Figure 1.
Remote sensing panoramic images of Lake Urmia 2022 (from Google Earth Pro).
Figure 1.
Remote sensing panoramic images of Lake Urmia 2022 (from Google Earth Pro).
Figure 2.
Remote sensing panoramic historical images of Lake Urmia from 1996 to 2014 (image from Google Earth Pro Software).
Figure 2.
Remote sensing panoramic historical images of Lake Urmia from 1996 to 2014 (image from Google Earth Pro Software).
Figure 3.
Remote sensing partial historical images of Lake Urmia from 2000 to 2014 (image from Google Earth Pro Software).
Figure 3.
Remote sensing partial historical images of Lake Urmia from 2000 to 2014 (image from Google Earth Pro Software).
Figure 4.
Results of image segmentation and image binarization of remote sensing images of Lake Urmia in 2000.
Figure 4.
Results of image segmentation and image binarization of remote sensing images of Lake Urmia in 2000.
Figure 5.
Partial results of the 2000 binarization image of Lake Urmia after erosion. (a) The result of the 10th erosion; (b) the result of the 30th erosion; (c) the result of the 50th erosion.
Figure 5.
Partial results of the 2000 binarization image of Lake Urmia after erosion. (a) The result of the 10th erosion; (b) the result of the 30th erosion; (c) the result of the 50th erosion.
Figure 6.
Partial difference image after erosion of binarization image of Lake Urmia in 2000. (a) The image of the difference between the 9th erosion and the 10th erosion results; (b) the image of the difference between the 29th and 30th erosion results; (c) the image of the difference between the 49th and 50th erosion results.
Figure 6.
Partial difference image after erosion of binarization image of Lake Urmia in 2000. (a) The image of the difference between the 9th erosion and the 10th erosion results; (b) the image of the difference between the 29th and 30th erosion results; (c) the image of the difference between the 49th and 50th erosion results.
Figure 7.
U-Net-STN model prediction process.
Figure 7.
U-Net-STN model prediction process.
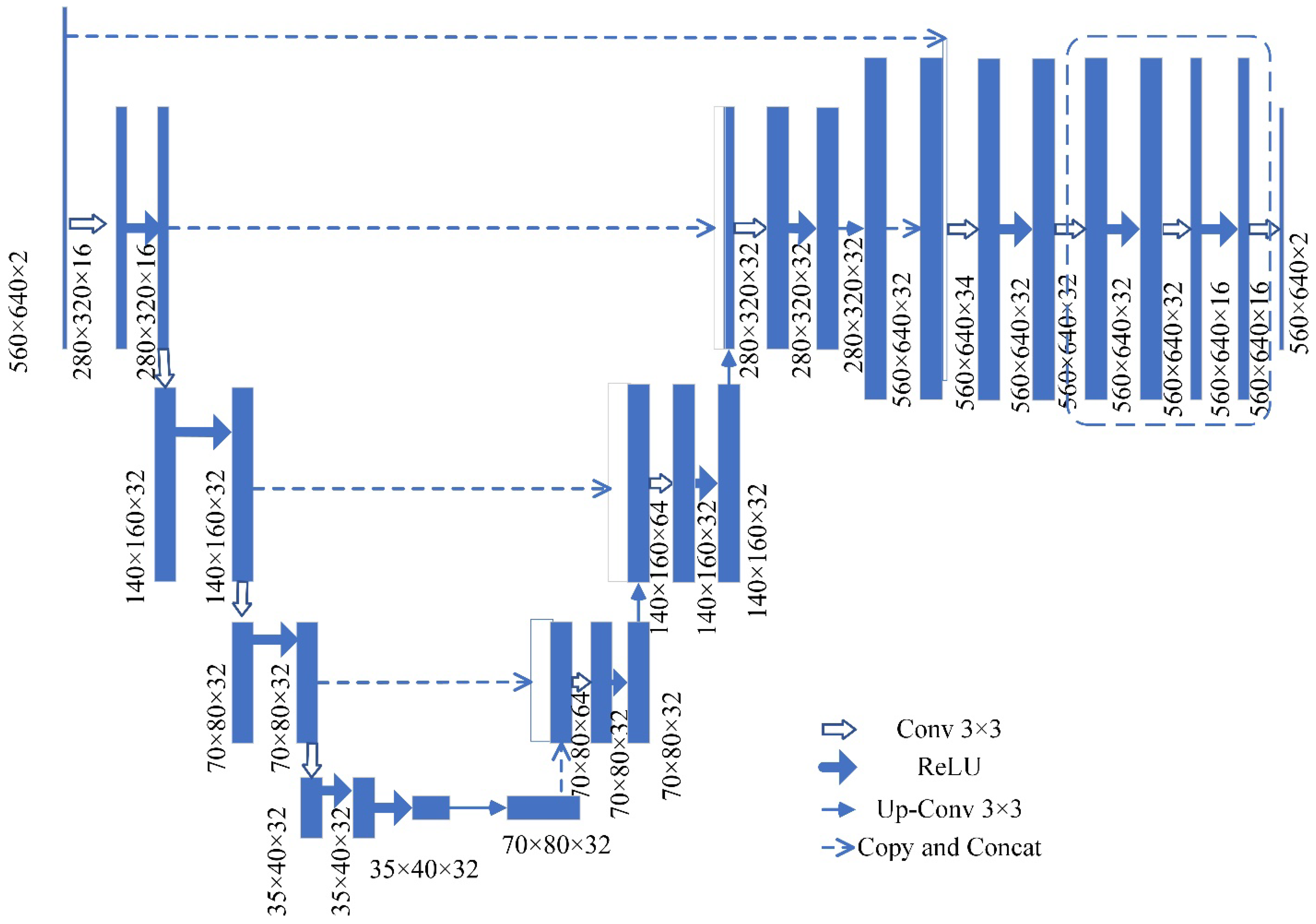
Figure 8.
U-Net structure diagram.
Figure 8.
U-Net structure diagram.
Figure 9.
Network structure diagram of the evolutionary feature extraction module.
Figure 9.
Network structure diagram of the evolutionary feature extraction module.
Figure 10.
Schematic diagram of prediction flow of spatial transformation module.
Figure 10.
Schematic diagram of prediction flow of spatial transformation module.
Figure 11.
Schematic diagram of DICE indicator calculation.
Figure 11.
Schematic diagram of DICE indicator calculation.
Figure 12.
