

Landslide Susceptibility Mapping in Xinjiang: Identifying Critical Thresholds and Interaction Effects Among Disaster-Causing Factors


Abstract
1. Introduction
2. Materials and Methods
2.1. Study Area
2.2. Data Collection and Preprocessing
2.2.1. Acquisition and Processing of Landslide Points
2.2.2. Acquisition and Processing of Possible Landslide Conditioning Factors (LCFs)
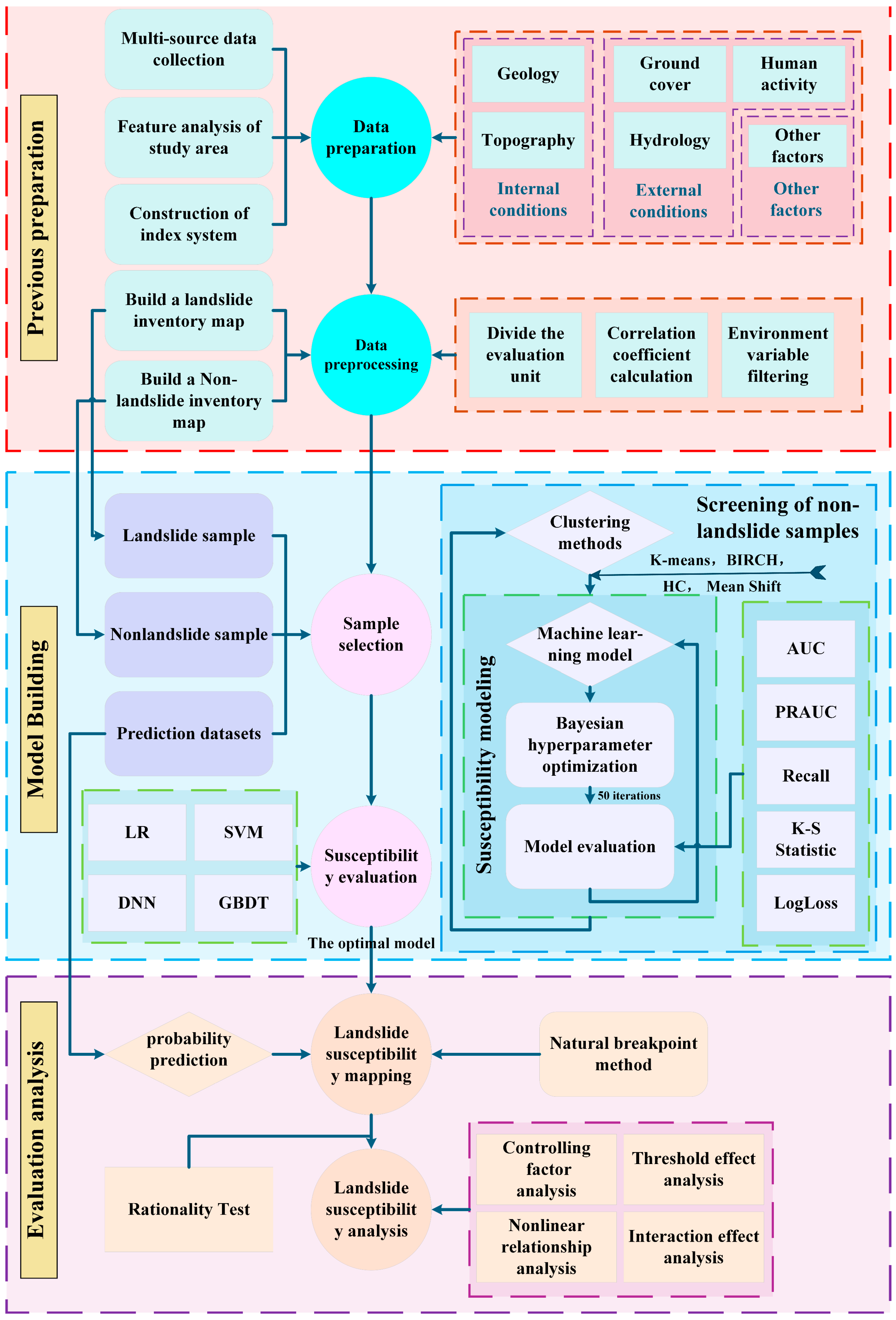
2.3. Technical Workflow of LSM
2.4. Research Methods
2.4.1. Screening of Non-Landslide Samples
2.4.2. Hyperparameter Optimization Algorithm
2.4.3. Landslide Classification Model
2.4.4. Model Evaluation Method
3. Results
3.1. Screening of LCFs
3.2. Model Evaluation and Testing
3.2.1. Model Accuracy Test
3.2.2. Screening Method Test
3.2.3. Rationality Test
3.3. Main Control Factor Analysis
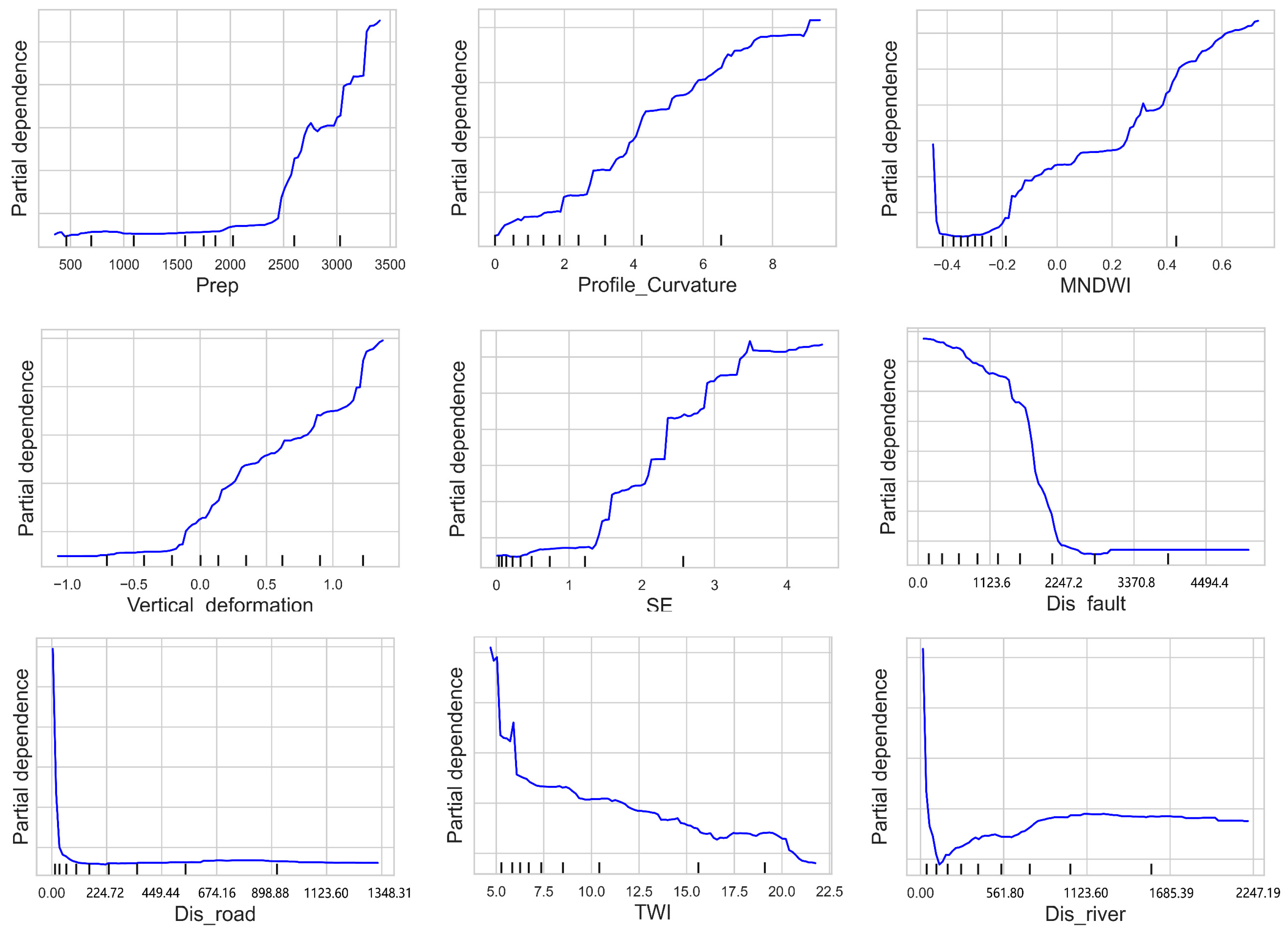
3.4. Nonlinear Relation Analysis
3.5. Interaction Effect Analysis
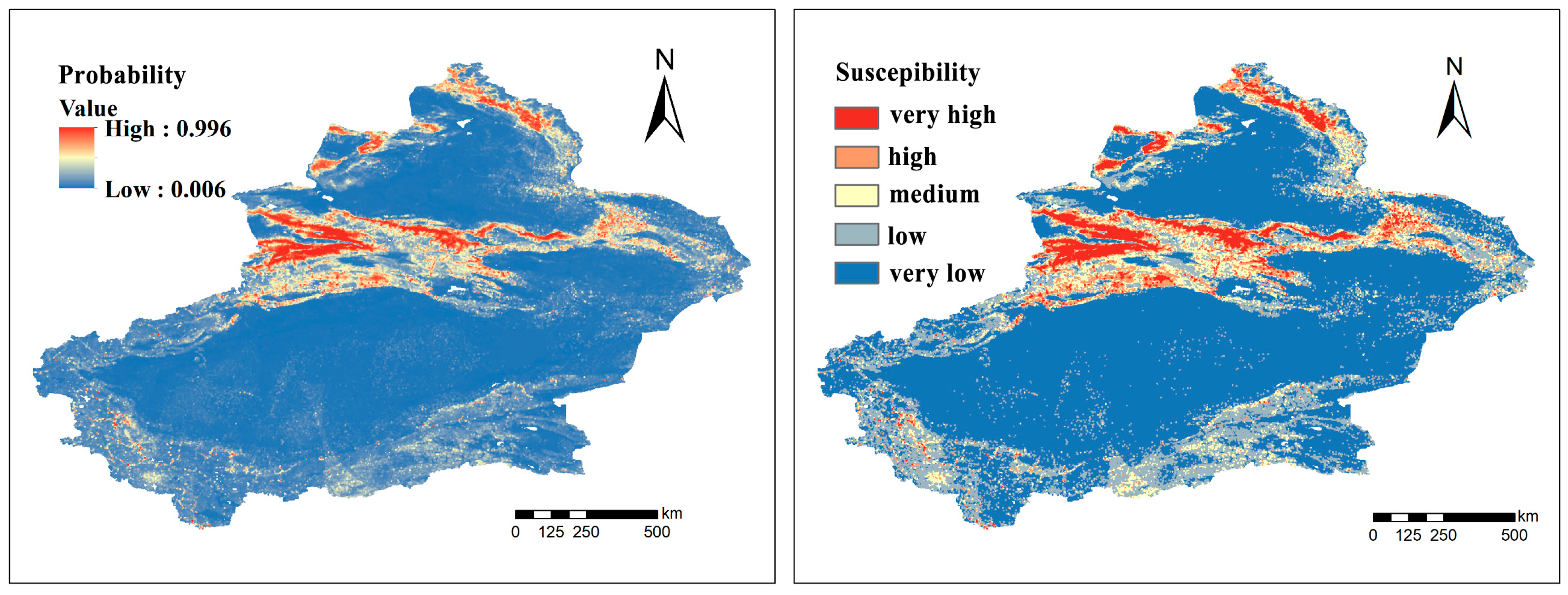
3.6. Spatial Prediction of Landslide Susceptibility
4. Discussion
4.1. Effectiveness of the GBDT
4.2. Threshold and Interaction Effects of LCFs
4.3. Limitations
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Boubazine, L.; Boumezbeur, A.; Hadji, R.; Kessasra, F. Slope failure characterization: A joint multi-geophysical and geotechnical analysis, case study of Babor Mountains range, NE Algeria. Min. Miner. Depos. 2022, 16, 65–70. [Google Scholar] [CrossRef]
- Feizizadeh, B.; Roodposhti, M.S.; Jankowski, P.; Blaschke, T. A GIS-based extended fuzzy multi-criteria evaluation for landslide susceptibility mapping. Comput. Geosci. 2014, 73, 208–221. [Google Scholar] [CrossRef]
- Froude, M.J.; Petley, D.N. Global fatal landslide occurrence from 2004 to 2016. Nat. Hazards Earth Syst. Sci. 2018, 18, 2161–2181. [Google Scholar] [CrossRef]
- Li, W.; Zhu, J.; Fu, L.; Zhu, Q.; Guo, Y.; Gong, Y. Arapid 3D reproduction system ofdam-break floods constrained by post-disaster information. Environ. Modell. Softw. 2021, 139, 104994. [Google Scholar] [CrossRef]
- Li, W.; Zhu, J.; Fu, L.; Zhu, Q.; Xie, Y.; Hu, Y. An augmented representation method of debris flow scenes to improve public perception. Int. J. Geogr. Inf. Sci. 2021, 35, 1521–1544. [Google Scholar] [CrossRef]
- Wang, Z.; Xu, S.; Liu, J.; Wang, Y.; Ma, X.; Jiang, T.; He, X.; Han, Z. A Combination of Deep Autoencoder and Multi-Scale Residual Network for Landslide Susceptibility Evaluation. Remote Sens. 2023, 15, 653. [Google Scholar] [CrossRef]
- Shichuan, L.; Hua, Q.; Dong, L.; Qiang, H. Distribution characteristics and main controlling factors of geohazards in Ili Valley. Arid Land Geogr. 2023, 46, 880–888. [Google Scholar]
- Borrelli, L.; Ciurleo, M.; Gulla, G. Shallow landslide susceptibility assessment in granitic rocks using GIS-based statistical methods: The contribution of the weathering grade map. Landslides 2018, 15, 1127–1142. [Google Scholar] [CrossRef]
