
Integrating Spatiotemporal and Travel-Related Information for Accurate Urban Passenger Profiling Using GANs

Abstract
1. Introduction
2. Related Work
2.1. Travel Activity Representation
2.2. Generative Adversarial Networks
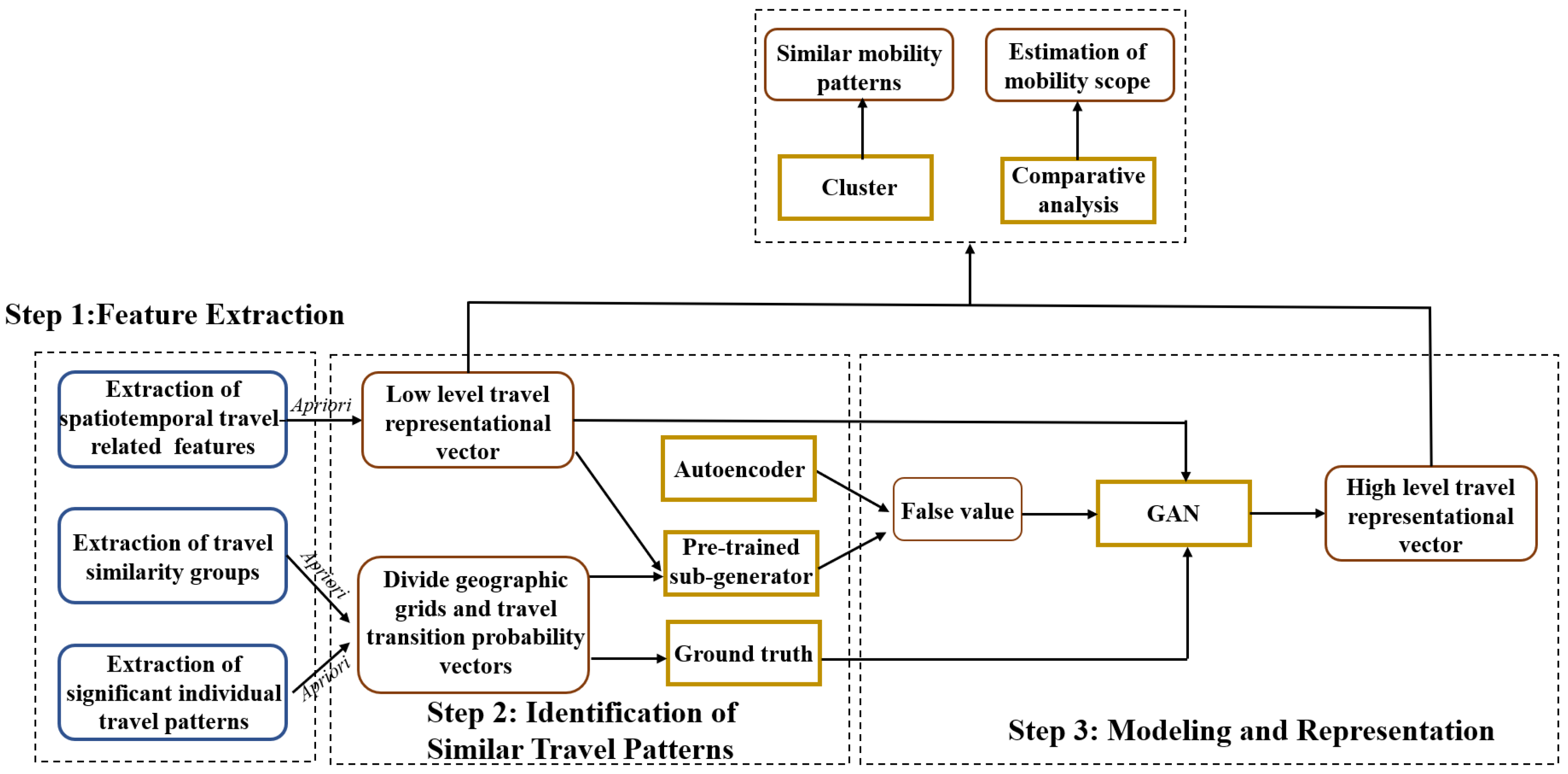
3. Materials and Methods
3.1. Definitions
3.2. Algorithm Details
3.3. Extraction of Significant Travel Patterns
| Algorithm 1. Individual Significance Extraction Algorithm |
