Development of a Historical Multi-Year Land Cover Classification Incorporating Wildfire Effects


Abstract
:1. Introduction
2. Methods
2.1. Study Area
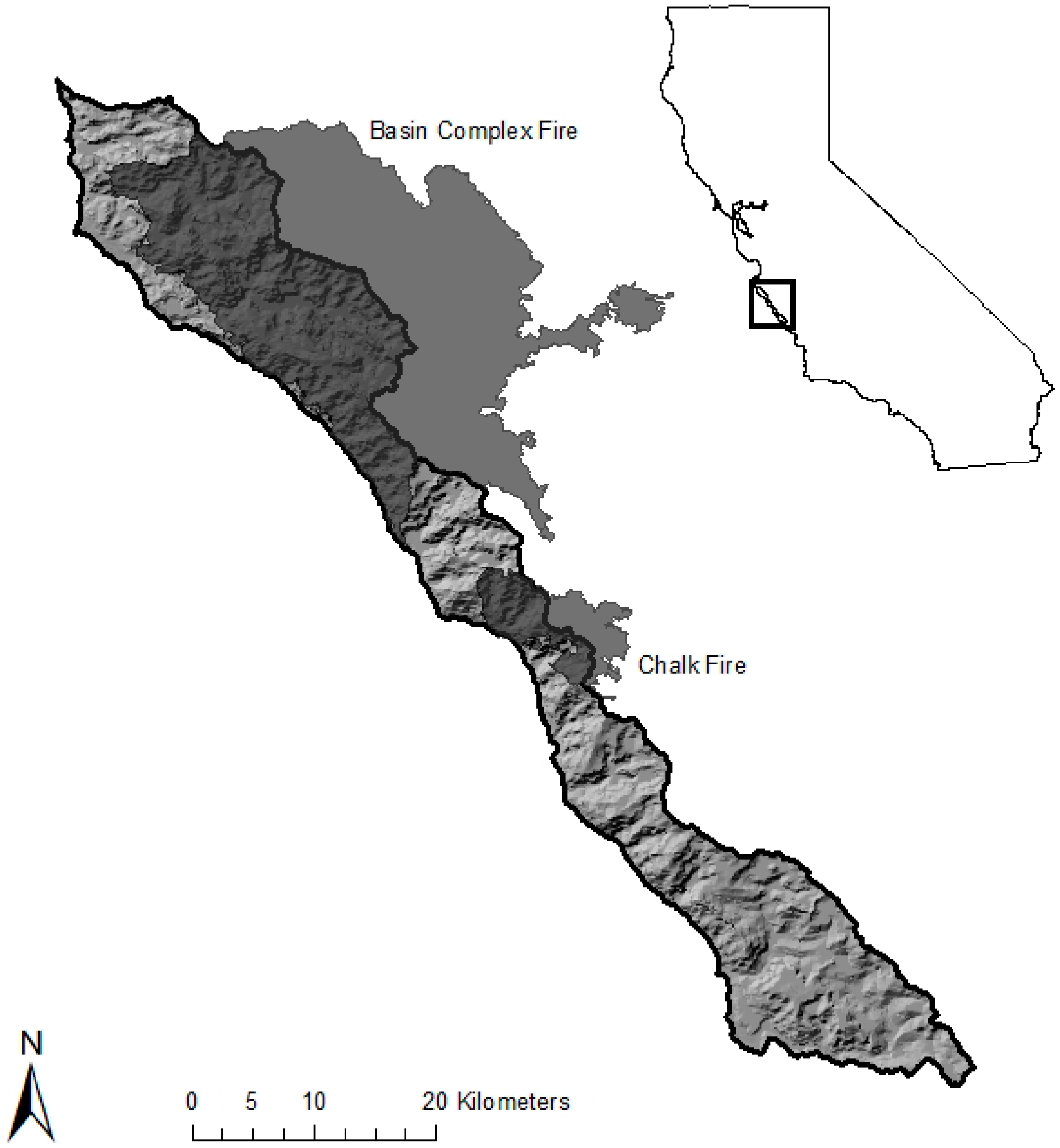
2.2. Satellite and Ancillary Data

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sensor | Year | Month/Day |
|---|---|---|
| Landsat TM | 2005 | July/8 |
| 2006 | July/11 | |
| 2007 | July/14 | |
| 2008 | August/1 | |
| 2009 | July/19 | |
| 2010 | August/23 | |
| 2011 | July/25 | |
| Landsat ETM+ | 2012 | July/19 |
| 2012 | July/3 |
| Variable | Description |
|---|---|
| Spectral | |
| Band 1 (B1) | 0.45–0.52 µm TM, 0.45–0.515 µm ETM+ |
| Band 2 (B2) | 0.52–0.60 µm TM, 0.525–0.605 µm ETM+ |
| Band 3 (B3) | 0.63–0.69 µm TM, ETM+ |
| Band 4 (B4) | 0.76–0.90 µm TM, 0.75–0.90 µm ETM+ |
| Band 5 (B5) | 1.55–1.75 µm TM,ETM+ |
| Band 7 (B7) | 2.09–2.35 µm TM, 2.09–2.35 µm ETM+ |
| Low Band 1 | 3 × 3 Mean Filter of Band 1 reflectance |
| Low Band 2 | 3 × 3 Mean Filter of Band 2 reflectance |
| Low Band 3 | 3 × 3 Mean Filter of Band 3 reflectance |
| Low Band 4 | 3 × 3 Mean Filter of Band 4 reflectance |
| Low Band 5 | 3 × 3 Mean Filter of Band 5 reflectance |
| Low Band 7 | 3 × 3 Mean Filter of Band 7 reflectance |
| 4/3 ratio | B4/B3 |
| 7/4 ratio | B7/B4 |
| NDVI | (B4 − B3)/(B4 + B3) |
| NBR | (B7 − B4)/(B7 + B4) |
| TCB | 0.2043 × B1 + 0.4158 × B2 + 0.5524 × B3 + 0.5741 × B4 + 0.3124 × B5 + 0.2303 × B7 |
| TCW | 0.0315 × B1 + 0.2021 × B2 + 0.3102 × B3 + 0.1594 × B4 − 0.6806 × B5 − 0.6109 × B7 |
| TCG | −0.1603 × B1 − 0.2819 × B2 − 0.4934 × B3 + 0.7940 × B4 − 0.0002 × B5 − 0.1446 × B7 |
| Ancillary | |
| Aspect | North, South, East, West Categories |
| Slope | Degrees |
| Elevation | Meters |
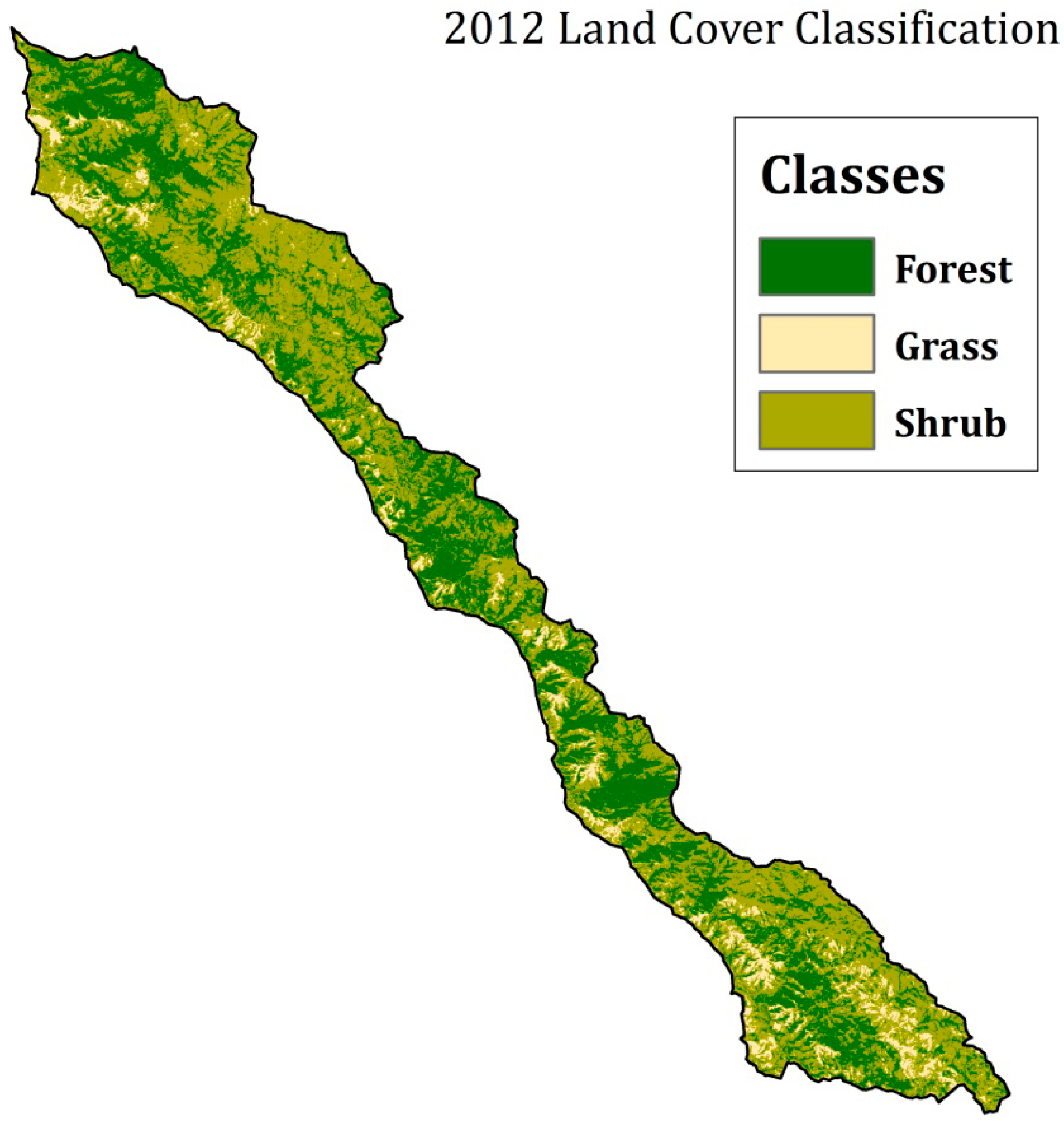
2.3. Classification Scheme and Reference Data
| Land-Cover Class | Class Description |
|---|---|
| Forest | Areas dominated by trees generally greater than 5 m tall and greater than 20 percent of total vegetation cover; includes both evergreen forest, where canopy is never without foliage, and mixed forest, where neither deciduous nor evergreen species are greater than 75% of the total tree cover |
| Shrub | Areas dominated by shrubs less than 5 m tall with shrub canopy typically greater than 20% of total vegetation; includes true shrubs, young trees in the early successional stage or foliage stunted from environmental conditions |
