1. Introduction
The problem of the optimal spatial and temporal resolution for rainfall estimates in urban hydrology applications has been widely debated. On the one hand, many studies analyse the ideal resolution for model application. The optimal temporal and spatial resolutions for urban hydrology is studied by Schilling [
1] as a function of hydrologic parameters of the catchment. In the work of Berne et al. [
2], equations are derived to calculate the optimal spatial and temporal resolutions, given the area of a catchment, and they recommend 5 min–3 km for catchments of 1000 ha and 3 min–2 km for catchments of 100 ha. Gabellani et al. [
3] suggest that a temporal resolution equal to 0.2 the characteristic catchment time and a spatial resolution of 0.2 the characteristic catchment dimension are the minimum requirements to avoid major errors in runoff estimation. Nevertheless, models have drastically evolved in the last 20 years and the concept of optimal resolution with them. Thanks to the increased computation capabilities, models are more complex and can represent finer scale phenomena, especially in the urban environment. There is a trend of moving towards integrated models, able to predict both the water quality and quantity, representing urban drainage networks, surface runoff processes, river hydraulics, chemical dynamics, wastewater treatment plants, and so on [
4]. At the same time, rainfall measurements have improved with the use of weather radars, which are able to achieve a finer spatial resolution and improved the accuracy thanks to technological advancements such as the use of dual polarization and Doppler capabilities [
5,
6]. Today, weather radars can provide rainfall estimates at 5-min/1 km resolutions, although they still present a lower accuracy compared to point measurements, due to the indirect nature of the radar rainfall estimation [
7,
8]. Radar data at fine temporal resolution can present temporal sampling errors, which can be reduced with accumulation or with advanced storm advection techniques [
9,
10,
11]. Merging radar and rain gauge rainfall information is recognized to improve the radar rainfall estimation accuracy, maintaining the radar spatial resolution characteristics [
12,
13,
14,
15,
16] and the accuracy of the point rain gauge measurements. Among the most popular techniques, Kriging with External Drift (KED) and Conditional Merging (CM) proved to achieve a good performance [
12,
14,
17,
18]. Although KED has the advantage of providing a strong platform for uncertainty estimation, thanks to the easily derivable kriging variance, it may not perform comparably well at short temporal resolutions, which are often necessary for urban hydrological applications [
19]. In particular, KED is very sensitive to low quality data at fine temporal resolutions [
19]. A possible approach is to improve robustness of KED using a co-kriging with external drift approach, or an extensive data pre-processing to achieve a sufficient data quality [
20,
21].
This work aims at exploring the possibility of using KED at a coarser temporal resolution, in order to improve the result stability and reduce the impact of random errors, and subsequently downscale the results. By downscaling both the KED estimation and the associated variance, the rainfall uncertainty can be studied and propagated in urban hydrological models. Most of the downscaling techniques discussed in the literature are stochastic [
22,
23,
24,
25], usually used to explore climatic variability. Instead, in this work, we use a data-driven approach, based on the radar data available at 5-min resolution to downscale the KED estimates and variance. The aim of this approach is to study the uncertainty associated with the rainfall data, rather than the process variability.
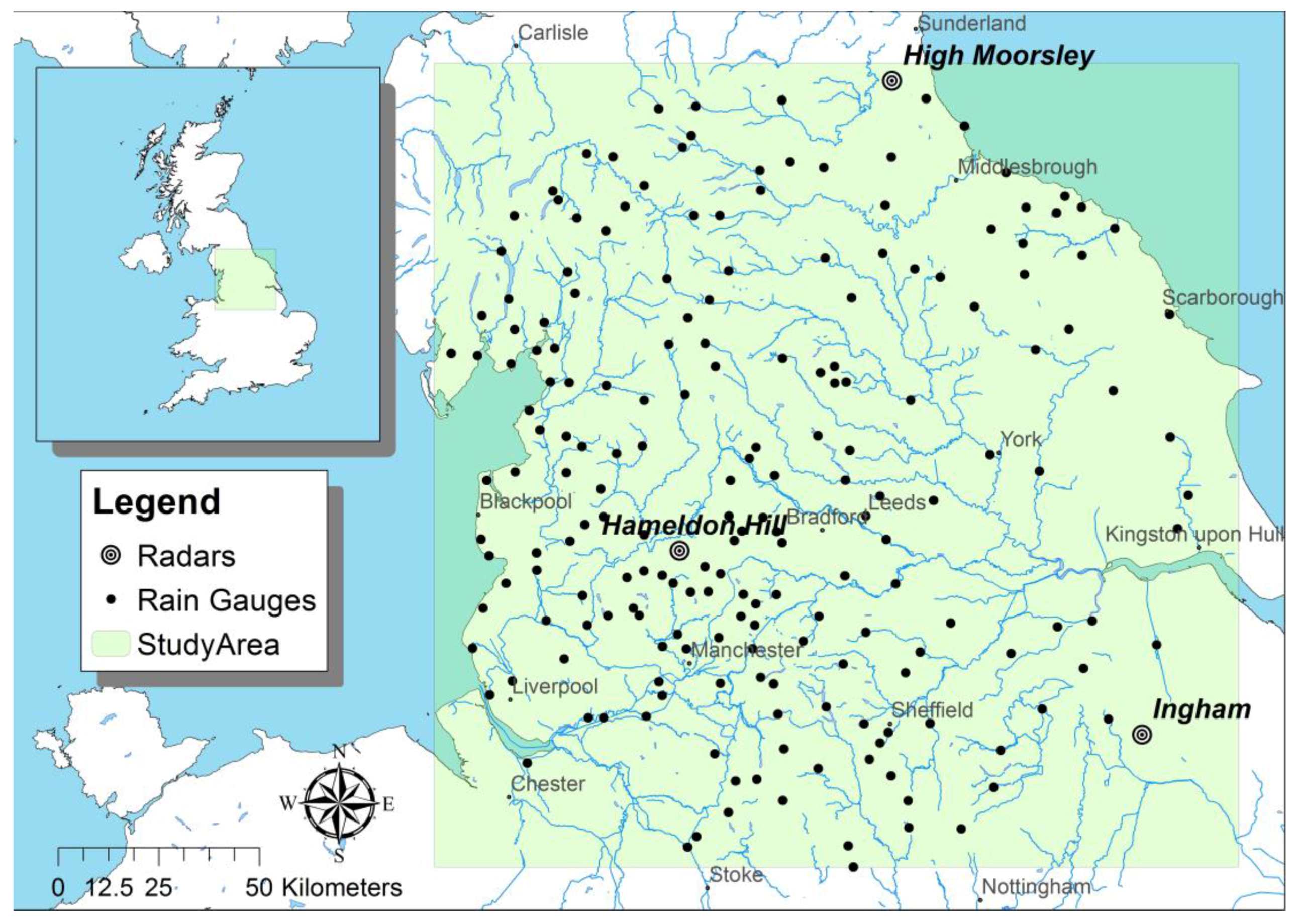
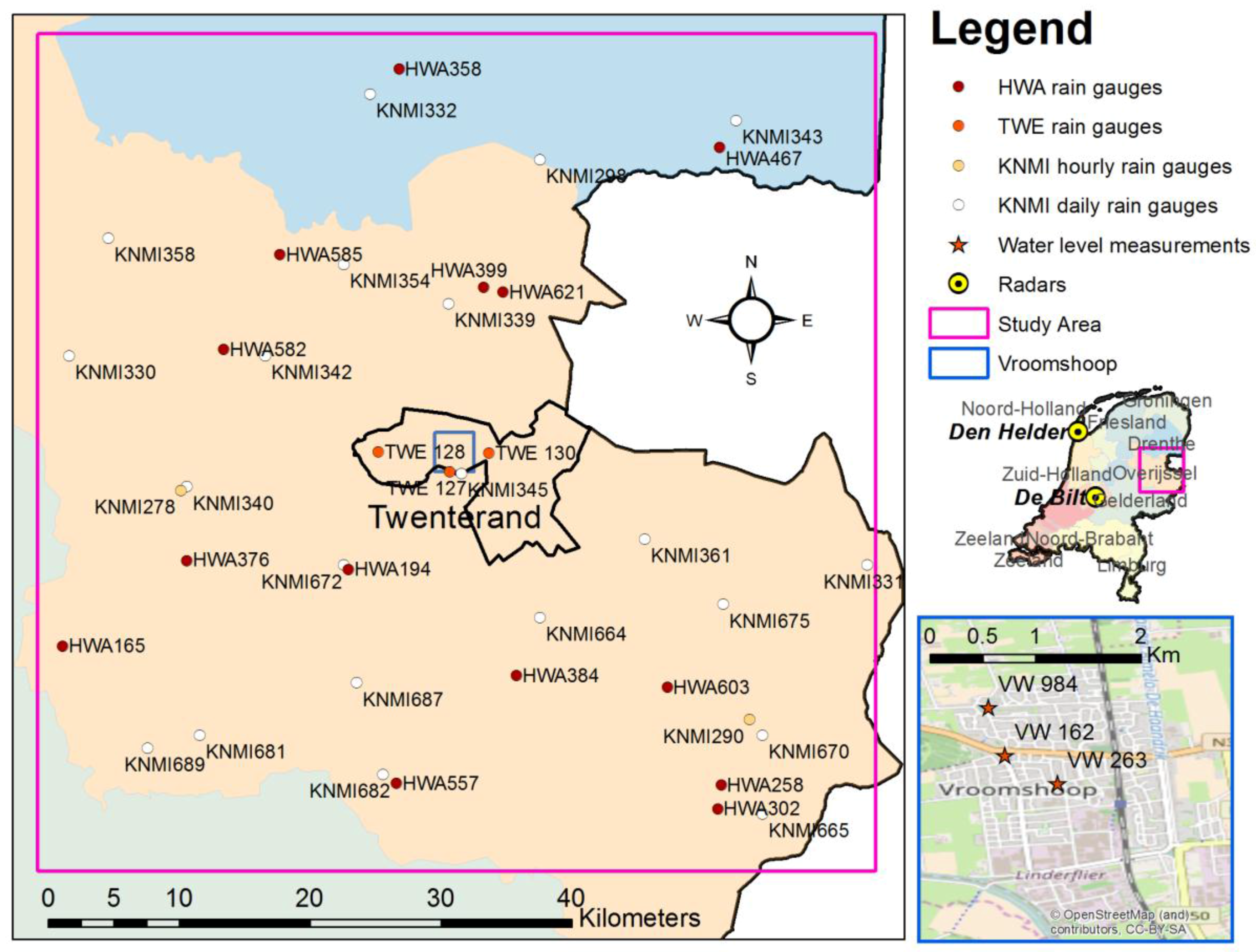
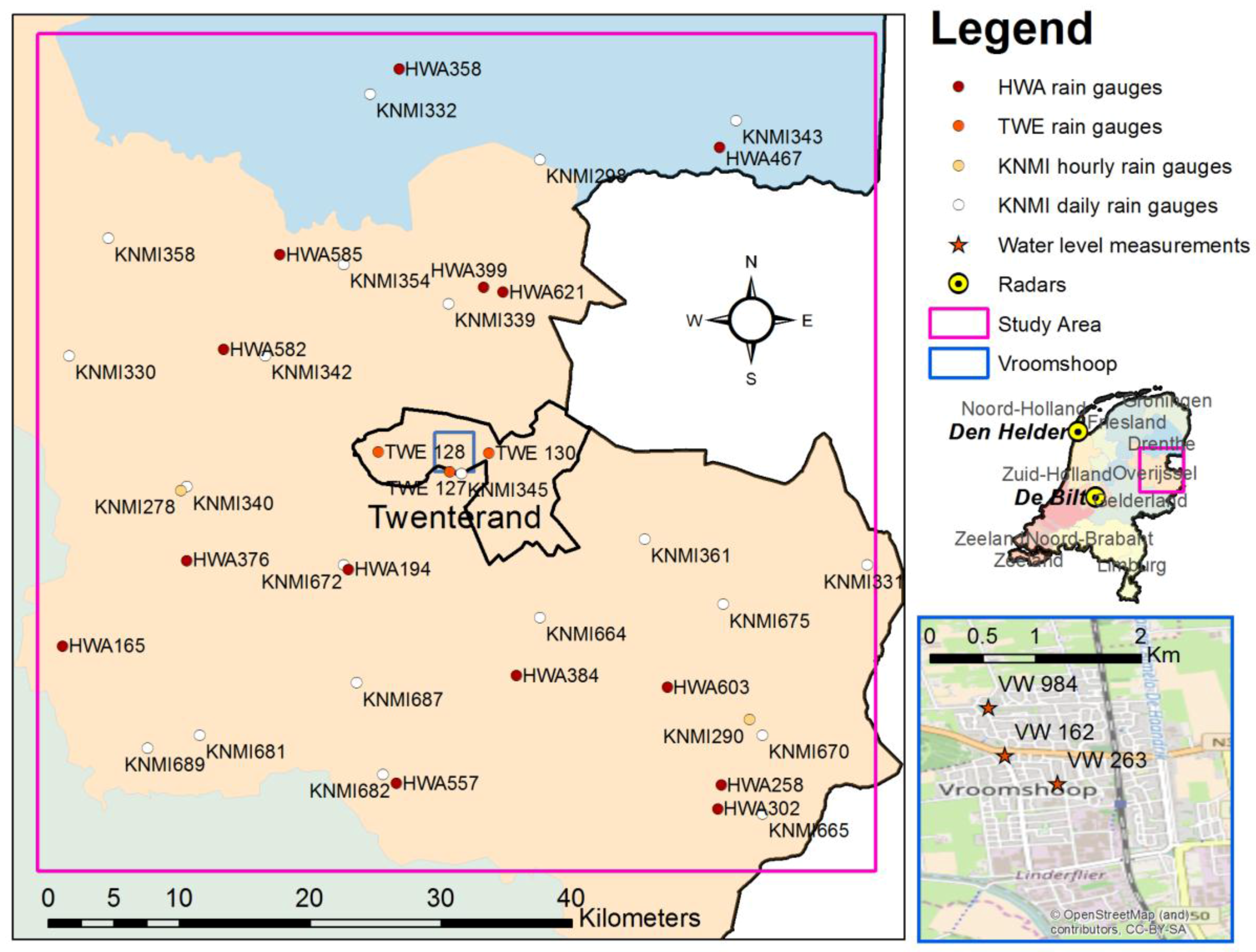
A case study with about 200 rain gauges and radar composites from 3 C-band radars, in an area of about 200 by 200 km2 in England is used to perform cross-validation and verify the methodology. Twelve combinations of different accumulation and downscaling resolutions are tested. Additionally, an example of application to urban modelling is presented. The optimal accumulation and downscaling resolutions for a specific model are identified by comparing different products with 14 combinations of accumulation resolutions and downscaling resolutions in a case study in the Netherlands. The generated rainfall products are tested, using an InfoWorks urban hydrological model. The case study is based on a high-intensity convective rainfall event that occurred in the Municipality of Twenterand, in the east of the Netherlands, causing severe flooding in the village of Vroomshoop. The InfoWorks model of the Vroomshoop area and water level measurements are used to identify the optimal combination of accumulation and downscaling resolutions for the specific model, by comparing the deterministic KED predictions. For the selected product, the uncertainty propagation is studied, producing an ensemble from the probabilistic KED result and using it in the InfoWorks model.
