
Spatial Interactions between Planned Settlements and Small Businesses: Evidence from the Jakarta Metropolitan Area, Indonesia



Abstract
1. Introduction
1.1. Background
1.2. Literature Review
2. Data and Methods
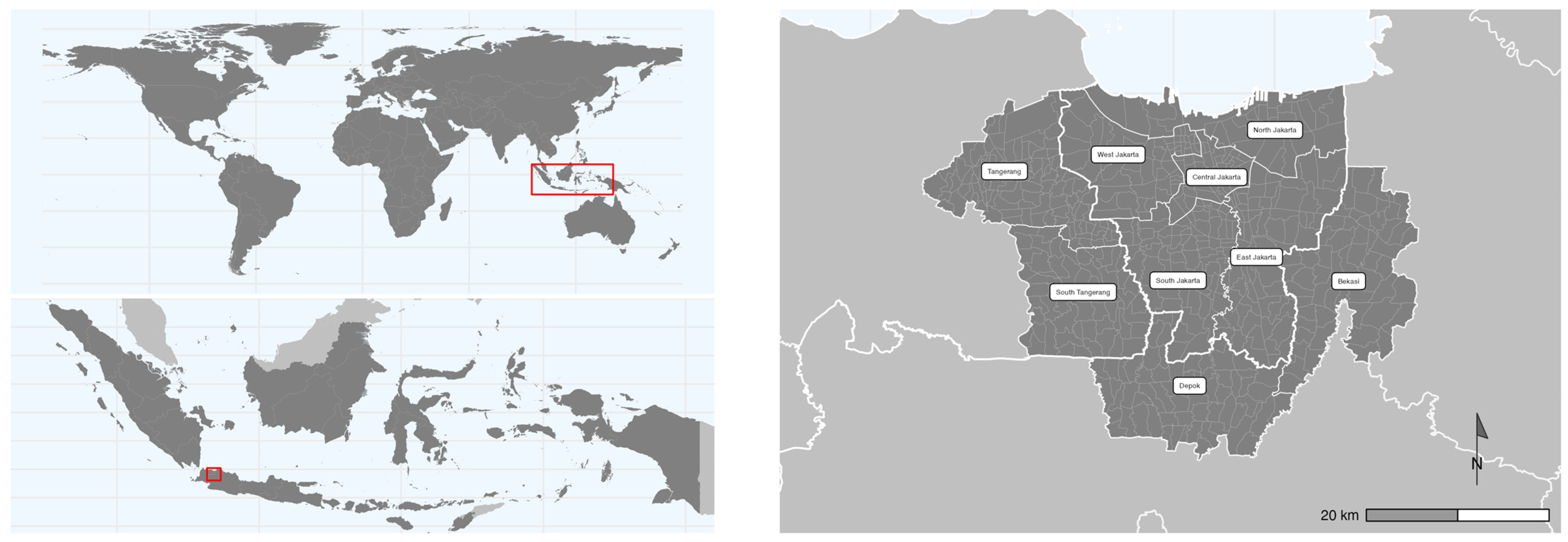
2.1. Data
2.2. Statistical Analysis
3. Results
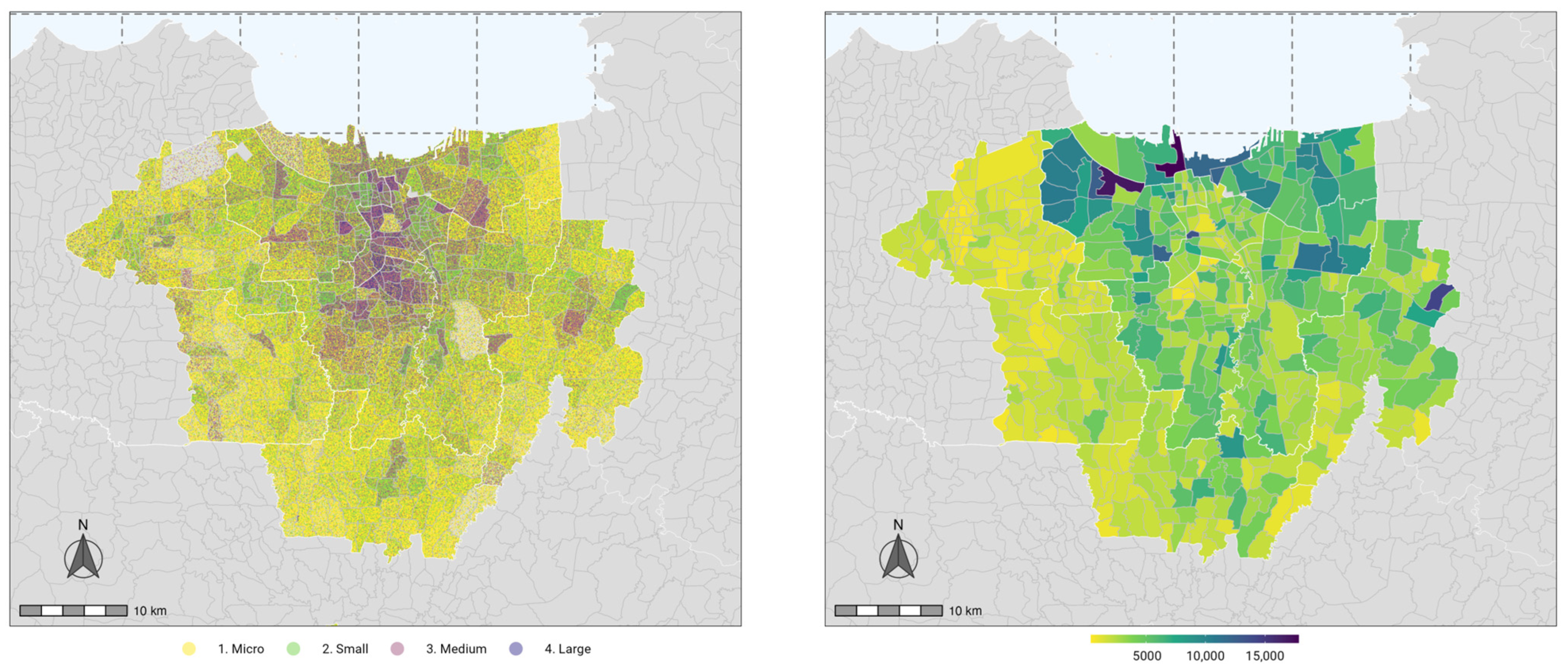
3.1. Descriptive Statistics
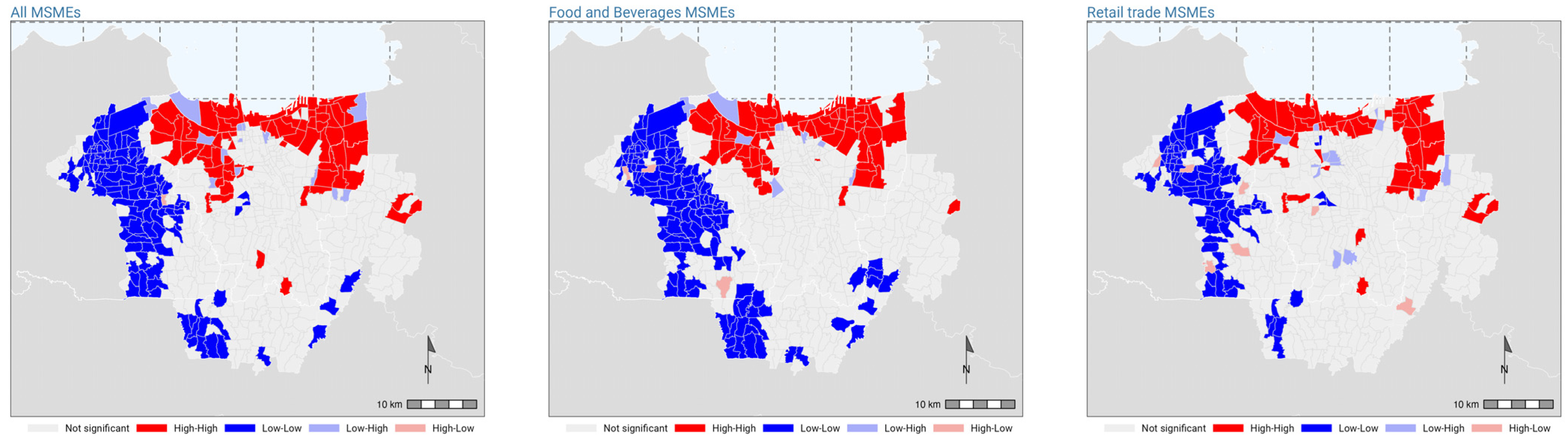
3.2. Tests for Spatial Autocorrelation
3.3. Spatial Regression
3.3.1. Choice of Spatial Regression Model
3.3.2. SLM Assessment
3.3.3. Sensitivity of OLS and SEM
4. Discussion
4.1. Overall Patterns of MSMEs and Planned Settlements
4.2. Implications
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- World Bank Enterprise Survey 2009. 2009. Available online: https://microdata.worldbank.org/index.php/catalog/700 (accessed on 24 November 2023).