| Grass | Areas dominated by graminoid or herbaceous vegetation, generally greater than 80% of the total vegetation; includes grazing |
| Year | Data Source | Number of Sites | Utility |
|---|---|---|---|
| 2012 | Field; NAIP | 164; 270 | Training for 2012 classification |
| Field; NAIP | 55; 90 | Validation for 2012 classification | |
| 2009 | NAIP | 164 | Validation for 2009 classification |
| 2005 | NAIP | 180 | Validation for 2005 classification |
| -- | Persistent Sites from NAIP | 147 | Validation for 2006, 2007, 2008, 2010 and 2011 classifications |
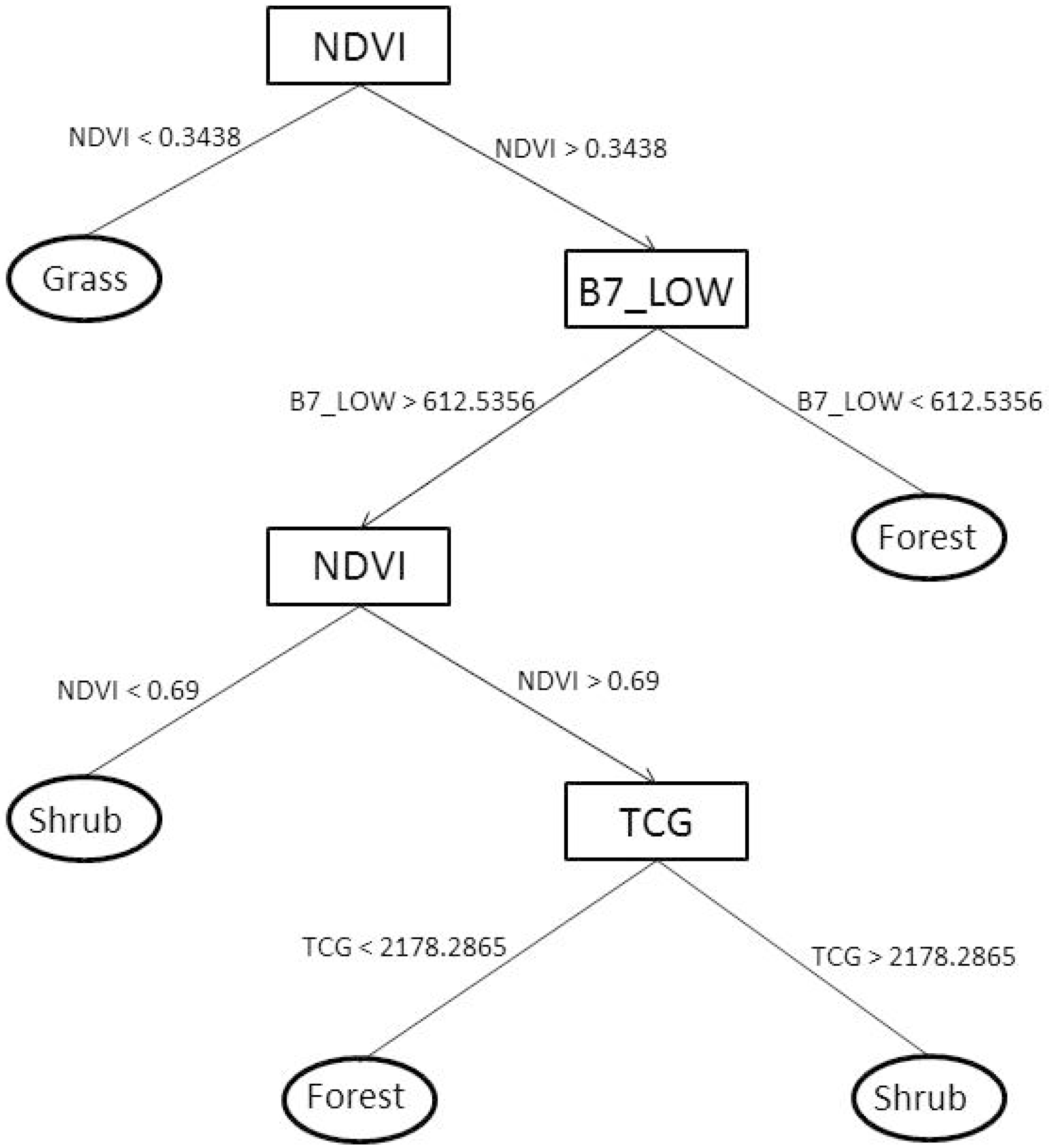
2.4. Classification Tree
2.5. Accuracy Assessment
3. Results
3.1. Classification Tree
3.2. Classification Accuracy
| Reference | Reference | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Year 2005 | Forest | Shrub | Grass | Total | Commission Error | Year 2009 | Forest | Shrub | Grass | Total | Commission Error | ||
| Classified | Forest | 70 | 18 | 1 | 89 | 0.21 | Classified | Forest | 56 | 23 | 0 | 79 | 0.29 |
| Shrub | 15 | 48 | 1 | 64 | 0.25 | Shrub | 7 | 49 | 4 | 60 | 0.18 | ||
| Grass | 0 | 9 | 18 | 27 | 0.33 | Grass | 1 | 4 | 20 | 25 | 0.20 | ||
| Total | 85 | 75 | 20 | 0.76 | Overall | Total | 64 | 76 | 24 | 0.76 | Overall | ||
| Omission Error | 0.18 | 0.36 | 0.10 | 0.59 | Kappa | Omission Error | 0.13 | 0.36 | 0.17 | 0.62 | Kappa | ||
| 2006 | Forest | Shrub | Grass | Total | Commission Error | 2010 | Forest | Shrub | Grass | Total | Commission Error | ||
| Forest | 58 | 14 | 1 | 73 | 0.21 | Forest | 63 | 10 | 0 | 73 | 0.14 | ||
| Shrub | 9 | 39 | 8 | 56 | 0.30 | Shrub | 11 | 44 | 1 | 56 | 0.21 | ||
| Grass | 0 | 3 | 15 | 18 | 0.17 | Grass | 0 | 3 | 15 | 18 | 0.17 | ||
| Total | 67 | 56 | 24 | 0.76 | Overall | Total | 74 | 57 | 16 | 0.83 | Overall | ||
| Omission Error | 0.13 | 0.30 | 0.38 | 0.61 | Kappa | Omission Error | 0.15 | 0.23 | 0.06 | 0.71 | Kappa | ||
| 2007 | Forest | Shrub | Grass | Total | Commission Error | 2011 | Forest | Shrub | Grass | Total | Commission Error | ||
| Forest | 47 | 24 | 2 | 73 | 0.36 | Forest | 59 | 14 | 0 | 73 | 0.19 | ||
| Shrub | 3 | 46 | 7 | 56 | 0.18 | Shrub | 16 | 39 | 1 | 56 | 0.30 | ||
| Grass | 0 | 1 | 17 | 18 | 0.06 | Grass | 0 | 7 | 11 | 18 | 0.39 | ||
| Total | 50 | 71 | 26 | 0.75 | Overall | Total | 75 | 60 | 12 | 0.74 | Overall | ||
