Applying Text Mining for Identifying Future Signals of Land Administration

Abstract
1. Introduction
2. Future Signal Detection
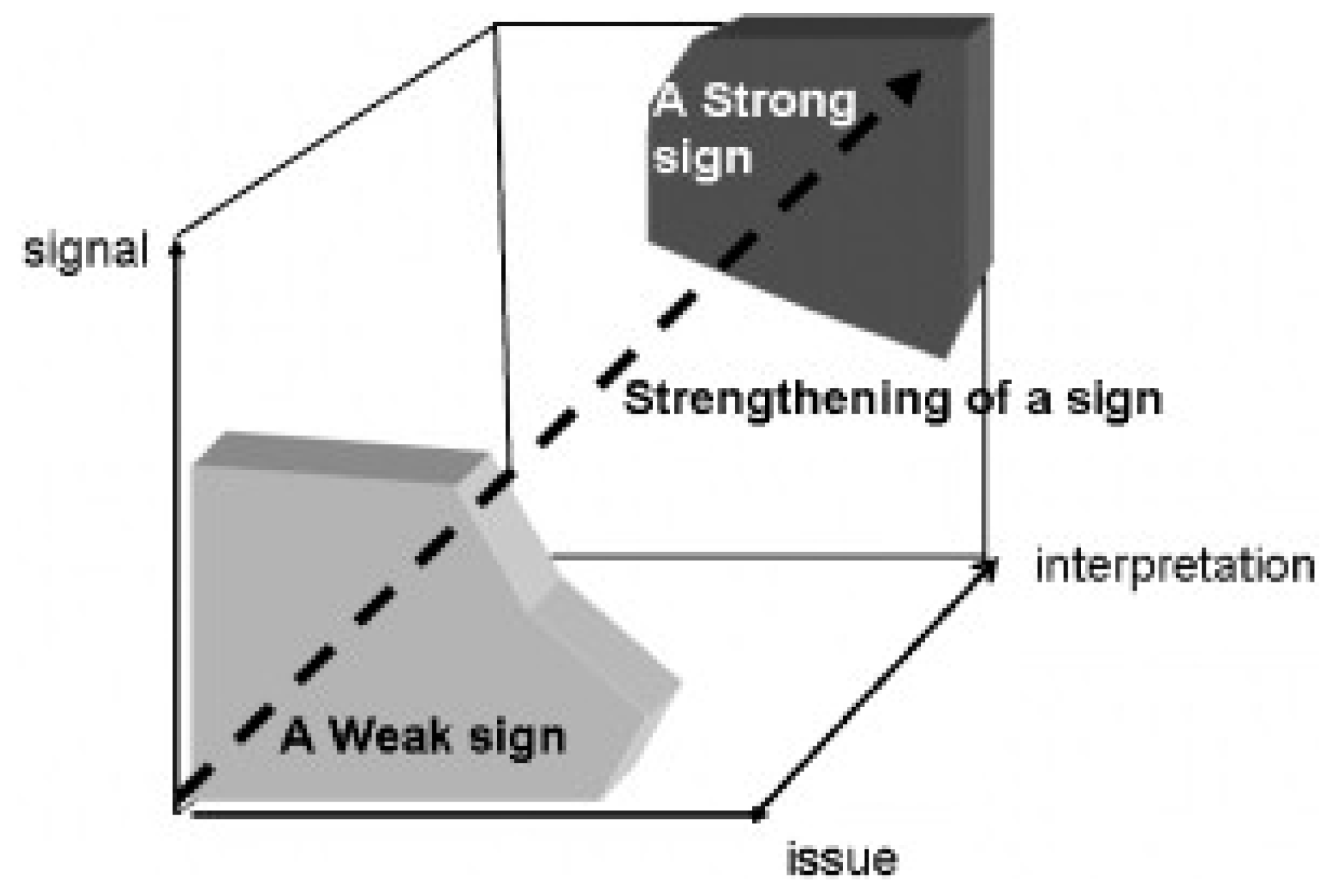
2.1. Weak Signals in Futures Studies
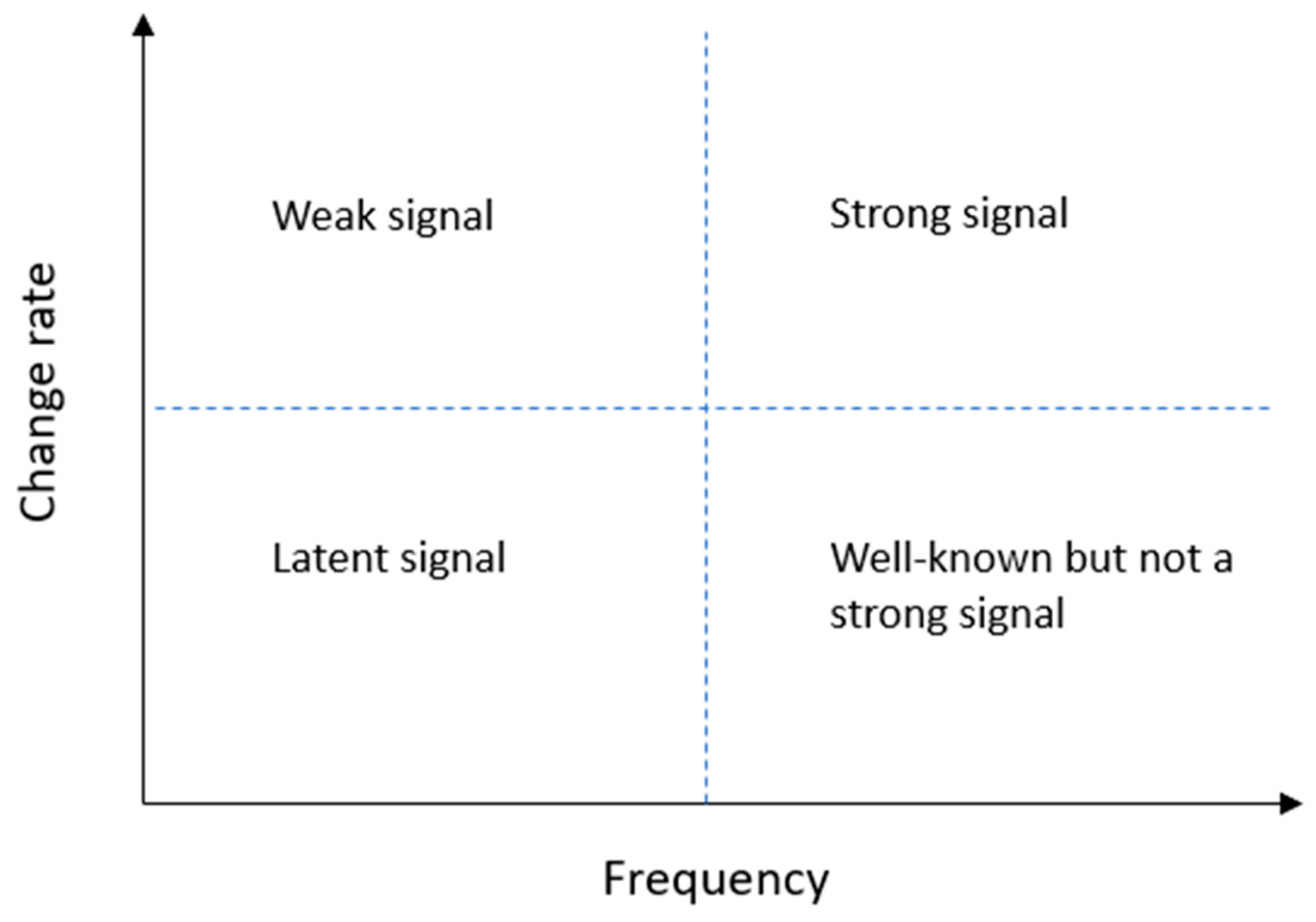
2.2. Future Signals in Text Mining Applications
3. Methods and Materials
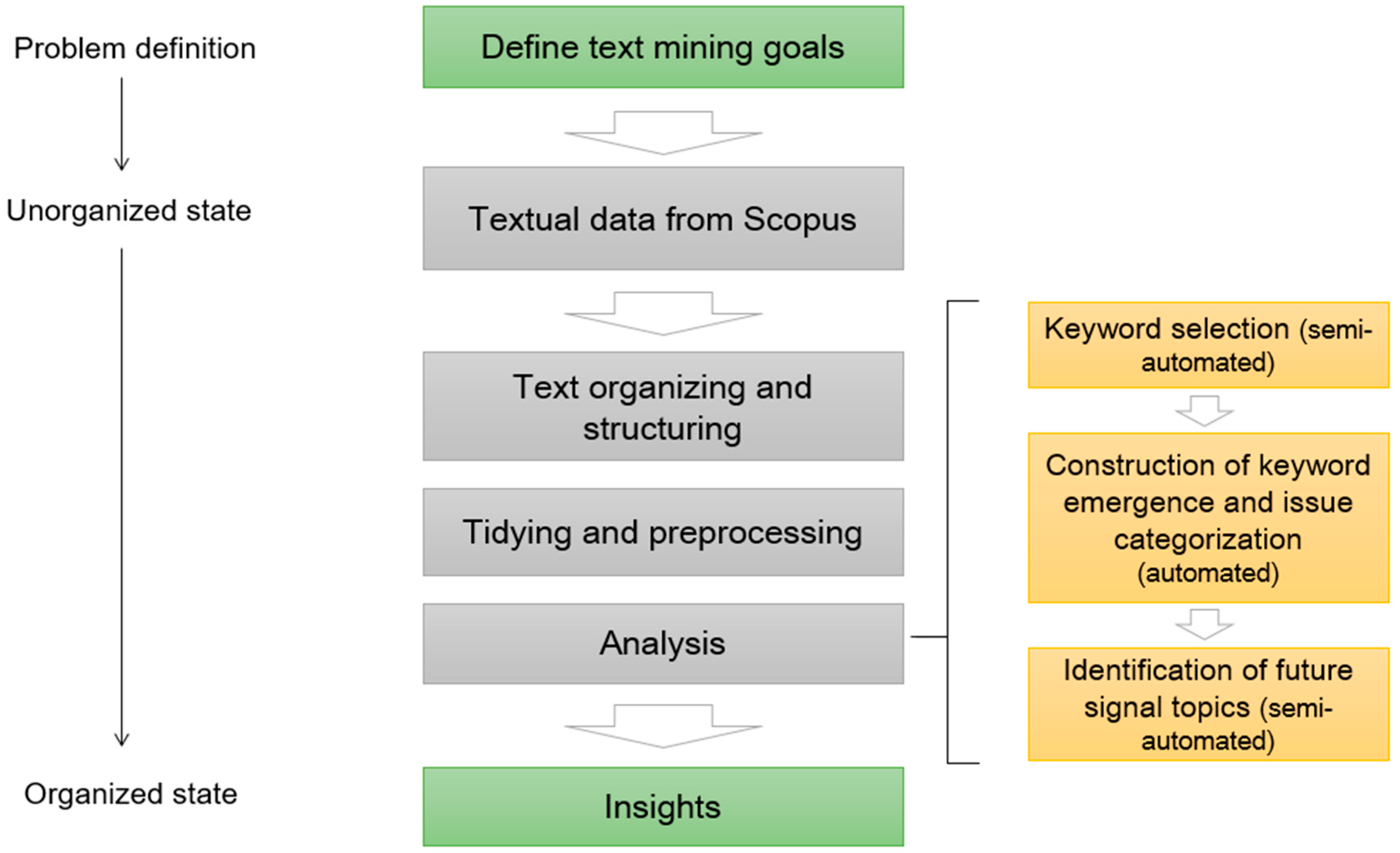
3.1. Overview of the Research Process
3.2. Text Mining Tools
3.2.1. Term and Document Frequency
3.2.2. Degree of Visibility (DoV) and Degree of Diffusion (DoD)
3.2.3. Topic Modeling
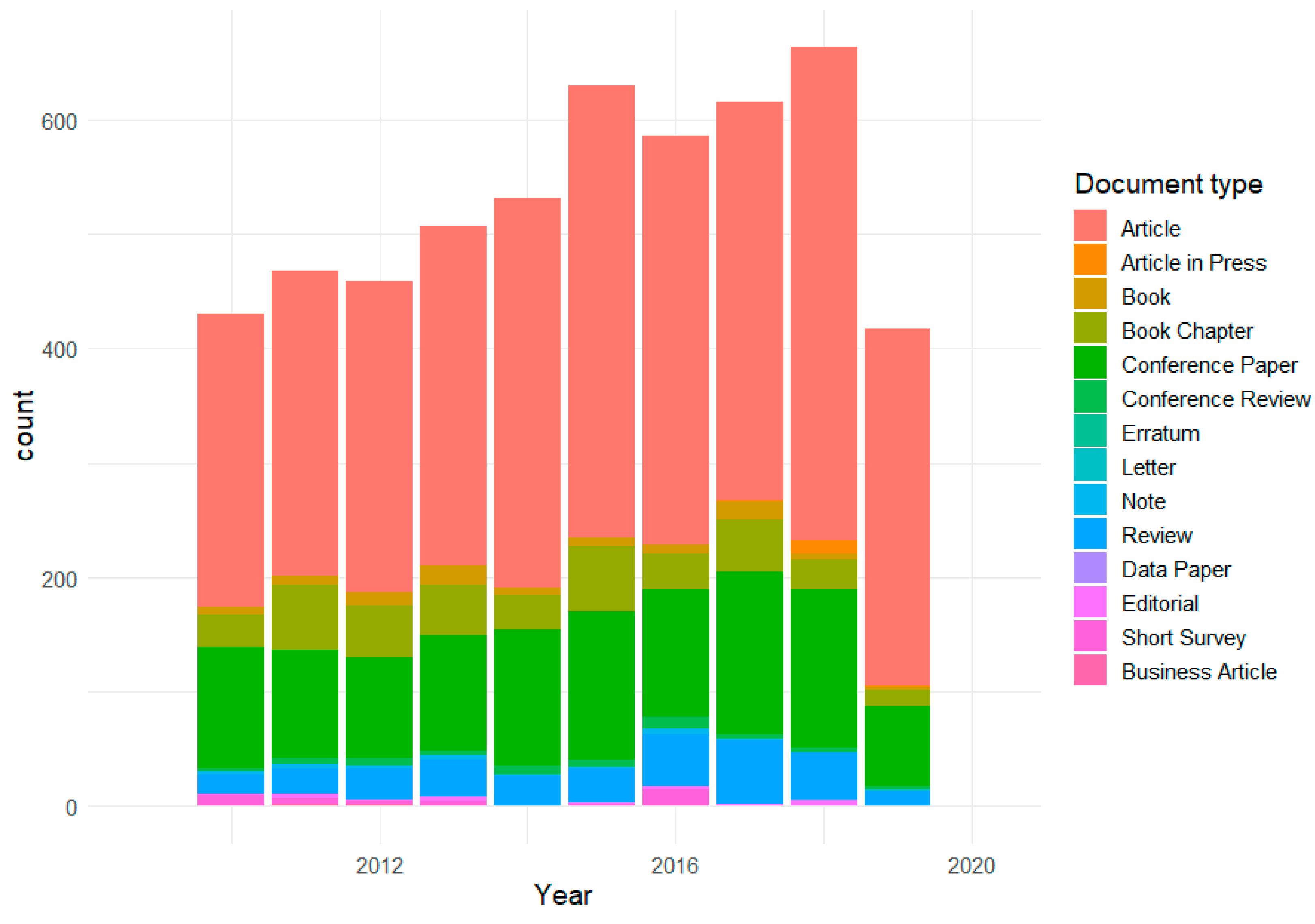
3.3. Data Collection and Materials
4. Results
4.1. Keyword Selection
4.2. Future Signals
5. Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Author Keyword | N | Author Keyword | N |
