Multi-Agent Reinforcement Learning Using Linear Fuzzy Model Applied to Cooperative Mobile Robots


Abstract
:1. Introduction
2. MARL with Linear Fuzzy Parameterization
2.1. Single Agent Case
2.2. Multi Agent System Case
2.3. Mapping the Joint Q-Function for MAS
2.4. Linear Fuzzy Parameterization of the Joint Q-Function
2.5. Reinforcement Learning Algorithm for Continuous State Space
- Let , setwhere is the probability of choose a greedy action in the state x, and is the probability of choose a random joint-action in
- Repeat in each iteration k
- For state we select a joint action with a suitable exploration. At each step a random action with probability is used.
- Applying the linear fuzzy parameterization with membership functions and discrete actions , the threshold
- Until:
- Output:
3. Results
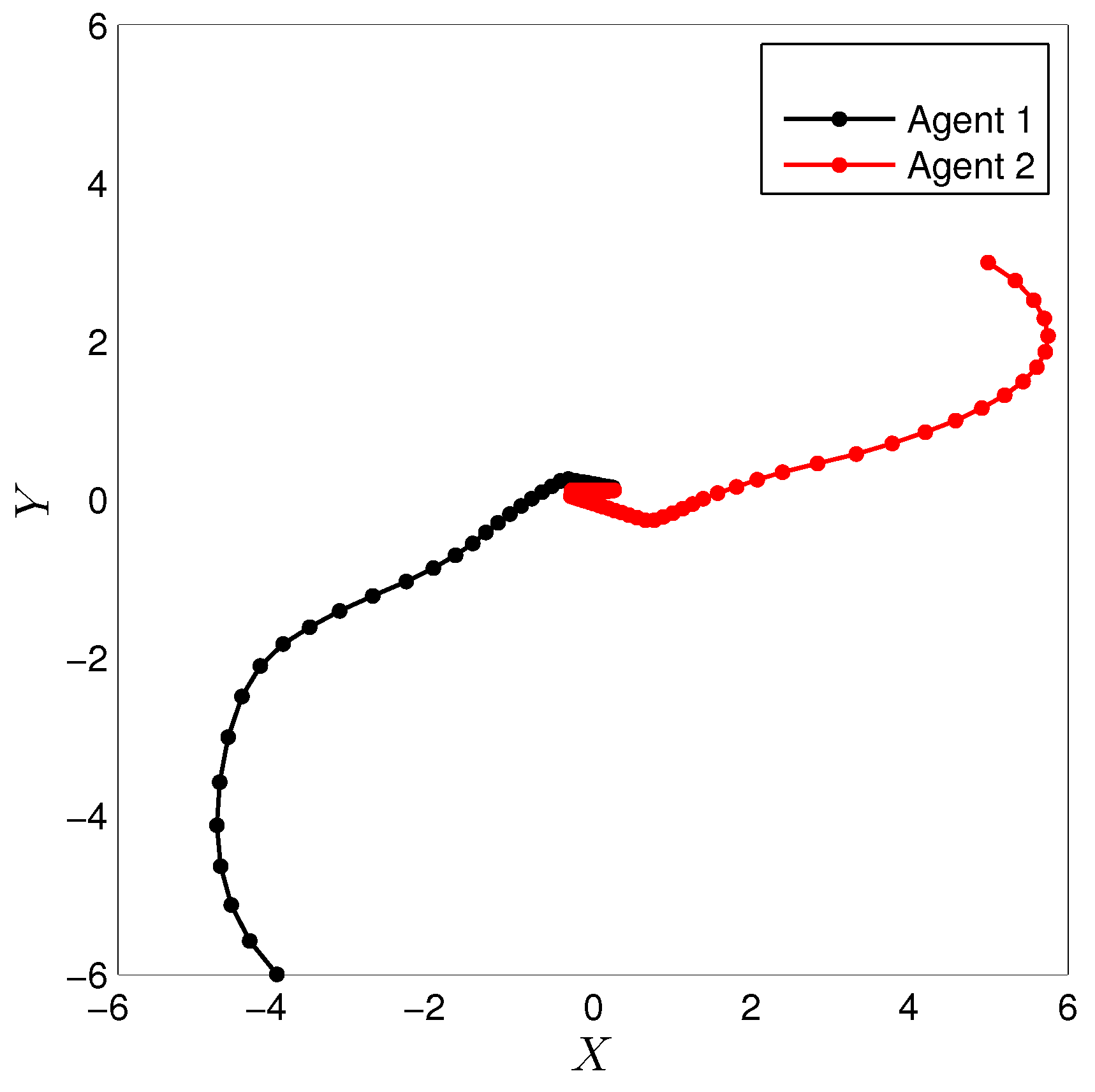
3.1. Simulation of a Cooperative Task with Mobile Robots
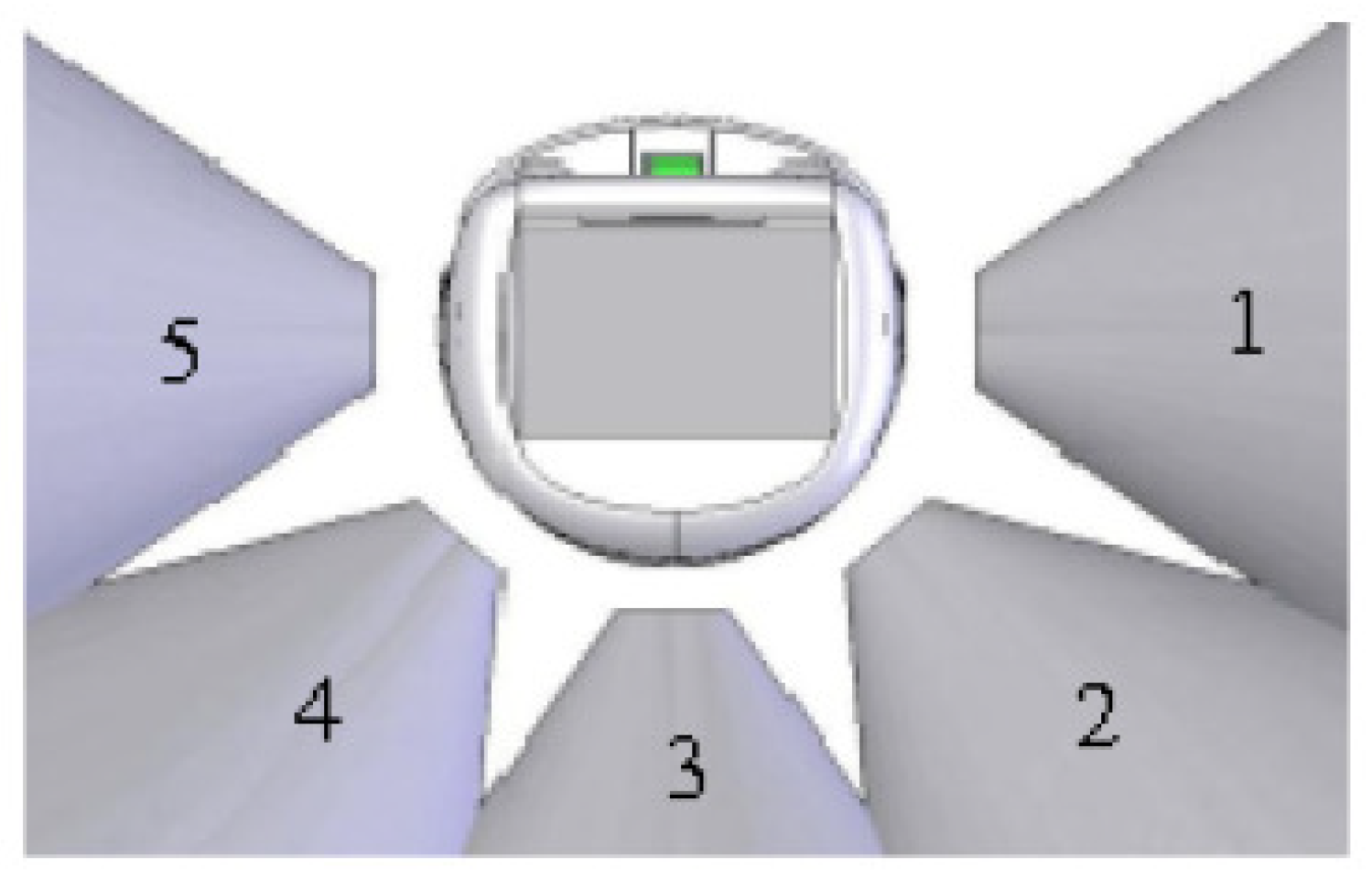
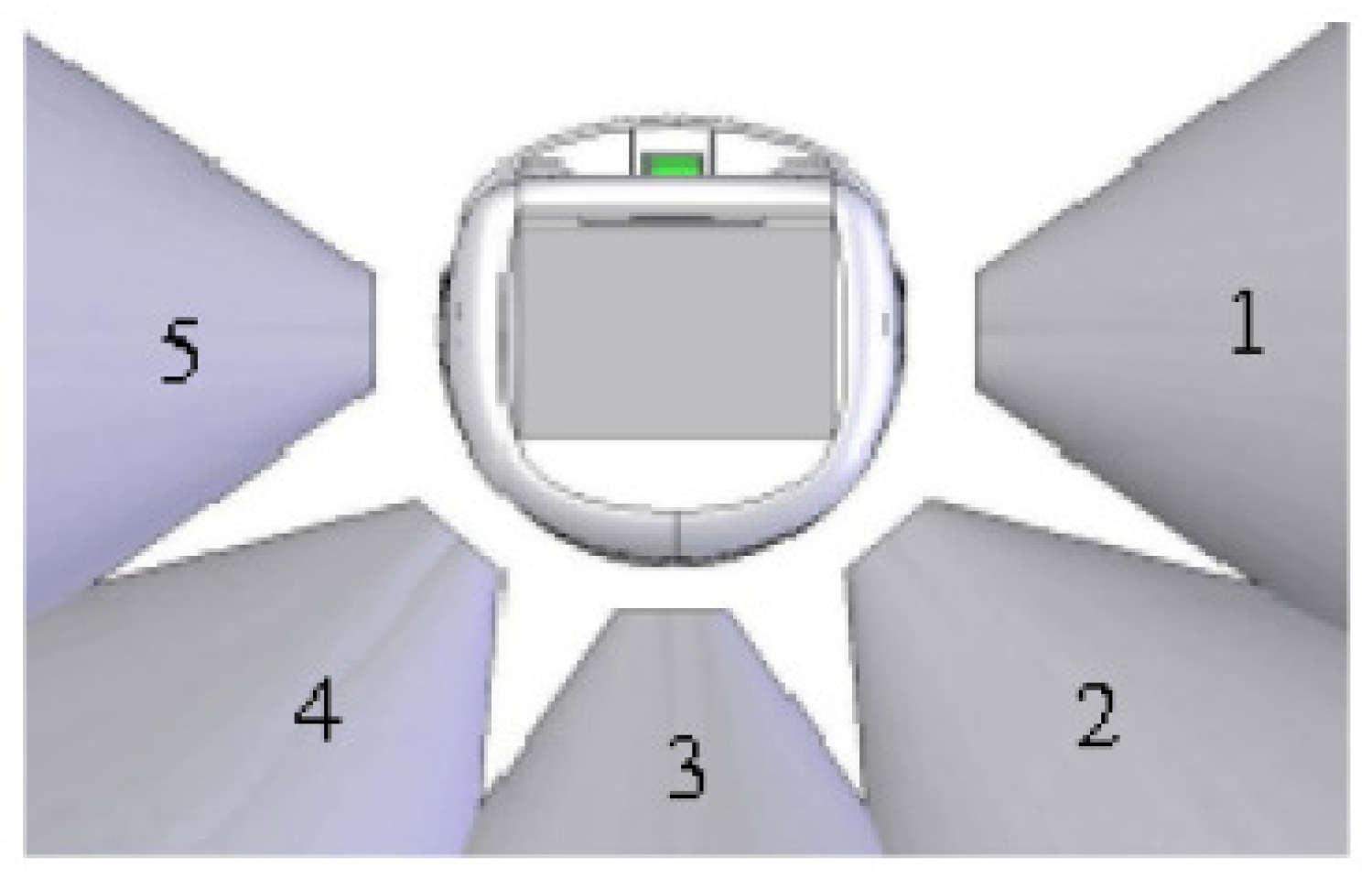
3.2. Experimental Set-up
- Move forward
- Turn in clockwise direction
- Turn in counter clockwise direction
- Stand-Still
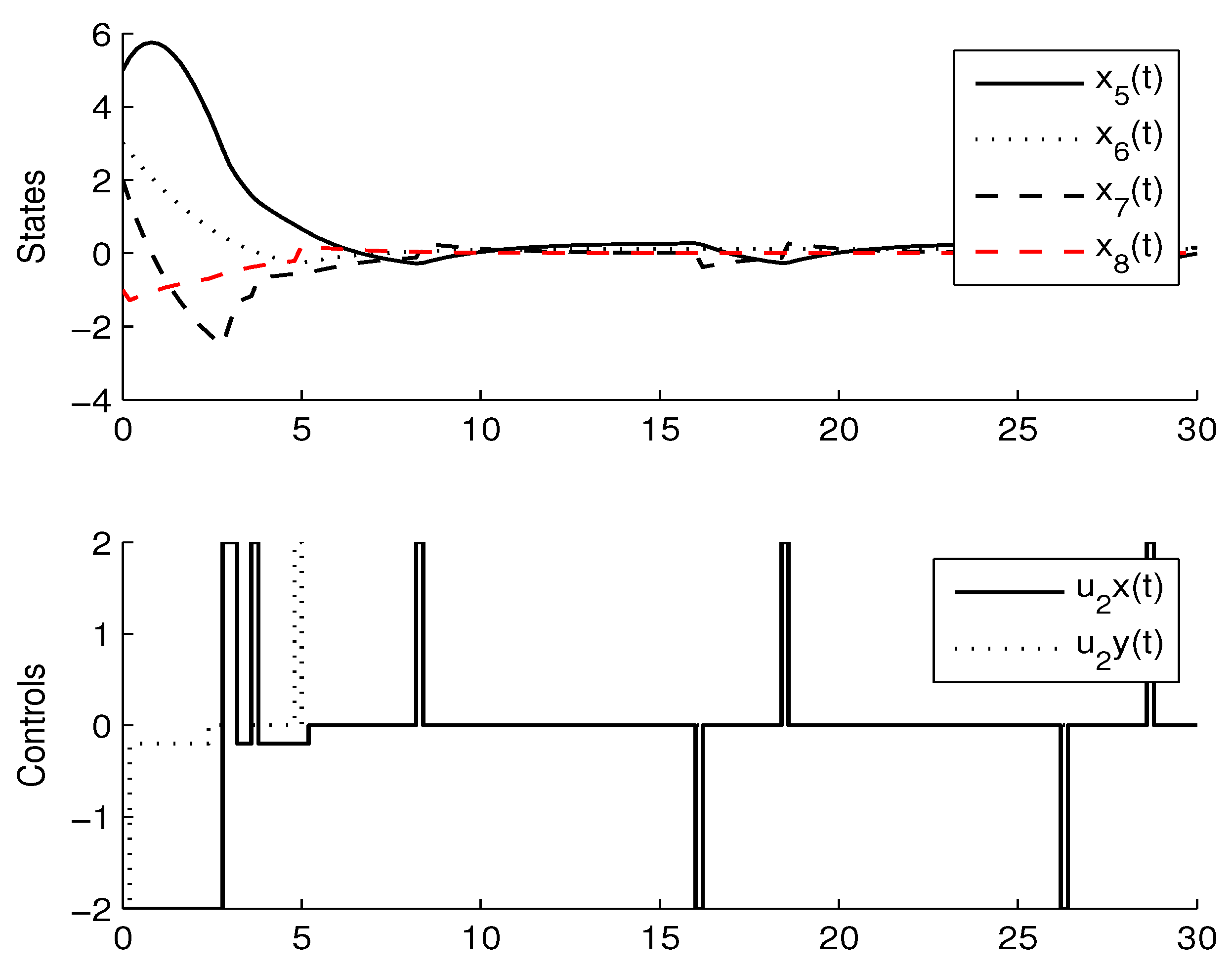
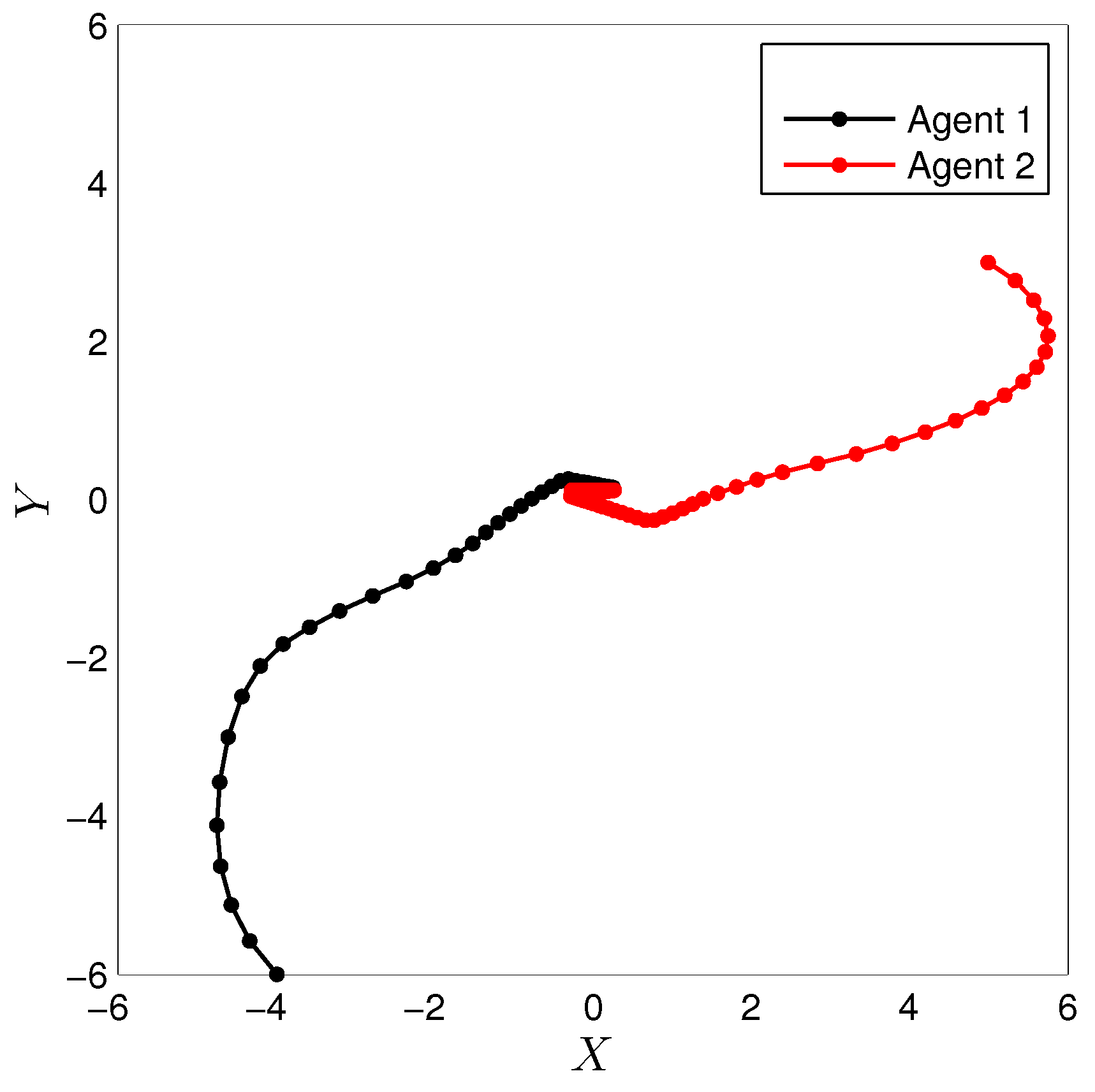
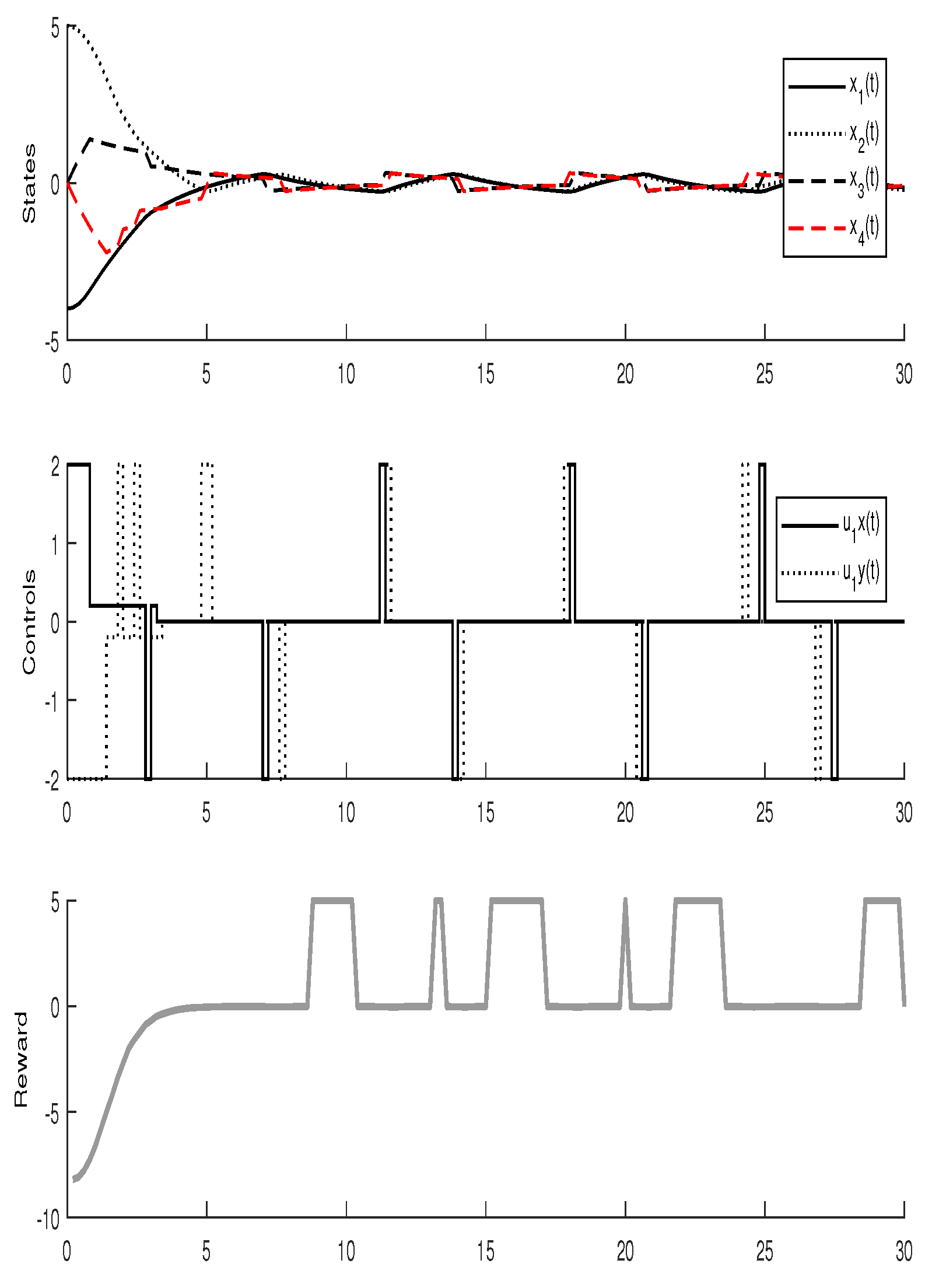
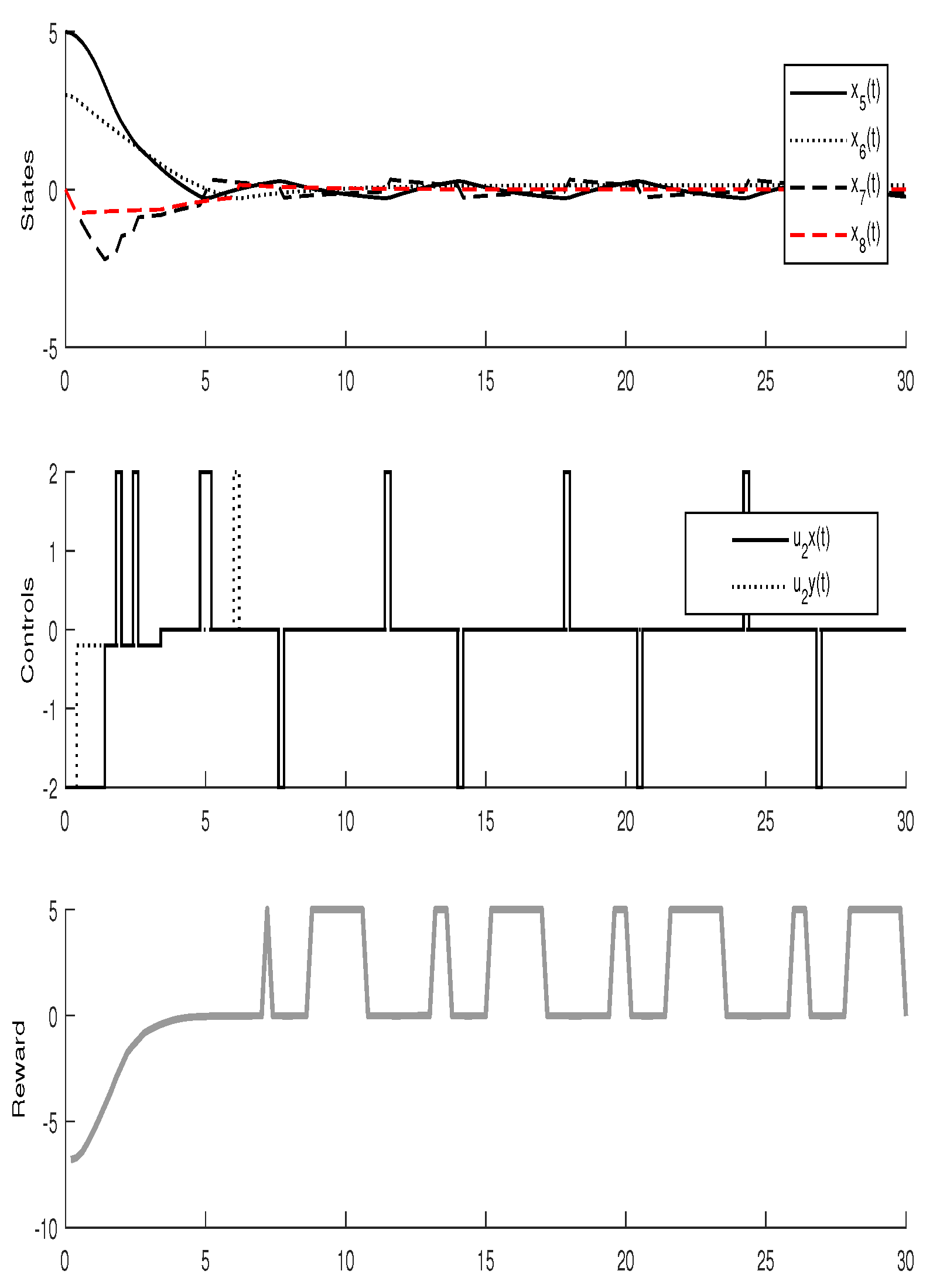
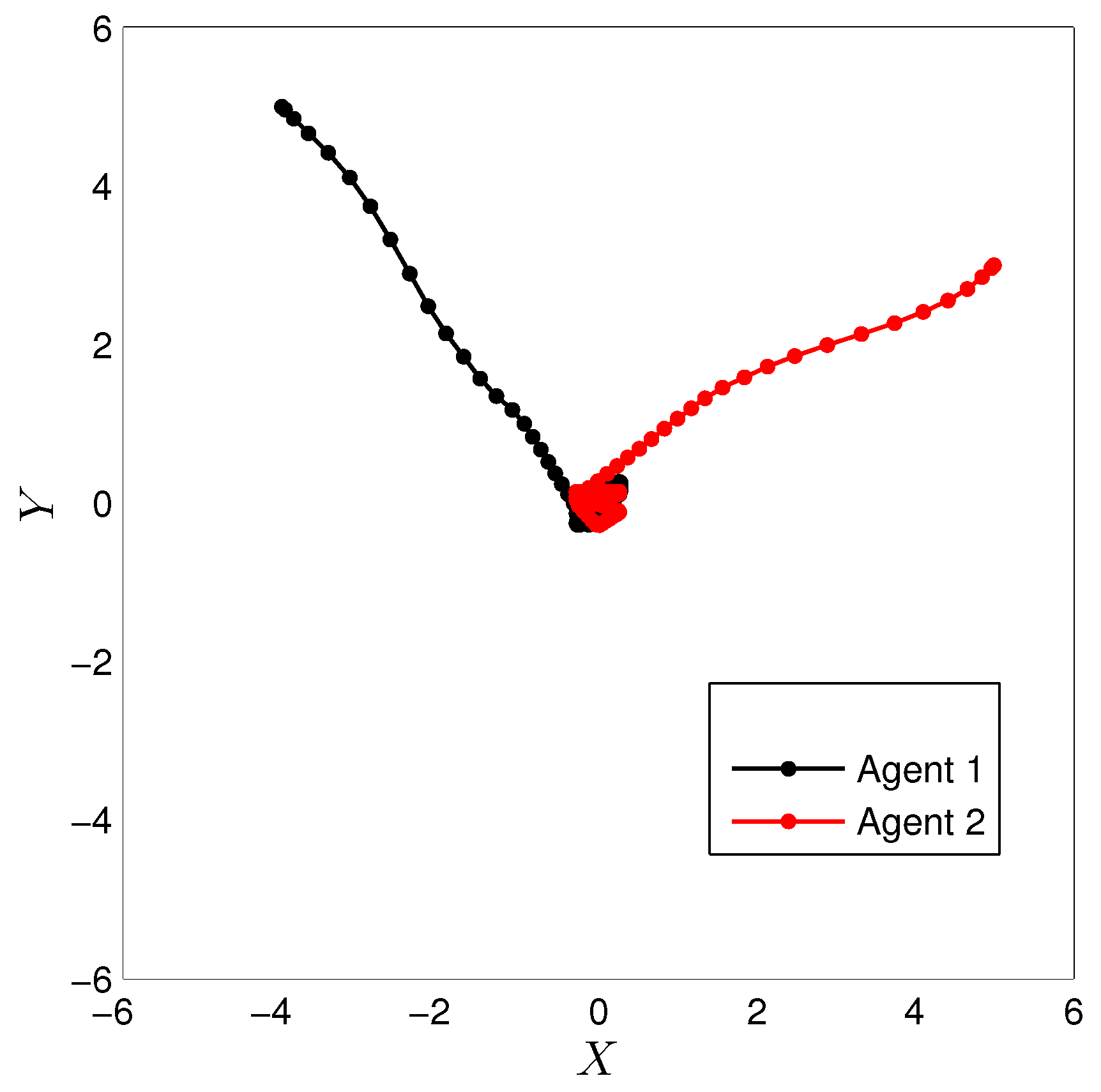
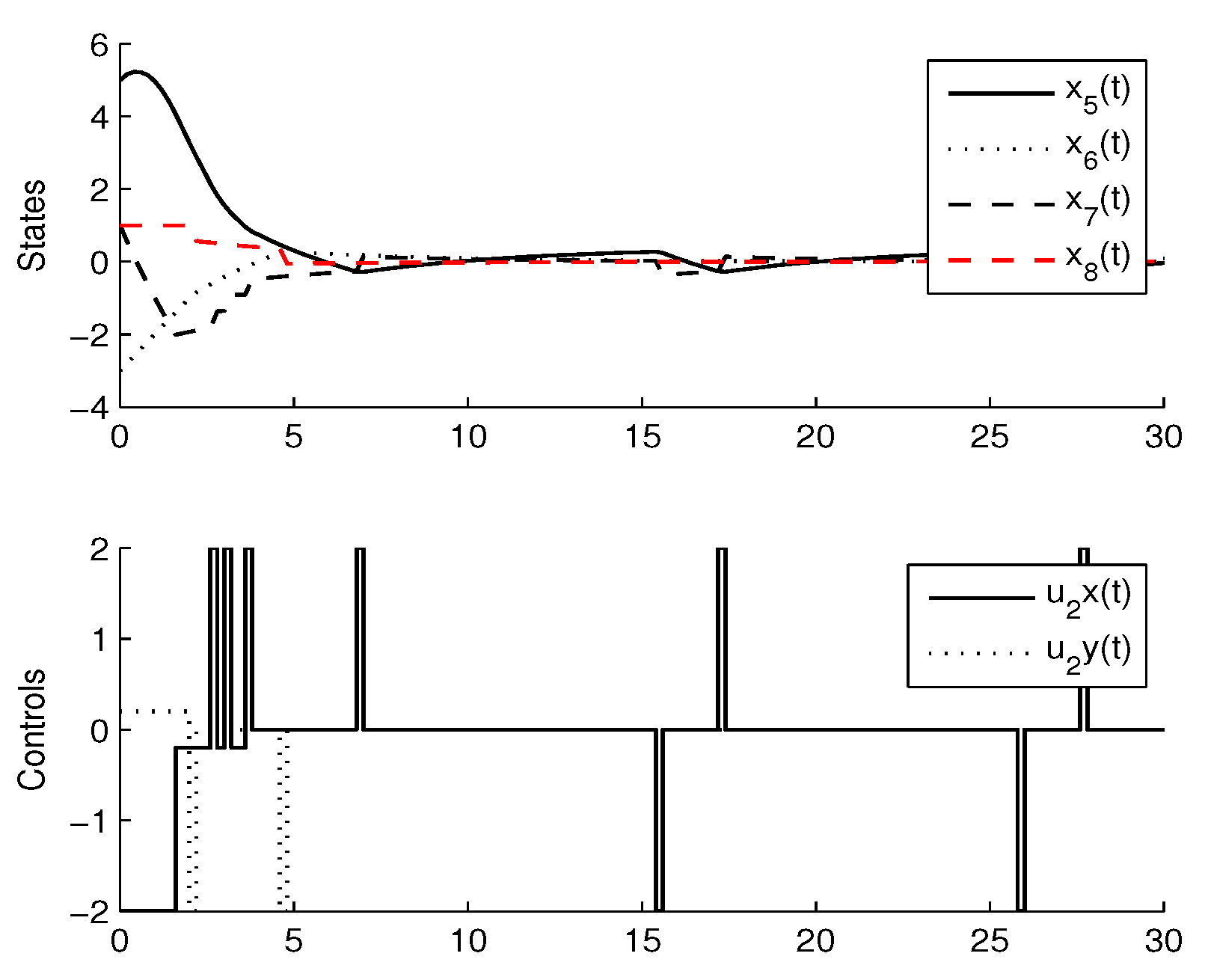