- Ciampalini, A.; Raspini, F.; Lagomarsino, D.; Catani, F.; Casagli, N. Landslide susceptibility map refinement using PSInSAR data. Remote Sens. Environ. 2016, 184, 302–315. [Google Scholar] [CrossRef]
- Wu, W.; Zhang, Q.; Singh, V.P.; Wang, G.; Zhao, J.; Shen, Z.; Sun, S. A Data-Driven Model on Google Earth Engine for Landslide Susceptibility Assessment in the Hengduan Mountains, the Qinghai-Tibetan Plateau. Remote Sens. 2022, 14, 4662. [Google Scholar] [CrossRef]
- Bhandary, N.P.; Dahal, R.K.; Timilsina, M.; Yatabe, R. Rainfall event-based landslide susceptibility zonation mapping. Nat. Hazards 2013, 69, 365–388. [Google Scholar] [CrossRef]
- Hong, H.; Naghibi, S.A.; Pourghasemi, H.R.; Pradhan, B. GIS-based landslide spatial modeling in Ganzhou City, China. Arab. J. Geosci. 2016, 9, 112. [Google Scholar] [CrossRef]
- Regmi, N.R.; Giardino, J.R.; Vitek, J.D. Assessing susceptibility to landslides: Using models to understand observed changes in slopes. Geomorphology 2010, 122, 25–38. [Google Scholar] [CrossRef]
- Van Westen, C.J.; Castellanos, E.; Kuriakose, S.L. Spatial data for landslide susceptibility, hazard, and vulnerability assessment: An overview. Eng. Geol. 2008, 102, 112–131. [Google Scholar] [CrossRef]
- Akgun, A.; Kıncal, C.; Pradhan, B. Application of remote sensing data and GIS for landslide risk assessment as an environmental threat to Izmir city (west Turkey). Environ. Monit. Assess. 2012, 184, 5453–5470. [Google Scholar] [CrossRef]
- Huang, J.; Zeng, X.; Ding, L.; Yin, Y.; Li, Y. Landslide Susceptibility Evaluation Using Different Slope Units Based on BP Neural Network. Comput. Intell. Neurosci. 2022, 2022, 9923775. [Google Scholar] [CrossRef]
- Chen, W.; Sun, Z.; Han, J. Landslide Susceptibility Modeling Using Integrated Ensemble Weights of Evidence with Logistic Regression and Random Forest Models. Appl. Sci. 2019, 9, 171. [Google Scholar] [CrossRef]
- Hong, H.; Pourghasemi, H.R.; Pourtaghi, Z.S. Landslide susceptibility assessment in Lianhua County (China): A comparison between a random forest data mining technique and bivariate and multivariate statistical models. Geomorphology 2016, 259, 105–118. [Google Scholar] [CrossRef]
- Trigila, A.; Iadanza, C.; Esposito, C.; Scarascia-Mugnozza, G. Comparison of Logistic Regression and Random Forests techniques for shallow landslide susceptibility assessment in Giampilieri (NE Sicily, Italy). Geomorphology 2015, 249, 119–136. [Google Scholar] [CrossRef]
- Zhou, C.; Yin, K.; Cao, Y.; Ahmed, B.; Li, Y.; Catani, F.; Pourghasemi, H.R. Landslide susceptibility modeling applying machine learning methods: A case study from Longju in the Three Gorges Reservoir area, China. Comput. Geosci. 2018, 112, 23–37. [Google Scholar] [CrossRef]
- Wang, Y.; Fang, Z.; Niu, R.; Peng, L. Landslide susceptibility analysis based on deep learning. J. Geo-Inf. Sci. 2021, 23, 2244–2260. [Google Scholar]