| Input: Collection of travel chains for all passengers within M days Trips = {T1, T2, T3, …, Tn-1, Tn},travel time fluctuation threshold σ, support threshold θ, confidence threshold δ, Minimum frequent pattern set length threshold γ. Output: Significant travel chain collection of all passengers within M days ETrips = {ET1, ET2, ET3, …, ETn-1, ETn} 1: Initialize Q←∅, L←∅, k←1, j←1 2: for each trip in Trips do 3: R_j.append(trip.places) 4: Q←UpdateQ(trip) 5: end for 6: Lj←ExtractFrequentPattern(Rj, θ) 7: while len(Lk) > γ do 8: L.append(Lk) 9: k←k + 1 10: Rk←ExpandRSet(Lj, Lk, δ, Q, σ) 11: Lk←ExtractFrequentPattern(Rk, θ) 12: End while 13: ETrips = ExtractPersonMotif(L, Trips) |
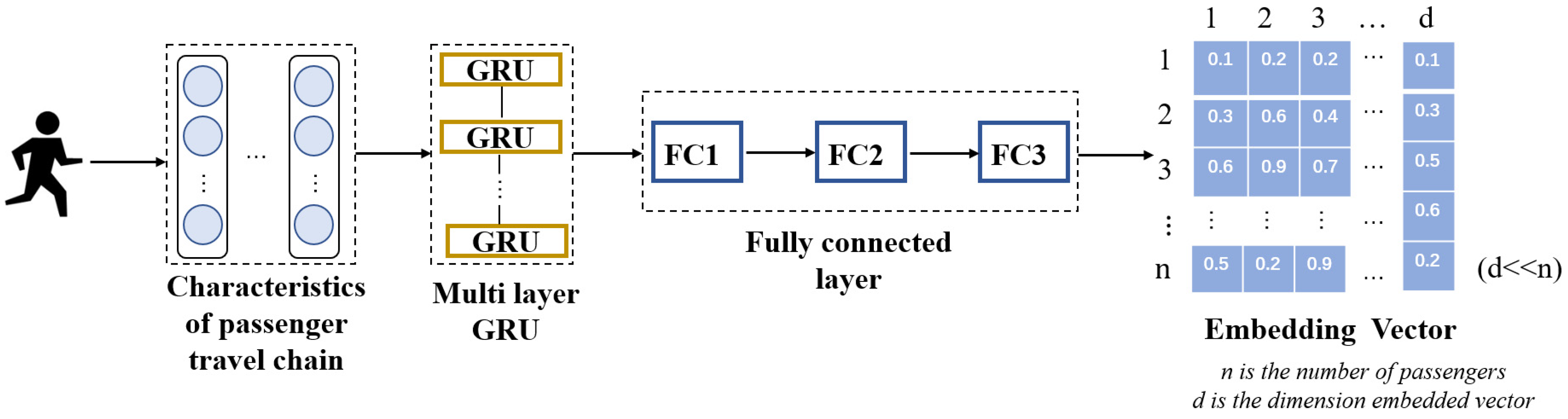
3.4. Travel Activity Vector Representation
| Algorithm 2. Geographic Grid Division Algorithm |
| Input: The scope of the area to be divided G = [lowerLeftLng, lowerLeftLat, upperLeftLng, upperLeftLat], Grid edge length limit threshold γ, Maximum flow limit threshold