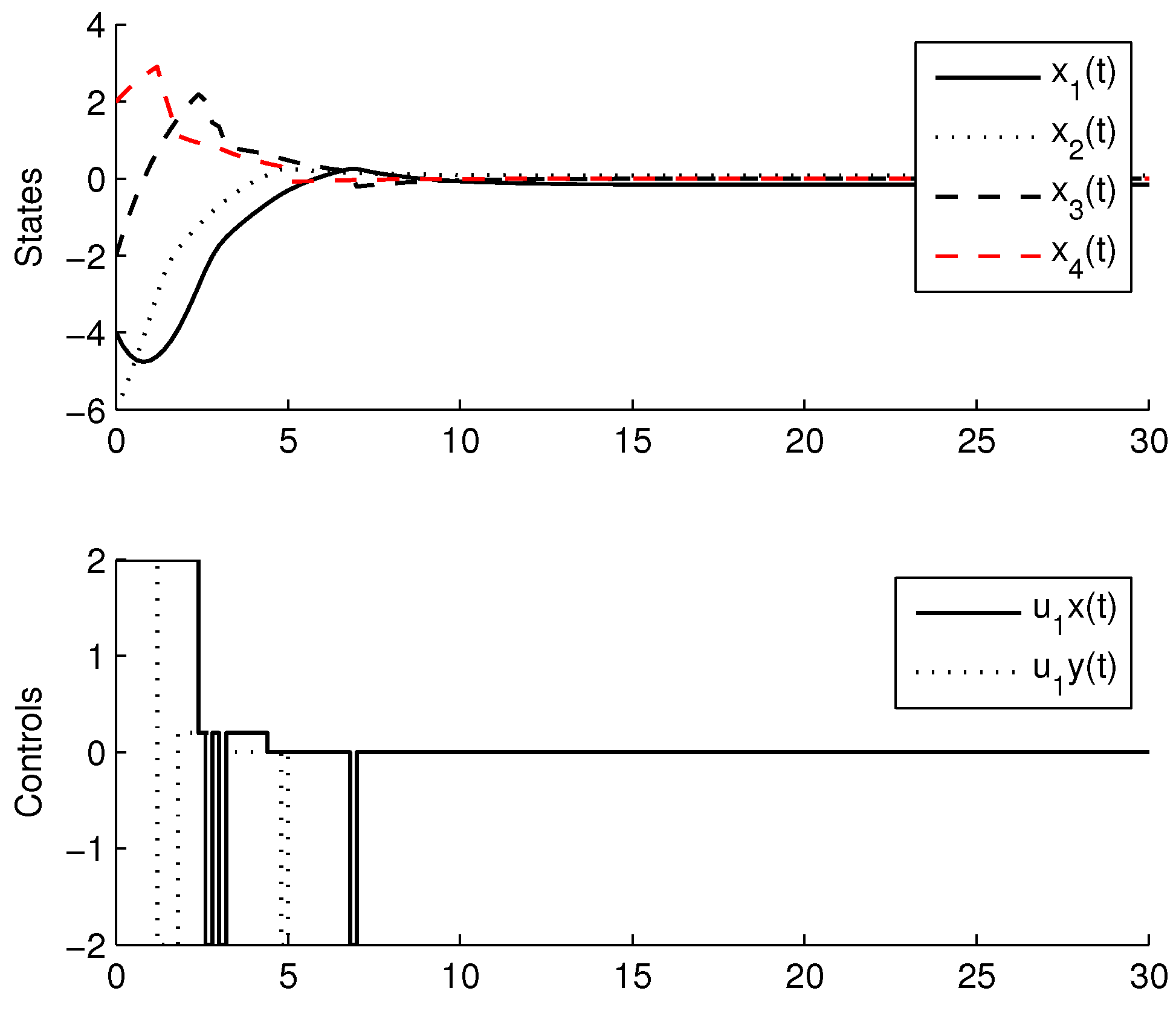
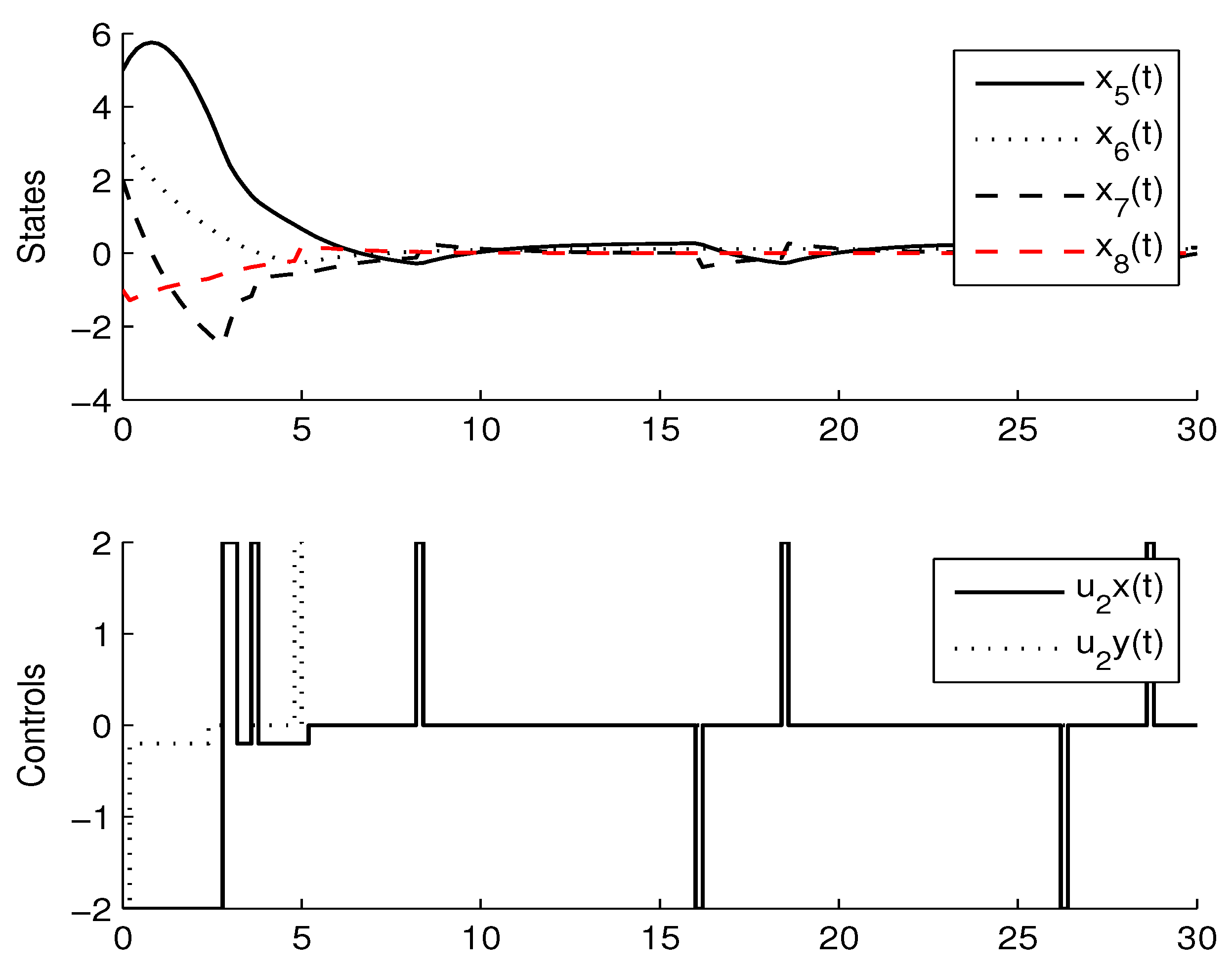
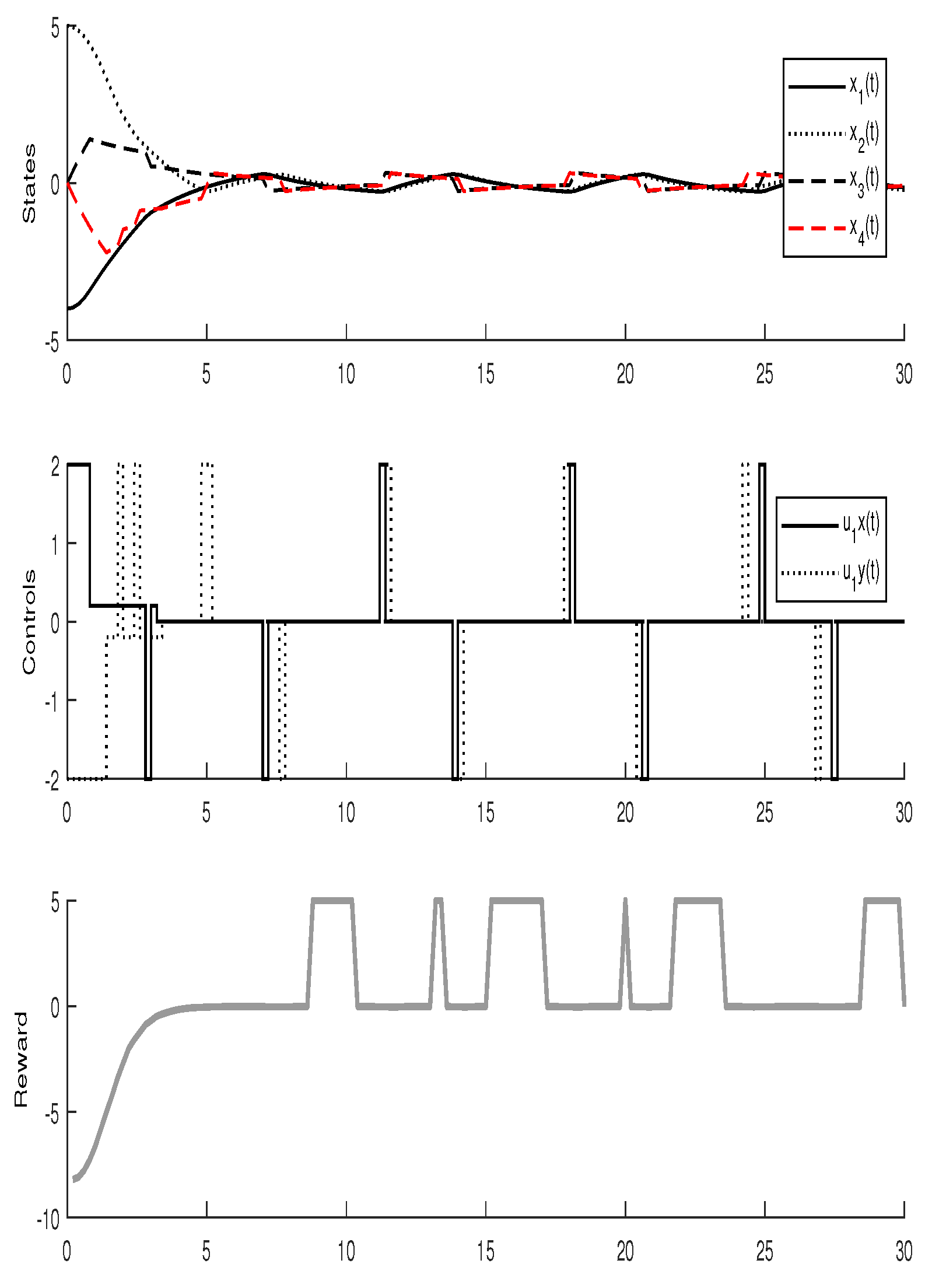
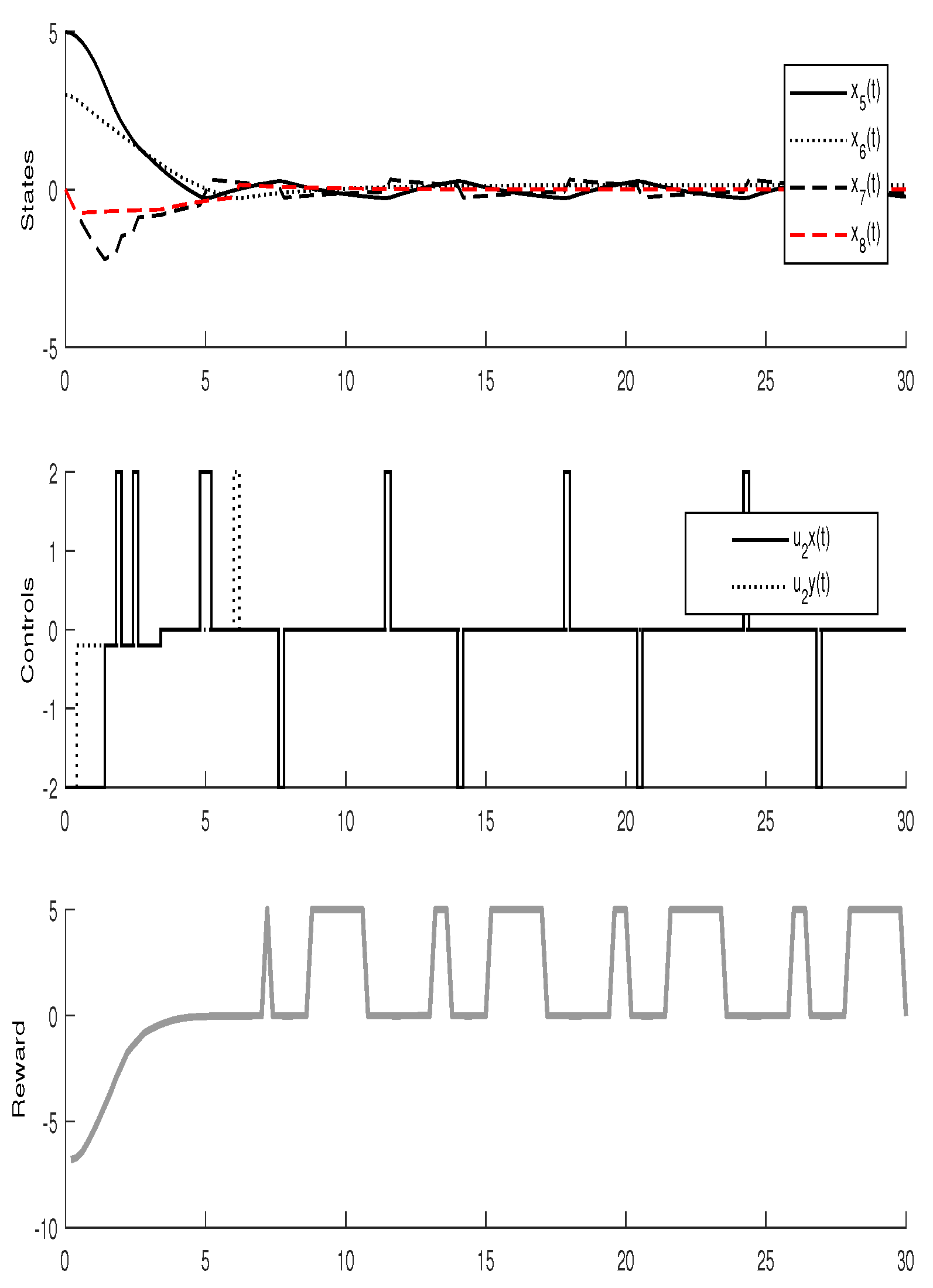
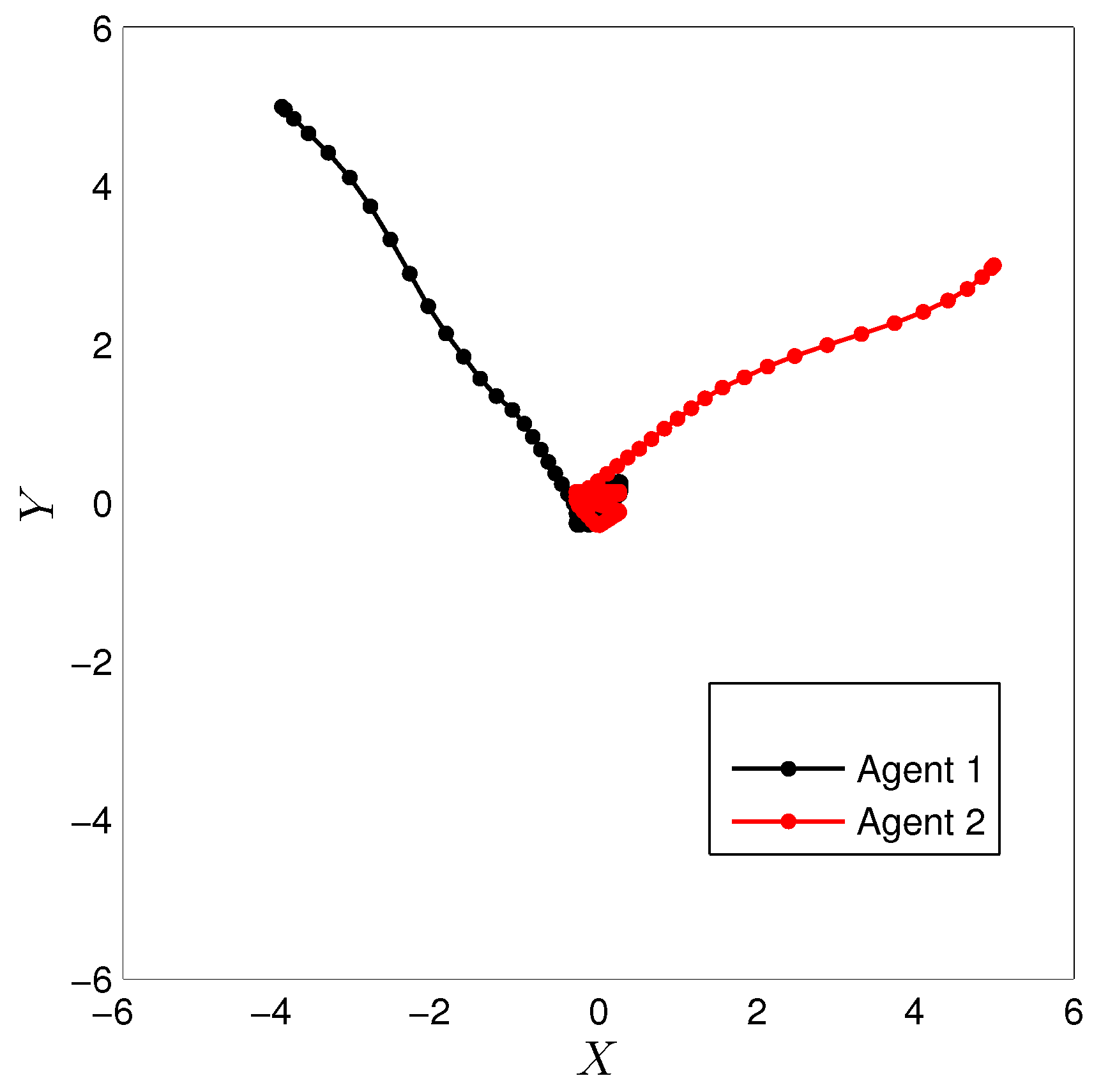
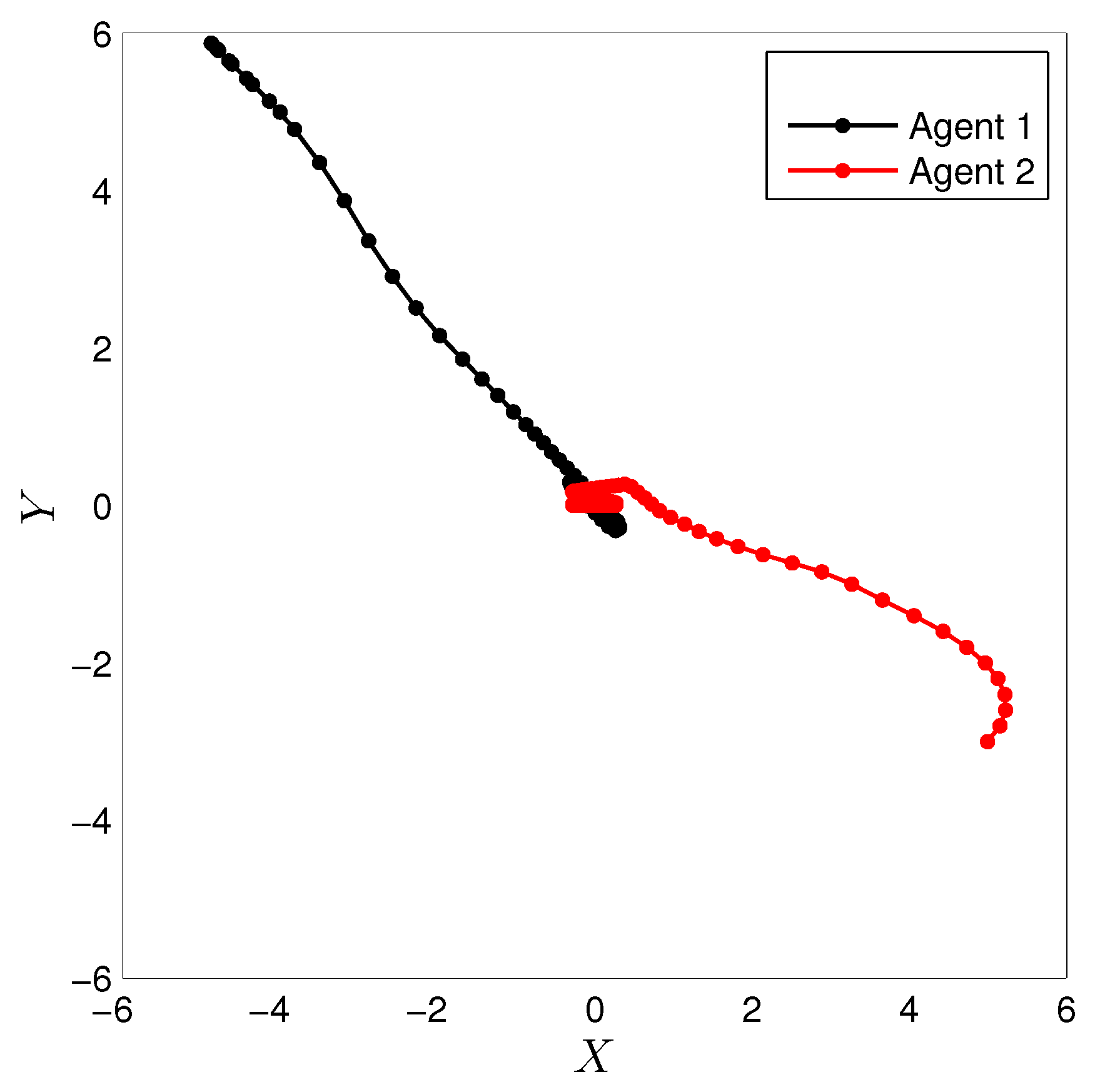
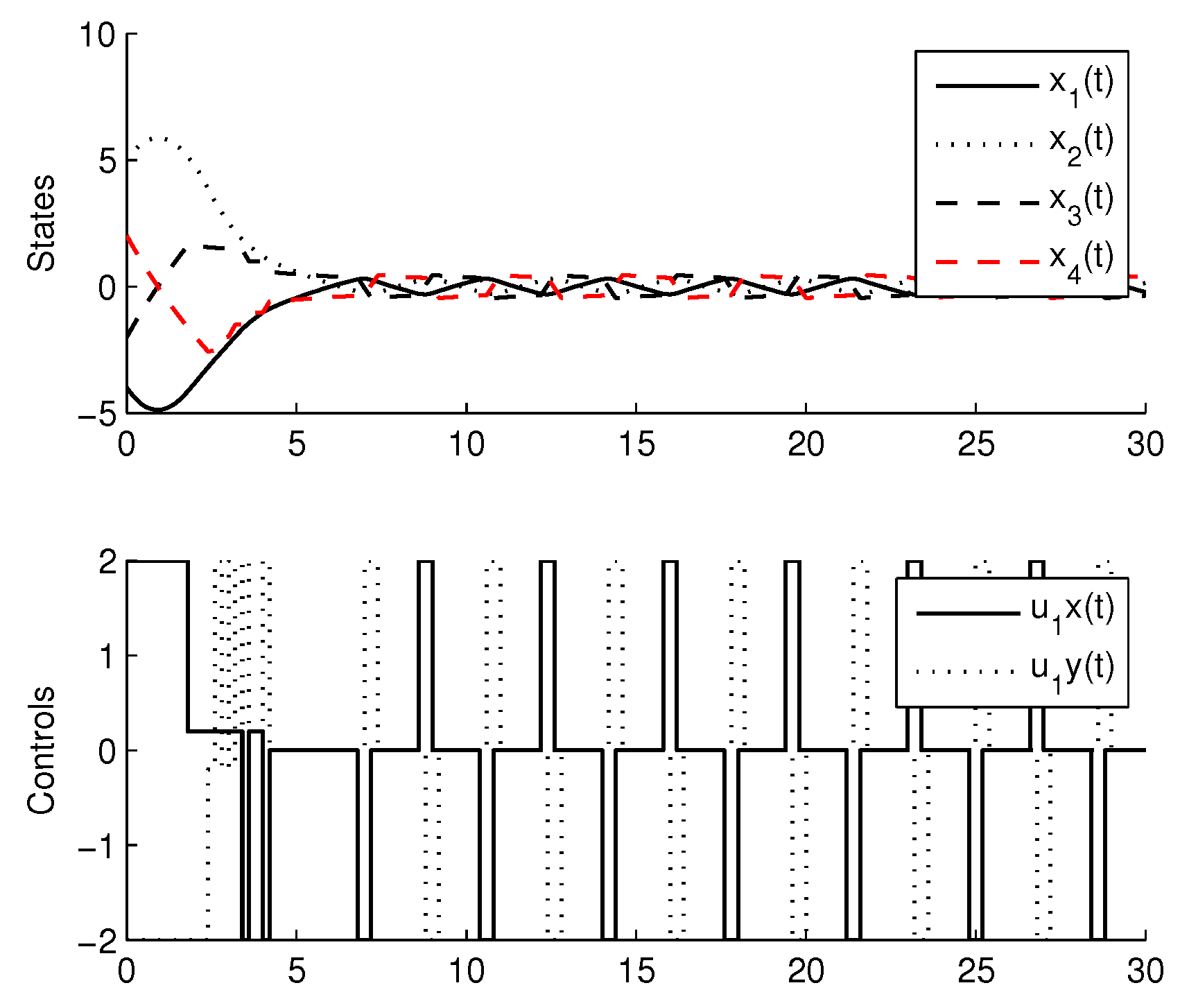
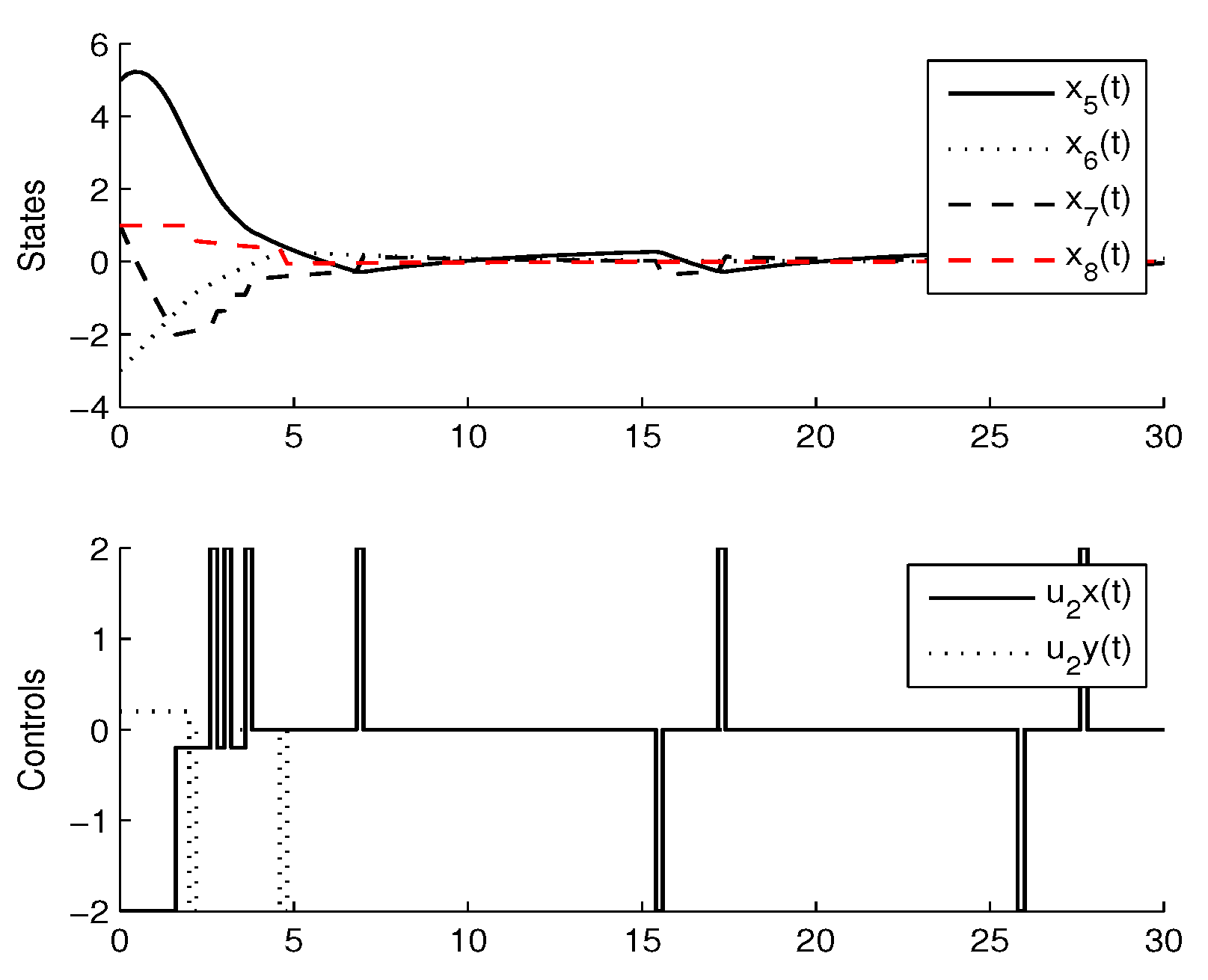
3.3. Experimental Results
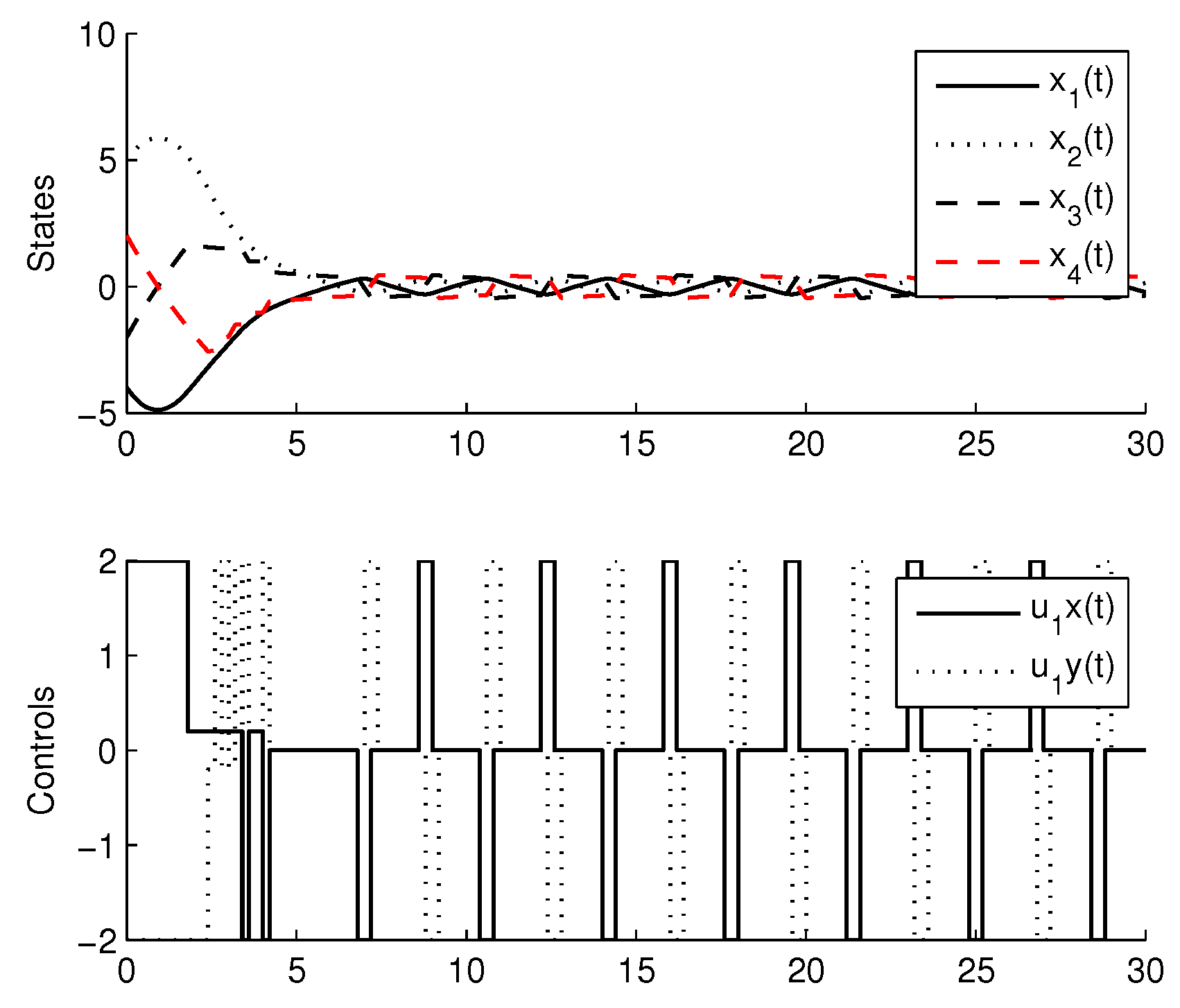
4. Comparison with CMOMMT Algorithm for Multi-Agent Systems
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Sen, S.; Weiss, G. Multiagent Systems: A Modern Approach to Distributed Artificial Intelligence; MIT Press: Cambridge, MA, USA, 1999. [Google Scholar]
- Stone, P.; Veloso, M. Multiagent systems: A survey from machine learning perspective. Auton. Robots 2000, 8, 345–383. [Google Scholar] [CrossRef]
- Wooldridge, M. An Introduction to MultiAgent Systems; John Wiley & Sons: Hoboken, NL, USA, 2002. [Google Scholar]
- Rashid, A.T.; Ali, A.A.; Frasca, M.; Fortuna, L. Path planning with obstacle avoidance based on visibility binary tree algorithm. Robot. Auton. Syst. 2013, 61, 1440–1449. [Google Scholar] [CrossRef]
- Kaelbling, L.P.; Littman, M.L.; Moore, A.W. Reinforcement Learning: A Survey. J. Artif. Intell. Res. 1996, 4, 237–285. [Google Scholar] [CrossRef]
