
Application of Transformer-Based Deep Learning Models for Predicting the Suitability of Water for Agricultural Purposes


Abstract
1. Introduction
2. Literature Review
2.1. Major Pollutants in Water Bodies
2.2. Machine Learning Approaches to Identify Pollutants in Water Bodies
2.3. Research Gap
3. Materials and Methods
3.1. Dataset and Parameters Used
3.2. Training
3.3. Machine Learning (ML) Models
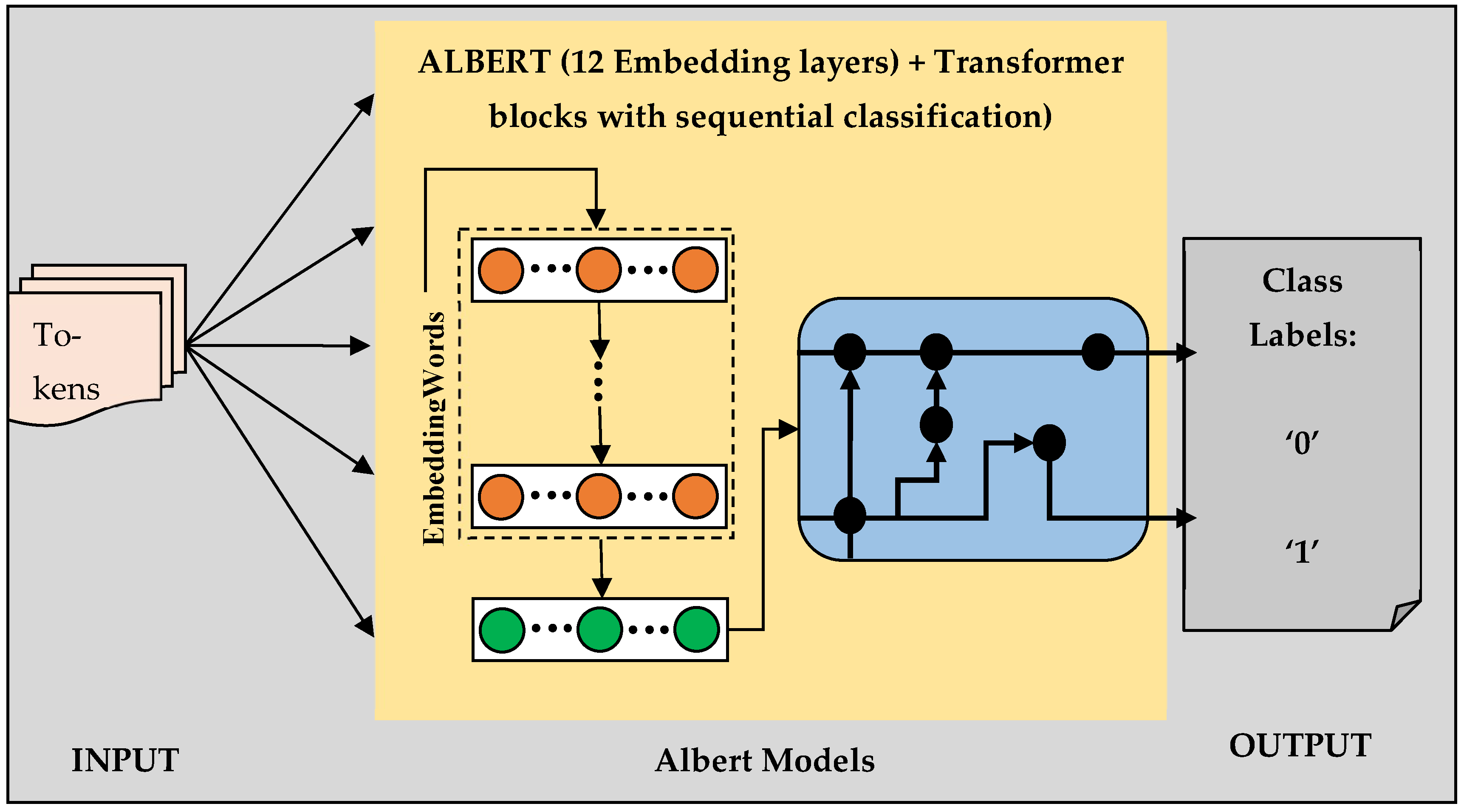
3.3.1. Proposed Architecture
3.3.2. Adopted Traditional Model Architecture
3.4. Machine Learning Algorithms
Experimental Procedure
| Algorithm 1. Feed-forward algorithm |
| Data split: train and test with parameters = feature ‘x (train), y (test)’, size = 0.05 and random state = 42. Dataset initiation: Train X data with Tokenizer as Input of maximum length 512, and Test Y data with Tokenizer as Input of maximum length 512. Dataset loading: Train data_load with batch size as 64 and set parameter ‘shuffle’ as true; Test data_load with batch size as 64 and set parameter ‘shuffle’ as false. |
| Algorithm 2. NN algorithm |
| Step 1: Import python libraries torch and pandas; from torch import NN and Adam optimizer, from sk-learn, import train-test-split, MSE, MAE, R2 metrics, and from transformers import Auto-tokenizer and AutoModel; Step 2: Initiate pre-processing of datasets and pass the pre-processed data as ‘inputvalue’. Initiate the ALBERT Base v2 model; Step 3: Apply sigmoid and ReLU activation functions on data to classify the processed data as output; Step 4: Finally, return the value ‘0’ or ‘1’ as per the obtained output and classify the potability. |
3.5. Metric Evaluation Techniques Adopted
3.6. Importance of Confusion-Matrix
4. Results and Findings
4.1. ALBERT-V2 and ALBERT-WPD Models Accuracy and Loss Estimation
4.2. Performance Metric Evaluation
4.3. Findings:
5. Data Analysis
5.1. Analysis of Different Machine Learning Models in Predicting Water Potability and Quality
5.2. Analysis of Different Machine Learning Models with Same Datasets
5.3. Comparative Analysis
6. Conclusions
7. Future Recommendations
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Dwivedi, A.K. Researches in water pollution: A review. Int. Res. J. Nat. Appl. Sci. 2017, 4, 118–142. [Google Scholar]
- Upadhyayula, K.K.; Deng, S.; Mitchell, M.C.; Smith, G.B. Application of carbon nanotube technology for removal of contaminants in drinking water: A review. Sci. Total Environ. 2009, 408, 1–13. [Google Scholar] [CrossRef]
- Ali, S.A.; de-Oliveria, J.A.P. Pollution and economic development: An empirical research review. Environ. Res. Lett. 2018, 13, 123003. [Google Scholar] [CrossRef]
- Khasanova, S.; Alieva, E.; Shemilkhanova, A. Environmental Pollution: Types, Causes and Consequences. BIO Web Conf. 2023, 63, 07014. [Google Scholar] [CrossRef]