for grid θ Output: A set of geographic grids that meet the conditions FG = {fgrid1, fgrid2,…, fgridn} 1: Initialize FG←∅, SG←G 2: for each sg in SG do 3: if sg.flow > θ and sg.width > γ and sg.height > γ then 4: gTmp = SplitGrid(sg) 5: FilterByQuatree(gTmp) 6: else then 7: FG.append(sg.copy()) 8: end if 9: end for |
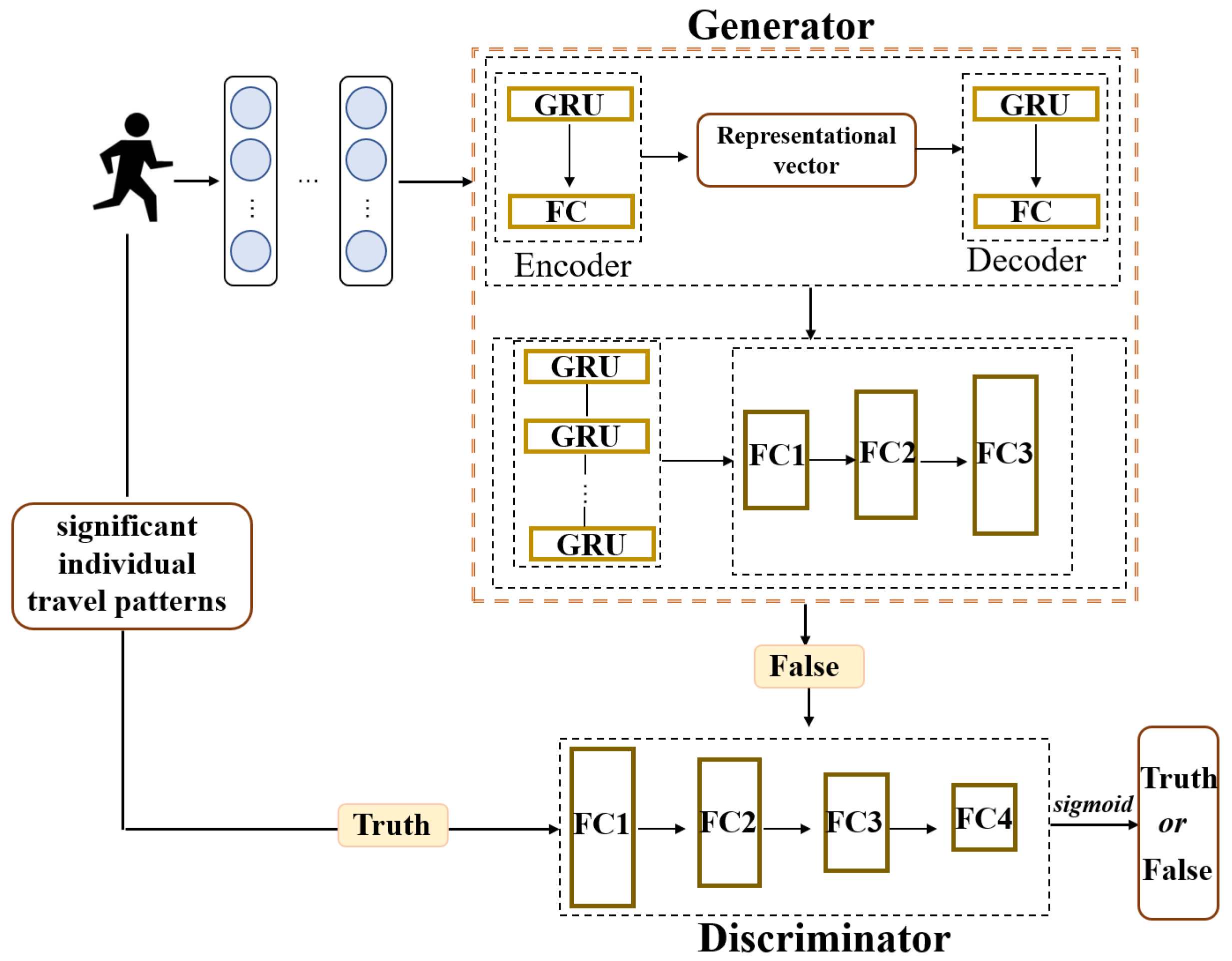
3.5. Travel Pattern Representation
3.5.1. Pre-Training
3.5.2. Generative Adversarial Networks Module
3.6. Loss Function