In
Section 2, the case studies are described, presenting the datasets and the model. In
Section 3, the methods used to compare the accumulation and downscaling times, to merge radar and rain gauge data, to downscale the merged products, and to produce the ensemble are presented.
Section 4 and
Section 5 present and discuss the results respectively.
Section 6 summarizes the conclusions and recommendations.
3. Methods
This work studies the possibility to find an optimal temporal aggregation
to merge radar and rain gauge rainfall data using kriging with external drift and an optimal temporal downscaling
to disaggregate the merged product and use it in an urban hydrologic model. It must be considered that this work aims at illustrating the methodology to follow, and the identified optimal resolutions for the case study in the Netherlands are specific for the presented case study and sewer model. The combinations in
Table 2 are used for validation in the UK case study, while the combinations in
Table 3,
Table 4 and
Table 5 are tested for the Dutch case study.
An accumulation to a 15-min scale was also tested, but resulted in major instabilities. In particular, the KED algorithm aims at finding the optimal linear relationship between the studied process (rainfall as measured by the rain gauges) and the drift (radar estimates). At fine temporal resolution radar and rain gauges can disagree due to the uncertainty in the rain gauge data timing and the uncertainty in the radar rainfall intensity and spatial position. Such a situation can result in an optimal linear relationship with negative coefficients, which is unrealistic. The problem is much rarer at coarser resolutions. As concerns the UK case study, being the rain gauge data at 15-min resolution, finer downscaling resolutions could not be validated, therefore downscaling resolutions of 15, 30 and 60 min are used.
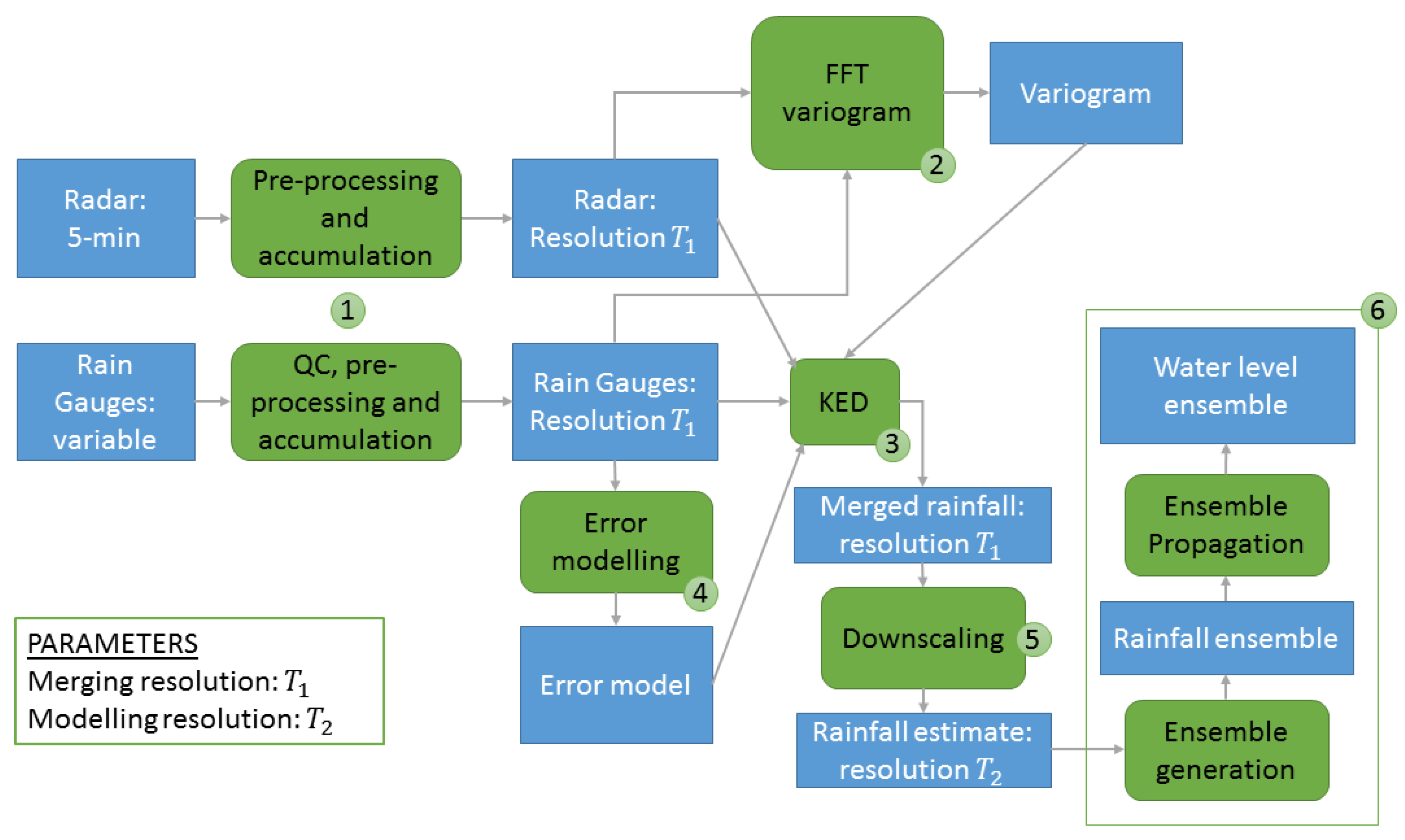
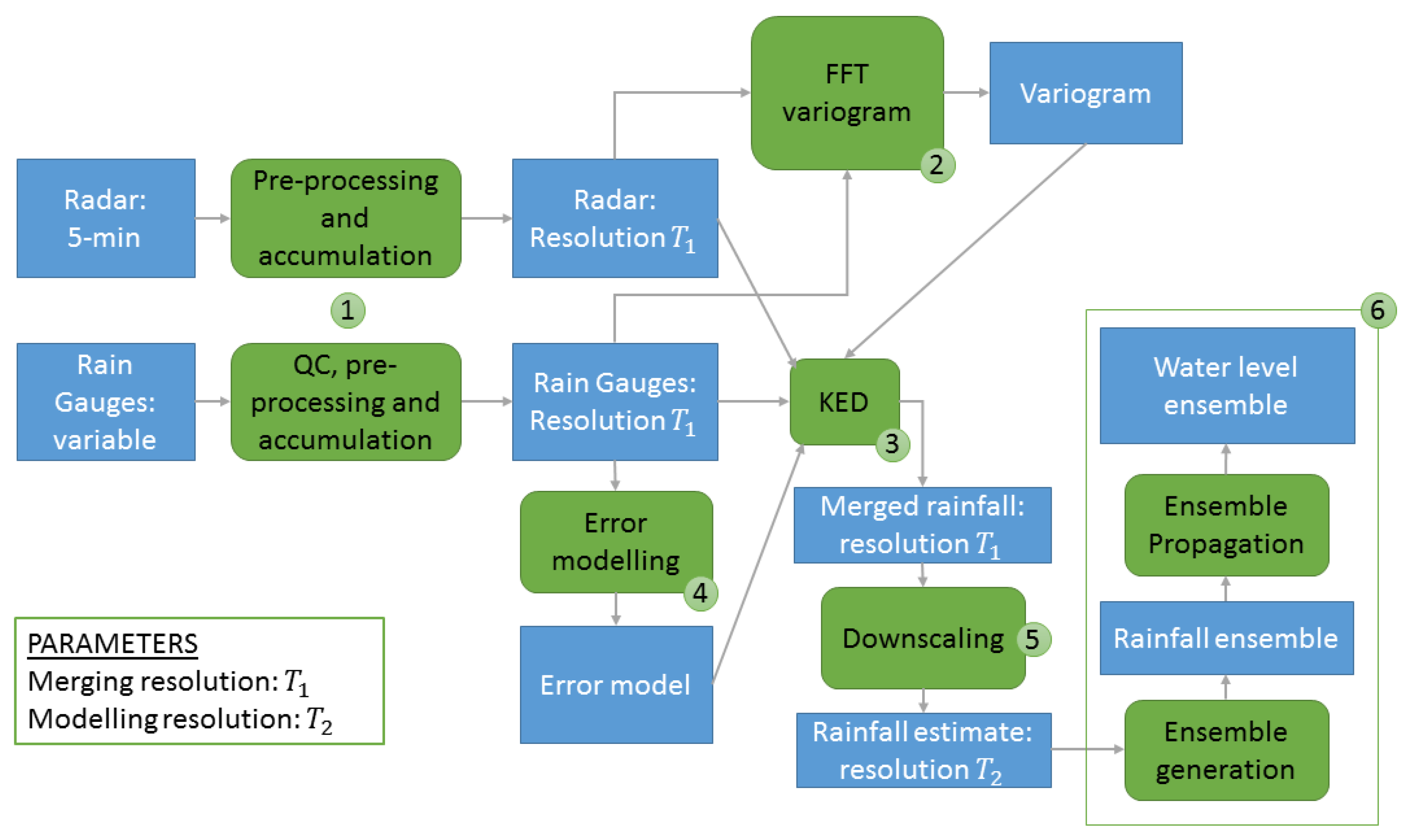
The methodology followed in this work is illustrated in
Figure 4 and the passages are explained in the following sections.
3.1. Data Pre-Processing and Accumulation
3.1.1. Radar
As concerns the radar pre-processing, for each accumulation interval, all of the 5-min radar measurements available are used. The UK Met Office radar data are already corrected for errors, are available as rainfall intensity in (mm/h), and only require accumulation to .
The KNMI data are already corrected for ground clutter and anomalous propagation as well [
32], but the data are provided in (dBZ) and a conversion to (mm
6/m
3) is necessary. Then, the rainfall rate is calculated using the Z-R relationship [
32]:
As suggested by Overeem et al. [
32], the values below 7 dBZ are not converted to avoid an excessive impact of noise, and are directly set to 0 mm/h. Once all the 5-min acquisitions are correctly converted from (dBZ) to rainfall rates in (mm/h), they are accumulated on the desired accumulation
.
