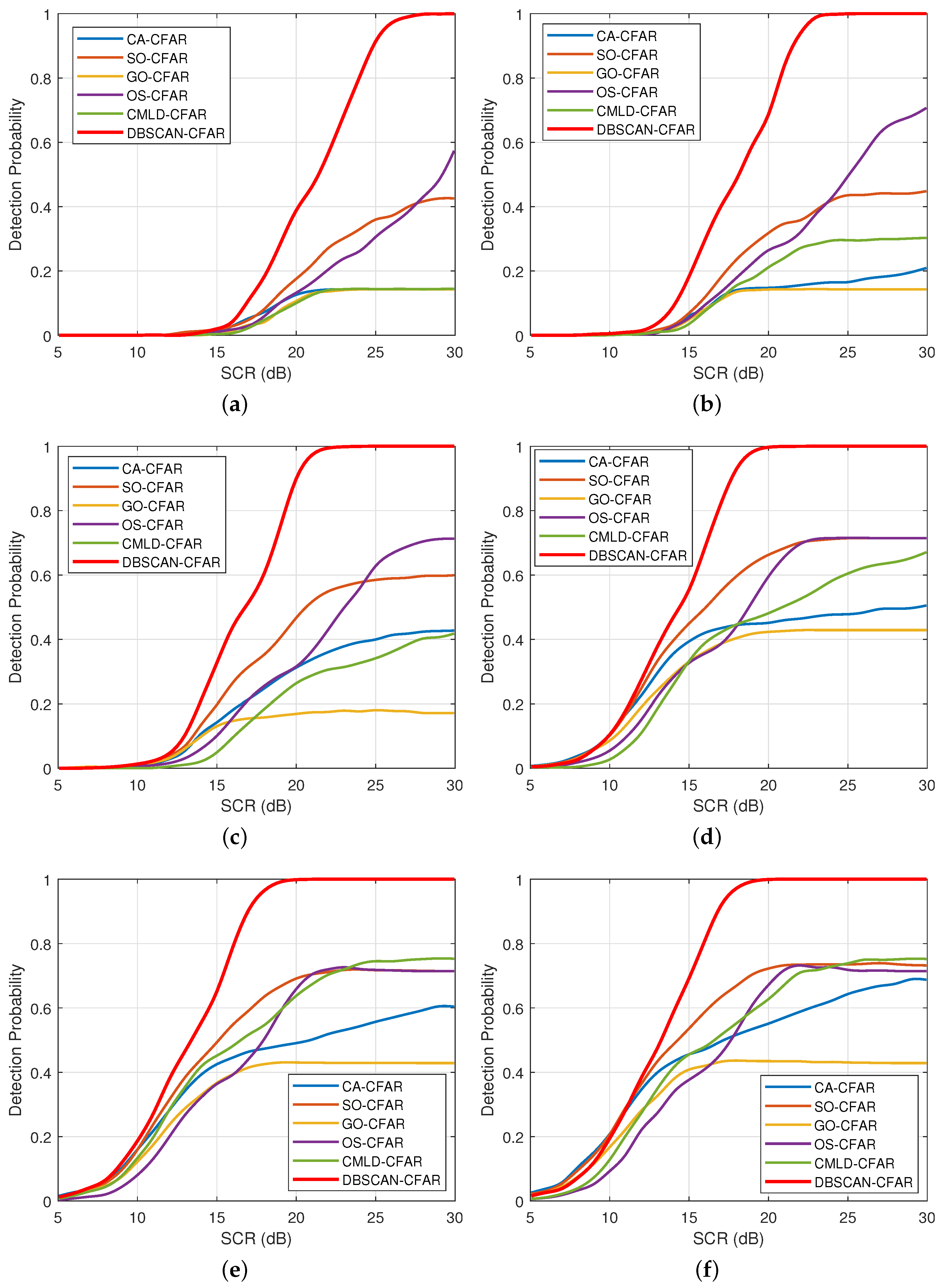
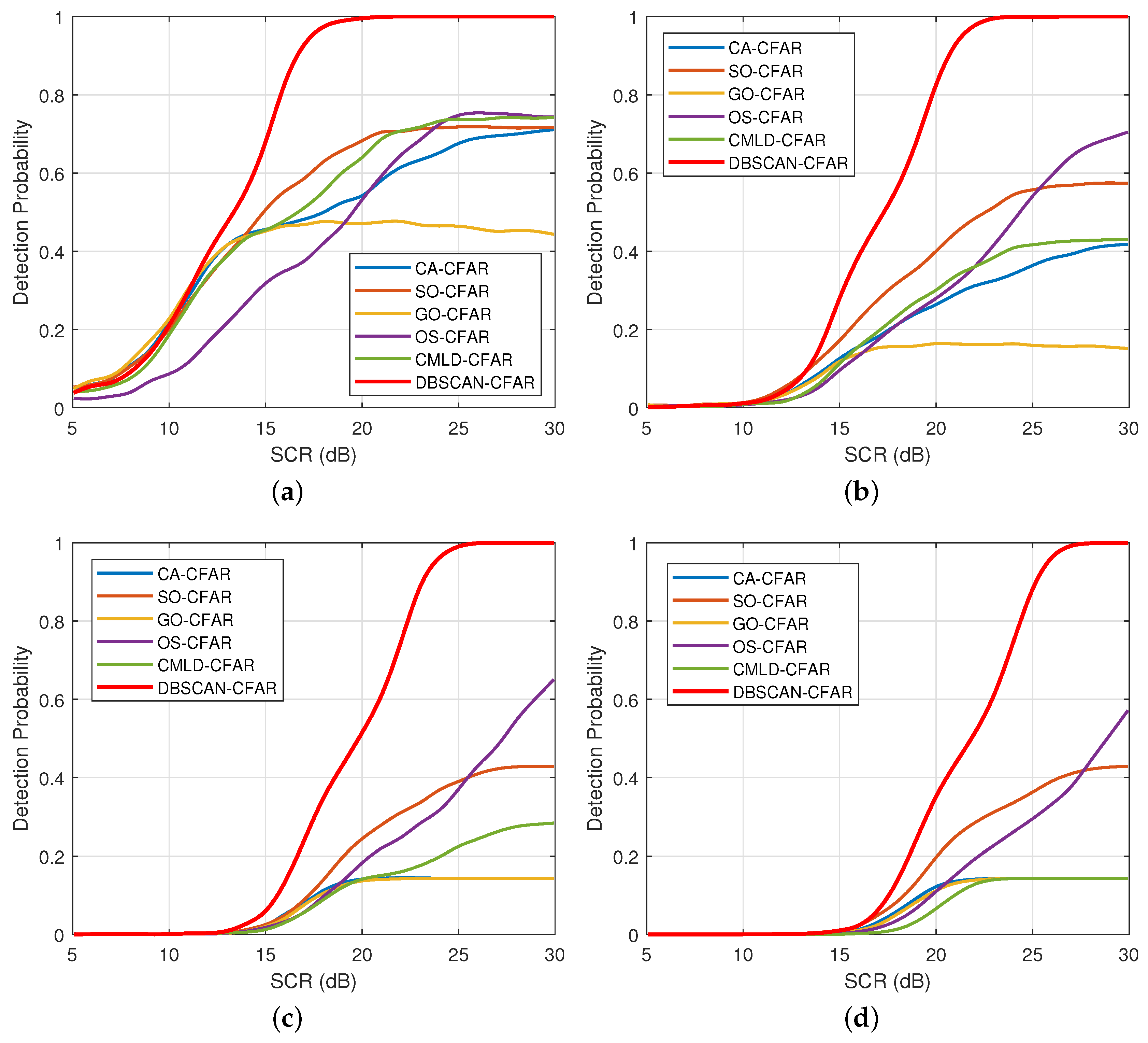
4.2. Impact of Interference Target Number
4.3. Impact of Various Shape Parameter
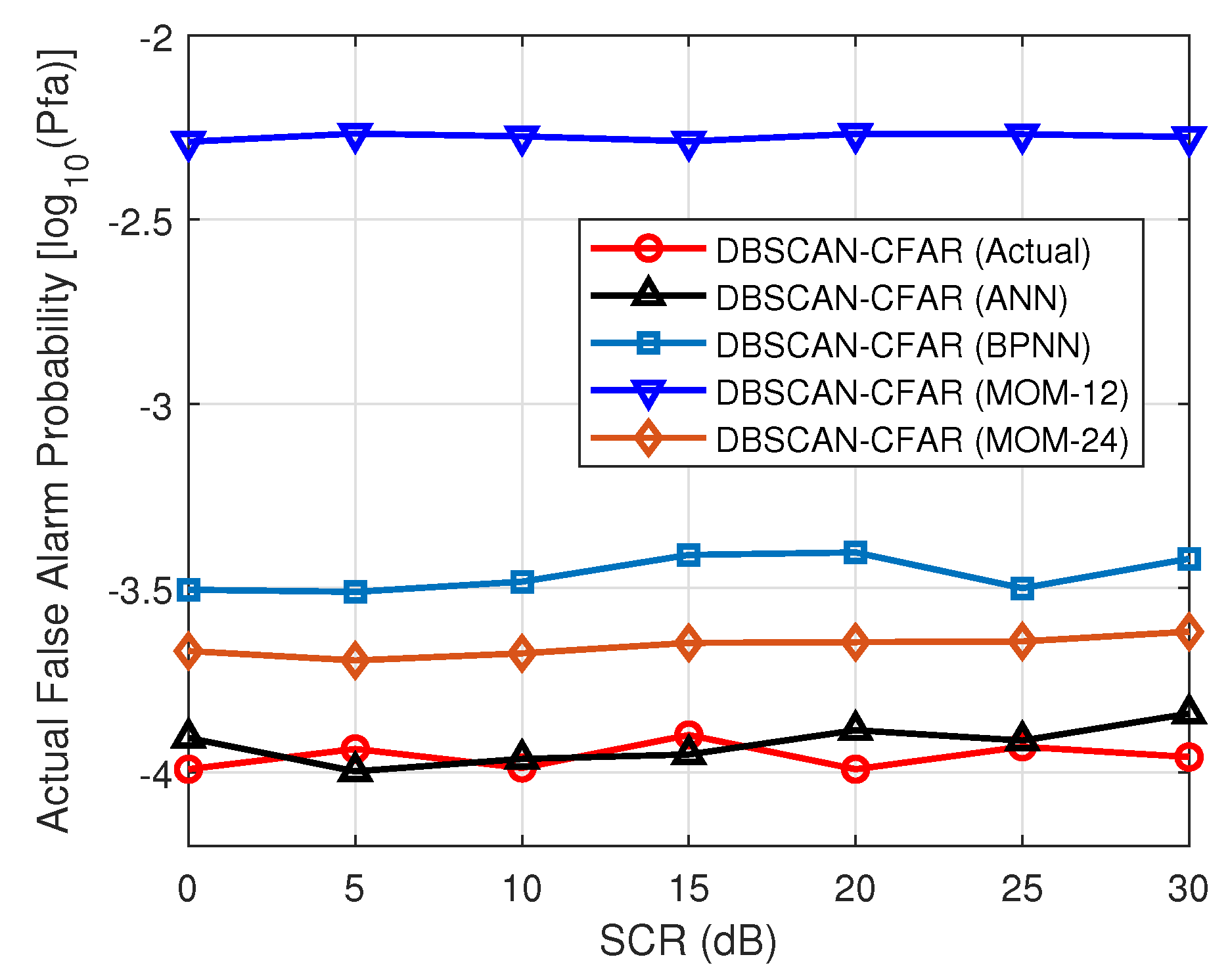
4.4. Impact of False Alarm Probability
4.5. Analysis of Time Elapsed
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| ANN | Artificial neural network |
| BN | Batch normalization |
| BPNN | Back propagation neural network |
| CA-CFAR | Cell averaging constant false alarm rate |
| CFAR | Constant false alarm rate |
| CMLD-CFAR | Censored mean level detector constant false alarm rate |
| CUT | Cell under test |
| DBSCAN | Density-based spatial clustering of applications with noise |
| GO-CFAR | Greatest-of constant false alarm rate |
| ICR | Interfering-to-clutter ratio |
| LOF | Local outlier factor |
| LReLU | Leaky rectified linear unit |
| MLE | Maximum likelihood estimation |
| MOM | Method of moments |
| OS-CFAR | Ordered statistics constant false alarm rate |
| Probability density function | |
| ReLU | Rectified linear unit |
| RMSE | Root mean squared error |
| SAR | Synthetic aperture radar |
| SCR | Signal-to-clutter ratio |
| SO-CFAR | Smallest-of constant false alarm rate |
| Tanh | Hyperbolic tangent |
| TS-CFAR | Truncated statistic constant false alarm rate |
| VI-CFAR | Variability index constant false alarm rate |
References
- Greco, M.; Bordoni, F.; Gini, F. X-band sea-clutter nonstationarity: Influence of long waves. IEEE J. Ocean. Eng. 2004, 29, 269–283. [Google Scholar] [CrossRef]
- Angelliaume, S.; Rosenberg, L.; Ritchie, M. Modeling the Amplitude Distribution of Radar Sea Clutter. Remote. Sens. 2019, 11, 319. [Google Scholar] [CrossRef]
- Jakeman, E.; Pusey, P. A model for non-Rayleigh sea echo. IEEE Trans. Antennas Propag. 1976, 24, 806–814. [Google Scholar] [CrossRef]
- Shi, S.; Shui, P. Optimum coherent detection in homogenous K-distributed clutter. IET Radar Sonar Navig. 2016, 10, 1477–1484. [Google Scholar] [CrossRef]