4. Results
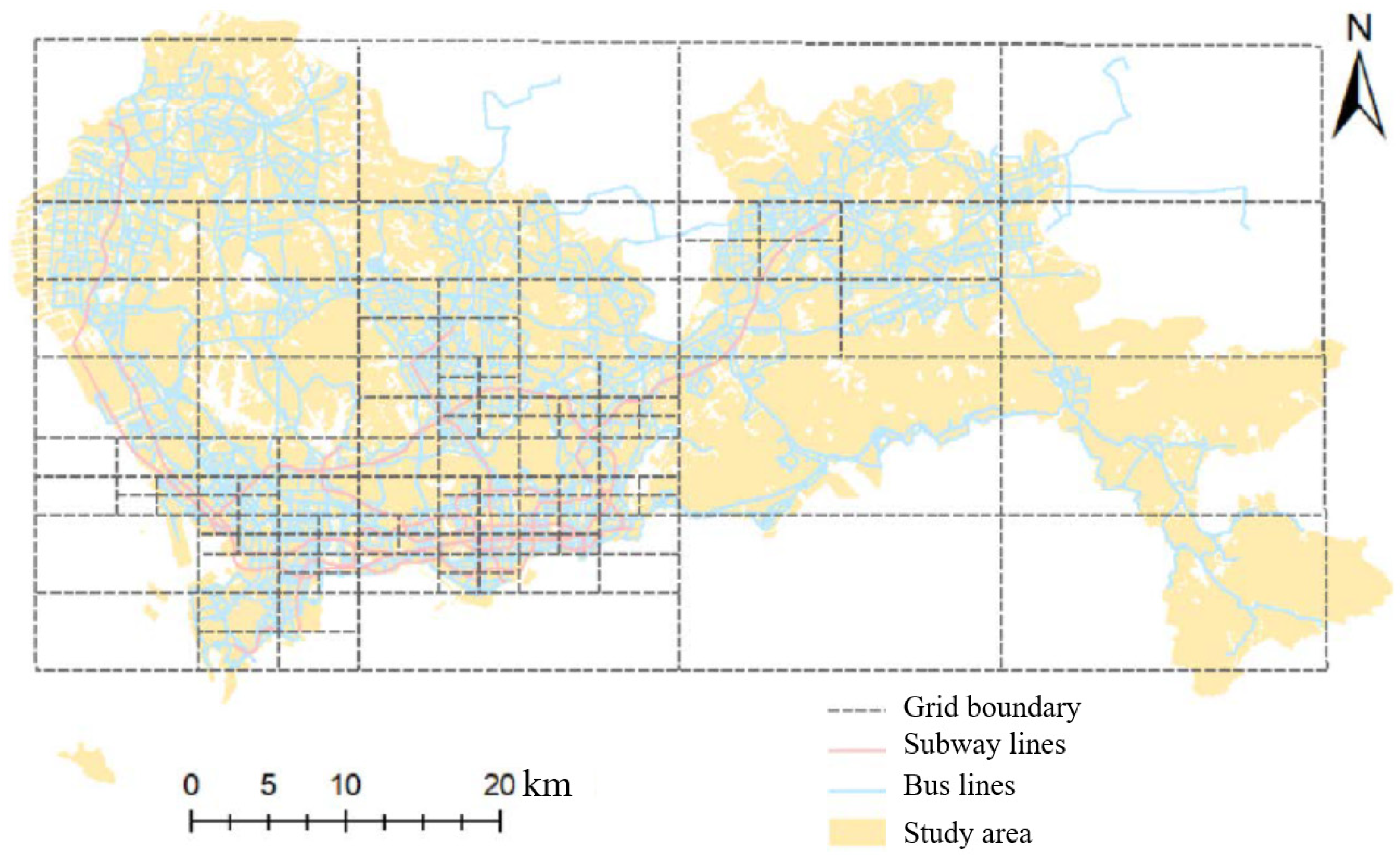
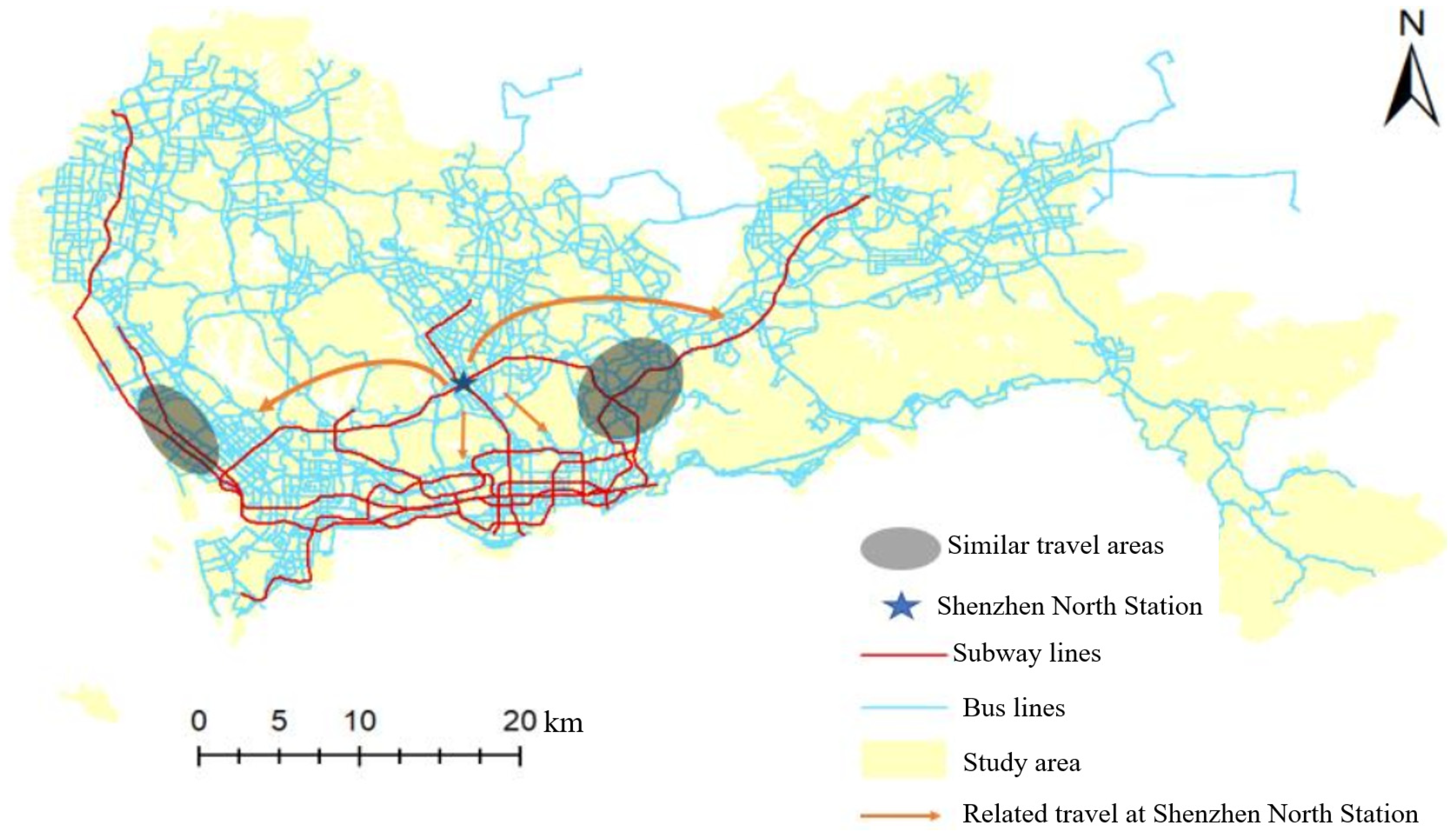
4.1. Data Description and Preprocessing
4.2. Indicator Description and Empirical Evaluation Configuration
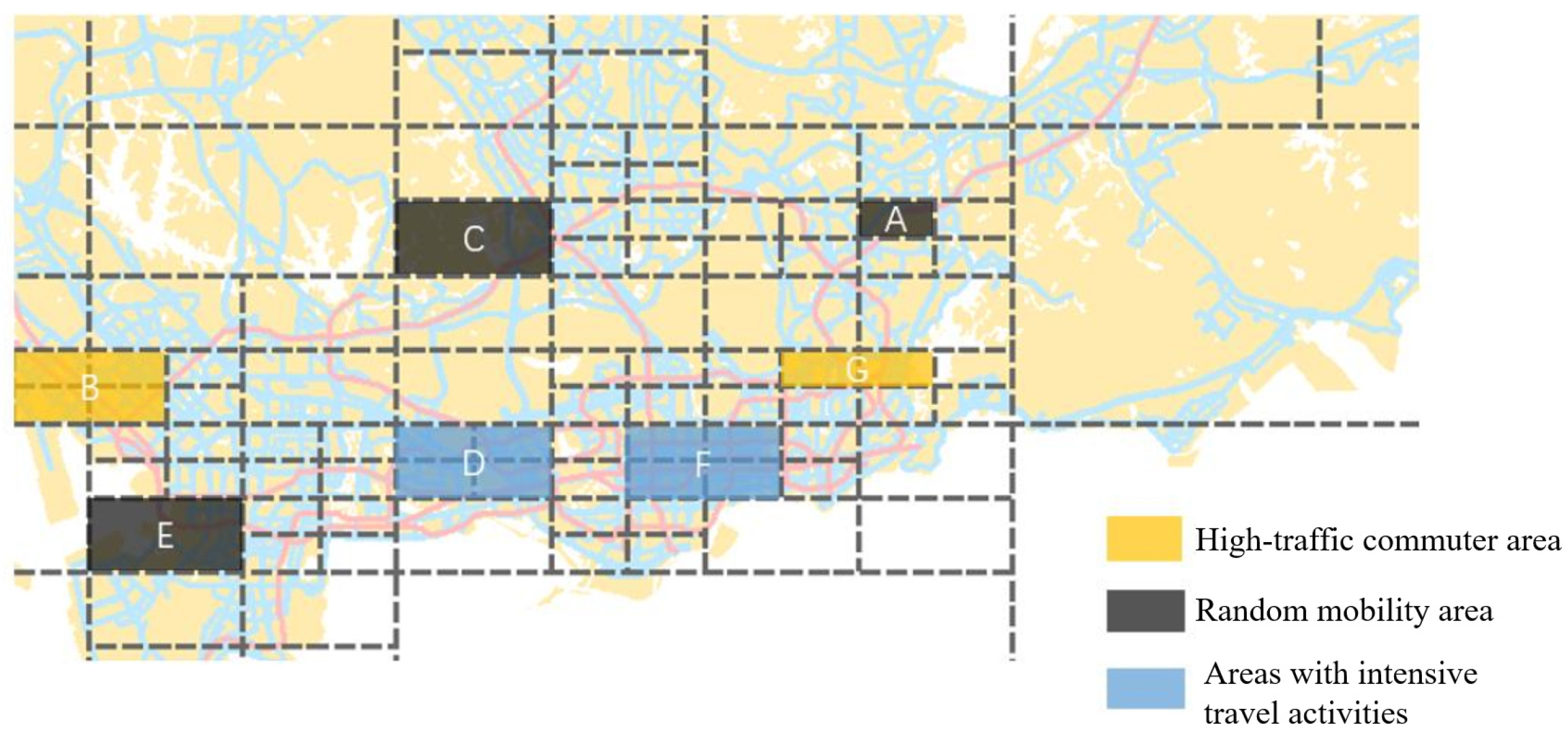
4.3. Cluster Analysis of Travel Spatiotemporal Patterns
4.4. Method Comparison and Analysis
- Proposed model (Ours): this model incorporates the full architecture, including the pre-trained sub-generator, as described in this study.
