1. Introduction
Land subsidence (LS) is a global environmental issue caused by natural (e.g., earthquakes) or human-induced processes (e.g., over-exploitation of groundwater, dissolution of calcareous bedrock, extraction of natural gases and minerals) [
1]. These processes can result in soil compaction and reduction in pore water pressure, leading to the gradual sinking of the ground surface and detrimental environmental and economic impacts [
1,
2]. Flooding and increased vulnerability to natural disasters are among the negative environmental consequences of LS [
3,
4], and the adverse impacts of LS on the economy include “lower agricultural productivity, water pollution, infrastructure destruction, and decreased real estate value” [
5].
Some studies have examined LS using numerical and hydraulic modeling [
6]. For example, Luo and Feng [
7] simulated groundwater exploitation and its impact on LS using a finite element model for Cangzhou City, Hebei Province, China, and identified a one-month time lag between groundwater exploitation and LS. Shi et al. [
8] studied the correlation between groundwater level and surface displacement by analyzing the impact of groundwater depression discs in different hydro-stratigraphic units using numerical simulation. To prevent further land subsidence, they concluded that excessive groundwater extraction must be prevented. In addition, several studies have used numerical groundwater models to investigate the relationship between groundwater extraction and aquifer deformation and to generate LS maps [
9,
10,
11].
Numerous studies have demonstrated that machine learning approaches (MLAs) are more accurate than conventional parametric methods [
12,
13]. MLAs incorporate different historical datasets and analyze influential factors (e.g., soil characteristics, permeability) to classify and predict the LS susceptibility of a given area [
2,
3,
4,
5,
6,
7,
8,
9,
10,
11,
12,
13,
14,
15]. Using MLAs to detect LS-prone areas can enhance decision-making processes in water management and land use planning. Understanding the risk of subsidence enables planners to identify the most susceptible spots, allocate resources appropriately, and mitigate any further losses. In addition, these approaches can help identify potential areas of LS, allowing for improved use of targeted monitoring and early warning systems. Hence, several studies have been dedicated to investigating the accuracy and performance of different MLAs in modeling LS. Mohammady et al. [
16] investigated land subsidence susceptibility in Semnan Plain, Iran, using Random Forest (RF). Rahmati et al. [
17] compared the performance of the two models of maximum entropy (MaxEnt) and genetic algorithm rule-set production (GARP) for modeling land subsidence in Kashmar Plain (Iran). They concluded that the GARP model’s performance was better than MaxEnt. Arabaameri et al. [
18] investigated the performance of four single and hybrid MLAs, including MaxEnt, general linear model (GLM), artificial neural network (ANN), and support vector machine (SVM), in Kashan plain (Iran). They highlighted the more accurate modeling abilities of the ANN model. Zhao et al. [
19] combined a new approach to improve decision stump classification (DSC) with different MLAs (e.g., J48 decision tree, alternating decision tree) to map land subsidence susceptibility. They stated that their proposed approach enhanced the accuracy of LS prediction significantly. In another study, Mohammady et al. [
16] investigated the accuracy of three MLAs, namely multivariate adaptive regression spline (MARS), mixture discriminant analysis (MDA), and boosted regression tree (BRT), for predicting LS susceptibility in Semnan Plain, Iran. They reported that MARS outperformed other MLAs in the study area. Liu et al. [
20] addressed LS in urban planning and infrastructure management by using two machine learning models, including the extreme gradient boosting regressor (XGBR) and long short-term memory (LSTM). They identified groundwater level (GWL) and building concentration (BC) as key factors influencing LS. They also revealed that there could be a significant decrease in LS by 2040 in a scenario where the GWL (i.e., groundwater table) and BC impacts were reduced by 80%. This result highlights the importance of implementing strategic policy interventions. Eghrari et al. [
21] conducted a study in Kashan Plain, Iran, to analyze the land subsidence susceptibility using RF and XGBoost MLAs and considered twelve influential factors, such as topography, vegetation, hydrological elements, and anthropogenic features.
MLAs can also be applied to understand how LS may be affected by climate change. By analyzing historical data and projecting future trends, MLAs can help identify areas where subsidence is expected to be most severe [
22]. Collados-Lara et al. [
23] developed a new method using regression models to investigate the impacts of climate change scenarios on land subsidence induced by groundwater drawdown. They reported a 54% increase in the LS rate in Vega de Granada in Spain under the representative concentration pathway (RCP) 8.5 climate change scenario.