- Shatkin, G. The City and the Bottom Line: Urban Megaprojects and the Privatization of Planning in Southeast Asia. Environ. Plan. Econ. Space 2008, 40, 383–401. [Google Scholar] [CrossRef]
- Li, Y.; Rama, M. (Eds.) Private Cities: Outstanding Examples from Developing Countries and Their Implications for Urban Policy; World Bank: Washington, DC, USA, 2023; ISBN 978-1-4648-1833-2. [Google Scholar]
- UN HABITAT. Planned City Extensions: Analysis of Historical Examples, 1st ed.; UN HABITAT: Nairobi, Kenya, 2015. [Google Scholar]
- Zheng, S.; Tan, Z.; Jansson, V. Toward Urban Economic Vibrancy: Patterns and Practices in Asia’s New Cities (SA+P Press): Patterns and Practices in Asia’s New Cities; SA+P Press: Cambridge, MA, USA, 2020; ISBN 978-0-9981170-7-2. [Google Scholar]
- Garner, J. (Ed.) The Company Town: Architecture and Society in the Early Industrial Age, 1st ed.; Oxford University Press: New York, NY, USA, 1992; ISBN 978-0-19-507027-9. [Google Scholar]
- Rigg, J. Unplanned Development: Tracking Change in South-East Asia; Zed Books Ltd.: London, UK, 2012; ISBN 978-1-84813-991-6. [Google Scholar]
- Dovey, K.; King, R. Forms of Informality: Morphology and Visibility of Informal Settlements. Built Environ. 2011, 37, 11–29. [Google Scholar] [CrossRef]
- Fält, L. New Cities and the Emergence of “Privatized Urbanism” in Ghana. Built Environ. 2019, 44, 438–460. [Google Scholar] [CrossRef]
- Peimani, N.; Kamalipour, H. Informal Street Vending: A Systematic Review. Land 2022, 11, 829. [Google Scholar] [CrossRef]
- Kamalipour, H.; Peimani, N. Negotiating Space and Visibility: Forms of Informality in Public Space. Sustainability 2019, 11, 4807. [Google Scholar] [CrossRef]
- Furszyfer Del Rio, D.D.; Sovacool, B.K. Of Cooks, Crooks and Slum-Dwellers: Exploring the Lived Experience of Energy and Mobility Poverty in Mexico’s Informal Settlements. World Dev. 2023, 161, 106093. [Google Scholar] [CrossRef]
- Dovey, K.; van Oostrum, M.; Chatterjee, I.; Shafique, T. Towards a Morphogenesis of Informal Settlements. Habitat Int. 2020, 104, 102240. [Google Scholar] [CrossRef]
- Winarso, H.; Hudalah, D.; Firman, T. Peri-Urban Transformation in the Jakarta Metropolitan Area. Habitat Int. 2015, 49, 221–229. [Google Scholar] [CrossRef]
- Leisch, H. Gated Communities in Indonesia. Cities 2002, 19, 341–350. [Google Scholar] [CrossRef]
- Monkkonen, P. Urban Land-Use Regulations and Housing Markets in Developing Countries: Evidence from Indonesia on the Importance of Enforcement. Land Use Policy 2013, 34, 255–264. [Google Scholar] [CrossRef]
- Firman, T. New Town Development in Jakarta Metropolitan Region: A Perspective of Spatial Segregation. Habitat Int. 2004, 28, 349–368. [Google Scholar] [CrossRef]
- JICA; Almec Corporation. JABODETABEK Urban Transportation Policy Integration Project Phase 2 in the Republic of Indonesia—Annex 05: Working Paper on Transportation Surveys; JICA: Jakarta, Indonesia, 2019. [Google Scholar]
