1. Introduction
Accurately estimating bedload transport in gravel-bed rivers is difficult in practice. Transport equations are extremely sensitive, such that small errors in estimating hydraulic shear stress available to mobilize particles can lead to large errors in the predicted transport rate [
1]. Accurately determining the characteristic grain size or grain size distribution of the active portion of the riverbed is also problematic [
2]. Errors become amplified since grain size has a large effect on the predicted bedload transport volume, and since many models use riverbed grain size distribution to estimate the size distribution of the bedload. Finally, the thresholds for initiation of particle motion exhibit dependence on the way riverbed particles are either exposed to the flow or shielded by neighboring particles [
3], which is, in turn, dependent on the distribution of grain sizes, and is thus also uncertain.
Early efforts to produce bedload models for practical applications relied on simple functions of stream power (e.g., [
4]) or bed shear stress (e.g., [
5]) in excess of a critical threshold for particle mobility. This critical shear stress, or critical Shields stress in non-dimensional form [
6], was often assumed to be a constant, even though there were various interpretations of what that value should be, as summarized in the thorough review by Buffington and Montgomery [
7]. Model progress advanced significantly when it was realized that the structure or arrangement of grains on the riverbed develops in response to establishment of a quasi-equilibrium between the bedload in motion and the riverbed material [
3]. Thus, thresholds for grain mobility are not well represented by a single number, but depend on both the riverbed grain size distribution and the degree of surface coarsening [
8,
9].
In the decades since these fundamental developments, there have been efforts to improve on estimates of key model parameters. Andrews [
8] predicted critical Shields stress for initiation of particle motion from the ratio of grain size to median grain size of the subsurface. Parker, Klingeman and McLean [
10] substituted a “reference” Shields stress, corresponding to a small but measureable bedload transport rate, for Shields stress at initiation of motion, and developed a similar predictive equation, again based on the ratio of grain size to median subsurface grain size. Parker [
11] adopted a more complex formulation specifically for surface particles, which, in addition to the ratio of grain size to surface geometric mean grain size, included a factor to account for changes in the surface particle arrangement under increasingly intense flow conditions. Wilcock and Crowe [
12] presented a relationship for predicting the reference Shields stress separately for the sand and gravel components of the riverbed, based on the percent sand content. Barry et al. [
13,
14] abandoned the excess shear stress paradigm in favor of predicting bedload as a simple power function of discharge, and argued that the exponent in the equation could be predicted from an index of supply-related bed surface coarsening, while the equation coefficient was a power function of watershed drainage area.
These advances notwithstanding, when greater accuracy is desired, an alternative to the traditional approach of computing bedload with an equation from the literature must be sought. One such approach is to develop a statistical model, using linear regression techniques for example, based on a large number of bedload samples (at least 20 to 30), collected over a broad range of flows [
15,
16]. However, obtaining enough samples for a robust statistical model is expensive and time-consuming.
Advances in computing power, reach-scale mapping, and the use of multi-dimensional hydraulic models have made it possible to reduce the uncertainties associated with correctly estimating hydraulic shear stress. Segura and Pitlick [
17] used a two-dimensional hydraulic model to compute the spatiotemporal distribution of shear stress, which was then applied to a theoretical bedload transport function, that of Parker and Klingeman (1982) [
3]. Monsalve et al. [
18] employed a quasi-3D hydraulic model to compute shear-stress distributions, and sampled grain size distributions on mapped streambed patches to account for spatial particle size variability in their model calculations. These distributions were then used to compute bedload transport using Parker’s (1990) model [
11]. This approach was shown to enhance the accuracy of bedload estimates in a steep (10%), boulder cascade stream, conditions known to make the use of reach-averaged parameters particularly problematic.
A third approach, the use of site-calibrated models for predicting sediment transport, has been slow to gain acceptance, despite its advantages in terms of predictive accuracy and its relative simplicity compared to the aforementioned techniques employing multi-dimensional models. Site calibration refers to the process of adjusting the coefficients of a physically based model from the literature to obtain an optimum fit to a site of interest by means of a small number of bedload calibration samples. A site-calibrated model can be shown to achieve the greatest overall accuracy, at the lowest field sampling cost, when contrasted with the purely statistical approach described above, or the use of a model from the literature in the absence of bedload calibration samples [
19]. Bakke et al. [
20] described a process for calibrating the Parker–Klingeman (1982) model [
3] by adjusting a pair of “hiding factor” constants, which govern the reference Shields stress for particle mobility by grain size, to fit bedload data. The procedure, which was made available in a FORTRAN program, fits the model to the data with zero bias between sampled and computed bedload, and minimum sum of squared errors. Moreover, this procedure used a distribution of hydraulic shear stresses based on the distribution of depths in a representative cross section to compute bedload, rather than a single, reach-averaged value, which offered greater effectiveness in handling of hydraulic complexity. Wilcock [
19] described a similar site-calibrated approach, in which the bedload is represented by two components (sand and gravel [
12]), and calibration is accomplished by finding a reference Shields stress for each component such that the model best fits the data. Both of these models have subsequently been made available in an easy-to-use Excel spreadsheet macro format [
21]. Nevertheless, to the extent that practitioners rely on popular software packages like HEC-RAS and SAM, they are forced to use uncalibrated theoretical models [
19,
22].
A site-calibrated approach to modeling has the advantage of adjusting the model to accommodate, and thus diminish, the combined effects of uncertainty in hydraulic shear stress, grain sizes available for transport, and particle motion thresholds [
1]. Moreover, since one performs the calibration on a physically tenable bedload transport function, fewer samples are needed to achieve a given improvement in accuracy than would be the case if one were to fit the bedload sample data to a curve whose form is not known a priori, as is true with a purely statistical approach such as linear regression [
19]. Furthermore, a site-calibrated model can be extrapolated more confidently than a statistical regression line, since it is based on physical principles that presumably extend beyond the range of available on-site data. Because the exact sources of error in estimating shear stress, initiation threshold of particle motion or grain-size distribution matter less when one uses a site-calibrated model, the technique can be used in streams that differ morphologically from the streams originally used to develop the transport function, and for a wider range of sediment sizes, including a sand component in mixed sand–gravel streambeds [
20].
Our purpose here is to present a new site-calibrated model procedure, which will be shown to work well in situations that are hydraulically complex enough to render uncalibrated models impractical, but where only a small number of bedload samples exist. Advances also include the use of graphical techniques that facilitate an informed perspective of what the various calibration procedures are actually doing. Use of the model will be illustrated with three examples from study sites representing different degrees of modeling difficulty, as determined by bedload-data richness and hydraulic complexity: Oak Creek, Oregon, USA (a data-rich site, from which the Parker–Klingeman model [
3,
10] was originally developed), Paradise Creek, Oregon, USA (a site with a moderate amount of high-quality bedload data), and, finally, South Fork Thornton Creek in Seattle, Washington, USA (a site with a smaller amount of bedload data, which typifies many practical, but difficult, bedload modeling applications).
Finally, model calibration procedures greatly affect the applicability to particular modeling goals. These features include whether to optimize the fit of the model to bedload data using loads versus logarithms of loads, whether to include an adjustment to eliminate bias by matching total modeled load with total sample load, and the choice of representing the bedload by a single grain size, two grain size fractions or multiple grain sizes. A practical discussion of the implications of these decisions will be presented.
