1. Introduction
A rainfall–runoff (RR) model is a mathematical model used to describe the RR process of a watershed, which generally produces a surface runoff hydrograph (output) using a hyetograph (input) [
1]. The RR model is calibrated: (1) for estimating the model structure and parameters that enable the model to closely match the behavior of the real system it represents; and (2) for estimating model uncertainties. A hydrologist wants to develop a hydrological model with not only high accuracy (i.e., the former case for minimizing a bias) and but also high precision (i.e., the latter case for a reliable performance).
During the past two decades, the development and calibration of RR models have been the focus of hydrological research [
2,
3]. Various RR models have been developed and are classified into lumped and distributed models. The former is based on the assumption that the entire basin has a homogeneous hydrological characteristic, whereas the latter divides the basin into elementary unit areas resembling a grid network to consider the spatial variability of the basin characteristics. The Sacramento Soil Moisture Accounting (SAC-SMA) model is an example of a lumped model, whereas the Systeme Hydrologique Européen-Transport (SHETRAN) [
4] is a distributed model.
RR models never perfectly represent an actual system of interest, and the data used for calibration always contain measurement errors [
5]. Although the main focus of hydrological research has been the development of automatic parameter calibration approaches, efforts have also been made to assess parameter uncertainty in RR models to quantify the inability of the model to produce precise and accurate results [
2,
5,
6,
7,
8,
9,
10,
11]. The present study focuses on the development of efficient and effective automatic parameter calibration methods.
The governing equations of RR models are used to define the RR processes, which consist of model parameters and variables. Traditionally, a manual approach has been applied in which a hydrologist estimates the value of the model parameters through a trial-and-error process in which the model matches the behavior of the actual system it represents [
2]. The hydrologist’s experience and knowledge of the model (e.g., the model structure and sensitivity of model parameters) are key factors for the success of the model calibration in this approach. However, there is no guarantee that the hydrologist will find the best parameter set yielding the highest accuracy of the RR model through these time-consuming efforts because the optimal parameter calibration problem is highly nonlinear, multimodal, and nonconvex [
12] for which a simple gradient-based technique cannot be used.
To overcome the limitation of the manual approach in the speed and reliability of the RR model calibration, an automatic, computer-based approach has been widely used during the last two decades [
3]. Generally, an RR model is linked to stochastic optimization algorithms to evaluate the fitness of potential parameter sets and to identify the optimal parameter set resulting in the best accuracy for the model [
13]. These algorithms include simulated annealing (SA) [
14], genetic algorithm (GA) [
15,
16], particle swarm optimization (PSO) [
17], harmony search (HS) [
18], and shuffled complex evolution-University of Arizona (SCE-UA) [
12]. The most popular measure of the fit of the model is the mean-square-error (MSE) estimator [
2]. By using the automatic calibration method, the solution space can be explored in less time than that taken when using the manual approach.
Various model accuracy measures have been introduced to consider the different aspects of model accuracy. For example, use of maximum absolute error (MAE) focuses on the robustness of the model accuracy to minimize the worst deviation between the observed and simulated values [
19,
20,
21,
22,
23]. The peak flow difference can generally be considered in the RR model for hydraulic structure design [
19,
20,
21,
22,
23,
24,
25]. Therefore, a pair of competing model accuracy measures can exist among various measures. During the model calibration process, hydrologists often observe that increasing a model accuracy measure (e.g., the mass balance measure) cannot be achieved without sacrificing or decreasing another measure (e.g., the peak difference). This phenomenon has triggered the advent of multiobjective automatic model calibration models [
2,
10], which explore the trade-off in the relationship among two or three competing model accuracy measures.
Efstratiadis and Koutsoyiannis [
26] provided a thorough review and summarized the critical issues in multiobjective calibration. They classified multiobjective calibration studies into aggregate and pure Pareto approaches. The former combines multiple objectives into a single objective by weighting them, whereas the latter identifies multiobjective optimal solutions (i.e., the Pareto optimal solution) by simultaneously seeking multiple objectives. Recently, calibration methodologies used specifically for pure multiobjective schemes have been introduced. Asadzadeh et al. [
27] proposed a selection measure known as convex hull control (CHC) for solving a multiobjective calibration problem with a known and approximated convex Pareto solution.
Zhang et al. [
28] performed sensitivity analysis of the parameters of the non-dominated sorting genetic algorithm-II (NSGA-II) [
29] on the accuracy of a distributed hydrological model known as Systeme Hydrologique Européen-Transport (SHETRAN) [
4,
30,
31,
32,
33,
34,
35,
36]. Simulated binary crossover (SBX) [
37] and polynomial mutation (PM) [
38] were used for the crossover and mutation, respectively, of three NSGA-II algorithms: the original NSGA-II, the reference point-based-NSGA-II (R-NSGA-II) [
39], and the extension ER-NSGA-II [
40]. The root-mean-square error (RMSE) and logarithmically transformed RMSE (LOGE) between the observed and simulated hourly discharges were minimized simultaneously. Three combinations of crossover and mutation distribution indices (C
DI and M
DI, respectively), the parameters of SBX and PM, respectively, with values of (0.5, 0.5), (2.0, 0.5), and (20, 20), which were kept constant during optimization were applied. C
DI and M
DI control the closeness of the children solutions to the parent solutions in the crossover and mutation, respectively. Higher parameter values (e.g., C
DI = 20) result in children solutions that are more similar to the parent solutions, which are assigned more weight on exploitation.
Zhang et al. [
28] assumed that the algorithm’s balance between exploration (diversification) and exploitation (intensification) did not change over generations, which is a static approach. The former is defined as the algorithm’s ability to search wide areas of the solution space (e.g., the random search of HS), and the latter refines the neighborhood of previously found promising areas in solution space (e.g., the crossover of GA). However, some studies reported that the balance should be variable to guarantee the best performance [
41,
42,
43] because the effectiveness of wide search and fine-tuning depends on the optimization phase. Cuevas et al. [
44] stated that a common strategy for balancing exploration and exploitation is to start with exploration and then gradually increase exploitation as good fitness points are identified. It would be a better strategy in the automatic calibration of a hydrological model to focus on searching various parameter sets broadly in the early optimization phase and to give more weight to fine-tuning the solutions found in the latter phase.
This study introduces variable balancing approaches for the exploration and exploitation of the NSGA-II with SBX and PM in the multiobjective automatic parameter calibration of a lumped hydrological model, the HYMOD model. The proposed balancing approaches, which migrate the focus between exploration and exploitation over generations by varying the crossover and mutation distribution indices, CDI and MDI, respectively, were compared to traditional static balancing approaches (the two dices value is fixed during optimization) in a benchmark hydrological calibration problem for the Leaf River (1950 km2) near Collins, Mississippi. Three performance metrics, solution quality, spacing, and convergence, were used to quantitatively compare the performance of the two different balancing approaches.
2. Methodology
This study compared static and variable balancing approaches for the NSGA-II by using SBX and PM operators in the multiobjective automatic calibration of a lumped RR model, the HYMOD model. Two types of parameters are used throughout the study: algorithm parameters (e.g., crossover rate, C
DI, and M
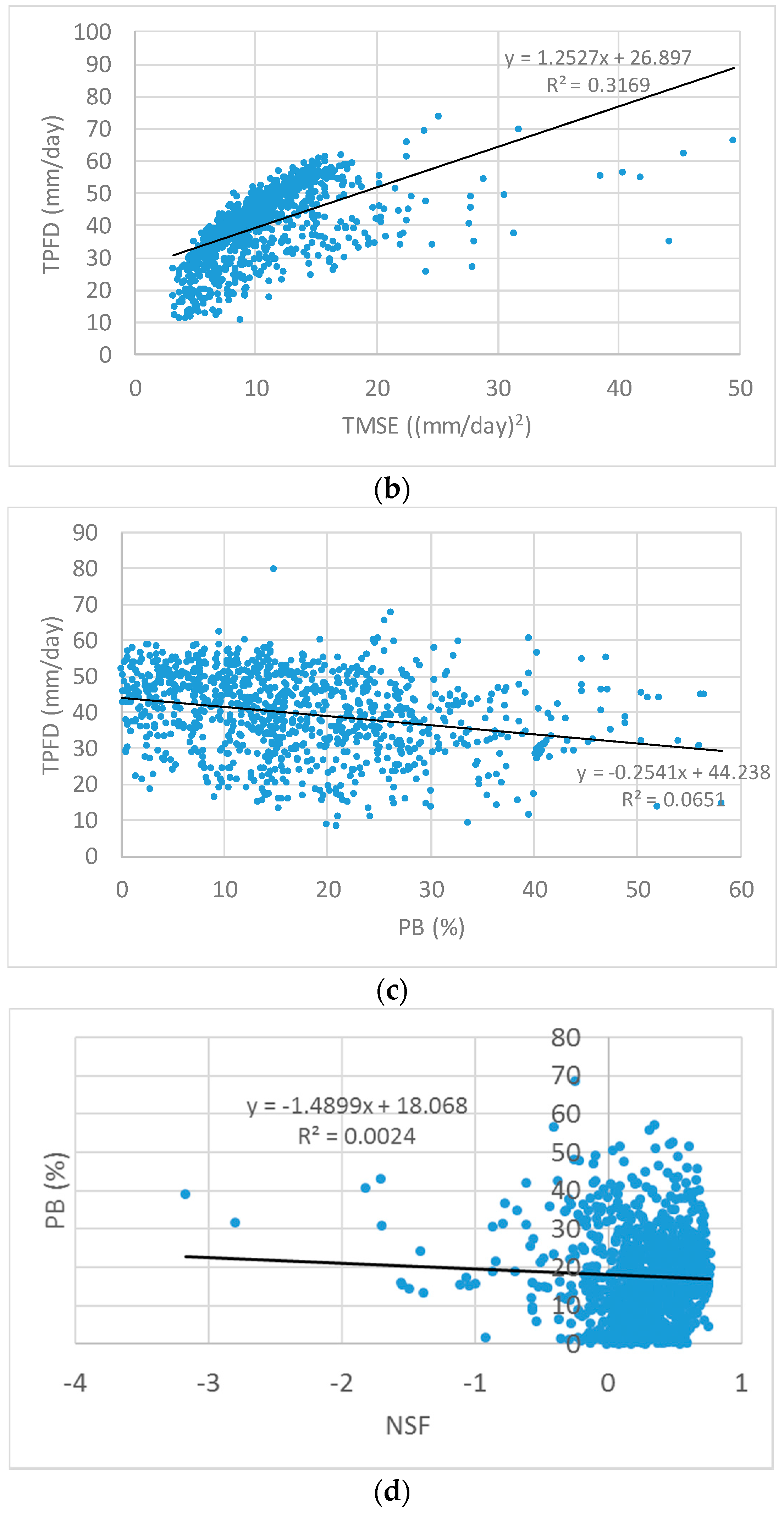
DI) and model parameters (HYMOD model parameters). An improved version of the HYMOD model was used to simulate the RR process of the Leaf River basin located north of Collins, Mississippi. First, the correlation among various model accuracy indicators (MAIs) was inspected by visual inspection, linear regression, and Pearson correlation analysis to select two competing objectives to be minimized in the calibration. In this study, the trade-off relationship between percent bias (PB) and the sum of three peak flow differences (TPFD) was explored by using the static and variable balancing approaches. The performance measures, solution quality, spacing, and convergence [
45] of the Pareto optimal solutions were quantified to identify the best balancing strategy. The following sections describe the objective selection process, the multiobjective calibration model, NSGA-II, SBX, PM, performance metrics, and the improved HYMOD model.
2.1. Objective Selection Process
The accuracy of the RR model was evaluated by comparing the observed and simulated discharge values at specific points in the basin. The model parameters were calibrated to minimize the model error. The prediction always contains errors (i.e., deviations from the observed value) that are jointly influenced by: (1) measurement error; (2) inappropriate representation of the actual system; and (3) the lack of basin information for model development and parameter calibration [
26].
