Deep Recurrent Neural Network and Data Filtering for Rumor Detection on Sina Weibo

Abstract
:1. Introduction
1.1. RNN
1.2. Automatic Rumor Detection
2. Materials and Methods
2.1. Dataset
2.1.1. Sina Weibo dataset
2.1.2. Twitter Dataset
2.2. Methods
2.2.1. Problem Definition
2.2.2. Text Vectorization
2.2.3. DRNN Architecture
3. Results
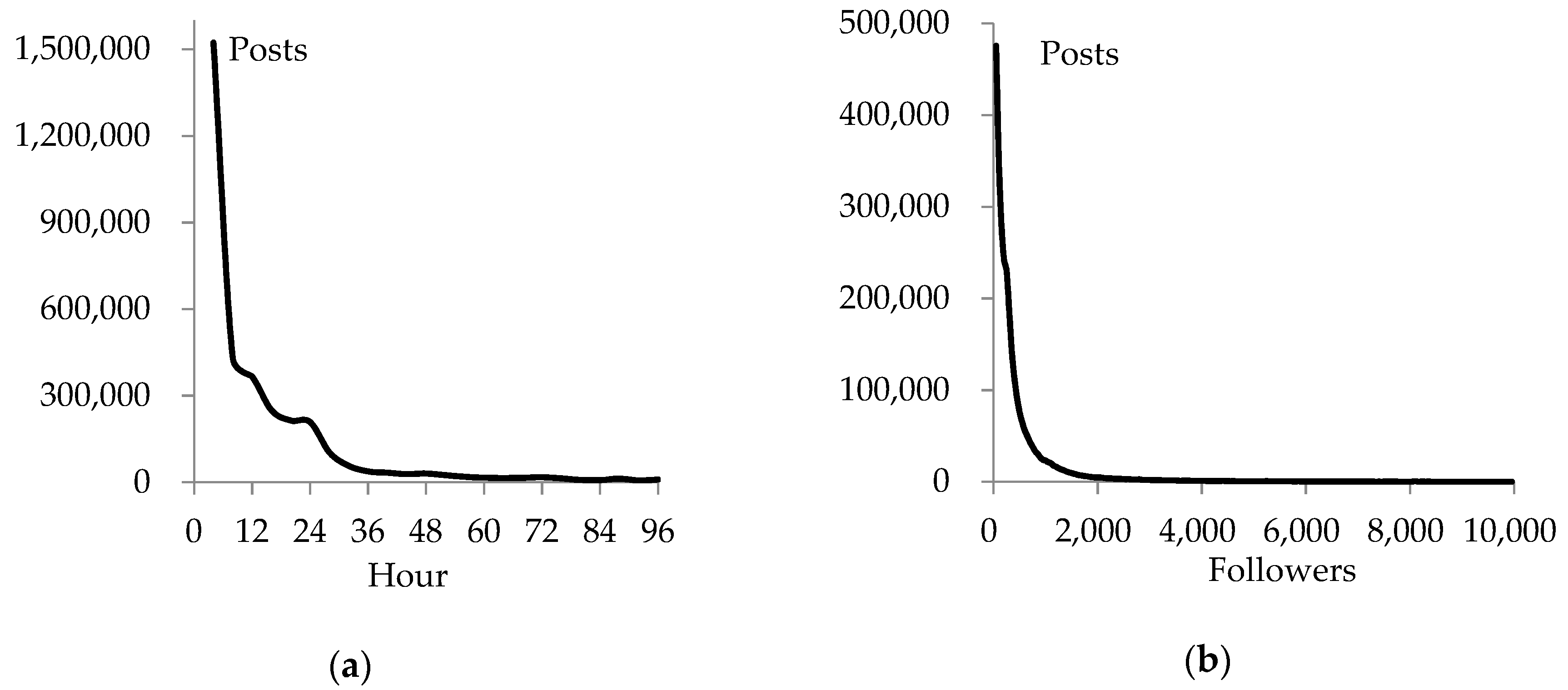
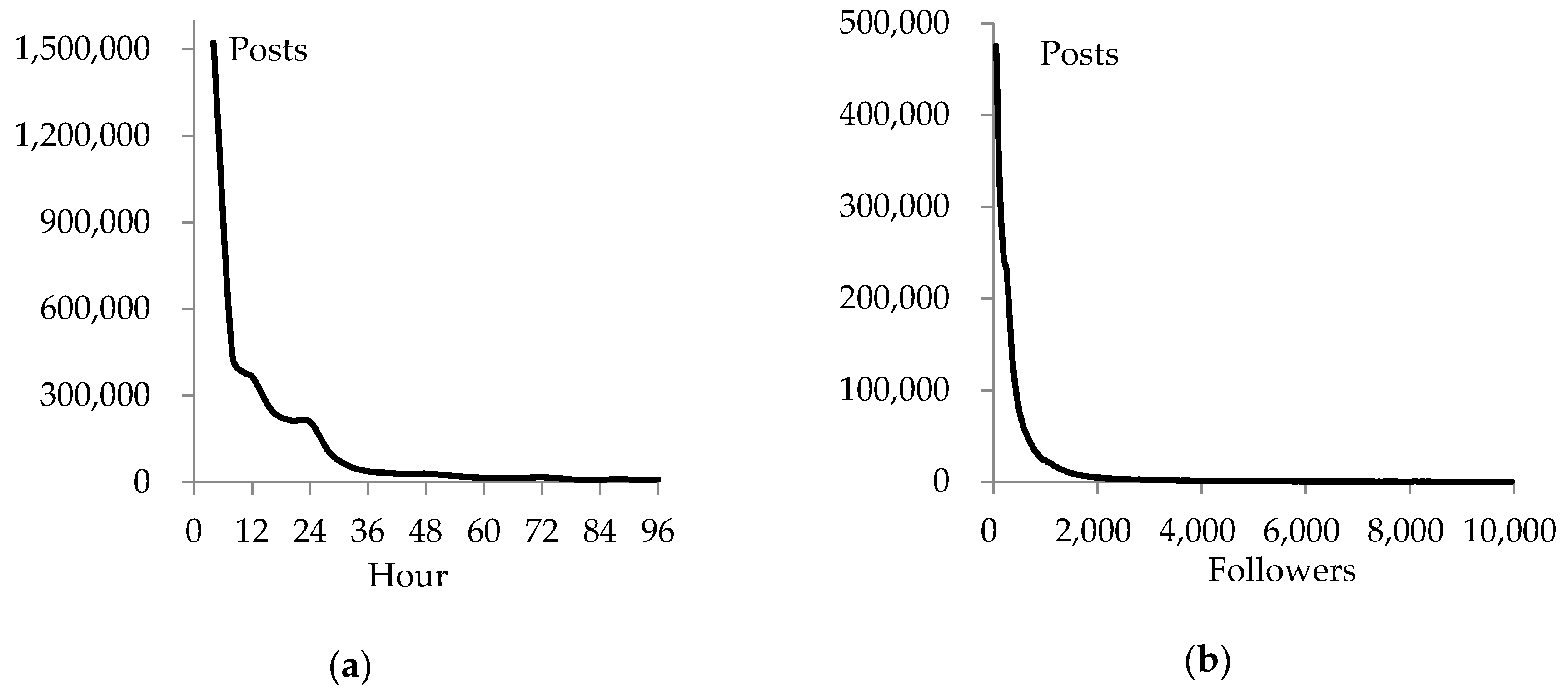