- Lewinski, D. Nonstationary probabilistic target and clutter scattering models. IEEE Trans. Antennas Propag. 1983, 31, 490–498. [Google Scholar] [CrossRef]
- Gandhi, P.P.; Kassam, S.A. Analysis of CFAR processors in nonhomogeneous background. IEEE Trans. Aerosp. Electron. Syst. 1988, 24, 427–445. [Google Scholar] [CrossRef]
- Zhao, J.; Jiang, R.; Yang, H.; Wang, X.; Gao, H. Reconfigurable hardware architecture for Mean Level and log-t CFAR detectors in FPGA implementations. IEICE Electron. Express 2019, 16, 1–6. [Google Scholar] [CrossRef]
- Weiss, M. Analysis of some modified cell-averaging CFAR processors in multiple-target situations. IEEE Trans. Aerosp. Electron. Syst. 1982, 18, 102–114. [Google Scholar] [CrossRef]
- Hansen, V.G.; Sawyers, J.H. Detectability loss due to Greatest Of selection in a cell-averaging CFAR. IEEE Trans. Aerosp. Electron. Syst. 1980, 16, 115–118. [Google Scholar] [CrossRef]
- Trunk, G.V. Range resolution of targets using automatic detectors. IEEE Trans. Aerosp. Electron. Syst. 1978, 14, 750–755. [Google Scholar] [CrossRef]
- Rohling, H. Radar CFAR thresholding in clutter and multiple target situations. IEEE Trans. Aerosp. Electron. Syst. 1983, 19, 608–621. [Google Scholar] [CrossRef]
- Rickard, J.T.; Dillard, G.M. Adaptive detection algorithms for multiple-target situations. IEEE Trans. Aerosp. Electron. Syst. 1977, 13, 338–343. [Google Scholar] [CrossRef]
- Smith, M.E.; Varshney, P.K. Intelligent CFAR processor based on data variability. IEEE Trans. Aerosp. Electron. Syst. 2000, 36, 837–847. [Google Scholar] [CrossRef]
- Ivković, D.; Andrić, M.; Zrnić, B.; Okiljević, P.; Kozić, N. CATM-CFAR detector in the receiver of the software defined radar. Sci. Tech. Rev. 2014, 64, 27–38. [Google Scholar]
- Tao, D.; Anfinsen, S.N.; Brekke, C. Robust CFAR detector based on truncated statistics in multiple-target situations. IEEE Trans. Geosci. Remote. Sens. 2015, 54, 117–134. [Google Scholar] [CrossRef]