Various model accuracy measures have been formulated and used for automatic calibration of RR models.
Table 1 summarizes several MAIs used by the National Weather Service for calibration of the Sacramento soil moisture accounting (SAC-SMA) model and MSE-based measures widely used in the domain of hydrological model calibration. Different measures represent different aspects of model error. For example, an MSE measure is appropriate when measurement errors are uncorrelated and more weights should be given to minimizing error at high flows. In contrast, the sum of peak differences is considered when an RR model is used for flood management when peak discharge is the main concern. Therefore, the appropriate model error measure should be carefully selected and used for effective model parameter calibration.
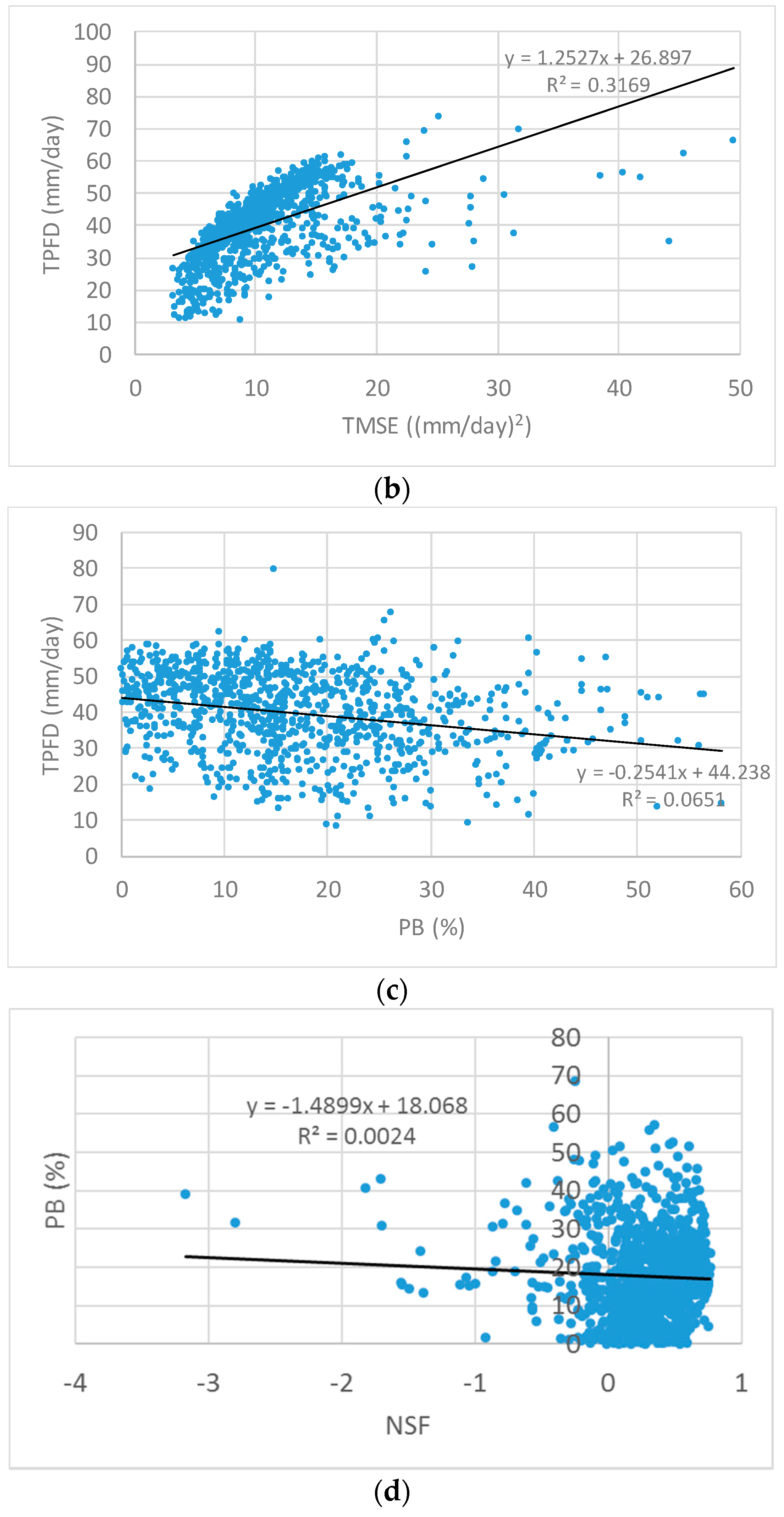
In order to construct a multiobjective automatic parameter calibration model, two competing MAIs should be identified. The two correlated indicators should not be simultaneously considered in the model because minimizing/maximizing one indicator would have the same effect on the other indicator. To that end, uniform random sampling within the upper and lower bounds of parameters, which is determined by physical reasonability, engineering knowledge, and Monte Carlo simulations (MCS) generates random parameter sets. A simulated hydrograph is obtained from the RR simulation using each generated parameter set for which the MAIs in
Table 1 are calculated. Finally, the scatter plot of each pair of the MAIs in
Table 1 and its linear regression line are drawn and inspected to detect the potential correlation.
2.2. Multiobjective Automatic Parameter Calibration Model
The two objectives selected from the objective selection process were optimized in the multiobjective automatic parameter calibration model of the hydrological model. Most MSE-type objectives are to be minimized, whereas a few accuracy measures are to be maximized (e.g., the Nash–Sutcliffe measure (NSF)). The decision variables of the model are the parameters (
θ) of the hydrological model. The observed dataset of flow discharge was selected and provided to the model for fitting the simulated results. Therefore, the multiobjective parameter calibration model was formulated as
where MAI1 and MAI2 are the first and second different MAIs calculated given the model parameter
θ, respectively; and Θ is the feasible parameter space defined by the minimum and maximum values of each parameter, assuming that the two objectives are to be minimized.
The two objectives were simultaneously optimized; they were not aggregated in this study. In the field of hydrological model calibration, the NSGA-II, Multiobjective Complex Evolution (MOCOM) algorithm and the Multiobjective Shuffled Complex Evolution Metropolis (MOSCEM) algorithm are widely used [
8,
46,
47,
48,
49,
50,
51,
52,
53,
54,
55,
56,
57,
58,
59]. A set of Pareto optimal solutions (non-dominated parameter sets) was obtained from the model. Then, a best-compromise parameter set is identified and suggested among multiple Pareto optimal parameter sets based chiefly on the user’s judgment according to the analysis of the shape of the Pareto front.
2.3. NSGA-II with SBX and PM
This study used NSGA-II to find the Pareto optimal parameter sets in the multiobjective calibration model introduced in the previous section. The main mechanisms of NSGA-II compared with other multiobjective metaheuristic algorithms are the non-dominated ranking and consideration of crowding distance [
29]. That is, a solution distant to others in the solution space and dominating other solutions with respect to fitness is more likely to survive to the next generation. Details of NSGA-II have been reported by Deb et al. [
29].
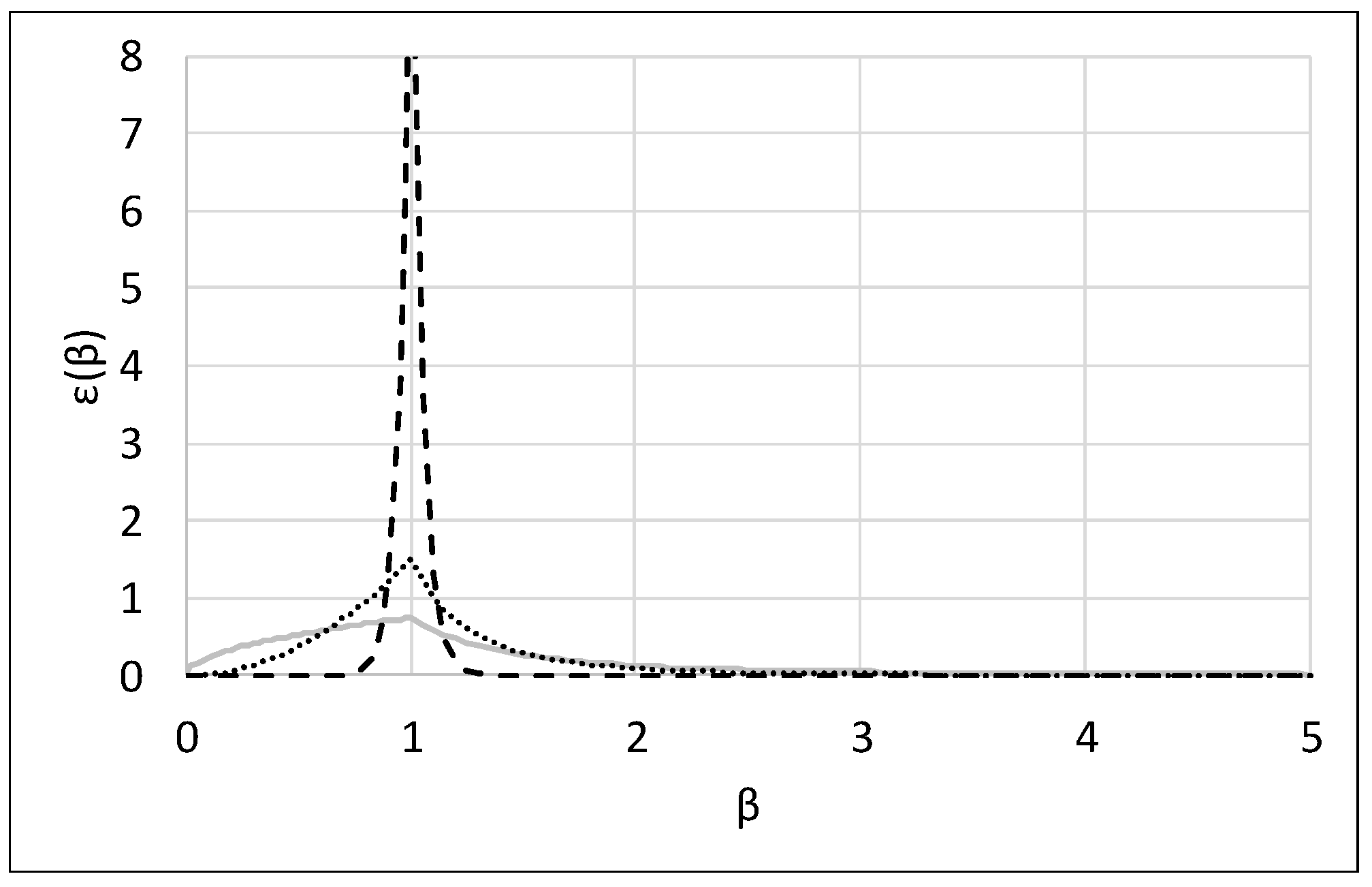
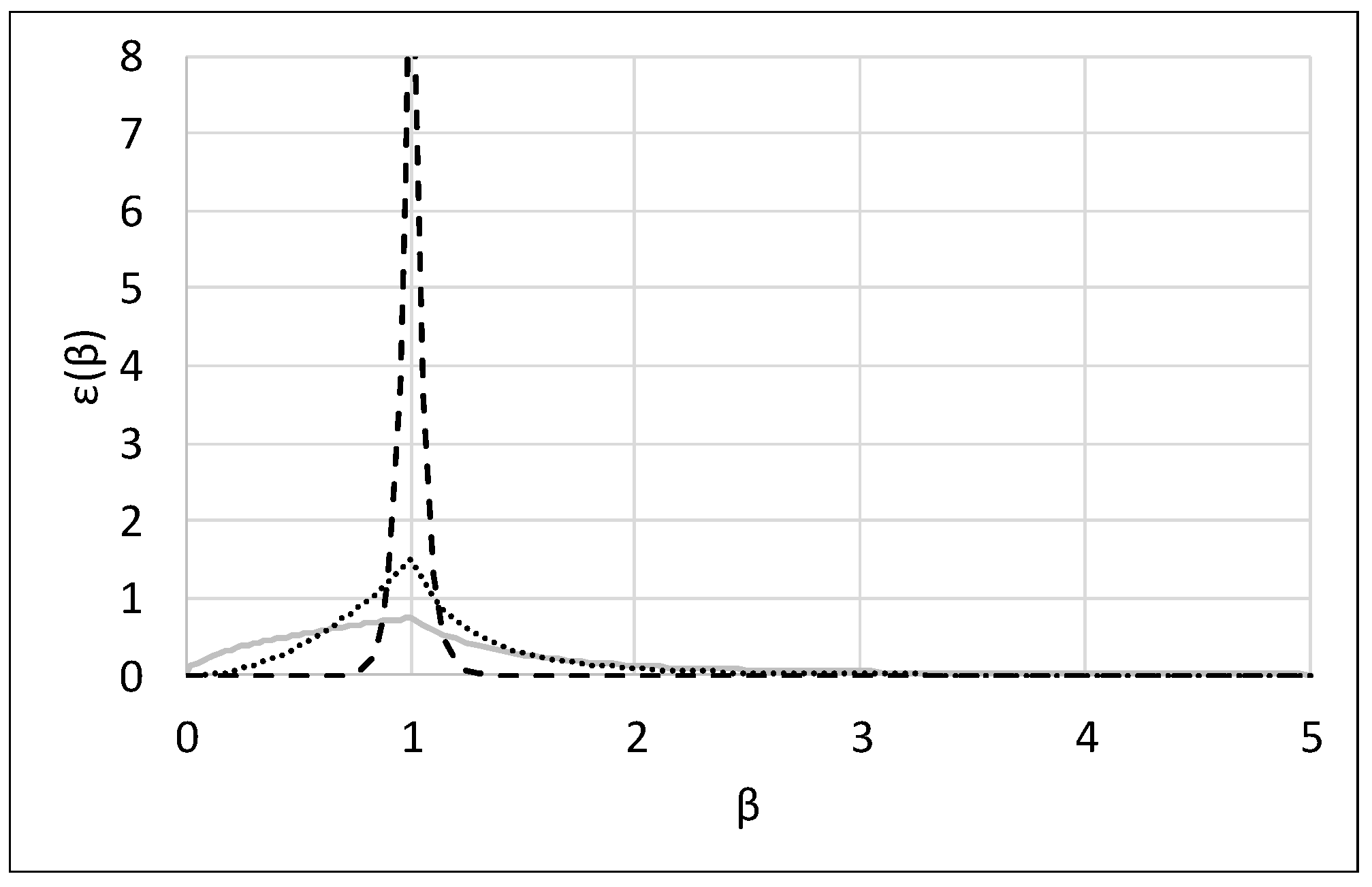
This study employed SBX and PM operators for the crossover and mutation, respectively, of NSGA-II to improve the search power. It should be noted that the occurrences of the crossover and mutation operations are complementary, and their frequency is controlled by the crossover rate (Crate). Therefore, if the Crate is 0.9, the rate of mutation is 0.1. The SBX and PM operators control the spread of the children solutions compared with the selected parent solutions by CDI and MDI . Therefore, the best strategy for the control of CDI and MDI should be identified and used to obtain the best effectiveness and efficiency of NSGA-II with SBX and PM.