3.1. Filtering Data by the Followers
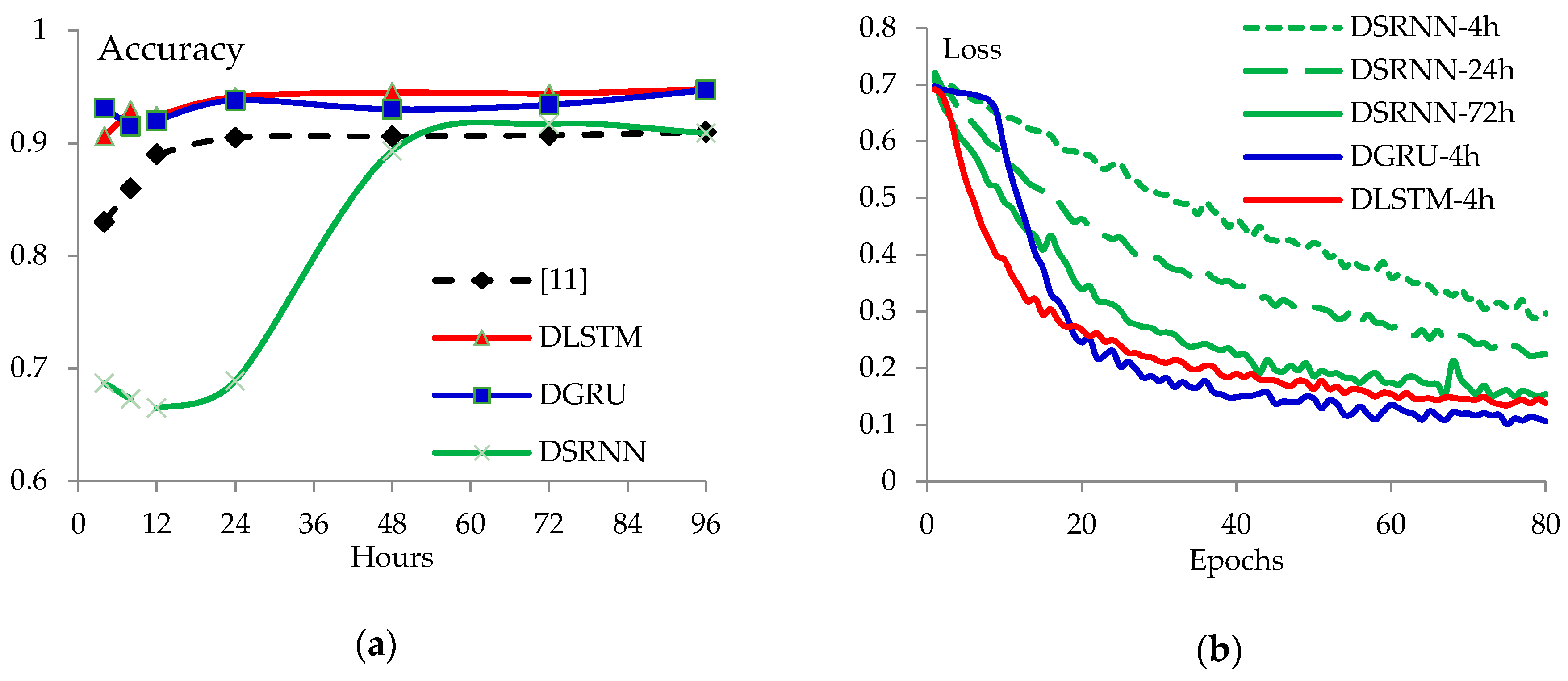
3.2. Comparisons with Different Models
3.3. Early Detection
3.4. Extensions to Twitter Dataset
4. Discussion
4.1. Data Filtering
4.2. Sequential Encoding
4.3. Performance of Different Models
4.4. Early Detection
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Pew Research Center. Available online: http://www.journalism.org/2017/09/07/news-use-across-social -media-platforms-2017/ (accessed on 31 October 2019).
- Sohu-INC. Available online: http://www.sohu.com/a/246000912_393779 (accessed on 31 October 2019).
- Sina Weibo. Available online: https://weibo.com/1866405545/FFwn4EnNV?type=comment#_ rnd1543636471604 (accessed on 31 October 2019).
- CNBC. Available online: https://www.cnbc.com/id/100646197 (accessed on 31 October 2019).