- Wu, R.; Hu, X.; Mei, H.; He, J.; Yang, J. Spatial Susceptibility Assessment of Landslides Basedon Random Forest: A Case Study from Hubei Sectionin the Three Gorges Reservoir Area. Earth Sci. 2021, 46, 321–330. [Google Scholar]
- Abbas, F.; Zhang, F.; Abbas, F.; Ismail, M.; Iqbal, J.; Hussain, D.; Khan, G.; Alrefaei, A.F.; Albeshr, M.F. Landslide Susceptibility Mapping: Analysis of Different Feature Selection Techniques with Artificial Neural Network Tuned by Bayesian and Metaheuristic Algorithms. Remote Sens. 2023, 15, 4330. [Google Scholar] [CrossRef]
- Zhao, L.; Wu, X.; Niu, R.; Wang, Y.; Zhang, K. Using the rotation and random forest models of ensemble learning to predict landslide susceptibility. Geomat. Nat. Hazards Risk 2020, 11, 1542–1564. [Google Scholar] [CrossRef]
- Demczuk, P.; Zydroń, T.; Siłuch, M. Rainfall thresholds for the occurrence of shallow landslides determined for slopes in the Nowy Wiśnicz Foothills (Polish Flysch Carpathians). Geol. Q. 2019, 63, 822–838. [Google Scholar] [CrossRef]
- Huang, F.; Xiong, H.; Yao, C.; Catani, F.; Zhou, C.; Huang, J. Uncertainties of landslide susceptibility prediction considering different landslide types. J. Rock Mech. Geotech. Eng. 2023, 15, 2954–2972. [Google Scholar] [CrossRef]
- Shu, H.; He, J.; Zhang, F.; Zhang, M.; Ma, J.; Chen, Y.; Yang, S. Construction of landslide warning by combining rainfall threshold and landslide susceptibility in the gully region of the Loess Plateau: A case of Lanzhou City, China. J. Hydrol. 2024, 645, 132148. [Google Scholar] [CrossRef]
- Rohan, T.; Shelef, E.; Bain, D.; Ramsey, M.S.; Werne, J.; Iannacchione, A.Z. Enhancing Landslide Susceptibility Analysis through Citizen Science, Geospatial Analysis, and Precipitation Thresholds in Urbanizing Environments. Doctoral Dissertation, University of Pittsburgh, Pittsburgh, PA, USA, 2023. [Google Scholar]
- Avci, P.; Ercanoglu, M. Utilization of streamflow rates for determination of precipitation thresholds for landslides in a data-scarce region (Eastern Bartın, NW Türkiye). Environ. Earth Sci. 2024, 83, 192. [Google Scholar] [CrossRef]
- Li, Y.; Ming, D.; Zhang, L.; Niu, Y.; Chen, Y. Seismic Landslide Susceptibility Assessment Using Newmark Displacement Based on a Dual-Channel Convolutional Neural Network. Remote Sens. 2024, 16, 566. [Google Scholar] [CrossRef]
- Jinrui, Z.; Yang, W.; Xiao, F.; Yuanyao, L.; Bijing, J.; Chao, Z.; Xin, Z.; Yang, D. Analysis of spatial-temporal variations in landslide susceptibility assessment considering surface deformation and land use dynamics. Bull. Geol. Sci. Technol. 2024, 43, 184–195. [Google Scholar]
- Abbaszadeh Shahri, A.; Spross, J.; Johansson, F.; Larsson, S. Landslide susceptibility hazard map in southwest Sweden using artificial neural network. CATENA 2019, 183, 104225. [Google Scholar] [CrossRef]