The SBX operator produces two children solutions
and
from the two selected parent solutions
and
by using polynomial probability distributions
where
which can be obtained by inverse transform sampling with a randomly generated number
, and
is a probability function. As indicated in
Figure 1, large values of C
DI result in a high probability of creating children solutions close to the parent solutions. Then, the children solutions are derived from the equations below:
The PM operator creates the child solution
from the parent solution
by using the polynomial probability distribution:
where
and
is a probability distribution function.
The child solution is then produced by the equation
where
and
are the upper and lower bounds of the
ith decision variable, respectively.
Five parameters are used in NSGA-II with SBX and PM operators that affect the algorithm performance: the number of generations (NGEN), the number of populations (NPOP), Crate, CDI, and MDI.
2.4. Variable Exploration and Exploitation Balancing Approaches
The success of the metaheuristic optimization algorithm depends on the balance between the algorithm’s exploration (diversification) and exploitation (intensification) capability [
44,
60,
61,
62,
63]. This study proposes variable changing methods for the C
DI and M
DI of SBX and PM, respectively. Using higher parameter values (e.g., C
DI = 20) assigns more weight to exploitation, whereas smaller parameter values (e.g., C
DI = 0.5) emphasize exploration (
Figure 1).
We can vary the balance between exploration and exploitation over generations by changing the C
DI and M
DI values. An example of the variable balancing approach is the so-called parameter-setting-free (PSF) method, which has been used by a few researchers in the field of applied mathematics for removing the burden on the user in selecting algorithm parameters [
41,
42,
43].
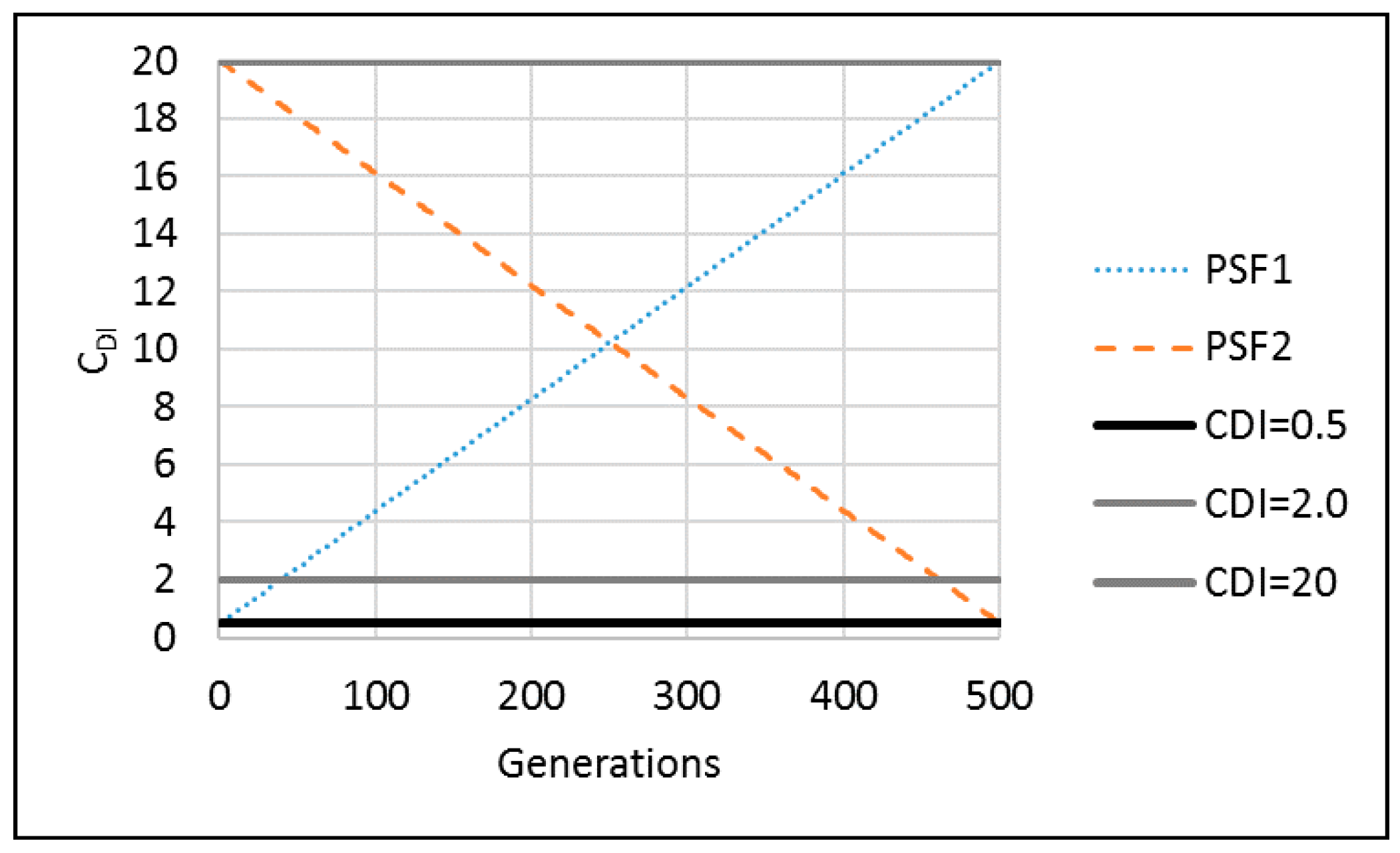
Two respective representative PSF methods increase the algorithm parameter value from its minimum to maximum (PSF1) and decrease the algorithm parameter value from its maximum to its minimum (PSF2) (
Figure 2). Therefore, the algorithm parameter at the generation
igen,
pigen (e.g.,
p = C
DI or M
DI), is calculated as
where
pmin and
pmax are the minimum and maximum value of the algorithm parameter
p, respectively. Four different variable balancing approaches for exploration and exploitation are generated from the combination of PSF1 and PSF2 for C
DI and M
DI. Therefore, Approach 1 uses PSF1 for both C
DI and M
DI, whereas Approach 2 applies PSF2 for both indices. In contrast, Approach 3 uses PSF1 for C
DI and PSF2 for M
DI, and Approach 4 applies PSF2 for C
DI and PSF1 for M
DI.
2.5. Performance Metrics
In order to compare the Pareto optimal solutions obtained from different approaches, three performance metrics were used: solution quality metric (SQM), spacing metric (SPM), and convergence metric (COM). The original SQM and COM were introduced by Wang et al. [
64] and Kollat and Reed [
65], respectively. SPM was originally proposed by Zheng et al. [
45] for measuring run-time performance of multiobjective algorithms, which was modified in this study for the evaluation of the final Pareto solutions.