- Zhou, W.; Xie, J.; Li, G.; Du, Y. Robust CFAR detector with weighted amplitude iteration in nonhomogeneous sea clutter. IEEE Trans. Aerosp. Electron. Syst. 2017, 53, 1520–1535. [Google Scholar] [CrossRef]
- Domingos, P.M. A few useful things to know about machine learning. Commun. ACM 2012, 55, 78–87. [Google Scholar] [CrossRef]
- Saxena, A.; Prasad, M.; Gupta, A.; Bharill, N.; Patel, O.P.; Tiwari, A.; Er, M.J.; Ding, W.; Lin, C. A review of clustering techniques and developments. Neurocomputing 2017, 267, 664–681. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; IEEE: Las Vegas, NV, USA, 2016; pp. 770–778. [Google Scholar]
- Peng, S.; Jiang, H.; Wang, H.; Alwageed, H.; Yu, Z.; Sebdani, M.M.; Yao, Y.D. Modulation classification based on signal constellation diagrams and deep learning. IEEE Trans. Neural Networks Learn. Syst. 2018, 30, 718–727. [Google Scholar] [CrossRef]
- Jiang, R.; Wang, X.; Cao, S.; Zhao, J.; Li, X. Deep Neural Networks for Channel Estimation in Underwater Acoustic OFDM Systems. IEEE Access 2019, 7, 23579–23594. [Google Scholar] [CrossRef]
- Fernández, J.R.M.; Vidal, J.D.B. Fast selection of the sea clutter preferential distribution with neural networks. Eng. Appl. Artif. Intell. 2018, 70, 123–129. [Google Scholar] [CrossRef]
- Schwegmann, C.P.; Kleynhans, W.; Salmon, B.P.; Mdakane, L.W.; Meyer, R.G. Very deep learning for ship discrimination in synthetic aperture radar imagery. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; IEEE: Beijing, China, 2016; pp. 104–107. [Google Scholar]
- Akhtar, J.; Olsen, K.E. A neural network target detector with partial CA-CFAR supervised training. In Proceedings of the International Conference on Radar (RADAR), Brisbane, Australia, 27–31 August 2018; IEEE: Brisbane, Australia, 2018; pp. 1–6. [Google Scholar]