- Christaller, W. Central Places in Southern Germany; Fischer: Waldatal, Gernany, 1933. [Google Scholar]
- Hotelling, H. Stability in Competition. Econ. J. 1929, 39, 41–57. [Google Scholar] [CrossRef]
- Stahl, K. Therories of Urban Business Location. In Handbook of Regional and Urban Economics; Mills, E.S., Ed.; Elsevier: Amsterdam, The Netherlands, 1987; Volume 2, pp. 759–820. [Google Scholar]
- Lösch, A. The Economics of Location; Yale University Press: New Haven, CT, USA, 1966. [Google Scholar]
- Sevtsuk, A. Location and Agglomeration: The Distribution of Retail and Food Businesses in Dense Urban Environments. J. Plan. Educ. Res. 2014, 34, 374–393. [Google Scholar] [CrossRef]
- Abrigo, M.; Francisco, K.A. Location Choice and Spatial Externalities among MSMEs in the Philippines; Asian Institute of Management: Makati, Philippines, 2013. [Google Scholar]
- Chłoń-Domińczak, A.; Fiedukowicz, A.; Olszewski, R. Geographical and Economic Factors Affecting the Spatial Distribution of Micro, Small, and Medium Enterprises: An Empirical Study of The Kujawsko-Pomorskie Region in Poland. ISPRS Int. J. Geo-Inf. 2020, 9, 426. [Google Scholar] [CrossRef]
- International Labour Organization. The Power of Small: Unlocking the Potential of SMEs. Available online: https://www.ilo.org/infostories/en-GB/Stories/Employment/SMEs#intro (accessed on 2 June 2022).
- Banerjee, A.; Fischer, G.; Karlan, D.; Lowe, M.; Roth, B.N. Does the Invisible Hand Efficiently Guide Entry and Exit? Evidence from a Vegetable Market Experiment in India; National Bureau of Economic Research: Cambridge, MA, USA, 2022. [Google Scholar]
- Caraka, R.E.; Kurniawan, R.; Nasution, B.I.; Jamilatuzzahro, J.; Gio, P.U.; Basyuni, M.; Pardamean, B. Micro, Small, and Medium Enterprises’ Business Vulnerability Cluster in Indonesia: An Analysis Using Optimized Fuzzy Geodemographic Clustering. Sustainability 2021, 13, 7807. [Google Scholar] [CrossRef]
- Charman, A.; Govender, T. The Relational Economy of Informality: Spatial Dimensions of Street Trading in Ivory Park, South Africa. Urban Forum 2016, 27, 311–328. [Google Scholar] [CrossRef]
- Chin, J.T. Location Choice of New Business Establishments: Understanding the Local Context and Neighborhood Conditions in the United States. Sustainability 2020, 12, 501. [Google Scholar] [CrossRef]
- JICA; ALMEC Corporation. JABODETABEK Urban Transportation Policy Integration Project Phase 2 in the Republic of Indonesia—Annex 02: JABODETABEK Urban Transportation Master Plan (Detailed RITJ); JICA: Jakarta, Indonesia, 2019. [Google Scholar]
- Porta, S.; Strano, E.; Iacoviello, V.; Messora, R.; Latora, V.; Cardillo, A.; Wang, F.; Scellato, S. Street Centrality and Densities of Retail and Services in Bologna, Italy. Environ. Plan. B Plan. Des. 2009, 36, 450–465. [Google Scholar] [CrossRef]
- Cervero, R.; Kockelman, K. Travel Demand and the 3Ds: Density, Diversity, and Design. Transp. Res. Part Transp. Environ. 1997, 2, 199–219. [Google Scholar] [CrossRef]