- Arel, I.; Liu, C.; Urbanik, T.; Kohls, A.G. Reinforcement learning-based multi-agent system for network traffic signal control. IET Intell. Transp. Syst. 2010, 4, 128–135. [Google Scholar] [CrossRef]
- Cherkassky, V.; Mulier, F. Learning from data: Concepts, Theory and Methods; Wiley-IEEE Press: Hoboken, NL, USA, 2007. [Google Scholar]
- Barlow, S.V. Unsupervised learning. In Unsupervised Learning: Foundations of Neural Computation, 1st ed.; Sejnowski, T.J., Hinton, G., Eds.; MIT Press: Cambridge, MA, USA, 1999; pp. 1–18. ISBN 9780262581684. [Google Scholar]
- Zhang, W.; Ma, L.; Li, X. Multi-agent reinforcement learning based on local communication. Clust. Comput. 2018, 1–10. [Google Scholar] [CrossRef]
- Hu, X.; Wang, Y. Consensus of Linear Multi-Agent Systems Subject to Actuator Saturation. Int. J. Control Autom. Syst. 2013, 11, 649–656. [Google Scholar] [CrossRef]
- Luviano, D.; Yu, W. Path planning in unknown environment with kernel smoothing and reinforcement learning for multi-agent systems. In Proceedings of the 12th International Conference on Electrical Engineering, Computing Science and Automatic Control (CCE), Mexico City, Mexico, 28–30 October 2015. [Google Scholar]
- Abul, O.; Polat, F.; Alhajj, R. Multi-agent reinforcement learning using function approximation. IEEE Trans. Syst. Man Cybern. Part C Appl. Rev. 2000, 485–497. [Google Scholar] [CrossRef]