- Fernández, J.R.M.; Vidal, J.D.B.; Ferry, N.C. A neural network approach to Weibull distributed sea clutter parameter’s estimation. Intel. Artif. 2015, 18, 3–13. [Google Scholar] [CrossRef]
- Fernández, J.R.M.; Vidal, J.D.B. Improved shape parameter estimation in Pareto distributed clutter with neural networks. Int. J. Interact. Multimed. Artif. Intell. 2016, 4, 7–11. [Google Scholar] [CrossRef]
- Machado, J.F.; Vidal, J.D.B. Improved shape parameter estimation in K clutter with neural networks and deep learning. Int. J. Interact. Multimed. Artif. Intell. 2016, 3, 96–103. [Google Scholar]
- Fernández, J.R.M.; Delgado, B.G.; Gil, A.M. A neural network approach to the recognition of the K distribution shape parameter associated with sea clutter. Rev. Ing. 2017, 27, 14–24. [Google Scholar]
- Shen, J.; Hao, X.; Liang, Z.; Liu, Y.; Wang, W.; Shao, L. Real-time superpixel segmentation by DBSCAN clustering algorithm. IEEE Trans. Image Process. 2016, 25, 5933–5942. [Google Scholar] [CrossRef]
- Hou, J.; Gao, H.; Li, X. DSets-DBSCAN: a parameter-free clustering algorithm. IEEE Trans. Image Process. 2016, 25, 3182–3193. [Google Scholar] [CrossRef]
- Bryant, A.; Cios, K. RNN-DBSCAN: A density-based clustering algorithm using reverse nearest neighbor density estimates. IEEE Trans. Knowl. Data Eng. 2018, 30, 1109–1121. [Google Scholar] [CrossRef]
- Zhou, W.; Xie, J.; Xi, K.; Du, Y. Modified cell averaging CFAR detector based on Grubbs criterion in non-homogeneous background. IET Radar Sonar Navig. 2018, 13, 104–112. [Google Scholar] [CrossRef]
- Shui, P.; Liu, M.; Xu, S. Shape-parameter-dependent coherent radar target detection in K-distributed clutter. IEEE Trans. Aerosp. Electron. Syst. 2016, 52, 451–465. [Google Scholar] [CrossRef]
- Roberts, W.J.; Furui, S. Maximum likelihood estimation of K-distribution parameters via the expectation-maximization algorithm. IEEE Trans. Signal Process. 2000, 48, 3303–3306. [Google Scholar]