| Omission Error | 0.06 | 0.35 | 0.35 | 0.60 | Kappa | Omission Error | 0.21 | 0.35 | 0.08 | 0.56 | Kappa | ||
| 2008 | Forest | Shrub | Grass | Total | Commission Error | 2012 | Forest | Shrub | Grass | Total | Commission Error | ||
| Forest | 49 | 24 | 0 | 73 | 0.33 | Forest | 35 | 13 | 0 | 48 | 0.27 | ||
| Shrub | 3 | 49 | 4 | 56 | 0.13 | Shrub | 1 | 44 | 1 | 46 | 0.04 | ||
| Grass | 0 | 1 | 17 | 18 | 0.06 | Grass | 0 | 0 | 50 | 50 | 0.00 | ||
| Total | 52 | 74 | 21 | 0.78 | Overall | Total | 36 | 57 | 51 | 0.90 | Overall | ||
| Omission Error | 0.06 | 0.34 | 0.19 | 0.65 | Kappa | Omission Error | 0.03 | 0.23 | 0.02 | 0.84 | Kappa | ||

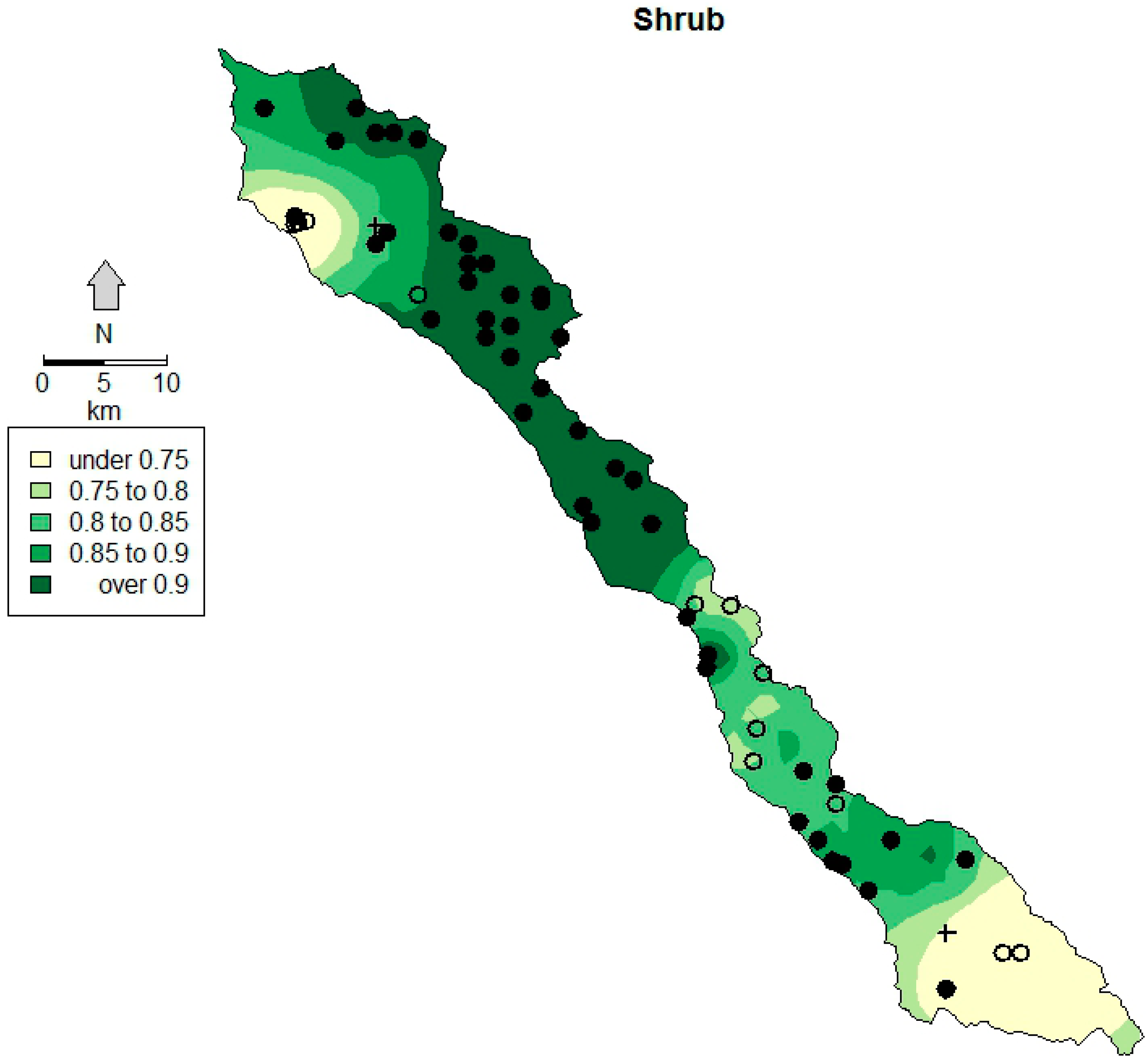
| Year | Class | Min | 1st Q | Median | Mean | 3rd Q | Max | IQR |
|---|---|---|---|---|---|---|---|---|
| 2012 | Forest | 0.84 | 0.88 | 0.91 | 0.91 | 0.93 | 1.00 | 0.045 |
| Shrub | 0.60 | 0.85 | 0.90 | 0.89 | 0.93 | 1.00 | 0.082 | |
| Grass | 0.91 | 0.99 | 1.00 | 0.99 | 1.00 | 1.00 | 0.008 |
4. Discussion
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Lambin, E.F.; Turner, B.L.; Geist, H.J.; Agbola, S.B.; Angelsen, A.; Bruce, J.W.; Coomes, O.T.; Dirzo, R.; Fischer, G.; Folke, C.; et al. The causes of land-use and land-cover change: Moving beyond the myths. Glob. Environ. Chang. 2001, 11, 261–269. [Google Scholar]
- Turner, M. Landscape ecology: The effect of pattern on process. Annu. Rev. Ecol. Syst. 1989, 20, 171–197. [Google Scholar]
- Turner, M.; Dale, V. Comparing large, infrequent disturbances: What have we learned? Ecosystems 1998, 1, 493–496. [Google Scholar]
- Dale, V.H.; Joyce, L.A.; Mcnulty, S.; Neilson, R.P.; Ayres, M.P.; Flannigan, M.D.; Hanson, P.J.; Irland, L.C.; Lugo, A.E.; Peterson, C.J.; et al. Climate change and forest disturbances. Bioscience 2001, 51, 723–734. [Google Scholar]
- Epting, J.; Verbyla, D.; Sorbel, B. Evaluation of remotely sensed indices for assessing burn severity in Interior Alaska using Landsat TM and ETM+. Remote Sens. Environ. 2005, 96, 328–339. [Google Scholar]
- Patterson, M.; Yool, S. Mapping fire-induced vegetation mortality using Landsat Thematic Mapper data: A comparison of linear transformation techniques. Remote Sens. Environ. 1998, 65, 132–142. [Google Scholar]