- Proposed model without sub-generator (OursD): This model is identical to the proposed model except for the omission of the pre-trained sub-generator. It serves to evaluate the impact of the sub-generator on the overall performance of the model.
- Autoencoder-based model (AE): This model uses a standard autoencoder structure, where both the encoder and decoder are composed of GRU layers and fully connected layers. The central embedding layer serves as a reference for the compact representation. The AE model is used to assess the effectiveness of conventional deep learning feature compression methods.
- Raw travel chain feature model (Raw): This model utilizes the raw travel chain features, as described in Section 3.2. Given that a passenger may take multiple trips, these are aggregated by averaging them to form a single composite vector. This model is used to validate the effectiveness of direct feature expression.
- Collaborative filtering (CF): this is a popular method used in recommendation systems, where the goal is to suggest items (e.g., products, services, or in this case, travel routes) based on the preferences of similar users.
- Spatiotemporal clustering (STC): This is a technique used to group data points based on both spatial (location) and temporal (time) dimensions. This method is particularly useful in contexts where data are influenced by both where an event occurs and when it happens, such as in urban transportation systems, weather patterns, or social media trends.
5. Conclusions and Discussion
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Li, Y.; Yang, G.; Su, Z.; Li, S.; Wang, Y. Human activity recognition based on multienvironment sensor data. Inf. Fusion 2023, 91, 47–63. [Google Scholar] [CrossRef]
- Barabási, A.-L. The origin of bursts and heavy tails in human dynamics. Nature 2005, 435, 207–211. [Google Scholar] [CrossRef]
- Brockmann, D.; Lars, H.; Theo, G. The scaling laws of human travel. Nature 2006, 439, 462–465. [Google Scholar] [CrossRef]
- Barbosa, H.; Barthelemy, M.; Ghoshal, G.; James, C.R.; Lenormand, M.; Louail, T.; Menezes, R.; Ramasco, J.J.; Simini, F.; Tomasini, M. Human mobility: Models and applications. Phys. Rep. 2018, 734, 1–74. [Google Scholar] [CrossRef]
- Shi, Y.; Zheng, Y.; Chen, D.; Yang, J.; Cao, Y.; Cui, A. Research on the Correlation between the Dynamic Distribution Patterns of Urban Population Density and Land Use Morphology Based on Human–Land Big Data: A Case Study of the Shanghai Central Urban Area. Land 2024, 13, 1547. [Google Scholar] [CrossRef]
- Ray, A.; Kolekar, M.H.; Balasubramanian, R.; Hafiane, A. Transfer learning enhanced vision-based human activity recognition: A decade-long analysis. Int. J. Inf. Manag. Data Insights 2022, 3, 100142. [Google Scholar] [CrossRef]
- Li, X.; Lu, Z. Spatiotemporal Evolution of Land Use Structure and Function in Rapid Urbanization: The Case of the Beijing–Tianjin–Hebei Region. Land 2024, 13, 1651. [Google Scholar] [CrossRef]
- Xu, Y.; Belyi, A.; Bojic, I.; Ratti, C. Human mobility and socioeconomic status: Analysis of Singapore and Boston. Comput. Environ. Urban Syst. 2018, 72, 51–67. [Google Scholar] [CrossRef]