- Fernandez, F.; Parker, L.E. Learning in large cooperative multi-robots systems. Int. J. Robot. Autom. Spec. Issue Comput. Intell. Tech. Coop. Robots 2001, 16, 217–226. [Google Scholar]
- Foerster, J.; Nardelli, N.; Farquhar, G.; Afouras, T.; Torr, P.H.; Kohli, P.; Whiteson, S. Stabilising experience replay for deep multi-agent reinforcement learning. arXiv, 2017; arXiv:1702.08887. [Google Scholar]
- Tamakoshi, H.; Ishi, S. Multi agent reinforcement learning applied to a chase problem in a continuous world. Artif. Life Robot. 2001, 202–206. [Google Scholar] [CrossRef]
- Ishiwaka, Y.; Sato, T.; Kakazu, Y. An approach to pursuit problem on a heterogeneous multiagent system using reinforcement learning. Robot. Auton. Syst. 2003, 43, 245–256. [Google Scholar] [CrossRef]
- Radac, M.-B.; Precup, R.-E.; Roman, R.-C. Data-driven model reference control of MIMO vertical tank systems with model-free VRFT and Q-Learning. ISA Trans. 2017. [Google Scholar] [CrossRef] [PubMed]
- Pandian, B.J.; Noel, M.M. Control of a bioreactor using a new partially supervised reinforcement learning algorithm. J. Process Control 2018, 69, 16–29. [Google Scholar] [CrossRef]
- Watkins, C.J.; Dayan, P. Q-learning. Mach. Learn. 1992, 8, 279–292. [Google Scholar] [CrossRef] [Green Version]
- Nguyen, T.; Nguyen, N.D.; Nahavandi, S. Multi-Agent Deep Reinforcement Learning with Human Strategies. arXiv, 2018; arXiv:1806.04562. [Google Scholar]