|---|---|---|---|
| 1. Cadastre | 201 | 16. Urban planning | 25 |
| 2. GIS | 152 | 17. Land cadastre | 23 |
| 3. Land administration | 110 | 18. Land registry | 23 |
| 4. Land use | 75 | 19. Mapping | 23 |
| 5. Remote sensing | 75 | 20. Agriculture | 23 |
| 6. 3D cadastre | 59 | 21. Landscape | 21 |
| 7. LADM | 43 | 22. Soil moisture | 21 |
| 8. Climate change | 36 | 23. CityGML | 20 |
| 9. Land | 32 | 24. Photogrammetry | 20 |
| 10. Land management | 31 | 25. Geographic information systems | 18 |
| 11. Sustainability | 29 | 26. Database | 17 |
| 12. China | 29 | 27. Land cover | 17 |
| 13. Land consolidation | 27 | 28. Land reform | 17 |
| 14. Property rights | 27 | 29. Real estate | 17 |
| 15. Sustainable development | 26 | 30. Cadastral map | 17 |
References
- Enemark, S. The land management paradigm for sustainable development. In Sustainability and Land Administration Systems; Williamson, I., Enemark, S., Wallace, J., Eds.; Department of Geomatics, University of Melbourne: Melbourne, Australia, 2006. [Google Scholar]
- Feder, G.; Nishio, A. The benefits of land registration and titling: Economic and social perspectives. Land Use Policy 1999, 15, 25–43. [Google Scholar] [CrossRef]
- Williamson, I.; Enemark, S.; Wallace, J.; Rajabifard, A. Land Administration for Sustainable Development; ESRI Press: Redlands, CA, USA, 2010. [Google Scholar]
