

A Proposed Methodology for Determining the Economically Optimal Number of Sample Points for Carbon Stock Estimation in the Canadian Prairies

Abstract
1. Introduction
2. Materials and Methods
2.1. Soil Data and Sampling Design
2.2. Environmental Covariates
2.3. Model Development
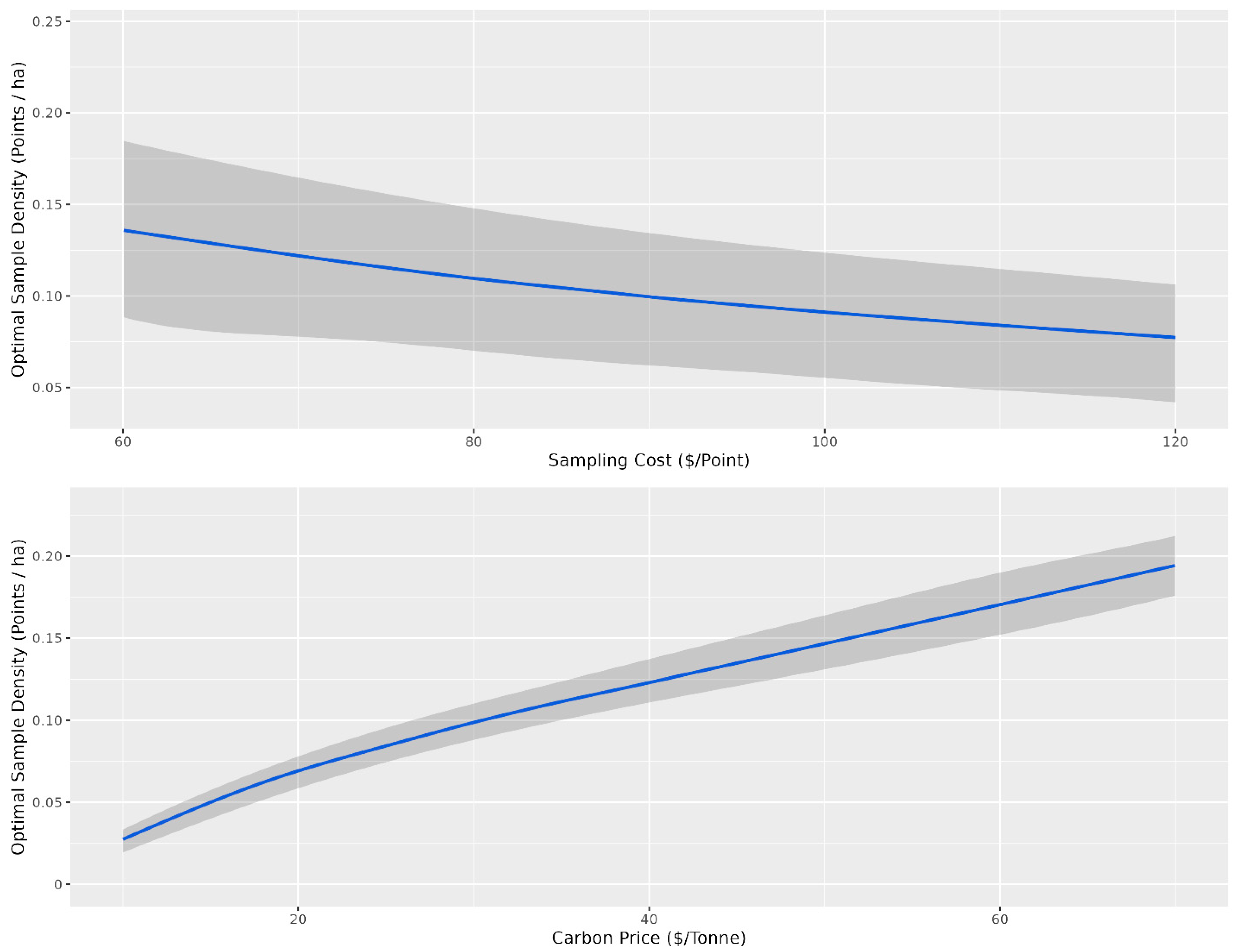
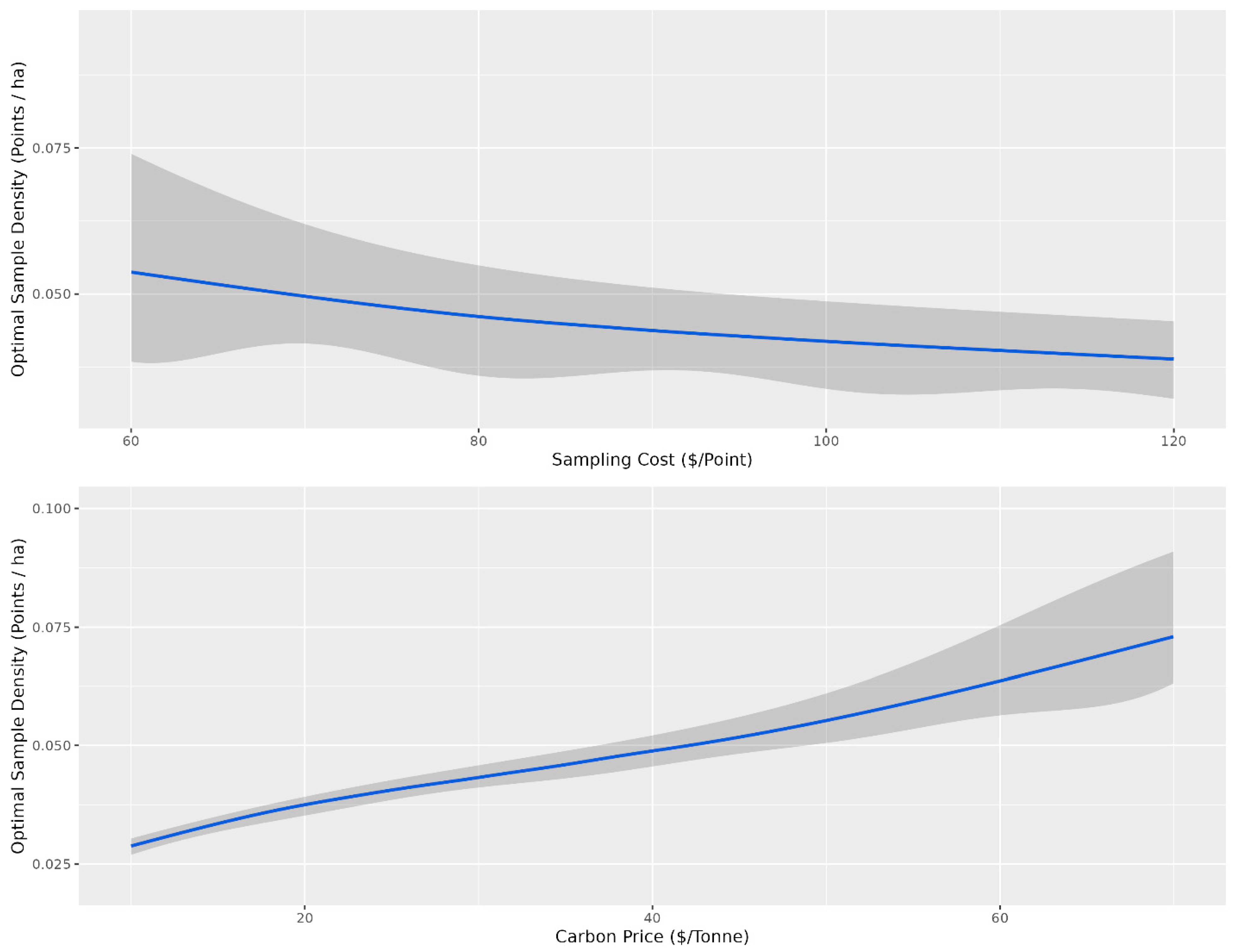
2.4. Cost–Benefit Analysis
- (1)
- Sampling cost is the cost to obtain a soil sample;
- (2)
- The n parameter is the number of soil samples;
- (3)
- Soil carbon stock error is the soil organic carbon stock error on a Mg ha−1 basis as a function of the number of samples;
- (4)
- Carbon price is the price of carbon the producer receives;
- (5)
- Total area is the total area of interest on a hectare basis.
2.5. Analysis of Statistically Optimal Number of Points
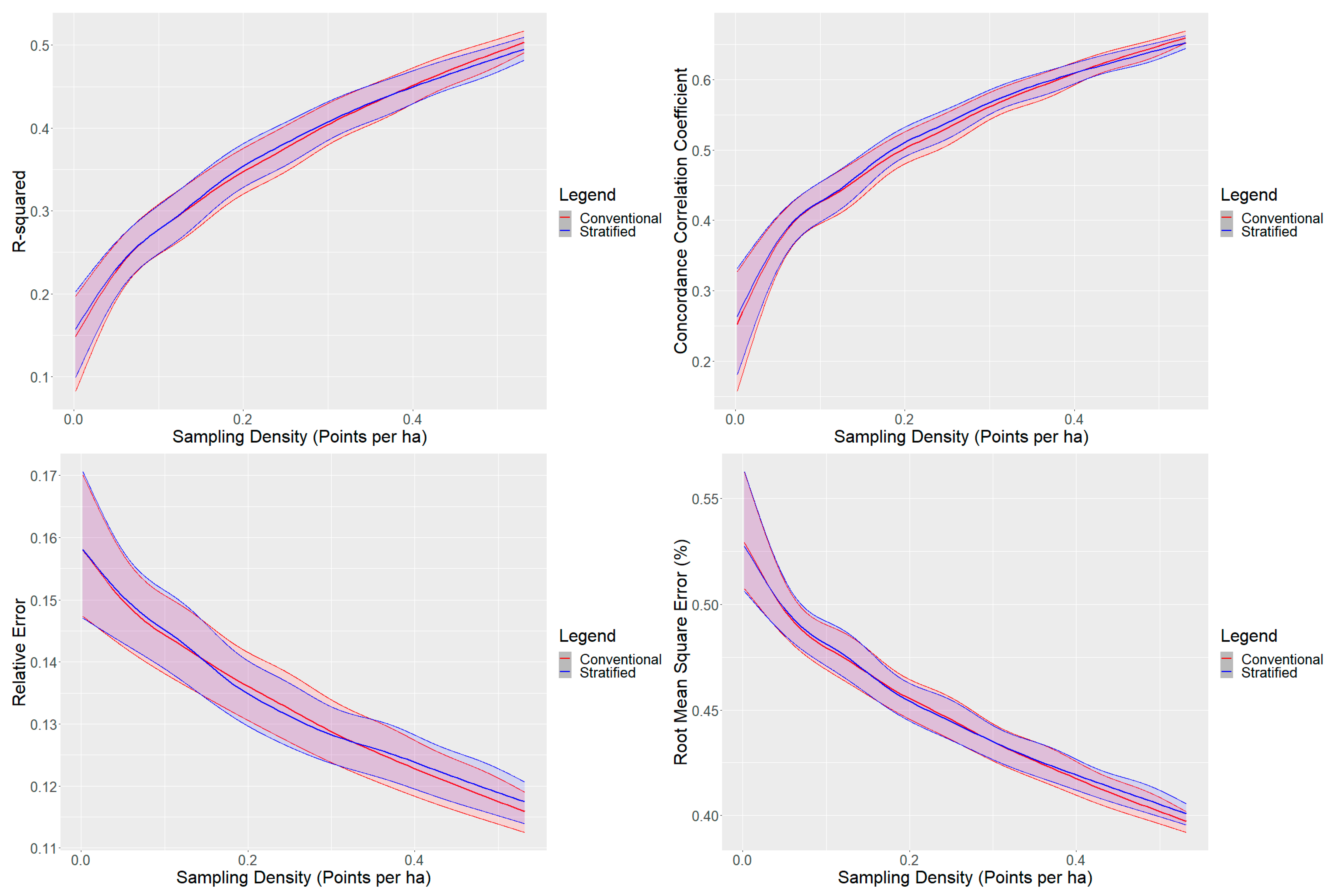
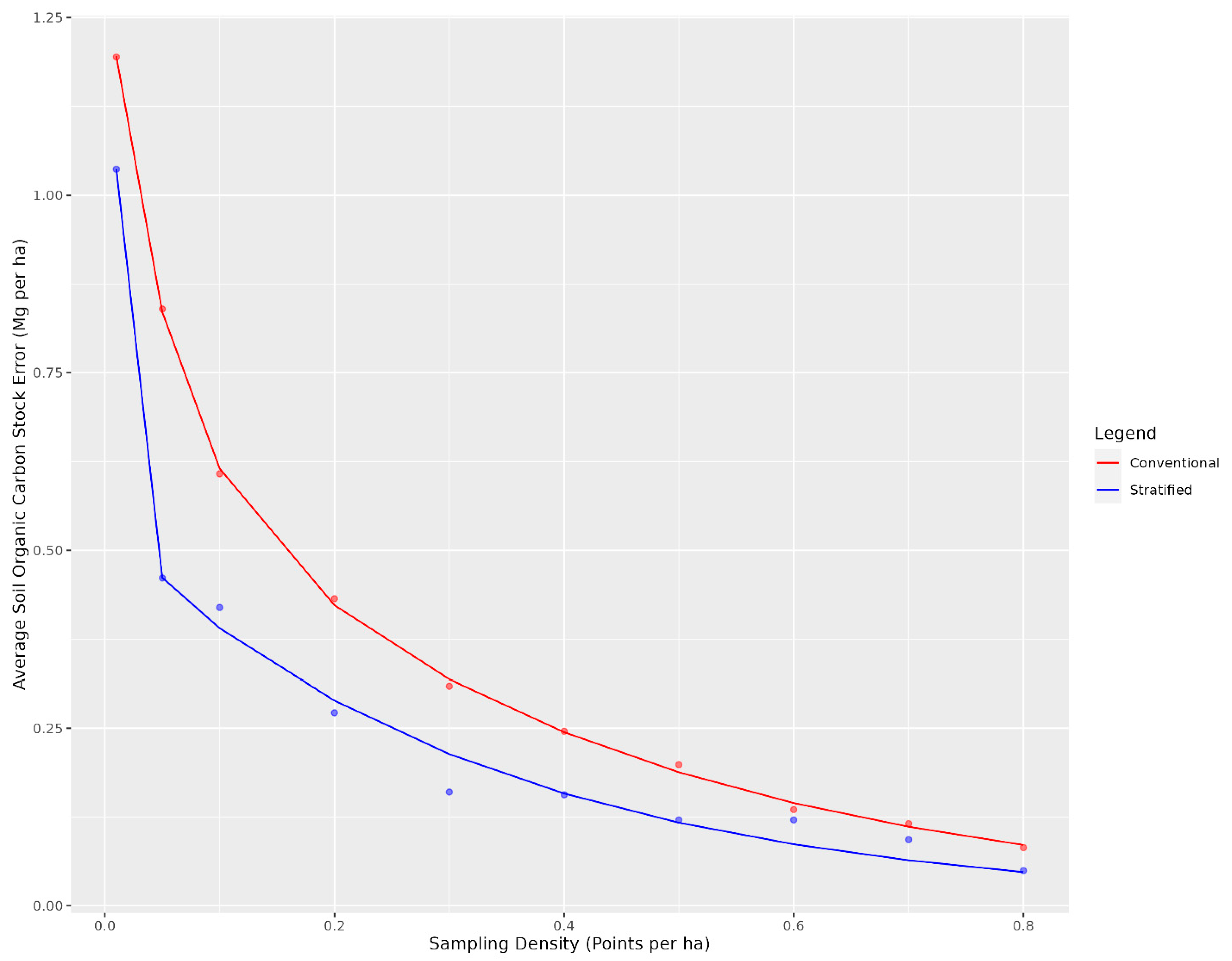
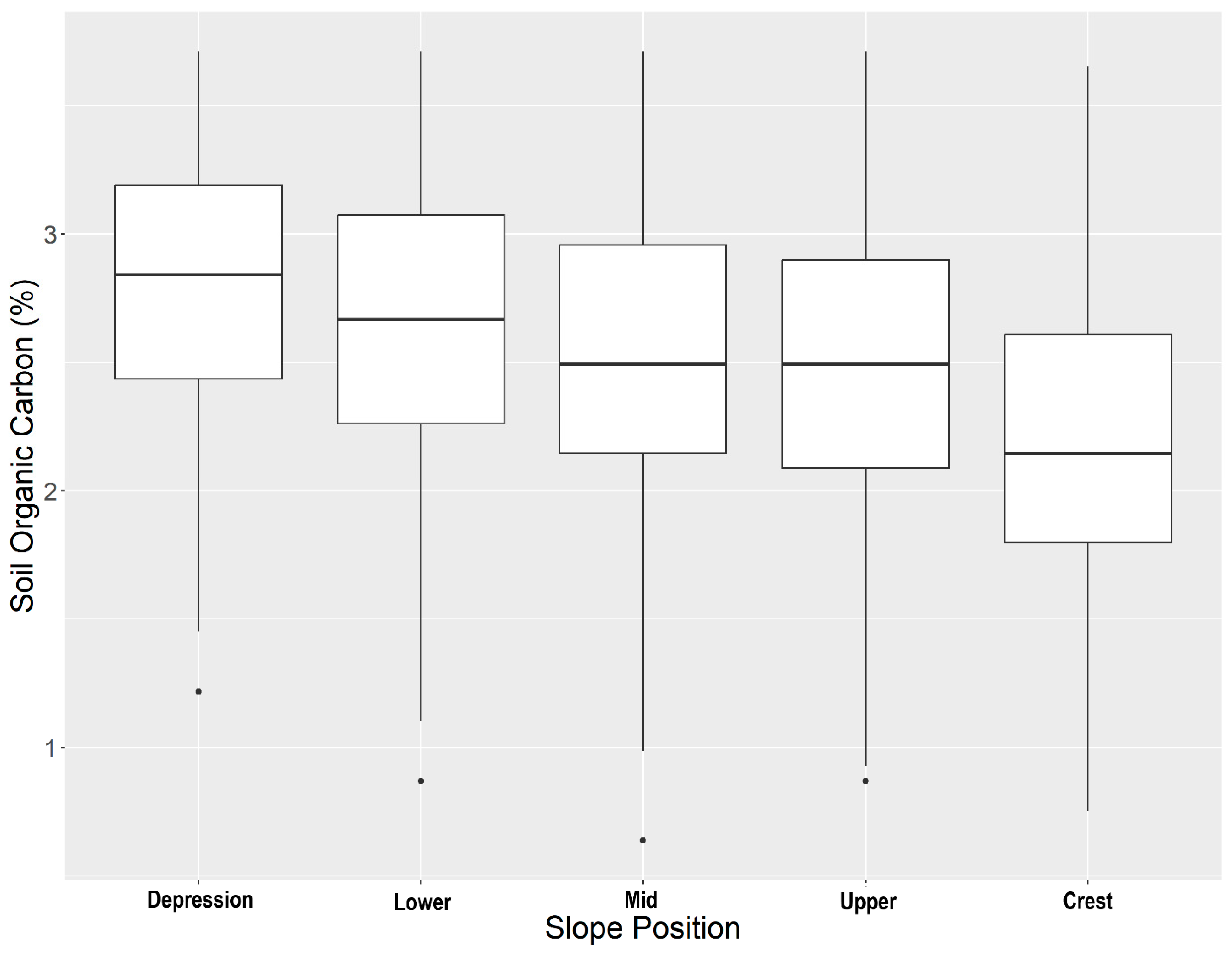
3. Results and Discussion