- Boutilier, C. Planning, Learning and Coordination in Multiagent Decision Processes. In Proceedings of the Sixth Conference on Theoretical Aspects of Rationality and Knowledge (TARK96), De Zeeuwse Stromen, The Netherlands, 17–20 March 1996; pp. 195–210. [Google Scholar]
- Harsanyi, J.C.; Selten, R. A General Theory of Equilibrium Selection in Games, 1st ed.; MIT Press: Cambridge, MA, USA, 1988; ISBN 9780262081733. [Google Scholar]
- Busoniu, L.; De Schutter, B.; Babuska, R. Decentralized Reinforcement Learning Control of a robotic Manipulator. In Proceedings of the International Conference on Control, Automation, Robotics and Vision, Singapore, 5–8 December 2006. [Google Scholar]
- Littman, M.L. Value-function reinforcement learning in Markov games. J. Cogn. Syst. Res. 2001, 2, 55–66. [Google Scholar] [CrossRef] [Green Version]
- Guestrin, C.; Lagoudakis, M.G.; Parr, R. Coordinated reinforcement learning. In Proceedings of the 19th International Conference on Machine Learning (ICML-2002), Sydney, Australia, 8–12 July 2002; pp. 227–234. [Google Scholar]
- Bowling, M.; Veloso, M. Multiagent learning using a variable learning rate. Artif. Intell. 2002, 136, 215–250. [Google Scholar] [CrossRef]
- Bertsekas, D.P. Dynamic Programming and optimal control vol. 2, 4th ed.; Athena Scientific: Belmont, MA, USA, 2017; ISBN 1-886529-44-2. [Google Scholar]