3. Results
Results of model calibration for the three study sites are given in
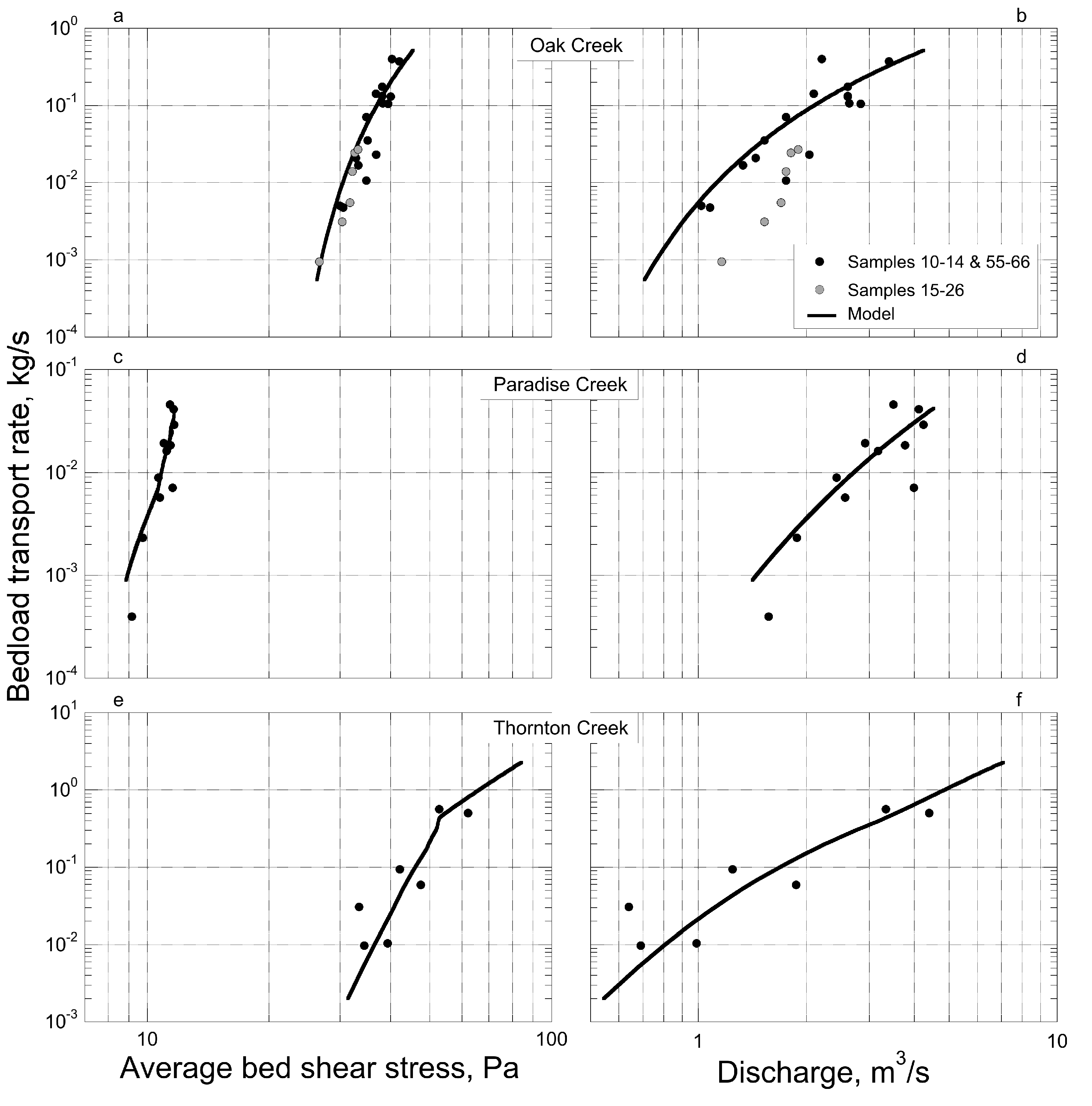
Table 1, which also summarizes site characteristics and modeling challenges. Total bedload is shown in
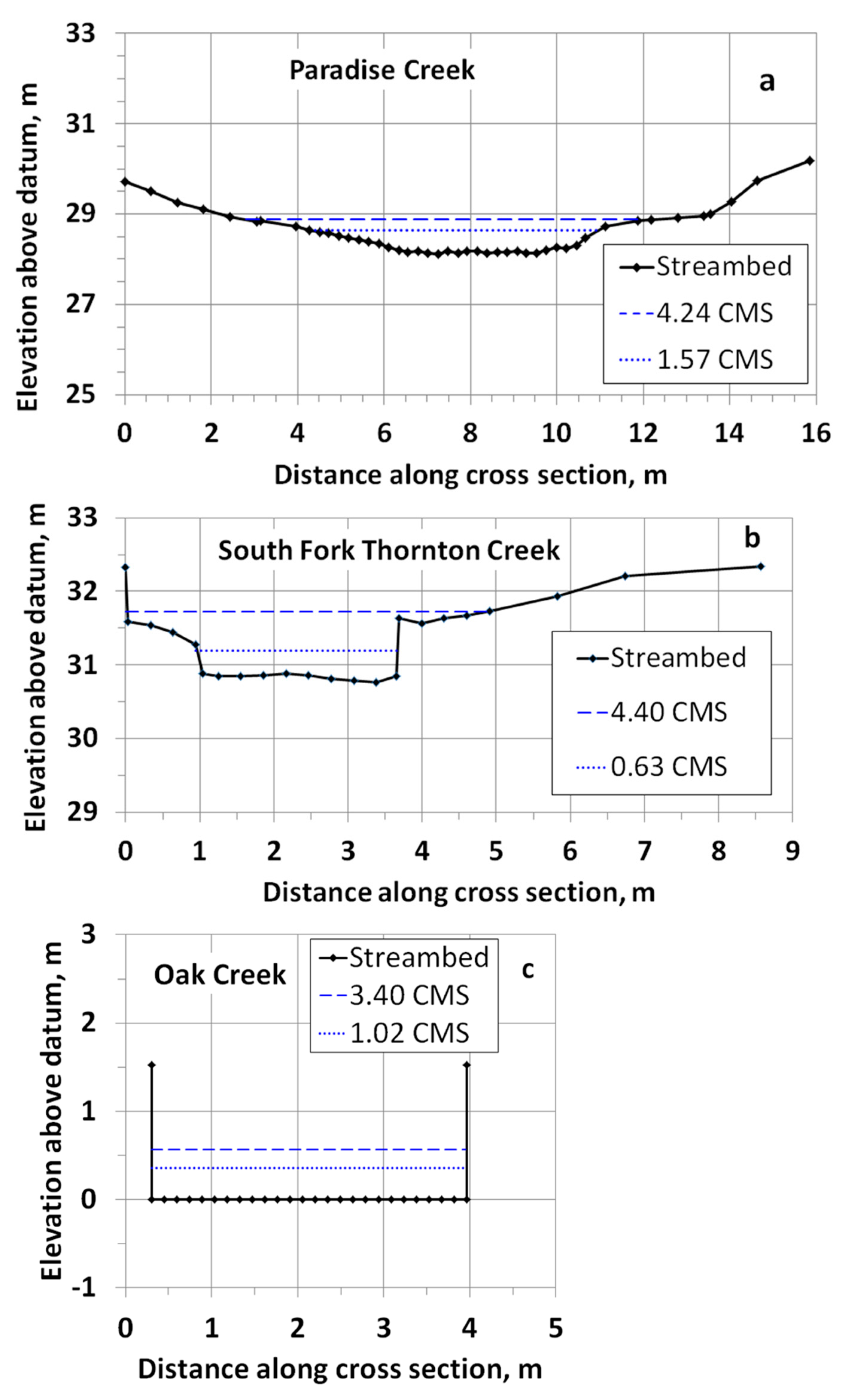
Figure 4, using cross-section average shear stress as the independent variable. Since the use of bedload sediment rating curves is common and intuitive, we also plot the model calibrations results with water discharge as the independent variable in
Figure 4.
