
Evaluating Flood Exposure for Properties in Urban Areas Using a Multivariate Modelling Technique

Abstract
:1. Introduction
- Develop a multivariate model to identify and rank significant variables contributing to the exposure to urban flooding;
- To develop a model to quantify areas prone to urban flooding.
2. Materials/Access to Data
2.1. Case Area
2.2. Insurance Data
- Installation: A description of where the malfunction that has led to the damage is located, e.g., water pipes indoor, outdoor, sewer mains;
- Source: A description of the underlying reason for the damage, e.g., precipitation, water supply;
- Cause: Describes the actual cause for the damage, e.g., stop in sewers, aging, frost, malfunction.
- Address (property where the damage occurred);
- Compensation sum;
- Classification into codes for Installation, Source, and Cause.
2.3. Geocoding
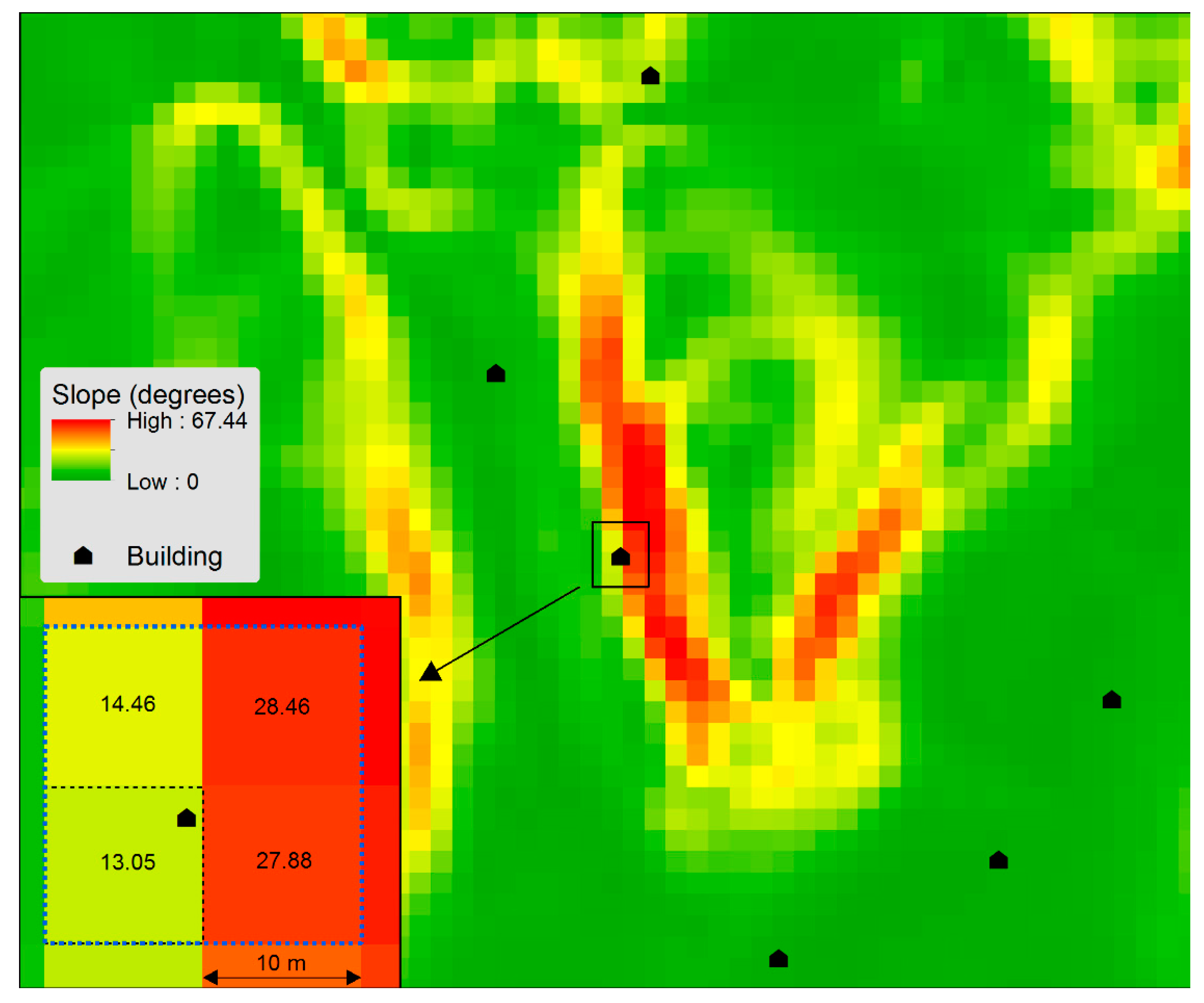
2.4. Terrain Parameters
- Distance (elevation z, distance to coast). This group includes the altitude above mean sea level (z) and distance to the coast measured from each building’s central points (BCP);