- Wu, Z.; Chen, Y.; Zhu, Y.; Feng, X.; Ou, J.; Li, G.; Tong, Z.; Yan, Q. Mapping Soil Organic Carbon in Floodplain Farmland: Implications of Effective Range of Environmental Variables. Land 2023, 12, 1198. [Google Scholar] [CrossRef]
- Zhang, Z.; Zhang, T.; Yu, X.; Lv, Q.; Lai, R.; Jia, J.; Liu, X. Zonation of Disaster Environments of Collapse, Landslide and Debris Flow Geologic Hazards and Their Formation Mechanisms in Xinjiang. J. Eng. Geol. 2023, 31, 1129–1144. [Google Scholar] [CrossRef]
- Jiang, Y.; Wang, W.; Zou, L.; Cao, Y. Regional landslide susceptibility assessment based on improved semi-supervised clustering and deep learning. Acta Geotech. 2024, 19, 509–529. [Google Scholar] [CrossRef]
- Guo, Z.; Shi, Y.; Huang, F.; Fan, X.; Huang, J. Landslide susceptibility zonation method based on C5.0 decision tree and K-means cluster algorithms to improve the efficiency of risk management. Geosci. Front. 2021, 12, 101249. [Google Scholar] [CrossRef]
- Wu, Z.; Zhao, S. A Study of Enhanced Index based Built-up Index Based on Landsat TM Imagery. Remote Sens. Land Resour. 2012, 24, 50–55. [Google Scholar] [CrossRef]
- Xu, H. A Study on Information Extraction of Water Body with the Modified Norm a lized Difference Water Index (MNDWI). J. Remote Sens. 2005, 5, 589–595. [Google Scholar] [CrossRef]
- Li, J.; He, H.; Zeng, Q.; Chen, L.; Sun, R. A Chinese soil conservation dataset preventing soil water erosion from 1992 to 2019. Sci. Data 2023, 10, 319. [Google Scholar] [CrossRef]
- Zhou, P.; Deng, H.; Jiang, W.; Xue, D.; Wu, X.; Zhuo, W. Landslide Susceptibility Evaluation Based on Information Value Modeland Machine Learning Method: A Case Study of Lixian County, Sichuan Province. Sci. Geogr. Sin. 2022, 42, 1665–1675. [Google Scholar] [CrossRef]
- Chen, W.; Xie, X.; Wang, J.; Pradhan, B.; Hong, H.; Bui, D.T.; Duan, Z.; Ma, J. A comparative study of logistic model tree, random forest, and classification and regression tree models for spatial prediction of landslide susceptibility. CATENA 2017, 151, 147–160. [Google Scholar] [CrossRef]
- Tien Bui, D.; Tuan, T.A.; Hoang, N.-D.; Thanh, N.Q.; Nguyen, D.B.; Van Liem, N.; Pradhan, B. Spatial prediction of rainfall-induced landslides for the Lao Cai area (Vietnam) using a hybrid intelligent approach of least squares support vector machines inference model and artificial bee colony optimization. Landslides 2017, 14, 447–458. [Google Scholar] [CrossRef]
- Malmgren-Hansen, D.; Sohnesen, T.; Fisker, P.; Baez, J. Sentinel-1 Change Detection Analysis for Cyclone Damage Assessment in Urban Environments. Remote Sens. 2020, 12, 2409. [Google Scholar] [CrossRef]
- Iotti, M.; Bonazzi, G. Tomato Processing Firms’ Management: A Comparative Application of Economic And Financial Analyses. Am. J. Appl. Sci. 2014, 11, 1135–1151. [Google Scholar] [CrossRef]
- Mwakapesa, D.S.; Lan, X.; Mao, Y. Landslide susceptibility assessment using deep learning considering unbalanced samples distribution. Heliyon 2024, 10, e30107. [Google Scholar] [CrossRef]