Comparison of the bedload plotted against average shear stress versus water discharge for each site reveals less scatter when shear stress is used as a predictor of bedload. This is particularly evident at Oak Creek, where six of the samples were taken during hydraulic conditions that necessitated a different water surface elevation—to discharge rating curve. Inflexions in the lines representing model-predicted bedload versus shear stress for Paradise Creek and South Fork Thornton Creek are due the fact that these lines were determined using equally-spaced intervals of water discharge, back-calculating the water surface elevation from the discharge rating curve, and then computing an average hydraulic radius and corresponding average bed shear stress. Bedload, however, was computed at each of 25 or more locations on the channel cross section using local depth to compute shear stress, and then summed to give total bedload. Since bedload increases exponentially with depth, inflexions in the cross section shape, and inflexions due to the use of a compound rating curve (necessary with overbank flow), become amplified, and total computed bedload is influenced more greatly by zones of maximum depth than by average shear stress.
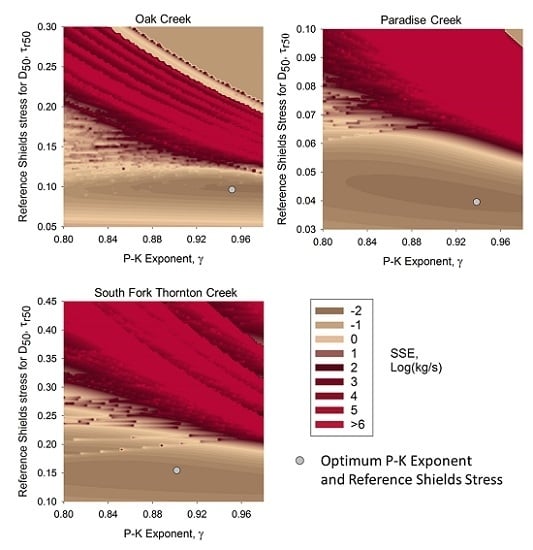
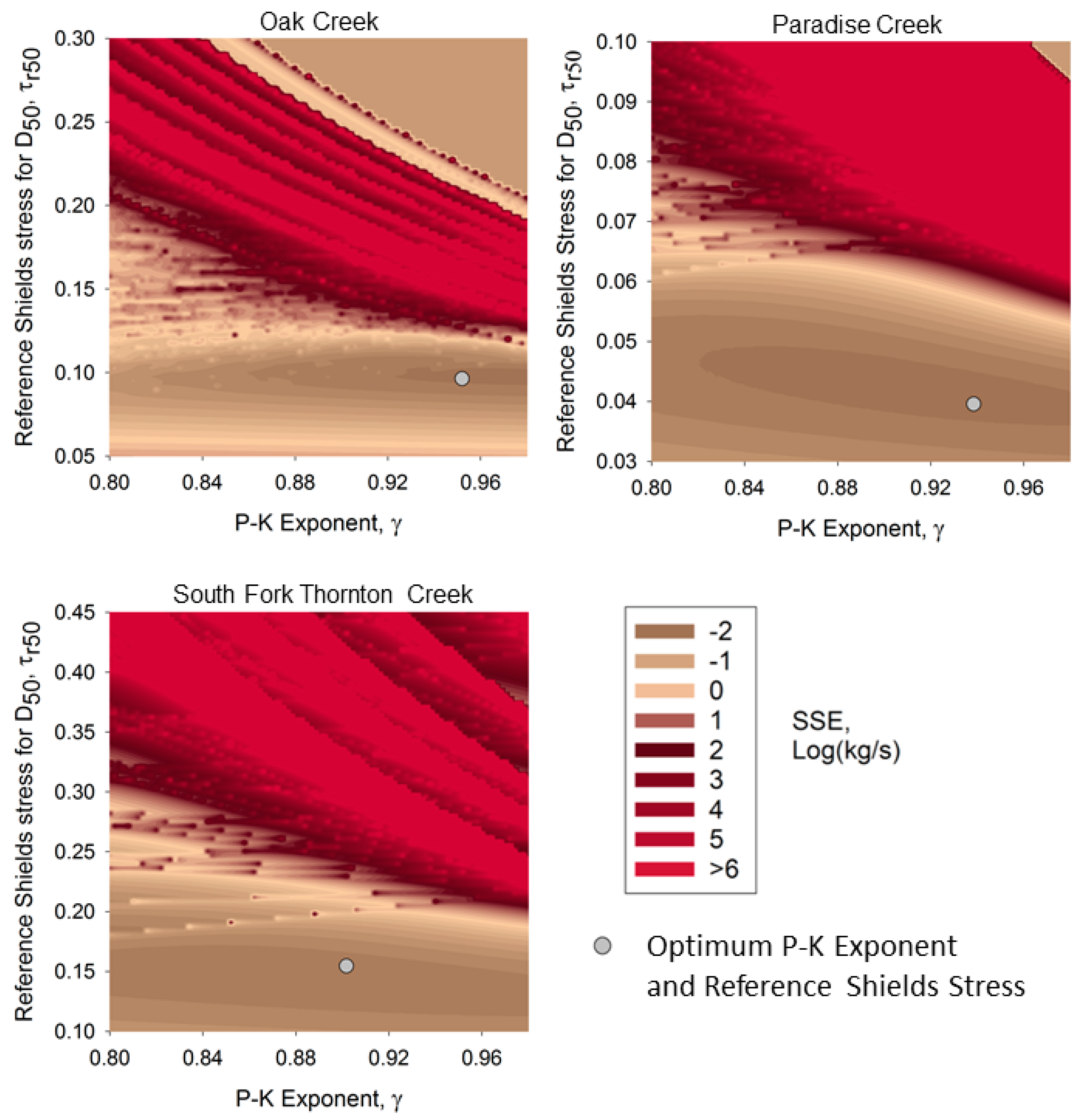
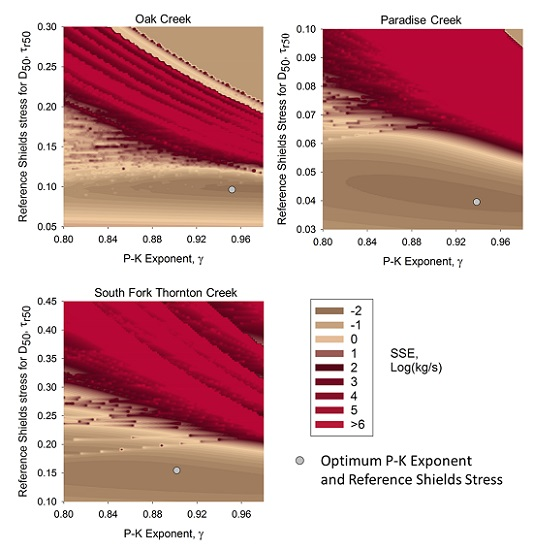
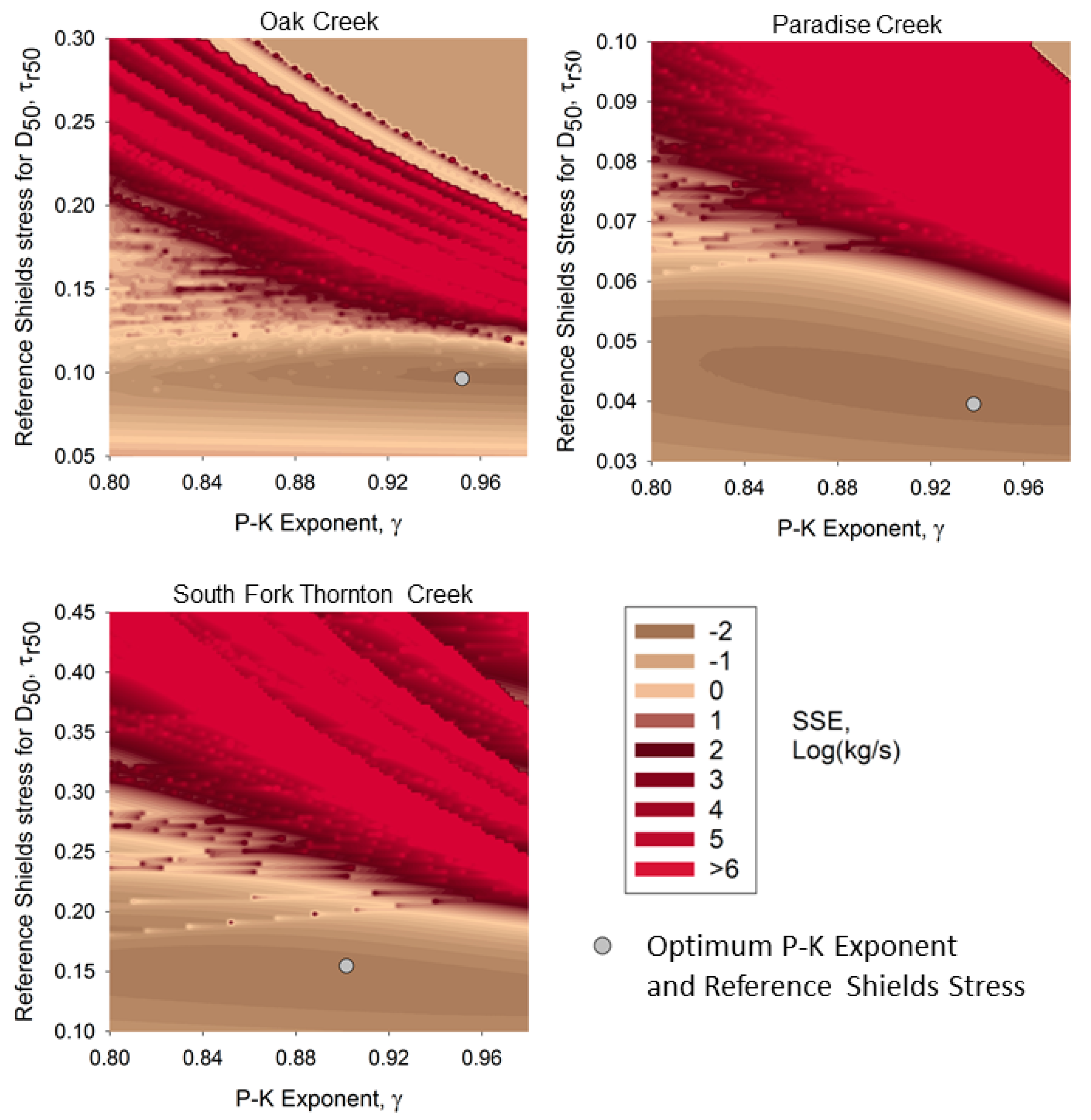
Figure 5 shows how the sum of squared error (SSE), determined from the calibrated model and calculated as the square of [log(measured load) − log(computed load)], varies with the choice of reference Shields stress (
) and hiding factor exponent (
γ). Each grain size for each sample is included in this sum. Two observations require further explanation.
First, the use of log units equalizes the influence of large and small samples, but results in the “spiky” appearance of these graphs. The spikes in the figures represent locations in the field of versus γ where a grain size is at the threshold of incipient motion, according to the model transport function. Since the logarithm of zero is undefined, this grain size had to be excluded from the computation of squared error. Moving slightly in either the or γ axis direction, one reaches a location where a miniscule amount of bedload of that grain size is predicted. In logarithms, that bedload corresponds to a large negative number, resulting in the abrupt appearance of a “large” spike in SSE.
Secondly, the optimum combination of
and
γ, as determined from the method described earlier using reach-averaged shear stress and total bedload for the whole cross section, does not necessarily fall on the apparent lowest SSE point in
Figure 5. This is due to determination of optimum
and
γ from average shear stress, while the model is computing bedload (and thus SSE) from locally-determined shear stress along the cross section.