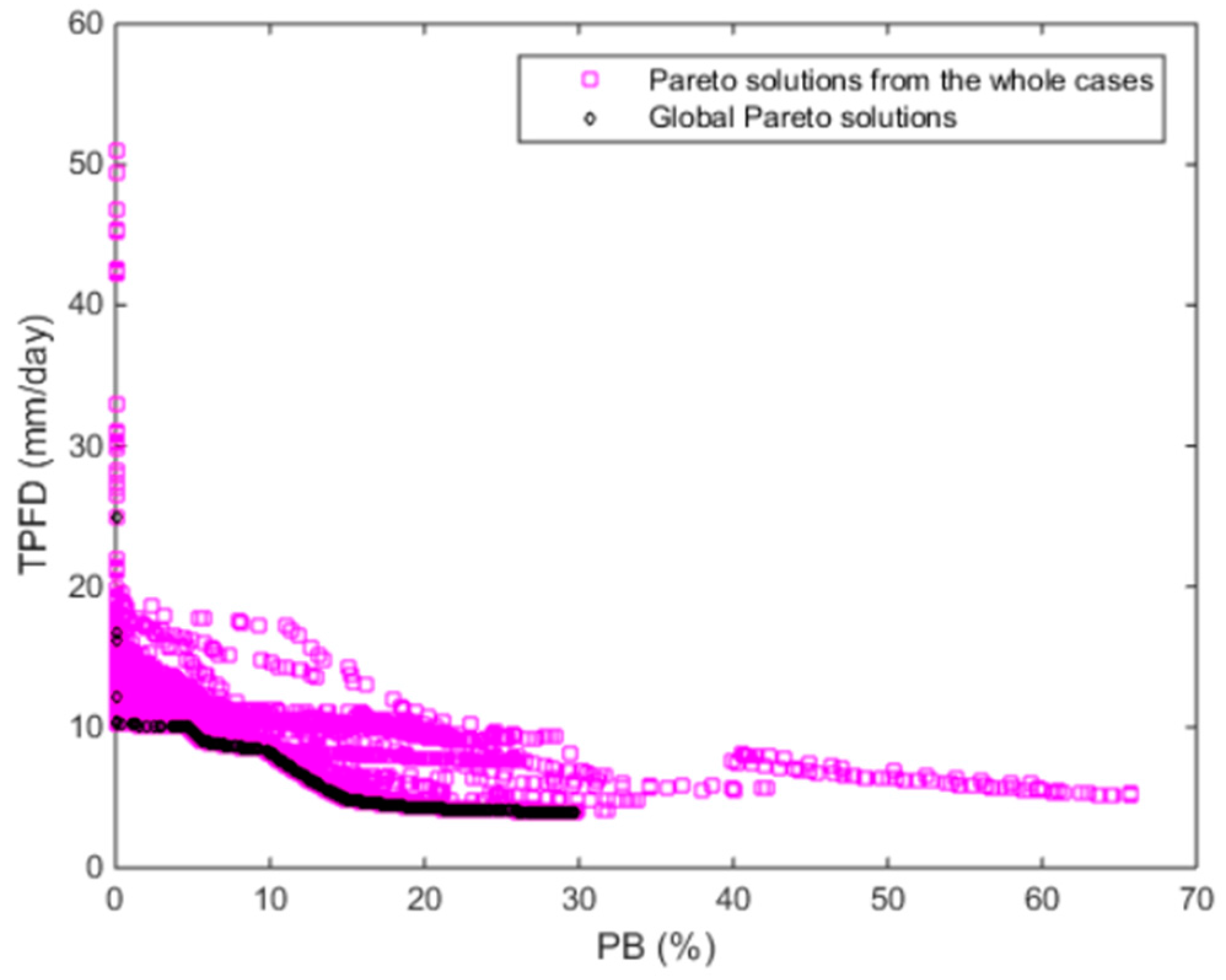
SQM quantifies an algorithm’s ability to find non-dominated solutions. The steps for calculating SQM are briefly described here. The final optimal Pareto solutions of all algorithms (all approaches or cases) are gathered to identify the global non-dominated solutions, also referred to as the global Pareto solution or the global Pareto front, Z*. The SQM of a case is equal to the number of non-dominated solutions found by the case in Z*.
Deb et al. [
29] considered crowding distance to be an important factor for the selection of the children population so that NSGA-II would develop a wide-spread Pareto front, which is favored with respect to the final solution diversity and exploration [
66]. The Pareto front with a wide range of objective function values means that the decision maker can choose from more parameter set alternatives. SPM quantifies the extent of the Pareto front relative to the Pareto front Z* as
where
Fi is the objective function vector of the
ith solution in the algorithm population (population size =
N, i.e., Z = {
F1,
F2, …,
FN}); dist(
X,
Y) is the Euclidean distance between the two vectors
X and
Y; and
F and
G are any solution vectors on the global Pareto front Z*. To calculate SPM, each objective function value of the solutions in Z* is normalized to have a maximum value equal to 1. Then, each dimension of Z is normalized on the basis of the ranges of Z*.
COM measures the averaged Euclidean distance between an algorithm’s front and the global Pareto front Z* as
where
is the minimum Euclidean distance between the
ith solution of the algorithm population and any solution vector
F on the global Pareto front Z*. Therefore, larger values of SQM and SPM are preferred, whereas smaller values of COM (i.e., shorter distance to the Pareto front) are preferred.
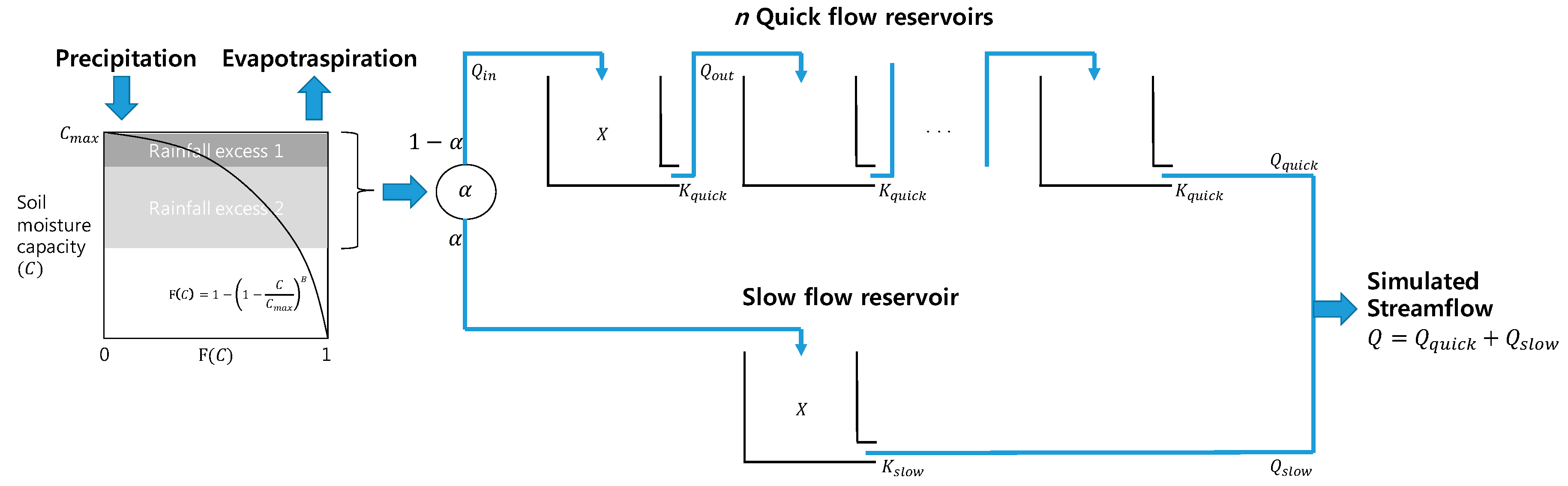
2.6. Modified HYMOD
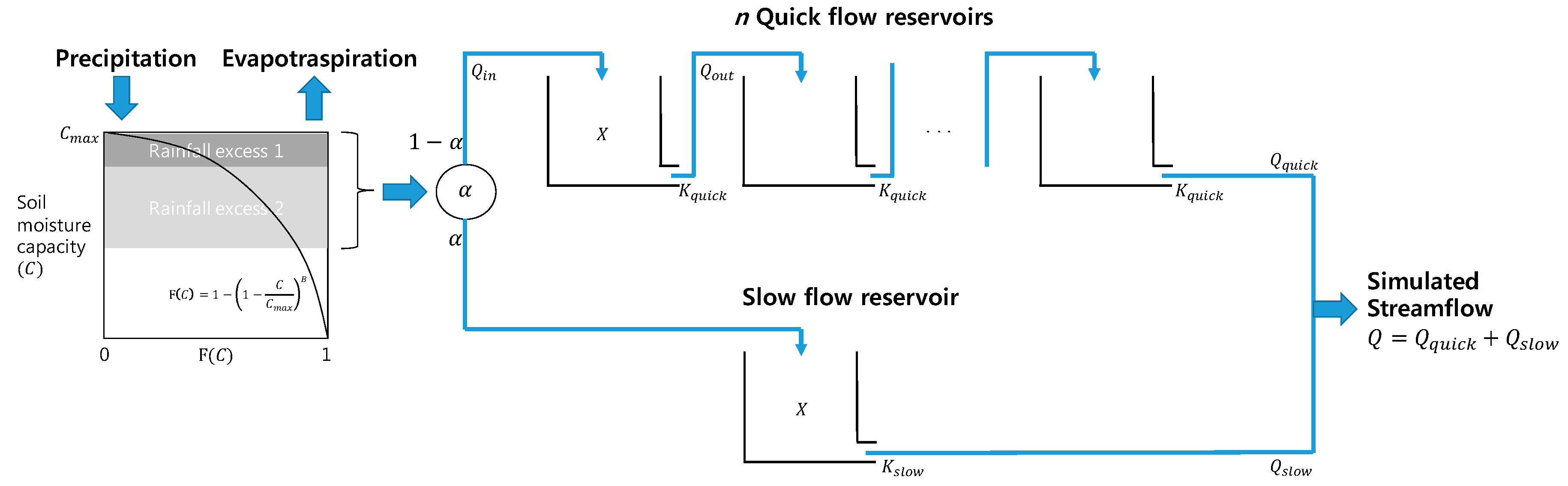
The original HYMOD model is a conceptual lumped RR model based on the probability-distributed principle [
67]. The model consists of a simple two-parameter rainfall excess model linked with two series of parallel linear reservoirs for flow routing: three quick flow tanks and a slow flow tank. The distribution between the quick and slow flow tanks is adjusted by the parameter α, where 1-α is used for quick flow, and α is used for slow flow.
Figure 3 shows a schematic diagram of the model structure.
The model assumes that a basin consists of soil moisture storage with varying capacity. The spatial variability of soil moisture capacity (
C) is represented by the following cumulative distribution function:
where
Cmax is the maximum storage capacity of the basin, and
B is the degree of spatial variability of the soil moisture capacity of the basin. The time-varying total water storage of the basin (
S(
t)
) is simulated by assuming that all storage within the basin is filled to the same critical level. Surface runoff is generated from a saturated area, whereas water is infiltrated into unsaturated areas. Further details on the rainfall excess model have been reported by Moore [
67,
68]. Therefore, the two parameters in the distribution function of soil moisture capacity,
Cmax and
B, are important parameters to be calibrated.
The outflow from a reservoir (
Qout(
t) in mm/day) and the reservoir state (
X(
t) in mm) during the time interval
t are calculated following the assumption of a linear reservoir and mass conservation, respectively, as
where
K is the leakage rate in 1/day, which is identical to
Kquick from the quick flow tanks and
Kslow from the slow flow tank, and
Qin(
t) is the inflow into the reservoir at time interval
t. Inflow to a reservoir on the quick flow pathway can be either outflow from the basin or
Qout from another tank.
This study used a modified HYMOD model, which considers the number of quick flow reservoirs (
n) as a parameter to be calibrated. Therefore, the timing of quick flow release to the river channel or the residence time of the quick flow reservoirs can be determined for a specific watershed.
Table 2 summarizes the definition and range of the six parameters to be calibrated.
6. Summary and Conclusions
This study proposed variable balancing approaches for the exploration and exploitation of NSGA-II with SBX and PM in the multiobjective automatic parameter calibration of a lumped hydrological model, the HYMOD model. Six model parameters for maximum storage capacity, soil moisture capacity distribution, ratio between quick and slow flows, the number of quick flow reservoirs, and leakage rates for quick and slow flow tanks were used. The two objectives of minimizing the percent bias and minimizing the sum of the absolute error at three peak flow days were selected by visual inspection, linear regression, and Pearson correlation analysis of a pair of various MAIs quantified by using randomly generated model parameter values. The proposed balancing approaches, which migrate the focus between exploration and exploitation over generations by varying CDI and MDI, were compared with traditional static balancing approaches (the two dices value is fixed during optimization) in a benchmark hydrological calibration problem for the Leaf River (1950 km2) near Collins, Mississippi. Three performance metrics, the solution quality, spacing, and convergence (SQM, SPM, and COM, respectively), were used to quantitatively compare the performance of the two different balancing approaches. NPOP = 100 and NGEN = 500 were selected from sensitivity analysis and were used for optimization.