Comparison results of regularization parameter of evolution field: (a,b) are the true images of 2013 and 2014, respectively; (c,d) is the prediction of 2014 when is 0.01 and 0.1, respectively.
Figure 12.
Comparison results of regularization parameter of evolution field: (a,b) are the true images of 2013 and 2014, respectively; (c,d) is the prediction of 2014 when is 0.01 and 0.1, respectively.
Figure 13.
Comparison of prediction result of Experiment 1. (a) Difference image between (b,c); (b) prediction results using data from the first 2 years; (c) ground truth image for the year 2001; (d) prediction results using data from the first 5 years; (e) difference image between (d,c); (f) difference image between (g,h); (g) prediction results using data from the first 2 years; (h) ground truth image for the year 2006; (i) prediction results using data from the first 12 years; (j) difference image between (i,h); (k) difference image between (l,m); (l) prediction results using data from the first 2 years; (m) ground truth image for the year 2011; (n) prediction results using data from the first 15 years; (o) difference image between (n,m).
Figure 13.
Comparison of prediction result of Experiment 1. (a) Difference image between (b,c); (b) prediction results using data from the first 2 years; (c) ground truth image for the year 2001; (d) prediction results using data from the first 5 years; (e) difference image between (d,c); (f) difference image between (g,h); (g) prediction results using data from the first 2 years; (h) ground truth image for the year 2006; (i) prediction results using data from the first 12 years; (j) difference image between (i,h); (k) difference image between (l,m); (l) prediction results using data from the first 2 years; (m) ground truth image for the year 2011; (n) prediction results using data from the first 15 years; (o) difference image between (n,m).
Figure 14.
Experiment 2 predictive results comparative diagram. (a) Difference image for (b,c); (b) predicted results using data from the first 2 years; (c) ground truth image for the year 2010; (d) predicted results using data from the first 5 years; (e) difference image between (d,c); (f) difference image between (g,h); (g) predicted results using data from the first 2 years; (h) ground truth image for the year 2011; (i) predicted results using data from the first 6 years; (j) difference image between (i,h); (k) difference image between (l,m); (l) predicted results using data from the first 2 years; (m) ground truth image for the year 2012; (n) predicted results using data from the first 7 years; (o) difference image between (n,m).