- Slope (the slope gradient) includes the slope value from the cells. The variable sl_r100 gives the mean slope within a 100-meter radius for an area elevated higher than the BCP. The other slope values are derived from the cells at the three different resolutions mentioned above;
- Area (permeable, impermeable, and sum) was derived from the BCP and arranged in the contributing area into permeable and impermeable surface areas, all within a 100 m radius from the BCP. The upstream sealed area shown in Table 1 was calculated in two ways (abbreviations are explained in Table 1): One includes roads elevated higher than the BCP (a_Up_ro) and another includes all upstream built-up areas (a_US_im) according to [20]. When calculating an upstream area, all cells elevated higher than the BCP were included. This is a limitation, as not all those cells will drain through the BCP. A more accurate way to calculate the upstream drain area might be an opportunity for improvement in further studies. These variables were calculated in a similar way, and we considered that this simplification would not led to statistical bias;
- Curvature profile (plan and profile). Terrain curvature is expressed as the plan or profile curvature, measured along the steepest descent and the contour, respectively. The curvature number is also known as the second derivate value of the input surface by cells, based on the algorithm described by Zevenbergen and Thorne [21].
2.5. Sewer Data
2.6. Sampling
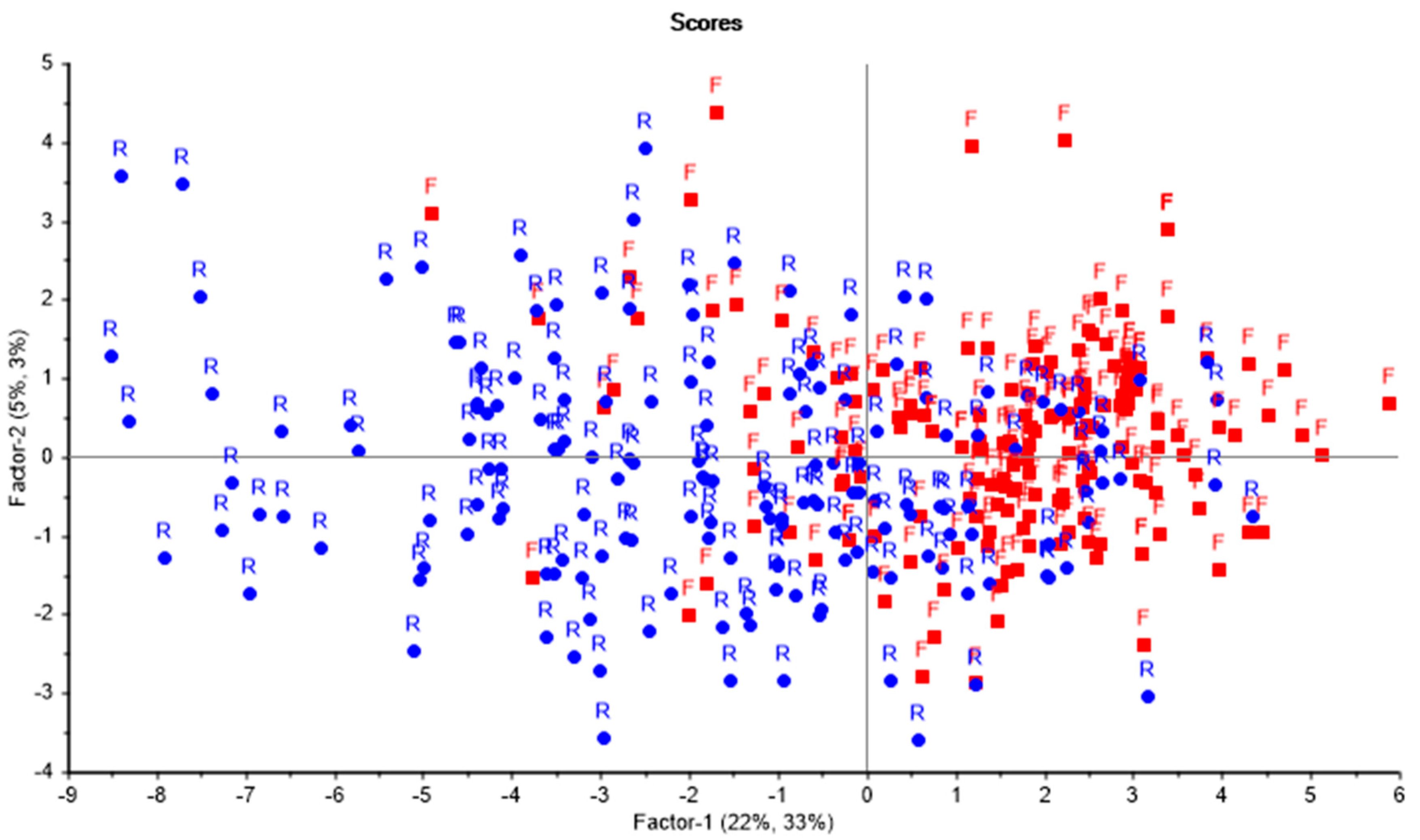
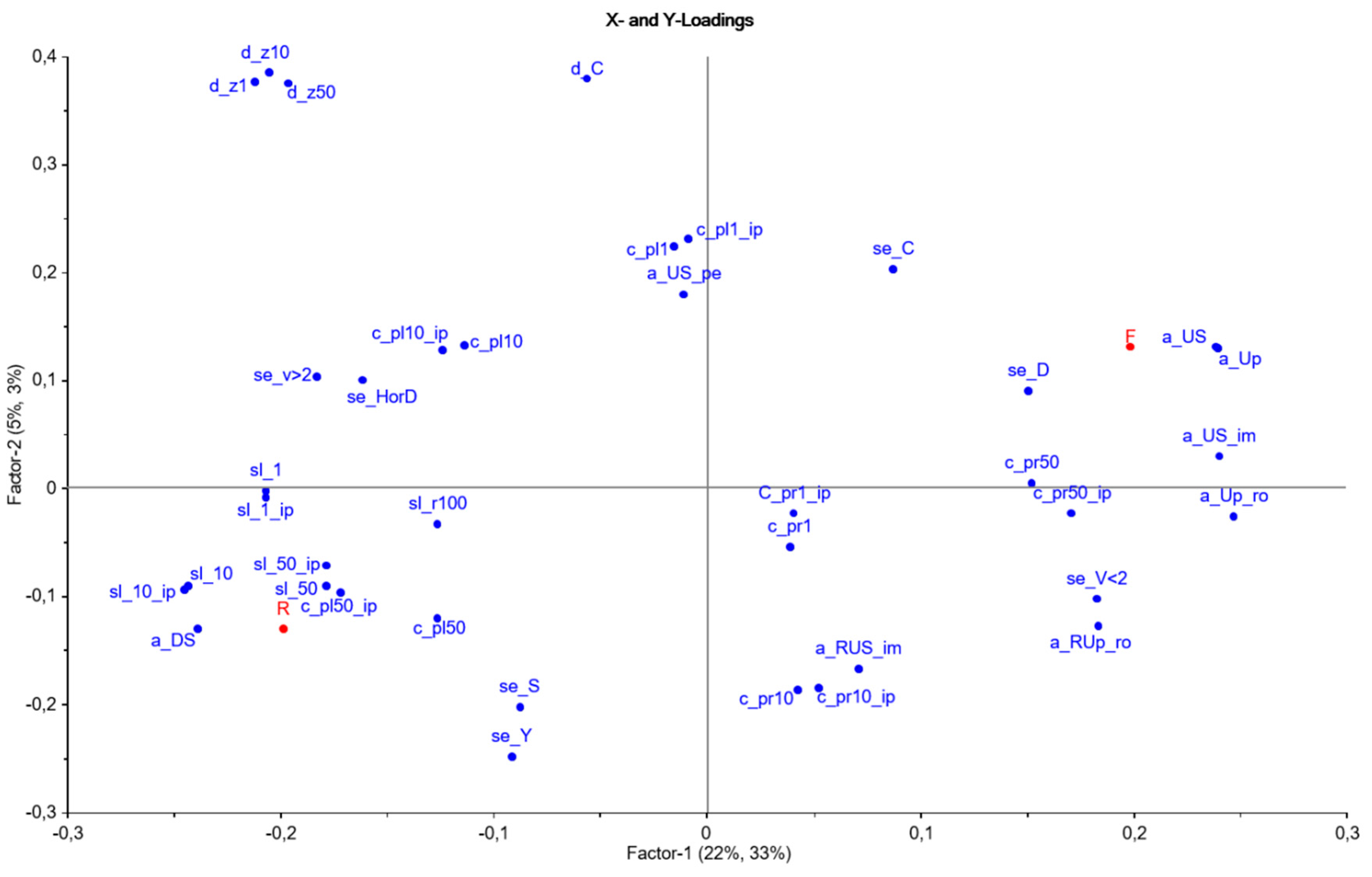
3. Method
4. Results
5. Discussion
6. Conclusions
Acknowledgments
Author contributions
- Geir Torgersen: conception and design of the work, analysis, interpretation and drafting;
- Jan Ketil Rød: design of the work, analysis and interpretation;
- Knut Kvaal: design of the work, analysis and interpretation;
- Jarle T. Bjerkholt: conception and design of the work, analysis and interpretation;
- Oddvar G. Lindholm: conception and design of the work, analysis and interpretation.
Conflicts of interest
References
- Dawson, R.; Speight, L.; Hall, J.; Djordjevic, S.; Savic, D.; Leandro, J. Attribution of flood risk in urban areas. J. Hydroinform. 2008, 10, 275–288. [Google Scholar] [CrossRef]
- Government U.K. Foresight Future Flooding; Office of Science and Technology: London, UK, 2004.
- Nyeggen, E. Gjensidige Forsikring Climate Change—New Challenges for the Insurance Industry? (Translated). Available online: http://www.forsikringsforeningen.no/wp-content/uploads/2012/08/2007-Nyeggen.pdf (accessed on 2 March 2017).
- Finance Norway VASK—National Register of Water Damages (Translated). Available online: http://www.finansnorge.no/statistikk/skadeforsikring/vask/ (accessed on 2 March 2017).
- Special Report of IPCC 2012: Managing the Risks of Extreme Events and Disasters to Advance Climate Change Adaptation; Cambridge University Press: Cambridge, UK; New York, NY, USA, 2012; p. 582.
- Crichton, D. Flood Plain Speaking, 3rd ed. Available online: http://www.cii.co.uk/knowledge/claims/articles/flood-plain-speaking/16686 (accessed on 16 October 2015).