- Song, C.; Qu, Z.; Blumm, N.; Barabási, A.-L. Limits of predictability in human mobility. Science 2010, 327, 1018–1021. [Google Scholar] [CrossRef]
- Zipf, G.K. The P 1 P 2/D hypothesis: On the intercity movement of persons. Am. Sociol. Rev. 1946, 11, 677–686. [Google Scholar] [CrossRef]
- Simini, F.; González, M.C.; Maritan, A.; Barabási, A.-L. A universal model for mobility and migration patterns. Nature 2012, 484, 96–100. [Google Scholar] [CrossRef] [PubMed]
- Masucci, A.P.; Serras, J.; Johansson, A.; Batty, M. Gravity versus radiation models: On the importance of scale and heterogeneity in commuting flows. Phys. Rev. E Stat. Nonlinear Soft Matter Phys. 2013, 88, 022812. [Google Scholar] [CrossRef] [PubMed]
- Gordon, J.B.; Koutsopoulos, H.N.; Wilson, N.H.M.; Attanucci, J.P. Automated inference of linked transit journeys in london using fare-transaction and vehicle location data. Transp. Res. Rec. 2013, 2343, 17–24. [Google Scholar] [CrossRef]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. Adv. Neural Inf. Process. Syst. 2013, 26, 1–9. [Google Scholar]
- Wang, P.; Fu, Y.; Xiong, H.; Li, X. Adversarial substructured representation learning for mobile user profiling. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019. [Google Scholar]
- Gao, Q.; Zhou, F.; Zhang, K.; Trajcevski, G.; Luo, X.; Zhang, F. Identifying Human Mobility via Trajectory Embeddings. Twenty-Sixth International Joint Conference on Artificial Intelligence. In Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence Melbourne Australia, 19–25 August 2017; Volume 17. [Google Scholar]
- Dai, Q.; Li, Q.; Tang, J.; Wang, D. Adversarial network embedding. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. No. 1. [Google Scholar]
- Gong, S.; Dong, X.; Wang, K.; Lei, B.; Jia, Z.; Qin, J.; Roadknight, C.; Liu, Y.; Cao, R. Agent-based modelling with geographically weighted calibration for intra-urban activities simulation using taxi GPS trajectories. Int. J. Appl. Earth Obs. Geoinf. 2023, 122, 103368. [Google Scholar] [CrossRef]
- Mor, M.; Dalyot, S.; Ram, Y. Who is a tourist? Classifying international urban tourists using machine learning. Tour. Manag. 2022, 95, 104689. [Google Scholar] [CrossRef]
- Primerano, F.; Taylor, M.A.; Pitaksringkarn, L.; Tisato, P. Defining and understanding trip chaining behavior. Transportation 2008, 35, 55–72. [Google Scholar] [CrossRef]
- Yang, H.; Wang, L.; Tang, F.; Fu, M.; Xiong, Y. Differences in Urban Vibrancy Enhancement among Different Mixed Land Use Types: Evidence from Shenzhen, China. Land 2024, 13, 1661. [Google Scholar] [CrossRef]
- Zhou, F.; Yin, R.; Zhang, K.; Trajcevski, G.; Zhong, T.; Wu, J. Adversarial point-of-interest recommendation. In Proceedings of the The World Wide Web Conference, Raleigh, NC, USA, 26–30 April 2010. [Google Scholar]
- Chen, C.; Liao, C.; Xie, X.; Wang, Y.; Zhao, J. Trip2Vec: A deep embedding approach for clustering and profiling taxi trip purposes. Pers. Ubiquitous Comput. 2018, 23, 53–66. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets, NIPS. 2014. Available online: https://proceedings.neurips.cc/paper_files/paper/2014/hash/5ca3e9b122f61f8f06494c97b1afccf3-Abstract.html (accessed on 10 October 2024).