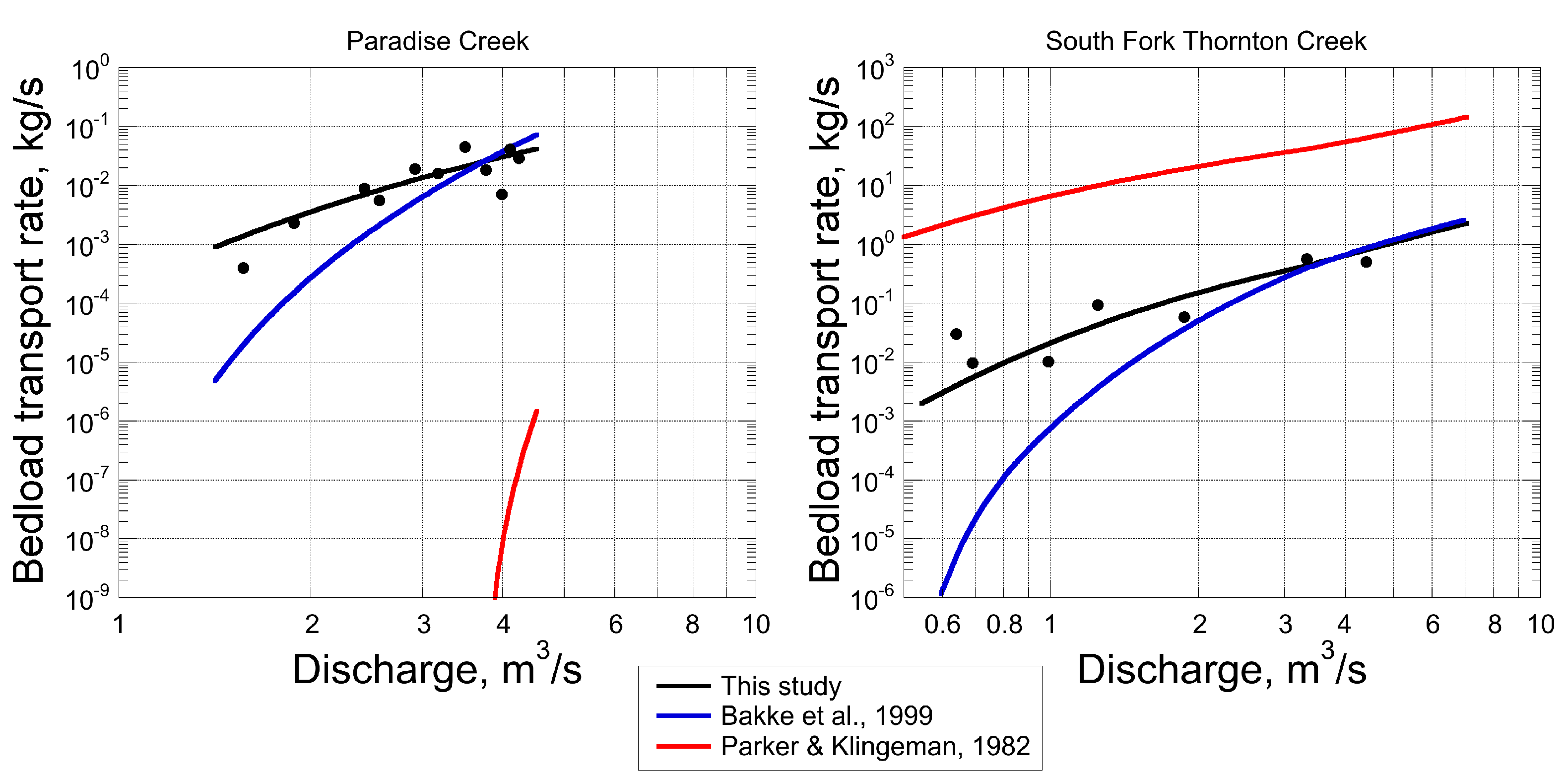
In the case of the most difficult example presented herein, South Fork Thornton Creek, the new Parker–Klingeman model calibration algorithm outperformed several similar approaches attempted (
Figure 6). For example, the algorithm of Bakke, et al. [
20] is calibrated by adjusting the hiding factor exponent to obtain minimum logSSE while maximizing grain movement prediction accuracy, and then adjusting the reference Shields stress (
) to obtain zero bias. This algorithm could be calibrated easily, but the resulting transport curve has a very large slope, and predicts unreasonably large transport rates when extrapolated to larger peaks flows, unlike the new algorithm described above. Bedload Assessment for Gravel-bed Streams (BAGS), a publicly available spreadsheet-based modeling package [
21], which calibrates the Parker–Klingeman model by minimizing arithmetic SSE, would not converge to a calibrated solution for this site, probably due to the high sediment loads measured. Theoretical models, including the (uncalibrated) version of Parker–Klingeman, all yielded unreasonably high bedload transport predictions, when juxtaposed against the total annual load estimates from dredging records [
27].
4. Discussion
Several modeling considerations are illustrated by these examples. Although these issues are particular to the site-calibrated modeling approach, they are inherent in the development of published theoretical models as well. In the site-calibrated approach, these considerations are explicitly addressed, which ultimately improves confidence in the results.
4.1. Optimization Using Arithmetic Loads versus Logarithms of Loads
First, development of a site- calibrated model requires choice of criteria for fitting the model to the data. One way to do this is to use a minimum average of squared errors (SSE) approach, where errors are defined as the difference between the computed and measured loads. This is the approach used in BAGS [