- Robichaud, P.; Beyers, J.; Neary, D. Evaluating the Effectiveness of Postfire Rehabilitation Treatments; U.S. Department of Agriculture: Washington, DC, USA, 2000; p. 89. [Google Scholar]
- Sleeter, B.M.; Wilson, T.S.; Soulard, C.E.; Liu, J. Estimation of late Twentieth Century land-cover change in California. Environ. Monit. Assess. 2011, 173, 251–266. [Google Scholar]
- Davis, F.W.; Borchert, M.I. Central coast bioregion. In Fire in Califorina’s Ecosystems; Sugihara, N.G., Wagtendonk, J.W., Shaffer, K.E., Fites-Kaufman, J., Thode, A.E., Eds.; University of California Press: Oakland, CA, USA, 2006; p. 596. [Google Scholar]
- Goodridge, B.M.; Melack, J.M. Land use control of stream nitrate concentrations in mountainous coastal California watersheds. J. Geophys. Res. Biogeosci. 2012, 117, 1–17. [Google Scholar]
- Bowen, L.; Miles, A.; Kolden, C.; Saarinen, J.; Murray, M.; Tinker, T. Effects of wildfire on sea otter (Enhydra lutris) immune function. Mar. Mammal Sci. 2014. [Google Scholar] [CrossRef]
- Venn-Watson, S.; Smith, C.R.; Jensen, E.D.; Rowles, T. Assessing the potential health impacts of the 2003 and 2007 firestorms on bottlenose dolphins (Trusiops trucatus) in San Diego. Inhal. Toxicol. 2013, 29, 481–491. [Google Scholar]
- U.S. Fish & Wildlife Service Species Profile: Southern Sea Otter. Available online: http://ecos.fws.gov/speciesProfile/profile/speciesProfile.action?spcode=A0A7 (accessed on 11 March 2014).
- Bodkin, J.; Ballachey, B.; Dean, T.; Fukuyama, A.; Jewett, S.; McDonald, L.; Monson, D.; O’Clari, C.; VanBlaricom, G. Sea otter population status and the process of recovery from the 1989 “Exxon Valdez”oil spill. Mar. Ecol. Prog. Ser. 2002, 241, 237–253. [Google Scholar]
- Johnson, C.K.; Tinker, M.T.; Estes, J.A.; Conrad, P.A.; Staedler, M.; Miller, M.A.; Jessup, D.A.; Mazet, J.A.K. Prey choice and habitat use drive sea otter pathogen exposure in a resource-limited coastal system. Proc. Natl. Acad. Sci. USA 2009, 106, 2242–2247. [Google Scholar]
- Conrad, P.A.; Miller, M.A.; Kreuder, C.; James, E.R.; Mazet, J.; Dabritz, H.; Jessup, D.A.; Gulland, F.; Grigg, M.E. Transmission of Toxoplasma: Clues from the study of sea otters as sentinels of Toxoplasma gondii flow into the marine environment. Int. J. Parasitol. 2005, 35, 1155–1168. [Google Scholar]