- Kaźmierczak, A.; Cavan, G. Surface water flooding risk to urban communities: Analysis of vulnerability, hazard and exposure. Landsc. Urb. Plan. 2011, 103, 185–197. [Google Scholar] [CrossRef]
- Spekkers, M.H.; Ten Veldhuis, M.-C.; Kok, M.; Clemens, F. Analysis of pluvial flood damage based on data from insurance companies in the Netherlands. In Proceedings of the International Symposium Urban Flood Risk Management, UFRIM, Graz, Austria, 21–23 September 2011; Zenz, G., Hornich, R., Eds.; Technische Universitat Graz: Graz, Austria, 2011. [Google Scholar]
- Spekkers, M.; Zhou, Q.; A.-N., K.; Clemens, F.; Veldhuis, M.-C.T. Correlations between rainfall data and insurance damage data related to sewer flooding for the case of Aarhus, Denmark. proceedings of the International Conference on Flood Resilience: Experiences in Asia and Europe, Exeter, UK, 5–7 September 2013. [Google Scholar]
- Zhou, Q.; Panduro, T.E.; Thorsen, B.J.; Arnbjerg-Nielsen, K. Verification of flood damage modelling using insurance data. Water Sci. Technol. 2013, 68, 425–432. [Google Scholar] [CrossRef] [PubMed]
- Spekkers, M.H.; Kok, M.; Clemens, F.H.L.R.; ten Veldhuis, J.A.E. Decision-tree analysis of factors influencing rainfall-related building structure and content damage. Nat. Hazards Earth Syst. Sci. 2014, 14, 2531–2547. [Google Scholar] [CrossRef]
- Merz, B.; Kreibich, H.; Lall, U. Multi-variate flood damage assessment: A tree-based data-mining approach. Nat. Hazards Earth Syst. Sci. 2013, 13, 53–64. [Google Scholar] [CrossRef]
- Aall, C.; Øyen, C.; Hafskjold, S.; Almås, A.; Groven, K.; Heiberg, E. Klimaendringenes Konsekvenser for Kommunal og Fylkeskommunal Infrastruktur. Delrapport 5. Available online: http://www.vestforsk.no/filearchive/r-ks-hindringsanalyse.pdf (accessed on 4 May 2017).
- Nie, L.; Lindholm, O.; Lindholm, G.; Syversen, E. Impacts of climate change on urban drainage systems—A case study in Fredrikstad, Norway. Urb. Water J. 2009, 6, 323–332. [Google Scholar] [CrossRef]
- Børstad, B. Fredrikstad Municipality, Flood Event 7. September 2002, Documentation of Rainfall and Sewers, Part 1 of 3 (Translated), COWI: Fredrikstad, Norway, 2007.
- Lindholm, O.; Schilling, W.; Crichton, D. Urban Water Management before the Court: Flooding in Fredrikstad, Norway. J. Water Law 2006, 17, 204–209. [Google Scholar]
- Fredrikstad Municipality Master Plan for Drainage and Storm Water (Translated), Fredrikstad Municipality: Kommune, Norway, 2007.
- Ebeltoft, M. Climate Change Makes New Challenges and Force New Solutions—Using Insurance Data as a Preventive Measure (Translated); Finance Norway: Oslo, Norway, 2012. [Google Scholar]
- Finance Norway. Explanation of the Codes in VASK—National Register of Water Damages (Translated). Available online: https://vask.fno.no/OmKoder.aspx (accessed on 2 March 2017).
- NFRI Documentation of AR50 (area categories). Available online: http://www.skogoglandskap.no/artikler/2007/nedlastingsinfo_ar50/newsitem (accessed on 2 March 2017).
- Zevenbergen, L.W.; Thorne, C.R. Quantitative analysis of land surface topography. Earth Surf. Process. Landf. 1987, 12, 47–56. [Google Scholar] [CrossRef]
- Brevik, R.; Aall, C.; Rød, J.K. Pilot Project on Testing of Damage Data From the Insurance Industry for Assessing Climate Vulnerability and Prevention of Climate-Related Natural Perils in Selected Municipality (Translated). Available online: http://www.vestforsk.no/filearchive/vf-rapport-7-2014-testing-av-skadedata.pdf (accessed on 2 March 2017.