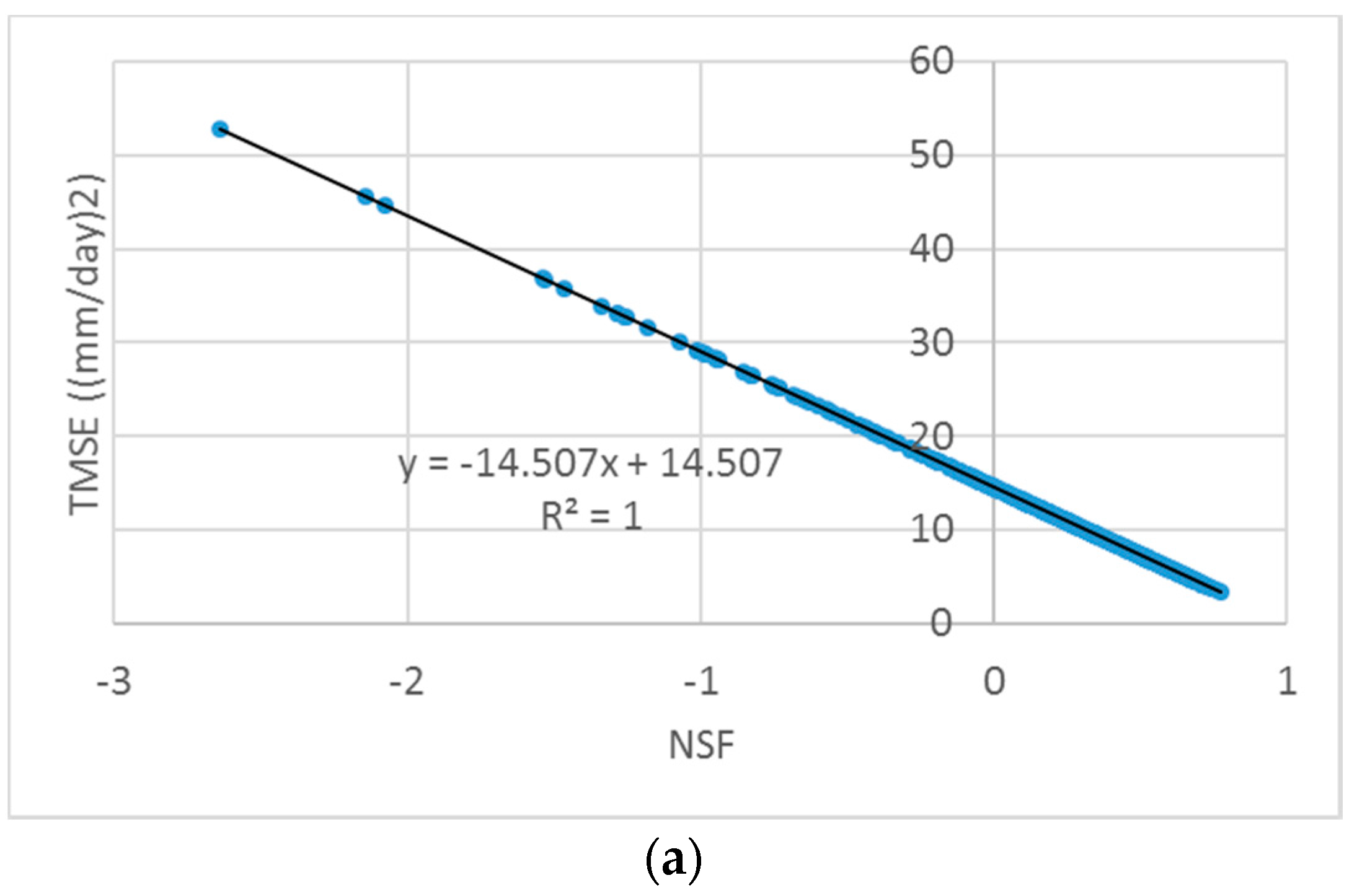
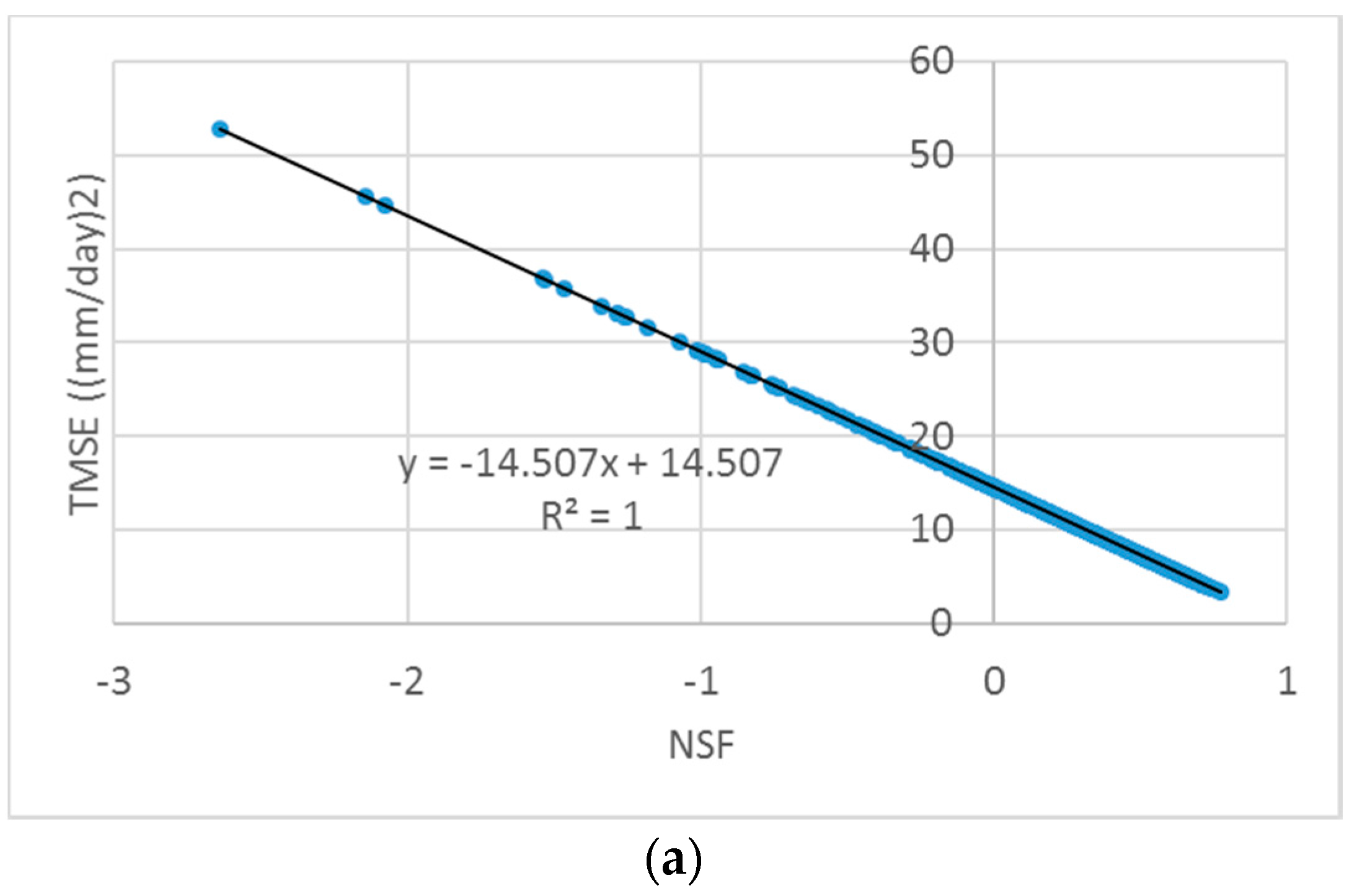
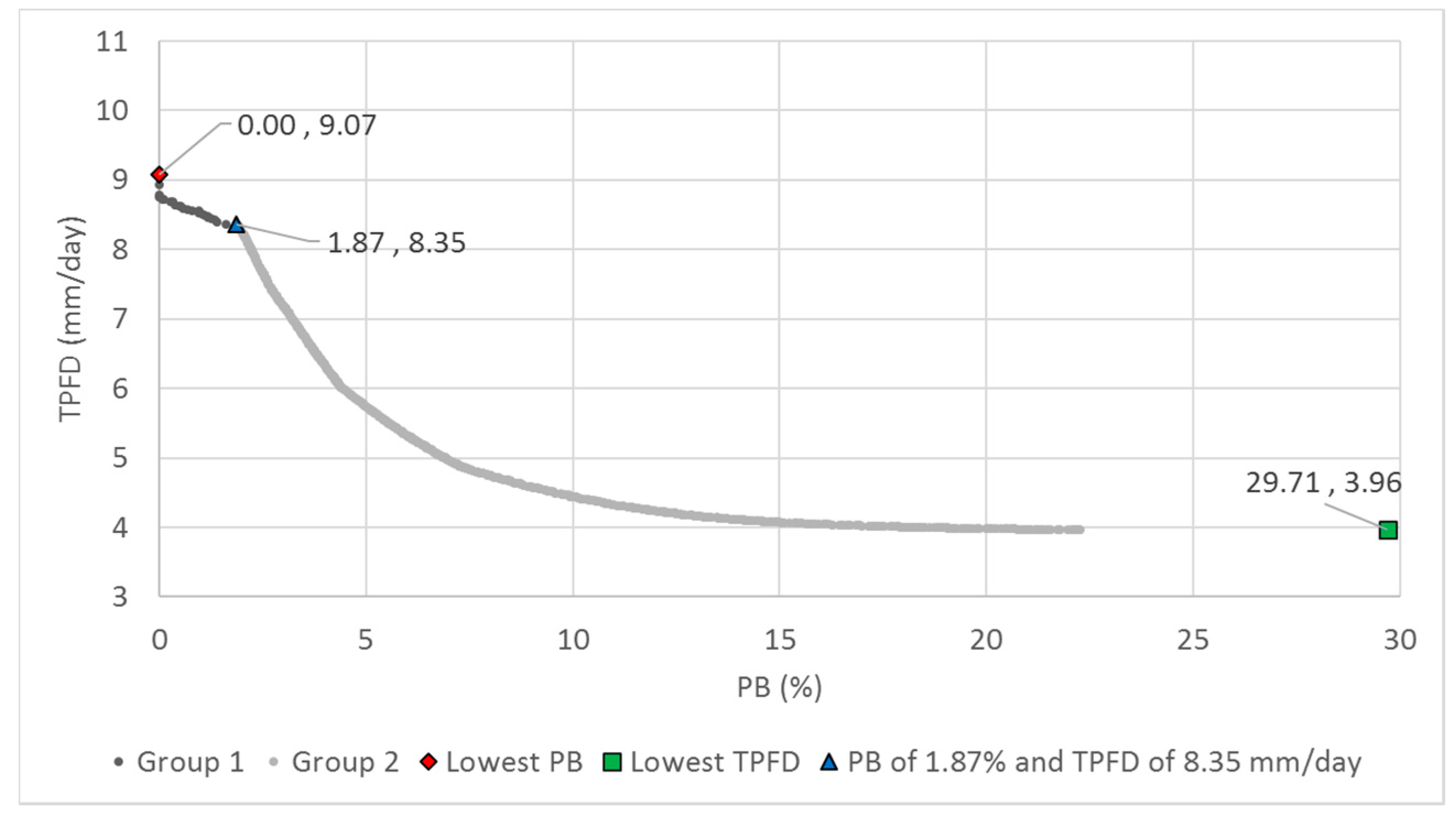
First, a scatter plot of a pair of the MAIs summarized was drawn for visual inspection for detecting the potential correlation between two indicators by using a fitted linear regression line. A trade-off relationship was found between PB and TPFD. PB measures the difference between the means of the observed and simulated streamflows, whereas TPFD calculates the sum of three peak flow differences. The Pearson correlation coefficient between the two measures was −0.228, indicating a negligible correlation exists.