- Savci, S. An agricultural pollutant: Chemical fertilizer. Int. J. Environ. Sci. Dev. 2012, 3, 73. [Google Scholar] [CrossRef]
- Kumar, M.; Mishra, G.V. Causes and Impacts of Water Pollution on Various Water Bodies in the State of Rajasthan, India: A Review. Environ. Ecol. 2023, 42, 645–654. [Google Scholar] [CrossRef]
- Andrade, L.; O’dwyer, J.; O’neill, E.; Hynds, P. Surface water flooding, groundwater contamination, and enteric disease in developed countries: A scoping review of connections and consequences. Environ. Pollut. 2018, 236, 540–549. [Google Scholar]
- Singh, J.; Yadav, P.; Pal, A.K.; Mishra, V. Water Pollutants: Origin and Status; Springer Publications: Berlin/Heidelberg, Germany, 2020. [Google Scholar]
- Shah, K.A.; Joshi, G.S. Evaluation of water quality index for River Sabarmati, Gujarat, India. Appl. Water Sci. 2017, 7, 1349–1358. [Google Scholar] [CrossRef]
- Anmala, J.; Meier, O.W.; Meier, A.J.; Grubb, S. GIS and Artificial Neural Network–Based Water Quality Model for a Stream Network in the Upper Green River Basin, Kentucky, USA. J. Environ. Eng. 2014, 141. [Google Scholar] [CrossRef]
- Solaraj, G.; Dhanakumar, S.; Murthy, K.R.; Mohanraj, R. Water quality in select regions of Cauvery Delta River basin, southern India, with emphasis on monsoonal variation. Environ. Monit. Assess. 2010, 166, 435–444. [Google Scholar] [CrossRef]
- Satish, N.; Anmala, J.; Rajitha, K.; Varma, M.R.R. Prediction of stream water quality in Godavari River Basin, India using statistical and artificial neural network models. H2 Open J. 2022, 5, 621–641. [Google Scholar]
- Fu, J.; Hu, X.; Tao, X.; Yu, H.; Zhang, X. Risk and toxicity assessments of heavy metals in sediments and fishes from the Yangtze River and Taihu Lake, China. Chemosphere 2013, 93, 1887–1895. [Google Scholar] [PubMed]
- Zhang, C.; Qiao, Q.; Piper, J.D.A.; Huang, B. Assessment of heavy metal pollution from a fe-smelting plant in urban river sediments using environmental magnetic and geochemical methods. Nitrogen Deposition, Critical Loads and Biodiversity. Environ. Pollut. 2011, 159, 3057–3070. [Google Scholar] [PubMed]
- Wu, Y.; Zhang, X.; Xiao, Y.; Feng, J. Attention neural network for water image classification under IoT environment. Appl. Sci. 2020, 10, 909. [Google Scholar] [CrossRef]
- Zhu, M.; Wang, J.; Yang, X.; Zhang, Y.; Zhang, L.; Ren, H.; Wu, B.; Ye, L. A review of the application of machine learning in water quality evaluation. Eco-Environ. Health 2022, 1, 107–116. [Google Scholar]
- Ahmed, U.; Mumtaz, R.; Anwar, H.; Shah, A.A.; Irfan, R.; García-Nieto, J. Efficient Water Quality Prediction Using Supervised Machine Learning. J. Water 2019, 11, 2210. [Google Scholar]