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Minasny, B.; Malone, B.P.; McBratney, A.B.; Angers, D.A.; Arrouays, D.; Chambers, A.; Chaplot, V.; Chen, Z.S.; Cheng, K.; Das, B.S.; et al. Soil Carbon 4 per Mille. Geoderma 2017, 292, 59–86. [Google Scholar] [CrossRef]
- Liddicoat, C.; Maschmedt, D.; Clifford, D.; Searle, R.; Herrmann, T.; MacDonald, L.M.; Baldock, J. Predictive Mapping of Soil Organic Carbon Stocks in South Australia’s Agricultural Zone. Soil Res. 2015, 53, 956–973. [Google Scholar] [CrossRef]
- Gomes, L.C.; Faria, R.M.; de Souza, E.; Veloso, G.V.; Schaefer, C.E.G.R.; Filho, E.I.F. Modelling and Mapping Soil Organic Carbon Stocks in Brazil. Geoderma 2019, 340, 337–350. [Google Scholar] [CrossRef]
- Lamichhane, S.; Kumar, L.; Wilson, B. Digital Soil Mapping Algorithms and Covariates for Soil Organic Carbon Mapping and Their Implications: A Review. Geoderma 2019, 352, 395–413. [Google Scholar] [CrossRef]
- Bartholomeus, H.; Kooistra, L.; Stevens, A.; van Leeuwen, M.; van Wesemael, B.; Ben-Dor, E.; Tychon, B. Soil Organic Carbon Mapping of Partially Vegetated Agricultural Fields with Imaging Spectroscopy. Int. J. Appl. Earth Obs. Geoinf. 2011, 13, 81–88. [Google Scholar] [CrossRef]
- Wang, S.; Zhuang, Q.; Wang, Q.; Jin, X.; Han, C. Mapping Stocks of Soil Organic Carbon and Soil Total Nitrogen in Liaoning Province of China. Geoderma 2017, 305, 250–263. [Google Scholar] [CrossRef]
- Sothe, C.; Gonsamo, A.; Arabian, J.; Snider, J. Large Scale Mapping of Soil Organic Carbon Concentration with 3D Machine Learning and Satellite Observations. Geoderma 2022, 405, 115402. [Google Scholar] [CrossRef]
- Black, C.; Brummit, C.; Campbell, N.; DuBuisson, M.; Harburg, D.; Matosziuk, L.; Motew, M.; Pinjuv, G.; Smith, E. Methodology for Improved Agricultural Land Management. 2023. Available online: https://verra.org/methodologies/vm0042-methodology-for-improved-agricultural-land-management-v2-0/ (accessed on 19 January 2024).