- Farahani, H.A.; Rahiminezhad, A.; Same, L.; immannezhad, K. A Comparison of Partial Least Squares (PLS) and Ordinary Least Squares (OLS) regressions in predicting of couples mental health based on their communicational patterns. Procedia—Soc. Behav. Sci. 2010, 5, 1459–1463. [Google Scholar] [CrossRef]
- Tobias, R.D. An introduction to partial least squares regression. In Proceedings of the SAS Users Group International 20 (SUGI 20), Orlando, FL, USA, 2–5 April 1995; pp. 2–5. [Google Scholar]
- Nash, M.S.; Chaloud, D.J. Partial Least Square Analyses of Landscape and Surface Water Biota Associations in the Savannah River Basin. ISRN Ecol. 2011, 2011. [Google Scholar] [CrossRef]
- Zhang, H.Y.; Shi, Z.H.; Fang, N.F.; Guo, M.H. Linking watershed geomorphic characteristics to sediment yield: Evidence from the Loess Plateau of China. Geomorphology 2015, 234, 19–27. [Google Scholar] [CrossRef]
- Camo. The Unscrambler—User Manuals 2015; CAMO software AS: Oslo, Norway, 2015. [Google Scholar]
- Westerhuis, J.A.; Hoefsloot, H.C.J.; Smit, S.; Vis, D.J.; Smilde, A.K.; Velzen, E.J.J.; Duijnhoven, J.P.M.; Dorsten, F.A. Assessment of PLSDA cross validation. Metabolomics 2008, 4, 81–89. [Google Scholar] [CrossRef]
- Indahl, U.G.; Martens, H.; Næs, T. From dummy regression to prior probabilities in PLS-DA. J. Chemom. 2007, 21, 529–536. [Google Scholar] [CrossRef]
- Pérez, N.F.; Ferré, J.; Boqué, R. Calculation of the reliability of classification in discriminant partial least-squares binary classification. Chemom. Intell. Lab. Syst. 2009, 95, 122–128. [Google Scholar] [CrossRef]
- Smith, G. Flash Flood Potential: Determining the Hydrologic Response of FFMP Basins to Heavy Rain by Analyzing Their Physiographic Characteristics; NWS Colorado River Forecast Center: Salt Lake City, Utah, USA, 2003. [Google Scholar]
- Zogg, J.; Deitsch, K. The Flash Flood Potential Index at WFO Des Moines, Iowa; National Weather Service Forecast Office: Des Moines, IA, USA, 2013.
- Willems, P. Impacts of Climate Change on Rainfall Extremes and Urban Drainage Systems; IWA Publishing: London, UK, 2012; p. 226. [Google Scholar]
- Cettner, A. Overcoming Inertia to Sustainable Stormwater Management Practice; Luleå University of Technology: Luleå, Sweden, 2012. [Google Scholar]
- Jha, A.K.; Bloch, R.; Lamond, J. Cities and Flooding: A Guide to Integrated Urban Flood Risk Management for the 21st Century; World Bank Publications: Washington, DC, USA, 2012. [Google Scholar]
- Van Ootegem, L.; Verhofstadt, E.; Van Herck, K.; Creten, T. Multivariate pluvial flood damage models. Environ. Impact Assess. Rev. 2015, 54, 91–100. [Google Scholar] [CrossRef]
- Khakpour, M. As Temporal as Spatial: It is Geographical: Exploring Spatio-Temporality in Modeling the Risk of Climate Change and Natural Hazard. Ph.D. Thesis, Norwegian University of Science and Technology, Trondheim, Norway, 2015. [Google Scholar]