- Istratesku, V. Fixed Point Theory: An introduction; Springer: Berlin, Germany, 2002; ISBN 978-1-4020-0301-1. [Google Scholar]
- Melo, F.S.; Meyn, S.P.; Ribeiro, M.I. An analysis of reinforcement learning with functions approximation. In Proceedings of the 25th International Conference on Machine Learning (ICML-08), Helsinki, Finland, 5–9 July 2008; pp. 664–671. [Google Scholar]
- Szepesvari., C.; Smart, W.D. Interpolation-based Q-learning. In Proceedings of the 21st International Conference on Machine Learning (ICML-04), Banff, AB, Canada, 4–8 July 2004; pp. 791–798. [Google Scholar]
- Sutton, R.S.; McAllester, D.A.; Singh, S.P.; Mansour, Y. Policy gradient methods for reinforcement learning with function approximation. In Proceedings of the 12th International Conference on Neural Information Processing Systems, Denver, CO, USA, 29 November–4 December 1999; pp. 1057–1063. [Google Scholar]
- Bertsekas, D.P.; Tsitsiklis, J.N. Neuro-Dynamic Programming, 1st ed.; Athena Scientific: Belmont, MA, USA, 1996; ISBN 1-886529-10-8. [Google Scholar]
- Tsitsiklis, J.N.; Van Roy, B. Feature-based methods for large scale dynamic programming. Mach. Learn. 1996, 22, 59–94. [Google Scholar] [CrossRef] [Green Version]
- Kruse, R.; Gebhardt, J.E.; Klowon, F. Foundations of Fuzzy Systems, 1st ed.; John Wiley & Sons: Hoboken, NL, USA, 1994; ISBN 047194243X. [Google Scholar]