- McBratney, A.B.; Mendonça Santos, M.L.; Minasny, B. On Digital Soil Mapping. Geoderma 2003, 117, 3–52. [Google Scholar] [CrossRef]
- Mulder, V.L.; de Bruin, S.; Schaepman, M.E.; Mayr, T.R. The Use of Remote Sensing in Soil and Terrain Mapping—A Review. Geoderma 2011, 162, 1–19. [Google Scholar] [CrossRef]
- Dobos, E.; Micheli, E.; Baumgardner, M.F.; Biehl, L.; Helt, T. Use of Combined Digital Elevation Model and Satellite Radiometric Data for Regional Soil Mapping. Geoderma 2000, 97, 367–391. [Google Scholar] [CrossRef]
- Hengl, T.; Leenaars, J.G.B.; Shepherd, K.D.; Walsh, M.G.; Heuvelink, G.B.M.; Mamo, T.; Tilahun, H.; Berkhout, E.; Cooper, M.; Fegraus, E.; et al. Soil Nutrient Maps of Sub-Saharan Africa: Assessment of Soil Nutrient Content at 250 m Spatial Resolution Using Machine Learning. Nutr. Cycl. Agroecosyst. 2017, 109, 77–102. [Google Scholar] [CrossRef] [PubMed]
- Guevara, M.; Arroyo, C.; Brunsell, N.; Cruz, C.O.; Domke, G.; Equihua, J.; Etchevers, J.; Hayes, D.; Hengl, T.; Ibelles, A.; et al. Soil Organic Carbon Across Mexico and the Conterminous United States (1991–2010). Glob. Biogeochem. Cycles 2020, 34, e2019GB006219. [Google Scholar] [CrossRef]
- Hengl, T.; Mendes de Jesus, J.; Heuvelink, G.B.M.; Ruiperez Gonzalez, M.; Kilibarda, M.; Blagotić, A.; Shangguan, W.; Wright, M.N.; Geng, X.; Bauer-Marschallinger, B.; et al. SoilGrids250m: Global Gridded Soil Information Based on Machine Learning. PLoS ONE 2017, 12, e0169748. [Google Scholar] [CrossRef] [PubMed]
- Lacoste, M.; Mulder, V.L.; Saby, N.; Arrouays, D. High-Resolution Spatial Modelling of Total Soil Depth for France. Available online: https://www.researchgate.net/profile/Vl-Mulder/publication/269400505_High-resolution_spatial_modelling_of_total_soil_depth_for_France/links/5489ac0c0cf2d1800d7a9da3/High-resolution-spatial-modelling-of-total-soil-depth-for-France.pdf (accessed on 30 October 2023).