- Huang, F.; Yin, K.; Huang, J.; Gui, L.; Wang, P. Landslide susceptibility mapping based on self-organizing-map network and extreme learning machine. Eng. Geol. 2017, 223, 11–22. [Google Scholar] [CrossRef]
- Liu, C. Optimization of negative sample selection for landslide susceptibility mapping based on machine learning using K-means-KNN algorithm. Earth Sci. Inform. 2023, 16, 4131–4152. [Google Scholar] [CrossRef]
- Czarnecki, W.M.; Podlewska, S.; Bojarski, A.J. Robust optimization of SVM hyperparameters in the classification of bioactive compounds. J. Cheminform. 2015, 7, 38. [Google Scholar] [CrossRef]
- Li, A.; La, J.; May, S.B.; Guffey, D.; da Costa, W.L.; Amos, C.I.; Bandyo, R.; Milner, E.M.; Kurian, K.M.; Chen, D.C.R.; et al. Derivation and Validation of a Clinical Risk Assessment Model for Cancer-Associated Thrombosis in Two Unique US Health Care Systems. J. Clin. Oncol. 2023, 41, 2926–2938. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2002, 29, 1189–1232. [Google Scholar] [CrossRef]
- Luque, A.; Carrasco, A.; Martín, A.; De Las Heras, A. The impact of class imbalance in classification performance metrics based on the binary confusion matrix. Pattern Recognit. 2019, 91, 216–231. [Google Scholar] [CrossRef]
- Gneiting, T.; Vogel, P. Receiver operating characteristic (ROC) curves: Equivalences, beta model, and minimum distance estimation. Mach. Learn. 2021, 111, 2147–2159. [Google Scholar] [CrossRef]
- Gorsevski, P.V.; Gessler, P.E.; Foltz, R.B.; Elliot, W.J. Spatial Prediction of Landslide Hazard Using Logistic Regression and ROC Analysis. Trans. GIS 2006, 10, 395–415. [Google Scholar] [CrossRef]
- Riegel, R.P.; Alves, D.D.; Schmidt, B.C.; De Oliveira, G.G.; Haetinger, C.; Osório, D.M.M.; Rodrigues, M.A.S.; De Quevedo, D.M. Assessment of susceptibility to landslides through geographic information systems and the logistic regression model. Nat. Hazards 2020, 103, 497–511. [Google Scholar] [CrossRef]
- Changrun, W.; Yuanmei, J.; Jinliang, W.; Hanhua, X.; Hua, Z.; Qiue, X. Frequency ratio and logistic regression models based coupling analysis for susceptibility of landslide in Shuangbai County. J. Nat. Disasters 2021, 30, 213–224. [Google Scholar]
- Reichenbach, P.; Rossi, M.; Malamud, B.D.; Mihir, M.; Guzzetti, F. A review of statistically-based landslide susceptibility models. Earth-Sci. Rev. 2018, 180, 60–91. [Google Scholar] [CrossRef]
- Dickson, M.E.; Perry, G.L.W. Identifying the controls on coastal cliff landslides using machine-learning approaches. Environ. Model. Softw. 2016, 76, 117–127. [Google Scholar] [CrossRef]
- Fang, R.; Liu, Y.; Huang, Z. A review of the methods of regional landslide hazard assessment based on machine learning. Chin. J. Geol. Hazard Control 2021, 32, 1–8. [Google Scholar] [CrossRef]
- Wang, G.; Guo, N.; Deng, B.; Tian, Y.; Ye, Z.; Xu, Z.; Xu, F.; Gao, Y. Analysis of Landslide Susceptibility and Accuracy in Different Combination Models. Northwestern Geol. 2021, 54, 259–272. [Google Scholar] [CrossRef]