- Balleri, A.; Nehorai, A.; Wang, J. Maximum likelihood estimation for compound-Gaussian clutter with inverse gamma texture. IEEE Trans. Aerosp. Electron. Syst. 2007, 43, 775–779. [Google Scholar] [CrossRef]
- Bouhlel, N.; Méric, S. Maximum-likelihood parameter estimation of the product model for multilook polarimetric SAR data. IEEE Trans. Geosci. Remote. Sens. 2018, 57, 1596–1611. [Google Scholar] [CrossRef]
- Iskander, D.R.; Zoubir, A.M. Estimation of the parameters of the K-distribution using higher order and fractional moments. IEEE Trans. Aerosp. Electron. Syst. 1999, 35, 1453–1457. [Google Scholar] [CrossRef]
- Ward, K.; Tough, R.; Watts, S. Sea Clutter: Scattering, the K-Distribution and Radar Performance, 2nd ed.; The Institution of Engineering and Technology: London, UK, 2013. [Google Scholar]
- Roussel, C.J.; Coatanhay, A.; Baussard, A. Estimation of the parameters of stochastic differential equations for sea clutter. IET Radar Sonar Navig. 2018, 13, 497–504. [Google Scholar] [CrossRef]
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. A density-based algorithm for discovering clusters in large spatial databases with noise. In Proceedings of the International Conference on Knowledge Discovery and Data Mining, Portland, OR, USA, 2–4 August 1996; AAAI Press: Portland, OR, USA, 1996; pp. 226–231. [Google Scholar]
- Tran, T.N.; Drab, K.; Daszykowski, M. Revised DBSCAN algorithm to cluster data with dense adjacent clusters. Chemom. Intell. Lab. Syst. 2013, 120, 92–96. [Google Scholar] [CrossRef]
- Chen, X.; Liu, W.; Qiu, H.; Lai, J. APSCAN: A parameter free algorithm for clustering. Pattern Recognit. Lett. 2011, 32, 973–986. [Google Scholar] [CrossRef]
- Lai, W.; Zhou, M.; Hu, F.; Bian, K.; Song, Q. A new DBSCAN parameters determination method based on improved MVO. IEEE Access 2019, 7, 104085–104095. [Google Scholar] [CrossRef]