- Miller, M.A.; Kudela, R.M.; Mekebri, A.; Crane, D.; Oates, S.C.; Tinker, M.T.; Staedler, M.; Miller, W.A.; Toy-Choutka, S.; Dominik, C.; et al. Evidence for a novel marine harmful algal bloom: Cyanotoxin (microcystin) transfer from land to sea otters. PLoS One 2010, 5. [Google Scholar] [CrossRef]
- Kolden, C.A.; Abatzoglou, J.T. wildfire consumption and interannual impacts by land cover in Alaskan boreal forest. Fire Ecol. 2012, 7, 98–114. [Google Scholar]
- Eidenshink, J.; Schwind, B.; Brewer, K.; Zhu, Z.; Quayle, B.; Howard, S.; Falls, S. A project for monitoring trends in burn severity. Fire Ecol. 2007, 3, 3–21. [Google Scholar]
- Brewer, C.K.; Winne, J.C.; Redmond, R.L.; Opitz, D.W.; Mangrich, M.V. Classifying and mapping wildfire severity: A comparison of methods. Photogramm. Eng. Remote Sens. 2005, 71, 1311–1320. [Google Scholar]
- Clark, J.; Parsons, A.; Zajkowski, T.; Lannom, K. Remote Sensing Imagery Support for Burned Area Emergency Response Teams on 2003 Southern California Wildfires; Remote Sensing Applications Center: Salt Lake City, UT, USA, 2003; p. 22. [Google Scholar]
- Kennedy, R.E.; Yang, Z.; Cohen, W.B. Detecting trends in forest disturbance and recovery using yearly Landsat time series: 1. LandTrendr—Temporal segmentation algorithms. Remote Sens. Environ. 2010, 114, 2897–2910. [Google Scholar]
- Cohen, W.B.; Yang, Z.; Kennedy, R. Detecting trends in forest disturbance and recovery using yearly Landsat time series: 2. TimeSync—Tools for calibration and validation. Remote Sens. Environ. 2010, 114, 2911–2924. [Google Scholar]
- Lu, D.; Weng, Q. A survey of image classification methods and techniques for improving classification performance. Int. J. Remote Sens. 2007, 28, 823–870. [Google Scholar]
- Breiman, L.; Freedman, J.; Olshen, R.; Stone, C. Classification and Regression Trees; Wadsworth: Belmont, CA, USA, 1984. [Google Scholar]
- Friedl, M.; Brodley, C. Decision tree classification of land cover from remotely sensed data. Remote Sens. Environ. 1997, 61, 399–409. [Google Scholar]
- Zambon, M.; Lawrence, R.; Bunn, A.; Powell, S. Effect of alternative splitting rules on image processing using classification tree analysis. Photogramm. Eng. Remote Sens. 2006, 72, 25–30. [Google Scholar]
- Rogan, J.; Miller, J.; Stow, D.; Franklin, J. Land-cover change monitoring with classification trees using Landsat TM and ancillary data. Photogramm. Eng. Remote Sens. 2003, 69, 793–804. [Google Scholar]