- Gordon, G.J. Reinforcement learning with function approximation converges to a region. Adv. Neural Inf. Process. Syst. 2001, 13, 1040–1046. [Google Scholar]
- Tsitsiklis, J.N. Asynchronous stochastic approximation and Q-learning. Mach. Learn. 1994, 16, 185–202. [Google Scholar] [CrossRef] [Green Version]
- Berenji, H.R.; Khedkar, P. Learning and tuning fuzzy logic controllers through reinforcements. IEEE Trans. Neural Netw. 1992, 3, 724–740. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Munos, R.; Moore, A. Variable-resolution discretization in optimal control. Mach. Learn. 2002, 49, 291–323. [Google Scholar] [CrossRef]
- Chow, C.S.; Tsitsiklis, J.N. An optimal one-way multi grid algorithm for discrete-time stochastic control. IEEE Trans. Autom. Control 1991, 36, 898–914. [Google Scholar] [CrossRef]
- Busoniu, L.; Ernst, D.; De Schutter, B.; Babuska, R. Approximate Dynamic programming with fuzzy parametrization. Automatica 2010, 46, 804–814. [Google Scholar] [CrossRef]
- Vlassis, N. A concise Introduction to Multi Agent Systems and Distributed Artificial Intelligence. In Synthesis Lectures in Artificial Intelligence and Machine Learning; Morgan & Claypool Publishers: San Rafael, CA, USA, 2007. [Google Scholar]
- K-Team Corporation. 2013. Available online: http://www-k-team.com (accessed on 15 January 2018).