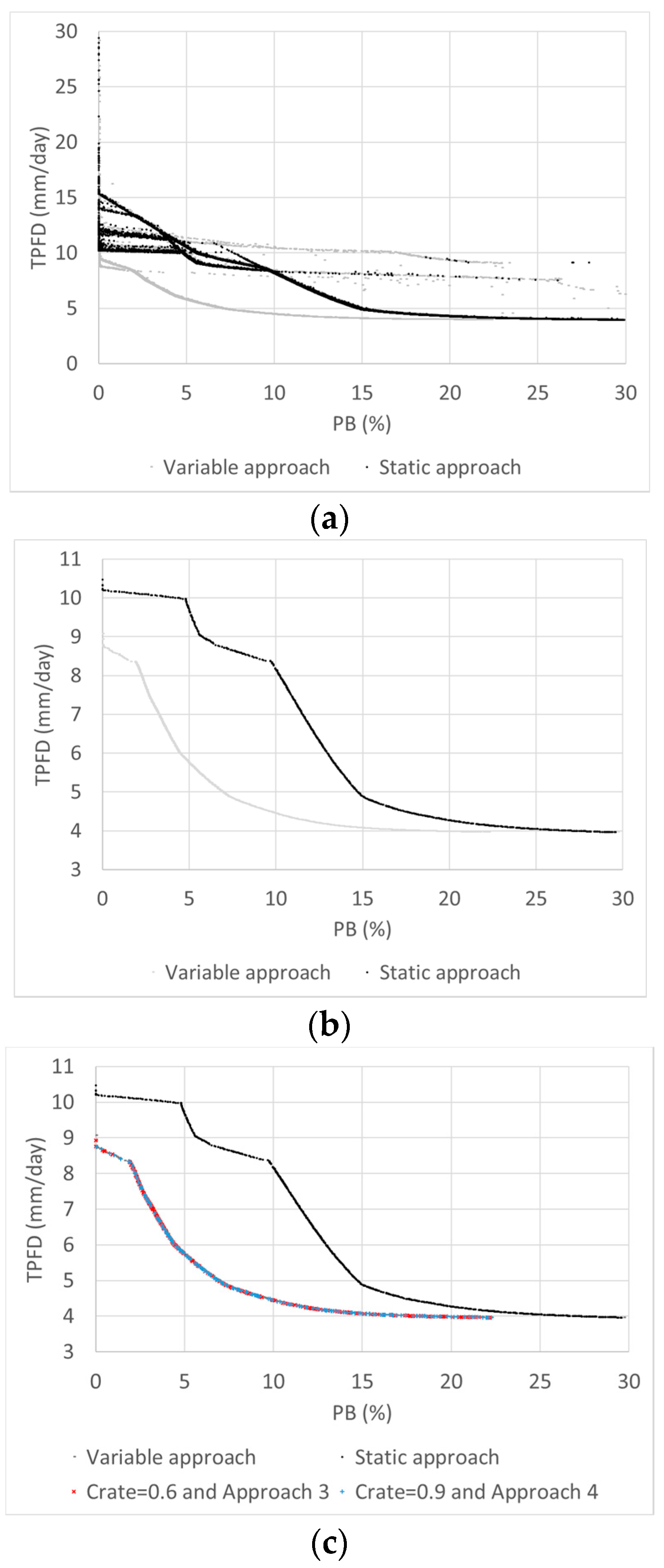
Then, the best static approach was identified from nine cases of Crate and (C
DI, M
DI) with combinations of Crates of 0.6, 0.75, and 0.9 and (C
DI, M
DI) values of (0.5, 0.5), (2.0, 0.5), and (20, 20). A high value of C
DI (or M
DI) results in children solutions that are more similar to the parent solutions (exploitation), whereas small values of C
DI (or M
DI) emphasize exploration. It was found that a Crate of 0.6 and (C
DI, M
DI) of (2.0, 0.5) and (20, 20) resulted in the best performance. The greatest number of global Pareto solutions (mean SQM = 13.9) was found in the case (C
DI, M
DI) of (20, 20), and the best convergence (mean COM = 0.006) was observed in the case (C
DI, M
DI) of (2.0, 0.5). These results are different from those of Zhang et al. [
28], who found the best performance with a Crate of 0.9 and (C
DI, M
DI) of (0.5, 0.5) in the calibration of a spatially distributed hydrological model. Therefore, sensitivity analysis on the algorithm parameters should be conducted to identify the best parameter set, particularly when an algorithm for use has not been previously combined with a hydrologic model.
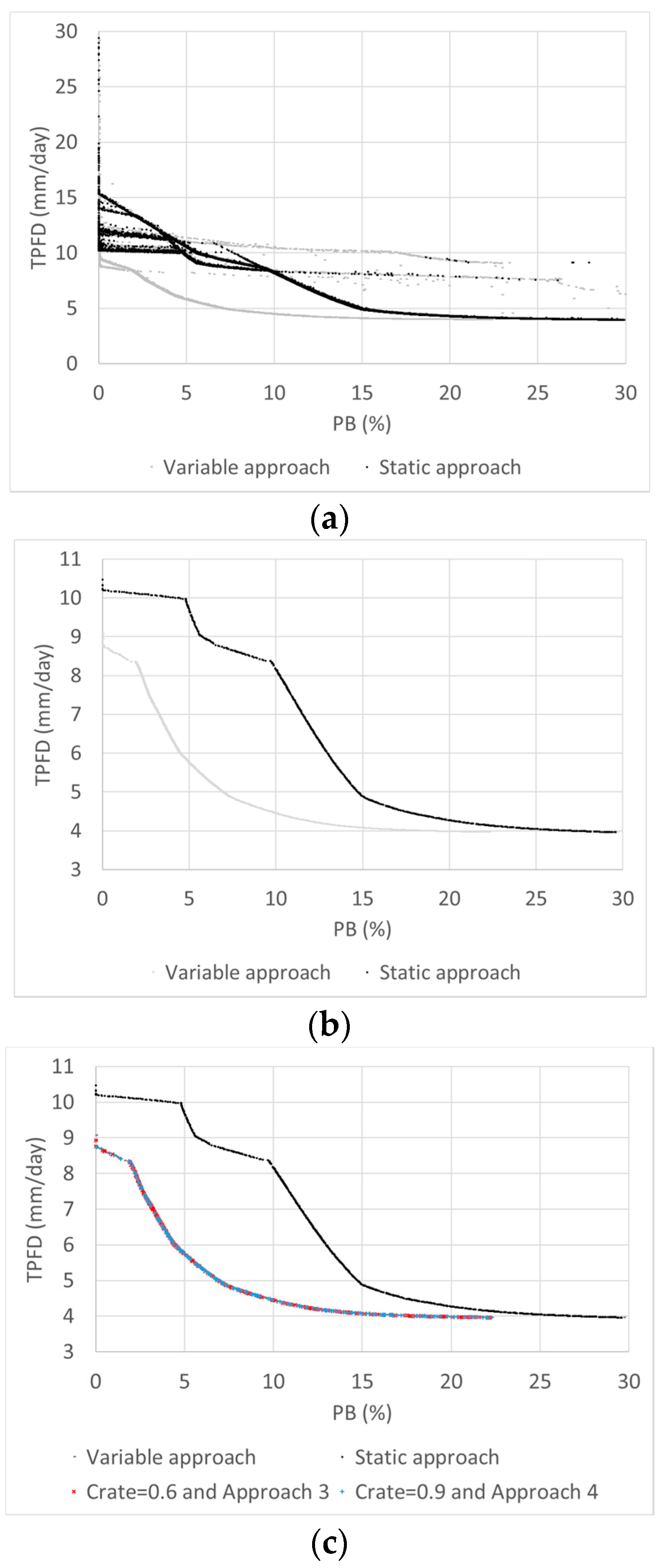
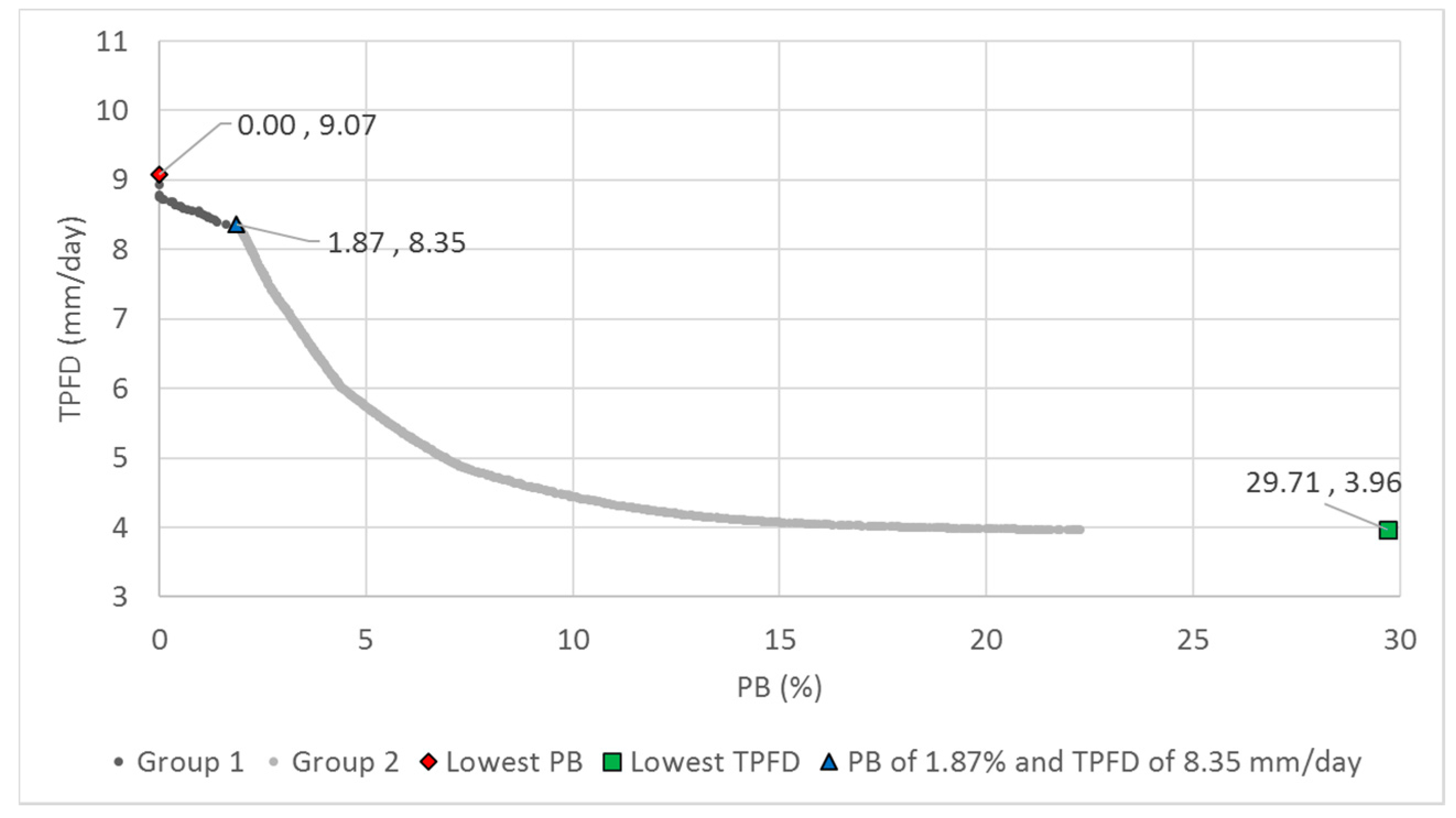
The overall best balancing approach was determined from the comparison of the nine static approaches and 12 variable approaches. Twelve cases of the variable approaches were generated from the combinations of Crate of 0.6, 0.75, and 0.9 (three cases) and four approaches for variable CDI and MDI (Approaches 1 to 4). Although the variable approaches with Crates of 0.6 and 0.9 and Approaches 3 and 4 outperformed other approaches, the greatest number of global Pareto solutions was found from the variable cases with a Crate of 0.6 and Approach 3 and with a Crate of 0.9 and Approach 4. Approaches 3 and 4 migrate the focus of exploration and exploitation differently for SBX and PM, which results in better performance than that with Approaches 1 and 2 using the same variable balancing scheme.