- Hubert-Moy, L.; Cotonnec, A.; Le Du, L. A comparison of parametric classification procedures of remotely sensed data applied on different landscape units. Remote Sens. Environ. 2001, 75, 174–187. [Google Scholar]
- Hansen, M.C.; DeFries, R.S.; Townshend, J.R.; Sohlberg, R. Global land cover classification at 1 km spatial resolution using a classification tree approach. Int. J. Remote Sens. 2000, 21, 1331–1364. [Google Scholar]
- Yang, X.; Lo, C.P. Using a time series of satellite imagery to detect land use and land cover changes in the Atlanta, Georgia metropolitan area. Int. J. Remote Sens. 2002, 23, 1775–1798. [Google Scholar]
- Lentile, L.B.; Holden, Z.A.; Smith, A.M.S.; Falkowski, M.J.; Morgan, P.; Lewis, S.A.; Gessler, P.E.; Benson, N.C. Remote sensing techniques to assess active fire characteristics and post-fire effects. Int. J. Wildland Fire 2006, 15, 319–345. [Google Scholar]
- Homer, C.; Huang, C.; Yang, L.; Wylie, B.; Coan, M. Development of a 2001 National Landcover Database for the United States. Photogramm. Eng. Remote Sens. 2004, 70, 829–840. [Google Scholar]
- Morrison, K.M.; Kolden, C.A. Impacts of wildfire on coastal watersheds and the nearshore environment in Big Sur, California. J. Env. Manag. 2014. under review. [Google Scholar]
- Davis, F.W.; Borchert, M.; Meentemeyer, R.K.; Flint, A.; Rizzo, D.M. Pre-impact forest composition and ongoing tree mortality associated with sudden oak death in the Big Sur region; California. For. Ecol. Manag. 2010, 259, 2342–2354. [Google Scholar]
- Myers, N.; Mittermeier, R.A.; Mittermeier, C.G.; da Fonseca, G.A.; Kent, J. Biodiversity hotspots for conservation priorities. Nature 2000, 403, 853–858. [Google Scholar]
- Masek, J.; Vermote, E. A Landsat surface reflectance dataset for North America, 1990–2000. IEEE Geosci. Remote Sens. Lett. 2006, 3, 68–72. [Google Scholar]
- Chander, G.; Markham, B.L.; Helder, D.L. Summary of current radiometric calibration coefficients for Landsat MSS, TM, ETM+, and EO-1 ALI sensors. Remote Sens. Environ. 2009, 113, 893–903. [Google Scholar]
- Tucker, C.J. Red and photographic infrared linear combinations for monitoring vegetation. Remote Sens. Environ. 1979, 8, 127–150. [Google Scholar]
- Rouse, J.W.; Haas, J.A.; Schell, J.A.; Deering, D.W.; Harlan, J.C. Monitoring the Vernal Advancement of Retrogradation of Natural Vegetation; NASA Goddard Space Flight Center: Greenbelt, MD, USA, 1974; p. 371. [Google Scholar]