- Ting, L.; Williamson, I. Cadastral trends: A synthesis. Aust. Surv. 1999, 44, 46–54. [Google Scholar] [CrossRef]
- Zevenbergen, J.; de Vries, W.T.; Bennett, R. Dynamics in Responsible Land Administration; change at five levels. In Proceedings of the FIG Congress 2018, Istanbul, Turkey, 6–11 May 2018. [Google Scholar]
- Krigsholm, P.; Zavialova, S.; Riekkinen, K.; Ståhle, P.; Viitanen, K. Understanding the future of the Finnish cadastral system—A Delphi study. Land Use Policy 2017, 68, 133–140. [Google Scholar] [CrossRef]
- Amanatidou, E.; Butter, M.; Carabias, V.; Könnölä, T.; Leis, M.; Saritas, O.; Schaper-Rinkel, P.; van Rij, V. On concepts and methods in horizon scanning: Lessons from initiating policy dialogues on emerging issues. Sci. Public Policy 2012, 39, 208–221. [Google Scholar] [CrossRef]
- Hiltunen, E. Weak Signals in Organizational Futures Learning. Ph.D. Thesis, Aalto University School of Economics, Espoo, Finland, 2010. [Google Scholar]
- Popper, R. How are foresight methods selected? Foresight 2008, 10, 62–89. [Google Scholar] [CrossRef]
- Popper, R. Foresight methodology. In The Handbook of Technology Foresight: Concepts and Practice; Georghiou, L., Harper, J.C., Keenan, M., Miles, I., Popper, R., Eds.; Edward Elgar: Cheltenham, UK, 2008; pp. 44–88. [Google Scholar]
- Sitra 2019. Heikot Signaalit Tulevaisuuden Avartajina. Available online: https://www.sitra.fi/julkaisut/heikot-signaalit-tulevaisuuden-avartajina/ (accessed on 1 November 2019).