- Manning, C.; Raghavan, P.; Schutze, H. Introduction to Information Retrieval; Cambridge University Press: Cambridge, UK, 2009. [Google Scholar]
- Raghavan, R. A method for estimating parameters of K-distributed clutter. IEEE Trans. Aerosp. Electron. Syst. 1991, 27, 238–246. [Google Scholar] [CrossRef]
- Li, C.; Xie, T.; Liu, Q.; Cheng, G. Cryptanalyzing image encryption using chaotic logistic map. Nonlinear Dyn. 2014, 78, 1545–1551. [Google Scholar] [CrossRef]
- Li, Y.; Wang, N.; Shi, J.; Hou, X.; Liu, J. Adaptive batch normalization for practical domain adaptation. Pattern Recognit. 2018, 80, 109–117. [Google Scholar] [CrossRef]
- Karlik, B.; Olgac, A.V. Performance analysis of various activation functions in generalized MLP architectures of neural networks. Int. J. Artif. Intell. Expert Syst. 2011, 1, 111–122. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the 27th International Conference on Machine Learning, Haifa, Israel, 21–24 June 2010; Omnipress: Haifa, Israel, 2010; pp. 807–814. [Google Scholar]
- Maas, A.L.; Hannun, A.Y.; Ng, A.Y. Rectifier nonlinearities improve neural network acoustic models. In Proceedings of the 30th International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013; Omnipress: Atlanta, GA, USA, 2013; pp. 1–6. [Google Scholar]
- Armstrong, B.; Griffiths, H. CFAR detection of fluctuating targets in spatially correlated K-distributed clutter. IEE Proc. F (Radar Signal Process.) 1991, 138, 139–152. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Training function | Levenberg-Marquardt |
| Error measurement | RMSE |
| Presentation of samples | Batch training |
| Size of mini-batch | |
| Maximum number of epochs | 20 |
| Frequency of network validation | 50 |
| Initial learning rate | |
| Number of epochs for dropping the learning rate | 5 |
| Factor for dropping the learning rate | 0.3 |
| Activation Function | Mathematical Expression | Training Error | Training Time (s) |
|---|---|---|---|