- Muhammad, S.Y.; Makhtar, M.; Rozaimee, A.; Aziz, A.A.; Jamal, A.A. ‘Classification Model for Water Quality Using Machine Learning Techniques’. Int. J. Softw. Eng. Its Appl. 2015, 9, 45–52. [Google Scholar] [CrossRef]
- Yogalakshmi, S.; Mahalakshmi, A. Efficient Water Quality Prediction for Indian Rivers Using Machine Learning. Asian J. Appl. Sci. Technol. (AJAST) 2021, 5, 100–109. [Google Scholar]
- Iberdrola, I. Water Pollution. 2021. Available online: https://www.iberdrola.com/sustainability/water-pollution#:~:text=The%20main%20water%20pollutants%20include,they%20are%20often%20invisible%20pollutants (accessed on 12 October 2024).
- Wu, J.; Song, C.; Dubinsky, E.A.; Stewart, J.R. Tracking Major Sources of Water Contamination Using Machine Learning. Front. Microbiol 2021, 11, 616692. [Google Scholar] [CrossRef]
- Banerjee, K.; Bali, V.; Nawaz, N.; Bali, S.; Mathur, S.; Mishra, R.K.; Rani, S. A Machine-Learning Approach for Prediction of Water Contamination Using Latitude, Longitude, and Elevation. Water 2022, 14, 728. [Google Scholar] [CrossRef]
- Ma, J.; Ding, Y.; Cheng, J.C.P.; Jiang, F.; Xu, Z. Soft Detection of 5-Day BOD with Sparse Matrix in City Harbor Water Using Deep Learning Techniques. Water Res. 2020, 170, 115350. [Google Scholar] [CrossRef] [PubMed]
- Ly, Q.V.; Nguyen, X.C.; Le, N.C.; Truong, T.D.; Hoang, T.T.; Park, T.J.; Maqbool, T.; Pyo, J.; Cho, K.H.; Lee, K.S.; et al. Application of machine learning for eutrophication analysis and algal bloom prediction in an urban river: A 10-year study of the Han River, South Korea. Sci. Total Environ. 2021, 797, 149040. [Google Scholar] [CrossRef]
- Park, Y.; Cho, K.H.; Park, J.; Cha, S.M.; Kim, J.H. Development of early-warning protocol for predicting chlorophyll-a concentration using machine learning models in freshwater and estuarine reservoirs, Korea. Sci. Total Environ. 2015, 502, 31–41. [Google Scholar] [CrossRef]
- Krivoguz, D.; Semenova, A.; Malko, S. Performance of Machine Learning Algorithms in Predicting Dissolved Oxygen Concentration. In Interagromash 2022; LNNS 574; Beskopylny, A., Shamtsyan, M., Artiukh, V., Eds.; Springer: Cham, Switzerland, 2023; pp. 1137–1144. [Google Scholar] [CrossRef]
- Göz, E.; Yuceer, M.; Karadurmuş, E. Machine Learning Application of Dissolved Oxygen Prediction in River Water Quality. In Proceedings of the 4th World Congress on Civil, Structural, and Environmental Engineering (CSEE’19), Rome, Italy, 7–9 April 2019. [Google Scholar] [CrossRef]
- Moon, J.; Lee, J.; Lee, S.; Yun, H. Urban River Dissolved Oxygen Prediction Model Using Machine Learning. Water 2022, 14, 1899. [Google Scholar] [CrossRef]
- Machiwal, D.; Jha, M.K. Role of Geographical Information System for Water Quality Evaluation, Chapter: 9. In Geographic Information Systems (GIS): Techniques, Applications and Technologies; Nova Science Publishers: Hauppauge, NY, USA, 2014; pp. 217–278. [Google Scholar]