- Ganapathy, V.; Soh, C.Y.; Lui, W.L.D. Utilization of webots and Khepera II as a Platform for neural Q-learning controllers. In Proceedings of the IEEE Symposium on Industrial Electronics and Applications, Kuala Lumpur, Malaysia, 25–27 May 2009. [Google Scholar]
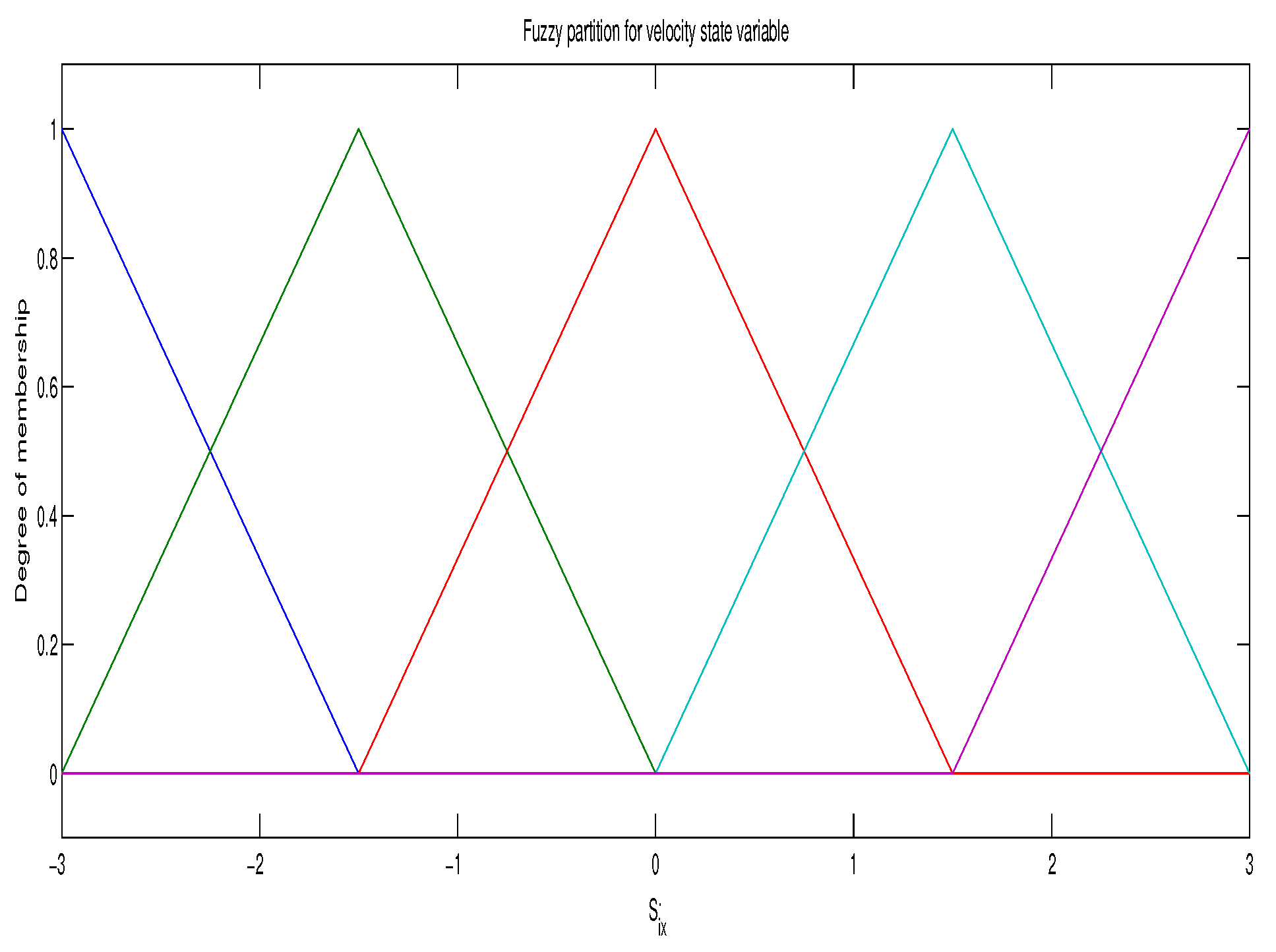




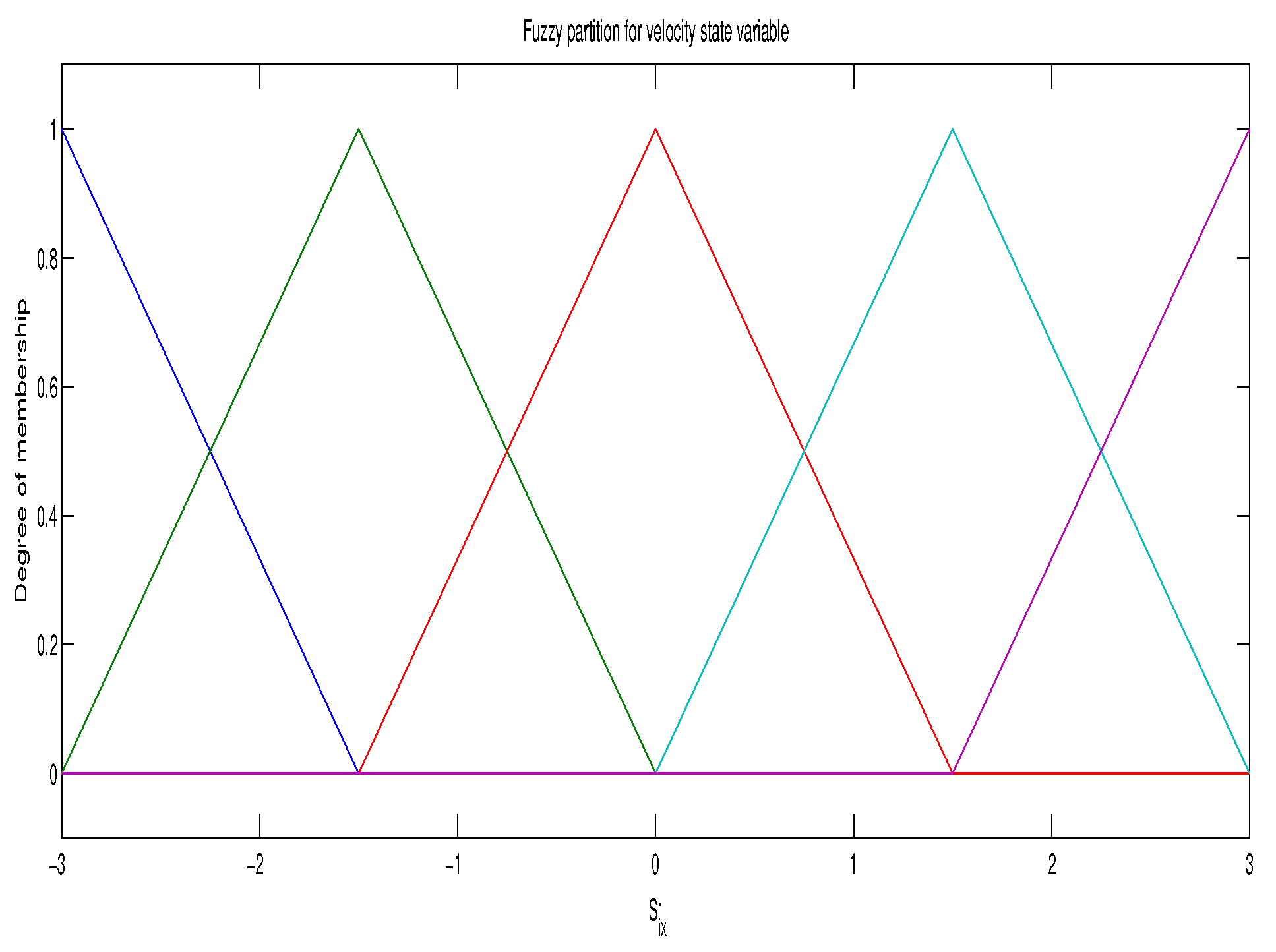{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training | CMOMMT | Fuzzy Parameterization |
|---|---|---|
| Error (cm) | 18 | 6 |
| Time (s) | 25 | 12 |
| Iterations | 34 | 27 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Luviano-Cruz, D.; Garcia-Luna, F.; Pérez-Domínguez, L.; Gadi, S.K. Multi-Agent Reinforcement Learning Using Linear Fuzzy Model Applied to Cooperative Mobile Robots. Symmetry 2018, 10, 461. https://doi.org/10.3390/sym10100461
Luviano-Cruz D, Garcia-Luna F, Pérez-Domínguez L, Gadi SK. Multi-Agent Reinforcement Learning Using Linear Fuzzy Model Applied to Cooperative Mobile Robots. Symmetry. 2018; 10(10):461. https://doi.org/10.3390/sym10100461
Chicago/Turabian StyleLuviano-Cruz, David, Francesco Garcia-Luna, Luis Pérez-Domínguez, and S. K. Gadi. 2018. "Multi-Agent Reinforcement Learning Using Linear Fuzzy Model Applied to Cooperative Mobile Robots" Symmetry 10, no. 10: 461. https://doi.org/10.3390/sym10100461
APA StyleLuviano-Cruz, D., Garcia-Luna, F., Pérez-Domínguez, L., & Gadi, S. K. (2018). Multi-Agent Reinforcement Learning Using Linear Fuzzy Model Applied to Cooperative Mobile Robots. Symmetry, 10(10), 461. https://doi.org/10.3390/sym10100461