| Sigmoid [48] | 0.0753 | 930 | |
| Tanh [48] | 0.0795 | 941 | |
| ReLU [49] | 0.0649 | 821 | |
| LReLU [50] | 0.0643 | 845 |
| Method | Result | ||||
|---|---|---|---|---|---|
| Best | |||||
| MOM-12 [38] | Worst | 1.6411 | 1.0543 | 0.9334 | 13.0210 |
| Mean | 1.2209 | 0.4716 | 0.8009 | 0.8595 | |
| Best | |||||
| MOM-24 [38] | Worst | 0.4589 | 1.0784 | 5.9198 | 20.9395 |
| Mean | 0.0494 | 0.1281 | 0.6145 | 0.4860 | |
| Best | |||||
| BPNN [27] | Worst | 5.5290 | 1.9183 | 1.8608 | 21.4984 |
| Mean | 0.1097 | 0.3019 | 0.2052 | 0.2088 | |
| Best | |||||
| ANN [proposed] | Worst | 0.9631 | 3.3025 | 1.7511 | 1.7246 |
| Mean | 0.0474 | 0.1102 | 0.1672 | 0.1601 |
| Processor | Runtime (ms) | |||
|---|---|---|---|---|
| ANN | BPNN | MOM-12 | MOM-24 | |
| CA-CFAR | 81.1 | 80.6 | 47.8 | 55.8 |
| SO-CFAR | 79.3 | 78.8 | 46.0 | 54.0 |
| GO-CFAR | 78.4 | 77.9 | 45.1 | 53.1 |
| OS-CFAR | 79.6 | 79.1 | 46.3 | 54.3 |
| CMLD-CFAR | 81.7 | 81.2 | 48.4 | 56.4 |
| DBSCAN-CFAR | 325.1 | 324.6 | 291.8 | 299.8 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, J.; Jiang, R.; Wang, X.; Gao, H. Robust CFAR Detection for Multiple Targets in K-Distributed Sea Clutter Based on Machine Learning. Symmetry 2019, 11, 1482. https://doi.org/10.3390/sym11121482
Zhao J, Jiang R, Wang X, Gao H. Robust CFAR Detection for Multiple Targets in K-Distributed Sea Clutter Based on Machine Learning. Symmetry. 2019; 11(12):1482. https://doi.org/10.3390/sym11121482
Chicago/Turabian StyleZhao, Jiafei, Rongkun Jiang, Xuetian Wang, and Hongmin Gao. 2019. "Robust CFAR Detection for Multiple Targets in K-Distributed Sea Clutter Based on Machine Learning" Symmetry 11, no. 12: 1482. https://doi.org/10.3390/sym11121482
APA StyleZhao, J., Jiang, R., Wang, X., & Gao, H. (2019). Robust CFAR Detection for Multiple Targets in K-Distributed Sea Clutter Based on Machine Learning. Symmetry, 11(12), 1482. https://doi.org/10.3390/sym11121482