- Zhang, M. The Role of Land Use in Travel Mode Choice: Evidence from Boston and Hong Kong. J. Am. Plann. Assoc. 2004, 70, 344–360. [Google Scholar] [CrossRef]
- Boeing, G. OSMnx: New Methods for Acquiring, Constructing, Analyzing, and Visualizing Complex Street Networks. Comput. Environ. Urban Syst. 2017, 65, 126–139. [Google Scholar] [CrossRef]
- Dill, J. Measuring Network Connectivity for Bicycling and Walking. In Proceedings of the 83rd annual meeting of the Transportation Research Board, Washington, DC, USA, 11–15 January 2004. [Google Scholar]
- Mecredy, G.; Pickett, W.; Janssen, I. Street Connectivity Is Negatively Associated with Physical Activity in Canadian Youth. Int. J. Environ. Res. Public. Health 2011, 8, 3333–3350. [Google Scholar] [CrossRef] [PubMed]
- Palacios, M.S.; El-geneidy, A. Cumulative versus Gravity-Based Accessibility Measures: Which One to Use? Findings 2022, 32444. [Google Scholar] [CrossRef]
- Hansen, W.G. How Accessibility Shapes Land Use. J. Am. Inst. Plann. 1959, 25, 73–76. [Google Scholar] [CrossRef]
- Levinson, D.; King, D. Transport Access Manual: A Guide for Measuring Connection between People and Places; Network Design Lab: Sydney, Australia, 2020; ISBN 978-1-71588-643-1. [Google Scholar]
- Pereira, R.H.M.; Saraiva, M.; Herszenhut, D.; Braga, C.K.V.; Conway, M.W. R5r: Rapid Realistic Routing on Multimodal Transport Networks with R5 in R. Findings 2021, 21262. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing; R Core Team: Vienna, Austria, 2013. [Google Scholar]
- Posit Team. RStudio: Integrated Development Environment for R; Posit Software, PBC: Boston, MA, 2023. [Google Scholar]
- SMERU Research Institute. Press Release: The Launching of the 2015 Poverty and Livelihood Map of Indonesia; SMERU Research Institute: Jakarta, Indonesia, 2015. [Google Scholar]
- Anselin, L. Spatial Econometrics: Methods and Models; Studies in Operational Regional Science; Springer: Dordrecht, The Netherlands, 1988; Volume 4, ISBN 978-90-481-8311-1. [Google Scholar]
- Burkey, M.L. Spatial Econometrics and GIS YouTube Playlist. Region 2018, 5, R13–R18. [Google Scholar] [CrossRef]
- Anselin, L. Local Indicators of Spatial Association—LISA. Geogr. Anal. 1995, 27, 93–115. [Google Scholar] [CrossRef]
- Li, H.; Calder, C.A.; Cressie, N. Beyond Moran’s I: Testing for Spatial Dependence Based on the Spatial Autoregressive Model. Geogr. Anal. 2007, 39, 357–375. [Google Scholar] [CrossRef]
- Yin, C.; Yuan, M.; Lu, Y.; Huang, Y.; Liu, Y. Effects of Urban Form on the Urban Heat Island Effect Based on Spatial Regression Model. Sci. Total Environ. 2018, 634, 696–704. [Google Scholar] [CrossRef]
- Bivand, R.S.; Wong, D.W.S. Comparing Implementations of Global and Local Indicators of Spatial Association. TEST 2018, 27, 716–748. [Google Scholar] [CrossRef]
- Li, X.; Anselin, L. rgeoda: R Library for Spatial Data Analysis. 2022. Available online: https://geodacenter.github.io/rgeoda/ (accessed on 24 November 2023).