- Huchhe, M.R.; Bandela, N.N. Study of Water Quality Parameter Assessment Using GIS and Remote Sensing in DR. B.A.M University, Aurangabad, MS. Int. J. Latest Technol. Eng. Manag. Appl. Sci. (IJLTEMAS) 2016, 5, 46–50. [Google Scholar]
- Venkataraman, T.; Manikumari, N. Spatial distribution of Water quality parameters with using GIS. Int. J. Innov. Technol. Explor. Eng. (IJITEE) 2019, 9, 3936–3941. [Google Scholar]
- Oseke, F.I.; Anornu, G.K.; Adjei, K.A.; Eduvie, M.O. Assessment of water quality using GIS techniques and water quality index in reservoirs affected by water diversion. Water-Energy Nexus 2021, 4, 25–34. [Google Scholar]
- Bindu, O.S.D.H.; Gayathri, V.; Swaranya, T.; Vyshnavi, J. Assessment of ground water quality using water quality index and GIS. E3S Web Conf. 2023, 391, 01208. [Google Scholar]
- Garabaghi, F.H.; Benzer, S.; Benzer, R. Performance evaluation of machine learning models with ensemble learning approach in classification of water quality indices based on different subset of features. Res. Sq. 2021, 1, 1–35. [Google Scholar]
- Shams, M.Y.; Elshewey, A.M.; El-kenawy, E.S.M.; Abdelhameed, I.; Talaat, F.M.; and Tarek, Z. Water quality prediction using machine learning models based on grid search method. Multimed. Tools Appl. 2024, 83, 35307–35334. [Google Scholar]
- Valdebenito, P.B.; Zabala-Blanco, D.; Ahumada-Garcia, R.; Soto, I.; Firoozabadi, A.D.; Flores-Calero, M. Extreme Learning Machines for Detecting the Water Quality for Human Consumption. In Proceedings of the 2023 IEEE Colombian Conference on Applications of Computational Intelligence (ColCACI), Bogota, DC, Colombia, 28 August 2023; pp. 1–6. [Google Scholar]
- Tharmalingam, L. Water Quality and Potability. 2023. Available online: https://www.kaggle.com/datasets/uom190346a/water-quality-and-potability (accessed on 20 September 2024).
- MainakRepositor. Datasets. 2021. Available online: https://github.com/MainakRepositor/Datasets/blob/master/water_potability.csv (accessed on 1 September 2024).
- World Health Organization (WHO). Guideline for Drinking Water Quality, 2nd ed.; Health Criteria and Other Supportinginformation; World Health Organization: Geneva, Switzerland, 1997; Volume 2, 9p. [Google Scholar]
- World Health Organization (WHO). Guideline for Drinking Water Quality; (WHO/SDE/WSH 03.04); WHO: Geneva, Switzerland, 2003. [Google Scholar]
- McGowan, W. Water Processing: Residential, Commercial, Light-Industrial, 3rd ed.; Water Quality Association: Lisle, IL, USA, 2000. [Google Scholar]
- Afaq, S.; Rao, S. Significnace of Epochs on Training a Neural Network. Int. J. Sci. Technol. Res. (IJSTR) 2020, 9, 485–488. Available online: https://www.ijstr.org/final-print/jun2020/Significance-Of-Epochs-On-Training-A-Neural-Network.pdf (accessed on 15 August 2024).