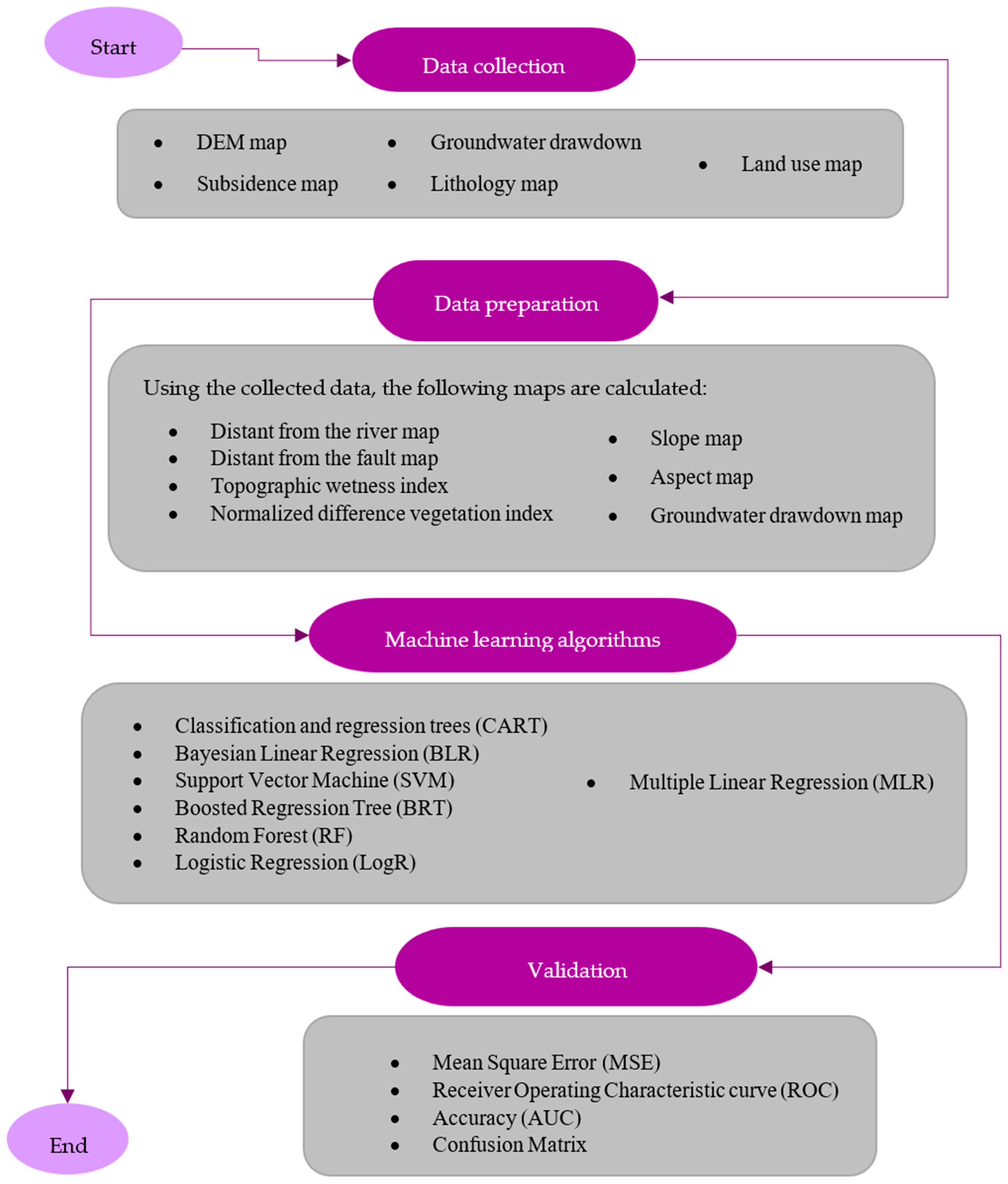
Several studies indicate that MLAs have proven useful for estimating LS susceptibility as well as generating LS susceptibility maps, since MLAs do not rely on accurate data, which can be challenging to acquire. Nonetheless, a thorough evaluation of the performance of different MLAs has not been carried out, as most previous studies only compared a small number of approaches. Moreover, to obtain more accurate results, influential factors, including natural and human-induced factors, should first be determined and then employed in the modeling process. The aim of this study was thus to answer the following questions:
Which MLA has higher accuracy for predicting LS in a given study area?
Do different MLAs vary in performance in study areas with different inherent characteristics and status (e.g., groundwater drawdown)?
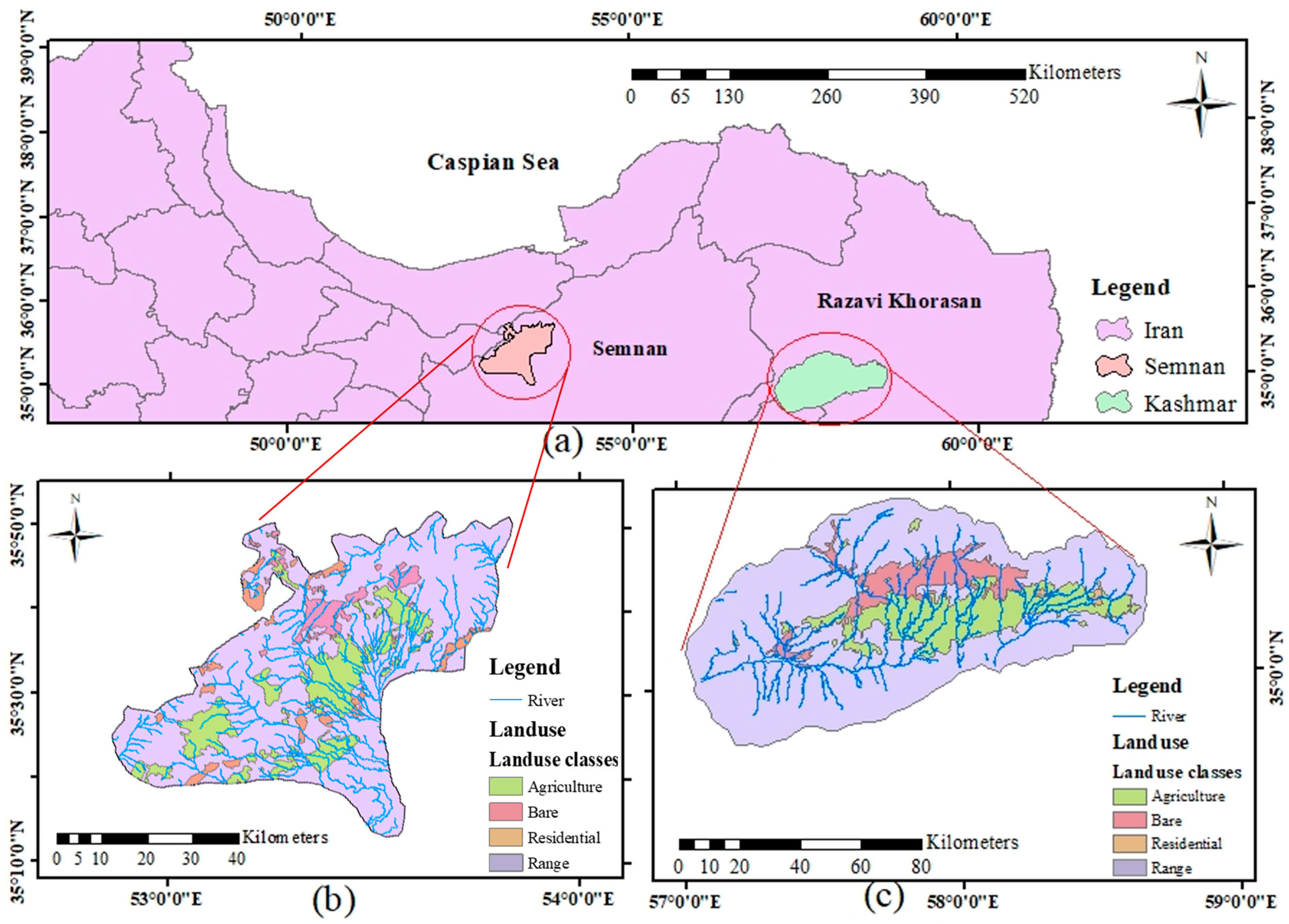
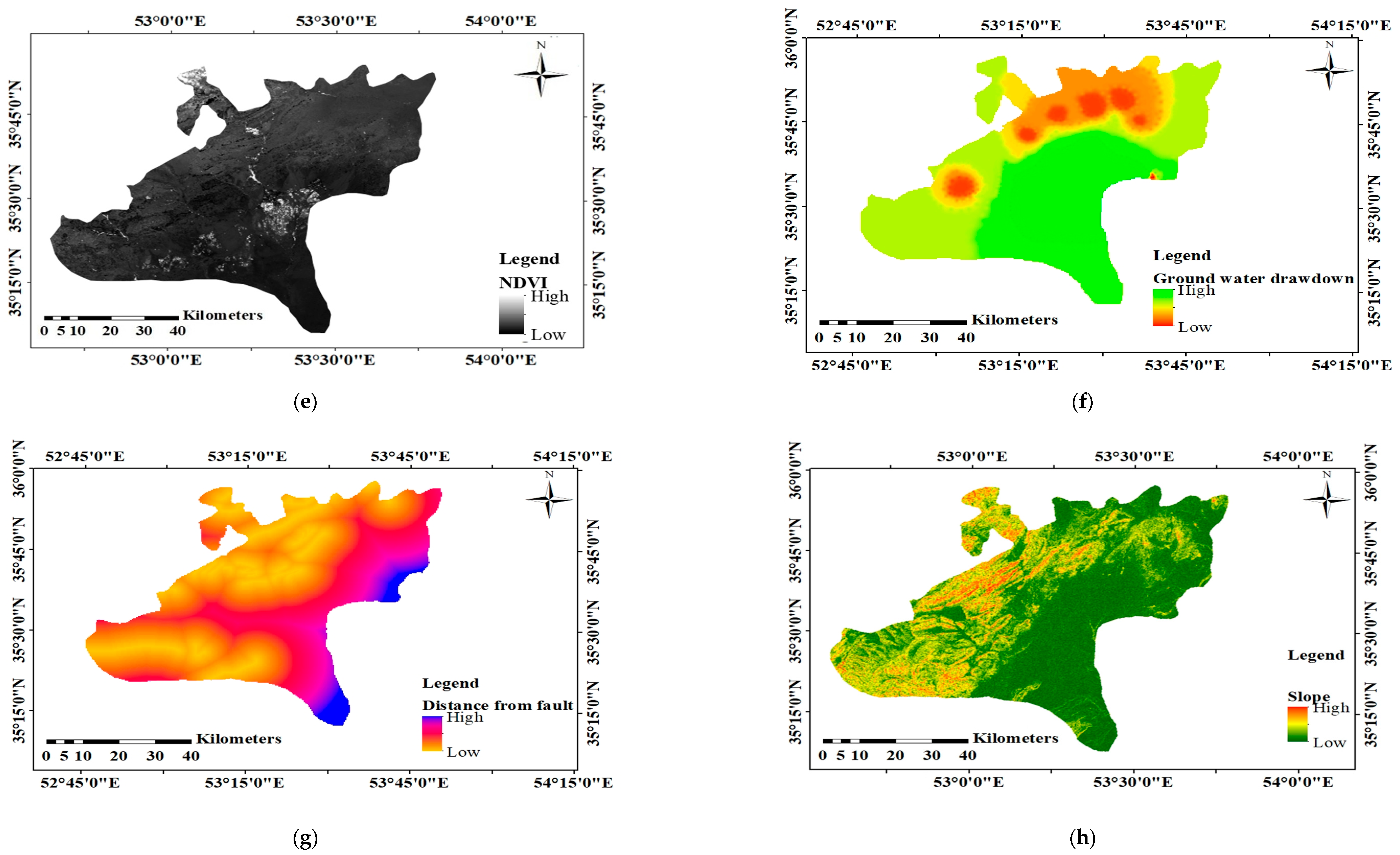
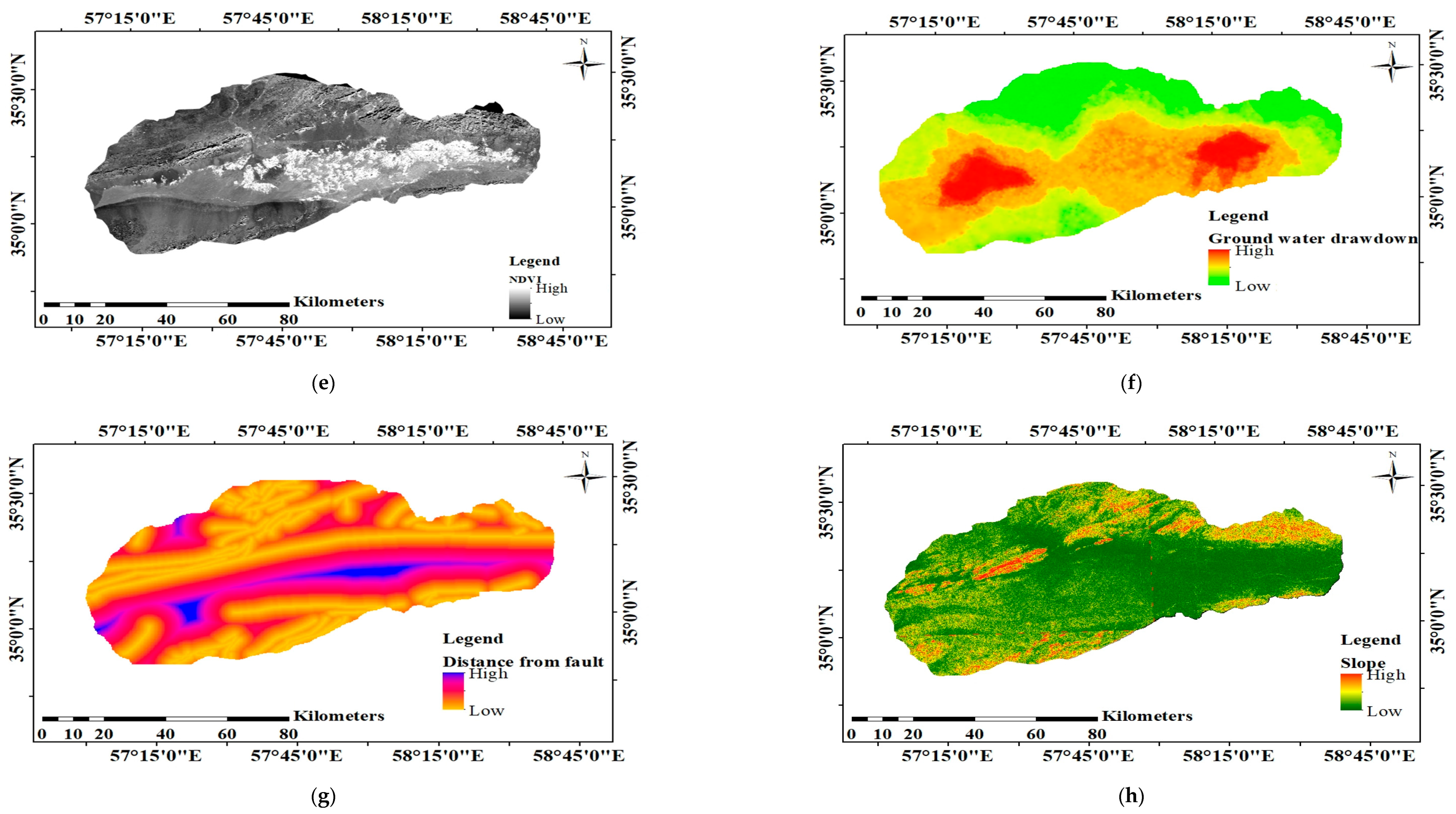
To achieve these aims, we scrutinized the performance of six classification MLAs (classification and regression tree (CART), Bayesian linear regression (BLR), SVM, boosted BRT, RF, and