- Anselin, L.; Bera, A. Spatial Dependence in Linear Regression Models with an Introduction to Spatial Econometrics. In Handbook of Applied Economic Statistics; Ullah, A., Giles, D.E.A., Eds.; CRC Press: Boca Raton, FL, USA, 1998; ISBN 978-0-429-17738-5. [Google Scholar]
- Anselin, L.; Rey, S. Properties of Tests for Spatial Dependence in Linear Regression Models. Geogr. Anal. 1991, 23, 112–131. [Google Scholar] [CrossRef]
- Baller, R.D.; Anselin, L.; Messner, S.F.; Deane, G.; Hawkins, D.F. Structural Covariates of U.s. County Homicide Rates: Incorporating Spatial Effects*. Criminology 2001, 39, 561–588. [Google Scholar] [CrossRef]
- Bartesaghi-Koc, C.; Osmond, P.; Peters, A. Innovative Use of Spatial Regression Models to Predict the Effects of Green Infrastructure on Land Surface Temperatures. Energy Build. 2022, 254, 111564. [Google Scholar] [CrossRef]
- Tobler, W.R. A Computer Movie Simulating Urban Growth in the Detroit Region. Econ. Geogr. 1970, 46, 234–240. [Google Scholar] [CrossRef]
- Bellefleur, D.; Murad, Z.; Tangkau, P. A Snapshot of Indonesian Entrepreneurship and Micro, Small, and Medium Sized Enterprise Development; United States Agency International Development: Washington, DC, USA, 2013. Available online: https://crawford.anu.edu.au/acde/ip/pdf/lpem/2012/20120507-SMERU-Dan-Thomson-Bellefleur.pdf (accessed on 24 November 2023).
- Wiryomartono, B. Urbanism and Superblock Mixed-Use Development in Jakarta: Politics of Gentrification of Post-Suharto Indonesia. In Traditions and Transformations of Habitation in Indonesia: Power, Architecture, and Urbanism; Wiryomartono, B., Ed.; Springer: Singapore, 2020; pp. 201–221. ISBN 9789811534058. [Google Scholar]
- Hudalah, D.; Winarso, H.; Woltjer, J. Gentrifying the Peri-Urban: Land Use Conflicts and Institutional Dynamics at the Frontier of an Indonesian Metropolis. Urban Stud. 2016, 53, 593–608. [Google Scholar] [CrossRef]
- Hoch, C.J.; Dalton, L.C.; So, F.S. (Eds.) The Practice of Local Government Planning, 3rd ed.; International City County Management Association: Washington, DC, USA, 2000; ISBN 978-0-87326-171-5. [Google Scholar]
- Guerra, E. Has Mexico City’s Shift to Commercially Produced Housing Increased Car Ownership and Car Use? J. Transp. Land Use 2015, 8, 171–189. [Google Scholar] [CrossRef]
- Ojeda, L.; Pino, A. Spatiality of Street Vendors and Sociospatial Disputes over Public Space: The Case of Valparaíso, Chile. Cities 2019, 95, 102275. [Google Scholar] [CrossRef]
- Rogerson, C.M. Informality and Migrant Entrepreneurs in Cape Town’s Inner City. Bull. Geogr. Socio-Econ. Ser. 2018, 157–171. [Google Scholar] [CrossRef]
- Lindell, I.; Ampaire, C.; Byerley, A. Governing Urban Informality: Re-Working Spaces and Subjects in Kampala, Uganda. Int. Dev. Plan. Rev. 2019, 41, 63–84. [Google Scholar] [CrossRef]
- Kementerian Agraria dan Tata Ruang; Badan Pertanahan Nasional. Permen Agraria/Kepala BPN No. 11 Tahun 2021. 2021. Available online: https://peraturan.bpk.go.id/Details/209795/permen-agrariakepala-bpn-no-11-tahun-2021 (accessed on 24 November 2023).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| N | Mean | SD | Min | Max | |
|---|---|---|---|---|---|
| Outcome variables | |||||
| MSMEs | 538 | 3439.4 | 2477.2 | 392 | 17,817 |