- Botzen, W.J.W.; Aerts, J.C.J.H.; van den Bergh, J.C.J.M. Willingness of homeowners to mitigate climate risk through insurance. Ecol. Econ. 2009, 68, 2265–2277. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| Group | No | Abbrev. | Parameter | Flooded (F) Addresses | Random (R) Addresses | BCP = Building Central Point Comments | ||
|---|---|---|---|---|---|---|---|---|
| Aver | (SD) | Aver | (SD) | |||||
| Distance | 1 | d_C | Distance to coast | 627 | (415) | 639 | (471) | Distance from BCP to coast (m) |
| Distance | 2 | d_z1 | elevation_1m area | 14.95 | (11) | 22.61 | (14) | Elevation extracted from 1 m resolution DEM at location of BCP |
| Distance | 3 | d_z10 | elevation_10m area | 15.34 | (11) | 22.60 | (14) | As above, 10 m resolution |
| Distance | 4 | d_z50 | elevation_50m area | 15.80 | (11) | 22.57 | (14) | As above, 50 m resolution |
| Slope | 5 | sl_1 | slope_1m | 2.6 | (3,1) | 5.1 | (4,6) | Mean slope extracted from 1 m resolution DEM at location of BCP |
| Slope | 6 | sl_10 | slope_10m | 2.2 | (2,2) | 5.3 | (4,2) | As above, 10 m resolution |
| Slope | 7 | sl_50 | slope_50m | 2.3 | (2,1) | 3.9 | (2,9) | As above, 50 m resolution |
| Slope | 8 | sl_r100 | Slope_r100 | 5.9 | (3,8) | 7.7 | (3,9) | Mean slope extracted from 100 m radius at location of BCP |
| Slope | 9 | sl_1_ip | slope_1m interpolated | 2.6 | (3,1) | 5.1 | (4,6) | Mean slope extracted from 1 m resolution DEM at location of BCP and its 8 first neighbors |
| Slope | 10 | sl_10_ip | slope_10m interpolated | 2.2 | (2,3) | 5.5 | (4,2) | As above, 10 m resolution |
| Slope | 11 | sl_50_ip | slope_50m interpolated | 2.4 | (2,0) | 3.9 | (2,6) | As above, 50 m resolution |
| Area | 12 | a_Up | UpSlope area | 18,047 | (4934) | 13,171 | (5381) | Area at higher ground than BCP within 100 m radius |
| Area | 13 | a_Up_ro | UpSlope impervious area | 1761 | (941) | 999 | (840) | Roads(impervious) at higher ground than BCP within 100 m radius |
| Area | 14 | a_RUp_ro | Rate UpSlope impervious area | 0.10 | 0.05 | 0.07 | 0,05 | Ratio No. 13/No. 12 |
| Area | 15 | a_DS | Cells downstream | 13,382 | (4957) | 18,183 | (5407) | Area at lower ground than BCP within 100 m radius |
| Area | 16 | a_US | Cells upstream | 17,986 | (4957) | 13,186 | (5407) | Area at higher ground than BCP within 100 m radius |
| Area | 17 | a_US_im | Cells impervious | 15,880 | (5168) | 11,167 | (5528) | Area of imperm surfaces at higher ground than BCP within 100 m radius |
| Area | 18 | a_US_pe | Cells pervious | 2106 | (3158) | 1966 | (3761) | Area of perm. surfaces at higher ground than BCP within 100 m radius |
| Area | 19 | a_RUS_im | Rate Cells impervious | 0.89 | (0,2) | 0.86 | 0,24 | Ratio No. 17/ No. 16 |
| Curvature | 20 | c_pr1 | curvature profile 1 m | 0.16 | (1,7) | −0.17 | (3,0) | Profile curvature extracted from 1 m resolution DEM at location of BCP |
| Curvature | 21 | c_pr10 | curvature profile 10 m | 0.07 | (0,3) | 0.04 | (0,6) | As above, 10 m resolution |
| Curvature | 22 | c_pr50 | curvature profile 50 m | 0.07 | (0,1) | −0.01 | (0,1) | As above, 50 m resolution |