- Heung, B.; Bulmer, C.E.; Schmidt, M.G. Predictive Soil Parent Material Mapping at a Regional-Scale: A Random Forest Approach. Geoderma 2014, 214–215, 141–154. [Google Scholar] [CrossRef]
- Kasraei, B.; Heung, B.; Saurette, D.D.; Schmidt, M.G.; Bulmer, C.E.; Bethel, W. Quantile Regression as a Generic Approach for Estimating Uncertainty of Digital Soil Maps Produced from Machine-Learning. Environ. Model. Softw. 2021, 144, 105139. [Google Scholar] [CrossRef]
- Fathololoumi, S.; Vaezi, A.R.; Alavipanah, S.K.; Ghorbani, A.; Saurette, D.; Biswas, A. Improved Digital Soil Mapping with Multitemporal Remotely Sensed Satellite Data Fusion: A Case Study in Iran. Sci. Total Environ. 2020, 721, 137703. [Google Scholar] [CrossRef]
- Wadoux, A.M.J.C.; Minasny, B.; McBratney, A.B. Machine Learning for Digital Soil Mapping: Applications, Challenges and Suggested Solutions. Earth Sci. Rev. 2020, 210, 103359. [Google Scholar] [CrossRef]
- Pennock, D.J. Designing Field Studies in Soil Science. Can. J. Soil Sci. 2004, 84, 1–10. [Google Scholar] [CrossRef]
- Biswas, A.; Zhang, Y. Sampling Designs for Validating Digital Soil Maps: A Review. Pedosphere 2018, 28, 1–15. [Google Scholar] [CrossRef]
- Minasny, B.; McBratney, A.B. A Conditioned Latin Hypercube Method for Sampling in the Presence of Ancillary Information. Comput. Geosci. 2006, 32, 1378–1388. [Google Scholar] [CrossRef]
- Malone, B.P.; Minansy, B.; Brungard, C. Some Methods to Improve the Utility of Conditioned Latin Hypercube Sampling. PeerJ 2019, 7, e6451. [Google Scholar] [CrossRef]
- Saurette, D.D.; Biswas, A.; Heck, R.J.; Gillespie, A.W.; Berg, A.A. Determining Minimum Sample Size for the Conditioned Latin Hypercube Sampling Algorithm. Pedosphere 2022. in press. [Google Scholar] [CrossRef]
- Yang, L.; Li, X.; Shi, J.; Shen, F.; Qi, F.; Gao, B.; Chen, Z.; Zhu, A.X.; Zhou, C. Evaluation of Conditioned Latin Hypercube Sampling for Soil Mapping Based on a Machine Learning Method. Geoderma 2020, 369, 114337. [Google Scholar] [CrossRef]
- Godinho Silva, S.H.; Owens, P.R.; Silva, B.M.; César de Oliveira, G.; Duarte de Menezes, M.; Pinto, L.C.; Curi, N. Evaluation of Conditioned Latin Hypercube Sampling as a Support for Soil Mapping and Spatial Variability of Soil Properties. Soil Sci. Soc. Am. J. 2015, 79, 603–611. [Google Scholar] [CrossRef]
- Ma, T.; Brus, D.J.; Zhu, A.-X.; Zhang, L.; Scholten, T. Comparison of Conditioned Latin Hypercube and Feature Space Coverage Sampling for Predicting Soil Classes Using Simulation from Soil Maps. Geoderma 2020, 370, 114366. [Google Scholar] [CrossRef]
- Wadoux, A.M.J.C.; Brus, D.J.; Heuvelink, G.B.M. Sampling Design Optimization for Soil Mapping with Random Forest. Geoderma 2019, 355, 113913. [Google Scholar] [CrossRef]
- Zhu, A.X.; Liu, J.; Du, F.; Zhang, S.J.; Qin, C.Z.; Burt, J.; Behrens, T.; Scholten, T. Predictive Soil Mapping with Limited Sample Data. Eur. J. Soil Sci. 2015, 66, 535–547. [Google Scholar] [CrossRef]
- Titia, V.L. Digital Soil Mapping; Boettinger, J.L., Howell, D.W., Moore, A.C., Hartemink, A.E., Kienast-Brown, S., Eds.; Springer: Dordrecht, The Netherlands, 2010; ISBN 978-90-481-8862-8. [Google Scholar]
- Stumpf, F.; Schmidt, K.; Behrens, T.; Schönbrodt-Stitt, S.; Buzzo, G.; Dumperth, C.; Wadoux, A.; Xiang, W.; Scholten, T.; Schönbrodt-Stitt, S.; et al. Incorporating Limited Field Operability and Legacy Soil Samples in a Hypercube Sampling Design for Digital Soil Mapping. J. Plant Nutr. Soil Sci. 2016, 179, 499–509. [Google Scholar] [CrossRef]
- Saurette, D.D.; Heck, R.J.; Gillespie, A.W.; Berg, A.A.; Biswas, A. Divergence Metrics for Determining Optimal Training Sample Size in Digital Soil Mapping. Geoderma 2023, 436, 116553. [Google Scholar] [CrossRef]
- Kollmuss, A.; Lazarus, M. Discounting Offsets: Issues and Options. Carbon Manag. 2011, 2, 539–549. [Google Scholar] [CrossRef]
- SKSIS Working Group Saskatchewan Soil Information System–SKSIS. Available online: https://soilsofsask.ca/saskatchewan-soil-information-system.php (accessed on 2 May 2021).