| MSMEs, food and beverages | 538 | 921.3 | 722.3 | 97 | 6335 |
| MSMEs, retail trade | 538 | 1327.2 | 1105.4 | 101 | 11,767 |
| Independent variables | |||||
| Neighborhood area (km2) | 538 | 2.6 | 1.9 | 0.3 | 17.6 |
| Land use | |||||
| Planned settl. (%) | 538 | 22.0 | 19.1 | 0.0 | 91.3 |
| Industrial (%) | 538 | 6.1 | 13.3 | 0.0 | 86.8 |
| Commercial (%) | 538 | 9.4 | 12.5 | 0.0 | 87.4 |
| Built environment | |||||
| Household density (per km2) | 538 | 5049.3 | 4670.5 | 120.9 | 54,053.1 |
| Land use entropy | 538 | 0.5 | 0.1 | 0.1 | 0.8 |
| Street nodes density (per km2) | 538 | 312.7 | 341.3 | 20.6 | 6806.0 |
| Connected Node Ratio | 538 | 0.8 | 0.1 | 0.6 | 1.0 |
| Economic | |||||
| Number of traditional markets | 538 | 2.1 | 2.7 | 0 | 36 |
| Number of accessible traditional markets (30-min) | 538 | 693.1 | 213.6 | 100 | 1041 |
| Large ent. Employees | 538 | 3087.2 | 5927.5 | 0 | 50,037 |
| Demographic | |||||
| Households in poverty (%) | 538 | 3.0 | 2.2 | 0.02 | 13.6 |
| Gini index | 538 | 0.3 | 0.03 | 0.2 | 0.5 |
| Moran’s I | p-Value | Significance | |
|---|---|---|---|
| All MSMEs | 0.457 | 0.000 | *** |
| F&B MSMEs | 0.490 | 0.000 | *** |
| Retail trade MSMEs | 0.305 | 0.000 | *** |
| Lagrange Multiplier | p-Value | Sig. | ||
|---|---|---|---|---|
| All MSMEs | LM (SLM) | 59.198 | 0.000 | *** |
| LM (SEM) | 35.715 | 0.000 | *** | |
| Robust LM (SLM) | 25.969 | 0.000 | *** | |
| Robust LM (SEM) | 2.486 | 0.115 | ||
| Food and Beverages MSMEs | LM (SLM) | 54.361 | 0.000 | *** |
| LM (SEM) | 35.398 | 0.000 | *** | |
| Robust LM (SLM) | 21.994 | 0.000 | *** | |
| Robust LM (SEM) | 3.029 | 0.081 | * | |
| Retail trade MSMEs | LM (SLM) | 26.944 | 0.000 | *** |
| LM (SEM) | 13.189 | 0.000 | *** | |
| Robust LM (SLM) | 13.755 | 0.000 | *** | |
| Robust LM (SEM) | 0.000 | 0.992 |
| All | F&B | Ret. Trade | ||||
|---|---|---|---|---|---|---|
| Coef. | Std. Error | Coef. | Std. Error | Coef. | Std. Error | |
| Neighborhood area (log) | 0.720 *** | (0.037) | 0.661 *** | (0.037) | 0.778 *** | (0.046) |
| Land use | ||||||
| Planned settl. (%) | −0.003 *** | (0.001) | −0.003 ** | (0.001) | −0.002 * | (0.001) |
| Industrial (%) | −0.003 * | (0.002) | −0.001 | (0.002) | −0.0002 | (0.002) |
| Commercial (%) | 0.009 *** | (0.002) | 0.007 *** | (0.002) | 0.013 *** | (0.002) |
| Built environment | ||||||
| Household density (log) | 0.526 *** | (0.029) | 0.549 *** | (0.031) | 0.492 *** | (0.036) |
| Land use entropy | −0.150 | (0.142) | −0.144 | (0.148) | −0.153 | (0.183) |
| Street nodes density (log) | −0.049 | (0.034) | −0.121 *** | (0.036) | −0.026 | (0.044) |
| Connected Node Ratio | 1.219 *** | (0.248) | 1.456 *** | (0.259) | 1.082 *** | (0.316) |
| Economic | ||||||
| Number of trad. markets | 0.016 *** | (0.006) | 0.011 * | (0.006) | 0.021 ** | (0.008) |
| Number of accessible trad. markets (30-min) | 0.0003 *** | (0.0001) | 0.0004 *** | (0.0001) | 0.0001 | (0.0001) |
| Large ent. employees | −0.00000 | (0.0000) | 0.0000 | (0.0000) | −0.00001 ** | (0.0000) |
| Demographic | ||||||
| Households poverty (%) | −0.002 | (0.007) | −0.005 | (0.007) | −0.005 | (0.009) |
| Gini index | −1.128 | (0.695) | −1.148 | (0.720) | −0.413 | (0.892) |
| Constant | −3.069 *** | (0.502) | −4.062 *** | (0.524) | −4.279 *** | (0.645) |
| N | 538 | 538 | 538 | |||