- Yu, X.; Zhang, Z.; Shi, G.; Li, C.; Liu, Y.; Zhu, J.; Chen, W. Evaluation of Geological Hazard Susceptibility Inemincounty, Xinjiang Based on Deterministic Coefficient and Information Coupling Model. J. Eng. Geol. 2023, 31, 1333–1349. [Google Scholar] [CrossRef]
- Hu, Y.; Zizhao, Z.; Lin, S. Evaluation of Landslide Susceptibility in Ili Valley, XinJiang Based on the Coupling of Woe Model and Logistic Regression. J. Eng. Geol. 2023, 31, 1350–1363. [Google Scholar] [CrossRef]
- Li, M.; Jiang, W.; Dong, J.; Jin, S.; Zhang, C.; Niu, R. Evaluation of landslide hazards susceptibility based on machine learning:Taking the Three Gorges Reservoir Area as an Example. South China Geol. 2023, 39, 413–427. [Google Scholar] [CrossRef]
- Liang, L. Application of Small-Sample Machine Learning Method Inevaluation of Landslide Disaster Susceptibility in Xinjiang. J. Eng. Geol. 2023, 31, 1394–1406. [Google Scholar] [CrossRef]
- Chen, K.; Chen, L.; Zhang, Z.; Chang, Y. Susceptibility and risk assessment of geological disasters in Xinjiang based on empirical investigation. J. Eng. Geol. 2023, 31, 1156–1166. [Google Scholar] [CrossRef]
- Nian, T.-K.; Feng, Z.-K.; Yu, P.-C.; Wu, H.-J. Strength behavior of slip-zone soils of landslide subject to the change of water content. Nat. Hazards 2013, 68, 711–721. [Google Scholar] [CrossRef]
- Cui, P.; Guo, J. Evolution Models, Risk Prevention and Control Countermeasures of the Valley Disaster Chain. Adv. Eng. Sci. 2021, 53, 5–18. [Google Scholar] [CrossRef]
- Wen, H.; Ni, S.M.; Wang, Y.T.; Wang, J.G.; Cai, C.F. A Study on Silty Soil Shear Strength and Its Influencing Factors in Different Vegetation Types in Benggang Erosion Area of Southern Jiangxi. Acta Pedofil. Sin. 2022, 59, 1517–1526. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, H.; Huang, L.; Li, H.; Wu, X. The formation mechanism of landslides in typical fault zones and protective countermeasures: A case study of the Nanpeng River fault zone. Front. Earth Sci. 2023, 10, 1092662. [Google Scholar] [CrossRef]
- Sadeghi, S.; Solgi, A.; Tsioras, P.A. Effects of traffic intensity and travel speed on forest soil disturbance at different soil moisture conditions. Int. J. For. Eng. 2022, 33, 146–154. [Google Scholar] [CrossRef]
- Ye, K.; Wang, Z.; Wang, T.; Luo, Y.; Chen, Y.; Zhang, J.; Cai, J. Deformation Monitoring and Analysis of Baige Landslide (China) Based on the Fusion Monitoring of Multi-Orbit Time-Series InSAR Technology. Sensors 2024, 24, 6760. [Google Scholar] [CrossRef]
- Deng, L.; Yuan, H.; Zhang, M.; Chen, J. Research progress on landslide deformation monitoring and early warning technology. J. Tsinghua Univ. (Sci. Technol.) 2023, 63, 849–864. [Google Scholar] [CrossRef]
- Ya, Z.; Wei, H.; Meng, L. Analysis on the Distribution and Drivers of Flash Floods in Yunnan Province. J. Catastrophaol. 2018, 33, 96–100. [Google Scholar]