- Yoon, J. Detecting Weak Signals for long-term business opportunities using text mining on Web news. Expert Syst. Appl. 2012, 39, 12543–12550. [Google Scholar] [CrossRef]
- Kim, H.; Han, Y.; Song, J.; Song, T.M. Application of social big data to identify trends of school bullying forms in South Korea. Int. J. Environ. Res. Public Health 2019, 16, 2596. [Google Scholar] [CrossRef]
- Lee, Y.-L.; Park, J.-Y. Identification of future signal based on the quantitative and qualitative text mining: A case study on ethical issues in artificial intelligence. Qual. Quant. 2018, 52, 653. [Google Scholar] [CrossRef]
- Ansoff, H.I. Managing strategic surprise by response to weak signals. Calif. Manag. Rev. 1975, 18, 21–33. [Google Scholar] [CrossRef]
- Mannermaa, M. Tulevaisuuden Hallinta—Skenaariot Strategiatyöskentelyssä; WSOY: Porvoo, Finland, 1999; p. 227. [Google Scholar]
- Hiltunen, E. Was It a Wild Card or Just Our Blindness to Gradual Change? J. Future Stud. 2006, 11, 67–74. [Google Scholar]
- Kuosa, T. Heikko signaali vai merkityksetön kohina: Pattern management—Ontologisesti uusi lähestymistapa heikkojen signaalien tarkasteluun ja tulkintaan. Futura 24 2005, 4, 115–120. [Google Scholar]
- Kuusi, O.; Hiltunen, E.; Linturi, H. Heikot tulevaisuussignaalit—Delfoi tutkimus. Futura 19 2000, 2, 78–92. [Google Scholar]
- Petersen, J.L.; Steinmüller, K.H.; Adeyema, H. Wild Cards. In Futures Research Methodology; Version 3.0.; Glenn, J.C., Gordon, T.J., Eds.; With Support from the Rockefeller Foundation. Millennium Project; CDROM. S. i–108; 2019; p. 1300. [Google Scholar]
- Moijanen, M. Heikot signaalit tulevaisuuden tutkimuksessa. Futura 2003, 4, 38–60. [Google Scholar]
- Hiltunen, E. The future sign and its three dimensions. Futures 2008, 40, 247–260. [Google Scholar] [CrossRef]
- Kuusi, O.; Hiltunen, E. The Signification Process of the Future Sign; FFRC eBook 4/2007; Finland Futures Research Centre, Turku School of Economics: Turku, Finland, 2007; p. 24. [Google Scholar]
- Kim, H.; Ahn, S.-J.; Jung, W.-S. Horizon scanning in policy research database with a probabilistic topic model. Technol. Forecast. Soc. Chang. 2019, 146, 588–594. [Google Scholar] [CrossRef]
- Blei, D.M. Probabilistic topic models. Commun. ACM 2012, 55, 77–84. [Google Scholar] [CrossRef]
- Yu, C.H.; Jannasch-Pennell, A.; DiGangi, S. Compatibility between Text Mining and Qualitative Research in the Perspectives of Grounded Theory, Content Analysis, and Reliability. Qual. Rep. 2011, 16, 730–744. [Google Scholar]
- Welbers, K.; Van Atteveldt, W.; Benoit, K. Text analysis in R. Commun. Methods Meas. 2017, 11, 245–265. [Google Scholar] [CrossRef]
- ISO 19152:2012. Geographic information—Land Administration Domain Model (LADM); The International Organization for Standardization: Geneva, Switzerland, 2012. [Google Scholar]
- UN Sustainable Development Goals. Available online: https://www.un.org/sustainabledevelopment/poverty (accessed on 1 November 2019).