| Log Likelihood | −174.391 | −194.218 | −307.587 | |||
| Wald Test (df = 1) | 56.440 *** | 54.409 *** | 28.999 *** | |||
| LR Test (df = 1) | 53.586 *** | 50.474 *** | 26.159 *** | |||
| AIC | 380.782 | 420.436 | 647.173 |
| All | F&B | Ret. Trade | ||||
|---|---|---|---|---|---|---|
| Coef. | Std. Eror | Coef. | Std. Eror | Coef. | Std. Eror | |
| Direct effect | −0.003 *** | (0.001) | −0.003 ** | (0.001) | −0.002 * | (0.001) |
| Indirect effect | −0.001 *** | (0.000) | −0.001 ** | (0.001) | −0.001 * | (0.000) |
| Total effect | −0.004 *** | (0.001) | −0.004 ** | (0.002) | −0.003 * | (0.002) |
| OLS | SEM | SLM † | ||||
|---|---|---|---|---|---|---|
| Coef. | Std. Error | Coef. | Std. Error | Coef. | Std. Error | |
| Neighborhood area (log) | 0.870 *** | (0.032) | 0.814 *** | (0.037) | 0.720 *** | (0.037) |
| Land use | ||||||
| Planned settl. (%) | −0.003 *** | (0.001) | −0.004 *** | (0.001) | −0.003 *** | (0.001) |
| Industrial (%) | −0.003 ** | (0.002) | −0.003 ** | (0.002) | −0.003 * | (0.002) |
| Commercial (%) | 0.011 *** | (0.002) | 0.010 *** | (0.002) | 0.009 *** | (0.002) |
| Built environment | ||||||
| Household density (log) | 0.641 *** | (0.027) | 0.581 *** | (0.031) | 0.526 *** | (0.029) |
| Land use entropy | −0.155 | (0.153) | −0.118 | (0.152) | −0.150 | (0.142) |
| Street nodes density (log) | −0.079 ** | (0.037) | −0.085 ** | (0.040) | −0.049 | (0.034) |
| Connected Node Ratio | 1.688 *** | (0.259) | 1.435 *** | (0.277) | 1.219 *** | (0.248) |
| Economic | ||||||
| Number of trad. markets | 0.010 | (0.006) | 0.015 ** | (0.006) | 0.016 *** | (0.006) |
| Number of accessible trad. markets (30-min) | 0.0004 *** | (0.0001) | 0.0004 *** | (0.0001) | 0.0003 *** | (0.0001) |
| Large ent. employees | −0.00000 | (0.0000) | −0.00000 | (0.0000) | −0.00000 | (0.0000) |
| Demographic | ||||||
| Households poverty (%) | 0.002 | (0.008) | −0.005 | (0.008) | −0.002 | (0.007) |
| Gini index | −1.596 ** | (0.745) | −0.870 | (0.760) | −1.128 | (0.695) |
| Constant | −2.854 *** | (0.539) | −2.413 *** | (0.604) | −3.069 *** | (0.502) |
| N | 538 | 538 | 538 | |||
| R-squared | 0.718 | |||||
| Adj. R-squared | 0.711 | |||||
| Log Likelihood | −182.289 | −174.391 | ||||
| Wald Test (df = 1) | 56.633 *** | 56.440 *** | ||||
| LR Test (df = 1) | 37.790 *** | 53.586 *** | ||||
| AIC | 396.579 | 380.782 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Widita, A.A.; Lechner, A.M. Spatial Interactions between Planned Settlements and Small Businesses: Evidence from the Jakarta Metropolitan Area, Indonesia. Land 2024, 13, 203. https://doi.org/10.3390/land13020203
Widita AA, Lechner AM. Spatial Interactions between Planned Settlements and Small Businesses: Evidence from the Jakarta Metropolitan Area, Indonesia. Land. 2024; 13(2):203. https://doi.org/10.3390/land13020203
Chicago/Turabian StyleWidita, Alyas A., and Alex M. Lechner. 2024. "Spatial Interactions between Planned Settlements and Small Businesses: Evidence from the Jakarta Metropolitan Area, Indonesia" Land 13, no. 2: 203. https://doi.org/10.3390/land13020203
APA StyleWidita, A. A., & Lechner, A. M. (2024). Spatial Interactions between Planned Settlements and Small Businesses: Evidence from the Jakarta Metropolitan Area, Indonesia. Land, 13(2), 203. https://doi.org/10.3390/land13020203