- Zubiaga, A.; Aker, A.; Bontcheva, K.; Liakata, M.; Procter, R. Detection and Resolution of Rumours in Social Media: A Survey. ACM Comput. Surv. 2018, 51. [Google Scholar] [CrossRef]
- Cao, J.; Guo, J.; Li, X.; Jin, Z.; Guo, H.; Li, J. Automatic Rumor Detection on Microblogs: A Survey. arXiv 2018, arXiv:1807.03505. [Google Scholar]
- Chen, F.; Ji, R.; Su, J.; Cao, D.; Gao, Y. Predicting microblog sentiments via weakly super-vised multi-modal deep learning. IEEE Trans. Multimed. 2017, 20, 997–1007. [Google Scholar] [CrossRef]
- Ji, R.; Chen, F.; Cao, L. Cross-Modality Microblog Sentiment Prediction via Bi-Layer Multimodal Hypergraph Learning. IEEE Trans. Multimed. 2019, 21, 1062–1075. [Google Scholar] [CrossRef]
- Qazvinian, V.; Rosengren, E.; Radev, D.R.; Mei, Q. Rumor has it: Identifying Misinformation in Microblogs; EMNLP 2011: Edinburgh, UK, 2011; pp. 1589–1599. [Google Scholar]
- Castillo, C.; Mendoza, M.; Poblete, B. Information Credibility on Twitter. In Proceedings of the International Conference on World Wide Web 2011, Hyderabad, India, 28 March–1 April 2011. [Google Scholar]
- Yang, F.; Yu, X.; Liu, Y.; Yang, M. Automatic Detection of Rumor on Sina Weibo. In Proceedings of the SIGKDD Workshop on Mining Data Semantics, Beijing, China, 12–16 Augest 2012. [Google Scholar]
- Kwon, S.; Cha, M.; Jung, K. Rumor detection over varying time windows. PLoS ONE 2017, 12. [Google Scholar] [CrossRef]
- Liang, G.; He, W.; Xu, C.; Chen, L.; Zeng, J. Rumor Identification in Microblogging Systems Based on Users’ Behavior. IEEE Trans. Comput. Soc. Syst. 2015, 2, 99–108. [Google Scholar] [CrossRef]
- Wu, K.; Yang, S.; Zhu, K. False Rumors Detection on Sina Weibo by Propagation Structures. In Proceedings of the ICDE2015, Seoul, Korea, 13–17 April 2015. [Google Scholar]
- Ma, J.; Gao, W.; Wei, Z.; Lu, Y. Detect Rumors Using Time Series of Social Context In-formation on Microblogging Websites. In Proceedings of the CIKM2015, Melbourne, Australia, 19–23 October 2015. [Google Scholar]
- Vosoughi, S. Automatic Detection and Verification of Rumors on Twitter. Ph.D. Dissertation, MIT, Cambridge, MA, USA, 2015. [Google Scholar]
- Mousavi Kahaki, S.M.; Nordin, M.J.; Ahmad, N.S.; Arzoky, M.; Ismail, W. Deep convolutional neural network designed for age assessment based on orthopantomography data. Neural Comput. Applic. 2019. [Google Scholar] [CrossRef]