- Yleisradio: Permission Needed for Foreign Residents to Buy Property in Finland from 2020. Available online: https://yle.fi/uutiset/osasto/news/permission_needed_for_foreign_residents_to_buy_property_in_finland_from_2020/11043532 (accessed on 5 November 2019).
- Olfat, H.; Jani, A.; Shojaei, D.; Darvill, A.; Briffa, M.; Rajabifard, A.; Badiee, F. Tackling the challenges of visualizing digital cadastral plans: The Victorian cadastre experience. Land Use Policy 2019, 83, 84–94. [Google Scholar] [CrossRef]
- Hjelmblom, M.; Paasch, J.M.; Paulsson, J.; Edlund, M.; Bökman, F. Towards Automation of the Swedish Property Formation Process: A structural and logical analysis of property subdivision. Nord. J. Surv. Real Estate Res. 2019, 14, 29–63. [Google Scholar]
- Bornmann, L.; Mutz, R. Growth rates of modern science: A bibliometric analysis based on the number of publications and cited references. J. Assoc. Inf. Sci. Technol. 2015, 66, 2215–2222. [Google Scholar] [CrossRef]
- Hiltunen, E. Good sources of weak signals: A global study of where futurists look for weak signals. J. Futures Stud. 2008, 12, 21–44. [Google Scholar]
| 1 | To avoid any confusion, we note that terms “keyword”, “search keyword”, and “author keyword” have specific meanings in this paper. The first one refers to words identified through the analysis, the second one to words used as search parameters in the document retrieval, and the third one to words nominated by the document authors as the best words to describe the content of document. |





| Keyword | Total Term Frequency | Total Document Frequency | DoV | DoD |
|---|---|---|---|---|
| rights | 1535 | 1135 | 1.650 | 1.275 |
| agricultural | 1247 | 545 | 1.373 | 0.577 |
| accuracy | 650 | 396 | 0.657 | 0.406 |
| gis | 663 | 409 | 0.647 | 0.405 |
| rural | 693 | 377 | 0.722 | 0.394 |
| administrative | 492 | 363 | 0.533 | 0.388 |
| 3d | 1557 | 333 | 1.724 | 0.363 |
| climate | 742 | 354 | 0.767 | 0.360 |
| buildings | 477 | 303 | 0.555 | 0.350 |
| database | 525 | 330 | 0.545 | 0.350 |
| service | 549 | 337 | 0.572 | 0.333 |
| cities | 514 | 296 | 0.568 | 0.326 |
| ownership | 412 | 275 | 0.394 | 0.276 |
| boundaries | 380 | 242 | 0.440 | 0.270 |
| authorities | 327 | 241 | 0.365 | 0.264 |
| sensing | 363 | 240 | 0.380 | 0.259 |
| road | 569 | 246 | 0.593 | 0.256 |
| institutions | 347 | 239 | 0.368 | 0.246 |
| vegetation | 477 | 235 | 0.478 | 0.240 |
| sector | 319 | 234 | 0.342 | 0.239 |
| Category | Signal Dimension | Issue Dimension | ||
|---|---|---|---|---|
| N | % | N | % | |
| Latent | 236 | 37 | 273 | 43 |
| Weak | 94 | 15 | 54 | 9 |
| Well-known but not strong | 27 | 4 | 45 | 7 |
| Strong | 278 | 44 | 263 | 41 |
| Topic | Keywords | Interpretation | Category |
|---|---|---|---|
| Non-universal enhancement of location measures | DGPS (differential GPS); ship; arctic; enabling; topology; cartography; collaboration | A ground reference station sending (non-universal) corrections. | latent |
| New data sources for socio-economic variables | NPP (national polar-orbiting partnership); urbanization; tourism; weather; offshore; shore | Weather and climate monitoring data sources (such as NPP) used increasingly as a proxy to measure socio-economic variables cheaply and in real-time. | latent |
| National security | Weapons; treaty; flux; holdings; monetary | Land as a critical strategic resource from a national security perspective. | latent |
| Plans in digital form | Geodatabase; cad; eplan; georeferenced; thematic; gis; software | Advances in the common GIS software enable digitizing planning documents. | weak |
| Topic | Keywords | Interpretation | Category |
|---|---|---|---|
| Participatory land consolidations | Procedural; rural; consolidation; cooperation; awareness; fragmentation; participatory | Participatory land consolidations as a tool to tackle land fragmentation. | well-known |