logistic regression (LogR)) and one regression method (multiple linear regression (MLR)) in identifying LS-prone areas and predicting the magnitude of LS. We applied the methods to two study areas, Semnan Plain and Kashmar Plain in Iran, both of which have experienced severe LS in recent decades [
16,
17,
18,
19,
20,
21,
22,
23,
24], using nine input variables: distance from the river, distance from the fault, groundwater drawdown, slope, aspect, land use, lithology, topographic wetness index (TWI), and normalized difference vegetation index (NDVI).
These seven MLAs were selected for analysis based on their performance merits and previous studies [
16,
17,
18,
19,
20,
21,
22,
23,
24,
25,
26,
27]. The CART approach can handle missing values in the training dataset and is insensitive to outliers since it uses surrogates [
28]. The BLR approach can detect influential subsidence factors using a two-state dependent variable [
29]. The SVM approach has excellent precision, robust generalization, and a higher pace of learning (REF). The BRT approach is intricate but concise, since it offers robust hydrological perception, and is thus an appropriate approach for a wide range of environmental applications. RF has higher prediction accuracy, higher efficiency when used with large datasets, low bias, and low variance by employing the bagging technique, which means that each occurrence has an equal chance of being chosen, and it avoids overfitting the data [
28]. One of the advantages of LogR is its simplicity and interpretability, as the coefficients of the independent variables can be easily interpreted as the effect of each variable on the predicted probability [
30]. The MLR approach is a powerful tool for modeling complex relationships between variables, as it allows analysts to examine the effect of multiple variables on a dependent variable while controlling for the effects of other variables. However, it is important to carefully consider the requirements of MLR, such as linearity, normality, and independence of errors, before applying the technique to a particular dataset.
The novel contributions of this work are comparing the ability of a broad range of classification MLAs to predict the susceptibility of an area to LS and that of a regression approach to determine the subsidence of a study area and to scrutinize the role of different factors and characteristics of a study area (e.g., amount of subsidence and data accessibility) in LS predictions, based on the outputs of these approaches.