21]. A disadvantage of using arithmetic loads to compute SSE is that the model calibration will be dominated by the larger samples. This can result in unrealistically high slopes for the load versus shear stress relationship. This can be a problem if the model is intended to be extrapolated for computation of load at large discharges, as would be the case in use for an effective discharge computation, or for computing average annual load [
29]. Furthermore, for some modeling objectives, such as determining threshold discharges for grain mobilization, or predicting sediment loads or size composition under conditions of marginal transport, the smaller samples should be weighted equally to the larger samples in the modeling optimization process.
One simple way to do this, which was the procedure followed here (as well as by Bakke et al., [
20]), is to compute SSE from the logarithms of loads, rather than the actual loads. However, since the logarithm of zero does not exist, combinations of model parameters that yield zero load for some of the grain samples will need to be excluded from the computation. Moreover, combinations of parameters that produce tiny amounts of predicted sediment transport will result in “spikes” in the two-dimensional surface representing SSE, since the logarithm of this tiny amount will be large and negative.
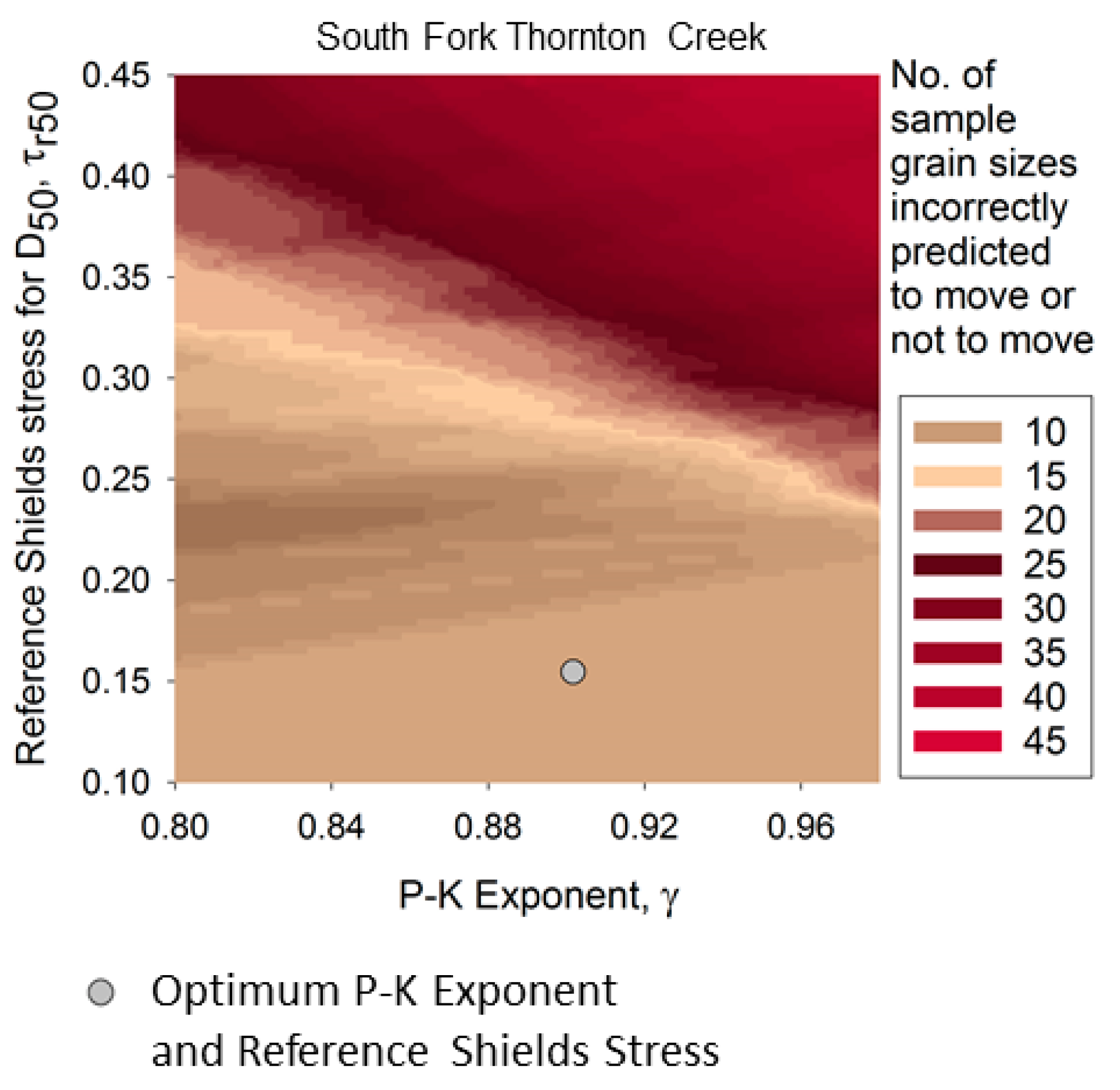
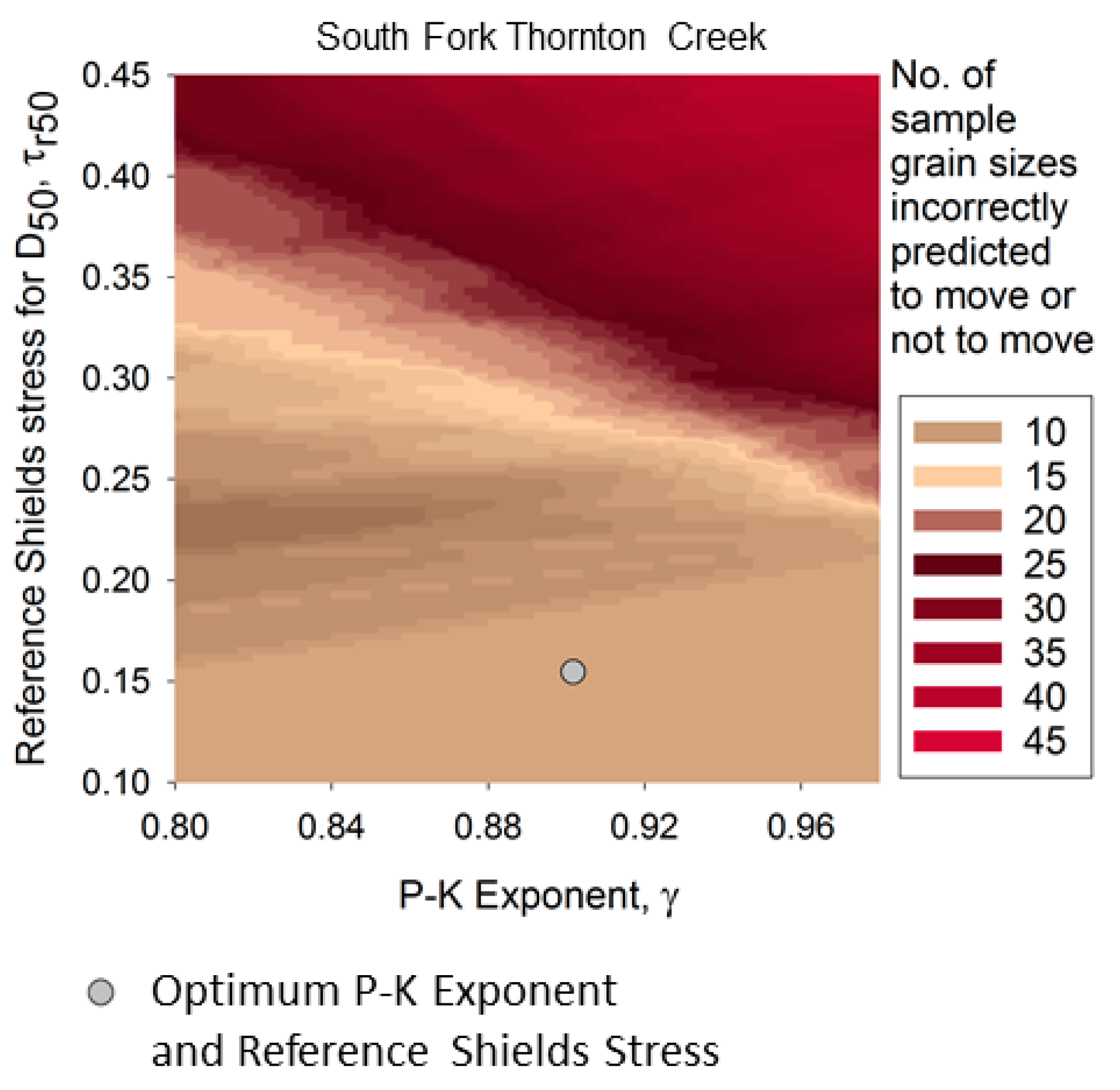
The exclusion of zero-load grain samples creates a dilemma, in that a “low” SSE region in the
Figure 5 can develop due to exclusion of grain samples, rather than best model fit. Thus, another criterion, such as optimum proportion of correctly predicted movement or non-movement of sample grain sizes, or zero overall bias, needs to be added to in order to interpret the log-load SSE diagram for model best fit. As an example,
Figure 7 shows grain movement prediction accuracy for South Fork Thornton Creek.