Figure 14.
Experiment 2 predictive results comparative diagram. (a) Difference image for (b,c); (b) predicted results using data from the first 2 years; (c) ground truth image for the year 2010; (d) predicted results using data from the first 5 years; (e) difference image between (d,c); (f) difference image between (g,h); (g) predicted results using data from the first 2 years; (h) ground truth image for the year 2011; (i) predicted results using data from the first 6 years; (j) difference image between (i,h); (k) difference image between (l,m); (l) predicted results using data from the first 2 years; (m) ground truth image for the year 2012; (n) predicted results using data from the first 7 years; (o) difference image between (n,m).
Figure 15.
The time series image prediction results. (a) Prediction of 2014 using previous 4 years’ data; (b) prediction of 2014 using previous 7 years’ data; (c) prediction of 2014 using previous 10 years’ data; (d) prediction of 2014 using previous 14 years’ data; (e) prediction of 2014 using previous 18 years’ data; (f) the difference image between (a) and true 2014 image; (g) the difference image between (b) and true 2014 image; (h) the difference image between (c) and true 2014 image; (i) the difference image between (d) and true 2014 image; (j) the difference image between (e) and true 2014 image.
Figure 15.
The time series image prediction results. (a) Prediction of 2014 using previous 4 years’ data; (b) prediction of 2014 using previous 7 years’ data; (c) prediction of 2014 using previous 10 years’ data; (d) prediction of 2014 using previous 14 years’ data; (e) prediction of 2014 using previous 18 years’ data; (f) the difference image between (a) and true 2014 image; (g) the difference image between (b) and true 2014 image; (h) the difference image between (c) and true 2014 image; (i) the difference image between (d) and true 2014 image; (j) the difference image between (e) and true 2014 image.
Figure 16.
The relationship between ACC, DICE, MSE, and time step n.
Figure 16.
The relationship between ACC, DICE, MSE, and time step n.
Figure 17.
The time series prediction results. (a) Prediction of 2014 using previous 5 years’ data; (b) prediction of 2014 using previous 6 years’ data; (c) prediction of 2014 using previous 7 years’ data; (d) prediction of 2014 using previous 8 years’ data; (e) the difference image between (a) and true 2014 image; (f) the difference image between (b) and true 2014 image; (g) the difference image between (c) and true 2014 image; (h) the difference image between (d) and true 2014 image.
Figure 17.
The time series prediction results. (a) Prediction of 2014 using previous 5 years’ data; (b) prediction of 2014 using previous 6 years’ data; (c) prediction of 2014 using previous 7 years’ data; (d) prediction of 2014 using previous 8 years’ data; (e) the difference image between (a) and true 2014 image; (f) the difference image between (b) and true 2014 image; (g) the difference image between (c) and true 2014 image; (h) the difference image between (d) and true 2014 image.
Figure 18.
Comparison of experimental results using pre-processed images and original images: (a) pre-processed ground truth image for the year 2014; (b) predicted results using pre-processed images from 5 years; (c) difference image between (a,b); (d) predicted results using pre-processed images from 9 years; (e) difference image between (a,d); (f) predicted results using pre-processed images from 13 years; (g) difference image between (a,f); (h) original ground truth image for the year 2014; (i) predicted results using original images from 5 years; (j) difference image between (h,i); (k) predicted results using original images from 9 years; (l) difference image between (h,k); (m) predicted results using original images from 13 years; (n) difference image between (h,m).
Figure 18.
Comparison of experimental results using pre-processed images and original images: (a) pre-processed ground truth image for the year 2014; (b) predicted results using pre-processed images from 5 years; (c) difference image between (a,b); (d) predicted results using pre-processed images from 9 years; (e) difference image between (a,d); (f) predicted results using pre-processed images from 13 years; (g) difference image between (a,f); (h) original ground truth image for the year 2014; (i) predicted results using original images from 5 years; (j) difference image between (h,i); (k) predicted results using original images from 9 years; (l) difference image between (h,k); (m) predicted results using original images from 13 years; (n) difference image between (h,m).
Figure 19.