- Wang, H.; Wang, J.; Wang, J.; Zhao, M.; Zhang, W.; Zhang, F.; Xie, X.; Guo, M. Graphgan: Graph representation learning with generative adversarial nets. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. No. 1. [Google Scholar]
- Zhou, F.; Yin, R.; Zhang, K.; Trajcevski, G.; Zhong, T.; Wu, J. Adversarial point-of-interest recommendation. In Proceedings of the WWW ‘19: The Web Conference, San Francisco, CA, USA, 13–17 May 2019. [Google Scholar]
- Gao, Q.; Zhang, F.; Yao, F.; Li, A.; Mei, L.; Zhou, F. Adversarial mobility learning for human trajectory classification. IEEE Access 2020, 8, 20563–20576. [Google Scholar] [CrossRef]
- Lasinio, G.J.; Santoro, M.; Mastrantonio, G. CircSpaceTime: An R package for spatial and spatio-temporal modelling of circular data. J. Stat. Comput. Simul. 2020, 90, 1315–1345. [Google Scholar] [CrossRef]
- Agrawal, R. Gast Algorithm for Mining Association Rules in Large Databases. In Proceedings of the 20th Very Large Data Bases Conference, Santiago de, Chile, Chile, 12–15 September 1994. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Number of Passengers | Average Travel Time (min) | Average Number of Stations Passed Through | Average Transfer Times | Random Passengers | Commuting Passengers | Short-Distance Passengers | Indeterminate Passengers |
|---|---|---|---|---|---|---|---|---|
| 1 | 2288 | 40.123 | 9.877 | 0.448 | 0.240 | 0.307 | 0.352 | 0.101 |
| 2 | 1839 | 42.516 | 11.183 | 0.662 | 0.557 | 0.214 | 0.141 | 0.088 |
| 3 | 5041 | 33.955 | 9.137 | 0.546 | 0.434 | 0.196 | 0.286 | 0.084 |
| 4 | 2002 | 34.208 | 9.266 | 0.531 | 0.433 | 0.202 | 0.262 | 0.103 |
| 5 | 681 | 35.169 | 9.488 | 0.543 | 0.423 | 0.206 | 0.268 | 0.103 |
| Sum | 11,851 | 36.587 | 9.639 | 0.542 | 0.415 | 0.222 | 0.271 | 0.092 |
| Category | Number of Passengers | Average Travel Time (min) | Average Number of Stations Passed Through | Average Transfer Times | Random Passengers | Commuting Passengers | Short-Distance Passengers | Indeterminate Passengers |
|---|---|---|---|---|---|---|---|---|
| 1 | 3506 | 42. 327 | 11.971 | 0.632 | 0.492 | 0.103 | 0.172 | 0.223 |
| 2 | 4233 | 30.387 | 8.812 | 0.491 | 0.371 | 0.172 | 0.349 | 0.108 |
| 3 | 3015 | 34. 835 | 9.712 | 0.552 | 0.432 | 0.227 | 0.212 | 0.129 |
| 4 | 857 | 35.208 | 9.466 | 0.551 | 0.411 | 0.213 | 0.258 | 0.118 |
| Sum | 11,611 | 35.503 | 10.047 | 0.554 | 0.426 | 0.168 | 0.253 | 0.149 |
| Category | Number of Passengers | Average Travel Time (min) | Average Number of Stations Passed Through | Average Transfer Times | Random Passengers | Commuting Passengers | Short-Distance Passengers | Indeterminate Passengers |
|---|---|---|---|---|---|---|---|---|
| 1 | 6001 | 36.395 | 9.568 | 0.523 | 0.414 | 0.233 | 0.263 | 0.089 |
| 2 | 1787 | 36.945 | 9.722 | 0.562 | 0.432 | 0.206 | 0.268 | 0.094 |
| 3 | 2277 | 36.917 | 9.773 | 0.561 | 0.416 | 0.196 | 0.286 | 0.102 |
| 4 | 768 | 35.499 | 9.351 | 0.541 | 0.393 | 0.243 | 0.274 | 0.089 |
| 5 | 1018 | 37.169 | 9.829 | 0.573 | 0.407 | 0.224 | 0.288 | 0.081 |
| Sum | 11,851 | 36.587 | 9.639 | 0.542 | 0.415 | 0.222 | 0.271 | 0.092 |
| Methods | AR (k = 3) | AP (k = 3) | AR (k = 5) | AP (k = 5) |
|---|---|---|---|---|
| Raw | 0.626 | 0.553 | 0.595 | 0.527 |
| AE | 0.637 | 0.551 | 0.609 | 0.531 |
| CF | 0.596 | 0.532 | 0.586 | 0.501 |
| STC | 0.620 | 0.544 | 0.598 | 0.529 |
| OursD | 0.707 | 0.594 | 0.674 | 0.562 |
| Ours | 0.723 | 0.637 | 0.709 | 0.581 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Duan, X.; Yang, J.; Yu, S.; Tian, Y. Integrating Spatiotemporal and Travel-Related Information for Accurate Urban Passenger Profiling Using GANs. Land 2024, 13, 2178. https://doi.org/10.3390/land13122178
Duan X, Yang J, Yu S, Tian Y. Integrating Spatiotemporal and Travel-Related Information for Accurate Urban Passenger Profiling Using GANs. Land. 2024; 13(12):2178. https://doi.org/10.3390/land13122178
Chicago/Turabian StyleDuan, Xiaoqi, Jianbing Yang, Sha Yu, and Youliang Tian. 2024. "Integrating Spatiotemporal and Travel-Related Information for Accurate Urban Passenger Profiling Using GANs" Land 13, no. 12: 2178. https://doi.org/10.3390/land13122178
APA StyleDuan, X., Yang, J., Yu, S., & Tian, Y. (2024). Integrating Spatiotemporal and Travel-Related Information for Accurate Urban Passenger Profiling Using GANs. Land, 13(12), 2178. https://doi.org/10.3390/land13122178