- Wang, J. Prediction and Risk Analysis of Reservoir Bank Landslide Under the Combined Action of Rainfall and Reservoir Water Level: A Case Study of Xinpu Landslide in Three Gorges Reservoir Area. Master’s Thesis, Changan Unicersity, Xi’an, China, 2021. [Google Scholar]
- Merghadi, A.; Yunus, A.P.; Dou, J.; Whiteley, J.; ThaiPham, B.; Bui, D.T.; Avtar, R.; Abderrahmane, B. Machine learning methods for landslide susceptibility studies: A comparative overview of algorithm performance. Earth-Sci. Rev. 2020, 207, 103225. [Google Scholar] [CrossRef]
- Goetz, J.N.; Brenning, A.; Petschko, H.; Leopold, P. Evaluating machine learning and statistical prediction techniques for landslide susceptibility modeling. Comput. Geosci. 2015, 81, 1–11. [Google Scholar] [CrossRef]
- Probst, P.; Boulesteix, A.-L.; Bischl, B. Tunability: Importance of hyperparameters of machine learning algorithms. J. Mach. Learn. Res. 2019, 20, 1934–1965. [Google Scholar]
- Gyamfi, C.; Ndambuki, J.; Salim, W. A Historical Analysis of Rainfall Trend in the Olifants Basin in South Africa. Earth Sci. Res. 2016, 5, 129. [Google Scholar] [CrossRef]
- Leyva, S.; Cruz-Pérez, N.; Rodríguez-Martín, J.; Miklin, L.; Santamarta, J.C. Rockfall and Rainfall Correlation in the Anaga Nature Reserve in Tenerife (Canary Islands, Spain). Rock Mech. Rock Eng. 2022, 55, 2173–2181. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Condition | Type | LCFs | Data Sources and Links |
|---|---|---|---|
| Internal conditions | Topography | Elevation | Geospatial Data Cloud (https://www.gscloud.cn/, accessed on 25 February 2025) |
| Slope, Profile Curvature, TWI, TRI, Aspect | Digital Elevation Model | ||
| Landforms | Chinese Academy Of Sciences Resource And Environment Science And Data Center (https://www.resdc.cn/, accessed on 25 February 2025) | ||
| Geology | Depth to bedrock | ISRIC World Soil Information (https://www.isric.org/, accessed on 25 February 2025) | |
| Dis_fault | Geoscientific Data Discovery Publishing System (http://dcc.ngac.org.cn/, accessed on 25 February 2025) | ||
| Lithology | USGS Geosciences and Environmental Change Science Center (https://www.usgs.gov/, accessed on 25 February 2025) | ||
| External conditions | Land cover | Landcover | |
| NDBBI, MNDWI, NDVI | Landsat8 Remote sensing imagery | ||
| Hydrology | Prep | PANGAEA Data Publisher (https://doi.pangaea.de/, accessed on 25 February 2025) | |
| Dis_river | OpenStreetMap (https://www.openstreetmap.org/, accessed on 25 February 2025) | ||
| Human activities | Dis_road | ||
| Dis_mine | Global Disaster Data Platform (https://www.gddat.cn/, accessed on 25 February 2025) | ||
| Other factors | Vertical deformation | National Earth System Science Data Center (http://www.geodata.cn, accessed on 25 February 2025) | |
| SE | Zenodo (https://zenodo.org/, accessed on 25 February 2025) |