3.1.2. Rain Gauges
The first step for rain gauge data preparation is a quality check. Rain gauge records are checked for typical malfunctioning behaviours and are compared with neighbouring rain gauges and with the radar data. In the case a rain gauge presents an anomalous behaviour (e.g., absence of records, signs of blockage, absence of zeros, etc.) for the full examined period, the rain gauge time series is removed from the dataset (as happened for the Twenterand rain gauge TWA 129 and the amateur rain gauge HWA 60); if the anomalous behaviour happens for a limited time, the affected records are substituted with “NA” (Not Available). After quality check, “NA” values affect the 3.7% of the dataset.
The EA rain gauges are already in a uniform and evenly distributed 15-min resolution, therefore accumulations can be performed directly. The rain gauges for the Dutch case study have variable accumulation times, from 3 min to one day. To correctly distribute the measured precipitation, the dataset is divided into 1 min intervals and the recorded precipitation is evenly distributed on the accumulation minutes. For example, if 10 mm are recorded over a 10 min interval, the previous 10 min will be assigned 1 mm each. Subsequently, the rain gauge records are accumulated to the desired accumulation . This passage helps to correctly distribute measurements recorded over two or more accumulation intervals. For large accumulation times, it results in a simplification, but it is still preferred to the option of considering all the rainfall accumulation at the end of the recorded period. For example, if a daily record measures 24 mm at 08:00 (CEST). over a 24-h period, we prefer to assign 16 mm to the day before, and 8 mm to the day of the record, rather than 24 mm on the day of the record. However, it must be considered that daily records are used only for daily accumulations.
After the accumulation, a check on the convective conditions is done. When precipitation has strong convective characteristics, the reliability of the rain gauges declines, because they cannot be considered representative of the 1 km cell they belong to [
8,
34,
35]. This effect is stronger for shorter accumulation times and can have very negative impact in the merging phase [
36]. To prevent this, a convective control routine is applied, similar to the one presented by Sideris et al. [
36]. For each rain gauge and for each time step, the coefficient of variation and the standard deviation of the 5 pixels by 5 pixels square around the rain gauge are calculated. The rain gauge is marked as unreliable if the coefficient of variation or the standard deviation passes an empirical threshold, dependent on the accumulation rate and on their temporal resolution. In such cases, the rain gauge is eliminated from the merging dataset for the specific time step.
3.2. Variogram Calculation
The variogram calculation presents two problems to be addressed:
For the Dutch case study, the number of rain gauges is limited, and their resolution highly variable, therefore a reliable time-variant variogram calculation based on ground measurements is difficult to calculate.
The variogram for KED needs to be calculated on rainfall residuals, rather than on the rainfall field itself [
37].
For this reason, the following approach in four passages, based on a Fast Fourier Transform (FFT), is used for each time step:
The variogram of the rainfall field is calculated with the FFT approach by Marcotte [
38], based on the radar data [
39].
The rain gauges are interpolated applying ordinary kriging with the calculated variogram.
The residuals are calculated subtracting the radar field from the interpolated rain gauge field.
The variogram of the residuals is calculated with the FFT approach.
Once the empirical 2D variogram is calculated, it is fitted every 10° between 0° and 180° in azimuth (the variogram is symmetric about the 0–180° direction) with a Gaussian function:
where
is the distance,
is the nugget,
is the sill, and
is the range. The average nugget, average sill, and average range over the tested directions are used for the merging.
3.3. Merging Using Kriging with External Drift
Universal kriging, as opposed to ordinary kriging, considers the mean of the studied field
non-stationary in space:
where
is the mean and
is a zero-mean stationary random process [
37]. Kriging with External Drift is a special case of universal kriging, in which the mean is considered a linear function of external factors. In the presented case, the mean of the rain gauge interpolation is considered a linear function of the radar rainfall estimate:
where
is the radar rainfall estimate in
, and
is a linear coefficient, and
is the intercept, to be determined.
The prediction in each point is derived from the observations with a weighted average:
where
is the estimated rainfall in a generic point
,
are the measured values in the rain gauge locations
,
is the number of observations, and
are the kriging weights, estimated solving the kriging system:
where
is a covariance function,
and
are generic rain gauge locations,
is the radar rainfall estimate in the position
, and
and
are Lagrange parameters [
37]. The covariance function
is directly related to the variogram function
fitted with a Gaussian model as follow:
The solution of such a system can be expressed in matrix form:
where
are the radar measurement at rain gauge locations
, while
is the radar measurement in the prediction location
. The matrix elements
represent the covariance function calculated on the distance between
and
.
The kriging mean and variance for each point
are then calculated as:
where
is the vector of the measurements at rain gauge locations.
3.4. Rain Gauge Error Modelling
The rain gauge errors can be included in the merging process using a Kriging for Uncertain Data (KUD) approach similar to the one by [
40], assuming that the rain gauges are affected only by random errors, and that biases are already removed with calibration.
The idea is that rain gauge random errors can be modelled as a nugget effect in the variogram [
37,
41]. To model a different error for different rain gauges, the covariance matrix
needs to be modified. The advantage of using a covariance function rather than a variogram function, as in most kriging formulations [
37,
40,
42], is that the covariance function is affected by the nugget only at distance
, therefore the covariance matrix modification is simple:
where
is the nugget effect due to the uncertainty of the
rain gauge. The nugget effect for each rain gauge can be calculated separately using the rain gauge error models illustrated below, that calculate the error as function of the rainfall rate
, and of the accumulation
.
3.4.1. Tipping Bucket Rain Gauge Error Model
The random errors for tipping bucket rain gauges are modelled according to the model by Ciach [
43]. This error model is applied to the rain gauges in the UK case study, to the ones from the Municipality of Twenterand (TWE), and to the rain gauges from the Het Weer Actueel network (HWA). The standard error is calculated as:
where
is the rainfall intensity at accumulation
minutes, while
and
are coefficients dependant on the accumulation time. Figure 6 in Ciach’s work [
43] shows the errors of the rain gauge data. Using this figure, we derived an approximated analytical formulation where
is expressed in minutes:
For each tipping bucket rain gauge at each time step, for each accumulation
, the nugget can be calculated as:
3.4.2. KNMI Automatic Rain Gauges
KNMI automatic rain gauges are not tipping bucket devices. They measure the water level using the accurate measurement of a floating device position on the water surface. This type of rain gauges is more precise than the tipping bucket type, especially at low rainfall intensity, it is subject to less measuring errors, and it is calibrated by the KNMI [
31,
44].
A quantitative measurement of the KNMI automatic rain gauge accuracy can be derived from the laboratory test results reported in the KNMI technical report TR-287 [
44], studying and comparing the accuracy of several rain gauges, in order to select devices able to meet the World Meteorological Organisation standards.
In particular, the results reported in
Section 3.2 and Figure 57 of the TR-287 report [
44], show that the KNMI automatic rain gauges, after calibration, have an error around 1% at 1-min averaging, for intensities between 0 and 270 mm/h.
Considering that, in this work, we use different accumulations, the errors can be calculated considering the variance sum property:
where
is a general variable,
and
are generic indices.
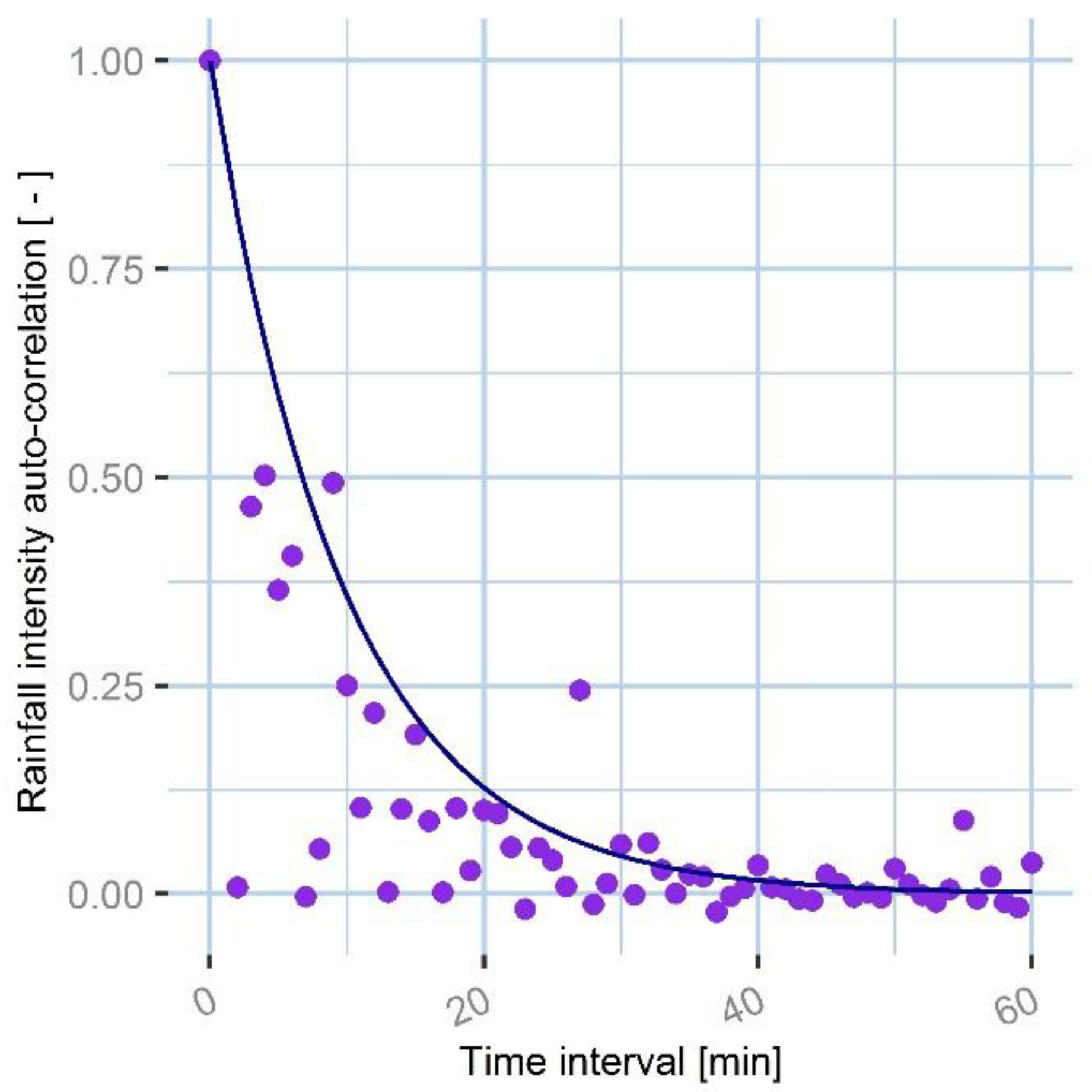
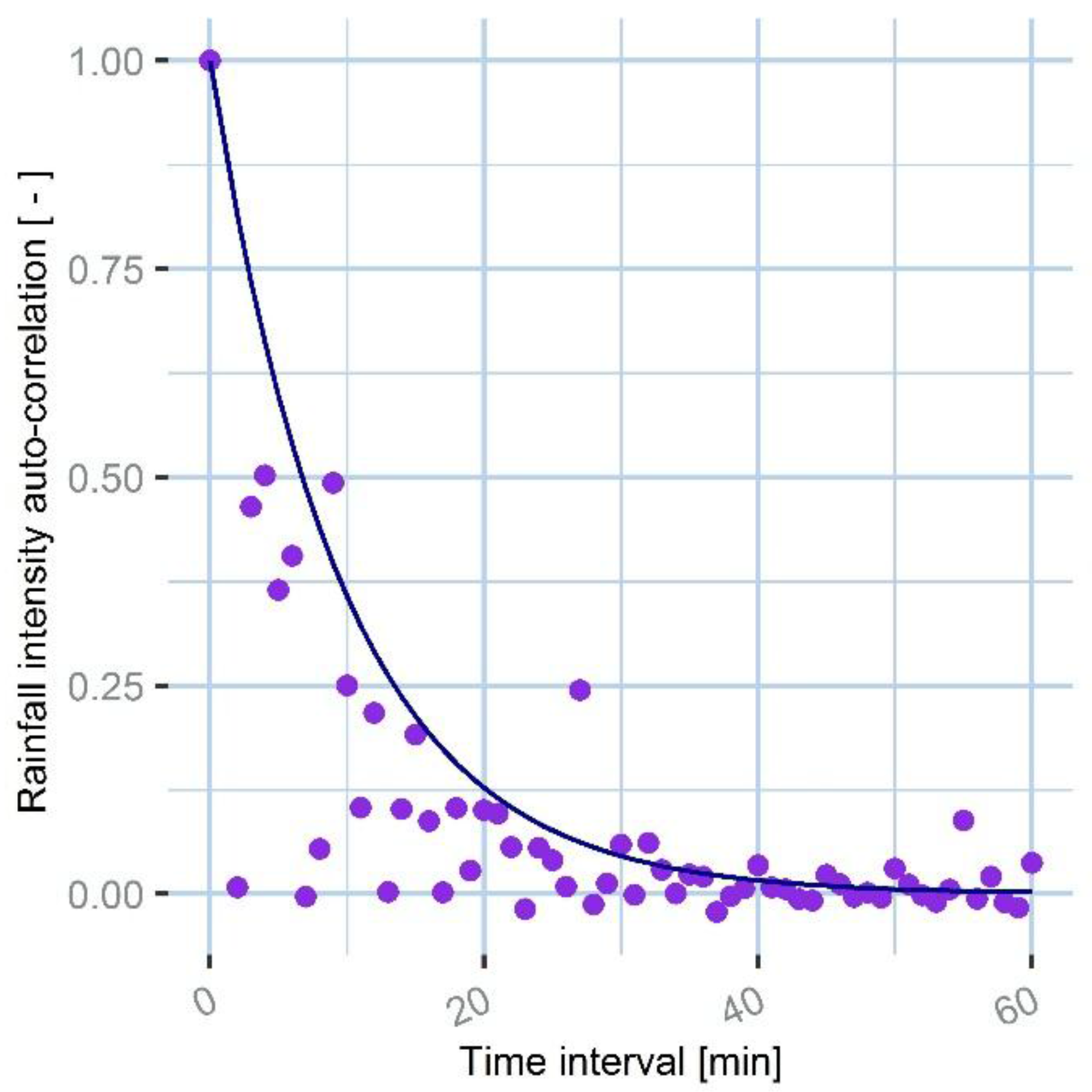
In the case of rainfall accumulation, the variable to be summed are rainfall intensities at 1-min resolution, recorded at different time steps. The covariance between two generic 1-min rainfall intensities is not known. We propose to estimate an approximation of it using the rainfall auto-correlation function. The rain gauge data from all the networks for the studied event are used to calculate the rainfall auto-correlation:
where,
is the auto-correlation,
is a generic time interval,
is the rainfall intensity at time
, whereas
and
are, respectively, the mean and the variance of the rainfall over the time series; the process is considered stationary for simplicity.