Comparison of the results of the prediction experiment using the pre-processed image and the original image for training, and the original image. (a) The result of using the original image training and original image prediction; (b) the real image; (c) the simulation result of using the pre-processed image training and original image prediction.
Figure 19.
Comparison of the results of the prediction experiment using the pre-processed image and the original image for training, and the original image. (a) The result of using the original image training and original image prediction; (b) the real image; (c) the simulation result of using the pre-processed image training and original image prediction.
Table 1.
Prediction and evaluation indexes of time series images in .
Table 1.
Prediction and evaluation indexes of time series images in .
| Predict 2001 | ACC | MSE | DICE |
| 2 years image | 0.8132 | 440.95 | 0.9786 |
| 5 years image | 0.8147 | 451.90 | 0.9787 |
| Predict 2006 | ACC | MSE | DICE |
| 2 years image | 0.8462 | 585.26 | 0.9643 |
| 10 years image | 0.8486 | 453.93 | 0.9714 |
| Predict 2011 | ACC | MSE | DICE |
| 2 years image | 0.8770 | 507.35 | 0.9603 |
| 15 years image | 0.8772 | 451.56 | 0.9622 |
Table 2.
Prediction and evaluation indexes of time series images in .
Table 2.
Prediction and evaluation indexes of time series images in .
| Predict 2010 | ACC | MAE | DICE |
| 2 years image | 0.74 | 10.65 | 0.9592 |
| 5 years image | 0.75 | 8.81 | 0.9758 |
| Forecast 2011 | ACC | MAE | DICE |
| 2 years image | 0.75 | 14.01 | 0.9550 |
| 6 years image | 0.76 | 12.62 | 0.9682 |
| Predict 2012 | ACC | MAE | DICE |
| 2 years image | 0.80 | 10.47 | 0.9447 |
| 7 years image | 0.82 | 4.87 | 0.9673 |
Table 3.
Prediction and evaluation indexes of time series images in the first 4, 7, 10, 14, and 18 years of model use.
Table 3.
Prediction and evaluation indexes of time series images in the first 4, 7, 10, 14, and 18 years of model use.
| Predict 2014 | ACC | MSE | DICE |
|---|
| 4 years image | 0.8888 | 376.59 | 0.9595 |
| 7 years image | 0.8916 | 363.57 | 0.9602 |
| 10 years image | 0.8901 | 409.29 | 0.9603 |
| 14 years image | 0.8915 | 398.75 | 0.9616 |
| 18 years image | 0.8943 | 234.79 | 0.9636 |
Table 4.
Prediction and evaluation indexes of 5, 6, 7, and 8 year time series images used in the model.
Table 4.
Prediction and evaluation indexes of 5, 6, 7, and 8 year time series images used in the model.
| Predict 2014 | ACC | MSE | DICE |
|---|
| 5 years image | 0.7914 | 1751.81 | 0.9329 |
| 6 years image | 0.7930 | 1643.69 | 0.9347 |
| 7 years image | 0.7950 | 1686.09 | 0.9361 |
| 8 years image | 0.7983 | 1526.30 | 0.9407 |
Table 5.
Prediction and evaluation indexes of the original image and pre-processed image used in the model.
Table 5.
Prediction and evaluation indexes of the original image and pre-processed image used in the model.
| Predict 2014 | ACC | MSE | DICE |
|---|
| 5 years of pre-processed images | 0.8896 | 406.49 | 0.9605 |
| 5 years original image | 0.4024 | 91.16 | 0.8894 |
| 9 years of pre-processing images | 0.8896 | 391.18 | 0.9673 |
| 9 years original image | 0.3725 | 71.77 | 0.8955 |
| 13 years of pre-processing images | 0.8934 | 226.57 | 0.9714 |
| 13 years original image | 0.3677 | 77.54 | 0.8827 |
Table 6.
The model uses the original image and pre-processed image training prediction evaluation index.
Table 6.
The model uses the original image and pre-processed image training prediction evaluation index.
| Predict 2014 | ACC | MSE | DICE |
|---|
| 18 years of pre-processed images | 0.6144 | 67.53 | 0.8950 |
| 18 years original image | 0.4658 | 139.60 | 0.8765 |




 ,
, 























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}