| Actual Positive Example | Actual Negative Examples | |
|---|---|---|
| Predict positive examples | TP | FP |
| Predict negative examples | FN | TN |
| Model | AUC | Recall | KS Statistic | LogLoss | PRAUC |
|---|---|---|---|---|---|
| LR | 0.802 | 0.242 | 0.626 | 0.394 | 0.724 |
| SVM | 0.842 | 0.158 | 0.756 | 0.385 | 0.848 |
| DNN | 0.807 | 0.167 | 0.746 | 1.243 | 0.847 |
| GBDT | 0.937 | 0.624 | 0.793 | 0.235 | 0.903 |
| Cluster Type | k-Means | HC | BIRCH | Mean_Shift | CG |
|---|---|---|---|---|---|
| AUC | 0.999 | 0.985 | 0.999 | 0.982 | 0.981 |
| AUC_STD | 0.000 | 0.003 | 0.000 | 0.002 | 0.003 |
| Recall | 0.963 | 0.767 | 0.950 | 0.723 | 0.711 |
| Recall_STD | 0.008 | 0.013 | 0.010 | 0.020 | 0.010 |
| KS Statistic | 0.976 | 0.896 | 0.965 | 0.863 | 0.848 |
| KS Statistic_STD | 0.006 | 0.015 | 0.005 | 0.007 | 0.014 |
| LogLoss | 0.031 | 0.112 | 0.037 | 0.139 | 0.143 |
| LogLoss_STD | 0.002 | 0.005 | 0.002 | 0.003 | 0.003 |
| PRAUC | 0.997 | 0.950 | 0.994 | 0.929 | 0.921 |
| PRAUC_STD | 0.002 | 0.007 | 0.001 | 0.006 | 0.011 |
| Susceptibility Level | Sai | Gei | Rei = Gei/Sai |
|---|---|---|---|
| Very low susceptibility I | 63.46% | 0.92% | 0.01 |
| Low susceptibility II | 19.52% | 3.63% | 0.19 |
| Medium susceptibility III | 8.15% | 4.92% | 0.60 |
| High susceptibility IV | 5.01% | 8.85% | 1.77 |
| Very high susceptibility V | 3.85% | 81.68% | 21.22 |
| Variable | Range1 | Range2 | KS-Statistic | p-Value |
|---|---|---|---|---|
| MNDWI | <−0.4 | >−0.4 | 0.141 | 0.000 |
| MNDWI | <−0.2 | >−0.2 | 0.282 | 0.000 |
| Dis_river | <150 | >150 | 0.056 | 0.018 |
| Dis_road | <30 | >30 | 0.072 | 0.008 |
| SE | <1.2 | >1.2 | 0.061 | 0.000 |
| SE | <3.5 | >3.5 | 0.090 | 0.000 |
| Vertical_deformation | <0 | >0 | 0.401 | 0.000 |
| Dis_fault | <3000 | >3000 | 0.326 | 0.000 |
| Prep | <2500 | >2500 | 0.449 | 0.000 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Feng, X.; Wu, Z.; Wu, Z.; Bai, J.; Liu, S.; Yan, Q. Landslide Susceptibility Mapping in Xinjiang: Identifying Critical Thresholds and Interaction Effects Among Disaster-Causing Factors. Land 2025, 14, 555. https://doi.org/10.3390/land14030555
Feng X, Wu Z, Wu Z, Bai J, Liu S, Yan Q. Landslide Susceptibility Mapping in Xinjiang: Identifying Critical Thresholds and Interaction Effects Among Disaster-Causing Factors. Land. 2025; 14(3):555. https://doi.org/10.3390/land14030555
Chicago/Turabian StyleFeng, Xiangyang, Zhaoqi Wu, Zihao Wu, Junping Bai, Shixiang Liu, and Qingwu Yan. 2025. "Landslide Susceptibility Mapping in Xinjiang: Identifying Critical Thresholds and Interaction Effects Among Disaster-Causing Factors" Land 14, no. 3: 555. https://doi.org/10.3390/land14030555
APA StyleFeng, X., Wu, Z., Wu, Z., Bai, J., Liu, S., & Yan, Q. (2025). Landslide Susceptibility Mapping in Xinjiang: Identifying Critical Thresholds and Interaction Effects Among Disaster-Causing Factors. Land, 14(3), 555. https://doi.org/10.3390/land14030555