The auto-correlation is then fitted using an auto-correlation function with an exponential form:
The exponential fitting of the rainfall auto-correlation function is shown in
Figure 5.
Knowing the auto-correlation function, Equation (16) can be expanded:
where
is the rainfall intensity at accumulation
minutes,
is the rainfall intensity at accumulation
min,
are the elements of the covariance matrix
between all the 1-min measurements in a
-minutes interval, and
are the elements of the auto-correlation matrix
, defined as follows:
where
is the function derived from Equation (18) with the interval in minutes.
As concerns the variance element
, it is defined following the KNMI report, as the square of the 1% of the rainfall intensity at 1-min accumulation. Since the rainfall intensity at 1-min accumulation is not known, because the KNMI data are available at hourly accumulation, it can be approximated as function of the accumulation time
:
Combining Equations (19)–(21), the relative error for each KNMI automatic rain gauge measurement in position
x, at time
t, and accumulation
can be expressed as follows:
where
The corresponding nugget effect, for the application of Equation (11), is:
3.4.3. KNMI Manual Rain Gauges
The KNMI manual rain gauges are based on a water level system; each day volunteers and amateurs read the water level at 08:00 (CEST) and communicate the reading to the KNMI. The KNMI Technical Report TR-347 provides an estimate of the manual rain gauge uncertainty [
31]. Differently from the previous error models that are considered bias-free, the report suggests that the KNMI manual rain gauges are affected by bias and we derived a correction.
In particular, we combined the information from Figures 14 and 16 of the TR-347 report [
31] to derive the following bias correction and error estimate as function of the rainfall rate:
where
is the bias corrected rainfall rate at time t and position
,
is the original rainfall rate before correction, and
is the standard deviation. The corresponding nugget is derived from Equation (24). The standard deviation calculation in Equation (26) is derived from the report and is a function of the original rainfall rate, before bias correction.
3.5. Downscaling
Once the KED produces a probabilistic estimation of the rainfall intensity at temporal accumulation , we need to downscale it to the desired temporal resolution . The probabilistic estimate is made of a prediction and a variance estimate, and both need to be downscaled.
3.5.1. Downscaling the KED Prediction
To downscale the prediction, the original radar acquisitions are used to determine how to distribute the accumulated KED rainfall
among the time steps at resolution
:
where
is the KED prediction at accumulation
, for position
and time step
;
is the accumulation at
of the uncorrected radar acquisitions;
is calculated accumulating the uncorrected radar at
; and
is the downscaled KED estimation at
. Since the radar has a resolution of 5 min, the downscaling resolution
has to be a multiple of 5 min.
To avoid divisions by zero or near-zero values, 0.00001 mm are added to the uncorrected radar estimates before accumulations, therefore both and , derived as accumulations of uncorrected radar estimates at and respectively, will be increased of 0.00001 mm for each contained radar estimate.
3.5.2. Downscaling the KED Variance
As regards the variance, the downscaling is based on two principles:
From the first principle and Equation (16) we can derive:
where
is the mean variance value for all the time steps at
resolution contained in each time step at
accumulation;
are the elements of an auto-correlation matrix similar to the one defined in Equation (20), but defined at time steps equal to
, that is:
To comply with the second principle instead, the following equation is derived:
where
is the actual standard deviation at resolution
while
is the average standard deviation of all the prediction at resolution
contained in each time step at resolution
.
and
are, respectively, the uncorrected radar estimates accumulated to
and
.
Combining Equations (28) and (30):
As in the prediction downscaling phase, to avoid divisions by zero or near-zero values, 0.00001 mm are added to the uncorrected radar estimates before accumulation, therefore both and , derived as accumulations of uncorrected radar estimates at and , respectively, will be increased by 0.00001 mm for each contained radar estimate.
3.6. Ensemble Generation and Propagation
Once a probabilistic estimate is derived, the uncertainty can be propagated with an ensemble, i.e., a collection of a large number of possible alternative realisations of rainfall time series.
Each ensemble member is modelled as:
where
is the
ensemble member;
and
are, respectively, the downscaled KED mean and the downscaled KED standard deviation; and
is a standardized, zero-mean, spatially auto-correlated residual field.
To generate
, an unconditional simulation is used, with mean equal to zero, and standard deviation equal to one, using the residuals’ variogram at the corresponding time step. Subsequently, in order to reconstruct the auto-correlation of the residuals, a
model is used. The auto-correlation and the parameters of the
model are derived from the residuals time series, calculated as in
Section 3.2.
5. Discussion
As regards the results of the methodology validation for the UK case study, as reported in
Section 4.1 and
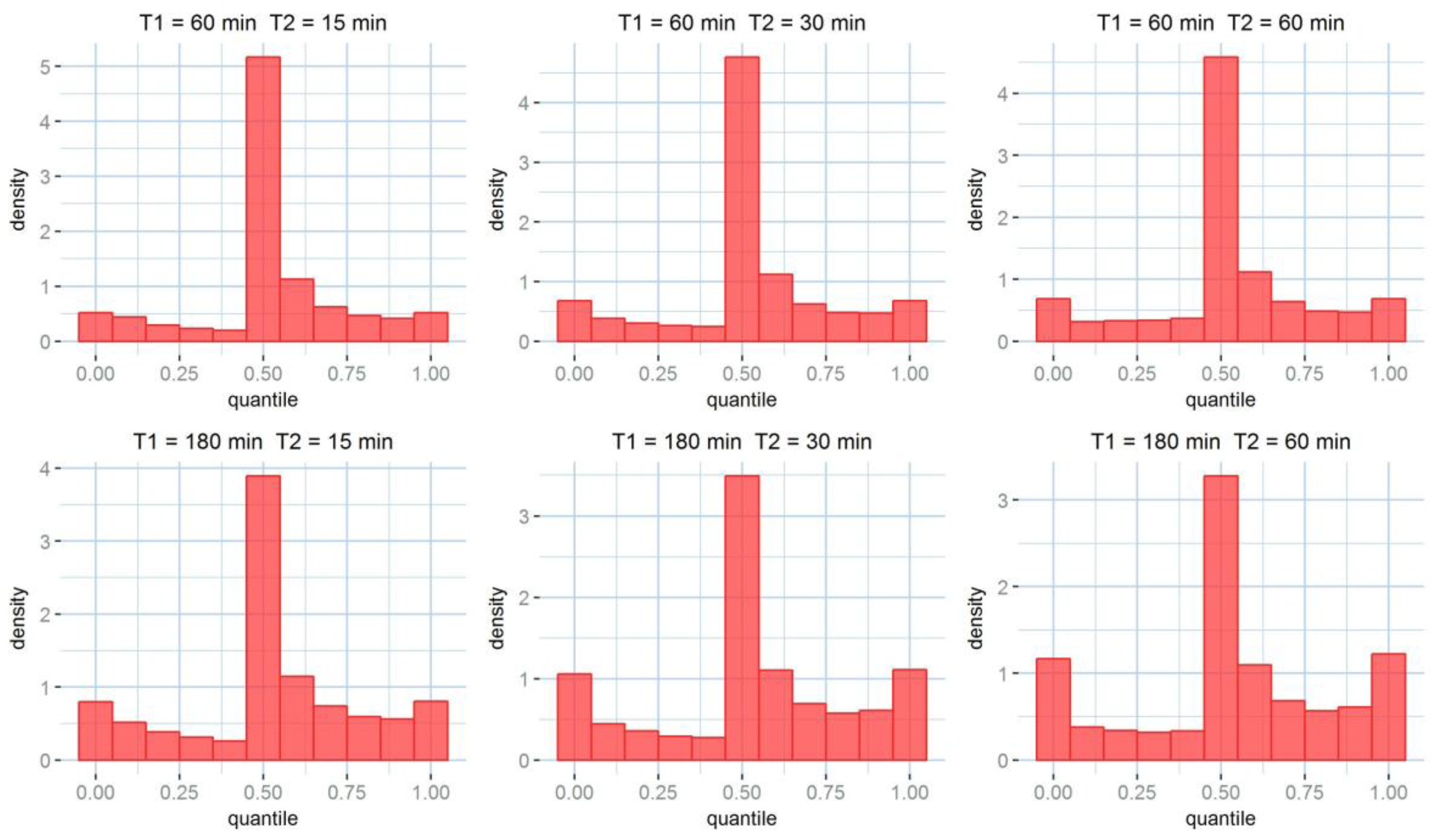
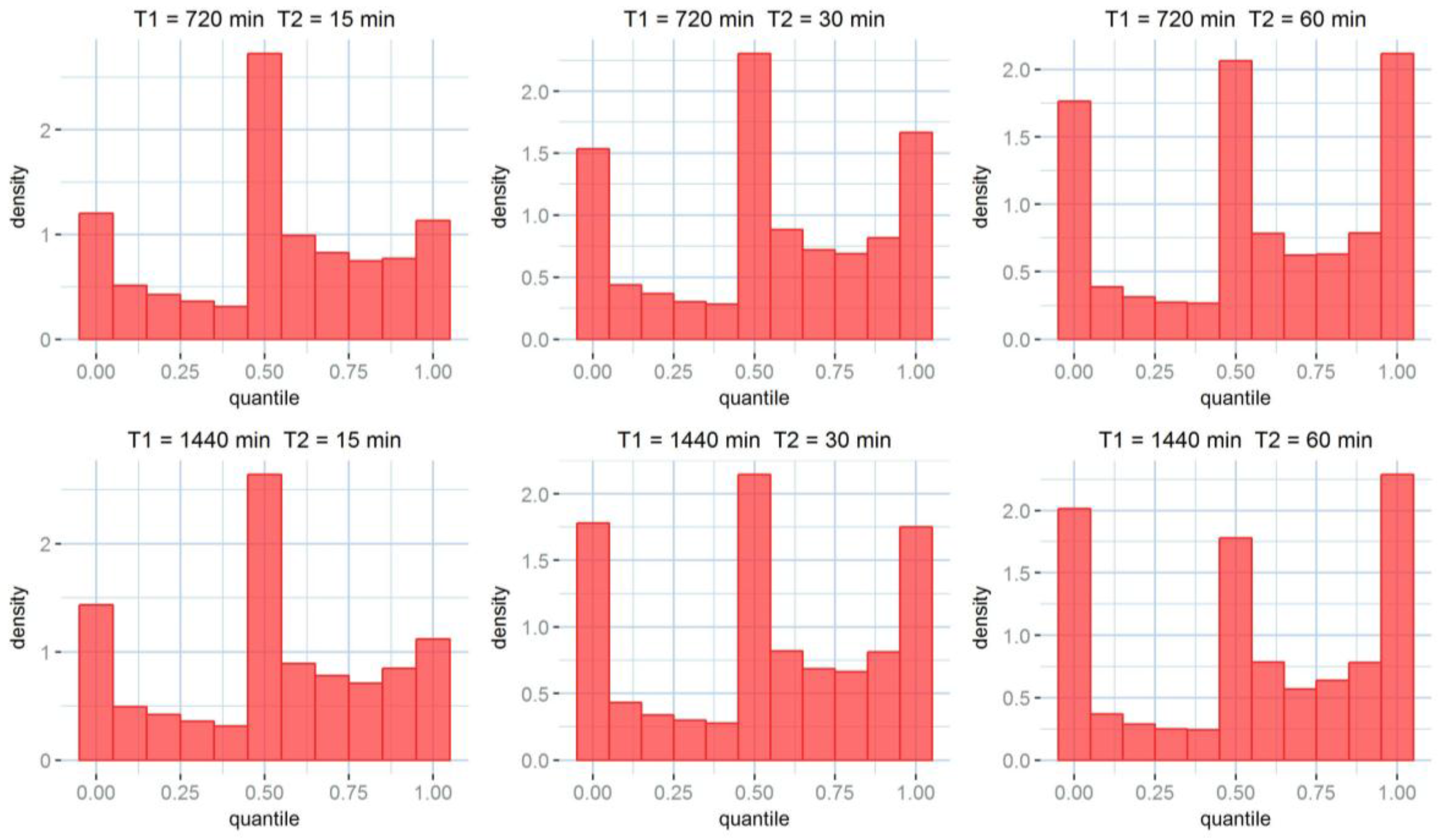
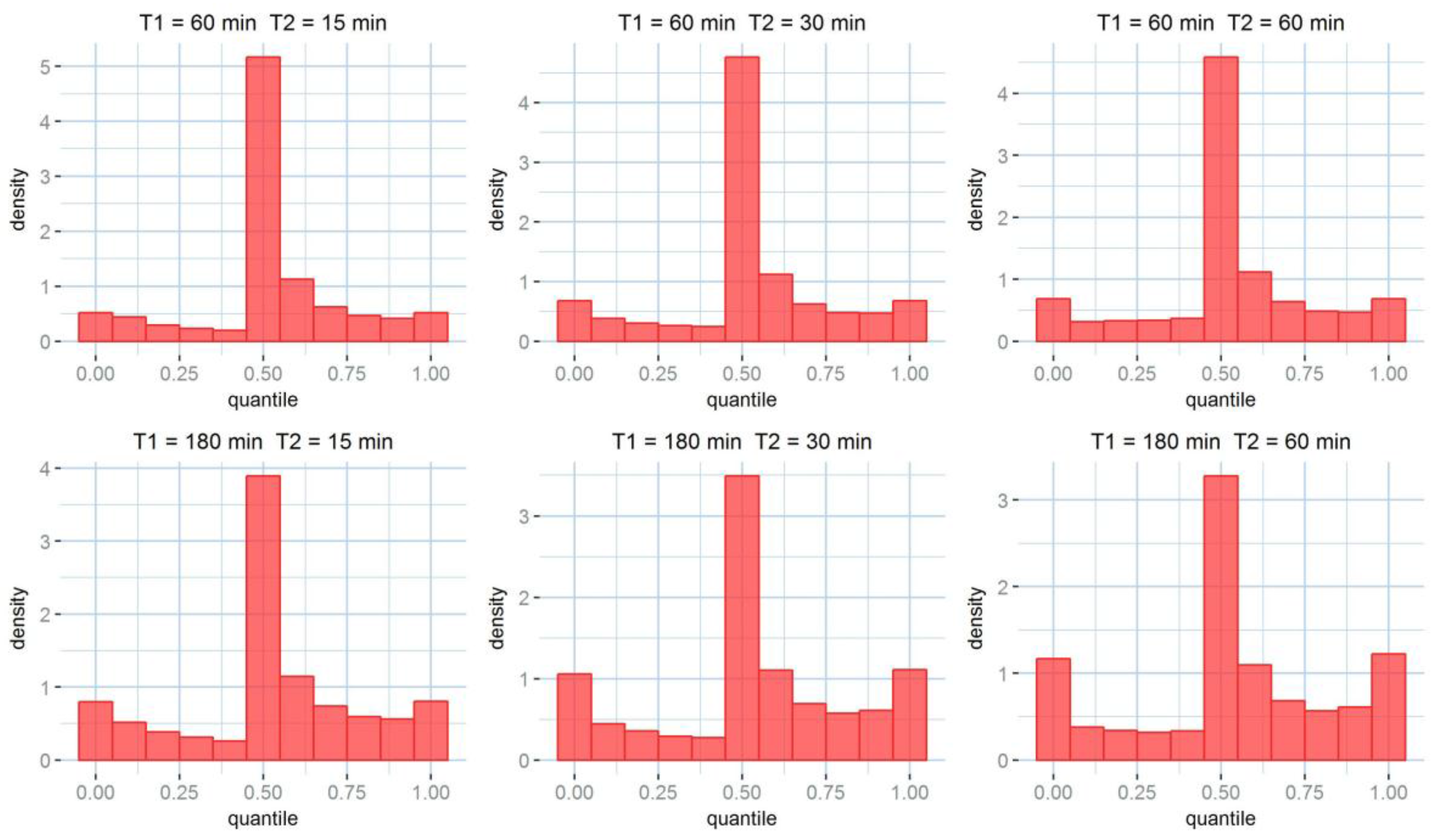
Table 6, it is no surprise that larger accumulations tend to perform better. As expected, the uncertainty on the rainfall products is reduced by accumulation. Larger accumulation resolutions, associated with larger downscaling resolutions perform best for all the tested skill scores. It must be noted that the cross-validation is done between Kriging products and rain gauges; therefore, an error is always present, even for the case at 60 min accumulation and no (60 min) downscaling. The uncertainty estimation, as illustrated by the rank histograms in
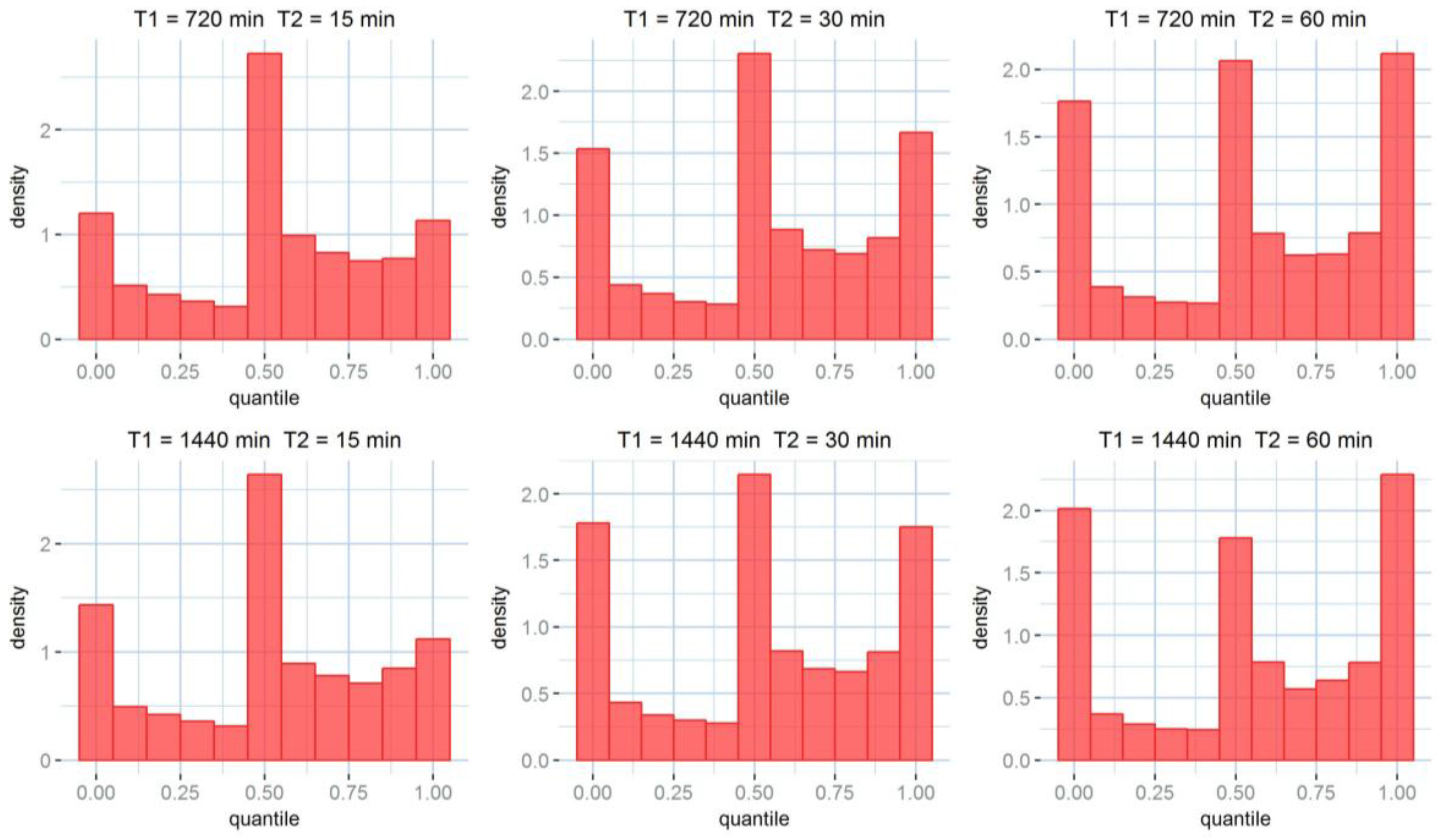
Figure 6, performs better at larger accumulations as well. In facts, if a perfect stochastic model were used, modelling a perfectly Gaussian process, and infinite observation points were available, rank histograms would be perfectly flat. This is not the case for any of the model histograms. Indeed, kriging produces a Gaussian probabilistic estimation, although rainfall errors are not Gaussian. Rainfall error probability distribution has a higher kurtosis, which results in a higher density of observations in the central and the extreme quantiles. While this is clearly visible for the coarser accumulations, the histograms relative to the finer accumulation scales show only a central higher peak. This usually corresponds to an overestimation of the uncertainty.