| 3D city models in visualization | Buildings, visualization; vertical; semantic; citygml; interoperability; feasibility; LOD (level of detail) | 3D city models leveraging up the visualization of land and building information. | strong |
| Transportation and safety | Transportation; safety; agencies; marine; highway; railway; emergency | The role of land administration as part of comprehensive security increases. | strong |
| Land conflicts | Tenure; conflict; reconstruction; earthquake; seismic; migration; informal | Land conflicts, e.g., as a result of humane and natural disasters, putting pressure on tenure security. | strong |
| Advances in photogrammetry and laser scanning | Accuracy; aerial; transformation; elevation; UAV; automated; terrain; scanning; ortophoto | Advances in photogrammetry and laser scanning techniques produce higher accuracy data. | strong |
| Advances in image sensors | Sensing; validation; cloud; imaging; sensor; scales; radar; calibration; spectral | Quality of image sensors increases rapidly, and new application fields emerge. | strong |
| Coordination of land use | Cities; governance; authorities; municipalities; irrigation; cultivation; coordination; competition; peasant; redevelopment | Decentralized land administration as a tool to support local land use. | strong |
| Responsive and flexible standardization | Standardization; underground; LADM; dimensional; restrictions; responsibilities; ISO; indoor; overlapping; BIM | Standards such as ISO 19152 [28] developing in line with new requirements such as multi-dimensionality and building information integration. | strong |
| Sustainable land use promotion | Vegetation; rainfall; Africa; degradation; valuation; renewable; NDVI (normalized difference vegetation index); tropical; barriers | Efforts to promote sustainable land use, supported by vegetation indices (NDVI) etc. | strong |
| Climate change mitigation | Climate; emissions; pollution; carbon; uncertainty; mitigation; deforestation | Increasing awareness of climate change impacts and the role of land use in climate change mitigation. | strong |
| Bio- and wildlife diversity | Species; organization; complexity; biodiversity; diversity; wildlife; accessible; toxic; permits | Diminishing bio- and wildlife diversity becomes a growing concern. | strong |
| Solar energy production | Capacity; solar; manage; platform; radiation; guidelines; assets; optimization; suburban | Solar panels as an energy source especially in suburban areas. | strong |
| Satellite imagery for data collection | Residential; Landsat; utility; secure; census; archives; sprawl | Landsat satellite imagery data offering insights into human activity, e.g. urban sprawl. | strong |
| Water-related threats | Flood; networks; availability; vulnerability; hydrological; hazards; adaptive; mitigation | Water-related threats, e.g. rising sea levels and flood, affecting the land interests | strong |
| Customary land rights | Conservation; sustainability; customary; statutory; integrate; landholders; | Providing tenure security for indigenous and other customary landholders. | strong |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Krigsholm, P.; Riekkinen, K. Applying Text Mining for Identifying Future Signals of Land Administration. Land 2019, 8, 181. https://doi.org/10.3390/land8120181
Krigsholm P, Riekkinen K. Applying Text Mining for Identifying Future Signals of Land Administration. Land. 2019; 8(12):181. https://doi.org/10.3390/land8120181
Chicago/Turabian StyleKrigsholm, Pauliina, and Kirsikka Riekkinen. 2019. "Applying Text Mining for Identifying Future Signals of Land Administration" Land 8, no. 12: 181. https://doi.org/10.3390/land8120181
APA StyleKrigsholm, P., & Riekkinen, K. (2019). Applying Text Mining for Identifying Future Signals of Land Administration. Land, 8(12), 181. https://doi.org/10.3390/land8120181