- Key, C.H.; Benson, N.C. Landscape Assessment (LA) Sampling and Analysis Methods; USDA Forest Service Gen. Technical Report RMRS-GTR-164-CD; U.S. Department of Agriculture: Washington, DC, USA, 2006; p. 55. [Google Scholar]
- Jensen, J.R. Biophysical remote sensing. Ann. Assoc. Am. Geogr. 1983, 73, 111–132. [Google Scholar]
- Jensen, J.R. Remote Sensing of the Environment An Earth Resource Perspective, 2nd ed.; Pearson Prentice Hall: Upper Saddle River, NJ, USA, 2007; p. 592. [Google Scholar]
- Smith, A.M.S.; Wooster, M.J.; Drake, N.A.; Dipotso, F.M.; Falkowski, M.J.; Hudak, A.T. Testing the potential of multi-spectral remote sensing for retrospectively estimating fire severity in African Savannahs. Remote Sens. Environ. 2005, 97, 92–115. [Google Scholar]
- Crist, E.P. A TM tasseled cap equivalent transformation for reflectance factor data. Remote Sens. Environ. 1985, 306, 301–306. [Google Scholar]
- Ghimire, B.; Rogan, J.; Miller, J. Contextual land-cover classification: Incorporating spatial dependence in land-cover classification models using random forests and the Getis statistic. Remote Sens. Lett. 2010, 1, 45–54. [Google Scholar]
- Atkinson, P.; Lewis, P. Geostatistical classification for remote sensing: An introduction. Comput. Geosci. 2000, 26, 361–371. [Google Scholar]
- Wulder, M.; Boots, B. Local spatial autocorrelation characteristics of remotely sensed imagery assessed with the Getis statistic. Int. J. Remote Sens. 1998, 19, 2223–2231. [Google Scholar]
- Jensen, J.R. Introductory Digital Image Processing, 3rd ed.; Prentice Hall: Upper Saddle River, NJ, USA, 2005; p. 526. [Google Scholar]
- Franklin, J.; McCullough, P.; Gray, C. Terrain variables used for predictive mapping of vegetation communities in southern California. In Terrain Analysis: Principles and Applications; Wilson, J.P., Gallant, J.C., Eds.; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2000; pp. 331–353. [Google Scholar]
- Pal, M.; Mather, P.M. An assessment of the effectiveness of decision tree methods for land cover classification. Remote Sens. Envron. 2003, 86, 554–565. [Google Scholar]
- Congalton, R.G.R. A review of assessing the accuracy of classifications of remotely sensed data. Remote Sens. Environ. 1991, 37, 35–46. [Google Scholar]