5. Conclusions
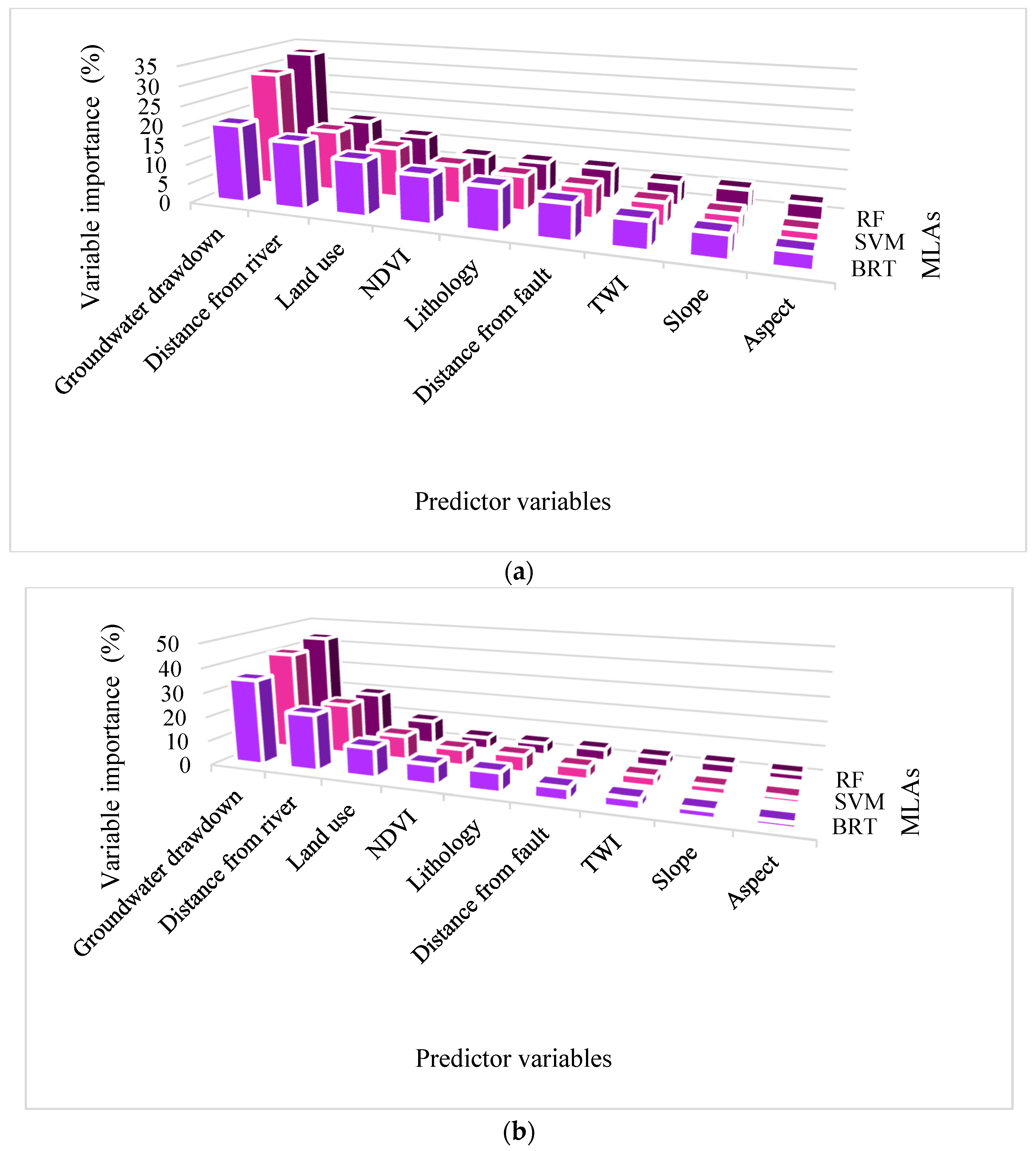
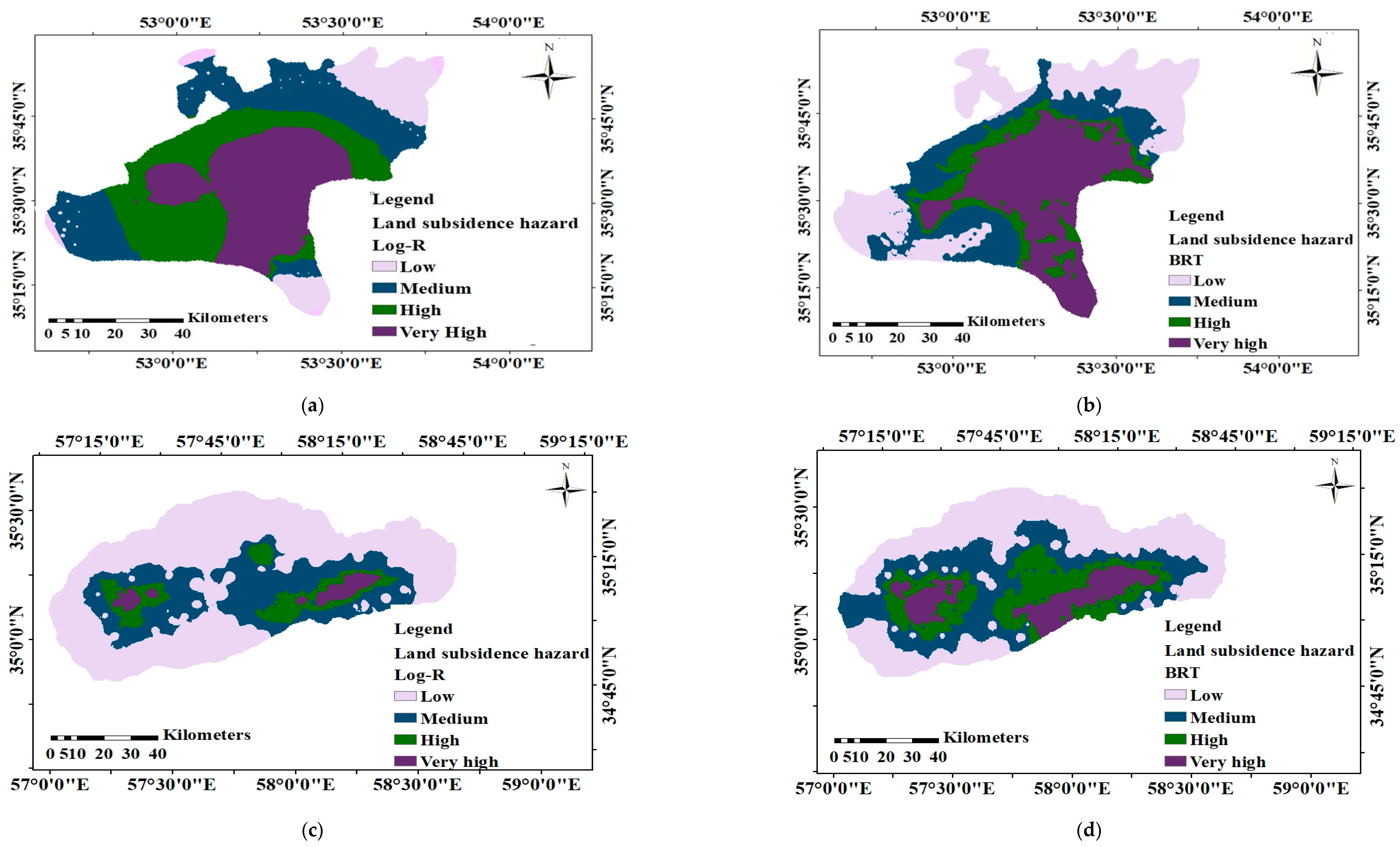
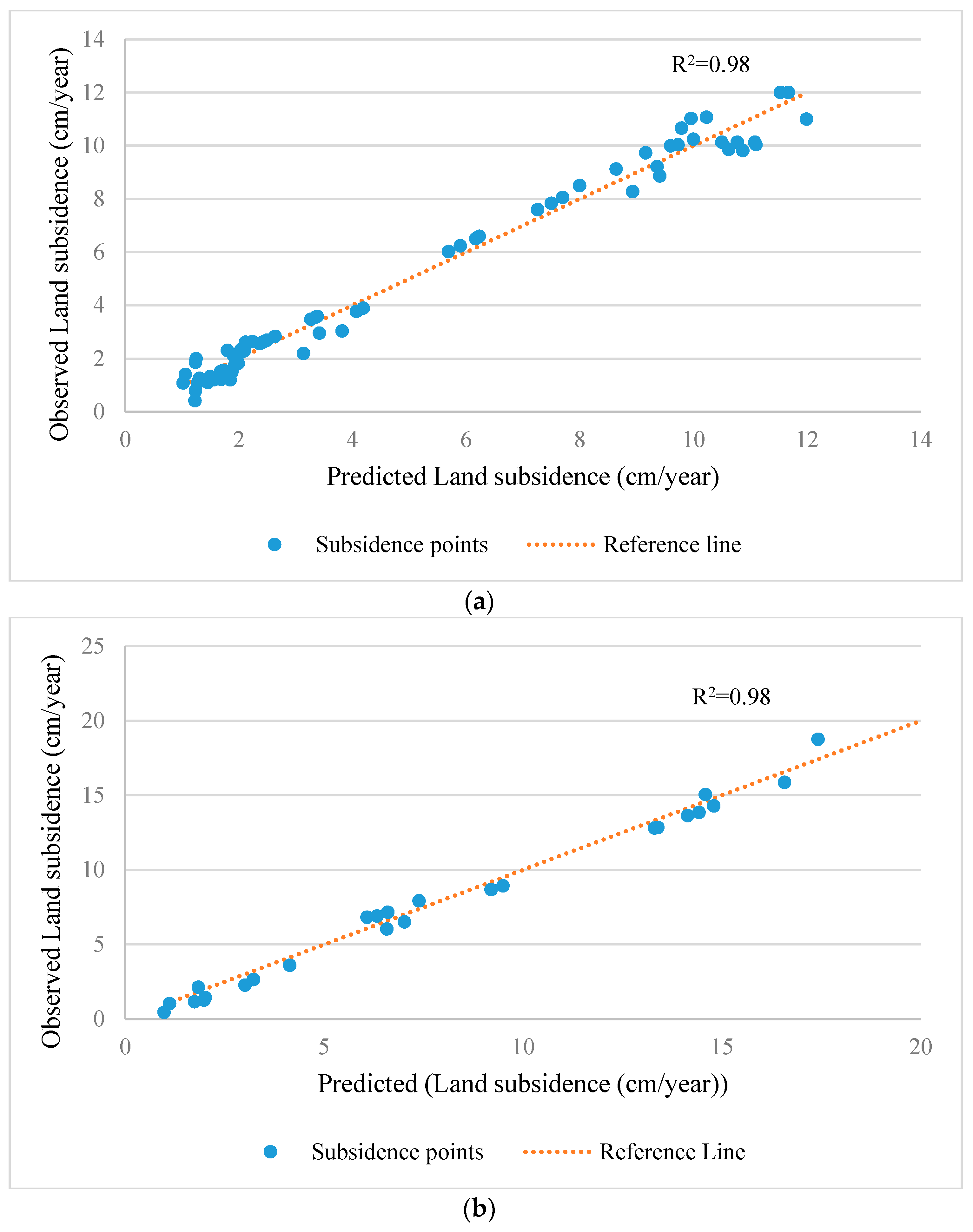
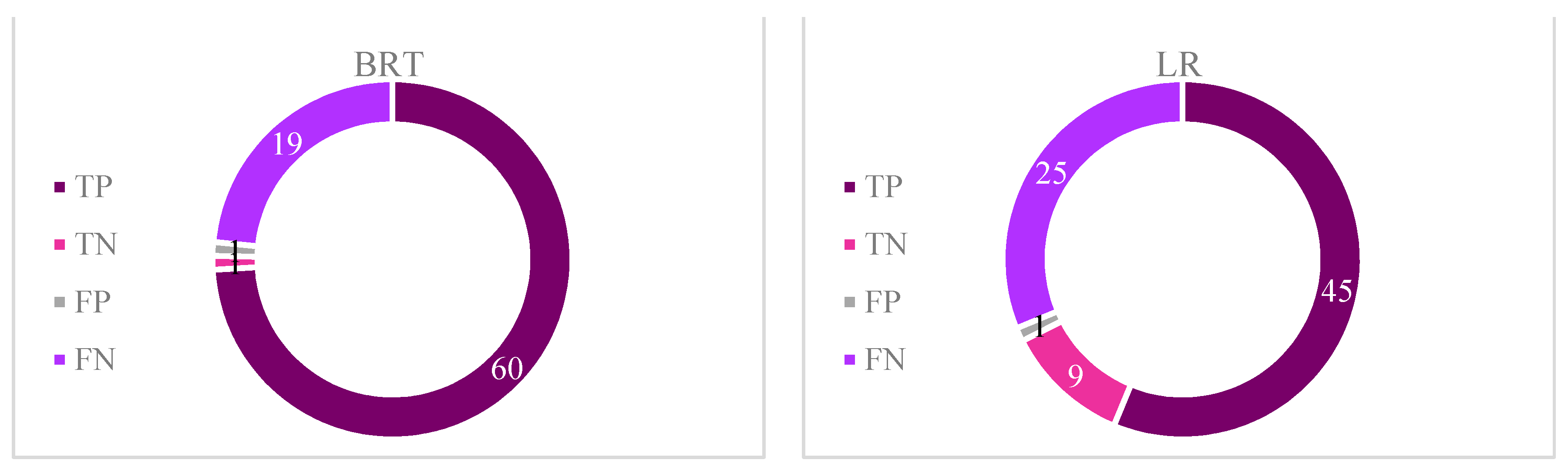
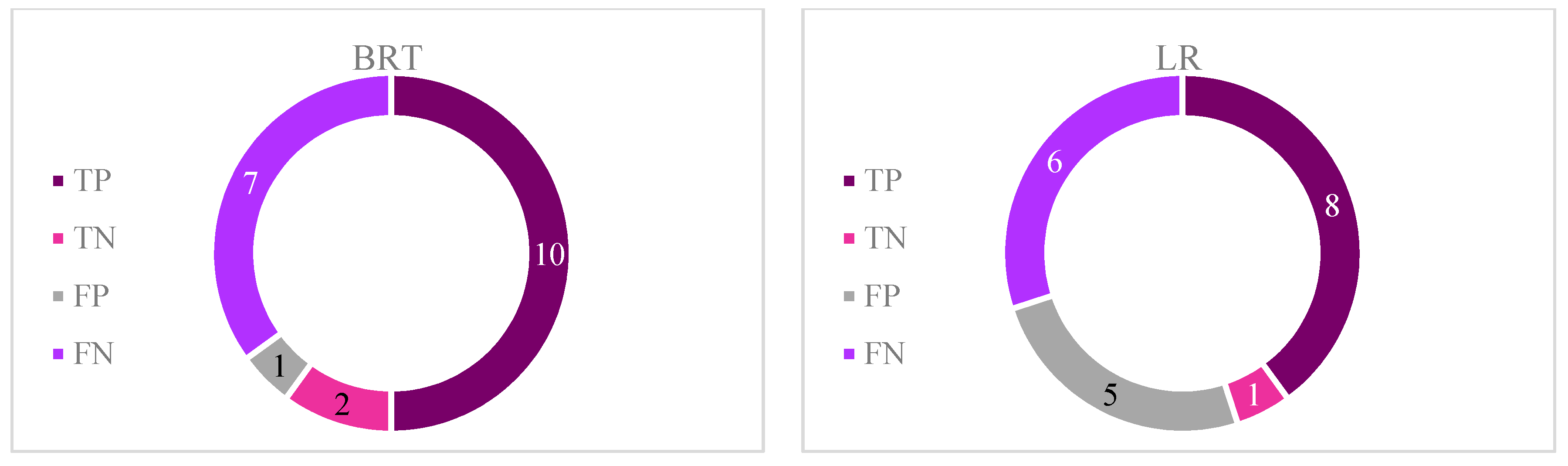
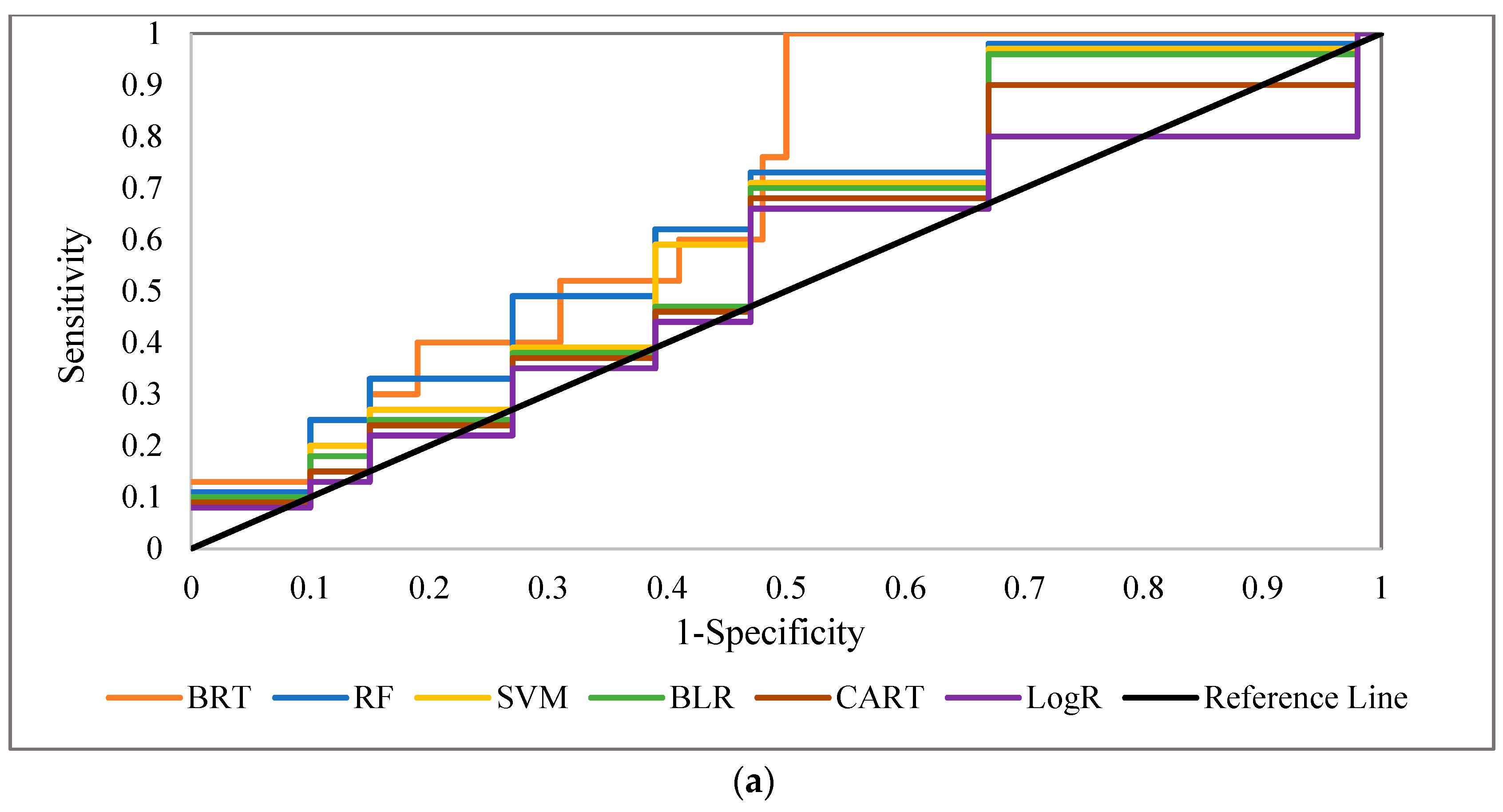
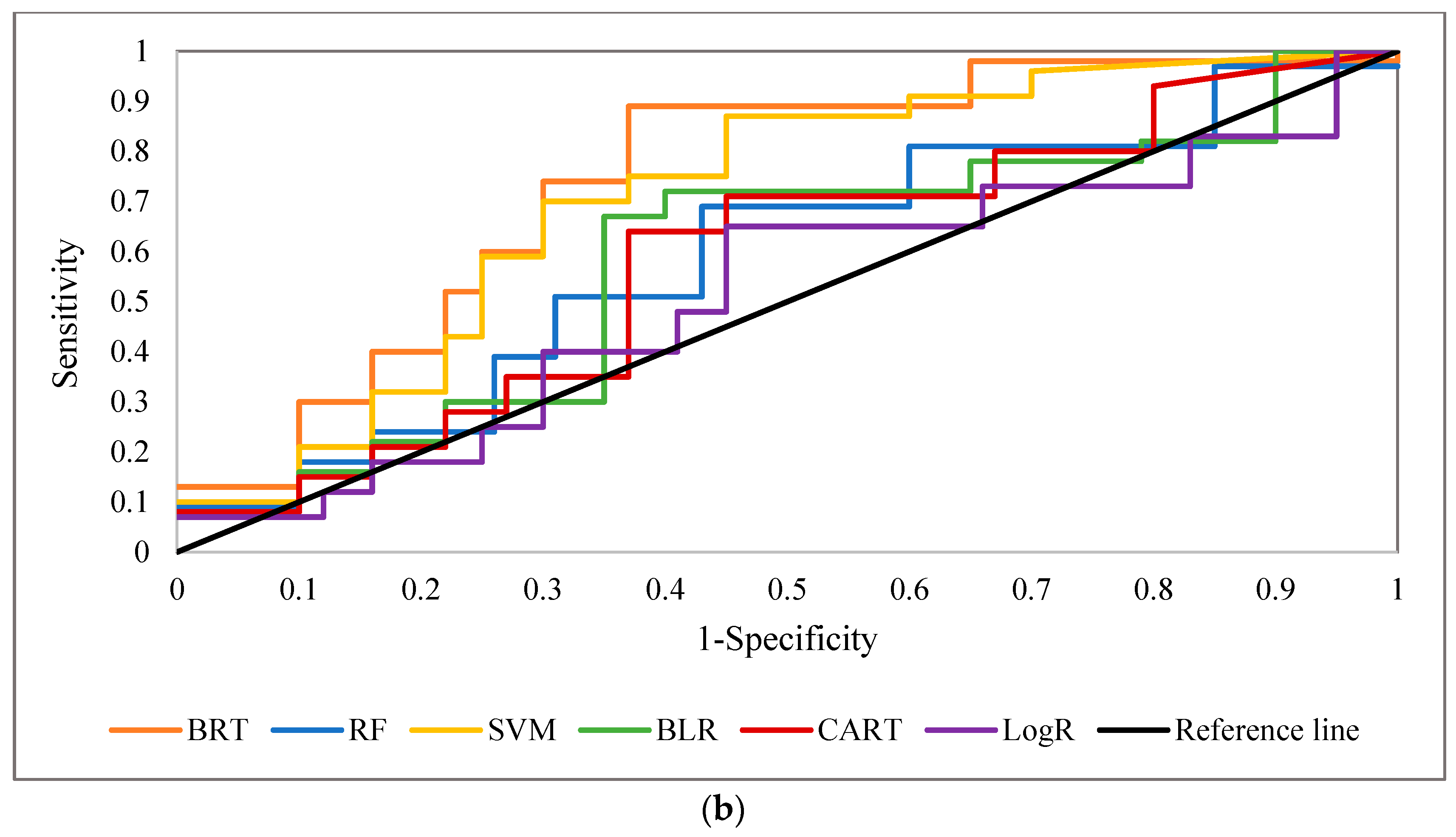
One of the detrimental natural hazards in both Semnan Plain and Kashmar Plain is land subsidence, which can result in infrastructure failure and environmental and economic issues. In this study, six classification-based MLAs (BRT, RF, SVM, BLR, CART, and LogR) were used to investigate LS in these two areas. In addition, MLR was applied to predict LS in the two areas. Lithology, slope, aspect, TWI, distance from the river, distance from the fault, land use, NDVI, and groundwater drawdown at the sites were all taken into consideration in LS modeling. The BRT approach was able to predict LS hazard in both study areas with a good degree of accuracy, while RF and SVM also showed good performance