- LaZerte, S.E.; Albers, S. Weathercan: Download and Format Weather Data from Environment and Climate Change Canada. J. Open Source Softw. 2018, 3, 571. [Google Scholar] [CrossRef]
- Kiss, J.; Bedard-Haughn, A.; Sorenson, P. Predictive Mapping of Wetland Soil Types in the Canadian Prairie Pothole Region Using High-Resolution Digital Elevation Model Terrain Derivatives. Can. J. Soil Sci. 2022, 103, 21–46. [Google Scholar] [CrossRef]
- Carter, M.R.; Gregorich, E.G. (Eds.) Soil Sampling and Methods of Analysis; CRC Press: Boca Raton, FL, USA, 2007; ISBN 9780429126222. [Google Scholar]
- Agriculture and Agri-Food Canada National Pedon Database. Available online: https://open.canada.ca/data/en/dataset/6457fad6-b6f5-47a3-9bd1-ad14aea4b9e0 (accessed on 16 February 2021).
- Stanley, P.; Spertus, J.; Chiartas, J.; Stark, P.B.; Bowles, T. Valid Inferences about Soil Carbon in Heterogeneous Landscapes. Geoderma 2023, 430, 116323. [Google Scholar] [CrossRef]
- Roudier, P. Clhs: A R Package for Conditioned Latin Hypercube Sampling. 2011. Available online: https://cran.r-project.org/web/packages/clhs/clhs.pdf (accessed on 30 October 2023).
- Boehner, J.; Selige, T. Spatial Prediction of Soil Attributes Using Terrain Analysis and Climate Regionalisation. In SAGA–Analyses and Modelling Applications; Boehner, J., McCloy, K.R., Strobl, J., Eds.; Göttinger Geographische Abhandlungen; Universität Göttingen: Göttingen, Germany, 2006; pp. 13–27. [Google Scholar]
- Brenning, A.; Bangs, D.; Becker, M. RSAGA: SAGA Geoprocessing and Terrain Analysis. 2018. Available online: https://cran.r-project.org/web/packages/RSAGA/index.html (accessed on 30 October 2023).
- Gorelick, N.; Hancher, M.; Dixon, M.; Ilyushchenko, S.; Thau, D.; Moore, R. Google Earth Engine: Planetary-Scale Geospatial Analysis for Everyone. Remote Sens. Environ. 2017, 202, 18–27. [Google Scholar] [CrossRef]
- Sorenson, P.T.; Shirtliffe, S.J.; Bedard-Haughn, A.K. Predictive Soil Mapping Using Historic Bare Soil Composite Imagery and Legacy Soil Survey Data. Geoderma 2021, 401, 115316. [Google Scholar] [CrossRef]
- Gallant, J.C.; Dowling, T.I. A Multiresolution Index of Valley Bottom Flatness for Mapping Depositional Areas. Water Resour. Res. 2003, 39, 1347. [Google Scholar] [CrossRef]
- Sorenson, P. Google Earth Engine Scripts for Generating Predictive Soil Mapping Environmental Covariates. Available online: https://github.com/prestonsorenson/Google_Earth_Engine_PSM/tree/main (accessed on 15 August 2021).
- Stevens, A.; Ramirez-Lopez, L. An Introduction to the Prospectr Package. 2014. Available online: https://cran.r-project.org/web/packages/prospectr/vignettes/prospectr.html (accessed on 30 October 2023).
- Sorenson, P.T.; Kiss, J.; Serdetchnaia, A.; Iqbal, J.; Bedard-Haughn, A.K. Predictive Soil Mapping in the Boreal Plains of Northern Alberta by Using Multi-Temporal Remote Sensing Data and Terrain Derivatives. Can. J. Soil Sci. 2022, 102, 852–866. [Google Scholar] [CrossRef]
- Wright, M.N.; Ziegler, A. Ranger: A Fast Implementation of Random Forests for High Dimensional Data in C++ and R. J. Stat. Softw. 2017, 77, 1–17. [Google Scholar] [CrossRef]
- Pinheiro, J.; Bates, D. nlme: Linear and Nonlinear Mixed Effects Models. 2022. Available online: https://cran.r-project.org/web/packages/nlme/nlme.pdf (accessed on 30 October 2023).
- R Core Team R: A Language and Environment for Statistical Computing. 2018. Available online: https://www.gbif.org/tool/81287/r-a-language-and-environment-for-statistical-computing (accessed on 30 October 2023).
- Indigo Agriculture. Carbon by Indigo Farmers Receive Second Carbon Farming Payment. Available online: https://www.indigoag.com/pages/news/carbon-by-indigo-farmers-receive-second-carbon-farming-payment (accessed on 30 October 2023).
- Saurette, D. Opendsm. Available online: https://github.com/newdale/opendsm (accessed on 18 December 2023).