| Curvature | 23 | c_pr1_ip | curvature profile 1 m interpolated | 0.14 | (1,2) | −0.13 | (2,1) | Weighted mean profile curvature extracted from 1 m resolution DEM based on four closest pixels to location of BCP |
| Curvature | 24 | c_pr10_ip | curvature profile 10 m interpolated | 0.08 | (0,2) | 0.03 | (0,6) | As above, 10 m resolution |
| Curvature | 25 | c_pr50_ip | curvature profile 50 m interpolated | 0.06 | (0,1) | 0.00 | (0,1) | As above, 50 m resolution |
| Curvature | 26 | c_pl1 | curvature plan 1 m | 0.18 | (1,9) | 0.02 | (1,8) | Plan curvature extracted from 1 m resolution DEM at location of BCP |
| Curvature | 27 | c_pl10 | curvature plan 10 m | −0.02 | (0,2) | 0.06 | (0,3) | As above, 10 m resolution |
| Curvature | 28 | c_pl50 | curvature plan 50 m | −0.02 | (0,1) | 0.03 | (0,1) | As above, 50 m resolution |
| Curvature | 29 | c_pl1_ip | curvature plan 1 m interpolated | 0.14 | (1,4) | 0.05 | (1,5) | Weighted mean plan curvature extracted from 1 m resolution DEM based on four closest pixels to location of BCP |
| Curvature | 30 | c_pl10_ip | curvature plan 10 m interpolated | −0.02 | (0,1) | 0.06 | (0,3) | As above, 10 m resolution |
| Curvature | 31 | c_pl50_ip | curvature plan 50 m interpolated | −0.02 | (0,0) | 0.02 | (0,1) | As above, 50 m resolution |
| Sewer | 32 | se_C | Combined sewer mains (rate) | 66% | 46% | Rate combined system (category var) | ||
| Sewer | 33 | se_S | Separate sewer mains (rate) | 34% | 54% | Rate separate system (category var) | ||
| Sewer | 34 | se_D | Diameter pipe(mm) | 369 | (225) | 269 | (134) | Diameter of nearest sewer pipe |
| Sewer | 35 | se_Y | Year of constructed pipe | 1972 | (26,2) | 1974 | (23,0) | Year of construction for the nearest sewer mains |
| Sewer | 36 | se_HorD | Horizontal dist to sewer | 20.9 | (9,9) | 29.2 | (23,3) | Horizontal distance from BCP to the nearest sewer |
| Sewer | 37 | se_V>2 | Vertical dist to sewer >2 m | 0% | 16% | Vertical distance from BCP to sewer mains >2 m (category variable) | ||
| Sewer | 38 | se_V<2 | Vertical dist to sewer <2 m | 100% | 84% | Vertical distance from BCP to sewer mains<2 m (category variable) | ||
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Torgersen, G.; Rød, J.K.; Kvaal, K.; Bjerkholt, J.T.; Lindholm, O.G. Evaluating Flood Exposure for Properties in Urban Areas Using a Multivariate Modelling Technique. Water 2017, 9, 318. https://doi.org/10.3390/w9050318
Torgersen G, Rød JK, Kvaal K, Bjerkholt JT, Lindholm OG. Evaluating Flood Exposure for Properties in Urban Areas Using a Multivariate Modelling Technique. Water. 2017; 9(5):318. https://doi.org/10.3390/w9050318
Chicago/Turabian StyleTorgersen, Geir, Jan Ketil Rød, Knut Kvaal, Jarle T. Bjerkholt, and Oddvar G. Lindholm. 2017. "Evaluating Flood Exposure for Properties in Urban Areas Using a Multivariate Modelling Technique" Water 9, no. 5: 318. https://doi.org/10.3390/w9050318
APA StyleTorgersen, G., Rød, J. K., Kvaal, K., Bjerkholt, J. T., & Lindholm, O. G. (2017). Evaluating Flood Exposure for Properties in Urban Areas Using a Multivariate Modelling Technique. Water, 9(5), 318. https://doi.org/10.3390/w9050318