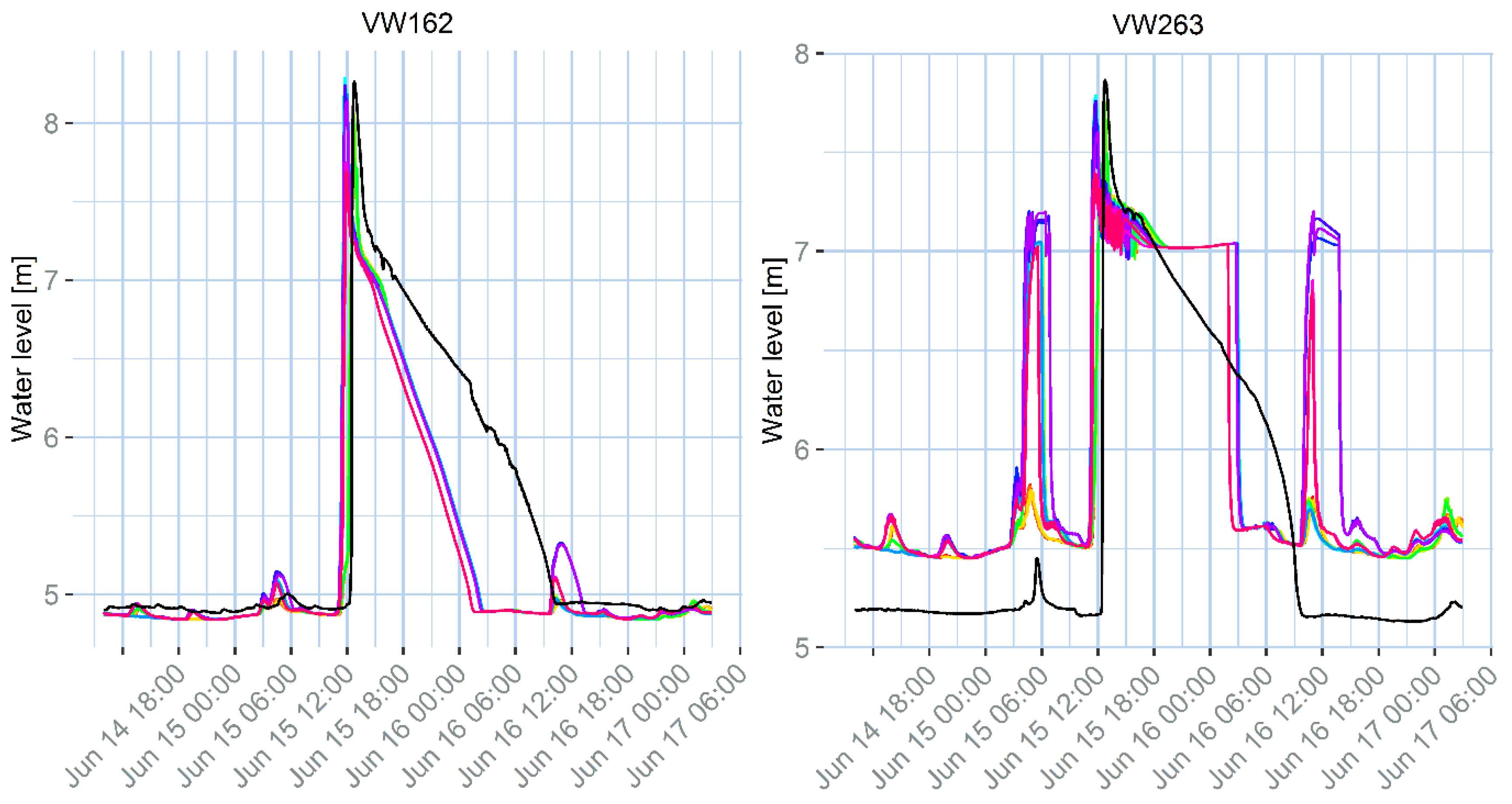
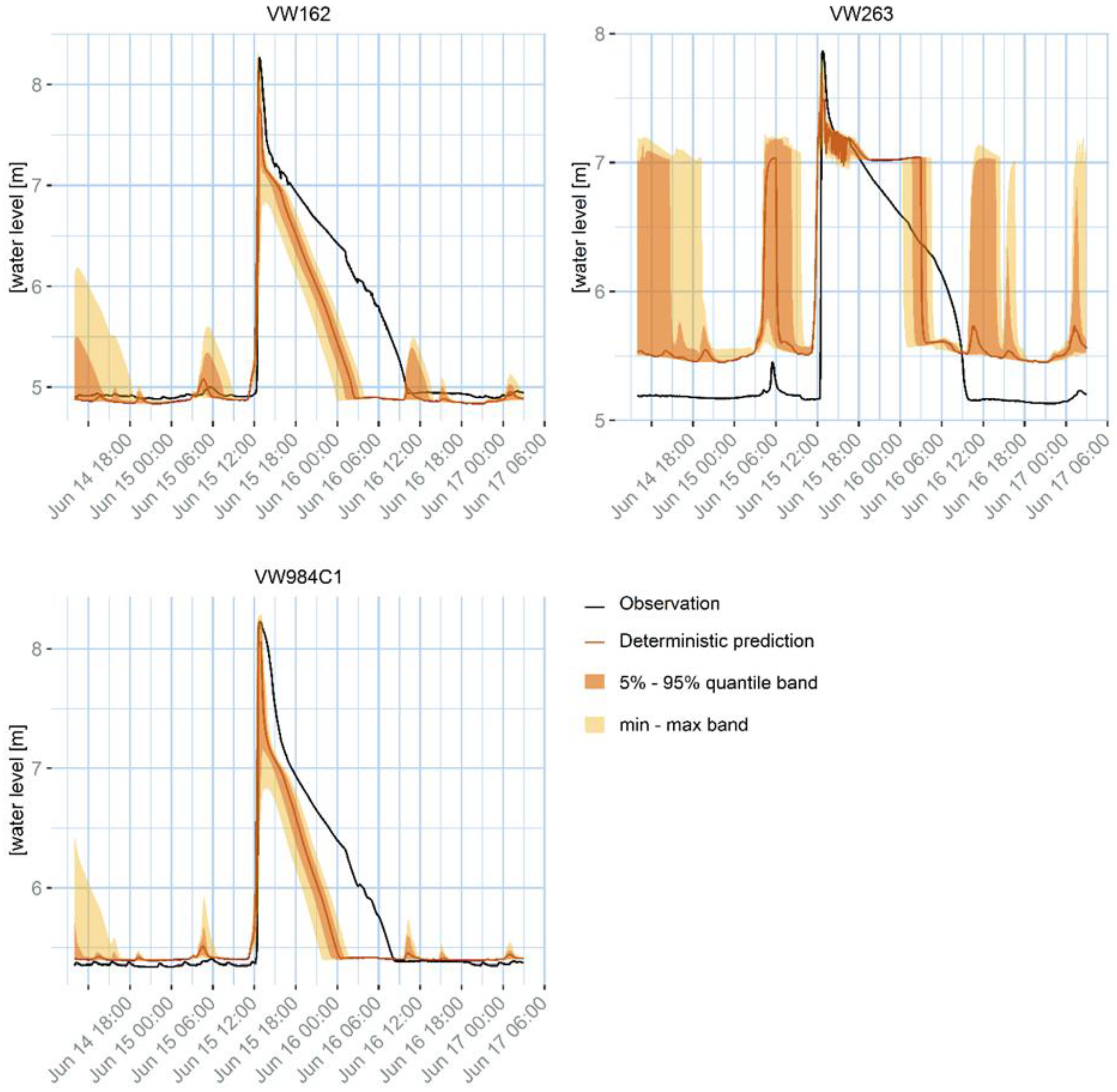
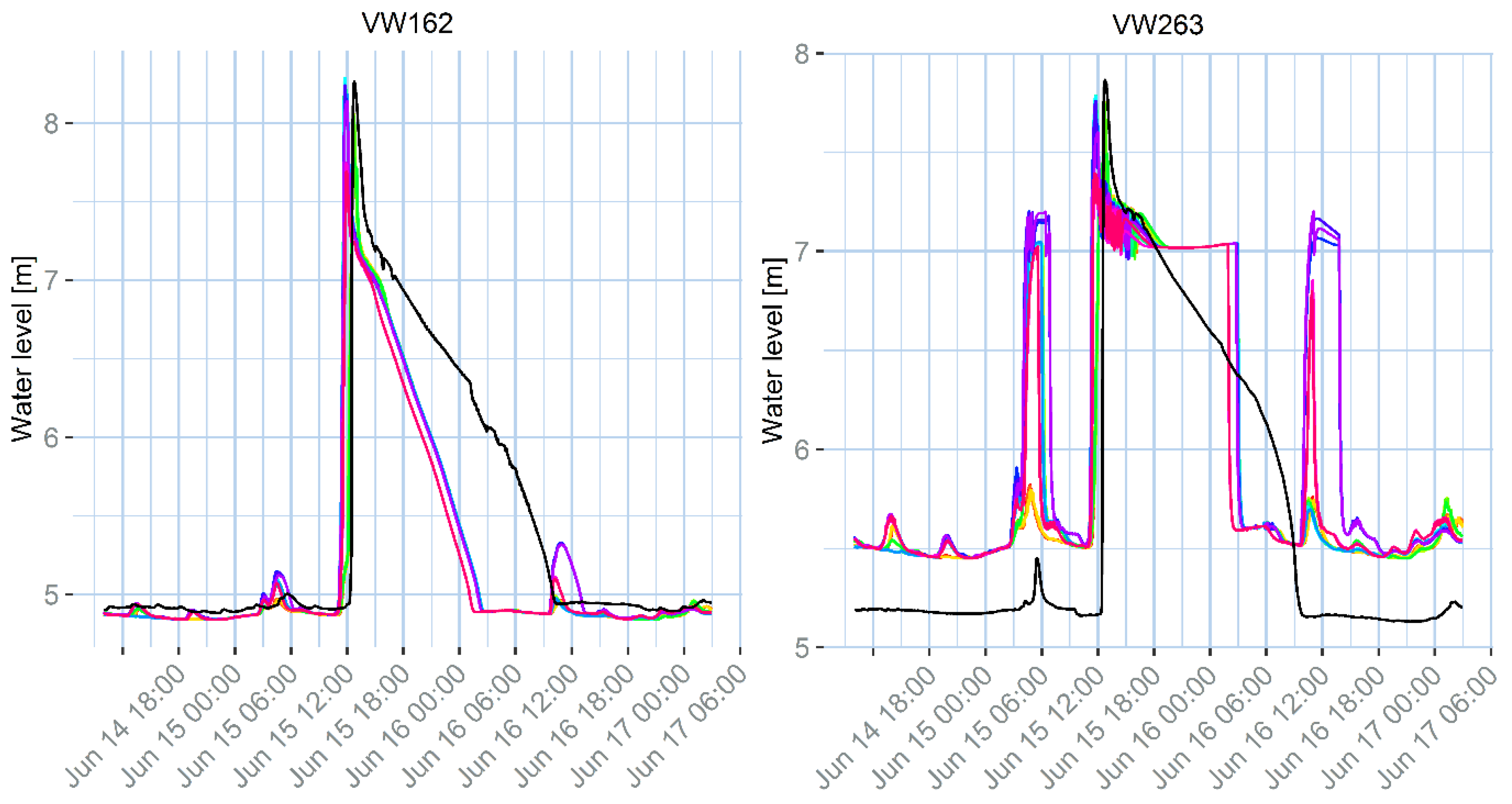
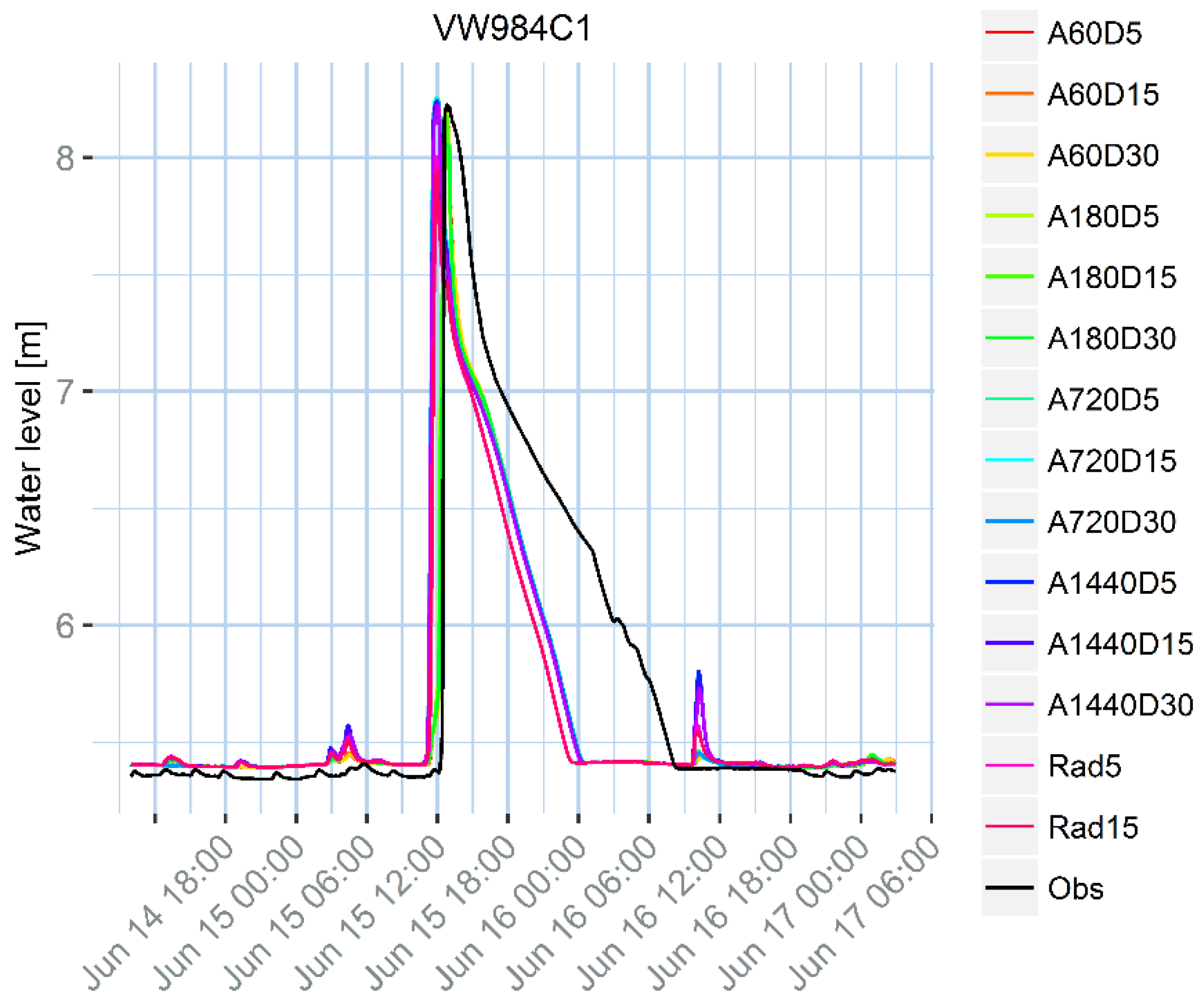
As concerns the example application in Twenterand, the first observable result from
Section 4.2,
Figure 7 is that the model is not appropriately calibrated for the studied event. The model is calibrated following the C2100 guideline [
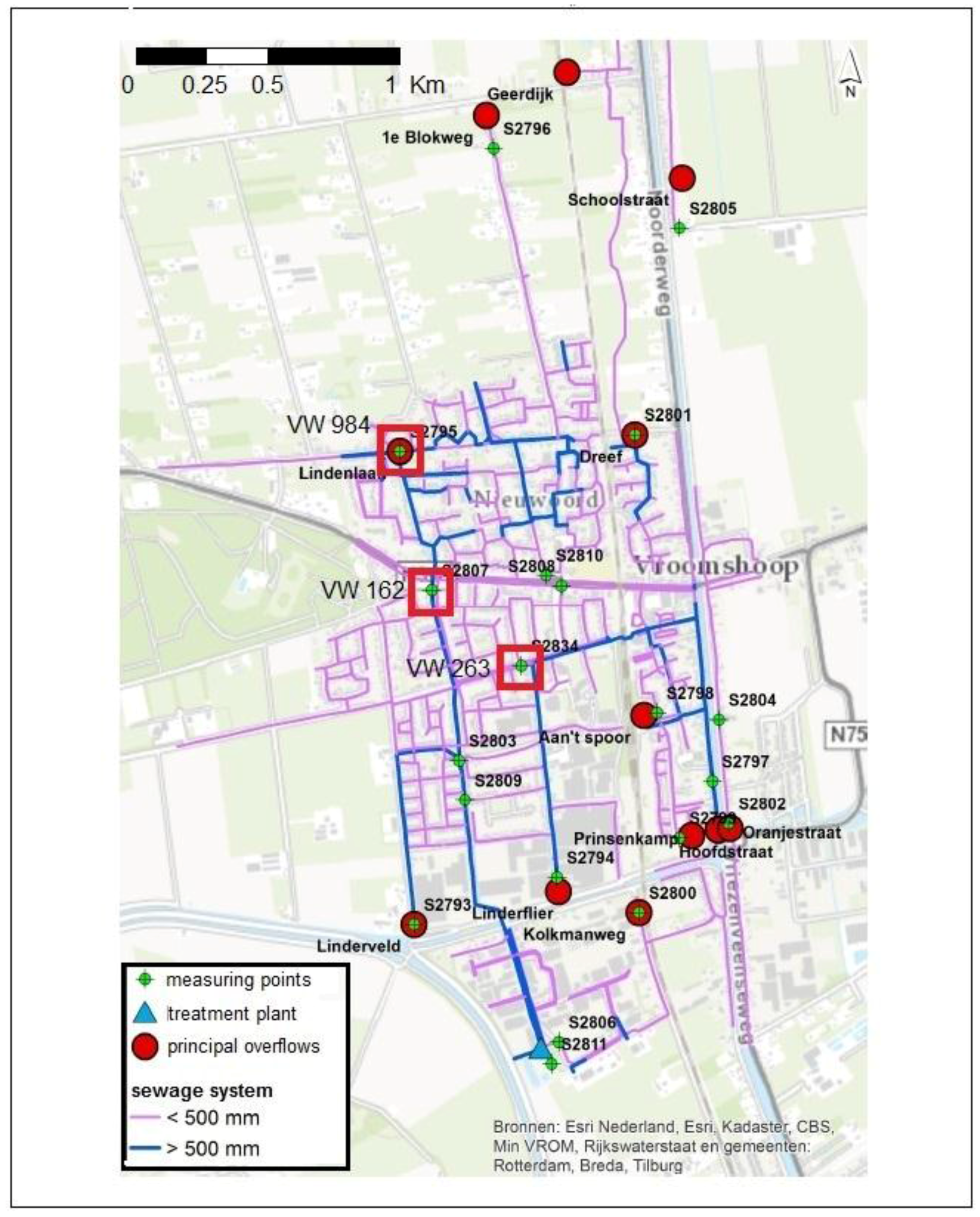
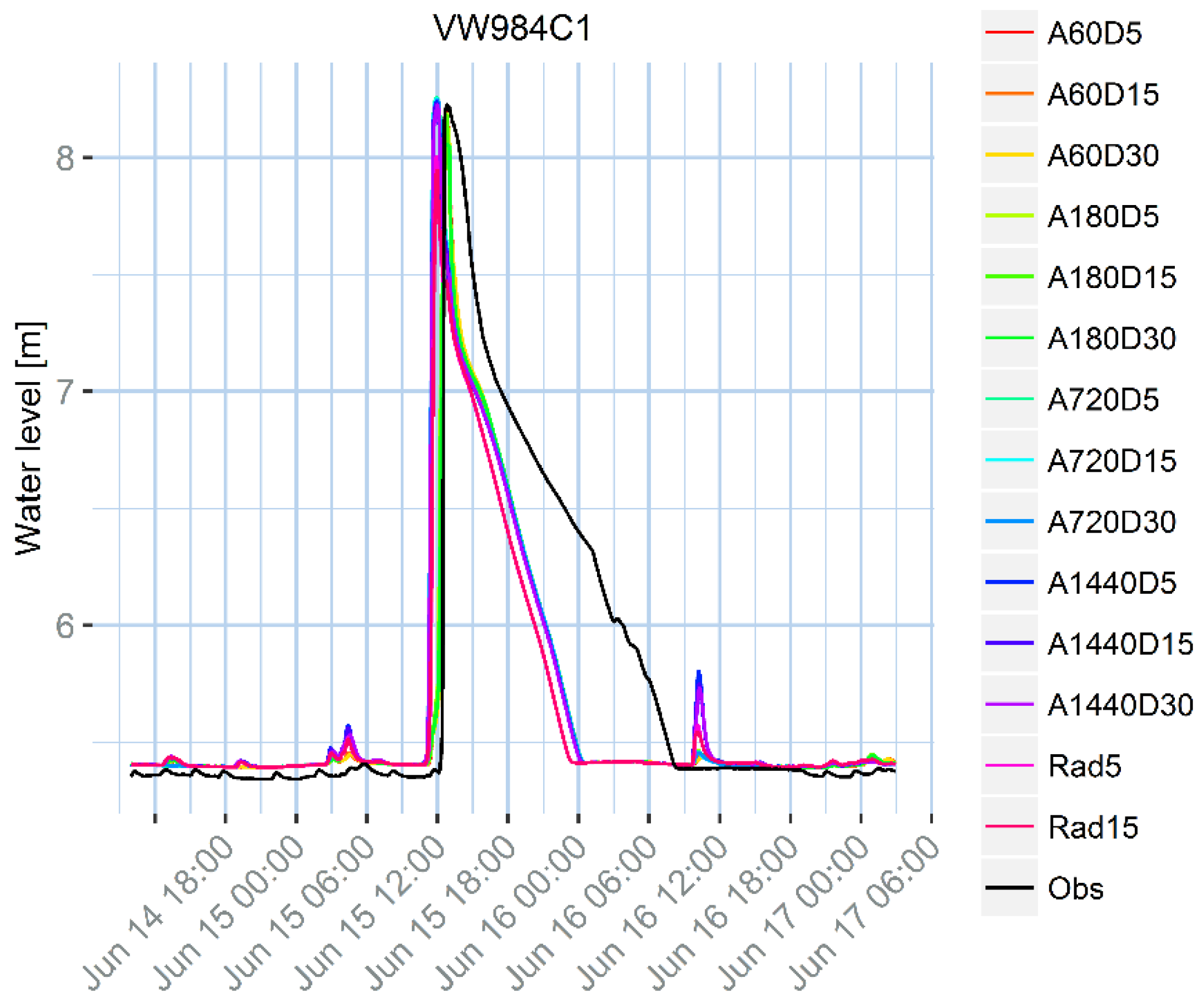
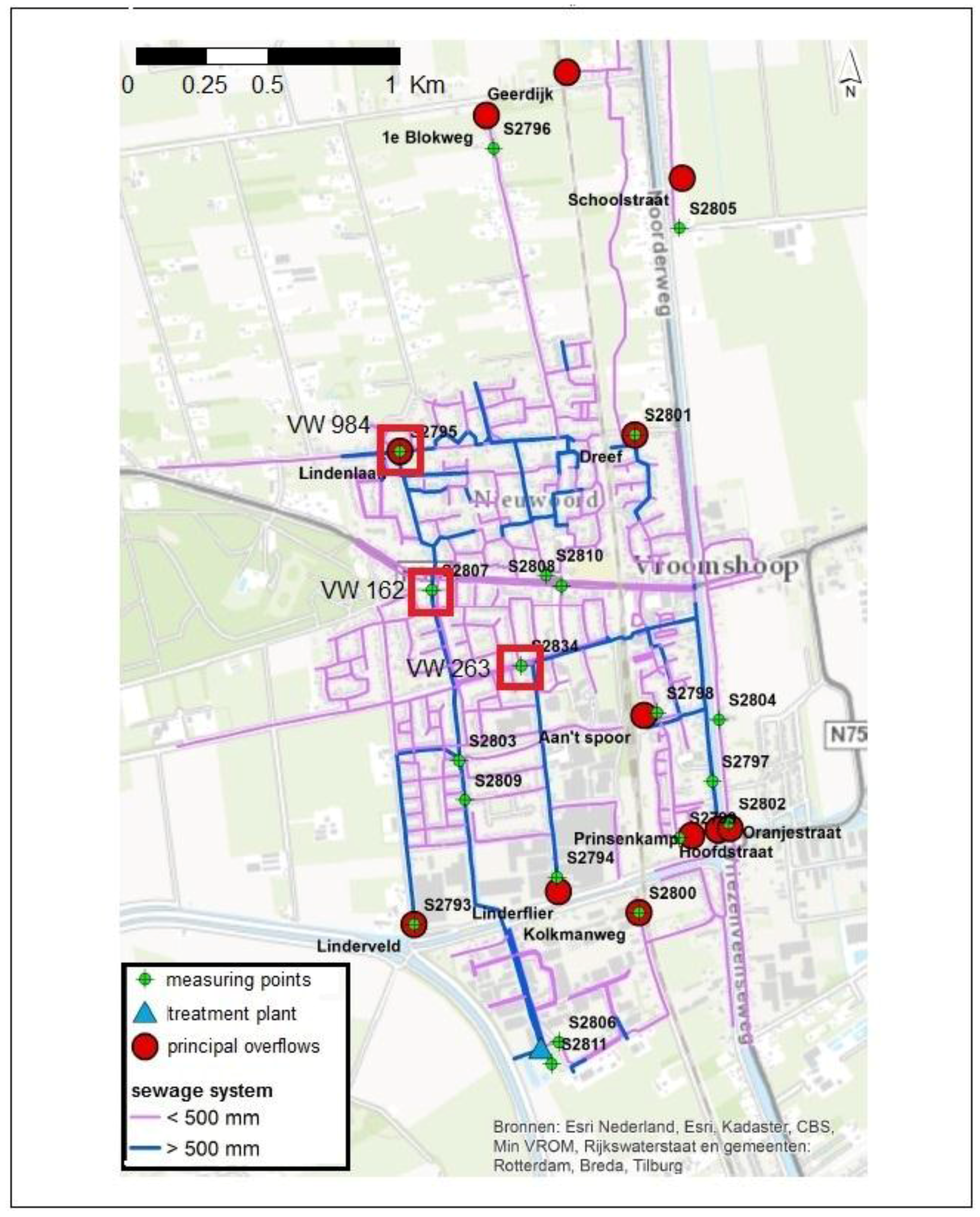
33], which is the standard nation-wide calibration procedure. Although the calibration aims at obtaining a set of parameters that performs well in a number of design storms with different return periods, it cannot perform at the highest standard in all the situations, since some parameters are actually not stationary. Additionally, the model is designed to properly model the flow in pressurized conducts, but does not properly represent surface water storage that can happen during a flood. This generates a mismatch between the model results and the observations that might not be due to the rainfall uncertainty, and is similar for all the tested rainfall products. For example, at location VW263 there is an evident bias, while in locations VW162 and VW984C1 the peak water level decreases too fast, compared to the observations. Additionally, some other sources of uncertainty can contribute to the mismatch, for example the inflow due to the urban sewage component, the uncertainty on the water level observations, or the model structure. In location VW263, the peak shows a different pattern compared to the observation. This effect might be linked to the presence of a pump close by, which may be modelled in an over-simplified way.