- Kim, Y. Convolutional Neural Networks for Sentence Classification. In Proceedings of the EMNLP 2014, Doha, Qatar, 25–29 October 2014. [Google Scholar]
- Qin, P.; Xu, W.; Guo, J. An Empirical Convolutional Neural Network approach for Semantic Relation Classification. Neurocomputing 2016, 190, 1–9. [Google Scholar] [CrossRef]
- Ma, J.; Cao, W.; Wong, K. Rumor Detection on Twitter with Tree-structured Recursive Neural Networks. In Proceedings of the ACL 2018, Melbourne, Australia, 15–20 July 2018. [Google Scholar]
- Nguyen, T.N.; Li, C.; Niederée, C. On Early-Stage Debunking Rumors on Twitter: Leveraging the Wisdom of Weak Learners. LNCS 2017, 10540, 141–158. [Google Scholar]
- Ma, J.; Cao, W.; Mitra, P.; Kwon, S.; Jansen, B.J.; Wong, K.-F.; Cha, M. Detecting Rumors from Microblogs with Recurrent Neural Networks. In Proceedings of the IJCAI2016, New York, NY, USA, 9–15 July 2016; pp. 3818–3824. [Google Scholar]
- Natali, R.; Seo, S.; Liu, Y. CSI: A Hybrid Deep Model for Fake News Detection. In Proceedings of the CIKM2017, Singapore, 6–10 November 2017. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 735–1780. [Google Scholar] [CrossRef]
- Cho, K.; van Merrienboer, B.; Bahdanau, D.; Bengio, Y. On the Properties of Neural Machine Translation: Encoder-Decoder Approaches. In Proceedings of the Eighth Workshop on Syntax, Semantics and Structure in Statistical Translation (SSST-8), Doha, Qatar, 25–29 October 2014. [Google Scholar]
- Graves, A.; Mohamed, A.R.; Hinton, G. Speech Recognition with Deep Recurrent Neu-ral Networks. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–30 May 2013. [Google Scholar]
- Pascanu, R.; Gülçehre, C.; Cho, K.; Bengio, Y. How to Construct Deep Recurrent Neural Networks. In Proceedings of the ICLR 2014, Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the ICML2015, Lille, France, 6–11 July 2015. [Google Scholar]
- Mousavi Kahaki, S.M.; Nordin, M.J.; Ashtari, A.H.; Zahra, J.S. Invariant Feature Matching for Image Registration Application Based on New Dissimilarity of Spatial Features. PLoS ONE 2016, 11, e0149710. [Google Scholar] [CrossRef] [PubMed]



{kind=link}
{kind=link}
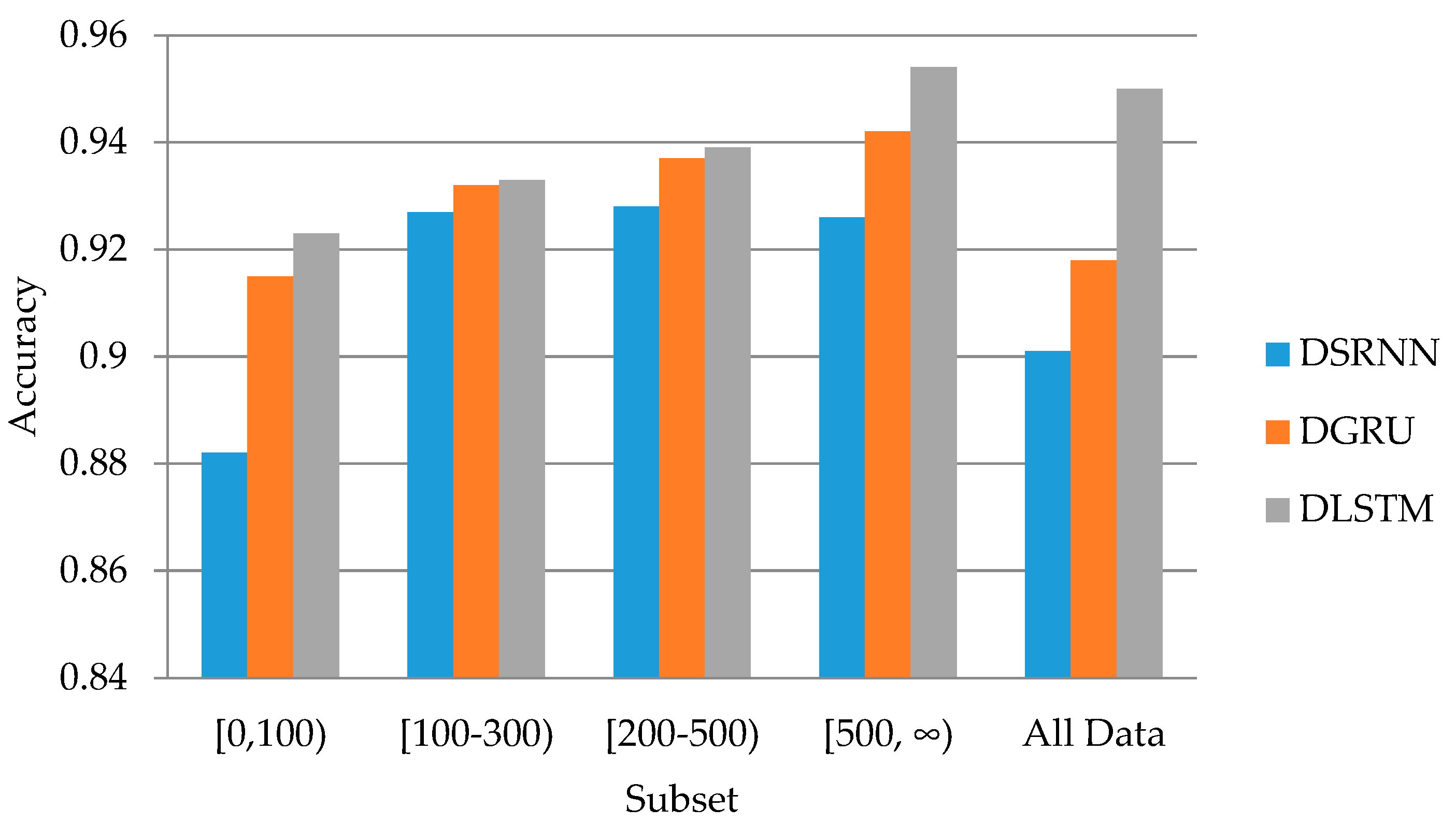{kind=link}
{kind=link}
| # of rumor | 2313 |
| # of non-rumor | 2351 |
| # of posts | 3,752,459 |
| # of users | 2,819,338 |
| Post-based features | post time, text, repost count, comment count, etc. |