- Gonsalves, T.; Upadhyay, J. Chapter Eight-Integrated deep learning for self-driving robotic cars. In Artificial Intelligence for Future Generation Robotics; Elsevier: Amsterdam, The Netherlands, 2021; pp. 93–118. [Google Scholar] [CrossRef]
- Ashwini, C.; Singh, U.P.; Pawar, E. Water Quality Monitoring Using Machine Learning and IOT. Int. J. Sci. Technol. Res. 2019, 8. [Google Scholar]
- Berry, M.W.; Mohamed, A.H.; Yap, B.W. Supervised and Unsupervised Learning for Data Science; Springer: Cham, Switzerland, 2019. [Google Scholar]
- Bhagat, S.K.; Tiyasha, T.; Awadh, S.M.; Tung, T.M.; Jawad, A.H.; Yaseen, Z.M. Prediction of sediment heavy metal at the Australian Bays using newly developed hybrid artificial intelligence models. Environ. Pollut. 2021, 268, 115663. [Google Scholar] [CrossRef] [PubMed]
- Chen, K.; Chen, H.; Zhou, C.; Huang, Y.; Qi, X.; Shen, R.; Liu, F.; Zuo, M.; Zuo, X.; Ren, H. Comparative analysis of surface water quality prediction performance and identification of key water parameters using different machine learning models based on big data. Water Res. 2020, 171, 115454. [Google Scholar] [CrossRef] [PubMed]
- Lin, Y.; Li, L.; Yu, J.; Hu, Y.; Zhang, T.; Ye, Z.; Syed, A.; Li, J. An optimized machine learning approach to water pollution variation monitoring with time-series Landsat images. Int. J. Appl. Earth Obs. Geoinf. 2021, 102, 102370. [Google Scholar] [CrossRef]
- Sheng, L.; Zhou, J.; Li, X.; Pan, Y.F.; Liu, L.F. Water quality prediction method based on preferred classification. IET Cyber-Phys. Syst. Theory Appl. 2020, 30, 176–180. [Google Scholar]
- Wang, L.; Zhu, Z.; Sassoubre, L.; Yu, G.; Liao, C.; Hu, Q.; Wang, Y. Improving the robustness of beach water quality modeling using an ensemble machine learning approach. Sci. Total Environ. 2021, 765, 142760. [Google Scholar] [CrossRef] [PubMed]
- Xu, X.; Lai, T.; Jahan, S.; Farid, F.; Bello, A. A Machine Learning Predictive Model to Detect Water Quality and Pollution. Future Internet 2022, 14, 324. [Google Scholar] [CrossRef]
- Zhou, J.; Wang, Y.Y.; Xiao, F.; Wang, Y.N.; Sun, L.J. Water quality prediction method based on IGRA and LSTM. Water 2018, 10, 1148. [Google Scholar] [CrossRef]
- Zounemat-Kermani, M.; Seo, Y.; Kim, S.; Ghorbani, M.A.; Samadianfard, S.; Naghshara, S.; Kim, N.W.; Singh, V.P. Can decomposition approaches always enhance soft computing models? Predicting the dissolved oxygen concentration in the St. Johns River, Florida. Appl. Sci. 2019, 9, 2534. [Google Scholar] [CrossRef]
- Goncalves, G.; Andriolo, U.; Pinto, L.; Bessa, F. Mapping marine litter using UAS on a beach-dune system: A multidisciplinary approach. Sci. Total Environ. 2020, 706, 135742. [Google Scholar] [CrossRef] [PubMed]
- Lan, Z.; Chen, M.; Goodman, S.; Gimpel, K.; Sharma, P.; Soricut, R. ALBERT: A Lite BERT for Self-Supervised Learning of Language Representations. In Proceedings of the 2020 ICLR Conference, Addis Ababa, Ethiopia, 30 April 2020; pp. 1–17. Available online: https://arxiv.org/pdf/1909.11942 (accessed on 15 October 2024).