for both areas. The LogR approach showed the worst performance in predicting LS in both study areas. Overall, the results indicated that LS in both areas is mainly occurring due to groundwater drawdown, but that the distance from the river, NDVI, land use, and lithology also have significant impacts.
According to the results, groundwater drawdown is one of the most influential factors responsible for LS in the study areas. Typically, one answer in such situations is to carry out water transfer projects to offer alternate resources for local communities. Due to the risks and high implementation costs of such projects, they are not advised for providing alternate water resources. Improving water management across various sectors, utilizing water purification techniques by industries to prevent water pollution, and enacting laws regulating water usage in different demand sectors (e.g., municipal, industrial, agriculture) can aid in replenishing water resources. Furthermore, implementing projects aiming at reducing water consumption in agricultural sectors such as utilizing modern irrigation techniques (e.g., drip and rain irrigation methods), cultivating crops with higher resilience to water scarcity, close monitoring of groundwater level, and prohibiting illegal groundwater extraction can hinder the further overexploitation of resources.
In this study, land subsidence was investigated between the years 2015 and 2017. Access to more updated temporal data can enhance the accuracy of results. The primary limitation of the current study stems from the unavailability of subsidence rate data in the region. The absence of such data prevents a comprehensive analysis of the gradual influence of various factors on land subsidence over time, hindering the ability to simulate real-time possibilities of subsidence. Utilizing the interferometric synthetic aperture radar (InSAR) time series analysis technique could address this limitation. Therefore, it is recommended that future research explores the use of subsidence rate as a response variable in predicting land subsidence susceptibility using machine learning models, contingent upon the availability of relevant datasets.
Furthermore, certain critical factors, such as sedimentation rate, altitude, soil type, and curvature, were not considered in this study. Incorporating these factors into the prediction process in future studies is crucial for obtaining more accurate results. The inclusion of such data can significantly enhance the precision of the outputs.
Furthermore, there is potential for future studies to focus on developing a practical risk framework. This framework could incorporate vulnerability components, integrating data on assets and populations susceptible to the impacts of land subsidence. While these tasks hold significant value for addressing real-world land subsidence challenges, they necessitate further investigation that includes the acquisition of relevant datasets. This not only applies to the present study regions but also extends to global considerations.
This study compared the performance of a range of classification MLAs in predicting LS hazards, but future studies should also include deep learning and hybrid approaches in the analysis. Future studies can use the results obtained here to investigate management scenarios and climate change scenarios for improving the resilience of areas to subsidence and reduce adverse economic and environmental impacts.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}