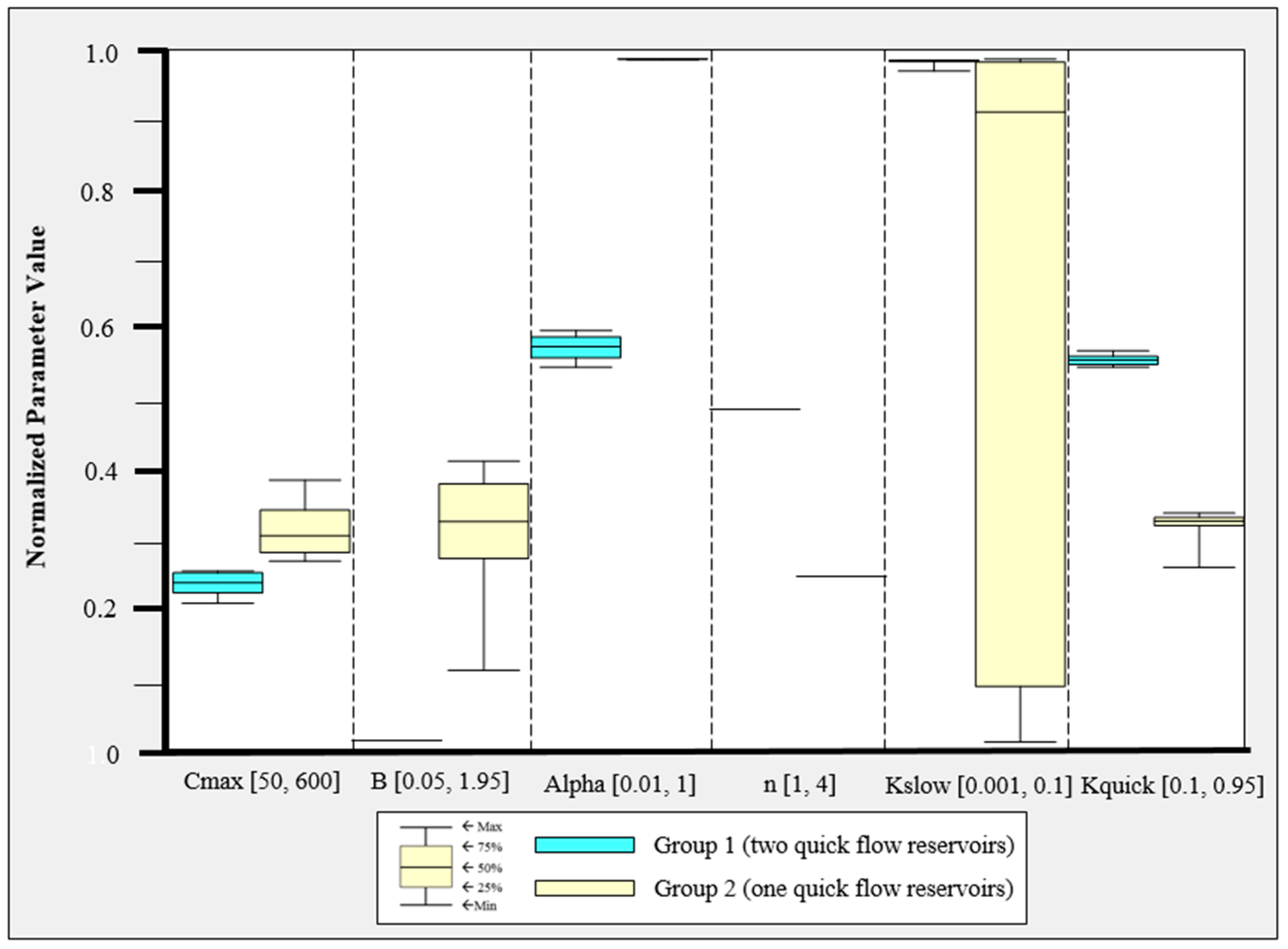
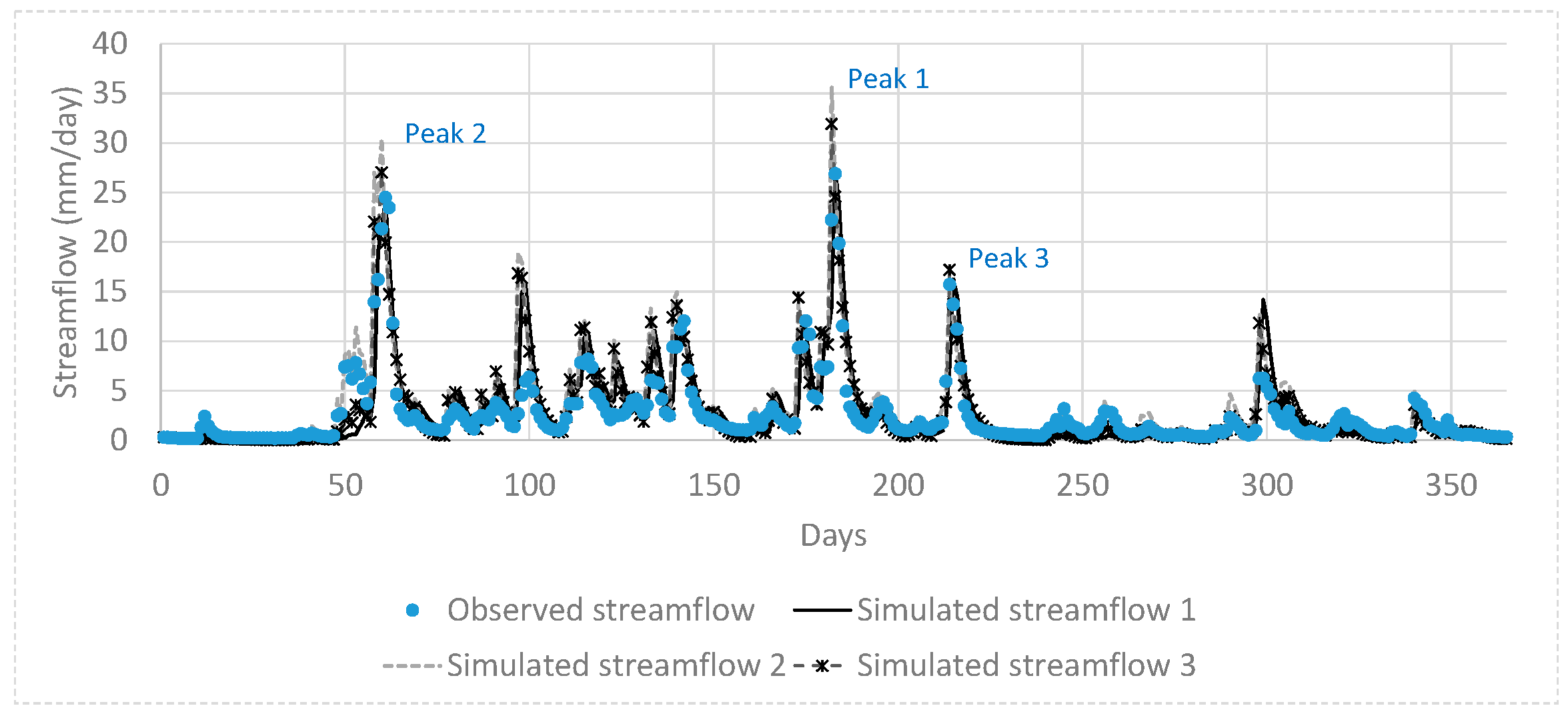
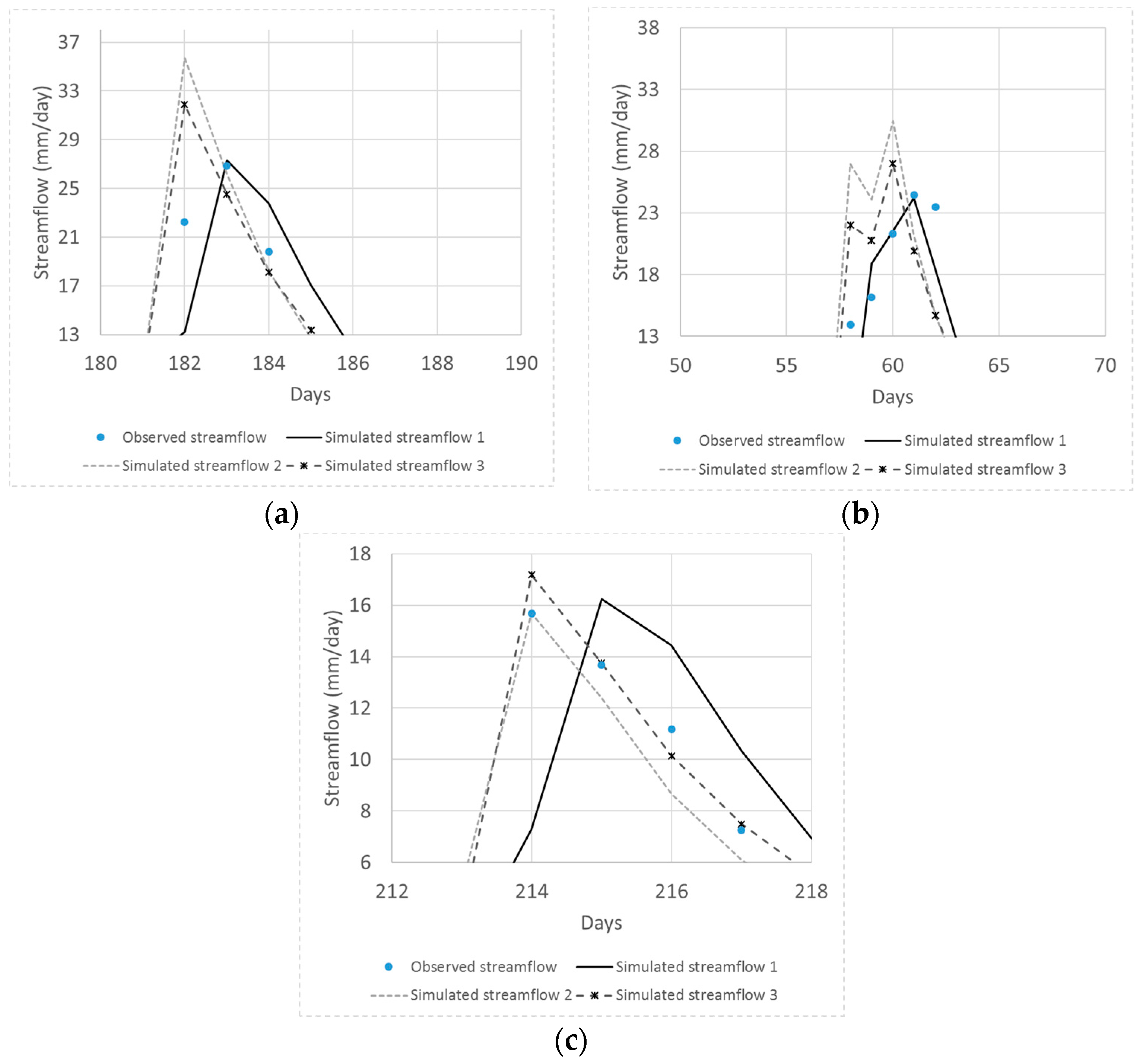
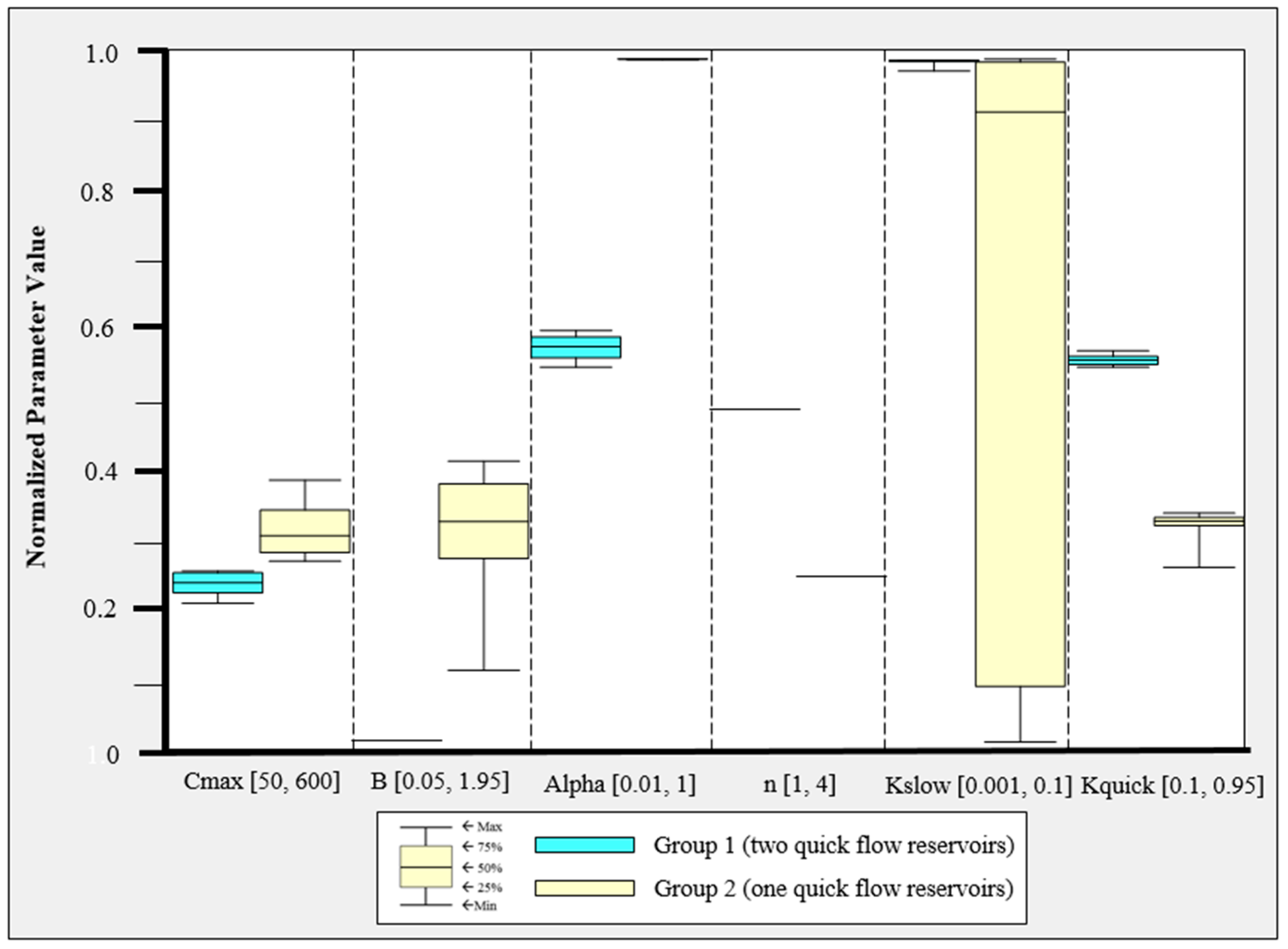
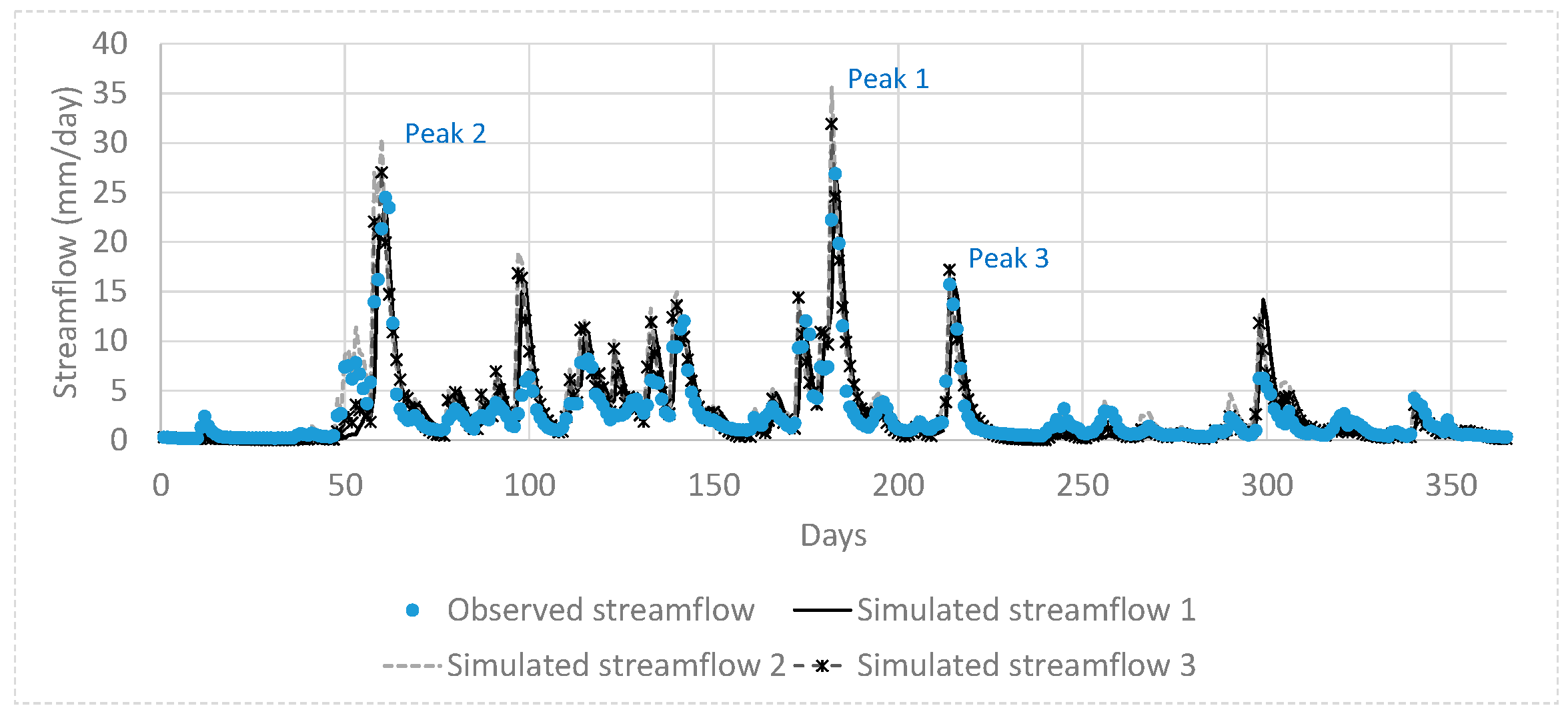
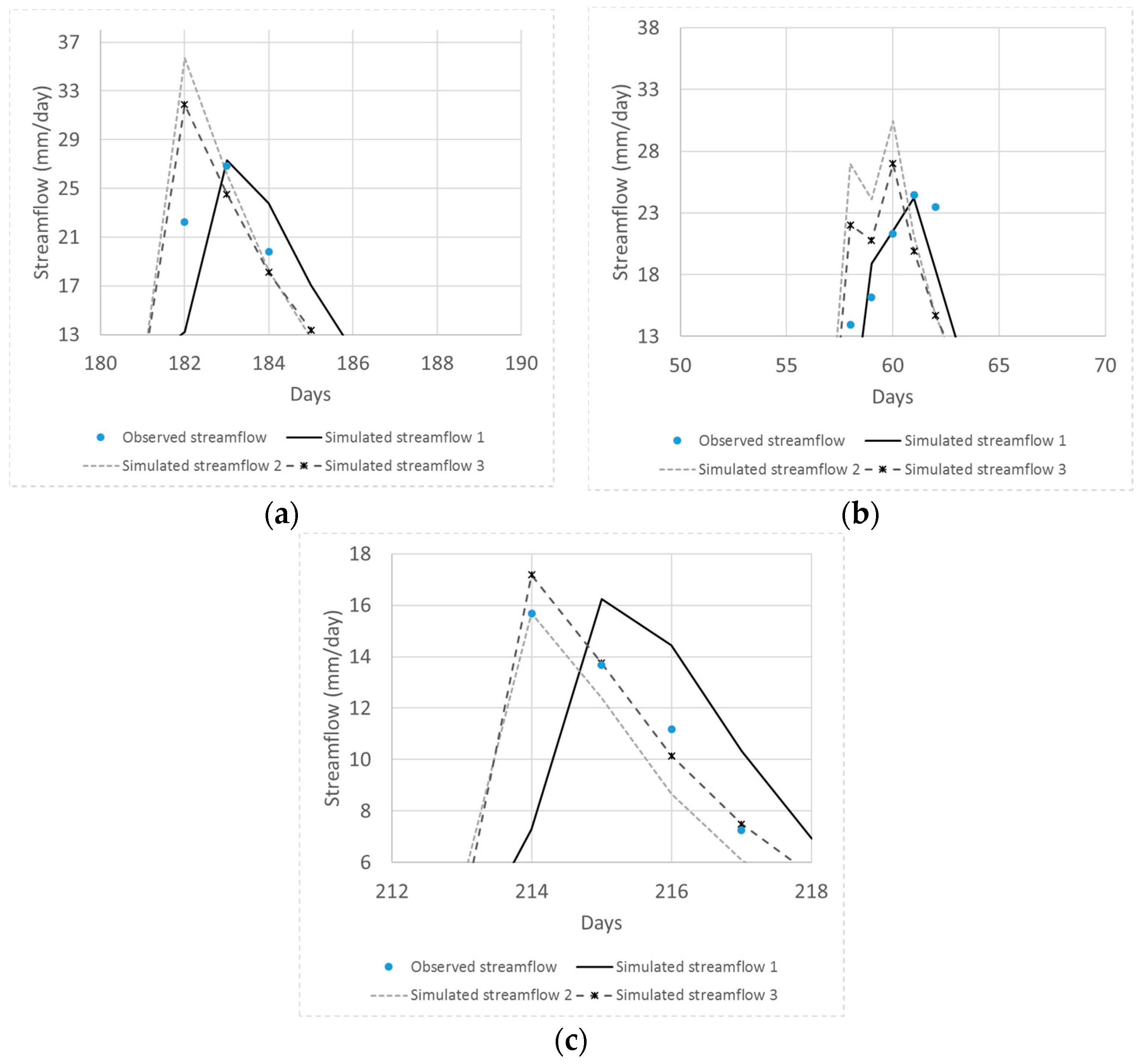
Finally, the parameter ranges of the global Pareto solutions were examined to determine which differences in model parameter values result in different objective function values. The global Pareto parameter set with two quick flow reservoirs resulted in low PB and high TPFD, whereas that with a single quick flow reservoir had irregular parameter values. In addition, three representative simulated hydrographs and the observed hydrograph were compared. Greedy blind searching characteristics of the automatic calibration were detected from the global Pareto solutions with a single quick flow reservoir. That is, the error at neighboring times of peak flow days was increased in order to minimize TPFD. The low PB solutions sacrificed the accuracy of the smallest of the three peak flows. It is recommended that the sum of the absolute error at the peak flow days and the error at their neighborhood time intervals at both sides of the rising and falling limbs be considered when formulating peak flow accuracy measures.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}