- Azizah, S.F.N.; Cahyono, H.D.; Sihwi, S.W.; Widiarto, W. Performance Analysis of Transformer Based Models (BERT, ALBERT, and RoBERTa) in Fake News Detection. In Proceedings of the 6th International Conference on Information and Communications Technology (ICOIACT), Yogyakarta, Indonesia, 11 November 2023; pp. 425–430. [Google Scholar] [CrossRef]
- Sy, C.Y.; Maceda, L.L.; Canon, M.J.P.; Flores, N.M. Beyond BERT: Exploring the Efficacy of RoBERTa and ALBERT in Supervised Multiclass Text Classification. (IJACSA) Int. J. Adv. Comput. Sci. Appl. 2024, 15, 223–233. [Google Scholar] [CrossRef]
- Sinap, V. Comparative analysis of machine learning techniques for detecting potability of water. J. Sci. Rep. -A 2024, 58, 135–161. [Google Scholar] [CrossRef]
- Budi, I.; Yaniasih, Y. Understanding the meanings of citations using sentiment, role, and citation function classifications. Scientometrics 2023, 128, 735–759. [Google Scholar] [CrossRef]
- Biswas, P. Importance of Loss functions in Deep Learning and Python Implementation. In Medium–Towards Data Science. 2021. Available online: https://towardsdatascience.com/importance-of-loss-functions-in-deep-learning-and-python-implementation-4307bfa92810 (accessed on 15 September 2024).
- Yang, S.; Berdine, G. Confusion matrix. Southwest Respir. Crit. Care Chron. 2024, 12, 75–79. [Google Scholar] [CrossRef]
- Tessler, M. Univariate analysis: Variance, Variables, Data and Measurement. In Social Science Research in the Arab World and Beyond; Briefs in Sociology; Springer: Cham, Switzerland, 2022; pp. 19–50. [Google Scholar] [CrossRef]
- Vujovic, Z.D. Classification Model Evaluation Metrics. (IJACSA) Int. J. Adv. Comput. Sci. Appl. 2021, 12, 599–606. [Google Scholar] [CrossRef]
- Haghiabi, A.H.; Nasrolahi, A.H.; Parsaie, A. Water quality prediction using machine learning methods. Water Qual. Res. J. (WQRJ) 2018, 53, 3–13. [Google Scholar] [CrossRef]
- Hussein, E.E.; Jat Baloch, M.Y.; Nigar, A.; Abualkhair, H.F.; Aldawood, F.K.; Tageldin, E. Machine Learning Algorithms for Predicting the Water Quality Index. Water 2023, 15, 3540. [Google Scholar] [CrossRef]
- Rana, R.; Kalia, A.; Boora, A.; Alfaisal, F.M.; Alharbi, R.S.; Berwal, P.; Alam, S.; Khan, M.A.; Qamar, O. Artificial Intelligence for Surface Water Quality Evaluation, Monitoring and Assessment. Water 2023, 15, 3919. [Google Scholar] [CrossRef]
- Farzana, S.Z.; Paudyal, D.R.; Chadalavada, S.; Alam, M.J. Prediction of Water Quality in Reservoirs: A Comparative Assessment of Machine Learning and Deep Learning Approaches in the Case of Toowoomba, Queensland, Australia. Geosciences 2023, 13, 293. [Google Scholar] [CrossRef]
- Patel, J.; Amipara, C.; Ahanger, T.A.; Ladhva, K.; Gupta, R.K.; Alsaab, H.O.; Althobaiti, Y.S.; Ratna, R. A Machine Learning-Based Water Potability Prediction Model by Using Synthetic Minority Oversampling Technique and Explainable AI. Hindawi Comput. Intell. Neurosci. 2022, 2022, 9283293. [Google Scholar] [CrossRef]
- Roitero, K.; Portelli, B.; Serra, G.; Mea, V.D.; Mizzaro, S.; Cerro, G.; Vitelli, M.; Molinara, M. Detection of wastewater pollution through natural language generation with a low-cost sensing platform. IEEE Access 2023, 11, 50272–50284. [Google Scholar] [CrossRef]
- Patel, S.; Shah, K.; Vaghela, S.; Aglodiya, M.; Bhattad, R. Water potability prediction using machine learning. Res. Sq. 2023; Pre-Print. [Google Scholar]
- Zaky, U.; Naswin, A.; Sumiyatun, S.; Murdiyanto, A.W. Performance Analysis of the Decision Tree Classification Algorithm on the Water Quality and Potability Dataset. Indones. J. Data Sci. 2023, 4, 145–150. [Google Scholar] [CrossRef]