4.2. Rationale for a Two-Stage Optimization
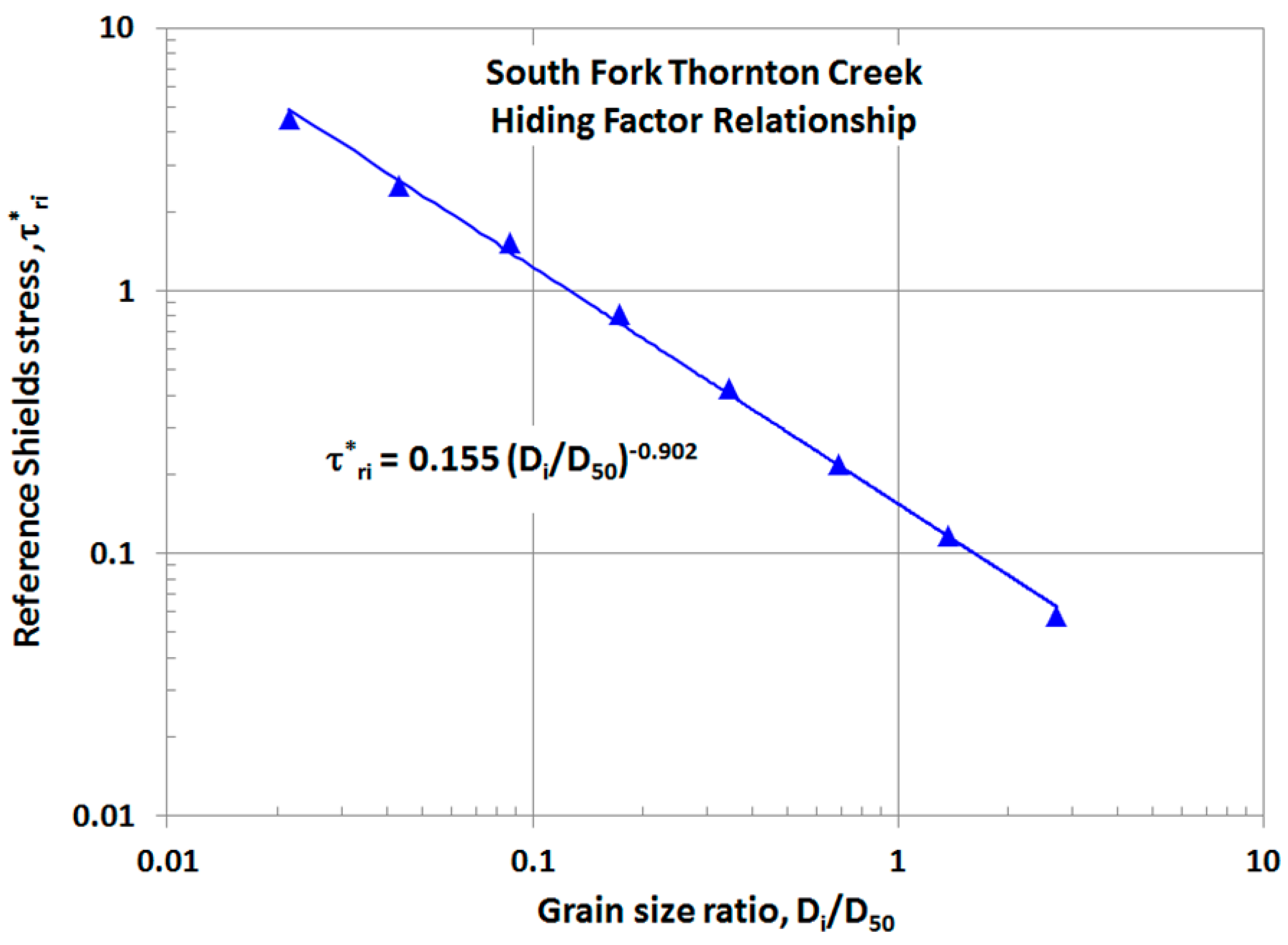
In our calibration procedure, optimization is accomplished in two steps. First, in development of the hiding factor constants
and
γ, SSE in dimensionless bedload,
, and Shields stress,
, are minimized to develop the regression lines used to predict
. This is done in log units, but since only the (finite) bedload samples are used, there is no zero exclusion or spiking issue. Second, the transport function constant is adjusted to achieve equality between total sampled and computed bedload (zero bias). Alternatively, this could have been done with a second stage of SSE minimization, using
versus
, as Parker and Klingeman [
3] originally did to fit the transport function curve to their data. Use of the zero-bias approach, however, is simpler. It also effectively adapts the original transport function, which was based on reach-averaged shear stress, to the quasi-two-dimensional computation being used here, which computes bedload at each point on the cross section.
4.3. One-Dimensional versus Quasi-Two-Dimensional Model Approach
Typically, sediment transport models are made one-dimensional, meaning that the sample site is represented by a single average cross section and average shear stress. This approach works well for streams like Oak Creek, which has a flume-like, rectangular cross section, but not as well for Paradise Creek, South Fork Thornton Creek or other typical alluvial streams that have a definite Thalweg. Local shear stress can be quite different in the deeper Thalweg than the cross-section average, which has implications for model prediction accuracy. A simple way to account for this is to compute shear stress and bedload using local depth rather than average hydraulic radius, and to sum the incremental bedload values over the cross section. Since the bedload transport function is highly non-linear, the difference in computed bedload using this quasi-two-dimensional approach versus a single average shear stress can be striking, and leads to optimum values for the transport function coefficient, β, which are quite different from the literature. It also results in more accurate prediction of the largest grain sizes moved for a given total bedload.
In electing to use this approach, another issue arises, however. Since the bedload samples are composites for the whole cross section, there is insufficient information to compute values for individual points on the cross section. Only an average can be computed from the data, and this requires a corresponding single (e.g., average) value of Shields stress for determination of the hiding factor coefficients. However, when the model computes bedload according to the transport function (Equation (6)), a local value of Shields stress is used. The result of this difference is that the bedload transport rate, , corresponding to = = 0.002, is different when computed from local depth than what its corresponding value would be when based on cross-section average shear stress in the hiding factor coefficient analysis. The second stage of the calibration process, adjusting the transport function coefficient β, eliminates this difference. Although adjustment of β could be done by another round of minimization of SSE, shifting the transport function vertically downward to pass through either the centroid of the data or to equalize the sum of total computed and measured loads is far simpler as it eliminates the complexity associated with the zero exclusion issue without affecting the fit of the curve to the data in a substantial way. Moreover, we opted to use the zero bias criterion as a way of insuring that cross sections with deep Thalwegs would not yield models that overpredict bedload at larger discharges. If predictions at marginal transport were the main objective, then an approach of adjusting β such that the transport function intersects the centroid of the data would be an appropriate choice.