| User-based features | registered time, location, follower count, friend count, post count, etc. |
| Layer | Name | Description |
|---|---|---|
| 1 | Input | The input layer accepts x0, x1, …, xt sequentially and the dimension of xi is 3000. |
| 2 | Norm | This layer normalizes the inputs |
| 3 | Fully-Conn1 | A fully-connected layer with ReLU activation, transforms the dimension of the data to 800. |
| 4 | Fully-Conn2 | A fully-connected layer with ReLU activation, transforms the dimension of the data to 256. |
| 5 | RNN1 | RNN layer, transforms the dimension of the data to 32. |
| 6 | RNN2 | The second RNN layer, keeps the dimension of the data. |
| 7 | Fully-Conn3 | A fully-connected layer with Sigmoid activation, transforms the dimension of the data to 1 |
| 8 | Prob | The output layer, which is the probability of an event being a rumor. |
| Interval of followers | [0,100) | [100−300) | [200−500) | [500, ∞) |
| Posts | 1,205,463 | 1,109,832 | 1,007,667 | 902,490 |
| Percentage of posts | 32% | 30% | 27% | 24% |
| Literature | Model | Accuracy | Precision | Recall | F1 |
|---|---|---|---|---|---|
| [22] | SVM-TS | 0.857 | 0.839 | 0.885 | 0.861 |
| GRU-2 | 0.910 | 0.876 | 0.956 | 0.914 | |
| [23] | CI | 0.928 | - | - | 0.927 |
| Proposed | DSRNN | 0.926 | 0.947 | 0.898 | 0.918 |
| DGRU | 0.942 | 0.968 | 0.916 | 0.940 | |
| DLSTM | 0.954 | 0.975 | 0.935 | 0.953 |
| Interval of followers | [0,80) | [80,250) | [250,700) | (700,∞) | All data |
| Accuracy | 0.591 | 0.636 | 0.682 | 0.864 | 0.818 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, Y.; Wang, C.; Dan, Z.; Sun, S.; Dong, F. Deep Recurrent Neural Network and Data Filtering for Rumor Detection on Sina Weibo. Symmetry 2019, 11, 1408. https://doi.org/10.3390/sym11111408
Xu Y, Wang C, Dan Z, Sun S, Dong F. Deep Recurrent Neural Network and Data Filtering for Rumor Detection on Sina Weibo. Symmetry. 2019; 11(11):1408. https://doi.org/10.3390/sym11111408
Chicago/Turabian StyleXu, Yichun, Chen Wang, Zhiping Dan, Shuifa Sun, and Fangmin Dong. 2019. "Deep Recurrent Neural Network and Data Filtering for Rumor Detection on Sina Weibo" Symmetry 11, no. 11: 1408. https://doi.org/10.3390/sym11111408
APA StyleXu, Y., Wang, C., Dan, Z., Sun, S., & Dong, F. (2019). Deep Recurrent Neural Network and Data Filtering for Rumor Detection on Sina Weibo. Symmetry, 11(11), 1408. https://doi.org/10.3390/sym11111408