- Chatterjee, D.; Ghosh, P.; Banerjee, A.; Das, S.S. Optimizing machine learning for water safety: A comparative analysis with dimensionality reduction and classifier performance in potability prediction. PLoS Water 2024, 3, e0000259. [Google Scholar] [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Author and Year | Machine Learning Technique/Model Architecture | Parameters | Prediction Class | Accuracy/Results |
|---|---|---|---|---|
| Ma et al. [23] | Hybrid: deep neural networks (DNNs) + deep matrix factorization (DMF) | Biological Oxygen Demand (BOD), turbidity, Ecoli, coliform, fluoride, chlorine, and dissolved oxygen (DO). | Biological Oxygen Demand (BOD) | RMSE scores: 17.23% and 25.16% lower than the traditional and conventional ML models, respectively. |
| Ly et al. [24] | Adaptive neuro-fuzzy inference system (ANFIS), regression models (SVR, DTR, and linear), deep learning (GRU, RNN, and LSTM), and time–series (SARIMAX) | Twenty parameters: COD (chemical oxygen demand), BOD (bio-chemical oxygen demand), TSS (total SS), TOC (total organic carbon), TP (total phosphorus), TN (total nitrogen), pH, DTP (dissolved TP), DTN (dissolved TN), PO4 (phosphates), NO3 (nitrates), NH3 (ammonia), Fcoli, Tcoli, temperature, DO (dissolved oxygen), electrical conductivity (EC), precipitation, chlorophyll-a (Chl-a), and flow rate. | Eutrophication and algal blooms | ANFIS obtained the highest accuracy, 90% (MAE = 0.090). |
| Park et al. [25] | SVM, artificial neural networks (ANNs) | Chl-a, NO3-N, PO4-P, NH3-N, wind speed, temperature, and solar radiation. | Chlorophyll-a (Chl-a) Concentration | SVM obtained a more accurate prediction than ANN. |
| Krivoguz [26] | Six different machine learning algorithms (kNN, RF, SVM, NN, decision tree, and logistic regression) | Salinity of sea surface, Chl-a, temperature, DO, PO4, NH3, and NPP (net primary product). | Dissolved oxygen (DO) | Random forest with AUC: 0.996. |
| Göz et al. [27] | Extreme Learning Machine (ELM) and Kernel Extreme Learning Machine (KELM) | pH, temperature, conductivity, and DO. | Dissolved oxygen (DO) | KELM procured higher success in predicting DO, with an R-test score of 0.9855, an MAPE-test score of 2.8471, and an RMSE-test score of 0.3807. |
| Moon et al. [28] | AdaBoost, random forest, and gradient boosting. | Nine parameters: pH, SS, DTP, TN, NH3-N, temperature, COD, DTN, and NO3-N. | Optimal water quality (WQ) | CVRMSE: 17.404; R2: 0.912. |
| S. No | Parameters | Float Type and Parameter Type | Description | Compound/Property |
|---|---|---|---|---|
| 1 | pH | Input; float64 | Water‘s potential of hydrogen level | Chemical compound |
| 2 | Chloramines | Input; float64 | Concentration of chloramines in water | Chemical compound |
| 3 | Solids | Input; float64 | Solids completely dissolved in water | Physicochemical property |
| 4 | Hardness | Input; float64 | Mineral-content-measurement-based water hardness | Physicochemical property |
| 5 | Conductivity | Input; float64 | Water’s electrical conductivity | Physical property |
| 6 | Sulphate | Input; float64 | Concentration of Sulphates in water | Chemical compound |
| 7 | Trihalomethanes (THMs) | Input; float64 | Concentration of the tri-halo-methane in water | Chemical compound |
| 8 | Organic_carbon | Input; float64 | The organic-carbon-based contents present in water | Physicochemical property |
| 9 | Turbidity | Input; float64 | Measurement of water clarity or the turbidity level | Physical property |
| 10 | Potability | Output: int64‘ | ‘Target level’ in research with ‘0’ being not potable and ‘1’ being potable | Physicochemical property |