4.4. Advantages of a Multi-Grain-Size Model
More generally, another issue that arises in transport modeling is which model to use, and whether to use a model that predicts total sediment volumes only, or the grain-size distribution of the bedload sediment. In regard to the data-calibrated approach described herein, two considerations are paramount.
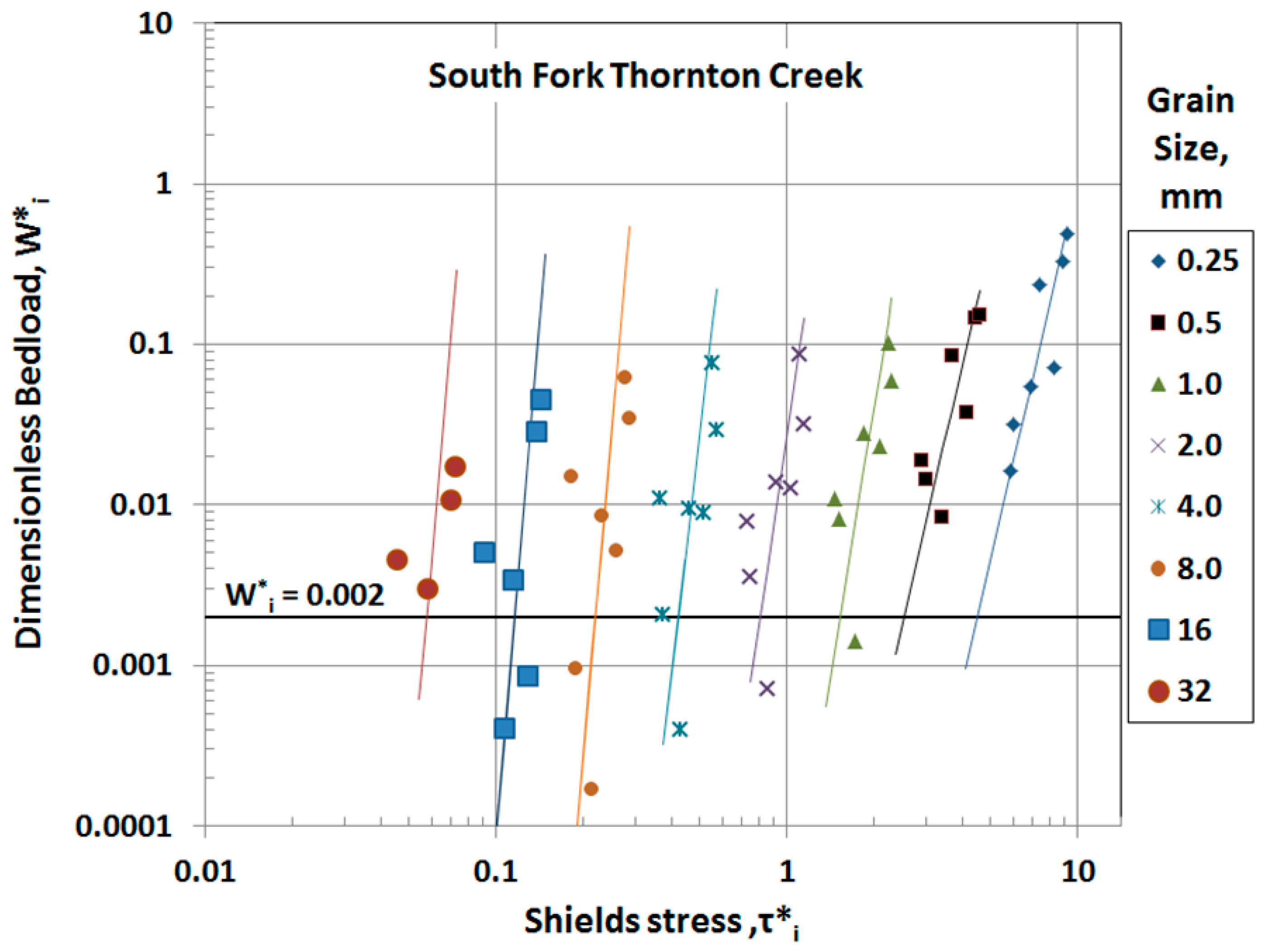
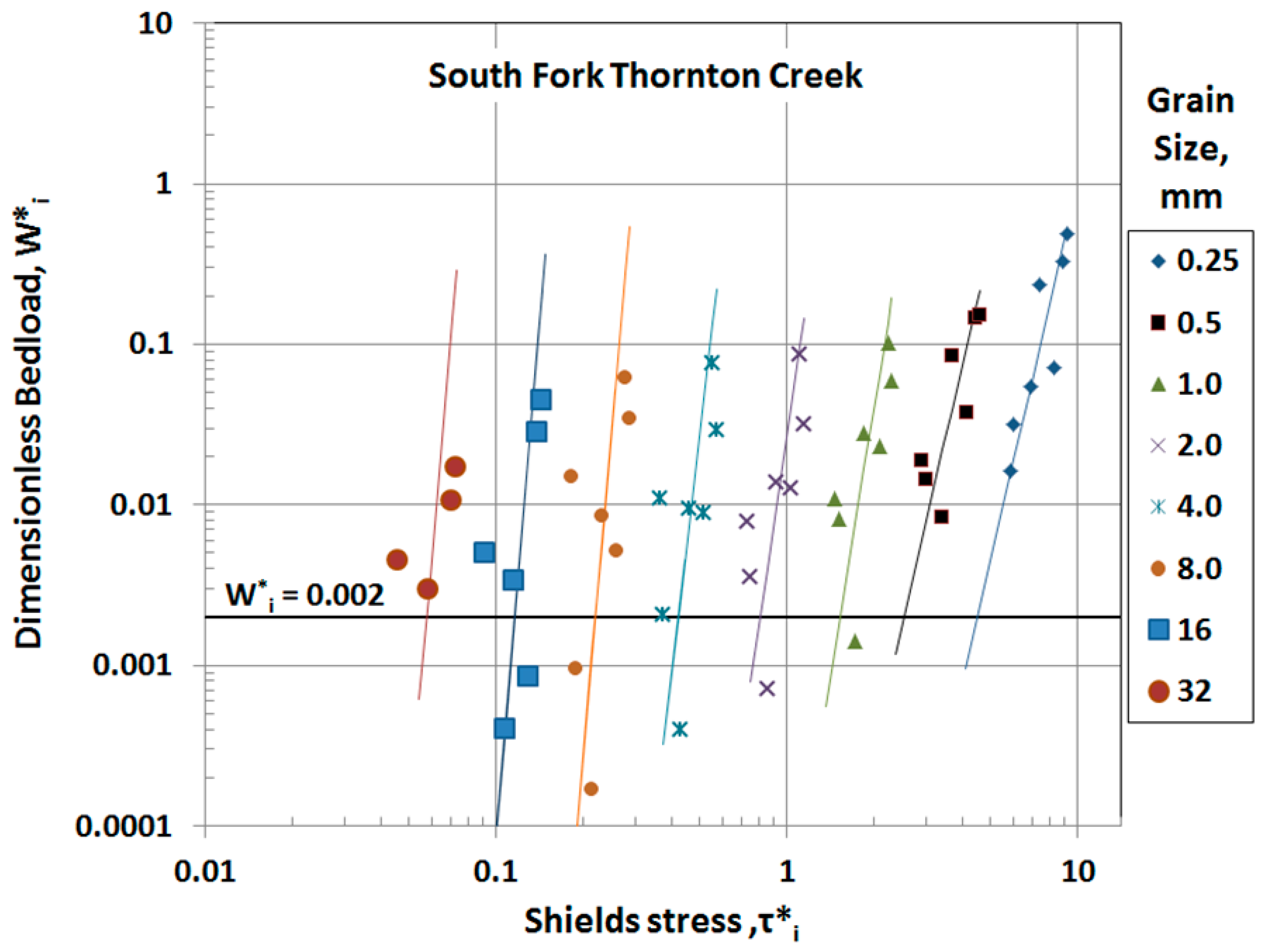
First, when only a few bedload samples are available, as was the case here with South Fork Thornton Creek, practitioners need tools for assessing data quality. One of the advantages of a multi-grain-size model is that the grain size distribution of the data contains useful information about its appropriateness for model calibration. If the site fits the assumption that the bedload approaches an equilibrium with the streambed material, which is implicit in all of the physically based models, then the data should produce a family of nearly- parallel curves such as displayed in
Figure 1, and the slopes of these curves should be close to that expected for a bedload transport function, which is 4.5 in the case of the Parker–Klingeman model. The information contained in the relationship between grain sizes thus becomes part of the calibration process, which effectively expands a single bedload measurement into a sub-set of measurements, one for each grain size. This allows the practitioner to spot departures from equilibrium and, conversely, to spot irregularities in data that might suggest poor sample quality if equilibrium is expected due to other lines of evidence. The patterns visible in bedload data stratified by grain size help the modeler to diagnose whether a sample “outlier” represents a measure of the variability found in nature or, conversely, represents a sample that is deficient in some regard, and should justifiably be excluded from the calibration. An example of this departure is shown in
Figure 8, for the North Fork of Thornton Creek, which was a sampling site in close proximity to the confluence with the South Fork presented above. This diagnostic power is not available when using a model that predicts only a single, average sediment volume or two components (gravel, sand), as opposed to a series of multiple grain sizes.
Finally, although most any model can, in principle, be calibrated with bedload data, the most state-of-the-art gravel transport models incorporate some form of a “hiding factor” to account for the way that the structure of the streambed causes particle mobility by grain size to adjust over what it would be in a streambed of uniform-sized particles, and thereby to achieve equilibrium between the streambed material and the bedload in transport [
3]. Without this hiding factor, which effectively increases the apparent mobility of larger particles and reduces that of smaller particles, a model will invariably over-predict transport of small grain sizes and under-predict the large sizes, and typically will over-predict the total sediment load [
22]. Moreover, a site-calibrated model should incorporate a transport function whose form derives from basic physical principles, ensuring consistency with the body of work under which the original model was derived.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}