The evident mismatch between the model and the observations does not prevent the methodology presented in this work to be effective, and presents a real case scenario: as mentioned before, operational models are often calibrated against a number of design rainfall events, but cannot be optimal in all the cases. We want to propose a methodology that is effective regardless of the other additional sources of uncertainty that may affect the model. However, it could be argued that the results are affected by the non-optimal working conditions of the model. This is indeed true, and it must be kept in mind that the optimization in such conditions is specific for the given model, in the given conditions and cannot be generalized. The presented case study should be considered only as an application example of the proposed methodology and no generalization on the obtained results should be drawn.
Although the differences between the rainfall products are small compared to the mismatch between the model outputs and the water level observations, there are some noticeable differences, especially for minor peaks, that can still help us in selecting the best rainfall input. The first and the last minor peaks generated by the model for the VW263 measurement point are too high for daily accumulations (1440 min), but reasonably low for accumulations between 60 min and 12 h (720 min). The same effect can be observed for the small peaks following the major ones for locations VW162 and VW984C1.
The results in
Table 7 show that different products perform differently for the three measurement points. Nevertheless, it is possible to evaluate which ones perform sufficiently well in all the cases. In terms of accumulation interval, the best results are obtained for an accumulation of three hours (180 min). Sixty-minute products perform well too, but have a more variable behaviour in the different analysed cases. In terms of downscaling time, the differences are smaller, but the products downscaled at 30 min tend to perform slightly better, especially for the accumulations at 3 h. This is probably due to the reduction in rainfall errors thanks to a coarser accumulation, rather than an advantage at model level. Although, in this application, we select the product downscaled at 30 min, the other downscaling resolutions would work similarly well. Indeed, urban drainage models often work better at finer resolutions [
2,
48,
49]. However, both the rain gauges and the radar used are subject to non-negligible errors and the reduction of uncertainty due to accumulation seems dominant in respect to the reduction of uncertainty due to the model capacity to represent finer temporal scales.
The validation results are not in contrast with the results of the Dutch case study, used to optimise the resolution for modelling application. Indeed, the downscaling brings an advantage in the model application, where finer scale phenomena need to be represented correctly. The fact that the optimal downscaling resolution has been found at 30 min is due to the balance between the rainfall uncertainty reduction at larger downscaling resolutions, and the model uncertainty reduction at smaller downscaling resolutions. In fact, it can be observed that the differences between the results at different downscaling resolutions at model level in the second case study are much smaller than the differences at rainfall level in the first case study, where larger downscaling resolutions clearly produce better results.
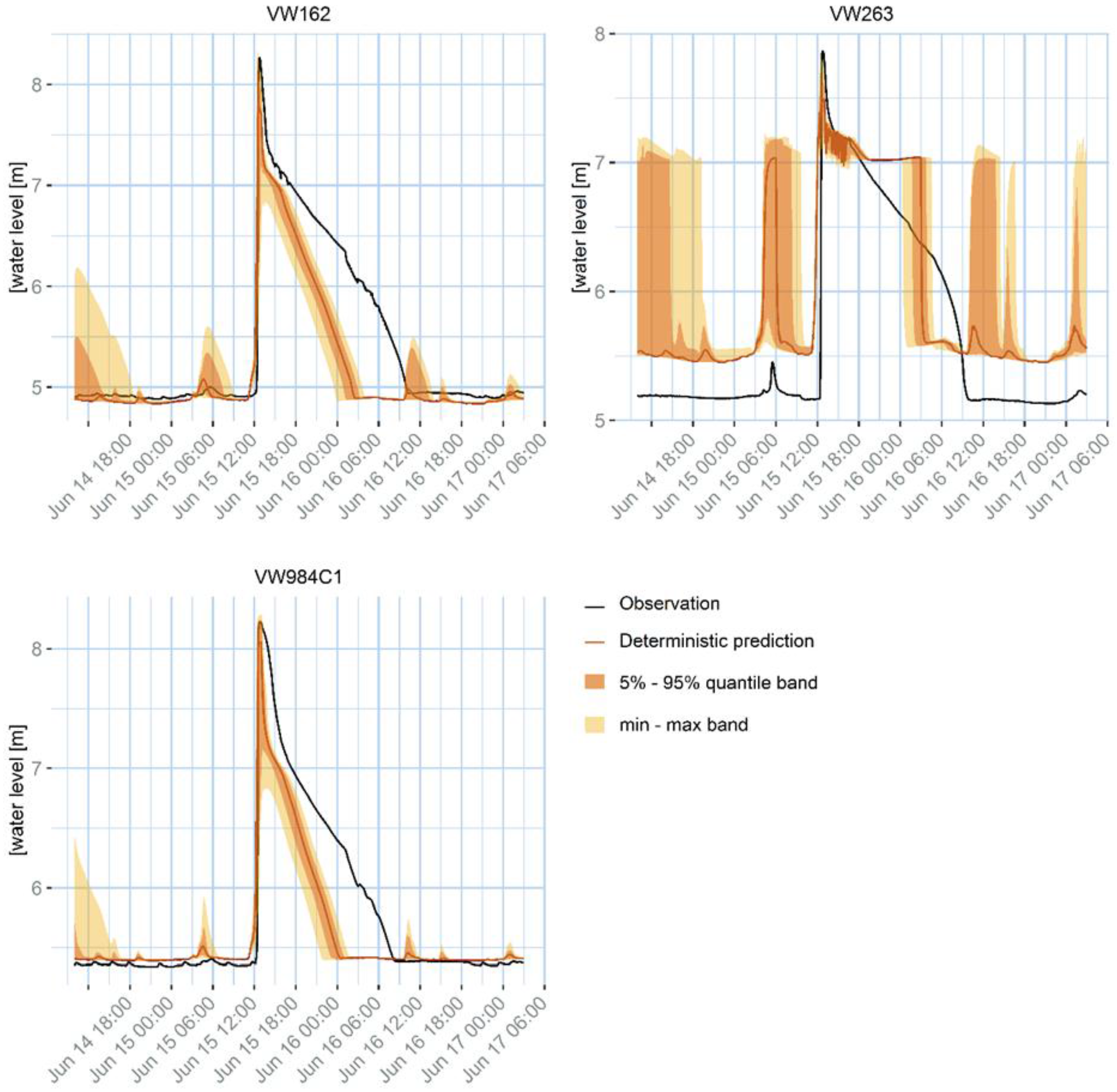
The results of the uncertainty propagation, as reported in
Section 4.3,
Figure 8, show that the rainfall uncertainty is not sufficient to explain the mismatch with the observations: as already mentioned in the previous section, the mismatch can be due to the model calibration, to other inputs’ uncertainty, to the water level observation uncertainty, and to the model simplification.
The fact that the uncertainty bands correspond to the variability of the 14 products observed in
Figure 7 confirms that the uncertainty model is robust. In fact, the uncertainty model is independent on the other 13 products tested in the previous phase, but it is still able to capture the uncertainty due, in this case, to the temporal resolution uncertainty. Additionally, it covers also other sources of rainfall uncertainty, such as rain gauge errors or interpolation approximations. The fact that the uncertainty band does not always cover the water level observations, confirms that the InfoWorks model is affected by other sources of uncertainty such as calibration, model structure, or other data errors.
Additionally, the ensemble shows that the uncertainty tends to be larger in correspondence of peaks, but for some peaks the uncertainty band is much larger than for others. This is because kriging variance is proportional to the rainfall intensity and to the distance between the measurement points and the prediction points: two rainfall peaks with the same intensity can have a different associated uncertainty if they are closer or farther away from the rain gauge locations. The effect is even stronger if some measurements are missing, or removed because of convective conditions. Both the effects are realistic: rainfall uncertainty is known to be proportional to the rainfall intensity and is reasonable that the fewer measurements are available, the less certain the rainfall estimation is.
It must be noted that the InfoWorks model of Vroomshoop covers an area smaller than the one studied for the rainfall products, using therefore only a portion of the KED products. The use of a larger area for the rainfall estimation assures that the rainfall estimation is robust, while the sensitivity of the uncertainty model to the rain gauge quality assures that the uncertainty is correctly dependant on the quality of the rain gauges closer to the Vroomshoop area.
The proposed methodology is successful in improving the KED merging results for urban application, considering the associated uncertainty and its propagation to model outputs. However, some improvements could still be introduced. The tested accumulation and downscaling resolutions are just a limited number, used as an example to illustrate the methodology, rather than to actually identify the optimal resolutions with high accuracy; using a larger number of combinations could help identify the optimal resolutions more accurately. Furthermore, an existing operational model calibrated according to national guidelines was used, with some associated calibration uncertainty. The case study is informative in terms of robustness of the proposed method and in terms of evaluating the relative importance of the rainfall uncertainty in respect to the overall model uncertainty, but more precise results could have been obtained with a model calibrated specifically for the actual study event.
It must be considered that this work aims at illustrating an effective methodology for producing rainfall products optimized for a specific model, and the quantitative results are specific for the dataset and the model used. Additionally, it must be noted that this work does not aim at proposing a different merging technique; it aims at dealing with temporal scales with an existing merging technique, in this case KED. It could potentially be applied to other merging techniques, where sensitivity to rainfall data quality is noticed, and an accumulation of the rainfall data would be advisable, but, for model applications, a sufficiently fine resolution is required. It is therefore subject to the benefits and limitations of the used merging techniques.
Additionally, the ensemble generation is accomplished using an AR(2) model for the residuals auto-correlation; the AR(2) generates auto-correlated residuals, but cannot achieve the level of auto-correlation observed in the time series. A different approach could be adopted to improve the ensembles in this direction. Finally, the use of a 2D variogram approach has the potential to use an anisotropic and directional variogram for the KED merging, which was not investigated in this work.
6. Conclusions
Rainfall is a phenomenon highly variable in space and time. For this reason, a lot of effort is often put in the identification of the optimal spatio-temporal resolution for its representation, especially when it is used as input in small-scale urban models [
1,
2,
49,
50]. Although a fine resolution allows representing small-scale phenomena and provides more details, available data fix a lower limit to the achievable resolution, and accumulation is recommended to reduce the impact of random errors. Merging radar and rain gauge rainfall information is recognised to improve the rainfall estimates and Kriging with External Drift is one of the most used merging methods thanks to its good performance and efficiency [
12,
14,
17,
18]. Nevertheless, KED is sensitive to low quality data using a fine temporal scale, and accumulation is recommended [
19].
This paper proposes an approach for using rainfall data accumulated to a coarser temporal resolution for KED merging, and then downscaling the results to a finer temporal scale, so it can be used in an urban hydrological model. The methodology allows to consider the uncertainty associated to the estimates as well and to propagate it in the studied model.
A first case study, based on six months of data in the north of England, is used to validate the methodology. Twelve KED products obtained using different accumulation and downscaling resolutions are cross-validated against rain gauges. The results confirm that, in terms of rainfall product quality, larger accumulations reduce the uncertainty.
Another case study in the municipality of Twenterand, in the Netherlands, is presented as an urban application example. In a first phase, 14 different rainfall products are tested, using different accumulation resolutions to perform the KED merging and different downscaling resolutions, in order to identify the optimal temporal accumulation and downscaling resolutions for the case study. Water level observations are compared to the InfoWorks results using the 14 different rainfall products as input, and the product accumulated at 3-h resolution for the KED application and then downscaled at 30-min resolution is identified as optimal in the specific application example.
For this product, the uncertainty is then considered in a second evaluation stage, and propagated in the InfoWorks model. The kriging prediction (mean) and the kriging variance are used to produce a rainfall ensemble composed of 100 alternative rainfall time series. Each ensemble member is used in the model, obtaining an ensemble of 100 alternative water level estimates.
The used InfoWorks model presents some additional sources of uncertainty, due mainly to the impossibility to model surface storage, calibration, other inputs uncertainty, model structure, or observation errors. The proposed methodology correctly estimates the uncertainty in the water level due to the rainfall uncertainty, and does not cover the whole observable mismatch between the model output and the observations. This also allows evaluating the relative importance of the rainfall uncertainty in the overall model output uncertainty.
Although some details can still be improved, the illustrated methodology is successful in generating robust and accurate rainfall estimates and associated uncertainty. The methodology can be applied to different case studies and different models and a more accurate identification of the optimal resolutions for accumulation and for downscaling is easily achievable.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}