| S. No | Parameters | WHO Standards (with Units) |
|---|---|---|
| 1 | pH (calculated using a scale ranging from 0 to 14 to measure the alkalinity or acidity of substances; where 0–6 = most acidic; 7 = neutral and >7 = basic) | 6.5–8.5 |
| 2 | Solids | 500–1000 milligram/liter (mg/L) |
| 3 | Chloramines | 4 mg/L |
| 4 | Sulfate | 3–30 mg/L in freshwater & 2700 mg/L in seawater |
| 5 | Conductivity | 400 µS/cm (Microsiemens/centimeter) |
| 6 | Organic_carbon | <2 mg/L to <4 mg/L |
| 7 | Trihalomethanes | 80 ppm (parts per million) |
| 8 | Turbidity | 0.98–5.00 NTU (Nephelometric Turbidity unit) |
| 9 | Hardness (water with calcium carbonate concentrations: CaCO3 is measured here) | 120–170 mg/L |
| Features (9 Inputs) | Before Filling in the Values | Filled-In Missing Data |
|---|---|---|
| Ph | 491 | 0 |
| Hardness | 0 | 0 |
| Solids | 0 | 0 |
| Chloramines | 0 | 0 |
| Sulphate | 781 | 0 |
| Conductivity | 0 | 0 |
| Organic_Carbon | 0 | 0 |
| Trihalomethanes | 162 | 0 |
| Turbidity | 0 | 0 |
| Precision | Recall | F1-Score | Support | ||
|---|---|---|---|---|---|
| ALBERT Base v2 model’s classification: ALBERT-base-v2 | Potable | 0.84 | 0.98 | 0.91 | 44 |
| Non potable | 0.98 | 0.86 | 0.91 | 56 | |
| Accuracy | 0.91 | 100 | |||
| Macro-average | 0.91 | 0.92 | 0.91 | 100 | |
| Weighted-average | 0.92 | 0.91 | 0.91 | 100 | |
| ALBERT-WPD model’s classification: ALBERT-WPD | Potable | 0.93 | 0.98 | 0.96 | 44 |
| Non potable | 0.98 | 0.95 | 0.96 | 56 | |
| Accuracy | 0.96 | 100 | |||
| Macro-average | 0.96 | 0.96 | 0.96 | 100 | |
| Weighted-average | 0.96 | 0.96 | 0.96 | 100 |
| Author | Year | Architecture | Accuracy |
|---|---|---|---|
| Haghiabi et al. [64] | 2018 | ANN and SVM | 96% |
| Hussein et al. [65] | 2023 | SVM | 90.80% |
| Rana et al. [66] | 2023 | ANN + LSTM | 95% |
| Farzana et al. [67] | 2023 | RNN | 90% |
| Patel et al. [68] | 2022 | SVM | 81% |
| Roitero et al. [69] | 2023 | Transformer | 91% |
| Proposed ALBERT-WPD | 2024 | Transformer | 96% |
| Author | Year | Architecture | Accuracy |
|---|---|---|---|
| Patel et al. [70] | 2023 | Random Forest | 74% |
| Zaky et al. [71] | 2023 | Ensemble model of 5-fold cross-validation technique | 54.33% |
| Chatterjee et al. [72] | 2024 | SVM | 69% |
| Sinap [58] | 2024 | Random Forest | 83% |
| Proposed ALBERT-WPD | 2024 | Transformer | 96% |
| Models | Class | Metrics | |||
|---|---|---|---|---|---|
| Precision | Recall | F1-Score | Accuracy | ||
| Baseline model | 0 | 0.73 | 0.79 | 0.76 | 69% |
| 1 | 0.59 | 0.51 | 0.55 | ||
| ALBERT Base-V2 | 0 | 0.84 | 0.98 | 0.91 | 91% |
| 1 | 0.98 | 0.86 | 0.91 | ||
| ALBERT-WPD | 0 | 0.93 | 0.98 | 0.96 | 96% |
| 1 | 0.98 | 0.95 | 0.96 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rejini, K.; Visumathi, J.; Genitha, C.H. Application of Transformer-Based Deep Learning Models for Predicting the Suitability of Water for Agricultural Purposes. Water 2025, 17, 1347. https://doi.org/10.3390/w17091347
Rejini K, Visumathi J, Genitha CH. Application of Transformer-Based Deep Learning Models for Predicting the Suitability of Water for Agricultural Purposes. Water. 2025; 17(9):1347. https://doi.org/10.3390/w17091347
Chicago/Turabian StyleRejini, K., J. Visumathi, and C. Heltin Genitha. 2025. "Application of Transformer-Based Deep Learning Models for Predicting the Suitability of Water for Agricultural Purposes" Water 17, no. 9: 1347. https://doi.org/10.3390/w17091347
APA StyleRejini, K., Visumathi, J., & Genitha, C. H. (2025). Application of Transformer-Based Deep Learning Models for Predicting the Suitability of Water for Agricultural Purposes. Water, 17(9), 1347. https://doi.org/10.3390/w17091347