- Comber, A.; Fisher, P.; Brunsdon, C.; Khmag, A. Spatial analysis of remote sensing image classification accuracy. Remote Sens. Environ. 2012, 127, 237–246. [Google Scholar]
- Fotheringham, S.A.; Brundsdon, C.; Charlton, M. Quantitative Geography; SAGE: London, UK, 2000; p. 270. [Google Scholar]
- Greenlee, J.; Langenheim, J. Historic fire regimes and their relation to vegetation patterns in the Monterey Bay area of California. Am. Midl. Nat. 1990, 124, 239–253. [Google Scholar]
- Wulder, M.; Franklin, S.; White, J.; Linke, J.; Magnussen, S. An accuracy assessment framework for large-area land cover classification products derived from medium-resolution satellite data. Int. J. Remote Sens. 2006, 27, 663–683. [Google Scholar]
- Foody, G.M. Local characterization of thematic classification accuracy through spatially constrained confusion matrices. Int. J. Remote Sens. 2005, 26, 1217–1228. [Google Scholar]
- Comber, A. Geographically weighted methods for estimating local surfaces of overall, user and producer accuracies. Remote Sens. Lett. 2013, 4, 373–380. [Google Scholar]
- Kyriakidis, P.; Dungan, J. A geostatistical approach for mapping thematic classification accuracy and evaluating the impact of inaccurate spatial data on ecological model predictions. Environ. Ecol. Stat. 2001, 8, 311–330. [Google Scholar]
- California Department of Water Resources (CDWR). California’s Drought of 2007–2009: An Overview; CDWR: Sacramento, CA, USA, 2010; p. 128. [Google Scholar]
© 2014 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Morrison, K.D.; Kolden, C.A. Development of a Historical Multi-Year Land Cover Classification Incorporating Wildfire Effects. Land 2014, 3, 1214-1231. https://doi.org/10.3390/land3041214
Morrison KD, Kolden CA. Development of a Historical Multi-Year Land Cover Classification Incorporating Wildfire Effects. Land. 2014; 3(4):1214-1231. https://doi.org/10.3390/land3041214
Chicago/Turabian StyleMorrison, Katherine D., and Crystal A. Kolden. 2014. "Development of a Historical Multi-Year Land Cover Classification Incorporating Wildfire Effects" Land 3, no. 4: 1214-1231. https://doi.org/10.3390/land3041214
APA StyleMorrison, K. D., & Kolden, C. A. (2014). Development of a Historical Multi-Year Land Cover Classification Incorporating Wildfire Effects. Land, 3(4), 1214-1231. https://doi.org/10.3390/land3041214