- Landi, A.; Mermut, A.R.; Anderson, D.W. Carbon Distribution in a Hummocky Landscape from Saskatchewan, Canada. Soil Sci. Soc. Am. J. 2004, 68, 175–184. [Google Scholar] [CrossRef]
- Pennock, D.; Bedard-Haughn, A.; Kiss, J.; van der Kamp, G. Application of Hydropedology to Predictive Mapping of Wetland Soils in the Canadian Prairie Pothole Region. Geoderma 2014, 235–236, 199–211. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Min | 25th Percentile | Median | 75th Percentile | Max |
|---|---|---|---|---|---|
| Soil organic carbon (%) | 0.64 | 2.09 | 2.49 | 2.96 | 3.71 |
| Mean | Standard Deviation | Coefficient of Variation | Kurtosis | Skewness | |
| 2.52 | 0.59 | 0.23 | 2.44 | −0.01 |
| Feature | Date |
|---|---|
| Sentinel-2 bare soil composite imagery ● Band 8 (near infrared) ● Band 11 (shortwave infrared 1) ● Band 12 (shortwave infrared 2) | Median of bare soil pixels from April to October from 2017 to 2022. |
| Sentinel-2 imagery ● Band 2 (blue) ● Band 3 (green) ● Band 4 (red) ● Band 5 (red edge 1) ● Band 6 (red edge 2) ● Band 7 (red edge 3) ● Band 8 (near infrared) ● Band 8a (red edge 4) ● Band 11 (shortwave infrared 1) ● Band 12 (shortwave infrared 2) | Median of pixels from May to October from 2017 to 2022. |
| Normalized difference vegetation index derived from Sentinel-2 imagery ● May-to-October NDVI ● May NDVI ● June NDVI ● July NDVI ● August NDVI ● September NDVI ● October NDVI ● Max NDVI minus minimum NDVI ● Standard deviation of NDVI | Median of pixels from May to October from 2017 to 2022. |
| Sentinel-1 Data ● Vertical–vertical polarization (VV) ● Vertical–horizontal polarization (VH) ● Normalized difference of VV and VH polarizations | Median of pixels from May to October from 2017 to 2022. |
| Terrain attributes ● Normalized height [41] ● Slope height [41] ● Saga wetness index [41] ● Multiresolution ridge top flatness index [45] ● Multiresolution valley bottom flatness [45] ● Plan curvature ● Profile curvature | Derived from light detection and ranging digital elevation model. The original DEM resolution was 0.5 m, and it was resampled to 5 m. |
| Slope Position | Value | Standard Error | t-Value | p-Value | |
|---|---|---|---|---|---|
| Overall | Intercept | 0.37 | 0.0008 | 459.63 | <0.01 |
| Type: Stratified | 0.002 | 0.0005 | 3.39 | <0.01 | |
| Depression | Intercept | 0.27 | 0.0003 | 678.68 | <0.01 |
| Type: Stratified | 0.05 | 0.0005 | 92.10 | <0.01 | |
| Lower slope | Intercept | 0.24 | 0.0008 | 277.14 | <0.01 |
| Type: Stratified | −0.03 | 0.001 | −24.45 | <0.01 | |
| Mid-slope | Intercept | 0.30 | 0.0005 | 565.07 | <0.01 |
| Type: Stratified | 0.004 | 0.0006 | 6.56 | <0.01 | |
| Upper slope | Intercept | 0.35 | 0.0005 | 693.31 | <0.01 |
| Type: Stratified | −0.004 | 0.006 | −7.37 | <0.01 | |
| Crest | Intercept | 0.44 | 0.0008 | 535.06 | <0.01 |
| Type: Stratified | −0.01 | 0.0009 | −9.88 | <0.01 |
| Percent Confidence | Minimum (Samples/Density) | Mean (Samples/Density) | Median (Samples/Density) | Maximum (Samples/Density) | Standard Deviation (Samples/Density) |
|---|---|---|---|---|---|
| 90 | 92/0.02 | 438/0.09 | 327/0.07 | 1089/0.23 | 287/0.06 |
| 95 | 92/0.02 | 578/0.12 | 428/0.09 | 1783/0.37 | 425/0.09 |
| 99 | 92/0.02 | 1819/0.38 | 695/0.15 | 13151/2.80 | 2821/0.60 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sorenson, P.T.; Kiss, J.; Bedard-Haughn, A. A Proposed Methodology for Determining the Economically Optimal Number of Sample Points for Carbon Stock Estimation in the Canadian Prairies. Land 2024, 13, 114. https://doi.org/10.3390/land13010114
Sorenson PT, Kiss J, Bedard-Haughn A. A Proposed Methodology for Determining the Economically Optimal Number of Sample Points for Carbon Stock Estimation in the Canadian Prairies. Land. 2024; 13(1):114. https://doi.org/10.3390/land13010114
Chicago/Turabian StyleSorenson, Preston Thomas, Jeremy Kiss, and Angela Bedard-Haughn. 2024. "A Proposed Methodology for Determining the Economically Optimal Number of Sample Points for Carbon Stock Estimation in the Canadian Prairies" Land 13, no. 1: 114. https://doi.org/10.3390/land13010114
APA StyleSorenson, P. T., Kiss, J., & Bedard-Haughn, A. (2024). A Proposed Methodology for Determining the Economically Optimal Number of Sample Points for Carbon Stock Estimation in the Canadian Prairies. Land, 13(1), 114. https://doi.org/10.3390/land13010114